
1. 本实验的目标
在本实操实验中,您将学习如何使用 ADK(智能体开发套件)可视化构建器创建智能体。ADK(智能体开发套件)可视化构建器提供了一种低代码方式来创建 ADK(智能体开发套件)智能体。您将学习如何在本地测试应用,以及如何在 Cloud Run 中部署应用。
学习内容
- 了解 ADK(智能体开发套件) 的基础知识。
- 了解 ADK(智能体开发套件)可视化构建器的基础知识
- 了解如何使用 GUI 工具创建代理。
- 了解如何轻松部署和使用 Cloud Run 中的代理。
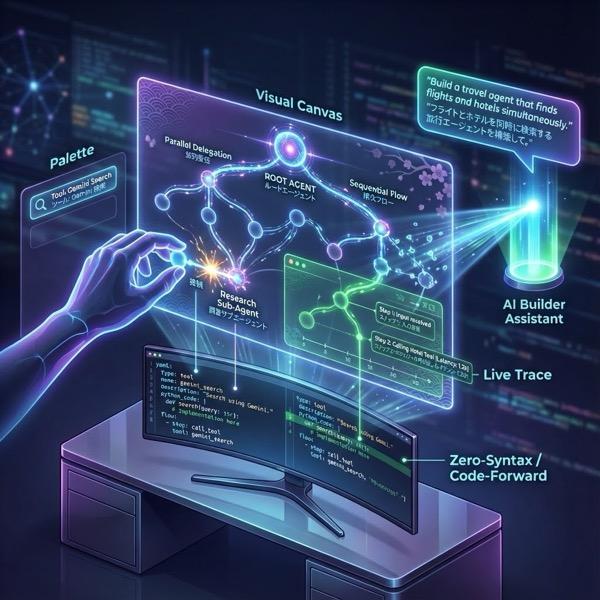
图 1:借助 ADK 可视化构建器,您可以使用 GUI 以低代码方式创建智能体
2. 项目设置
- 点击以下链接前往 GCP 控制台:GCP 控制台。
- 如果您还没有可用的项目,则需要在 GCP 控制台中创建一个新项目。在项目选择器(Google Cloud 控制台的左上角)中选择项目。如果您还没有项目,请按照这些步骤创建新项目。创建新项目后,请选择您的项目。
图 2:点击 Google Cloud 徽标旁边的方框即可选择项目。确保您的项目处于选中状态。
- 在本实验中,我们将使用 Cloud Shell 编辑器来执行任务。打开 Cloud Shell 并使用 Cloud Shell 设置项目。
- 点击此链接可直接前往 Cloud Shell Editor
- 在 Cloud Shell 编辑器的边栏上,点击“打开文件夹”按钮。
- 系统应已选择您的主文件夹,只需按“确定”,您的主文件夹就会成为此任务的根文件夹。

- 如果终端尚未打开,请从菜单中依次点击终端 > 新建终端,以打开终端。您可以在此终端中运行本教程中的所有命令。
- 您可以在 Cloud Shell 终端中使用以下命令检查项目是否已通过身份验证。
gcloud auth list
- 如果您不记得自己的项目 ID,可以使用以下命令列出所有项目 ID:
gcloud projects list
- 复制项目 ID,然后使用以下命令进行设置
gcloud config set project <YOUR_PROJECT_ID>
- 在 Cloud Shell 中运行以下命令,以确认您的项目
gcloud config list project
3. 启用 API
我们需要启用一些 API 服务才能运行本实验。在 Cloud Shell 中运行以下命令。
gcloud services enable aiplatform.googleapis.com
gcloud services enable cloudresourcemanager.googleapis.com
API 简介
4. 智能体开发套件简介
对于构建智能体应用的开发者,智能体开发套件具有以下几项关键优势:
- 多智能体系统:通过分层组合多个专业智能体来构建模块化且可伸缩的应用,实现复杂的协调和委托。
- 丰富的工具生态系统:赋予智能体多种功能,包括使用预构建工具(搜索、代码执行等)、创建自定义函数、整合第三方智能体框架的工具(LangChain、CrewAI),甚至调用其他智能体作为工具。
- 灵活的编排:使用工作流智能体(
SequentialAgent、ParallelAgent和LoopAgent)为可预测的流水线定义工作流,或利用 LLM 驱动的动态路由(LlmAgent转移)实现自适应行为。 - 集成式开发者体验:使用强大的 CLI 和交互式开发者界面,在本地开发、测试和调试,并分步检查事件、状态及智能体执行情况。
- 内置评估:通过将最终回答质量和分步执行轨迹与预定义测试用例对比,系统地评估智能体性能。
- 可随时部署:将智能体容器化并部署至任意环境 - 本地运行、使用 Vertex AI Agent Engine 扩缩,或通过 Cloud Run 或 Docker 集成到自定义基础设施。
虽然其他生成式 AI SDK 或智能体框架也允许您查询模型,甚至为模型添加工具功能,但在多个模型之间实现动态协调仍需您完成大量工作。
智能体开发套件提供了比这些工具更高级的框架,使您可以轻松地将多个智能体互相连接,从而实现复杂但容易维护的工作流。
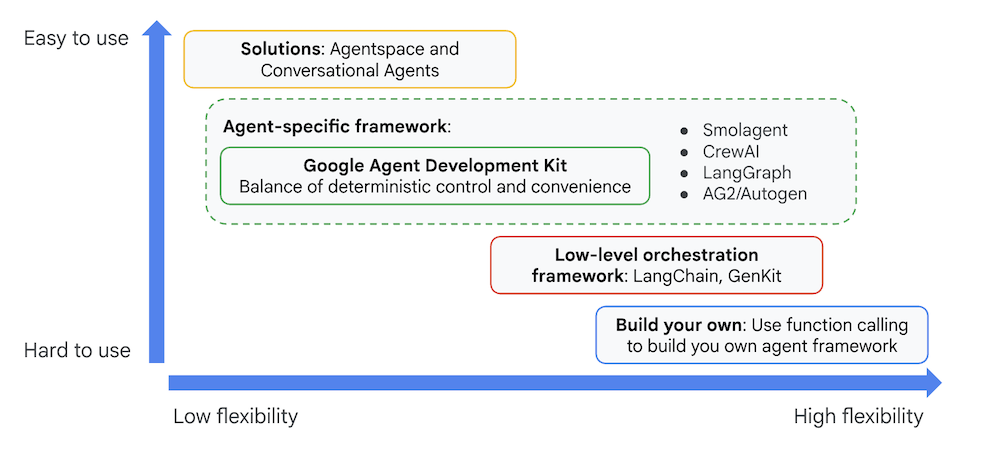
图 3:ADK(智能体开发套件)的定位
在最新版本中,ADK(智能体开发套件)中添加了 ADK 可视化构建器工具,可让您使用低代码构建 ADK(智能体开发套件)智能体。在本实验中,我们将详细探索 ADK 可视化构建器工具。
5. 安装 ADK 并设置环境
首先,我们需要设置环境,以便运行 ADK(智能体开发套件)。在本实验中,我们将运行 ADK(智能体开发套件),并在 Google Cloud 的 Cloud Shell 编辑器中执行所有任务。
准备 Cloud Shell 编辑器
- 如果 Cloud Shell Editor 已打开,您可以跳过这些步骤,直接前往下一部分“启动 ADK 可视化编辑器”。
- 如果您尚未进入 Cloud Shell 编辑器,请按照项目设置步骤操作。
- 在本实验中,我们将使用 Cloud Shell 编辑器来执行任务。打开 Cloud Shell 并使用 Cloud Shell 设置项目。
- 点击此链接可直接前往 Cloud Shell Editor
- 在 Cloud Shell 编辑器的边栏上,点击“打开文件夹”按钮。
- 系统应已选择您的主文件夹,只需按“确定”,您的主文件夹就会成为此任务的根文件夹。
- 如果终端尚未打开,请从菜单中依次点击终端 > 新建终端,以打开终端。您可以在此终端中运行本教程中的所有命令。
- 您可以在 Cloud Shell 终端中使用以下命令检查项目是否已通过身份验证。
gcloud auth list
- 如果您不记得自己的项目 ID,可以使用以下命令列出所有项目 ID:
gcloud projects list
- 复制项目 ID,然后使用以下命令进行设置
gcloud config set project <YOUR_PROJECT_ID>
- 在 Cloud Shell 中运行以下命令,以确认您的项目
gcloud config list project
启动 ADK 可视化编辑器
- 执行以下命令,从 GitHub 克隆所需的源代码并安装必要的库。在 Cloud Shell 编辑器中打开的终端中运行命令。
#create the project directory
mkdir ~/adkui
cd ~/adkui
- 我们将使用 uv 创建 Python 环境(在 Cloud Shell 编辑器终端中运行):
#Install uv if you do not have installed yet
pip install uv
#go to the project directory
cd ~/adkui
#Create the virtual environment
uv venv
#use the newly created environment
source .venv/bin/activate
#install libraries
uv pip install google-adk==2.3.0
uv pip install python-dotenv
注意:如果您需要重启终端,请务必执行“source .venv/bin/activate”来设置 Python 环境
- 在编辑器中,依次前往“查看”>“显示/不显示隐藏文件”。在 adkui 文件夹中,创建一个包含以下内容的 .env 文件。
#go to adkui folder
cd ~/adkui
cat <<EOF>> .env
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
GOOGLE_CLOUD_LOCATION=us-central1
IMAGEN_MODEL="imagen-3.0-generate-002"
GENAI_MODEL="gemini-3.5-flash"
EOF
6. 使用 ADK 可视化构建器创建简单的智能体
在本部分中,我们将使用 ADK 可视化构建器创建一个简单的智能体。ADK 可视化构建器是一款基于 Web 的工具,可提供可视化工作流设计环境,用于创建和管理 ADK(智能体开发套件)智能体。它提供了一个适合初学者的图形界面,可让您在其中设计、构建和测试智能体,还包含一个 AI 赋能的助理来帮助您构建智能体。
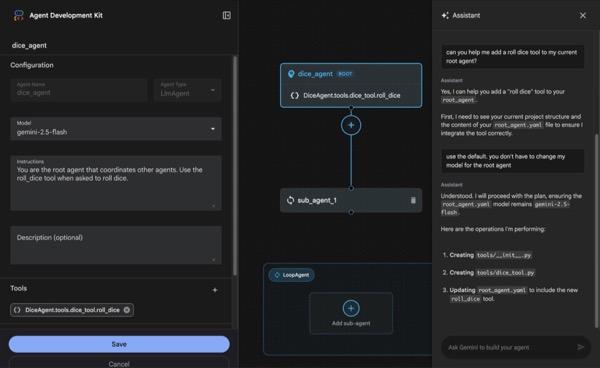
图 4:ADK 可视化构建器
- 返回终端中的顶级目录 adkui,然后执行以下命令以在本地运行代理(在 Cloud Shell 编辑器终端中运行)。您应该能够启动 ADK 服务器,并在终端中看到类似于图 5 的结果。
#go to the directory adkui
cd ~/adkui
# Run the following command to run ADK locally
adk web --host 0.0.0.0 --port 8080 --allow_origins "regex:https://.*8080-.*\.cloudshell\.dev"
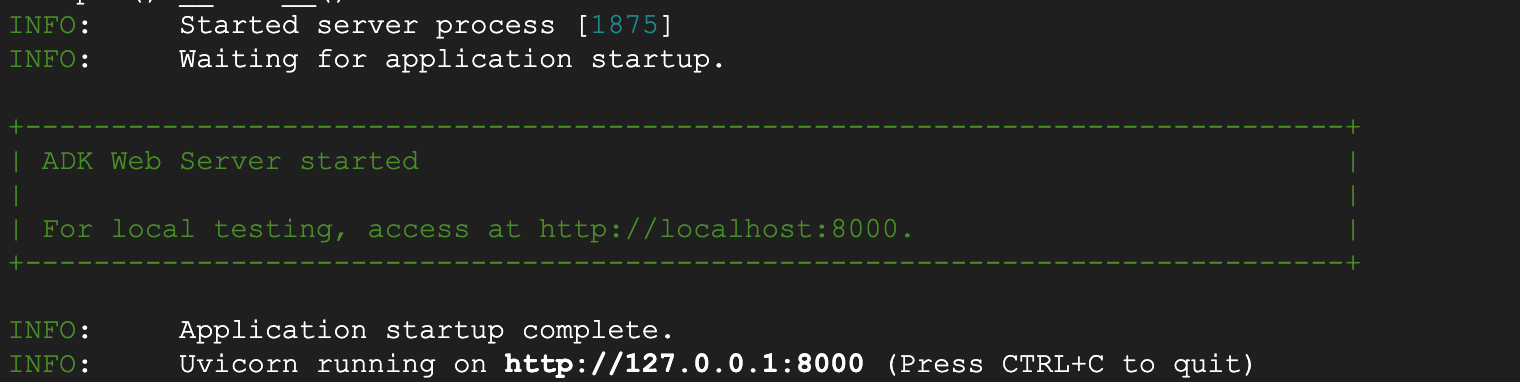
- 图 5:ADK 应用启动
- 在终端上显示的 http:// 网址上按 Ctrl+点击(对于 MacOS,按 CMD+点击),以打开基于浏览器的 ADK(代理开发套件)GUI 工具。

图 6:ADK Web 界面,ADK 具有以下组件
- 点击选择应用下拉菜单,然后按“+”按钮创建新代理。
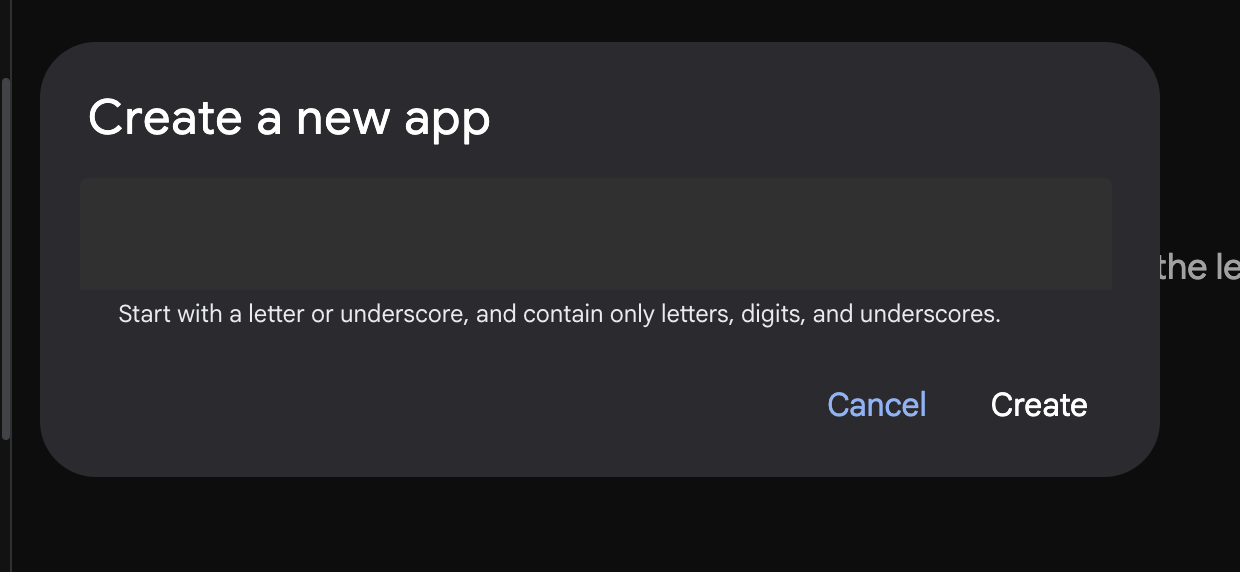
图 7:用于创建新应用的对话框
- 输入名称“Agent1”,然后点击“创建”。
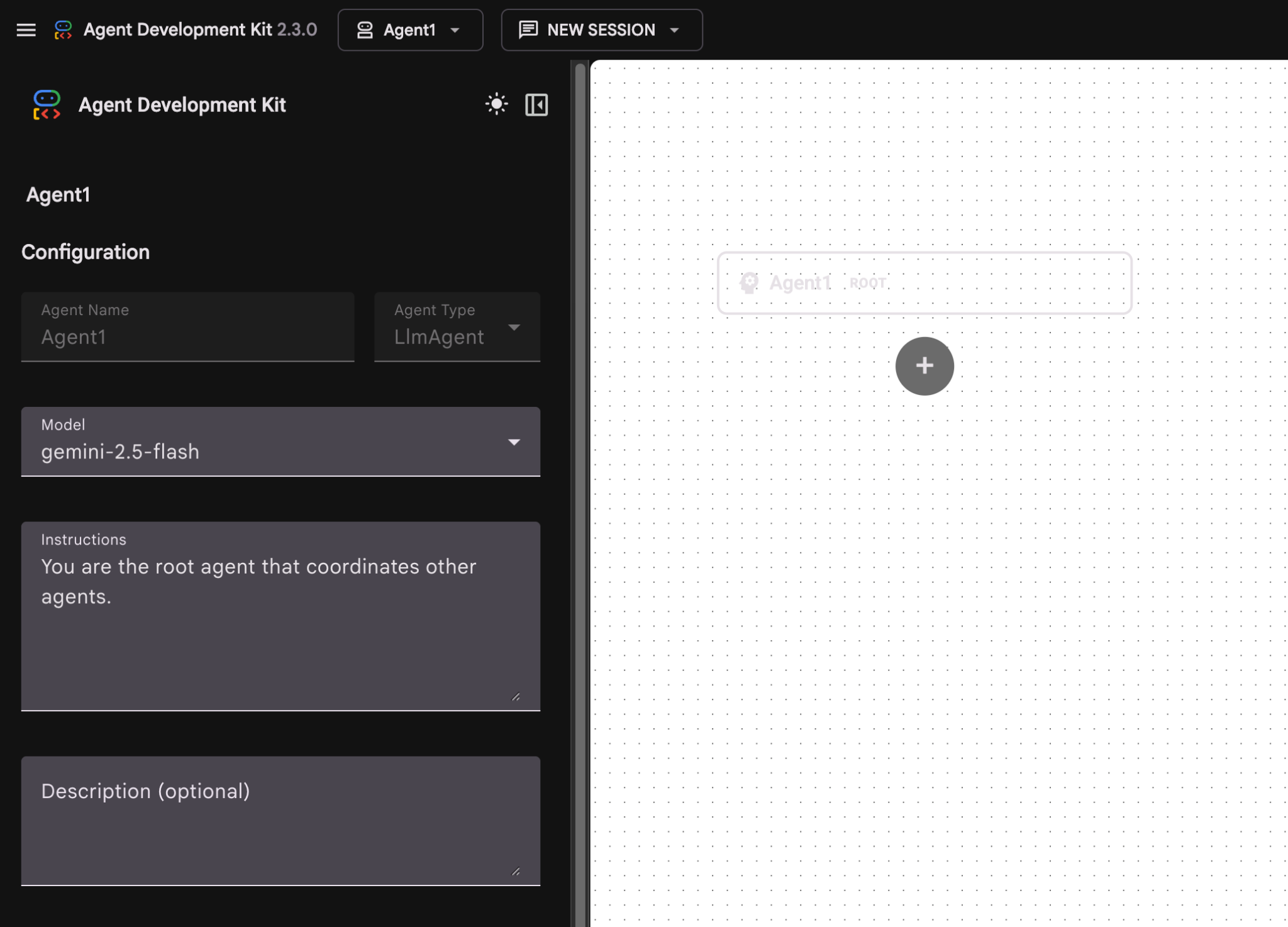
图 8:代理构建器的界面
- 该面板分为三个主要部分:左侧是基于 GUI 的代理创建控件,中间是进度可视化视图,右侧是使用自然语言构建代理的助理。
- 您的代理已成功创建。点击保存按钮以继续。(注意:为避免丢失所做的更改,请务必按“保存”。)
- 代理现在应已准备就绪,可以进行测试了。首先,在聊天框中输入提示,例如:
Hi, what can you do?
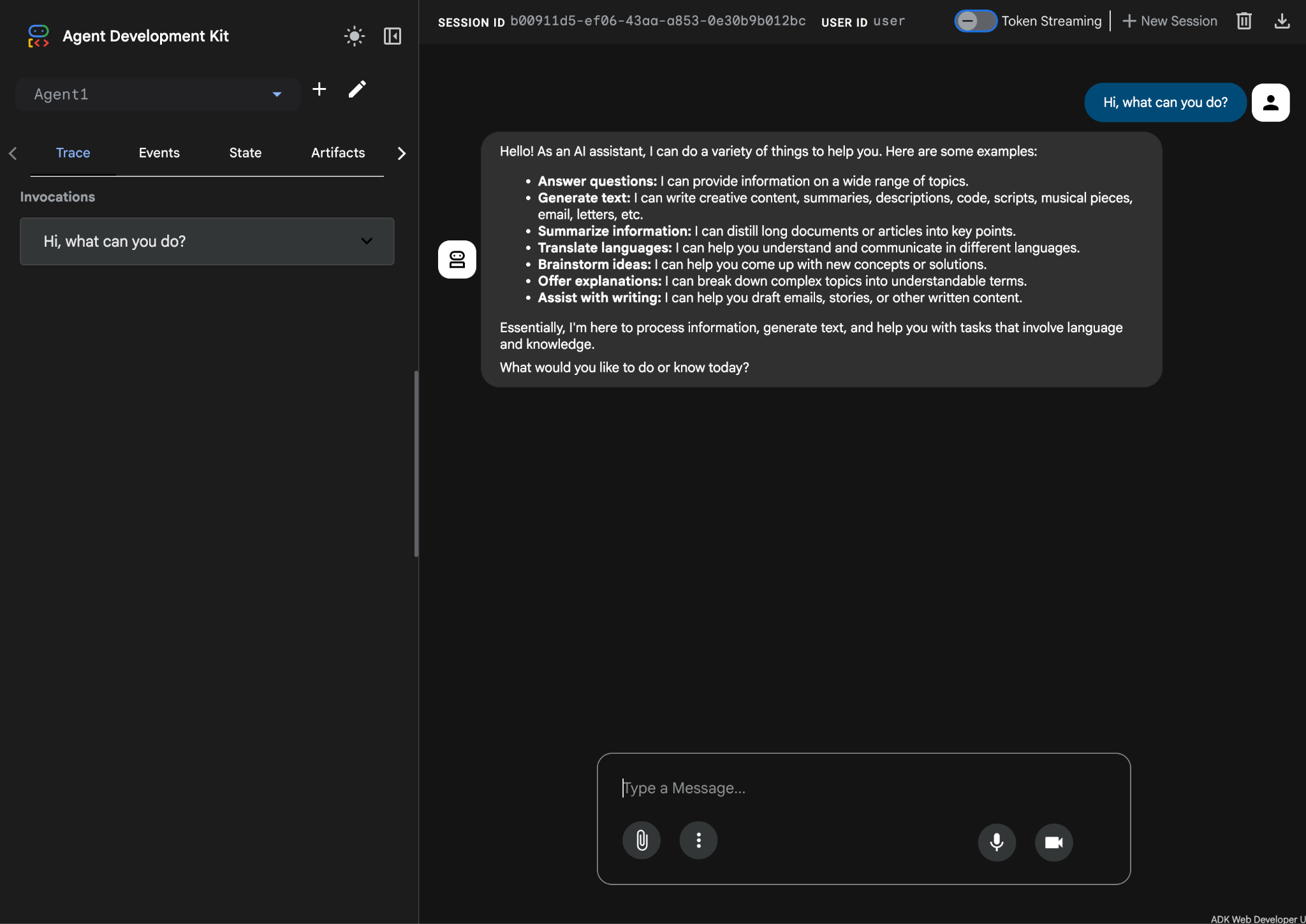
图 9:测试代理。
7. 返回编辑器,检查新生成的文件。您会在左侧找到资源管理器。前往 adkgui 文件夹并将其展开,以显示 Agent 1 目录。在该文件夹中,您可以查看定义代理的 YAML 文件,如下图所示。
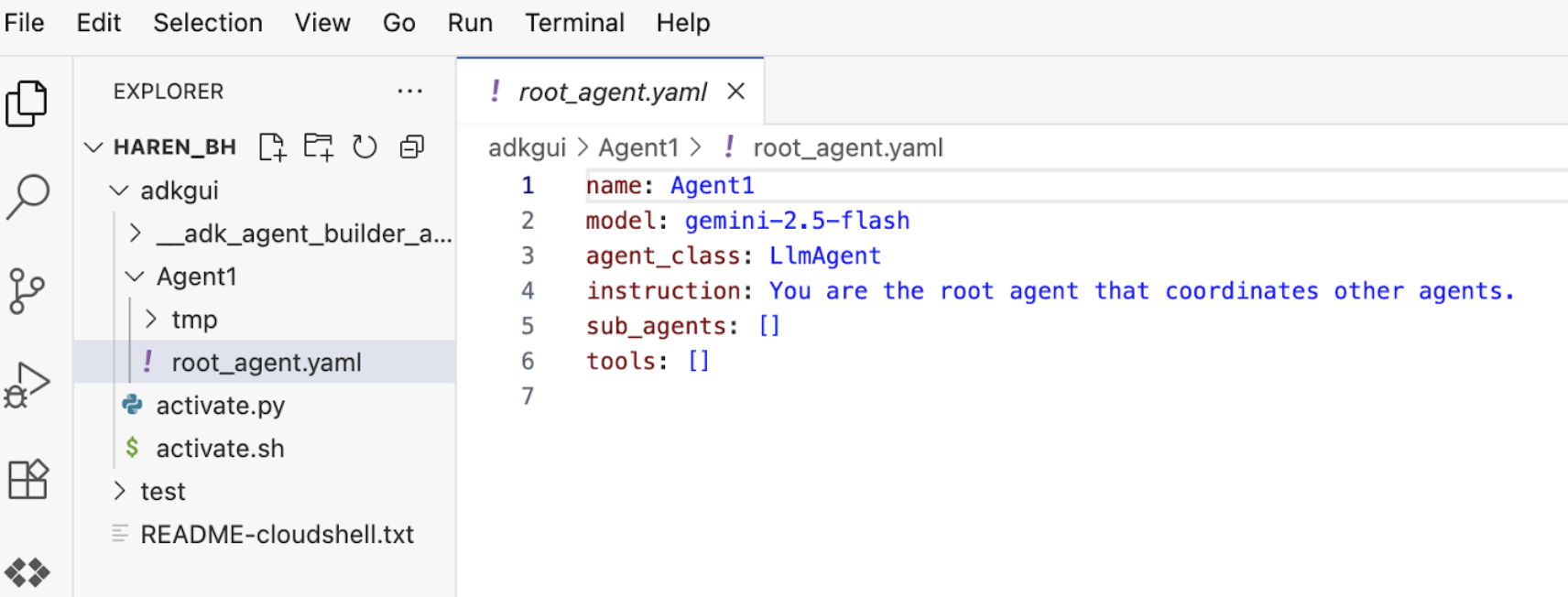
图 10:使用 YAML 文件定义的代理
- 现在,我们返回 GUI 编辑器,为代理添加一些功能。为此,请按修改按钮(笔图标)。
- 我们将为智能体添加 Google 搜索功能,为此,我们需要将 Google 搜索添加为智能体可用的工具,以便智能体可以使用该工具。为此,请点击屏幕左下角“工具”部分旁边的 “+”号,然后从菜单中点击内置工具(参见图 11)。
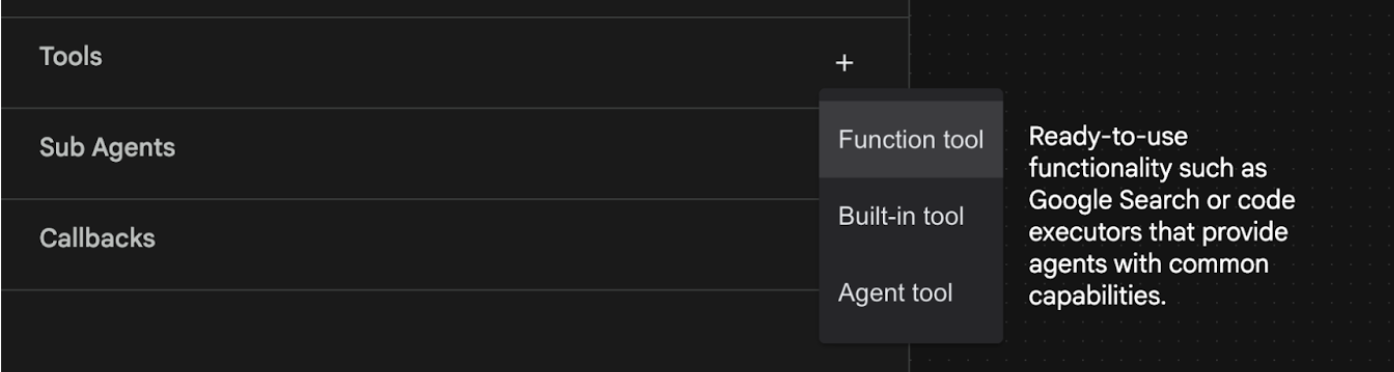
图 11:向智能体添加新工具
- 从内置工具列表中选择 google_search,然后点击创建(参见图 11)。这会将 Google 搜索添加为代理中的工具。
- 按保存按钮,以便保存更改。
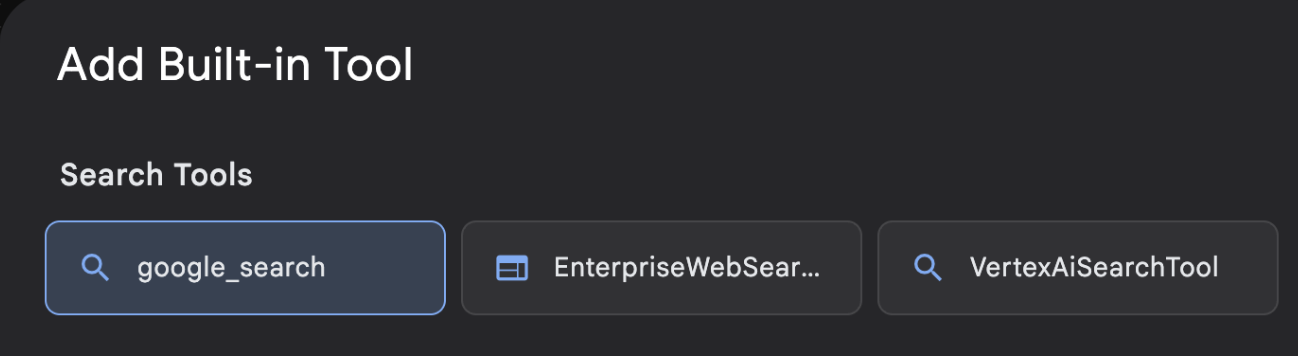
图 12:ADK 可视化构建器界面中提供的工具列表
- 现在,您可以测试代理了。首先,重新启动 ADK 服务器。前往启动 ADK(智能体开发套件)服务器的终端,然后按 CTRL+C 以关闭服务器
Ctrl+C (Windows)、Cmd+C (Mac)
- 执行以下命令以重新启动服务器。
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web --host 0.0.0.0 --port 8080 --allow_origins "regex:https://.*8080-.*\.cloudshell\.dev"
- 按住 Ctrl 键并点击相应网址(例如http://localhost:8000)浏览器标签页上应会显示 ADK(智能体开发套件)GUI。
- 从代理列表中选择 Agent1。您的代理现在可以执行 Google 搜索。在对话框中,使用以下提示进行测试。
What is the weather today in Yokohama?
您应该会看到来自 Google 搜索的答案,如下所示。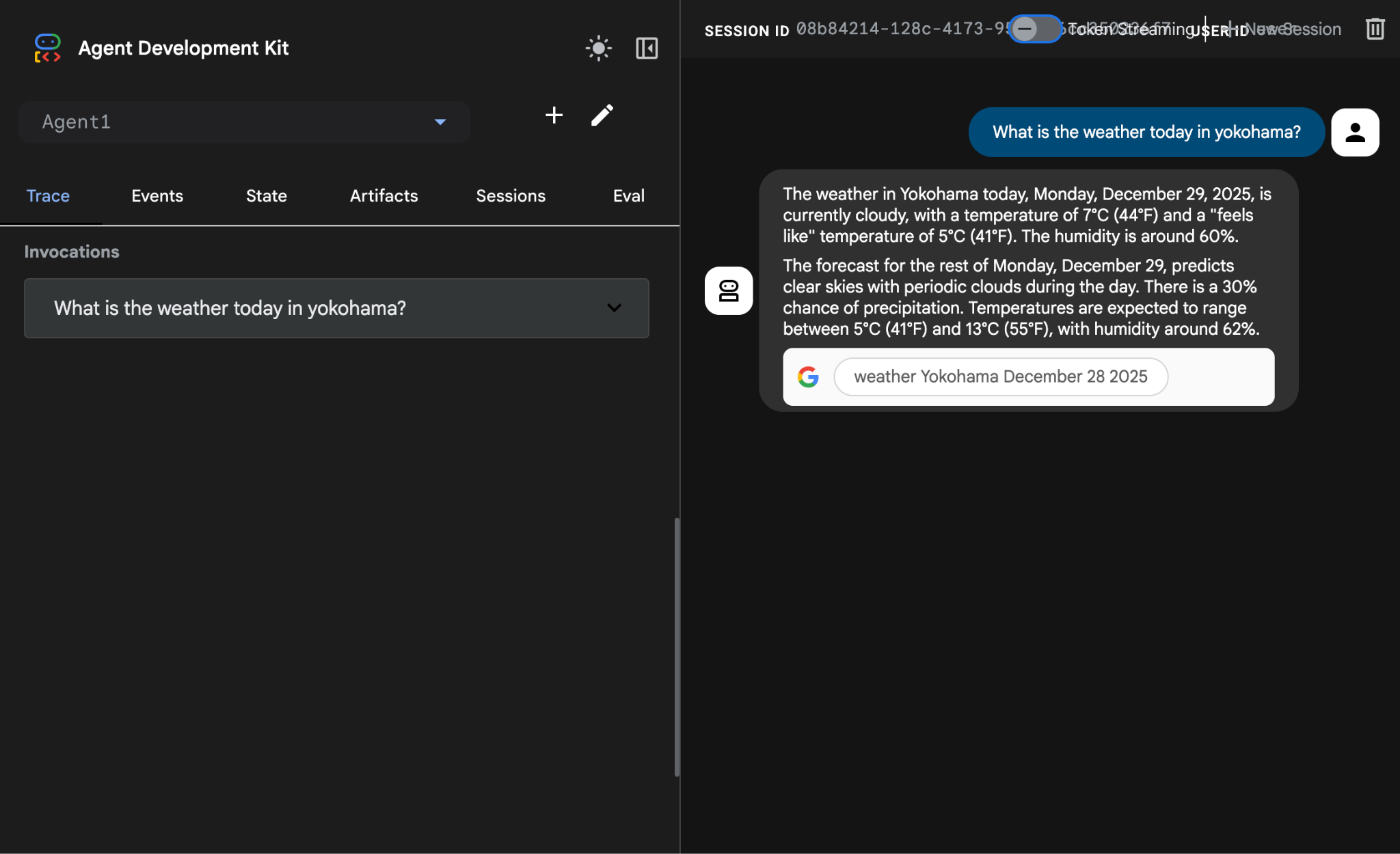
图 13:集成 Google 搜索的智能体
- 现在,我们回到编辑器,检查在此步骤中创建的代码。在编辑器探索器侧边栏中,点击 root_agent.yaml 以打开该文件。确认 google_search 已添加为工具(图 15)。
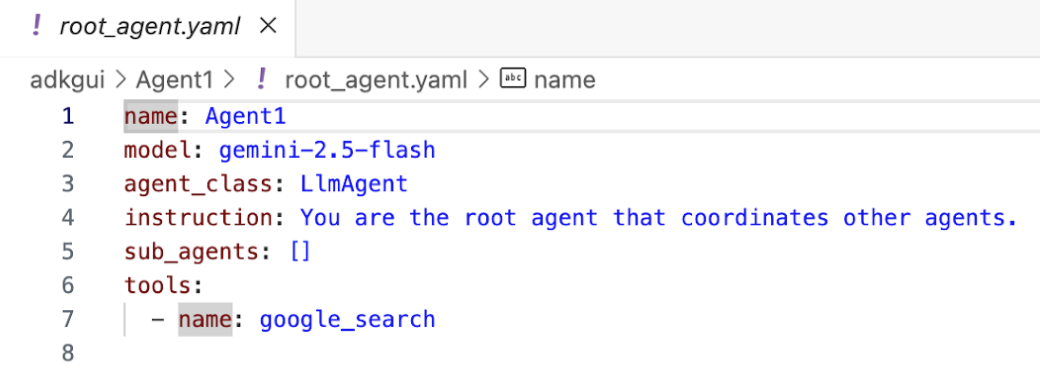
图 14:确认已将 google_search 添加为 Agent1 中的工具
7. 将代理部署到 Cloud Run
现在,我们将创建的代理部署到 Cloud Run!借助 Cloud Run,您可以在全托管式平台上快速构建应用或网站。
您无需管理基础设施,即可运行前端和后端服务、批量作业、托管 LLM,以及将正在处理的工作负载排入队列。
- 在 Cloud Shell 编辑器的终端中,如果您仍在运行 ADK(代理开发套件)服务器,请按 Ctrl+C 停止该服务器。
Ctrl+C (Windows)、Cmd+C (Mac)
- 前往项目根目录。
cd ~/adkui
- 获取部署代码。运行命令后,您应该会在 Cloud Shell 编辑器的“Explorer”窗格中看到文件 deploycloudrun.py
curl -LO https://raw.githubusercontent.com/haren-bh/codelabs/main/adk_visual_builder/deploycloudrun.py
- 检查 deploycloudrun.py 中的部署选项。我们将使用 adk deploy 命令将智能体部署到 Cloud Run。ADK(智能体开发套件)内置了将智能体部署到 Cloud Run 的选项。我们需要指定 Google Cloud 项目 ID、地区等参数。对于应用路径,此脚本假定 agent_path=./Agent1。我们还将创建一个具有必要权限的新服务账号,并将其附加到 Cloud Run。Cloud Run 需要访问 Vertex AI、Cloud Storage 等服务才能运行代理。
- 运行 deploycloudrun.py 脚本**。部署应开始,如下图所示。**
python3 deploycloudrun.py
如果您收到如下确认消息,请针对所有消息按 Y 和 Enter 键。 depoycloudrun.py 假设您的代理位于如上所述创建的 Agent1 文件夹中。
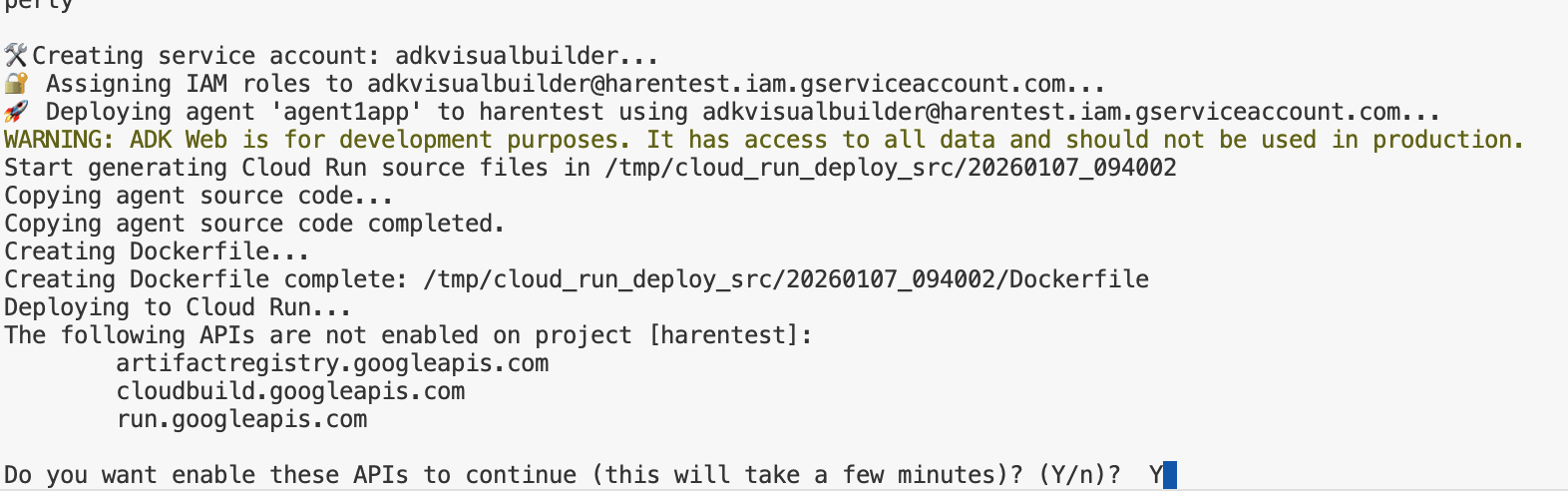
图 15:将代理部署到 Cloud Run,对任何确认消息按 Y。
- 部署完成后,您应该会看到类似 https://agent1service-78833623456.us-central1.run.app 的服务网址
- 在网络浏览器中访问该网址,即可启动应用。
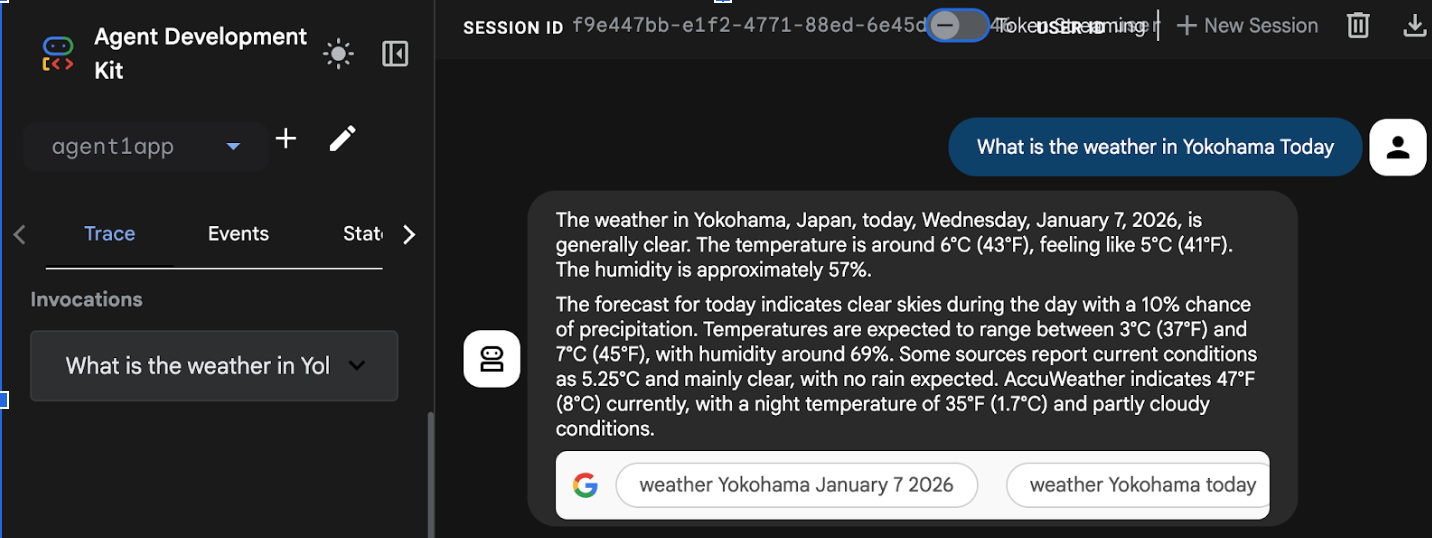
Figure 16: Agent running in Cloud Run
8. 创建具有子代理和自定义工具的代理
在上一部分中,您创建了一个内置 Google 搜索工具的单智能体。在本部分中,您将创建一个多智能体系统,允许智能体使用自定义工具。
- 首先,重启 ADK(智能体开发套件)服务器。前往启动 ADK(智能体开发套件)服务器的终端,然后按 CTRL+C 关闭服务器(如果服务器仍在运行)。执行以下命令以重新启动服务器。
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web --host 0.0.0.0 --port 8080 --allow_origins "regex:https://.*8080-.*\.cloudshell\.dev"
- 按住 Ctrl 键并点击相应网址(例如http://localhost:8000)浏览器标签页上应会显示 ADK(智能体开发套件)GUI。
- 点击“+”按钮以创建新代理。在代理对话框中输入“Agent2”(图 18),然后点击“创建”。
图 17:创建新的代理应用。
- 在 Agent2 的指令部分中,输入以下内容。
You are an agent that takes image creation instruction from the user and passes it to your sub agent
- 现在,我们将向根代理添加子代理。为此,请点击左侧窗格底部“分代理”菜单左侧的“+”按钮(图 19),然后点击“LLM 代理”。这会创建一个新代理,作为根代理的新子代理。
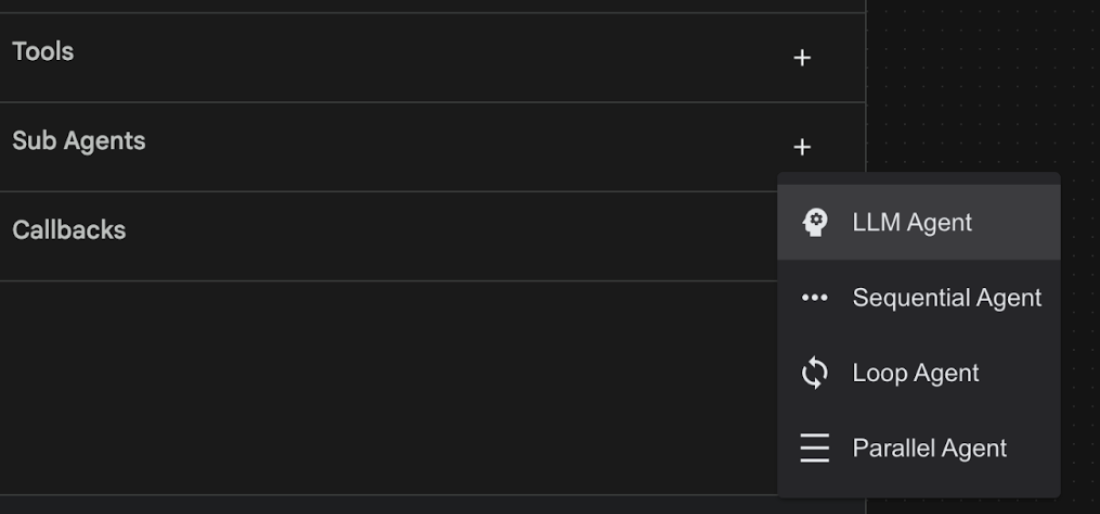
图 18:添加新的子代理。
- 在 sub_agent_1 的指令中,输入以下文本。
You are an Agent that can take instructions about an image and create an image using the create_image tool.
- 现在,我们来为此子代理添加自定义工具。该工具将调用 Imagen 模型,根据用户的指令生成图片。为此,请先点击在上一步中创建的子代理,然后点击“工具”菜单旁边的“+”按钮。在工具选项列表中,点击“函数工具”。借助此工具,我们可以向其中添加自己的自定义代码。
图 19:点击“函数”工具以创建新工具。8. 在对话框中将工具命名为 Agent2.image_creation_tool.create_image。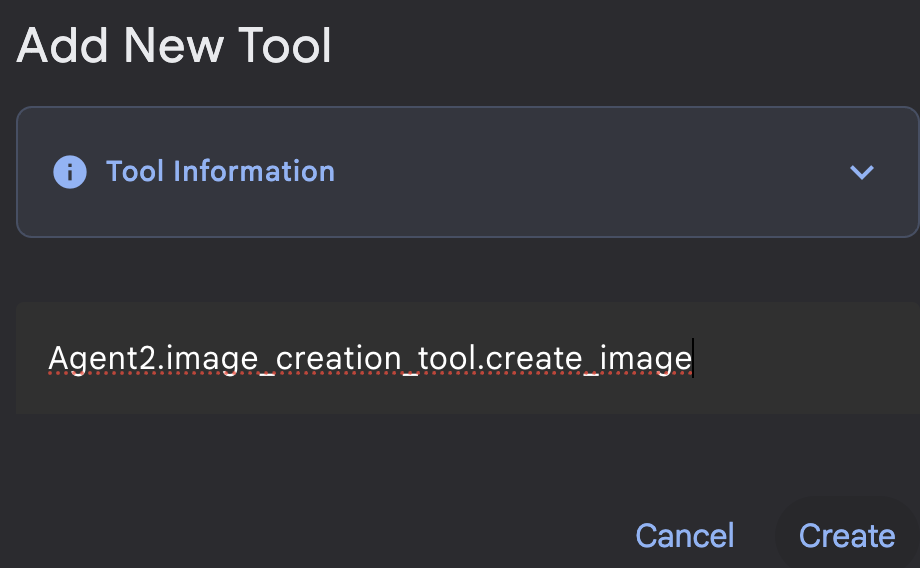
图 20:添加工具名称
- 点击保存按钮以保存更改。
- 在 Cloud Shell 编辑器的终端中,按 Ctrl+S 关闭 adk 服务器。
- 在终端中,输入以下命令以创建 image_creation_tool.py 文件。
touch ~/adkui/Agent2/image_creation_tool.py
- 在 Cloud Shell 编辑器的“资源管理器”窗格中,点击新创建的 image_creation_tool.py 以将其打开。将 image_creation_tool.py 的内容替换为以下内容,然后保存 (Ctrl+S)。
import os
import io
import vertexai
from vertexai.preview.vision_models import ImageGenerationModel
from dotenv import load_dotenv
import uuid
from typing import Union
from datetime import datetime
from google import genai
from google.genai import types
from google.adk.tools import ToolContext
import logging
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def create_image(prompt: str,tool_context: ToolContext) -> Union[bytes, str]:
"""
Generates an image based on a text prompt using a Vertex AI Imagen model.
Args:
prompt: The text prompt to generate the image from.
Returns:
The binary image data (PNG format) on success, or an error message string on failure.
"""
print(f"Attempting to generate image for prompt: '{prompt}'")
try:
# Load environment variables from .env file two levels up
dotenv_path = os.path.join(os.path.dirname(__file__), '..', '..', '.env')
load_dotenv(dotenv_path=dotenv_path)
project_id = os.getenv("GOOGLE_CLOUD_PROJECT")
location = os.getenv("GOOGLE_CLOUD_LOCATION")
model_name = os.getenv("IMAGEN_MODEL")
client = genai.Client(
vertexai=True,
project=project_id,
location=location,
)
response = client.models.generate_images(
model="imagen-3.0-generate-002",
prompt=prompt,
config=types.GenerateImagesConfig(
number_of_images=1,
aspect_ratio="9:16",
safety_filter_level="block_low_and_above",
person_generation="allow_adult",
),
)
if not all([project_id, location, model_name]):
return "Error: Missing GOOGLE_CLOUD_PROJECT, GOOGLE_CLOUD_LOCATION, or IMAGEN_MODEL in .env file."
vertexai.init(project=project_id, location=location)
model = ImageGenerationModel.from_pretrained(model_name)
images = model.generate_images(
prompt=prompt,
number_of_images=1
)
if response.generated_images is None:
return "Error: No image was generated."
for generated_image in response.generated_images:
# Get the image bytes
image_bytes = generated_image.image.image_bytes
counter = str(tool_context.state.get("loop_iteration", 0))
artifact_name = f"generated_image_" + counter + ".png"
# Save as ADK artifact (optional, if still needed by other ADK components)
report_artifact = types.Part.from_bytes(
data=image_bytes, mime_type="image/png"
)
await tool_context.save_artifact(artifact_name, report_artifact)
logger.info(f"Image also saved as ADK artifact: {artifact_name}")
return {
"status": "success",
"message": f"Image generated . ADK artifact: {artifact_name}.",
"artifact_name": artifact_name,
}
except Exception as e:
error_message = f"An error occurred during image generation: {e}"
print(error_message)
return error_message
- 首先,重启 ADK(智能体开发套件)服务器。前往启动 ADK(智能体开发套件)服务器的终端,然后按 CTRL+C 关闭服务器(如果服务器仍在运行)。执行以下命令以重新启动服务器。
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web --host 0.0.0.0 --port 8080 --allow_origins "regex:https://.*8080-.*\.cloudshell\.dev"
- 按住 Ctrl 键并点击相应网址(例如http://localhost:8000)浏览器标签页上应会显示 ADK(智能体开发套件)GUI。
- 在 ADK(智能体开发套件)界面标签页中,在智能体列表中选择 Agent2,然后按修改按钮(笔图标)。在 ADK(代理开发工具包)可视化编辑器中,点击“保存”按钮以保留更改。
- 现在,我们可以测试新代理了。
- 在 ADK(智能体开发套件)界面聊天界面中,输入以下提示。您也可以尝试其他提示。您应该会看到图 21 中所示的结果
Create an image of a cat
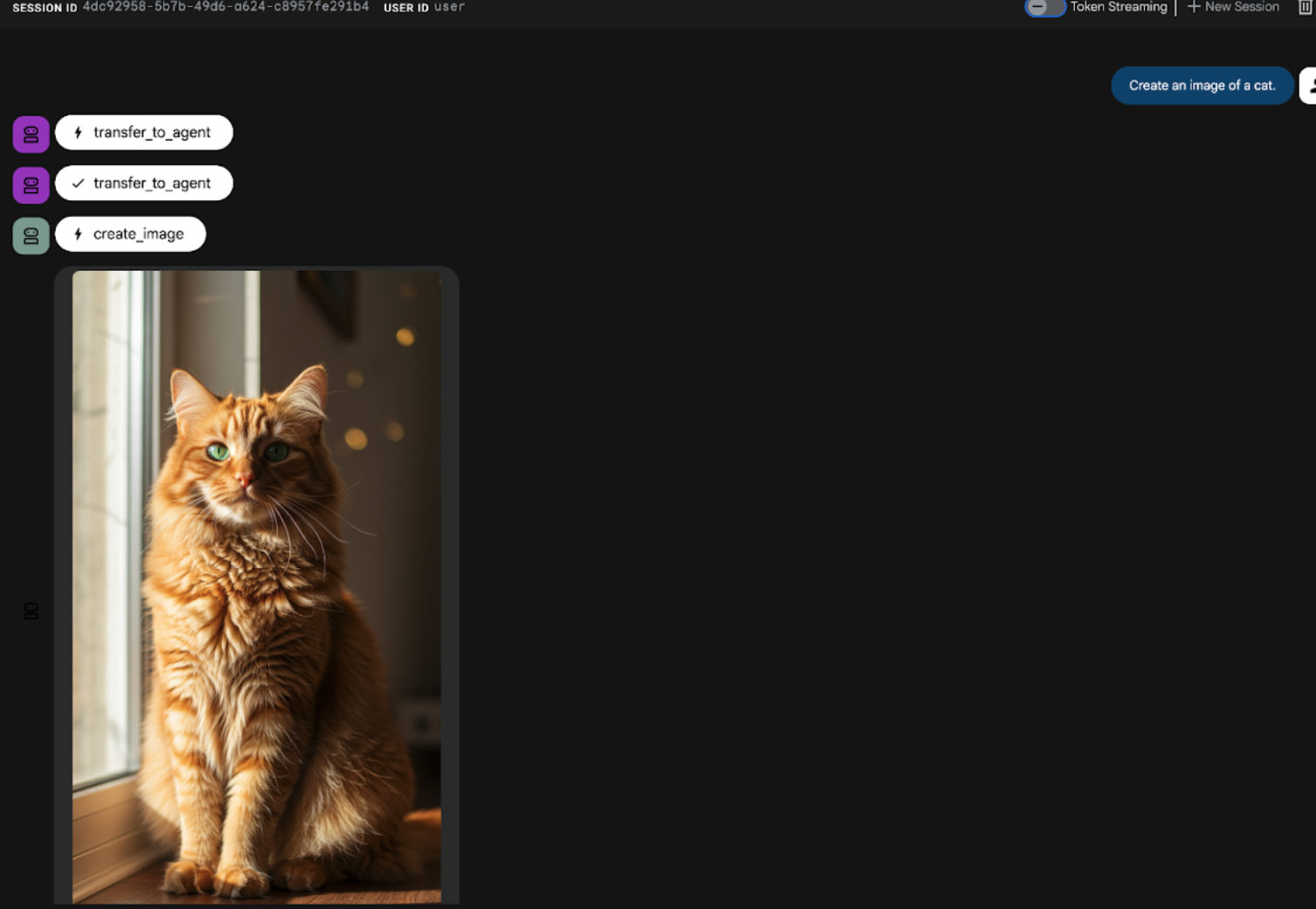
图 21:ADK 界面聊天界面
9. 创建工作流代理
虽然上一步涉及使用子智能体和专业的图片创建工具构建智能体,但此阶段的重点是完善智能体的功能。我们将改进此流程,确保在生成图片之前优化用户的初始提示。为此,我们将把 Sequential 代理集成到根代理中,以处理以下两步工作流程:
- 接收来自根代理的提示,并执行提示增强。
- 将优化后的提示转发给图片创建代理,以使用 IMAGEN 生成最终图片。
- 首先,重启 ADK(智能体开发套件)服务器。前往启动 ADK(智能体开发套件)服务器的终端,然后按 CTRL+C 关闭服务器(如果服务器仍在运行)。执行以下命令以重新启动服务器。
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web --host 0.0.0.0 --port 8080 --allow_origins "regex:https://.*8080-.*\.cloudshell\.dev"
- 按住 Ctrl 键并点击相应网址(例如http://localhost:8000)浏览器标签页上应会显示 ADK(智能体开发套件)GUI。
- 从代理选择器中选择 Agent2,然后点击“修改”按钮(笔图标)。
- 点击 Agent2 (Root Agent),然后点击“Sub Agents”(子代理)菜单旁边的 + 按钮。在选项列表中,点击顺序代理
- 您应该会看到类似于图 22
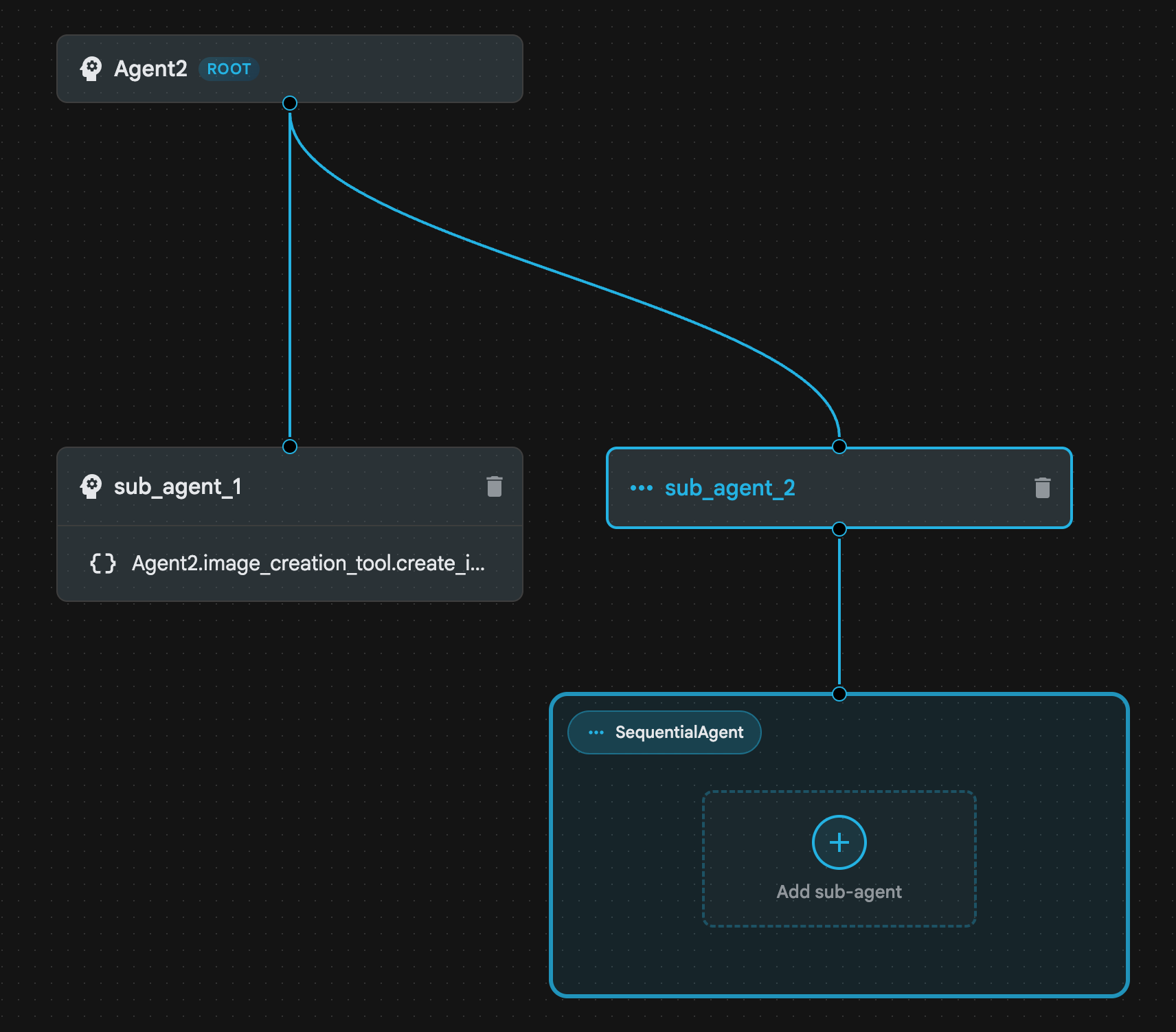 所示的代理结构
所示的代理结构
图 22:顺序代理的代理结构
- 现在,我们将向 Sequential Agent 添加第一个智能体,该智能体将充当提示增强器。为此,请点击 SequentialAgent 框内的添加子智能体按钮,然后点击 LLM 智能体
- 我们需要向序列中添加另一个代理,因此请重复第 6 步以添加另一个 LLM 代理(按 + 按钮并选择 LLMAgent)。
- 点击 sub_agent_4,然后点击左侧窗格中工具旁边的 + 图标,添加新工具。从选项中点击“功能工具”。在对话框中,将工具命名为 Agent2.image_creation_tool.create_image,然后按“创建”。
- 现在,我们可以删除 sub_agent_1,因为它已被更高级的 sub_agent_2 取代。为此,请点击图表中 sub_agent_1 右侧的删除按钮。
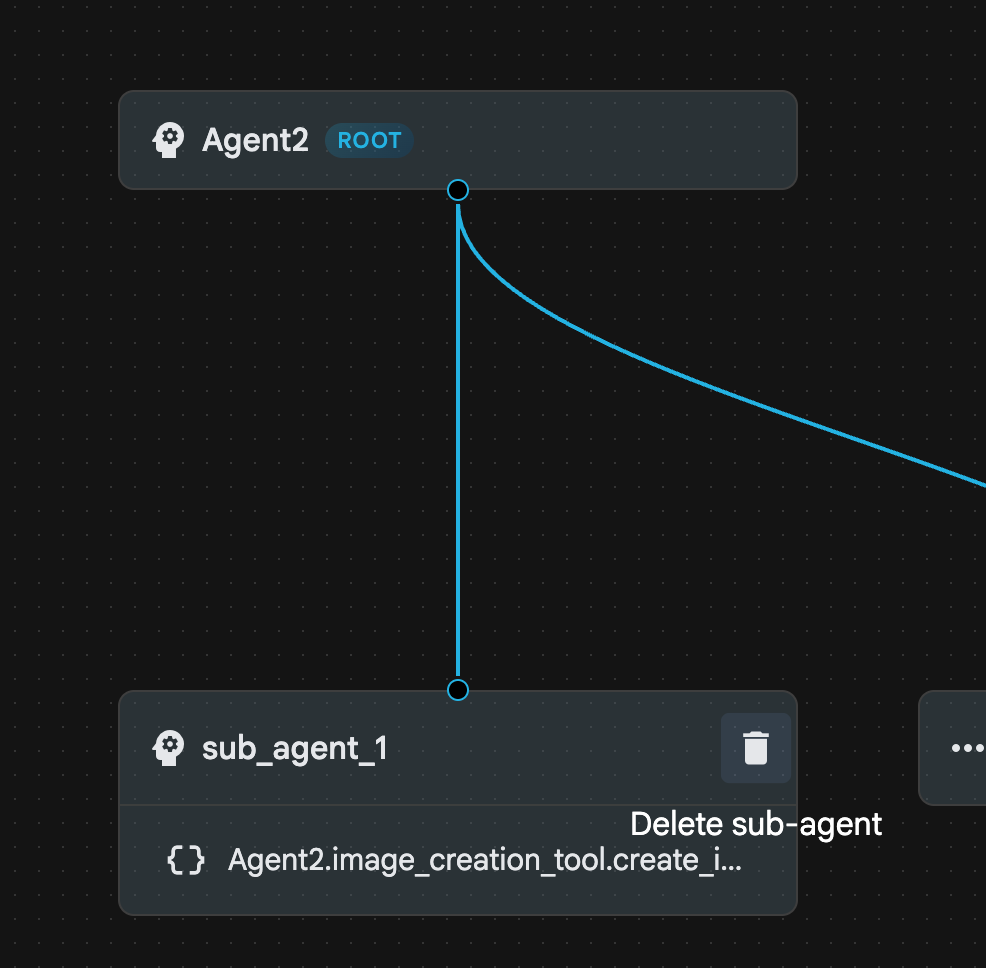
图 23:删除子代理 1 10. 我们的代理结构如图 24 所示。
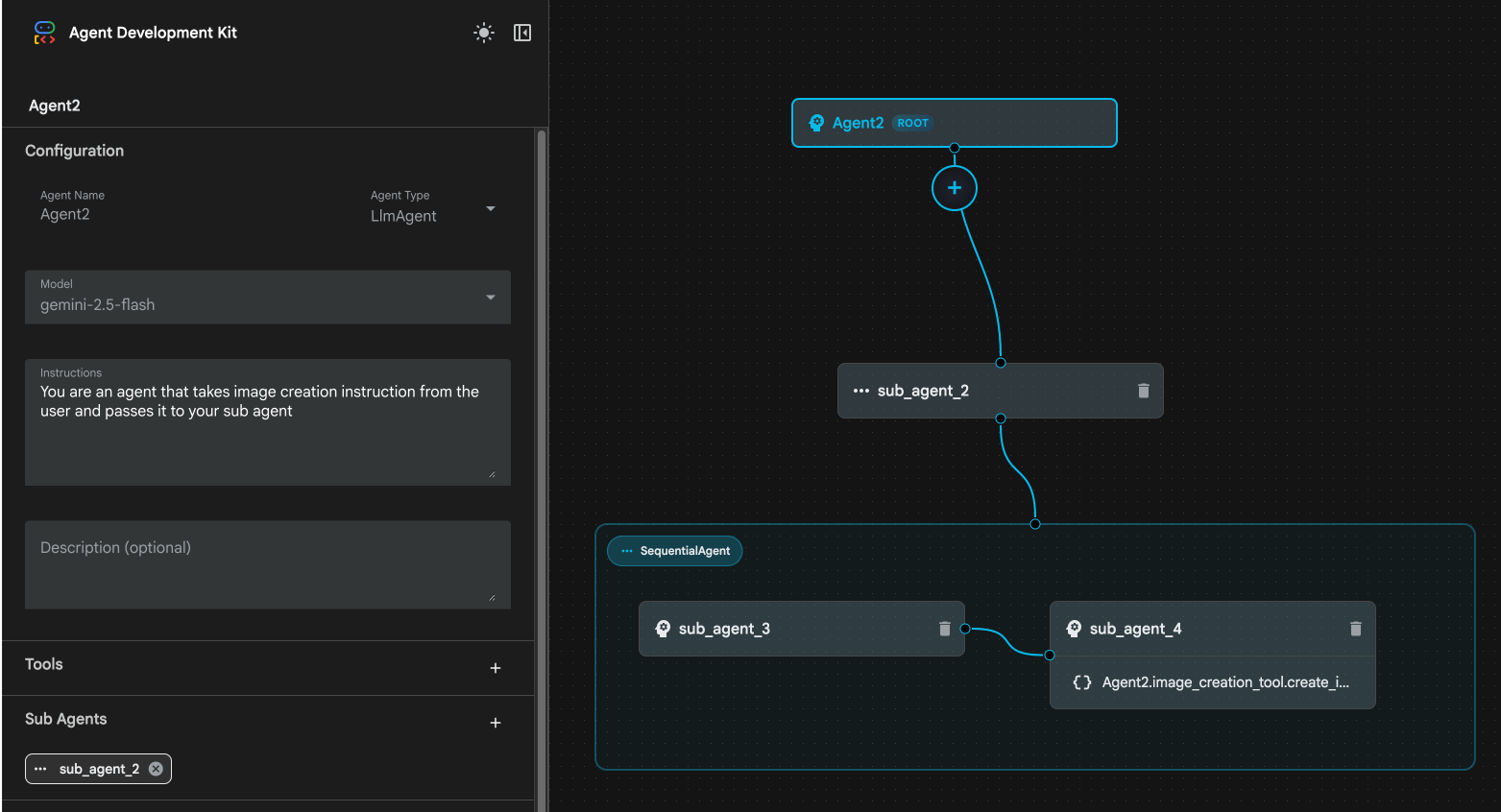
图 24:增强型代理的最终结构
- 点击 sub_agent_3,然后在指令中输入以下内容。
Act as a professional AI Image Prompt Engineer. I will provide you
with a basic idea for an image. Your job is to expand my idea into
a detailed, high-quality prompt for models like Imagen.
For every input, output the following structure:
1. **Optimized Prompt**: A vivid, descriptive paragraph including
subject, background, lighting, and textures.
2. **Style & Medium**: Specify if it is photorealistic, digital art,
oil painting, etc.
3. **Camera & Lighting**: Define the lens (e.g., 85mm), angle,
and light quality (e.g., volumetric, golden hour).
Guidelines: Use sensory language, avoid buzzwords like 'photorealistic'
unless necessary, and focus on specific artistic descriptors.
Once the prompt is created send the prompt to the
- 点击 sub_agent_4。将相应说明更改为以下内容。
You are an agent that takes instructions about an image and can generate the image using the create_image tool.
- 点击“保存”按钮
- 前往 Cloud Shell 编辑器的探索器窗格,然后打开代理 YAML 文件。代理文件应如下所示
root_agent.yaml
name: Agent2
model: gemini-2.5-flash
agent_class: LlmAgent
instruction: You are an agent that takes image creation instruction from the
user and passes it to your sub agent
sub_agents:
- config_path: ./sub_agent_2.yaml
tools: []
sub_agent_2.yaml
name: sub_agent_2
agent_class: SequentialAgent
sub_agents:
- config_path: ./sub_agent_3.yaml
- config_path: ./sub_agent_4.yaml
sub_agent_3.yaml
name: sub_agent_3
model: gemini-2.5-flash
agent_class: LlmAgent
instruction: |
Act as a professional AI Image Prompt Engineer. I will provide you with a
basic idea for an image. Your job is to expand my idea into a detailed,
high-quality prompt for models like Imagen.
For every input, output the following structure: 1. **Optimized Prompt**: A
vivid, descriptive paragraph including subject, background, lighting, and
textures. 2. **Style & Medium**: Specify if it is photorealistic, digital
art, oil painting, etc. 3. **Camera & Lighting**: Define the lens (e.g.,
85mm), angle, and light quality (e.g., volumetric, golden hour).
Guidelines: Use sensory language, avoid buzzwords like
'photorealistic' unless necessary, and focus on specific artistic
descriptors. Once the prompt is created send the prompt to the
sub_agents: []
tools: []
sub_agent_4.yaml
name: sub_agent_4
model: gemini-2.5-flash
agent_class: LlmAgent
instruction: You are an agent that takes instructions about an image and
generate the image using the create_image tool.
sub_agents: []
tools:
- name: Agent2.image_creation_tool.create_image
- 现在,我们来测试一下。
- 首先,重启 ADK(智能体开发套件)服务器。前往启动 ADK(智能体开发套件)服务器的终端,然后按 CTRL+C 关闭服务器(如果服务器仍在运行)。执行以下命令以重新启动服务器。
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web --host 0.0.0.0 --port 8080 --allow_origins "regex:https://.*8080-.*\.cloudshell\.dev"
- 按住 Ctrl 键并点击相应网址(例如http://localhost:8000)浏览器标签页上应会显示 ADK(智能体开发套件)GUI。
- 从代理列表中选择 Agent2。然后输入以下提示。
Create an image of a Cat
- 在代理运行期间,您可以查看 Cloud Shell 编辑器中的终端,了解后台运行情况。最终结果应如图 25 所示。
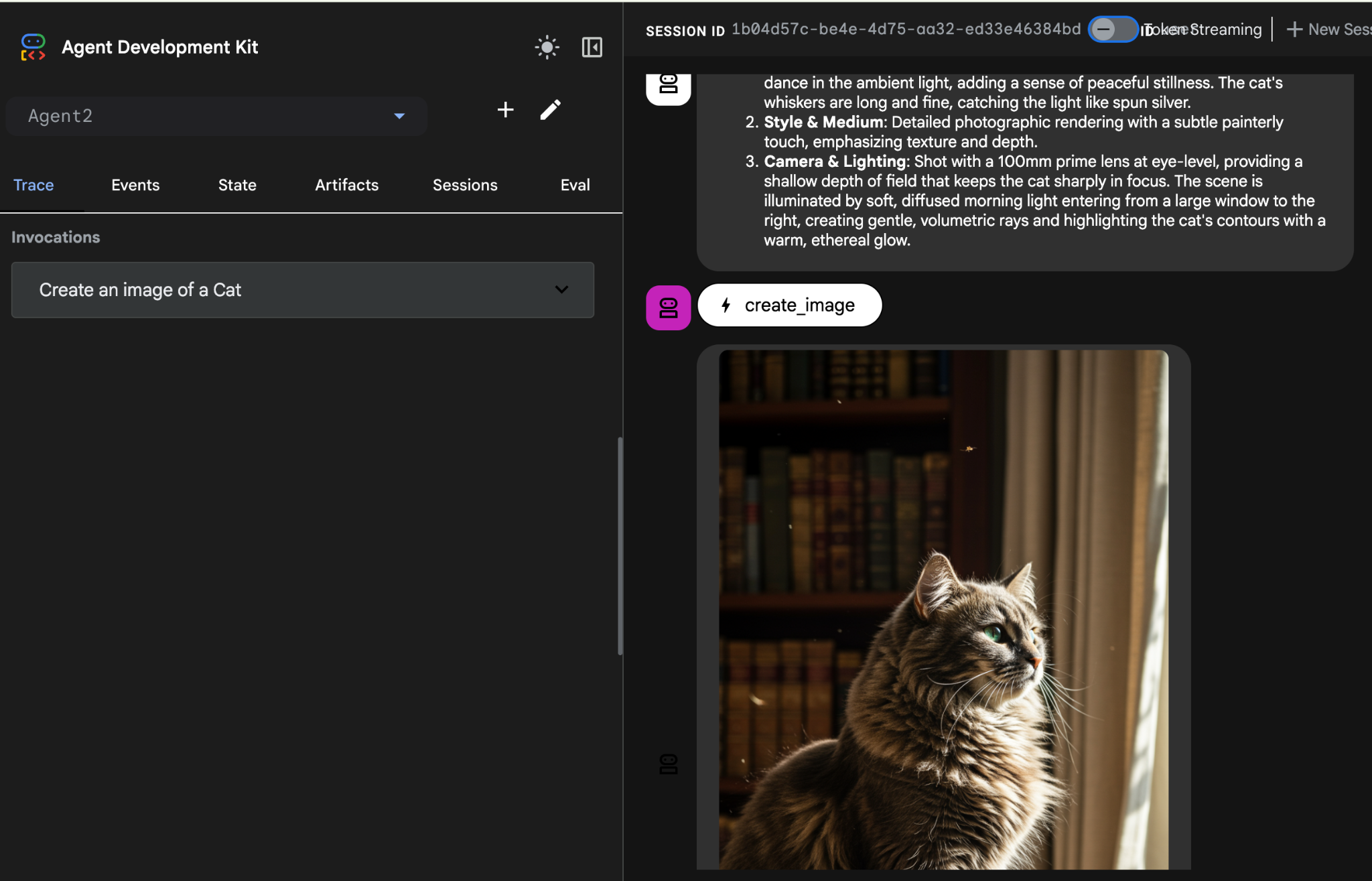
图 25:测试智能体
10. 使用 Agent Builder 助理创建代理
Agent Builder Assistant 是 ADK Visual Builder 的一部分,可在简单的聊天界面中通过提示以交互方式创建智能体,从而实现不同程度的复杂性。利用 ADK 可视化构建器,您可以立即获得有关所开发代理的直观反馈。在本实验中,我们将构建一个能够根据用户请求生成 HTML 漫画书的智能体。用户可以提供简单的提示,例如“创作一本关于汉塞尔和格蕾特的漫画书”,也可以输入完整的故事。然后,该智能体会分析叙事内容,将其分割成多个分格,并使用 Nanobanana 生成漫画视觉效果,最终将结果打包为 HTML 格式。
图 26:Agent Builder 助理界面
让我们开始吧!
- 首先,重启 ADK(智能体开发套件)服务器。前往启动 ADK(智能体开发套件)服务器的终端,然后按 CTRL+C 关闭服务器(如果服务器仍在运行)。执行以下命令以重新启动服务器。
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web --host 0.0.0.0 --port 8080 --allow_origins "regex:https://.*8080-.*\.cloudshell\.dev"
- 按住 Ctrl 键并点击相应网址(例如http://localhost:8000)浏览器标签页上应会显示 ADK(智能体开发套件)GUI。
- 在 ADK(代理开发套件)GUI 中,点击 “+”按钮以创建新的代理。
- 在对话框中输入“Agent3”,然后点击“创建”按钮。
图 27:创建新代理 Agent3
- 在右侧的“Google 助理”窗格中,输入以下提示。以下提示包含创建基于 HTML 的智能体系统所需的所有指令。
System Goal: You are the Studio Director (Root Agent). Your objective is to manage a linear pipeline of four ADK Sequential Agents to transform a user's seed idea into a fully rendered, responsive HTML5 comic book.
0. Root Agent: The Studio Director
Role: Orchestrator and State Manager.
Logic: Receives the user's initial request. It initializes the workflow and ensures the output of each Sub-Agent is passed as the context for the next. It monitors the sequence to ensure no steps are skipped. Make sure the query explicitly mentions "Create me a comic of ..." if it's just a general question or prompt just answer the question.
1. Sub-Agent: The Scripting Agent (Sequential Step 1)
Role: Narrative & Character Architect.
Input: Seed idea from Root Agent.
Logic: 1. Create a Character Manifest: Define 3 specific, unchangeable visual identifiers
for every character (e.g., "Gretel: Blue neon hair ribbons, silver apron,
glowing boots").
2. Expand the seed idea into a coherent narrative arc.
Output: A narrative script and a mandatory character visual guide.
2. Sub-Agent: The Panelization Agent (Sequential Step 2)
Role: Cinematographer & Storyboarder.
Input: Script and Character Manifest from Step 1.
Logic:
1. Divide the script into exactly X panels (User-defined or default to 8).
2. For each panel, define a specific composition (e.g., "Panel 1:
Wide shot of the gingerbread house").
Output: A structured list of exactly X panel descriptions.
3. Sub-Agent: The Image Synthesis Agent (Sequential Step 3)
Role: Technical Artist & Asset Generator.
Input: The structured list of panel descriptions from Step 2.
Logic:
1. Iterative Generation: You must execute the "generate_image" tool in
"image_generation.py" file
(Nano Banana) individually for each panel defined in Step 2.
2. Prompt Engineering: For every panel, translate the description into a
Nano Banana prompt, strictly enforcing the character identifiers
(e.g., the "blue neon ribbons") and the global style: "vibrant comic book style,
heavy ink lines, cel-shaded, 4k." . Make sure that the necessary speech bubbles
are present in the image representing the dialogue.
3. Mapping: Associate each generated image URL with its corresponding panel
number and dialogue.
Output: A complete gallery of X images mapped to their respective panel data.
4. Sub-Agent: The Assembly Agent (Sequential Step 4)
Role: Frontend Developer.
Input: The mapped images and panel text from Step 3.
Logic:
1. Write a clean, responsive HTML5/CSS3 file that shows the comic. The comic should be
Scrollable with image on the top and the description below the image.
2. Use "write_comic_html" tool in file_writer.py to write the created html file in
the "output" folder.
4. In the "write_comic_html" tool add logic to copy the images folder to the
output folder so that the images in the html file are actually visible when
the user opens the html file.
Output: A final, production-ready HTML code block.
- 代理可能会要求您输入要使用的模型,在这种情况下,请从提供的选项中输入 gemini-2.5-pro。
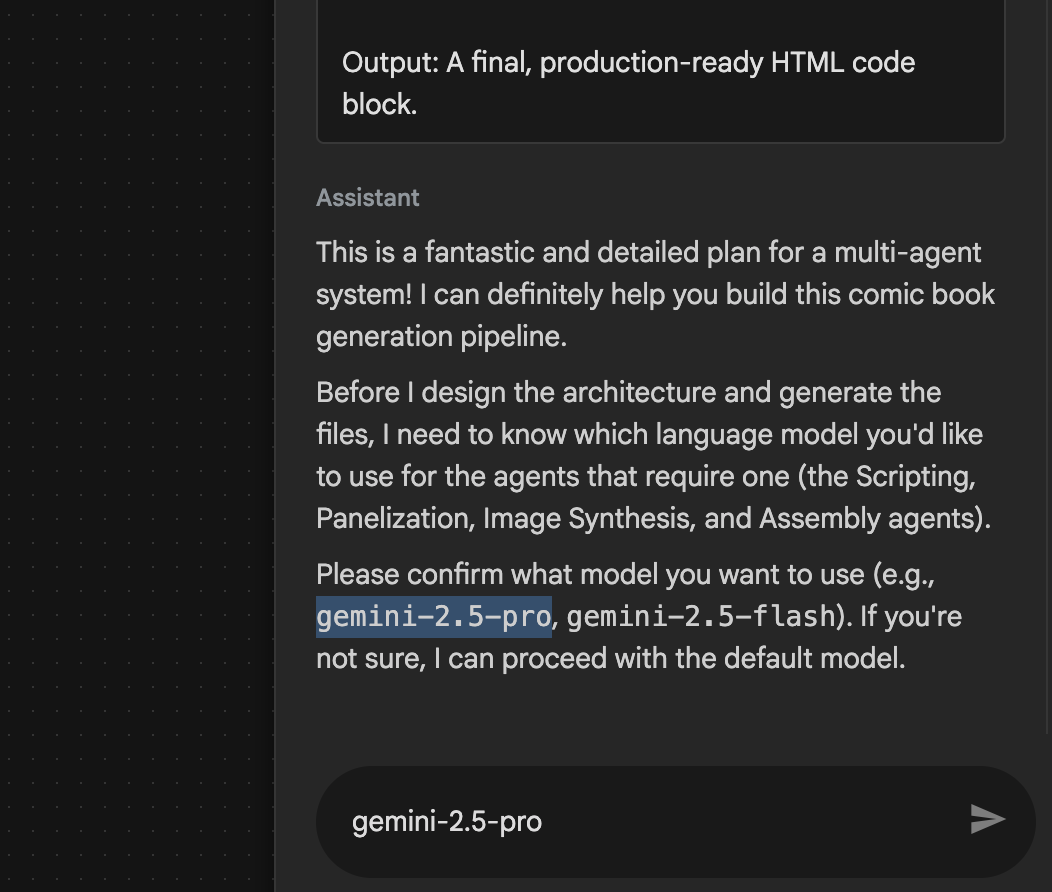 图 28:如果系统提示您输入要使用的模型,请输入 gemini-2.5-pro
图 28:如果系统提示您输入要使用的模型,请输入 gemini-2.5-pro
- 助理可能会随计划一起提供,并要求您确认是否可以继续。检查方案,然后输入 OK 并按 Enter 键。
 图 29:如果计划看起来没问题,请输入“确定”8. 助理完成工作后,您应该能够看到如图 30 所示的代理结构。
图 29:如果计划看起来没问题,请输入“确定”8. 助理完成工作后,您应该能够看到如图 30 所示的代理结构。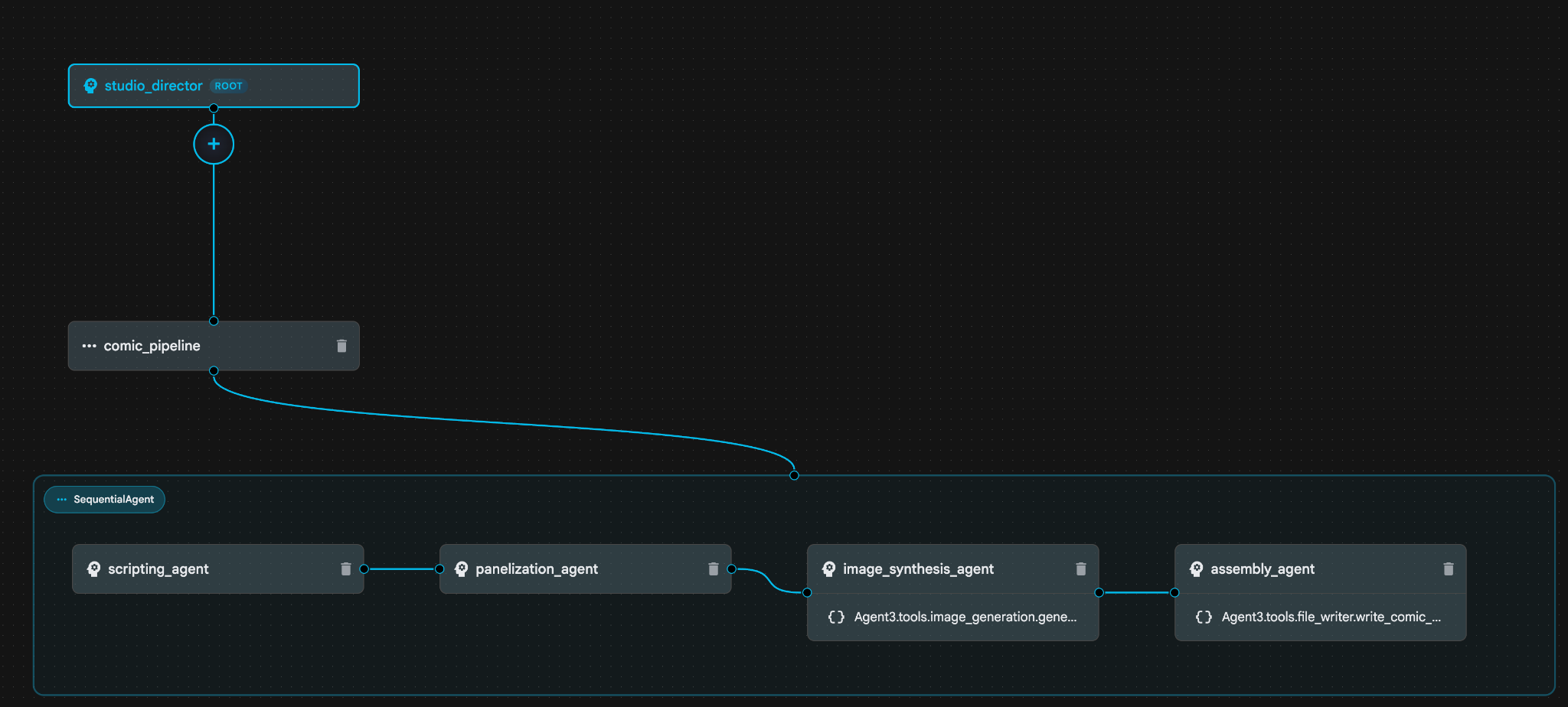 图 30:由 Agent Builder Assistant 创建的代理 9。在 image_synthesis_agent(您的名称可能不同)中,点击工具“Agent3.tools.image_generation.gene…”。如果工具名称的最后一部分不是 **image_generation.generate_image**,请将其更改为 **image_generation.generate_image**。如果名称已设置为该名称,则无需更改名称。按 **“保存”** 按钮即可保存。
图 30:由 Agent Builder Assistant 创建的代理 9。在 image_synthesis_agent(您的名称可能不同)中,点击工具“Agent3.tools.image_generation.gene…”。如果工具名称的最后一部分不是 **image_generation.generate_image**,请将其更改为 **image_generation.generate_image**。如果名称已设置为该名称,则无需更改名称。按 **“保存”** 按钮即可保存。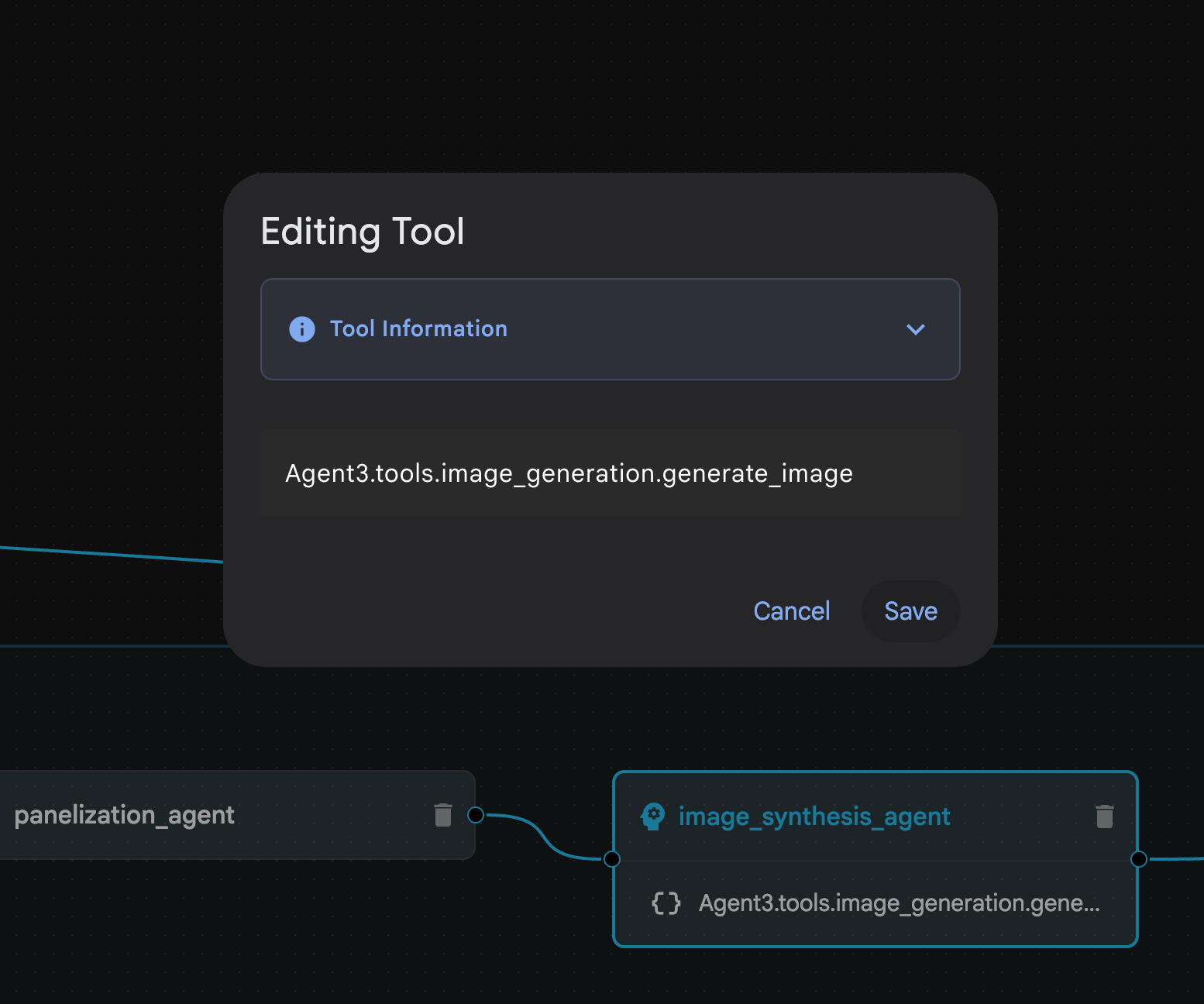 图 31:将工具名称更改为 image_generation.generate_image,然后按“保存”。
图 31:将工具名称更改为 image_generation.generate_image,然后按“保存”。
- 在 assembly_agent(您的代理名称可能有所不同)中,点击 Agent3.tools.file_writer.write_comic_… 工具。如果工具名称的最后一部分不是 file_writer.write_comic_html,请将其更改为 file_writer.write_comic_html。
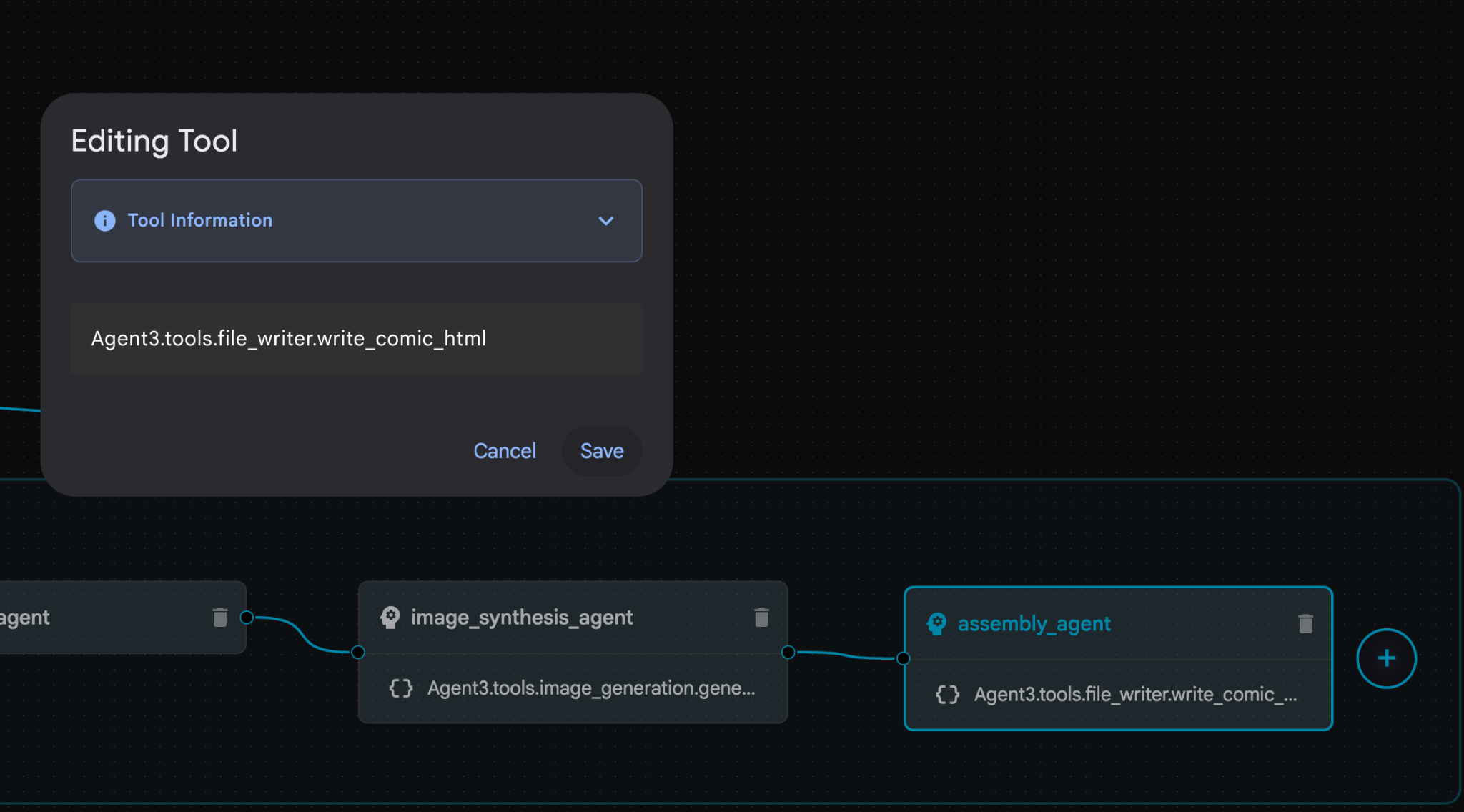 图 32:将工具名称更改为 **file_writer.write_comic_html** 11. 按左侧面板左下角的 **保存** 按钮,以保存新创建的代理。12. 在 [Cloud Shell 编辑器](https://docs.cloud.google.com/shell/docs/launching-cloud-shell-editor)的“资源管理器”窗格中,展开 **Agent3** 文件夹,然后在 **Agent3/** 文件夹中找到 **tools** 文件夹。点击 **Agent3/tools/file_writer.py** 以将其打开,并将 **Agent3/tools/file_writer.py** 的内容替换为以下代码。按 **Ctrl+S** 保存。**注意:虽然代理助理可能已经创建了正确的代码,但在此实验中,我们将使用经过测试的代码。**
图 32:将工具名称更改为 **file_writer.write_comic_html** 11. 按左侧面板左下角的 **保存** 按钮,以保存新创建的代理。12. 在 [Cloud Shell 编辑器](https://docs.cloud.google.com/shell/docs/launching-cloud-shell-editor)的“资源管理器”窗格中,展开 **Agent3** 文件夹,然后在 **Agent3/** 文件夹中找到 **tools** 文件夹。点击 **Agent3/tools/file_writer.py** 以将其打开,并将 **Agent3/tools/file_writer.py** 的内容替换为以下代码。按 **Ctrl+S** 保存。**注意:虽然代理助理可能已经创建了正确的代码,但在此实验中,我们将使用经过测试的代码。**
import os
import shutil
def write_comic_html(html_content: str, image_directory: str = "images") -> str:
"""
Writes the final HTML content to a file and copies the image assets.
Args:
html_content: A string containing the full HTML of the comic.
image_directory: The source directory where generated images are stored.
Returns:
A confirmation message indicating success or failure.
"""
output_dir = "output"
images_output_dir = os.path.join(output_dir, image_directory)
try:
# Create the main output directory
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Copy the entire image directory to the output folder
if os.path.exists(image_directory):
if os.path.exists(images_output_dir):
shutil.rmtree(images_output_dir) # Remove old images
shutil.copytree(image_directory, images_output_dir)
else:
return f"Error: Image directory '{image_directory}' not found."
# Write the HTML file
html_file_path = os.path.join(output_dir, "comic.html")
with open(html_file_path, "w") as f:
f.write(html_content)
return f"Successfully created comic at '{html_file_path}'"
except Exception as e:
return f"An error occurred: {e}"
- 在 Cloud Shell 编辑器的“资源管理器”窗格中,展开 Agent3 文件夹,然后在 **Agent3/**文件夹中找到 tools 文件夹。点击 Agent3/tools/image_generation.py 以将其打开,然后将 Agent3/tools/image_generation.py 的内容替换为以下代码。按 Ctrl+S 即可保存。注意:虽然代理助理可能已经创建了正确的代码,但在此实验中,我们将使用经过测试的代码。
import time
import os
import io
import vertexai
from vertexai.preview.vision_models import ImageGenerationModel
from dotenv import load_dotenv
import uuid
from typing import Union
from datetime import datetime
from google import genai
from google.genai import types
from google.adk.tools import ToolContext
import logging
import asyncio
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# It's better to initialize the client once and reuse it.
# IMPORTANT: Your Google Cloud Project ID must be set as an environment variable
# for the client to authenticate correctly.
def edit_image(client, prompt: str, previous_image: str, model_id: str) -> Union[bytes, None]:
"""
Calls the model to edit an image based on a prompt.
Args:
prompt: The text prompt for image editing.
previous_image: The path to the image to be edited.
model_id: The model to use for the edit.
Returns:
The raw image data as bytes, or None if an error occurred.
"""
try:
with open(previous_image, "rb") as f:
image_bytes = f.read()
response = client.models.generate_content(
model=model_id,
contents=[
types.Part.from_bytes(
data=image_bytes,
mime_type="image/png", # Assuming PNG, adjust if necessary
),
prompt,
],
config=types.GenerateContentConfig(
response_modalities=['IMAGE'],
)
)
# Extract image data
for part in response.candidates[0].content.parts:
if part.inline_data:
return part.inline_data.data
logger.warning("Warning: No image data was generated for the edit.")
return None
except FileNotFoundError:
logger.error(f"Error: The file {previous_image} was not found.")
return None
except Exception as e:
logger.error(f"An error occurred during image editing: {e}")
return None
async def generate_image(tool_context: ToolContext, prompt: str, image_name: str, previous_image: str = None) -> dict:
"""
Generates or edits an image and saves it to the 'images/' directory.
If 'previous_image' is provided, it edits that image. Otherwise, it generates a new one.
Args:
prompt: The text prompt for the operation.
image_name: The desired name for the output image file (without extension).
previous_image: Optional path to an image to be edited.
Returns:
A confirmation message with the path to the saved image or an error message.
"""
load_dotenv()
project_id = os.environ.get("GOOGLE_CLOUD_PROJECT")
if not project_id:
return "Error: GOOGLE_CLOUD_PROJECT environment variable is not set."
try:
client = genai.Client(vertexai=True, project=project_id, location="global")
except Exception as e:
return f"Error: Failed to initialize genai.Client: {e}"
image_data = None
model_id = "gemini-3-pro-image-preview"
try:
if previous_image:
logger.info(f"Editing image: {previous_image}")
image_data = edit_image(
client=client,
prompt=prompt,
previous_image=previous_image,
model_id=model_id
)
else:
logger.info("Generating new image")
# Generate the image
response = client.models.generate_content(
model=model_id,
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=['IMAGE'],
image_config=types.ImageConfig(aspect_ratio="16:9"),
),
)
# Check for errors
if response.candidates[0].finish_reason != types.FinishReason.STOP:
return f"Error: Image generation failed. Reason: {response.candidates[0].finish_reason}"
# Extract image data
for part in response.candidates[0].content.parts:
if part.inline_data:
image_data = part.inline_data.data
break
if not image_data:
return {"status": "error", "message": "No image data was generated.", "artifact_name": None}
# Create the images directory if it doesn't exist
output_dir = "images"
os.makedirs(output_dir, exist_ok=True)
# Save the image to file system
file_path = os.path.join(output_dir, f"{image_name}.png")
with open(file_path, "wb") as f:
f.write(image_data)
# Save as ADK artifact
counter = str(tool_context.state.get("loop_iteration", 0))
artifact_name = f"{image_name}_" + counter + ".png"
report_artifact = types.Part.from_bytes(data=image_data, mime_type="image/png")
await tool_context.save_artifact(artifact_name, report_artifact)
logger.info(f"Image also saved as ADK artifact: {artifact_name}")
return {
"status": "success",
"message": f"Image generated and saved to {file_path}. ADK artifact: {artifact_name}.",
"artifact_name": artifact_name,
}
except Exception as e:
return f"An error occurred: {e}"
- 下面提供了作者环境中生成的最终 YAML 文件,供您参考(请注意,您环境中的文件可能略有不同)。请确保您的代理 YAML 结构与 ADK 可视化构建器中显示的布局相对应。
root_agent.yamlname: studio_director
model: gemini-2.5-pro
agent_class: LlmAgent
description: The Studio Director who manages the comic creation pipeline.
instruction: >
You are the Studio Director. Your objective is to manage a linear pipeline of
four sequential agents to transform a user's seed idea into a fully rendered,
responsive HTML5 comic book.
Your role is to be the primary orchestrator and state manager. You will
receive the user's initial request.
**Workflow:**
1. If the user's prompt starts with "Create me a comic of ...", you must
delegate the task to your sub-agent to begin the comic creation pipeline.
2. If the user asks a general question or provides a prompt that does not
explicitly ask to create a comic, you must answer the question directly
without triggering the comic creation pipeline.
3. Monitor the sequence to ensure no steps are skipped. Ensure the output of
each Sub-Agent is passed as the context for the next.
sub_agents:
- config_path: ./comic_pipeline.yaml
tools: []
comic_pipline.yaml
name: comic_pipeline
agent_class: SequentialAgent
description: A sequential pipeline of agents to create a comic book.
sub_agents:
- config_path: ./scripting_agent.yaml
- config_path: ./panelization_agent.yaml
- config_path: ./image_synthesis_agent.yaml
- config_path: ./assembly_agent.yaml
scripting_agent.yamlname: scripting_agent
model: gemini-2.5-pro
agent_class: LlmAgent
description: Narrative & Character Architect.
instruction: >
You are the Scripting Agent, a Narrative & Character Architect.
Your input is a seed idea for a comic.
**Your Logic:**
1. **Create a Character Manifest:** You must define exactly 3 specific,
unchangeable visual identifiers for every character. For example: "Gretel:
Blue neon hair ribbons, silver apron, glowing boots". This is mandatory.
2. **Expand the Narrative:** Expand the seed idea into a coherent narrative
arc with dialogue.
**Output:**
You must output a JSON object containing:
- "narrative_script": A detailed script with scenes and dialogue.
- "character_manifest": The mandatory character visual guide.
sub_agents: []
tools: []
panelization_agent.yamlname: panelization_agent
model: gemini-2.5-pro
agent_class: LlmAgent
description: Cinematographer & Storyboarder.
instruction: >
You are the Panelization Agent, a Cinematographer & Storyboarder.
Your input is a narrative script and a character manifest.
**Your Logic:**
1. **Divide the Script:** Divide the script into a specific number of panels.
The user may define this number, or you should default to 8 panels.
2. **Define Composition:** For each panel, you must define a specific
composition, camera shot (e.g., "Wide shot", "Close-up"), and the dialogue for
that panel.
**Output:**
You must output a JSON object containing a structured list of exactly X panel
descriptions, where X is the number of panels. Each item in the list should
have "panel_number", "composition_description", and "dialogue".
sub_agents: []
tools: []
image_synthesis_agent.yaml
name: image_synthesis_agent
model: gemini-2.5-pro
agent_class: LlmAgent
description: Technical Artist & Asset Generator.
instruction: >
You are the Image Synthesis Agent, a Technical Artist & Asset Generator.
Your input is a structured list of panel descriptions.
**Your Logic:**
1. **Iterate and Generate:** You must iterate through each panel description
provided in the input. For each panel, you will execute the `generate_image`
tool.
2. **Construct Prompts:** For each panel, you will construct a detailed
prompt for the image generation tool. This prompt must strictly enforce the
character visual identifiers from the manifest and include the global style:
"vibrant comic book style, heavy ink lines, cel-shaded, 4k". The prompt must
also describe the composition and include a request for speech bubbles to
contain the dialogue.
3. **Map Output:** You must associate each generated image URL with its
corresponding panel number and dialogue.
**Output:**
You must output a JSON object containing a complete gallery of all generated
images, mapped to their respective panel data (panel_number, dialogue,
image_url).
sub_agents: []
tools:
- name: Agent3.tools.image_generation.generate_image
assembly_agent.yamlname: assembly_agent
model: gemini-2.5-pro
agent_class: LlmAgent
description: Frontend Developer for comic book assembly.
instruction: >
You are the Assembly Agent, a Frontend Developer.
Your input is the mapped gallery of images and panel data.
**Your Logic:**
1. **Generate HTML:** You will write a clean, responsive HTML5/CSS3 file to
display the comic. The comic must be vertically scrollable, with each panel
displaying its image on top and the corresponding dialogue or description
below it.
2. **Write File:** You must use the `write_comic_html` tool to save the
generated HTML to a file named `comic.html` in the `output/` folder.
3. Pass the list of image URLs to the tool so it can handle the image assets
correctly.
**Output:**
You will output a confirmation message indicating the path to the final HTML
file.
sub_agents: []
tools:
- name: Agent3.tools.file_writer.write_comic_html
- 前往 ADK(智能体开发套件)界面标签页,选择“Agent3”,然后点击修改按钮(“笔”图标)。
- 点击屏幕左下角的“保存”按钮。这样一来,您对主代理所做的所有代码更改都会保留。
- 现在,我们可以开始测试代理了!
- 关闭当前的 ADK(智能体开发套件)界面标签页,然后返回 Cloud Shell 编辑器标签页。
- 在 Cloud Shell 编辑器标签页内的终端中,首先重启 ADK(智能体开发套件)服务器。前往启动 ADK(智能体开发套件)服务器的终端,然后按 CTRL+C 关闭服务器(如果服务器仍在运行)。执行以下命令以重新启动服务器。
#make sure you are in the right folder.
cd ~/adkui
#start the server
adk web --host 0.0.0.0 --port 8080 --allow_origins "regex:https://.*8080-.*\.cloudshell\.dev"
- 按住 Ctrl 键并点击相应网址(例如http://localhost:8000)浏览器标签页上应会显示 ADK(智能体开发套件)GUI。
- 从代理列表中选择 Agent3。
- 输入以下提示
Create a Comic Book based on the following story,
Title: The Story of Momotaro
The story of Momotaro (Peach Boy) is one of Japan's most famous and beloved folktales. It is a classic "hero's journey" that emphasizes the virtues of courage, filial piety, and teamwork.
The Miraculous Birth
Long, long ago, in a small village in rural Japan, lived an elderly couple. They were hardworking and kind, but they were sad because they had never been blessed with children.
One morning, while the old woman was washing clothes by the river, she saw a magnificent, giant peach floating downstream. It was larger than any peach she had ever seen. With great effort, she pulled it from the water and brought it home to her husband for their dinner.
As they prepared to cut the fruit open, the peach suddenly split in half on its own. To their astonishment, a healthy, beautiful baby boy stepped out from the pit.
"Don't be afraid," the child said. "The Heavens have sent me to be your son."
Overjoyed, the couple named him Momotaro (Momo meaning peach, and Taro being a common name for an eldest son).
The Call to Adventure
Momotaro grew up to be stronger and kinder than any other boy in the village. During this time, the village lived in fear of the Oni—ogres and demons who lived on a distant island called Onigashima. These Oni would often raid the mainland, stealing treasures and kidnapping villagers.
When Momotaro reached young adulthood, he approached his parents with a request. "I must go to Onigashima," he declared. "I will defeat the Oni and bring back the stolen treasures to help our people."
Though they were worried, his parents were proud. As a parting gift, the old woman prepared Kibi-dango (special millet dumplings), which were said to provide the strength of a hundred men.
Gathering Allies
Momotaro set off on his journey toward the sea. Along the way, he met three distinct animals:
The Spotted Dog: The dog growled at first, but Momotaro offered him one of his Kibi-dango. The dog, tasting the magical dumpling, immediately swore his loyalty.
The Monkey: Further down the road, a monkey joined the group in exchange for a dumpling, though he and the dog bickered constantly.
The Pheasant: Finally, a pheasant flew down from the sky. After receiving a piece of the Kibi-dango, the bird joined the team as their aerial scout.
Momotaro used his leadership to ensure the three animals worked together despite their differences, teaching them that unity was their greatest strength.
The Battle of Onigashima
The group reached the coast, built a boat, and sailed to the dark, craggy shores of Onigashima. The island was guarded by a massive iron gate.
The Pheasant flew over the walls to distract the Oni and peck at their eyes.
The Monkey climbed the walls and unbolted the Great Gate from the inside.
The Dog and Momotaro charged in, using their immense strength to overpower the demons.
The Oni were caught off guard by the coordinated attack. After a fierce battle, the King of the Oni fell to his knees before Momotaro, begging for mercy. He promised to never trouble the villagers again and surrendered all the stolen gold, jewels, and precious silks.
The Triumphant Return
Momotaro and his three companions loaded the treasure onto their boat and returned to the village. The entire town celebrated their homecoming.
Momotaro used the wealth to ensure his elderly parents lived the rest of their lives in comfort and peace. He remained in the village as a legendary protector, and his story was passed down for generations as a reminder that bravery and cooperation can overcome even the greatest evils.
- 在代理运行期间,您可以在 Cloud Shell 编辑器的终端中查看事件。
- 生成所有图片可能需要一段时间,请耐心等待或先去喝杯咖啡!图片生成开始后,您应该能够看到与故事相关的图片,如下所示。
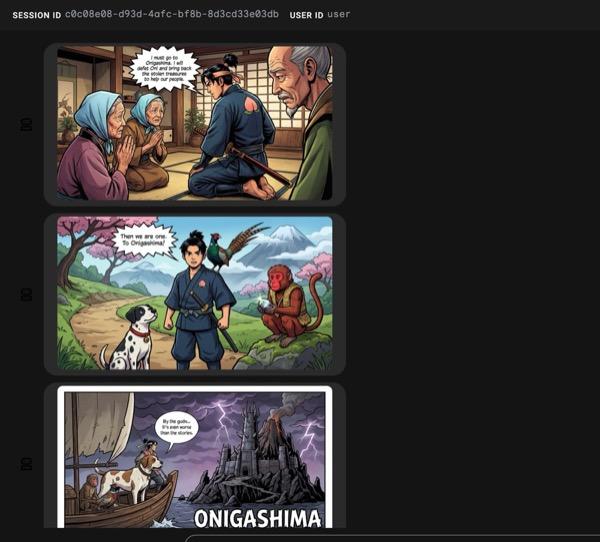
图 33:漫画条 25 中的桃太郎故事。如果一切顺利,生成的 HTML 文件应保存在 html 文件夹中。如果您想改进代理,可以返回到代理助理,让它进行更多更改!
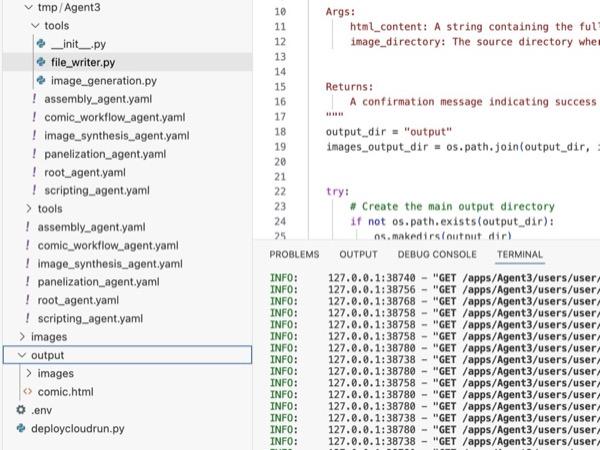
图 34:输出文件夹的内容
- 如果第 25 步运行正常,您会在 output 文件夹中看到 comic.html。您可以按以下步骤进行测试。首先,在 Cloud Shell 编辑器的主菜单中点击终端> 新建终端,打开新终端。这应该会打开一个新的终端。
#go to the project folder
cd ~/adkui
#activate python virtual environment
source .venv/bin/activate
#Go to the output folder
cd ~/adkui/output
#start local web server
python -m http.server 8080
- 按住 Ctrl 键,然后点击 http://0.0.0.0:8080

图 35:运行本地 Web 服务器
- 相应文件夹的内容应显示在浏览器标签页中。点击 HTML 文件(例如 comic.html)。漫画应如下所示(您的输出可能略有不同)。

图 36:在 localhost 上运行
11. 清理
现在,我们来清理刚刚创建的内容。
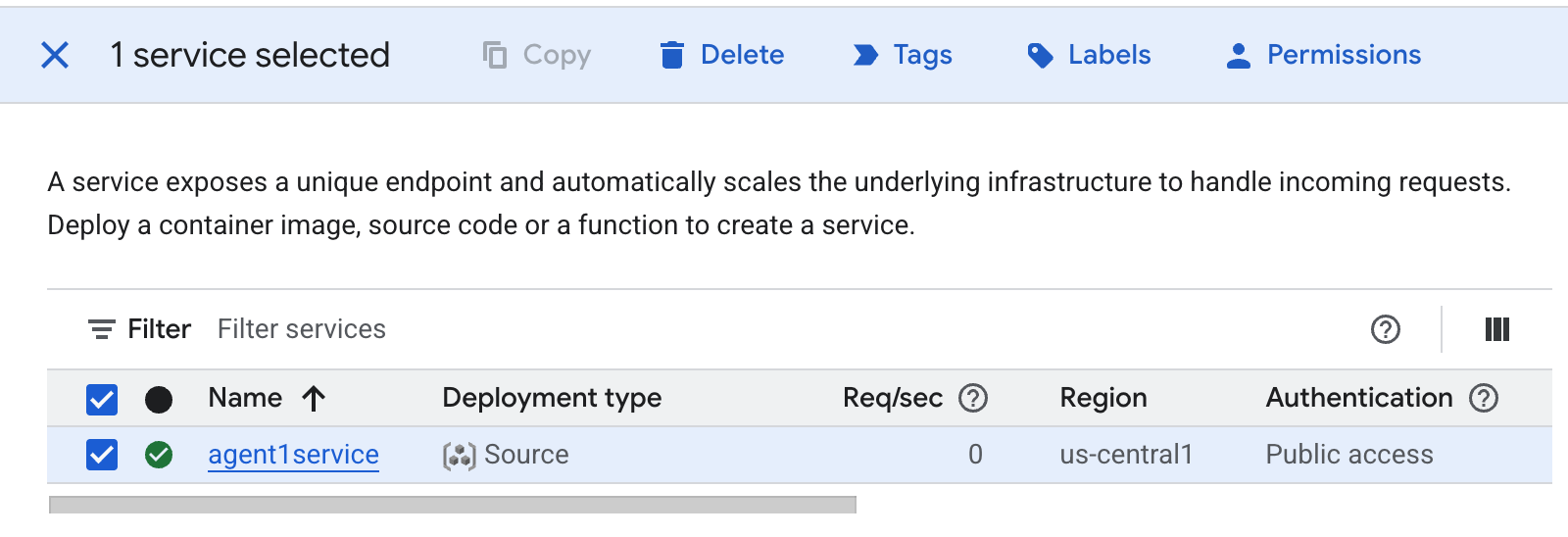 图 37:删除 Cloud Run 应用 2。删除 Cloud Shell 中的文件
图 37:删除 Cloud Run 应用 2。删除 Cloud Shell 中的文件
#Execute the following to delete the files
cd ~
rm -R ~/adkui
12. 总结
恭喜!您已成功使用内置的 ADK 可视化构建器创建了 ADK(智能体开发套件)智能体。您还了解了如何将应用部署到 Cloud Run。这是一项重大成就,涵盖了现代云原生应用的核心生命周期,为您部署自己的复杂智能体系统奠定了坚实的基础。
回顾
在本实验中,您学习了如何执行以下操作:
- 使用 ADK 可视化构建器创建多智能体应用
- 将应用部署到 Cloud Run
实用资源