
1. Giriş

Google Cloud Dataflow
Last Updated: 2023-Jul-5
Dataflow nedir?
Dataflow, çeşitli veri işleme kalıplarını yürütmek için kullanılan yönetilen bir hizmettir. Bu sitedeki dokümanlarda, hizmet özelliklerinin kullanımıyla ilgili talimatlar da dahil olmak üzere, Dataflow'u kullanarak toplu ve akış veri işleme ardışık düzenlerinizi nasıl dağıtacağınız gösterilmektedir.
Apache Beam SDK, hem toplu işleme hem de akış ardışık düzenleri geliştirmenize olanak tanıyan açık kaynaklı bir programlama modelidir. Ardışık düzenlerinizi Apache Beam programıyla oluşturur ve ardından Dataflow hizmetinde çalıştırırsınız. Apache Beam dokümanlarında, Apache Beam programlama modeli, SDK'lar ve diğer çalıştırıcılar hakkında ayrıntılı kavramsal bilgiler ve referans materyalleri yer alır.
Hızlı akış verisi analizi
Dataflow daha düşük veri gecikmesiyle hızlı, basitleştirilmiş akış veri ardışık düzeni geliştirilebilmesini sağlar.
İşlemleri ve yönetimi basitleştirin
Dataflow'un sunucusuz yaklaşımı, veri mühendisliği iş yüklerindeki ek işlem yükünü ortadan kaldırır. Böylece ekiplerin sunucu kümelerini yönetmek yerine programlamaya zaman ayırabilmesini sağlayabilirsiniz.
Toplam mülkiyet maliyetini düşürme
Otomatik kaynak ölçeklendirme ile maliyet açısından optimize edilmiş toplu işlem özelliğinin bir arada sunulması, Dataflow'un sezonluk ve ani artışlar gösteren iş yüklerinizi aşırı harcama yapmadan yönetme konusunda neredeyse sınırsız bir kapasite sunduğu anlamına gelir.
Temel özellikler
Otomatik kaynak yönetimi ve dinamik iş dengeleme
Dataflow, gecikme süresini azaltmak ve kullanımı en üst düzeye çıkarmak için kaynak işleme süreçlerinin sağlanmasını ve yönetimini otomatik hale getirir. Böylece örnekleri hızla başlatmanıza veya elle ayırmanıza gerek kalmaz. İş bölümlendirme, geciken işleri dinamik olarak yeniden dengelemek için otomatik hale getirilmiş ve optimize edilmiştir. "Kısayol tuşları" aramanıza veya giriş verilerini önceden işlemenize gerek yoktur.
Yatay otomatik ölçeklendirme
Optimum işleme hızı için çalışan kaynaklarının yatay olarak otomatik ölçeklendirilmesi, genel fiyat-performans oranını iyileştirir.
Toplu işlem için esnek kaynak planlama fiyatlandırması
Gece devam etmesi gereken işlerde olduğu gibi iş planlama süresinde esneklik ile işlem yapmak için esnek kaynak planlama (FlexRS) imkanı, toplu işlem için daha düşük bir fiyat sunar. Bu esnek işler, altı saatlik süre içinde yürütmeye alınacakları garantisiyle bir kuyruğa yerleştirilir.
Bu işlem kapsamında çalıştırılacaklar
Apache Beam etkileşimli çalıştırıcısını JupyterLab not defterleriyle kullanarak ardışık düzenleri yinelemeli olarak geliştirebilir, ardışık düzen grafiğinizi inceleyebilir ve oku-değerlendir-yazdır-başa dön (REPL) iş akışında tek tek PCollection'ları ayrıştırabilirsiniz. Bu Apache Beam not defterleri, en yeni veri bilimi ve makine öğrenimi çerçevelerinin önceden yüklü olduğu not defteri sanal makinelerini barındıran, yönetilen bir hizmet olan Vertex AI Workbench üzerinden kullanılabilir.
Bu codelab, Apache Beam not defterlerinin sunduğu işlevlere odaklanmaktadır.
Neler öğreneceksiniz?
- Not defteri örneği oluşturma
- Temel bir ardışık düzen oluşturma
- Sınırsız kaynaktan veri okuma
- Verileri görselleştirme
- Not defterinden Dataflow işi başlatma
- Not defteri kaydetme
Gerekenler
- Faturalandırmanın etkin olduğu bir Google Cloud Platform projesi.
- Google Cloud Dataflow ve Google Cloud PubSub etkinleştirilmiş olmalıdır.
2. Hazırlanma
- Cloud Console'da, proje seçici sayfasında bir Cloud projesi seçin veya oluşturun.
Aşağıdaki API'lerin etkinleştirildiğinden emin olun:
- Dataflow API
- Cloud Pub/Sub API
- Compute Engine
- Notebooks API
API'ler ve Hizmetler sayfasını kontrol ederek bunu doğrulayabilirsiniz.
Bu kılavuzda, Pub/Sub aboneliğinden veri okuyacağız. Bu nedenle, Compute Engine varsayılan hizmet hesabının Düzenleyici rolüne sahip olduğundan emin olun veya hesaba Pub/Sub Düzenleyici rolünü verin.
3. Apache Beam not defterlerini kullanmaya başlama
Apache Beam not defteri örneği başlatma
- Console'da Dataflow'u başlatın:
- Soldaki menüyü kullanarak Workbench sayfasını seçin.
- User-managed notebooks (Kullanıcı tarafından yönetilen not defterleri) sekmesinde olduğunuzdan emin olun.
- Araç çubuğunda Yeni Not Defteri'ni tıklayın.
- Apache Beam > Without GPUs'u (GPU'suz) seçin.
- Yeni not defteri sayfasında, not defteri sanal makinesi için bir alt ağ seçin ve Oluştur'u tıklayın.
- Bağlantı etkinleştiğinde Open JupyterLab'i (JupyterLab'i aç) tıklayın. Vertex AI Workbench, yeni bir Apache Beam not defteri örneği oluşturur.
4. Ardışık düzeni oluşturma
Not defteri örneği oluşturma
Dosya > Yeni > Not Defteri'ne gidin ve Apache Beam 2.47 veya sonraki bir sürümünü içeren bir çekirdek seçin.
Not defterinize kod eklemeye başlama
- Her bölümdeki kodu kopyalayıp not defterinizdeki yeni bir hücreye yapıştırın.
- Hücreyi çalıştırma

Apache Beam etkileşimli çalıştırıcısını JupyterLab not defterleriyle kullanarak ardışık düzenleri yinelemeli olarak geliştirebilir, ardışık düzen grafiğinizi inceleyebilir ve oku-değerlendir-yazdır-başa dön (REPL) iş akışında tek tek PCollection'ları ayrıştırabilirsiniz.
Apache Beam, not defteri örneğinize yüklenir. Bu nedenle, interactive_runner ve interactive_beam modüllerini not defterinize ekleyin.
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
Not defterinizde diğer Google hizmetleri kullanılıyorsa aşağıdaki içe aktarma ifadelerini ekleyin:
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
Etkileşim seçeneklerini ayarlama
Aşağıdaki kod, veri yakalama süresini 60 saniye olarak ayarlar. Daha hızlı yineleme yapmak istiyorsanız süreyi daha düşük bir değere (ör. "10 sn") ayarlayın.
ib.options.recording_duration = '60s'
Ek etkileşimli seçenekler için interactive_beam.options sınıfına bakın.
Ardışık düzeni bir InteractiveRunner nesnesi kullanarak başlatın.
# Setting up the Apache Beam pipeline options.
options = pipeline_options.PipelineOptions()
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Sets the project to the default project in your current Google Cloud environment.
# The project will be used for creating a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
# The Google Cloud PubSub topic for this example.
topic = "projects/pubsub-public-data/topics/shakespeare-kinglear"
p = beam.Pipeline(InteractiveRunner(), options=options)
Verileri okuma ve görselleştirme
Aşağıdaki örnekte, verilen Pub/Sub konusuna abonelik oluşturan ve abonelikten okuma yapan bir Apache Beam ardışık düzeni gösterilmektedir.
words = p | "read" >> beam.io.ReadFromPubSub(topic=topic)
İşlem hattı, kaynakta kelimeleri pencerelere göre sayar. Her pencerenin 10 saniye sürdüğü sabit bir pencereleme oluşturur.
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
Veriler aralıklandırıldıktan sonra kelimeler aralığa göre sayılır.
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
Verileri görselleştirme
show() yöntemi, sonuçta elde edilen PCollection'ı not defterinde görselleştirir.
ib.show(windowed_word_counts, include_window_info=True)
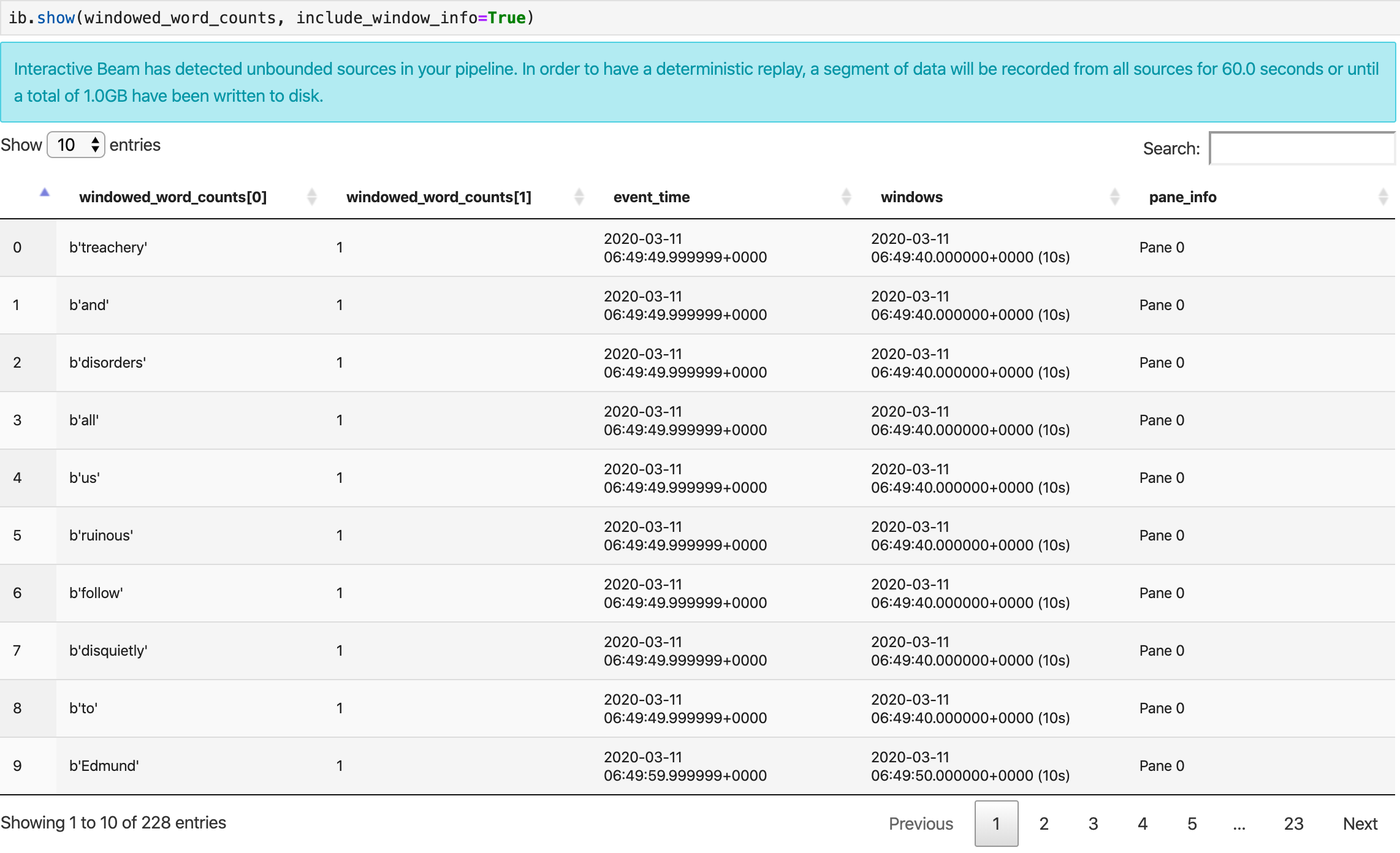
Verilerinizin görselleştirmelerini göstermek için visualize_data=True değerini show() yöntemine iletin. Yeni hücre ekleme:
ib.show(windowed_word_counts, include_window_info=True, visualize_data=True)
Görselleştirmelerinize birden fazla filtre uygulayabilirsiniz. Aşağıdaki görselleştirme, etikete ve eksene göre filtreleme yapmanıza olanak tanır:

5. Pandas DataFrame kullanma
Apache Beam not defterlerindeki bir diğer yararlı görselleştirme Pandas DataFrame'dir. Aşağıdaki örnekte önce kelimeler küçük harfe dönüştürülür, ardından her kelimenin sıklığı hesaplanır.
windowed_lower_word_counts = (windowed_words
| "to lower case" >> beam.Map(lambda word: word.lower())
| "count lowered" >> beam.combiners.Count.PerElement())
collect() yöntemi, çıkışı Pandas DataFrame'de sağlar.
ib.collect(windowed_lower_word_counts, include_window_info=True)
6. (İsteğe bağlı) Not defterinizden Dataflow işleri başlatma
- Dataflow'da iş çalıştırmak için ek izinlere ihtiyacınız vardır. Compute Engine varsayılan hizmet hesabının Düzenleyici rolüne sahip olduğundan emin olun veya hesaba aşağıdaki IAM rollerini verin:
- Dataflow Yöneticisi
- Dataflow Çalışanı
- Depolama Alanı Yöneticisi ve
- Hizmet Hesabı Kullanıcısı (roles/iam.serviceAccountUser)
Roller hakkında daha fazla bilgiyi belgelerde bulabilirsiniz.
- (İsteğe bağlı) Not defterinizi Dataflow işlerini çalıştırmak için kullanmadan önce çekirdeği yeniden başlatın, tüm hücreleri yeniden çalıştırın ve çıkışı doğrulayın.
- Aşağıdaki içe aktarma ifadelerini kaldırın:
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
- Aşağıdaki içe aktarma ifadesini ekleyin:
from apache_beam.runners import DataflowRunner
- Aşağıdaki kayıt süresi seçeneğini kaldırın:
ib.options.recording_duration = '60s'
- Aşağıdakileri işlem hattı seçeneklerinize ekleyin. Cloud Storage konumunu, zaten sahip olduğunuz bir paketi işaret edecek şekilde ayarlamanız veya bu amaçla yeni bir paket oluşturmanız gerekir. Bölge değerini
us-central1simgesinden de değiştirebilirsiniz.
# Set the Google Cloud region to run Dataflow.
options.view_as(GoogleCloudOptions).region = 'us-central1'
# Choose a Cloud Storage location.
dataflow_gcs_location = 'gs://<change me>/dataflow'
# Choose a location for your output files
output_gcs_location = '%s/results/' % dataflow_gcs_location
# Set the staging location. This location is used to stage the
# Dataflow pipeline and SDK binary.
options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location
# Set the temporary location. This location is used to store temporary files
# or intermediate results before outputting to the sink.
options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location
beam.Pipeline()oluşturucusundaInteractiveRunnerdeğeriniDataflowRunnerile değiştirin.p, ardışık düzeninizi oluştururken kullanılan ardışık düzen nesnesidir.
p = beam.Pipeline(DataflowRunner(), options=options)
- Etkileşimli çağrıları kodunuzdan kaldırın. Örneğin, kodunuzdan
show(),collect(),head(),show_graph()vewatch()karakterlerini kaldırın. - Sonuçları görebilmek için bir havuz eklemeniz gerekir. Önceki bölümde sonuçları not defterinde görselleştiriyorduk ancak bu kez işi bu not defterinin dışında, Dataflow'da çalıştırıyoruz. Bu nedenle, sonuçlarımız için harici bir konuma ihtiyacımız var. Bu örnekte, sonuçları GCS'deki (Google Cloud Storage) metin dosyalarına yazacağız. Bu bir akış hattı olduğundan ve veri pencereleme kullanıldığından pencere başına bir metin dosyası oluşturmamız gerekir. Bunu yapmak için işlem hattınıza aşağıdaki adımları ekleyin:
result = (windowed_lower_word_counts
| "decode words and format" >> beam.Map(lambda x: f"{x[0].decode('utf-8')}: {x[1]}")
| "write events to file" >> beam.io.fileio.WriteToFiles(path=output_gcs_location, shards=1, max_writers_per_bundle=0))
p.run()simgesini işlem hattı kodunuzun sonuna ekleyin.- Şimdi tüm değişiklikleri eklediğinizi onaylamak için not defteri kodunuzu inceleyin. Şuna benzer görünmelidir:
import apache_beam as beam
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
from apache_beam.runners import DataflowRunner
# Setting up the Apache Beam pipeline options.
options = pipeline_options.PipelineOptions()
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Sets the project to the default project in your current Google Cloud environment.
# The project will be used for creating a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
# Set the Google Cloud region to run Dataflow.
options.view_as(GoogleCloudOptions).region = 'us-central1'
# Choose a Cloud Storage location.
dataflow_gcs_location = 'gs://<change me>/dataflow'
# Choose a location for your output files
output_gcs_location = '%s/results/' % dataflow_gcs_location
# Set the staging location. This location is used to stage the
# Dataflow pipeline and SDK binary.
options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location
# Set the temporary location. This location is used to store temporary files
# or intermediate results before outputting to the sink.
options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location
# The Google Cloud PubSub topic for this example.
topic = "projects/pubsub-public-data/topics/shakespeare-kinglear"
p = beam.Pipeline(DataflowRunner(), options=options)
words = p | "read" >> beam.io.ReadFromPubSub(topic=topic)
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
windowed_words_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
windowed_lower_word_counts = (windowed_words
| "to lower case" >> beam.Map(lambda word: word.lower())
| "count lowered" >> beam.combiners.Count.PerElement())
result = (windowed_lower_word_counts
| "decode words and format" >> beam.Map(lambda x: f"{x[0].decode('utf-8')}: {x[1]}")
| "write events to file" >> beam.io.fileio.WriteToFiles(path=output_gcs_location, shards=1, max_writers_per_bundle=0))
p.run()
- Hücreleri çalıştırın.
- Aşağıdakine benzer bir çıkış alırsınız:
<DataflowPipelineResult <Job
clientRequestId: '20230623100011457336-8998'
createTime: '2023-06-23T10:00:33.447347Z'
currentStateTime: '1970-01-01T00:00:00Z'
id: '2023-06-23_03_00_33-11346237320103246437'
location: 'us-central1'
name: 'beamapp-root-0623075553-503897-boh4u4wb'
projectId: 'your-project-id'
stageStates: []
startTime: '2023-06-23T10:00:33.447347Z'
steps: []
tempFiles: []
type: TypeValueValuesEnum(JOB_TYPE_STREAMING, 2)> at 0x7fc7e4084d60>
- İşin çalışıp çalışmadığını doğrulamak için Dataflow'un İşler sayfasına gidin. Listede yeni bir iş görmeniz gerekir. İşin verileri işlemeye başlaması yaklaşık 5-10 dakika sürer.
- Veriler işlendikten sonra Cloud Storage'a gidin ve Dataflow'un sonuçları depoladığı dizine (tanımladığınız
output_gcs_location) gidin. Pencere başına bir dosya olacak şekilde metin dosyalarının listesini görürsünüz.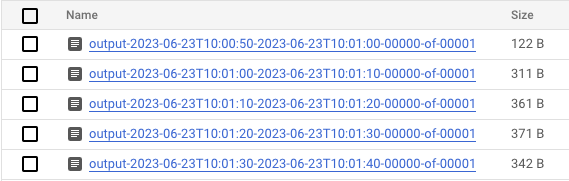
- Dosyayı indirip içeriği inceleyin. Bu dosya, sayılarıyla birlikte eşleştirilmiş kelimelerin listesini içermelidir. Alternatif olarak, dosyaları incelemek için komut satırı arayüzünü kullanın. Bu işlemi, not defterinizdeki yeni bir hücrede aşağıdakileri çalıştırarak yapabilirsiniz:
! gsutils cat gs://<your-bucket-here>/results/<file-name>
- Şuna benzer bir çıkış görürsünüz:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- İşte bu kadar. Oluşturduğunuz işi temizlemeyi ve durdurmayı unutmayın (bu codelab'in son adımına bakın).
Etkileşimli bir not defterinde bu dönüşümün nasıl yapılacağına dair bir örnek için not defteri örneğinizdeki Dataflow Word Count not defterine bakın.
Alternatif olarak, not defterinizi yürütülebilir bir komut dosyası olarak dışa aktarabilir, oluşturulan .py dosyasını önceki adımları kullanarak değiştirebilir ve ardından iş hattınızı Dataflow hizmetine dağıtabilirsiniz.
7. Not defterinizi kaydetme
Oluşturduğunuz not defterleri, çalıştırdığınız not defteri örneğine yerel olarak kaydedilir. Geliştirme sırasında not defteri örneğini sıfırlarsanız veya kapatırsanız bu yeni not defterleri, /home/jupyter dizini altında oluşturuldukları sürece kalıcı olarak saklanır. Ancak bir not defteri örneği silinirse bu not defterleri de silinir.
Not defterlerinizi ileride kullanmak üzere saklamak için bunları iş istasyonunuza yerel olarak indirin, GitHub'a kaydedin veya farklı bir dosya biçimine aktarın.
8. Temizleme
Apache Beam not defteri örneğinizi kullanmayı bitirdikten sonra, Google Cloud'da oluşturduğunuz kaynakları temizlemek için not defteri örneğini kapatın ve çalıştırdıysanız akış işini durdurun.
Alternatif olarak, yalnızca bu codelab için bir proje oluşturduysanız projeyi tamamen kapatabilirsiniz.