
1. परिचय

Google Cloud Dataflow
पिछली बार अपडेट किया गया: 05-07-2023
डेटाफ़्लो क्या है?
Dataflow, मैनेज की गई एक सेवा है. इसकी मदद से, डेटा प्रोसेसिंग के अलग-अलग पैटर्न को लागू किया जा सकता है. इस साइट पर मौजूद दस्तावेज़ में बताया गया है कि Dataflow का इस्तेमाल करके, बैच और स्ट्रीमिंग डेटा प्रोसेसिंग पाइपलाइन कैसे डिप्लॉय की जाती हैं. इसमें सेवा की सुविधाओं को इस्तेमाल करने के निर्देश भी शामिल हैं.
Apache Beam SDK, ओपन सोर्स प्रोग्रामिंग मॉडल है. इसकी मदद से, बैच और स्ट्रीमिंग, दोनों तरह की पाइपलाइन डेवलप की जा सकती हैं. Apache Beam प्रोग्राम की मदद से पाइपलाइन बनाई जाती हैं. इसके बाद, उन्हें Dataflow सेवा पर चलाया जाता है. Apache Beam के दस्तावेज़ में, Apache Beam प्रोग्रामिंग मॉडल, एसडीके, और अन्य रनर के बारे में पूरी जानकारी और रेफ़रंस मटीरियल दिया गया है.
तेज़ी से स्ट्रीमिंग डेटा का विश्लेषण करना
Dataflow की मदद से, स्ट्रीमिंग डेटा पाइपलाइन को तेज़ी से और आसानी से डेवलप किया जा सकता है. साथ ही, डेटा को प्रोसेस होने में कम समय लगता है.
ऑपरेशन और मैनेजमेंट को आसान बनाना
टीमों को सर्वर क्लस्टर मैनेज करने के बजाय प्रोग्रामिंग पर फ़ोकस करने की अनुमति दें, क्योंकि Dataflow के सर्वरलेस अप्रोच से डेटा इंजीनियरिंग के वर्कलोड से ऑपरेशनल ओवरहेड हट जाता है.
टोटल कॉस्ट ऑफ़ ओनरशिप कम करना
लागत के हिसाब से ऑप्टिमाइज़ की गई बैच प्रोसेसिंग की सुविधाओं के साथ-साथ, संसाधन अपने-आप स्केल होने की सुविधा का मतलब है कि Dataflow, आपके सीज़नल और अचानक बढ़ने वाले वर्कलोड को मैनेज करने के लिए, लगभग असीमित क्षमता देता है. इसके लिए, आपको ज़्यादा खर्च करने की ज़रूरत नहीं होती.
मुख्य सुविधाएं
अपने-आप संसाधन मैनेज होने और काम के हिसाब से कर्मचारियों को असाइन होने की सुविधा
Dataflow, प्रोसेसिंग संसाधनों को अपने-आप उपलब्ध कराता है और उन्हें मैनेज करता है, ताकि कम से कम समय में ज़्यादा से ज़्यादा काम किया जा सके. इससे आपको इंस्टेंस शुरू करने या उन्हें मैन्युअल तरीके से रिज़र्व करने की ज़रूरत नहीं पड़ती. काम को बांटने की प्रोसेस भी अपने-आप होती है. साथ ही, इसे ऑप्टिमाइज़ किया जाता है, ताकि काम को डाइनैमिक तरीके से फिर से बैलेंस किया जा सके. आपको "हॉट की" ढूंढने या इनपुट डेटा को पहले से प्रोसेस करने की ज़रूरत नहीं है.
हॉरिज़ॉन्टल ऑटोस्केलिंग
वर्कलोड को मैनेज करने वाले रिसॉर्स की हॉरिज़ॉन्टल ऑटोस्केलिंग से, थ्रूपुट के बेहतर नतीजे मिलते हैं. इससे, कीमत के हिसाब से बेहतर परफ़ॉर्मेंस मिलती है.
बैच प्रोसेसिंग के लिए, संसाधन शेड्यूल करने की सुविधा के लिए तय की गई कीमत
जॉब शेड्यूल करने के समय में फ़्लेक्सिबिलिटी के साथ प्रोसेसिंग करने के लिए, जैसे कि रात भर चलने वाले जॉब, फ़्लेक्सिबल रिसोर्स शेड्यूलिंग (FlexRS) बैच प्रोसेसिंग के लिए कम कीमत ऑफ़र करता है. इन फ़्लेक्सिबल जॉब को एक कतार में रखा जाता है. साथ ही, यह गारंटी दी जाती है कि इन्हें छह घंटे के अंदर प्रोसेस किया जाएगा.
आपको इस प्रोग्राम के तहत क्या-क्या चलाना होगा
JupyterLab नोटबुक के साथ Apache Beam इंटरैक्टिव रनर का इस्तेमाल करके, पाइपलाइन को बार-बार डेवलप किया जा सकता है. साथ ही, पाइपलाइन ग्राफ़ की जांच की जा सकती है. इसके अलावा, रीड-इवैल-प्रिंट-लूप (आरईपीएल) वर्कफ़्लो में अलग-अलग पीकलेक्शन को पार्स किया जा सकता है. ये Apache Beam नोटबुक, Vertex AI Workbench के ज़रिए उपलब्ध कराई जाती हैं. यह एक मैनेज की गई सेवा है. यह नोटबुक वर्चुअल मशीनों को होस्ट करती है. इनमें डेटा साइंस और मशीन लर्निंग के सबसे नए फ़्रेमवर्क पहले से इंस्टॉल होते हैं.
यह कोडलैब, Apache Beam नोटबुक की मदद से शुरू की गई सुविधा पर फ़ोकस करता है.
आपको क्या सीखने को मिलेगा
- नोटबुक इंस्टेंस बनाने का तरीका
- एक बुनियादी पाइपलाइन बनाना
- अनबाउंडेड सोर्स से डेटा पढ़ना
- डेटा को विज़ुअलाइज़ करना
- नोटबुक से डेटाफ़्लो जॉब लॉन्च करना
- नोटबुक सेव करना
आपको इन चीज़ों की ज़रूरत होगी
- बिलिंग की सुविधा वाला Google Cloud Platform प्रोजेक्ट.
- Google Cloud Dataflow और Google Cloud PubSub चालू हों.
2. सेट अप करना
- Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर जाकर, कोई Cloud प्रोजेक्ट चुनें या बनाएं.
पक्का करें कि आपने ये एपीआई चालू किए हों:
- Dataflow API
- Cloud Pub/Sub API
- Compute Engine
- Notebooks API
इसकी पुष्टि करने के लिए, एपीआई और सेवाएं पेज पर जाएं.
इस गाइड में, हम Pub/Sub सदस्यता से डेटा पढ़ेंगे. इसलिए, पक्का करें कि Compute Engine के डिफ़ॉल्ट सेवा खाते के पास एडिटर की भूमिका हो या उसे Pub/Sub एडिटर की भूमिका असाइन करें.
3. Apache Beam नोटबुक का इस्तेमाल शुरू करना
Apache Beam की नोटबुक का इंस्टेंस लॉन्च करना
- Console पर Dataflow लॉन्च करें:
- बाईं ओर मौजूद मेन्यू का इस्तेमाल करके, वर्कबेंच पेज चुनें.
- पक्का करें कि आप उपयोगकर्ता के मैनेज किए गए नोटबुक टैब पर हों.
- टूलबार में, नई नोटबुक पर क्लिक करें.
- Apache Beam > Without GPUs चुनें.
- नई नोटबुक पेज पर, नोटबुक वीएम के लिए कोई सबनेटवर्क चुनें. इसके बाद, बनाएं पर क्लिक करें.
- लिंक के चालू होने पर, JupyterLab खोलें पर क्लिक करें. Vertex AI Workbench, Apache Beam का नया नोटबुक इंस्टेंस बनाता है.
4. पाइपलाइन बनाना
नोटबुक इंस्टेंस बनाना
फ़ाइल > नया > नोटबुक पर जाएं और ऐसा कर्नल चुनें जो Apache Beam 2.47 या इसके बाद का हो.
अपनी नोटबुक में कोड जोड़ना शुरू करें
- अपनी नोटबुक में मौजूद नई सेल में, हर सेक्शन से कोड को कॉपी करके चिपकाएं
- सेल को चलाना

JupyterLab नोटबुक के साथ Apache Beam इंटरैक्टिव रनर का इस्तेमाल करके, पाइपलाइन को बार-बार डेवलप किया जा सकता है. साथ ही, पाइपलाइन ग्राफ़ की जांच की जा सकती है. इसके अलावा, रीड-इवैल-प्रिंट-लूप (आरईपीएल) वर्कफ़्लो में अलग-अलग पीकलेक्शन को पार्स किया जा सकता है.
Apache Beam, आपके नोटबुक इंस्टेंस पर इंस्टॉल है. इसलिए, अपनी नोटबुक में interactive_runner और interactive_beam मॉड्यूल शामिल करें.
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
अगर आपकी नोटबुक में Google की अन्य सेवाओं का इस्तेमाल किया जाता है, तो इंपोर्ट करने के ये स्टेटमेंट जोड़ें:
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
इंटरैक्टिविटी के विकल्प सेट करना
नीचे दिए गए कोड से, डेटा कैप्चर करने की अवधि 60 सेकंड पर सेट हो जाती है. अगर आपको तेज़ी से बदलाव करने हैं, तो इसे कम अवधि पर सेट करें. उदाहरण के लिए, ‘10 सेकंड'.
ib.options.recording_duration = '60s'
इंटरैक्टिव विकल्पों के बारे में ज़्यादा जानने के लिए, interactive_beam.options क्लास देखें.
InteractiveRunner ऑब्जेक्ट का इस्तेमाल करके, पाइपलाइन शुरू करें.
# Setting up the Apache Beam pipeline options.
options = pipeline_options.PipelineOptions()
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Sets the project to the default project in your current Google Cloud environment.
# The project will be used for creating a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
# The Google Cloud PubSub topic for this example.
topic = "projects/pubsub-public-data/topics/shakespeare-kinglear"
p = beam.Pipeline(InteractiveRunner(), options=options)
डेटा को पढ़ना और विज़ुअलाइज़ करना
यहां दिए गए उदाहरण में, Apache Beam पाइपलाइन दिखाई गई है. यह पाइपलाइन, दिए गए Pub/Sub विषय की सदस्यता बनाती है और सदस्यता से डेटा पढ़ती है.
words = p | "read" >> beam.io.ReadFromPubSub(topic=topic)
पाइपलाइन, सोर्स से विंडो के हिसाब से शब्दों की गिनती करती है. इससे फ़िक्स्ड विंडोइंग बनती है. हर विंडो की अवधि 10 सेकंड होती है.
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
डेटा को विंडो में बांटने के बाद, हर विंडो में शब्दों की संख्या गिनी जाती है.
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
डेटा को विज़ुअलाइज़ करना
show() तरीके से, नोटबुक में PCollection के नतीजे को विज़ुअलाइज़ किया जाता है.
ib.show(windowed_word_counts, include_window_info=True)

अपने डेटा के विज़ुअलाइज़ेशन दिखाने के लिए, visualize_data=True को show() तरीके में पास करें. नई सेल जोड़ें:
ib.show(windowed_word_counts, include_window_info=True, visualize_data=True)
अपने विज़ुअलाइज़ेशन में एक से ज़्यादा फ़िल्टर लागू किए जा सकते हैं. इस विज़ुअलाइज़ेशन में, लेबल और ऐक्सिस के हिसाब से फ़िल्टर किया जा सकता है:

5. Pandas Dataframe का इस्तेमाल करना
Apache Beam नोटबुक में एक और काम का विज़ुअलाइज़ेशन, Pandas DataFrame है. यहां दिए गए उदाहरण में, शब्दों को पहले छोटे अक्षरों में बदला जाता है. इसके बाद, हर शब्द की फ़्रीक्वेंसी का हिसाब लगाया जाता है.
windowed_lower_word_counts = (windowed_words
| "to lower case" >> beam.Map(lambda word: word.lower())
| "count lowered" >> beam.combiners.Count.PerElement())
collect() मेथड, आउटपुट को Pandas DataFrame में दिखाता है.
ib.collect(windowed_lower_word_counts, include_window_info=True)
6. (ज़रूरी नहीं) अपनी नोटबुक से Dataflow जॉब लॉन्च करना
- Dataflow पर जॉब चलाने के लिए, आपको कुछ और अनुमतियां चाहिए. पक्का करें कि Compute Engine के डिफ़ॉल्ट सेवा खाते के पास एडिटर की भूमिका हो. इसके अलावा, उसे आईएएम की ये भूमिकाएं दें:
- डेटाफ़्लो एडमिन
- Dataflow वर्कर
- स्टोरेज एडमिन, और
- Service Account User (roles/iam.serviceAccountUser)
भूमिकाओं के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
- (ज़रूरी नहीं) Dataflow जॉब चलाने के लिए अपनी नोटबुक का इस्तेमाल करने से पहले, कर्नल को रीस्टार्ट करें, सभी सेल को फिर से चलाएं, और आउटपुट की पुष्टि करें.
- इंपोर्ट करने के इन स्टेटमेंट को हटाएं:
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
- यह इंपोर्ट स्टेटमेंट जोड़ें:
from apache_beam.runners import DataflowRunner
- रिकॉर्डिंग की अवधि के इस विकल्प को हटाएं:
ib.options.recording_duration = '60s'
- अपने पाइपलाइन विकल्पों में इन्हें जोड़ें. आपको Cloud Storage की जगह में बदलाव करना होगा, ताकि वह उस बकेट की ओर पॉइंट करे जिसका मालिकाना हक आपके पास पहले से है. इसके अलावा, इस काम के लिए नई बकेट बनाई जा सकती है.
us-central1से भी क्षेत्र की वैल्यू बदली जा सकती है.
# Set the Google Cloud region to run Dataflow.
options.view_as(GoogleCloudOptions).region = 'us-central1'
# Choose a Cloud Storage location.
dataflow_gcs_location = 'gs://<change me>/dataflow'
# Choose a location for your output files
output_gcs_location = '%s/results/' % dataflow_gcs_location
# Set the staging location. This location is used to stage the
# Dataflow pipeline and SDK binary.
options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location
# Set the temporary location. This location is used to store temporary files
# or intermediate results before outputting to the sink.
options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location
beam.Pipeline()के कंस्ट्रक्टर में,InteractiveRunnerकोDataflowRunnerसे बदलें.pआपकी पाइपलाइन बनाने वाला पाइपलाइन ऑब्जेक्ट है.
p = beam.Pipeline(DataflowRunner(), options=options)
- अपने कोड से इंटरैक्टिव कॉल हटाएं. उदाहरण के लिए, अपने कोड से
show(),collect(),head(),show_graph(), औरwatch()हटाएं. - कोई भी नतीजा देखने के लिए, आपको सिंक जोड़ना होगा. पिछले सेक्शन में, हमने नोटबुक में नतीजों को विज़ुअलाइज़ किया था. हालांकि, इस बार हम इस नोटबुक के बाहर, Dataflow में जॉब चला रहे हैं. इसलिए, हमें अपने नतीजों के लिए किसी बाहरी जगह की जानकारी चाहिए. इस उदाहरण में, हम नतीजों को GCS (Google Cloud Storage) में मौजूद टेक्स्ट फ़ाइलों में लिखेंगे. यह एक स्ट्रीमिंग पाइपलाइन है, जिसमें डेटा विंडोइंग की सुविधा है. इसलिए, हम हर विंडो के लिए एक टेक्स्ट फ़ाइल बनाना चाहेंगे. इसके लिए, अपनी पाइपलाइन में यह तरीका जोड़ें:
result = (windowed_lower_word_counts
| "decode words and format" >> beam.Map(lambda x: f"{x[0].decode('utf-8')}: {x[1]}")
| "write events to file" >> beam.io.fileio.WriteToFiles(path=output_gcs_location, shards=1, max_writers_per_bundle=0))
- अपने पाइपलाइन कोड के आखिर में
p.run()जोड़ें. - अब अपने नोटबुक कोड की समीक्षा करें, ताकि यह पुष्टि की जा सके कि आपने सभी बदलाव शामिल कर लिए हैं. यह कुछ ऐसा दिखना चाहिए:
import apache_beam as beam
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
from apache_beam.runners import DataflowRunner
# Setting up the Apache Beam pipeline options.
options = pipeline_options.PipelineOptions()
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Sets the project to the default project in your current Google Cloud environment.
# The project will be used for creating a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
# Set the Google Cloud region to run Dataflow.
options.view_as(GoogleCloudOptions).region = 'us-central1'
# Choose a Cloud Storage location.
dataflow_gcs_location = 'gs://<change me>/dataflow'
# Choose a location for your output files
output_gcs_location = '%s/results/' % dataflow_gcs_location
# Set the staging location. This location is used to stage the
# Dataflow pipeline and SDK binary.
options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location
# Set the temporary location. This location is used to store temporary files
# or intermediate results before outputting to the sink.
options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location
# The Google Cloud PubSub topic for this example.
topic = "projects/pubsub-public-data/topics/shakespeare-kinglear"
p = beam.Pipeline(DataflowRunner(), options=options)
words = p | "read" >> beam.io.ReadFromPubSub(topic=topic)
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
windowed_words_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
windowed_lower_word_counts = (windowed_words
| "to lower case" >> beam.Map(lambda word: word.lower())
| "count lowered" >> beam.combiners.Count.PerElement())
result = (windowed_lower_word_counts
| "decode words and format" >> beam.Map(lambda x: f"{x[0].decode('utf-8')}: {x[1]}")
| "write events to file" >> beam.io.fileio.WriteToFiles(path=output_gcs_location, shards=1, max_writers_per_bundle=0))
p.run()
- सेल चलाएं.
- आपको इससे मिलता-जुलता आउटपुट दिखेगा:
<DataflowPipelineResult <Job
clientRequestId: '20230623100011457336-8998'
createTime: '2023-06-23T10:00:33.447347Z'
currentStateTime: '1970-01-01T00:00:00Z'
id: '2023-06-23_03_00_33-11346237320103246437'
location: 'us-central1'
name: 'beamapp-root-0623075553-503897-boh4u4wb'
projectId: 'your-project-id'
stageStates: []
startTime: '2023-06-23T10:00:33.447347Z'
steps: []
tempFiles: []
type: TypeValueValuesEnum(JOB_TYPE_STREAMING, 2)> at 0x7fc7e4084d60>
- यह पुष्टि करने के लिए कि जॉब चल रही है, Dataflow के जॉब पेज पर जाएं. आपको सूची में एक नया काम दिखेगा. डेटा को प्रोसेस करने में, जॉब को करीब ~5 से 10 मिनट लगेंगे.
- डेटा प्रोसेस होने के बाद, Cloud Storage पर जाएं. इसके बाद, उस डायरेक्ट्री पर जाएं जहां Dataflow, नतीजे सेव कर रहा है (आपके हिसाब से तय की गई
output_gcs_location). आपको टेक्स्ट फ़ाइलों की एक सूची दिखेगी. हर विंडो के लिए एक फ़ाइल होगी.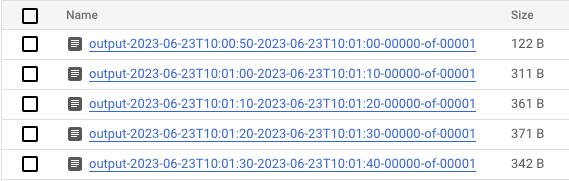
- फ़ाइल डाउनलोड करें और कॉन्टेंट की जांच करें. इसमें शब्दों की सूची और उनकी संख्या होनी चाहिए. इसके अलावा, फ़ाइलों की जांच करने के लिए कमांड लाइन इंटरफ़ेस का इस्तेमाल करें. इसके लिए, अपनी नोटबुक की नई सेल में यह कोड चलाएं:
! gsutils cat gs://<your-bucket-here>/results/<file-name>
- आपको इससे मिलता-जुलता आउटपुट दिखेगा:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- हो गया! आपने जो जॉब बनाई है उसे बंद करना और साफ़ करना न भूलें. इसके लिए, इस कोडलैब का आखिरी चरण देखें.
इंटरैक्टिव नोटबुक पर इस कन्वर्ज़न को करने के तरीके का उदाहरण देखने के लिए, अपने नोटबुक इंस्टेंस में Dataflow Word Count नोटबुक देखें.
इसके अलावा, अपनी नोटबुक को एक्ज़ीक्यूटेबल स्क्रिप्ट के तौर पर एक्सपोर्ट किया जा सकता है. इसके बाद, पिछले चरणों का इस्तेमाल करके जनरेट की गई .py फ़ाइल में बदलाव किया जा सकता है. इसके बाद, Dataflow सेवा में अपनी पाइपलाइन डिप्लॉय करें.
7. आपकी नोटबुक सेव की जा रही है
आपकी बनाई गई नोटबुक, आपके चालू नोटबुक इंस्टेंस में सेव की जाती हैं. अगर डेवलपमेंट के दौरान, नोटबुक इंस्टेंस को रीसेट या बंद कर दिया जाता है, तो नई नोटबुक तब तक बनी रहती हैं, जब तक उन्हें /home/jupyter डायरेक्ट्री में बनाया जाता है. हालांकि, अगर किसी नोटबुक इंस्टेंस को मिटा दिया जाता है, तो उससे जुड़ी नोटबुक भी मिट जाती हैं.
नोटबुक को आने वाले समय में इस्तेमाल करने के लिए, उन्हें अपने वर्कस्टेशन पर डाउनलोड करें, GitHub में सेव करें या किसी दूसरे फ़ाइल फ़ॉर्मैट में एक्सपोर्ट करें.
8. स्टोरेज खाली करना
Apache Beam नोटबुक इंस्टेंस का इस्तेमाल करने के बाद, Google Cloud पर बनाए गए संसाधनों को मिटा दें. इसके लिए, नोटबुक इंस्टेंस बंद करें और अगर आपने कोई स्ट्रीमिंग जॉब चलाई है, तो उसे बंद करें.
इसके अलावा, अगर आपने इस कोडलैब के लिए कोई प्रोजेक्ट बनाया है, तो उसे पूरी तरह से बंद भी किया जा सकता है.