
1. قبل البدء
قد تعتقد أنّ الإحصاءات المجمَّعة لا تسرّب أي معلومات عن الأفراد الذين تخصّهم. ومع ذلك، هناك العديد من الطرق التي يمكن للمهاجم من خلالها الحصول على معلومات حساسة عن الأفراد من الإحصاءات المجمّعة.
في هذا الدرس التطبيقي حول الترميز، ستتعلّم كيفية إنشاء إحصاءات خاصة باستخدام عمليات تجميع مراعية للخصوصية التفاضلية من PipelineDP لحماية خصوصية الأفراد. PipelineDP هو إطار عمل بلغة Python يتيح لك تطبيق الخصوصية التفاضلية على مجموعات البيانات الكبيرة باستخدام أنظمة المعالجة المجمّعة، مثل Apache Spark وApache Beam. لمزيد من المعلومات حول كيفية احتساب الإحصاءات التي تحافظ على الخصوصية التفاضلية في Go، يُرجى الاطّلاع على الدرس التطبيقي حول الترميز Privacy on Beam.
تعني الخصوصية أنّ الناتج يتم إنتاجه بطريقة لا تؤدي إلى تسريب أي معلومات خاصة عن الأفراد في البيانات. يمكنك تحقيق هذه النتيجة من خلال الخصوصية التفاضلية، وهي مفهوم قوي للخصوصية يخص إخفاء الهوية، أي عملية تجميع البيانات من عدة مستخدمين لحماية خصوصية المستخدم. تستخدم جميع طرق إخفاء الهوية التجميع، ولكن لا تؤدي جميع طرق التجميع إلى إخفاء الهوية. من ناحية أخرى، توفّر الخصوصية التفاضلية ضمانات قابلة للقياس بشأن تسريب المعلومات والخصوصية.
المتطلبات الأساسية
- الإلمام بلغة Python
- الإلمام بتجميع البيانات الأساسي
- خبرة في استخدام مكتبات pandas وSpark وBeam
أهداف الدورة التعليمية
- أساسيات الخصوصية التفاضلية
- كيفية احتساب إحصاءات الملخّص المحافظة على الخصوصية التفاضلية باستخدام PipelineDP
- كيفية تعديل نتائجك باستخدام مَعلمات إضافية للخصوصية والفائدة
المتطلبات
- إذا أردت تشغيل برنامج التدريب العملي في بيئتك الخاصة، عليك تثبيت الإصدار 3.7 من Python أو إصدار أحدث على جهاز الكمبيوتر.
- إذا أردت اتّباع الخطوات الواردة في الدرس التطبيقي حول الترميز بدون بيئة خاصة بك، عليك الحصول على إذن الوصول إلى Colaboratory.
2. التعرّف على الخصوصية التفاضلية
لفهم الخصوصية التفاضلية بشكل أفضل، اطّلِع على هذا المثال البسيط.
لنفترض أنّك تعمل في قسم التسويق لدى بائع تجزئة للأزياء على الإنترنت وتريد معرفة المنتجات التي من المرجّح أن تُباع أكثر من غيرها.
يعرض هذا الرسم البياني المنتجات التي اطّلع عليها العملاء أولاً عند زيارة الموقع الإلكتروني للمتجر: القمصان أو البلوزات أو الجوارب أو الجينز. القمصان هي السلعة الأكثر رواجًا، بينما الجوارب هي السلعة الأقل رواجًا.
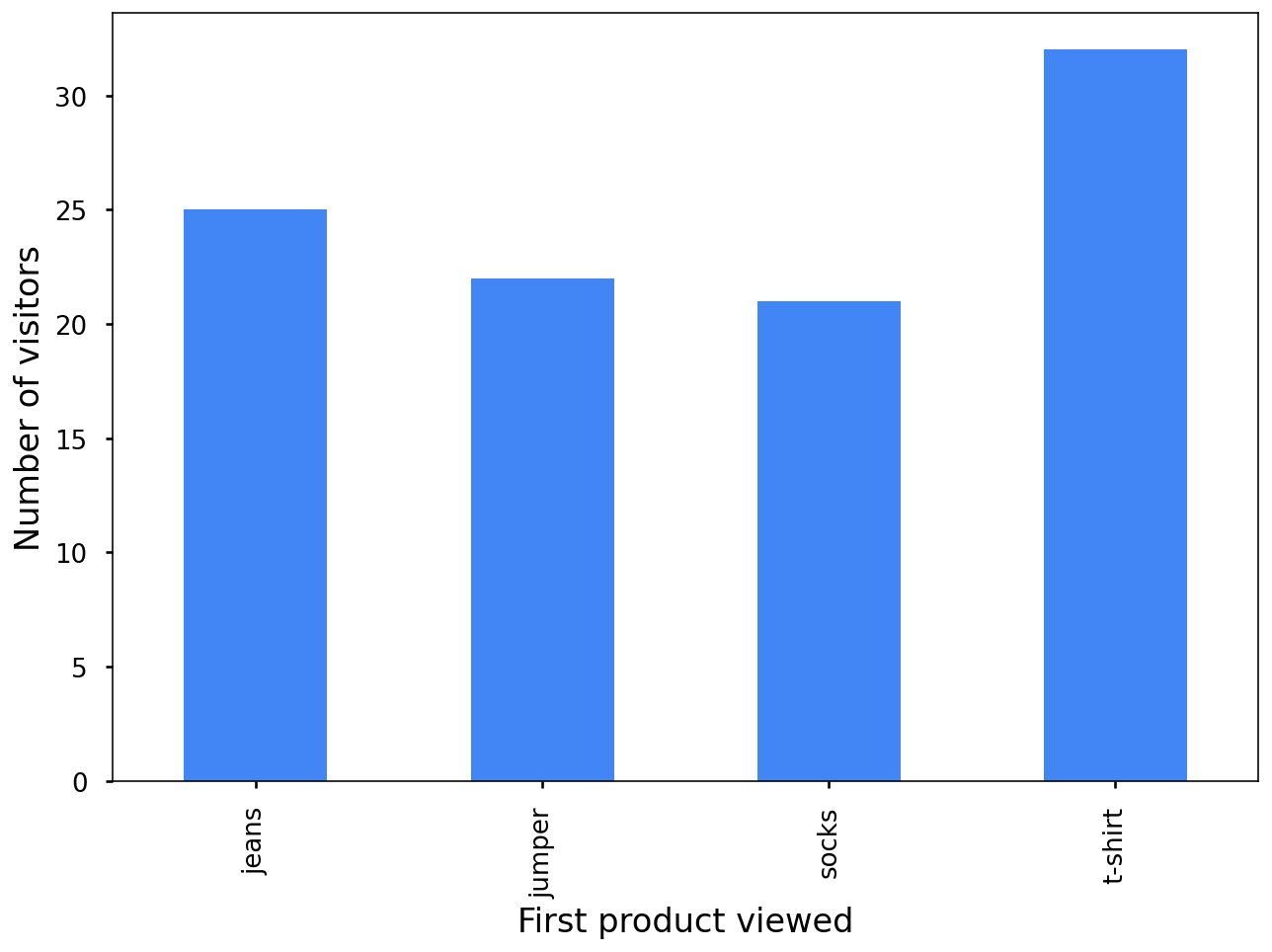
يبدو أنّ هذا الإجراء مفيد، ولكن هناك شرط. عندما تريد أخذ معلومات إضافية في الاعتبار، مثل ما إذا كان العملاء قد أجروا عملية شراء أو المنتج الذي اطّلعوا عليه ثانيًا، فإنّك تخاطر بالكشف عن هويات الأفراد في بياناتك.
يوضّح لك هذا الرسم البياني أنّ عميلاً واحدًا فقط اطّلع على سترة أولاً ثم أجرى عملية شراء:
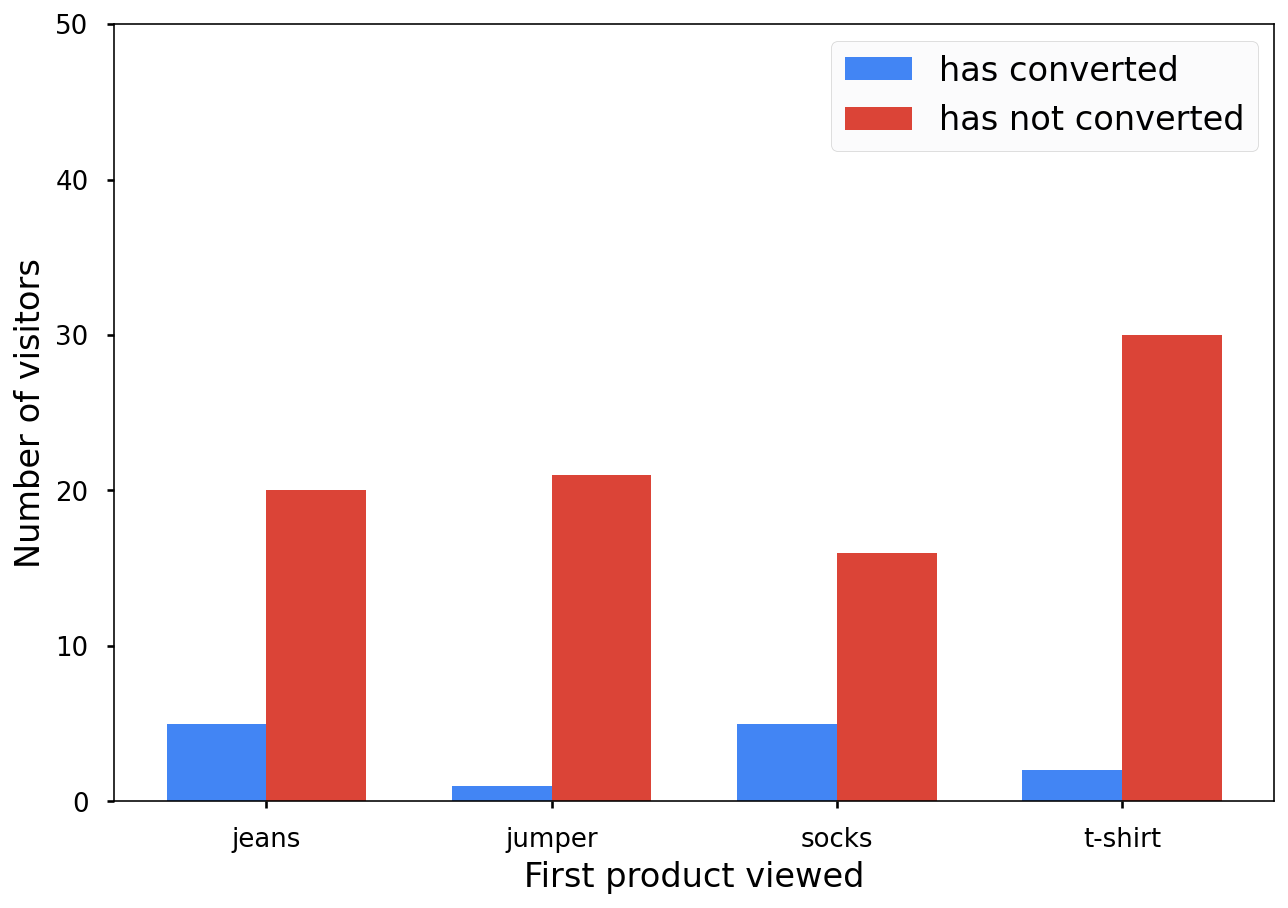
وهذا ليس جيدًا من منظور الخصوصية. يجب ألا تكشف الإحصاءات المجهولة الهوية عن مساهمات فردية، فماذا تفعل؟ يمكنك إضافة ضوضاء عشوائية إلى الرسوم البيانية الشريطية لجعلها أقل دقة.
لا يكون هذا الرسم البياني الشريطي دقيقًا تمامًا، ولكنّه يظل مفيدًا ولا يكشف عن مساهمات فردية:
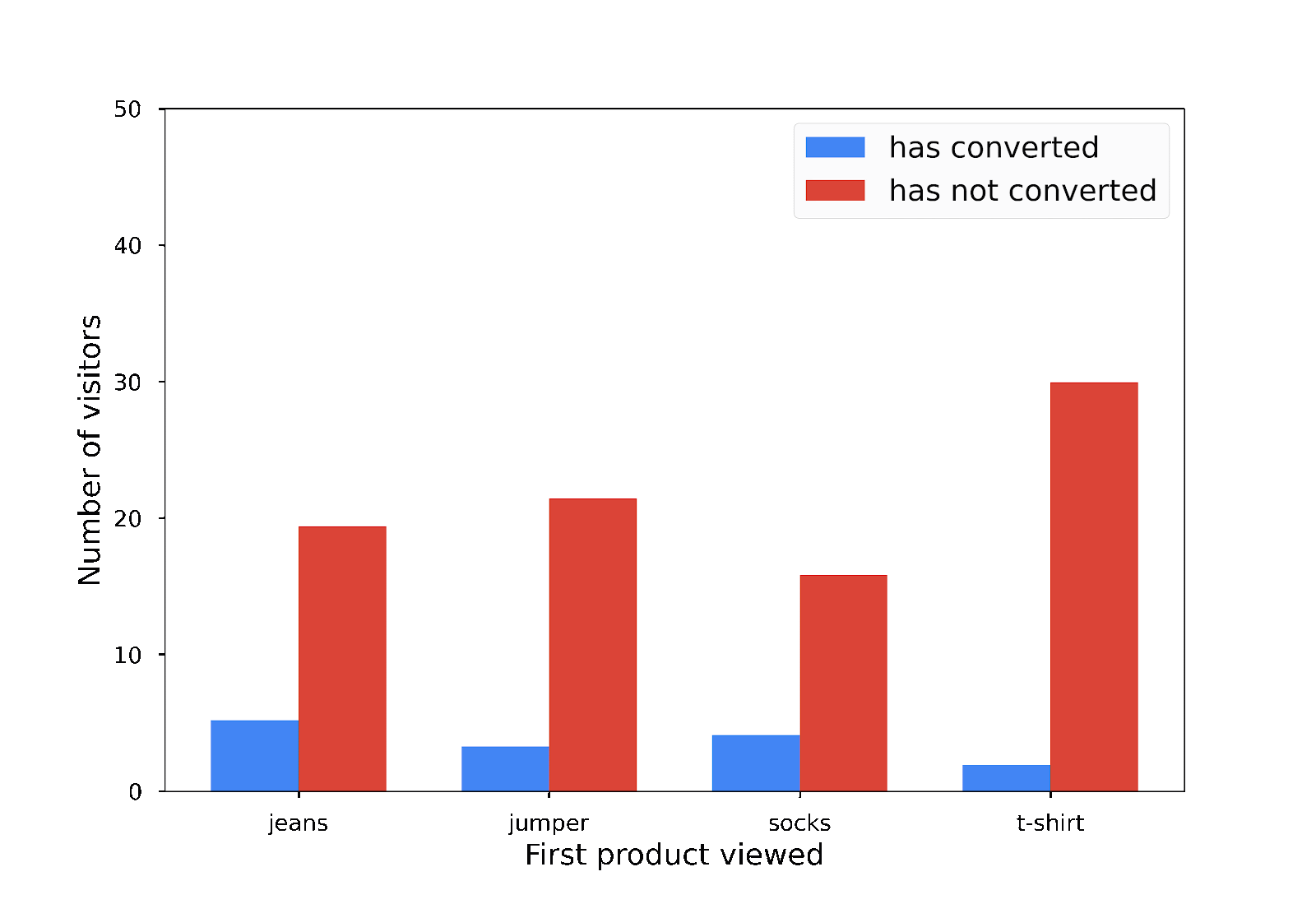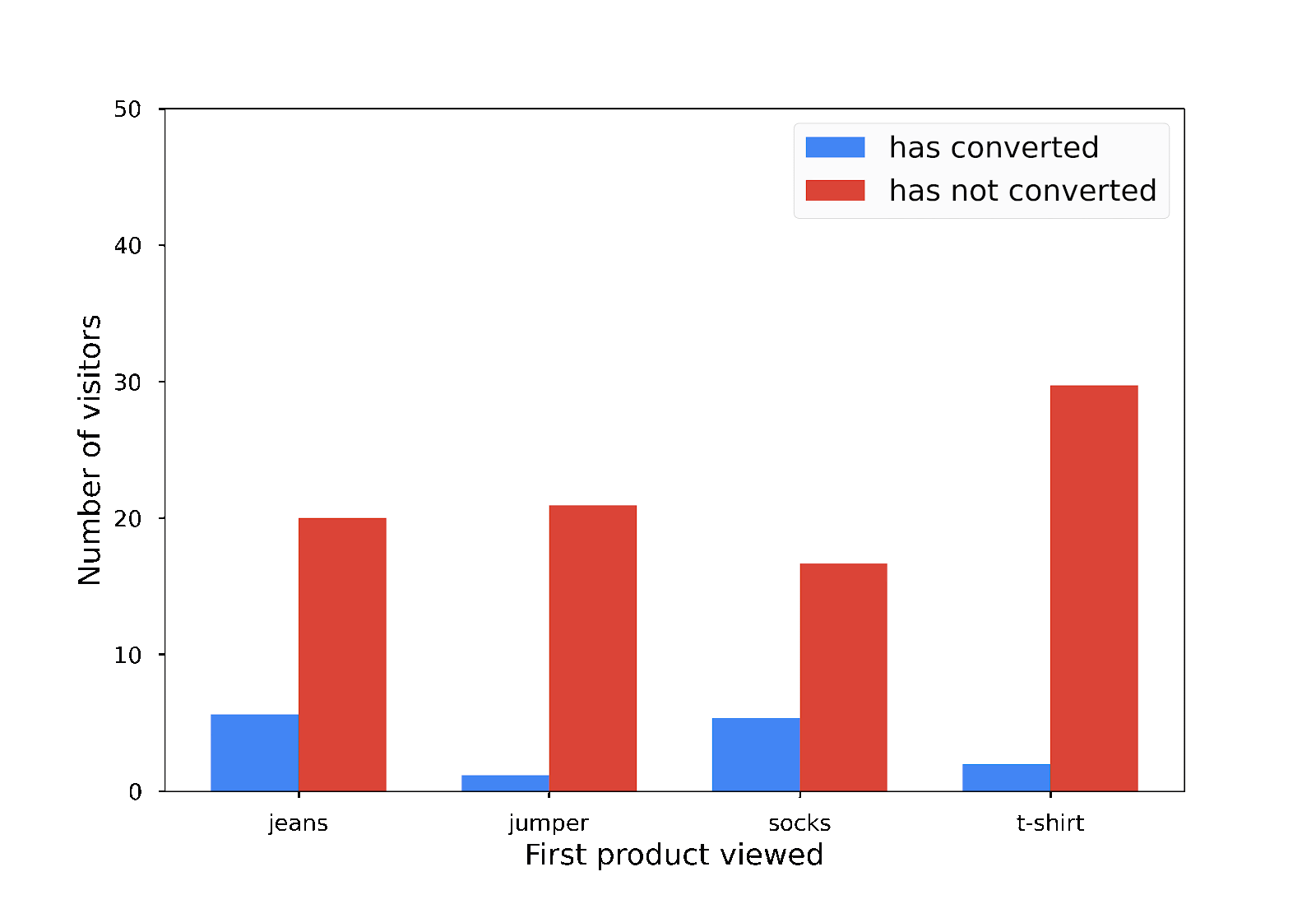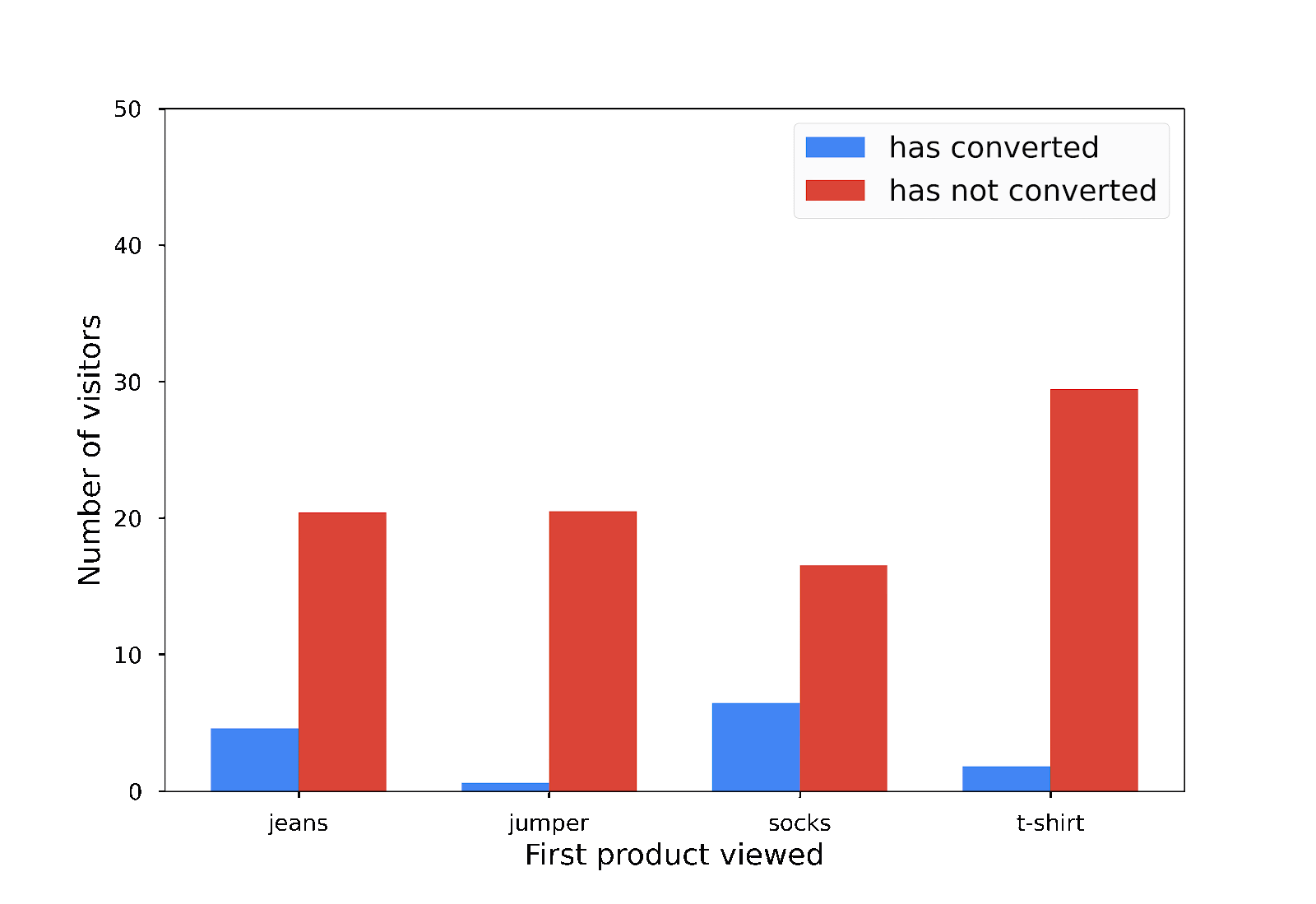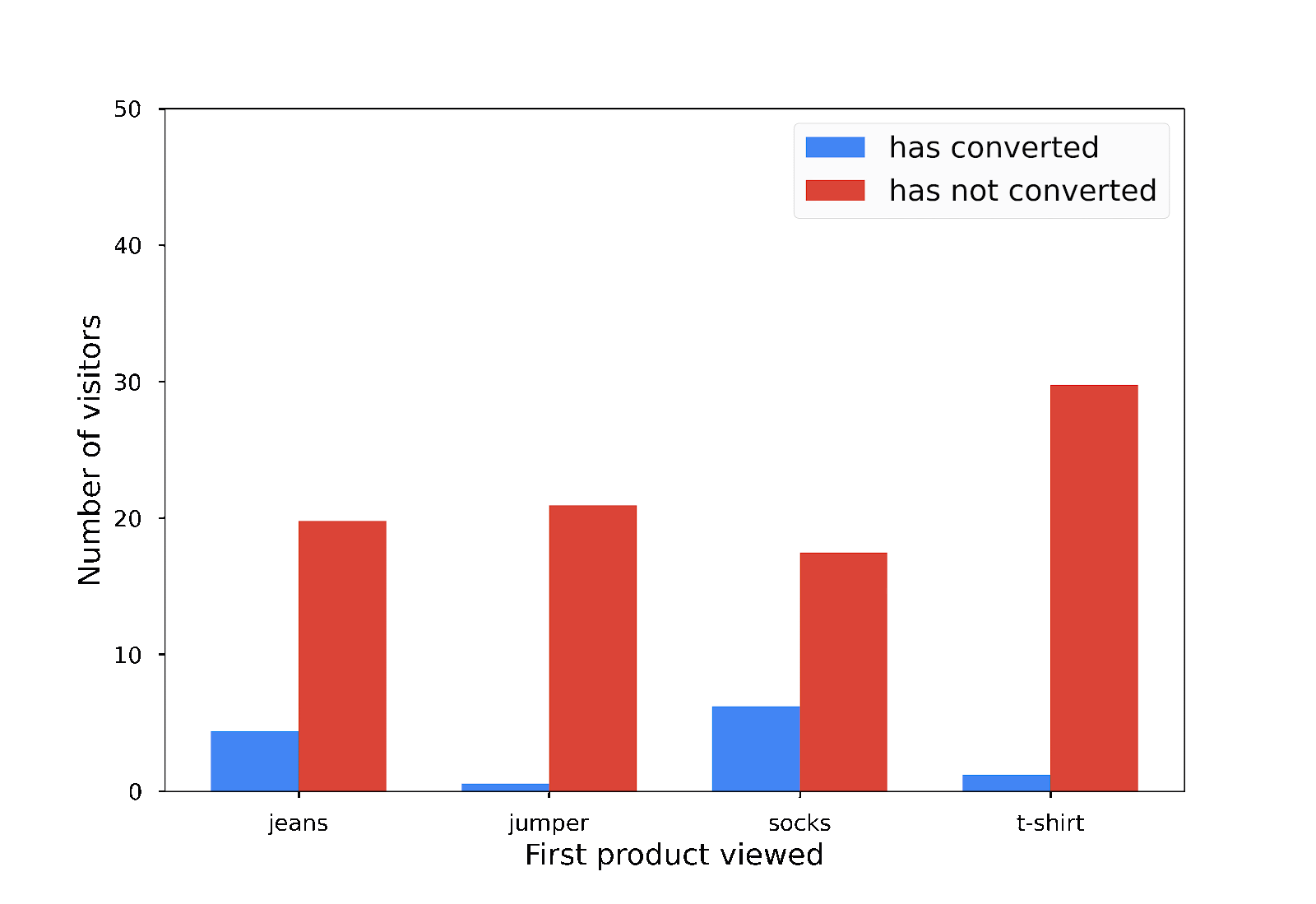
الخصوصية التفاضلية هي إضافة القدر المناسب من التشويش العشوائي لإخفاء المساهمات الفردية.
هذا المثال مبسط بشكل مفرط. يتطلّب التنفيذ السليم لتقنية الخصوصية التفاضلية المزيد من الجهد، ويتضمّن عددًا من التفاصيل الدقيقة غير المتوقّعة. على غرار التشفير، قد لا يكون من المستحسن إنشاء تطبيقك الخاص للخصوصية التفاضلية. بدلاً من ذلك، يمكنك استخدام PipelineDP.
3- تنزيل وتثبيت PipelineDP
لست بحاجة إلى تثبيت PipelineDP لمتابعة هذا الدرس التطبيقي حول الترميز لأنّه يمكنك العثور على جميع الرموز والرسومات البيانية ذات الصلة في هذا المستند.
لتجربة PipelineDP أو استخدامها لاحقًا، اتّبِع الخطوات التالية:
- نزِّل PipelineDP وثبِّته:
pip install pipeline-dp
إذا كنت تريد تشغيل المثال باستخدام Apache Beam، اتّبِع الخطوات التالية:
- نزِّل Apache Beam وثبِّتها:
pip install apache_beam
يمكنك العثور على الرمز البرمجي لهذا الدرس التطبيقي حول الترميز ومجموعة البيانات في الدليل PipelineDP/examples/codelab/.
4. احتساب مقاييس الإحالات الناجحة لكل منتج يتمّ الاطّلاع عليه أولاً
لنفترض أنّك تعمل في متجر لبيع الأزياء بالتجزئة على الإنترنت وتريد معرفة فئات المنتجات المختلفة التي تحقّق أكبر عدد من الإحالات الناجحة وأعلى قيمة لها عند عرضها أولاً. تريد مشاركة هذه المعلومات مع وكالة التسويق بالإضافة إلى فِرق داخلية أخرى، ولكنّك تريد منع تسرُّب معلومات عن أي عميل فردي.
لاحتساب مقاييس الإحالات الناجحة لكل منتج يتمّ عرضه أوّلاً على الموقع الإلكتروني، اتّبِع الخطوات التالية:
- راجِع مجموعة البيانات التجريبية الخاصة بالزيارات إلى موقعك الإلكتروني في الدليل
PipelineDP/examples/codelab/.
لقطة الشاشة هذه هي مثال على مجموعة البيانات. يحتوي على رقم تعريف المستخدِم والمنتجات التي اطّلع عليها المستخدِم وما إذا كان الزائر قد أجرى إحالة ناجحة، وإذا كان الأمر كذلك، قيمة الإحالة الناجحة.
user_id | product_view_0 | product_view_1 | product_view_2 | product_view_3 | product_view_4 | has_conversion | conversion_value |
0 | جينز | t_shirt | t_shirt | لا ينطبق | لا ينطبق | خطأ | 0.0 |
1 | جينز | t_shirt | جينز | وصلة | لا ينطبق | خطأ | 0.0 |
2 | t_shirt | وصلة | t_shirt | t_shirt | لا ينطبق | صحيح | 105.19 |
3 | t_shirt | t_shirt | جينز | لا ينطبق | لا ينطبق | خطأ | 0.0 |
4 | t_shirt | جوارب | جينز | جينز | لا ينطبق | خطأ | 0.0 |
أنت مهتم بالمقاييس التالية:
view_counts: عدد المرات التي يرى فيها زوّار موقعك الإلكتروني كل منتج للمرة الأولى.total_conversion_value: إجمالي المبلغ الذي ينفقه الزوّار عند إكمال الإحالة الناجحة.conversion_rate: معدّل الإحالات الناجحة للزوّار
- إنشاء المقاييس بطريقة غير خاصة:
conversion_metrics = df.groupby(['product_view_0'
])[['conversion_value', 'has_conversion']].agg({
'conversion_value': [len, np.sum],
'has_conversion': np.mean
})
conversion_metrics = conversion_metrics.rename(
columns={
'len': 'view_counts',
'sum': 'total_conversion_value',
'mean': 'conversion_rate'
}).droplevel(
0, axis=1)
كما تعلّمت سابقًا، يمكن أن تكشف هذه الإحصاءات عن معلومات حول الأفراد في مجموعة البيانات. على سبيل المثال، لم يُجرِ سوى مستخدم واحد إحالة ناجحة بعد أن رأى إعلانًا عن سترة أولاً. بالنسبة إلى 22 مشاهدة، يكون معدّل الإحالات الناجحة 0.05 تقريبًا. عليك الآن تحويل كل رسم بياني شريطي إلى مخطط خاص.
- حدِّد مَعلمات الخصوصية باستخدام الفئة
pipeline_dp.NaiveBudgetAccountant، ثم حدِّد الوسيطتَينepsilonوdeltaاللتين تريد استخدامهما في تحليلك.
تعتمد طريقة ضبط هذه الوسيطات على مشكلتك المحدّدة. لمزيد من المعلومات عن هذه المَعلمات، راجِع القسم اختياري: تعديل مَعلمات الخصوصية التفاضلية.
يستخدم مقتطف الرمز هذا قيمًا نموذجية:
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=1e-5)
- إعداد مثيل
LocalBackend:
ops = pipeline_dp.LocalBackend()
يمكنك استخدام مثيل LocalBackend لأنّك تشغّل هذا البرنامج محليًا بدون أُطر إضافية، مثل Beam أو Spark.
- إعداد مثيل
DPEngine:
dp_engine = pipeline_dp.DPEngine(budget_accountant, ops)
تتيح لك PipelineDP تحديد مَعلمات إضافية من خلال فئة pipeline_dp.AggregateParams، ما يؤثّر في إنشاء إحصاءاتك الخاصة.
params = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.COUNT],
max_partitions_contributed=1,
max_contributions_per_partition=1)
- حدِّد أنّك تريد احتساب مقياس
countواستخدام توزيع التشويشLAPLACE. - اضبط وسيطة
max_partitions_contributedعلى القيمة1.
يحدّد هذا الوسيط عدد الزيارات المختلفة التي يمكن أن يساهم بها المستخدم. تتوقّع أن يزور المستخدمون الموقع الإلكتروني مرة واحدة في اليوم، ولا يهمّك ما إذا كانوا يزورونه عدة مرات خلال اليوم.
- اضبط وسيطة
max_contributions_per_partitionsعلى القيمة1.
تحدّد هذه الوسيطة عدد المساهمات التي يمكن أن يقدّمها زائر واحد إلى قسم فردي أو فئة منتجات في هذه الحالة.
- أنشئ مثيلاً من
data_extractorيحدّد مكان العثور على الحقولprivacy_idوpartitionوvalue.
يجب أن تبدو التعليمات البرمجية على النحو التالي:
def run_pipeline(data, ops):
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=1e-5)
dp_engine = pipeline_dp.DPEngine(budget_accountant, ops)
params = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.COUNT],
max_partitions_contributed=1, # A single user can only contribute to one partition.
max_contributions_per_partition=1, # For a single partition, only one contribution per user is used.
)
data_extractors = pipeline_dp.DataExtractors(
privacy_id_extractor=lambda row: row.user_id,
partition_extractor=lambda row: row.product_view_0
value_extractor=lambda row: row.has_conversion)
dp_result = dp_engine.aggregate(data, params, data_extractors)
budget_accountant.compute_budgets()
return dp_result
- أضِف الرمز التالي لتحويل Pandas DataFrame إلى قائمة صفوف يمكنك من خلالها حساب الإحصاءات المحافظة على الخصوصية التفاضلية مباشرةً:
rows = [index_row[1] for index_row in df.iterrows()]
dp_result_local = run_pipeline(rows, ops) # Returns generator
list(dp_result_local)
تهانينا! لقد حسبت إحصاءاتك الأولى التي تحافظ على الخصوصية التفاضلية.
يعرض هذا الرسم البياني نتيجة العدد الخاص بك الذي يحافظ على الخصوصية التفاضلية بجانب العدد غير الخاص الذي حسبته سابقًا:
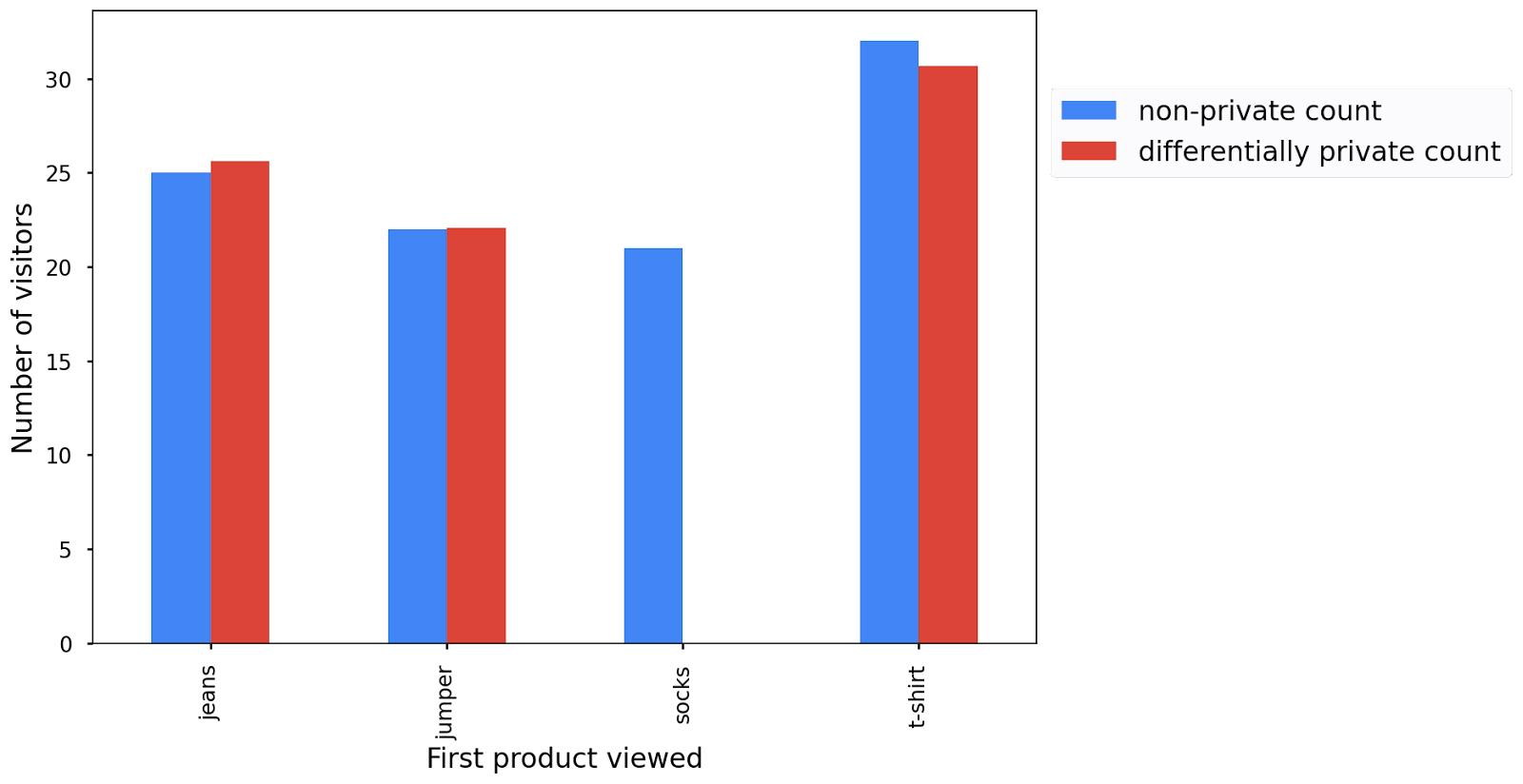
قد يختلف المخطط الشريطي الذي يظهر لك عند تشغيل الرمز عن هذا المخطط، وهذا أمر طبيعي. بسبب التشويش في الخصوصية التفاضلية، يظهر لك مخطط شريطي مختلف في كل مرة تشغّل فيها الرمز، ولكن يمكنك ملاحظة أنّها متشابهة مع المخطط الشريطي الأصلي غير الخاص.
يُرجى العِلم أنّه من المهم جدًا ألا يتم تشغيل سلسلة المعالجة عدة مرات لضمان الخصوصية. لمزيد من المعلومات، اطّلِع على مقالة "حساب إحصاءات متعددة".
5- استخدام الأقسام العامة
في القسم السابق، ربما لاحظت أنّك أسقطت جميع بيانات الزيارات لقسم معيّن، أي الزوّار الذين شاهدوا الجوارب لأول مرة على موقعك الإلكتروني.
يرجع ذلك إلى اختيار الأقسام أو تحديد الحدّ الأدنى، وهي خطوة مهمة لضمان توفّر ضمانات الخصوصية التفاضلية عندما يعتمد وجود أقسام الإخراج على بيانات المستخدم نفسها. في هذه الحالة، يمكن أن يؤدي مجرد توفّر قسم في الناتج إلى تسرُّب معلومات حول وجود مستخدم فردي في البيانات. لمزيد من المعلومات حول سبب انتهاك ذلك للخصوصية، يُرجى الاطّلاع على منشور المدوّنة هذا. لمنع انتهاك الخصوصية هذا، لا يحتفظ PipelineDP إلا بالأقسام التي تتضمّن عددًا كافيًا من المستخدمين.
عندما لا تعتمد قائمة أقسام الإخراج على بيانات المستخدم الخاصة، لن تحتاج إلى خطوة اختيار الأقسام هذه. وينطبق ذلك في الواقع على مثالك لأنّك تعرف جميع فئات المنتجات المحتملة التي يمكن أن يراها العميل أولاً.
لاستخدام الأقسام، اتّبِع الخطوات التالية:
- أنشئ قائمة بالأقسام المحتملة:
public_partitions_products = ['jeans', 'jumper', 'socks', 't-shirt']
- مرِّر القائمة إلى الدالة
run_pipeline()التي تضبطها كإدخال إضافي للفئةpipeline_dp.AggregateParams:
run_pipeline(
rows, ops, total_delta=0, public_partitions=public_partitions_products)
# Returns generator
params = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.COUNT],
max_partitions_contributed=1,
max_contributions_per_partition=1,
public_partitions=public_partitions_products)
في حال استخدام الأقسام العامة والضوضاء التفاضلية LAPLACE، من الممكن ضبط الوسيطة total_delta على القيمة 0.
يظهر الآن في النتيجة أنّه يتم تسجيل بيانات جميع الأقسام أو المنتجات.
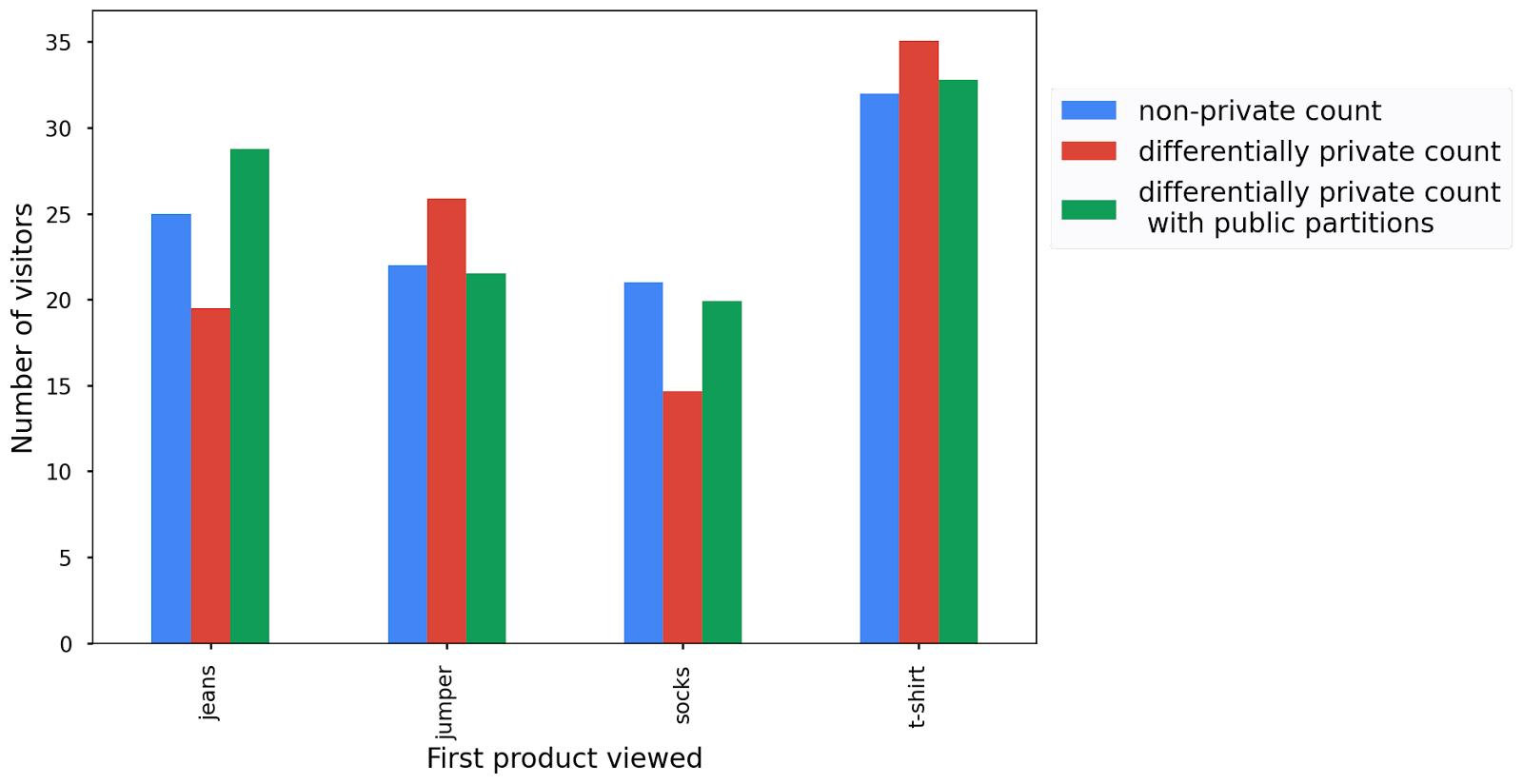
لا تتيح لك الأقسام العامة الاحتفاظ بالمزيد من الأقسام فحسب، بل إنّها تضيف أيضًا نصف مقدار التشويش تقريبًا لأنّك لا تنفق أي ميزانية للخصوصية على اختيار الأقسام، وبالتالي يكون الفرق بين عدد مرات الظهور الأولية وعدد مرات الظهور الخاصة أقل قليلاً مقارنةً بعملية التنفيذ السابقة.
هناك نقطتان مهمّتان يجب مراعاتهما عند استخدام الأقسام العامة:
- يجب توخّي الحذر عند استخلاص قائمة الأقسام من البيانات الأولية. إذا لم يتم إجراء ذلك بطريقة تحافظ على الخصوصية التفاضلية، لن يوفّر مسار البيانات ضمانات الخصوصية التفاضلية. لمزيد من المعلومات، اطّلِع على مقالة "متقدّم: استخلاص الأقسام من البيانات".
- إذا لم تتوفّر بيانات لبعض الأقسام العلنية، عليك تطبيق التشويش على هذه الأقسام للحفاظ على الخصوصية التفاضلية. على سبيل المثال، إذا استخدمت منتجًا إضافيًا مثل السراويل، والذي لا يظهر في مجموعة البيانات أو على موقعك الإلكتروني، سيظلّ ذلك تشويشًا وقد تُظهر النتائج بعض الزيارات إلى المنتجات عندما لم تكن هناك أي زيارات.
متقدّم: استخلاص الأقسام من البيانات
إذا كنت تُجري عمليات تجميع متعددة باستخدام قائمة الأقسام غير العلنية نفسها في مسار الإعداد نفسه، يمكنك استخلاص قائمة الأقسام مرة واحدة باستخدام الطريقة dp_engine.select_private_partitions() وتوفير الأقسام لكل عملية تجميع كإدخال public_partitions. لا يوفّر هذا الإجراء الأمان من منظور الخصوصية فحسب، بل يتيح لك أيضًا إضافة تشويش أقل لأنّك تستخدم ميزانية الخصوصية في اختيار الأقسام مرة واحدة فقط لجميع مسار البيانات.
def get_private_product_views(data, ops):
"""Obtains the list of product_views in a private manner.
This does not calculate any private metrics; it merely obtains the list of
product_views but does so while making sure the result is differentially private.
"""
# Set the total privacy budget.
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=1e-5)
# Create a DPEngine instance.
dp_engine = pipeline_dp.DPEngine(budget_accountant, ops)
# Specify how to extract privacy_id, partition_key, and value from a
# single element.
data_extractors = pipeline_dp.DataExtractors(
partition_extractor=lambda row: row.product_view_0,
privacy_id_extractor=lambda row: row.user_id)
# Run aggregation.
dp_result = dp_engine.select_partitions(
data, pipeline_dp.SelectPrivatePartitionsParams(
max_partitions_contributed=1),
data_extractors=data_extractors)
budget_accountant.compute_budgets()
return dp_result
6. حساب إحصاءات متعددة
بعد أن تعرّفت على طريقة عمل PipelineDP، يمكنك الاطّلاع على كيفية استخدامها في بعض حالات الاستخدام الأكثر تقدّمًا. كما ذكرنا في البداية، أنت مهتم بثلاث إحصاءات. تتيح لك PipelineDP احتساب إحصاءات متعدّدة في الوقت نفسه طالما أنّها تشترك في المَعلمات نفسها في مثيل AggregateParams، والذي ستراه لاحقًا. لا يقتصر الأمر على أنّها أكثر وضوحًا وأسهل في احتساب مقاييس متعددة في خطوة واحدة، بل إنّها أفضل أيضًا من ناحية الخصوصية.
إذا كنت تتذكّر المَعلمتَين epsilon وdelta اللتين تقدّمهما إلى الفئة NaiveBudgetAccountant، فهما تمثّلان ما يُعرف باسم ميزانية الخصوصية، وهي مقياس لمقدار خصوصية المستخدم التي يتم تسريبها من البيانات.
من المهم تذكُّر أنّ ميزانية الخصوصية هي ميزانية تراكمية. إذا شغّلت مسار معالجة مع قيمة إبسيلون ε ودلتا δ معيّنتَين لمرّة واحدة، ستنفق ميزانية (ε,δ). إذا نفّذت العملية مرة ثانية، ستنفق ميزانية إجمالية قدرها (2ε, 2δ). وبالمثل، إذا كنت تحسب إحصاءات متعدّدة باستخدام طريقة NaiveBudgetAccountant وميزانية خصوصية متتالية تبلغ ε,δ، فإنّك تنفق ميزانية إجمالية تبلغ (2ε, 2δ). وهذا يعني أنّك تقلّل من ضمانات الخصوصية.
لتجنُّب ذلك، عليك استخدام مثيل NaiveBudgetAccountant واحد مع إجمالي الميزانية التي تريد استخدامها عندما تحتاج إلى احتساب إحصاءات متعدّدة على البيانات نفسها. بعد ذلك، عليك تحديد قيمتَي epsilon وdelta اللتين تريد استخدامهما لكل عملية تجميع. في النهاية، ستحصل على ضمان الخصوصية نفسه بشكل عام، ولكن كلما زادت قيمتا epsilon وdelta في عملية تجميع معيّنة، زادت دقتها.
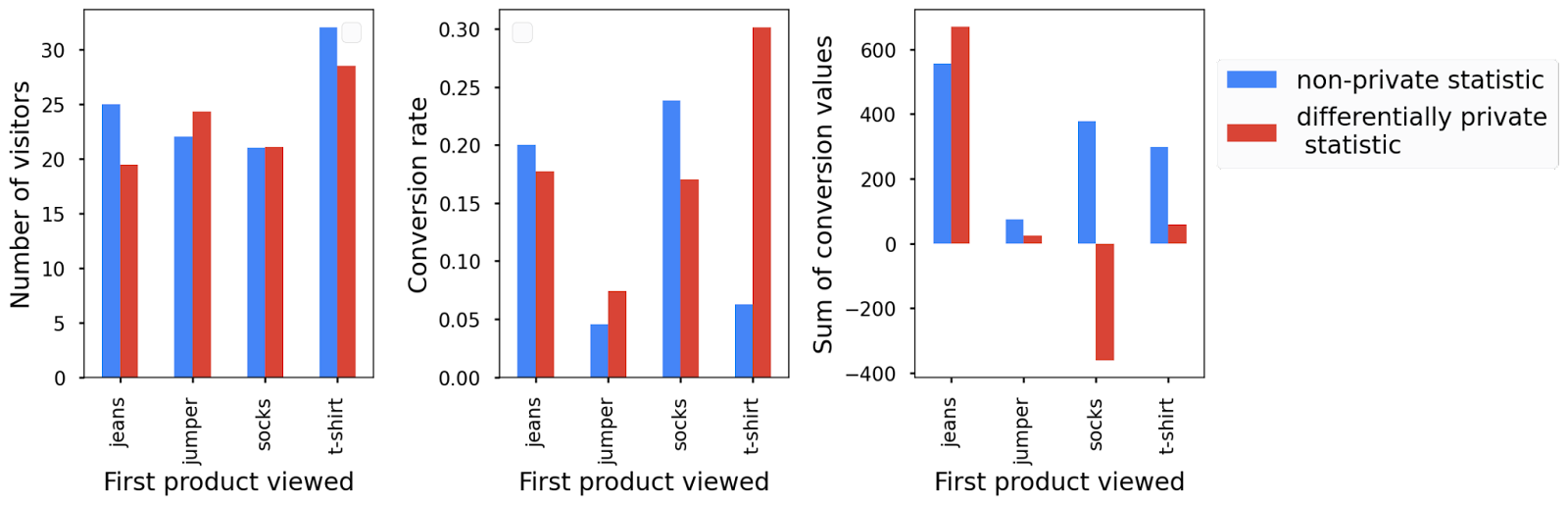
لمشاهدة هذا الإجراء عمليًا، يمكنك احتساب إحصاءات count وmean وsum.
يمكنك احتساب الإحصاءات استنادًا إلى مقياسَين مختلفَين: مقياس conversion_value، الذي تستخدمه لاستنتاج مقدار الأرباح التي تحقّقت استنادًا إلى المنتج الذي تمّت مشاهدته أولاً، ومقياس has_conversion، الذي تستخدمه لاحتساب عدد الزوّار إلى موقعك الإلكتروني ومتوسط معدّل الإحالات الناجحة.
لكل مقياس، عليك تحديد المَعلمات التي توجّه عملية احتساب الإحصاءات الخاصة بشكلٍ منفصل. يمكنك تقسيم ميزانية الخصوصية بين المقياسَين. تحسب إحصاءَين من المقياس has_conversion، لذا تريد تخصيص ثلثَي ميزانيتك الأولية له وتخصيص الثلث الآخر للمقياس conversion_value.
لاحتساب إحصاءات متعدّدة:
- اضبط محاسب ميزانية الخصوصية باستخدام إجمالي قيمتَي
epsilonوdeltaاللتين تريد استخدامهما في الإحصاءات الثلاث:
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=0)
- ابدأ
DPEngineلاحتساب مقاييسك:
dp_engine = pipeline_dp.DPEngine(budget_accountant, ops)
- حدِّد مَعلمات هذا المقياس.
params_conversion_value_metrics = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.SUM],
max_partitions_contributed=1,
max_contributions_per_partition=1,
min_value=0,
max_value=100,
public_partitions=public_partitions,
budget_weight=1/3)
تحدّد الوسيطة الأخيرة بشكل اختياري وزن ميزانية الخصوصية. يمكنك منح الوزن نفسه للجميع، ولكن عليك ضبط هذه الوسيطة على الثلث كما هو موضّح سابقًا.
يمكنك أيضًا ضبط الوسيطتَين min_value وmax_value لتحديد الحدّ الأدنى والأقصى المطبّقَين على قيمة تساهم بها وحدة الخصوصية في قسم. هذه المَعلمات مطلوبة عندما تريد احتساب مجموع أو متوسط خاص. لا تتوقّع قيمًا سالبة، لذا يمكنك افتراض أنّ 0 و100 هما حدود معقولة.
- استخرِج البيانات ذات الصلة ثم مرِّرها إلى دالة التجميع:
data_extractors_conversion_value_metrics = pipeline_dp.DataExtractors(
privacy_id_extractor=lambda row: row.user_id,
partition_extractor=lambda row: row.product_view_0,
value_extractor=lambda row: row.conversion_value)
dp_result_conversion_value_metrics = (
dp_engine.aggregate(data, params_conversion_value_metrics,
data_extractors_conversion_value_metrics))
- اتّبِع الخطوات نفسها لاحتساب المقياسَين استنادًا إلى المتغيّر
has_conversion:
params_conversion_rate_metrics = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.COUNT, pipeline_dp.Metrics.MEAN],
max_partitions_contributed=1,
max_contributions_per_partition=1,
min_value=0,
max_value=1,
public_partitions=public_partitions,
budget_weight=2/3)
data_extractors_conversion_rate_metrics = pipeline_dp.DataExtractors(
privacy_id_extractor=lambda row: row.user_id,
partition_extractor=lambda row: row.product_view_0,
value_extractor=lambda row: row.has_conversion)
dp_result_conversion_rate_metrics = (
dp_engine.aggregate(data, params_conversion_rate_metrics,
data_extractors_conversion_rate_metrics))
التغيير الوحيد هو في المثال pipeline_dp.AggregateParams، حيث تحدّد الآن mean وcount كتجميعات، وتخصّص ثلثَي ميزانية الخصوصية لهذه العملية الحسابية. بما أنّك تريد أن تكون حدود المساهمة نفسها لكلّ من الإحصاءات وحسابها على المتغيّر has_conversion نفسه، يمكنك الجمع بينهما في مثيل pipeline_dp.AggregateParams نفسه وحسابهما في الوقت نفسه.
- استدعِ طريقة
budget_accountant.compute_budgets():
budget_accountant.compute_budgets()
يمكنك رسم جميع الإحصاءات الخاصة الثلاثة مقارنةً بالإحصاءات الأصلية. استنادًا إلى الضوضاء المضافة، نلاحظ أنّ النتائج يمكن أن تقع خارج المقياس المعقول. في هذه الحالة، ستظهر لك نسبة إحالات ناجحة سالبة وإجمالي قيمة إحالات ناجحة سالبة للمستخدمين الذين يتنقّلون بين الصفحات لأنّ التشويش المضاف متماثل حول الصفر. لإجراء المزيد من التحليلات والمعالجة، من الأفضل عدم معالجة الإحصاءات الخاصة يدويًا بعد ذلك، ولكن إذا أردت إضافة هذه الرسومات البيانية إلى تقرير، يمكنك ببساطة ضبط الحد الأدنى على صفر بعد ذلك بدون انتهاك ضمانات الخصوصية.
7. تشغيل سلسلة المعالجة باستخدام Beam
تتطلّب معالجة البيانات في الوقت الحالي التعامل مع كميات هائلة من البيانات، لدرجة أنّه لا يمكنك معالجتها محليًا. بدلاً من ذلك، يستخدم العديد من الأشخاص أُطرًا لمعالجة البيانات على نطاق واسع، مثل Beam أو Spark، ويشغّلون خطوط الأنابيب الخاصة بهم على السحابة الإلكترونية.
تتوافق PipelineDP مع Beam وSpark مع إجراء تغييرات بسيطة فقط على الرمز البرمجي.
لتشغيل مسار البيانات باستخدام Beam مع واجهة برمجة التطبيقات private_beam، اتّبِع الخطوات التالية:
- يمكنك إعداد متغيّر
runnerثم إنشاء مسار تنفيذي تطبّق فيه عمليات الخصوصية على تمثيل Beam لـrows:
runner = fn_api_runner.FnApiRunner() # local runner
with beam.Pipeline(runner=runner) as pipeline:
beam_data = pipeline | beam.Create(rows)
- أنشئ متغيّر
budget_accountantيتضمّن مَعلمات الخصوصية المطلوبة:
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=0)
- أنشئ متغيّر
pcolأو مجموعة خاصة، ما يضمن توافق أي عمليات تجميع مع متطلبات الخصوصية:
pcol = beam_data | pbeam.MakePrivate(
budget_accountant=budget_accountant,
privacy_id_extractor=lambda
row: row.user_id)
- حدِّد مَعلمات التجميع الخاص في الفئة المناسبة.
في هذا المثال، يمكنك استخدام الفئة pipeline_dp.aggregate_params.SumParams() لأنّك تحتسب مجموع عدد مرّات عرض المنتج.
- مرِّر مَعلمات التجميع إلى طريقة
pbeam.Sumلاحتساب الإحصاءات:
dp_result = pcol | pbeam.Sum(params)
- في النهاية، يجب أن يبدو الرمز البرمجي على النحو التالي:
import pipeline_dp.private_beam as pbeam
runner = fn_api_runner.FnApiRunner() # local runner
with beam.Pipeline(runner=runner) as pipeline:
beam_data = pipeline | beam.Create(rows)
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=0)
# Create private collection.
pcol = beam_data | pbeam.MakePrivate(
budget_accountant=budget_accountant,
privacy_id_extractor=lambda row:
row.user_id)
# Specify parameters.
params = pipeline_dp.aggregate_params.SumParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
max_partitions_contributed=1,
max_contributions_per_partition=1,
min_value=0,
max_value=100,
public_partitions=public_partitions_product_views,
partition_extractor=lambda row: row.product_view_0,
value_extractor=lambda row:row.conversion_value)
dp_result = pcol | pbeam.Sum(params)
budget_accountant.compute_budgets()
dp_result | beam.Map(print)
8. اختياري: تعديل مَعلمات الخصوصية والفائدة
لقد رأيت عددًا قليلاً من المَعلمات المذكورة في هذا الدرس العملي، مثل المَعلمات epsilon وdelta وmax_partitions_contributed. يمكن تقسيمها تقريبًا إلى فئتين: مَعلمات الخصوصية ومَعلمات الأداة المساعدة.
مَعلمات الخصوصية
تحدّد المَعلمتان epsilon وdelta مقدار الخصوصية التي توفّرها الخصوصية التفاضلية. وبشكل أكثر دقة، هي مقياس لمقدار المعلومات التي يمكن أن يحصل عليها مهاجم محتمل حول البيانات من الناتج المخفي الهوية. كلّما زادت قيمة المَعلمات، زادت المعلومات التي يحصل عليها المهاجم عن البيانات، ما يشكّل خطرًا على الخصوصية. من ناحية أخرى، كلما انخفضت قيمة المَعلمتَين epsilon وdelta، زادت الضوضاء التي عليك إضافتها إلى الناتج لإخفاء هوية المستخدمين، وزاد عدد المستخدمين الفريدين الذين تحتاج إليهم في كل قسم لإبقائهم في الناتج المخفي الهوية. في هذه الحالة، يجب تحقيق التوازن بين الفائدة والخصوصية.
في PipelineDP، عليك تحديد ضمانات الخصوصية المطلوبة للناتج المجهول الهوية عند ضبط إجمالي ميزانية الخصوصية في مثيل NaiveBudgetAccountant. يجب الانتباه إلى أنّه إذا كنت تريد الحفاظ على ضمانات الخصوصية، عليك استخدام مثيل NaiveBudgetAccountant منفصل لكل عملية تجميع بيانات أو تشغيل سلسلة المعالجة عدة مرات لتجنُّب الإفراط في استخدام ميزانيتك.
لمزيد من المعلومات حول الخصوصية التفاضلية ومعنى مَعلمات الخصوصية، يُرجى الاطّلاع على قائمة قراءة حول الخصوصية التفاضلية.
مَعلمات الأداة
لا تؤثّر مَعلمات الأداة في ضمانات الخصوصية، ولكنّها تؤثّر في دقة النتائج وبالتالي في فائدتها. يتم توفيرها في مثيل AggregateParams وتُستخدَم لتوسيع نطاق التشويش المُضاف.
إحدى مَعلمات الأداة المضمّنة في مثيل AggregateParams والتي تنطبق على جميع عمليات التجميع هي المَعلَمة max_partitions_contributed. يتوافق القسم مع مفتاح البيانات التي تعرضها عملية تجميع البيانات في PipelineDP، لذا تحدّ المَعلمة max_partitions_contributed عدد قيم المفاتيح المختلفة التي يمكن للمستخدم المساهمة بها في الناتج. إذا ساهم مستخدم في عدد من المفاتيح يتجاوز قيمة المَعلمة max_partitions_contributed، سيتم إسقاط بعض المساهمات لكي تساهم في القيمة الدقيقة للمَعلمة max_partitions_contributed.
وبالمثل، تحتوي معظم عمليات التجميع على المَعلمة max_contributions_per_partition. يتم توفيرها أيضًا في مثيل AggregateParams، ويمكن أن يتضمّن كل تجميع قيمًا منفصلة لها. وهي تحدّد مساهمة المستخدم لكل مفتاح.
يتم قياس الضوضاء المضافة إلى الناتج باستخدام المَعلمتَين max_partitions_contributed وmax_contributions_per_partition، لذا هناك مقايضة هنا: تعني القيم الأكبر التي يتم تعيينها لكل مَعلمة أنّك تحتفظ بمزيد من البيانات، ولكنك تحصل على نتيجة أكثر تشويشًا.
تتطلّب بعض عمليات التجميع المَعلمتَين min_value وmax_value، اللتين تحدّدان حدود مساهمات كل مستخدم. إذا ساهم المستخدم بقيمة أقل من القيمة المخصّصة للمَعلمة min_value، يتمّ رفع القيمة إلى قيمة المَعلمة. وبالمثل، إذا أضاف المستخدم قيمة أكبر من قيمة المَعلمة max_value، يتم تخفيض القيمة إلى قيمة المَعلمة. للاحتفاظ بالمزيد من القيم الأصلية، عليك تحديد حدود أكبر. يتم قياس الضوضاء حسب حجم الحدود، لذا تتيح لك الحدود الأكبر الاحتفاظ بالمزيد من البيانات، ولكن ينتهي بك الأمر بنتيجة أكثر ضوضاءً.
أخيرًا، تتوافق المَعلمة noise_kind مع آليتَي تشويش مختلفتَين في PipelineDP: التشويش GAUSSIAN والتشويش LAPLACE. يوفّر توزيع LAPLACE فائدة أفضل مع حدود مساهمة منخفضة، ولهذا السبب تستخدمه PipelineDP تلقائيًا. ومع ذلك، إذا أردت استخدام ضوضاء توزيع GAUSSIAN، يمكنك تحديدها في مثيل AggregateParams.
9- تهانينا
أحسنت صنعًا. لقد أكملت درسًا تطبيقيًا حول الترميز في PipelineDP وعرفت الكثير عن الخصوصية التفاضلية وPipelineDP.