
1. Introduction
In this codelab, you will learn how to use Document AI Specialized Processors to classify and parse specialized documents with Python. For the classification and splitting, we will be using an example pdf file containing invoices, receipts, and utility statements. Then, for the parsing and entity extraction, we will use an invoice as an example.
This procedure and example code will work with any specialized document supported by Document AI.
Prerequisites
This codelab builds upon content presented in other Document AI Codelabs.
It is recommended that you complete the following Codelabs before proceeding:
- Optical Character Recognition (OCR) with Document AI and Python
- Form Parsing with Document AI (Python)
What you'll learn
- How to classify and identify split points for specialized documents.
- How to extract schematized entities using specialized processors.
What you'll need
2. Getting set up
This codelab assumes you have completed the Document AI Setup steps listed in the Introductory Codelab.
Please complete the following steps before proceeding:
You will also need to install Pandas, a popular Data Analysis library for Python.
pip3 install --upgrade pandas
3. Create specialized processors
You must first create instances of the processors you will use for this tutorial.
- In the console, navigate to the Document AI Platform Overview
- Click Create Processor, scroll down to Specialized and select Procurement Doc Splitter.
- Give it the name "codelab-procurement-splitter" (Or something else you'll remember) and select the closest region on the list.
- Click Create to create your processor
- Copy the processor ID. You must use this in your code later.
- Repeat Steps 2-6 with the Invoice Parser (which you can name "codelab-invoice-parser")
Test processor in the Console
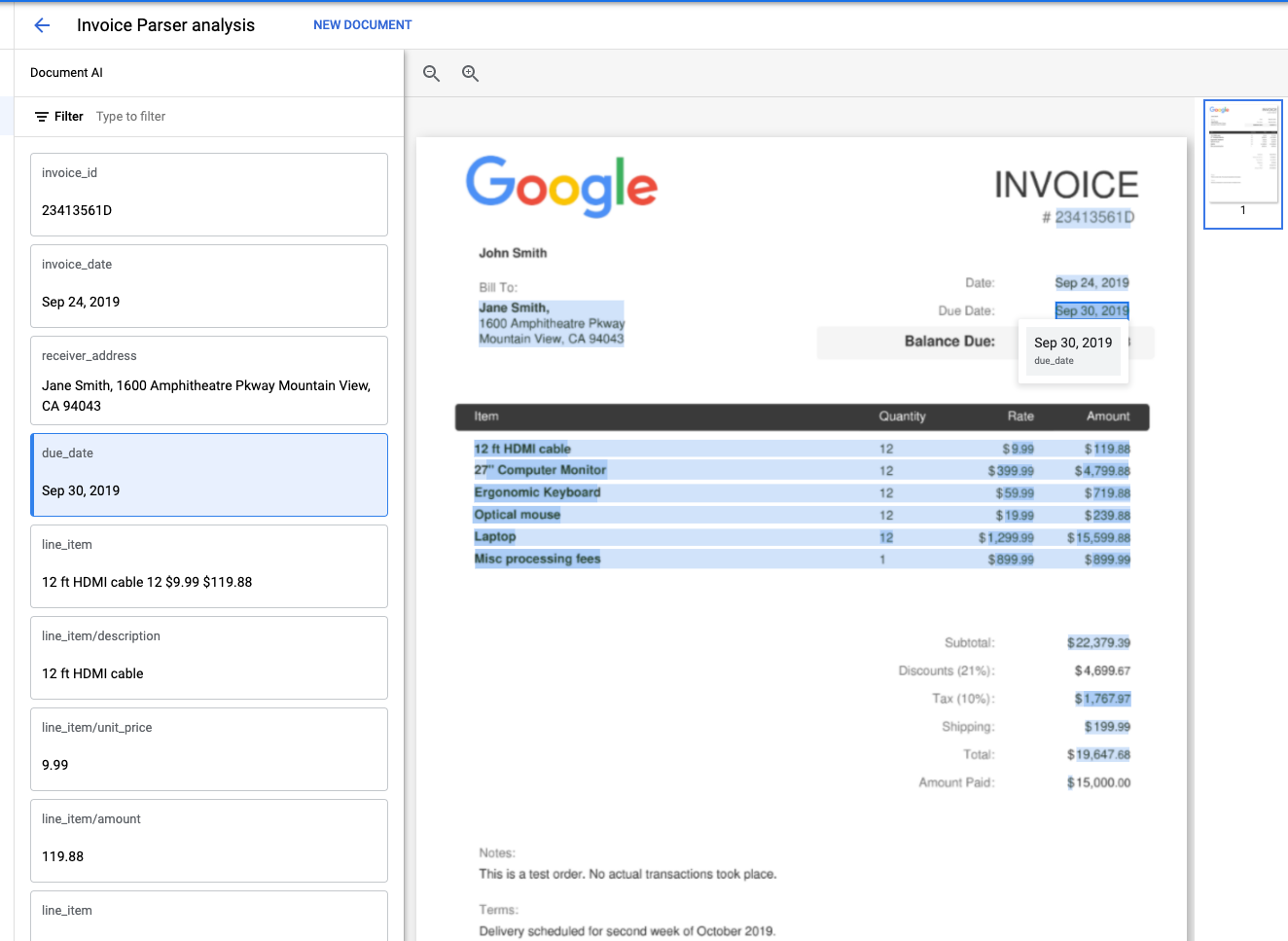
You can test out the Invoice Parser in the console by uploading a document.
Click Upload Document and select an invoice to parse. You can download and use this sample invoice if you do not have one available to use.
Your output should look like this:
4. Download sample documents
We have a few sample documents to use for this lab.
You can download the PDFs using the following links. Then upload them to the Cloud Shell instance.
Alternatively, you can download them from our public Cloud Storage Bucket using gsutil.
gsutil cp gs://cloud-samples-data/documentai/codelabs/specialized-processors/procurement_multi_document.pdf .
gsutil cp gs://cloud-samples-data/documentai/codelabs/specialized-processors/google_invoice.pdf .
5. Classify & split the documents
In this step you will use the online processing API to classify and detect logical split points for a multi-page document.
You can also use the batch processing API if you want to send multiple files or if the file size exceeds the online processing maximum pages. You can review how to do this in the Document AI OCR Codelab.
The code for making the API request is identical for a general processor aside from the Processor ID.
Procurement Splitter/Classifier
Create a file called classification.py and use the code below.
Replace PROCUREMENT_SPLITTER_ID with the ID for the Procurement Splitter Processor you created earlier. Replace YOUR_PROJECT_ID and YOUR_PROJECT_LOCATION with your Cloud Project ID and Processor Location respectively.
classification.py
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as file:
file_content = file.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=file_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(name=resource_name, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "PROCUREMENT_SPLITTER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "procurement_multi_document.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
print("Document processing complete.")
types = []
confidence = []
pages = []
# Each Document.entity is a classification
for entity in document.entities:
classification = entity.type_
types.append(classification)
confidence.append(f"{entity.confidence:.0%}")
# entity.page_ref contains the pages that match the classification
pages_list = []
for page_ref in entity.page_anchor.page_refs:
pages_list.append(page_ref.page)
pages.append(pages_list)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame({"Classification": types, "Confidence": confidence, "Pages": pages})
print(df)
Your output should look something like this:
$ python3 classification.py
Document processing complete.
Classification Confidence Pages
0 invoice_statement 100% [0]
1 receipt_statement 98% [1]
2 other 81% [2]
3 utility_statement 100% [3]
4 restaurant_statement 100% [4]
Note the Procurement Splitter/Classifier correctly identified the document types on pages 0-1 and 3-4.
Page 2 contains a generic medical intake form, so the classifier correctly identified it as other.
6. Extract the entities
Now you can extract the schematized entities from the files, including confidence scores, properties, and normalized values.
The code for making the API request is identical to the previous step, and it can be done with online or batch requests.
We will access the following information from the entities:
- Entity Type
- (e.g.
invoice_date,receiver_name,total_amount)
- (e.g.
- Raw Values
- Data values as presented in the original document file.
- Normalized Values
- Data values in a normalized and standard format, if applicable.
- Also can include enrichment from Enterprise Knowledge Graph
- Confidence Values
- How "sure" the model is that the values are accurate.
Some entity types, such as line_item can also include properties which are nested entities such as line_item/unit_price and line_item/description.
This example flattens out the nested structure for ease of viewing.
Invoice Parser
Create a file called extraction.py and use the code below.
Replace INVOICE_PARSER_ID with the ID for the Invoice Parser Processor you created earlier and use the file google_invoice.pdf
extraction.py
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as file:
file_content = file.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=file_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(name=resource_name, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "INVOICE_PARSER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "google_invoice.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
types = []
raw_values = []
normalized_values = []
confidence = []
# Grab each key/value pair and their corresponding confidence scores.
for entity in document.entities:
types.append(entity.type_)
raw_values.append(entity.mention_text)
normalized_values.append(entity.normalized_value.text)
confidence.append(f"{entity.confidence:.0%}")
# Get Properties (Sub-Entities) with confidence scores
for prop in entity.properties:
types.append(prop.type_)
raw_values.append(prop.mention_text)
normalized_values.append(prop.normalized_value.text)
confidence.append(f"{prop.confidence:.0%}")
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame(
{
"Type": types,
"Raw Value": raw_values,
"Normalized Value": normalized_values,
"Confidence": confidence,
}
)
print(df)
Your output should look something like this:
$ python3 extraction.py
Type Raw Value Normalized Value Confidence
0 vat $1,767.97 100%
1 vat/tax_amount $1,767.97 1767.97 USD 0%
2 invoice_date Sep 24, 2019 2019-09-24 99%
3 due_date Sep 30, 2019 2019-09-30 99%
4 total_amount 19,647.68 19647.68 97%
5 total_tax_amount $1,767.97 1767.97 USD 92%
6 net_amount 22,379.39 22379.39 91%
7 receiver_name Jane Smith, 83%
8 invoice_id 23413561D 67%
9 receiver_address 1600 Amphitheatre Pkway\nMountain View, CA 94043 66%
10 freight_amount $199.99 199.99 USD 56%
11 currency $ USD 53%
12 supplier_name John Smith 19%
13 purchase_order 23413561D 1%
14 receiver_tax_id 23413561D 0%
15 supplier_iban 23413561D 0%
16 line_item 9.99 12 12 ft HDMI cable 119.88 100%
17 line_item/unit_price 9.99 9.99 90%
18 line_item/quantity 12 12 77%
19 line_item/description 12 ft HDMI cable 39%
20 line_item/amount 119.88 119.88 92%
21 line_item 12 399.99 27" Computer Monitor 4,799.88 100%
22 line_item/quantity 12 12 80%
23 line_item/unit_price 399.99 399.99 91%
24 line_item/description 27" Computer Monitor 15%
25 line_item/amount 4,799.88 4799.88 94%
26 line_item Ergonomic Keyboard 12 59.99 719.88 100%
27 line_item/description Ergonomic Keyboard 32%
28 line_item/quantity 12 12 76%
29 line_item/unit_price 59.99 59.99 92%
30 line_item/amount 719.88 719.88 94%
31 line_item Optical mouse 12 19.99 239.88 100%
32 line_item/description Optical mouse 26%
33 line_item/quantity 12 12 78%
34 line_item/unit_price 19.99 19.99 91%
35 line_item/amount 239.88 239.88 94%
36 line_item Laptop 12 1,299.99 15,599.88 100%
37 line_item/description Laptop 83%
38 line_item/quantity 12 12 76%
39 line_item/unit_price 1,299.99 1299.99 90%
40 line_item/amount 15,599.88 15599.88 94%
41 line_item Misc processing fees 899.99 899.99 1 100%
42 line_item/description Misc processing fees 22%
43 line_item/unit_price 899.99 899.99 91%
44 line_item/amount 899.99 899.99 94%
45 line_item/quantity 1 1 63%
7. Optional: Try out other specialized processors
You've successfully used Document AI for Procurement to classify documents and parse an invoice. Document AI also supports the other specialized solutions listed here:
You can follow the same procedure and use the same code to handle any specialized processor.
If you would like to try out the other specialized solutions, you can re-run the lab with other processor types and specialized sample documents.
Sample Documents
Here are some sample documents you can use to try out the other specialized processors.
Solution | Processor Type | Document |
Identity | ||
Lending | ||
Lending | ||
Contracts |
You can find other sample documents and processor output in the documentation.
8. Congratulations
Congratulations, you've successfully used Document AI to classify and extract data from specialized documents. We encourage you to experiment with other specialized document types.
Cleanup
To avoid incurring charges to your Google Cloud account for the resources used in this tutorial:
- In the Cloud Console, go to the Manage resources page.
- In the project list, select your project then click Delete.
- In the dialog, type the project ID and then click Shut down to delete the project.
Learn More
Continue learning about Document AI with these follow-up Codelabs.
- Managing Document AI processors with Python
- Document AI: Human in the Loop
- Document AI Workbench: Uptraining
- Document AI Workbench: Custom Processors
Resources
- The Future of Documents - YouTube Playlist
- Document AI Documentation
- Document AI Python Client Library
- Document AI Samples
License
This work is licensed under a Creative Commons Attribution 2.0 Generic License.