
1. Visão geral

O que é a Document AI?
A Document AI é uma plataforma que permite extrair insights dos seus documentos. Basicamente, ele oferece uma lista crescente de processadores de documentos (também chamados de analisadores ou divisores, dependendo da funcionalidade).
Há duas maneiras de gerenciar os processadores da Document AI:
- manualmente, no console da Web;
- de maneira programática, usando a API Document AI.
Confira um exemplo de captura de tela mostrando sua lista de processadores, tanto do console da Web quanto do código Python:
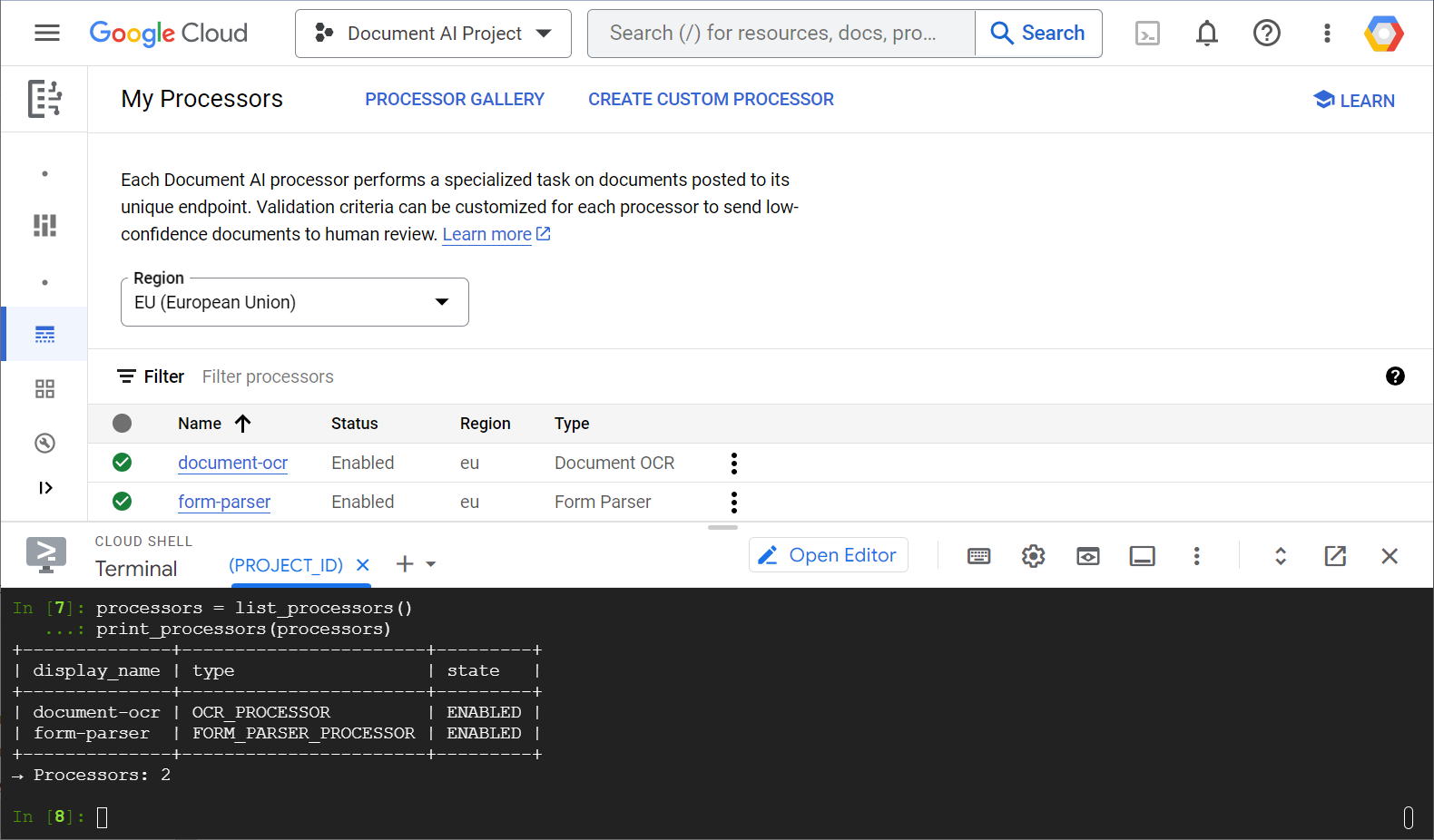
Neste laboratório, você vai se concentrar no gerenciamento programático de processadores da Document AI com a biblioteca de cliente Python.
O que você vai ver
- Como configurar seu ambiente
- Como buscar tipos de processadores
- Como criar processadores
- Como listar processadores de projetos
- Como usar processadores
- Como ativar/desativar processadores
- Como gerenciar versões do processador
- Como excluir processadores
O que é necessário
- um projeto do Google Cloud;
- Use um navegador, como o Chrome ou o Firefox.
- Familiaridade com o Python
Pesquisa
Como você vai usar este tutorial?
Como você classificaria sua experiência com Python?
Como você classificaria sua experiência com os serviços do Google Cloud?
2. Configuração e requisitos
Configuração de ambiente autoguiada
- Faça login no Console do Google Cloud e crie um novo projeto ou reutilize um existente. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.

- O Nome do projeto é o nome de exibição para os participantes do projeto. É uma string de caracteres não usada pelas APIs do Google e pode ser atualizada quando você quiser.
- O ID do projeto precisa ser exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Cloud gera automaticamente uma string exclusiva. Em geral, não importa o que seja. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, normalmente identificado como
PROJECT_ID. Se você não gostar do ID gerado, crie outro aleatório. Se preferir, teste o seu e confira se ele está disponível. Ele não pode ser mudado após essa etapa e permanece durante o projeto. - Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
- Em seguida, ative o faturamento no console do Cloud para usar os recursos/APIs do Cloud. A execução deste codelab não vai ser muito cara, se tiver algum custo. Para encerrar os recursos e evitar cobranças além deste tutorial, exclua os recursos criados ou exclua o projeto. Novos usuários do Google Cloud estão qualificados para o programa de US$ 300 de avaliação sem custos.
Inicie o Cloud Shell
Embora o Google Cloud possa ser operado remotamente em seu laptop, neste laboratório você vai usar o Cloud Shell, um ambiente de linha de comando executado no Cloud.
Ativar o Cloud Shell
- No Console do Cloud, clique em Ativar o Cloud Shell
 .
.

Se esta for a primeira vez que você inicia o Cloud Shell, uma tela intermediária vai aparecer com a descrição dele. Se isso acontecer, clique em Continuar.
Leva apenas alguns instantes para provisionar e se conectar ao Cloud Shell.

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, quase todo o trabalho pode ser feito com um navegador.
Depois de se conectar ao Cloud Shell, você vai ver que sua conta já está autenticada e que o projeto está configurado com o ID do seu projeto.
- Execute o seguinte comando no Cloud Shell para confirmar se a conta está autenticada:
gcloud auth list
Resposta ao comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto:
gcloud config list project
Resposta ao comando
[core] project = <PROJECT_ID>
Se o projeto não estiver configurado, configure-o usando este comando:
gcloud config set project <PROJECT_ID>
Resposta ao comando
Updated property [core/project].
3. configuração do ambiente
Antes de começar a usar a Document AI, execute o seguinte comando no Cloud Shell para ativar a API Document AI:
gcloud services enable documentai.googleapis.com
Você verá algo como:
Operation "operations/..." finished successfully.
Agora você pode usar a Document AI.
Navegue até o diretório principal:
cd ~
Crie um ambiente virtual do Python para isolar as dependências:
virtualenv venv-docai
Ative o ambiente virtual:
source venv-docai/bin/activate
Instale o IPython, a biblioteca de cliente da Document AI e o python-tabulate (que você vai usar para imprimir os resultados da solicitação de forma organizada):
pip install ipython google-cloud-documentai tabulate
Você verá algo como:
... Installing collected packages: ..., tabulate, ipython, google-cloud-documentai Successfully installed ... google-cloud-documentai-2.15.0 ...
Agora você já pode usar a biblioteca de cliente da Document AI.
Configure as variáveis de ambiente a seguir:
export PROJECT_ID=$(gcloud config get-value core/project)
# Choose "us" or "eu"
export API_LOCATION="us"
A partir de agora, todas as etapas precisam ser concluídas na mesma sessão.
Verifique se as variáveis de ambiente estão definidas corretamente:
echo $PROJECT_ID
echo $API_LOCATION
Nas próximas etapas, você vai usar um interpretador interativo chamado IPython, que acabou de instalar. Inicie uma sessão executando ipython no Cloud Shell:
ipython
Você verá algo como:
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] Type 'copyright', 'credits' or 'license' for more information IPython 9.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
Copie o seguinte código na sua sessão do IPython:
import os
from typing import Iterator, MutableSequence, Optional, Sequence, Tuple
import google.cloud.documentai_v1 as docai
from tabulate import tabulate
PROJECT_ID = os.getenv("PROJECT_ID", "")
API_LOCATION = os.getenv("API_LOCATION", "")
assert PROJECT_ID, "PROJECT_ID is undefined"
assert API_LOCATION in ("us", "eu"), "API_LOCATION is incorrect"
# Test processors
document_ocr_display_name = "document-ocr"
form_parser_display_name = "form-parser"
test_processor_display_names_and_types = (
(document_ocr_display_name, "OCR_PROCESSOR"),
(form_parser_display_name, "FORM_PARSER_PROCESSOR"),
)
def get_client() -> docai.DocumentProcessorServiceClient:
client_options = {"api_endpoint": f"{API_LOCATION}-documentai.googleapis.com"}
return docai.DocumentProcessorServiceClient(client_options=client_options)
def get_parent(client: docai.DocumentProcessorServiceClient) -> str:
return client.common_location_path(PROJECT_ID, API_LOCATION)
def get_client_and_parent() -> Tuple[docai.DocumentProcessorServiceClient, str]:
client = get_client()
parent = get_parent(client)
return client, parent
Você está pronto para fazer sua primeira solicitação e buscar os tipos de processador.
4. Buscando tipos de processadores
Antes de criar um processador na próxima etapa, busque os tipos de processador disponíveis. É possível recuperar essa lista com fetch_processor_types.
Adicione as seguintes funções à sua sessão do IPython:
def fetch_processor_types() -> MutableSequence[docai.ProcessorType]:
client, parent = get_client_and_parent()
response = client.fetch_processor_types(parent=parent)
return response.processor_types
def print_processor_types(processor_types: Sequence[docai.ProcessorType]):
def sort_key(pt):
return (not pt.allow_creation, pt.category, pt.type_)
sorted_processor_types = sorted(processor_types, key=sort_key)
data = processor_type_tabular_data(sorted_processor_types)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor types: {len(sorted_processor_types)}")
def processor_type_tabular_data(
processor_types: Sequence[docai.ProcessorType],
) -> Iterator[Tuple[str, str, str, str]]:
def locations(pt):
return ", ".join(sorted(loc.location_id for loc in pt.available_locations))
yield ("type", "category", "allow_creation", "locations")
yield ("left", "left", "left", "left")
if not processor_types:
yield ("-", "-", "-", "-")
return
for pt in processor_types:
yield (pt.type_, pt.category, f"{pt.allow_creation}", locations(pt))
Liste os tipos de processador:
processor_types = fetch_processor_types()
print_processor_types(processor_types)
Você vai receber algo parecido com isto:
+--------------------------------------+-------------+----------------+-----------+ | type | category | allow_creation | locations | +--------------------------------------+-------------+----------------+-----------+ | CUSTOM_CLASSIFICATION_PROCESSOR | CUSTOM | True | eu, us | ... | FORM_PARSER_PROCESSOR | GENERAL | True | eu, us | | LAYOUT_PARSER_PROCESSOR | GENERAL | True | eu, us | | OCR_PROCESSOR | GENERAL | True | eu, us | | BANK_STATEMENT_PROCESSOR | SPECIALIZED | True | eu, us | | EXPENSE_PROCESSOR | SPECIALIZED | True | eu, us | ... +--------------------------------------+-------------+----------------+-----------+ → Processor types: 19
Agora você tem todas as informações necessárias para criar processadores na próxima etapa.
5. Como criar processadores
Para criar um processador, chame create_processor com um nome de exibição e um tipo de processador.
Adicione a seguinte função:
def create_processor(display_name: str, type: str) -> docai.Processor:
client, parent = get_client_and_parent()
processor = docai.Processor(display_name=display_name, type_=type)
return client.create_processor(parent=parent, processor=processor)
Crie os processadores de teste:
separator = "=" * 80
for display_name, type in test_processor_display_names_and_types:
print(separator)
print(f"Creating {display_name} ({type})...")
try:
create_processor(display_name, type)
except Exception as err:
print(err)
print(separator)
print("Done")
Você vai receber o seguinte:
================================================================================ Creating document-ocr (OCR_PROCESSOR)... ================================================================================ Creating form-parser (FORM_PARSER_PROCESSOR)... ================================================================================ Done
Você criou novos processadores!
Em seguida, veja como listar os processadores.
6. Como listar processadores de projetos
list_processors retorna a lista de todos os processadores pertencentes ao seu projeto.
Adicione as seguintes funções:
def list_processors() -> MutableSequence[docai.Processor]:
client, parent = get_client_and_parent()
response = client.list_processors(parent=parent)
return list(response.processors)
def print_processors(processors: Optional[Sequence[docai.Processor]] = None):
def sort_key(processor):
return processor.display_name
if processors is None:
processors = list_processors()
sorted_processors = sorted(processors, key=sort_key)
data = processor_tabular_data(sorted_processors)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processors: {len(sorted_processors)}")
def processor_tabular_data(
processors: Sequence[docai.Processor],
) -> Iterator[Tuple[str, str, str]]:
yield ("display_name", "type", "state")
yield ("left", "left", "left")
if not processors:
yield ("-", "-", "-")
return
for processor in processors:
yield (processor.display_name, processor.type_, processor.state.name)
Chame as funções:
processors = list_processors()
print_processors(processors)
Você vai receber o seguinte:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Para recuperar um processador pelo nome de exibição, adicione a seguinte função:
def get_processor(
display_name: str,
processors: Optional[Sequence[docai.Processor]] = None,
) -> Optional[docai.Processor]:
if processors is None:
processors = list_processors()
for processor in processors:
if processor.display_name == display_name:
return processor
return None
Teste a função:
processor = get_processor(document_ocr_display_name, processors)
assert processor is not None
print(processor)
Você verá algo como:
name: "projects/PROJECT_NUM/locations/LOCATION/processors/PROCESSOR_ID" type_: "OCR_PROCESSOR" display_name: "document-ocr" state: ENABLED ...
Agora você sabe como listar e recuperar os processadores do projeto pelos nomes de exibição. Em seguida, saiba como usar um processador.
7. Como usar processadores
Os documentos podem ser processados de duas maneiras:
- De forma síncrona: chame
process_documentpara analisar um único documento e use os resultados diretamente. - De forma assíncrona: chame
batch_process_documentspara iniciar um processamento em lote em vários documentos ou documentos grandes.
O documento de teste ( PDF) é um questionário digitalizado preenchido com respostas manuscritas. Faça o download para o diretório de trabalho diretamente da sessão do IPython:
!gsutil cp gs://cloud-samples-data/documentai/form.pdf .
Confira o conteúdo do diretório de trabalho:
!ls
Você precisa ter o seguinte:
... form.pdf ... venv-docai ...
Você pode usar o método síncrono process_document para analisar um arquivo local. Adicione a seguinte função:
def process_file(
processor: docai.Processor,
file_path: str,
mime_type: str,
) -> docai.Document:
client = get_client()
with open(file_path, "rb") as document_file:
document_content = document_file.read()
document = docai.RawDocument(content=document_content, mime_type=mime_type)
request = docai.ProcessRequest(raw_document=document, name=processor.name)
response = client.process_document(request)
return response.document
Como seu documento é um questionário, escolha o analisador de formulários. Além de extrair o texto (impresso e manuscrito), o que todos os processadores fazem, esse processador geral detecta campos de formulário.
Analise o documento:
processor = get_processor(form_parser_display_name)
assert processor is not None
file_path = "./form.pdf"
mime_type = "application/pdf"
document = process_file(processor, file_path, mime_type)
Todos os processadores executam uma primeira passagem de reconhecimento óptico de caracteres (OCR) no documento. Revise o texto detectado pela passagem de OCR:
document.text.split("\n")
Será exibido um resultado parecido com este:
['FakeDoc M.D.', 'HEALTH INTAKE FORM', 'Please fill out the questionnaire carefully. The information you provide will be used to complete', 'your health profile and will be kept confidential.', 'Date:', '9/14/19', 'Name:', 'Sally Walker', 'DOB: 09/04/1986', 'Address: 24 Barney Lane', 'City: Towaco', 'State: NJ Zip: 07082', 'Email: Sally, walker@cmail.com', '_Phone #: (906) 917-3486', 'Gender: F', 'Marital Status:', ... ]
Adicione as seguintes funções para imprimir os campos de formulário detectados:
def print_form_fields(document: docai.Document):
sorted_form_fields = form_fields_sorted_by_ocr_order(document)
data = form_field_tabular_data(sorted_form_fields, document)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Form fields: {len(sorted_form_fields)}")
def form_field_tabular_data(
form_fields: Sequence[docai.Document.Page.FormField],
document: docai.Document,
) -> Iterator[Tuple[str, str, str]]:
yield ("name", "value", "confidence")
yield ("right", "left", "right")
if not form_fields:
yield ("-", "-", "-")
return
for form_field in form_fields:
name_layout = form_field.field_name
value_layout = form_field.field_value
name = text_from_layout(name_layout, document)
value = text_from_layout(value_layout, document)
confidence = value_layout.confidence
yield (name, value, f"{confidence:.1%}")
Adicione também estas funções utilitárias:
def form_fields_sorted_by_ocr_order(
document: docai.Document,
) -> MutableSequence[docai.Document.Page.FormField]:
def sort_key(form_field):
# Sort according to the field name detected position
text_anchor = form_field.field_name.text_anchor
return text_anchor.text_segments[0].start_index if text_anchor else 0
fields = (field for page in document.pages for field in page.form_fields)
return sorted(fields, key=sort_key)
def text_from_layout(
layout: docai.Document.Page.Layout,
document: docai.Document,
) -> str:
full_text = document.text
segs = layout.text_anchor.text_segments
text = "".join(full_text[seg.start_index : seg.end_index] for seg in segs)
if text.endswith("\n"):
text = text[:-1]
return text
Imprima os campos de formulário detectados:
print_form_fields(document)
Você vai receber uma impressão como esta:
+-----------------+-------------------------+------------+ | name | value | confidence | +-----------------+-------------------------+------------+ | Date: | 9/14/19 | 83.0% | | Name: | Sally Walker | 87.3% | | DOB: | 09/04/1986 | 88.5% | | Address: | 24 Barney Lane | 82.4% | | City: | Towaco | 90.0% | | State: | NJ | 89.4% | | Zip: | 07082 | 91.4% | | Email: | Sally, walker@cmail.com | 79.7% | | _Phone #: | walker@cmail.com | 93.2% | | | (906 | | | Gender: | F | 88.2% | | Marital Status: | Single | 85.2% | | Occupation: | Software Engineer | 81.5% | | Referred By: | None | 76.9% | ... +-----------------+-------------------------+------------+ → Form fields: 17
Revise os nomes e valores dos campos detectados ( PDF). Esta é a metade superior do questionário:

Você analisou um formulário com texto impresso e escrito à mão. Você também detectou os campos com alta confiança. O resultado é que seus pixels foram transformados em dados estruturados.
8. Como ativar e desativar processadores
Com disable_processor e enable_processor, você pode controlar se um processador pode ser usado.
Adicione as seguintes funções:
def update_processor_state(processor: docai.Processor, enable_processor: bool):
client = get_client()
if enable_processor:
request = docai.EnableProcessorRequest(name=processor.name)
operation = client.enable_processor(request)
else:
request = docai.DisableProcessorRequest(name=processor.name)
operation = client.disable_processor(request)
operation.result() # Wait for operation to complete
def enable_processor(processor: docai.Processor):
update_processor_state(processor, True)
def disable_processor(processor: docai.Processor):
update_processor_state(processor, False)
Desative o processador do analisador de formulários e verifique o estado dos seus processadores:
processor = get_processor(form_parser_display_name)
assert processor is not None
disable_processor(processor)
print_processors()
Você vai receber o seguinte:
+--------------+-----------------------+----------+ | display_name | type | state | +--------------+-----------------------+----------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | DISABLED | +--------------+-----------------------+----------+ → Processors: 2
Reative o processador do analisador de formulários:
enable_processor(processor)
print_processors()
Você vai receber o seguinte:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Em seguida, saiba como gerenciar versões de processadores.
9. Gerenciar versões do processador
Os processadores podem estar disponíveis em várias versões. Confira como usar os métodos list_processor_versions e set_default_processor_version.
Adicione as seguintes funções:
def list_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
client = get_client()
response = client.list_processor_versions(parent=processor.name)
return list(response)
def get_sorted_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
def sort_key(processor_version: docai.ProcessorVersion):
return processor_version.name
versions = list_processor_versions(processor)
return sorted(versions, key=sort_key)
def print_processor_versions(processor: docai.Processor):
versions = get_sorted_processor_versions(processor)
default_version_name = processor.default_processor_version
data = processor_versions_tabular_data(versions, default_version_name)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor versions: {len(versions)}")
def processor_versions_tabular_data(
versions: Sequence[docai.ProcessorVersion],
default_version_name: str,
) -> Iterator[Tuple[str, str, str]]:
yield ("version", "display name", "default")
yield ("left", "left", "left")
if not versions:
yield ("-", "-", "-")
return
for version in versions:
mapping = docai.DocumentProcessorServiceClient.parse_processor_version_path(
version.name
)
processor_version = mapping["processor_version"]
is_default = "Y" if version.name == default_version_name else ""
yield (processor_version, version.display_name, is_default)
Liste as versões disponíveis para o processador de OCR:
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Você recebe as versões do processador:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | Y | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Agora, adicione uma função para mudar a versão padrão do processador:
def set_default_processor_version(processor: docai.Processor, version_name: str):
client = get_client()
request = docai.SetDefaultProcessorVersionRequest(
processor=processor.name,
default_processor_version=version_name,
)
operation = client.set_default_processor_version(request)
operation.result() # Wait for operation to complete
Mude para a versão mais recente do processador:
processor = get_processor(document_ocr_display_name)
assert processor is not None
versions = get_sorted_processor_versions(processor)
new_version = versions[-1] # Latest version
set_default_processor_version(processor, new_version.name)
# Update the processor info
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Você recebe a configuração da nova versão:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | Y | +--------------------------------+--------------------------+---------+ → Processor versions: 5
E, em seguida, o método final de gerenciamento de processadores (exclusão).
10. Excluir processadores
Por fim, confira como usar o método delete_processor.
Adicione a seguinte função:
def delete_processor(processor: docai.Processor):
client = get_client()
operation = client.delete_processor(name=processor.name)
operation.result() # Wait for operation to complete
Exclua os processadores de teste:
processors_to_delete = [dn for dn, _ in test_processor_display_names_and_types]
print("Deleting processors...")
for processor in list_processors():
if processor.display_name not in processors_to_delete:
continue
print(f" Deleting {processor.display_name}...")
delete_processor(processor)
print("Done\n")
print_processors()
Você vai receber o seguinte:
Deleting processors... Deleting form-parser... Deleting document-ocr... Done +--------------+------+-------+ | display_name | type | state | +--------------+------+-------+ | - | - | - | +--------------+------+-------+ → Processors: 0
Você aprendeu todos os métodos de gerenciamento de processadores. Quase tudo pronto...
11. Parabéns!
Você aprendeu a gerenciar processadores da Document AI usando Python.
Limpar
Para limpar o ambiente de desenvolvimento, no Cloud Shell:
- Se você ainda estiver na sessão do IPython, volte ao shell:
exit - Pare de usar o ambiente virtual do Python:
deactivate - Exclua a pasta do ambiente virtual:
cd ~ ; rm -rf ./venv-docai
Para excluir seu projeto do Google Cloud, no Cloud Shell:
- Recupere o ID do projeto atual:
PROJECT_ID=$(gcloud config get-value core/project) - Confirme se este é o projeto que você quer excluir:
echo $PROJECT_ID - Excluir o projeto:
gcloud projects delete $PROJECT_ID
Saiba mais
- Teste a Document AI no seu navegador: https://cloud.google.com/document-ai/docs/drag-and-drop
- Detalhes do processador da Document AI: https://cloud.google.com/document-ai/docs/processors-list
- Python no Google Cloud: https://cloud.google.com/python
- Bibliotecas de cliente do Cloud para Python: https://github.com/googleapis/google-cloud-python
Licença
Este conteúdo está sob a licença Atribuição 2.0 Genérica da Creative Commons.