
1. はじめに

Google Cloud Dataflow
最終更新日: 2023 年 7 月 5 日
Dataflow とは
Dataflow は、さまざまなデータ処理パターンの実行に対応したマネージド サービスです。このサイトのドキュメントでは、Dataflow を使用してバッチおよびストリーミングのデータ処理パイプラインをデプロイする方法と、サービス機能の使用方法について説明しています。
Apache Beam SDK はオープンソースのプログラミング モデルであり、バッチとストリーミングの両方のパイプラインの開発に使用できます。Apache Beam プログラムでパイプラインを作成し、Dataflow サービスで実行します。Apache Beam のドキュメントには、詳細なコンセプト情報と Apache Beam のプログラミング モデル、SDK、その他のランナーのリファレンス情報が記載されています。
高速なストリーミング データ分析
Dataflow を使用すると、データ レイテンシを低く抑えながら、ストリーミング データ パイプラインを迅速かつ簡単に開発できます。
運用と管理の簡素化
Dataflow のサーバーレス アプローチにより、データ エンジニアリングのワークロードから運用上のオーバーヘッドが取り除かれ、チームはサーバー クラスタの管理ではなくプログラミングに集中できます。
総所有コストを削減
リソースの自動スケーリングとコスト最適化されたバッチ処理機能を組み合わせることにより、Dataflow で実質無制限の容量を利用できます。過剰な費用をかけずに、時季変動したり急変動したりするワークロードを管理できます。
主な機能
自動化されたリソース管理と動的作業再調整
Dataflow は、処理リソースのプロビジョニングと管理を自動化してレイテンシを最小限に抑え、使用率を最大化します。そのため、手動でインスタンスをスピンアップしたり予約したりする必要はありません。作業のパーティショニングも自動化、最適化され、遅れている作業を動的に再調整します。「ホットキー」を追跡する必要がない入力データを前処理することもできます。
水平自動スケーリング
ワーカー リソースの水平自動スケーリングによってスループットが最適化されるため、全体的なコスト パフォーマンスが向上します。
バッチ処理に適したフレキシブル リソース スケジューリング料金
夜間のジョブなど、ジョブのスケジュールに柔軟性を持たせた処理には、Flexible Resource Scheduling(FlexRS)の方が低価格でバッチ処理できます。このようなフレキシブル ジョブはキューに入り、6 時間以内に確実にキューから取り出されて実行されます。
ワークショップの一環として実施する
JupyterLab ノートブックで Apache Beam インタラクティブ ランナーで、入力、評価、出力ループ(REPL)ワークフローでパイプラインの反復した開発、パイプライン グラフの検査、個々の PCollection の解析ができます。これらの Apache Beam ノートブックは、Vertex AI Workbench で提供されます。Vertex AI Workbench は、最新のデータ サイエンスと ML フレームワークがプリインストールされたノートブック仮想マシンをホストするマネージド サービスです。
この Codelab では、Apache Beam ノートブックによって導入された機能を中心に学習します。
学習内容
- ノートブック インスタンスの作成方法
- 基本的なパイプラインの作成
- 無限ソースからのデータの読み取り
- データの可視化
- ノートブックから Dataflow ジョブを起動する
- ノートブックの保存
必要なもの
- 課金が有効になっている Google Cloud Platform プロジェクト。
- Google Cloud Dataflow と Google Cloud PubSub が有効になっている。
2. 設定方法
- Cloud コンソールの [プロジェクト セレクタ] ページで、Cloud プロジェクトを選択または作成します。
次の API が有効になっていることを確認します。
- Dataflow API
- Cloud Pub/Sub API
- Compute Engine
- Notebooks API
これを確認するには、API のサービスページ。
このガイドでは、Pub/Sub サブスクリプションからデータを読み取るため、Compute Engine のデフォルトのサービス アカウントに編集者のロールを割り当てるか、Pub/Sub 編集者のロールを付与します。
3. Apache Beam ノートブックのスタートガイド
Apache Beam ノートブック インスタンスの起動
- コンソールで Dataflow を起動します。
- 左側のメニューを使用して [Workbench] ページを選択します。
- [ユーザー管理のノートブック] タブが表示されていることを確認します。
- ツールバーで [新しいノートブック] をクリックします。
- [Apache Beam] > [Withoug GPUs] を選択します。
- [新しいノートブック] ページでノートブック VM のサブネットワークを選択し、[作成] をクリックします。
- リンクがアクティブになったら、[JupyterLab を開く] をクリックします。Vertex AI Workbench により、新しい Apache Beam ノートブック インスタンスを作成します。
4. パイプラインの作成
ノートブック インスタンスの作成
[ファイル] >新規 >Notebook」を選択し、Apache Beam 2.47 以降のカーネルを選択します。
ノートブックへのコードの追加を開始する
- 各セクションのコードをコピーして、ノートブックの新しいセル内に貼り付けます。
- セルを実行する
JupyterLab ノートブックで Apache Beam インタラクティブ ランナーを使用すると、パイプラインの開発、パイプライン グラフの検査、個々の PCollection の解析(read-eval-print-loop)ワークフローが可能になります。
Apache Beam はノートブック インスタンスにインストールされているため、ノートブックには interactive_runner モジュールと interactive_beam モジュールが含まれます。
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
ノートブックで他の Google サービスを使用している場合は、次の import ステートメントを追加します。
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
インタラクティビティ オプションの設定
次の例では、データ キャプチャ期間を 60 秒に設定しています。反復処理を高速化する場合は、期間を短くします(「10s」など)。
ib.options.recording_duration = '60s'
その他のインタラクティブ オプションについては、Interactive_beam.options クラスをご覧ください。
InteractiveRunner オブジェクトを使用して、パイプラインを初期化します。
# Setting up the Apache Beam pipeline options.
options = pipeline_options.PipelineOptions()
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Sets the project to the default project in your current Google Cloud environment.
# The project will be used for creating a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
# The Google Cloud PubSub topic for this example.
topic = "projects/pubsub-public-data/topics/shakespeare-kinglear"
p = beam.Pipeline(InteractiveRunner(), options=options)
データの読み取りと可視化
次の例は、指定された Pub/Sub トピックへのサブスクリプションを作成し、そのサブスクリプションから読み取る Apache Beam パイプラインを示しています。
words = p | "read" >> beam.io.ReadFromPubSub(topic=topic)
パイプラインは、ソースからウィンドウごとに単語をカウントします。固定されたウィンドウを作成し、各ウィンドウの長さを 10 秒に設定します。
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
データがウィンドウ処理されると、ウィンドウごとに単語をカウントします。
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
データの可視化
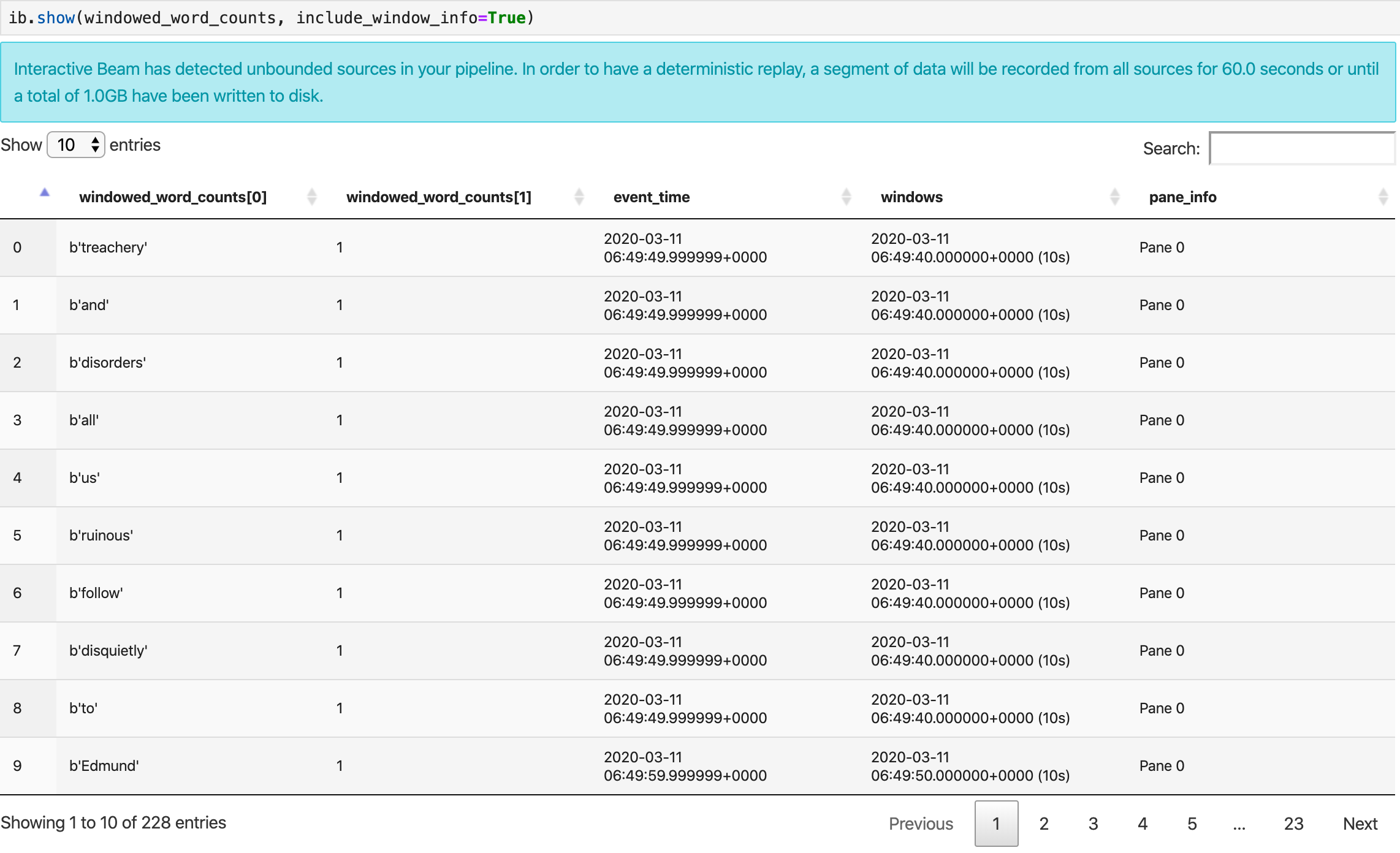
show() メソッドは、作成された PCollection をノートブックに可視化します。
ib.show(windowed_word_counts, include_window_info=True)
データの可視化を表示するには、show() メソッドに visualize_data=True を渡します。新しいセルを追加します。
ib.show(windowed_word_counts, include_window_info=True, visualize_data=True)
可視化には複数のフィルタを適用できます。次の可視化では、ラベルと軸でフィルタリングできます。
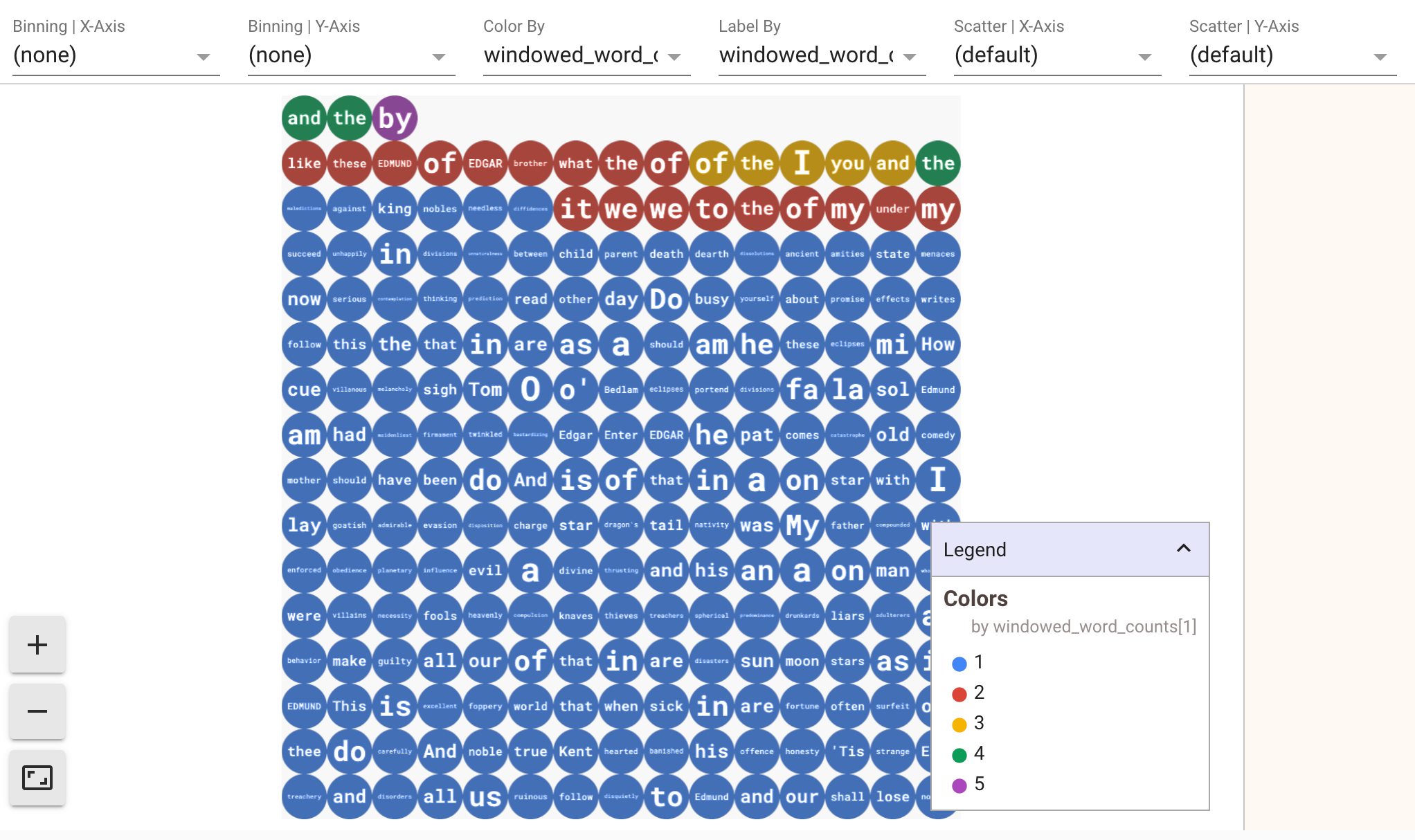
5. Pandas DataFrame の使用
Apache Beam ノートブックの可視化では、Pandas DataFrame も役立ちます。次の例では、最初に単語を小文字に変換してから、各単語の頻度を計算します。
windowed_lower_word_counts = (windowed_words
| "to lower case" >> beam.Map(lambda word: word.lower())
| "count lowered" >> beam.combiners.Count.PerElement())
collect() メソッドにより、Pandas DataFrame の出力を取得できます。
ib.collect(windowed_lower_word_counts, include_window_info=True)
6. (省略可)ノートブックから Dataflow ジョブを起動する
- Dataflow でジョブを実行するには、追加の権限が必要です。Compute Engine のデフォルトのサービス アカウントに編集者のロールがあることを確認するか、次の IAM ロールを付与します。
- Dataflow 管理者
- Dataflow ワーカー
- ストレージ管理者
- サービス アカウント ユーザー(roles/iam.serviceAccountUser)
ロールの詳細については、ドキュメントをご覧ください。
- (省略可)ノートブックを使用して Dataflow ジョブを実行する前に、カーネルを再起動し、すべてのセルを再実行して出力を確認します。
- 次の import ステートメントを削除します。
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
- 次の import ステートメントを追加します。
from apache_beam.runners import DataflowRunner
- 次の録画時間オプションを削除してください。
ib.options.recording_duration = '60s'
- パイプライン オプションに以下を追加します。すでに所有しているバケットを指すように Cloud Storage のロケーションを調整する必要があります。または、この目的のために新しいバケットを作成することもできます。リージョンの値を
us-central1から変更することもできます。
# Set the Google Cloud region to run Dataflow.
options.view_as(GoogleCloudOptions).region = 'us-central1'
# Choose a Cloud Storage location.
dataflow_gcs_location = 'gs://<change me>/dataflow'
# Choose a location for your output files
output_gcs_location = '%s/results/' % dataflow_gcs_location
# Set the staging location. This location is used to stage the
# Dataflow pipeline and SDK binary.
options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location
# Set the temporary location. This location is used to store temporary files
# or intermediate results before outputting to the sink.
options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location
beam.Pipeline()のコンストラクタで、InteractiveRunnerをDataflowRunnerに置き換えます。pは、パイプライン作成時のパイプライン オブジェクトです。
p = beam.Pipeline(DataflowRunner(), options=options)
- インタラクティブな呼び出しをコードから削除します。たとえば、
show()、collect()、head()、show_graph()、およびwatch()をコードから削除します。 - 結果を表示できるようにするには、シンクを追加する必要があります。前のセクションでは、ノートブックで結果を可視化していましたが、今回はこのノートブックの外部でジョブを Dataflow で実行しています。そのため、結果には外部の場所が必要です。この例では、結果を GCS(Google Cloud Storage)のテキスト ファイルに書き込みます。これはデータ ウィンドウ処理を使用するストリーミング パイプラインなので、ウィンドウごとに 1 つのテキスト ファイルを作成します。これを実現するには、パイプラインに次のステップを追加します。
result = (windowed_lower_word_counts
| "decode words and format" >> beam.Map(lambda x: f"{x[0].decode('utf-8')}: {x[1]}")
| "write events to file" >> beam.io.fileio.WriteToFiles(path=output_gcs_location, shards=1, max_writers_per_bundle=0))
- パイプライン コードの末尾に
p.run()を追加します。 - ノートブックのコードを調べて、すべての変更が反映されていることを確認します。次のようになります。
import apache_beam as beam
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
from apache_beam.runners import DataflowRunner
# Setting up the Apache Beam pipeline options.
options = pipeline_options.PipelineOptions()
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Sets the project to the default project in your current Google Cloud environment.
# The project will be used for creating a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
# Set the Google Cloud region to run Dataflow.
options.view_as(GoogleCloudOptions).region = 'us-central1'
# Choose a Cloud Storage location.
dataflow_gcs_location = 'gs://<change me>/dataflow'
# Choose a location for your output files
output_gcs_location = '%s/results/' % dataflow_gcs_location
# Set the staging location. This location is used to stage the
# Dataflow pipeline and SDK binary.
options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location
# Set the temporary location. This location is used to store temporary files
# or intermediate results before outputting to the sink.
options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location
# The Google Cloud PubSub topic for this example.
topic = "projects/pubsub-public-data/topics/shakespeare-kinglear"
p = beam.Pipeline(DataflowRunner(), options=options)
words = p | "read" >> beam.io.ReadFromPubSub(topic=topic)
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
windowed_words_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
windowed_lower_word_counts = (windowed_words
| "to lower case" >> beam.Map(lambda word: word.lower())
| "count lowered" >> beam.combiners.Count.PerElement())
result = (windowed_lower_word_counts
| "decode words and format" >> beam.Map(lambda x: f"{x[0].decode('utf-8')}: {x[1]}")
| "write events to file" >> beam.io.fileio.WriteToFiles(path=output_gcs_location, shards=1, max_writers_per_bundle=0))
p.run()
- セルを実行します。
- 出力は次のようになります。
<DataflowPipelineResult <Job
clientRequestId: '20230623100011457336-8998'
createTime: '2023-06-23T10:00:33.447347Z'
currentStateTime: '1970-01-01T00:00:00Z'
id: '2023-06-23_03_00_33-11346237320103246437'
location: 'us-central1'
name: 'beamapp-root-0623075553-503897-boh4u4wb'
projectId: 'your-project-id'
stageStates: []
startTime: '2023-06-23T10:00:33.447347Z'
steps: []
tempFiles: []
type: TypeValueValuesEnum(JOB_TYPE_STREAMING, 2)> at 0x7fc7e4084d60>
- ジョブが実行されているかどうかを検証するには、Dataflow の [ジョブ] ページに移動します。リストに新しいジョブが表示されます。ジョブでデータの処理が開始されるまでに 5 ~ 10 分ほどかかります。
- データが処理されたら、Cloud Storage に移動し、Dataflow が結果を保存しているディレクトリ(定義した
output_gcs_location)に移動します。ウィンドウごとに 1 つのファイルを含むテキスト ファイルのリストが表示されます。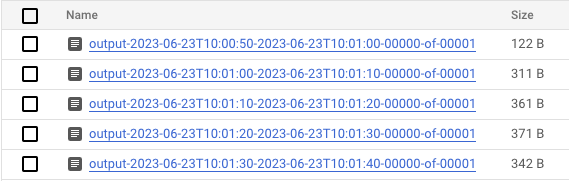
- ファイルをダウンロードして内容を確認します。単語のリストとそれらの単語の数が含まれている必要があります。または、コマンドライン インターフェースを使用してファイルを検査します。これを行うには、ノートブックの新しいセルで次のコマンドを実行します。
! gsutils cat gs://<your-bucket-here>/results/<file-name>
- 次のような出力が表示されます。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- これで、作成したジョブをクリーンアップして停止することを忘れないでください(この Codelab の最後のステップを参照)。
インタラクティブ ノートブックでこの変換を実行する方法の例については、ノートブック インスタンスの Dataflow Word Count ノートブックを参照してください。
または、ノートブックを実行可能スクリプトとしてエクスポートし、生成された .py ファイルを前の手順で変更してから、Dataflow サービスにパイプラインをデプロイすることもできます。
7. ノートブックの保存
作成したノートブックは、実行中のノートブック インスタンスにローカルに保存されます。開発中にノートブック インスタンスをリセットまたはシャットダウンした場合、これらの新しいノートブックは、/home/jupyter ディレクトリの下に作成されている限り保持されます。ただし、ノートブック インスタンスが削除されると、それらのノートブックも削除されます。
ノートブックを今後も使用するために保存するには、ワークステーションにローカルにダウンロードするか、GitHub に保存するか、別のファイル形式にエクスポートします。
8. クリーンアップ
Apache Beam ノートブック インスタンスの使用が終了したら、ノートブック インスタンスをシャットダウンし、実行している場合はストリーミング ジョブを停止して、Google Cloud で作成したリソースをクリーンアップします。
また、この Codelab の目的でのみプロジェクトを作成した場合は、プロジェクトを完全にシャットダウンすることもできます。