
1. 이 실습의 목표
이 실습에서는 ADK (에이전트 개발 키트) 시각적 빌더를 사용하여 에이전트를 만드는 방법을 알아봅니다. ADK (에이전트 개발 키트) 시각적 빌더는 ADK (에이전트 개발 키트) 에이전트를 로우 코드로 만들 수 있는 방법을 제공합니다. 애플리케이션을 로컬에서 테스트하고 Cloud Run에 배포하는 방법을 알아봅니다.
학습할 내용
- ADK (에이전트 개발 키트) 의 기본사항을 이해합니다.
- ADK (에이전트 개발 키트) 시각적 빌더의 기본사항 이해
- GUI 도구를 사용하여 에이전트를 만드는 방법을 알아봅니다.
- Cloud Run에서 에이전트를 쉽게 배포하고 사용하는 방법을 알아봅니다.
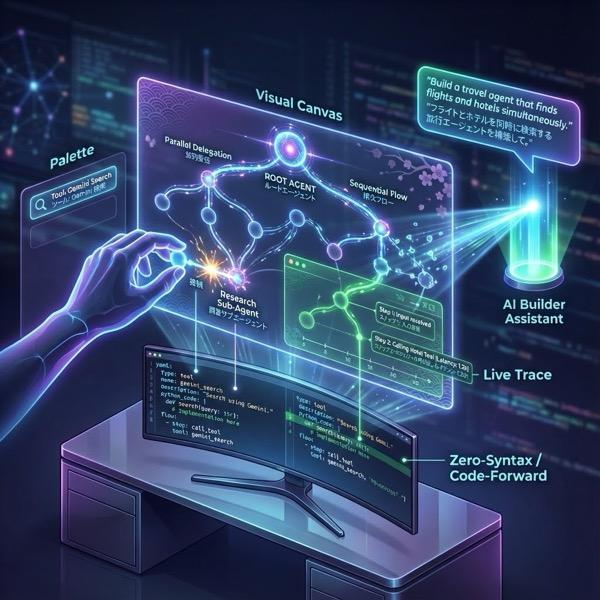
그림 1: ADK 시각적 빌더를 사용하면 로우 코드로 GUI를 사용하여 에이전트를 만들 수 있습니다.
2. 프로젝트 설정
그림 2: Google Cloud 로고 바로 옆에 있는 상자를 클릭하면 프로젝트를 선택할 수 있습니다. 프로젝트가 선택되어 있는지 확인합니다.
- 이 실습에서는 Cloud Shell 편집기를 사용하여 작업을 수행합니다. Cloud Shell을 열고 Cloud Shell을 사용하여 프로젝트를 설정합니다.
- 이 링크를 클릭하여 Cloud Shell 편집기로 바로 이동합니다.
- 메뉴에서 터미널 > 새 터미널을 클릭하여 터미널을 엽니다(아직 열려 있지 않은 경우). 이 터미널에서 이 튜토리얼의 모든 명령어를 실행할 수 있습니다.
- Cloud Shell 터미널에서 다음 명령어를 사용하여 프로젝트가 이미 인증되었는지 확인할 수 있습니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 프로젝트를 확인합니다.
gcloud config list project
- 프로젝트 ID를 복사하고 다음 명령어를 사용하여 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
- 프로젝트 ID가 기억나지 않는 경우 다음 명령어를 사용하여 모든 프로젝트 ID를 나열할 수 있습니다.
gcloud projects list
3. API 사용 설정
이 실습을 실행하려면 일부 API 서비스를 사용 설정해야 합니다. Cloud Shell에서 다음 명령어를 실행합니다.
gcloud services enable aiplatform.googleapis.com
gcloud services enable cloudresourcemanager.googleapis.com
API 소개
- Vertex AI API (
aiplatform.googleapis.com)를 사용하면 Vertex AI 플랫폼에 액세스할 수 있으므로 애플리케이션이 텍스트 생성, 채팅 세션, 함수 호출을 위해 Gemini 모델과 상호작용할 수 있습니다. - Cloud Resource Manager API (
cloudresourcemanager.googleapis.com)를 사용하면 다른 도구와 SDK에서 프로젝트 ID와 이름과 같은 Google Cloud 프로젝트의 ID와 권한을 확인하는 데 필요한 메타데이터를 프로그래매틱 방식으로 관리할 수 있습니다.
4. 크레딧이 적용되었는지 확인하기
프로젝트 설정 단계에서 Google Cloud의 서비스를 사용할 수 있는 무료 크레딧을 신청했습니다. 크레딧을 적용하면 'Google Cloud Platform 체험판 결제 계정'이라는 새 무료 결제 계정이 생성됩니다. 크레딧이 적용되었는지 확인하려면 Cloud Shell 편집기에서 다음 단계를 따르세요.
curl -s https://raw.githubusercontent.com/haren-bh/gcpbillingactivate/main/activate.py | python3
성공하면 아래와 같은 결과가 표시됩니다. '프로젝트가 연결되었습니다'가 표시되면 결제 계정이 올바르게 설정된 것입니다. 위 단계를 실행하면 계정이 연결되어 있는지 확인할 수 있으며, 연결되어 있지 않은 경우 연결됩니다. 프로젝트를 선택하지 않은 경우 프로젝트를 선택하라는 메시지가 표시되거나 프로젝트 설정의 단계에 따라 미리 선택할 수 있습니다. 
그림 3: 연결된 결제 계정 확인
5. 에이전트 개발 키트 소개
에이전트 개발 키트는 에이전트형 애플리케이션을 빌드하는 개발자에게 다음과 같은 여러 주요 이점을 제공합니다.
- 멀티 에이전트 시스템: 계층 구조 내에서 여러 전문 에이전트를 조합하여 확장 가능한 모듈식 애플리케이션을 빌드합니다. 복잡한 조정과 위임도 구현할 수 있습니다.
- 다양한 도구 생태계: 에이전트에 다양한 기능을 제공합니다. 사전 빌드된 도구(검색, 코드 실행 등)를 사용하거나, 커스텀 함수를 만들거나, 서드 파티 에이전트 프레임워크(LangChain, CrewAI)의 도구를 통합하거나, 심지어 다른 에이전트를 도구로 사용할 수도 있습니다.
- 유연한 조정: 워크플로 에이전트 (
SequentialAgent,ParallelAgent,LoopAgent)를 사용하여 예측 가능한 파이프라인을 위한 워크플로를 정의하거나 LLM 기반 동적 라우팅 (LlmAgent전송)을 활용하여 적응형 동작을 구현합니다. - 개발자 환경 통합: 강력한 CLI와 대화형 개발 UI를 사용하여 로컬에서 개발, 테스트, 디버그를 수행합니다. 이벤트, 상태, 에이전트 실행을 단계별로 검사합니다.
- 기본으로 제공되는 평가: 사전 정의된 테스트 사례를 기준으로 최종 대답 품질과 단계별 실행 궤적을 평가하여 에이전트 성능을 체계적으로 판단합니다.
- 배포 준비 완료: 에이전트를 컨테이너화하고 어디에나 배포합니다. 로컬에서 실행하거나, Vertex AI Agent Engine으로 확장하거나, Cloud Run 또는 Docker를 사용하여 커스텀 인프라에 통합할 수도 있습니다.
다른 생성형 AI SDK나 에이전트 프레임워크를 사용하여 모델을 쿼리하고 도구를 사용하여 모델을 강화할 수도 있지만, 여러 모델을 동적으로 조율하려면 상당한 양의 작업을 수행해야 합니다.
에이전트 개발 키트는 이러한 도구보다 높은 수준의 프레임워크를 제공합니다. 따라서 여러 에이전트를 쉽게 연결하여 복잡하지만 간편하게 유지관리 가능한 워크플로를 구현할 수 있습니다.
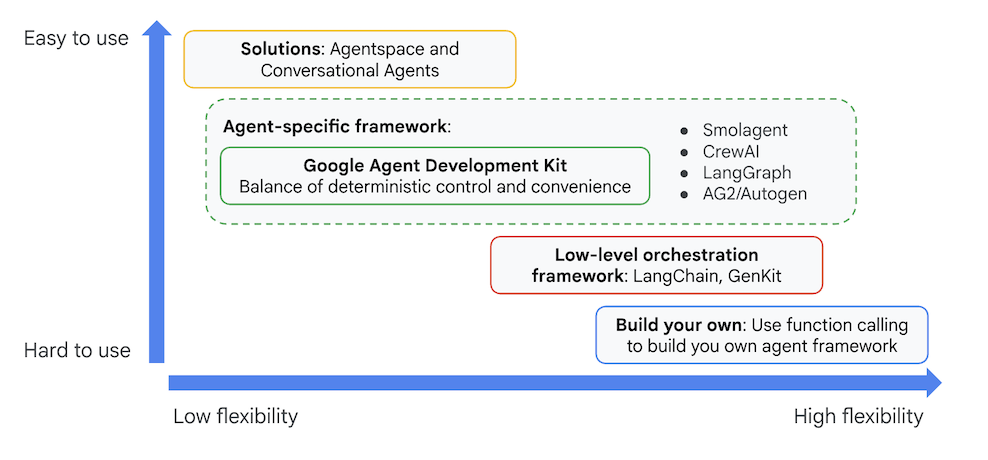
그림 4: ADK (에이전트 개발 키트)의 포지셔닝
최근 버전에서는 ADK (에이전트 개발 키트)에 ADK 시각적 빌더 도구가 추가되어 로우 코드로 ADK (에이전트 개발 키트) 에이전트를 빌드할 수 있습니다. 이 실습에서는 ADK 시각적 빌더 도구를 자세히 살펴봅니다.
6. ADK 설치 및 환경 설정
먼저 ADK (에이전트 개발 키트)를 실행할 수 있도록 환경을 설정해야 합니다. 이 실습에서는 ADK (에이전트 개발 키트)를 실행하고 Google Cloud의 Cloud Shell 편집기에서 모든 작업을 실행합니다 .
Cloud Shell 편집기 준비
- 이 링크를 클릭하여 Cloud Shell 편집기로 바로 이동합니다.
- 계속을 클릭합니다.
- Cloud Shell을 승인하라는 메시지가 표시되면 승인을 클릭합니다.
- 이 실습의 나머지 부분에서는 이 창을 Cloud Shell 편집기 및 Cloud Shell 터미널이 있는 IDE로 사용할 수 있습니다.
- Cloud Shell 편집기에서 터미널>새 터미널을 사용하여 새 터미널을 엽니다. 아래의 모든 명령어는 이 터미널에서 실행됩니다.
ADK 비주얼 편집기 시작
- 다음 명령어를 실행하여 github에서 필요한 소스를 클론하고 필요한 라이브러리를 설치합니다. Cloud Shell 편집기에서 연 터미널에서 명령어를 실행합니다.
#create the project directory
mkdir ~/adkui
cd ~/adkui
- uv를 사용하여 Python 환경을 만듭니다 (Cloud Shell 편집기 터미널에서 실행).
#Install uv if you do not have installed yet
pip install uv
#go to the project directory
cd ~/adkui
#Create the virtual environment
uv venv
#use the newly created environment
source .venv/bin/activate
#install libraries
uv pip install google-adk==1.22.1
uv pip install python-dotenv
참고: 터미널을 다시 시작해야 하는 경우 'source .venv/bin/activate'을 실행하여 Python 환경을 설정해야 합니다.
- 편집기에서 보기->숨김 파일 전환으로 이동합니다. adkui 폴더에서 다음 콘텐츠로 .env 파일을 만듭니다.
#go to adkui folder
cd ~/adkui
cat <<EOF>> .env
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
GOOGLE_CLOUD_LOCATION=us-central1
IMAGEN_MODEL="imagen-3.0-generate-002"
GENAI_MODEL="gemini-2.5-flash"
EOF
7. ADK 시각적 빌더로 간단한 에이전트 만들기
이 섹션에서는 ADK 시각적 빌더를 사용하여 간단한 에이전트를 만듭니다.ADK 시각적 빌더는 ADK (에이전트 개발 키트) 에이전트를 만들고 관리하기 위한 시각적 워크플로 설계 환경을 제공하는 웹 기반 도구입니다. 초보자 친화적인 그래픽 인터페이스에서 에이전트를 설계, 빌드, 테스트할 수 있으며, 에이전트 빌드를 지원하는 AI 기반 어시스턴트가 포함되어 있습니다.
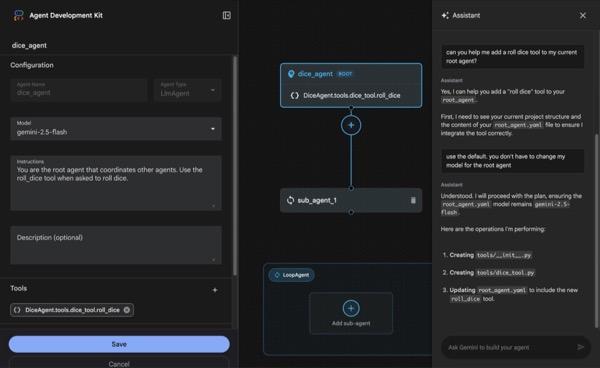
그림 5: ADK 시각적 빌더
- 터미널에서 최상위 디렉터리 adkui로 돌아가 다음 명령어를 실행하여 에이전트를 로컬로 실행합니다 (Cloud Shell 편집기 터미널에서 실행). ADK 서버를 시작하고 터미널에서 그림 6과 유사한 결과를 확인할 수 있습니다.
#go to the directory adkui
cd ~/adkui
# Run the following command to run ADK locally
adk web
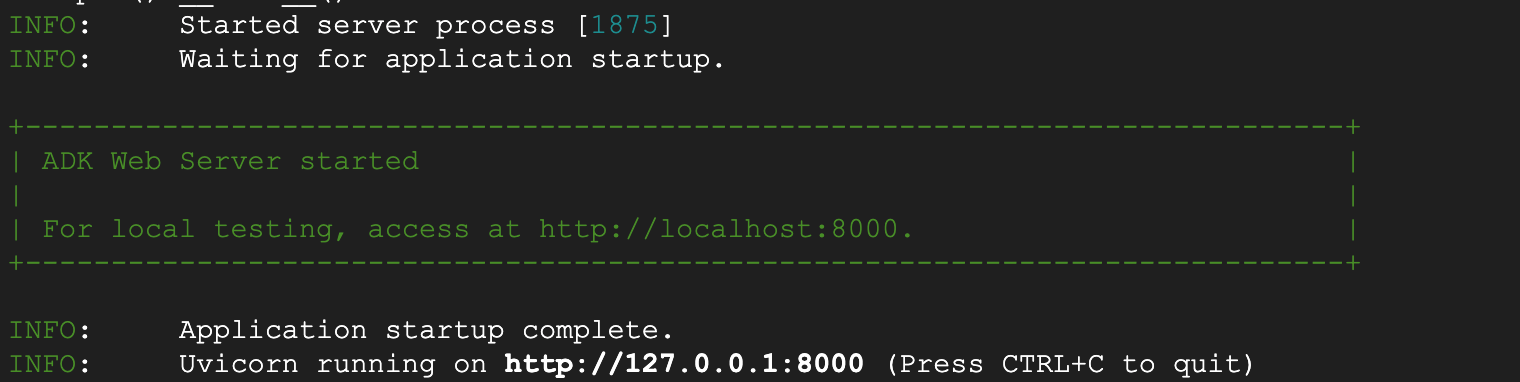
그림 6: ADK 애플리케이션 시작
- 터미널에 표시된 http:// URL을 Ctrl+클릭 (MacOS의 경우 CMD+클릭)하여 ADK (Agent Development Kit) 브라우저 기반 GUI 도구를 엽니다.
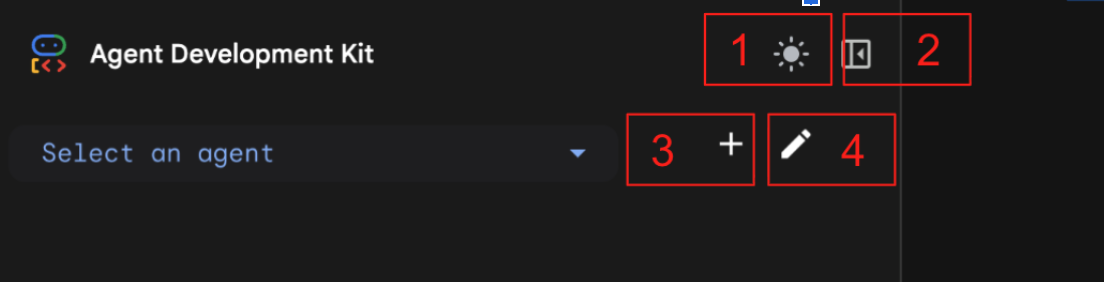
그림 7: ADK 웹 UI, ADK에는 다음 구성요소가 있습니다. 1: 밝은 모드와 어두운 모드 전환 2: 패널 축소 3: 에이전트 만들기 4: 에이전트 수정
- 새 에이전트를 만들려면 '+' 버튼을 누릅니다.
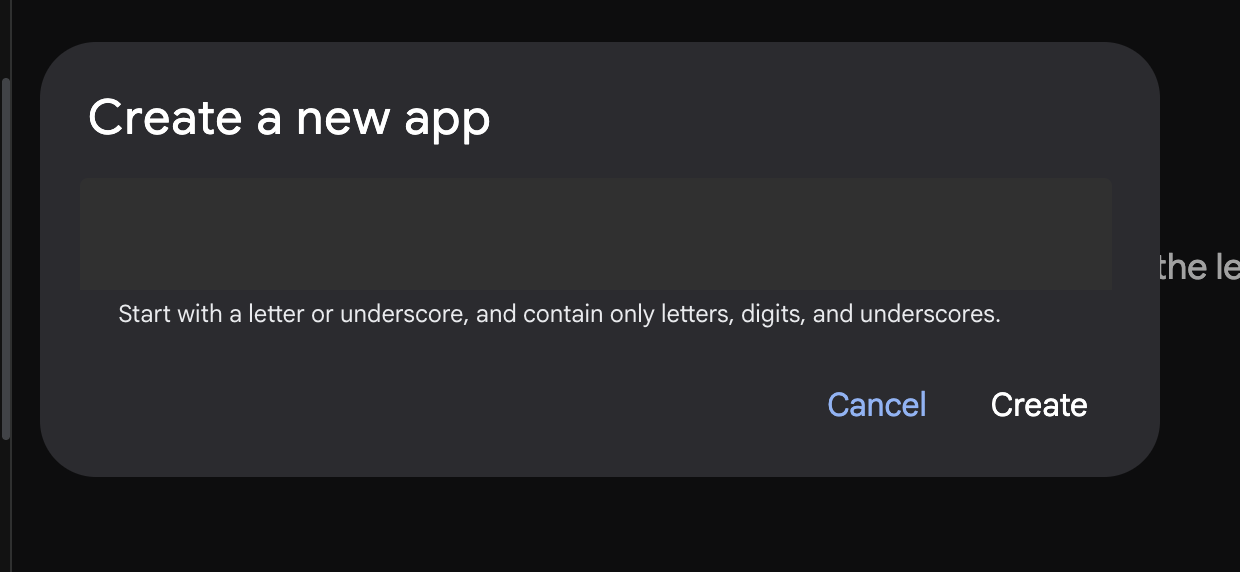
그림 8: 새 앱을 만드는 대화상자
- 이름을 'Agent1'로 지정하고 '만들기'를 클릭합니다.
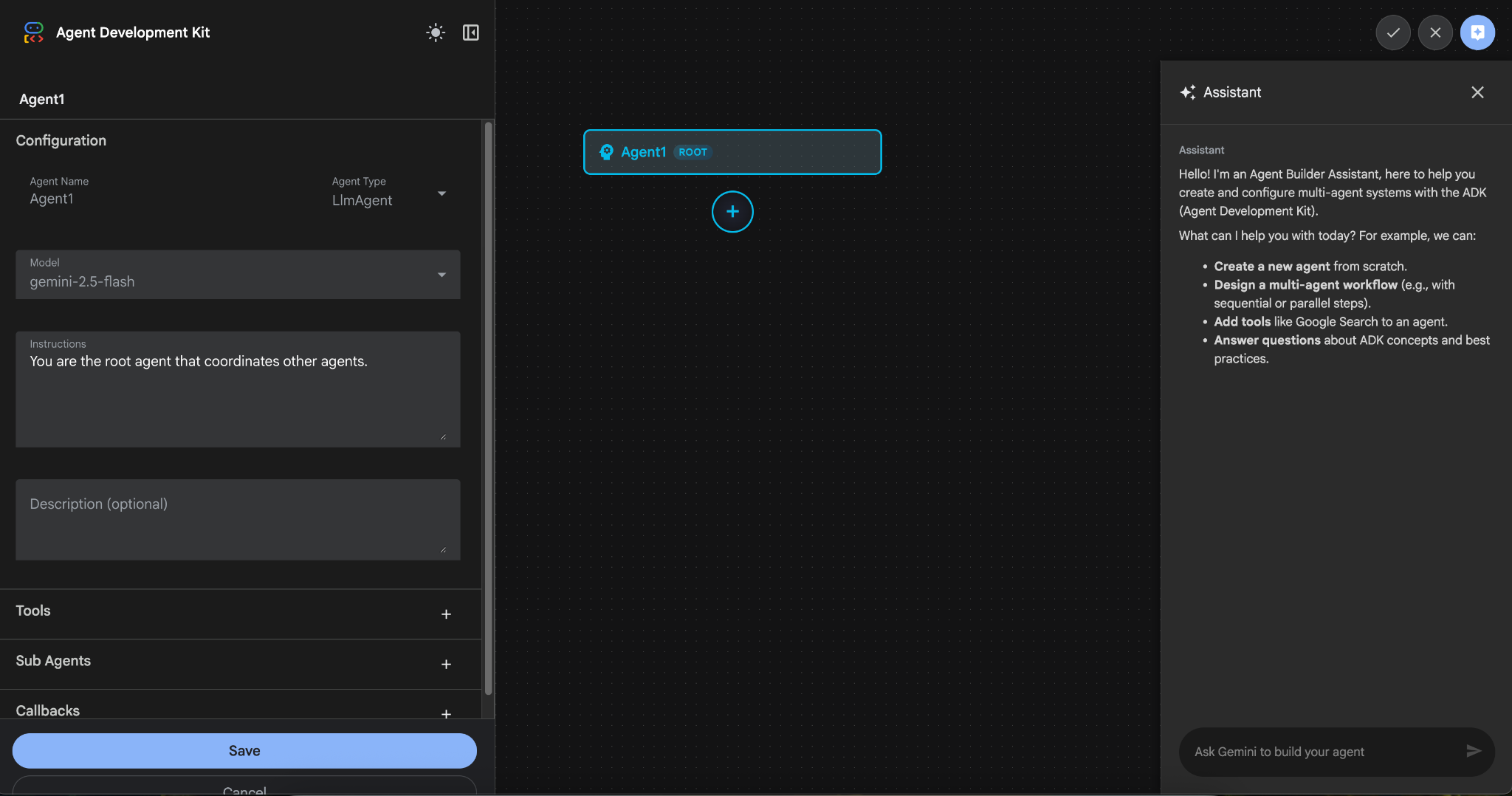
그림 9: 에이전트 빌더 UI
- 패널은 세 가지 주요 섹션으로 구성됩니다. 왼쪽에는 GUI 기반 에이전트 생성을 위한 컨트롤이 있고, 중앙에는 진행 상황이 시각화되어 있으며, 오른쪽에는 자연어를 사용하여 에이전트를 빌드하는 어시스턴트가 있습니다.
- 에이전트가 생성되었습니다. 저장 버튼을 클릭하여 계속합니다. (참고: 변경사항이 손실되지 않도록 저장 버튼을 누르는 것이 중요합니다.)
- 이제 에이전트를 테스트할 수 있습니다. 시작하려면 채팅 상자에 다음과 같은 프롬프트를 입력하세요.
Hi, what can you do?
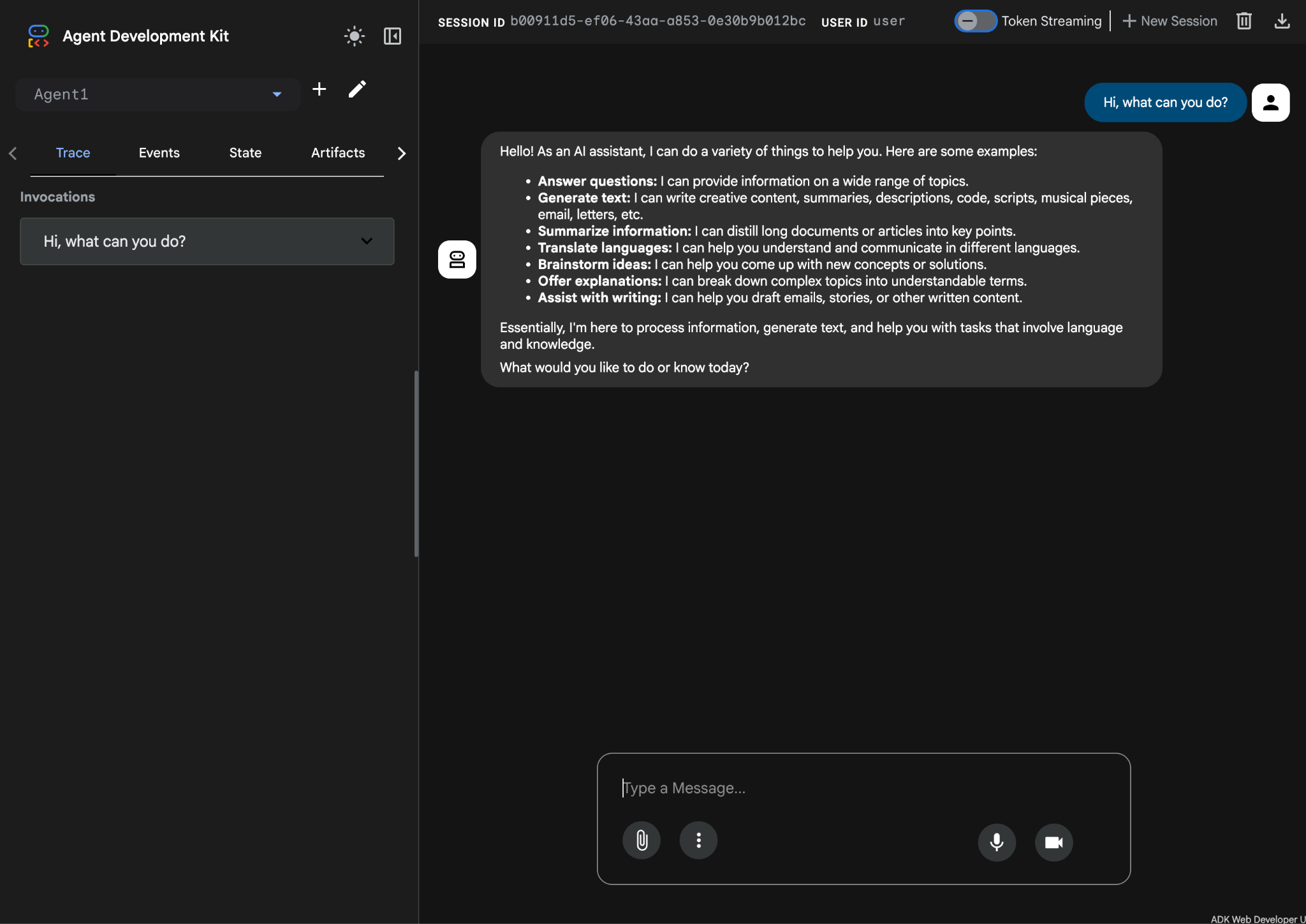
그림 10: 에이전트 테스트
7.편집기로 돌아가 새로 생성된 파일을 살펴보겠습니다. 왼쪽에 탐색기가 표시됩니다. adkgui 폴더로 이동하여 펼쳐 Agent 1 디렉터리를 표시합니다. 폴더에서 아래 그림과 같이 에이전트를 정의하는 YAML 파일을 확인할 수 있습니다.
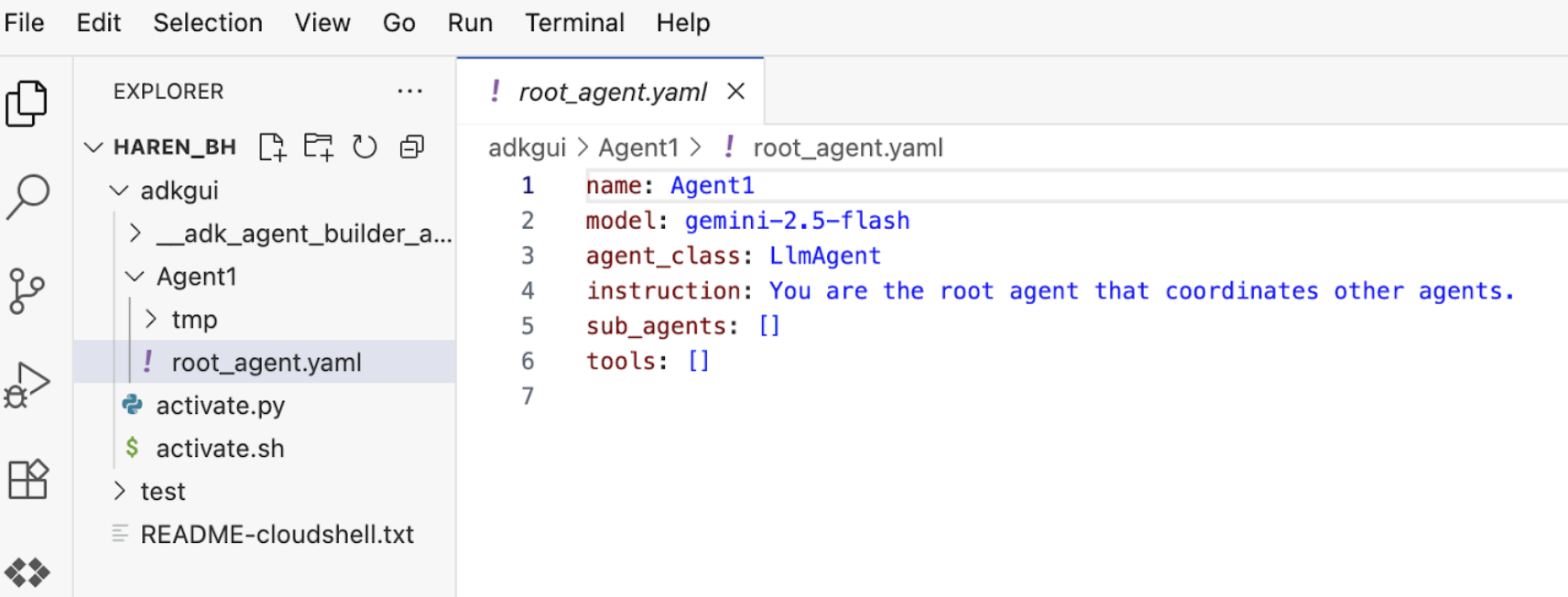
그림 11: YAML 파일을 사용한 에이전트 정의
- 이제 GUI 편집기로 돌아가 에이전트에 몇 가지 기능을 추가해 보겠습니다. 이렇게 하려면 수정 버튼 (그림 7, 구성요소 번호 4, 펜 아이콘 참고)을 누릅니다.
- 에이전트에 Google 검색 기능을 추가하려고 합니다. 이를 위해 에이전트가 사용할 수 있는 도구로 Google 검색을 추가해야 합니다. 이렇게 하려면 화면 왼쪽 하단의 도구 섹션 옆에 있는 '+' 기호를 클릭하고 메뉴에서 내장 도구를 클릭합니다 (그림 12 참고).
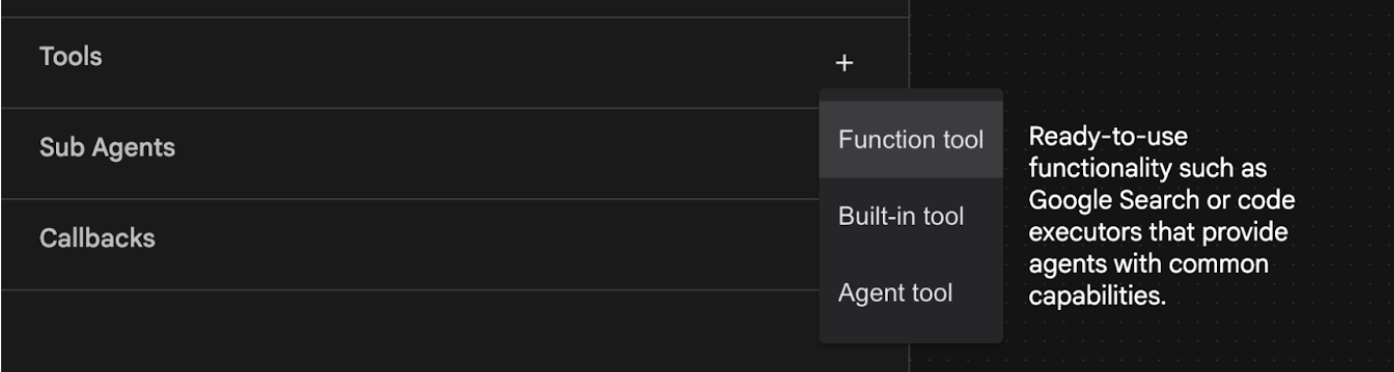
그림 12: 에이전트에 새 도구 추가
- 기본 제공 도구 목록에서 google_search를 선택하고 만들기 (그림 12 참고)를 클릭합니다. 이렇게 하면 Google 검색이 에이전트의 도구로 추가됩니다.
- 저장 버튼을 눌러 변경사항을 저장합니다.
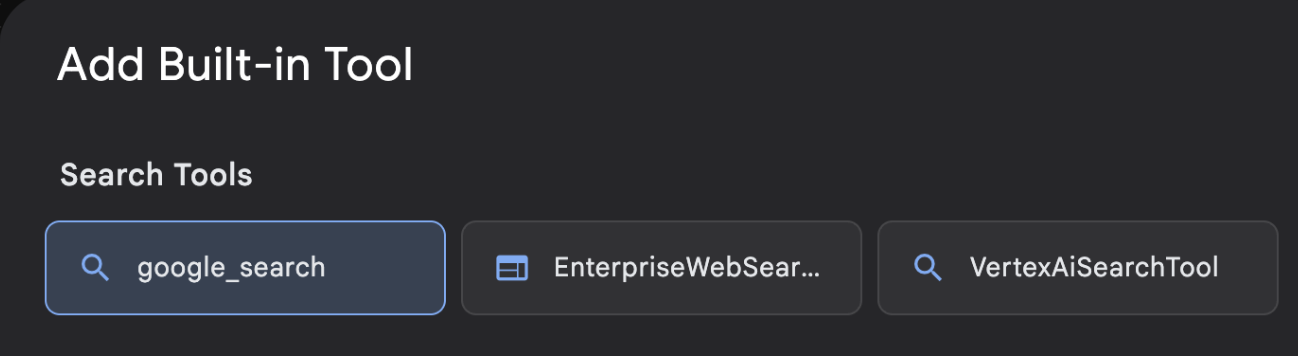
그림 13: ADK Visual Builder UI에서 사용할 수 있는 도구 목록
- 이제 에이전트를 테스트할 준비가 되었습니다. 먼저 ADK 서버를 다시 시작합니다. ADK (에이전트 개발 키트) 서버를 시작한 터미널로 이동하여 서버가 아직 실행 중인 경우 Ctrl+C를 눌러 서버를 종료합니다. 다음을 실행하여 서버를 다시 시작합니다.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- URL을 Ctrl+클릭합니다 (예: http://localhost:8000)이 화면에 표시됩니다. 브라우저 탭에 ADK (에이전트 개발 키트) GUI가 표시됩니다.
- 상담사 목록에서 Agent1을 선택합니다. 이제 에이전트가 Google 검색을 할 수 있습니다. 채팅 상자에서 다음 프롬프트로 테스트합니다.
What is the weather today in Yokohama?
아래와 같이 Google 검색의 답변이 표시됩니다. 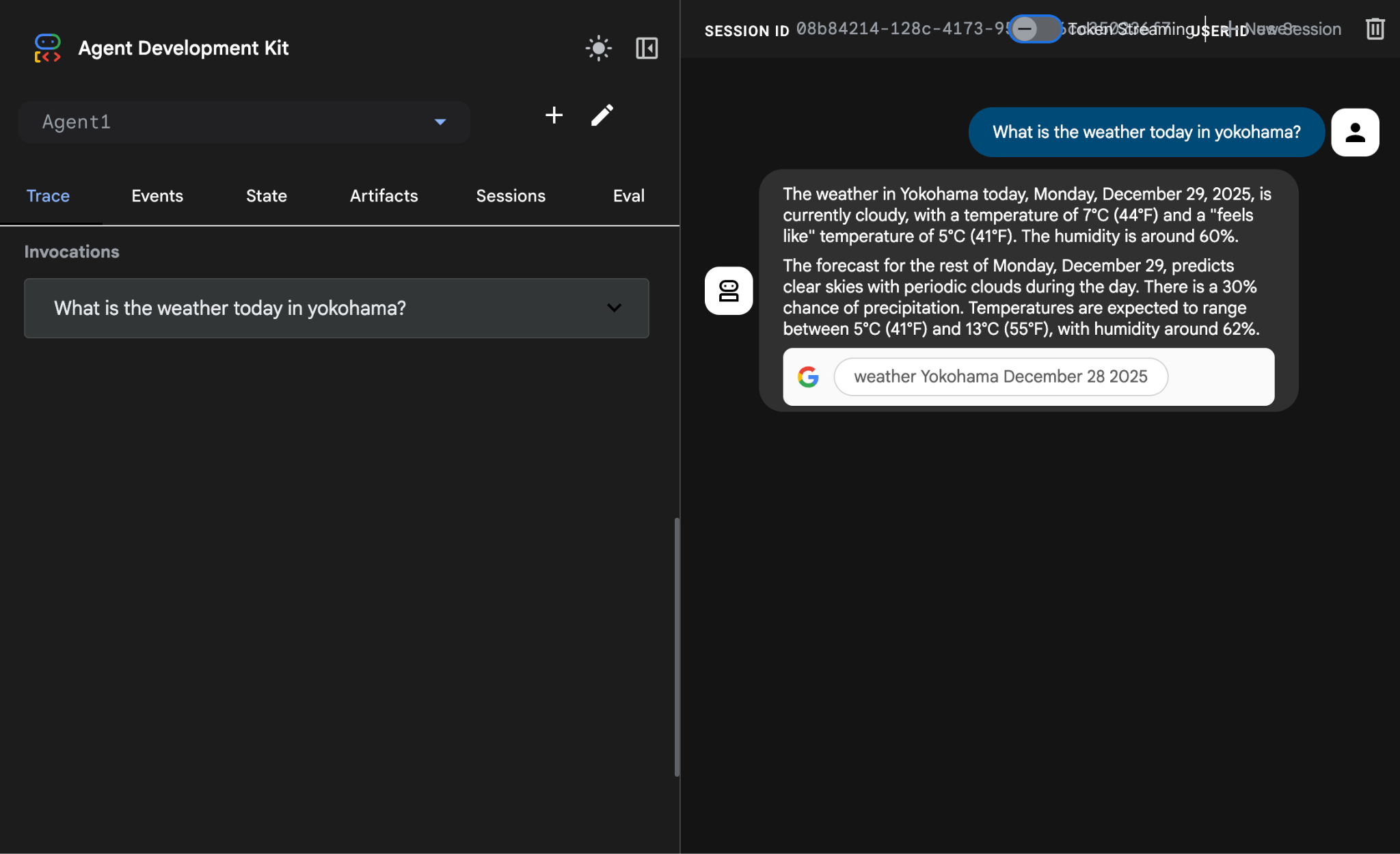
그림 14: 에이전트가 포함된 Google 검색
- 이제 편집기로 돌아가 이 단계에서 생성된 코드를 확인해 보겠습니다. 편집기 탐색기 측면 패널에서 root_agent.yaml을 클릭하여 엽니다. google_search가 도구로 추가되었는지 확인합니다 (그림 15).
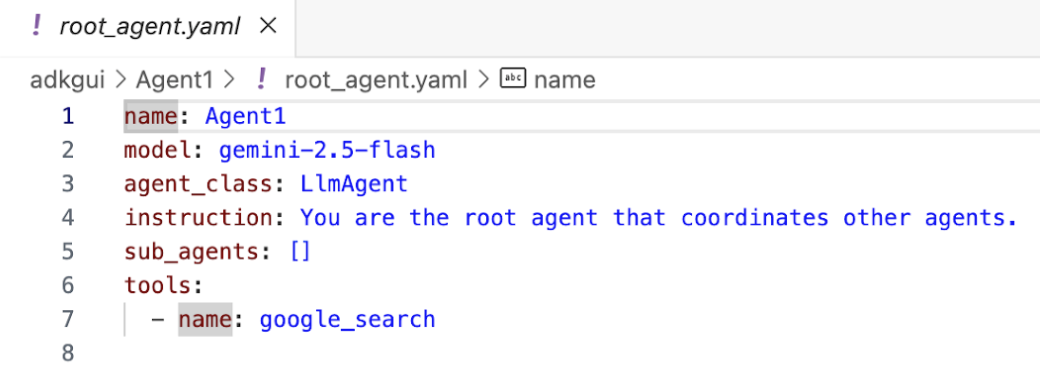
그림 15: Agent1에 google_search가 도구로 추가되었음을 확인
8. Cloud Run에 에이전트 배포
이제 생성된 에이전트를 Cloud Run에 배포해 보겠습니다. Cloud Run을 사용하면 완전 관리형 플랫폼에서 앱 또는 웹사이트를 빠르게 빌드할 수 있습니다.
인프라를 관리할 필요 없이 프런트엔드 및 백엔드 서비스를 실행하고, 작업을 일괄 처리하고, LLM을 호스팅하며, 처리 워크로드를 큐에 추가할 수 있습니다.
Cloud Shell 편집기 터미널에서 ADK (Agent Development Kit) 서버를 아직 실행 중인 경우 Ctrl+C를 눌러 중지합니다.
- 프로젝트 루트 디렉터리로 이동합니다.
cd ~/adkui
- 배포 코드를 가져옵니다. 명령어를 실행하면 Cloud Shell 편집기 탐색기 창에 deploycloudrun.py 파일이 표시됩니다.
curl -LO https://raw.githubusercontent.com/haren-bh/codelabs/main/adk_visual_builder/deploycloudrun.py
- deploycloudrun.py에서 배포 옵션을 확인합니다. adk deploy 명령어를 사용하여 에이전트를 Cloud Run에 배포합니다. ADK (에이전트 개발 키트)에는 에이전트를 Cloud Run에 배포하는 옵션이 내장되어 있습니다. Google Cloud 프로젝트 ID, 리전 등의 매개변수를 지정해야 합니다. 앱 경로의 경우 이 스크립트는 agent_path=./Agent1이라고 가정합니다. 또한 필요한 권한이 있는 새 서비스 계정을 만들어 Cloud Run에 연결합니다. Cloud Run은 에이전트를 실행하기 위해 Vertex AI, Cloud Storage와 같은 서비스에 액세스해야 합니다.
command = [
"adk", "deploy", "cloud_run",
f"--project={project_id}",
f"--region={location}",
f"--service_name={service_name}",
f"--app_name={app_name}",
f"--artifact_service_uri=memory://",
f"--with_ui",
agent_path,
f"--",
f"--service-account={sa_email}",
]
- deploycloudrun.py 스크립트를 실행합니다**. 배포는 아래 그림과 같이 시작됩니다.**
python3 deploycloudrun.py
아래와 같은 확인 메시지가 표시되면 모든 메시지에 대해 Y와 Enter를 누릅니다. depoycloudrun.py 은 에이전트가 위에서 만든 것처럼 Agent1 폴더에 있다고 가정합니다.
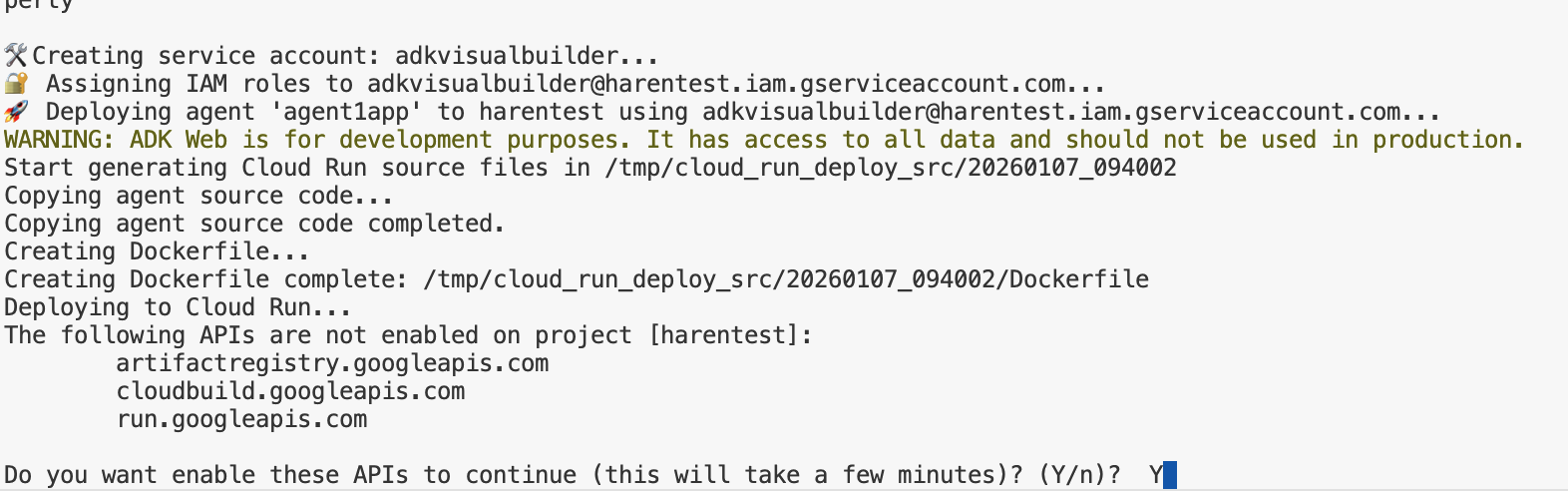
그림 16: Cloud Run에 에이전트 배포, 확인 메시지에 Y를 누릅니다.
- 배포가 완료되면 https://agent1service-78833623456.us-central1.run.app과 같은 서비스 URL이 표시됩니다.
- 웹브라우저에서 URL에 액세스하여 앱을 실행합니다.
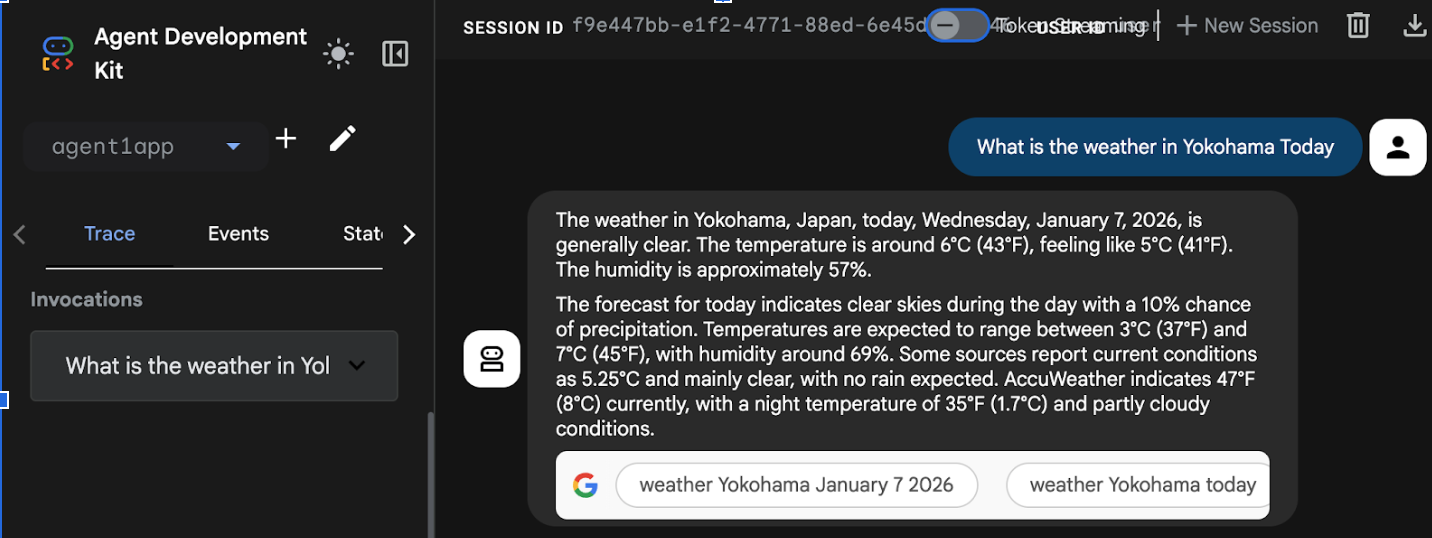
Figure 17: Agent running in Cloud Run
9. 하위 에이전트 및 맞춤 도구로 에이전트 만들기
이전 섹션에서는 Google 검색 도구가 내장된 단일 에이전트를 만들었습니다. 이 섹션에서는 에이전트가 맞춤 도구를 사용할 수 있는 멀티 에이전트 시스템을 만듭니다.
- 먼저 ADK (에이전트 개발 키트) 서버를 다시 시작합니다. ADK (에이전트 개발 키트) 서버를 시작한 터미널로 이동하여 아직 실행 중인 경우 Ctrl+C를 눌러 서버를 종료합니다. 다음을 실행하여 서버를 다시 시작합니다.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- URL을 Ctrl+클릭합니다 (예: http://localhost:8000)이 화면에 표시됩니다. 브라우저 탭에 ADK (에이전트 개발 키트) GUI가 표시됩니다.
- '+' 버튼을 클릭하여 새 에이전트를 만듭니다. 에이전트 대화상자에서 'Agent2' (그림 18)를 입력하고 '만들기'를 클릭합니다.
그림 18: 새 에이전트 앱 만들기
- Agent2의 요청 사항 섹션에 다음을 입력합니다.
You are an agent that takes image creation instruction from the user and passes it to your sub agent
- 이제 루트 에이전트에 하위 에이전트를 추가합니다. 이렇게 하려면 왼쪽 창 하단의 하위 에이전트 메뉴 왼쪽에 있는 '+' 버튼을 클릭하고 'LLM 에이전트'를 클릭합니다 (그림 19). 이렇게 하면 루트 에이전트의 새 하위 에이전트로 새 에이전트가 생성됩니다.
그림 19: 새 하위 에이전트 추가
- sub_agent_1의 요청 사항에 다음 텍스트를 입력합니다.
You are an Agent that can take instructions about an image and create an image using the create_image tool.
- 이제 이 하위 에이전트에 맞춤 도구를 추가해 보겠습니다. 이 도구는 Imagen 모델을 호출하여 사용자의 지침에 따라 이미지를 생성합니다. 이렇게 하려면 먼저 이전 단계에서 만든 하위 에이전트를 클릭하고 도구 메뉴 옆에 있는 '+' 버튼을 클릭합니다. 도구 옵션 목록에서 '함수 도구'를 클릭합니다. 이 도구를 사용하면 도구에 자체 맞춤 코드를 추가할 수 있습니다.
그림 20: 함수 도구를 클릭하여 새 도구를 만듭니다. 8. 대화상자에서 도구 이름을 Agent2.image_creation_tool.create_image로 지정합니다. 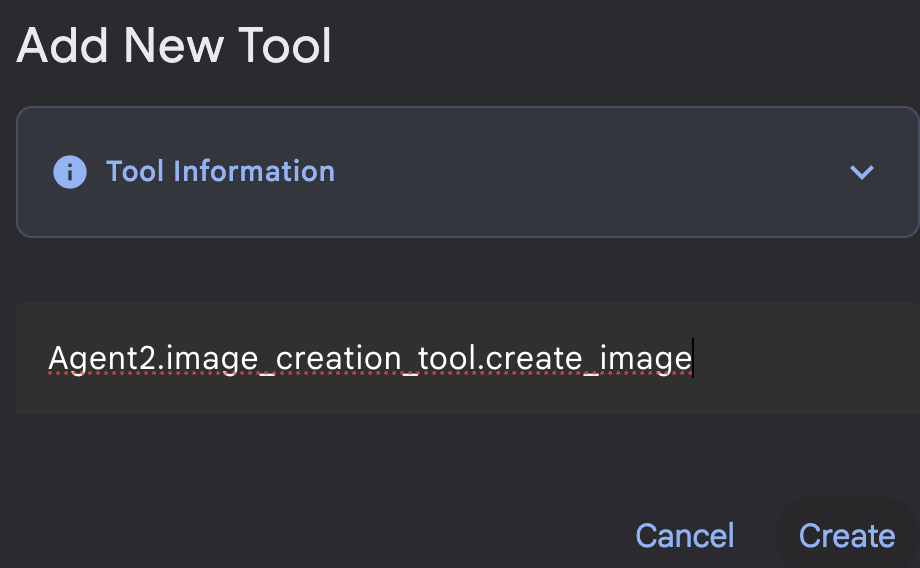
그림 21: 도구 이름 추가
- 저장 버튼을 클릭하여 변경사항을 저장합니다.
- Cloud Shell 편집기 터미널에서 Ctrl+S를 눌러 adk 서버를 종료합니다.
- 터미널에서 다음 명령어를 입력하여 image_creation_tool.py 파일을 만듭니다.
touch ~/adkui/Agent2/image_creation_tool.py
- Cloud Shell 편집기의 탐색기 창에서 새로 만든 image_creation_tool.py를 클릭하여 엽니다. image_creation_tool.py의 콘텐츠를 다음으로 바꾸고 저장 (Ctrl+S)합니다.
import os
import io
import vertexai
from vertexai.preview.vision_models import ImageGenerationModel
from dotenv import load_dotenv
import uuid
from typing import Union
from datetime import datetime
from google import genai
from google.genai import types
from google.adk.tools import ToolContext
import logging
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def create_image(prompt: str,tool_context: ToolContext) -> Union[bytes, str]:
"""
Generates an image based on a text prompt using a Vertex AI Imagen model.
Args:
prompt: The text prompt to generate the image from.
Returns:
The binary image data (PNG format) on success, or an error message string on failure.
"""
print(f"Attempting to generate image for prompt: '{prompt}'")
try:
# Load environment variables from .env file two levels up
dotenv_path = os.path.join(os.path.dirname(__file__), '..', '..', '.env')
load_dotenv(dotenv_path=dotenv_path)
project_id = os.getenv("GOOGLE_CLOUD_PROJECT")
location = os.getenv("GOOGLE_CLOUD_LOCATION")
model_name = os.getenv("IMAGEN_MODEL")
client = genai.Client(
vertexai=True,
project=project_id,
location=location,
)
response = client.models.generate_images(
model="imagen-3.0-generate-002",
prompt=prompt,
config=types.GenerateImagesConfig(
number_of_images=1,
aspect_ratio="9:16",
safety_filter_level="block_low_and_above",
person_generation="allow_adult",
),
)
if not all([project_id, location, model_name]):
return "Error: Missing GOOGLE_CLOUD_PROJECT, GOOGLE_CLOUD_LOCATION, or IMAGEN_MODEL in .env file."
vertexai.init(project=project_id, location=location)
model = ImageGenerationModel.from_pretrained(model_name)
images = model.generate_images(
prompt=prompt,
number_of_images=1
)
if response.generated_images is None:
return "Error: No image was generated."
for generated_image in response.generated_images:
# Get the image bytes
image_bytes = generated_image.image.image_bytes
counter = str(tool_context.state.get("loop_iteration", 0))
artifact_name = f"generated_image_" + counter + ".png"
# Save as ADK artifact (optional, if still needed by other ADK components)
report_artifact = types.Part.from_bytes(
data=image_bytes, mime_type="image/png"
)
await tool_context.save_artifact(artifact_name, report_artifact)
logger.info(f"Image also saved as ADK artifact: {artifact_name}")
return {
"status": "success",
"message": f"Image generated . ADK artifact: {artifact_name}.",
"artifact_name": artifact_name,
}
except Exception as e:
error_message = f"An error occurred during image generation: {e}"
print(error_message)
return error_message
- 먼저 ADK (에이전트 개발 키트) 서버를 다시 시작합니다. ADK (에이전트 개발 키트) 서버를 시작한 터미널로 이동하여 아직 실행 중인 경우 Ctrl+C를 눌러 서버를 종료합니다. 다음을 실행하여 서버를 다시 시작합니다.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- URL을 Ctrl+클릭합니다 (예: http://localhost:8000)이 화면에 표시됩니다. 브라우저 탭에 ADK (에이전트 개발 키트) GUI가 표시됩니다.
- ADK (에이전트 개발 키트) UI 탭의 에이전트 목록에서 Agent2를 선택하고 수정 버튼 (펜 아이콘)을 누릅니다. ADK (Agent Development Kit) 시각적 편집기에서 저장 버튼을 클릭하여 변경사항을 유지합니다.
- 이제 새 에이전트를 테스트할 수 있습니다.
- ADK (에이전트 개발 키트) UI 채팅 인터페이스에 다음 프롬프트를 입력합니다. 다른 프롬프트를 사용해 볼 수도 있습니다. 그림 22와 같은 결과가 표시됩니다.
Create an image of a cat
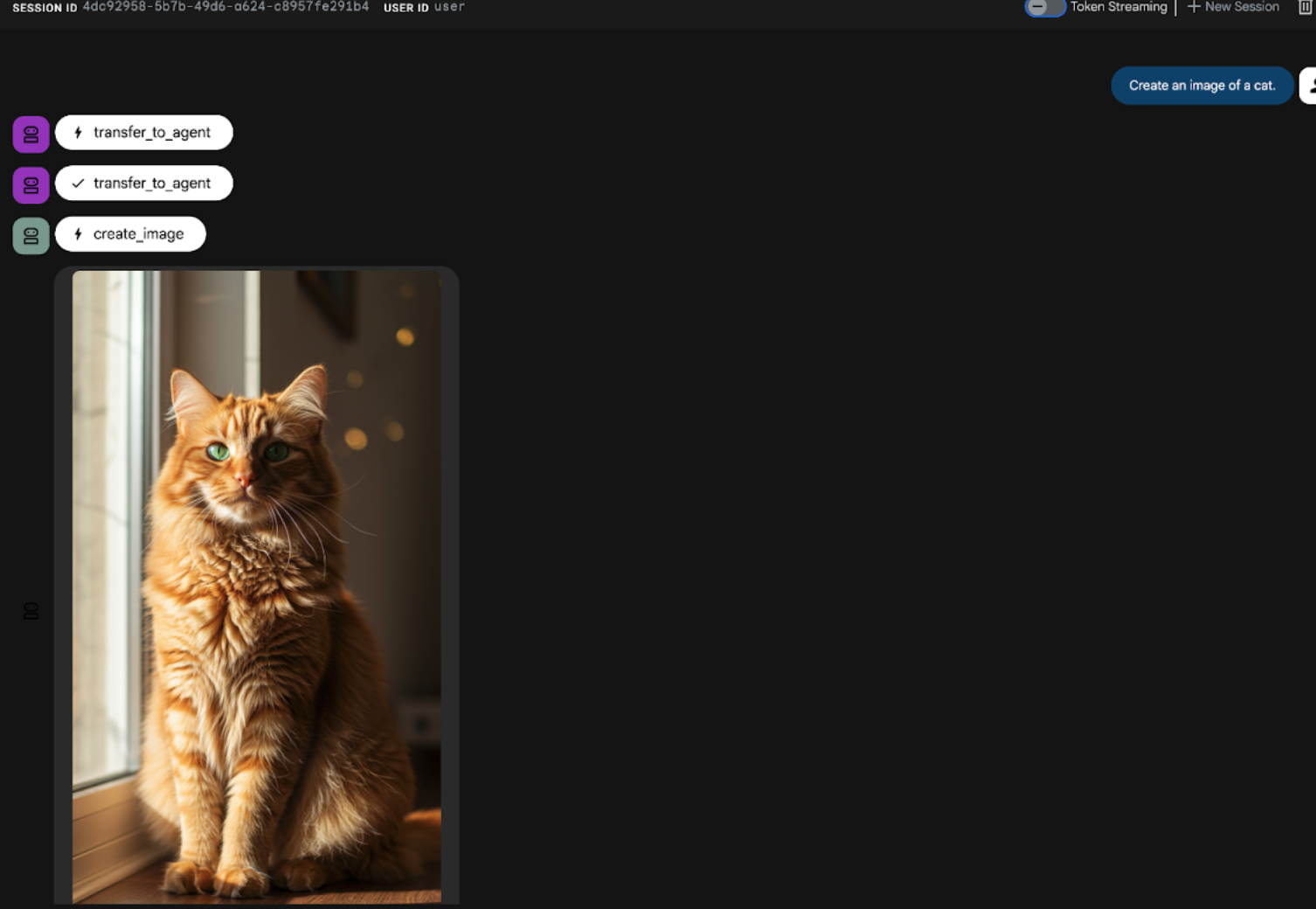
그림 22: ADK UI 채팅 인터페이스
10. 워크플로 에이전트 만들기
이전 단계에서는 하위 에이전트와 전문 이미지 생성 도구를 사용하여 에이전트를 빌드했지만, 이 단계에서는 에이전트의 기능을 개선하는 데 중점을 둡니다. 이미지 생성 전에 사용자의 초기 프롬프트가 최적화되도록 하여 프로세스를 개선할 예정입니다. 이를 위해 순차적 에이전트가 루트 에이전트에 통합되어 다음 2단계 워크플로를 처리합니다.
- 기본 상담사로부터 프롬프트를 받아 프롬프트를 개선합니다.
- IMAGEN을 사용하여 최종 이미지를 생성하도록 개선된 프롬프트를 이미지 생성기 에이전트에게 전달합니다.
- 먼저 ADK (에이전트 개발 키트) 서버를 다시 시작합니다. ADK (에이전트 개발 키트) 서버를 시작한 터미널로 이동하여 아직 실행 중인 경우 Ctrl+C를 눌러 서버를 종료합니다. 다음을 실행하여 서버를 다시 시작합니다.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- URL을 Ctrl+클릭합니다 (예: http://localhost:8000)이 화면에 표시됩니다. 브라우저 탭에 ADK (에이전트 개발 키트) GUI가 표시됩니다.
- 에이전트 선택기에서 Agent2를 선택하고 수정 버튼 (펜 아이콘)을 클릭합니다.
- Agent2 (루트 에이전트)를 클릭하고 하위 에이전트 메뉴 옆에 있는 '+' 버튼을 클릭합니다. 옵션 목록에서 순차적 에이전트를 클릭합니다.
- 그림 23과 같은 에이전트 구조가 표시됩니다.
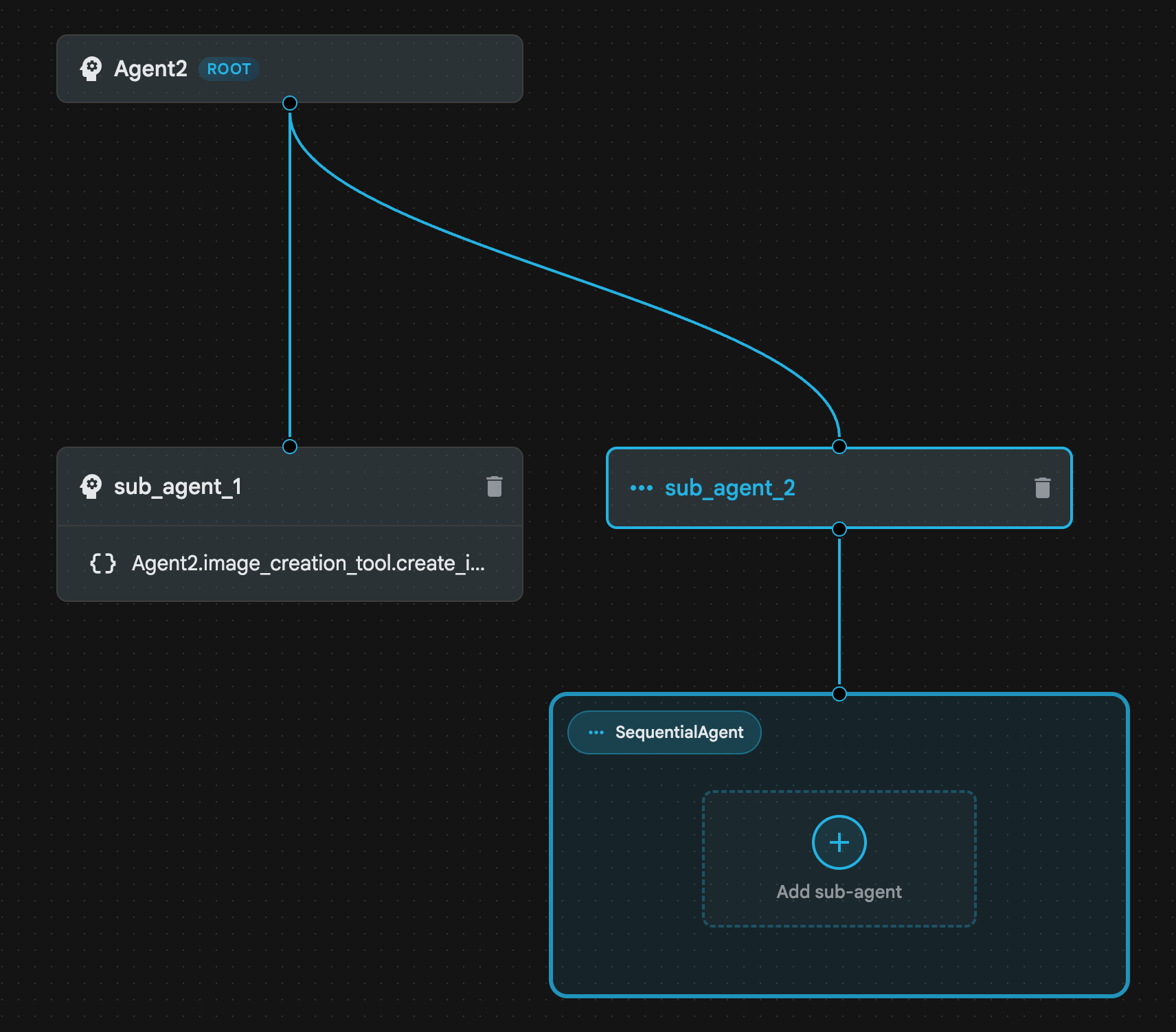
그림 23: 순차적 에이전트 에이전트 구조
- 이제 프롬프트 개선 도구 역할을 할 첫 번째 에이전트를 Sequential Agent에 추가합니다. 이렇게 하려면 SequentialAgent 상자 내에서 하위 에이전트 추가 버튼을 클릭하고 LLM 에이전트를 클릭합니다.
- 시퀀스에 다른 에이전트를 추가해야 하므로 6단계를 반복하여 다른 LLM 에이전트를 추가합니다 (+ 버튼을 누르고 LLMAgent를 선택).
- sub_agent_4를 클릭하고 왼쪽 창의 도구 옆에 있는 '+' 아이콘을 클릭하여 새 도구를 추가합니다. 옵션에서 '함수 도구'를 클릭합니다. 대화상자에서 도구 이름을 Agent2.image_creation_tool.create_image로 지정하고 만들기를 누릅니다.
- 이제 더 고급 sub_agent_2로 대체되었으므로 sub_agent_1을 삭제할 수 있습니다. 이렇게 하려면 다이어그램에서 sub_agent_1 오른쪽에 있는 삭제 버튼을 클릭합니다.
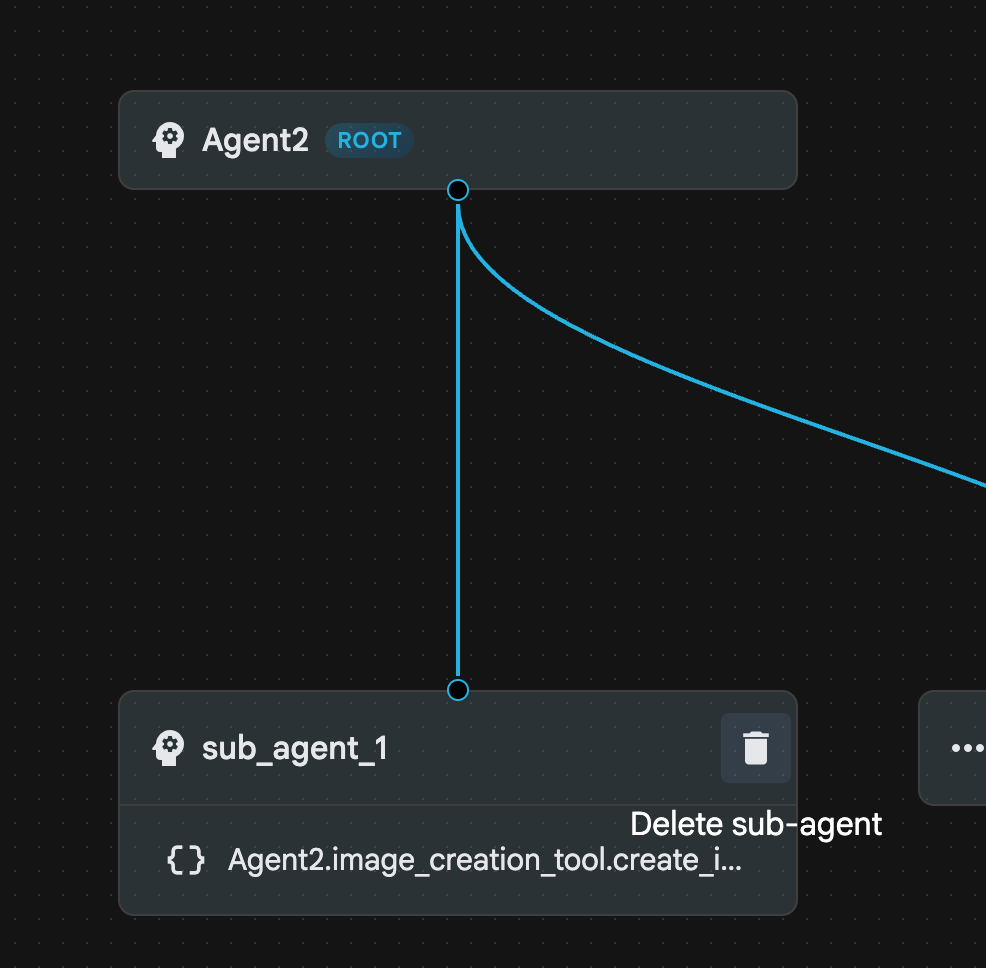
그림 24: sub_agent_1 10 삭제 에이전트 구조는 그림 25와 같습니다.
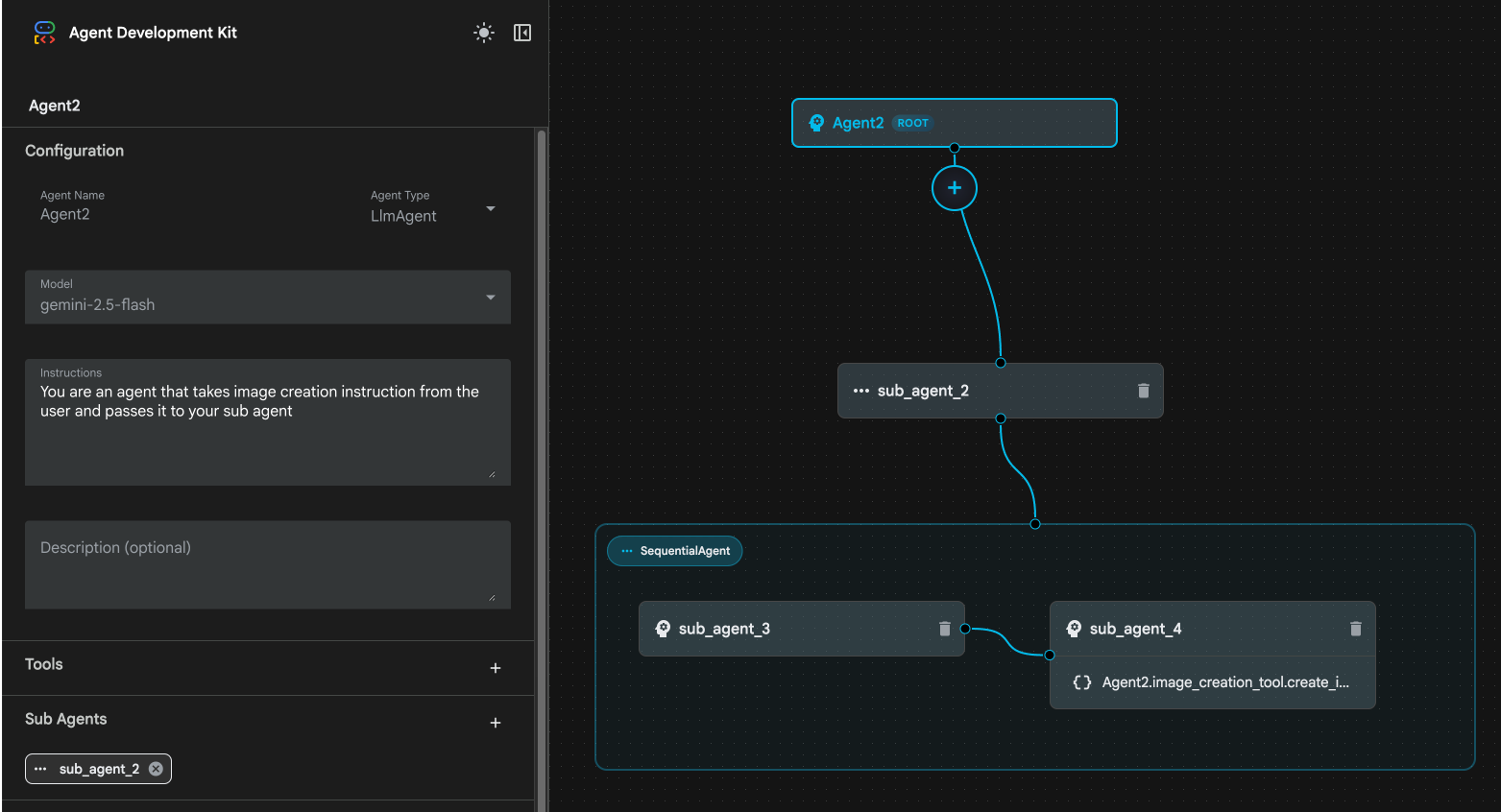
그림 25: 향상된 에이전트 최종 구조
- sub_agent_3을 클릭하고 안내에 다음을 입력합니다.
Act as a professional AI Image Prompt Engineer. I will provide you
with a basic idea for an image. Your job is to expand my idea into
a detailed, high-quality prompt for models like Imagen.
For every input, output the following structure:
1. **Optimized Prompt**: A vivid, descriptive paragraph including
subject, background, lighting, and textures.
2. **Style & Medium**: Specify if it is photorealistic, digital art,
oil painting, etc.
3. **Camera & Lighting**: Define the lens (e.g., 85mm), angle,
and light quality (e.g., volumetric, golden hour).
Guidelines: Use sensory language, avoid buzzwords like 'photorealistic'
unless necessary, and focus on specific artistic descriptors.
Once the prompt is created send the prompt to the
- sub_agent_4를 클릭합니다. 명령어를 다음과 같이 변경합니다.
You are an agent that takes instructions about an image and can generate the image using the create_image tool.
- 저장 버튼을 클릭합니다.
- Cloud Shell 편집기 탐색기 창으로 이동하여 에이전트 yaml 파일을 엽니다. 에이전트 파일은 다음과 같이 표시됩니다.
root_agent.yaml
name: Agent2
model: gemini-2.5-flash
agent_class: LlmAgent
instruction: You are an agent that takes image creation instruction from the
user and passes it to your sub agent
sub_agents:
- config_path: ./sub_agent_2.yaml
tools: []
sub_agent_2.yaml
name: sub_agent_2
agent_class: SequentialAgent
sub_agents:
- config_path: ./sub_agent_3.yaml
- config_path: ./sub_agent_4.yaml
sub_agent_3.yaml
name: sub_agent_3
model: gemini-2.5-flash
agent_class: LlmAgent
instruction: |
Act as a professional AI Image Prompt Engineer. I will provide you with a
basic idea for an image. Your job is to expand my idea into a detailed,
high-quality prompt for models like Imagen.
For every input, output the following structure: 1. **Optimized Prompt**: A
vivid, descriptive paragraph including subject, background, lighting, and
textures. 2. **Style & Medium**: Specify if it is photorealistic, digital
art, oil painting, etc. 3. **Camera & Lighting**: Define the lens (e.g.,
85mm), angle, and light quality (e.g., volumetric, golden hour).
Guidelines: Use sensory language, avoid buzzwords like
'photorealistic' unless necessary, and focus on specific artistic
descriptors. Once the prompt is created send the prompt to the
sub_agents: []
tools: []
sub_agent_4.yaml
name: sub_agent_4
model: gemini-2.5-flash
agent_class: LlmAgent
instruction: You are an agent that takes instructions about an image and
generate the image using the create_image tool.
sub_agents: []
tools:
- name: Agent2.image_creation_tool.create_image
- 이제 테스트해 보겠습니다.
- 먼저 ADK (에이전트 개발 키트) 서버를 다시 시작합니다. ADK (에이전트 개발 키트) 서버를 시작한 터미널로 이동하여 아직 실행 중인 경우 Ctrl+C를 눌러 서버를 종료합니다. 다음을 실행하여 서버를 다시 시작합니다.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- URL을 Ctrl+클릭합니다 (예: http://localhost:8000)이 화면에 표시됩니다. 브라우저 탭에 ADK (에이전트 개발 키트) GUI가 표시됩니다.
- 에이전트 목록에서 Agent2를 선택합니다. 다음 프롬프트를 입력합니다.
Create an image of a Cat
- 에이전트가 작동하는 동안 Cloud Shell 편집기의 터미널을 살펴보면 백그라운드에서 어떤 일이 일어나고 있는지 확인할 수 있습니다. 최종 결과는 그림 26과 같이 표시됩니다.
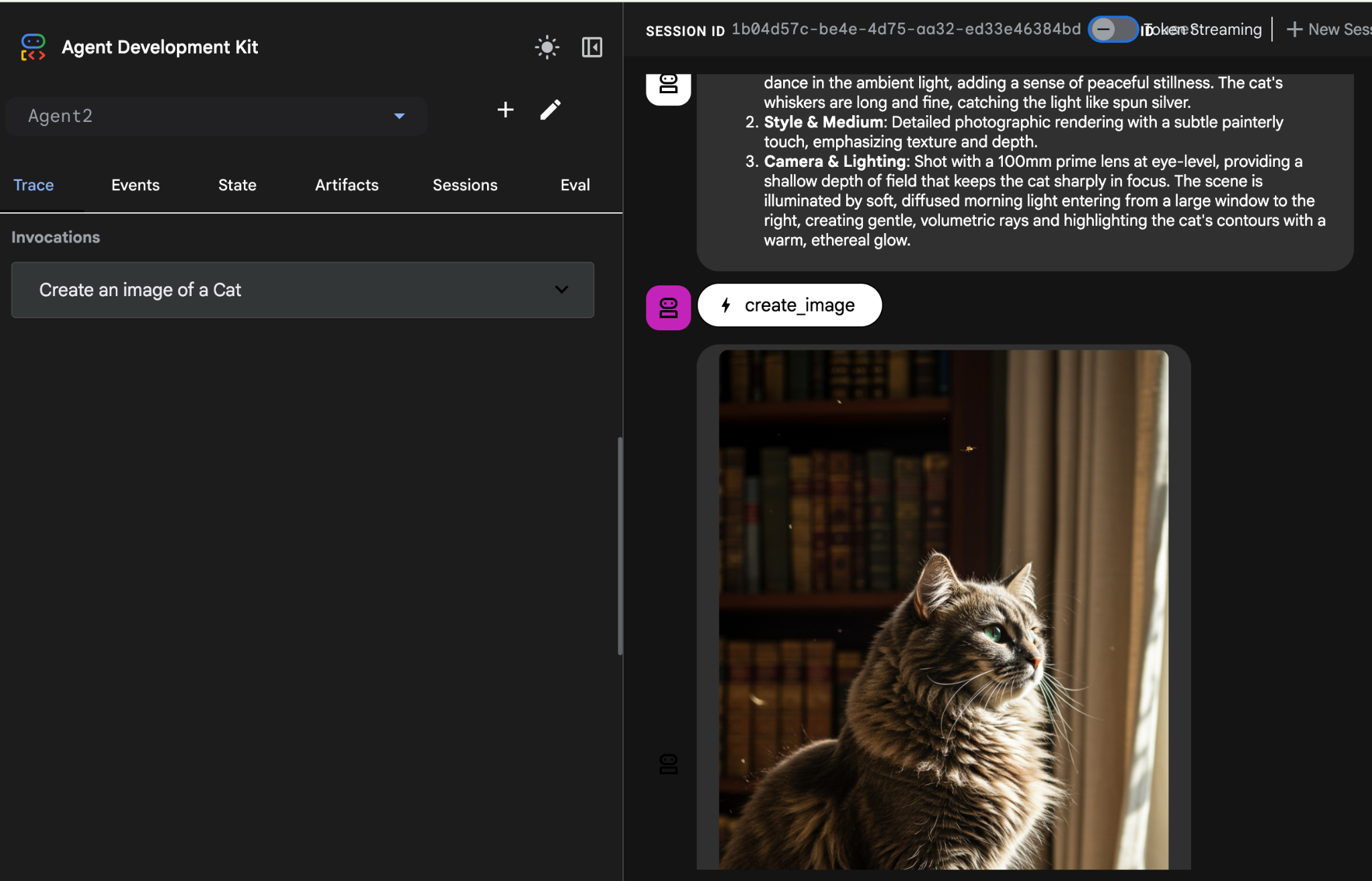
그림 26: 에이전트 테스트
11. Agent Builder 어시스턴트로 에이전트 만들기
Agent Builder Assistant는 ADK Visual Builder의 일부로, 간단한 채팅 인터페이스에서 프롬프트를 통해 에이전트를 대화형으로 생성하여 다양한 수준의 복잡성을 지원합니다. ADK 시각적 빌더를 사용하면 개발한 에이전트에 대한 시각적 피드백을 즉시 받을 수 있습니다. 이 실습에서는 사용자의 요청에 따라 HTML 만화책을 생성할 수 있는 에이전트를 빌드합니다. 사용자는 '헨젤과 그레텔에 관한 만화를 만들어 줘'와 같은 간단한 프롬프트를 제공하거나 전체 이야기를 입력할 수 있습니다. 그러면 에이전트가 내러티브를 분석하고 여러 패널로 분류하며 Nanobanana를 사용하여 만화 시각적 요소를 생성하고 최종적으로 결과를 HTML 형식으로 패키징합니다.
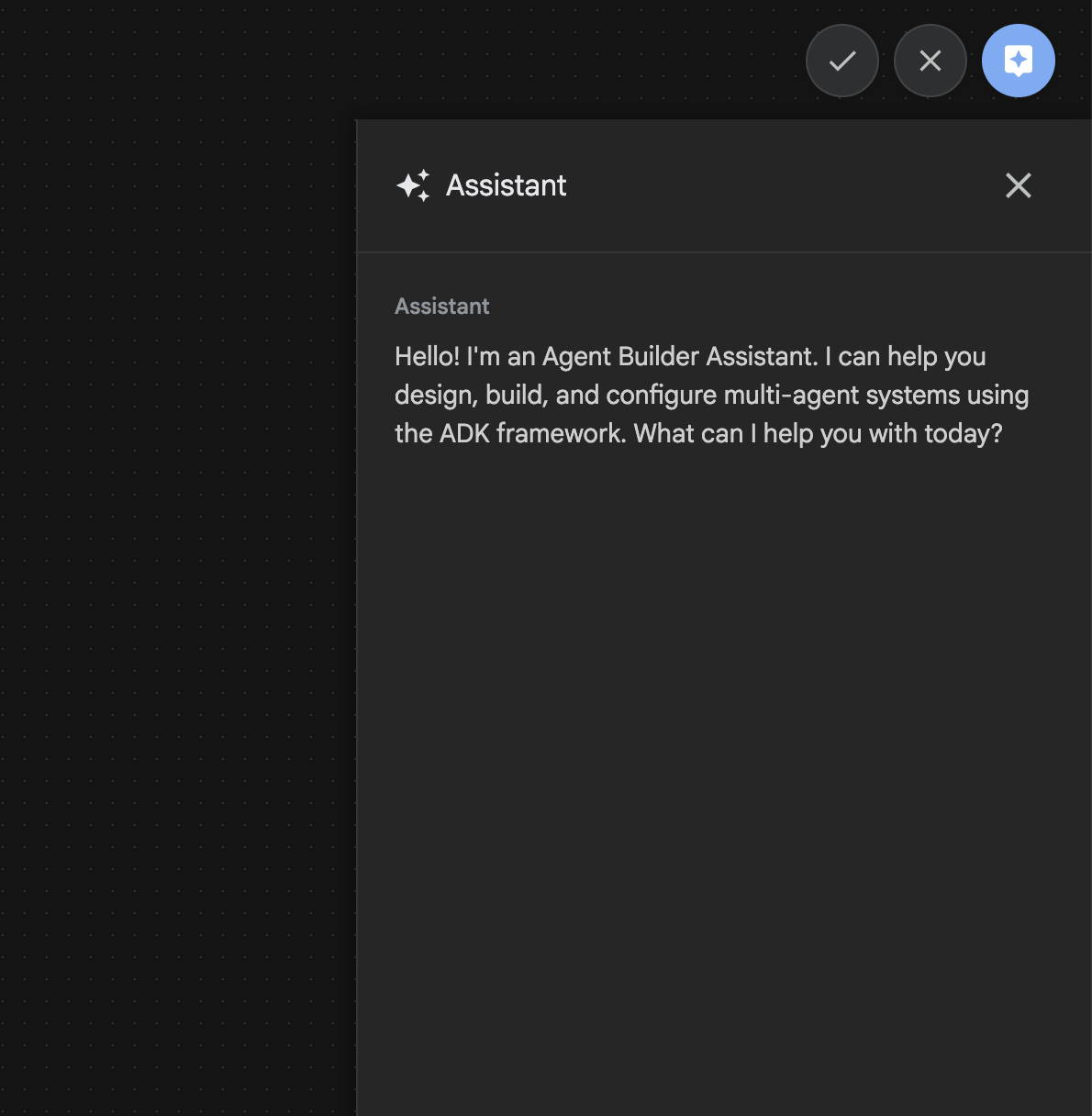
그림 27: Agent Builder 어시스턴트 UI
지금 시작해 보세요.
- 먼저 ADK (에이전트 개발 키트) 서버를 다시 시작합니다. ADK (에이전트 개발 키트) 서버를 시작한 터미널로 이동하여 아직 실행 중인 경우 Ctrl+C를 눌러 서버를 종료합니다. 다음을 실행하여 서버를 다시 시작합니다.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- URL을 Ctrl+클릭합니다 (예: http://localhost:8000)이 화면에 표시됩니다. 브라우저 탭에 ADK (에이전트 개발 키트) GUI가 표시됩니다.
- ADK (에이전트 개발 키트) GUI에서 '+' 버튼을 클릭하여 새 에이전트를 만듭니다.
- 대화상자에 'Agent3'을 입력하고 '만들기' 버튼을 클릭합니다.
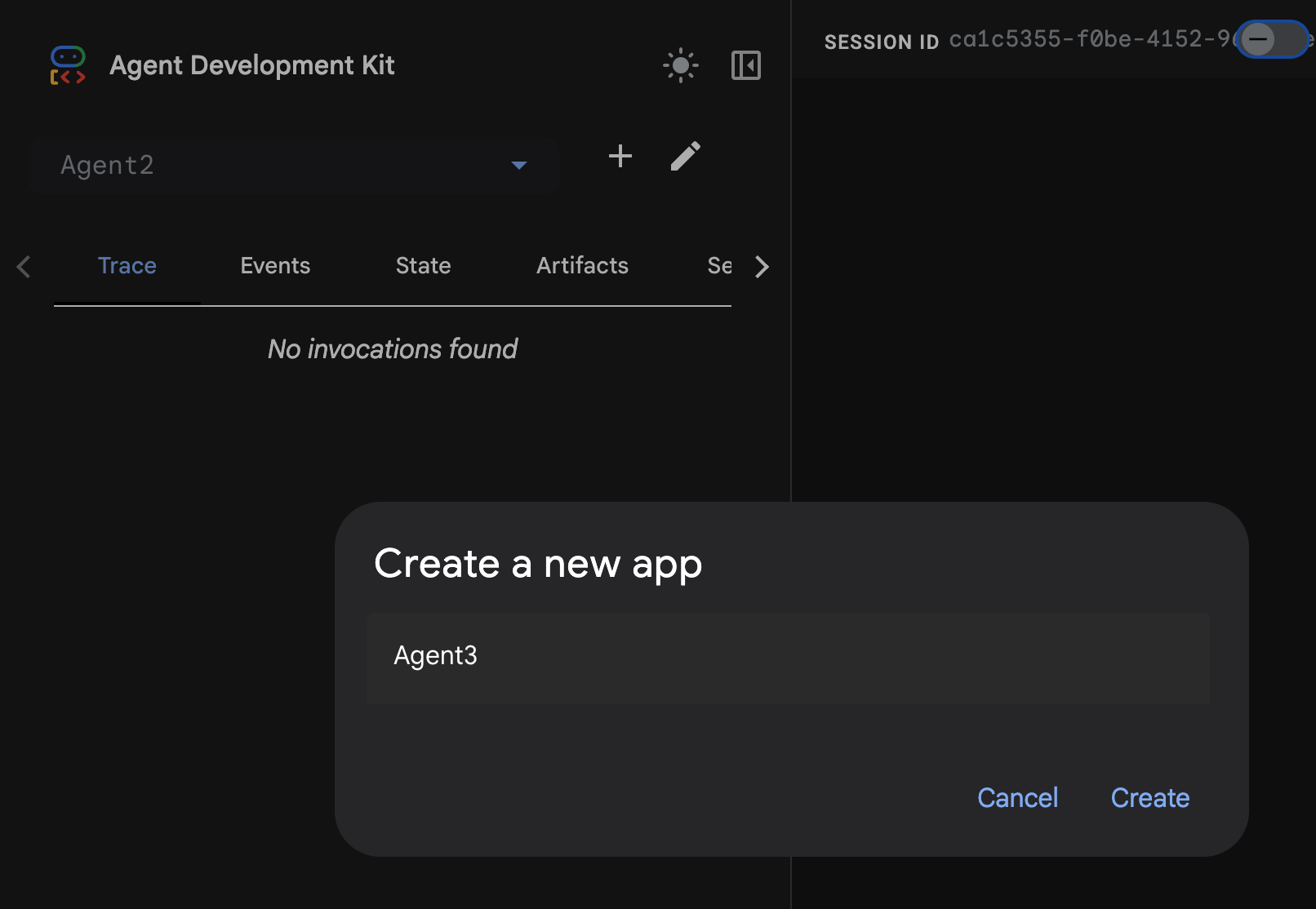
그림 28: 새 에이전트 Agent3 만들기
- 오른쪽의 어시스턴트 창에 다음 프롬프트를 입력합니다. 아래 프롬프트에는 HTML 기반 에이전트를 만들기 위한 에이전트 시스템을 만드는 데 필요한 모든 안내가 포함되어 있습니다.
System Goal: You are the Studio Director (Root Agent). Your objective is to manage a linear pipeline of four ADK Sequential Agents to transform a user's seed idea into a fully rendered, responsive HTML5 comic book.
0. Root Agent: The Studio Director
Role: Orchestrator and State Manager.
Logic: Receives the user's initial request. It initializes the workflow and ensures the output of each Sub-Agent is passed as the context for the next. It monitors the sequence to ensure no steps are skipped. Make sure the query explicitly mentions "Create me a comic of ..." if it's just a general question or prompt just answer the question.
1. Sub-Agent: The Scripting Agent (Sequential Step 1)
Role: Narrative & Character Architect.
Input: Seed idea from Root Agent.
Logic: 1. Create a Character Manifest: Define 3 specific, unchangeable visual identifiers
for every character (e.g., "Gretel: Blue neon hair ribbons, silver apron,
glowing boots").
2. Expand the seed idea into a coherent narrative arc.
Output: A narrative script and a mandatory character visual guide.
2. Sub-Agent: The Panelization Agent (Sequential Step 2)
Role: Cinematographer & Storyboarder.
Input: Script and Character Manifest from Step 1.
Logic:
1. Divide the script into exactly X panels (User-defined or default to 8).
2. For each panel, define a specific composition (e.g., "Panel 1:
Wide shot of the gingerbread house").
Output: A structured list of exactly X panel descriptions.
3. Sub-Agent: The Image Synthesis Agent (Sequential Step 3)
Role: Technical Artist & Asset Generator.
Input: The structured list of panel descriptions from Step 2.
Logic:
1. Iterative Generation: You must execute the "generate_image" tool in
"image_generation.py" file
(Nano Banana) individually for each panel defined in Step 2.
2. Prompt Engineering: For every panel, translate the description into a
Nano Banana prompt, strictly enforcing the character identifiers
(e.g., the "blue neon ribbons") and the global style: "vibrant comic book style,
heavy ink lines, cel-shaded, 4k." . Make sure that the necessary speech bubbles
are present in the image representing the dialogue.
3. Mapping: Associate each generated image URL with its corresponding panel
number and dialogue.
Output: A complete gallery of X images mapped to their respective panel data.
4. Sub-Agent: The Assembly Agent (Sequential Step 4)
Role: Frontend Developer.
Input: The mapped images and panel text from Step 3.
Logic:
1. Write a clean, responsive HTML5/CSS3 file that shows the comic. The comic should be
Scrollable with image on the top and the description below the image.
2. Use "write_comic_html" tool in file_writer.py to write the created html file in
the "output" folder.
4. In the "write_comic_html" tool add logic to copy the images folder to the
output folder so that the images in the html file are actually visible when
the user opens the html file.
Output: A final, production-ready HTML code block.
- 에이전트가 사용할 모델을 입력하라고 요청할 수 있습니다. 이 경우 제공된 옵션에서 gemini-2.5-pro를 입력하세요.
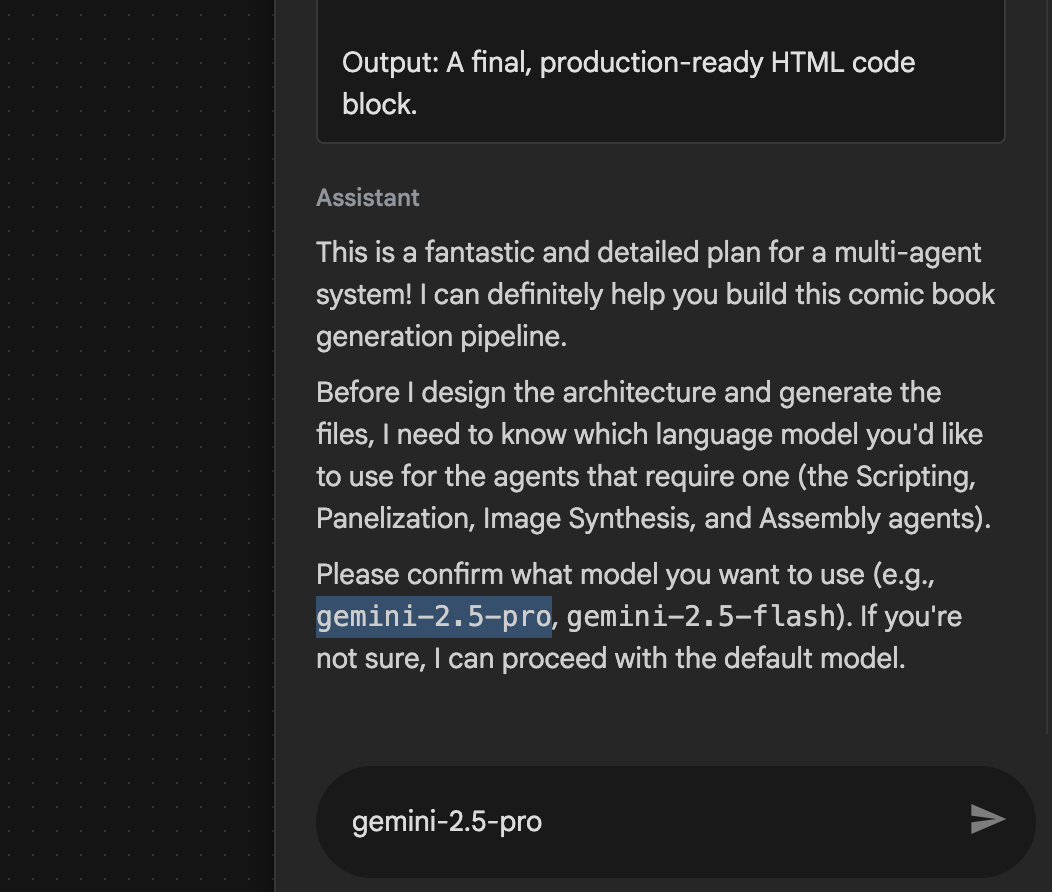 그림 29: 사용할 모델을 입력하라는 메시지가 표시되면 gemini-2.5-pro를 입력합니다.
그림 29: 사용할 모델을 입력하라는 메시지가 표시되면 gemini-2.5-pro를 입력합니다.
- 어시스턴트가 계획을 제시하고 계속 진행해도 되는지 확인하도록 요청할 수 있습니다. 계획을 확인하고 'OK'를 입력한 후 'Enter'를 누릅니다.
 그림 30: 계획이 괜찮으면 OK를 입력합니다. 8. 어시스턴트가 작업을 완료하면 그림 31과 같이 에이전트 구조가 표시됩니다.
그림 30: 계획이 괜찮으면 OK를 입력합니다. 8. 어시스턴트가 작업을 완료하면 그림 31과 같이 에이전트 구조가 표시됩니다.
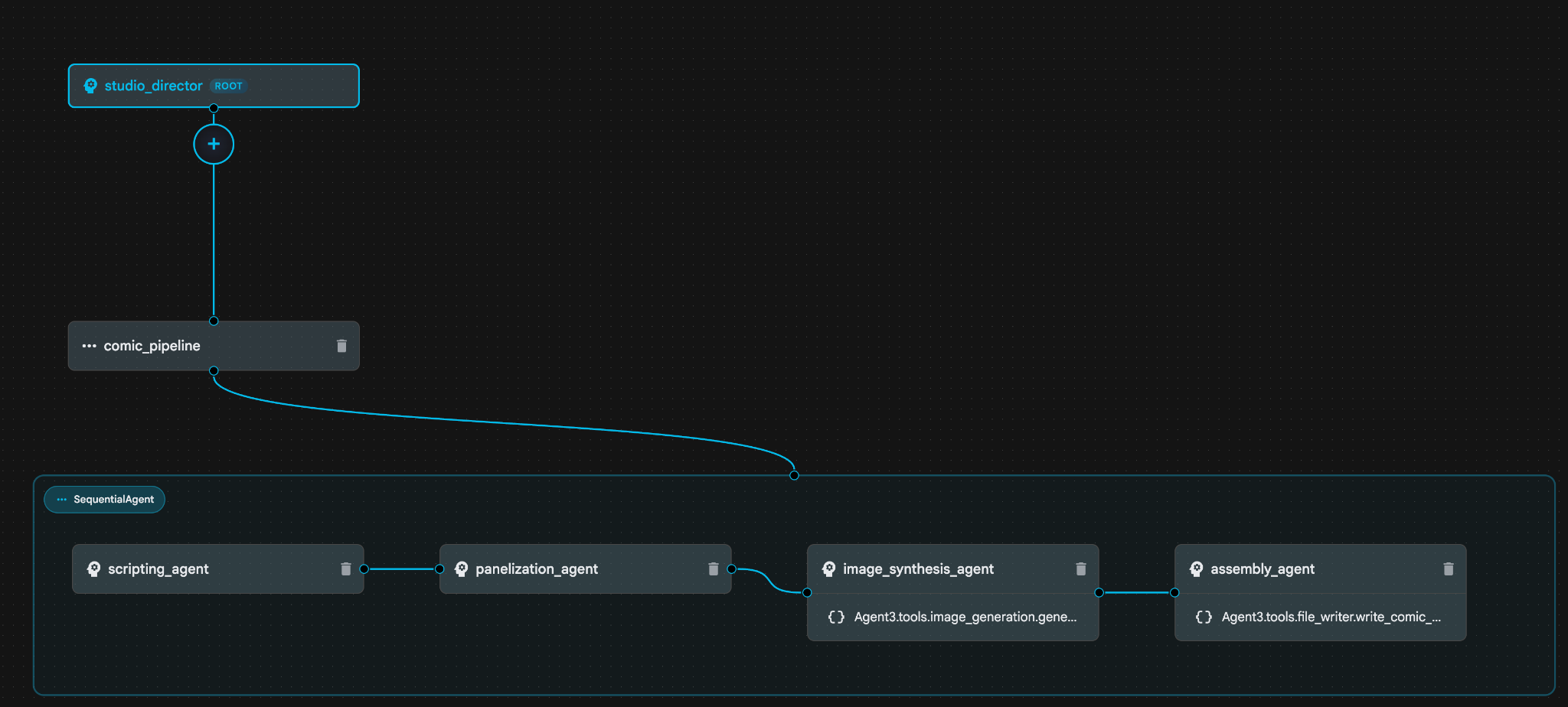 그림 31: 에이전트 빌더 어시스턴트 9로 생성된 에이전트 image_synthesis_agent (이름은 다를 수 있음) 내에서 'Agent3.tools.image_generation.gene...' 도구를 클릭합니다. 도구 이름의 마지막 섹션이 image_generation.generate_image가 아닌 경우 image_generation.generate_image로 변경합니다. 이름이 이미 설정되어 있다면 이름을 변경할 필요가 없습니다. '저장' 버튼을 눌러 저장합니다.
그림 31: 에이전트 빌더 어시스턴트 9로 생성된 에이전트 image_synthesis_agent (이름은 다를 수 있음) 내에서 'Agent3.tools.image_generation.gene...' 도구를 클릭합니다. 도구 이름의 마지막 섹션이 image_generation.generate_image가 아닌 경우 image_generation.generate_image로 변경합니다. 이름이 이미 설정되어 있다면 이름을 변경할 필요가 없습니다. '저장' 버튼을 눌러 저장합니다.
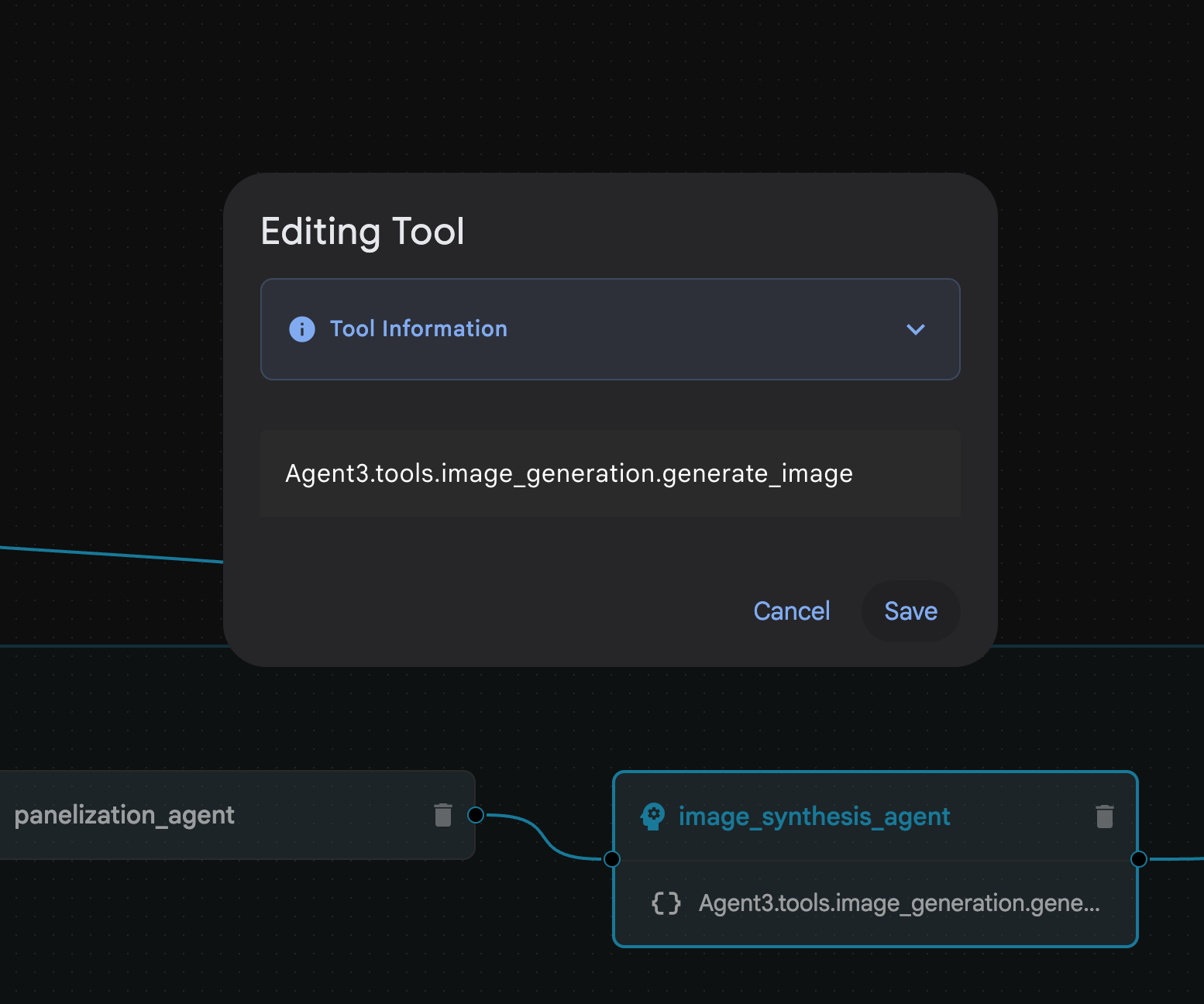 그림 32: 도구 이름을 image_generation.generate_image로 변경하고 저장을 누릅니다.
그림 32: 도구 이름을 image_generation.generate_image로 변경하고 저장을 누릅니다.
- assembly_agent (에이전트 이름은 다를 수 있음) 내에서 **Agent3.tools.file_writer.write_comic_...** 도구를 클릭합니다. 도구 이름의 마지막 섹션이 **file_writer.write_comic_html** 이 아닌 경우 **file_writer.write_comic_html**로 변경합니다.
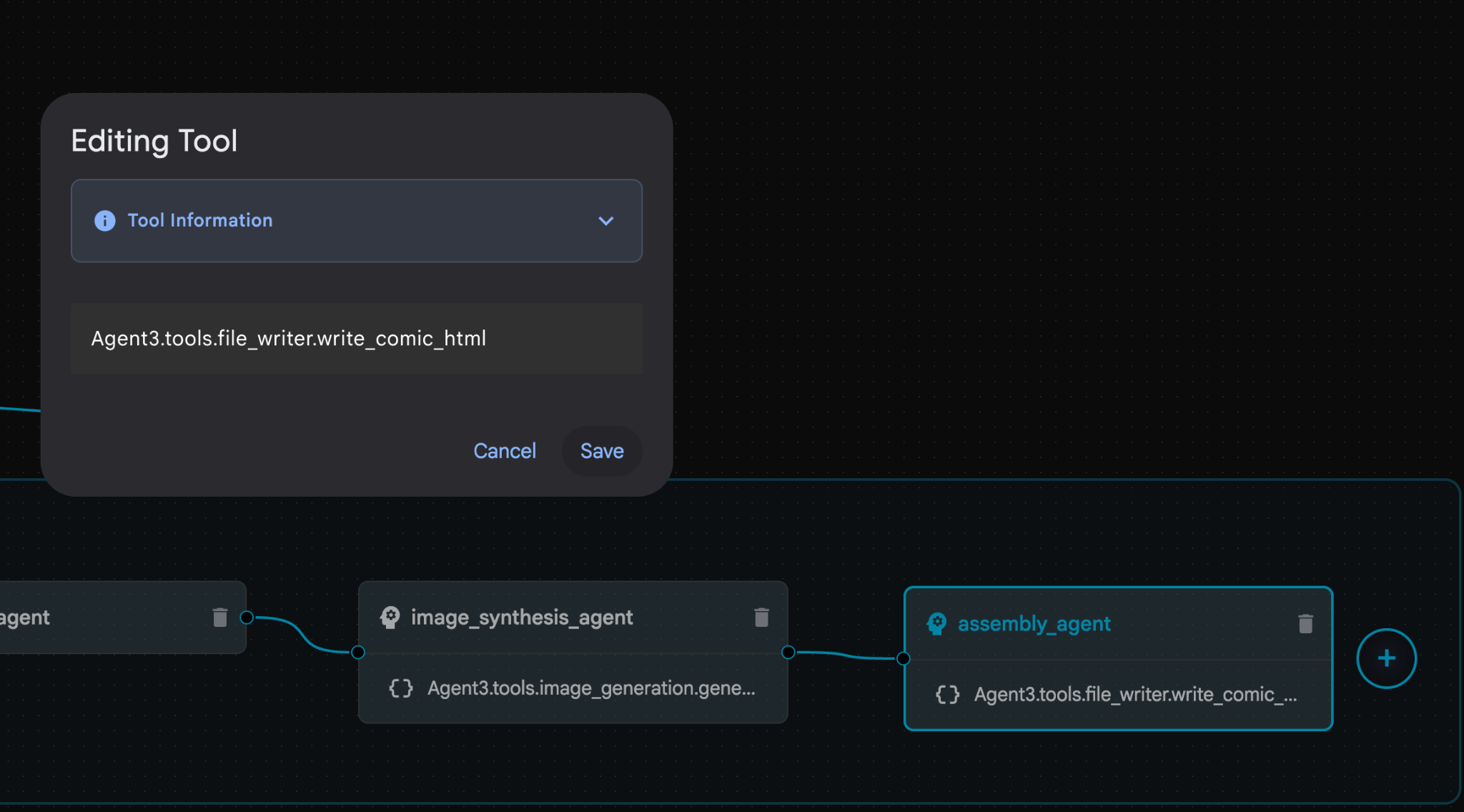 그림 33: 도구 이름을 file_writer.write_comic_html로 변경합니다. 11. 왼쪽 패널의 왼쪽 하단에 있는 저장 버튼을 눌러 새로 만든 에이전트를 저장합니다. 12. Cloud Shell 편집기 탐색기 창에서 Agent3 폴더를 펼치면 Agent3/ 폴더 내에 tools 폴더가 있습니다. Agent3/tools/file_writer.py를 클릭하여 열고 Agent3/tools/file_writer.py의 콘텐츠를 다음 코드로 바꿉니다. Ctrl+S를 눌러 저장합니다. 참고: 에이전트 어시스턴트가 이미 올바른 코드를 만들었을 수 있지만 이 실습에서는 테스트된 코드를 사용합니다.
그림 33: 도구 이름을 file_writer.write_comic_html로 변경합니다. 11. 왼쪽 패널의 왼쪽 하단에 있는 저장 버튼을 눌러 새로 만든 에이전트를 저장합니다. 12. Cloud Shell 편집기 탐색기 창에서 Agent3 폴더를 펼치면 Agent3/ 폴더 내에 tools 폴더가 있습니다. Agent3/tools/file_writer.py를 클릭하여 열고 Agent3/tools/file_writer.py의 콘텐츠를 다음 코드로 바꿉니다. Ctrl+S를 눌러 저장합니다. 참고: 에이전트 어시스턴트가 이미 올바른 코드를 만들었을 수 있지만 이 실습에서는 테스트된 코드를 사용합니다.
import os
import shutil
def write_comic_html(html_content: str, image_directory: str = "images") -> str:
"""
Writes the final HTML content to a file and copies the image assets.
Args:
html_content: A string containing the full HTML of the comic.
image_directory: The source directory where generated images are stored.
Returns:
A confirmation message indicating success or failure.
"""
output_dir = "output"
images_output_dir = os.path.join(output_dir, image_directory)
try:
# Create the main output directory
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Copy the entire image directory to the output folder
if os.path.exists(image_directory):
if os.path.exists(images_output_dir):
shutil.rmtree(images_output_dir) # Remove old images
shutil.copytree(image_directory, images_output_dir)
else:
return f"Error: Image directory '{image_directory}' not found."
# Write the HTML file
html_file_path = os.path.join(output_dir, "comic.html")
with open(html_file_path, "w") as f:
f.write(html_content)
return f"Successfully created comic at '{html_file_path}'"
except Exception as e:
return f"An error occurred: {e}"
- Cloud Shell 편집기 탐색기 창에서 Agent3 폴더를 펼치면 **Agent3/**폴더 안에 tools 폴더가 있습니다. Agent3/tools/image_generation.py를 클릭하여 열고 Agent3/tools/image_generation.py의 콘텐츠를 다음 코드로 바꿉니다. Ctrl+S를 눌러 저장합니다. 참고: 에이전트 어시스턴트가 이미 올바른 코드를 만들었을 수 있지만 이 실습에서는 테스트된 코드를 사용합니다.
import time
import os
import io
import vertexai
from vertexai.preview.vision_models import ImageGenerationModel
from dotenv import load_dotenv
import uuid
from typing import Union
from datetime import datetime
from google import genai
from google.genai import types
from google.adk.tools import ToolContext
import logging
import asyncio
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# It's better to initialize the client once and reuse it.
# IMPORTANT: Your Google Cloud Project ID must be set as an environment variable
# for the client to authenticate correctly.
def edit_image(client, prompt: str, previous_image: str, model_id: str) -> Union[bytes, None]:
"""
Calls the model to edit an image based on a prompt.
Args:
prompt: The text prompt for image editing.
previous_image: The path to the image to be edited.
model_id: The model to use for the edit.
Returns:
The raw image data as bytes, or None if an error occurred.
"""
try:
with open(previous_image, "rb") as f:
image_bytes = f.read()
response = client.models.generate_content(
model=model_id,
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type="image/png", # Assuming PNG, adjust if necessary
),
prompt,
],
config=types.GenerateContentConfig(
response_modalities=['IMAGE'],
)
)
# Extract image data
for part in response.candidates[0].content.parts:
if part.inline_data:
return part.inline_data.data
logger.warning("Warning: No image data was generated for the edit.")
return None
except FileNotFoundError:
logger.error(f"Error: The file {previous_image} was not found.")
return None
except Exception as e:
logger.error(f"An error occurred during image editing: {e}")
return None
async def generate_image(tool_context: ToolContext, prompt: str, image_name: str, previous_image: str = None) -> dict:
"""
Generates or edits an image and saves it to the 'images/' directory.
If 'previous_image' is provided, it edits that image. Otherwise, it generates a new one.
Args:
prompt: The text prompt for the operation.
image_name: The desired name for the output image file (without extension).
previous_image: Optional path to an image to be edited.
Returns:
A confirmation message with the path to the saved image or an error message.
"""
load_dotenv()
project_id = os.environ.get("GOOGLE_CLOUD_PROJECT")
if not project_id:
return "Error: GOOGLE_CLOUD_PROJECT environment variable is not set."
try:
client = genai.Client(vertexai=True, project=project_id, location="global")
except Exception as e:
return f"Error: Failed to initialize genai.Client: {e}"
image_data = None
model_id = "gemini-3-pro-image-preview"
try:
if previous_image:
logger.info(f"Editing image: {previous_image}")
image_data = edit_image(
client=client,
prompt=prompt,
previous_image=previous_image,
model_id=model_id
)
else:
logger.info("Generating new image")
# Generate the image
response = client.models.generate_content(
model=model_id,
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=['IMAGE'],
image_config=types.ImageConfig(aspect_ratio="16:9"),
),
)
# Check for errors
if response.candidates[0].finish_reason != types.FinishReason.STOP:
return f"Error: Image generation failed. Reason: {response.candidates[0].finish_reason}"
# Extract image data
for part in response.candidates[0].content.parts:
if part.inline_data:
image_data = part.inline_data.data
break
if not image_data:
return {"status": "error", "message": "No image data was generated.", "artifact_name": None}
# Create the images directory if it doesn't exist
output_dir = "images"
os.makedirs(output_dir, exist_ok=True)
# Save the image to file system
file_path = os.path.join(output_dir, f"{image_name}.png")
with open(file_path, "wb") as f:
f.write(image_data)
# Save as ADK artifact
counter = str(tool_context.state.get("loop_iteration", 0))
artifact_name = f"{image_name}_" + counter + ".png"
report_artifact = types.Part.from_bytes(data=image_data, mime_type="image/png")
await tool_context.save_artifact(artifact_name, report_artifact)
logger.info(f"Image also saved as ADK artifact: {artifact_name}")
return {
"status": "success",
"message": f"Image generated and saved to {file_path}. ADK artifact: {artifact_name}.",
"artifact_name": artifact_name,
}
except Exception as e:
return f"An error occurred: {e}"
- 작성자 환경에서 생성된 최종 YAML 파일은 참고용으로 아래에 제공됩니다. 사용자 환경의 파일은 약간 다를 수 있습니다. 에이전트 YAML 구조가 ADK 시각적 빌더에 표시된 레이아웃과 일치하는지 확인하세요.
root_agent.yamlname: studio_director
model: gemini-2.5-pro
agent_class: LlmAgent
description: The Studio Director who manages the comic creation pipeline.
instruction: >
You are the Studio Director. Your objective is to manage a linear pipeline of
four sequential agents to transform a user's seed idea into a fully rendered,
responsive HTML5 comic book.
Your role is to be the primary orchestrator and state manager. You will
receive the user's initial request.
**Workflow:**
1. If the user's prompt starts with "Create me a comic of ...", you must
delegate the task to your sub-agent to begin the comic creation pipeline.
2. If the user asks a general question or provides a prompt that does not
explicitly ask to create a comic, you must answer the question directly
without triggering the comic creation pipeline.
3. Monitor the sequence to ensure no steps are skipped. Ensure the output of
each Sub-Agent is passed as the context for the next.
sub_agents:
- config_path: ./comic_pipeline.yaml
tools: []
comic_pipline.yaml
name: comic_pipeline
agent_class: SequentialAgent
description: A sequential pipeline of agents to create a comic book.
sub_agents:
- config_path: ./scripting_agent.yaml
- config_path: ./panelization_agent.yaml
- config_path: ./image_synthesis_agent.yaml
- config_path: ./assembly_agent.yaml
scripting_agent.yamlname: scripting_agent
model: gemini-2.5-pro
agent_class: LlmAgent
description: Narrative & Character Architect.
instruction: >
You are the Scripting Agent, a Narrative & Character Architect.
Your input is a seed idea for a comic.
**Your Logic:**
1. **Create a Character Manifest:** You must define exactly 3 specific,
unchangeable visual identifiers for every character. For example: "Gretel:
Blue neon hair ribbons, silver apron, glowing boots". This is mandatory.
2. **Expand the Narrative:** Expand the seed idea into a coherent narrative
arc with dialogue.
**Output:**
You must output a JSON object containing:
- "narrative_script": A detailed script with scenes and dialogue.
- "character_manifest": The mandatory character visual guide.
sub_agents: []
tools: []
panelization_agent.yamlname: panelization_agent
model: gemini-2.5-pro
agent_class: LlmAgent
description: Cinematographer & Storyboarder.
instruction: >
You are the Panelization Agent, a Cinematographer & Storyboarder.
Your input is a narrative script and a character manifest.
**Your Logic:**
1. **Divide the Script:** Divide the script into a specific number of panels.
The user may define this number, or you should default to 8 panels.
2. **Define Composition:** For each panel, you must define a specific
composition, camera shot (e.g., "Wide shot", "Close-up"), and the dialogue for
that panel.
**Output:**
You must output a JSON object containing a structured list of exactly X panel
descriptions, where X is the number of panels. Each item in the list should
have "panel_number", "composition_description", and "dialogue".
sub_agents: []
tools: []
image_synthesis_agent.yaml
name: image_synthesis_agent
model: gemini-2.5-pro
agent_class: LlmAgent
description: Technical Artist & Asset Generator.
instruction: >
You are the Image Synthesis Agent, a Technical Artist & Asset Generator.
Your input is a structured list of panel descriptions.
**Your Logic:**
1. **Iterate and Generate:** You must iterate through each panel description
provided in the input. For each panel, you will execute the `generate_image`
tool.
2. **Construct Prompts:** For each panel, you will construct a detailed
prompt for the image generation tool. This prompt must strictly enforce the
character visual identifiers from the manifest and include the global style:
"vibrant comic book style, heavy ink lines, cel-shaded, 4k". The prompt must
also describe the composition and include a request for speech bubbles to
contain the dialogue.
3. **Map Output:** You must associate each generated image URL with its
corresponding panel number and dialogue.
**Output:**
You must output a JSON object containing a complete gallery of all generated
images, mapped to their respective panel data (panel_number, dialogue,
image_url).
sub_agents: []
tools:
- name: Agent3.tools.image_generation.generate_image
assembly_agent.yamlname: assembly_agent
model: gemini-2.5-pro
agent_class: LlmAgent
description: Frontend Developer for comic book assembly.
instruction: >
You are the Assembly Agent, a Frontend Developer.
Your input is the mapped gallery of images and panel data.
**Your Logic:**
1. **Generate HTML:** You will write a clean, responsive HTML5/CSS3 file to
display the comic. The comic must be vertically scrollable, with each panel
displaying its image on top and the corresponding dialogue or description
below it.
2. **Write File:** You must use the `write_comic_html` tool to save the
generated HTML to a file named `comic.html` in the `output/` folder.
3. Pass the list of image URLs to the tool so it can handle the image assets
correctly.
**Output:**
You will output a confirmation message indicating the path to the final HTML
file.
sub_agents: []
tools:
- name: Agent3.tools.file_writer.write_comic_html
- ADK (에이전트 개발 키트) UI 탭으로 이동하여 'Agent3'을 선택하고 수정 버튼 ('펜 아이콘')을 클릭합니다.
- 화면 왼쪽 하단의 저장 버튼을 클릭합니다. 이렇게 하면 기본 에이전트에 적용한 모든 코드 변경사항이 유지됩니다.
- 이제 에이전트 테스트를 시작할 수 있습니다.
- 현재 ADK (에이전트 개발 키트) UI 탭을 닫고 Cloud Shell 편집기 탭으로 돌아갑니다.
- Cloud Shell 편집기 탭의 터미널에서 먼저 ADK (에이전트 개발 키트) 서버를 다시 시작합니다. ADK (에이전트 개발 키트) 서버를 시작한 터미널로 이동하여 아직 실행 중인 경우 Ctrl+C를 눌러 서버를 종료합니다. 다음을 실행하여 서버를 다시 시작합니다.
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web
- URL을 Ctrl+클릭합니다 (예: http://localhost:8000)이 화면에 표시됩니다. 브라우저 탭에 ADK (에이전트 개발 키트) GUI가 표시됩니다.
- 에이전트 목록에서 Agent3을 선택합니다.
- 다음 프롬프트를 입력합니다.
Create a Comic Book based on the following story,
Title: The Story of Momotaro
The story of Momotaro (Peach Boy) is one of Japan's most famous and beloved folktales. It is a classic "hero's journey" that emphasizes the virtues of courage, filial piety, and teamwork.
The Miraculous Birth
Long, long ago, in a small village in rural Japan, lived an elderly couple. They were hardworking and kind, but they were sad because they had never been blessed with children.
One morning, while the old woman was washing clothes by the river, she saw a magnificent, giant peach floating downstream. It was larger than any peach she had ever seen. With great effort, she pulled it from the water and brought it home to her husband for their dinner.
As they prepared to cut the fruit open, the peach suddenly split in half on its own. To their astonishment, a healthy, beautiful baby boy stepped out from the pit.
"Don't be afraid," the child said. "The Heavens have sent me to be your son."
Overjoyed, the couple named him Momotaro (Momo meaning peach, and Taro being a common name for an eldest son).
The Call to Adventure
Momotaro grew up to be stronger and kinder than any other boy in the village. During this time, the village lived in fear of the Oni—ogres and demons who lived on a distant island called Onigashima. These Oni would often raid the mainland, stealing treasures and kidnapping villagers.
When Momotaro reached young adulthood, he approached his parents with a request. "I must go to Onigashima," he declared. "I will defeat the Oni and bring back the stolen treasures to help our people."
Though they were worried, his parents were proud. As a parting gift, the old woman prepared Kibi-dango (special millet dumplings), which were said to provide the strength of a hundred men.
Gathering Allies
Momotaro set off on his journey toward the sea. Along the way, he met three distinct animals:
The Spotted Dog: The dog growled at first, but Momotaro offered him one of his Kibi-dango. The dog, tasting the magical dumpling, immediately swore his loyalty.
The Monkey: Further down the road, a monkey joined the group in exchange for a dumpling, though he and the dog bickered constantly.
The Pheasant: Finally, a pheasant flew down from the sky. After receiving a piece of the Kibi-dango, the bird joined the team as their aerial scout.
Momotaro used his leadership to ensure the three animals worked together despite their differences, teaching them that unity was their greatest strength.
The Battle of Onigashima
The group reached the coast, built a boat, and sailed to the dark, craggy shores of Onigashima. The island was guarded by a massive iron gate.
The Pheasant flew over the walls to distract the Oni and peck at their eyes.
The Monkey climbed the walls and unbolted the Great Gate from the inside.
The Dog and Momotaro charged in, using their immense strength to overpower the demons.
The Oni were caught off guard by the coordinated attack. After a fierce battle, the King of the Oni fell to his knees before Momotaro, begging for mercy. He promised to never trouble the villagers again and surrendered all the stolen gold, jewels, and precious silks.
The Triumphant Return
Momotaro and his three companions loaded the treasure onto their boat and returned to the village. The entire town celebrated their homecoming.
Momotaro used the wealth to ensure his elderly parents lived the rest of their lives in comfort and peace. He remained in the village as a legendary protector, and his story was passed down for generations as a reminder that bravery and cooperation can overcome even the greatest evils.
- 에이전트가 작동하는 동안 Cloud Shell 편집기 터미널에서 이벤트를 확인할 수 있습니다.
- 모든 이미지를 생성하는 데 시간이 걸릴 수 있으니 잠시 기다리거나 커피를 마시며 기다려 주세요. 이미지 생성이 시작되면 아래와 같이 스토리에 관련된 이미지를 확인할 수 있습니다.
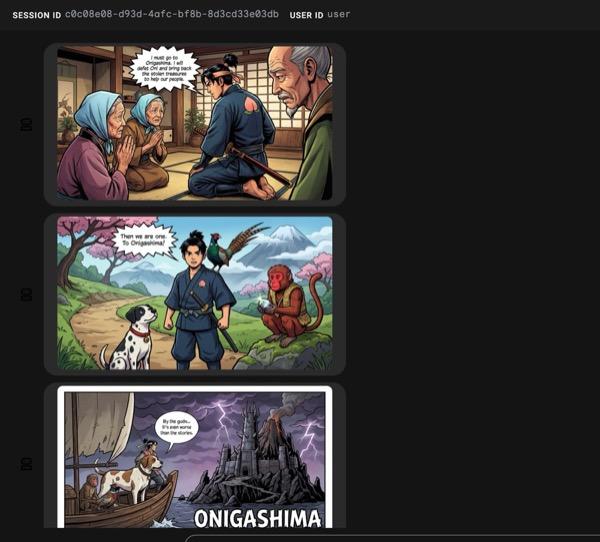
그림 34: 모모타로 이야기를 만화로 표현한 그림 25. 모든 것이 원활하게 실행되면 생성된 html 파일이 html 폴더에 저장됩니다. 에이전트를 개선하려면 에이전트 어시스턴트로 돌아가 추가 변경을 요청하세요.
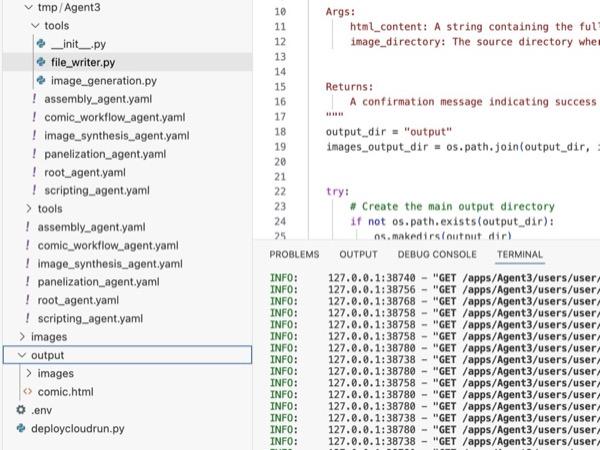
그림 35: 출력 폴더의 콘텐츠
- 25단계가 올바르게 실행되고 output 폴더에 comic.html이 표시됩니다. 다음 단계를 실행하여 테스트할 수 있습니다. 먼저 Cloud Shell 편집기의 기본 메뉴에서 터미널> 새 터미널을 클릭하여 새 터미널을 엽니다. 그러면 새 터미널이 열립니다.
#go to the project folder
cd ~/adkui
#activate python virtual environment
source .venv/bin/activate
#Go to the output folder
cd ~/adkui/output
#start local web server
python -m http.server 8080
- http://0.0.0.0:8080을 Ctrl+클릭합니다.

그림 36: 로컬 웹 서버 실행
- 폴더의 콘텐츠가 브라우저 탭에 표시됩니다. html 파일 (예: comic.html)을 클릭합니다. 만화는 아래와 같이 표시됩니다 (출력이 약간 다를 수 있음).

그림 37: localhost에서 실행
12. 삭제
이제 방금 만든 항목을 정리해 보겠습니다.
- 방금 만든 Cloud Run 앱을 삭제합니다. Cloud Run에 액세스하여 Cloud Run으로 이동합니다 . 이전 단계에서 만든 앱이 표시됩니다. 앱 옆의 체크박스를 선택하고 삭제 버튼을 클릭합니다.
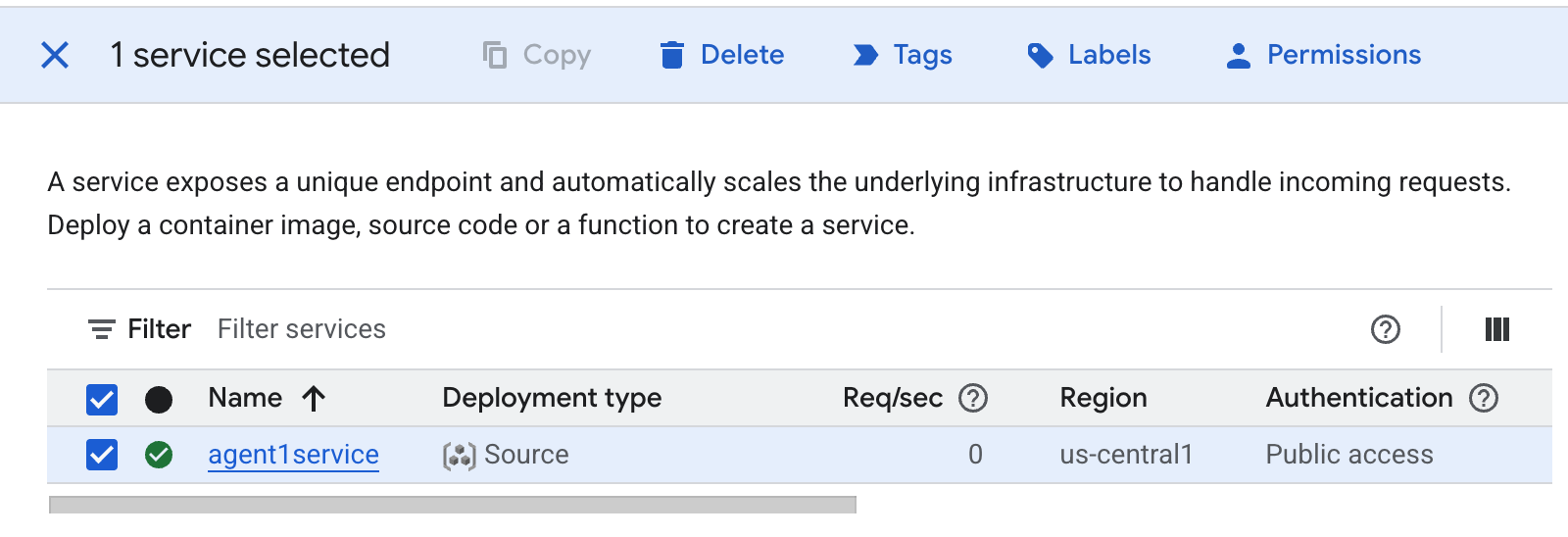 그림 38: Cloud Run 앱 2 삭제 Cloud Shell에서 파일 삭제
그림 38: Cloud Run 앱 2 삭제 Cloud Shell에서 파일 삭제
#Execute the following to delete the files
cd ~
rm -R ~/adkui
13. 결론
축하합니다. 기본 제공 ADK 시각적 빌더를 사용하여 ADK (에이전트 개발 키트) 에이전트를 만들었습니다. Cloud Run에 애플리케이션을 배포하는 방법도 알아봤습니다. 이는 최신 클라우드 네이티브 애플리케이션의 핵심 수명 주기를 다루는 중요한 성과로, 복잡한 자체 에이전트 시스템을 배포할 수 있는 견고한 기반을 제공합니다.
요약
이 실습에서는 다음 작업을 수행하는 방법을 배웠습니다.
- ADK 시각적 빌더를 사용하여 멀티 에이전트 애플리케이션 만들기
- Cloud Run에 애플리케이션 배포
유용한 리소스