
1. परिचय
इस कोडलैब में, Python की मदद से हाथ से लिखे गए फ़ॉर्म को पार्स करने के लिए, Document AI के फ़ॉर्म पार्सर का इस्तेमाल करने का तरीका बताया गया है.
हम एक सामान्य मेडिकल इंटेक फ़ॉर्म का इस्तेमाल उदाहरण के तौर पर करेंगे. हालांकि, यह तरीका DocAI के साथ काम करने वाले किसी भी सामान्य फ़ॉर्म के लिए काम करेगा.
ज़रूरी शर्तें
यह कोडलैब, Document AI के अन्य कोडलैब में दिए गए कॉन्टेंट पर आधारित है.
हमारा सुझाव है कि आगे बढ़ने से पहले, इन कोडलैब को पूरा कर लें.
आपको क्या सीखने को मिलेगा
- Document AI Form Parser का इस्तेमाल करके, स्कैन किए गए फ़ॉर्म से डेटा को पार्स और एक्सट्रैक्ट करने का तरीका.
आपको इन चीज़ों की ज़रूरत होगी
सर्वे
इस ट्यूटोरियल का इस्तेमाल कैसे किया जाएगा?
Python के साथ अपने अनुभव को आप क्या रेटिंग देंगे?
Google Cloud की सेवाओं को इस्तेमाल करने के अपने अनुभव को आप क्या रेटिंग देंगे?
2. सेटअप और ज़रूरी शर्तें
इस कोडलैब में यह माना गया है कि आपने Document AI OCR कोडलैब में दिए गए, Document AI को सेट अप करने के चरण पूरे कर लिए हैं.
आगे बढ़ने से पहले, कृपया यह तरीका अपनाएं:
आपको Python के लिए, ओपन सोर्स डेटा विश्लेषण लाइब्रेरी Pandas भी इंस्टॉल करनी होगी.
pip3 install --upgrade pandas
3. फ़ॉर्म पार्सर प्रोसेसर बनाना
इस ट्यूटोरियल में, Document AI Platform में इस्तेमाल करने के लिए, आपको सबसे पहले फ़ॉर्म पार्सर प्रोसेसर का एक इंस्टेंस बनाना होगा.
- कंसोल में, Document AI Platform की खास जानकारी पर जाएं
- प्रोसेसर बनाएं पर क्लिक करें. इसके बाद, फ़ॉर्म पार्सर
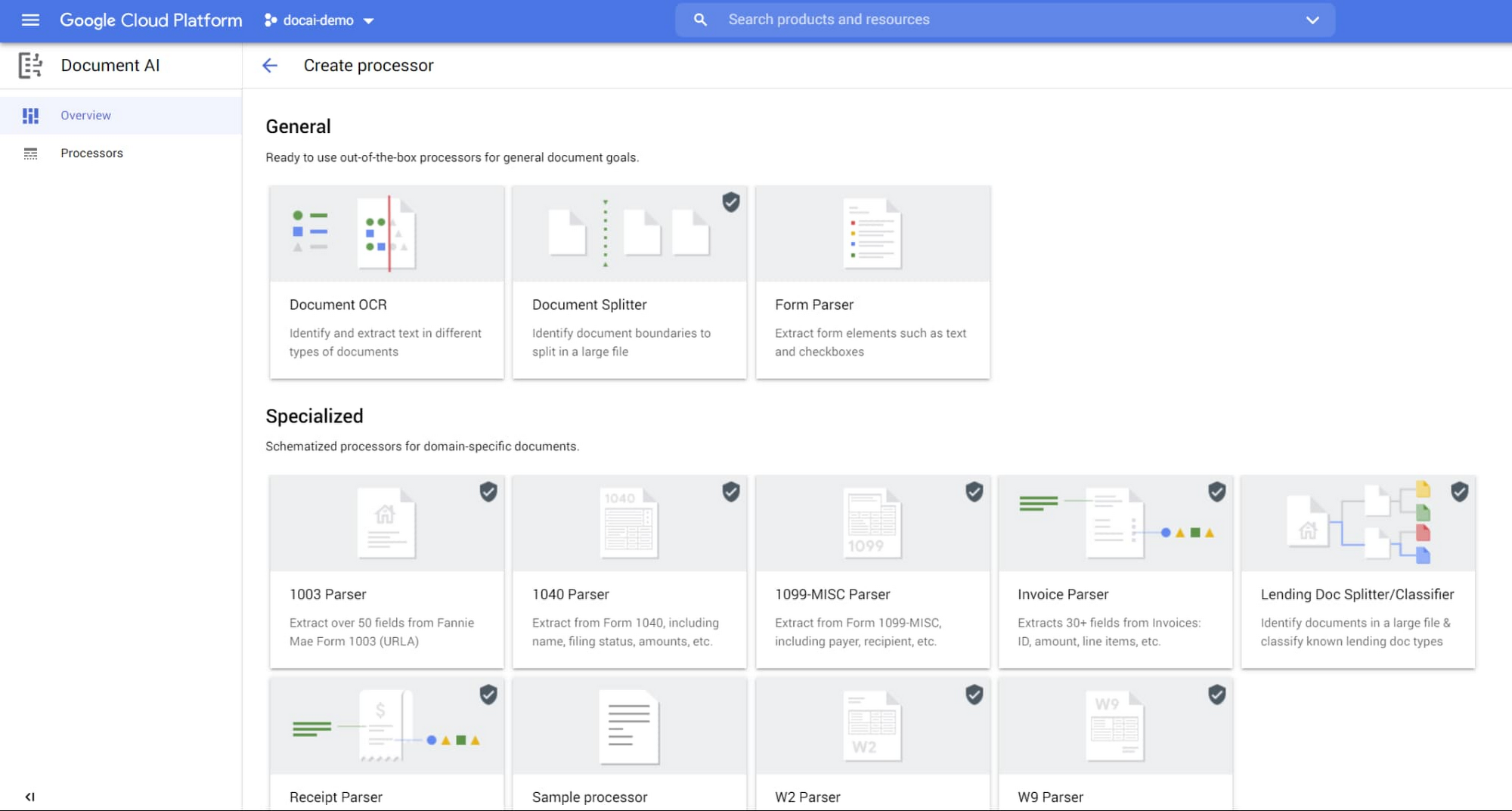 चुनें
चुनें - प्रोसेसर का नाम डालें और सूची से अपना देश/इलाका चुनें.
- प्रोसेसर बनाने के लिए, बनाएं पर क्लिक करें
- अपने प्रोसेसर आईडी को कॉपी करें. आपको इसका इस्तेमाल बाद में अपने कोड में करना होगा.
Cloud Console में प्रोसेसर की जांच करना
कंसोल में कोई दस्तावेज़ अपलोड करके, अपने प्रोसेसर को आज़माया जा सकता है. दस्तावेज़ अपलोड करें पर क्लिक करें और पार्स करने के लिए कोई फ़ॉर्म चुनें. अगर आपके पास कोई फ़ॉर्म उपलब्ध नहीं है, तो इस सैंपल फ़ॉर्म को डाउनलोड करके इस्तेमाल किया जा सकता है.

आपका आउटपुट ऐसा दिखना चाहिए: 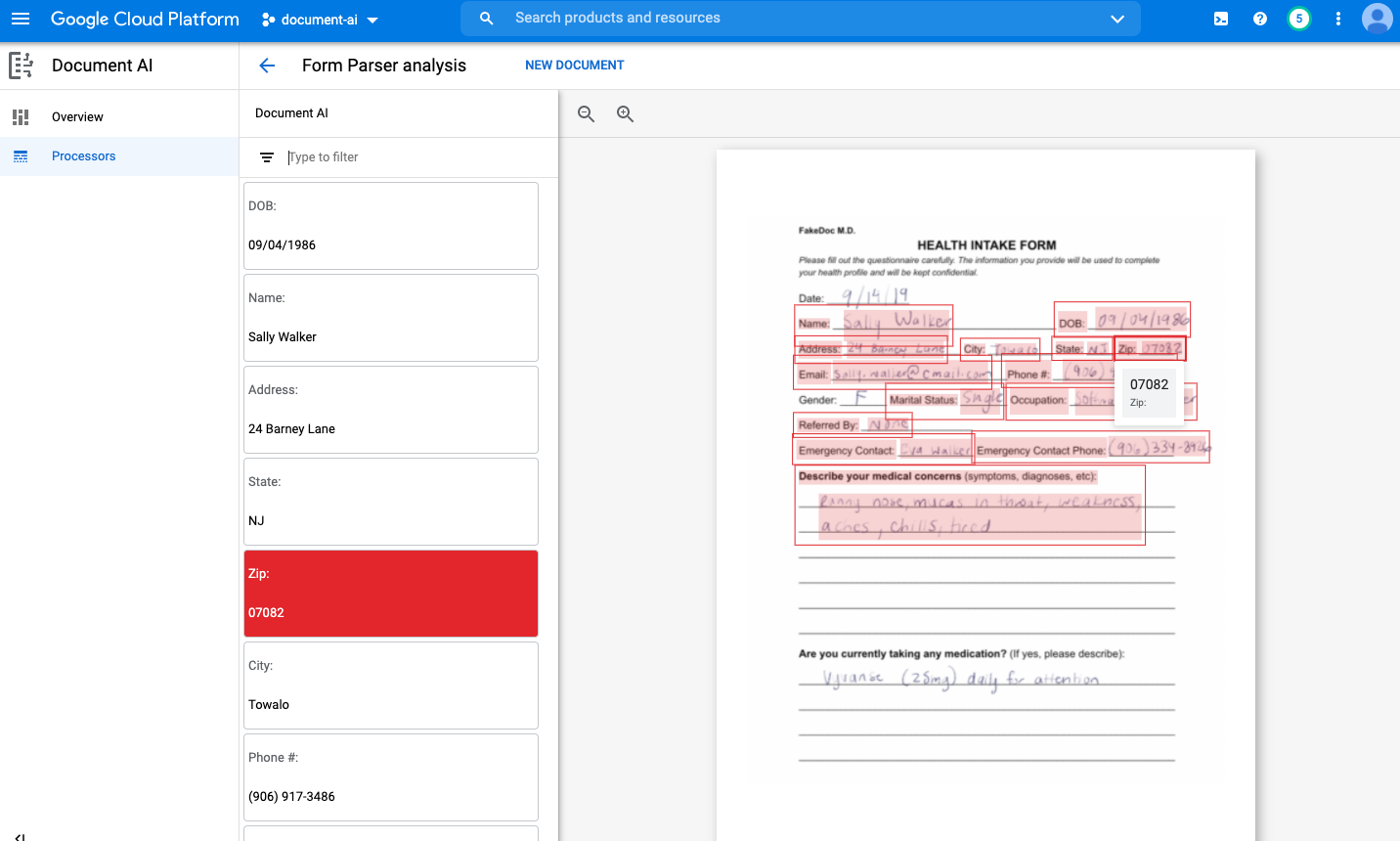
4. सैंपल फ़ॉर्म डाउनलोड करें
हमारे पास एक सैंपल दस्तावेज़ है, जिसमें सामान्य मेडिकल इंटेक फ़ॉर्म शामिल है.
इस लिंक का इस्तेमाल करके, PDF डाउनलोड किया जा सकता है. इसके बाद, इसे Cloud Shell इंस्टेंस पर अपलोड करें.
इसके अलावा, gsutil का इस्तेमाल करके, इसे हमारे सार्वजनिक Google Cloud Storage बकेट से डाउनलोड किया जा सकता है.
gsutil cp gs://cloud-samples-data/documentai/codelabs/form-parser/intake-form.pdf .
नीचे दिए गए निर्देश का इस्तेमाल करके पुष्टि करें कि फ़ाइल, Cloud Shell में डाउनलोड हो गई है:
ls -ltr intake-form.pdf
5. फ़ॉर्म के की/वैल्यू पेयर निकालना
इस चरण में, ऑनलाइन प्रोसेसिंग एपीआई का इस्तेमाल करके, फ़ॉर्म पार्सर प्रोसेसर को कॉल किया जाएगा. यह प्रोसेसर आपने पहले बनाया था. इसके बाद, आपको दस्तावेज़ में मौजूद कुंजी-वैल्यू पेयर को एक्सट्रैक्ट करना होगा.
ऑनलाइन प्रोसेसिंग का इस्तेमाल, सिर्फ़ एक दस्तावेज़ भेजने और जवाब मिलने तक इंतज़ार करने के लिए किया जाता है. अगर आपको एक साथ कई फ़ाइलें भेजनी हैं या फ़ाइल का साइज़, ऑनलाइन प्रोसेसिंग के लिए तय की गई ज़्यादा से ज़्यादा सीमा से ज़्यादा है, तो बैच प्रोसेसिंग का इस्तेमाल करें. इस प्रोसेस के बारे में ज़्यादा जानने के लिए, ओसीआर कोडलैब पर जाएं.
प्रोसेसिंग का अनुरोध करने के लिए इस्तेमाल किया जाने वाला कोड, प्रोसेसर आईडी को छोड़कर हर प्रोसेसर टाइप के लिए एक जैसा होता है.
Document रिस्पॉन्स ऑब्जेक्ट में, इनपुट दस्तावेज़ के पेजों की सूची होती है.
हर page ऑब्जेक्ट में, फ़ॉर्म फ़ील्ड की सूची और टेक्स्ट में उनकी जगह की जानकारी होती है.
नीचे दिया गया कोड, हर पेज पर जाकर हर कुंजी, वैल्यू, और कॉन्फ़िडेंस स्कोर को निकालता है. यह स्ट्रक्चर्ड डेटा होता है. इसे डेटाबेस में आसानी से सेव किया जा सकता है या अन्य ऐप्लिकेशन में इस्तेमाल किया जा सकता है.
form_parser.py नाम की एक फ़ाइल बनाएं और नीचे दिए गए कोड का इस्तेमाल करें.
form_parser.py
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type
)
# Configure the process request
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document
)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
def trim_text(text: str):
"""
Remove extra space characters from text (blank, newline, tab, etc.)
"""
return text.strip().replace("\n", " ")
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "FORM_PARSER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "intake-form.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
names = []
name_confidence = []
values = []
value_confidence = []
for page in document.pages:
for field in page.form_fields:
# Get the extracted field names
names.append(trim_text(field.field_name.text_anchor.content))
# Confidence - How "sure" the Model is that the text is correct
name_confidence.append(field.field_name.confidence)
values.append(trim_text(field.field_value.text_anchor.content))
value_confidence.append(field.field_value.confidence)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame(
{
"Field Name": names,
"Field Name Confidence": name_confidence,
"Field Value": values,
"Field Value Confidence": value_confidence,
}
)
print(df)
अब अपना कोड चलाएं. आपको कंसोल में टेक्स्ट दिखेगा.
हमारे सैंपल दस्तावेज़ का इस्तेमाल करने पर, आपको यह आउटपुट दिखेगा:
$ python3 form_parser.py
Field Name Field Name Confidence Field Value Field Value Confidence
0 Phone #: 0.999982 (906) 917-3486 0.999982
1 Emergency Contact: 0.999972 Eva Walker 0.999972
2 Marital Status: 0.999951 Single 0.999951
3 Gender: 0.999933 F 0.999933
4 Occupation: 0.999914 Software Engineer 0.999914
5 Referred By: 0.999862 None 0.999862
6 Date: 0.999858 9/14/19 0.999858
7 DOB: 0.999716 09/04/1986 0.999716
8 Address: 0.999147 24 Barney Lane 0.999147
9 City: 0.997718 Towaco 0.997718
10 Name: 0.997345 Sally Walker 0.997345
11 State: 0.996944 NJ 0.996944
...
6. टेबल पार्स करना
फ़ॉर्म पार्सर, दस्तावेज़ों में मौजूद टेबल से भी डेटा निकाल सकता है. इस चरण में, हम एक नया सैंपल दस्तावेज़ डाउनलोड करेंगे और टेबल से डेटा निकालेंगे. डेटा को Pandas में लोड किया जा रहा है. इसलिए, इस डेटा को CSV फ़ाइल और कई अन्य फ़ॉर्मैट में आउटपुट किया जा सकता है. इसके लिए, सिर्फ़ एक तरीके का इस्तेमाल करना होगा.
टेबल वाला सैंपल फ़ॉर्म डाउनलोड करें
हमारे पास एक सैंपल दस्तावेज़ है. इसमें एक सैंपल फ़ॉर्म और एक टेबल है.
इस लिंक का इस्तेमाल करके, PDF डाउनलोड किया जा सकता है. इसके बाद, इसे Cloud Shell इंस्टेंस पर अपलोड करें.
इसके अलावा, gsutil का इस्तेमाल करके, इसे हमारे सार्वजनिक Google Cloud Storage बकेट से डाउनलोड किया जा सकता है.
gsutil cp gs://cloud-samples-data/documentai/codelabs/form-parser/form_with_tables.pdf .
नीचे दिए गए निर्देश का इस्तेमाल करके पुष्टि करें कि फ़ाइल, Cloud Shell में डाउनलोड हो गई है:
ls -ltr form_with_tables.pdf
टेबल का डेटा एक्सट्रैक्ट करना
टेबल के डेटा को प्रोसेस करने का अनुरोध, की-वैल्यू पेयर निकालने के अनुरोध जैसा ही होता है. इन दोनों में अंतर यह है कि हम जवाब में किस फ़ील्ड से डेटा निकालते हैं. टेबल का डेटा, pages[].tables[] फ़ील्ड में सेव किया जाता है.
इस उदाहरण में, हर टेबल और पेज के लिए, टेबल हेडर वाली लाइनों और बॉडी वाली लाइनों से जानकारी निकाली जाती है. इसके बाद, टेबल को प्रिंट किया जाता है और उसे CSV फ़ाइल के तौर पर सेव किया जाता है.
table_parsing.py नाम की एक फ़ाइल बनाएं और नीचे दिए गए कोड का इस्तेमाल करें.
table_parsing.py
# type: ignore[1]
"""
Uses Document AI online processing to call a form parser processor
Extracts the tables and data in the document.
"""
from os.path import splitext
from typing import List, Sequence
import pandas as pd
from google.cloud import documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type
)
# Configure the process request
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document
)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
def get_table_data(
rows: Sequence[documentai.Document.Page.Table.TableRow], text: str
) -> List[List[str]]:
"""
Get Text data from table rows
"""
all_values: List[List[str]] = []
for row in rows:
current_row_values: List[str] = []
for cell in row.cells:
current_row_values.append(
text_anchor_to_text(cell.layout.text_anchor, text)
)
all_values.append(current_row_values)
return all_values
def text_anchor_to_text(text_anchor: documentai.Document.TextAnchor, text: str) -> str:
"""
Document AI identifies table data by their offsets in the entirety of the
document's text. This function converts offsets to a string.
"""
response = ""
# If a text segment spans several lines, it will
# be stored in different text segments.
for segment in text_anchor.text_segments:
start_index = int(segment.start_index)
end_index = int(segment.end_index)
response += text[start_index:end_index]
return response.strip().replace("\n", " ")
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "FORM_PARSER_ID" # Create processor before running sample
# The local file in your current working directory
FILE_PATH = "form_with_tables.pdf"
# Refer to https://cloud.google.com/document-ai/docs/file-types
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
header_row_values: List[List[str]] = []
body_row_values: List[List[str]] = []
# Input Filename without extension
output_file_prefix = splitext(FILE_PATH)[0]
for page in document.pages:
for index, table in enumerate(page.tables):
header_row_values = get_table_data(table.header_rows, document.text)
body_row_values = get_table_data(table.body_rows, document.text)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame(
data=body_row_values,
columns=pd.MultiIndex.from_arrays(header_row_values),
)
print(f"Page {page.page_number} - Table {index}")
print(df)
# Save each table as a CSV file
output_filename = f"{output_file_prefix}_pg{page.page_number}_tb{index}.csv"
df.to_csv(output_filename, index=False)
अब अपना कोड चलाएं. आपको कंसोल में टेक्स्ट दिखेगा.
हमारे सैंपल दस्तावेज़ का इस्तेमाल करने पर, आपको यह आउटपुट दिखेगा:
$ python3 table_parsing.py
Page 1 - Table 0
Item Description
0 Item 1 Description 1
1 Item 2 Description 2
2 Item 3 Description 3
Page 1 - Table 1
Form Number: 12345678
0 Form Date: 2020/10/01
1 Name: First Last
2 Address: 123 Fake St
आपके पास उस डायरेक्ट्री में दो नई CSV फ़ाइलें भी होनी चाहिए जहां से कोड चलाया जा रहा है.
$ ls form_with_tables_pg1_tb0.csv form_with_tables_pg1_tb1.csv table_parsing.py
7. बधाई हो
बधाई हो, आपने हाथ से लिखे गए फ़ॉर्म से डेटा निकालने के लिए, Document AI API का इस्तेमाल कर लिया है. हमारा सुझाव है कि आप फ़ॉर्म वाले अन्य दस्तावेज़ों का इस्तेमाल करके देखें.
खाली करने के लिए जगह
इस ट्यूटोरियल में इस्तेमाल किए गए संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए:
- Cloud Console में, संसाधन मैनेज करें पेज पर जाएं.
- प्रोजेक्ट की सूची में, अपना प्रोजेक्ट चुनें. इसके बाद, मिटाएं पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें.
ज़्यादा जानें
इन फ़ॉलो-अप कोडलैब की मदद से, Document AI के बारे में ज़्यादा जानें.
- Document AI (Python) के साथ खास प्रोसेसर
- Python की मदद से Document AI प्रोसेसर मैनेज करना
- Document AI: ह्यूमन इन द लूप
संसाधन
लाइसेंस
इस काम के लिए, Creative Commons एट्रिब्यूशन 2.0 जेनेरिक लाइसेंस के तहत लाइसेंस मिला है.