
1. نظرة عامة

ما هي خدمة Document AI؟
Document AI هي منصة تتيح لك استخراج الإحصاءات من مستنداتك. في الأساس، يقدّم هذا التطبيق قائمة متزايدة من أدوات معالجة المستندات (تُعرف أيضًا باسم أدوات التحليل أو التقسيم، حسب وظائفها).
هناك طريقتان يمكنك من خلالهما إدارة معالِجات Document AI:
- يدويًا، من وحدة تحكّم الويب
- آليًا باستخدام Document AI API.
في ما يلي لقطة شاشة تعرض قائمة المعالِجات، سواء من وحدة تحكّم الويب أو من رمز Python البرمجي:
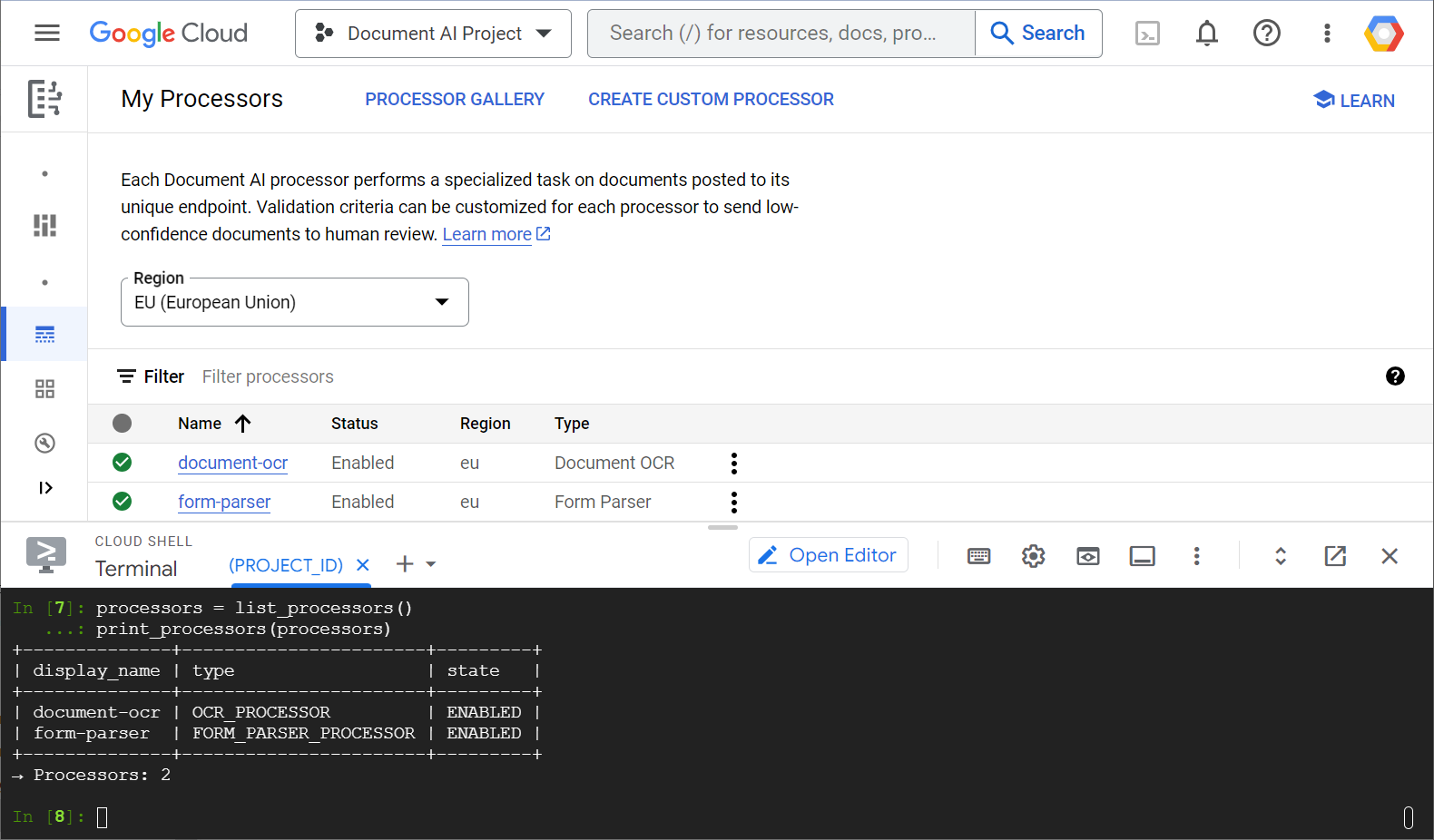
في هذا التمرين العملي، ستركز على إدارة معالِجات Document AI آليًا باستخدام مكتبة برامج Python.
البيانات التي ستظهر لك
- كيفية إعداد بيئتك
- كيفية استرداد أنواع المعالِجات
- كيفية إنشاء معالِجات
- كيفية إدراج معالِجات المشاريع
- كيفية استخدام المعالِجات
- كيفية تفعيل/إيقاف المعالِجات
- كيفية إدارة إصدارات المعالج
- كيفية حذف أدوات المعالجة
المتطلبات
استطلاع الرأي
كيف ستستخدم هذا البرنامج التعليمي؟
كيف تقيّم تجربتك مع Python؟
كيف تقيّم تجربتك مع خدمات Google Cloud؟
2. الإعداد والمتطلبات
إعداد البيئة بالسرعة التي تناسبك
- سجِّل الدخول إلى Google Cloud Console وأنشِئ مشروعًا جديدًا أو أعِد استخدام مشروع حالي. إذا لم يكن لديك حساب على Gmail أو Google Workspace، عليك إنشاء حساب.

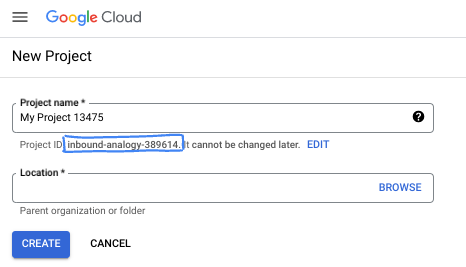
- اسم المشروع هو الاسم المعروض للمشاركين في هذا المشروع. وهي سلسلة أحرف لا تستخدمها Google APIs. ويمكنك تعديلها في أي وقت.
- رقم تعريف المشروع هو معرّف فريد في جميع مشاريع Google Cloud ولا يمكن تغييره بعد ضبطه. تنشئ Cloud Console تلقائيًا سلسلة فريدة، ولا يهمّك عادةً ما هي. في معظم دروس البرمجة، عليك الرجوع إلى رقم تعريف مشروعك (يُشار إليه عادةً باسم
PROJECT_ID). إذا لم يعجبك رقم التعريف الذي تم إنشاؤه، يمكنك إنشاء رقم تعريف عشوائي آخر. يمكنك بدلاً من ذلك تجربة اسم مستخدم من اختيارك ومعرفة ما إذا كان متاحًا. لا يمكن تغيير هذا الخيار بعد هذه الخطوة وسيظل ساريًا طوال مدة المشروع. - للعلم، هناك قيمة ثالثة، وهي رقم المشروع، تستخدمها بعض واجهات برمجة التطبيقات. يمكنك الاطّلاع على مزيد من المعلومات عن كل هذه القيم الثلاث في المستندات.
- بعد ذلك، عليك تفعيل الفوترة في Cloud Console لاستخدام موارد/واجهات برمجة تطبيقات Cloud. لن تكلفك تجربة هذا الدرس التطبيقي حول الترميز الكثير، إن وُجدت أي تكلفة على الإطلاق. لإيقاف الموارد وتجنُّب تحمّل تكاليف تتجاوز هذا البرنامج التعليمي، يمكنك حذف الموارد التي أنشأتها أو حذف المشروع. يمكن لمستخدمي Google Cloud الجدد الاستفادة من برنامج الفترة التجريبية المجانية بقيمة 300 دولار أمريكي.
بدء Cloud Shell
على الرغم من إمكانية تشغيل Google Cloud عن بُعد من الكمبيوتر المحمول، ستستخدم في هذا المختبر Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
تفعيل Cloud Shell
- من Cloud Console، انقر على تفعيل Cloud Shell
 .
.

إذا كانت هذه هي المرة الأولى التي تبدأ فيها Cloud Shell، ستظهر لك شاشة وسيطة توضّح ماهية هذه الخدمة. إذا ظهرت لك شاشة وسيطة، انقر على متابعة.
يستغرق توفير Cloud Shell والاتصال به بضع لحظات فقط.

يتم تحميل هذا الجهاز الافتراضي بجميع أدوات التطوير اللازمة. توفّر هذه الخدمة دليلًا رئيسيًا دائمًا بسعة 5 غيغابايت وتعمل في Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يمكن إنجاز معظم عملك في هذا الدرس التطبيقي حول الترميز، إن لم يكن كله، باستخدام متصفح.
بعد الاتصال بـ Cloud Shell، من المفترض أن يظهر لك أنّه تم إثبات هويتك وأنّه تم ضبط المشروع على رقم تعريف مشروعك.
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من إكمال عملية المصادقة:
gcloud auth list
ناتج الأمر
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك:
gcloud config list project
ناتج الأمر
[core] project = <PROJECT_ID>
إذا لم يكن كذلك، يمكنك تعيينه من خلال هذا الأمر:
gcloud config set project <PROJECT_ID>
ناتج الأمر
Updated property [core/project].
3- إعداد البيئة
قبل أن تتمكّن من بدء استخدام Document AI، شغِّل الأمر التالي في Cloud Shell لتفعيل واجهة برمجة التطبيقات Document AI API:
gcloud services enable documentai.googleapis.com
ينبغي أن تظهر لك على النحو التالي:
Operation "operations/..." finished successfully.
يمكنك الآن استخدام Document AI.
انتقِل إلى دليل المنزل:
cd ~
أنشئ بيئة Python افتراضية لعزل التبعيات:
virtualenv venv-docai
فعِّل البيئة الافتراضية:
source venv-docai/bin/activate
ثبِّت IPython ومكتبة عميل Document AI وpython-tabulate (التي ستستخدمها لعرض نتائج الطلب بتنسيق جميل):
pip install ipython google-cloud-documentai tabulate
ينبغي أن تظهر لك على النحو التالي:
... Installing collected packages: ..., tabulate, ipython, google-cloud-documentai Successfully installed ... google-cloud-documentai-2.15.0 ...
يمكنك الآن استخدام مكتبة برامج Document AI.
اضبط متغيرات البيئة التالية:
export PROJECT_ID=$(gcloud config get-value core/project)
# Choose "us" or "eu"
export API_LOCATION="us"
من الآن فصاعدًا، يجب إكمال جميع الخطوات في الجلسة نفسها.
تأكَّد من تحديد متغيّرات البيئة بشكلٍ سليم:
echo $PROJECT_ID
echo $API_LOCATION
في الخطوات التالية، ستستخدم برنامجًا تفاعليًا لتفسير لغة Python يُسمى IPython، وهو البرنامج الذي ثبّتته للتو. ابدأ جلسة من خلال تنفيذ ipython في Cloud Shell:
ipython
ينبغي أن تظهر لك على النحو التالي:
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] Type 'copyright', 'credits' or 'license' for more information IPython 9.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
انسخ الرمز التالي إلى جلسة IPython:
import os
from typing import Iterator, MutableSequence, Optional, Sequence, Tuple
import google.cloud.documentai_v1 as docai
from tabulate import tabulate
PROJECT_ID = os.getenv("PROJECT_ID", "")
API_LOCATION = os.getenv("API_LOCATION", "")
assert PROJECT_ID, "PROJECT_ID is undefined"
assert API_LOCATION in ("us", "eu"), "API_LOCATION is incorrect"
# Test processors
document_ocr_display_name = "document-ocr"
form_parser_display_name = "form-parser"
test_processor_display_names_and_types = (
(document_ocr_display_name, "OCR_PROCESSOR"),
(form_parser_display_name, "FORM_PARSER_PROCESSOR"),
)
def get_client() -> docai.DocumentProcessorServiceClient:
client_options = {"api_endpoint": f"{API_LOCATION}-documentai.googleapis.com"}
return docai.DocumentProcessorServiceClient(client_options=client_options)
def get_parent(client: docai.DocumentProcessorServiceClient) -> str:
return client.common_location_path(PROJECT_ID, API_LOCATION)
def get_client_and_parent() -> Tuple[docai.DocumentProcessorServiceClient, str]:
client = get_client()
parent = get_parent(client)
return client, parent
أنت الآن جاهز لإرسال طلبك الأول واسترداد أنواع المعالجات.
4. جارٍ جلب أنواع المعالِجات
قبل إنشاء معالج في الخطوة التالية، استرجِع أنواع المعالجات المتاحة. يمكنك استرداد هذه القائمة باستخدام fetch_processor_types.
أضِف الدالتَين التاليتَين إلى جلسة IPython:
def fetch_processor_types() -> MutableSequence[docai.ProcessorType]:
client, parent = get_client_and_parent()
response = client.fetch_processor_types(parent=parent)
return response.processor_types
def print_processor_types(processor_types: Sequence[docai.ProcessorType]):
def sort_key(pt):
return (not pt.allow_creation, pt.category, pt.type_)
sorted_processor_types = sorted(processor_types, key=sort_key)
data = processor_type_tabular_data(sorted_processor_types)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor types: {len(sorted_processor_types)}")
def processor_type_tabular_data(
processor_types: Sequence[docai.ProcessorType],
) -> Iterator[Tuple[str, str, str, str]]:
def locations(pt):
return ", ".join(sorted(loc.location_id for loc in pt.available_locations))
yield ("type", "category", "allow_creation", "locations")
yield ("left", "left", "left", "left")
if not processor_types:
yield ("-", "-", "-", "-")
return
for pt in processor_types:
yield (pt.type_, pt.category, f"{pt.allow_creation}", locations(pt))
أدرِج أنواع المعالجات:
processor_types = fetch_processor_types()
print_processor_types(processor_types)
من المفترض أن تحصل على نتيجة مشابهة لما يلي:
+--------------------------------------+-------------+----------------+-----------+ | type | category | allow_creation | locations | +--------------------------------------+-------------+----------------+-----------+ | CUSTOM_CLASSIFICATION_PROCESSOR | CUSTOM | True | eu, us | ... | FORM_PARSER_PROCESSOR | GENERAL | True | eu, us | | LAYOUT_PARSER_PROCESSOR | GENERAL | True | eu, us | | OCR_PROCESSOR | GENERAL | True | eu, us | | BANK_STATEMENT_PROCESSOR | SPECIALIZED | True | eu, us | | EXPENSE_PROCESSOR | SPECIALIZED | True | eu, us | ... +--------------------------------------+-------------+----------------+-----------+ → Processor types: 19
أصبحت لديك الآن كل المعلومات اللازمة لإنشاء معالِجات في الخطوة التالية.
5- إنشاء معالِجات
لإنشاء معالج، استخدِم الدالة create_processor مع اسم معروض ونوع معالج.
أضِف الدالة التالية:
def create_processor(display_name: str, type: str) -> docai.Processor:
client, parent = get_client_and_parent()
processor = docai.Processor(display_name=display_name, type_=type)
return client.create_processor(parent=parent, processor=processor)
أنشئ معالِجات الاختبار:
separator = "=" * 80
for display_name, type in test_processor_display_names_and_types:
print(separator)
print(f"Creating {display_name} ({type})...")
try:
create_processor(display_name, type)
except Exception as err:
print(err)
print(separator)
print("Done")
من المفترض أن تحصل على ما يلي:
================================================================================ Creating document-ocr (OCR_PROCESSOR)... ================================================================================ Creating form-parser (FORM_PARSER_PROCESSOR)... ================================================================================ Done
لقد أنشأت معالِجات جديدة.
بعد ذلك، تعرَّف على كيفية إدراج المعالِجات.
6. معالجات المشاريع المدرَجة
تعرض السمة list_processors قائمة بجميع المعالِجات التابعة لمشروعك.
أضِف الدوال التالية:
def list_processors() -> MutableSequence[docai.Processor]:
client, parent = get_client_and_parent()
response = client.list_processors(parent=parent)
return list(response.processors)
def print_processors(processors: Optional[Sequence[docai.Processor]] = None):
def sort_key(processor):
return processor.display_name
if processors is None:
processors = list_processors()
sorted_processors = sorted(processors, key=sort_key)
data = processor_tabular_data(sorted_processors)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processors: {len(sorted_processors)}")
def processor_tabular_data(
processors: Sequence[docai.Processor],
) -> Iterator[Tuple[str, str, str]]:
yield ("display_name", "type", "state")
yield ("left", "left", "left")
if not processors:
yield ("-", "-", "-")
return
for processor in processors:
yield (processor.display_name, processor.type_, processor.state.name)
استدعاء الدوال:
processors = list_processors()
print_processors(processors)
من المفترض أن تحصل على ما يلي:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
لاسترداد معالج حسب اسمه المعروض، أضِف الدالة التالية:
def get_processor(
display_name: str,
processors: Optional[Sequence[docai.Processor]] = None,
) -> Optional[docai.Processor]:
if processors is None:
processors = list_processors()
for processor in processors:
if processor.display_name == display_name:
return processor
return None
اختبِر الدالة:
processor = get_processor(document_ocr_display_name, processors)
assert processor is not None
print(processor)
ينبغي أن تظهر لك على النحو التالي:
name: "projects/PROJECT_NUM/locations/LOCATION/processors/PROCESSOR_ID" type_: "OCR_PROCESSOR" display_name: "document-ocr" state: ENABLED ...
أصبحت الآن تعرف كيفية إدراج معالِجات مشروعك واستردادها حسب أسمائها المعروضة. بعد ذلك، تعرَّف على كيفية استخدام معالج.
7. استخدام المعالِجات
يمكن معالجة المستندات بطريقتَين:
- بشكل متزامن: يمكنك طلب
process_documentلتحليل مستند واحد واستخدام النتائج مباشرةً. - بشكل غير متزامن: استخدِم
batch_process_documentsلتشغيل معالجة على دفعات لمستندات متعددة أو كبيرة.
مستند الاختبار ( PDF) هو استبيان تم مسحه ضوئيًا وتمت الإجابة عنه بخط اليد. نزِّلها في دليل العمل مباشرةً من جلسة IPython:
!gsutil cp gs://cloud-samples-data/documentai/form.pdf .
تحقَّق من محتوى دليل العمل:
!ls
يجب توفّر ما يلي:
... form.pdf ... venv-docai ...
يمكنك استخدام طريقة process_document المتزامنة لتحليل ملف محلي. أضِف الدالة التالية:
def process_file(
processor: docai.Processor,
file_path: str,
mime_type: str,
) -> docai.Document:
client = get_client()
with open(file_path, "rb") as document_file:
document_content = document_file.read()
document = docai.RawDocument(content=document_content, mime_type=mime_type)
request = docai.ProcessRequest(raw_document=document, name=processor.name)
response = client.process_document(request)
return response.document
بما أنّ المستند هو استبيان، اختَر أداة تحليل النماذج. بالإضافة إلى استخراج النص (المطبوع والمكتوب بخط اليد)، وهو ما تفعله جميع أدوات المعالجة، ترصد أداة المعالجة العامة هذه حقول النماذج.
حلِّل المستند:
processor = get_processor(form_parser_display_name)
assert processor is not None
file_path = "./form.pdf"
mime_type = "application/pdf"
document = process_file(processor, file_path, mime_type)
تُجري جميع أدوات المعالجة عملية "التعرّف البصري على الأحرف" (OCR) أولاً على المستند. راجِع النص الذي تم رصده من خلال عملية التعرّف البصري على الأحرف:
document.text.split("\n")
من المفترض أن يظهر لك ما يلي:
['FakeDoc M.D.', 'HEALTH INTAKE FORM', 'Please fill out the questionnaire carefully. The information you provide will be used to complete', 'your health profile and will be kept confidential.', 'Date:', '9/14/19', 'Name:', 'Sally Walker', 'DOB: 09/04/1986', 'Address: 24 Barney Lane', 'City: Towaco', 'State: NJ Zip: 07082', 'Email: Sally, walker@cmail.com', '_Phone #: (906) 917-3486', 'Gender: F', 'Marital Status:', ... ]
أضِف الدالتَين التاليتَين لطباعة حقول النموذج التي تم رصدها:
def print_form_fields(document: docai.Document):
sorted_form_fields = form_fields_sorted_by_ocr_order(document)
data = form_field_tabular_data(sorted_form_fields, document)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Form fields: {len(sorted_form_fields)}")
def form_field_tabular_data(
form_fields: Sequence[docai.Document.Page.FormField],
document: docai.Document,
) -> Iterator[Tuple[str, str, str]]:
yield ("name", "value", "confidence")
yield ("right", "left", "right")
if not form_fields:
yield ("-", "-", "-")
return
for form_field in form_fields:
name_layout = form_field.field_name
value_layout = form_field.field_value
name = text_from_layout(name_layout, document)
value = text_from_layout(value_layout, document)
confidence = value_layout.confidence
yield (name, value, f"{confidence:.1%}")
أضِف أيضًا وظائف الأدوات المساعدة التالية:
def form_fields_sorted_by_ocr_order(
document: docai.Document,
) -> MutableSequence[docai.Document.Page.FormField]:
def sort_key(form_field):
# Sort according to the field name detected position
text_anchor = form_field.field_name.text_anchor
return text_anchor.text_segments[0].start_index if text_anchor else 0
fields = (field for page in document.pages for field in page.form_fields)
return sorted(fields, key=sort_key)
def text_from_layout(
layout: docai.Document.Page.Layout,
document: docai.Document,
) -> str:
full_text = document.text
segs = layout.text_anchor.text_segments
text = "".join(full_text[seg.start_index : seg.end_index] for seg in segs)
if text.endswith("\n"):
text = text[:-1]
return text
اطبع حقول النموذج التي تم رصدها:
print_form_fields(document)
من المفترض أن تحصل على نسخة مطبوعة مشابهة لما يلي:
+-----------------+-------------------------+------------+ | name | value | confidence | +-----------------+-------------------------+------------+ | Date: | 9/14/19 | 83.0% | | Name: | Sally Walker | 87.3% | | DOB: | 09/04/1986 | 88.5% | | Address: | 24 Barney Lane | 82.4% | | City: | Towaco | 90.0% | | State: | NJ | 89.4% | | Zip: | 07082 | 91.4% | | Email: | Sally, walker@cmail.com | 79.7% | | _Phone #: | walker@cmail.com | 93.2% | | | (906 | | | Gender: | F | 88.2% | | Marital Status: | Single | 85.2% | | Occupation: | Software Engineer | 81.5% | | Referred By: | None | 76.9% | ... +-----------------+-------------------------+------------+ → Form fields: 17
راجِع أسماء الحقول والقيم التي تم رصدها ( PDF). في ما يلي النصف العلوي من الاستبيان:

لقد حلّلت نموذجًا يحتوي على نص مطبوع ومكتوب بخط اليد. لقد رصدت أيضًا حقوله بدقة عالية. والنتيجة هي تحويل وحدات البكسل إلى بيانات منظَّمة.
8. تفعيل المعالِجات وإيقافها
باستخدام disable_processor وenable_processor، يمكنك التحكّم في إمكانية استخدام معالج.
أضِف الدوال التالية:
def update_processor_state(processor: docai.Processor, enable_processor: bool):
client = get_client()
if enable_processor:
request = docai.EnableProcessorRequest(name=processor.name)
operation = client.enable_processor(request)
else:
request = docai.DisableProcessorRequest(name=processor.name)
operation = client.disable_processor(request)
operation.result() # Wait for operation to complete
def enable_processor(processor: docai.Processor):
update_processor_state(processor, True)
def disable_processor(processor: docai.Processor):
update_processor_state(processor, False)
أوقِف معالج محلّل النماذج وتحقَّق من حالة المعالِجات:
processor = get_processor(form_parser_display_name)
assert processor is not None
disable_processor(processor)
print_processors()
من المفترض أن تحصل على ما يلي:
+--------------+-----------------------+----------+ | display_name | type | state | +--------------+-----------------------+----------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | DISABLED | +--------------+-----------------------+----------+ → Processors: 2
أعِد تفعيل معالج محلّل النماذج باتّباع الخطوات التالية:
enable_processor(processor)
print_processors()
من المفترض أن تحصل على ما يلي:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
بعد ذلك، تعرَّف على كيفية إدارة إصدارات المعالج.
9- إدارة إصدارات المعالِج
يمكن أن تتوفّر المعالِجات بنُسخ متعددة. تعرَّف على كيفية استخدام طريقتَي list_processor_versions وset_default_processor_version.
أضِف الدوال التالية:
def list_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
client = get_client()
response = client.list_processor_versions(parent=processor.name)
return list(response)
def get_sorted_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
def sort_key(processor_version: docai.ProcessorVersion):
return processor_version.name
versions = list_processor_versions(processor)
return sorted(versions, key=sort_key)
def print_processor_versions(processor: docai.Processor):
versions = get_sorted_processor_versions(processor)
default_version_name = processor.default_processor_version
data = processor_versions_tabular_data(versions, default_version_name)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor versions: {len(versions)}")
def processor_versions_tabular_data(
versions: Sequence[docai.ProcessorVersion],
default_version_name: str,
) -> Iterator[Tuple[str, str, str]]:
yield ("version", "display name", "default")
yield ("left", "left", "left")
if not versions:
yield ("-", "-", "-")
return
for version in versions:
mapping = docai.DocumentProcessorServiceClient.parse_processor_version_path(
version.name
)
processor_version = mapping["processor_version"]
is_default = "Y" if version.name == default_version_name else ""
yield (processor_version, version.display_name, is_default)
أدرِج الإصدارات المتاحة لمعالج التعرّف البصري على الأحرف:
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
ستحصل على إصدارات المعالج التالية:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | Y | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | | +--------------------------------+--------------------------+---------+ → Processor versions: 5
الآن، أضِف دالة لتغيير إصدار المعالج التلقائي:
def set_default_processor_version(processor: docai.Processor, version_name: str):
client = get_client()
request = docai.SetDefaultProcessorVersionRequest(
processor=processor.name,
default_processor_version=version_name,
)
operation = client.set_default_processor_version(request)
operation.result() # Wait for operation to complete
التبديل إلى أحدث إصدار من المعالج:
processor = get_processor(document_ocr_display_name)
assert processor is not None
versions = get_sorted_processor_versions(processor)
new_version = versions[-1] # Latest version
set_default_processor_version(processor, new_version.name)
# Update the processor info
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
ستحصل على إعدادات الإصدار الجديد:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | Y | +--------------------------------+--------------------------+---------+ → Processor versions: 5
بعد ذلك، طريقة إدارة المعالجات النهائية (الحذف).
10. حذف المعالِجات
أخيرًا، اطّلِع على كيفية استخدام طريقة delete_processor.
أضِف الدالة التالية:
def delete_processor(processor: docai.Processor):
client = get_client()
operation = client.delete_processor(name=processor.name)
operation.result() # Wait for operation to complete
احذف معالِجات الاختبار باتّباع الخطوات التالية:
processors_to_delete = [dn for dn, _ in test_processor_display_names_and_types]
print("Deleting processors...")
for processor in list_processors():
if processor.display_name not in processors_to_delete:
continue
print(f" Deleting {processor.display_name}...")
delete_processor(processor)
print("Done\n")
print_processors()
من المفترض أن تحصل على ما يلي:
Deleting processors... Deleting form-parser... Deleting document-ocr... Done +--------------+------+-------+ | display_name | type | state | +--------------+------+-------+ | - | - | - | +--------------+------+-------+ → Processors: 0
لقد تناولنا جميع طرق إدارة المعالج. أوشكت على الانتهاء...
11. تهانينا!
تعرّفت على كيفية إدارة أدوات معالجة Document AI باستخدام Python.
تَنظيم
لتنظيف بيئة التطوير، اتّبِع الخطوات التالية من Cloud Shell:
- إذا كنت لا تزال في جلسة IPython، ارجع إلى واجهة الأوامر:
exit - أوقِف استخدام البيئة الافتراضية للغة Python:
deactivate - احذف مجلد البيئة الافتراضية:
cd ~ ; rm -rf ./venv-docai
لحذف مشروعك على Google Cloud، اتّبِع الخطوات التالية من Cloud Shell:
- استرداد رقم تعريف مشروعك الحالي:
PROJECT_ID=$(gcloud config get-value core/project) - تأكَّد من أنّ هذا هو المشروع الذي تريد حذفه:
echo $PROJECT_ID - احذف المشروع:
gcloud projects delete $PROJECT_ID
مزيد من المعلومات
- جرِّب Document AI في متصفّحك: https://cloud.google.com/document-ai/docs/drag-and-drop
- تفاصيل معالج Document AI: https://cloud.google.com/document-ai/docs/processors-list
- Python على Google Cloud: https://cloud.google.com/python
- مكتبات العملاء على السحابة الإلكترونية للغة Python: https://github.com/googleapis/google-cloud-python
الترخيص
يخضع هذا العمل لترخيص المشاع الإبداعي مع نسب العمل إلى مؤلفه 2.0 Generic License.