
1. Hinweis
Sie denken vielleicht, dass aggregierte Statistiken keine Informationen über die Personen preisgeben, auf die sie sich beziehen. Es gibt jedoch viele Möglichkeiten, wie ein Angreifer aus aggregierten Statistiken vertrauliche Informationen über Einzelpersonen erhalten kann.
In diesem Codelab erfahren Sie, wie Sie mit differenziell privaten Aggregationen aus PipelineDP private Statistiken erstellen, um die Privatsphäre von Einzelpersonen zu schützen. PipelineDP ist ein Python-Framework, mit dem Sie differenziellen Datenschutz auf große Datasets mit Batchverarbeitungssystemen wie Apache Spark und Apache Beam anwenden können. Weitere Informationen zum Berechnen von Statistiken mit differenziellem Datenschutz in Go finden Sie im Codelab Privacy on Beam.
Vertraulich bedeutet, dass die Ausgabe so erstellt wird, dass keine privaten Informationen über die Personen in den Daten preisgegeben werden. Dies lässt sich durch Differential Privacy erreichen, eine starke Datenschutzmethode zur Anonymisierung. Dabei werden Daten mehrerer Nutzer aggregiert, um den Datenschutz zu gewährleisten. Bei allen Anonymisierungsmethoden wird die Aggregation verwendet, aber nicht bei allen Aggregationsmethoden wird eine Anonymisierung erreicht. Differential Privacy hingegen bietet messbare Garantien in Bezug auf Informationslecks und Datenschutz.
Vorbereitung
- Python-Vorkenntnisse
- Grundlegende Kenntnisse der Datenaggregation
- Erfahrung mit pandas, Spark und Beam
Lerninhalte
- Grundlagen von Differential Privacy
- Differenziell datenschutzkonforme Zusammenfassungsstatistiken mit PipelineDP berechnen
- Ergebnisse mit zusätzlichen Datenschutz- und Nützlichkeitsparametern optimieren
Voraussetzungen
- Wenn Sie das Codelab in Ihrer eigenen Umgebung ausführen möchten, muss Python 3.7 oder höher auf Ihrem Computer installiert sein.
- Wenn Sie das Codelab ohne eigene Umgebung durcharbeiten möchten, benötigen Sie Zugriff auf Colaboratory.
2. Differential Privacy
Betrachten wir ein einfaches Beispiel, um den differenziellen Datenschutz besser zu verstehen.
Stellen Sie sich vor, Sie arbeiten in der Marketingabteilung eines Online-Modehändlers und möchten wissen, welche Ihrer Produkte sich am wahrscheinlichsten verkaufen.
In diesem Diagramm sehen Sie, welche Produkte sich die Kunden als Erstes angesehen haben, als sie die Website des Shops besucht haben: T-Shirts, Pullover, Socken oder Jeans. T‑Shirts sind der beliebteste Artikel, Socken der am wenigsten beliebte.
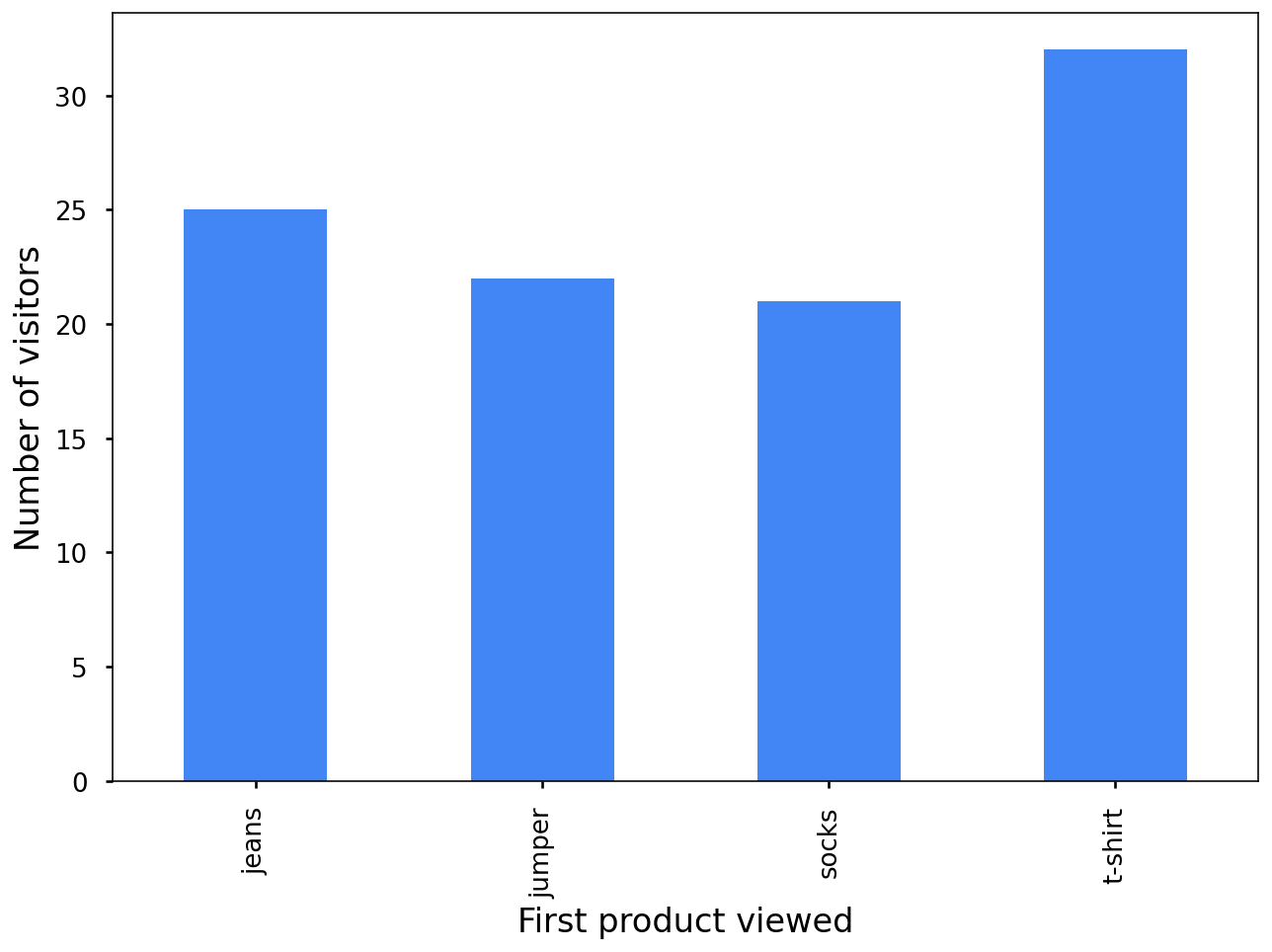
Das sieht nützlich aus, hat aber einen Haken. Wenn Sie zusätzliche Informationen berücksichtigen möchten, z. B. ob Kunden einen Kauf getätigt haben oder welches Produkt sie als Zweites angesehen haben, besteht das Risiko, dass Personen in Ihren Daten offengelegt werden.
In diesem Diagramm sehen Sie, dass nur ein Kunde zuerst einen Pullover angesehen und dann tatsächlich einen Kauf getätigt hat:

Aus Datenschutzsicht ist das nicht optimal. Anonymisierte Statistiken sollten keinen Aufschluss über individuelle Beiträge geben. Was können Sie also tun? Sie fügen Ihren Balkendiagrammen zufälliges Rauschen hinzu, um sie etwas ungenauer zu machen.
Dieses Balkendiagramm ist nicht vollständig korrekt, aber dennoch nützlich und es werden keine einzelnen Beiträge offengelegt:
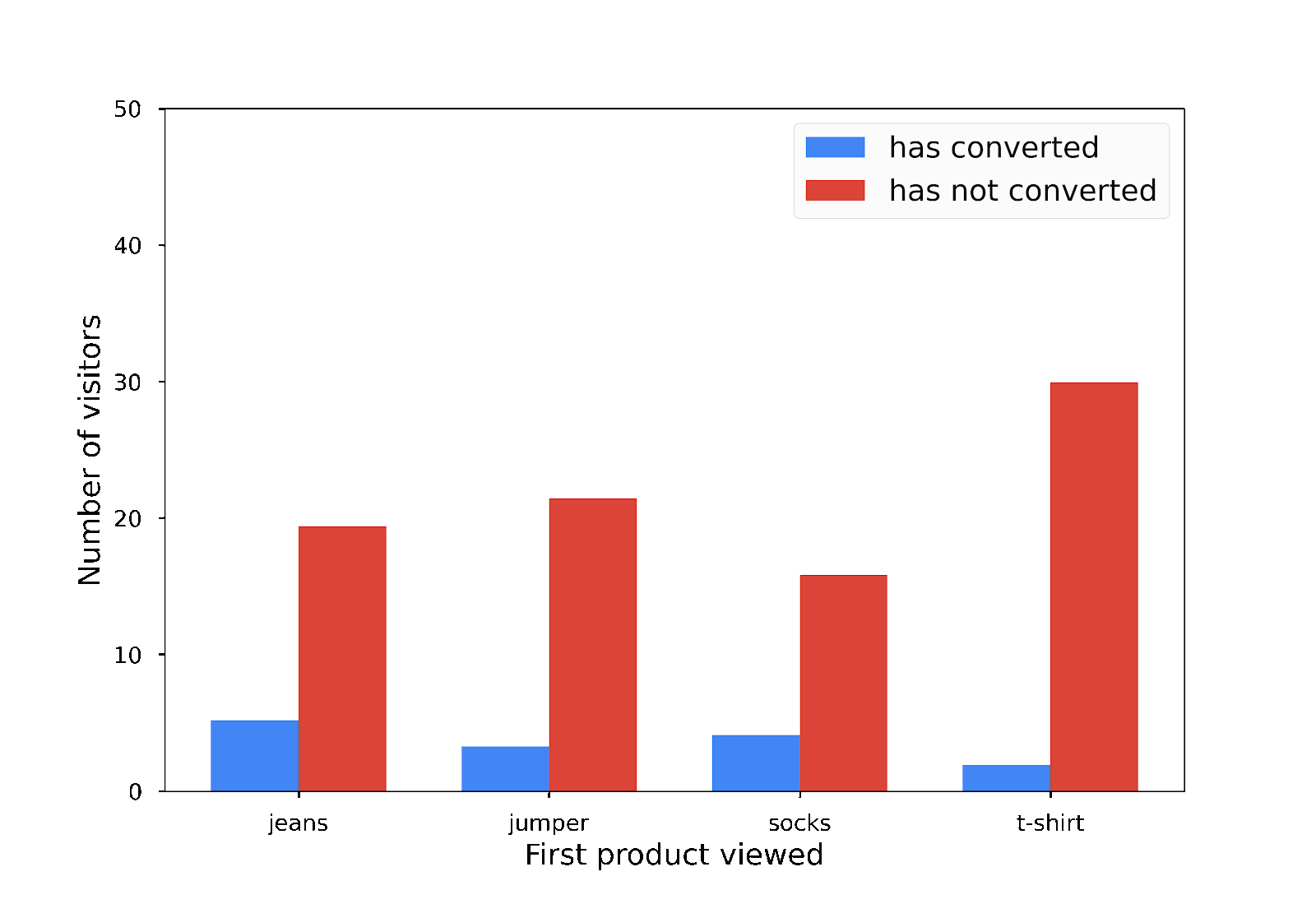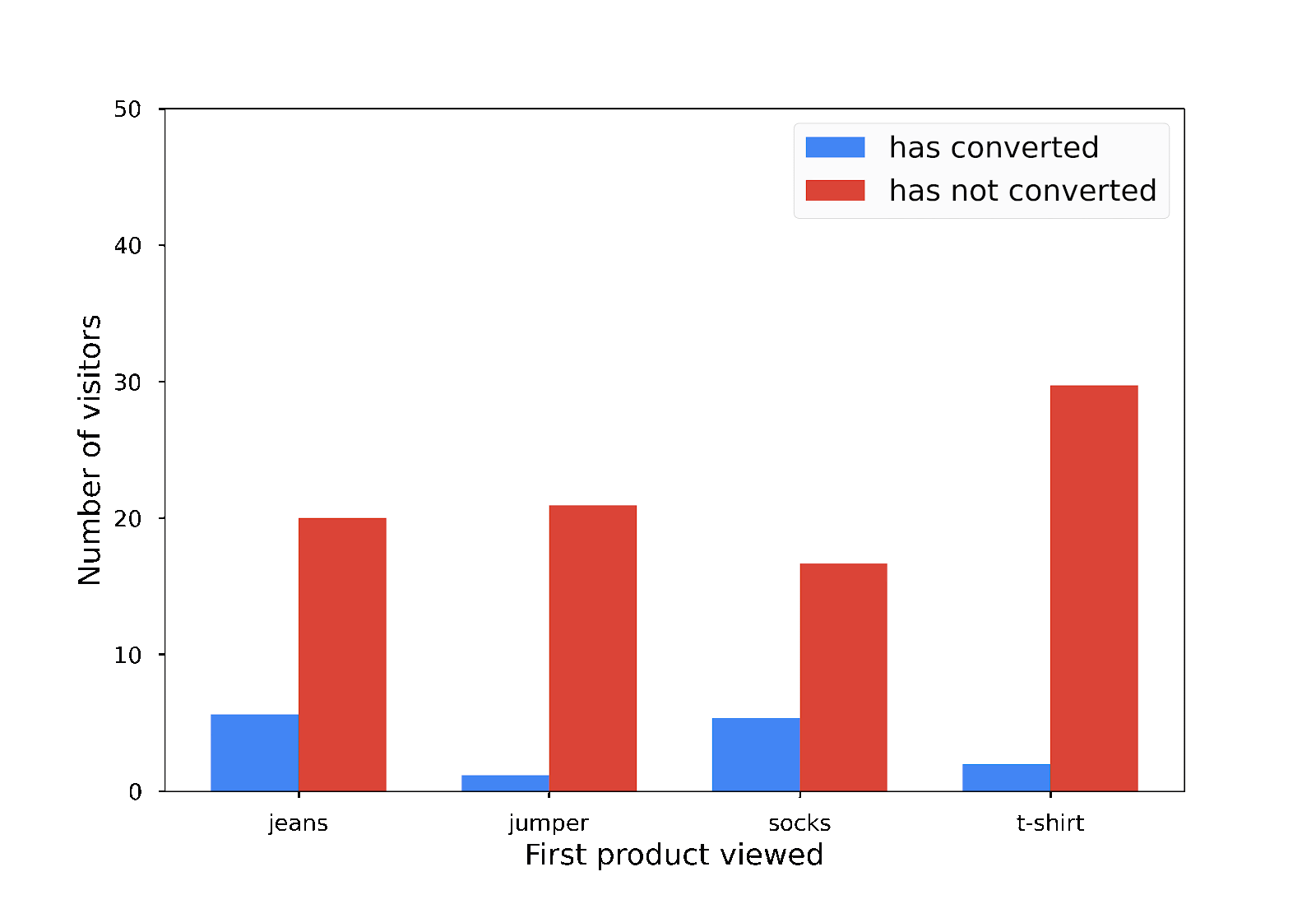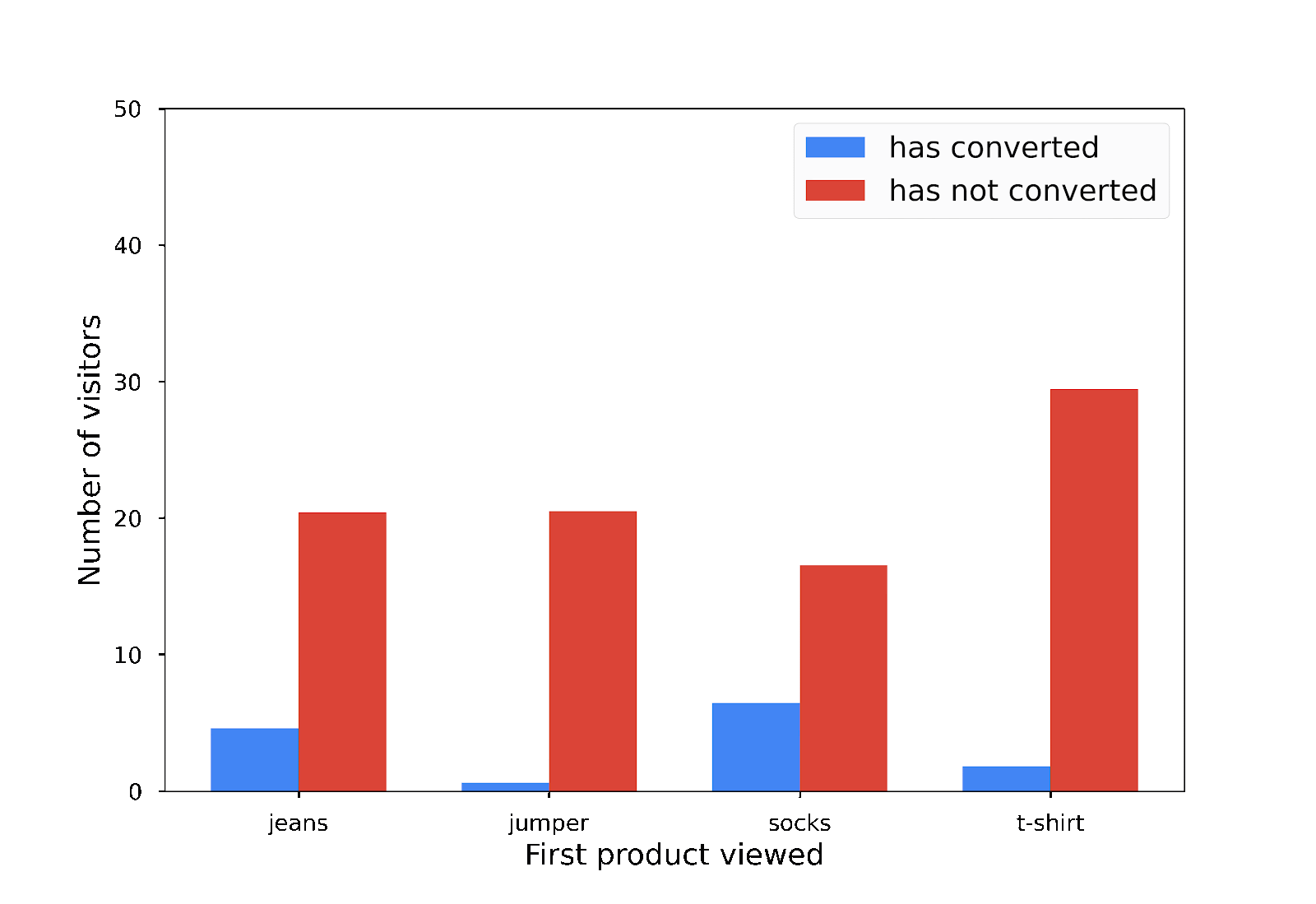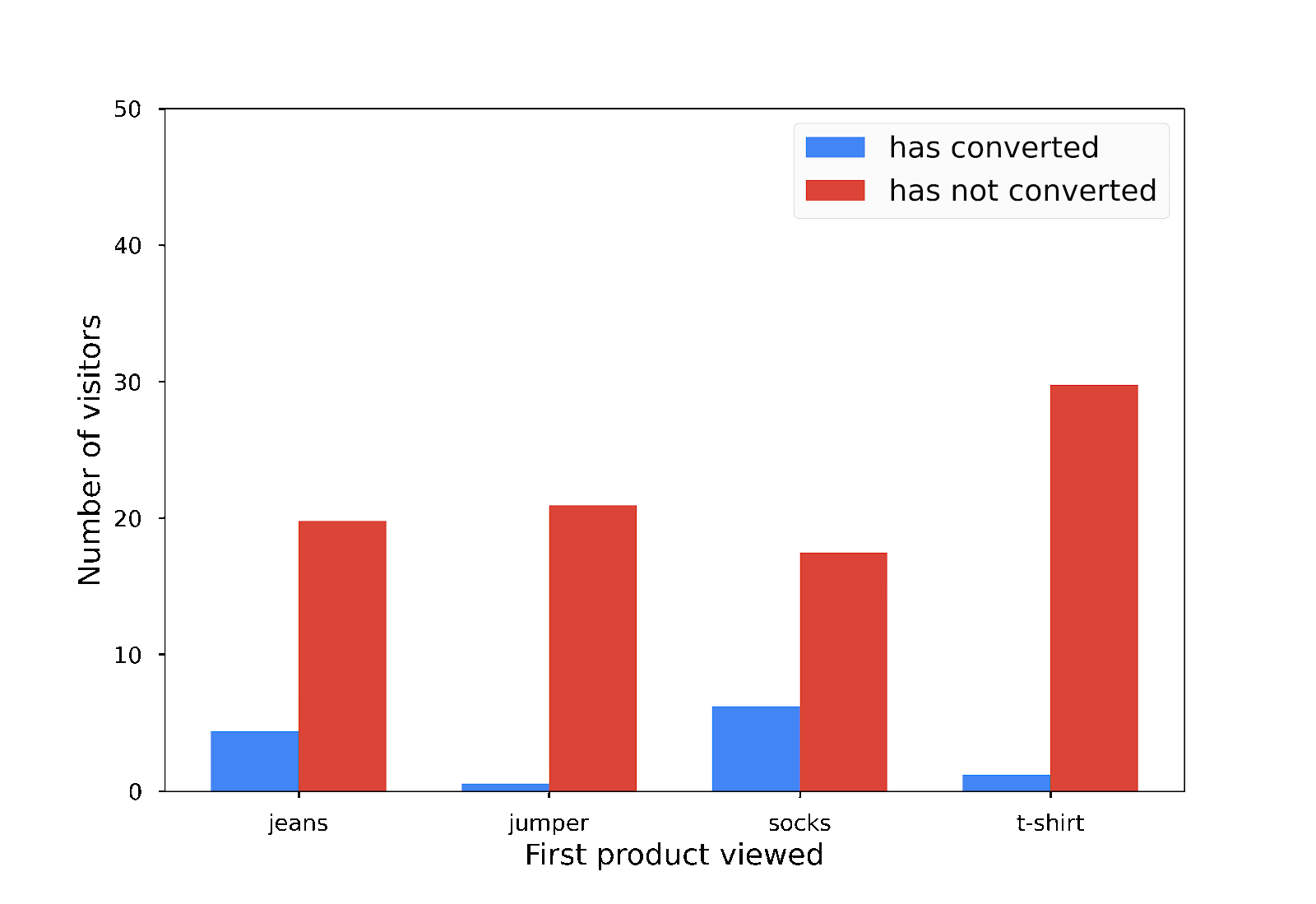
Bei Differential Privacy wird den Daten genau die richtige Menge an zufälligem Rauschen hinzugefügt, um einzelne Beiträge zu verschleiern.
Dieses Beispiel ist stark vereinfacht. Die korrekte Implementierung von Differential Privacy ist komplexer und birgt eine Reihe unerwarteter Implementierungsdetails. Ähnlich wie bei der Kryptografie ist es möglicherweise keine gute Idee, eine eigene Implementierung von Differential Privacy zu erstellen. Stattdessen können Sie PipelineDP verwenden.
3. PipelineDP herunterladen und installieren
Sie müssen PipelineDP nicht installieren, um diesem Codelab zu folgen, da Sie den gesamten relevanten Code und alle Grafiken in diesem Dokument finden.
So können Sie PipelineDP ausprobieren, selbst ausführen oder später verwenden:
- PipelineDP herunterladen und installieren:
pip install pipeline-dp
So führen Sie das Beispiel mit Apache Beam aus:
- Laden Sie Apache Beam herunter und installieren Sie es:
pip install apache_beam
Den Code für dieses Codelab und den Datensatz finden Sie im Verzeichnis PipelineDP/examples/codelab/.
4. Conversion-Messwerte pro erstem angesehenen Produkt berechnen
Angenommen, Sie arbeiten bei einem Online-Modehändler und möchten wissen, welche Ihrer verschiedenen Produktkategorien die höchste Anzahl und den höchsten Wert von Conversions generieren, wenn sie zuerst angesehen werden. Sie möchten diese Informationen mit Ihrer Marketingagentur und anderen internen Teams teilen, aber verhindern, dass Informationen über einzelne Kunden weitergegeben werden.
So berechnen Sie Conversion-Messwerte pro erstem angesehenen Produkt für die Website:
- Sehen Sie sich den Mock-Datensatz mit Besuchen auf Ihrer Website im Verzeichnis
PipelineDP/examples/codelab/an.
Dieser Screenshot ist ein Beispiel für das Dataset. Sie enthält die ID des Nutzers, die Produkte, die er sich angesehen hat, ob er eine Conversion ausgeführt hat und, falls ja, den Wert der Conversion.
user_id | product_view_0 | product_view_1 | product_view_2 | product_view_3 | product_view_4 | has_conversion | conversion_value |
0 | Jeans | t_shirt | t_shirt | Keine | Keine | falsch | 0,0 |
1 | Jeans | t_shirt | Jeans | Jumper | Keine | falsch | 0,0 |
2 | t_shirt | Jumper | t_shirt | t_shirt | Keine | wahr | 105,19 |
3 | t_shirt | t_shirt | Jeans | Keine | Keine | falsch | 0,0 |
4 | t_shirt | Socken | Jeans | Jeans | Keine | falsch | 0,0 |
Sie interessieren sich für diese Messwerte:
view_counts: Die Anzahl der Nutzer, die ein bestimmtes Produkt zum ersten Mal auf Ihrer Website sehen.total_conversion_value: Der Gesamtbetrag, den Besucher ausgeben, wenn sie eine Conversion ausführen.conversion_rate: Die Rate, mit der Besucher Conversions ausführen.
- Messwerte auf nicht vertrauliche Weise generieren:
conversion_metrics = df.groupby(['product_view_0'
])[['conversion_value', 'has_conversion']].agg({
'conversion_value': [len, np.sum],
'has_conversion': np.mean
})
conversion_metrics = conversion_metrics.rename(
columns={
'len': 'view_counts',
'sum': 'total_conversion_value',
'mean': 'conversion_rate'
}).droplevel(
0, axis=1)
Wie Sie bereits gelernt haben, können diese Statistiken Informationen über Personen in Ihrem Dataset enthalten. Beispiel: Nur eine Person hat eine Conversion ausgeführt, nachdem sie zuerst einen Pullover gesehen hat. Bei 22 Aufrufen liegt die Conversion-Rate bei etwa 0, 05. Jetzt müssen Sie jedes Balkendiagramm in ein privates Diagramm umwandeln.
- Definieren Sie Ihre Datenschutzparameter mit der Klasse
pipeline_dp.NaiveBudgetAccountantund geben Sie dann die Argumenteepsilonunddeltaan, die Sie für Ihre Analyse verwenden möchten.
Wie Sie diese Argumente festlegen, hängt von Ihrem jeweiligen Problem ab. Weitere Informationen finden Sie unter Optional: Differenziellen Datenschutz anpassen.
In diesem Code-Snippet werden Beispielwerte verwendet:
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=1e-5)
- Initialisieren Sie die
LocalBackend-Instanz:
ops = pipeline_dp.LocalBackend()
Sie können die LocalBackend-Instanz verwenden, da Sie dieses Programm lokal ohne zusätzliche Frameworks wie Beam oder Spark ausführen.
- Initialisieren Sie die
DPEngine-Instanz:
dp_engine = pipeline_dp.DPEngine(budget_accountant, ops)
Mit PipelineDP können Sie über die Klasse pipeline_dp.AggregateParams weitere Parameter angeben, die sich auf die Generierung Ihrer vertraulichen Statistiken auswirken.
params = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.COUNT],
max_partitions_contributed=1,
max_contributions_per_partition=1)
- Geben Sie an, dass Sie den Messwert
countberechnen und die RauschverteilungLAPLACEverwenden möchten. - Legen Sie für das Argument
max_partitions_contributedden Wert1fest.
Mit diesem Argument wird begrenzt, wie viele verschiedene Besuche ein Nutzer beitragen kann. Sie gehen davon aus, dass Nutzer die Website einmal pro Tag besuchen, und es ist Ihnen egal, ob sie sie im Laufe des Tages mehrmals besuchen.
- Legen Sie für das Argument
max_contributions_per_partitionsden Wert1fest.
Mit diesem Argument wird angegeben, wie viele Beiträge ein einzelner Besucher zu einer einzelnen Partition oder in diesem Fall zu einer Produktkategorie leisten kann.
- Erstellen Sie eine
data_extractor-Instanz, in der angegeben wird, wo die Felderprivacy_id,partitionundvaluezu finden sind.
Ihr Code sollte so aussehen:
def run_pipeline(data, ops):
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=1e-5)
dp_engine = pipeline_dp.DPEngine(budget_accountant, ops)
params = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.COUNT],
max_partitions_contributed=1, # A single user can only contribute to one partition.
max_contributions_per_partition=1, # For a single partition, only one contribution per user is used.
)
data_extractors = pipeline_dp.DataExtractors(
privacy_id_extractor=lambda row: row.user_id,
partition_extractor=lambda row: row.product_view_0
value_extractor=lambda row: row.has_conversion)
dp_result = dp_engine.aggregate(data, params, data_extractors)
budget_accountant.compute_budgets()
return dp_result
- Fügen Sie diesen Code hinzu, um Ihren Pandas-DataFrame in eine Liste von Zeilen zu transformieren, aus denen Sie direkt differenziell private Statistiken berechnen können:
rows = [index_row[1] for index_row in df.iterrows()]
dp_result_local = run_pipeline(rows, ops) # Returns generator
list(dp_result_local)
Glückwunsch! Sie haben Ihre erste differenziell private Statistik berechnet.
In diesem Diagramm sehen Sie das Ergebnis Ihrer differenziell privaten Anzahl neben der nicht privaten Anzahl, die Sie zuvor berechnet haben:

Das Balkendiagramm, das Sie erhalten, wenn Sie den Code ausführen, kann sich von diesem unterscheiden. Das ist in Ordnung. Aufgrund des Rauschens beim differenziellen Datenschutz erhalten Sie jedes Mal, wenn Sie den Code ausführen, ein anderes Balkendiagramm. Sie können jedoch sehen, dass es dem ursprünglichen nicht vertraulichen Balkendiagramm ähnelt.
Es ist sehr wichtig, dass die Pipeline aus Datenschutzgründen nicht mehrmals ausgeführt wird. Weitere Informationen finden Sie unter „Mehrere Statistiken berechnen“.
5. Öffentliche Partitionen verwenden
Im vorherigen Abschnitt haben Sie möglicherweise bemerkt, dass Sie alle Besuchsdaten für eine Partition entfernt haben, nämlich Besucher, die zum ersten Mal Socken auf Ihrer Website gesehen haben.
Das liegt an der Auswahl von Partitionen oder der Schwellenwertbildung. Das ist ein wichtiger Schritt, um die Zusicherung von Differential Privacy zu gewährleisten, wenn das Vorhandensein von Ausgabepartitionen von den Nutzerdaten selbst abhängt. In diesem Fall kann allein das Vorhandensein einer Partition in der Ausgabe die Existenz eines einzelnen Nutzers in den Daten offenbaren. Weitere Informationen dazu, warum dies gegen den Datenschutz verstößt Um diesen Datenschutzverstoß zu verhindern, behält PipelineDP nur Partitionen mit einer ausreichenden Anzahl von Nutzern bei.
Wenn die Liste der Ausgabepartitionen nicht von privaten Nutzerdaten abhängt, ist dieser Schritt zur Partitionsauswahl nicht erforderlich. Das ist in Ihrem Beispiel tatsächlich der Fall, da Sie alle möglichen Produktkategorien kennen, die ein Kunde zuerst sehen könnte.
So verwenden Sie Partitionen:
- Erstellen Sie eine Liste der möglichen Partitionen:
public_partitions_products = ['jeans', 'jumper', 'socks', 't-shirt']
- Übergeben Sie die Liste an die Funktion
run_pipeline(), die sie als zusätzliche Eingabe für die Klassepipeline_dp.AggregateParamsfestlegt:
run_pipeline(
rows, ops, total_delta=0, public_partitions=public_partitions_products)
# Returns generator
params = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.COUNT],
max_partitions_contributed=1,
max_contributions_per_partition=1,
public_partitions=public_partitions_products)
Wenn Sie öffentliche Partitionen und LAPLACE-Rauschen verwenden, können Sie das Argument total_delta auf einen 0-Wert festlegen.
Im Ergebnis sehen Sie jetzt, dass Daten für alle Partitionen oder Produkte gemeldet werden.

Mit öffentlichen Partitionen können Sie nicht nur mehr Partitionen beibehalten, sondern auch das Rauschen wird um etwa die Hälfte reduziert, da kein Datenschutzbudget für die Auswahl von Partitionen aufgewendet wird. Der Unterschied zwischen Roh- und privaten Zählungen ist also etwas geringer als beim vorherigen Lauf.
Bei der Verwendung öffentlicher Partitionen sind zwei wichtige Punkte zu beachten:
- Seien Sie vorsichtig, wenn Sie die Liste der Partitionen aus Rohdaten ableiten. Wenn Sie das nicht auf differenziell private Weise tun, bietet Ihre Pipeline keine Differential Privacy-Garantien mehr. Weitere Informationen finden Sie unter „Erweitert: Partitionen aus Daten ableiten“.
- Wenn für einige der öffentlichen Partitionen keine Daten vorhanden sind, müssen Sie Rauschen auf diese Partitionen anwenden, um den differenziellen Datenschutz zu wahren. Wenn Sie beispielsweise ein zusätzliches Produkt wie „Hose“ verwendet haben, das in Ihrem Datensatz oder auf Ihrer Website nicht vorkommt, handelt es sich dennoch um Rauschen. In den Ergebnissen werden möglicherweise einige Besuche von Produkten angezeigt, obwohl es keine gab.
Erweitert: Partitionen aus Daten ableiten
Wenn Sie mehrere Aggregationen mit derselben Liste nicht öffentlicher Ausgabepartitionen in derselben Pipeline ausführen, können Sie die Liste der Partitionen einmal mit der Methode dp_engine.select_private_partitions() ableiten und die Partitionen als public_partitions-Eingabe für jede Aggregation bereitstellen. Das ist nicht nur aus Datenschutzsicht sicher, sondern ermöglicht es Ihnen auch, weniger Rauschen hinzuzufügen, da Sie das Datenschutzbudget nur einmal für die gesamte Pipeline für die Auswahl von Partitionen verwenden.
def get_private_product_views(data, ops):
"""Obtains the list of product_views in a private manner.
This does not calculate any private metrics; it merely obtains the list of
product_views but does so while making sure the result is differentially private.
"""
# Set the total privacy budget.
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=1e-5)
# Create a DPEngine instance.
dp_engine = pipeline_dp.DPEngine(budget_accountant, ops)
# Specify how to extract privacy_id, partition_key, and value from a
# single element.
data_extractors = pipeline_dp.DataExtractors(
partition_extractor=lambda row: row.product_view_0,
privacy_id_extractor=lambda row: row.user_id)
# Run aggregation.
dp_result = dp_engine.select_partitions(
data, pipeline_dp.SelectPrivatePartitionsParams(
max_partitions_contributed=1),
data_extractors=data_extractors)
budget_accountant.compute_budgets()
return dp_result
6. Mehrere Statistiken berechnen
Nachdem Sie nun wissen, wie PipelineDP funktioniert, können Sie sehen, wie Sie es für einige komplexere Anwendungsfälle verwenden können. Wie bereits erwähnt, interessieren Sie sich für drei Statistiken. Mit PipelineDP können Sie mehrere Statistiken gleichzeitig berechnen, sofern sie dieselben Parameter in der AggregateParams-Instanz haben, die Sie später sehen. Das ist nicht nur übersichtlicher und einfacher, um mehrere Messwerte gleichzeitig zu berechnen, sondern auch datenschutzfreundlicher.
Die Parameter epsilon und delta, die Sie für die Klasse NaiveBudgetAccountant angeben, stellen das sogenannte Datenschutzbudget dar. Das ist ein Maß dafür, wie viele Nutzerdaten Sie aus den Daten preisgeben.
Das Datenschutzbudget ist additiv. Wenn Sie eine Pipeline mit einem bestimmten Epsilon ε und Delta δ einmal ausführen, geben Sie ein (ε,δ)-Budget aus. Wenn Sie sie ein zweites Mal ausführen, geben Sie ein Gesamtbudget von (2ε, 2δ) aus. Wenn Sie mehrere Statistiken mit einer NaiveBudgetAccountant-Methode und nacheinander einem Datenschutzbudget von (ε,δ) berechnen, geben Sie ein Gesamtbudget von (2ε, 2δ) aus. Das bedeutet, dass Sie die Datenschutzgarantien einschränken.
Um dies zu umgehen, müssen Sie eine einzelne NaiveBudgetAccountant-Instanz mit dem Gesamtbudget verwenden, das Sie nutzen möchten, wenn Sie mehrere Statistiken für dieselben Daten berechnen müssen. Anschließend müssen Sie die Werte epsilon und delta angeben, die Sie für die einzelnen Aggregationen verwenden möchten. Letztendlich erhalten Sie dieselbe allgemeine Datenschutzgarantie. Je höher die epsilon- und delta-Werte einer bestimmten Aggregation sind, desto höher ist die Genauigkeit.
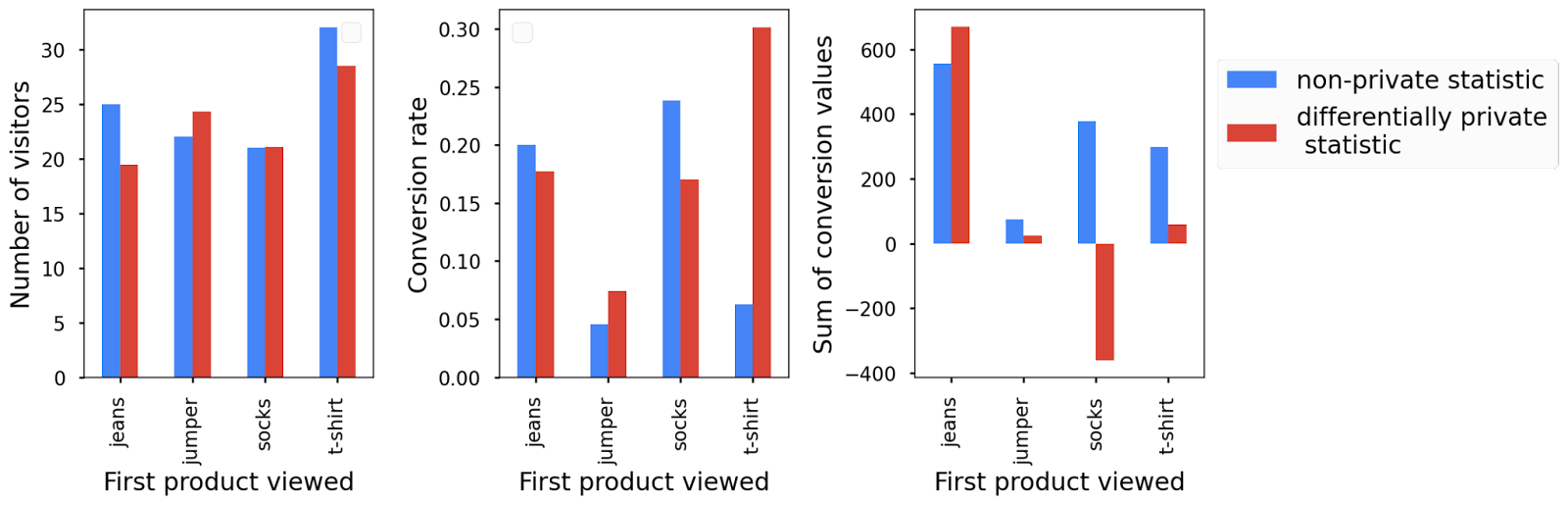
Um das in Aktion zu sehen, können Sie die Statistiken count, mean und sum berechnen.
Sie berechnen Statistiken anhand von zwei verschiedenen Messwerten: einem conversion_value-Messwert, mit dem Sie den Umsatz schätzen, der auf Grundlage des zuerst angesehenen Produkts generiert wurde, und einem has_conversion-Messwert, mit dem Sie die Anzahl der Besucher Ihrer Website und die durchschnittliche Conversion-Rate berechnen.
Für jeden Messwert müssen Sie die Parameter, die die Berechnung der privaten Statistiken steuern, separat angeben. Sie teilen Ihr Datenschutzbudget auf die beiden Messwerte auf. Sie berechnen zwei Statistiken aus dem Messwert has_conversion. Daher weisen Sie ihm zwei Drittel Ihres ursprünglichen Budgets zu und dem Messwert conversion_value das verbleibende Drittel.
So berechnen Sie mehrere Statistiken:
- Richten Sie Ihren Datenschutzbudget-Buchhalter mit den Gesamtwerten für
epsilonunddeltaein, die Sie für die drei Statistiken verwenden möchten:
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=0)
- Initialisieren Sie die
DPEngine, um Ihre Messwerte zu berechnen:
dp_engine = pipeline_dp.DPEngine(budget_accountant, ops)
- Geben Sie die Parameter für diesen Messwert an.
params_conversion_value_metrics = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.SUM],
max_partitions_contributed=1,
max_contributions_per_partition=1,
min_value=0,
max_value=100,
public_partitions=public_partitions,
budget_weight=1/3)
Mit dem letzten Argument kann optional das Gewicht Ihres Datenschutzbudgets angegeben werden. Sie könnten allen dieselbe Gewichtung geben, aber Sie möchten dieses Argument wie oben beschrieben auf ein Drittel festlegen.
Sie legen auch ein min_value- und ein max_value-Argument fest, um die Unter- und Obergrenze für einen Wert anzugeben, der von einer Einheit der Vertraulichkeit in einer Partition beigetragen wird. Diese Parameter sind erforderlich, wenn Sie eine private Summe oder einen privaten Mittelwert berechnen möchten. Da Sie keine negativen Werte erwarten, können Sie 0 und 100 als angemessene Grenzen annehmen.
- Extrahieren Sie die relevanten Daten und übergeben Sie sie dann an die Aggregationsfunktion:
data_extractors_conversion_value_metrics = pipeline_dp.DataExtractors(
privacy_id_extractor=lambda row: row.user_id,
partition_extractor=lambda row: row.product_view_0,
value_extractor=lambda row: row.conversion_value)
dp_result_conversion_value_metrics = (
dp_engine.aggregate(data, params_conversion_value_metrics,
data_extractors_conversion_value_metrics))
- Führen Sie dieselben Schritte aus, um die beiden Messwerte anhand Ihrer
has_conversion-Variablen zu berechnen:
params_conversion_rate_metrics = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.COUNT, pipeline_dp.Metrics.MEAN],
max_partitions_contributed=1,
max_contributions_per_partition=1,
min_value=0,
max_value=1,
public_partitions=public_partitions,
budget_weight=2/3)
data_extractors_conversion_rate_metrics = pipeline_dp.DataExtractors(
privacy_id_extractor=lambda row: row.user_id,
partition_extractor=lambda row: row.product_view_0,
value_extractor=lambda row: row.has_conversion)
dp_result_conversion_rate_metrics = (
dp_engine.aggregate(data, params_conversion_rate_metrics,
data_extractors_conversion_rate_metrics))
Die einzige Änderung betrifft die pipeline_dp.AggregateParams-Instanz. Hier definieren Sie jetzt mean und count als Aggregationen und weisen dieser Berechnung zwei Drittel Ihres Datenschutzbudgets zu. Da Sie für beide Statistiken dieselben Beitragsobergrenzen verwenden und sie auf Grundlage derselben has_conversion-Variablen berechnen möchten, können Sie sie in derselben pipeline_dp.AggregateParams-Instanz kombinieren und gleichzeitig berechnen.
- Rufen Sie die Methode
budget_accountant.compute_budgets()auf.
budget_accountant.compute_budgets()
Sie können alle drei privaten Statistiken im Vergleich zu den ursprünglichen Statistiken darstellen. Je nach hinzugefügtem Rauschen können die Ergebnisse tatsächlich außerhalb des plausiblen Bereichs liegen. In diesem Fall sehen Sie eine negative Conversion-Rate und einen negativen Conversion-Wert insgesamt für Sprungmarken, da das hinzugefügte Rauschen symmetrisch um null ist. Für weitere Analysen und die Verarbeitung ist es am besten, die privaten Statistiken nicht manuell nachzubearbeiten. Wenn Sie diese Grafiken jedoch einem Bericht hinzufügen möchten, können Sie das Minimum danach einfach auf null setzen, ohne die Datenschutzgarantien zu verletzen.
7. Pipeline mit Beam ausführen
Bei der Datenverarbeitung müssen heutzutage riesige Datenmengen verarbeitet werden, die nicht lokal verarbeitet werden können. Stattdessen verwenden viele Frameworks für die Verarbeitung großer Datenmengen wie Beam oder Spark und führen ihre Pipelines in der Cloud aus.
PipelineDP unterstützt Beam und Spark mit nur geringfügigen Änderungen an Ihrem Code.
So führen Sie die Pipeline mit Beam mit der private_beam API aus:
- Initialisieren Sie eine
runner-Variable und erstellen Sie dann eine Pipeline, in der Sie Ihre Datenschutzvorgänge auf eine Beam-Darstellung vonrowsanwenden:
runner = fn_api_runner.FnApiRunner() # local runner
with beam.Pipeline(runner=runner) as pipeline:
beam_data = pipeline | beam.Create(rows)
- Erstellen Sie eine
budget_accountant-Variable mit den erforderlichen Datenschutzparametern:
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=0)
- Erstellen Sie eine
pcol- oder private Sammlungsvariable, um sicherzustellen, dass alle Aggregationen Ihren Datenschutzanforderungen entsprechen:
pcol = beam_data | pbeam.MakePrivate(
budget_accountant=budget_accountant,
privacy_id_extractor=lambda
row: row.user_id)
- Geben Sie die Parameter Ihrer privaten Aggregation in der entsprechenden Klasse an.
Hier verwenden Sie die Klasse pipeline_dp.aggregate_params.SumParams(), weil Sie die Summe der Produktaufrufe berechnen.
- Übergeben Sie Ihre Aggregationsparameter an die Methode
pbeam.Sum, um die Statistik zu berechnen:
dp_result = pcol | pbeam.Sum(params)
- Am Ende sollte Ihr Code so aussehen:
import pipeline_dp.private_beam as pbeam
runner = fn_api_runner.FnApiRunner() # local runner
with beam.Pipeline(runner=runner) as pipeline:
beam_data = pipeline | beam.Create(rows)
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=0)
# Create private collection.
pcol = beam_data | pbeam.MakePrivate(
budget_accountant=budget_accountant,
privacy_id_extractor=lambda row:
row.user_id)
# Specify parameters.
params = pipeline_dp.aggregate_params.SumParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
max_partitions_contributed=1,
max_contributions_per_partition=1,
min_value=0,
max_value=100,
public_partitions=public_partitions_product_views,
partition_extractor=lambda row: row.product_view_0,
value_extractor=lambda row:row.conversion_value)
dp_result = pcol | pbeam.Sum(params)
budget_accountant.compute_budgets()
dp_result | beam.Map(print)
8. Optional: Datenschutz- und Nutzbarkeitsparameter anpassen
In diesem Codelab wurden bereits einige Parameter erwähnt, z. B. epsilon, delta und max_partitions_contributed. Sie lassen sich grob in zwei Kategorien unterteilen: Datenschutzparameter und Parameter für die Nützlichkeit.
Datenschutzparameter
Die Parameter epsilon und delta quantifizieren den Datenschutz, den Sie mit Differential Privacy bieten. Genauer gesagt, geben sie an, wie viele Informationen ein potenzieller Angreifer aus der anonymisierten Ausgabe über die Daten gewinnen kann. Je höher der Wert der Parameter, desto mehr Informationen erhält der Angreifer über die Daten, was ein Datenschutzrisiko darstellt. Je niedriger der Wert der Parameter epsilon und delta ist, desto mehr Rauschen muss der Ausgabe hinzugefügt werden, um sie zu anonymisieren. Außerdem ist dann eine höhere Anzahl eindeutiger Nutzer in jeder Partition erforderlich, damit diese in der anonymisierten Ausgabe enthalten ist. In diesem Fall gibt es einen Kompromiss zwischen Nützlichkeit und Datenschutz.
In PipelineDP müssen Sie die gewünschten Datenschutzgarantien für Ihre anonymisierte Ausgabe angeben, wenn Sie das gesamte Datenschutzbudget in der NaiveBudgetAccountant-Instanz festlegen. Wenn Sie möchten, dass Ihre Datenschutzgarantien eingehalten werden, müssen Sie für jede Aggregation eine separate NaiveBudgetAccountant-Instanz verwenden oder die Pipeline mehrmals ausführen, um eine Überschreitung Ihres Budgets zu vermeiden.
Weitere Informationen zum differenziellen Datenschutz und zur Bedeutung der Datenschutzparameter finden Sie in der Leseliste zum differenziellen Datenschutz.
Parameter für Dienstprogramme
Utility-Parameter haben keine Auswirkungen auf die Datenschutzgarantien, aber auf die Genauigkeit und damit auf die Nützlichkeit der Ausgabe. Sie werden in der AggregateParams-Instanz bereitgestellt und zum Skalieren des hinzugefügten Rauschens verwendet.
Ein in der AggregateParams-Instanz bereitgestellter Hilfsparameter, der für alle Aggregationen gilt, ist der Parameter max_partitions_contributed. Eine Partition entspricht einem Schlüssel der Daten, die vom PipelineDP-Aggregationsvorgang zurückgegeben werden. Der Parameter max_partitions_contributed begrenzt also die Anzahl der unterschiedlichen Schlüsselwerte, die ein Nutzer zum Ergebnis beitragen kann. Wenn ein Nutzer zu einer Anzahl von Schlüsseln beiträgt, die den Wert des Parameters max_partitions_contributed überschreitet, werden einige Beiträge verworfen, sodass sie genau dem Wert des Parameters max_partitions_contributed entsprechen.
Die meisten Aggregationen haben einen max_contributions_per_partition-Parameter. Sie sind auch in der AggregateParams-Instanz enthalten und jede Aggregation kann separate Werte dafür haben. Sie begrenzen den Beitrag eines Nutzers für jeden Schlüssel.
Das der Ausgabe hinzugefügte Rauschen wird durch die Parameter max_partitions_contributed und max_contributions_per_partition skaliert. Hier gibt es also einen Kompromiss: Wenn Sie jedem Parameter größere Werte zuweisen, behalten Sie mehr Daten bei, erhalten aber ein Ergebnis mit mehr Rauschen.
Für einige Aggregationen sind die Parameter min_value und max_value erforderlich, mit denen die Grenzen für die Beiträge der einzelnen Nutzer festgelegt werden. Wenn ein Nutzer einen Wert beiträgt, der niedriger ist als der Wert, der dem Parameter min_value zugewiesen ist, wird der Wert auf den Wert des Parameters erhöht. Wenn ein Nutzer einen Wert eingibt, der größer als der Wert des Parameters max_value ist, wird der Wert entsprechend verringert. Wenn Sie mehr der ursprünglichen Werte beibehalten möchten, müssen Sie größere Grenzen angeben. Rauschen wird durch die Größe der Grenzen skaliert. Bei größeren Grenzen können Sie mehr Daten behalten, aber das Ergebnis ist dann verrauschter.
Der Parameter noise_kind unterstützt zwei verschiedene Rauschmechanismen in PipelineDP: GAUSSIAN- und LAPLACE-Rauschen. Die LAPLACE-Verteilung bietet einen besseren Nutzen bei niedrigen Beitragsobergrenzen. Daher wird sie standardmäßig in PipelineDP verwendet. Wenn Sie jedoch ein GAUSSIAN-Verteilungsrauschen verwenden möchten, können Sie es in der AggregateParams-Instanz angeben.
9. Glückwunsch
Gut gemacht! Sie haben das PipelineDP-Codelab abgeschlossen und viel über differenziellen Datenschutz und PipelineDP gelernt.