
1. Introduction
Document AI is a document understanding solution that takes unstructured data, such as documents, emails, and so on, and makes the data easier to understand, analyze, and consume.
With Document AI Workbench, you can achieve higher document processing accuracy by creating fully customized models using your own training data.
In this lab, you will create a Custom Document Extraction processor, import a dataset, label example documents, and train the processor.
The document dataset used in this lab is from a Fake W-2 (US Tax Form) Dataset on Kaggle with a CC0: Public Domain License.
Prerequisites
This codelab builds upon content presented in other Document AI Codelabs.
It is recommended that you complete the following Codelabs before proceeding.
- Optical Character Recognition (OCR) with Document AI (Python)
- Form Parsing with Document AI (Python)
- Specialized Processors with Document AI (Python)
- Managing Document AI processors with Python
- Document AI: Human in the Loop
- Document AI: Uptraining
What you'll learn
- Create a Custom Document Extractor processor.
- Label Document AI training data using the annotation tool.
- Train a new model version.
- Evaluate the accuracy of the new model version.
What you'll need
2. Getting set up
This codelab assumes you have completed the Document AI Setup steps listed in the Introductory Codelab.
Please complete the following steps before proceeding:
3. Create a Processor
You must first create a Custom Document Extractor processor to use for this lab.
- In the console, navigate to the Document AI Overview page.
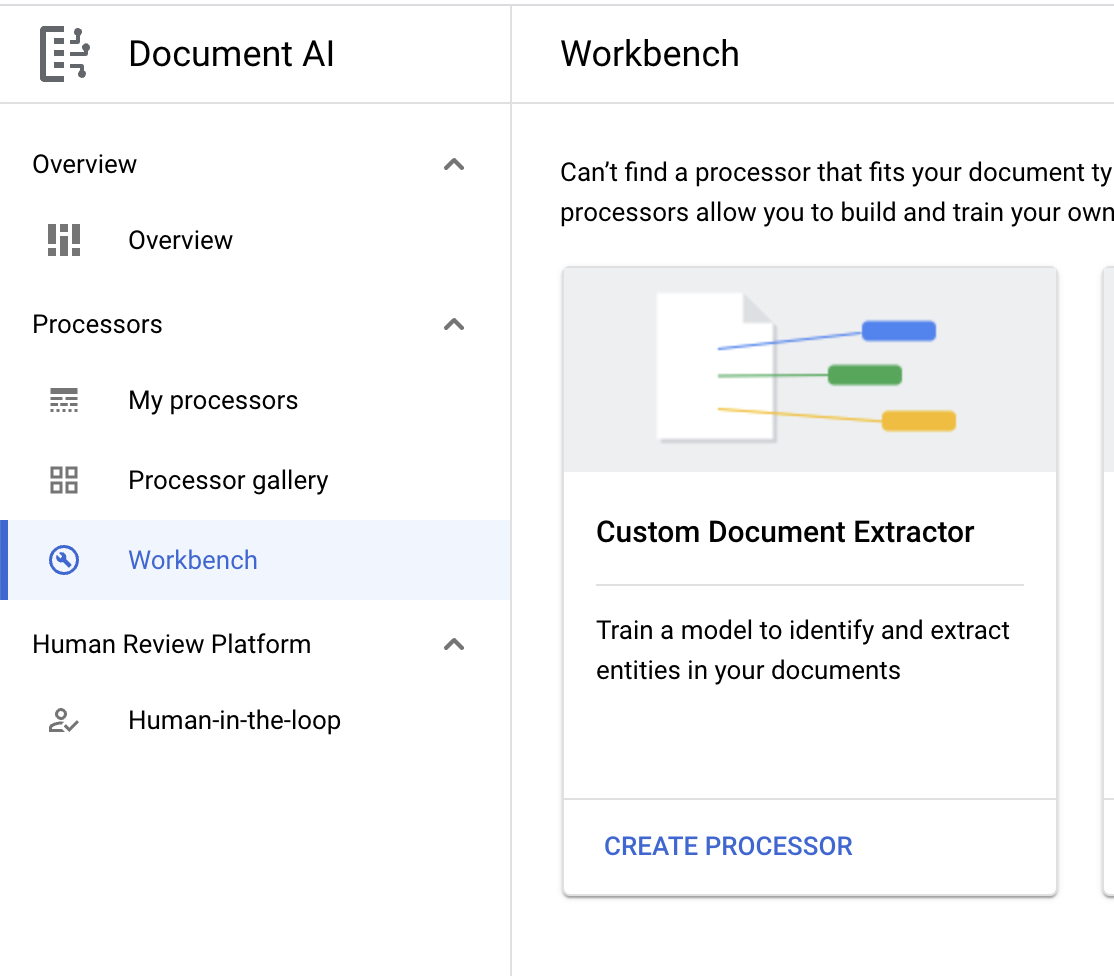
- Click Create Custom Processor and select Custom Document Extractor.
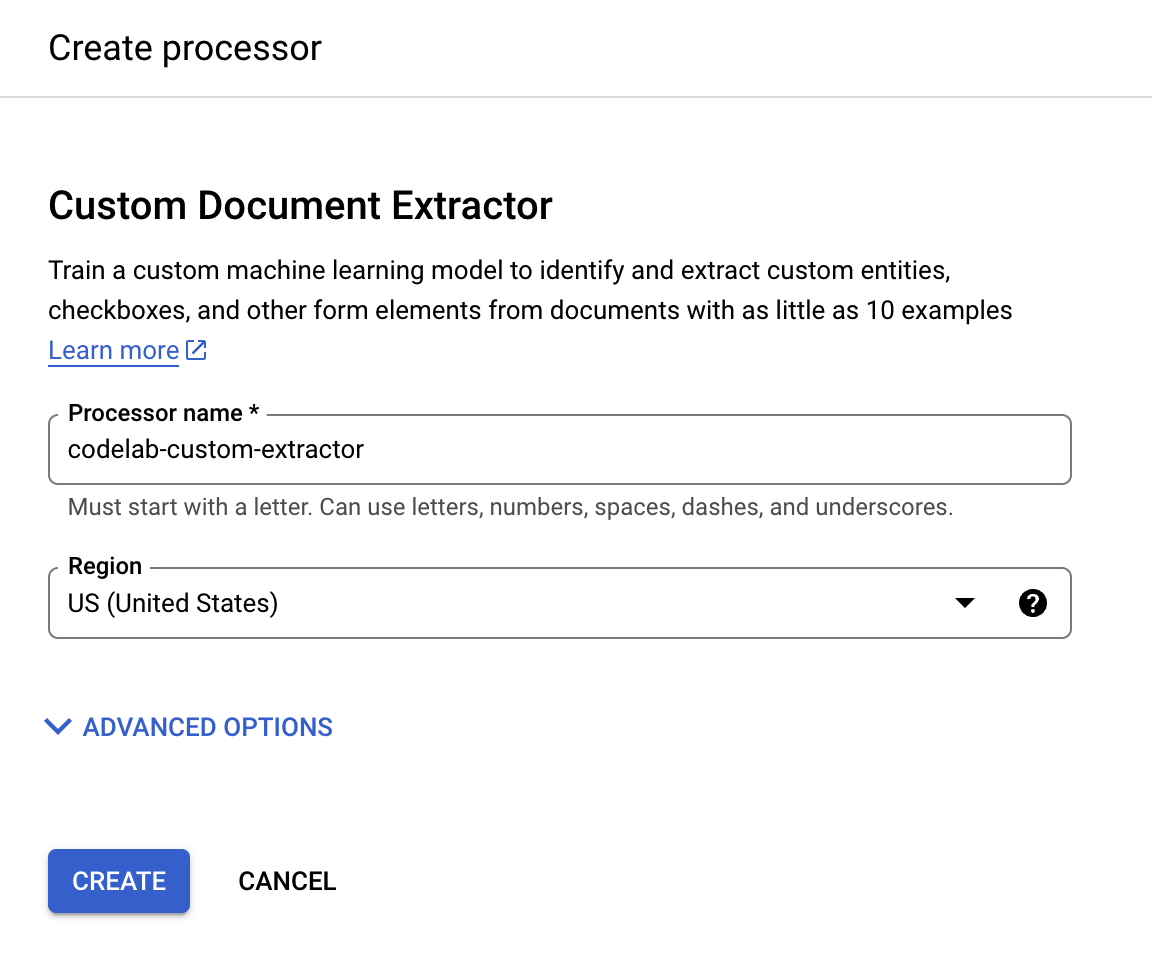
- Give it the name
codelab-custom-extractor(Or something else you'll remember) and select the closest region on the list.
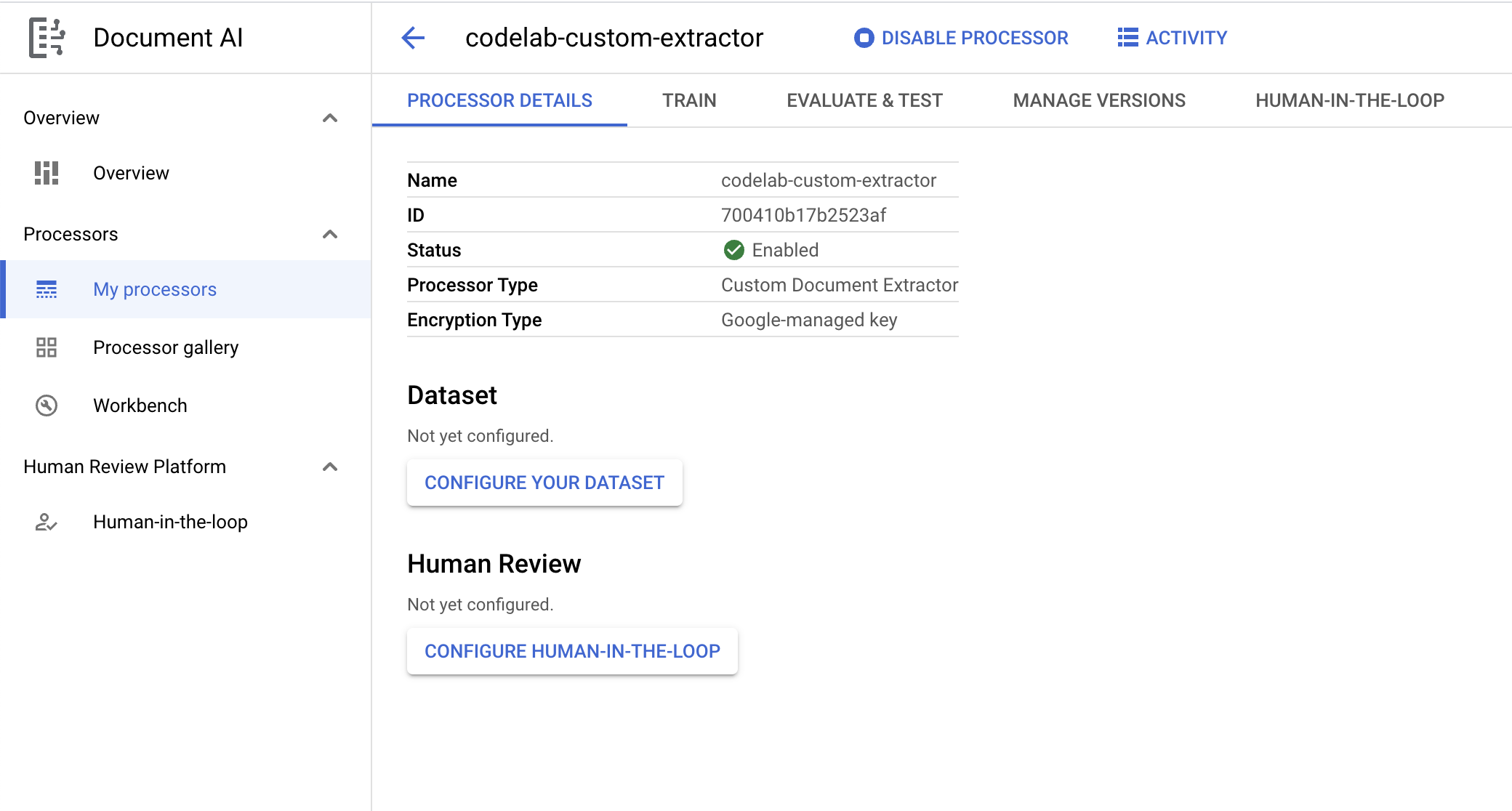
- Click Create to create your processor. You should then see the Processor Overview page.
4. Create a Dataset
In order to train our processor, we will have to create a dataset with training and testing data to help the processor identify the entities we want to extract.
- On the Processor Overview page, click on Configure Your Dataset.
- You should now be on the Configure Dataset page. If you want to specify your own bucket to store the training documents and labels, click on Show Advanced Options. Otherwise, just click Continue.
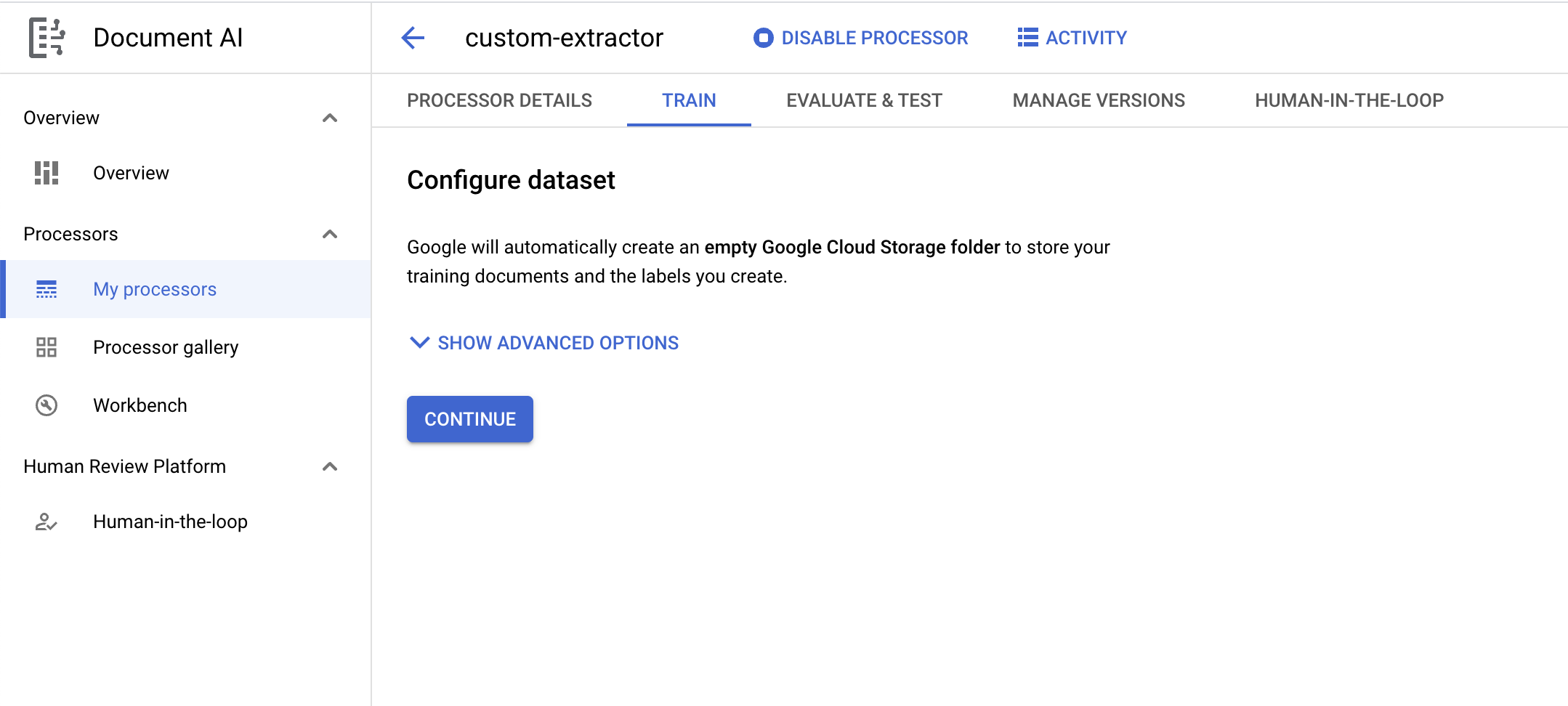
- Wait for the dataset to be created, then it should direct you to the Training page.
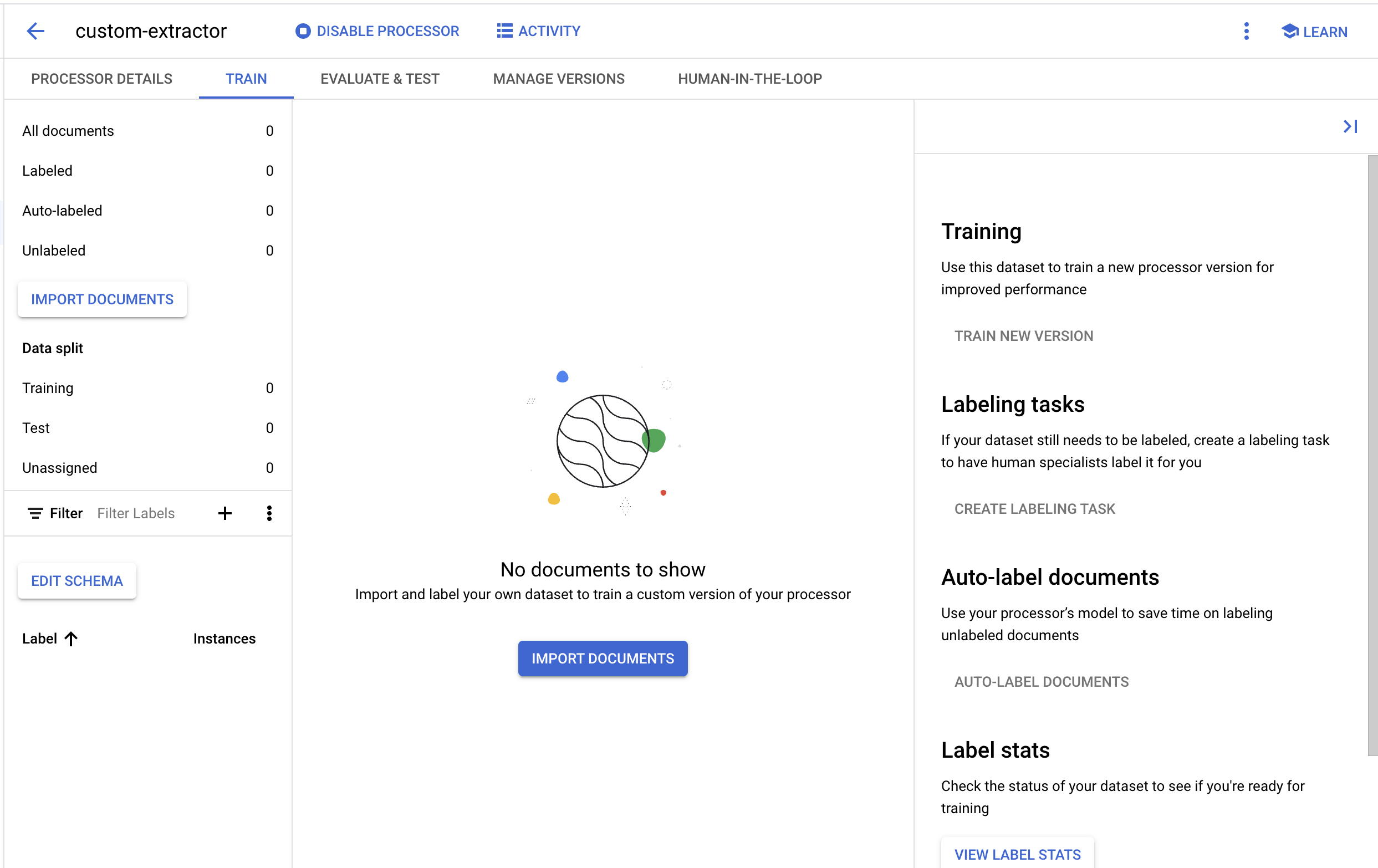
5. Import a Test Document
Now, let's import a sample W2 pdf into our dataset.
- Click on Import Documents
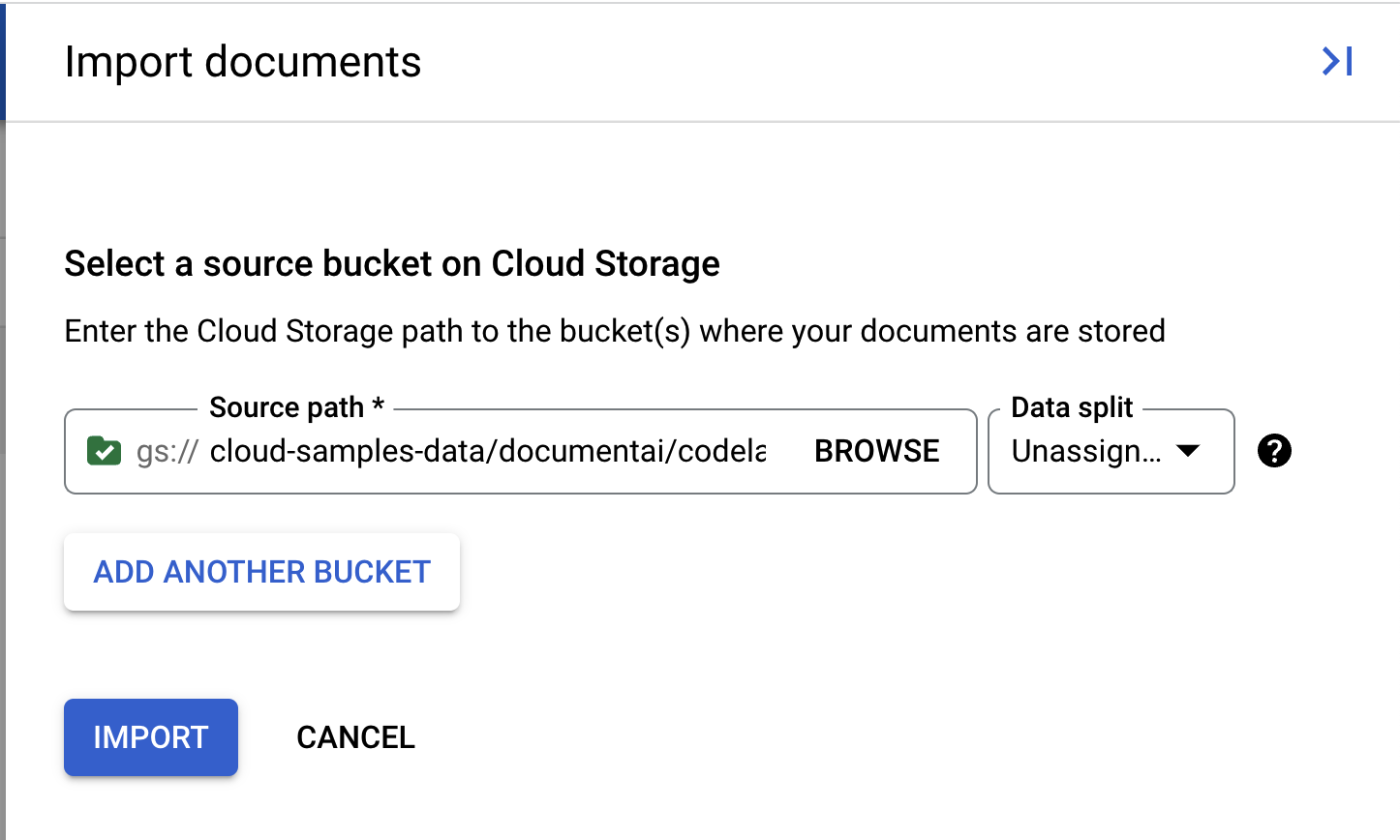
- We have a sample PDF for you to use in this lab. Copy and paste the following link into the Source Path box. Leave the "Data split" as "Unassigned" for now. Leave all other boxes unchecked. Click Import.
cloud-samples-data/documentai/codelabs/custom/extractor/pdfs
- Wait for the document to import. This should take less than 1 minute.
- When the import completes, you should see the Document in the Training page.
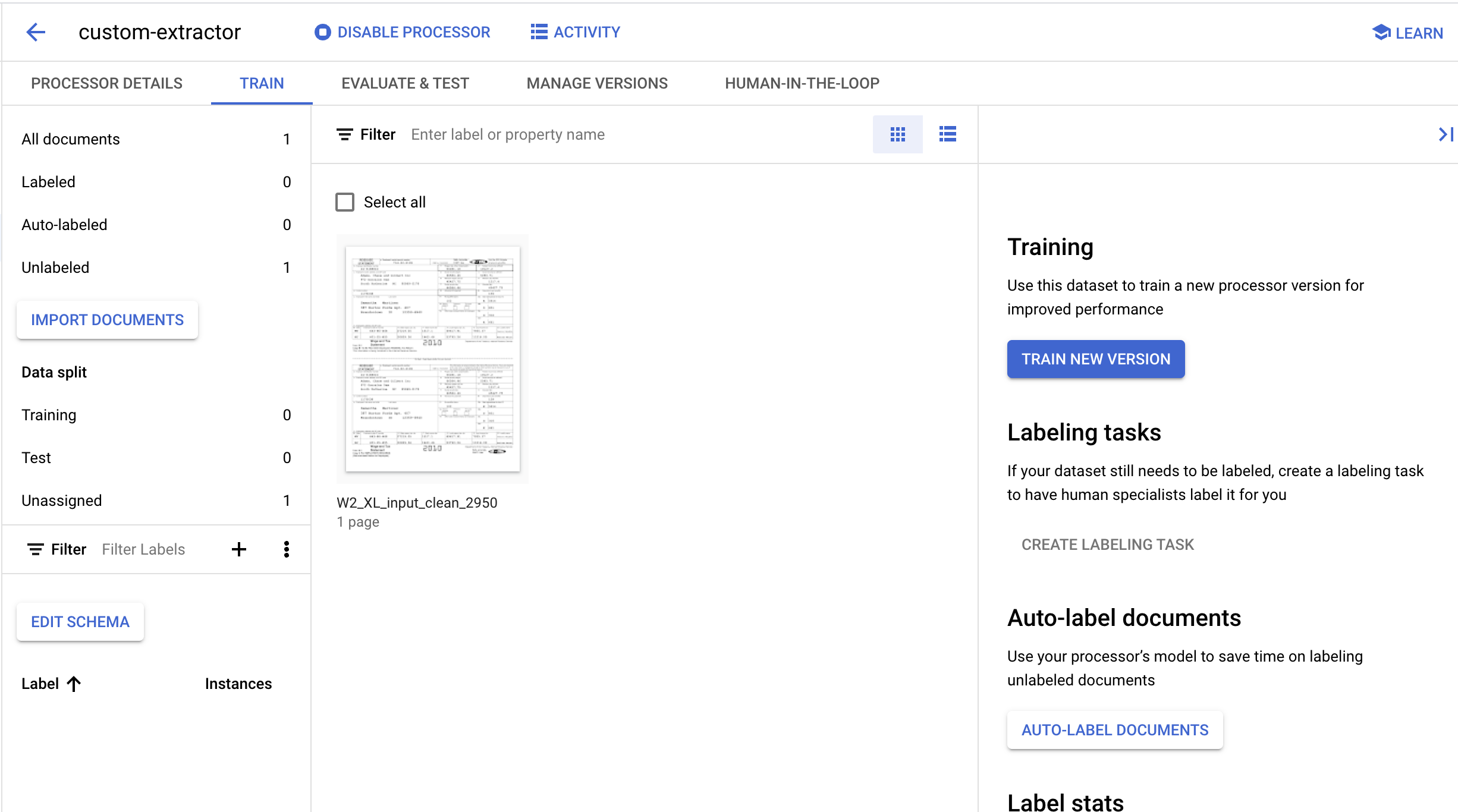
6. Create Labels
Since we are creating a new processor type, will need to create custom labels to tell Document AI which fields we want to extract.
- Click on Edit Schema in the bottom-left corner.
- You should now be in the Schema Management console.
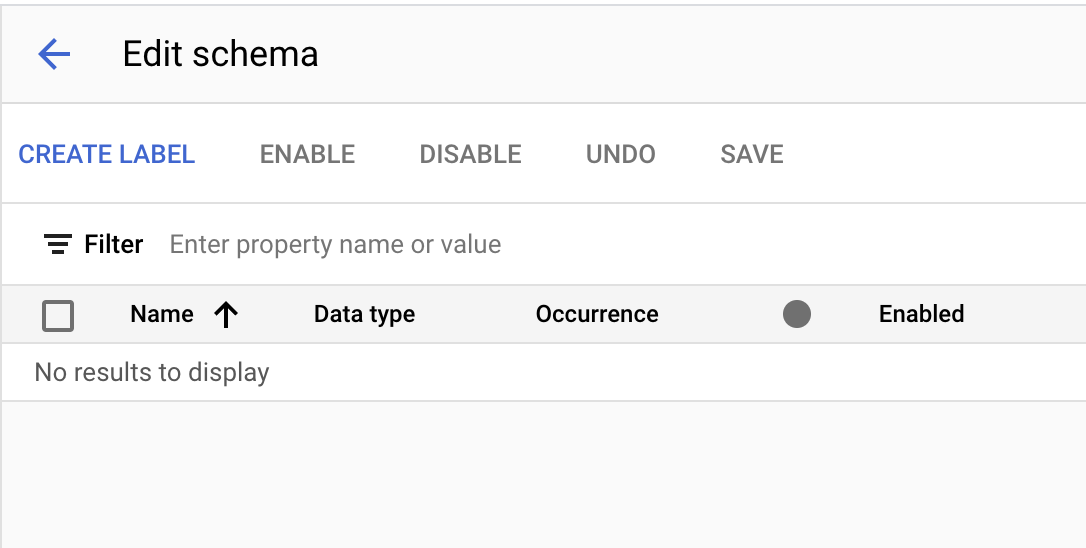
- Create the following labels using the Create Label button.
Name | Data Type | Occurrence |
| Number | Required multiple |
| Plain Text | Required multiple |
| Plain Text | Required multiple |
| Address | Required multiple |
| Money | Required multiple |
| Money | Required multiple |
| Money | Required multiple |
| Money | Required multiple |
- The Console should look like this when complete. Click Save when finished.
- Click on the Back arrow to return to the Training page. Notice that the labels we created show up in the lower-left corner.
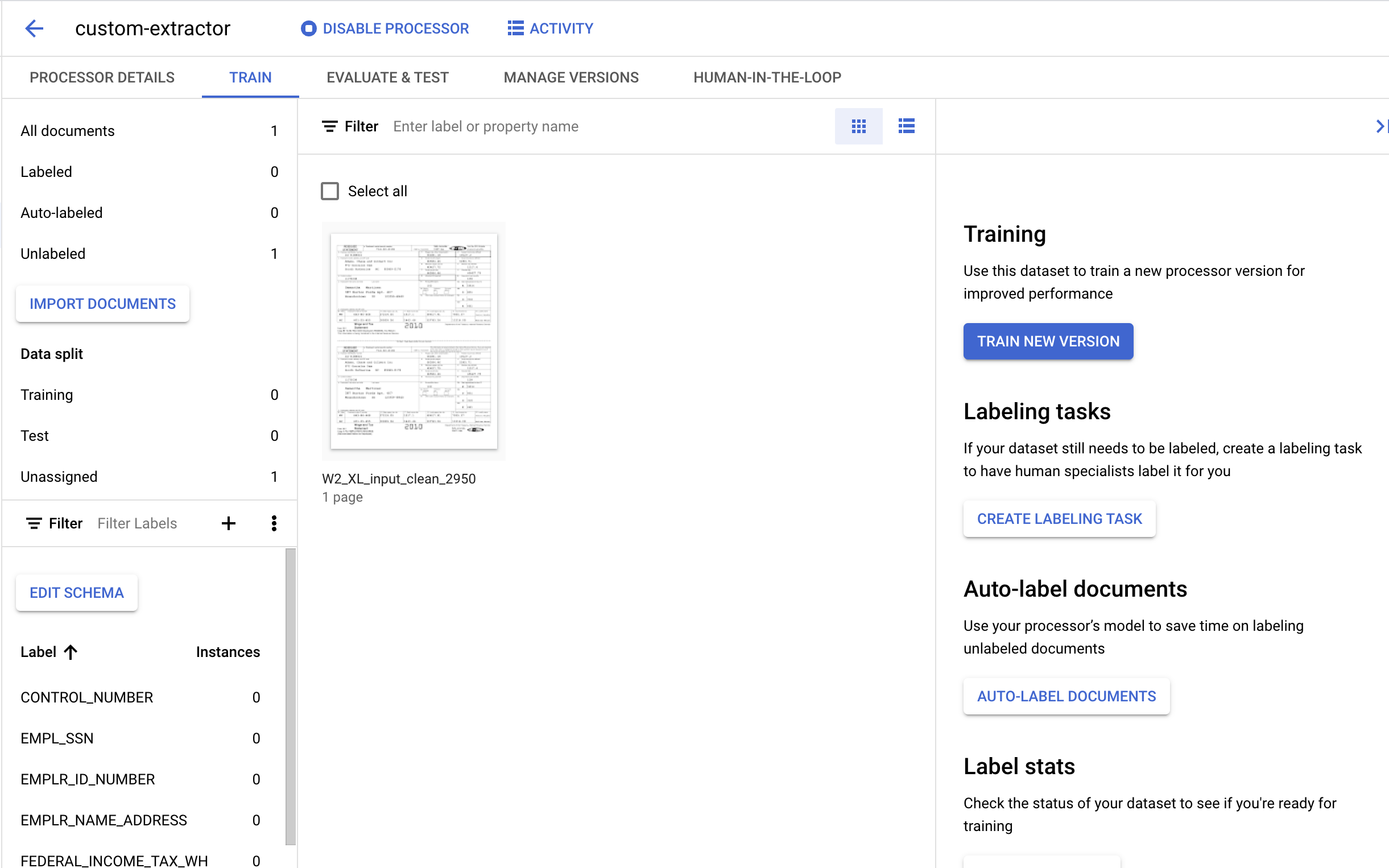
7. Label the Test Document
Next, we will identify text elements and labels for the entities we would like to extract. These labels will be used to train our model to parse this specific document structure and identify the correct types.
- Double-click on the document we imported earlier to enter the labeling console. It should look something like this.
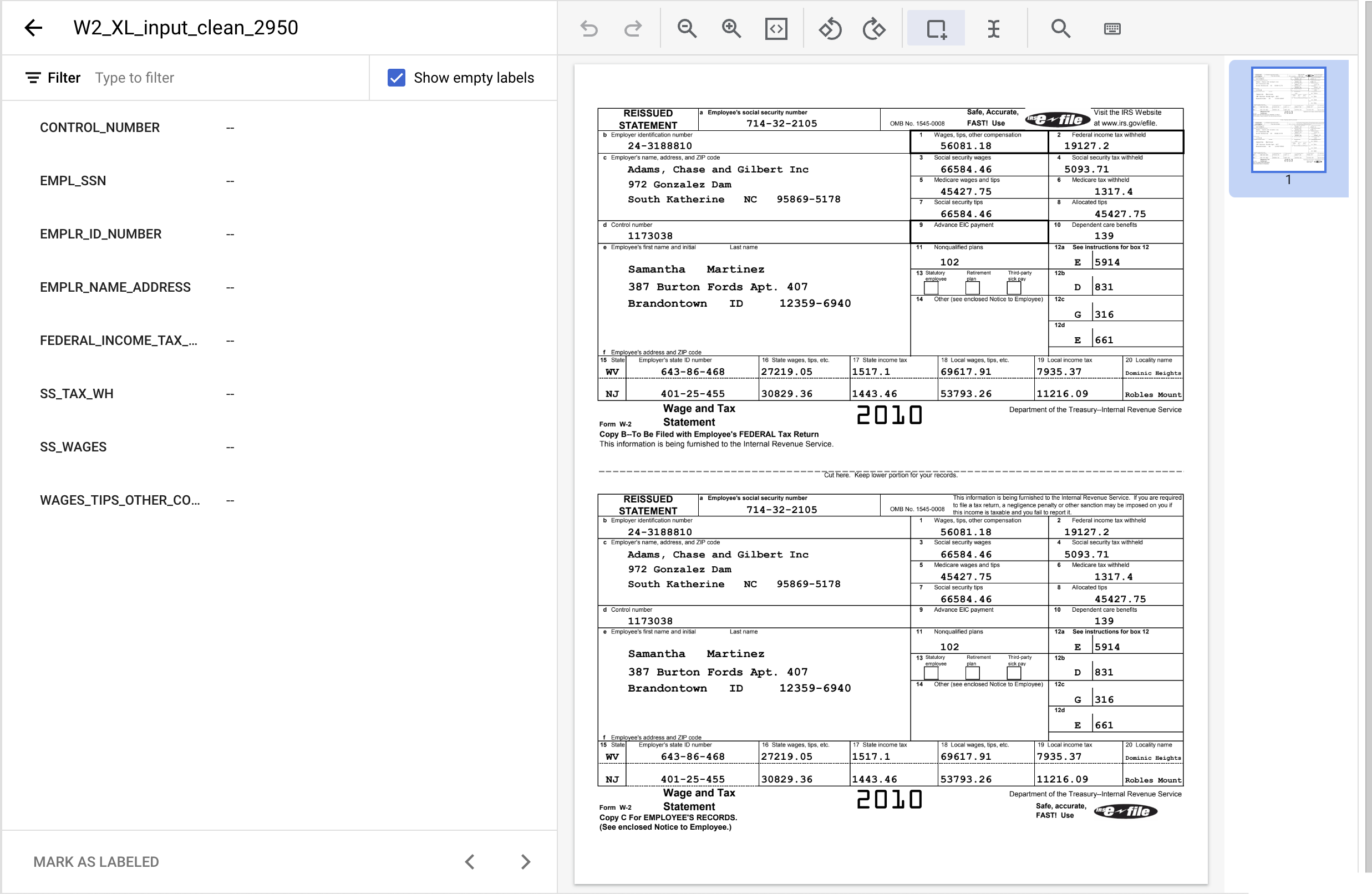
- Click on the "Bounding Box" Tool, then highlight the text "1173038" and assign the label
CONTROL_NUMBER. You can use the text filter to search for label names.
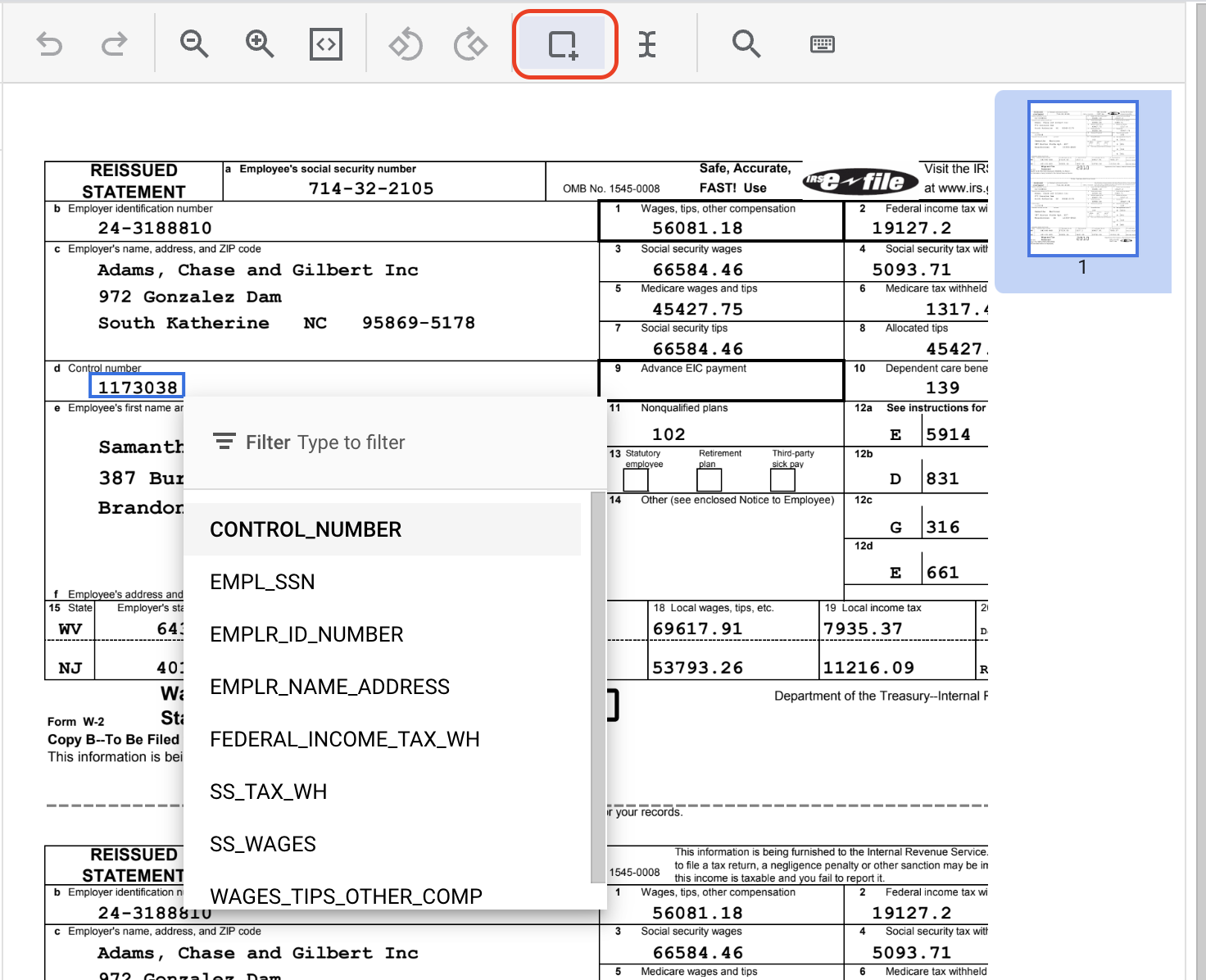
- Complete for the other instance of
CONTROL_NUMBERIt should look like this once labeled.
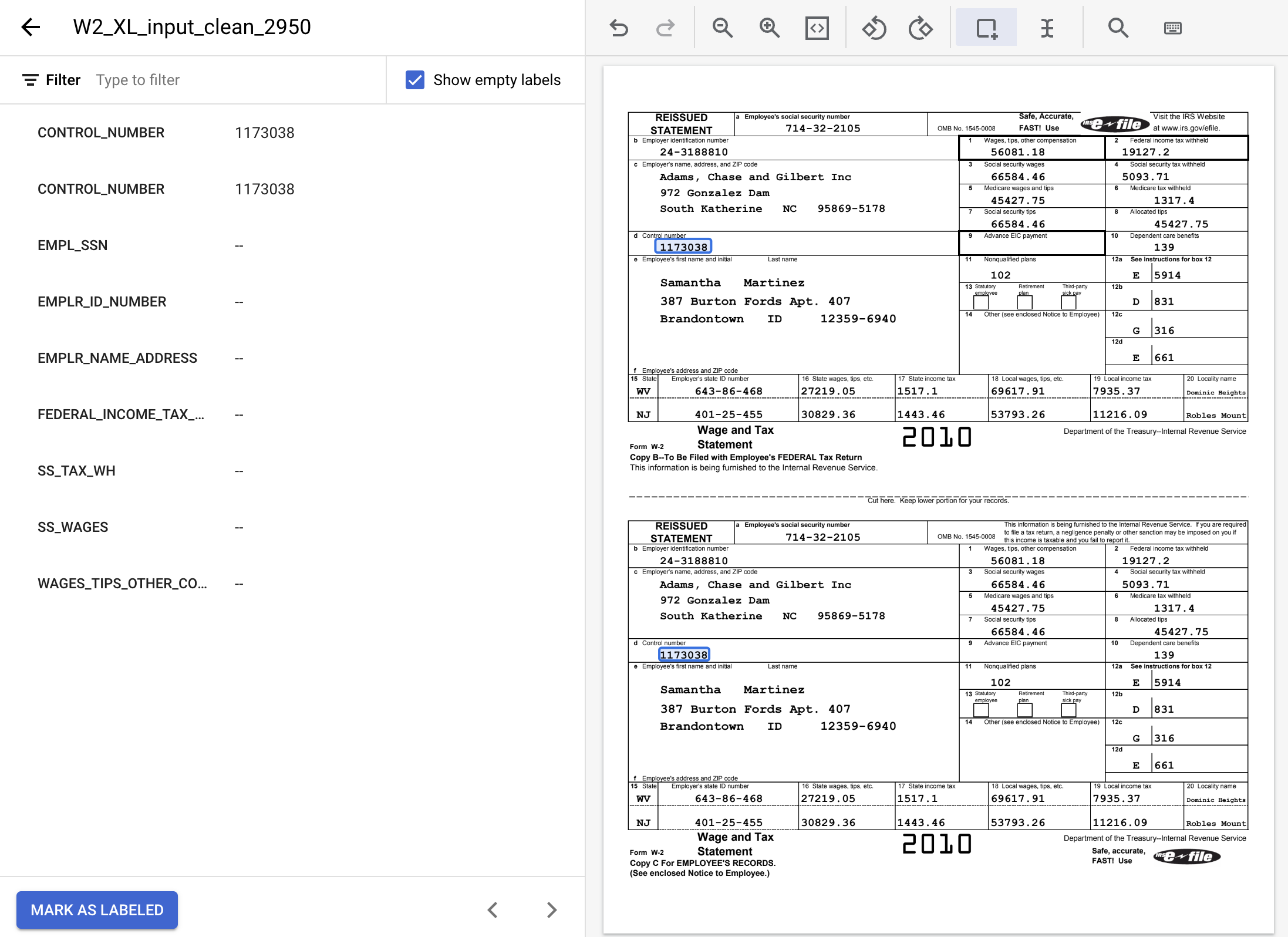
- Highlight all instances of the following text values and assign the appropriate labels.
Label Name | Text |
| 24-3188810 |
| 19127.2 |
| 5093.71 |
| 66584.46 |
| 56081.18 |
| 714-32-2105 |
| Adams, Chase and Gilbert Inc 972 Gonzalez Dam South Katherine NC 95869-5178 |
- The labeled document should look like this when complete. Note, you can make adjustments to these labels by clicking on the bounding box in the document or the label name/value on the left side menu. Click Mark As Labeled when you are finished labeling, then return to the Dataset management console.
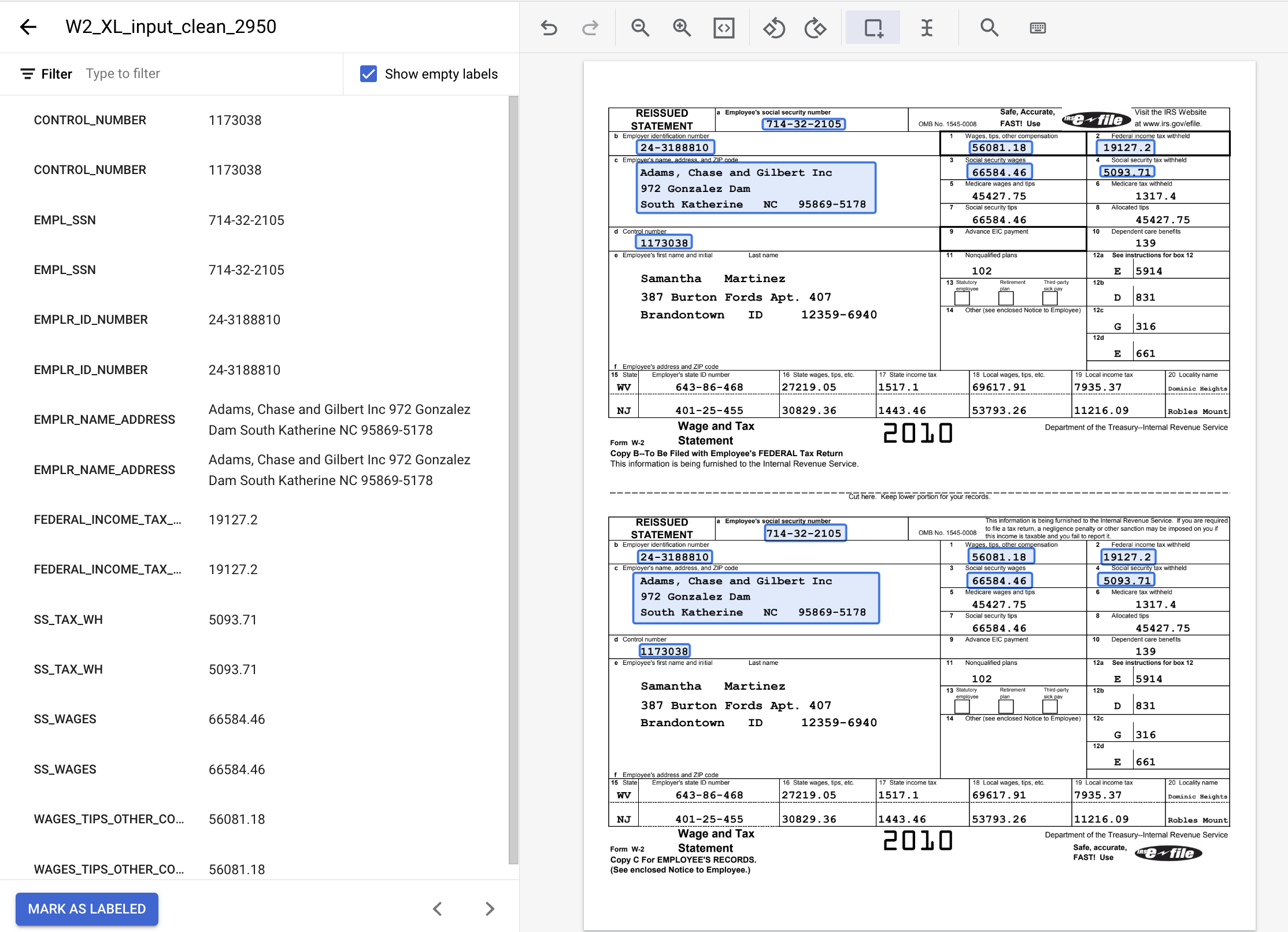
8. Assign Document to Training Set
You should now be back at the Dataset management console. Notice that the number of Labeled and Unlabeled documents and the number of instances per label have changed.
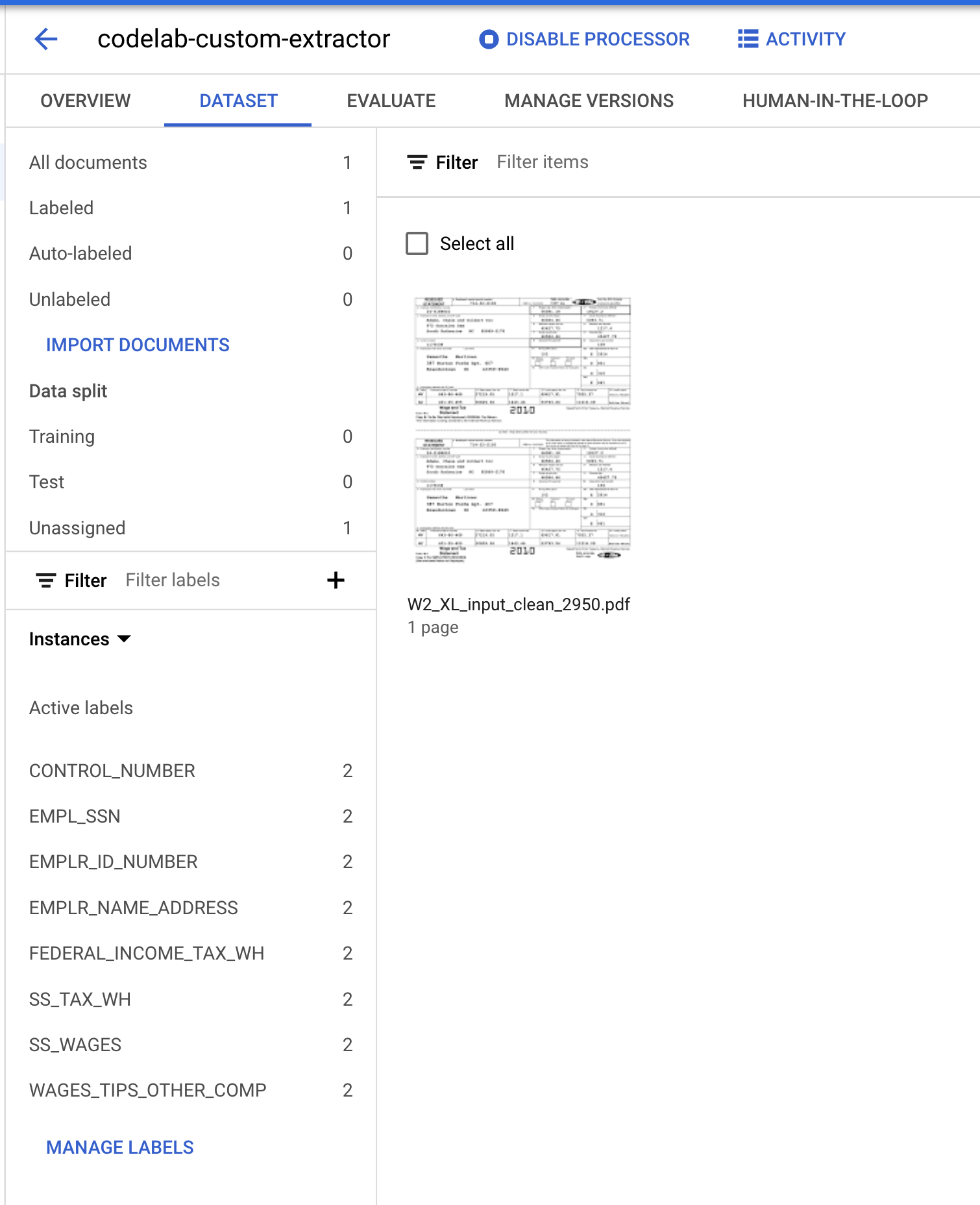
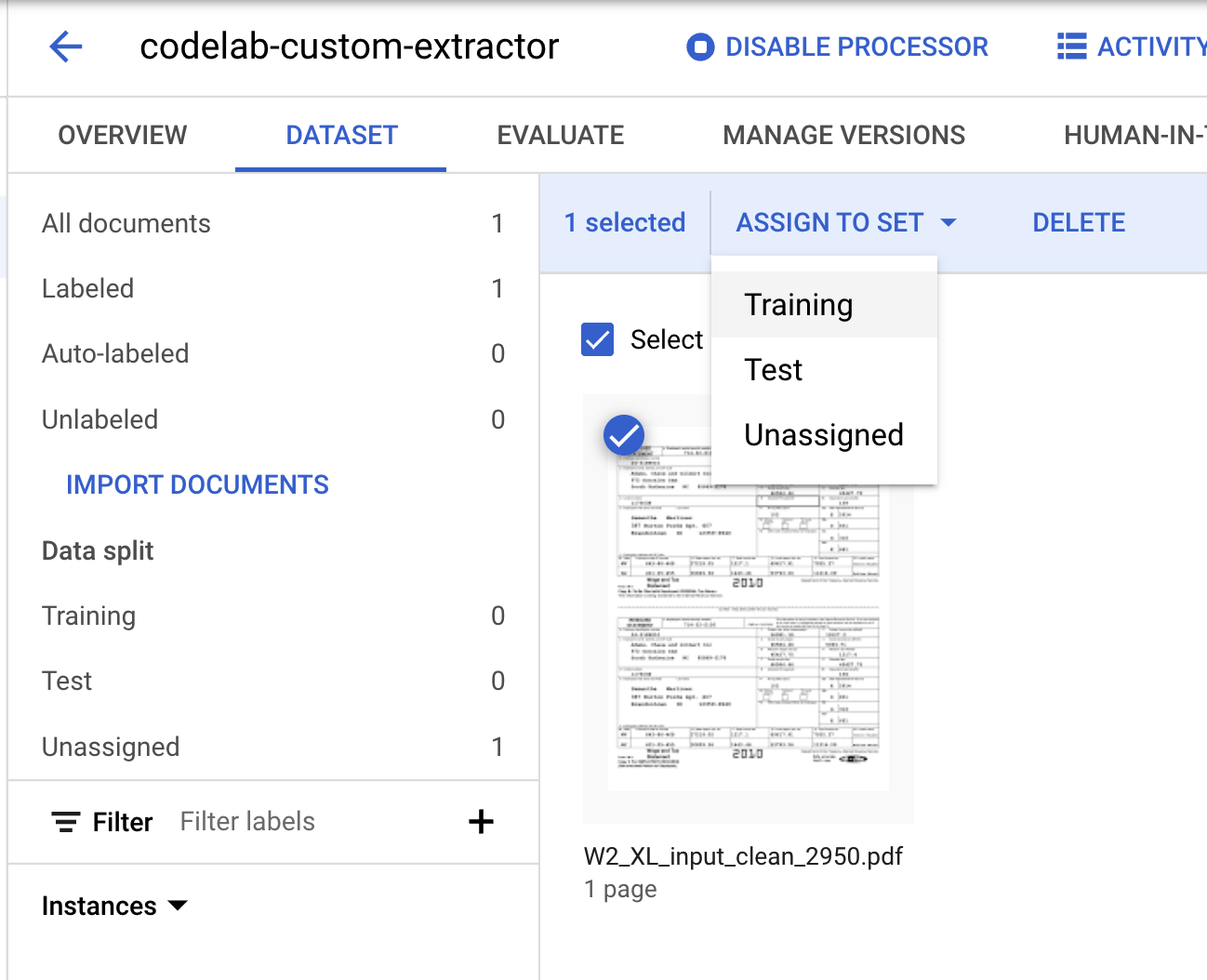
- We need to assign this document to either the "Training" or "Test" set. Click on the Document, click Assign to Set, then click on Training.
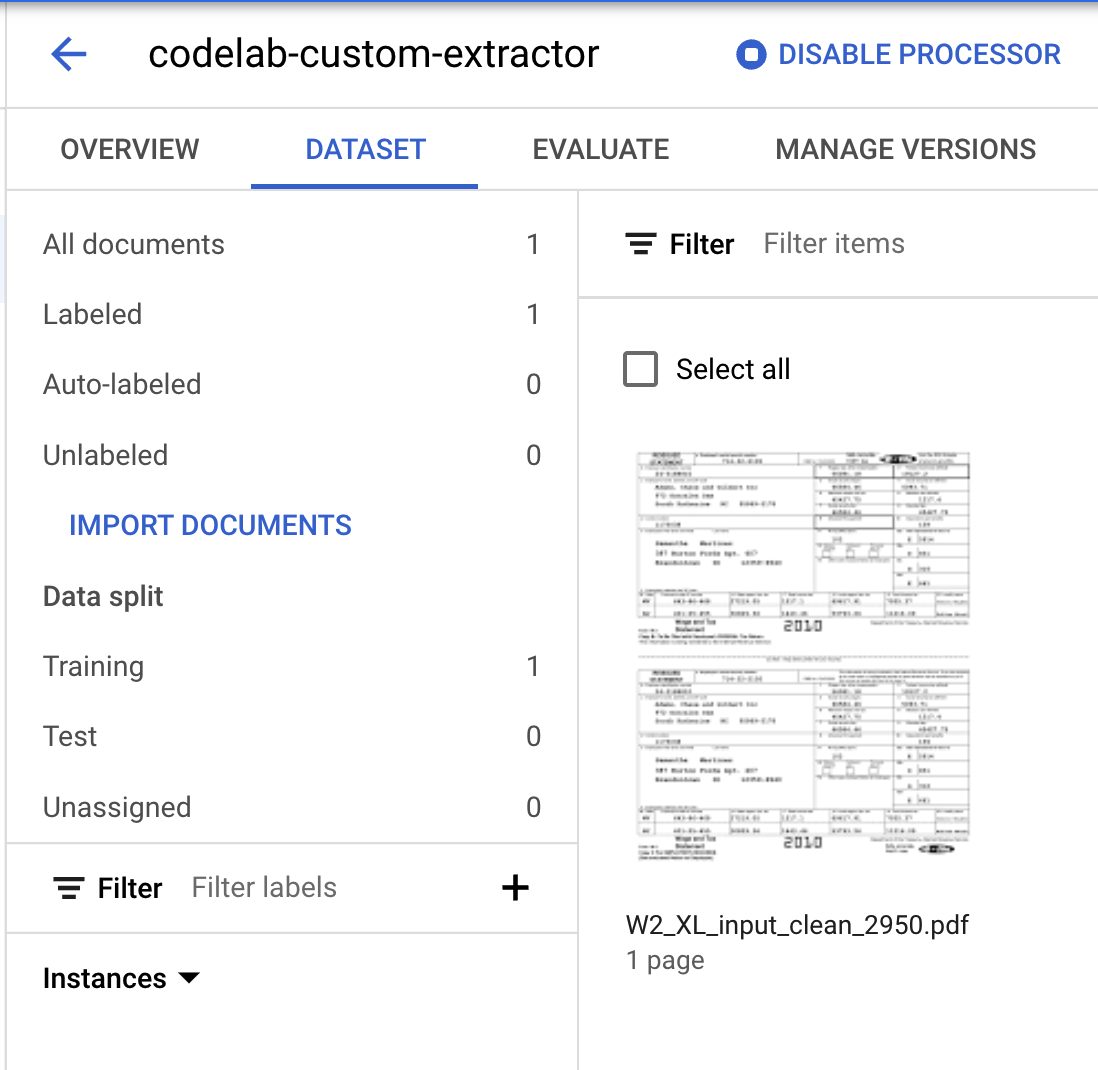
- Notice the Data Split numbers have changed.
9. Import Pre-Labeled Data
Document AI Custom Processors require a minimum of 10 documents in both the training and test sets, along with 10 instances of each label in each set.
It's recommended to have at least 50 documents in each set with 50 instances of each label for best performance. More training data generally equates to higher accuracy.
It will take a long time to manually label all of the documents, so we have some pre-labeled documents that you can import for this lab.
You can import pre-labeled document files in the Document.json format. These can be results from calling a processor and verifying the accuracy using Human in the Loop (HITL).
aside negative
NOTE: When importing pre-labeled data, it is highly recommended to manually review annotations before a model is trained.
- Click on Import Documents.
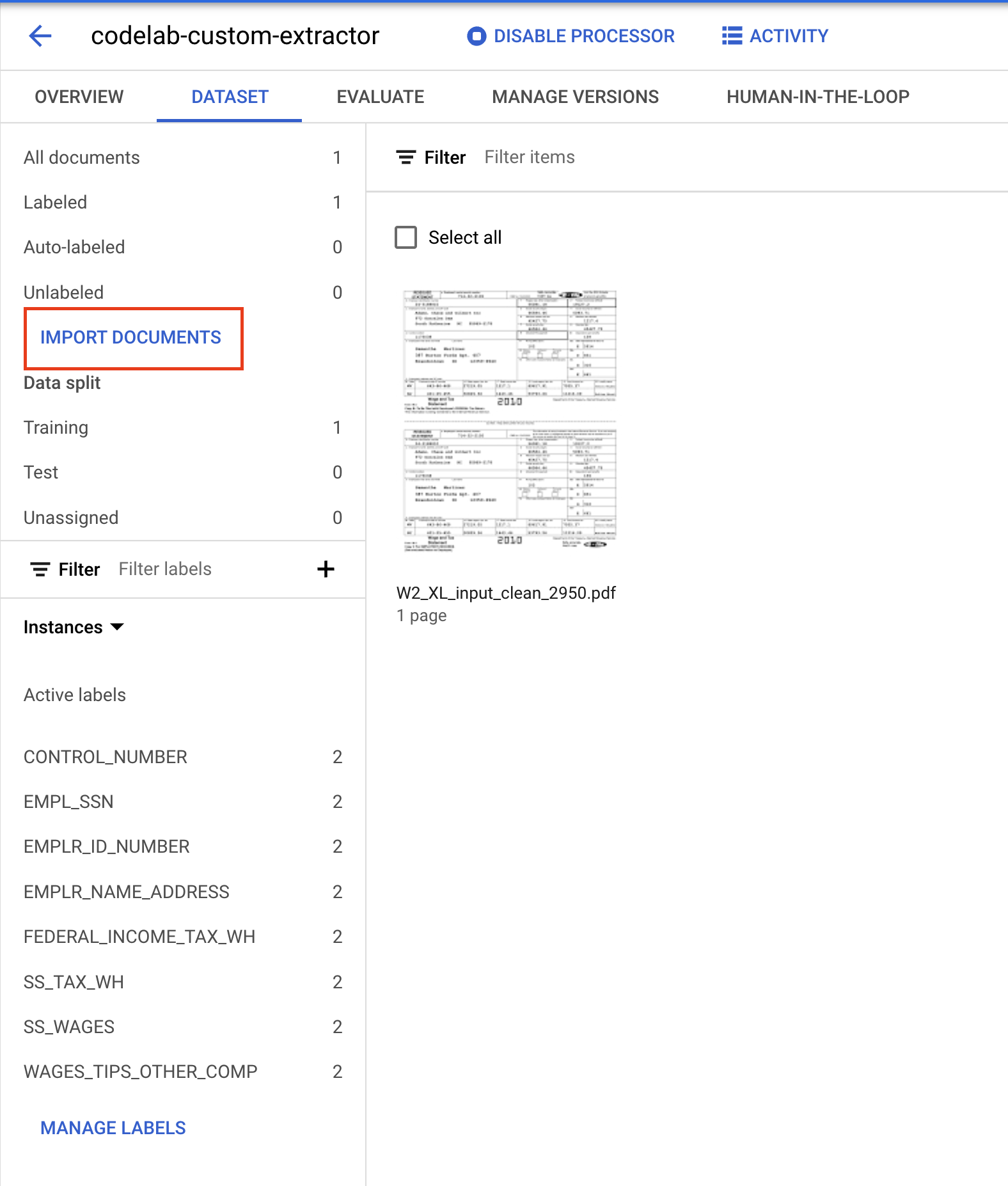
- Copy/Paste the following Cloud Storage path and assign it to the Training set.
cloud-samples-data/documentai/codelabs/custom/extractor/training
- Click on Add Another Folder. Then Copy/Paste the following Cloud Storage path and assign it to the Test set.
cloud-samples-data/documentai/codelabs/custom/extractor/test
- Click Import and wait for the documents to import. This will take longer than last time because there are more documents to process. This should take about 6 minutes, you can leave this page and return later.
- Once complete, you should see the documents in the Training page.
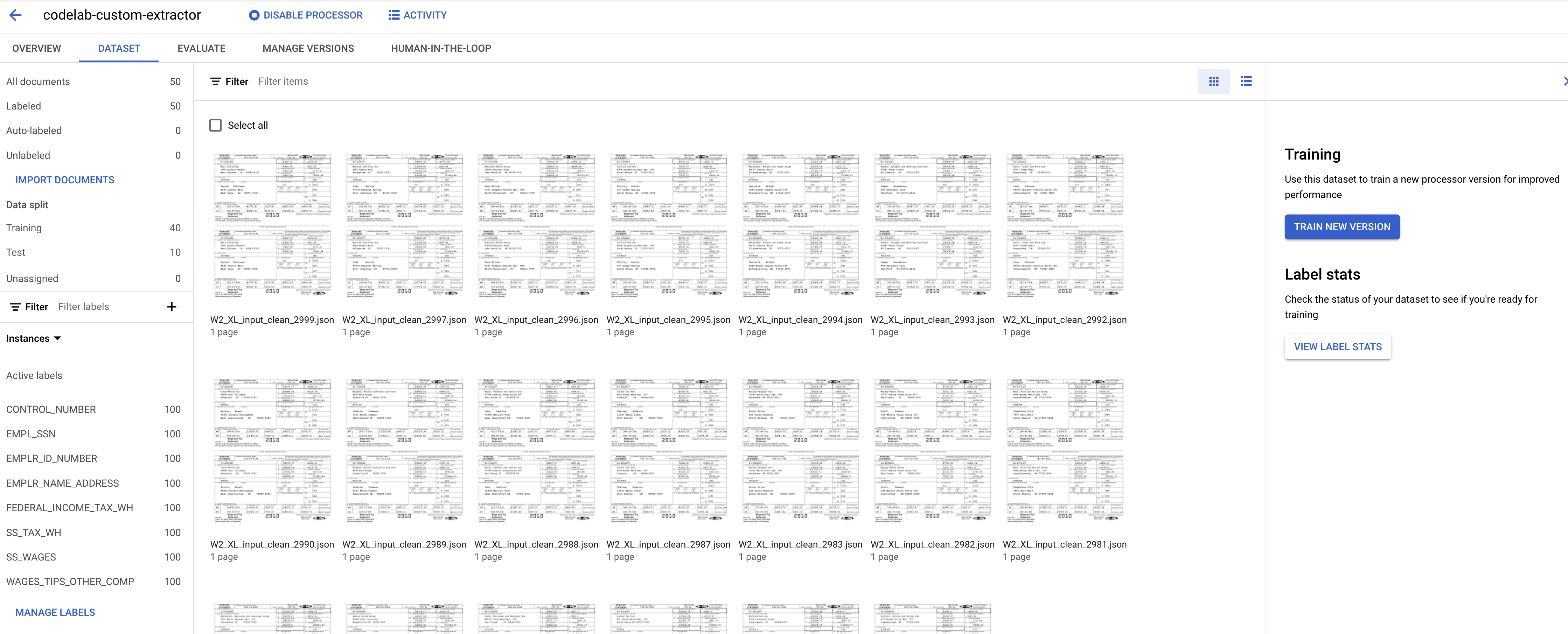
10. Train the Model
Now, we are ready to begin training our Custom Document Extractor.
- Click Train New Version
- Give your version a name that you'll remember, such as
codelab-custom-1. For "Training Method", select "Train from scratch".
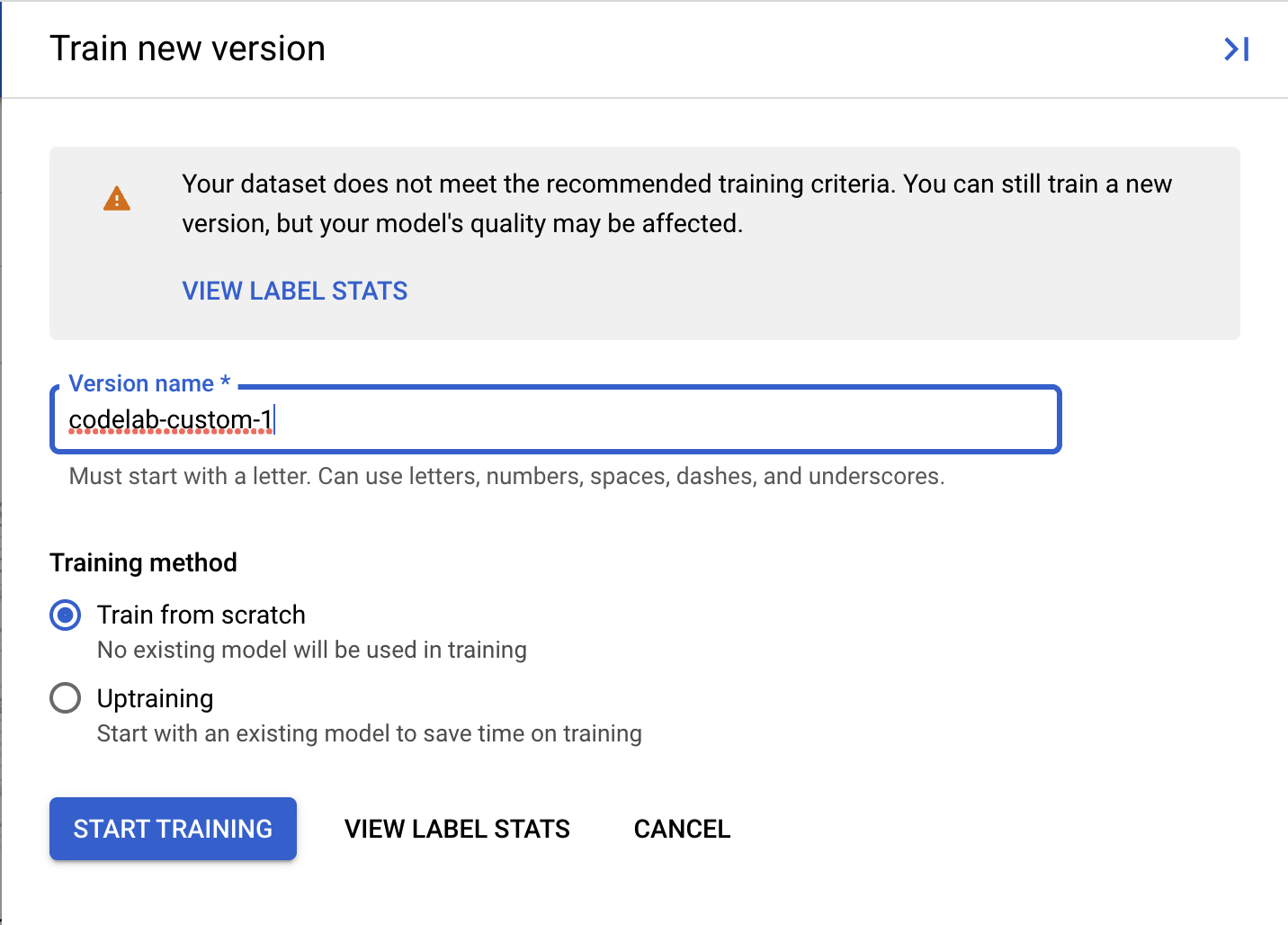
- (Optional) You can also select View Label Stats to see metrics about the labels in your dataset.
- Click on Start Training to begin the Training process. You should be redirected to the Dataset management page. You can view the training status on the right side. Training will take a few hours to complete. You can leave this page and return later.
- If you click on the version name, you will be directed to the Manage Versions page, which shows the Version ID and the current status of the Training Job.
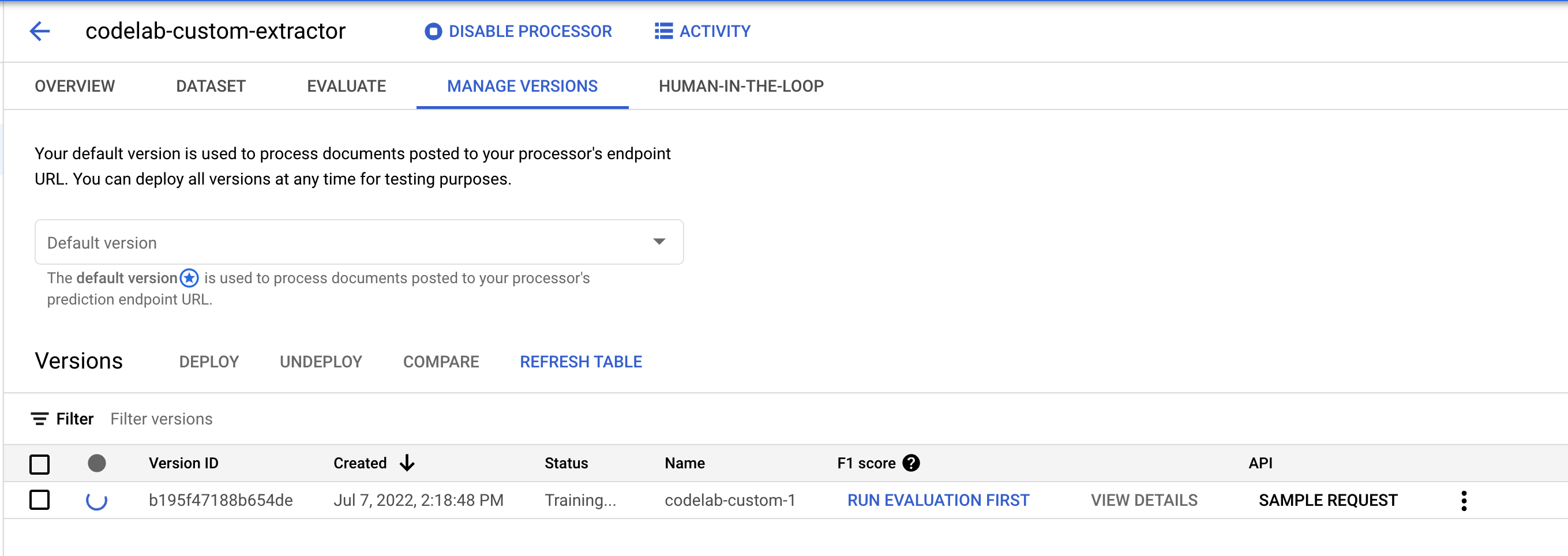
11. Test the New Model Version
Once the Training Job is complete (it took about 1 hour in my tests), you can now test out the new model version and start using it for predictions.
- Go to the Manage Versions page. Here you can see the current status and F1 Score.
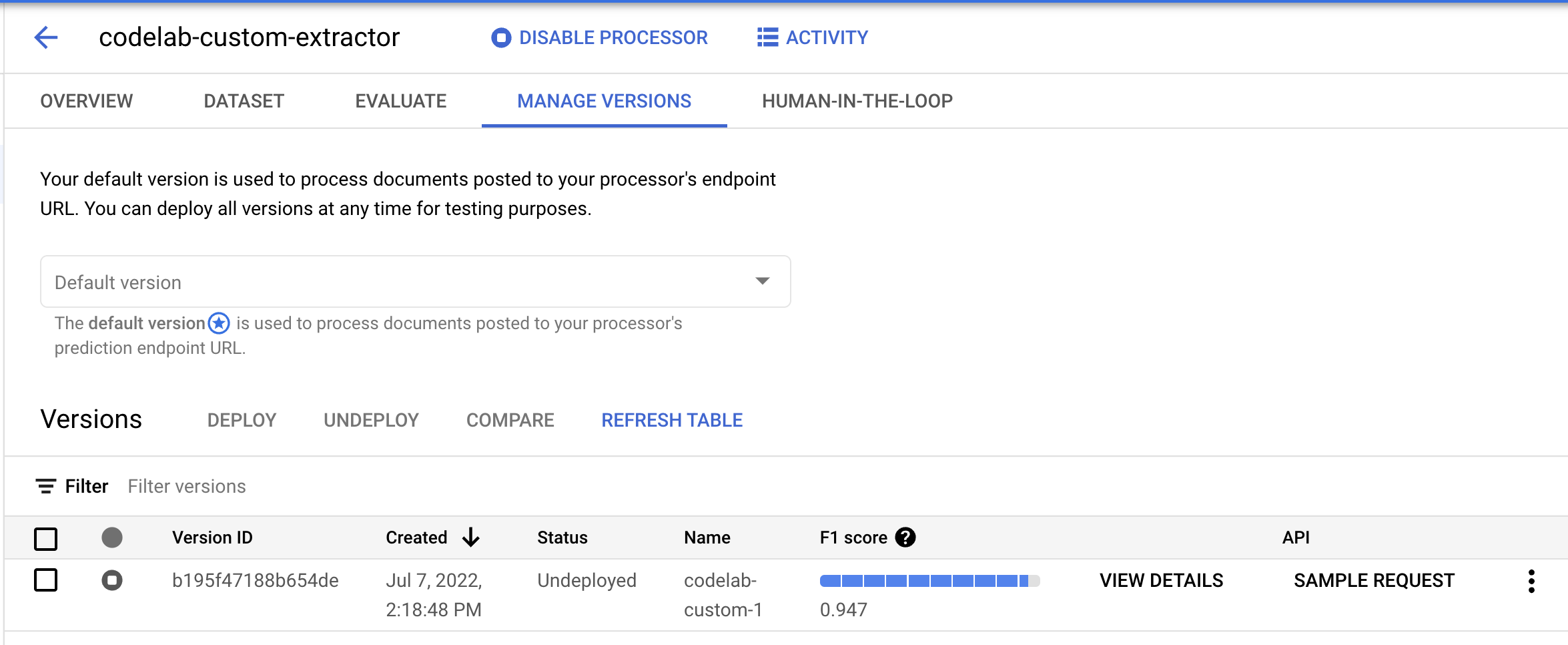
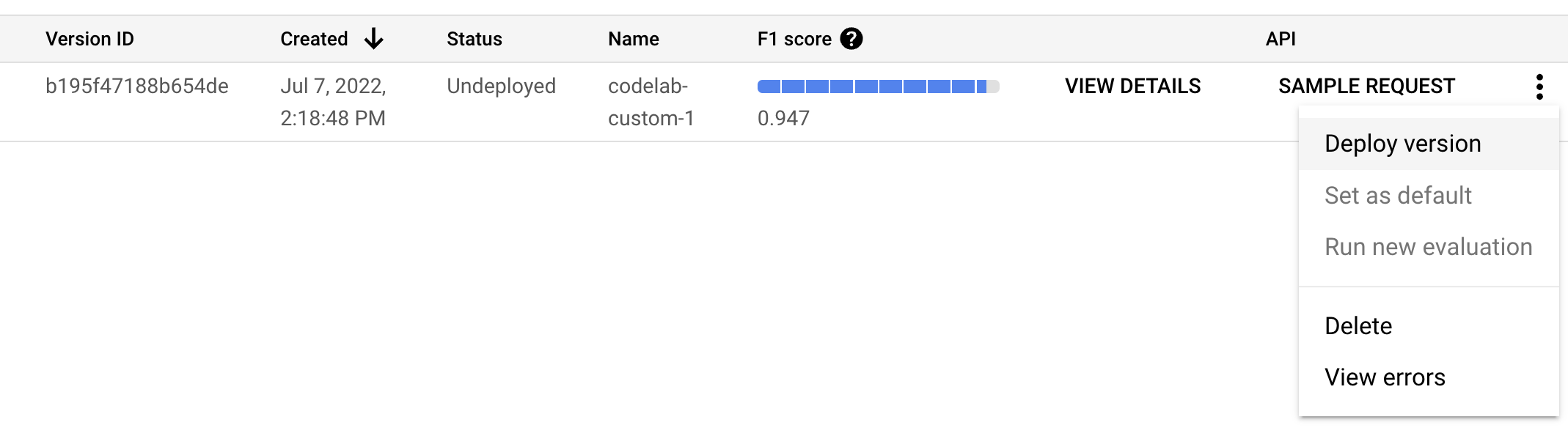
- We will need to deploy this model version before it can be used. Click on the vertical dots on the right side and select Deploy Version.
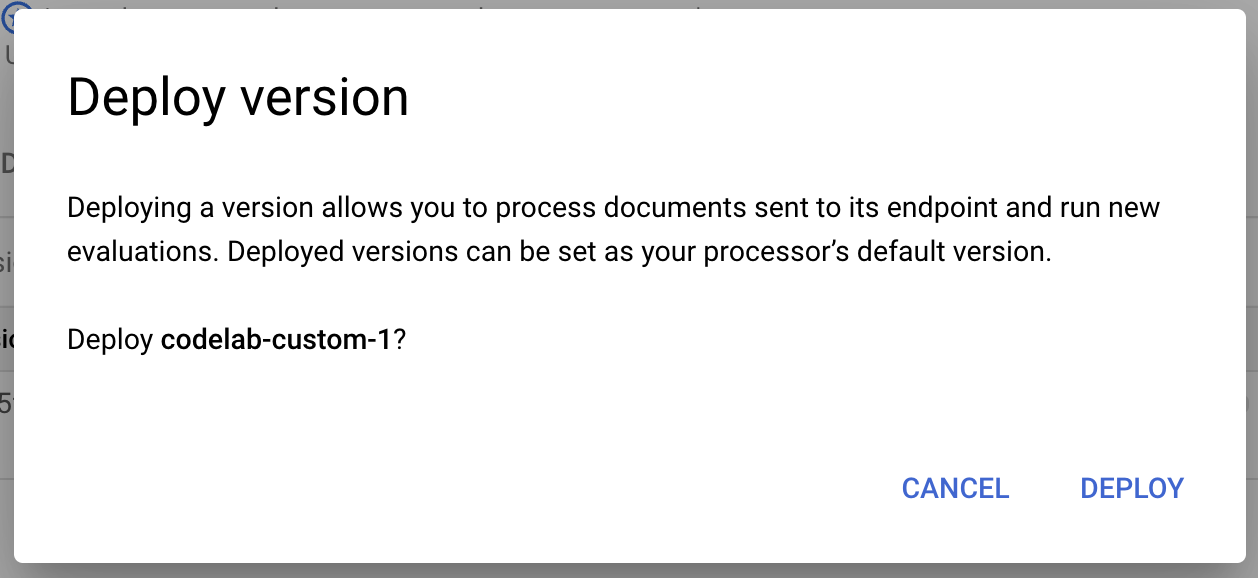
- Select Deploy from the pop-up window, when wait for the version to deploy. This will take a few minutes to complete. After it's deployed, you can also set this version as the Default Version.
- Once it's finished deploying, go to the Evaluate Tab. On this page, you can view evaluation metrics including the F1 score, Precision and Recall for the full document as well as individual labels. You can read more about these metrics in the AutoML Documentation.
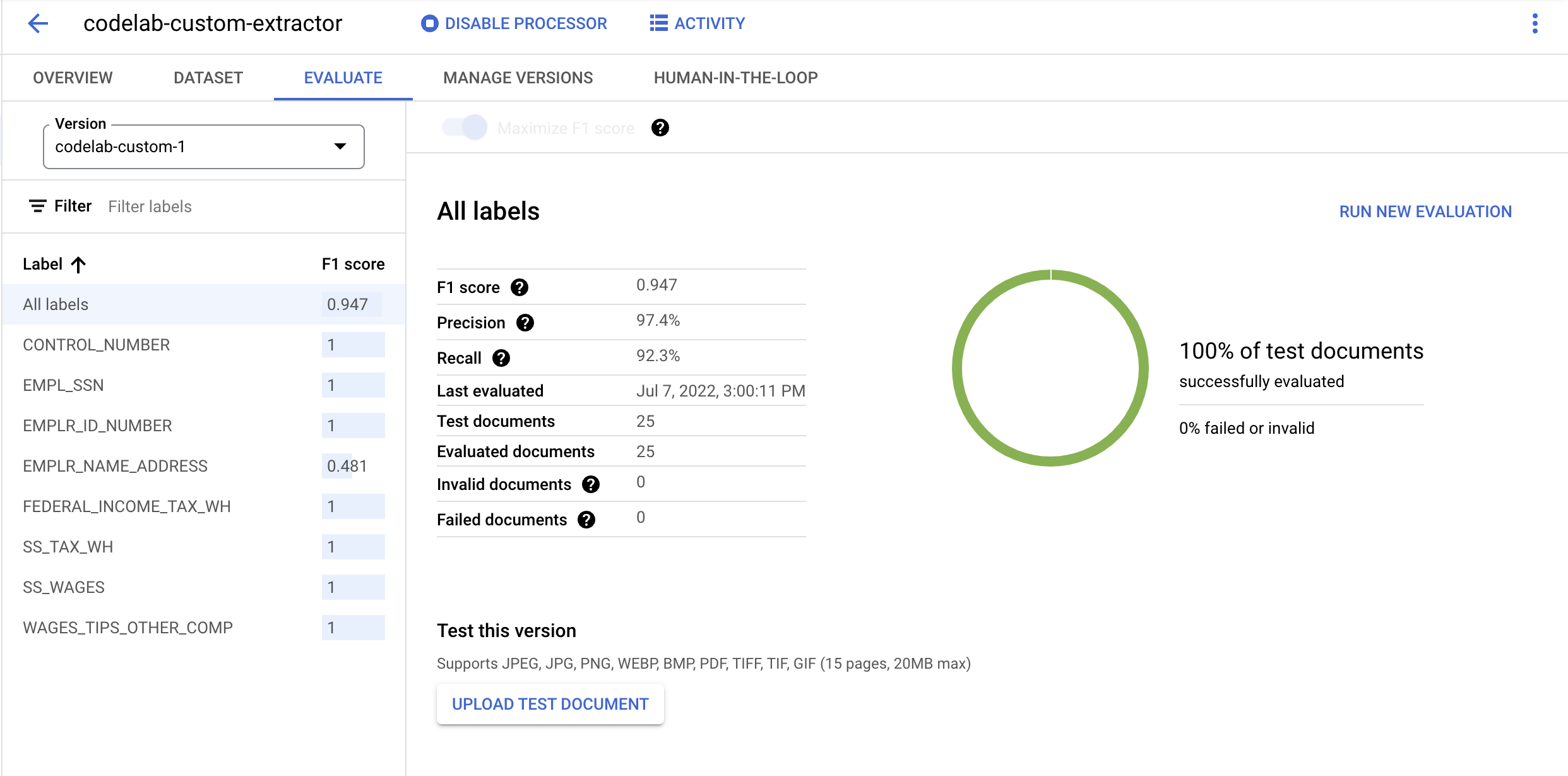
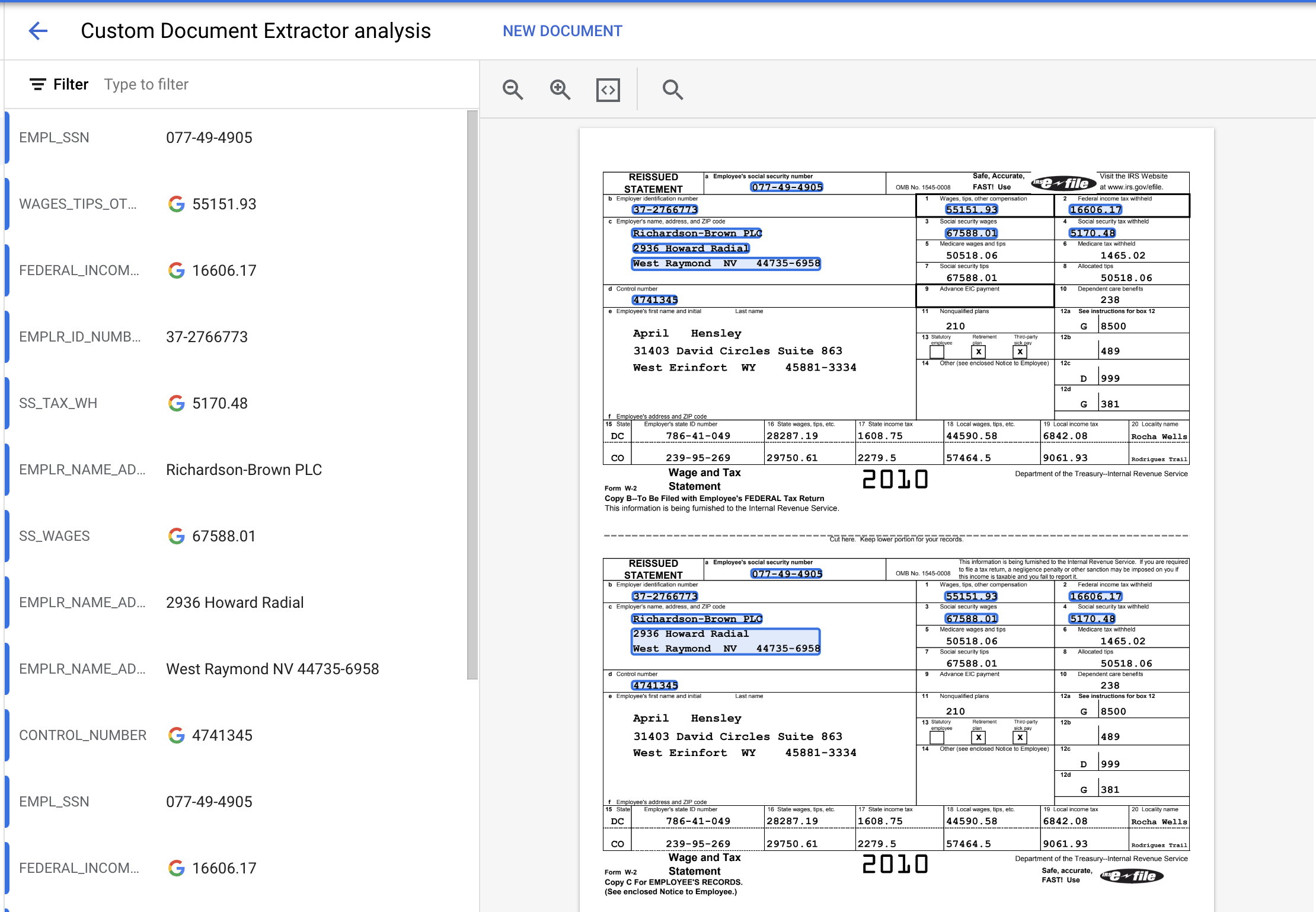
- Download the PDF File linked below. This is a sample W2 that was not included in the Training or Test set.
- Click on Upload Test Document and select the PDF file.
- The extracted entities should look something like this.
12. Optional: Auto-label newly imported documents
After deploying a trained processor version, you can use Auto-labeling to save time on labeling when importing new documents.
- On the Train page, Click Import Documents.
- Copy and paste the following {{storage_name}} path. This directory contains 5 unlabeled W2 PDFs. From the Data split dropdown list, select Training.
cloud-samples-data/documentai/Custom/W2/AutoLabel - In the Auto-labeling section, select the Import with auto-labeling checkbox.
- Select an existing processor version to label the documents.
- For example:
2af620b2fd4d1fcf
- Click Import and wait for the documents to import. You can leave this page and return later.
- When complete, the documents appear in the Train page in the Auto-labeled section.
- You cannot use auto-labeled documents for training or testing without marking them as labeled. Go to the Auto-labeled section to view the auto-labeled documents.
- Select the first document to enter the labeling console.
- Verify the labels, bounding boxes, and values to ensure they are correct. Label any values that were omitted.
- Select Mark as labeled when finished.
- Repeat the label verification for each auto-labeled document, then return to the Train page to use the data for training.
13. Conclusion
Congratulations, you've successfully used Document AI to train a Custom Document Extractor processor. You can now use this processor to parse documents in this format just as you would for any Specialized Processor.
You can refer to the Specialized Processors Codelab to review how to handle the processing response.
Cleanup
To avoid incurring charges to your Google Cloud account for the resources used in this tutorial:
- In the Cloud Console, go to the Manage resources page.
- In the project list, select your project then click Delete.
- In the dialog, type the project ID and then click Shut down to delete the project.
Resources
- Document AI Workbench Documentation
- The Future of Documents - YouTube Playlist
- Document AI Documentation
- Document AI Python Client Library
- Document AI Samples
License
This work is licensed under a Creative Commons Attribution 2.0 Generic License.