
Cet atelier de programmation décrit un workflow d'entreprise possible pour l'archivage d'images, leur analyse et la génération de rapports. Imaginons que votre organisation dispose d'une série d'images qui occupent de l'espace sur une ressource limitée. Vous souhaitez archiver ces données, analyser ces images et, surtout, générer un rapport récapitulant les emplacements archivés et les résultats des analyses, rassemblés et prêts à être exploités par les gestionnaires. Google Cloud fournit les outils nécessaires pour concrétiser cela grâce aux API de deux de ses gammes de produits : G Suite et Google Cloud Platform (GCP).
Dans notre scénario, l'utilisateur professionnel dispose d'images stockées sur Google Drive. Il semble logique de sauvegarder ces éléments dans un stockage plus "froid" et moins coûteux, tel que les classes de stockage disponibles dans Google Cloud Storage. Google Cloud Vision permet aux développeurs d'intégrer facilement des fonctionnalités de vision par ordinateur dans les applications, comme la détection d'objets et de points de repère, la reconnaissance optique des caractères (OCR), etc. Enfin, une feuille de calcul (Google Sheets) est un outil de visualisation très utile pour résumer tous ces éléments à l'attention de votre supérieur.
Après avoir suivi cet atelier de programmation et créé une solution qui exploite l'ensemble des services Google Cloud, nous espérons que cela vous inspirera à développer un projet encore plus utile pour votre organisation ou vos clients.
Points abordés
- Utiliser Cloud Shell
- Authentifier les requêtes API
- Installer la bibliothèque cliente des API Google pour Python
- Activer les API Google
- Télécharger des fichiers depuis Google Drive
- Importer des objets/blobs dans Cloud Storage
- Analyser des données avec Cloud Vision
- Écrire des lignes dans Google Sheets
Prérequis
- Un compte Google (l'approbation de l'administrateur peut être nécessaire pour les comptes G Suite)
- Un projet Google Cloud Platform avec un compte de facturation GCP actif
- Une connaissance des commandes de terminal ou d'interface système du système d'exploitation
- Des connaissances de base en Python (version 2 ou 3), mais vous pouvez utiliser n'importe quel langage compatible
Une connaissance des quatre produits Google Cloud répertoriés ci-dessus est utile, mais pas indispensable. Si vous avez le temps de vous familiariser avec ces outils, nous vous invitons à suivre les ateliers de programmation suivants avant de vous lancer dans cet exercice :
- Présentation de Google Drive (utilisation des API G Suite) (Python)
- Utiliser Cloud Vision avec Python (Python)
- Créer des outils de création de rapports personnalisés avec l'API Sheets (JS/Node)
- Importer des objets dans Google Cloud Storage (aucun code requis)
Enquête
Comment allez-vous utiliser ce tutoriel ?
Quel est votre niveau d'expérience avec Python ?
Quel est votre niveau d'expérience avec les services Google Cloud Platform ?
Quel est votre niveau d'expérience avec les services pour les développeurs G Suite ?
Aimeriez-vous voir plus d'ateliers de programmation orientés métier par opposition à ceux consacrés à la présentation de fonctionnalités de produits ?
Configuration de l'environnement au rythme de chacun
- Connectez-vous à Cloud Console, puis créez un projet ou réutilisez un projet existant. (Si vous n'avez pas encore de compte Gmail ou G Suite, vous devez en créer un.)



Mémorisez l'ID du projet. Il s'agit d'un nom unique permettant de différencier chaque projet Google Cloud (le nom ci-dessus est déjà pris ; vous devez en trouver un autre). Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
- Vous devez ensuite activer la facturation dans Cloud Console pour pouvoir utiliser les ressources Google Cloud.
L'exécution de cet atelier de programmation est très peu coûteuse, voire gratuite. Veillez à suivre les instructions de la section "Nettoyer" qui indique comment désactiver les ressources afin d'éviter les frais une fois ce tutoriel terminé. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai gratuit pour bénéficier d'un crédit de 300 $.
Démarrer Cloud Shell
Résumé
Bien que vous puissiez développer du code localement sur votre ordinateur portable, l'un des objectifs de cet atelier de programmation consiste à vous apprendre à utiliser Google Cloud Shell, un environnement de ligne de commande exécuté dans le cloud via un navigateur Web récent.
Activer Cloud Shell
- Dans Cloud Console, cliquez sur Activer Cloud Shell
.

Si vous n'avez encore jamais démarré Cloud Shell, un écran intermédiaire s'affiche en dessous de la ligne de séparation pour décrire de quoi il s'agit. Si tel est le cas, cliquez sur Continuer (cet écran ne s'affiche qu'une seule fois). Voici à quoi il ressemble :

Le provisionnement et la connexion à Cloud Shell ne devraient pas prendre plus de quelques minutes.

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle intègre un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances réseau et l'authentification. Vous pouvez réaliser une grande partie, voire la totalité, des activités de cet atelier dans un simple navigateur ou sur votre Chromebook.
Une fois connecté à Cloud Shell, vous êtes en principe authentifié et le projet est défini avec votre ID de projet.
- Exécutez la commande suivante dans Cloud Shell pour vérifier que vous êtes authentifié :
gcloud auth list
Résultat de la commande
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
Résultat de la commande
[core] project = <PROJECT_ID>
Si vous obtenez un résultat différent, exécutez cette commande :
gcloud config set project <PROJECT_ID>
Résultat de la commande
Updated property [core/project].
Cet atelier de programmation requiert l'utilisation du langage Python. Toutefois, les bibliothèques clientes des API Google sont compatibles avec un grand nombre de langages : n'hésitez donc pas à créer un équivalent dans votre outil de développement favori et à utiliser Python simplement sous forme de pseudo-code. En particulier, cet atelier de programmation est compatible avec Python 2 et 3, mais nous vous recommandons de passer à la version 3.x dès que possible.
Cloud Shell est un outil pratique que les utilisateurs peuvent exploiter directement depuis Cloud Console. Il ne nécessite pas d'environnement de développement local. Vous pouvez donc suivre ce tutoriel entièrement dans le cloud avec un navigateur Web. Cloud Shell est particulièrement utile si vous développez ou envisagez de continuer à développer en utilisant des produits et des API GCP. En particulier, pour cet atelier de programmation, Cloud Shell contient déjà les deux versions de Python pré-installées.
Cloud Shell inclut également IPython. Il s'agit d'un interpréteur Python interactif de haut niveau que nous recommandons, en particulier si vous faites partie de la communauté des data scientists ou du machine learning. Si tel est le cas, IPython est l'interpréteur par défaut pour les notebooks Jupyter et pour Colab, la collection de notebooks Jupyter hébergée par Google Research.
IPython privilégie un interpréteur Python 3, mais passe à Python 2 s'il n'y a pas de version 3.x disponible. IPython est accessible depuis Cloud Shell, mais il peut également être installé dans un environnement de développement local. Pour quitter, utiliser la combinaison de touches "^D" (Ctrl+D), puis acceptez l'invite. Les lignes ci-dessous représentent un exemple de la sortie affichée au démarrage de ipython :
$ ipython Python 3.7.3 (default, Mar 4 2020, 23:11:43) Type 'copyright', 'credits' or 'license' for more information IPython 7.13.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
Si IPython n'est pas l'interpréteur de votre choix, il est tout à fait acceptable d'utiliser un interpréteur interactif Python standard (que ce soit dans Cloud Shell dans votre environnement de développement local). Vous le quittez de la même manière avec ^D :
$ python Python 2.7.13 (default, Sep 26 2018, 18:42:22) [GCC 6.3.0 20170516] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> $ python3 Python 3.7.3 (default, Mar 10 2020, 02:33:39) [GCC 6.3.0 20170516] on linux Type "help", "copyright", "credits" or "license" for more information. >>>
L'atelier de programmation part également du principe que vous disposez de l'outil d'installation pip (gestionnaire de packages Python et résolveur de dépendances). Il est fourni avec les versions 2.7.9 et ultérieures, ou 3.4 et ultérieures. Si vous possédez une version de Python plus ancienne, consultez ce guide pour savoir comment l'installer. Selon vos autorisations, vous aurez peut-être besoin d'un accès sudo ou super-utilisateur, mais ce n'est généralement pas le cas. Vous pouvez également utiliser explicitement pip2 ou pip3 afin d'exécuter pip pour des versions spécifiques de Python.
Le reste de l'atelier de programmation suppose que vous utilisez Python 3. Des instructions spécifiques seront fournies pour Python 2 si elles diffèrent de la version 3.x de manière significative.
*Créer et utiliser des environnements virtuels
Cette section est facultative et n'est obligatoire que pour les utilisateurs devant utiliser un environnement virtuel pour cet atelier de programmation (conformément à l'avertissement ci-dessus). Si vous avez installé uniquement Python 3 sur votre ordinateur, vous pouvez simplement exécuter cette commande pour créer un environnement virtuel nommé my_env (vous pouvez choisir un autre nom si vous le souhaitez) :
virtualenv my_env
Toutefois, si Python 2 et 3 sont tous les deux installés sur votre ordinateur, nous vous recommandons d'installer un environnement virtuel Python 3, ce que vous pouvez faire à l'aide de l'option -p flag comme suit :
virtualenv -p python3 my_env
"Entrez" dans l'environnement virtuel que vous venez de créer en l'activant comme suit :
source my_env/bin/activate
Vérifiez que vous vous trouvez bien dans l'environnement en observant votre invite d'interface système, qui doit maintenant être précédée du nom de votre environnement, par exemple :
(my_env) $
Vous devriez maintenant pouvoir installer tous les packages requis à l'aide de la commande pip install, exécuter du code dans cet environnement, etc. Un autre avantage est que, si vous déréglez votre environnement, que vous parvenez à une situation dans laquelle votre installation Python est corrompue, ou autre problème majeur, vous pouvez simplement supprimer l'intégralité de cet environnement sans affecter le reste de votre système.
Cet atelier de programmation requiert l'utilisation de la bibliothèque cliente des API Google pour Python. Il s'agit donc d'un processus d'installation simple, voire qui ne requiert aucune action de votre part.
Un peu plus tôt, nous vous avons recommandé d'utiliser Cloud Shell pour plus de commodité. Vous pouvez suivre l'intégralité de ce tutoriel à partir d'un navigateur Web dans le cloud. Autre avantage de Cloud Shell : de nombreux outils de développement et bibliothèques nécessaires sont déjàpréinstallé.
*Installer les bibliothèques clientes
(Facultatif) Vous pouvez ignorer cette étape si vous utilisez Cloud Shell ou un environnement local dans lequel vous avez déjà installé les bibliothèques clientes. Vous ne devez effectuer cette opération que si vous développez en local et que les bibliothèques ne sont pas installées (ou si vous n'en êtes pas certain). Le moyen le plus simple consiste à utiliser pip (ou pip3) pour effectuer l'installation (y compris mettre à jour pip si nécessaire) :
pip install -U pip google-api-python-client oauth2client
Confirmer l'installation
Cette commande installe la bibliothèque cliente, ainsi que tous les packages dont elle dépend. Que vous utilisiez Cloud Shell ou votre propre environnement, vérifiez que la bibliothèque cliente est installée en important les packages nécessaires et en confirmant qu'il n'y a aucune erreur d'importation (ou sortie affichée) :
python3 -c "import googleapiclient, httplib2, oauth2client"
Si vous utilisez Python 2 (à partir de Cloud Shell), vous recevrez un avertissement indiquant que sa compatibilité est obsolète :
******************************************************************************* Python 2 is deprecated. Upgrade to Python 3 as soon as possible. See https://cloud.google.com/python/docs/python2-sunset To suppress this warning, create an empty ~/.cloudshell/no-python-warning file. The command will automatically proceed in seconds or on any key. *******************************************************************************
Dès lors que vous pouvez exécuter cette commande d'importation de test (sans erreur ni sortie), vous êtes prêt à communiquer avec les API Google.
Résumé
Du fait que cet atelier de programmation est de niveau intermédiaire, vous êtes déjà familiarisé avec la création et l'utilisation de projets dans la console. Si vous débutez avec les API Google, et les API G Suite en particulier, commencez par suivre l'atelier de programmation des API G Suite. En outre, si vous savez comment créer (ou réutiliser) des identifiants de compte utilisateur (et non de compte de service), déposez le fichier client_secret.json dans votre répertoire de travail, sautez le module suivant et passez à la section "Activer les API Google".
Vous pouvez ignorer cette section si vous avez déjà créé des identifiants d'autorisation via un compte utilisateur et que vous connaissez le processus. Cela diffère de l'autorisation via un compte de service, qui utilise une technique distincte. Veuillez continuer ci-dessous.
Présentation de l'autorisation (et quelques éléments concernant l'authentification)
Pour pouvoir envoyer des requêtes aux API, votre application doit disposer d'une autorisation appropriée. L'authentification, qui est un terme similaire, décrit les identifiants de connexion. Vous vous authentifiez lorsque vous vous connectez à votre compte Google à l'aide d'un identifiant et d'un mot de passe. Une fois authentifié, l'étape suivante consiste à vérifier si vous, ou plus exactement votre code, êtes autorisé à accéder à des données, telles que des fichiers blob sur Cloud Storage ou les fichiers personnels d'un utilisateur sur Google Drive.
Les API Google sont compatibles avec plusieurs types d'autorisation, mais le plus courant pour les utilisateurs de l'API G Suite est l'autorisation des utilisateurs. En effet, l'exemple d'application de cet atelier de programmation accède aux données des utilisateurs finaux. Ces utilisateurs finaux doivent autoriser votre application à accéder à leurs données. Cela signifie que votre code doit obtenir les identifiants OAuth2 du compte utilisateur.
Pour obtenir des identifiants OAuth2 pour l'autorisation des utilisateurs, revenez au gestionnaire d'API, puis sélectionnez l'onglet "Identifiants" (Credentials) dans le menu de navigation de gauche :
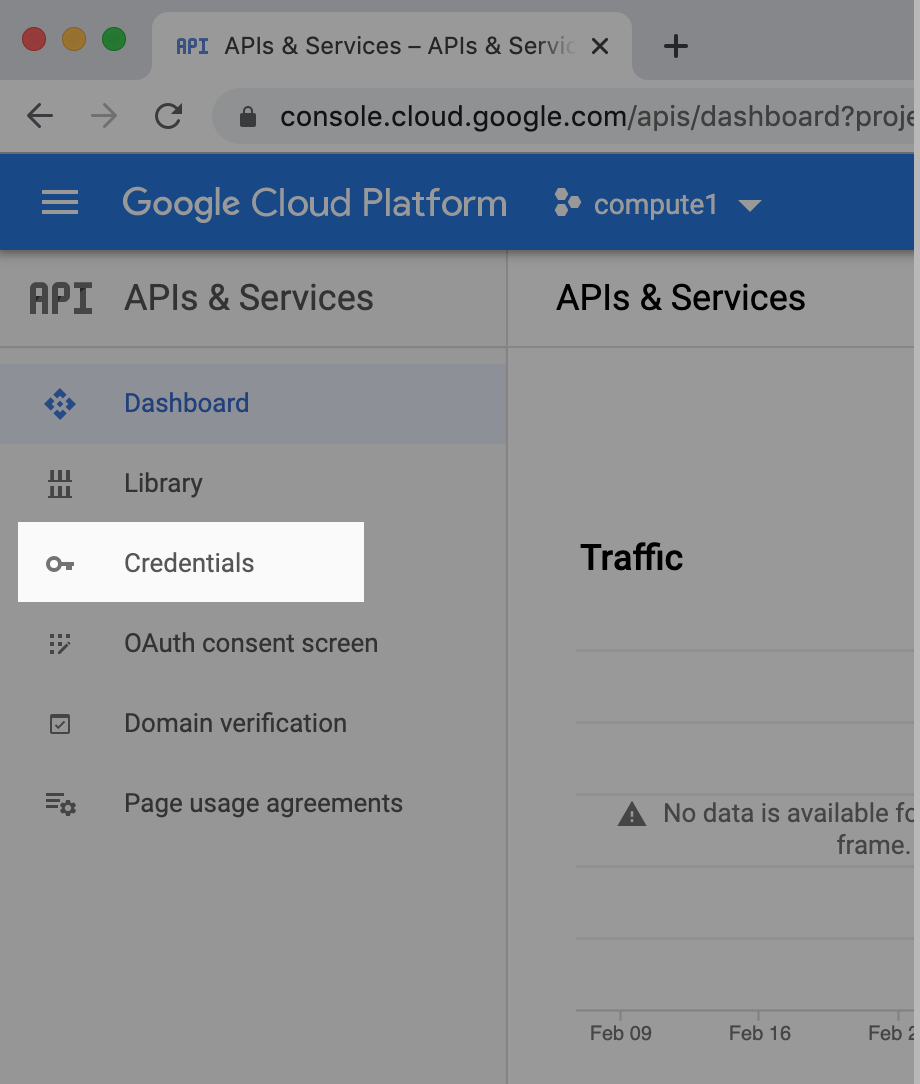
Une fois sur cet écran, vous verrez tous vos identifiants s'afficher dans trois sections distinctes :
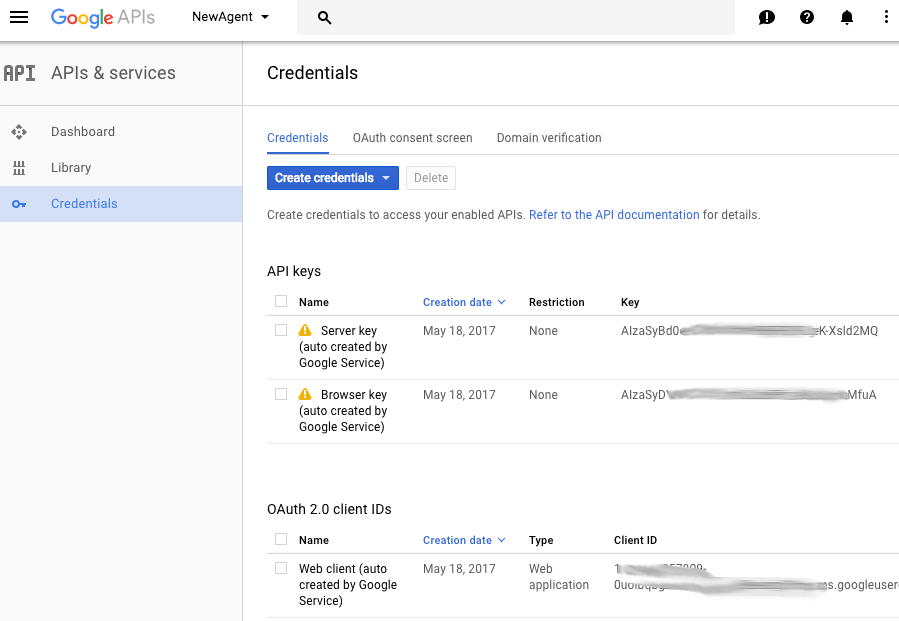
La première concerne les clés API, la deuxième les ID client OAuth 2.0, et la dernière concerne les comptes de service OAuth2. Celle que nous utilisons est la deuxième section.
Créer des identifiants
Sur la page "Identifiants", cliquez sur le bouton + Créer des identifiants (Create Credentials) qui se trouve en haut. Une boîte de dialogue s'affiche alors, dans laquelle vous devez choisir "ID client OAuth".

Sur l'écran suivant, vous avez deux actions à effectuer : configurer l'écran d'autorisation de votre application et choisir le type d'application :

Si vous n'avez pas configuré d'écran d'autorisation, un avertissement s'affiche dans la console et vous devez configurer l'écran d'autorisation dès maintenant. (Ignorez ces étapes si votre écran d'autorisation a déjà été configuré).
Écran d'autorisation OAuth
Cliquez sur "Configurer l'écran d'autorisation" (Configure consent screen), et vous devez alors sélectionner une application "Externe" (External) ou "Interne" (Internal) si vous êtes un client G Suite :
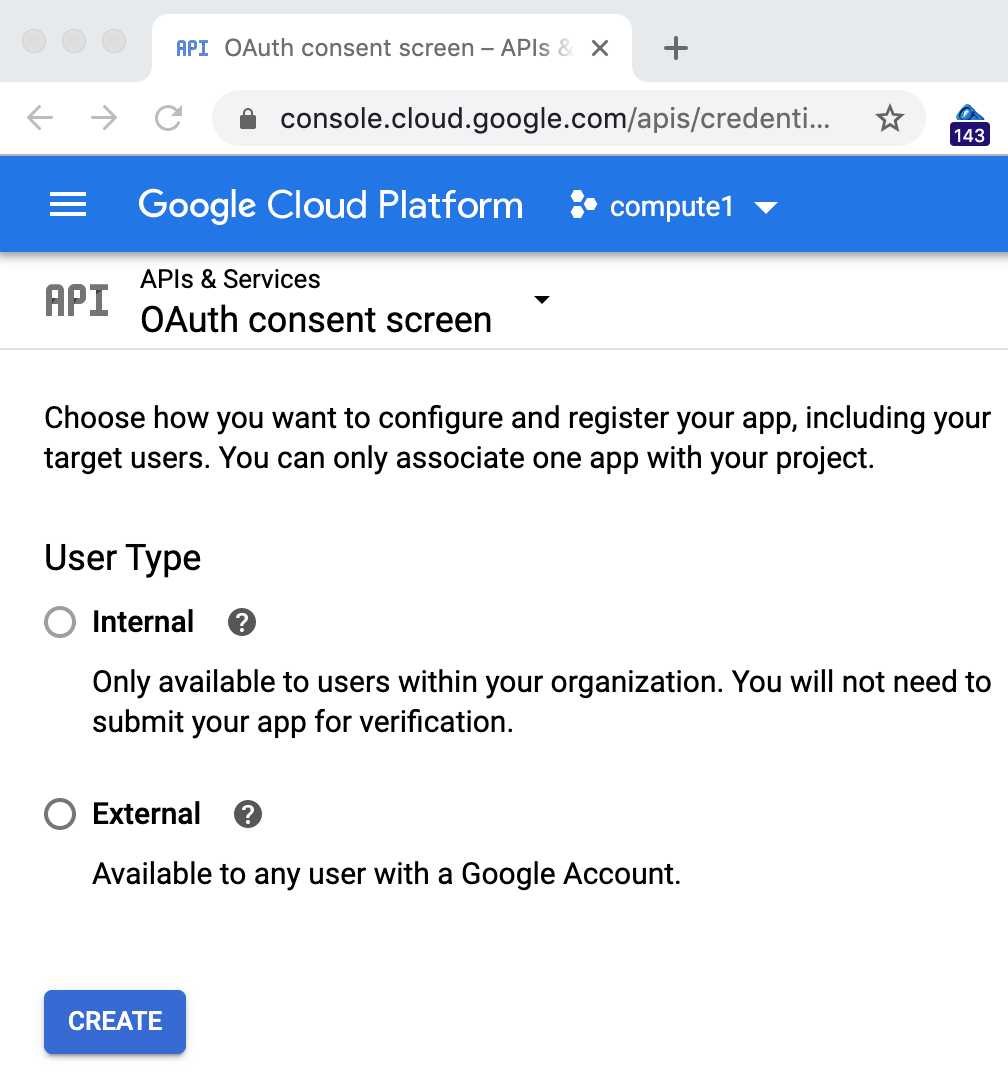
Notez que, dans le cadre de cet exercice, ce choix n'a pas d'importance, car vous n'allez pas publier votre exemple d'application de l'atelier de programmation. La plupart des utilisateurs sélectionnent "Externe" pour accéder à un écran plus complexe, mais il vous suffit de remplir le champ "Nom de l'application" (Application name) en haut :
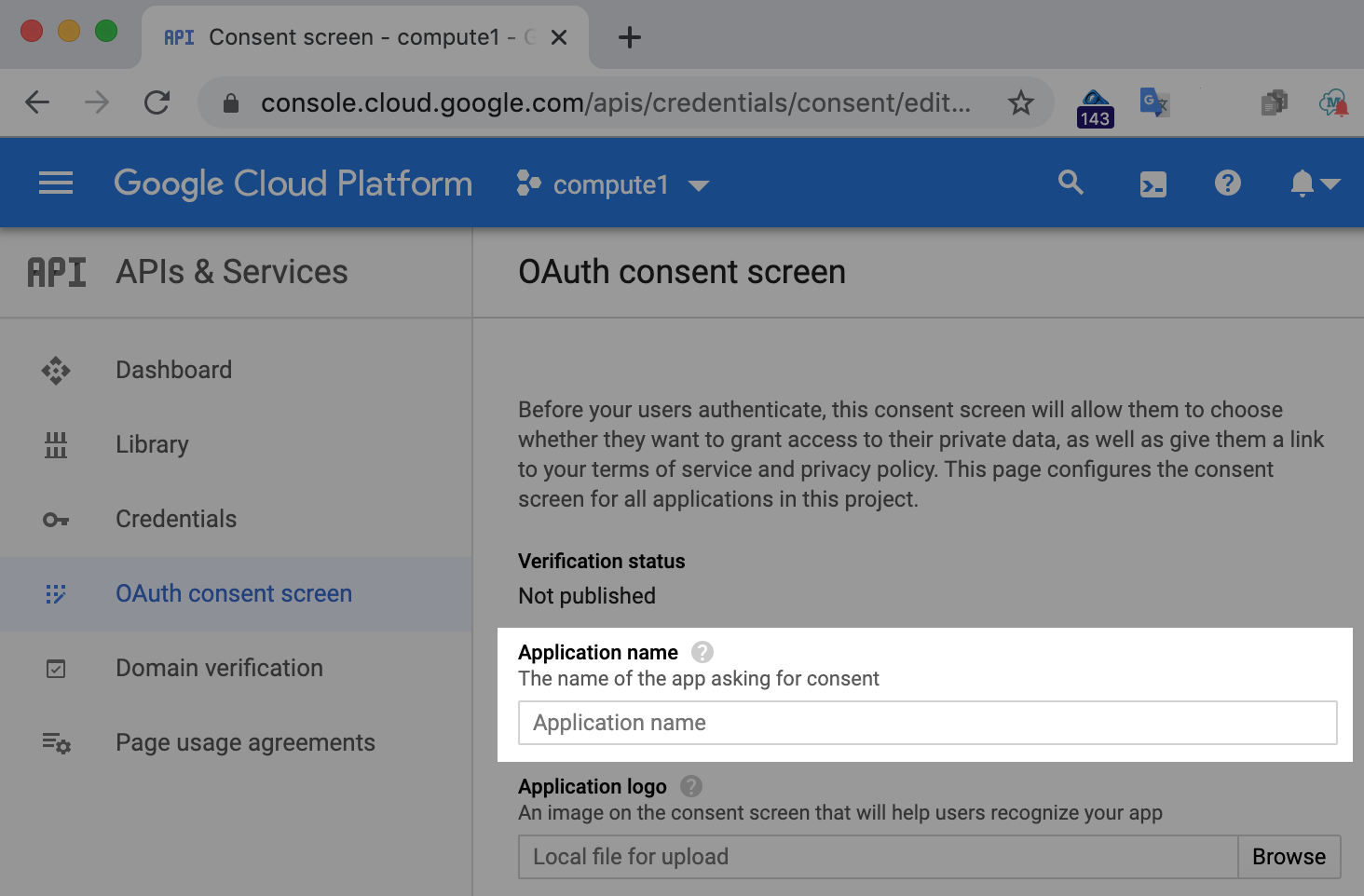
Pour le moment, il vous suffit d'indiquer un nom d'application. Choisissez donc un nom qui reflète l'atelier de programmation que vous êtes en train de suivre, puis cliquer sur Enregistrer (Save).
Création de l'ID client OAuth (authentification par compte utilisateur)
Revenez maintenant à l'onglet "Identifiants" (Credentials) pour créer un ID client OAuth2. Voici différents ID client OAuth que vous pouvez créer :
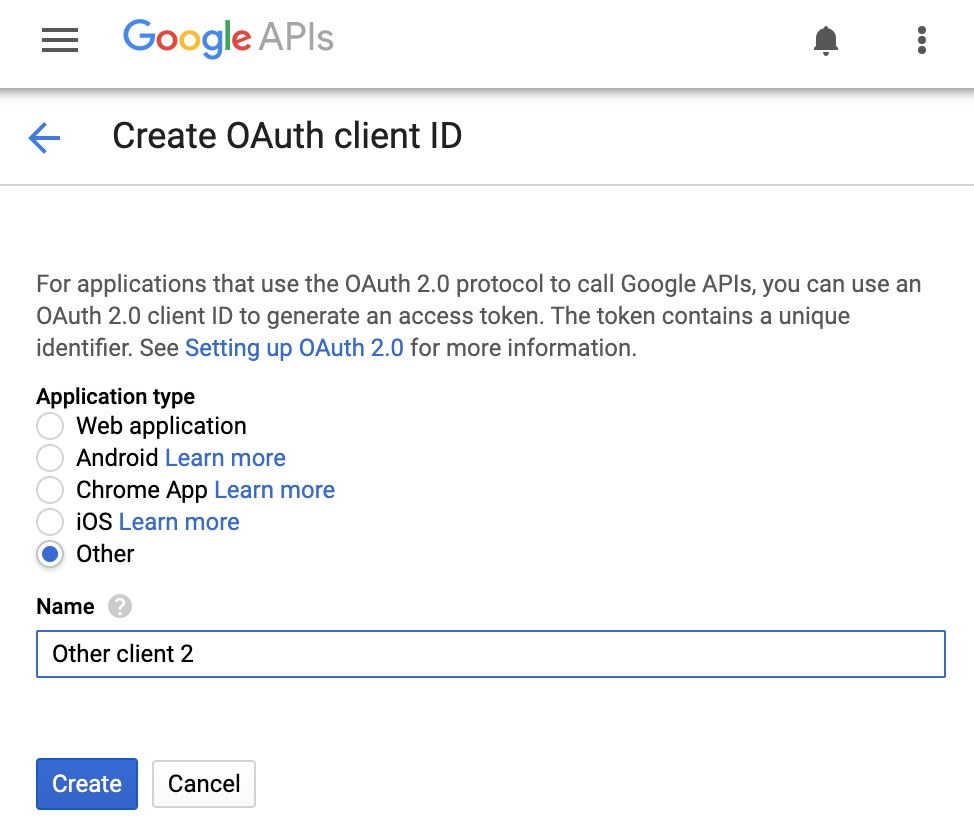
Nous développons un outil de ligne de commande de type Autre (Other). Sélectionnez donc cette option, puis cliquez sur le bouton Créer (Create). Choisissez un nom d'ID client qui reflète l'application que vous créez, ou conservez simplement le nom par défaut, qui est généralement : "Autre client N" (Other Client N).
Enregistrer vos identifiants
- Une boîte de dialogue contenant les nouveaux identifiants s'affiche. cliquez sur OK pour la fermer.

- Revenez à la page "Identifiants" (Credentials), faites défiler la page jusqu'à la section "ID client OAuth2" (OAuth2 Client IDs), puis cliquez sur l'icône de téléchargement
située à l'extrême droite de l'ID client que vous venez de créer.
- Cette action ouvre une boîte de dialogue permettant d'enregistrer un fichier nommé
client_secret-LONG-HASH-STRING.apps.googleusercontent.com.json, probablement dans votre dossier Téléchargements. Nous vous recommandons de raccourcir ce nom vers quelque chose de plus simple, par exempleclient_secret.json(qui est le nom utilisé par l'application d'exemple), puis de l'enregistrer dans le répertoire/dossier où vous allez créer l'exemple d'application dans le cadre de cet atelier de programmation.

Résumé
Vous êtes maintenant prêt à activer les API Google utilisées dans cet atelier de programmation. De plus, nous avons choisi comme nom d'application "Vision API demo" (Démonstration de l'API Vision) dans l'écran d'autorisation OAuth. Attendez-vous donc à voir apparaître ce nom dans un certain nombre des captures d'écran ci-dessous.
Introduction
Cet atelier de programmation utilise quatre (4) API Google Cloud, deux provenant de GCP (Cloud Storage et Cloud Vision) et deux provenant de G Suite (Google Drive et Google Sheets). Vous trouverez ci-dessous les instructions permettant d'activer uniquement l'API Vision. Une fois que vous savez comment activer une API, vous devez activer les trois autres par vous-même.
Avant de pouvoir utiliser les API Google, vous devez les activer. L'exemple ci-dessous montre ce que vous devez faire pour activer l'API Cloud Vision. Dans cet atelier de programmation, vous pouvez être amené à utiliser plusieurs API et vous devez donc suivre la même procédure pour les activer avant toute utilisation.
Depuis Cloud Shell
Dans Cloud Shell, vous pouvez activer l'API à l'aide de la commande suivante:
gcloud services enable vision.googleapis.com
Depuis Cloud Console
Vous pouvez également activer l'API Vision dans le gestionnaire d'API. Dans Cloud Console, accédez au Gestionnaire d'API, puis sélectionnez "Bibliothèque" (Library).

Dans la barre de recherche, commencez à saisir "vision", puis sélectionnez l'API Vision lorsqu'elle s'affiche. La recherche avec une saisie partielle doit ressembler à ceci :

Sélectionnez l'API Cloud Vision pour obtenir la boîte de dialogue visible ci-dessous, puis cliquez sur le bouton "Activer" (Enable) :

Coût
Bien que de nombreuses API Google puissent être utilisées gratuitement, l'utilisation de GCP (produits et API) est payante. Lorsque vous activez l'API Vision (comme décrit ci-dessus), vous pouvez être invité à renseigner un compte de facturation actif. Les informations tarifaires de l'API Vision doivent être référencées par l'utilisateur avant activation. N'oubliez pas que certains produits Google Cloud Platform (GCP) disposent d'un niveau "Always Free" que vous devez dépasser pour que la facturation démarre. Pour les besoins de l'atelier de programmation, chaque appel à l'API Vision est comptabilisé dans cette version gratuite. Tant que votre utilisation agrégée ne dépasse pas les limites (pour chaque mois), aucuns frais ne vous seront facturés.
Certaines API Google, par exemple G Suite, voient leur utilisation couverte par un abonnement mensuel. Par conséquent, il n'y a pas de facturation directe pour l'utilisation des API Gmail, Google Drive, Agenda, Docs, Sheets et Slides, par exemple. La procédure de facturation est différente selon les produits Google. Par conséquent, assurez-vous de vous référer à la documentation de votre API pour obtenir ces informations.
Résumé
Maintenant que Cloud Vision est activé, activez les trois autres API (Google Drive, Cloud Storage, Google Sheets) de la même manière. Dans Cloud Shell, utilisez la commande gcloud services enable. Dans Cloud Console :
- Revenez à la bibliothèque d'API.
- Lancez une recherche en saisissant quelques lettres du nom de l'API.
- Sélectionnez l'API souhaitée.
- Activez-la.
Et on reprend depuis le début. Pour Cloud Storage, il existe plusieurs options : choisissez l'API Google Cloud Storage JSON (Google Cloud Storage JSON API). L'API Cloud Storage nécessite également un compte de facturation actif.
Nous allons attaquer un extrait de code de taille moyenne. Il est donc souhaitable d'adopter des pratiques plutôt agiles et de garantir que les éléments d'infrastructure communs soient stables et fonctionnels avant d'aborder l'application principale. Vérifiez que client_secret.json est disponible dans votre répertoire actuel, puis lancez ipython et saisissez l'extrait de code suivant, ou enregistrez-le dans analyze_gsimg.py et exécutez ce fichier à partir de l'interface système (cette dernière solution est préférable, car nous allons continuer à enrichir cet l'exemple de code) :
from __future__ import print_function
from googleapiclient import discovery, http
from httplib2 import Http
from oauth2client import file, client, tools
# process credentials for OAuth2 tokens
SCOPES = 'https://www.googleapis.com/auth/drive.readonly'
store = file.Storage('storage.json')
creds = store.get()
if not creds or creds.invalid:
flow = client.flow_from_clientsecrets('client_secret.json', SCOPES)
creds = tools.run_flow(flow, store)
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
Ce composant principal inclut des blocs de code pour les importations de modules/packages, le traitement des identifiants pour l'authentification des utilisateurs et la création de points de terminaison de service d'API. Voici les éléments clés du code que vous devez examiner :
- L'importation de la fonction
print()rend cet exemple compatible avec Python 2-3. Les importations des bibliothèques Google apportent tous les outils nécessaires pour communiquer avec les API Google. - La variable
SCOPESreprésente les autorisations à demander à l'utilisateur. Il n'y en a pour le moment qu'une seule : l'autorisation de lire des données à partir de Google Drive. - Le reste du code de traitement des identifiants lit dans les jetons OAuth2 mis en cache et, si le jeton d'accès d'origine a expiré, effectue au besoin la mise à jour vers un nouveau jeton d'accès à l'aide du jeton d'actualisation.
- Si aucun jeton n'a été créé ou si la récupération d'un jeton d'accès valide a échoué pour une autre raison, l'utilisateur doit suivre le flux OAuth à trois acteurs (3LO), c'est-à-dire créer la boîte de dialogue avec les autorisations demandées et inviter l'utilisateur à les accepter. Une fois l'opération terminée, l'application se poursuit. Sinon,
tools.run_flow()génère une exception et l'exécution s'arrête. - Une fois que l'utilisateur a donné son autorisation, un client HTTP est créé pour communiquer avec le serveur et, pour des raisons de sécurité, toutes les requêtes sont signées avec les identifiants de l'utilisateur. Un point de terminaison de service associé à l'API Google Drive (version 3) est ensuite créé avec ce client HTTP, puis attribué à
DRIVE.
Exécuter l'application
La première fois que vous allez exécuter ce script, il ne sera pas autorisé à accéder aux fichiers de l'utilisateur (vous) sur Drive. Le résultat se présente comme suit, avec l'exécution mise en pause :
$ python3 ./analyze_gsimg.py
/usr/local/lib/python3.6/site-packages/oauth2client/_helpers.py:255: UserWarning: Cannot access storage.json: No such file or directory
warnings.warn(_MISSING_FILE_MESSAGE.format(filename))
Your browser has been opened to visit:
https://accounts.google.com/o/oauth2/auth?client_id=LONG-STRING.apps.googleusercontent.com&redirect_uri=http%3A%2F%2Flocalhost%3A8080%2F&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive.readonly&access_type=offline&response_type=code
If your browser is on a different machine then exit and re-run this
application with the command-line parameter
--noauth_local_webserver
Si vous travaillez dans Cloud Shell, passez directement à la section "Depuis Cloud Shell ". Le cas échéant, faites défiler la page vers le haut pour consulter les écrans adéquats dans la section "Depuis l'environnement de développement local".
Depuis l'environnement de développement local
Le script de ligne de commande est mis en pause tandis qu'une fenêtre de navigateur s'ouvre. Il est possible que vous soyez confronté à une page d'avertissement un peu inquiétante, qui ressemble à ceci :

C'est un problème légitime, car vous tentez d'exécuter une application qui accède aux données d'un utilisateur. Étant donné qu'il s'agit simplement d'une application de démonstration, et que vous en êtes bien le développeur, vous devriez vous faire suffisamment confiance pour poursuivre. Pour mieux comprendre cette situation, mettez-vous à la place de l'utilisateur : vous êtes invité à autoriser le code d'une autre personne à accéder à vos données. Si vous avez l'intention de publier une application de ce type, vous devez passer par le processus de validation. Ainsi, vos utilisateurs ne verront pas cet écran.
Une fois que vous avez cliqué sur le lien d'accès à l'application non sécurisée ("Go to app (unsafe)"), vous accédez à une boîte de dialogue d'autorisations OAuth2 semblable à l'exemple ci-dessous. Nous améliorons constamment notre interface utilisateur, donc ne vous inquiétez pas si la version que vous voyez ne correspond pas exactement à cette capture d'écran :

La boîte de dialogue de flux OAuth2 détaille les autorisations demandées par le développeur (via la variable SCOPES). Dans ce cas, il est demandé d'autoriser l'application à consulter le contenu du stockage Google Drive de l'utilisateur et à en télécharger des fichiers. Dans le code de l'application, ces niveaux d'accès apparaissent sous forme d'URI, mais ils sont traduits dans la langue spécifiée par les paramètres régionaux de l'utilisateur. Ici, l'utilisateur doit explicitement accorder son autorisation pour les autorisations demandées. Sinon, une exception est levée afin d'empêcher le script de poursuivre le processus.
Vous pouvez même obtenir une boîte de dialogue supplémentaire demandant votre confirmation :

REMARQUE : Certains utilisateurs se connectent à différents comptes à l'aide de différents navigateurs Web. Par conséquent, cette demande d'autorisation peut apparaître dans un onglet ou une fenêtre de navigateur incorrects. Vous devrez peut-être couper le lien correspondant à cette requête et le coller dans un navigateur connecté au compte approprié.
Depuis Cloud Shell
Depuis Cloud Shell, aucune fenêtre de navigateur ne s'affiche et vous êtes bloqué. Notez alors que le message de diagnostic figurant en bas (et copié ci-dessous) vous était destiné :
If your browser is on a different machine then exit and re-run this application with the command-line parameter --noauth_local_webserver
Vous devez alors appuyer sur ^C (Ctrl+C ou autre touche pour interrompre l'exécution du script), puis l'exécuter à partir de votre interface système avec l'option supplémentaire requise. Lorsque vous exécutez la commande de cette manière, vous obtenez le résultat suivant :
$ python3 analyze_gsimg.py --noauth_local_webserver
/usr/local/lib/python3.7/site-packages/oauth2client/_helpers.py:255: UserWarning: Cannot access storage.json: No such file or directory
warnings.warn(_MISSING_FILE_MESSAGE.format(filename))
Go to the following link in your browser:
https://accounts.google.com/o/oauth2/auth?client_id=LONG-STRING.apps.googleusercontent.com&redirect_uri=urn%3Aietf%3Awg%3Aoauth%3A2.0%3Aoob&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive.readonly&access_type=offline&response_type=code
Enter verification code:
(Vous pouvez ignorer l'avertissement, car nous savons que storage.json n'a pas encore été créé). Si vous suivez les instructions visibles dans autre onglet du navigateur avec cette URL, vous bénéficierez d'une expérience presque identique à celle décrite ci-dessus pour les environnements de développement locaux (reportez-vous aux captures d'écran ci-dessus). À la fin du processus, un dernier écran s'affiche avec le code de validation à saisir dans Cloud Shell :

Copiez et collez ce code dans la fenêtre de terminal.
Résumé
Ne vous attendez pas à d'autres éléments que la sortie "Authentication successful". N'oubliez pas qu'il ne s'agit là que de la configuration : vous n'avez encore rien fait proprement dit. Ce que vous avez effectivement réussi, c'est d'avoir établi un environnement où votre application a de bonnes chances de s'exécuter correctement dès la première tentative. Le meilleur, c'est que vous n'avez été invité à accorder votre autorisation qu'une seule fois : toutes les exécutions ultérieures ignoreront cette étape, car vos autorisations ont été mises en cache. Passons maintenant au code pour lui faire réaliser un vrai travail et produire un résultat concret.
Dépannage
Si vous obtenez une erreur au lieu d'un résultat vide, cela peut être dû à une ou plusieurs causes, par exemple :
À l'étape précédente, nous vous avons recommandé de créer le code en tant que fichier analyze_gsimg.py et de le modifier à partir de ce fichier. Il est également possible de couper-coller les caractères directement dans IPython ou l'interface système Python standard. Cependant, cette opération est plus fastidieuse, car nous allons continuer à créer l'application élément par élément.
Supposons que votre application a été autorisée et que le point de terminaison du service d'API a bien été créé. Dans votre code, il est représenté par la variable DRIVE. Recherchez maintenant un fichier image sur Google Drive et
définissez-le dans une variable appelée NAME. Saisissez cet élément ainsi que la fonction drive_get_img() suivante juste en dessous du code de l'étape 0 :
FILE = 'YOUR_IMG_ON_DRIVE' # fill-in with name of your Drive file
def drive_get_img(fname):
'download file from Drive and return file info & binary if found'
# search for file on Google Drive
rsp = DRIVE.files().list(q="name='%s'" % fname,
fields='files(id,name,mimeType,modifiedTime)'
).execute().get('files', [])
# download binary & return file info if found, else return None
if rsp:
target = rsp[0] # use first matching file
fileId = target['id']
fname = target['name']
mtype = target['mimeType']
binary = DRIVE.files().get_media(fileId=fileId).execute()
return fname, mtype, target['modifiedTime'], binary
La collection Drive files() dispose d'une méthode list() qui exécute une requête (le paramètre q) pour le fichier spécifié. Le paramètre fields permet de spécifier les valeurs de retour qui vous intéressent : pourquoi obtenir tous les éléments et ralentir les choses si vous ne vous souciez pas des autres valeurs ? Si vous débutez avec l'utilisation des masques de champ pour filtrer les valeurs renvoyées par une API, consultez cet article de blog avec vidéo. Sinon, exécutez la requête et récupérez l'attribut files renvoyé. La valeur par défaut est un tableau de liste vide s'il n'existe aucune correspondance.
S'il n'y a aucun résultat, le reste de la fonction est ignoré et la valeur None est renvoyée (de manière implicite). Sinon, récupérez la première réponse correspondante (rsp[0]), renvoyez le nom de fichier, son type MIME, l'horodatage de dernière modification et, enfin, sa charge utile binaire, extraite par la fonction get_media() (via son ID de fichier), également dans la collection files(). (Les noms de méthodes peuvent varier légèrement dans les versions des bibliothèques clientes consacrées à d'autres langages.)
La dernière partie est le corps principal ("main") qui gère la totalité de l'application :
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
else:
print('ERROR: Cannot download %r from Drive' % fname)
Avec une image nommée section-work-card-img_2x.jpg dans Drive et définie dans FILE, si l'exécution du script réussit, vous devriez voir un résultat confirmant qu'il a pu lire le fichier à partir de Drive (mais que celui-ci n'a pas été enregistré sur votre ordinateur):
$ python3 analyze_gsimg.py Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Dépannage
Si vous n'obtenez pas le résultat positif décrit ci-dessus, cela peut être dû à une ou plusieurs causes, par exemple :
Résumé
Dans cette section, vous avez appris comment (en deux appels d'API distincts) vous connecter à l'API Drive pour rechercher un fichier spécifique, puis le télécharger. Cas d'utilisation métier : archivez vos données Drive et analysez-les, par exemple avec les outils GCP. À ce stade, le code de votre application doit correspondre au contenu du dépôt visible dans le fichier step1-drive/analyze_gsimg.py.
Pour en savoir plus sur le téléchargement de fichiers depuis Google Drive, consultez cette page ou consultez cet article de blog avec vidéo. Cette partie de l'atelier de programmation est presque identique à l'intégralité de l'atelier de programmation de présentation des API G Suite. Seules différences : au lieu de télécharger un fichier, cet atelier affiche les 100 premiers fichiers/dossiers de l'espace Google Drive d'un utilisateur et utilise un niveau d'accès plus restrictif.
L'étape suivante consiste à ajouter la prise en charge de Google Cloud Storage. Pour cela, nous devons importer un autre package Python, io. Vérifiez que la section d'importation en tête du fichier se présente désormais comme suit :
from __future__ import print_function
import io
En plus du nom de fichier Drive, nous avons besoin d'informations pour savoir où stocker ce fichier sur Cloud Storage, en particulier le nom du "bucket" dans lequel vous allez le déposer et tous les préfixes de dossier parent requis. Nous allons en voir un peu plus à ce sujet d'ici peu :
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
Quelques mots sur les buckets. Cloud Storage permet de stocker des blobs amorphes. Contrairement à Google Drive, ce service de stockage ne comprend pas le concept de type de fichiers, d'extension, etc. Pour Cloud Storage, ce sont simplement des "blobs". De plus, il n'existe aucun concept de dossier ou sous-répertoire dans Cloud Storage.
Oui, vous pouvez utiliser des barres obliques (/) dans les noms de fichiers pour représenter l'abstraction de plusieurs sous-dossiers. Toutefois, en fin de compte, tous vos blobs sont placés dans un même bucket, et les barres obliques "/" sont simplement des caractères figurant dans les noms des fichiers. Pour en savoir plus, consultez la page relative aux conventions d'attribution de noms aux buckets et aux objets.
L'étape 1 ci-dessus a demandé le niveau d'accès "read-only" (en lecture seule) à Google Drive. Jusqu'ici, c'est tout ce dont vous aviez besoin. Maintenant, vous avez besoin de l'autorisation d'importation (lecture-écriture, read-write) dans Cloud Storage. Modifiez SCOPES pour passer d'une variable de chaîne unique à un tableau (tuple [ou liste] Python) de champs d'application d'autorisation, de manière à obtenir un résultat semblable à ce qui suit :
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
)
Créez maintenant un point de terminaison de service vers Cloud Storage juste en dessous de celui créé pour Drive. Notez que nous avons légèrement modifié l'appel afin de réutiliser le même objet client HTTP : en effet, il n'est pas nécessaire d'en créer un autre s'il peut s'agir d'une ressource partagée.
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
Ajoutez la fonction suivante (après drive_get_img()) qui importe des éléments dans Cloud Storage :
def gcs_blob_upload(fname, bucket, media, mimetype):
'upload an object to a Google Cloud Storage bucket'
# build blob metadata and upload via GCS API
body = {'name': fname, 'uploadType': 'multipart', 'contentType': mimetype}
return GCS.objects().insert(bucket=bucket, body=body,
media_body=http.MediaIoBaseUpload(io.BytesIO(media), mimetype),
fields='bucket,name').execute()
L'appel objects.().insert() requiert le nom du bucket, les métadonnées du fichier et l'objet blob binaire proprement dit. Pour filtrer les valeurs renvoyées, la variable fields demande uniquement les noms de bucket et d'objet renvoyés par l'API. Pour en savoir plus sur ces masques de champ pour les requêtes en lecture de l'API, consultez cet article avec vidéo.
Intégrez maintenant l'utilisation de gcs_blob_upload() dans l'application principale :
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
La variable gcsname fusionne les noms de tous les "sous-répertoires parents" avec le nom de fichier proprement dit. Lorsqu'elle est préfixée par le nom du bucket, cette valeur donne l'impression que vous archivez le fichier à l'emplacement "/bucket/parent.../filename". Déposez ce fragment de code juste après la première fonction print(), au-dessus de la clause else, afin que la section "main" complète ressemble à ceci :
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
else:
print('ERROR: Cannot download %r from Drive' % fname)
Imaginons que nous spécifions un bucket nommé "vision-demo" avec "analyzed_imgs" comme "sous-répertoire parent". Une fois que vous aurez défini ces variables et exécuté à nouveau le script, section-work-card-img_2x.jpg sera téléchargé à partir de Drive, puis importé dans Cloud Storage, n'est-ce-pas ? NON !
$ python3 analyze_gsimg.py
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Traceback (most recent call last):
File "analyze_gsimg.py", line 85, in <module>
io.BytesIO(data), mimetype=mtype), mtype)
File "analyze_gsimg.py", line 72, in gcs_blob_upload
media_body=media, fields='bucket,name').execute()
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/googleapiclient/_helpers.py", line 134, in positional_wrapper
return wrapped(*args, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/googleapiclient/http.py", line 898, in execute
raise HttpError(resp, content, uri=self.uri)
googleapiclient.errors.HttpError: <HttpError 403 when requesting https://storage.googleapis.com/upload/storage/v1/b/PROJECT_ID/o?fields=bucket%2Cname&alt=json&uploadType=multipart returned "Insufficient Permission">
Regardez attentivement : le téléchargement à partir de Drive a bien été exécuté, mais l'importation dans Cloud Storage a échoué. Pourquoi ?
Lorsque nous avons accordé les autorisations initiales à cette application à l'étape 1, nous avons uniquement autorisé l'accès à Google Drive en lecture seule. Nous avons effectivement ajouté le niveau d'accès en lecture-écriture pour Cloud Storage, mais nous n'avons jamais demandé à l'utilisateur d'autoriser cet accès. Pour que cela fonctionne, nous devons supprimer le fichier storage.json, qui ne contient pas ce niveau d'accès, et réexécuter le code.
Une fois que vous réexécutez l'ensemble (confirmez cela en vérifiant que vous avez bien deux niveaux d'accès dans le fichier storage.json), vous obtenez le résultat attendu :
$ python3 analyze_gsimg.py
. . .
Authentication successful.
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Uploaded 'analyzed_imgs/section-work-card-img_2x.jpg' to GCS bucket 'vision-demo'
Résumé
C'est un point très important qui vous montre, en quelques lignes de code seulement, comment transférer des fichiers entre deux systèmes de stockage dans le cloud. Ici, le cas d'utilisation métier consiste à sauvegarder une ressource potentiellement limitée dans un système de stockage plus "froid" et moins coûteux, comme indiqué précédemment. Cloud Storage propose différentes classes de stockage selon la fréquence d'accès à vos données, mensuelle, trimestrielle ou annuelle.
Bien entendu, les développeurs nous demandent de temps à autre pourquoi il existe deux systèmes, Google Drive et Cloud Storage... Ne sont-ils pas tous deux des systèmes de stockage de fichiers dans le cloud ? C'est la raison pour laquelle nous avons créé cette vidéo. À ce stade, le code doit correspondre au contenu du dépôt visible dans le fichier step2-gcs/analyze_gsimg.py.
Nous savons maintenant que vous pouvez déplacer des données entre GCP et G Suite, mais nous n'avons pas encore procédé à l'analyse. Il est donc temps de transmettre l'image à Cloud Vision pour l'annotation de thèmes (c'est-à-dire la détection d'objets). Pour cela, nous devons encoder les données en base64, ce qui implique donc d'utiliser un autre module Python, base64. Vérifiez que la section d'importation en tête du fichier ressemble maintenant à ceci :
from __future__ import print_function
import base64
import io
Par défaut, l'API Vision renvoie toutes les étiquettes identifiées. Pour garantir la cohérence, demandons simplement d'inclure les cinq meilleures (ce nombre peut naturellement être ajusté par l'utilisateur). Pour ce faire, nous allons utiliser une variable constante TOP. Ajoutez-la sous l'ensemble des autres constantes :
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
TOP = 5 # TOP # of VISION LABELS TO SAVE
Comme pour les étapes précédentes, nous avons besoin d'un autre niveau d'accès d'autorisation, cette fois pour l'API Vision. Mettez à jour SCOPES pour ajouter la chaîne correspondante :
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
'https://www.googleapis.com/auth/cloud-vision',
)
Créez maintenant un point de terminaison de service vers Cloud Vision, cohérent avec les autres points de terminaisons déjà définis :
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
VISION = discovery.build('vision', 'v1', http=HTTP)
Ajoutez maintenant la fonction qui transmet la charge utile de l'image à Cloud Vision :
def vision_label_img(img, top):
'send image to Vision API for label annotation'
# build image metadata and call Vision API to process
body = {'requests': [{
'image': {'content': img},
'features': [{'type': 'LABEL_DETECTION', 'maxResults': top}],
}]}
rsp = VISION.images().annotate(body=body).execute().get('responses', [{}])[0]
# return top labels for image as CSV for Sheet (row)
if 'labelAnnotations' in rsp:
return ', '.join('(%.2f%%) %s' % (
label['score']*100., label['description']) \
for label in rsp['labelAnnotations'])
L'appel images().annotate() requiert les données ainsi que les fonctionnalités d'API souhaitées. La limite maximale de cinq étiquettes fait également partie de la charge utile (mais cette valeur est entièrement facultative). Si l'appel aboutit, la charge utile renvoie les cinq principales étiquettes d'objets, ainsi que le score de confiance de chaque objet dans l'image. (Si aucune réponse ne s'affiche, attribuez un dictionnaire Python vide afin que l'instruction if suivante n'échoue pas.) Cette fonction permet simplement de classer ces données dans une chaîne CSV en vue de leur utilisation ultérieure dans notre rapport.
Ces cinq lignes qui appellent vision_label_img() doivent être placées juste après le transfert réussi vers Cloud Storage :
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'), TOP)
if rsp:
print('Top %d labels from Vision API: %s' % (TOP, rsp))
else:
print('ERROR: Vision API cannot analyze %r' % fname)
Après cet ajout, le contenu du corps principal "main" doit se présenter comme suit :
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'), TOP)
if rsp:
print('Top %d labels from Vision API: %s' % (TOP, rsp))
else:
print('ERROR: Vision API cannot analyze %r' % fname)
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
else:
print('ERROR: Cannot download %r from Drive' % fname)
Si vous supprimez storage.json pour actualiser les niveaux d'accès et réexécutez l'application mise à jour, vous devriez obtenir un résultat semblable à ce qui suit, avec maintenant le résultat de l'analyse de Cloud Vision :
$ python3 analyze_gsimg.py
. . .
Authentication successful.
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Uploaded 'analyzed_imgs/section-work-card-img_2x.jpg' to GCS bucket 'vision-demo'
Top 5 labels from Vision API: (89.94%) Sitting, (86.09%) Interior design, (82.08%) Furniture, (81.52%) Table, (80.85%) Room
Résumé
Tout le monde ne possède pas forcément l'expertise en machine learning requise pour créer et entraîner ses propres modèles de ML afin d'analyser ses données. L'équipe Google Cloud a mis à disposition certains des modèles pré-entraînés de Google pour une utilisation générale et les met en œuvre sous forme d'API, contribuant ainsi à démocratiser l'IA et le ML pour tous.
Si vous êtes développeur et que vous savez appeler une API, vous pouvez utiliser le machine learning. Cloud Vision n'est que l'un des services d'API avec lesquels vous pouvez analyser vos données. Cliquez ici pour en savoir plus sur les autres services disponibles. Le code doit maintenant correspondre au contenu du dépôt visible dans le fichier step3-vision/analyze_gsimg.py.
À ce stade, vous êtes capable d'archiver des données d'entreprise et de les analyser, mais il manque encore un récapitulatif du travail effectué. Nous allons organiser tous les résultats dans un rapport unique que vous pouvez transmettre à votre responsable. Qu'y a-t-il de plus simple à présenter à un responsable qu'une feuille de calcul ?
Aucune importation supplémentaire n'est nécessaire pour l'API Google Sheets. La seule nouvelle information nécessaire est l'ID de fichier d'une feuille de calcul existante préalablement mise en forme et qui n'attend qu'une nouvelle ligne de données, d'où la constante SHEET. Nous vous recommandons de créer une feuille de calcul semblable à celle-ci :

L'URL de cette feuille de calcul doit se présenter comme suit : https://docs.google.com/spreadsheets/d/FILE_ID/edit. Prenez cet élément FILE_ID et affectez-le en tant que chaîne à la variable SHEET.
Nous avons également inséré une toute petite fonction nommée k_ize(), qui convertit les octets en kilo-octets. Elle est définie en tant que lambda Python, car il s'agit d'une simple ligne. Une fois ces deux éléments intégrés aux autres constantes, cette section du code se présente comme suit :
k_ize = lambda b: '%6.2fK' % (b/1000.) # bytes to kBs
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
SHEET = 'YOUR_SHEET_ID'
TOP = 5 # TOP # of VISION LABELS TO SAVE
Comme pour les étapes précédentes, nous avons besoin d'un autre niveau d'accès d'autorisation, cette fois en lecture/écriture pour l'API Sheets. SCOPES comporte désormais les quatre éléments requis :
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
'https://www.googleapis.com/auth/cloud-vision',
'https://www.googleapis.com/auth/spreadsheets',
)
À présent, créez un point de terminaison de service pour Google Sheets à la suite des points de terminaison existants, de manière à obtenir le résultat suivant :
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
VISION = discovery.build('vision', 'v1', http=HTTP)
SHEETS = discovery.build('sheets', 'v4', http=HTTP)
La fonctionnalité de la fonction sheet_append_row() est simple : recevoir une ligne de données et l'ID d'une feuille de calcul, puis ajouter cette ligne à cette feuille de calcul :
def sheet_append_row(sheet, row):
'append row to a Google Sheet, return #cells added'
# call Sheets API to write row to Sheet (via its ID)
rsp = SHEETS.spreadsheets().values().append(
spreadsheetId=sheet, range='Sheet1',
valueInputOption='USER_ENTERED', body={'values': [row]}
).execute()
if rsp:
return rsp.get('updates').get('updatedCells')
L'appel spreadsheets().values().append() requiert l'ID de fichier de la feuille de calcul Sheets, une plage de cellules, la manière dont les données doivent être insérées et les données proprement dites. L'ID de fichier est simple. La plage de cellules est indiquée en notation A1. Une plage de données de "Sheet1" correspond à l'intégralité de la feuille de calcul. Cela indique à l'API d'ajouter la ligne après l'ensemble des données figurant déjà dans la feuille. Il existe plusieurs options concernant la manière dont les données doivent être ajoutées à la feuille, "RAW" (insérer les données de chaîne telles quelles) ou "USER_ENTERED" (insérer les données comme si elles avaient été saisies par un utilisateur sur son clavier dans l'application Google Sheets, en conservant toutes les caractéristiques de mise en forme des cellules).
Si l'appel aboutit, la valeur renvoyée n'est pas vraiment utile. Nous avons donc choisi d'obtenir le nombre de cellules mises à jour par la requête API. Vous trouverez ci-dessous le code qui appelle cette fonction :
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [PARENT,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
BUCKET, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(SHEET, row)
if rsp:
print('Updated %d cells in Google Sheet' % rsp)
else:
print('ERROR: Cannot write row to Google Sheets')
La feuille Google Sheets comporte des colonnes représentant des données telles que les éventuels "sous-répertoires parents", l'emplacement du fichier archivé sur Cloud Storage (bucket + nom du fichier), le type MIME du fichier, la taille du fichier (à l'origine en octets, mais convertie en kilo-octets à l'aide de k_ize()), et enfin la chaîne des étiquettes Cloud Vision. Notez également que l'emplacement d'archivage est un lien hypertexte. Votre responsable peut donc cliquer dessus pour confirmer qu'il a bien été sauvegardé.
L'ajout du bloc de code ci-dessus juste après l'affichage des résultats obtenus avec Cloud Vision complète le corps "main" de l'application, même si sa structure est légèrement complexe :
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'))
if rsp:
print('Top %d labels from Vision API: %s' % (TOP, rsp))
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [PARENT,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
BUCKET, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(SHEET, row)
if rsp:
print('Updated %d cells in Google Sheet' % rsp)
else:
print('ERROR: Cannot write row to Google Sheets')
else:
print('ERROR: Vision API cannot analyze %r' % fname)
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
else:
print('ERROR: Cannot download %r from Drive' % fname)
Si vous supprimez storage.json une dernière fois et que vous exécutez à nouveau l'application mise à jour, vous devriez obtenir un résultat semblable à ce qui suit, avec maintenant le résultat de l'analyse de Cloud Vision :
$ python3 analyze_gsimg.py
. . .
Authentication successful.
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Uploaded 'analyzed_imgs/section-work-card-img_2x.jpg' to GCS bucket 'vision-demo'
Top 5 labels from Vision API: (89.94%) Sitting, (86.09%) Interior design, (82.08%) Furniture, (81.52%) Table, (80.85%) Room
Updated 6 cells in Google Sheet
Cette dernière ligne de résultat, bien qu'elle soit utile, est bien plus lisible dans la feuille de calcul Google Sheets mise à jour : les informations correspondantes figurent dans la dernière ligne (ligne 7 dans l'exemple ci-dessous) de l'ensemble de données existant et préalablement inséré à la feuille :

Résumé
Dans les trois premières étapes de ce tutoriel, vous vous êtes connecté aux API G Suite et GCP pour déplacer des données et les analyser, ce qui représentait 80 % du travail de cet atelier de programmation. Au bout du compte, cela n'a guère d'intérêt à moins que vous ne puissiez présenter à votre responsable des informations sur le travail accompli. Pour mieux visualiser les résultats, les résumer dans un rapport généré automatiquement est bien plus efficace et éloquent.
Pour accroître l'intérêt de cette analyse au-delà de la simple insertion des résultats dans une feuille de calcul, une amélioration possible consisterait à indexer ces cinq étiquettes principales pour chaque image. Ainsi, vous pouvez créer une base de données interne permettant aux employés autorisés d'interroger les images à l'aide de termes de recherche, mais la réalisation de cette solution est laissée au lecteur à titre d'exercice.
En l'état, les résultats sont dans une feuille de calcul et sont accessibles à votre responsable. À ce stade, le code de votre application doit correspondre au contenu du dépôt visible dans le fichier step4-sheets/analyze_gsimg.py. La dernière étape consiste à nettoyer le code et à le transformer en script utilisable.
(Facultatif) L'application fonctionne, c'est formidable. Pouvons-nous l'améliorer ? Oui. En particulier, le corps principal de l'application "main" est un bric-à-brac désordonné. Plaçons-le dans une fonction dédiée et permettons-lui d'utiliser des valeurs fournies par l'utilisateur plutôt que des constantes fixes. Pour ce faire, nous allons utiliser le module argparse. Ouvrons également un onglet du navigateur Web afin d'afficher la feuille Sheets après l'insertion de notre ligne de données. Vous pouvez pour cela utiliser le module webbrowser. Intégrez ces importations à celles existantes en tête du code afin d'obtenir un résultat semblable à ceci :
from __future__ import print_function
import argparse
import base64
import io
import webbrowser
Pour pouvoir utiliser ce code dans d'autres applications, nous devons être en mesure de supprimer la sortie. Nous allons donc ajouter une option DEBUG à cet effet, en ajoutant la ligne suivante à la fin de la section consacrée aux constantes en tête du fichier :
DEBUG = False
Passons maintenant au corps principal "main" de l'application. À mesure que nous avons construit cet exemple, vous avez dû commencer à ressentir un certain inconfort car, avec l'ajout de chaque service, nous ajoutions au code un niveau supplémentaire d'imbrication. Si vous avez ressenti cela, vous n'êtes pas seul, car cela augmente la complexité du code comme décrit dans cet article du blog Google Testing.
Pour suivre cette bonne pratique, réorganisons la partie principale de l'application en une fonction et insérons des return à chaque "point d'arrêt" au lieu d'imbriquer les éléments (afin de renvoyer None si une étape quelconque échoue et True si l'ensemble de l'application réussit).
def main(fname, bucket, sheet_id, folder, top, debug):
'"main()" drives process from image download through report generation'
# download img file & info from Drive
rsp = drive_get_img(fname)
if not rsp:
return
fname, mtype, ftime, data = rsp
if debug:
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (folder, fname)
rsp = gcs_blob_upload(gcsname, bucket, data, mtype)
if not rsp:
return
if debug:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'))
if not rsp:
return
if debug:
print('Top %d labels from Vision API: %s' % (top, rsp))
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [folder,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
bucket, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(sheet_id, row)
if not rsp:
return
if debug:
print('Added %d cells to Google Sheet' % rsp)
return True
Le code est ainsi plus net et plus propre, et cela permet d'éliminer cette impression de chaîne récursive d'instructions if-else tout en réduisant la complexité du code, comme décrit ci-dessus. Le dernier élément de ce puzzle consiste à créer un véritable pilote "main", qui permet à l'utilisateur de personnaliser la fonction et de minimiser la sortie (sauf si vous le souhaitez) :
if __name__ == '__main__':
# args: [-hv] [-i imgfile] [-b bucket] [-f folder] [-s Sheet ID] [-t top labels]
parser = argparse.ArgumentParser()
parser.add_argument("-i", "--imgfile", action="store_true",
default=FILE, help="image file filename")
parser.add_argument("-b", "--bucket_id", action="store_true",
default=BUCKET, help="Google Cloud Storage bucket name")
parser.add_argument("-f", "--folder", action="store_true",
default=PARENT, help="Google Cloud Storage image folder")
parser.add_argument("-s", "--sheet_id", action="store_true",
default=SHEET, help="Google Sheet Drive file ID (44-char str)")
parser.add_argument("-t", "--viz_top", action="store_true",
default=TOP, help="return top N (default %d) Vision API labels" % TOP)
parser.add_argument("-v", "--verbose", action="store_true",
default=DEBUG, help="verbose display output")
args = parser.parse_args()
print('Processing file %r... please wait' % args.imgfile)
rsp = main(args.imgfile, args.bucket_id,
args.sheet_id, args.folder, args.viz_top, args.verbose)
if rsp:
sheet_url = 'https://docs.google.com/spreadsheets/d/%s/edit' % args.sheet_id
print('DONE: opening web browser to it, or see %s' % sheet_url)
webbrowser.open(sheet_url, new=1, autoraise=True)
else:
print('ERROR: could not process %r' % args.imgfile)
Si toutes les étapes réussissent, le script lance un navigateur Web ouvrant la feuille de calcul spécifiée, dans laquelle la nouvelle ligne de données a été insérée.
Résumé
Il n'est pas nécessaire de supprimer storage.json, car aucune modification n'a eu lieu sur les niveaux d'accès. Réexécuter l'application mise à jour révèle l'ouverture d'une nouvelle fenêtre de navigateur ouvrant la feuille de calcul modifiée, ainsi qu'une réduction du nombre de lignes en sortie. L'utilisation d'une option -h permet aux utilisateurs de voir leurs options, y compris -v qui permet restaurer l'affichage des lignes de sortie que nous venons de supprimer :
$ python3 analyze_gsimg.py Processing file 'section-work-card-img_2x.jpg'... please wait DONE: opening web browser to it, or see https://docs.google.com/spreadsheets/d/SHEET_ID/edit $ python3 analyze_gsimg.py -h usage: analyze_gsimg.py [-h] [-i] [-t] [-f] [-b] [-s] [-v] optional arguments: -h, --help show this help message and exit -i, --imgfile image file filename -t, --viz_top return top N (default 5) Vision API labels -f, --folder Google Cloud Storage image folder -b, --bucket_id Google Cloud Storage bucket name -s, --sheet_id Google Sheet Drive file ID (44-char str) -v, --verbose verbose display output
Les autres options permettent aux utilisateurs de choisir des noms de fichiers Drive différents, des noms de "sous-répertoires" Cloud Storage et de buckets différents, le nombre "N" des résultats de Cloud Vision, ainsi que les ID de fichiers Sheets correspondant aux feuilles de calcul. Avec ces dernières adaptations, la version finale de votre code doit maintenant correspondre au contenu du dépôt visible dans le fichier final/analyze_gsimg.py, visible ci-dessous dans son intégralité :
## Copyright 2020 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
'''
analyze_gsimg.py - analyze G Suite image processing workflow
Download image from Google Drive, archive to Google Cloud Storage, send
to Google Cloud Vision for processing, add results row to Google Sheet.
'''
from __future__ import print_function
import argparse
import base64
import io
import webbrowser
from googleapiclient import discovery, http
from httplib2 import Http
from oauth2client import file, client, tools
k_ize = lambda b: '%6.2fK' % (b/1000.) # bytes to kBs
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
SHEET = 'YOUR_SHEET_ID'
TOP = 5 # TOP # of VISION LABELS TO SAVE
DEBUG = False
# process credentials for OAuth2 tokens
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
'https://www.googleapis.com/auth/cloud-vision',
'https://www.googleapis.com/auth/spreadsheets',
)
store = file.Storage('storage.json')
creds = store.get()
if not creds or creds.invalid:
flow = client.flow_from_clientsecrets('client_secret.json', SCOPES)
creds = tools.run_flow(flow, store)
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
VISION = discovery.build('vision', 'v1', http=HTTP)
SHEETS = discovery.build('sheets', 'v4', http=HTTP)
def drive_get_img(fname):
'download file from Drive and return file info & binary if found'
# search for file on Google Drive
rsp = DRIVE.files().list(q="name='%s'" % fname,
fields='files(id,name,mimeType,modifiedTime)'
).execute().get('files', [])
# download binary & return file info if found, else return None
if rsp:
target = rsp[0] # use first matching file
fileId = target['id']
fname = target['name']
mtype = target['mimeType']
binary = DRIVE.files().get_media(fileId=fileId).execute()
return fname, mtype, target['modifiedTime'], binary
def gcs_blob_upload(fname, bucket, media, mimetype):
'upload an object to a Google Cloud Storage bucket'
# build blob metadata and upload via GCS API
body = {'name': fname, 'uploadType': 'multipart', 'contentType': mimetype}
return GCS.objects().insert(bucket=bucket, body=body,
media_body=http.MediaIoBaseUpload(io.BytesIO(media), mimetype),
fields='bucket,name').execute()
def vision_label_img(img, top):
'send image to Vision API for label annotation'
# build image metadata and call Vision API to process
body = {'requests': [{
'image': {'content': img},
'features': [{'type': 'LABEL_DETECTION', 'maxResults': top}],
}]}
rsp = VISION.images().annotate(body=body).execute().get('responses', [{}])[0]
# return top labels for image as CSV for Sheet (row)
if 'labelAnnotations' in rsp:
return ', '.join('(%.2f%%) %s' % (
label['score']*100., label['description']) \
for label in rsp['labelAnnotations'])
def sheet_append_row(sheet, row):
'append row to a Google Sheet, return #cells added'
# call Sheets API to write row to Sheet (via its ID)
rsp = SHEETS.spreadsheets().values().append(
spreadsheetId=sheet, range='Sheet1',
valueInputOption='USER_ENTERED', body={'values': [row]}
).execute()
if rsp:
return rsp.get('updates').get('updatedCells')
def main(fname, bucket, sheet_id, folder, top, debug):
'"main()" drives process from image download through report generation'
# download img file & info from Drive
rsp = drive_get_img(fname)
if not rsp:
return
fname, mtype, ftime, data = rsp
if debug:
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (folder, fname)
rsp = gcs_blob_upload(gcsname, bucket, data, mtype)
if not rsp:
return
if debug:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'), top)
if not rsp:
return
if debug:
print('Top %d labels from Vision API: %s' % (top, rsp))
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [folder,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
bucket, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(sheet_id, row)
if not rsp:
return
if debug:
print('Added %d cells to Google Sheet' % rsp)
return True
if __name__ == '__main__':
# args: [-hv] [-i imgfile] [-b bucket] [-f folder] [-s Sheet ID] [-t top labels]
parser = argparse.ArgumentParser()
parser.add_argument("-i", "--imgfile", action="store_true",
default=FILE, help="image file filename")
parser.add_argument("-b", "--bucket_id", action="store_true",
default=BUCKET, help="Google Cloud Storage bucket name")
parser.add_argument("-f", "--folder", action="store_true",
default=PARENT, help="Google Cloud Storage image folder")
parser.add_argument("-s", "--sheet_id", action="store_true",
default=SHEET, help="Google Sheet Drive file ID (44-char str)")
parser.add_argument("-t", "--viz_top", action="store_true",
default=TOP, help="return top N (default %d) Vision API labels" % TOP)
parser.add_argument("-v", "--verbose", action="store_true",
default=DEBUG, help="verbose display output")
args = parser.parse_args()
print('Processing file %r... please wait' % args.imgfile)
rsp = main(args.imgfile, args.bucket_id,
args.sheet_id, args.folder, args.viz_top, args.verbose)
if rsp:
sheet_url = 'https://docs.google.com/spreadsheets/d/%s/edit' % args.sheet_id
print('DONE: opening web browser to it, or see %s' % sheet_url)
webbrowser.open(sheet_url, new=1, autoraise=True)
else:
print('ERROR: could not process %r' % args.imgfile)
Nous mettrons tout en œuvre pour garder à jour le contenu de ce tutoriel, mais à l'occasion, c'est le dépôt qui hébergera la version la plus récente du code.
Il y a assurément beaucoup à apprendre dans cet atelier de programmation, et vous y êtes parvenu : vous avez survécu à l'un des ateliers de programmation les plus longs qui soient. Le résultat en est que vous avez traité un scénario d'entreprise potentiel en environ 130 lignes de code Python, en vous appuyant sur l'ensemble des services Google Cloud (GCP et G Suite) et en déplaçant les données entre services pour créer une solution opérationnelle. N'hésitez pas à explorer le dépôt Open Source pour découvrir toutes les versions de cette application (plus d'informations ci-dessous).
Nettoyer
- L'utilisation des API GCP est payante, tandis que les API G Suite sont couvertes par vos frais d'abonnement mensuels pour G Suite, ou vos frais mensuels nuls en tant qu'utilisateur de Gmail. Aucun nettoyage ou désactivation d'API n'est donc requis pour les utilisateurs G Suite. Pour GCP, vous pouvez accéder à votre tableau de bord Cloud Console et consulter la "fiche" de facturation pour afficher les frais estimés.
- Pour Cloud Vision, vous disposez gratuitement d'un nombre fixe d'appels d'API par mois. Tant que vous restez en deçà de ces limites, il n'est pas nécessaire d'arrêter quoi que ce soit, ni de désactiver ou supprimer votre projet. Pour en savoir plus sur la facturation et le quota gratuit de l'API Cloud Vision, consultez la page des tarifs correspondante.
- Certains utilisateurs de Cloud Storage disposent d'une capacité de stockage gratuite par mois. Si les images que vous archivez à l'aide de cet atelier de programmation n'entraînent pas de dépassement de votre quota, aucuns frais ne vous seront facturés. Pour plus d'informations sur la facturation GCS et sur le quota gratuit, consultez la page des tarifs correspondante. Vous pouvez afficher et supprimer facilement des blobs depuis le navigateur Cloud Storage.
- Votre utilisation de Google Drive peut également être soumise à un quota de stockage. Si vous dépassez ce quota (ou que vous vous en approchez), vous pouvez utiliser l'outil que vous avez créé dans cet atelier de programmation pour archiver ces images dans Cloud Storage afin de libérer de l'espace dans Drive. Pour plus d'informations sur l'espace de stockage Google Drive, consultez la page de tarification appropriée pour les utilisateurs de G Suite Basic ou les utilisateurs de Gmail.
Bien que la plupart des forfaits G Suite Business et Enterprise soient dotés d'un espace de stockage illimité, vos dossiers Drive risquent la surcharge et le désordre. L'application créée dans ce tutoriel est un excellent moyen d'archiver les fichiers superflus et de nettoyer votre espace Google Drive.
Autres versions
Même si final/analyze_gsimg.py constitue la "dernière" version officielle de ce tutoriel, ce n'est pas la fin de l'histoire. L'un des problèmes que pose cette version finale de l'application est qu'elle utilise des bibliothèques d'authentification anciennes et obsolètes. Nous avons choisi cette voie car, au moment de la rédaction de cet atelier, les bibliothèques d'authentification les plus récentes n'étaient pas compatibles avec plusieurs éléments clés : la gestion du stockage des jetons OAuth et la fonctionnalité de sécurisation threadsafe.
Bibliothèques d'authentification actuelles (plus récentes)
Cependant, à terme, ces anciennes bibliothèques d'authentification ne seront plus prises en charge. Nous vous encourageons donc à vérifier les versions qui utilisent les bibliothèques d'authentification les plus récentes (actuelles) dans le dossier alt du dépôt, même si celles ne sont pas threadsafe (mais vous pouvez créer votre propre solution threadsafe). Recherchez les fichiers dont le nom contient *newauth*.
Bibliothèques clientes des produits GCP
Google Cloud recommande à tous les développeurs d'utiliser les bibliothèques clientes des produits lorsqu'ils utilisent des API GCP. Malheureusement, il n'existe pas encore de bibliothèques de ce type pour les API non-GCP pour le moment. L'utilisation des bibliothèques de plate-forme de plus bas niveau permet une utilisation cohérente des API et offre une meilleure lisibilité. À l'instar de la recommandation ci-dessus, des versions alternatives utilisant les bibliothèques clientes des produits GCP sont à votre disposition dans le dossier alt du dépôt. Recherchez les fichiers dont le nom contient *-gcp*.
Autorisation via un compte de service
Lorsque vous travaillez exclusivement dans le cloud, les données ne sont généralement pas détenues par des utilisateurs humains. C'est pourquoi les comptes de service et l'autorisation via des comptes de service sont principalement utilisés avec GCP. Cependant, les documents G Suite appartiennent généralement à des utilisateurs humains. C'est pourquoi ce tutoriel utilise l'autorisation via un compte utilisateur. Cela ne signifie pas qu'il n'est pas possible d'utiliser les API G Suite avec des comptes de service. Tant que ces comptes disposent du niveau d'accès approprié, ils peuvent tout à fait être utilisés dans des applications. À l'instar des remarques ci-dessus, des versions alternatives utilisant l'autorisation via des comptes de service sont à votre disposition dans le dossier alt du dépôt. Recherchez les fichiers dont le nom contient *-svc*.
Catalogue des autres versions
Vous trouverez ci-dessous toutes les autres versions disponibles de l'application final/analyze_gsimg.py, chacune présentant une ou plusieurs des propriétés ci-dessus. Dans le nom de fichier de chaque version, recherchez les éléments suivants :
- "
oldauth" pour les versions utilisant les anciennes bibliothèques d'authentification (en complément definal/analyze_gsimg.py) - "
newauth" pour les versions utilisant les bibliothèques d'authentification actuelles ou plus récentes gcppour les versions utilisant les bibliothèques clientes des produits GCP, c'est-à-dire google-cloud-storage, etc.- "
svc" pour les versions utilisant un compte de service ("svc acct") au lieu d'un compte utilisateur
Voici toutes les versions disponibles :
Nom de fichier | Description |
| L'exemple principal, qui utilise les anciennes bibliothèques d'authentification |
| Identique à |
| Identique à |
| Identique à |
| Identique à |
| Identique à |
| Identique à |
| Identique à |
Avec la configuration d'origine final/analyze_gsimg.py, vous disposez de toutes les combinaisons possibles de la solution finale, quel que soit votre environnement de développement d'API Google. Vous pouvez donc choisir la solution qui correspond le mieux à vos besoins. Consultez également le document alt/README.md pour obtenir les mêmes explications.
Approfondir
Vous trouverez ci-dessous quelques idées pour vous aider à prolonger cet exercice. Vous pouvez élargir l'éventail de problèmes pouvant être géré par la solution actuelle et apporter les améliorations suivantes :
- (plusieurs images dans des dossiers) Au lieu de traiter une image unique, imaginons que vous ayez des images dans des dossiers Google Drive.
- (plusieurs images dans des fichiers ZIP) Au lieu d'un dossier d'images, comment traiter les archives ZIP contenant des fichiers d'images ? Si vous utilisez Python, envisagez d'utiliser le module
zipfile. - (analyser les thèmes Vision) Regroupez les images similaires, en commençant par exemple par rechercher le thème les plus courant, puis le deuxième thème le plus courant, etc.
- (créer des graphiques) En complément de la suggestion #3, générez avec l'API Sheets des graphiques basés sur l'analyse et la catégorisation réalisées par l'API Vision.
- (classer des documents) Au lieu d'analyser des images avec l'API Cloud Vision, imaginons que vous avez des fichiers PDF à classer avec l'API Cloud Natural Language. Avec les solutions ci-dessus, ces fichiers PDF peuvent se trouver dans des dossiers Drive ou dans des archives ZIP sur Drive.
- (créer des présentations) Utilisez l'API Slides pour générer une présentation à partir du contenu du rapport Google Sheets. Pour plus d'inspiration, consultez cet article de blog avec vidéo sur la génération de diapositives à partir des données de feuilles de calcul.
- (exporter au format PDF) Exportez la feuille de calcul et/ou la présentation au format PDF : toutefois, ce n'est pas une fonctionnalité des API Sheets ni Slides. Indice : API Google Drive. Points en plus : fusionnez les fichiers PDF Sheets et Slides en un seul fichier PDF maître à l'aide d'outils tels que Ghostscript (Linux, Windows) ou
Combine PDF Pages.action(Mac OS X).
En savoir plus
Ateliers de programmation
- Présentation des API G Suite (API Google Drive) (Python)
- Utiliser Cloud Vision avec Python (Python)
- Créer des outils de création de rapports personnalisés (API Google Sheets) (JS/Node)
- Importer des objets dans Google Cloud Storage (aucun code requis)
Général
G Suite
- Page d'accueil de l'API Google Drive
- Page d'accueil de l'API Google Sheets
- Présentation et documentation de G Suite pour les développeurs
Google Cloud Platform (GCP)
- Page d'accueil de Google Cloud Storage
- Page d'accueil et démonstration en direct de Google Cloud Vision
- Documentation de l'API Cloud Vision
- Documentation sur l'ajout d'étiquettes à des images avec l'API Vision
- Python sur Google Cloud Platform
- Bibliothèques clientes des produits GCP
- Documentation de GCP
Licence
Ce document est publié sous une licence Creative Commons Attribution 2.0 Generic.