
1. Introduzione

Google Cloud Dataflow
Ultimo aggiornamento: 5 luglio 2023
Che cos'è Dataflow?
Dataflow è un servizio gestito per l'esecuzione di un'ampia varietà di pattern di elaborazione dati. La documentazione di questo sito mostra come eseguire il deployment delle pipeline di elaborazione dei dati batch e di streaming utilizzando Dataflow, incluse le istruzioni per l'utilizzo delle funzionalità del servizio.
L'SDK Apache Beam è un modello di programmazione open source che consente di sviluppare pipeline batch e di streaming. Crea le pipeline con un programma Apache Beam e poi le esegui sul servizio Dataflow. La documentazione di Apache Beam fornisce informazioni concettuali approfondite e materiale di riferimento per il modello di programmazione Apache Beam, gli SDK e altri runner.
Analizza rapidamente i flussi di dati
Dataflow velocizza e semplifica lo sviluppo di pipeline di dati in modalità flusso garantendo una latenza dei dati minore.
Semplifica operazioni e gestione
Puoi consentire ai team di concentrarsi sulla programmazione invece che sulla gestione dei cluster di server grazie all'approccio serverless di Dataflow, che elimina i problemi di sovraccarico operativo dai carichi di lavoro di data engineering.
Ridurre il costo totale di proprietà
Grazie alla scalabilità automatica delle risorse e all'ottimizzazione dei costi per l'elaborazione batch, Dataflow offre una capacità praticamente illimitata per gestire i carichi di lavoro durante i picchi e i periodi di punta stagionali senza spendere troppo.
Funzionalità principali
Gestione automatizzata delle risorse e ridistribuzione dinamica del lavoro
Dataflow automatizza il provisioning e la gestione delle risorse di elaborazione per ridurre al minimo i tempi di latenza e ottimizzare l'utilizzo, evitando la necessità di avviare o prenotare le istanze manualmente. Anche il partizionamento del lavoro è automatizzato e ottimizzato per ridistribuire dinamicamente il lavoro in sospeso. Non è necessario andare alla ricerca di tasti di scelta rapida o pre-elaborare i dati di input.
Scalabilità automatica orizzontale
La scalabilità automatica orizzontale delle risorse worker per ottimizzare la velocità effettiva si traduce in un migliore rapporto prezzo-prestazioni complessivo.
Prezzi flessibili di pianificazione delle risorse per l'elaborazione batch
Per consentire un'elaborazione flessibile nei tempi di pianificazione dei job, come i job notturni, la pianificazione flessibile delle risorse (FlexRS) offre prezzi inferiori per l'elaborazione batch. Questi job flessibili sono inseriti in una coda con la garanzia che verranno recuperati per l'esecuzione entro un lasso di tempo di sei ore.
Cosa verrà eseguito nell'ambito di questa operazione
L'utilizzo di Apache Beam Interactive Runner con i blocchi note JupyterLab consente di sviluppare pipeline in modo iterativo, ispezionare il grafico della pipeline e analizzare singole PCollection in un flusso di lavoro Read-Eval-Print Loop (REPL). Questi blocchi note Apache Beam sono resi disponibili tramite Vertex AI Workbench, un servizio gestito che ospita macchine virtuali notebook con i più recenti framework di data science e machine learning preinstallati.
Questo codelab si concentra sulla funzionalità introdotta dai blocchi note Apache Beam.
Cosa imparerai a fare
- Come creare un'istanza di notebook
- Creazione di una pipeline di base
- Lettura dei dati da un'origine senza limiti
- Visualizzare i dati
- Avvio di un job Dataflow dal notebook
- Salvataggio di un notebook
Che cosa ti serve
- Un progetto Google Cloud con la fatturazione abilitata.
- Google Cloud Dataflow e Google Cloud Pub/Sub abilitati.
2. Preparazione
- Nella console Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Cloud.
Assicurati di aver abilitato le seguenti API:
- API Dataflow
- API Cloud Pub/Sub
- Compute Engine
- API Notebooks
Puoi verificarlo controllando la pagina API e servizi.
In questa guida, leggeremo i dati da un abbonamento Pub/Sub, quindi assicurati che il service account predefinito di Compute Engine abbia il ruolo Editor o concedigli il ruolo Editor Pub/Sub.
3. Guida introduttiva ai notebook Apache Beam
Avvio di un'istanza di notebook Apache Beam
- Avvia Dataflow nella console:
- Seleziona la pagina Workbench utilizzando il menu a sinistra.
- Assicurati di essere nella scheda Blocchi note gestiti dall'utente.
- Nella barra degli strumenti, fai clic su Nuovo blocco note.
- Seleziona Apache Beam > Senza GPU.
- Nella pagina Nuovo notebook, seleziona una subnet per la VM notebook e fai clic su Crea.
- Fai clic su Apri JupyterLab quando il link diventa attivo. Vertex AI Workbench crea una nuova istanza del notebook Apache Beam.
4. crea la pipeline
Creazione di un'istanza di notebook
Vai a File > Nuovo > Blocco note e seleziona un kernel Apache Beam 2.47 o versioni successive.
Inizia ad aggiungere codice al tuo notebook
- Copia e incolla il codice di ogni sezione in una nuova cella del notebook.
- Esegui la cella
L'utilizzo di Apache Beam Interactive Runner con i blocchi note JupyterLab consente di sviluppare pipeline in modo iterativo, ispezionare il grafico della pipeline e analizzare singole PCollection in un flusso di lavoro Read-Eval-Print Loop (REPL).
Apache Beam è installato nell'istanza notebook, quindi includi i moduli interactive_runner e interactive_beam nel notebook.
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
Se il tuo blocco note utilizza altri servizi Google, aggiungi le seguenti istruzioni di importazione:
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
Impostare le opzioni di interattività
Il seguente comando imposta la durata dell'acquisizione dei dati a 60 secondi. Se vuoi eseguire iterazioni più rapidamente, imposta una durata inferiore, ad esempio "10 secondi".
ib.options.recording_duration = '60s'
Per altre opzioni interattive, consulta la classe interactive_beam.options.
Inizializza la pipeline utilizzando un oggetto InteractiveRunner.
# Setting up the Apache Beam pipeline options.
options = pipeline_options.PipelineOptions()
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Sets the project to the default project in your current Google Cloud environment.
# The project will be used for creating a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
# The Google Cloud PubSub topic for this example.
topic = "projects/pubsub-public-data/topics/shakespeare-kinglear"
p = beam.Pipeline(InteractiveRunner(), options=options)
Lettura e visualizzazione dei dati
L'esempio seguente mostra una pipeline Apache Beam che crea una sottoscrizione all'argomento Pub/Sub specificato e legge dalla sottoscrizione.
words = p | "read" >> beam.io.ReadFromPubSub(topic=topic)
La pipeline conta le parole per finestra dall'origine. Crea finestre fisse di 10 secondi ciascuna.
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
Dopo la suddivisione in finestre dei dati, le parole vengono conteggiate per finestra.
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
Visualizzare i dati
Il metodo show() visualizza il PCollection risultante nel notebook.
ib.show(windowed_word_counts, include_window_info=True)
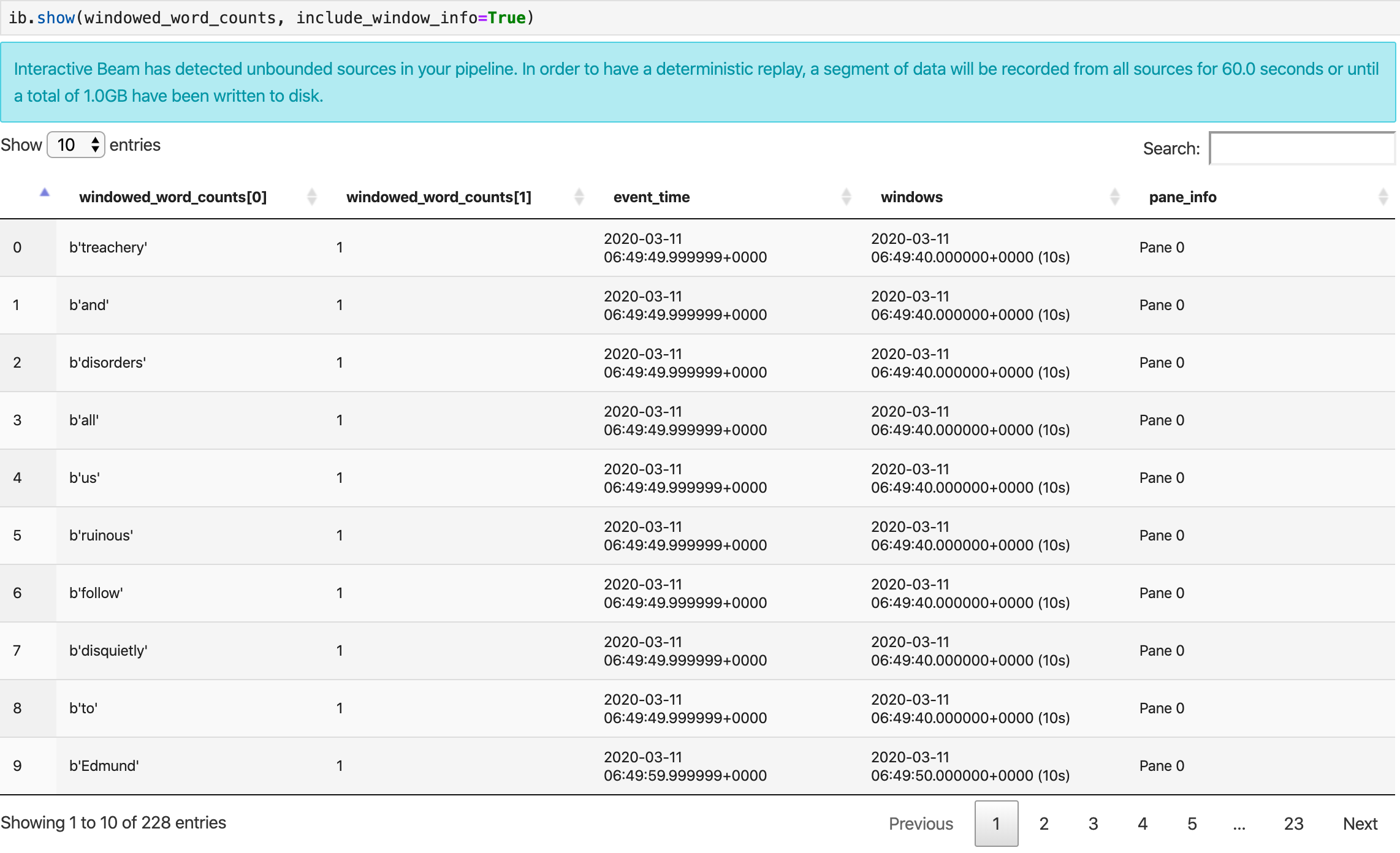
Per visualizzare le visualizzazioni dei dati, passa visualize_data=True al metodo show(). Aggiungere una nuova cella:
ib.show(windowed_word_counts, include_window_info=True, visualize_data=True)
Puoi applicare più filtri alle visualizzazioni. La seguente visualizzazione consente di filtrare per etichetta e asse:
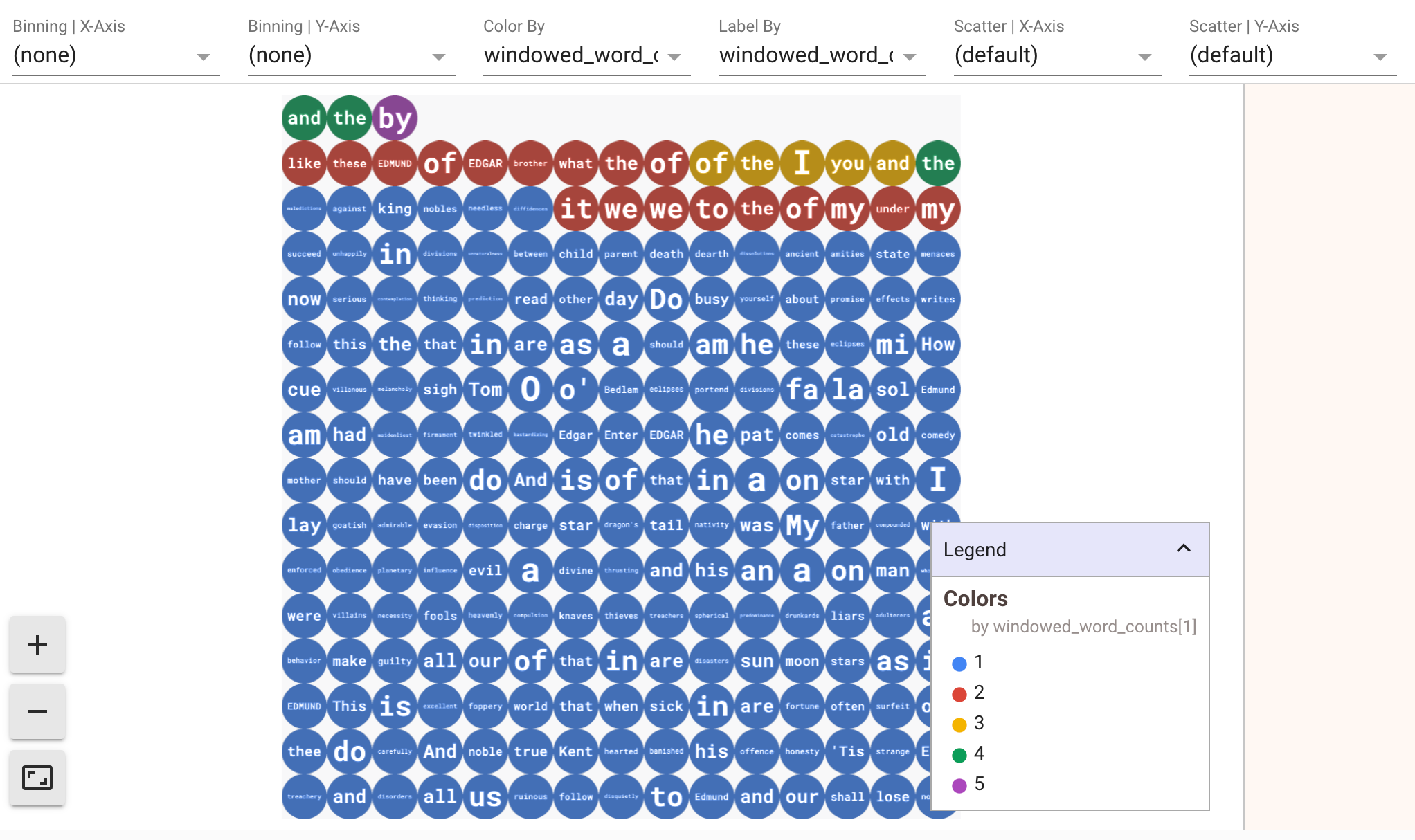
5. Utilizzo di un DataFrame Pandas
Un'altra visualizzazione utile nei blocchi note Apache Beam è un DataFrame Pandas. L'esempio seguente converte prima le parole in minuscolo e poi calcola la frequenza di ogni parola.
windowed_lower_word_counts = (windowed_words
| "to lower case" >> beam.Map(lambda word: word.lower())
| "count lowered" >> beam.combiners.Count.PerElement())
Il metodo collect() fornisce l'output in un DataFrame Pandas.
ib.collect(windowed_lower_word_counts, include_window_info=True)
6. (Facoltativo) Avvio dei job Dataflow dal notebook
- Per eseguire job su Dataflow, devi disporre di autorizzazioni aggiuntive. Assicurati che il service account predefinito di Compute Engine abbia il ruolo Editor oppure concedigli i seguenti ruoli IAM:
- Dataflow Admin
- Dataflow Worker
- Amministratore Storage e
- Utente service account (roles/iam.serviceAccountUser)
Scopri di più sui ruoli nella documentazione.
- (Facoltativo) Prima di utilizzare il notebook per eseguire i job Dataflow, riavvia il kernel, esegui di nuovo tutte le celle e verifica l'output.
- Rimuovi le seguenti istruzioni di importazione:
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
- Aggiungi la seguente istruzione di importazione:
from apache_beam.runners import DataflowRunner
- Rimuovi la seguente opzione di durata della registrazione:
ib.options.recording_duration = '60s'
- Aggiungi quanto segue alle opzioni della pipeline. Dovrai modificare la posizione di Cloud Storage in modo che punti a un bucket di tua proprietà oppure puoi creare un nuovo bucket a questo scopo. Puoi anche modificare il valore della regione da
us-central1.
# Set the Google Cloud region to run Dataflow.
options.view_as(GoogleCloudOptions).region = 'us-central1'
# Choose a Cloud Storage location.
dataflow_gcs_location = 'gs://<change me>/dataflow'
# Choose a location for your output files
output_gcs_location = '%s/results/' % dataflow_gcs_location
# Set the staging location. This location is used to stage the
# Dataflow pipeline and SDK binary.
options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location
# Set the temporary location. This location is used to store temporary files
# or intermediate results before outputting to the sink.
options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location
- Nel costruttore di
beam.Pipeline(), sostituisciInteractiveRunnerconDataflowRunner.pè l'oggetto pipeline creato durante la creazione della pipeline.
p = beam.Pipeline(DataflowRunner(), options=options)
- Rimuovi le chiamate interattive dal codice. Ad esempio, rimuovi
show(),collect(),head(),show_graph()ewatch()dal codice. - Per poter visualizzare i risultati, devi aggiungere un sink. Nella sezione precedente abbiamo visualizzato i risultati nel notebook, ma questa volta eseguiamo il job al di fuori di questo notebook, in Dataflow. Pertanto, abbiamo bisogno di una posizione esterna per i nostri risultati. In questo esempio, scriveremo i risultati in file di testo in GCS (Google Cloud Storage). Poiché si tratta di una pipeline di streaming, con il raggruppamento dei dati in finestre, vogliamo creare un file di testo per finestra. Per farlo, aggiungi i seguenti passaggi alla pipeline:
result = (windowed_lower_word_counts
| "decode words and format" >> beam.Map(lambda x: f"{x[0].decode('utf-8')}: {x[1]}")
| "write events to file" >> beam.io.fileio.WriteToFiles(path=output_gcs_location, shards=1, max_writers_per_bundle=0))
- Aggiungi
p.run()alla fine del codice della pipeline. - Ora rivedi il codice del notebook per verificare di aver incorporato tutte le modifiche. Dovrebbe avere un aspetto simile a questo:
import apache_beam as beam
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
from apache_beam.runners import DataflowRunner
# Setting up the Apache Beam pipeline options.
options = pipeline_options.PipelineOptions()
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Sets the project to the default project in your current Google Cloud environment.
# The project will be used for creating a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
# Set the Google Cloud region to run Dataflow.
options.view_as(GoogleCloudOptions).region = 'us-central1'
# Choose a Cloud Storage location.
dataflow_gcs_location = 'gs://<change me>/dataflow'
# Choose a location for your output files
output_gcs_location = '%s/results/' % dataflow_gcs_location
# Set the staging location. This location is used to stage the
# Dataflow pipeline and SDK binary.
options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location
# Set the temporary location. This location is used to store temporary files
# or intermediate results before outputting to the sink.
options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location
# The Google Cloud PubSub topic for this example.
topic = "projects/pubsub-public-data/topics/shakespeare-kinglear"
p = beam.Pipeline(DataflowRunner(), options=options)
words = p | "read" >> beam.io.ReadFromPubSub(topic=topic)
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
windowed_words_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
windowed_lower_word_counts = (windowed_words
| "to lower case" >> beam.Map(lambda word: word.lower())
| "count lowered" >> beam.combiners.Count.PerElement())
result = (windowed_lower_word_counts
| "decode words and format" >> beam.Map(lambda x: f"{x[0].decode('utf-8')}: {x[1]}")
| "write events to file" >> beam.io.fileio.WriteToFiles(path=output_gcs_location, shards=1, max_writers_per_bundle=0))
p.run()
- Esegui le celle.
- Dovresti vedere un output simile al seguente:
<DataflowPipelineResult <Job
clientRequestId: '20230623100011457336-8998'
createTime: '2023-06-23T10:00:33.447347Z'
currentStateTime: '1970-01-01T00:00:00Z'
id: '2023-06-23_03_00_33-11346237320103246437'
location: 'us-central1'
name: 'beamapp-root-0623075553-503897-boh4u4wb'
projectId: 'your-project-id'
stageStates: []
startTime: '2023-06-23T10:00:33.447347Z'
steps: []
tempFiles: []
type: TypeValueValuesEnum(JOB_TYPE_STREAMING, 2)> at 0x7fc7e4084d60>
- Per verificare se il job è in esecuzione, vai alla pagina Job di Dataflow. Dovresti vedere un nuovo job nell'elenco. L'avvio dell'elaborazione dei dati del job richiederà circa 5-10 minuti.
- Una volta che i dati vengono elaborati, vai a Cloud Storage e naviga nella directory in cui Dataflow archivia i risultati (il
output_gcs_locationche hai definito). Dovresti visualizzare un elenco di file di testo, con un file per finestra.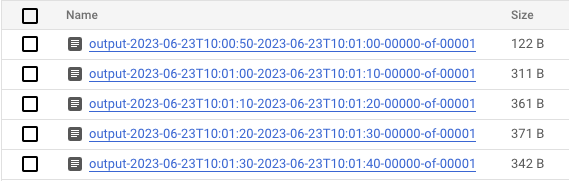
- Scarica il file e ispeziona i contenuti. Deve contenere l'elenco delle parole accoppiate al relativo conteggio. In alternativa, utilizza l'interfaccia a riga di comando per esaminare i file. Puoi farlo eseguendo il seguente codice in una nuova cella del notebook:
! gsutils cat gs://<your-bucket-here>/results/<file-name>
- Vedrai un output simile a questo:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- Questo è tutto! Non dimenticare di pulire e arrestare il job che hai creato (vedi il passaggio finale di questo codelab).
Per un esempio di come eseguire questa conversione in un blocco note interattivo, consulta il blocco note Conteggio parole di Dataflow nell'istanza del blocco note.
In alternativa, puoi esportare il notebook come script eseguibile, modificare il file .py generato seguendo i passaggi precedenti e poi deployare la pipeline nel servizio Dataflow.
7. Salvataggio del notebook in corso
Notebooks che crei vengono salvati localmente nell'istanza del notebook in esecuzione. Se reimposti o arresti l'istanza del notebook durante lo sviluppo, i nuovi notebook vengono mantenuti purché vengano creati nella directory /home/jupyter. Tuttavia, se un'istanza di blocco note viene eliminata, vengono eliminati anche i relativi blocchi note.
Per conservare i notebook per un utilizzo futuro, scaricali localmente sulla tua workstation, salvali su GitHub o esportali in un formato file diverso.
8. Pulizia
Dopo aver terminato di utilizzare l'istanza del notebook Apache Beam, pulisci le risorse che hai creato su Google Cloud arrestando l'istanza del notebook e interrompendo il job di streaming, se ne hai eseguito uno.
In alternativa, se hai creato un progetto con l'unico scopo di questo codelab, puoi anche chiuderlo completamente.