
1. Introdução

Google Cloud Dataflow
Última atualização:5 de julho de 2023
O que é o Dataflow?
O Dataflow é um serviço gerenciado que executa uma ampla variedade de padrões de processamento de dados. A documentação neste site mostra como implantar os pipelines de processamento de dados em lote e streaming usando o Dataflow, incluindo instruções de uso dos recursos do serviço.
O SDK do Apache Beam é um modelo de programação de código aberto que permite desenvolver pipelines em lote e de streaming. Os pipelines são criados com um programa do Apache Beam e executados no serviço Dataflow. A documentação do Apache Beam (em inglês) fornece informações conceituais aprofundadas e material de referência para o modelo de programação, os SDKs e outros executores do Apache Beam.
Análise de dados de streaming com velocidade
O Dataflow permite o desenvolvimento rápido e simplificado de pipelines de dados de streaming com menor latência de dados.
Simplifique as operações e o gerenciamento
As equipes podem se concentrar na programação em vez de gerenciar clusters de servidor, já que a abordagem sem servidor do Dataflow remove a sobrecarga operacional das cargas de trabalho de engenharia de dados.
Reduzir o custo total de propriedade
O escalonamento automático de recursos aliado ao potencial de processamento em lote com custo otimizado permitem ao Dataflow oferecer uma capacidade praticamente ilimitada de gerenciar altos e baixos nas cargas de trabalho sem gastar demais.
Principais recursos
Gerenciamento automatizado de recursos e rebalanceamento dinâmico de trabalho
O Dataflow automatiza o provisionamento e o gerenciamento de recursos de processamento para minimizar a latência e maximizar a utilização. Assim, você não precisa ativar instâncias ou reservá-las manualmente. O particionamento de trabalho também é automatizado e otimizado para reequilibrar dinamicamente o trabalho atrasado. Não é preciso procurar teclas de atalho ou pré-processar dados de entrada.
Escalonamento automático horizontal
Escalonamento automático horizontal de recursos de worker para alcançar os melhores resultados de capacidade com o melhor custo-benefício.
Preços flexíveis de programação de recursos para processamento em lote
Para o processamento com flexibilidade no tempo de agendamento do job, como jobs noturnos, o agendamento flexível de recursos (FlexRS) oferece um preço menor para o processamento em lote. Esses jobs flexíveis são colocados em uma fila com a garantia de que serão recuperados para execução dentro de seis horas.
O que você executará como parte deste
O uso do executor interativo do Apache Beam com notebooks do JupyterLab permite desenvolver pipelines de maneira iterativa, inspecionar o gráfico do pipeline e analisar PCollections individuais em um fluxo de trabalho de leitura-avaliação-impressão-loop (REPL). Esses notebooks do Apache Beam são disponibilizados pelo Vertex AI Workbench, um serviço gerenciado que hospeda máquinas virtuais de notebook pré-instaladas com os frameworks mais recentes de ciência de dados e machine learning.
Este codelab se concentra na funcionalidade introduzida pelos notebooks do Apache Beam.
O que você vai aprender
- Como criar uma instância de notebook
- Como criar um pipeline básico
- Leitura de dados de fonte ilimitada
- Como ver os dados
- Como iniciar um job do Dataflow no notebook
- Como salvar um notebook
O que é necessário
- Um projeto do Google Cloud Platform com o faturamento ativado.
- Google Cloud Dataflow e Google Cloud PubSub ativados.
2. Etapas da configuração
- No console do Cloud, na página do seletor de projetos, selecione ou crie um projeto do Cloud.
Verifique se as seguintes APIs estão ativadas:
- API Dataflow
- API Cloud Pub/Sub
- Compute Engine
- API Notebooks
Você pode confirmar isso consultando o "Serviços".
Neste guia, vamos ler os dados de uma assinatura do Pub/Sub. Portanto, verifique se a conta de serviço padrão do Compute Engine tem o papel de editor ou conceda o papel de editor do Pub/Sub.
3. Primeiros passos com os notebooks do Apache Beam
Como iniciar uma instância de notebooks do Apache Beam
- Inicie o Dataflow no console:
- Selecione a página Workbench no menu à esquerda.
- Verifique se você está na guia Notebooks gerenciados pelo usuário.
- Na barra de ferramentas, clique em Novo Notebook.
- Selecione Apache Beam > Sem GPUs.
- Na página Novo notebook, selecione uma sub-rede para a VM do notebook e clique em Criar.
- Clique em Abrir JupyterLab quando o link ficar ativo. O Vertex AI Workbench cria uma nova instância de notebook do Apache Beam.
4. Como criar o pipeline
Como criar uma instância de notebook
Navegue até Arquivo > Novo > Notebook e selecione um kernel Apache Beam 2.47 ou posterior.
Comece a adicionar o código ao seu notebook
- Copie e cole o código de cada seção em uma nova célula no notebook.
- Executar a célula
O uso do executor interativo do Apache Beam com notebooks do JupyterLab permite desenvolver pipelines de maneira iterativa, inspecionar o gráfico do pipeline e analisar PCollections individuais em um fluxo de trabalho de leitura-avaliação-impressão-loop (REPL).
O Apache Beam está instalado na instância do notebook. Portanto, inclua os módulos interactive_runner e interactive_beam no notebook.
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
Caso o notebook use outros Serviços do Google, adicione as seguintes instruções de importação:
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
Como definir opções de interatividade
O exemplo a seguir define a duração da captura de dados em 60 segundos. Se quiser iterar mais rapidamente, defina uma duração menor, por exemplo, "10s".
ib.options.recording_duration = '60s'
Para opções interativas adicionais, consulte a classeinteractive_beam.options.
Inicialize o pipeline usando um objeto InteractiveRunner.
# Setting up the Apache Beam pipeline options.
options = pipeline_options.PipelineOptions()
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Sets the project to the default project in your current Google Cloud environment.
# The project will be used for creating a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
# The Google Cloud PubSub topic for this example.
topic = "projects/pubsub-public-data/topics/shakespeare-kinglear"
p = beam.Pipeline(InteractiveRunner(), options=options)
Como ler e visualizar os dados
O exemplo a seguir mostra um pipeline do Apache Beam que cria uma assinatura para o tópico do Pub/Sub fornecido e lê a partir dessa assinatura.
words = p | "read" >> beam.io.ReadFromPubSub(topic=topic)
O pipeline conta as palavras por janelas a partir da origem. Ele cria um janelamento fixo, e cada janela tem 10 segundos de duração.
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
Após a disposição dos dados em janelas, as palavras são contadas por janela.
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
Como visualizar os dados
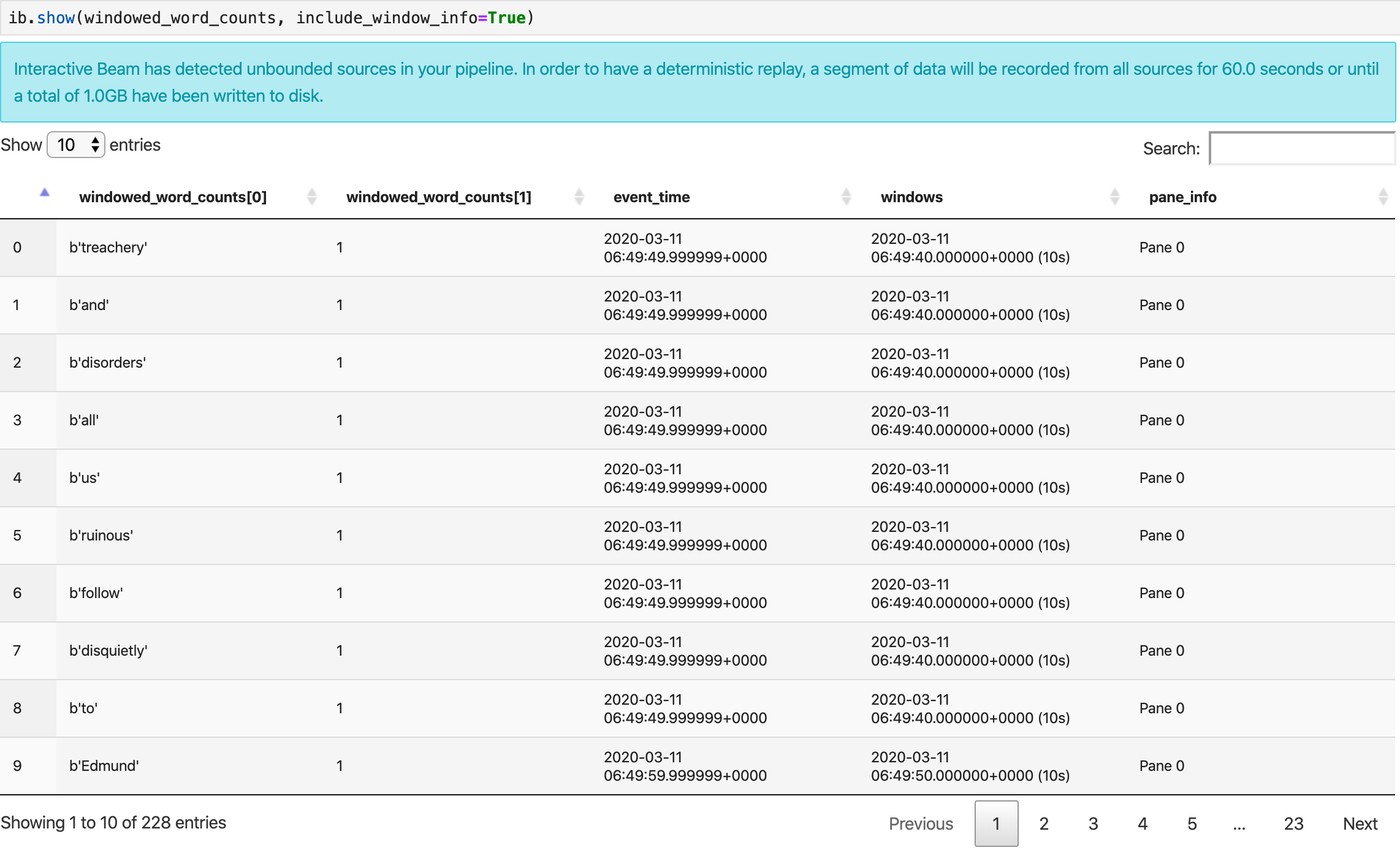
O método show() visualiza a PCollection resultante no notebook.
ib.show(windowed_word_counts, include_window_info=True)
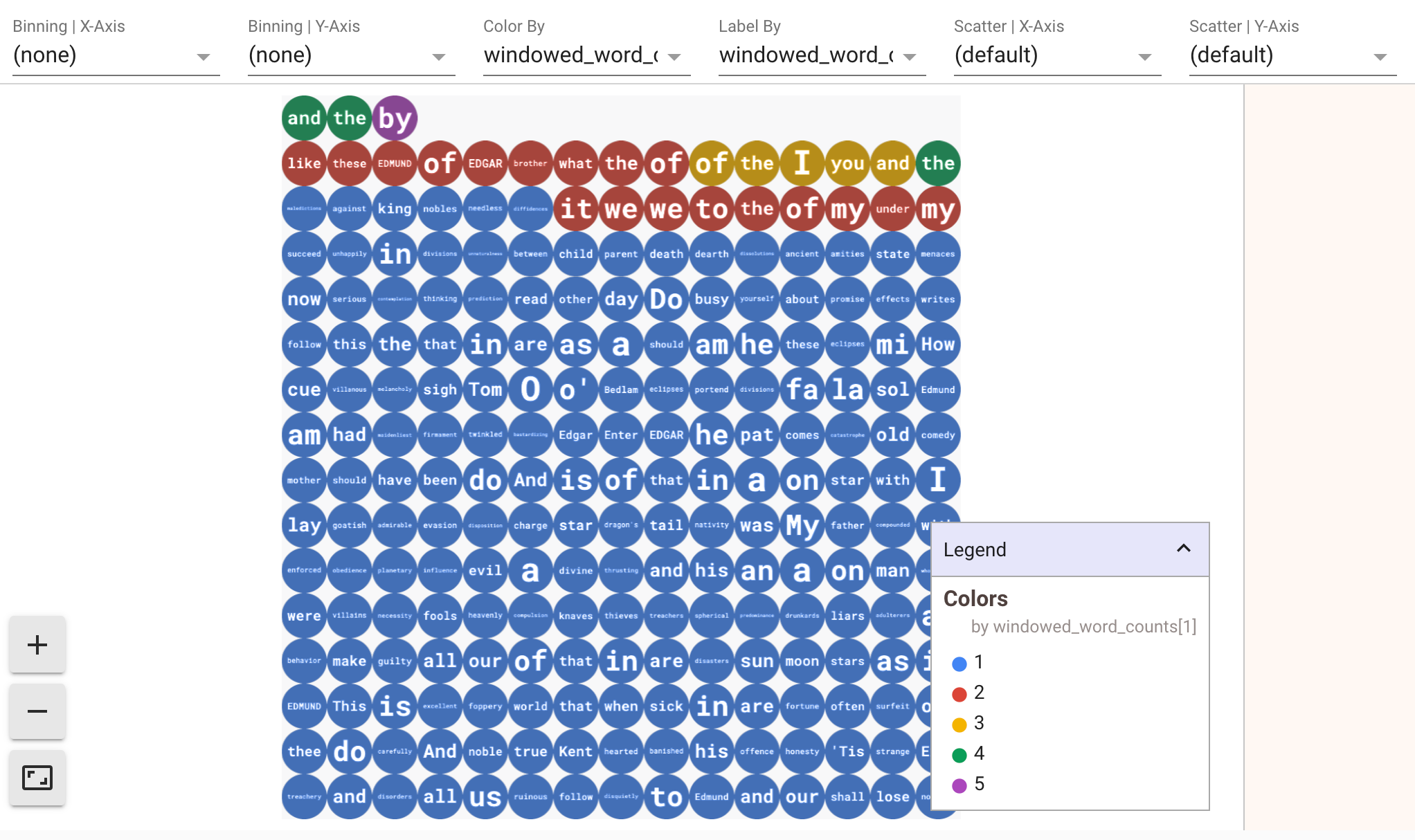
Para exibir visualizações dos seus dados, transmita visualize_data=True para o método show(). Adicionar uma célula:
ib.show(windowed_word_counts, include_window_info=True, visualize_data=True)
É possível aplicar vários filtros às suas visualizações. A seguinte visualização permite filtrar por etiqueta e eixo:
5. Como usar um DataFrame do Pandas
Outra visualização útil em notebooks do Apache Beam é um DataFrame de Pandas. O seguinte exemplo converte as palavras em minúsculas e depois calcula a frequência de cada uma delas.
windowed_lower_word_counts = (windowed_words
| "to lower case" >> beam.Map(lambda word: word.lower())
| "count lowered" >> beam.combiners.Count.PerElement())
O método collect() fornece a saída em um DataFrame de Pandas.
ib.collect(windowed_lower_word_counts, include_window_info=True)
6. (Opcional) Como iniciar jobs do Dataflow no notebook
- Para executar jobs no Dataflow, são necessárias outras permissões. Verifique se a conta de serviço padrão do Compute Engine tem o papel de editor ou conceda os seguintes papéis do IAM:
- Administrador do Dataflow
- Worker do Dataflow
- Administrador do Storage
- Usuário da conta de serviço (roles/iam.serviceAccountUser)
Saiba mais sobre os papéis na documentação.
- (Opcional) Antes de usar o notebook para executar jobs do Dataflow, reinicie o kernel, execute novamente todas as células e verifique a saída.
- Remova as seguintes declarações de importação:
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
- Adicione a seguinte declaração de importação:
from apache_beam.runners import DataflowRunner
- Remova a seguinte opção de duração de gravação:
ib.options.recording_duration = '60s'
- Adicione o seguinte às opções do seu pipeline. Ajuste o local do Cloud Storage para apontar para um bucket que você já tem ou crie um novo bucket para essa finalidade. Também é possível alterar o valor da região de
us-central1.
# Set the Google Cloud region to run Dataflow.
options.view_as(GoogleCloudOptions).region = 'us-central1'
# Choose a Cloud Storage location.
dataflow_gcs_location = 'gs://<change me>/dataflow'
# Choose a location for your output files
output_gcs_location = '%s/results/' % dataflow_gcs_location
# Set the staging location. This location is used to stage the
# Dataflow pipeline and SDK binary.
options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location
# Set the temporary location. This location is used to store temporary files
# or intermediate results before outputting to the sink.
options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location
- No construtor de
beam.Pipeline(), substituaInteractiveRunnerporDataflowRunner.pé o objeto de pipeline criado na criação do pipeline.
p = beam.Pipeline(DataflowRunner(), options=options)
- Remova as chamadas interativas do código. Por exemplo, remova
show(),collect(),head(),show_graph()ewatch()do código. - Para acessar resultados, você precisa adicionar um coletor. Na seção anterior, estávamos visualizando os resultados no notebook, mas, desta vez, estamos executando o job fora do notebook, no Dataflow. Portanto, precisamos de um local externo para nossos resultados. Neste exemplo, vamos gravar os resultados em arquivos de texto no GCS (Google Cloud Storage). Como este é um pipeline de streaming, com janelamento de dados, vamos criar um arquivo de texto por janela. Para fazer isso, adicione as seguintes etapas ao seu pipeline:
result = (windowed_lower_word_counts
| "decode words and format" >> beam.Map(lambda x: f"{x[0].decode('utf-8')}: {x[1]}")
| "write events to file" >> beam.io.fileio.WriteToFiles(path=output_gcs_location, shards=1, max_writers_per_bundle=0))
- Adicione
p.run()ao final do código do pipeline. - Agora revise o código do notebook para confirmar que você incorporou todas as alterações. A aparência será semelhante a esta:
import apache_beam as beam
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
from apache_beam.runners import DataflowRunner
# Setting up the Apache Beam pipeline options.
options = pipeline_options.PipelineOptions()
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Sets the project to the default project in your current Google Cloud environment.
# The project will be used for creating a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
# Set the Google Cloud region to run Dataflow.
options.view_as(GoogleCloudOptions).region = 'us-central1'
# Choose a Cloud Storage location.
dataflow_gcs_location = 'gs://<change me>/dataflow'
# Choose a location for your output files
output_gcs_location = '%s/results/' % dataflow_gcs_location
# Set the staging location. This location is used to stage the
# Dataflow pipeline and SDK binary.
options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location
# Set the temporary location. This location is used to store temporary files
# or intermediate results before outputting to the sink.
options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location
# The Google Cloud PubSub topic for this example.
topic = "projects/pubsub-public-data/topics/shakespeare-kinglear"
p = beam.Pipeline(DataflowRunner(), options=options)
words = p | "read" >> beam.io.ReadFromPubSub(topic=topic)
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
windowed_words_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
windowed_lower_word_counts = (windowed_words
| "to lower case" >> beam.Map(lambda word: word.lower())
| "count lowered" >> beam.combiners.Count.PerElement())
result = (windowed_lower_word_counts
| "decode words and format" >> beam.Map(lambda x: f"{x[0].decode('utf-8')}: {x[1]}")
| "write events to file" >> beam.io.fileio.WriteToFiles(path=output_gcs_location, shards=1, max_writers_per_bundle=0))
p.run()
- Execute as células.
- O resultado será parecido com este:
<DataflowPipelineResult <Job
clientRequestId: '20230623100011457336-8998'
createTime: '2023-06-23T10:00:33.447347Z'
currentStateTime: '1970-01-01T00:00:00Z'
id: '2023-06-23_03_00_33-11346237320103246437'
location: 'us-central1'
name: 'beamapp-root-0623075553-503897-boh4u4wb'
projectId: 'your-project-id'
stageStates: []
startTime: '2023-06-23T10:00:33.447347Z'
steps: []
tempFiles: []
type: TypeValueValuesEnum(JOB_TYPE_STREAMING, 2)> at 0x7fc7e4084d60>
- Para validar se o job está em execução, acesse a página Jobs do Dataflow. Você verá um novo job na lista. O job leva cerca de 5 a 10 minutos para começar a processar os dados.
- Quando os dados estiverem sendo processados, acesse o Cloud Storage e vá até o diretório em que o Dataflow está armazenando os resultados (o
output_gcs_locationdefinido). Você verá uma lista de arquivos de texto, com um arquivo por janela.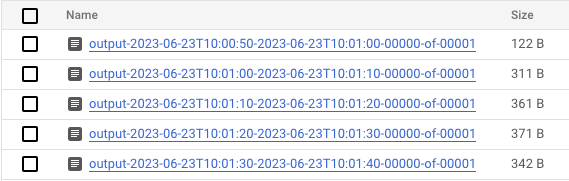
- Faça o download do arquivo e inspecione o conteúdo. Ela deve conter a lista de palavras pareadas com a contagem. Como alternativa, use a interface de linha de comando para inspecionar os arquivos. Para isso, execute o seguinte em uma célula nova do notebook:
! gsutils cat gs://<your-bucket-here>/results/<file-name>
- O resultado será parecido com este:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- Pronto! Não se esqueça de limpar e interromper o job criado (veja a etapa final deste codelab).
Para ver um exemplo de como realizar essa conversão em um notebook interativo, consulte o notebook do Dataflow na instância do notebook.
Outra opção é exportar o notebook como um script executável, modificar o arquivo .py gerado seguindo as etapas anteriores e depois implantar o pipeline no serviço do Dataflow.
7. Como o notebook
Os notebooks criados são salvos localmente na instância do notebook em execução. Se você redefinir ou encerrar a instância do notebook durante o desenvolvimento, esses novos notebooks serão mantidos enquanto forem criados no diretório /home/jupyter. No entanto, se uma instância de notebook for excluída, isso também acontecerá.
Para manter os notebooks para uso futuro, faça o download deles localmente na estação de trabalho, salve-os no GitHub ou exporte-os para um formato de arquivo diferente.
8. Limpar
Depois de usar a instância do notebook do Apache Beam, limpe os recursos criados no Google Cloud encerrando a instância do notebook e interrompendo o job de streaming, se você tiver executado um.
Como alternativa, se você criou um projeto apenas para os fins deste codelab, também é possível encerrá-lo totalmente.