
1. Ziel dieses Labs
In diesem praktischen Lab lernen Sie, wie Sie mit dem ADK (Agent Development Kit) Visual Builder Agenten erstellen. Der ADK (Agent Development Kit) Visual Builder bietet eine Low-Code-Möglichkeit zum Erstellen von ADK (Agent Development Kit)-Agenten. Sie erfahren, wie Sie die Anwendung lokal testen und in Cloud Run bereitstellen.
Lerninhalte
- Sie kennen die Grundlagen des ADK (Agent Development Kit) .
- Grundlagen des ADK (Agent Development Kit) Visual Builder
- Hier erfahren Sie, wie Sie Agenten mit GUI-Tools erstellen.
- Informationen zum einfachen Bereitstellen und Verwenden der Agents in Cloud Run
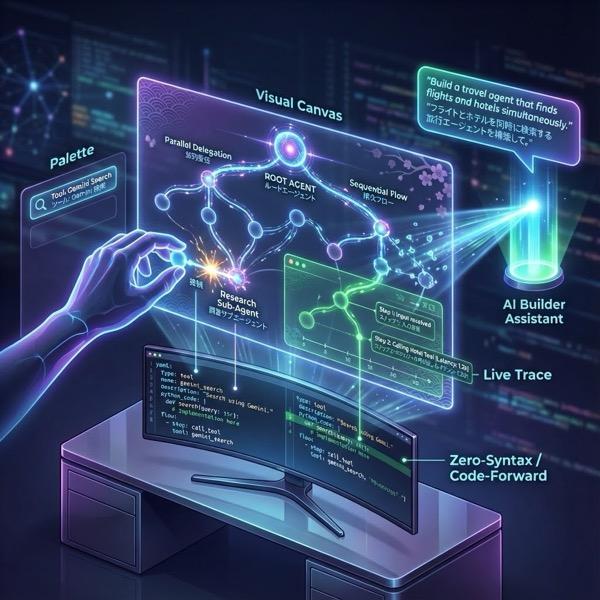
Abbildung 1: Mit dem ADK Visual Builder können Sie Agents mit einer GUI und wenig Code erstellen.
2. Projekt einrichten
- Wenn Sie noch kein Projekt haben, das Sie verwenden können, müssen Sie ein neues Projekt in der GCP Console erstellen. Wählen Sie das Projekt in der Projektauswahl (oben links in der Google Cloud Console) aus.
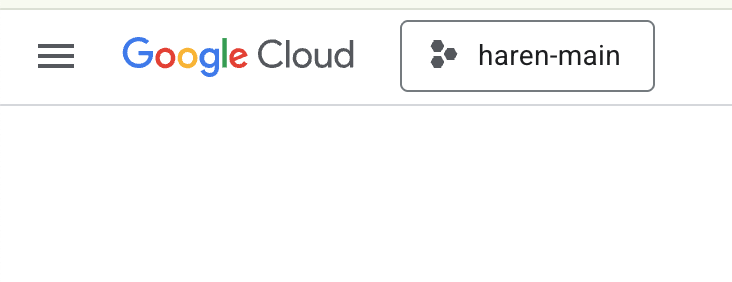
Abbildung 2: Wenn Sie auf das Feld direkt neben dem Google Cloud-Logo klicken, können Sie Ihr Projekt auswählen. Achten Sie darauf, dass Ihr Projekt ausgewählt ist.
- In diesem Lab verwenden wir den Cloud Shell-Editor, um unsere Aufgaben auszuführen. Öffnen Sie Cloud Shell und legen Sie das Projekt mit Cloud Shell fest.
- Klicken Sie auf diesen Link, um direkt zum Cloud Shell-Editor zu gelangen.
- Öffnen Sie das Terminal, falls es noch nicht geöffnet ist. Klicken Sie dazu im Menü auf Terminal > Neues Terminal. Sie können alle Befehle in dieser Anleitung in diesem Terminal ausführen.
- Mit dem folgenden Befehl im Cloud Shell-Terminal können Sie prüfen, ob das Projekt bereits authentifiziert ist.
gcloud auth list
- Führen Sie in Cloud Shell den folgenden Befehl aus, um Ihr Projekt zu bestätigen:
gcloud config list project
- Kopieren Sie die Projekt-ID und legen Sie sie mit dem folgenden Befehl fest.
gcloud config set project <YOUR_PROJECT_ID>
- Wenn Sie sich nicht mehr an Ihre Projekt-ID erinnern, können Sie alle Ihre Projekt-IDs mit dem folgenden Befehl auflisten:
gcloud projects list
3. APIs aktivieren
Für dieses Lab müssen wir einige API-Dienste aktivieren. Führen Sie in Cloud Shell den folgenden Befehl aus.
gcloud services enable aiplatform.googleapis.com
gcloud services enable cloudresourcemanager.googleapis.com
Einführung in die APIs
- Die Vertex AI API (
aiplatform.googleapis.com) ermöglicht den Zugriff auf die Vertex AI -Plattform. So kann Ihre Anwendung mit Gemini-Modellen für die Textgenerierung, Chats und Funktionsaufrufe interagieren. - Mit der Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) können Sie Metadaten für Ihre Google Cloud-Projekte programmatisch verwalten, z. B. Projekt-ID und -Name. Diese sind häufig für andere Tools und SDKs erforderlich, um die Projektidentität und -berechtigungen zu bestätigen.
4. Prüfen, ob Ihre Gutschriften angewendet wurden
In der Phase „Projekteinrichtung“ haben Sie das kostenlose Guthaben beantragt, mit dem Sie die Dienste in Google Cloud nutzen können. Wenn Sie das Guthaben einlösen, wird ein neues kostenloses Rechnungskonto mit dem Namen „Google Cloud Platform Trial Billing Account“ erstellt. So prüfen Sie, ob die Gutschriften angewendet wurden:
curl -s https://raw.githubusercontent.com/haren-bh/gcpbillingactivate/main/activate.py | python3
Wenn der Vorgang erfolgreich war, sollte das Ergebnis so aussehen: Wenn Sie „Projekt erfolgreich verknüpft“ sehen, ist Ihr Rechnungskonto richtig eingerichtet. Wenn Sie den Schritt oben ausführen, können Sie prüfen, ob Ihr Konto verknüpft ist. Falls nicht, wird es verknüpft. Wenn Sie das Projekt noch nicht ausgewählt haben, werden Sie aufgefordert, ein Projekt auszuwählen. Sie können dies auch vorab tun, indem Sie die Schritte unter „Projekteinrichtung“ ausführen. 
Abbildung 3: Bestätigung der Verknüpfung des Rechnungskontos
5. Einführung in das Agent Development Kit
Das Agent Development Kit bietet mehrere entscheidende Vorteile für Entwicklerinnen und Entwickler, die agentische Anwendungen erstellen:
- Multi-Agenten-Systeme: Erstellen Sie modulare und skalierbare Anwendungen, indem Sie mehrere spezialisierte Agenten in einer Hierarchie zusammenstellen. Ermöglichen Sie komplexe Koordination und Delegation.
- Umfangreiches Tool-Ökosystem: Statten Sie Agenten mit verschiedenen Kompetenzen aus. Verwenden Sie vorgefertigte Tools (Suche, Code-Ausführung usw.), erstellen Sie benutzerdefinierte Funktionen, integrieren Sie Tools aus Agenten-Frameworks von Drittanbietern (LangChain, CrewAI) oder nutzen Sie sogar andere Agenten als Tools.
- Flexible Orchestrierung: Definieren Sie Workflows mit Workflow-Agents (
SequentialAgent,ParallelAgentundLoopAgent) für vorhersagbare Pipelines oder nutzen Sie LLM-basiertes dynamisches Routing (LlmAgent-Transfer) für adaptives Verhalten. - Integrierte Entwicklungsumgebung: Entwickeln, testen und debuggen Sie lokal mit einer leistungsstarken Befehlszeile und einer interaktiven Entwicklungs-UI. Prüfen Sie Ereignisse, Status und Agentenausführung Schritt für Schritt.
- Integrierte Bewertung: Bewerten Sie die Leistung des Agenten systematisch, indem Sie sowohl die Qualität der endgültigen Antwort als auch den schrittweisen Ausführungsablauf anhand vordefinierter Testläufe bewerten.
- Schnelle Bereitstellung: Sie können Ihre Agenten überall containerisieren und bereitstellen. Führen Sie sie lokal aus, skalieren Sie sie mit der Vertex AI Agent Engine oder integrieren Sie sie mit Cloud Run oder Docker in Ihre eigene Infrastruktur.
Während andere SDKs oder Agenten-Frameworks auf Basis generativer KI Ihnen ebenfalls ermöglichen, Modelle abzufragen und sie sogar mit Tools auszustatten, erfordert die dynamische Koordination zwischen mehreren Modellen einen erheblichen Arbeitsaufwand Ihrerseits.
Das Agent Development Kit bietet ein übergeordnetes Framework, mit dem Sie problemlos mehrere Agenten miteinander verbinden können, um komplexe, aber einfach zu wartende Workflows zu erstellen.
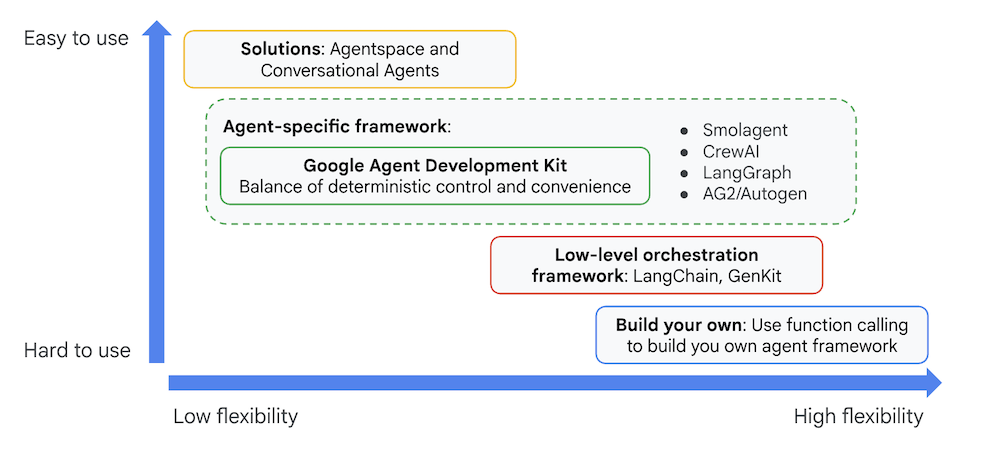
Abbildung 4: Positionierung des ADK (Agent Development Kit)
In den aktuellen Versionen wurde dem ADK (Agent Development Kit) das Tool ADK Visual Builder hinzugefügt, mit dem Sie ADK (Agent Development Kit)-Agents mit wenig Code erstellen können. In diesem Lab sehen wir uns das Tool ADK Visual Builder genauer an.
6. ADK installieren und Umgebung einrichten
Zuerst müssen wir die Umgebung so einrichten, dass wir das ADK (Agent Development Kit) ausführen können. In diesem Lab führen wir das ADK (Agent Development Kit) aus und erledigen alle Aufgaben in Google Cloud im Cloud Shell Editor .
Cloud Shell-Editor vorbereiten
- Klicken Sie auf diesen Link, um direkt zum Cloud Shell-Editor zu gelangen.
- Klicken Sie auf Weiter.
- Wenn Sie zur Autorisierung der Cloud Shell aufgefordert werden, klicken Sie auf Autorisieren.
- Im weiteren Verlauf dieses Labs dient dieses Fenster als IDE für das Arbeiten im Cloud Shell-Editor und Cloud Shell-Terminal.
- Öffnen Sie im Cloud Shell-Editor ein neues Terminal über Terminal> Neues Terminal. Alle Befehle unten werden in diesem Terminal ausgeführt.
ADK Visual Editor starten
- Führen Sie die folgenden Befehle aus, um die erforderliche Quelle von GitHub zu klonen und die erforderlichen Bibliotheken zu installieren. Führen Sie die Befehle im Terminal aus, das im Cloud Shell-Editor geöffnet ist.
#create the project directory
mkdir ~/adkui
cd ~/adkui
- Wir verwenden uv, um eine Python-Umgebung zu erstellen (im Terminal des Cloud Shell-Editors ausführen):
#Install uv if you do not have installed yet
pip install uv
#go to the project directory
cd ~/adkui
#Create the virtual environment
uv venv
#use the newly created environment
source .venv/bin/activate
#install libraries
uv pip install google-adk==1.22.1
uv pip install python-dotenv
Hinweis: Wenn Sie das Terminal neu starten müssen, müssen Sie Ihre Python-Umgebung mit dem Befehl source .venv/bin/activate festlegen.
- Klicken Sie im Editor auf „Ansicht“ > „Versteckte Dateien einblenden“. Erstellen Sie im Ordner adkui eine .env-Datei mit folgendem Inhalt.
#go to adkui folder
cd ~/adkui
cat <<EOF>> .env
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
GOOGLE_CLOUD_LOCATION=us-central1
IMAGEN_MODEL="imagen-3.0-generate-002"
GENAI_MODEL="gemini-2.5-flash"
EOF
7. Einen einfachen Agent mit ADK Visual Builder erstellen
In diesem Abschnitt erstellen wir einen einfachen Agenten mit dem ADK Visual Builder.Der ADK Visual Builder ist ein webbasiertes Tool, das eine visuelle Workflow-Designumgebung zum Erstellen und Verwalten von ADK-Agenten (Agent Development Kit) bietet. Damit können Sie Ihre Agents in einer anfängerfreundlichen grafischen Benutzeroberfläche entwerfen, erstellen und testen. Außerdem ist ein KI-basierter Assistent enthalten, der Sie beim Erstellen von Agents unterstützt.
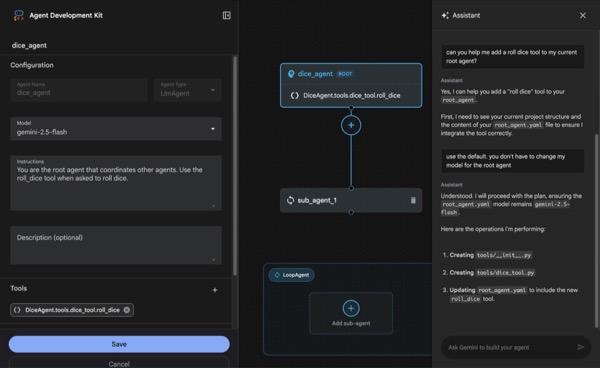
Abbildung 5: ADK Visual Builder
- Kehren Sie im Terminal zum obersten Verzeichnis adkui zurück und führen Sie den folgenden Befehl aus, um den Agenten lokal auszuführen (im Cloud Shell-Editor-Terminal ausführen). Sie sollten den ADK-Server starten und im Terminal Ergebnisse sehen können, die denen in Abbildung 6 ähneln.
#go to the directory adkui
cd ~/adkui
# Run the following command to run ADK locally
adk web
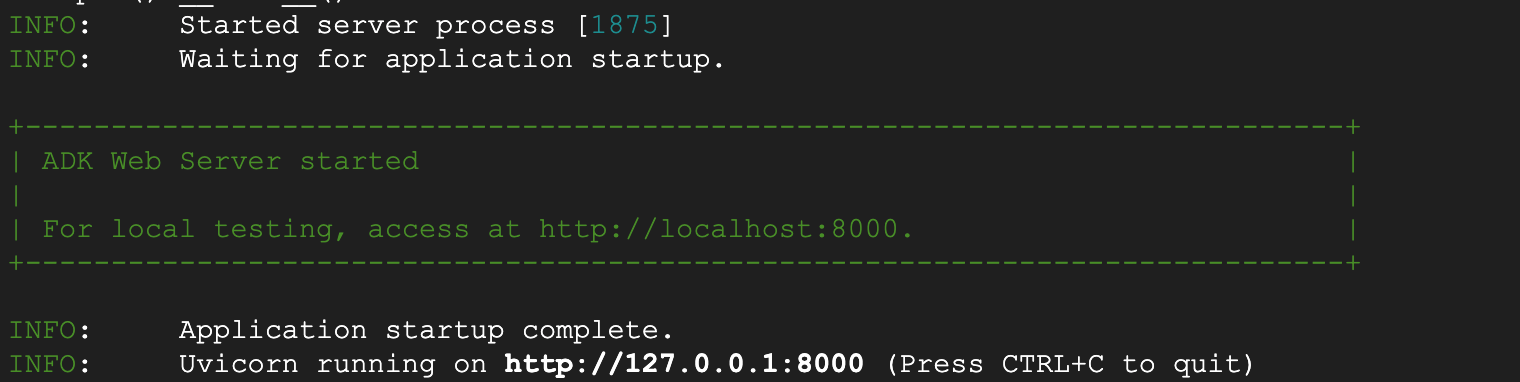
Abbildung 6: ADK-Anwendungsstart
- Strg + Klick (CMD + Klick für MacOS) auf die im Terminal angezeigte http://-URL, um das browserbasierte GUI-Tool ADK (Agent Development Kit) zu öffnen.
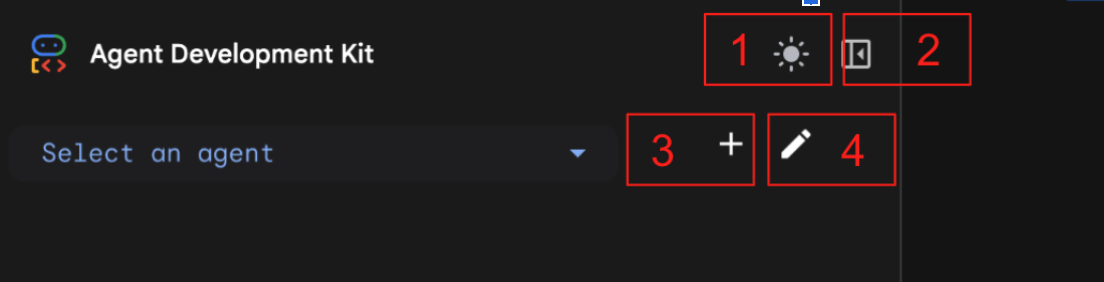
Abbildung 7: ADK-Web-UI. Das ADK hat die folgenden Komponenten: 1. Helles und dunkles Design umschalten, 2. Bereich minimieren, 3. Agent erstellen, 4. Agent bearbeiten.
- Wenn Sie einen neuen Agent erstellen möchten, drücken Sie die Schaltfläche „+“.
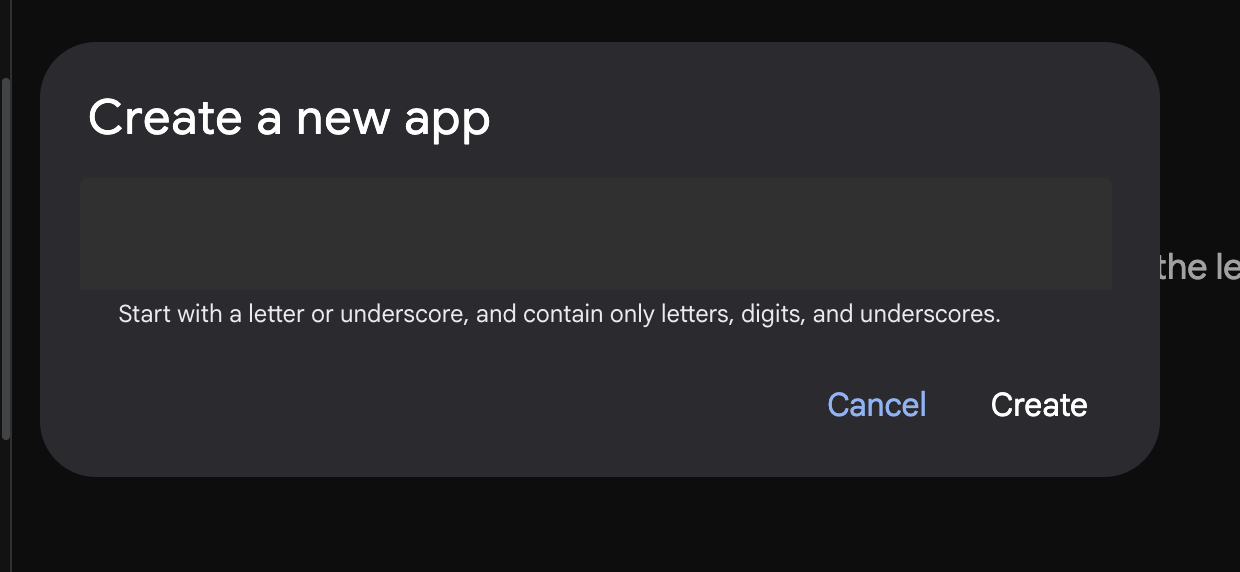
Abbildung 8: Dialogfeld zum Erstellen einer neuen App
- Geben Sie den Namen „Agent1“ ein und klicken Sie auf „Erstellen“.
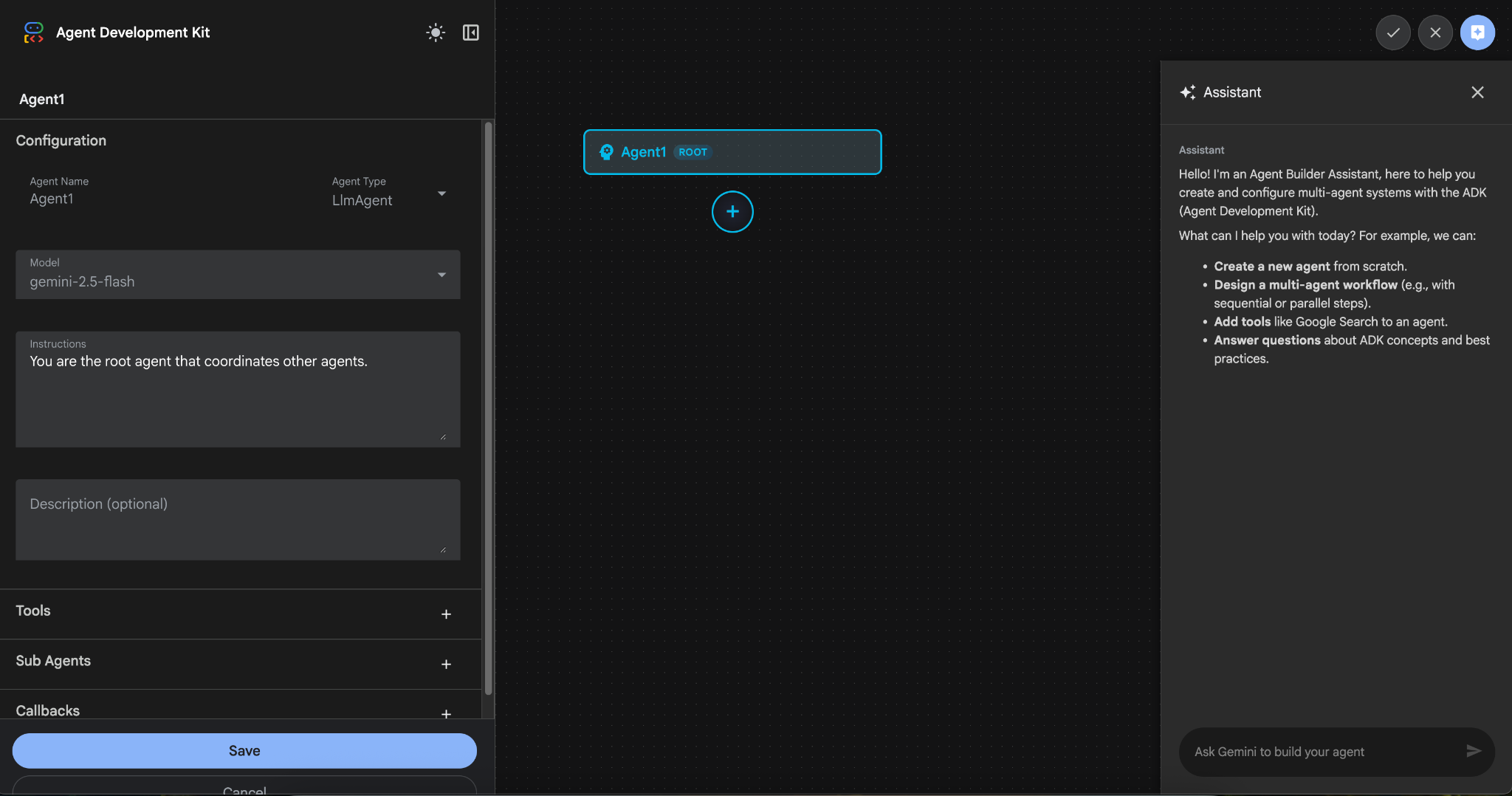
Abbildung 9: Benutzeroberfläche für den Agent-Builder
- Der Bereich ist in drei Hauptabschnitte unterteilt: Auf der linken Seite befinden sich die Steuerelemente für die GUI-basierte Agentenerstellung, in der Mitte wird der Fortschritt visualisiert und auf der rechten Seite befindet sich der Assistant zum Erstellen von Agents mithilfe von natürlicher Sprache.
- Ihr KI-Agent wurde erstellt. Klicken Sie auf Speichern, um fortzufahren. Hinweis: Damit Ihre Änderungen nicht verloren gehen, müssen Sie auf „Speichern“ klicken.
- Der Agent sollte jetzt bereit für Tests sein. Geben Sie zuerst einen Prompt in das Chatfeld ein, z. B.:
Hi, what can you do?
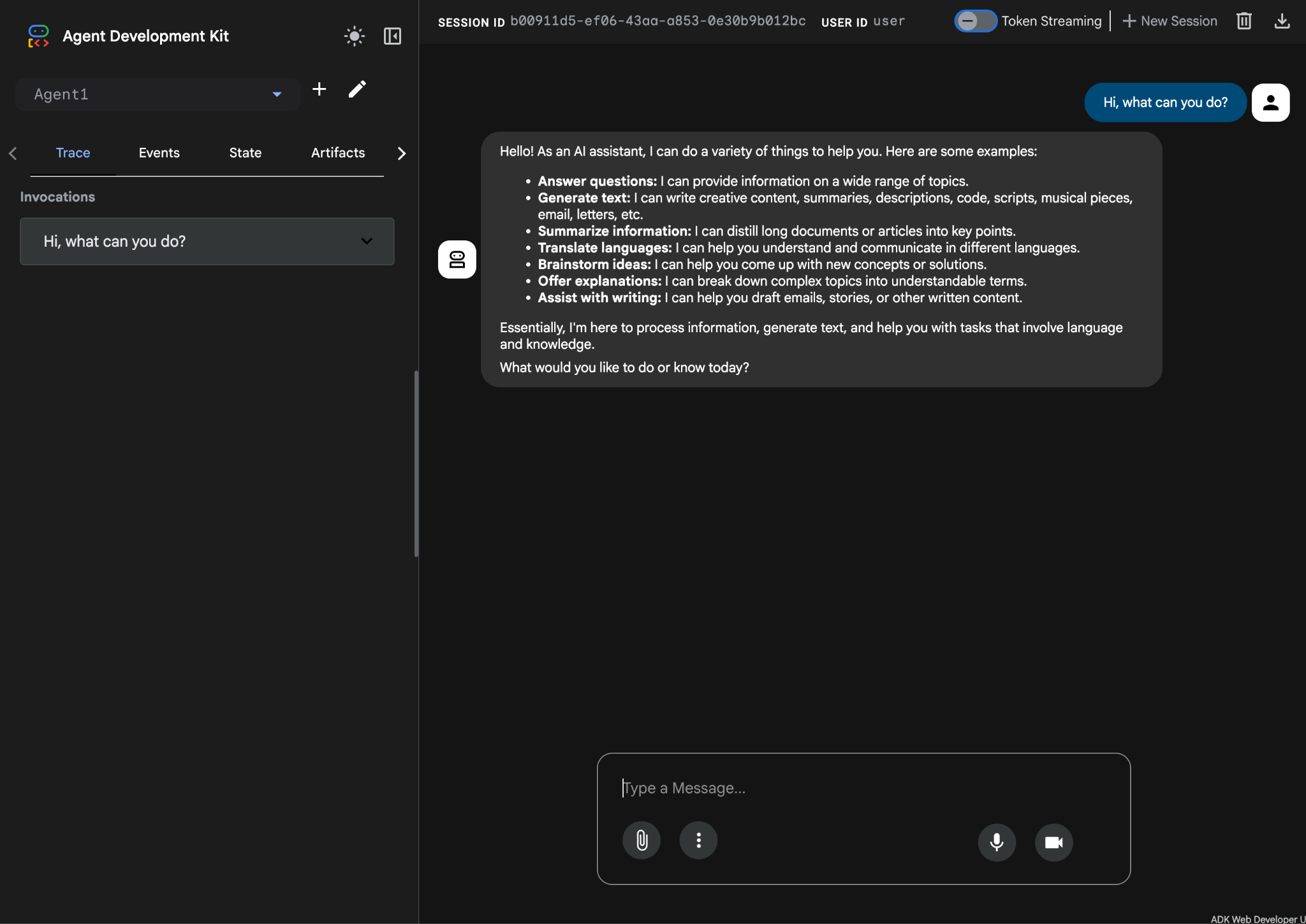
Abbildung 10: Agent testen.
7.Kehren Sie zum Editor zurück und sehen Sie sich die neu generierten Dateien an. Der Explorer befindet sich auf der linken Seite. Rufen Sie den Ordner „adkgui“ auf und maximieren Sie ihn, um das Verzeichnis „Agent 1“ aufzurufen. In diesem Ordner können Sie die YAML-Datei prüfen, in der der Agent definiert ist (siehe Abbildung unten).
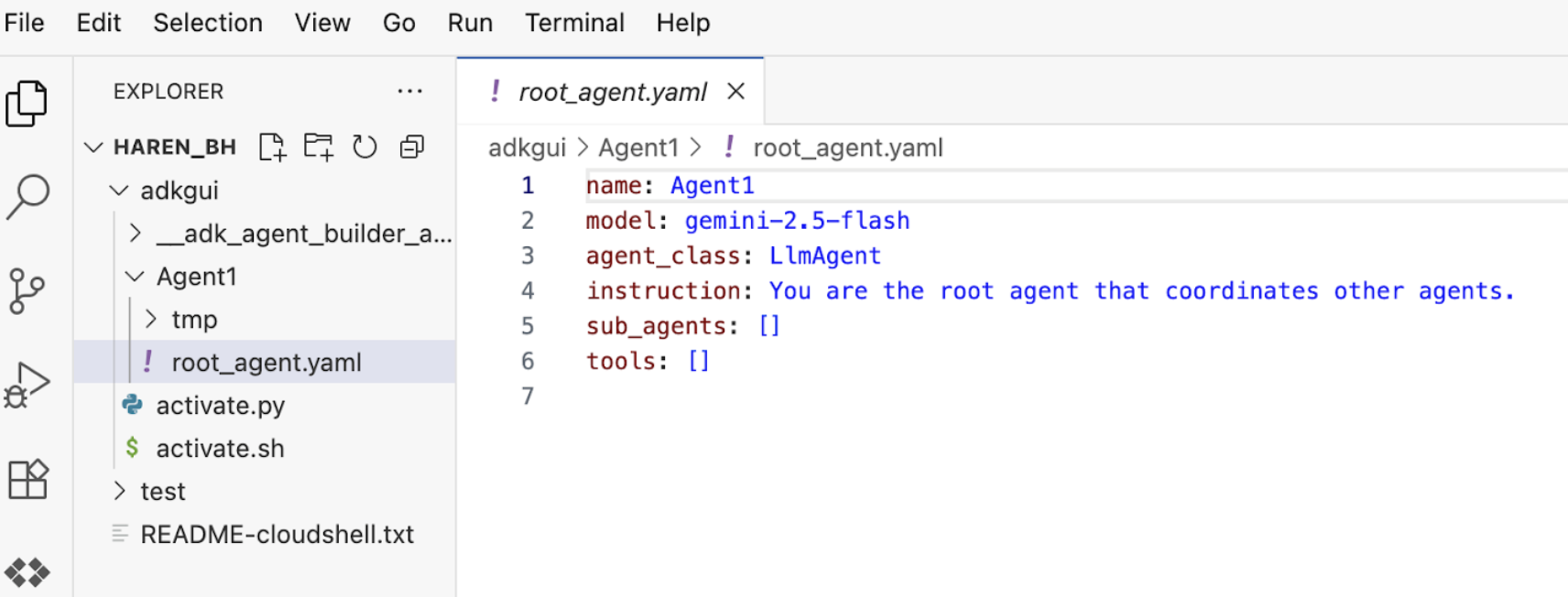
Abbildung 11: KI-Agentendefinition mit YAML-Datei
- Kehren wir nun zum GUI-Editor zurück und fügen wir dem Agent einige Funktionen hinzu. Drücken Sie dazu die Schaltfläche „Bearbeiten“ (siehe Abbildung 7, Komponentennummer 4, Stiftsymbol).
- Wir fügen dem Agenten die Funktion Google Suche hinzu. Dazu müssen wir die Google Suche als Tool hinzufügen, das für den Agenten verfügbar ist und das er verwenden kann. Klicken Sie dazu unten links auf dem Bildschirm neben dem Bereich Tools auf das +-Zeichen und wählen Sie im Menü Integriertes Tool aus (siehe Abbildung 12).
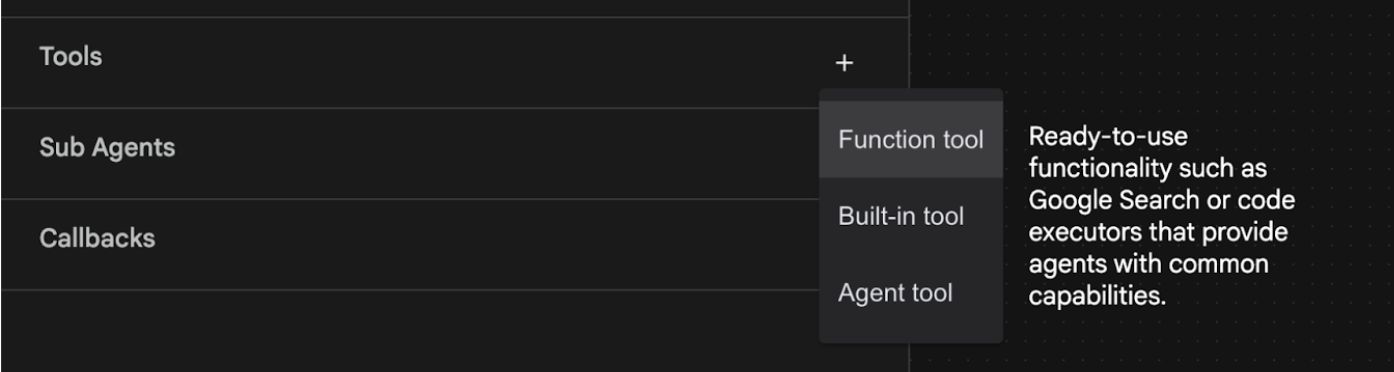
Abbildung 12: Einem Agenten ein neues Tool hinzufügen
- Wählen Sie in der Liste Integriertes Tool die Option google_search aus und klicken Sie auf Erstellen (siehe Abbildung 12). Dadurch wird die Google Suche als Tool in Ihrem KI-Agenten hinzugefügt.
- Klicken Sie auf die Schaltfläche Speichern, damit die Änderungen gespeichert werden.
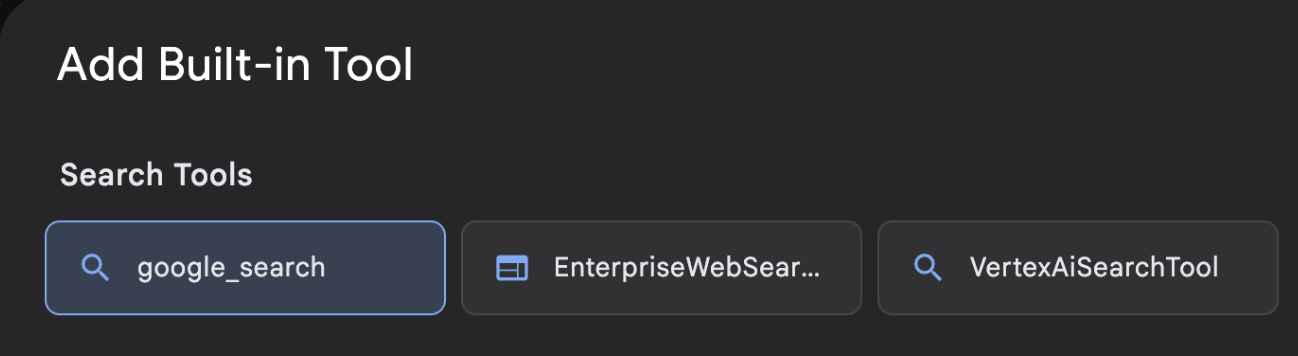
Abbildung 13: Liste der in der ADK Visual Builder-Benutzeroberfläche verfügbaren Tools
- Jetzt können Sie den Agenten testen. Starten Sie zuerst den ADK-Server neu. Wechseln Sie zum Terminal, in dem Sie den ADK-Server (Agent Development Kit) gestartet haben, und drücken Sie STRG + C, um den Server zu beenden, falls er noch ausgeführt wird. Führen Sie den folgenden Befehl aus, um den Server neu zu starten.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- Strg + Klick auf die URL (z. B. http://localhost:8000) auf dem Bildschirm angezeigt wird. Die ADK-GUI (Agent Development Kit) sollte auf dem Browser-Tab angezeigt werden.
- Wählen Sie Agent1 aus der Liste der Kundenservicemitarbeiter aus. Ihr Agent kann jetzt Google-Suchanfragen durchführen. Testen Sie im Chatfeld mit dem folgenden Prompt.
What is the weather today in Yokohama?
Die Antwort aus der Google Suche sollte so aussehen: 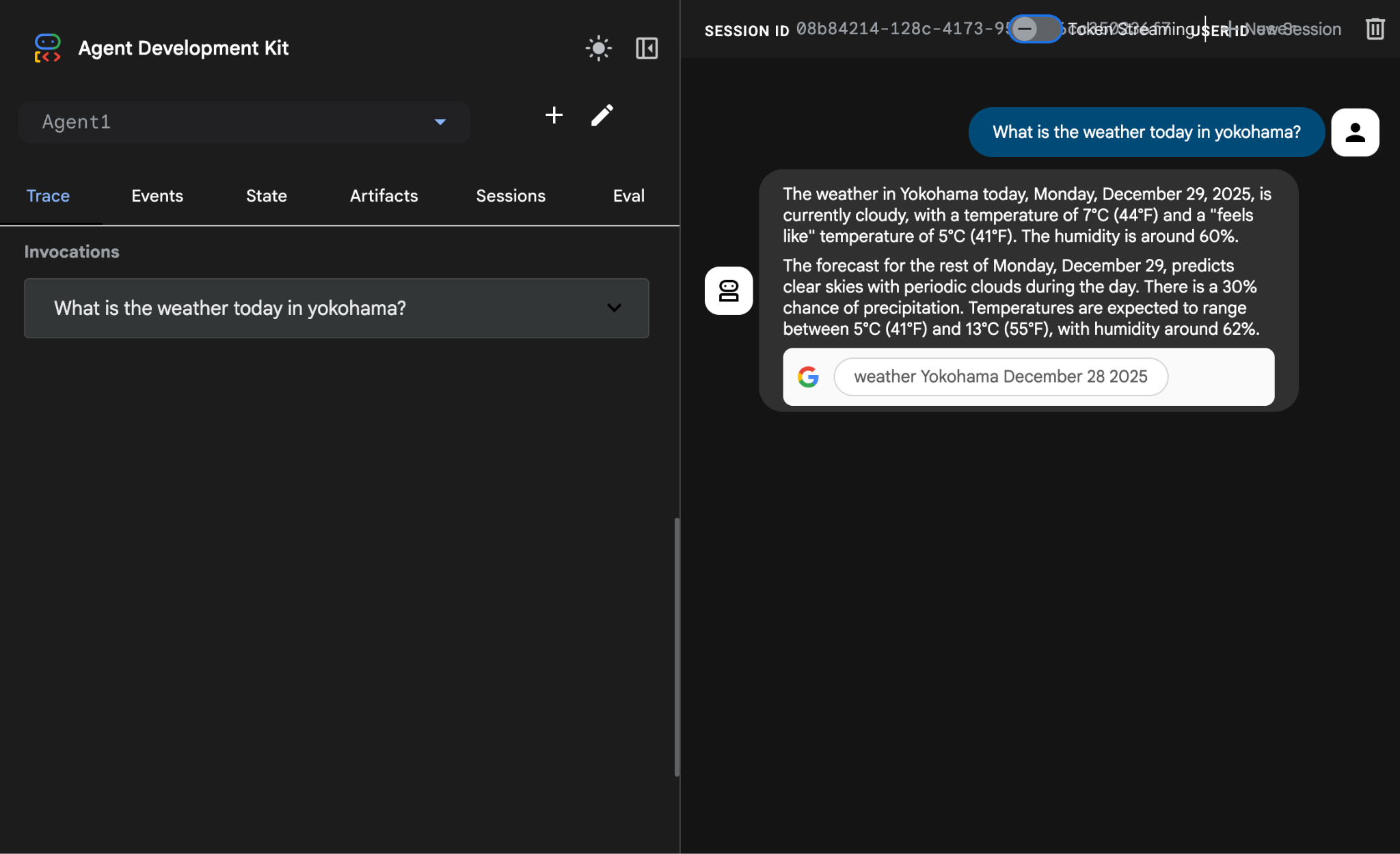
Abbildung 14: Google Suche mit dem Agenten
- Kehren wir nun zum Editor zurück und sehen uns den Code an, der in diesem Schritt erstellt wurde. Klicken Sie in der Seitenleiste Explorer des Editors auf root_agent.yaml, um die Datei zu öffnen. Prüfen Sie, ob google_search als Tool hinzugefügt wurde (Abbildung 15).
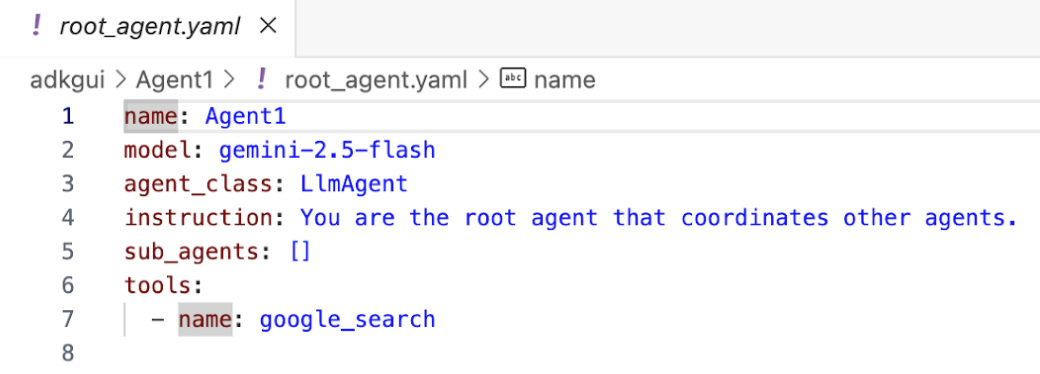
Abbildung 15: Bestätigung, dass Agent1 hinzugefügt wurde
8. Agent in Cloud Run bereitstellen
Stellen wir den erstellten Agenten nun in Cloud Run bereit. Mit Cloud Run können Sie Apps oder Websites schnell auf einer vollständig verwalteten Plattform erstellen.
Sie können Frontend- und Backend-Dienste ausführen, Batchjobs ausführen, LLMs hosten und Arbeitslasten in einer Warteschlange verarbeiten, ohne die Infrastruktur verwalten zu müssen.
Wenn Sie im Terminal des Cloud Shell-Editors noch den ADK-Server (Agent Development Kit) ausführen, drücken Sie Strg + C, um ihn zu beenden.
- Wechseln Sie zum Stammverzeichnis des Projekts.
cd ~/adkui
- Rufen Sie den Bereitstellungscode ab. Nachdem Sie den Befehl ausgeführt haben, sollte die Datei deploycloudrun.py im Explorer-Bereich des Cloud Shell-Editors angezeigt werden.
curl -LO https://raw.githubusercontent.com/haren-bh/codelabs/main/adk_visual_builder/deploycloudrun.py
- Sehen Sie sich die Bereitstellungsoptionen in deploycloudrun.py an. Wir verwenden den Befehl adk deploy, um den KI-Agenten in Cloud Run bereitzustellen. Das ADK (Agent Development Kit) bietet die integrierte Option, den Agenten in Cloud Run bereitzustellen. Wir müssen die Parameter wie Google Cloud-Projekt-ID, Region usw. angeben. Für den App-Pfad wird in diesem Skript davon ausgegangen, dass agent_path=./Agent1. Wir erstellen außerdem ein neues Dienstkonto mit den erforderlichen Berechtigungen und hängen es an Cloud Run an. Cloud Run benötigt Zugriff auf Dienste wie Vertex AI und Cloud Storage, um den Agent auszuführen.
command = [
"adk", "deploy", "cloud_run",
f"--project={project_id}",
f"--region={location}",
f"--service_name={service_name}",
f"--app_name={app_name}",
f"--artifact_service_uri=memory://",
f"--with_ui",
agent_path,
f"--",
f"--service-account={sa_email}",
]
- Führen Sie das Skript deploycloudrun.py aus. Die Bereitstellung sollte wie in der Abbildung unten beginnen.**
python3 deploycloudrun.py
Wenn Sie die Bestätigungsnachricht wie unten erhalten, drücken Sie für alle Nachrichten „Y“ und die Eingabetaste. Bei depoycloudrun.py wird davon ausgegangen, dass sich Ihr Agent im Ordner „Agent1“ befindet, wie oben beschrieben.
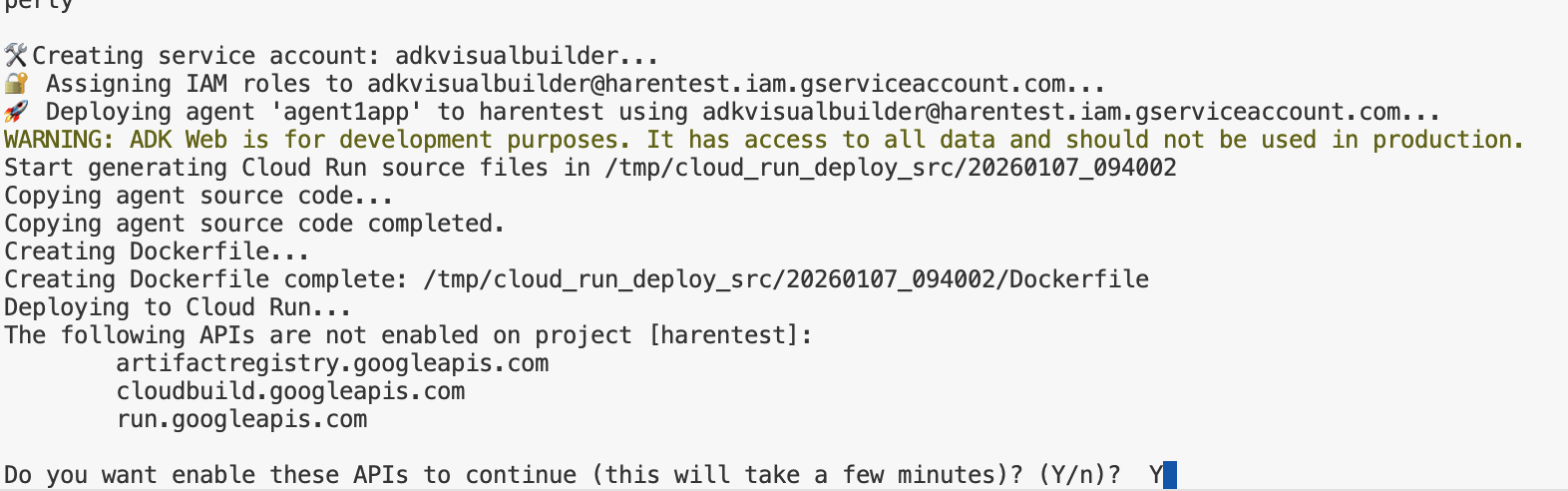
Abbildung 16:Agent in Cloud Run bereitstellen. Drücken Sie bei Bestätigungsnachrichten auf „Y“.
- Nach Abschluss der Bereitstellung sollte die Dienst-URL angezeigt werden, z. B. https://agent1service-78833623456.us-central1.run.app.
- Rufen Sie die URL in Ihrem Webbrowser auf, um die App zu starten.
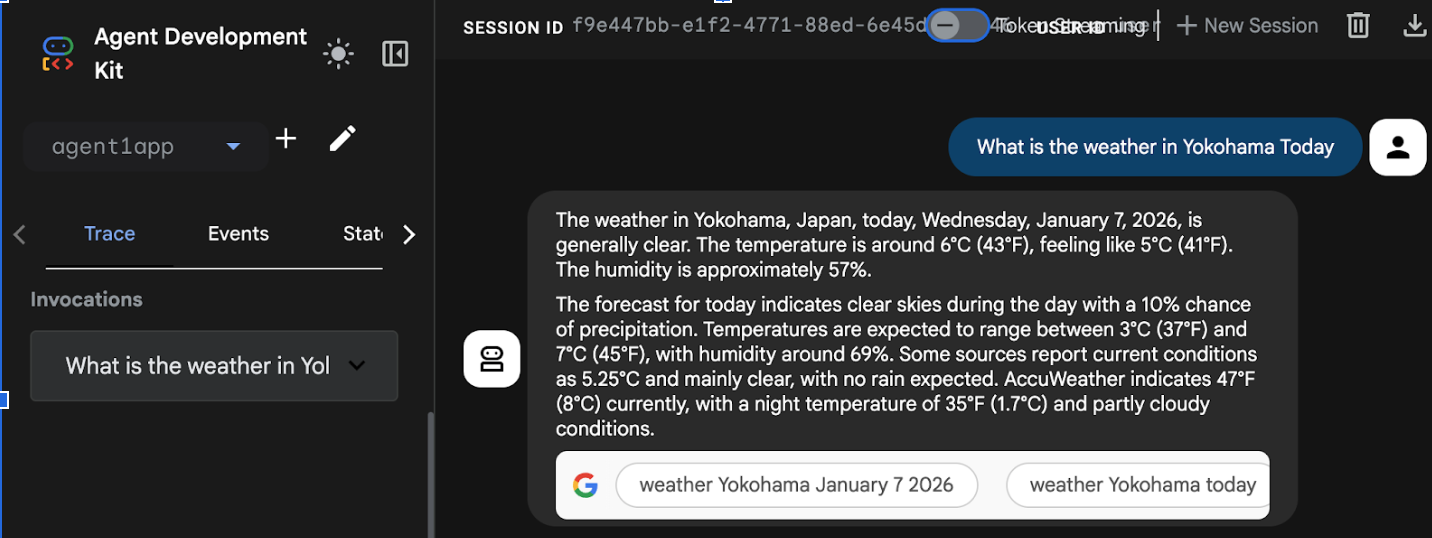
Figure 17: Agent running in Cloud Run
9. Agent mit untergeordnetem Agent und benutzerdefiniertem Tool erstellen
Im vorherigen Abschnitt haben Sie einen einzelnen Agenten mit einem integrierten Google-Suchtool erstellt. In diesem Abschnitt erstellen Sie ein Multi-Agent-System, in dem die Agenten die benutzerdefinierten Tools verwenden dürfen.
- Starten Sie zuerst den ADK-Server (Agent Development Kit) neu. Wechseln Sie zum Terminal, in dem Sie den ADK-Server (Agent Development Kit) gestartet haben, und drücken Sie STRG + C, um den Server zu beenden, falls er noch ausgeführt wird. Führen Sie den folgenden Befehl aus, um den Server neu zu starten.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- Strg + Klick auf die URL (z. B. http://localhost:8000) auf dem Bildschirm angezeigt wird. Die ADK-GUI (Agent Development Kit) sollte auf dem Browser-Tab angezeigt werden.
- Klicken Sie auf das Pluszeichen, um einen neuen Agent zu erstellen. Geben Sie im Agent-Dialogfeld „Agent2“ ein (Abbildung 18) und klicken Sie auf „Erstellen“.
Abbildung 18: Neue Agent-App erstellen.
- Geben Sie im Anweisungsabschnitt von Agent2 Folgendes ein.
You are an agent that takes image creation instruction from the user and passes it to your sub agent
- Jetzt fügen wir dem Stamm-Agent einen Sub-Agent hinzu. Klicken Sie dazu links neben dem Unteragentenmenü unten im linken Bereich auf das Pluszeichen (+) (Abbildung 19) und dann auf LLM Agent (LLM-Agent). Dadurch wird ein neuer Agent als neuer untergeordneter Agent des Stamm-Agents erstellt.
Abbildung 19: Neuen Sub-Agenten hinzufügen.
- Geben Sie in die Anleitung für sub_agent_1 den folgenden Text ein.
You are an Agent that can take instructions about an image and create an image using the create_image tool.
- Jetzt fügen wir diesem Sub-Agent ein benutzerdefiniertes Tool hinzu. Mit diesem Tool wird das Imagen-Modell aufgerufen, um ein Bild anhand der Anweisungen des Nutzers zu generieren. Klicken Sie dazu zuerst auf den im vorherigen Schritt erstellten untergeordneten Agenten und dann neben dem Menü „Tools“ auf das Symbol „+“. Klicken Sie in der Liste der Tool-Optionen auf Funktionstool. Mit diesem Tool können wir dem Tool unseren eigenen benutzerdefinierten Code hinzufügen.
Abbildung 20: Klicken Sie auf das Funktionstool, um ein neues Tool zu erstellen. 8. Geben Sie im Dialogfeld den Namen Agent2.image_creation_tool.create_image für das Tool ein. 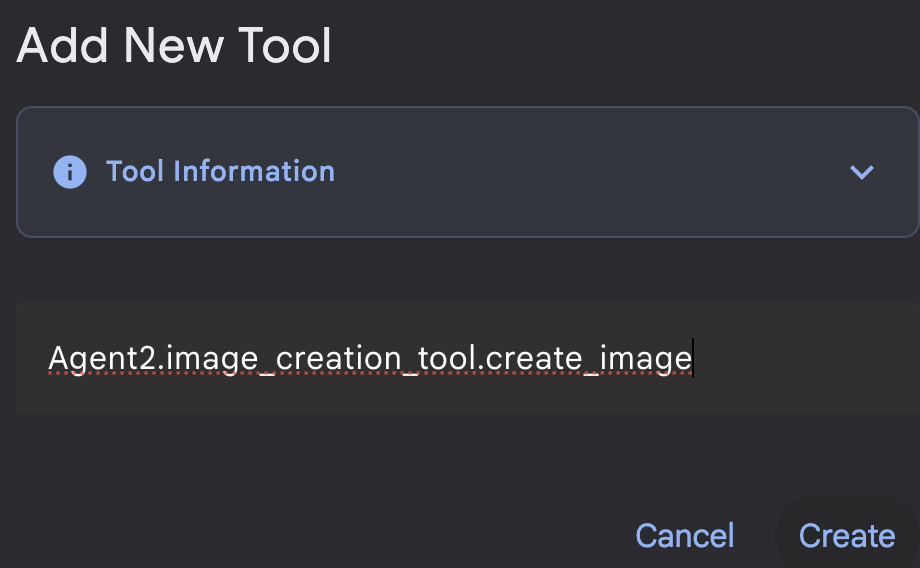
Abbildung 21: Toolname hinzufügen
- Klicken Sie auf die Schaltfläche Speichern, um die Änderungen zu speichern.
- Drücken Sie im Terminal des Cloud Shell-Editors Strg+S, um den ADK-Server herunterzufahren.
- Geben Sie im Terminal den folgenden Befehl ein, um die Datei image_creation_tool.py zu erstellen.
touch ~/adkui/Agent2/image_creation_tool.py
- Öffnen Sie die neu erstellte Datei image_creation_tool.py, indem Sie im Explorer-Bereich des Cloud Shell-Editors darauf klicken. Ersetzen Sie den Inhalt von image_creation_tool.py durch Folgendes und speichern Sie die Datei (Strg+S).
import os
import io
import vertexai
from vertexai.preview.vision_models import ImageGenerationModel
from dotenv import load_dotenv
import uuid
from typing import Union
from datetime import datetime
from google import genai
from google.genai import types
from google.adk.tools import ToolContext
import logging
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def create_image(prompt: str,tool_context: ToolContext) -> Union[bytes, str]:
"""
Generates an image based on a text prompt using a Vertex AI Imagen model.
Args:
prompt: The text prompt to generate the image from.
Returns:
The binary image data (PNG format) on success, or an error message string on failure.
"""
print(f"Attempting to generate image for prompt: '{prompt}'")
try:
# Load environment variables from .env file two levels up
dotenv_path = os.path.join(os.path.dirname(__file__), '..', '..', '.env')
load_dotenv(dotenv_path=dotenv_path)
project_id = os.getenv("GOOGLE_CLOUD_PROJECT")
location = os.getenv("GOOGLE_CLOUD_LOCATION")
model_name = os.getenv("IMAGEN_MODEL")
client = genai.Client(
vertexai=True,
project=project_id,
location=location,
)
response = client.models.generate_images(
model="imagen-3.0-generate-002",
prompt=prompt,
config=types.GenerateImagesConfig(
number_of_images=1,
aspect_ratio="9:16",
safety_filter_level="block_low_and_above",
person_generation="allow_adult",
),
)
if not all([project_id, location, model_name]):
return "Error: Missing GOOGLE_CLOUD_PROJECT, GOOGLE_CLOUD_LOCATION, or IMAGEN_MODEL in .env file."
vertexai.init(project=project_id, location=location)
model = ImageGenerationModel.from_pretrained(model_name)
images = model.generate_images(
prompt=prompt,
number_of_images=1
)
if response.generated_images is None:
return "Error: No image was generated."
for generated_image in response.generated_images:
# Get the image bytes
image_bytes = generated_image.image.image_bytes
counter = str(tool_context.state.get("loop_iteration", 0))
artifact_name = f"generated_image_" + counter + ".png"
# Save as ADK artifact (optional, if still needed by other ADK components)
report_artifact = types.Part.from_bytes(
data=image_bytes, mime_type="image/png"
)
await tool_context.save_artifact(artifact_name, report_artifact)
logger.info(f"Image also saved as ADK artifact: {artifact_name}")
return {
"status": "success",
"message": f"Image generated . ADK artifact: {artifact_name}.",
"artifact_name": artifact_name,
}
except Exception as e:
error_message = f"An error occurred during image generation: {e}"
print(error_message)
return error_message
- Starten Sie zuerst den ADK-Server (Agent Development Kit) neu. Wechseln Sie zum Terminal, in dem Sie den ADK-Server (Agent Development Kit) gestartet haben, und drücken Sie STRG + C, um den Server zu beenden, falls er noch ausgeführt wird. Führen Sie den folgenden Befehl aus, um den Server neu zu starten.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- Strg + Klick auf die URL (z. B. http://localhost:8000) auf dem Bildschirm angezeigt wird. Die ADK-GUI (Agent Development Kit) sollte auf dem Browser-Tab angezeigt werden.
- Wählen Sie auf dem UI-Tab ADK (Agent Development Kit) in der Agent-Liste „Agent2“ aus und klicken Sie auf die Schaltfläche „Bearbeiten“ (Stiftsymbol). Klicken Sie im ADK (Agent Development Kit) Visual Editor auf die Schaltfläche „Speichern“, um die Änderungen zu übernehmen.
- Jetzt können wir den neuen Agent testen.
- Geben Sie in der Chat-Benutzeroberfläche der ADK-UI (Agent Development Kit) den folgenden Prompt ein. Sie können auch andere Prompts ausprobieren. Die Ergebnisse sollten wie in Abbildung 22 aussehen.
Create an image of a cat
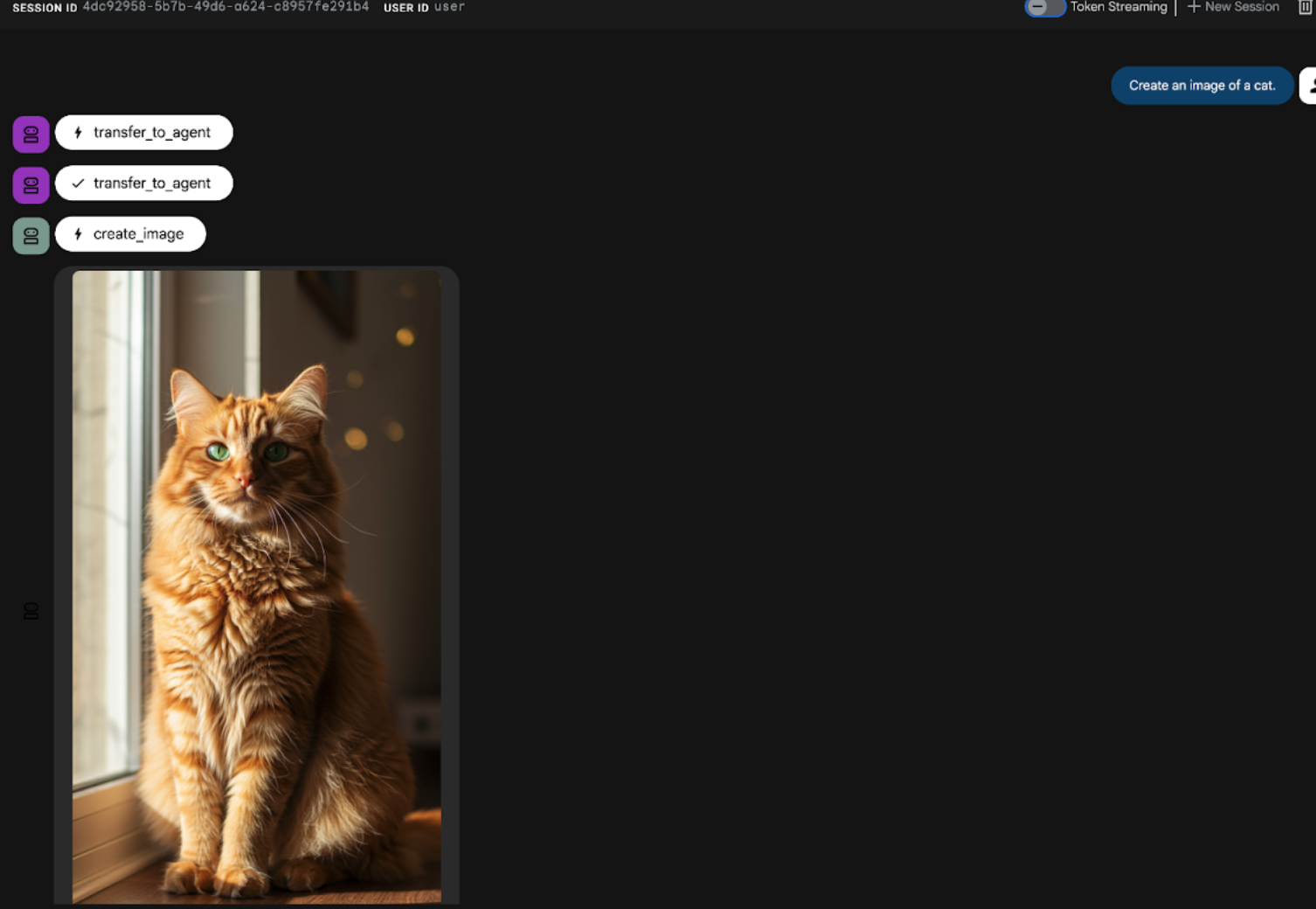
Abbildung 22: ADK-UI-Chatoberfläche
10. Workflow-Agent erstellen
Im vorherigen Schritt wurde ein Agent mit einem untergeordneten Agenten und speziellen Tools zur Bilderstellung erstellt. In dieser Phase geht es darum, die Funktionen des Agenten zu optimieren. Wir werden den Prozess optimieren, indem wir dafür sorgen, dass der ursprüngliche Prompt des Nutzers optimiert wird, bevor das Bild generiert wird. Dazu wird ein sequenzieller Agent in den Root-Agent integriert, um den folgenden zweistufigen Workflow zu verarbeiten:
- Sie erhalten den Prompt vom Root Agent und optimieren ihn.
- Leiten Sie den optimierten Prompt an den Agent für die Bildgenerierung weiter, um das endgültige Bild mit IMAGEN zu erstellen.
- Starten Sie zuerst den ADK-Server (Agent Development Kit) neu. Wechseln Sie zum Terminal, in dem Sie den ADK-Server (Agent Development Kit) gestartet haben, und drücken Sie STRG + C, um den Server zu beenden, falls er noch ausgeführt wird. Führen Sie den folgenden Befehl aus, um den Server neu zu starten.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- Strg + Klick auf die URL (z. B. http://localhost:8000) auf dem Bildschirm angezeigt wird. Die ADK-GUI (Agent Development Kit) sollte auf dem Browser-Tab angezeigt werden.
- Wählen Sie im Agent-Selektor Agent2 aus und klicken Sie auf die Schaltfläche „Bearbeiten“ (Stiftsymbol).
- Klicken Sie auf Agent2 (Root Agent) und dann neben dem Menü „Sub Agents“ auf die Schaltfläche +. Klicken Sie in der Liste der Optionen auf Sequenzieller Agent.
- Die Agent-Struktur sollte wie in Abbildung 23
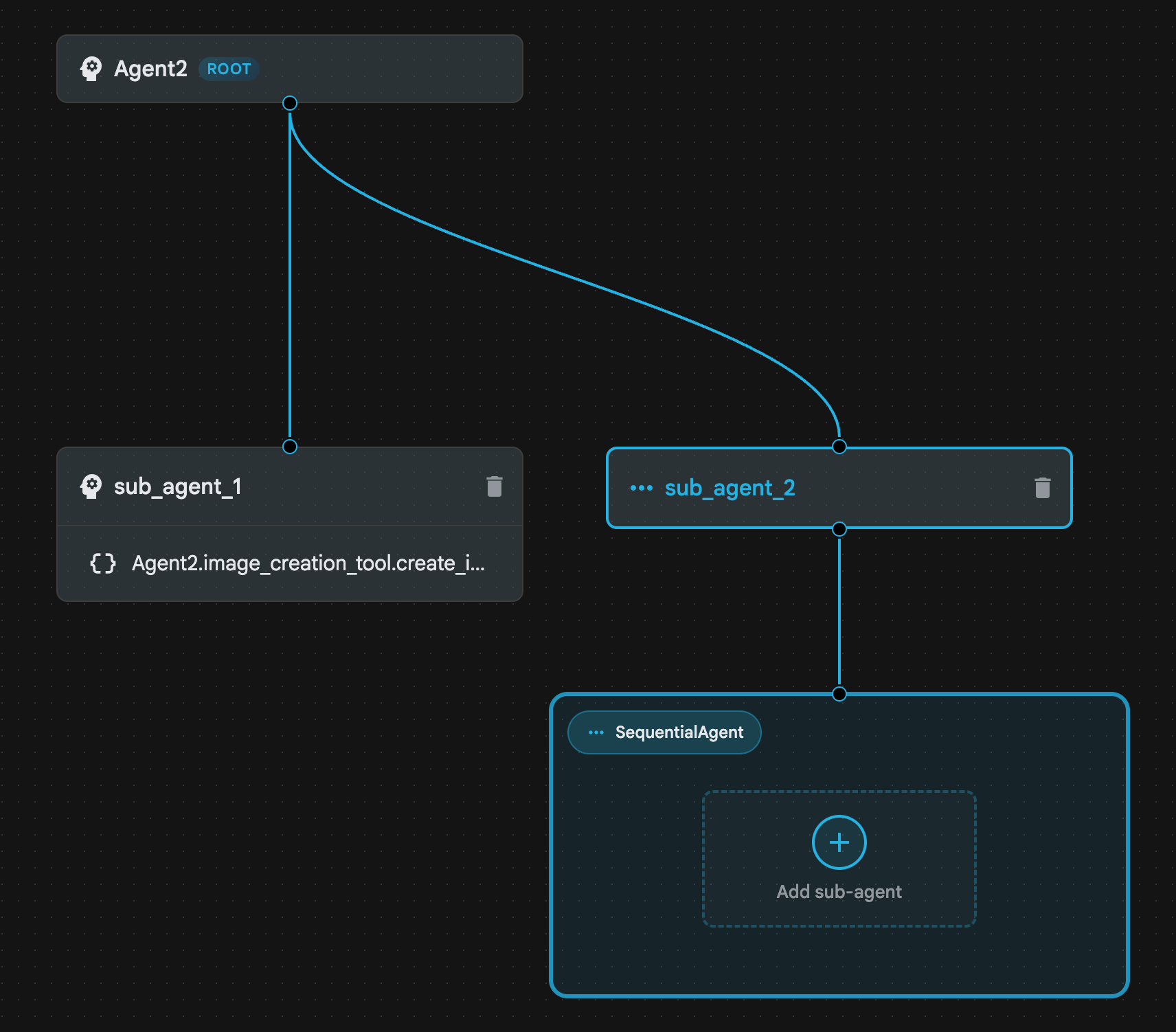 aussehen.
aussehen.
Abbildung 23: Sequenzielle Agent-Agent-Struktur
- Jetzt fügen wir den ersten Agent dem Sequential Agent hinzu, der als Prompt-Optimierer fungiert. Klicken Sie dazu im Feld „SequentialAgent“ auf die Schaltfläche „Untergeordneten Agent hinzufügen“ und dann auf „LLM-Agent“.
- Wir müssen der Sequenz einen weiteren Agent hinzufügen. Wiederholen Sie dazu Schritt 6, um einen weiteren LLM-Agent hinzuzufügen (drücken Sie die + Schaltfläche und wählen Sie LLMAgent aus).
- Klicken Sie auf „sub_agent_4“ und fügen Sie ein neues Tool hinzu, indem Sie im linken Bereich neben Tools auf das „+“-Symbol klicken. Klicken Sie in den Optionen auf Funktionstool. Geben Sie im Dialogfeld den Namen des Tools ein: Agent2.image_creation_tool.create_image und klicken Sie auf Erstellen.
- Jetzt können wir sub_agent_1 löschen, da er durch den fortschrittlicheren sub_agent_2 ersetzt wurde. Klicken Sie dazu im Diagramm rechts neben sub_agent_1 auf die Schaltfläche Löschen.
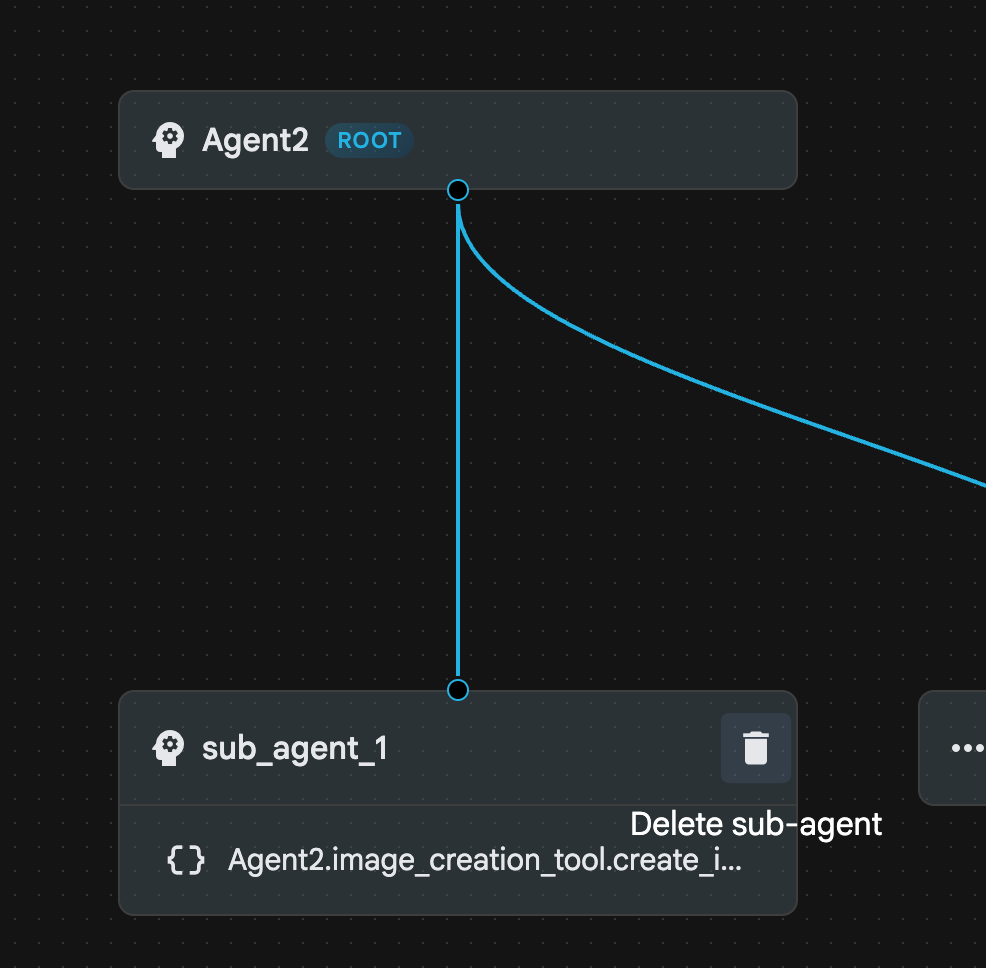
Abbildung 24: „sub_agent_1“ löschen 10. Unsere Agentstruktur sieht so aus wie in Abbildung 25.
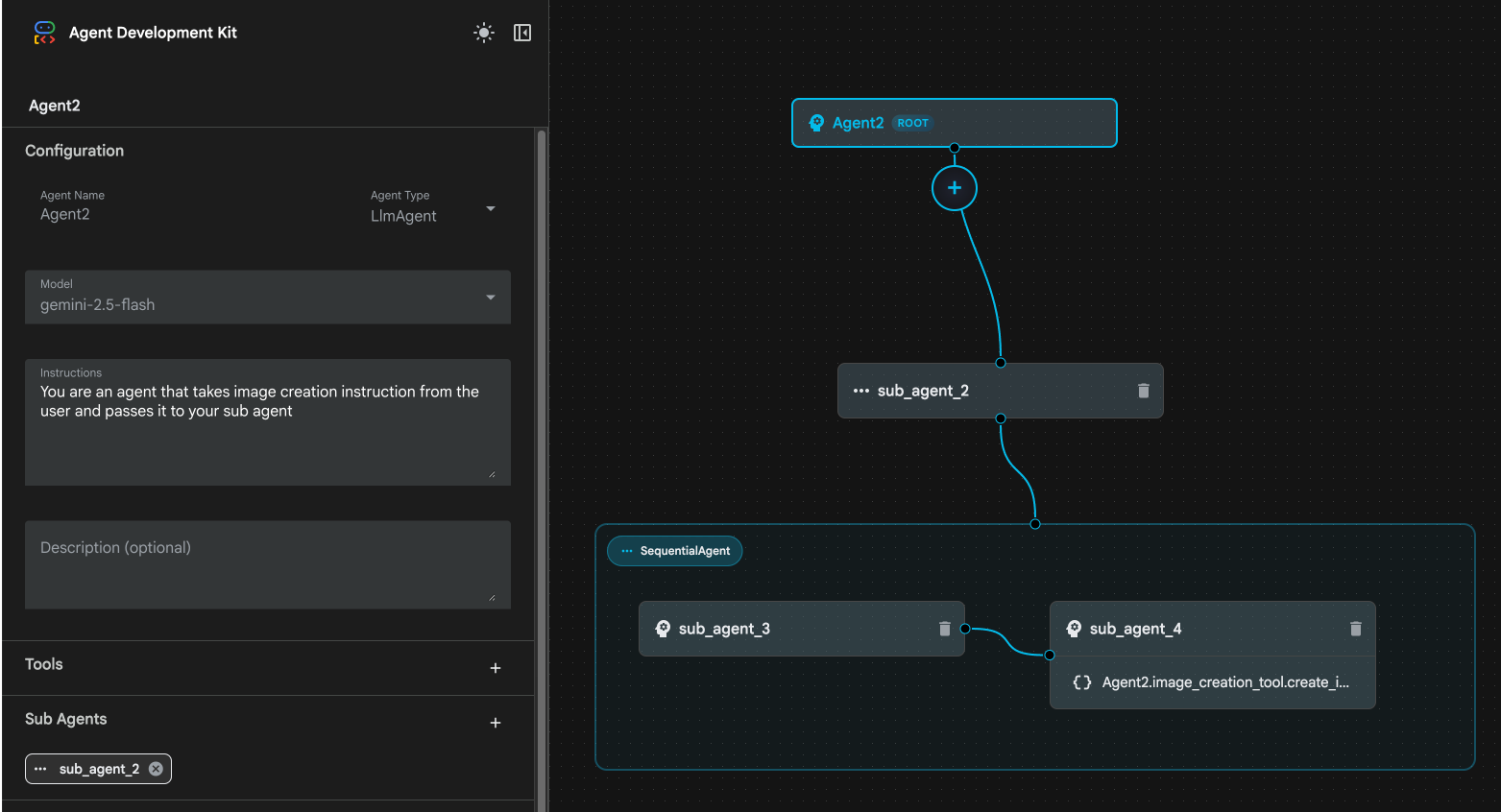
Abbildung 25: Endgültige Struktur des erweiterten Agenten
- Klicken Sie auf „sub_agent_3“ und geben Sie Folgendes in die Anleitung ein.
Act as a professional AI Image Prompt Engineer. I will provide you
with a basic idea for an image. Your job is to expand my idea into
a detailed, high-quality prompt for models like Imagen.
For every input, output the following structure:
1. **Optimized Prompt**: A vivid, descriptive paragraph including
subject, background, lighting, and textures.
2. **Style & Medium**: Specify if it is photorealistic, digital art,
oil painting, etc.
3. **Camera & Lighting**: Define the lens (e.g., 85mm), angle,
and light quality (e.g., volumetric, golden hour).
Guidelines: Use sensory language, avoid buzzwords like 'photorealistic'
unless necessary, and focus on specific artistic descriptors.
Once the prompt is created send the prompt to the
- Klicken Sie auf sub_agent_4. Ändern Sie die Anweisung so:
You are an agent that takes instructions about an image and can generate the image using the create_image tool.
- Klicken Sie auf die Schaltfläche „Speichern“.
- Rufen Sie im Explorer-Bereich des Cloud Shell-Editors die YAML-Dateien des Agents auf und öffnen Sie sie. Die Agent-Dateien sollten so aussehen:
root_agent.yaml
name: Agent2
model: gemini-2.5-flash
agent_class: LlmAgent
instruction: You are an agent that takes image creation instruction from the
user and passes it to your sub agent
sub_agents:
- config_path: ./sub_agent_2.yaml
tools: []
sub_agent_2.yaml
name: sub_agent_2
agent_class: SequentialAgent
sub_agents:
- config_path: ./sub_agent_3.yaml
- config_path: ./sub_agent_4.yaml
sub_agent_3.yaml
name: sub_agent_3
model: gemini-2.5-flash
agent_class: LlmAgent
instruction: |
Act as a professional AI Image Prompt Engineer. I will provide you with a
basic idea for an image. Your job is to expand my idea into a detailed,
high-quality prompt for models like Imagen.
For every input, output the following structure: 1. **Optimized Prompt**: A
vivid, descriptive paragraph including subject, background, lighting, and
textures. 2. **Style & Medium**: Specify if it is photorealistic, digital
art, oil painting, etc. 3. **Camera & Lighting**: Define the lens (e.g.,
85mm), angle, and light quality (e.g., volumetric, golden hour).
Guidelines: Use sensory language, avoid buzzwords like
'photorealistic' unless necessary, and focus on specific artistic
descriptors. Once the prompt is created send the prompt to the
sub_agents: []
tools: []
sub_agent_4.yaml
name: sub_agent_4
model: gemini-2.5-flash
agent_class: LlmAgent
instruction: You are an agent that takes instructions about an image and
generate the image using the create_image tool.
sub_agents: []
tools:
- name: Agent2.image_creation_tool.create_image
- Jetzt testen wir es.
- Starten Sie zuerst den ADK-Server (Agent Development Kit) neu. Wechseln Sie zum Terminal, in dem Sie den ADK-Server (Agent Development Kit) gestartet haben, und drücken Sie STRG + C, um den Server zu beenden, falls er noch ausgeführt wird. Führen Sie den folgenden Befehl aus, um den Server neu zu starten.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- Strg + Klick auf die URL (z. B. http://localhost:8000) auf dem Bildschirm angezeigt wird. Die ADK-GUI (Agent Development Kit) sollte auf dem Browser-Tab angezeigt werden.
- Wählen Sie „Agent2“ aus der Liste der Kundenservicemitarbeiter aus. Geben Sie den folgenden Prompt ein:
Create an image of a Cat
- Während der Agent arbeitet, können Sie sich im Cloud Shell-Editor das Terminal ansehen, um zu sehen, was im Hintergrund passiert. Das Endergebnis sollte wie in Abbildung 26 aussehen.
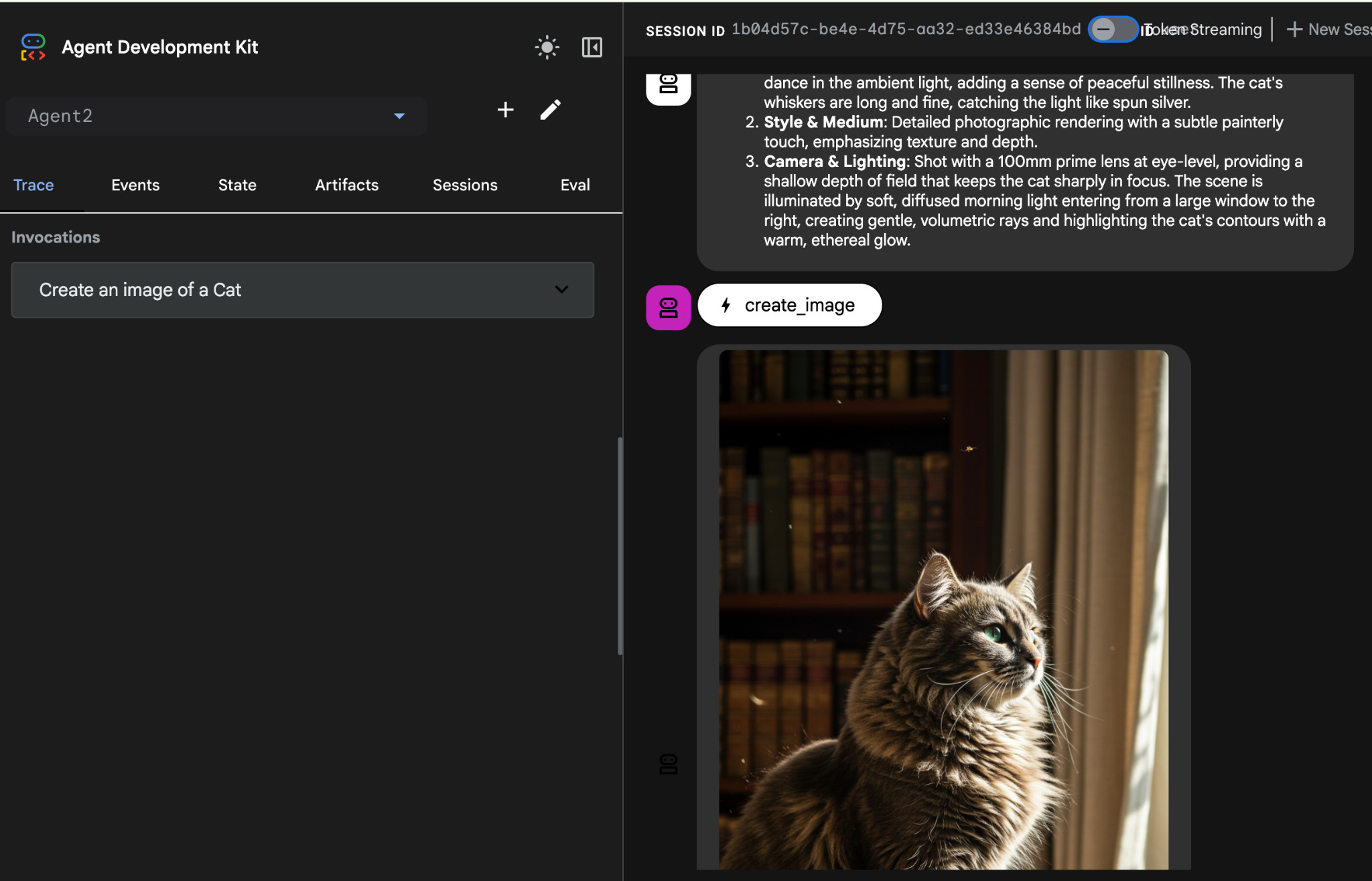
Abbildung 26: Agent testen
11. KI‑Agenten mit Agent Builder Assistant erstellen
Agent Builder Assistant ist Teil von ADK Visual Builder und ermöglicht die interaktive Erstellung von Agenten über Prompts in einer einfachen Chatoberfläche. Dabei sind unterschiedliche Komplexitätsgrade möglich. Mit dem ADK Visual Builder erhalten Sie sofort visuelles Feedback zu den von Ihnen entwickelten Agents. In diesem Lab erstellen wir einen Agenten, der auf Nutzeranfrage einen HTML-Comic generieren kann. Nutzer können einen einfachen Prompt wie „Erstelle ein Comic über Hänsel und Gretel“ eingeben oder eine ganze Geschichte. Der Agent analysiert dann die Geschichte, segmentiert sie in mehrere Panels und verwendet Nanobanana, um die Comic-Visuals zu erstellen. Das Ergebnis wird schließlich in einem HTML-Format verpackt.
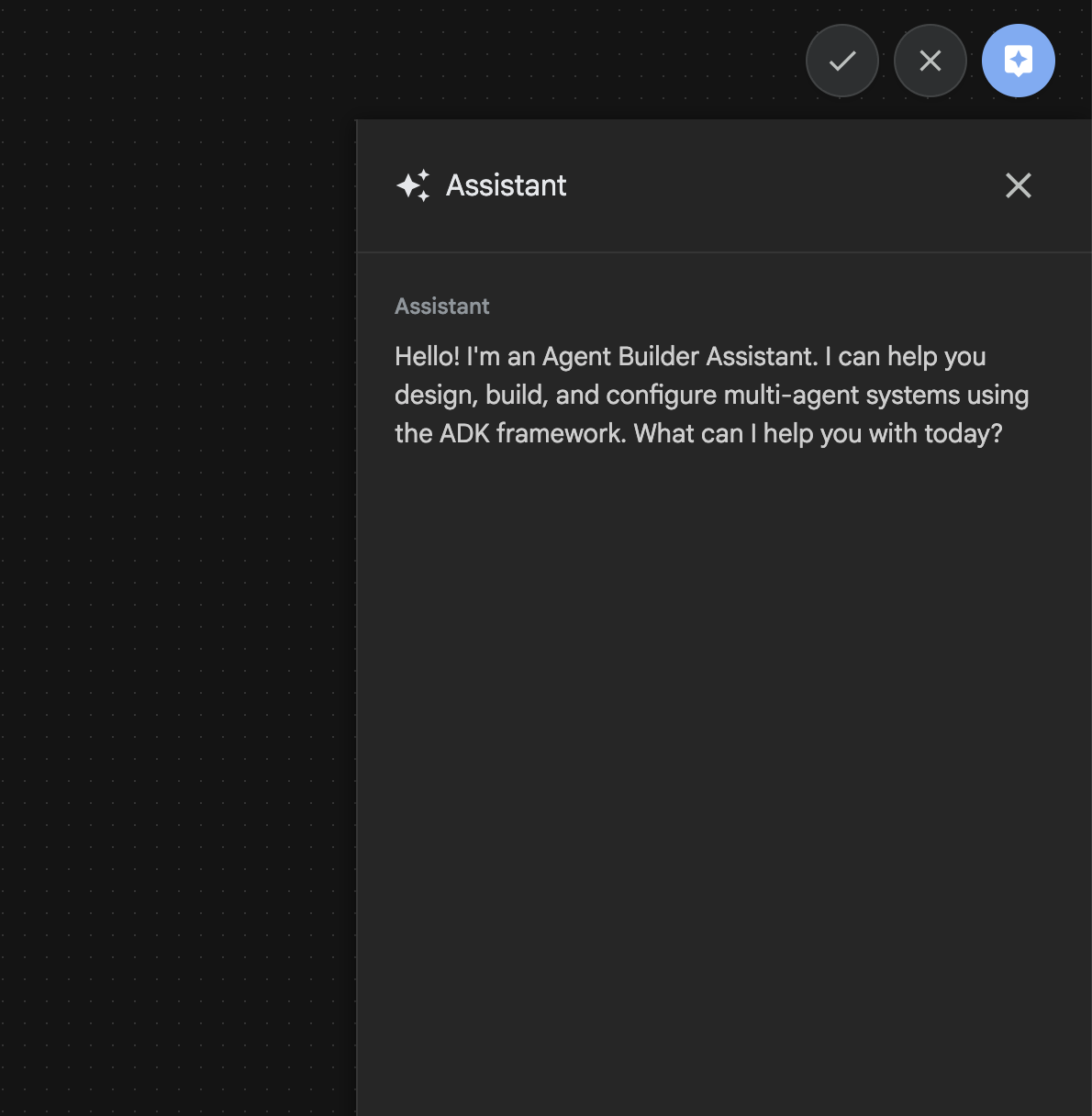
Abbildung 27: Benutzeroberfläche des Agent Builder-Assistenten
Los geht's!
- Starten Sie zuerst den ADK-Server (Agent Development Kit) neu. Wechseln Sie zum Terminal, in dem Sie den ADK-Server (Agent Development Kit) gestartet haben, und drücken Sie STRG + C, um den Server zu beenden, falls er noch ausgeführt wird. Führen Sie den folgenden Befehl aus, um den Server neu zu starten.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- Strg + Klick auf die URL (z. B. http://localhost:8000) auf dem Bildschirm angezeigt wird. Die ADK-GUI (Agent Development Kit) sollte auf dem Browser-Tab angezeigt werden.
- Klicken Sie in der GUI des ADK (Agent Development Kit) auf die Schaltfläche „+“, um einen neuen Agenten zu erstellen.
- Geben Sie im Dialogfeld „Agent3“ ein und klicken Sie auf die Schaltfläche Erstellen.
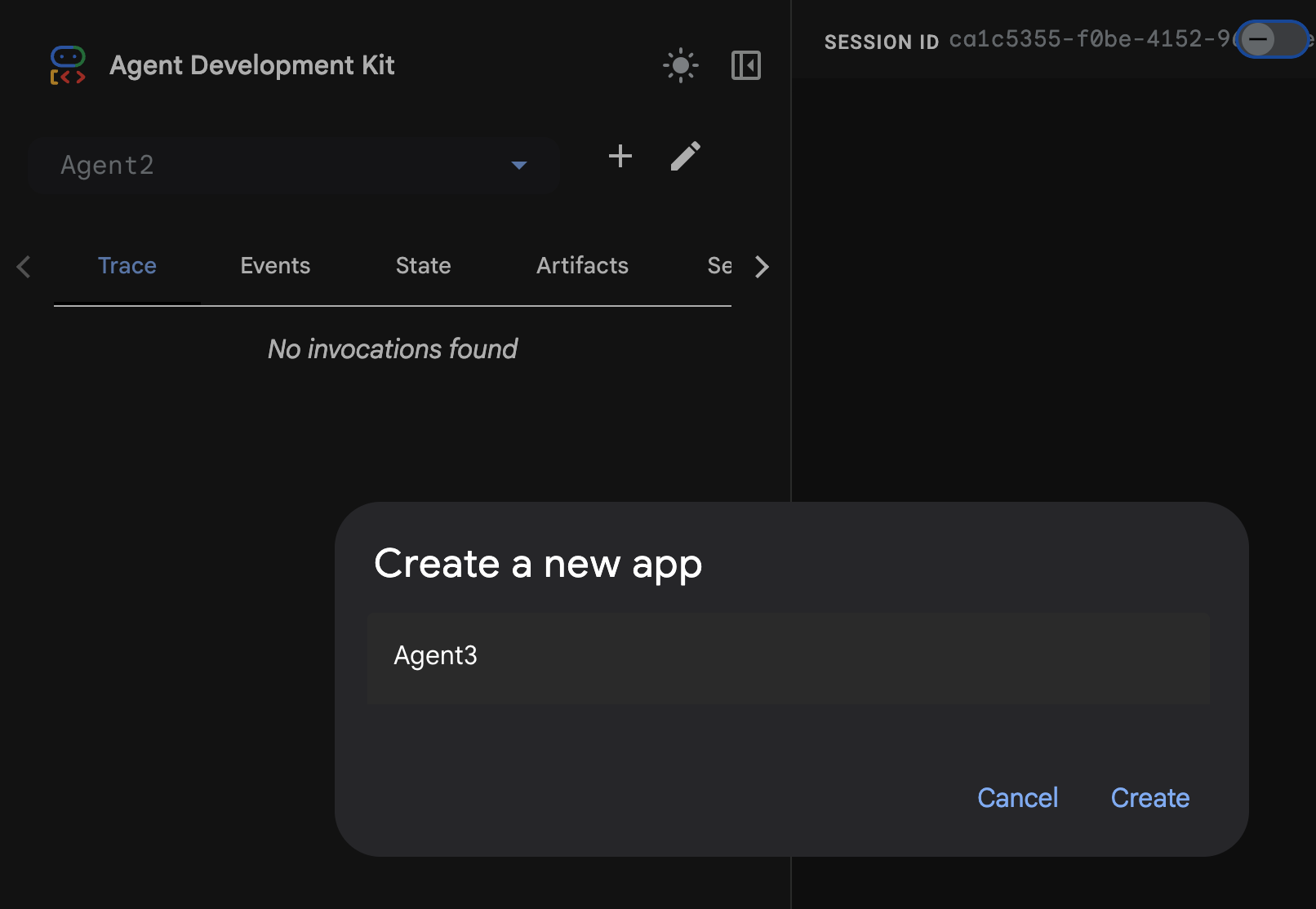
Abbildung 28: Neuen Agenten „Agent3“ erstellen
- Geben Sie im Assistant-Bereich auf der rechten Seite den folgenden Prompt ein. Der folgende Prompt enthält alle Anweisungen, die zum Erstellen eines Systems von Agents zum Erstellen eines HTML-basierten Agents erforderlich sind.
System Goal: You are the Studio Director (Root Agent). Your objective is to manage a linear pipeline of four ADK Sequential Agents to transform a user's seed idea into a fully rendered, responsive HTML5 comic book.
0. Root Agent: The Studio Director
Role: Orchestrator and State Manager.
Logic: Receives the user's initial request. It initializes the workflow and ensures the output of each Sub-Agent is passed as the context for the next. It monitors the sequence to ensure no steps are skipped. Make sure the query explicitly mentions "Create me a comic of ..." if it's just a general question or prompt just answer the question.
1. Sub-Agent: The Scripting Agent (Sequential Step 1)
Role: Narrative & Character Architect.
Input: Seed idea from Root Agent.
Logic: 1. Create a Character Manifest: Define 3 specific, unchangeable visual identifiers
for every character (e.g., "Gretel: Blue neon hair ribbons, silver apron,
glowing boots").
2. Expand the seed idea into a coherent narrative arc.
Output: A narrative script and a mandatory character visual guide.
2. Sub-Agent: The Panelization Agent (Sequential Step 2)
Role: Cinematographer & Storyboarder.
Input: Script and Character Manifest from Step 1.
Logic:
1. Divide the script into exactly X panels (User-defined or default to 8).
2. For each panel, define a specific composition (e.g., "Panel 1:
Wide shot of the gingerbread house").
Output: A structured list of exactly X panel descriptions.
3. Sub-Agent: The Image Synthesis Agent (Sequential Step 3)
Role: Technical Artist & Asset Generator.
Input: The structured list of panel descriptions from Step 2.
Logic:
1. Iterative Generation: You must execute the "generate_image" tool in
"image_generation.py" file
(Nano Banana) individually for each panel defined in Step 2.
2. Prompt Engineering: For every panel, translate the description into a
Nano Banana prompt, strictly enforcing the character identifiers
(e.g., the "blue neon ribbons") and the global style: "vibrant comic book style,
heavy ink lines, cel-shaded, 4k." . Make sure that the necessary speech bubbles
are present in the image representing the dialogue.
3. Mapping: Associate each generated image URL with its corresponding panel
number and dialogue.
Output: A complete gallery of X images mapped to their respective panel data.
4. Sub-Agent: The Assembly Agent (Sequential Step 4)
Role: Frontend Developer.
Input: The mapped images and panel text from Step 3.
Logic:
1. Write a clean, responsive HTML5/CSS3 file that shows the comic. The comic should be
Scrollable with image on the top and the description below the image.
2. Use "write_comic_html" tool in file_writer.py to write the created html file in
the "output" folder.
4. In the "write_comic_html" tool add logic to copy the images folder to the
output folder so that the images in the html file are actually visible when
the user opens the html file.
Output: A final, production-ready HTML code block.
- Der Agent kann Sie auffordern, das zu verwendende Modell einzugeben. Geben Sie in diesem Fall gemini-2.5-pro ein.
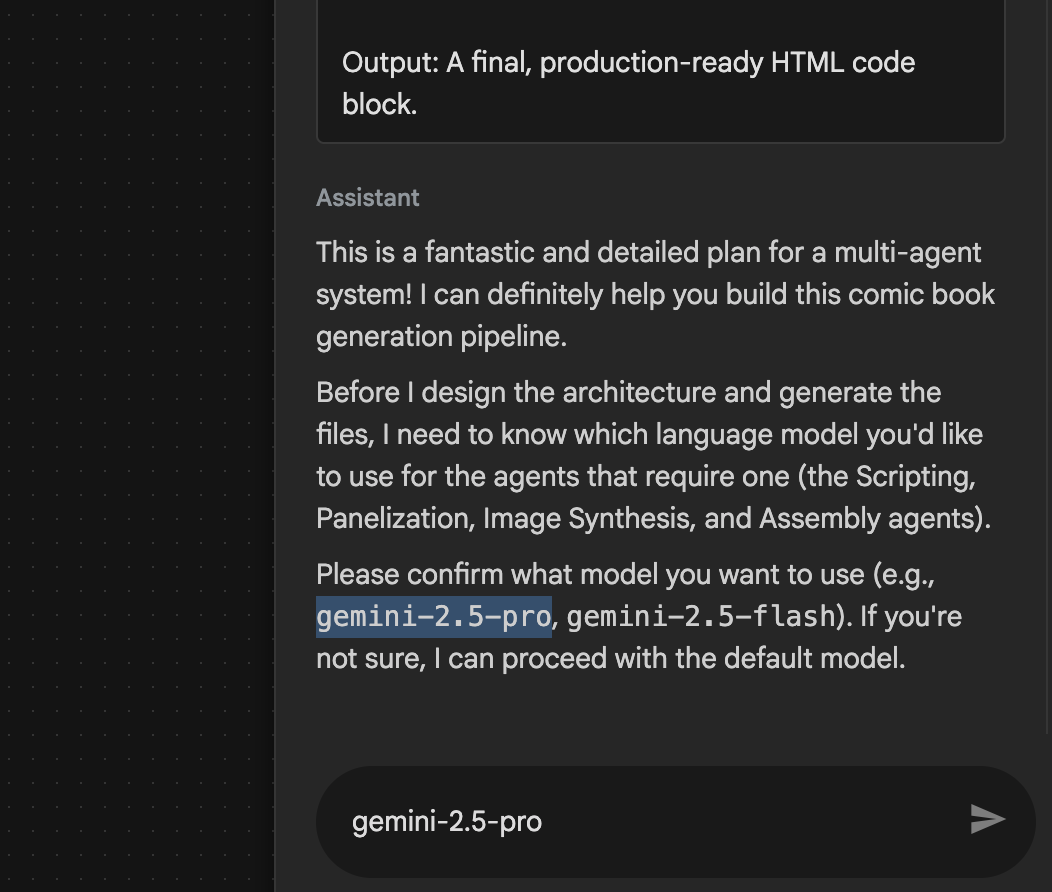 Abbildung 29: Geben Sie „gemini-2.5-pro“ ein, wenn Sie aufgefordert werden, das zu verwendende Modell anzugeben.
Abbildung 29: Geben Sie „gemini-2.5-pro“ ein, wenn Sie aufgefordert werden, das zu verwendende Modell anzugeben.
- Assistant schlägt möglicherweise einen Plan vor und bittet Sie, zu bestätigen, ob Sie fortfahren möchten. Prüfen Sie den Plan, geben Sie OK ein und drücken Sie die Eingabetaste.
 Abbildung 30: „OK“ eingeben, wenn der Plan in Ordnung ist 8. Nachdem Assistant die Arbeit abgeschlossen hat, sollte die Agent-Struktur wie in Abbildung 31 angezeigt werden.
Abbildung 30: „OK“ eingeben, wenn der Plan in Ordnung ist 8. Nachdem Assistant die Arbeit abgeschlossen hat, sollte die Agent-Struktur wie in Abbildung 31 angezeigt werden.
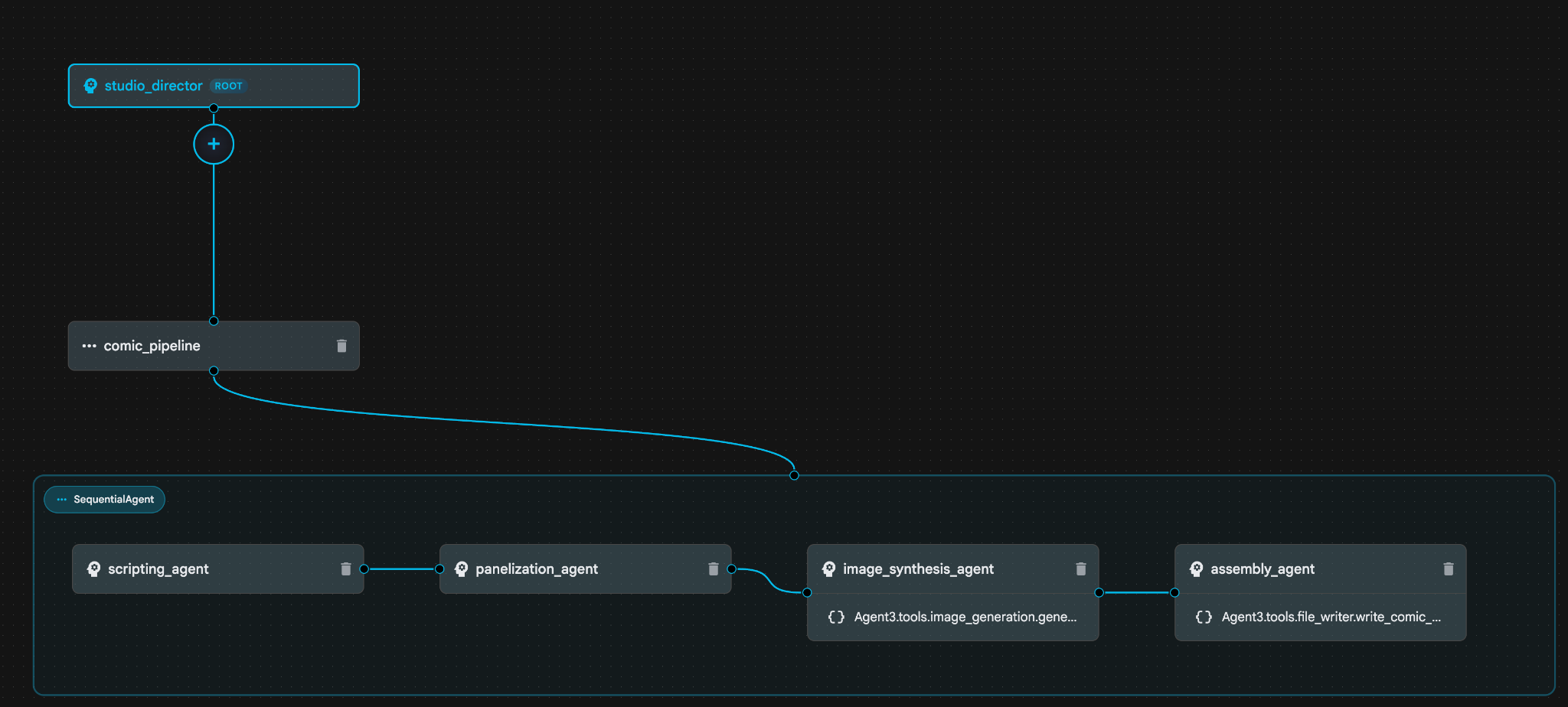 Abbildung 31: Agent, der vom Agent Builder Assistant 9 erstellt wurde. Klicken Sie im image_synthesis_agent (Ihr Name kann abweichen) auf das Tool „Agent3.tools.image_generation.gene...“. Wenn der letzte Abschnitt des Tool-Namens nicht image_generation.generate_image change ist, ändern Sie ihn in image_generation.generate_image. Wenn der Name bereits festgelegt ist, müssen Sie ihn nicht ändern. Drücken Sie zum Speichern auf die Schaltfläche Speichern.
Abbildung 31: Agent, der vom Agent Builder Assistant 9 erstellt wurde. Klicken Sie im image_synthesis_agent (Ihr Name kann abweichen) auf das Tool „Agent3.tools.image_generation.gene...“. Wenn der letzte Abschnitt des Tool-Namens nicht image_generation.generate_image change ist, ändern Sie ihn in image_generation.generate_image. Wenn der Name bereits festgelegt ist, müssen Sie ihn nicht ändern. Drücken Sie zum Speichern auf die Schaltfläche Speichern.
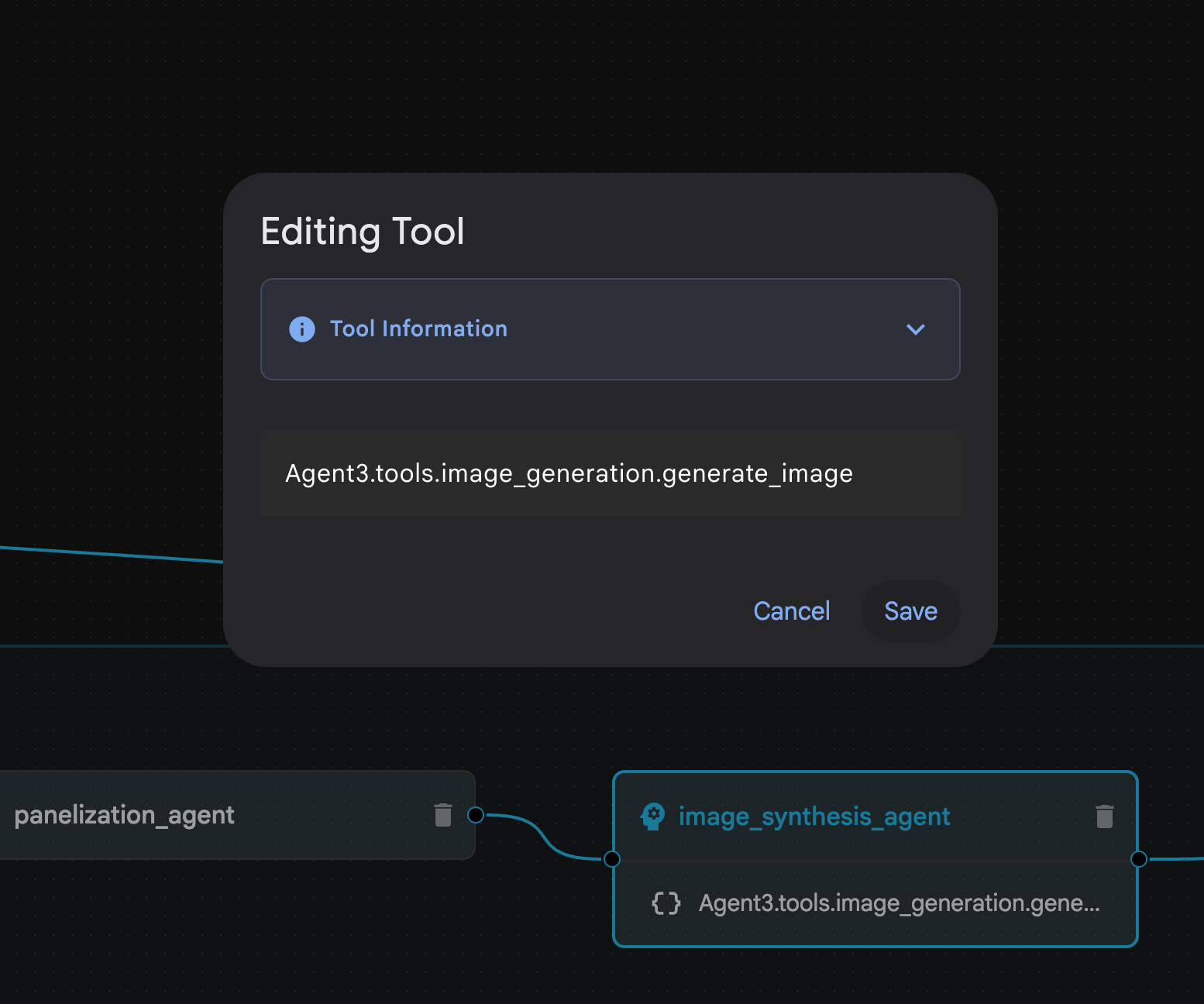 Abbildung 32: Ändern Sie den Tool-Namen in „image_generation.generate_image“ und klicken Sie auf „Speichern“.
Abbildung 32: Ändern Sie den Tool-Namen in „image_generation.generate_image“ und klicken Sie auf „Speichern“.
- Klicken Sie in „assembly_agent“ (der Name Ihres KI-Agenten kann abweichen) auf das Tool **Agent3.tools.file_writer.write_comic_...**. Wenn der letzte Abschnitt des Toolnamens nicht **file_writer.write_comic_html** ist, ändern Sie ihn in **file_writer.write_comic_html**.
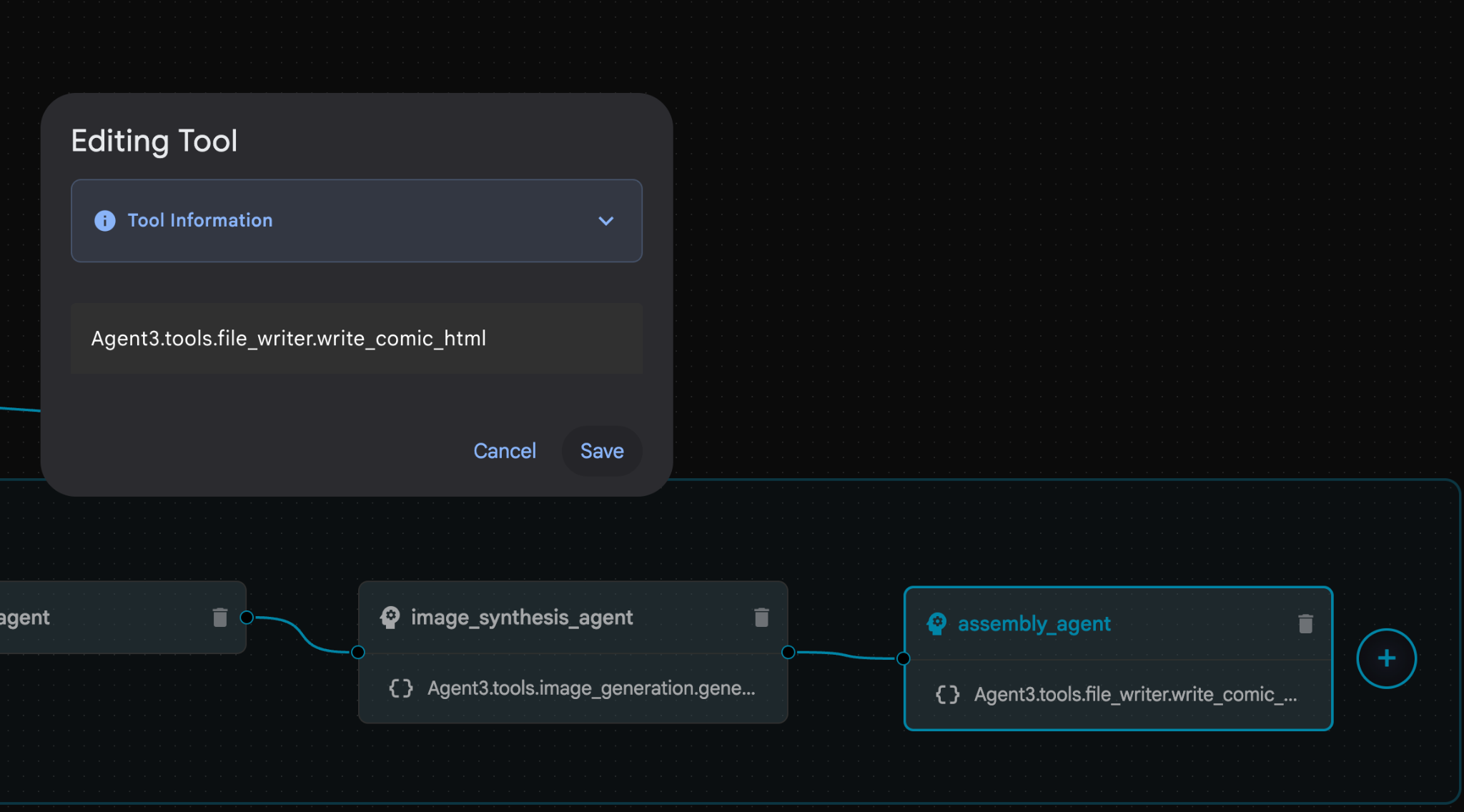 Abbildung 33: Ändern Sie den Toolnamen in file_writer.write_comic_html. 11. Klicken Sie links unten im linken Bereich auf die Schaltfläche Speichern, um den neu erstellten Agent zu speichern. 12. Maximieren Sie im Bereich Explorer des Cloud Shell-Editors den Ordner Agent3. Im Ordner Agent3/ sollte sich der Ordner tools befinden. Klicken Sie auf Agent3/tools/file_writer.py, um die Datei zu öffnen, und ersetzen Sie den Inhalt von Agent3/tools/file_writer.py durch den folgenden Code. Drücken Sie Strg + S, um die Änderungen zu speichern. Hinweis: Der Agent-Assistent hat möglicherweise bereits den richtigen Code erstellt. In diesem Lab verwenden wir jedoch den getesteten Code.
Abbildung 33: Ändern Sie den Toolnamen in file_writer.write_comic_html. 11. Klicken Sie links unten im linken Bereich auf die Schaltfläche Speichern, um den neu erstellten Agent zu speichern. 12. Maximieren Sie im Bereich Explorer des Cloud Shell-Editors den Ordner Agent3. Im Ordner Agent3/ sollte sich der Ordner tools befinden. Klicken Sie auf Agent3/tools/file_writer.py, um die Datei zu öffnen, und ersetzen Sie den Inhalt von Agent3/tools/file_writer.py durch den folgenden Code. Drücken Sie Strg + S, um die Änderungen zu speichern. Hinweis: Der Agent-Assistent hat möglicherweise bereits den richtigen Code erstellt. In diesem Lab verwenden wir jedoch den getesteten Code.
import os
import shutil
def write_comic_html(html_content: str, image_directory: str = "images") -> str:
"""
Writes the final HTML content to a file and copies the image assets.
Args:
html_content: A string containing the full HTML of the comic.
image_directory: The source directory where generated images are stored.
Returns:
A confirmation message indicating success or failure.
"""
output_dir = "output"
images_output_dir = os.path.join(output_dir, image_directory)
try:
# Create the main output directory
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Copy the entire image directory to the output folder
if os.path.exists(image_directory):
if os.path.exists(images_output_dir):
shutil.rmtree(images_output_dir) # Remove old images
shutil.copytree(image_directory, images_output_dir)
else:
return f"Error: Image directory '{image_directory}' not found."
# Write the HTML file
html_file_path = os.path.join(output_dir, "comic.html")
with open(html_file_path, "w") as f:
f.write(html_content)
return f"Successfully created comic at '{html_file_path}'"
except Exception as e:
return f"An error occurred: {e}"
- Erweitern Sie im Explorer-Bereich des Cloud Shell-Editors den Ordner „Agent3“. Im Ordner **Agent3/**sollte sich der Ordner tools befinden. Klicken Sie auf Agent3/tools/image_generation.py, um die Datei zu öffnen, und ersetzen Sie den Inhalt von Agent3/tools/image_generation.py durch den folgenden Code. Drücken Sie zum Speichern Strg + S. Hinweis: Der Agent-Assistent hat möglicherweise bereits den richtigen Code erstellt. In diesem Lab verwenden wir jedoch den getesteten Code.
import time
import os
import io
import vertexai
from vertexai.preview.vision_models import ImageGenerationModel
from dotenv import load_dotenv
import uuid
from typing import Union
from datetime import datetime
from google import genai
from google.genai import types
from google.adk.tools import ToolContext
import logging
import asyncio
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# It's better to initialize the client once and reuse it.
# IMPORTANT: Your Google Cloud Project ID must be set as an environment variable
# for the client to authenticate correctly.
def edit_image(client, prompt: str, previous_image: str, model_id: str) -> Union[bytes, None]:
"""
Calls the model to edit an image based on a prompt.
Args:
prompt: The text prompt for image editing.
previous_image: The path to the image to be edited.
model_id: The model to use for the edit.
Returns:
The raw image data as bytes, or None if an error occurred.
"""
try:
with open(previous_image, "rb") as f:
image_bytes = f.read()
response = client.models.generate_content(
model=model_id,
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type="image/png", # Assuming PNG, adjust if necessary
),
prompt,
],
config=types.GenerateContentConfig(
response_modalities=['IMAGE'],
)
)
# Extract image data
for part in response.candidates[0].content.parts:
if part.inline_data:
return part.inline_data.data
logger.warning("Warning: No image data was generated for the edit.")
return None
except FileNotFoundError:
logger.error(f"Error: The file {previous_image} was not found.")
return None
except Exception as e:
logger.error(f"An error occurred during image editing: {e}")
return None
async def generate_image(tool_context: ToolContext, prompt: str, image_name: str, previous_image: str = None) -> dict:
"""
Generates or edits an image and saves it to the 'images/' directory.
If 'previous_image' is provided, it edits that image. Otherwise, it generates a new one.
Args:
prompt: The text prompt for the operation.
image_name: The desired name for the output image file (without extension).
previous_image: Optional path to an image to be edited.
Returns:
A confirmation message with the path to the saved image or an error message.
"""
load_dotenv()
project_id = os.environ.get("GOOGLE_CLOUD_PROJECT")
if not project_id:
return "Error: GOOGLE_CLOUD_PROJECT environment variable is not set."
try:
client = genai.Client(vertexai=True, project=project_id, location="global")
except Exception as e:
return f"Error: Failed to initialize genai.Client: {e}"
image_data = None
model_id = "gemini-3-pro-image-preview"
try:
if previous_image:
logger.info(f"Editing image: {previous_image}")
image_data = edit_image(
client=client,
prompt=prompt,
previous_image=previous_image,
model_id=model_id
)
else:
logger.info("Generating new image")
# Generate the image
response = client.models.generate_content(
model=model_id,
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=['IMAGE'],
image_config=types.ImageConfig(aspect_ratio="16:9"),
),
)
# Check for errors
if response.candidates[0].finish_reason != types.FinishReason.STOP:
return f"Error: Image generation failed. Reason: {response.candidates[0].finish_reason}"
# Extract image data
for part in response.candidates[0].content.parts:
if part.inline_data:
image_data = part.inline_data.data
break
if not image_data:
return {"status": "error", "message": "No image data was generated.", "artifact_name": None}
# Create the images directory if it doesn't exist
output_dir = "images"
os.makedirs(output_dir, exist_ok=True)
# Save the image to file system
file_path = os.path.join(output_dir, f"{image_name}.png")
with open(file_path, "wb") as f:
f.write(image_data)
# Save as ADK artifact
counter = str(tool_context.state.get("loop_iteration", 0))
artifact_name = f"{image_name}_" + counter + ".png"
report_artifact = types.Part.from_bytes(data=image_data, mime_type="image/png")
await tool_context.save_artifact(artifact_name, report_artifact)
logger.info(f"Image also saved as ADK artifact: {artifact_name}")
return {
"status": "success",
"message": f"Image generated and saved to {file_path}. ADK artifact: {artifact_name}.",
"artifact_name": artifact_name,
}
except Exception as e:
return f"An error occurred: {e}"
- Die endgültigen YAML-Dateien, die in der Umgebung des Autors erstellt wurden, finden Sie unten als Referenz. Die Dateien in Ihrer Umgebung können sich etwas unterscheiden. Die YAML-Struktur Ihres KI-Agents muss dem Layout im ADK Visual Builder entsprechen.
root_agent.yamlname: studio_director
model: gemini-2.5-pro
agent_class: LlmAgent
description: The Studio Director who manages the comic creation pipeline.
instruction: >
You are the Studio Director. Your objective is to manage a linear pipeline of
four sequential agents to transform a user's seed idea into a fully rendered,
responsive HTML5 comic book.
Your role is to be the primary orchestrator and state manager. You will
receive the user's initial request.
**Workflow:**
1. If the user's prompt starts with "Create me a comic of ...", you must
delegate the task to your sub-agent to begin the comic creation pipeline.
2. If the user asks a general question or provides a prompt that does not
explicitly ask to create a comic, you must answer the question directly
without triggering the comic creation pipeline.
3. Monitor the sequence to ensure no steps are skipped. Ensure the output of
each Sub-Agent is passed as the context for the next.
sub_agents:
- config_path: ./comic_pipeline.yaml
tools: []
comic_pipline.yaml
name: comic_pipeline
agent_class: SequentialAgent
description: A sequential pipeline of agents to create a comic book.
sub_agents:
- config_path: ./scripting_agent.yaml
- config_path: ./panelization_agent.yaml
- config_path: ./image_synthesis_agent.yaml
- config_path: ./assembly_agent.yaml
scripting_agent.yamlname: scripting_agent
model: gemini-2.5-pro
agent_class: LlmAgent
description: Narrative & Character Architect.
instruction: >
You are the Scripting Agent, a Narrative & Character Architect.
Your input is a seed idea for a comic.
**Your Logic:**
1. **Create a Character Manifest:** You must define exactly 3 specific,
unchangeable visual identifiers for every character. For example: "Gretel:
Blue neon hair ribbons, silver apron, glowing boots". This is mandatory.
2. **Expand the Narrative:** Expand the seed idea into a coherent narrative
arc with dialogue.
**Output:**
You must output a JSON object containing:
- "narrative_script": A detailed script with scenes and dialogue.
- "character_manifest": The mandatory character visual guide.
sub_agents: []
tools: []
panelization_agent.yamlname: panelization_agent
model: gemini-2.5-pro
agent_class: LlmAgent
description: Cinematographer & Storyboarder.
instruction: >
You are the Panelization Agent, a Cinematographer & Storyboarder.
Your input is a narrative script and a character manifest.
**Your Logic:**
1. **Divide the Script:** Divide the script into a specific number of panels.
The user may define this number, or you should default to 8 panels.
2. **Define Composition:** For each panel, you must define a specific
composition, camera shot (e.g., "Wide shot", "Close-up"), and the dialogue for
that panel.
**Output:**
You must output a JSON object containing a structured list of exactly X panel
descriptions, where X is the number of panels. Each item in the list should
have "panel_number", "composition_description", and "dialogue".
sub_agents: []
tools: []
image_synthesis_agent.yaml
name: image_synthesis_agent
model: gemini-2.5-pro
agent_class: LlmAgent
description: Technical Artist & Asset Generator.
instruction: >
You are the Image Synthesis Agent, a Technical Artist & Asset Generator.
Your input is a structured list of panel descriptions.
**Your Logic:**
1. **Iterate and Generate:** You must iterate through each panel description
provided in the input. For each panel, you will execute the `generate_image`
tool.
2. **Construct Prompts:** For each panel, you will construct a detailed
prompt for the image generation tool. This prompt must strictly enforce the
character visual identifiers from the manifest and include the global style:
"vibrant comic book style, heavy ink lines, cel-shaded, 4k". The prompt must
also describe the composition and include a request for speech bubbles to
contain the dialogue.
3. **Map Output:** You must associate each generated image URL with its
corresponding panel number and dialogue.
**Output:**
You must output a JSON object containing a complete gallery of all generated
images, mapped to their respective panel data (panel_number, dialogue,
image_url).
sub_agents: []
tools:
- name: Agent3.tools.image_generation.generate_image
assembly_agent.yamlname: assembly_agent
model: gemini-2.5-pro
agent_class: LlmAgent
description: Frontend Developer for comic book assembly.
instruction: >
You are the Assembly Agent, a Frontend Developer.
Your input is the mapped gallery of images and panel data.
**Your Logic:**
1. **Generate HTML:** You will write a clean, responsive HTML5/CSS3 file to
display the comic. The comic must be vertically scrollable, with each panel
displaying its image on top and the corresponding dialogue or description
below it.
2. **Write File:** You must use the `write_comic_html` tool to save the
generated HTML to a file named `comic.html` in the `output/` folder.
3. Pass the list of image URLs to the tool so it can handle the image assets
correctly.
**Output:**
You will output a confirmation message indicating the path to the final HTML
file.
sub_agents: []
tools:
- name: Agent3.tools.file_writer.write_comic_html
- Rufen Sie den Tab ADK (Agent Development Kit) auf , wählen Sie Agent3 aus und klicken Sie auf die Schaltfläche „Bearbeiten“ (Stiftsymbol).
- Klicken Sie links unten auf dem Bildschirm auf die Schaltfläche „Speichern“. Dadurch werden alle Codeänderungen, die Sie am Haupt-Agent vorgenommen haben, beibehalten.
- Jetzt können wir mit dem Testen unseres KI-Agenten beginnen.
- Schließen Sie den aktuellen Tab mit der ADK-Benutzeroberfläche (Agent Development Kit) und kehren Sie zum Tab Cloud Shell-Editor zurück.
- Starten Sie im Terminal auf dem Tab Cloud Shell-Editor zuerst den ADK-Server (Agent Development Kit) neu. Wechseln Sie zum Terminal, in dem Sie den ADK-Server (Agent Development Kit) gestartet haben, und drücken Sie STRG + C, um den Server zu beenden, falls er noch ausgeführt wird. Führen Sie den folgenden Befehl aus, um den Server neu zu starten.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- Strg + Klick auf die URL (z. B. http://localhost:8000) auf dem Bildschirm angezeigt wird. Die ADK-GUI (Agent Development Kit) sollte auf dem Browser-Tab angezeigt werden.
- Wählen Sie in der Liste der Agents Agent3 aus.
- Geben Sie den folgenden Prompt ein:
Create a Comic Book based on the following story,
Title: The Story of Momotaro
The story of Momotaro (Peach Boy) is one of Japan's most famous and beloved folktales. It is a classic "hero's journey" that emphasizes the virtues of courage, filial piety, and teamwork.
The Miraculous Birth
Long, long ago, in a small village in rural Japan, lived an elderly couple. They were hardworking and kind, but they were sad because they had never been blessed with children.
One morning, while the old woman was washing clothes by the river, she saw a magnificent, giant peach floating downstream. It was larger than any peach she had ever seen. With great effort, she pulled it from the water and brought it home to her husband for their dinner.
As they prepared to cut the fruit open, the peach suddenly split in half on its own. To their astonishment, a healthy, beautiful baby boy stepped out from the pit.
"Don't be afraid," the child said. "The Heavens have sent me to be your son."
Overjoyed, the couple named him Momotaro (Momo meaning peach, and Taro being a common name for an eldest son).
The Call to Adventure
Momotaro grew up to be stronger and kinder than any other boy in the village. During this time, the village lived in fear of the Oni—ogres and demons who lived on a distant island called Onigashima. These Oni would often raid the mainland, stealing treasures and kidnapping villagers.
When Momotaro reached young adulthood, he approached his parents with a request. "I must go to Onigashima," he declared. "I will defeat the Oni and bring back the stolen treasures to help our people."
Though they were worried, his parents were proud. As a parting gift, the old woman prepared Kibi-dango (special millet dumplings), which were said to provide the strength of a hundred men.
Gathering Allies
Momotaro set off on his journey toward the sea. Along the way, he met three distinct animals:
The Spotted Dog: The dog growled at first, but Momotaro offered him one of his Kibi-dango. The dog, tasting the magical dumpling, immediately swore his loyalty.
The Monkey: Further down the road, a monkey joined the group in exchange for a dumpling, though he and the dog bickered constantly.
The Pheasant: Finally, a pheasant flew down from the sky. After receiving a piece of the Kibi-dango, the bird joined the team as their aerial scout.
Momotaro used his leadership to ensure the three animals worked together despite their differences, teaching them that unity was their greatest strength.
The Battle of Onigashima
The group reached the coast, built a boat, and sailed to the dark, craggy shores of Onigashima. The island was guarded by a massive iron gate.
The Pheasant flew over the walls to distract the Oni and peck at their eyes.
The Monkey climbed the walls and unbolted the Great Gate from the inside.
The Dog and Momotaro charged in, using their immense strength to overpower the demons.
The Oni were caught off guard by the coordinated attack. After a fierce battle, the King of the Oni fell to his knees before Momotaro, begging for mercy. He promised to never trouble the villagers again and surrendered all the stolen gold, jewels, and precious silks.
The Triumphant Return
Momotaro and his three companions loaded the treasure onto their boat and returned to the village. The entire town celebrated their homecoming.
Momotaro used the wealth to ensure his elderly parents lived the rest of their lives in comfort and peace. He remained in the village as a legendary protector, and his story was passed down for generations as a reminder that bravery and cooperation can overcome even the greatest evils.
- Während der Agent arbeitet, können Sie die Ereignisse im Cloud Shell-Editor-Terminal sehen.
- Es kann eine Weile dauern, bis alle Bilder generiert sind. Haben Sie also etwas Geduld oder holen Sie sich einen Kaffee. Wenn die Bildgenerierung beginnt, sollten Sie die Bilder zur Geschichte wie unten sehen können.
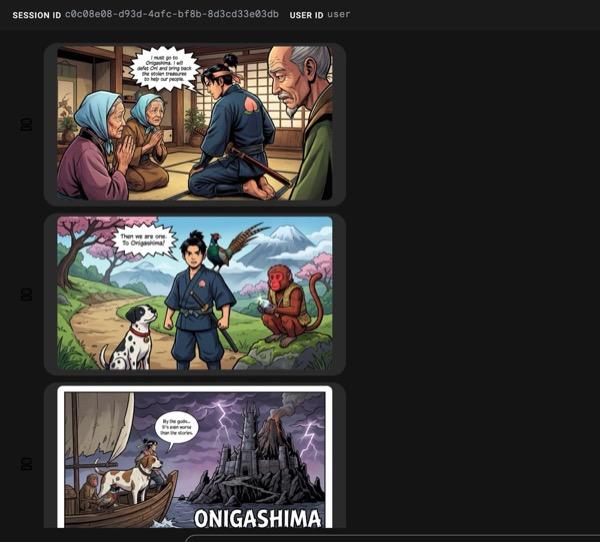
Abbildung 34: Die Geschichte von Momotaro als Comicstrip 25. Wenn alles reibungslos verläuft, sollte die generierte HTML-Datei im HTML-Ordner gespeichert werden. Wenn Sie den Agenten verbessern möchten, können Sie zum Agenten-Assistenten zurückkehren und ihn bitten, weitere Änderungen vorzunehmen.
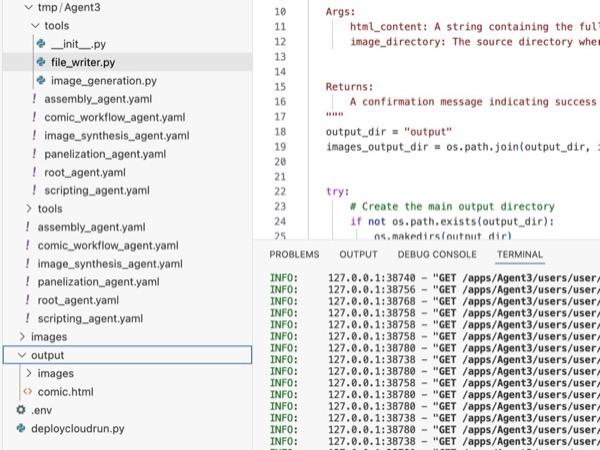
Abbildung 35: Inhalt des Ausgabeverzeichnisses
- Wenn Schritt 25 korrekt ausgeführt wird, erhalten Sie comic.html im Ordner output. Führen Sie die folgenden Schritte aus, um das zu testen. Öffnen Sie zuerst ein neues Terminal, indem Sie im Hauptmenü des Cloud Shell-Editors auf Terminal> Neues Terminal klicken. Dadurch sollte ein neues Terminal geöffnet werden.
#go to the project folder
cd ~/adkui
#activate python virtual environment
source .venv/bin/activate
#Go to the output folder
cd ~/adkui/output
#start local web server
python -m http.server 8080
- Strg+Klicken Sie auf http://0.0.0.0:8080.

Abbildung 36: Lokalen Webserver ausführen
- Der Inhalt des Ordners sollte auf dem Browser-Tab angezeigt werden. Klicken Sie auf die HTML-Datei (z. B. comic.html). Der Comic sollte wie unten dargestellt werden (Ihre Ausgabe kann etwas anders aussehen).

Abbildung 37: Ausführung auf localhost
12. Bereinigen
Jetzt räumen wir auf.
- Löschen Sie die gerade erstellte Cloud Run-App. Rufen Sie Cloud Run über Cloud Run auf . Sie sollten die App sehen, die Sie im vorherigen Schritt erstellt haben. Klicken Sie das Kästchen neben der App an und dann auf die Schaltfläche „Löschen“.
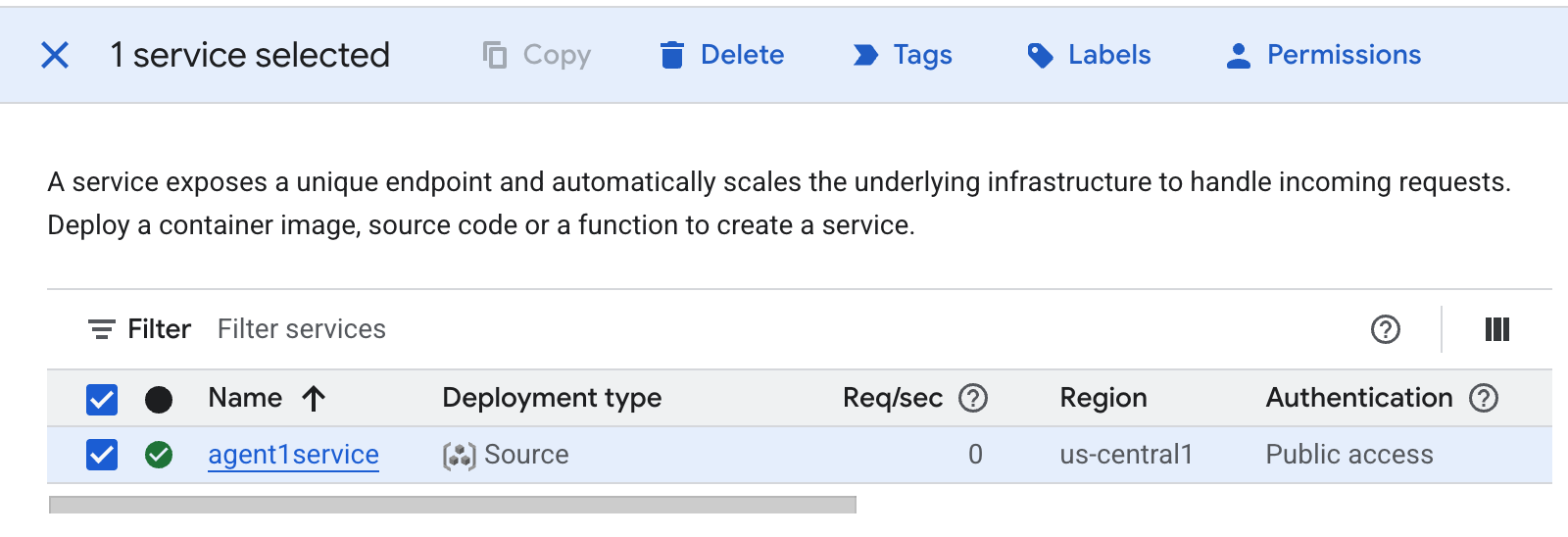 Abbildung 38: Cloud Run-App 2 löschen Dateien in Cloud Shell löschen
Abbildung 38: Cloud Run-App 2 löschen Dateien in Cloud Shell löschen
#Execute the following to delete the files
cd ~
rm -R ~/adkui
13. Fazit
Glückwunsch! Sie haben erfolgreich ADK-Agenten (Agent Development Kit) mit dem integrierten ADK Visual Builder erstellt. Außerdem haben Sie gelernt, wie Sie die Anwendung in Cloud Run bereitstellen. Dies ist ein wichtiger Schritt, der den Kernlebenszyklus einer modernen cloudnativen Anwendung abdeckt und Ihnen eine solide Grundlage für die Bereitstellung Ihrer eigenen komplexen agentenbasierten Systeme bietet.
Zusammenfassung
In diesem Lab haben Sie Folgendes gelernt:
- Multi-Agent-Anwendung mit dem ADK Visual Builder erstellen
- Anwendung in Cloud Run bereitstellen
Nützliche Ressourcen