
このコードラボでは、画像のアーカイブ、分析、レポート作成といった、企業で実行されるワークフローを想定しています。制約のあるリソースのスペースを占有する画像を所有している企業組織を想像してみてください。これらのデータをアーカイブし、画像を分析し、また最も重要なこととして、アーカイブされた場所と分析結果を要約したレポートを生成し、管理者が利用できるようにします。Google Cloud は、G Suite と Google Cloud Platform(GCP)の 2 つのプロダクト ラインの API を利用して、これを実現するためのツールを提供します。
このシナリオでは、ビジネス ユーザーは Google ドライブに画像を保存します。Google Cloud Storage で利用できるストレージ クラスなど、安価なコールド ストレージにバックアップすることがおすすめです。Google Cloud Vision を使用すると、オブジェクトやランドマークの検出機能、光学式文字認識(OCR)などの画像検出機能をアプリケーション内に簡単に統合できます。また、便利な可視化ツールである Google スプレッドシートを使用して、上司のためにデータをまとめることもできます。
このコードラボを完了して、Google Cloud のすべてを活用するソリューションを構築した後に、組織や顧客にとってさらに影響力のあるものを構築するためのインスピレーションを獲得していただければ幸いです。
ラボの内容
- Cloud Shell の使い方
- API リクエストを認証する方法
- Python 用 Google API クライアント ライブラリをインストールする方法
- Google API を有効にする方法
- Google ドライブからファイルをダウンロードする方法
- オブジェクトや blob を Cloud Storage にアップロードする方法
- Cloud Vision でデータを分析する方法
- Google スプレッドシートに行を書き込む方法
必要なもの
- Google アカウント(G Suite アカウントの場合、管理者の承認が必要となる可能性があります)
- 有効な GCP 請求先アカウントを持つ Google Cloud Platform プロジェクト
- オペレーティング システムのターミナル / シェルコマンドに精通していること
- Python 2 または 3 の基本的なスキル(サポートされている任意の言語を使用することもできます)
上記の 4 つの Google Cloud プロダクトの経験があると役立ちますが、必須ではありません。これらのプロダクトに慣れるための時間的余裕がある場合は、この演習に取り組む前に、各プロダクトのコードラボを行うことをおすすめします。
- Google ドライブ(G Suite API の使用)の概要(Python)
- Python での Cloud Vision の使用(Python)
- Sheets API でのカスタム レポートツールの作成(JS/Node)
- Google Cloud Storage へのオブジェクトのアップロード(コーディング不要)
アンケート
このチュートリアルをどのように使用されますか?
Python のご利用経験
Google Cloud Platform サービスのご利用経験
G Suite デベロッパー サービスのご利用経験
より「ビジネス指向」の Codelab とプロダクト機能の概要を紹介する Codelab のどちらをご覧になることを希望されますか?
セルフペース型の環境設定
- Cloud Console にログインし、新しいプロジェクトを作成するか、既存のプロジェクトを再利用します(Gmail アカウントまたは G Suite アカウントをお持ちでない場合は、アカウントを作成する必要があります)。



プロジェクト ID を忘れないようにしてください。プロジェクト ID はすべての Google Cloud プロジェクトを通じて一意の名前にする必要があります(上記の名前はすでに使用されているので使用できません)。以降、このコードラボでは PROJECT_ID と呼びます。
- 次に、Google Cloud リソースを使用するために、Cloud Console で課金を有効にする必要があります。
このコードラボを実行しても、費用はほとんどかからないはずです。このチュートリアル以外で請求が発生しないように、リソースのシャットダウン方法を説明する「クリーンアップ」セクションの手順に従うようにしてください。Google Cloud の新規ユーザーは $300 の無料トライアル プログラムをご利用いただけます。
Cloud Shell の起動
概要
ノートパソコンでローカルにコードを開発することもできますが、このコードラボでは、2 つ目の目標として、最新のウェブブラウザを介してクラウドで実行されるコマンドライン環境、Google Cloud Shell の使用方法を説明します。
Cloud Shell をアクティブにする
- Cloud Console で、[Cloud Shell をアクティブにする]
をクリックします。

Cloud Shell を起動したことがない場合、その内容を説明する中間画面が(スクロールしなければ見えない範囲に)が表示されます。その場合は、[続行] をクリックします(以後表示されなくなります)。このワンタイム スクリーンは次のようになります。

Cloud Shell のプロビジョニングと接続に少し時間がかかる程度です。

この仮想マシンには、必要な開発ツールがすべて準備されています。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働するため、ネットワーク パフォーマンスが充実しており認証もスムーズです。このコードラボでの作業のほとんどは、ブラウザまたは Chromebook から実行できます。
Cloud Shell に接続すると、すでに認証は完了しており、プロジェクトに各自のプロジェクト ID が設定されていることがわかります。
- Cloud Shell で次のコマンドを実行して、認証されたことを確認します。
gcloud auth list
コマンド出力
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
コマンド出力
[core] project = <PROJECT_ID>
上記のようになっていない場合は、次のコマンドで設定できます。
gcloud config set project <PROJECT_ID>
コマンド出力
Updated property [core/project].
このコードラボでは、Python 言語を使用する必要があります(Google API クライアント ライブラリでは多くの言語がサポートされているため、使い慣れた開発ツールで同等の機能を作成して、Python を疑似コードとして使用することもできます)。このコードラボは Python 2 と Python 3 をサポートしていますが、できるだけ早く 3.x に移行することをおすすめします。
Cloud Shell は、Cloud Console から直接利用できる便利なツールです。ローカル開発環境を必要としないため、ウェブブラウザを使用して、クラウドでこのチュートリアルを完了できます。Cloud Shell は、GCP のプロダクトと API で開発を行う場合、または今後開発を行う場合に特に便利です。このコードラボに関しては、すでに両方のバージョンの Python が Cloud Shell にインストールされています。
また、Cloud Shell には IPython もインストールされています。これは、特にデータサイエンスや機械学習のコミュニティに参加しているユーザーにおすすめできる、高レベルのインタラクティブな Python インタープリタです。該当する場合は、IPython が Jupyter ノートブックおよび Google Research がホストする Jupyter ノートブック、Colab のデフォルト インタープリタになります。
IPython は最初に Python 3 インタープリタを優先しますが、3.x が利用できない場合は Python 2 にフォールバックします。IPython は Cloud Shell からアクセスできますが、ローカル開発環境にインストールすることもできます。⌘D(Ctrl+D)で終了し、終了を確定させます。ipython の開始の出力例は次のようになります。
$ ipython Python 3.7.3 (default, Mar 4 2020, 23:11:43) Type 'copyright', 'credits' or 'license' for more information IPython 7.13.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
IPython を好まない場合は、標準の Python インタラクティブ インタープリタ(Cloud Shell または独自のローカル開発環境)を使用できます(⌘D で終了します)。
$ python Python 2.7.13 (default, Sep 26 2018, 18:42:22) [GCC 6.3.0 20170516] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> $ python3 Python 3.7.3 (default, Mar 10 2020, 02:33:39) [GCC 6.3.0 20170516] on linux Type "help", "copyright", "credits" or "license" for more information. >>>
このコードラボは、pip インストール ツール(Python パッケージ マネージャーと依存関係リゾルバ)も所有していることを前提としています。これは、バージョン 2.7.9 以降または 3.4 以降にバンドルされています。古いバージョンの Python をお使いの場合は、こちらのガイドでインストール手順をご確認ください。権限によっては、sudo またはスーパーユーザー アクセスが必要になる場合がありますが、通常は必要ありません。pip2 または pip3 を明示的に使用して、特定の Python バージョンに対して pip を実行することもできます。
このコードラボの残りの部分では、Python 3 を使用していることを前提とします。Python 2 が 3.x と大幅に異なる場合は、Python 2 向けの特定の手順を説明します。
*仮想環境を作成して使用する
このセクションはオプションであり、必須となるのは、このコードラボで仮想環境を使用する必要があるユーザー(上記の警告サイドバーのとおり)のみです。パソコンに Python 3 しかない場合、次のコマンドを実行して my_env という virtualenv を作成できます(必要に応じて別の名前を指定することもできます)。
virtualenv my_env
ただし、パソコンに Python 2 と 3 の両方をインストールしている場合は、次のように -p flag を使用して Python 3 virtualenv をインストールすることをおすすめします。
virtualenv -p python3 my_env
次のように「有効化」して、新しく作成した virtualenv を入力します。
source my_env/bin/activate
シェル プロンプトの前に環境名が付いていることを確認して、ユーザーが環境内にいることを確認します。
(my_env) $
これで、必要なパッケージを pip install したり、この環境内でコードを実行したりできます。また、完全にごちゃ混ぜになってしまった場合や、Python インストールが破損した場合などに、システムの他の部分に影響を与えることなく、この環境全体を完全に消去することができます。
このコードラボには Python 用 Google API クライアント ライブラリが必要です。そのために、簡単なインストール プロセスを実行する必要がある場合がありますが、何もしなくても良い場合もあります。
便宜上、Cloud Shell の使用を検討することはすでに説明しました。このチュートリアルは、ウェブブラウザを使用して、クラウドで完了できます。Cloud Shell を使用するもう 1 つの理由は、多くの一般的な開発ツールと必要なライブラリがすでにプリインストールされているためです。
*クライアント ライブラリをインストールする
(省略可)Cloud Shell を使用する場合、またはクライアント ライブラリがインストール済みのローカル環境を使用する場合は、この手順を省略できます。この操作を行う必要があるのは、ローカルで開発する場合で、インストールしていない(またはインストールしたかわからない)場合のみです。最も簡単な方法は、pip(または pip3)を使用してインストールを実行する方法です(必要に応じて pip 自体も更新します)。
pip install -U pip google-api-python-client oauth2client
インストールを確認する
このコマンドを実行すると、クライアント ライブラリと依存するすべてのパッケージがインストールされます。Cloud Shell を使用する場合も、独自の環境で使用する場合も、必要なパッケージをインポートしてクライアント ライブラリがインストールされていることを確認し、インポート エラーがない(出力がない)ことを確認します。
python3 -c "import googleapiclient, httplib2, oauth2client"
(Cloud Shell から)Python 2 を使用すると、Python 2 のサポートが非推奨になったことを示す警告が表示されます。
******************************************************************************* Python 2 is deprecated. Upgrade to Python 3 as soon as possible. See https://cloud.google.com/python/docs/python2-sunset To suppress this warning, create an empty ~/.cloudshell/no-python-warning file. The command will automatically proceed in seconds or on any key. *******************************************************************************
この import "test" コマンドをエラーや出力なしで正常に実行できたのであれば、Google API とのやり取りを行うための準備ができています。
概要
これは中級のコードラボであり、コンソールでプロジェクトを作成および使用した経験があることを前提としています。Google API、特に G Suite API を初めて使用する場合は、まず G Suite API の入門コードラボをお試しください。また、(サービス アカウントではなく)ユーザー アカウントの認証情報を作成(または既存のものを再利用)する方法を知っている場合は、client_secret.json ファイルを作業ディレクトリにドロップし、次のモジュールをスキップして、「Google API を有効にする」に移動します。
ユーザー アカウント承認認証情報をすでに作成していて、プロセスに精通している場合は、このセクションをスキップできます。これは、手法が異なるサービス アカウント承認と異なるため、次に進んでください。
認可の概要(およびいくつかの認証)
API にリクエストを行うには、アプリケーションに適切な認可が必要です。同様の言葉である認証は、ログイン認証情報を表します。こちらの場合は、ログインとパスワードを使用して Google アカウントにログインするときに自分自身を認証します。認証の後の次のステップは、データ(Cloud Storage 上の blob ファイルや Google ドライブ上にあるユーザーの個人ファイルなど)へのアクセス権限がユーザー(コード)に付与されているかどうかです。
Google API はいくつかの認可の種類をサポートしていますが、このコードラボのサンプル アプリケーションはエンドユーザーに属するデータにアクセスするため、G Suite API ユーザーが最もよく使用する認可はユーザー認可です。エンドユーザーは、自身のデータにアクセスするための権限をアプリに付与する必要があります。つまり、コードでユーザー アカウント OAuth2 認証情報を取得する必要があります。
ユーザー認証用の OAuth2 認証情報を取得するには、API Manager に戻り、左側のナビゲーションで [認証情報] タブを選択します。
ここでは、3 つの別々のセクションですべての認証情報が表示されます。
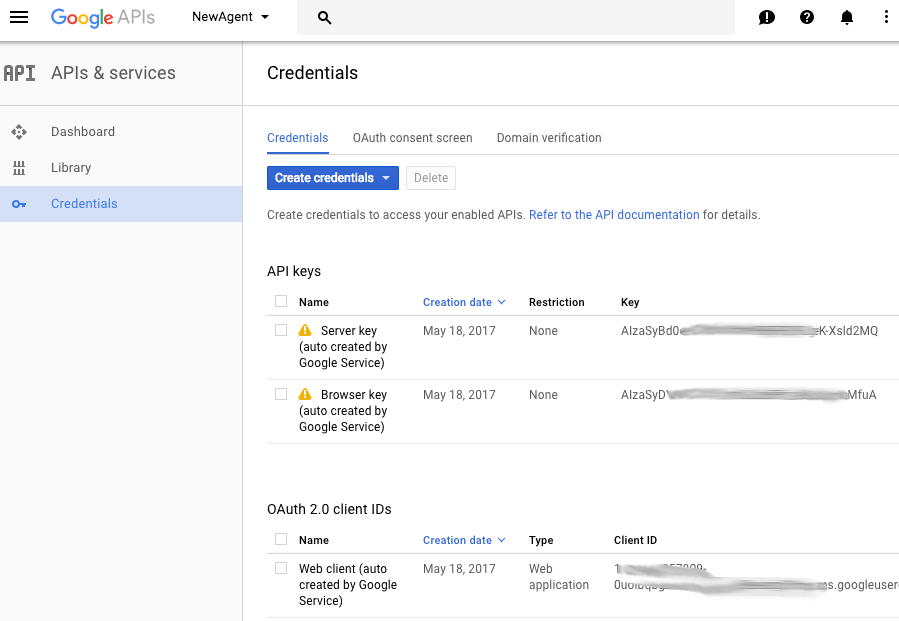
1 番目は API キー、2 番目は OAuth 2.0 クライアント ID、最後はOAuth2 サービス アカウントで、ここでは真ん中のものを使用します。
認証情報の作成
認証情報のページで、上部にある [+ 認証情報を作成] ボタンをクリックすると、[OAuth クライアント ID] を選択するためのダイアログが表示されます。

次の画面には、アプリの認可の「同意画面」の構成とアプリケーション タイプの選択の 2 つのアクションが示されています。

同意画面を設定していない場合は、コンソールに警告が表示されるので、すぐに設定する必要があります。(同意画面がすでに設定されている場合は、この手順を省略してください)。
OAuth 同意画面
[同意画面の構成] をクリックして、[外部] アプリ(G Suite をご利用の場合は [内部])を選択します。
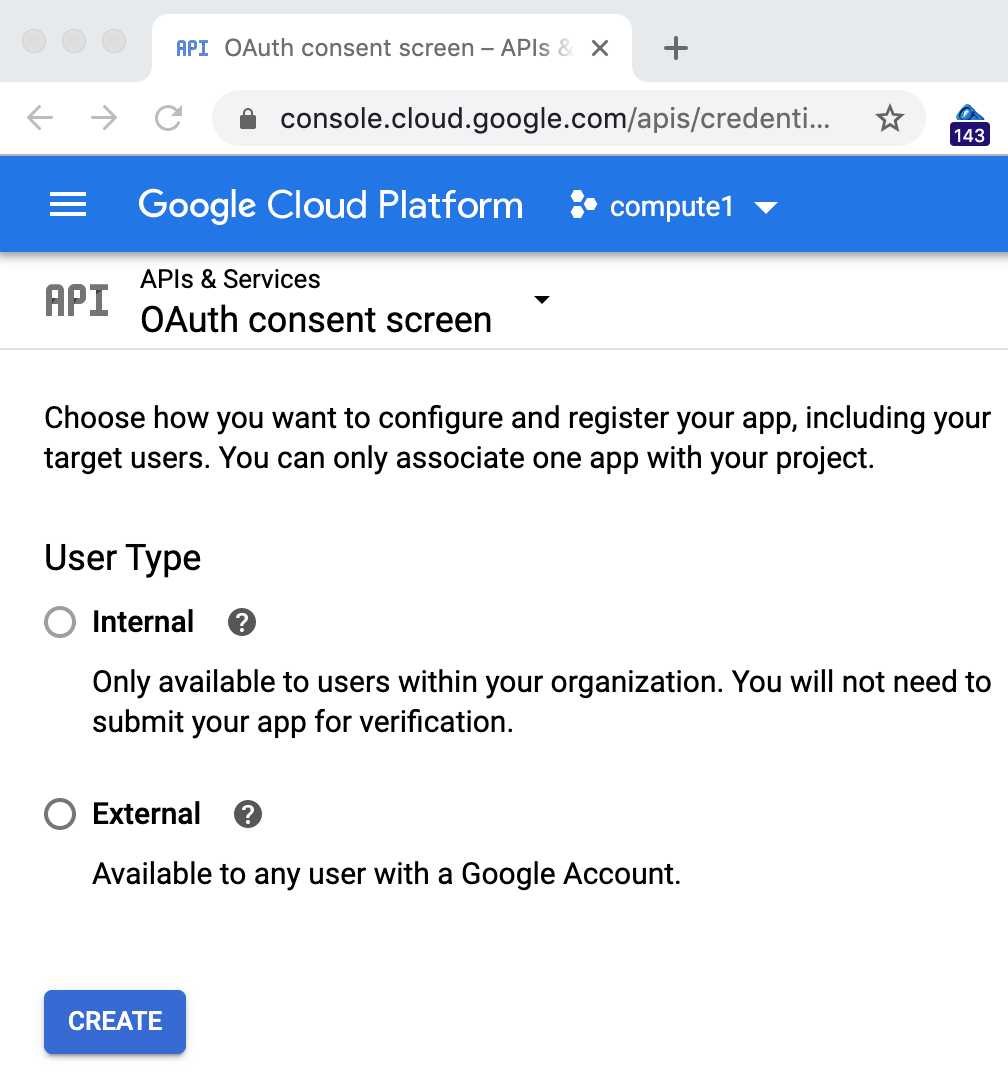
この演習では、コードラボのサンプルを公開しないため、どちらを選択してもかまいません。ほとんどの場合、[外部] を選択して複雑な画面に移動しますが、実際には、上部の「アプリケーション名」フィールドに入力するだけで済みます。
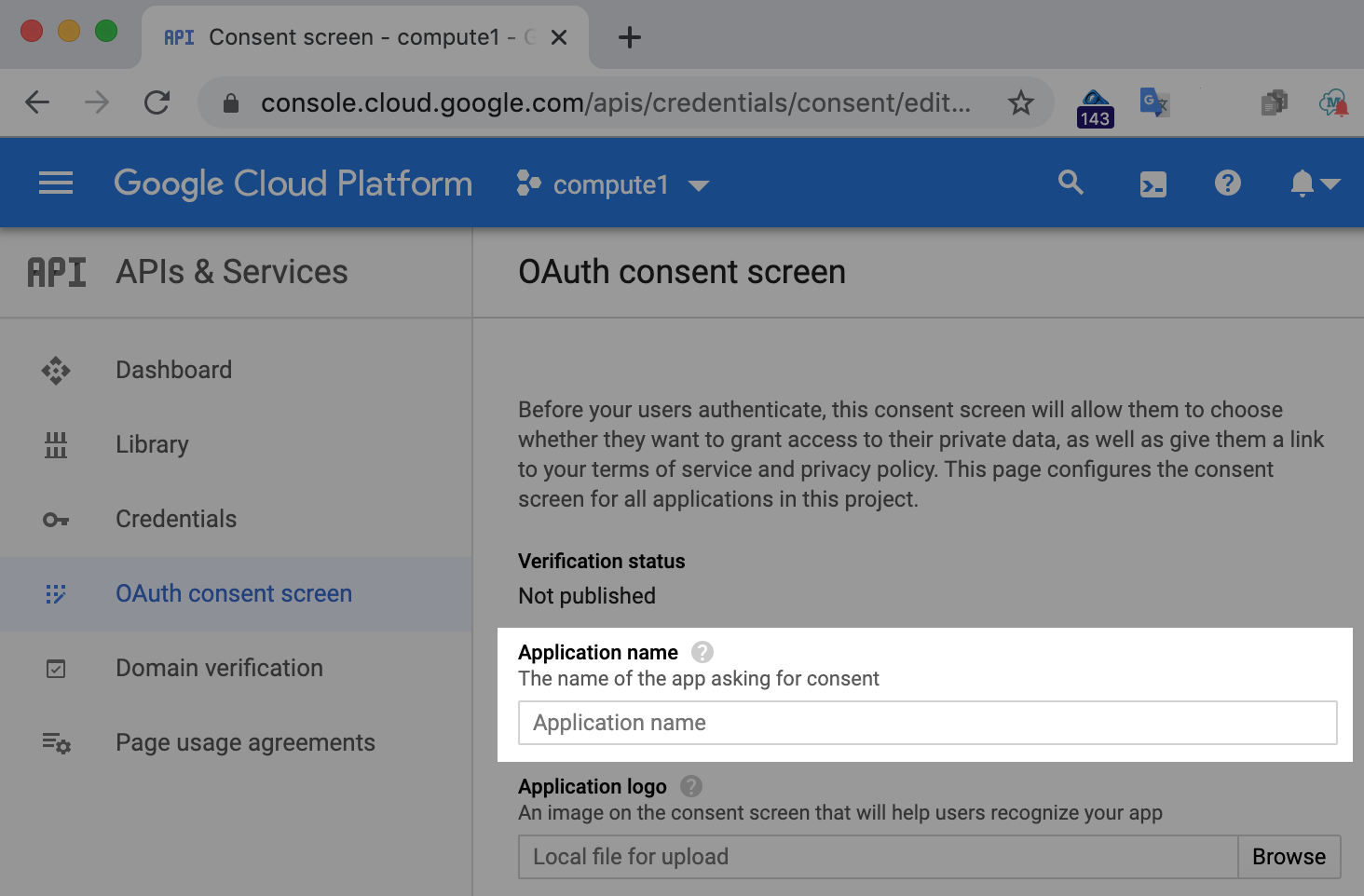
現時点で必要なのはアプリケーション名だけです。実行しているコードラボを反映する人を選択して、[保存] をクリックします。
OAuth クライアント ID(user acct auth)の作成
[認証情報] タブに戻って、OAuth2 クライアント ID を作成します。次のようなさまざまな OAuth クライアント ID を作成できます。
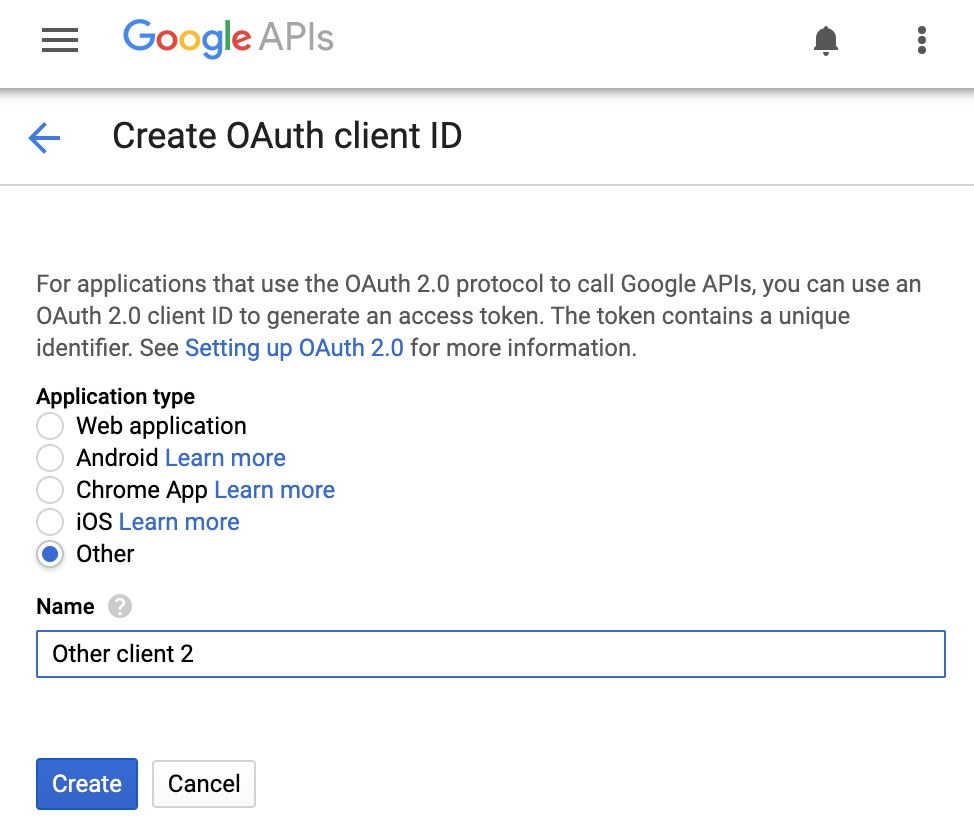
現在、Other というコマンドライン ツールを開発しているので、それを選択して、[作成] ボタンをクリックします。作成するアプリを反映したクライアント ID 名を選択するか、デフォルトの名前(通常は「Other client N」)を使用します。
認証情報の保存
- 新しい認証情報のダイアログが表示されます。[OK] をクリックして閉じます。

- [認証情報] ページに戻り、[OAuth2 クライアント ID] セクションまでスクロールして、新しく作成したクライアント ID の右下にあるダウンロード アイコン
をクリックします。
- ダイアログが開き、
client_secret-LONG-HASH-STRING.apps.googleusercontent.com.jsonという名前のファイルが通常であれば [ダウンロード] フォルダに保存されます。client_secret.json(サンプルアプリが使用する名前)のような簡単な名前に短縮してから、このコードラボでサンプルアプリを作成するディレクトリ / フォルダに保存することをおすすめします。

概要
これで、このコードラボで使用する Google API を有効にする準備が整いました。また、OAuth 同意画面のアプリケーション名として、「Vision API demo」を選択したので、以降のスクリーンショットでもこの名前が表示されます。
概要
このコードラボでは、4 つの Google Cloud API を使用します。1 つは GCP(Cloud Storage と Cloud Vision)のペア、もう 1 つは G Suite(Google ドライブと Google スプレッドシート)のペアです。Vision API のみを有効にする手順は以下のとおりです。1 つの API を有効にする方法を理解したら、自身で他の 3 つの API も有効にする必要があります。
Google API を使用するには、API を有効にする必要があります。以下の例は、Cloud Vision API を有効にするための方法を示しています。このコードラボでは 1 つ以上の API を使用しますが、同様の手順に従って使用前に有効にしてください。
Cloud Shell から
Cloud Shell で、次のコマンドを使用して API を有効にできます。
gcloud services enable vision.googleapis.com
Cloud Console から
API Manager で Vision API を有効にすることもできます。Cloud Console から API Manager に移動し、[ライブラリ] を選択します。

検索バーに「vision」と入力し、表示される Vision API を選択します。入力すると、次のようになります。

Cloud Vision API を選択して以下のダイアログを取得し、[有効にする] ボタンをクリックします。

料金
多くの Google API は無料でご利用いただけますが、GCP(プロダクトと API)の使用は有料です。(上記のように)Vision API を有効にすると、有効な請求先アカウントの入力を求められる場合があります。有効にする前に、Vision API の料金情報を確認してください。一部の Google Cloud Platform(GCP)プロダクトには、超過した場合のみに料金が発生する Always Free 枠が用意されています。このコードラボでは、Vision API のそれぞれの呼び出しが、その無料枠分に対してカウントされます。使用量の合計が上限(月ごと)を超えない限り、料金は発生しません。
一部の Google API(例: G Suite)は、月単位のサブスクリプションで利用されるため、Gmail、Google ドライブ、カレンダー、ドキュメント、スプレッドシート、スライドの API などの使用に伴う直接的な料金が発生することはありません。Google プロダクトごとに課金方法が異なるため、API ドキュメントで該当する情報を確認してください
概要
Cloud Vision が有効になったので、他の 3 つのAPI(Google ドライブ、Cloud Storage、Google スプレッドシート)を同じ方法(Cloud Shell、gcloud services enable、Cloud Console)で有効にします。
- API ライブラリに戻る
- 名前の最初の数文字を入力して検索を開始する
- 目的の API を選択する
- 有効にする
手順を繰り返します。Cloud Storage の場合、選択肢が複数あります。「Google Cloud Storage JSON API」を選択してください。Cloud Storage API には、有効な請求先アカウントも必要です。
これは中規模なコードの初めの部分です。メイン アプリケーションに取り組む前に、まずはアジャイルなプラクティスを実行し、通常の、安定して機能するインフラストラクチャを構築します。ダブルチェック client_secret.json は現在のディレクトリで利用できます。ipython を起動して次のコード スニペットを入力するか、analyze_gsimg.py に保存してシェルから実行します(コードサンプルには継続的に追加するため、後者をおすすめします)。
from __future__ import print_function
from googleapiclient import discovery, http
from httplib2 import Http
from oauth2client import file, client, tools
# process credentials for OAuth2 tokens
SCOPES = 'https://www.googleapis.com/auth/drive.readonly'
store = file.Storage('storage.json')
creds = store.get()
if not creds or creds.invalid:
flow = client.flow_from_clientsecrets('client_secret.json', SCOPES)
creds = tools.run_flow(flow, store)
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
このコア コンポーネントには、モジュール / パッケージ インポート、ユーザー承認認証情報の処理、API サービス エンドポイントの作成を行うためのコードブロックが含まれています。このコードで確認する必要のある重要な部分は以下のとおりです。
print()関数をインポートすると、このサンプルと Python 2 および 3 との互換性を確保できます。また、Google ライブラリをインポートすると、Google API との通信に必要なツールをすべて組み込めます。SCOPES変数は、ユーザーにリクエストする権限を表します。現時点では、Google ドライブからデータを読み取る権限のみがあります。- 認証情報処理コードの残りの部分は、キャッシュされた OAuth2 トークンを読み込みます。元のアクセス トークンの有効期限が切れている場合は、更新トークンを使用して新しいアクセス トークンに更新する場合があります。
- トークンが作成されていないか、別の理由で有効なアクセス トークンの取得に失敗した場合、ユーザーは OAuth2 3-legged フロー(3LO)を実行する必要があります(リクエストされた権限でダイアログを作成し、ユーザーに同意を求めます)。これを実行するとアプリは続行されます。それ以外の場合は
tools.run_flow()が例外をスローして実行を停止します。 - ユーザーが権限を付与すると、サーバーと通信するための HTTP クライアントが作成され、すべてのリクエストがセキュリティのためにユーザーの認証情報で署名されるようになります。次に、Google Drive API(バージョン3)へのサービス エンドポイントがその HTTP クライアントで作成され、
DRIVEに割り当てられます。
アプリケーションの実行
スクリプトを初めて実行する場合、(自分の)ドライブ上にあるファイルにアクセスする権限は付与されていません。実行が一時停止されると、出力は次のようになります。
$ python3 ./analyze_gsimg.py
/usr/local/lib/python3.6/site-packages/oauth2client/_helpers.py:255: UserWarning: Cannot access storage.json: No such file or directory
warnings.warn(_MISSING_FILE_MESSAGE.format(filename))
Your browser has been opened to visit:
https://accounts.google.com/o/oauth2/auth?client_id=LONG-STRING.apps.googleusercontent.com&redirect_uri=http%3A%2F%2Flocalhost%3A8080%2F&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive.readonly&access_type=offline&response_type=code
If your browser is on a different machine then exit and re-run this
application with the command-line parameter
--noauth_local_webserver
Cloud Shell から実行している場合は、「Cloud Shell から」セクションにスキップし、必要に応じて「ローカル開発環境から」の関連する画面を確認します。
ローカル開発環境から
ブラウザ ウィンドウを開くと、コマンドライン スクリプトが一時停止されます。次のような、恐ろしい見た目の警告ページが表示される場合があります。

ユーザーデータにアクセスするアプリを実行するわけですので、これはもっともな懸念事項です。これは単なるデモアプリであり、またあなたがデベロッパーであるため、特に気にすることなく実行できるはずです。これを理解するためには、ユーザーの立場に立つ必要があります。つまり、他の誰かのコードがあなたのデータにアクセスすることを許可するように求められています。このようなアプリを公開する場合は、確認プロセスを実行して、ユーザーにこの画面が表示されないようにします。
「安全でないアプリに移動」のリンクをクリックすると、次のような OAuth2 権限ダイアログが表示されます。ユーザー インターフェースは常に改善されているため、ダイアログがこれと完全に一致しないとしても心配する必要はありません。

OAuth2 フロー ダイアログは、デベロッパーが(SCOPES 変数を介して)リクエストしている権限を反映します。この場合、これはユーザーの Google ドライブから表示およびダウンロードする機能です。アプリケーション コードでは、これらの権限スコープは URI として表示されますが、ユーザーのロケールで指定された言語に翻訳されます。ここで、ユーザーはリクエストされた権限に対して明示的な認可を与える必要があります。そうしないと、例外がスローされ、スクリプトはそれ以上続行されません。
確認を求めるダイアログがもう 1 つ表示される場合もあります。

注: 異なるアカウントにログインしている複数のウェブブラウザを使用する場合もあるため、この承認リクエストで不適切なブラウザタブ / ウィンドウに移動する可能性があります。その場合、適切なアカウントでログインしているブラウザに、このリクエストのリンクをカット アンド ペーストする必要がある場合があります。
Cloud Shell から
Cloud Shell では、ブラウザ ウィンドウがポップアップせず、スタックしたままになります。下部にある診断メッセージはあなた専用のメッセージであり、次のようになっています。
If your browser is on a different machine then exit and re-run this application with the command-line parameter --noauth_local_webserver
最初に ⌘C(Ctrl-C または他のキーを押してスクリプトの実行を停止)を押して、シェルから追加フラグを指定して実行します。この方法で実行すると、代わりに次の出力が得られます。
$ python3 analyze_gsimg.py --noauth_local_webserver
/usr/local/lib/python3.7/site-packages/oauth2client/_helpers.py:255: UserWarning: Cannot access storage.json: No such file or directory
warnings.warn(_MISSING_FILE_MESSAGE.format(filename))
Go to the following link in your browser:
https://accounts.google.com/o/oauth2/auth?client_id=LONG-STRING.apps.googleusercontent.com&redirect_uri=urn%3Aietf%3Awg%3Aoauth%3A2.0%3Aoob&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive.readonly&access_type=offline&response_type=code
Enter verification code:
(storage.json はまだ作成されていないことがわかっているため、警告は無視します。)この URL を使用して別のブラウザタブの指示に従うと、ローカル開発環境に関して上記で説明したものとほぼ同じ結果が得られます(上記のスクリーンショットを参照)。最後に、Cloud Shell に入力する確認コードが記載された最終画面が 1 つ表示されます。

このコードをコピーしてターミナル ウィンドウに貼り付けます。
概要
「Authentication successful」以外の出力を期待しないでください。これは単なるセットアップであり、まだ何もしていません。ここまででしたことは、初めて適切に実行される可能性が高いものを開始する準備を正常にしただけです。(最良の部分は、承認のプロンプトが 1 回だけ表示されることです。承認がキャッシュされているため、後続のすべての実行では承認がスキップされます。)それでは、実際の出力を生成する、実際の作業をコードに実行させましょう。
トラブルシューティング
出力が表示されずにエラーが表示された場合は、次のような原因が考えられます。
前のステップで、コードを analyze_gsimg.py として作成し、そこから編集することをおすすめします。すべてを直接 iPython または標準の Python シェルにカット アンド ペーストすることもできますが、アプリを 1 つずつ作成し続けることになるため、面倒です。
アプリが認可され、API サービス エンドポイントが作成されていると想定します。コード内では、DRIVE 変数で表されます。次に、Google ドライブで画像ファイルを見つけて、
NAME という名前の変数に設定します。これを入力して、手順 0 のコードのすぐ下に次の drive_get_img() 関数を入力します。
FILE = 'YOUR_IMG_ON_DRIVE' # fill-in with name of your Drive file
def drive_get_img(fname):
'download file from Drive and return file info & binary if found'
# search for file on Google Drive
rsp = DRIVE.files().list(q="name='%s'" % fname,
fields='files(id,name,mimeType,modifiedTime)'
).execute().get('files', [])
# download binary & return file info if found, else return None
if rsp:
target = rsp[0] # use first matching file
fileId = target['id']
fname = target['name']
mtype = target['mimeType']
binary = DRIVE.files().get_media(fileId=fileId).execute()
return fname, mtype, target['modifiedTime'], binary
ドライブの files() コレクションには、指定したファイルのクエリ(q パラメータ)を行う list() メソッドがあります。fields パラメータは、関心のある戻り値を指定するために使用されます。他の値を気にしないのに、なぜすべてを元に戻し、速度を落とすのでしょうか。API 戻り値をフィルタするためのフィールド マスクを初めてご利用になる場合は、こちらのブログ投稿と動画をご覧ください。そうでない場合は、クエリを実行し、返された files 属性を取得します。一致するものがない場合は、デフォルトで空のリスト配列になります。
結果がない場合は、関数の残りの部分はスキップされ、暗黙的に None が返されます。それ以外の場合は、最初に一致するレスポンス(rsp[0])を取得し、ファイル名、MIME タイプ、最終変更タイムスタンプを返し、最後に、get_media() 関数によって(ファイル ID を介して)取得されたバイナリ ペイロードを files() コレクションに返します。(メソッド名は、他の言語のクライアント ライブラリと多少異なる場合があります)。
最後は、アプリケーション全体を駆動する「本体」についてです。
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
else:
print('ERROR: Cannot download %r from Drive' % fname)
ドライブに section-work-card-img_2x.jpg という名前の画像があり、FILE に設定されているとします。スクリプトが正常に実行されると、ドライブからファイルを読み取れたことを確認できる出力が表示されます(パソコンには保存されません)。
$ python3 analyze_gsimg.py Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
トラブルシューティング
上記のような正常な出力が得られない場合は、次のような原因が考えられます。
概要
このセクションでは、特定のファイルをクエリしてダウンロードする Drive API に(2 つの別々の API 呼び出しで)接続する方法を学習しました。ビジネス ユースケース: ドライブのデータをアーカイブし、GCP ツールなどで分析できます。この段階でのアプリのコードは、step1-drive/analyze_gsimg.py のリポジトリの内容と一致する必要があります。
Google ドライブのファイルのダウンロードについて詳しくは、こちら、または、こちらのブログ投稿と動画をご覧ください。コードラボのこの部分は、G Suite API の概要コードラボとほぼ同じです(ファイルをダウンロードする代わりに、ユーザーの Google ドライブにある最初の 100 個のファイル / フォルダを表示し、より制限されたスコープを使用します)。
次のステップでは、Google Cloud Storage のサポートを追加します。これを行うには、別の Python パッケージ io をインポートする必要があります。インポートの上部が次のようになっていることを確認します。
from __future__ import print_function
import io
ドライブのファイル名に加えて、このファイルを Cloud Storage のどこに保存するか、具体的には、ファイルを保存する「バケット」の名前と「親フォルダ」のプレフィックスに関する情報が必要です(これについてはすぐに詳しく説明します)。
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
バケットについて一言。Cloud Storage は、アモルファス blob ストレージを提供します。ファイルがアップロードされたときに、Cloud Storage は Google ドライブのようにファイル タイプや拡張子などのコンセプトを理解できません。これらは Cloud Storage の「blob」にすぎません。また、Cloud Storage にはフォルダやサブディレクトリの考え方はありません。
はい、複数のサブフォルダの抽象化を表すためにファイル名にスラッシュ(/)を含めることができますが、すべての blob は最終的にバケットに入るため、「/」はファイル名の単なる文字になります。詳しくは、バケットとオブジェクトの命名規則についてのページをご覧ください。
上記の手順 1 では、ドライブの読み取り専用スコープをリクエストしました。現時点で必要なものは以上です。ここで、Cloud Storage へのアップロード(読み取り / 書き込み)権限が必要です。SCOPES を単一の文字列変数から権限スコープの配列(Python タプル [またはリスト])に変更して、次のようにします。
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
)
次に、ドライブ用のサービス エンドポイントのすぐ下に Cloud Storage へのサービス エンドポイントを作成します。同じ HTTP クライアント オブジェクトを再利用するように呼び出しを少し変更しています。これは、共有リソースにできる場合は新しいオブジェクトを作成する必要がないためです。
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
次に、Cloud Storage にアップロードするこの関数(drive_get_img() の後)を追加します。
def gcs_blob_upload(fname, bucket, media, mimetype):
'upload an object to a Google Cloud Storage bucket'
# build blob metadata and upload via GCS API
body = {'name': fname, 'uploadType': 'multipart', 'contentType': mimetype}
return GCS.objects().insert(bucket=bucket, body=body,
media_body=http.MediaIoBaseUpload(io.BytesIO(media), mimetype),
fields='bucket,name').execute()
objects.().insert() の呼び出しでは、バケット名、ファイル メタデータ、バイナリ blob 自体が必要です。戻り値を除外するために、fields 変数は API から返されたバケット名とオブジェクト名のみをリクエストします。API 読み取りリクエストでのフィールド マスクの詳細については、こちらの投稿と動画をご覧ください。
次に gcs_blob_upload() の使用をメイン アプリケーションに統合します。
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
gcsname 変数は、ファイル名自体が追加された「親サブディレクトリ」名をマージします。バケット名をプレフィックスとして付けると、ファイルを「/bucket/parent.../filename」にアーカイブしているような印象を与えます。else 句のすぐ上にある最初の print() 関数の直後にこのチャンクを挿入して、「メイン」が次のようになるようにします。
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
else:
print('ERROR: Cannot download %r from Drive' % fname)
「親サブディレクトリ」として「analyzed_imgs」を使用して、「vision-demo」という名前のバケットを指定するとします。これらの変数を設定してスクリプトをもう一度実行すると、section-work-card-img_2x.jpg がドライブからダウンロードされ、その後 Cloud Storage にアップロードされますか?違います!
$ python3 analyze_gsimg.py
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Traceback (most recent call last):
File "analyze_gsimg.py", line 85, in <module>
io.BytesIO(data), mimetype=mtype), mtype)
File "analyze_gsimg.py", line 72, in gcs_blob_upload
media_body=media, fields='bucket,name').execute()
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/googleapiclient/_helpers.py", line 134, in positional_wrapper
return wrapped(*args, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/googleapiclient/http.py", line 898, in execute
raise HttpError(resp, content, uri=self.uri)
googleapiclient.errors.HttpError: <HttpError 403 when requesting https://storage.googleapis.com/upload/storage/v1/b/PROJECT_ID/o?fields=bucket%2Cname&alt=json&uploadType=multipart returned "Insufficient Permission">
よく見ると、ドライブのダウンロードは成功していますが、Cloud Storage へのアップロードが失敗しています。それはなぜでしょうか?
これは、手順 1 でこのアプリケーションを認可したとき、Google ドライブへの読み取り専用権限のみを付与したためです。Cloud Storage に対する読み取り / 書き込みスコープを追加していますが、ユーザーにそのアクセスを承認することを要求してはいません。これを機能させるには、このスコープが欠落している storage.json ファイルを完全に削除して、再実行する必要があります。
再承認した後(storage.json の内部を調べて両方のスコープを確認して、これを確認します)、出力は期待どおりになります。
$ python3 analyze_gsimg.py
. . .
Authentication successful.
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Uploaded 'analyzed_imgs/section-work-card-img_2x.jpg' to GCS bucket 'vision-demo'
概要
これは重要な作業です。数行のコードで、クラウドベースのストレージ システム間でファイルを転送する方法を説明します。ここでのビジネス ユースケースは、制約のある可能性のあるリソースを、前述のように安価な「コールド」ストレージにバックアップすることです。Cloud Storage は、データにアクセスする頻度(定期的、毎月、四半期ごと、毎年)に応じて選べる、さまざまなストレージ クラスを用意しています。
Google ドライブと Cloud Storage の両方が存在する理由を質問されることはよくあります(結局のところ、どちらもクラウド内のファイルストレージですよね?)。そこで、こちらの動画を用意しました。この段階でのコードは、step2-gcs/analyze_gsimg.py のリポジトリの内容と一致する必要があります。
GCP と G Suite 間でデータを移動できるようになりましたが、まだ分析は行っていません。そこで、ラベル アノテーション(オブジェクト検出)のための画像を Cloud Vision に送信します。これを行うには、データを Base64 でエンコードする必要があります。つまり、別の Python モジュール base64 を使用する必要があります。上部のインポート セクションが次のようになっていることを確認します。
from __future__ import print_function
import base64
import io
デフォルトでは、Vision API は検出したすべてのラベルを返します。一貫性を保つために、上位の 5 つのみをリクエストするようにします(もちろん、ユーザーが調整できます)。これを行うために、定数変数 TOP を使用します。他のすべての定数の下に、これを追加します。
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
TOP = 5 # TOP # of VISION LABELS TO SAVE
前の手順と同様に、別の権限スコープが必要です(ここでは Vision API)。its 文字列で SCOPES を更新します。
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
'https://www.googleapis.com/auth/cloud-vision',
)
ここでは、Cloud Vision へのサービス エンドポイントを作成し、次のように他のエンドポイントと整列させます。
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
VISION = discovery.build('vision', 'v1', http=HTTP)
次に、画像ペイロードを Cloud Vision に送信する次の関数を追加します。
def vision_label_img(img, top):
'send image to Vision API for label annotation'
# build image metadata and call Vision API to process
body = {'requests': [{
'image': {'content': img},
'features': [{'type': 'LABEL_DETECTION', 'maxResults': top}],
}]}
rsp = VISION.images().annotate(body=body).execute().get('responses', [{}])[0]
# return top labels for image as CSV for Sheet (row)
if 'labelAnnotations' in rsp:
return ', '.join('(%.2f%%) %s' % (
label['score']*100., label['description']) \
for label in rsp['labelAnnotations'])
images().annotate() 呼び出しには、データと適切な API 機能が必要です。上位 5 つのラベルキャップもペイロードの一部です(ただし、完全にオプションです)。呼び出しが成功すると、ペイロードはオブジェクトのラベル上位 5 つと、オブジェクトが画像内に存在するかに関する信頼度スコアを返します。(レスポンスがない場合は、次の if ステートメントが失敗しないように、空の Python 辞書を割り当てます)。この関数は、レポートで最終的に使用するために、そのデータを CSV 文字列に単純に照合します。
vision_label_img() を呼び出す次の 5 行は、Cloud Storage へのアップロードが成功した直後に配置する必要があります。
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'), TOP)
if rsp:
print('Top %d labels from Vision API: %s' % (TOP, rsp))
else:
print('ERROR: Vision API cannot analyze %r' % fname)
これを追加すると、メインドライバ全体が次のようになります。
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'), TOP)
if rsp:
print('Top %d labels from Vision API: %s' % (TOP, rsp))
else:
print('ERROR: Vision API cannot analyze %r' % fname)
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
else:
print('ERROR: Cannot download %r from Drive' % fname)
storage.json を削除してスコープを更新し、更新されたアプリケーションを再実行すると、次のような出力が得られます(Cloud Vision 分析が追加されています)。
$ python3 analyze_gsimg.py
. . .
Authentication successful.
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Uploaded 'analyzed_imgs/section-work-card-img_2x.jpg' to GCS bucket 'vision-demo'
Top 5 labels from Vision API: (89.94%) Sitting, (86.09%) Interior design, (82.08%) Furniture, (81.52%) Table, (80.85%) Room
概要
独自の ML モデルを作成してトレーニングし、データを分析するための機械学習の専門知識を誰もが持っているわけではありません。Google Cloud チームは、Google の事前トレーニング済みモデルの一部を一般的な使用で利用できるようにし、それらを API の背後に配置することで、あらゆるユーザーが AI と ML を利用できるようにしています。
API を呼び出すことができるデベロッパーの方は、機械学習を使用できます。Cloud Vision は、データの分析に使用できる API サービスの 1 つにすぎません。詳しくは、こちらをご覧ください。コードは step3-vision/analyze_gsimg.py のリポジトリの内容と一致する必要があります。
この時点で、企業データをアーカイブして分析することができましたが、この作業をまとめることがまだできていません。すべての結果を、上司に提出できる 1 つのレポートにまとめましょう。経営陣を説得できる、スプレッドシートよりも説得力の高いものはなんでしょうか?
Google Sheets API に追加のインポートは必要ありません。必要な新しい情報は、フォーマット済みで、新しいデータ行を受け入れる準備ができた、既存のスプレッドシートのファイル ID(SHEET 定数)のみです。次のような新しいスプレッドシートを作成することをおすすめします。

このスプレッドシートの URL は次のようになります: https://docs.google.com/spreadsheets/d/FILE_ID/edit。この FILE_ID を取得し、SHEET への文字列として割り当てます。
また、k_ize() と呼ばれる小さな関数で、バイトをキロバイトに変換し、それを Python lambda として簡単に定義しています。これらは両方とも他の定数と統合されており、次のようになります。
k_ize = lambda b: '%6.2fK' % (b/1000.) # bytes to kBs
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
SHEET = 'YOUR_SHEET_ID'
TOP = 5 # TOP # of VISION LABELS TO SAVE
前の手順と同様に、別の権限スコープが必要です(ここでは Sheets API の読み取り / 書き込み)。これで、SCOPES に必要な 4 つすべてが付与されました。
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
'https://www.googleapis.com/auth/cloud-vision',
'https://www.googleapis.com/auth/spreadsheets',
)
次に、Google スプレッドシートへのサービス エンドポイントを作成します。たとえば、次のようになります。
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
VISION = discovery.build('vision', 'v1', http=HTTP)
SHEETS = discovery.build('sheets', 'v4', http=HTTP)
sheet_append_row() の機能は単純です。データ行とシート ID を取得し、その行を that シートに追加します。
def sheet_append_row(sheet, row):
'append row to a Google Sheet, return #cells added'
# call Sheets API to write row to Sheet (via its ID)
rsp = SHEETS.spreadsheets().values().append(
spreadsheetId=sheet, range='Sheet1',
valueInputOption='USER_ENTERED', body={'values': [row]}
).execute()
if rsp:
return rsp.get('updates').get('updatedCells')
spreadsheets().values().append() の呼び出しには、スプレッドシートのファイル ID、セル範囲、データの入力方法、データ自体が必要です。ファイル ID は単純です。セルの範囲は A1 表記で指定します。範囲「Sheet1」はスプレッドシート全体を意味します。これは、スプレッドシート内のすべてのデータの後に行を追加するように API に指示します。スプレッドシートにデータを追加する方法には、「RAW」(文字列データを逐語的に入力)と「USER_ENTERED」(セルの書式設定を保持しつつ、ユーザーが Google スプレッドシート アプリケーションを使用して、キーボードでデータを入力したかのようにデータを書き込む)の 2 つがあります。
呼び出しが成功した場合、戻り値には実際にはあまり有用なものがないため、API リクエストで更新されたセルの数を取得するようにしました。この関数を呼び出すコードは、次のとおりです。
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [PARENT,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
BUCKET, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(SHEET, row)
if rsp:
print('Updated %d cells in Google Sheet' % rsp)
else:
print('ERROR: Cannot write row to Google Sheets')
Google スプレッドシートには、親の「サブディレクトリ」、Cloud Storage でファイルがアーカイブされた場所(バケット + ファイル名)、ファイルの MIME タイプ、ファイルサイズ(元はバイト単位だが、k_ize() でキロバイトに変換されます)、Cloud Vision のラベル文字列などのデータを表す列があります。また、アーカイブされた場所はハイパーリンクであるため、マネージャーはクリックして安全にバックアップされたことを確認できます。
Cloud Vision の結果を表示した直後に上記のコードブロックを追加すると、構造的に少し複雑ですが、アプリを駆動する主要部分が完成します。
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'))
if rsp:
print('Top %d labels from Vision API: %s' % (TOP, rsp))
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [PARENT,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
BUCKET, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(SHEET, row)
if rsp:
print('Updated %d cells in Google Sheet' % rsp)
else:
print('ERROR: Cannot write row to Google Sheets')
else:
print('ERROR: Vision API cannot analyze %r' % fname)
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
else:
print('ERROR: Cannot download %r from Drive' % fname)
もう一度 storage.json を削除して、更新されたアプリケーションを再実行すると、次のような出力が得られます(Cloud Vision 分析が追加されています)。
$ python3 analyze_gsimg.py
. . .
Authentication successful.
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Uploaded 'analyzed_imgs/section-work-card-img_2x.jpg' to GCS bucket 'vision-demo'
Top 5 labels from Vision API: (89.94%) Sitting, (86.09%) Interior design, (82.08%) Furniture, (81.52%) Table, (80.85%) Room
Updated 6 cells in Google Sheet
出力の追加行も便利ですが、更新された Google スプレッドシートを見てみると、よりよく可視化されていることがわかります。前に追加された既存のデータセットに、最後の行(以下の例では行 7)が追加されています。

概要
このチュートリアルの最初の 3 つのステップでは、G Suite と GCP API に接続してデータを移動し、分析しました。これは、すべての作業の 80% に相当します。ですが、これまでに達成したすべてのことを経営陣に提示できなければ、何の意味もありません。結果を可視化して、すべての結果を 1 つのレポートにまとめれば、説得力も上がります。
分析の有用性をさらに高めるために、結果をスプレッドシートに書き込むことに加えて、各画像に付与された上位 5 つのラベルにインデックスを付けることもできます。これにより、許可された従業員が検索で画像を照会できるようにする内部データベースを構築できますが、これについては読者向けの演習として残しておきます。
これで、結果はスプレッドシートにあり、経営陣がアクセスできるようになりました。この段階でのアプリのコードは、step4-sheets/analyze_gsimg.py のリポジトリの内容と一致する必要があります。最後のステップとして、コードをクリーンアップし、それを使用可能なスクリプトに変換します。
(省略可)アプリは正常に動作しますが、改善点はあるでしょうか?はい、特に、ごちゃごちゃと混乱しているようにみえるメイン アプリケーションに関してです。これを独自の関数に入れて、固定定数ではなくユーザー入力を可能にするようにします。これを行うために、argparse モジュールを使用します。また、データ行がスプレッドシートに書き込まれたら、ウェブブラウザ タブを開いてスプレッドシートを表示するようにします。これは、webbrowser モジュールを使用して行えます。これらのインポートを他のインポートと織り合わせて、上位のインポートが次のようになるようにします。
from __future__ import print_function
import argparse
import base64
import io
import webbrowser
このコードを他のアプリケーションで使用できるようにするには、出力を抑制する機能が必要です。そのために、DEBUG フラグを追加して、上部近くの定数セクションの最後にこの行を追加します。
DEBUG = False
次に、本体についてです。このサンプルを作成する際、コードでサービスを追加するたびに別のレベルのネストを追加するため、「不快」に感じたはずです。このように感じても、問題ありません。この Google Testing Blog の投稿で説明されているように、コードが複雑になることはよくあります。
このベスト プラクティスに従って、アプリの主要部分を関数に再編成し、ネストする代わりに各「ブレークポイント」で return します(いずれかのステップが失敗した場合は None を返し、すべてが成功した場合は True を返します)。
def main(fname, bucket, sheet_id, folder, top, debug):
'"main()" drives process from image download through report generation'
# download img file & info from Drive
rsp = drive_get_img(fname)
if not rsp:
return
fname, mtype, ftime, data = rsp
if debug:
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (folder, fname)
rsp = gcs_blob_upload(gcsname, bucket, data, mtype)
if not rsp:
return
if debug:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'))
if not rsp:
return
if debug:
print('Top %d labels from Vision API: %s' % (top, rsp))
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [folder,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
bucket, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(sheet_id, row)
if not rsp:
return
if debug:
print('Added %d cells to Google Sheet' % rsp)
return True
これはよりすっきりとしていて、上述したコードの複雑さを軽減するとともに、再帰的な if-else チェーンの感覚を残しています。パズルの最後のピースは、「実際の」メインドライバを作成し、ユーザーのカスタマイズを可能にし、出力を最小限に抑えることです(必要な場合を除く)。
if __name__ == '__main__':
# args: [-hv] [-i imgfile] [-b bucket] [-f folder] [-s Sheet ID] [-t top labels]
parser = argparse.ArgumentParser()
parser.add_argument("-i", "--imgfile", action="store_true",
default=FILE, help="image file filename")
parser.add_argument("-b", "--bucket_id", action="store_true",
default=BUCKET, help="Google Cloud Storage bucket name")
parser.add_argument("-f", "--folder", action="store_true",
default=PARENT, help="Google Cloud Storage image folder")
parser.add_argument("-s", "--sheet_id", action="store_true",
default=SHEET, help="Google Sheet Drive file ID (44-char str)")
parser.add_argument("-t", "--viz_top", action="store_true",
default=TOP, help="return top N (default %d) Vision API labels" % TOP)
parser.add_argument("-v", "--verbose", action="store_true",
default=DEBUG, help="verbose display output")
args = parser.parse_args()
print('Processing file %r... please wait' % args.imgfile)
rsp = main(args.imgfile, args.bucket_id,
args.sheet_id, args.folder, args.viz_top, args.verbose)
if rsp:
sheet_url = 'https://docs.google.com/spreadsheets/d/%s/edit' % args.sheet_id
print('DONE: opening web browser to it, or see %s' % sheet_url)
webbrowser.open(sheet_url, new=1, autoraise=True)
else:
print('ERROR: could not process %r' % args.imgfile)
すべての手順が成功すると、スクリプトは、新しいデータ行が追加された場所で指定されたスプレッドシートに対してウェブブラウザを起動します。
概要
スコープの変更が行われていないため、storage.json を削除する必要はありません。更新されたアプリケーションを再実行すると、変更されスプレッドシートに対して開かれた新しいブラウザ ウィンドウが表示され、出力行が少なくなります。-h オプションを発行すると、以前に表示された現在抑制されている出力行を復元するための -v などのオプションがユーザーに表示されます。
$ python3 analyze_gsimg.py Processing file 'section-work-card-img_2x.jpg'... please wait DONE: opening web browser to it, or see https://docs.google.com/spreadsheets/d/SHEET_ID/edit $ python3 analyze_gsimg.py -h usage: analyze_gsimg.py [-h] [-i] [-t] [-f] [-b] [-s] [-v] optional arguments: -h, --help show this help message and exit -i, --imgfile image file filename -t, --viz_top return top N (default 5) Vision API labels -f, --folder Google Cloud Storage image folder -b, --bucket_id Google Cloud Storage bucket name -s, --sheet_id Google Sheet Drive file ID (44-char str) -v, --verbose verbose display output
他のオプションを使用すると、ユーザーはさまざまなドライブ ファイル名、Cloud Storage の「サブディレクトリ」とバケット名、Cloud Vision の上位「N」個の結果、スプレッドシートのシートファイル ID を選択できます。これらの最後の更新で、コードの最終バージョンは、リポジトリの final/analyze_gsimg.py とここにあるものと完全に一致するはずです。
## Copyright 2020 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
'''
analyze_gsimg.py - analyze G Suite image processing workflow
Download image from Google Drive, archive to Google Cloud Storage, send
to Google Cloud Vision for processing, add results row to Google Sheet.
'''
from __future__ import print_function
import argparse
import base64
import io
import webbrowser
from googleapiclient import discovery, http
from httplib2 import Http
from oauth2client import file, client, tools
k_ize = lambda b: '%6.2fK' % (b/1000.) # bytes to kBs
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
SHEET = 'YOUR_SHEET_ID'
TOP = 5 # TOP # of VISION LABELS TO SAVE
DEBUG = False
# process credentials for OAuth2 tokens
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
'https://www.googleapis.com/auth/cloud-vision',
'https://www.googleapis.com/auth/spreadsheets',
)
store = file.Storage('storage.json')
creds = store.get()
if not creds or creds.invalid:
flow = client.flow_from_clientsecrets('client_secret.json', SCOPES)
creds = tools.run_flow(flow, store)
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
VISION = discovery.build('vision', 'v1', http=HTTP)
SHEETS = discovery.build('sheets', 'v4', http=HTTP)
def drive_get_img(fname):
'download file from Drive and return file info & binary if found'
# search for file on Google Drive
rsp = DRIVE.files().list(q="name='%s'" % fname,
fields='files(id,name,mimeType,modifiedTime)'
).execute().get('files', [])
# download binary & return file info if found, else return None
if rsp:
target = rsp[0] # use first matching file
fileId = target['id']
fname = target['name']
mtype = target['mimeType']
binary = DRIVE.files().get_media(fileId=fileId).execute()
return fname, mtype, target['modifiedTime'], binary
def gcs_blob_upload(fname, bucket, media, mimetype):
'upload an object to a Google Cloud Storage bucket'
# build blob metadata and upload via GCS API
body = {'name': fname, 'uploadType': 'multipart', 'contentType': mimetype}
return GCS.objects().insert(bucket=bucket, body=body,
media_body=http.MediaIoBaseUpload(io.BytesIO(media), mimetype),
fields='bucket,name').execute()
def vision_label_img(img, top):
'send image to Vision API for label annotation'
# build image metadata and call Vision API to process
body = {'requests': [{
'image': {'content': img},
'features': [{'type': 'LABEL_DETECTION', 'maxResults': top}],
}]}
rsp = VISION.images().annotate(body=body).execute().get('responses', [{}])[0]
# return top labels for image as CSV for Sheet (row)
if 'labelAnnotations' in rsp:
return ', '.join('(%.2f%%) %s' % (
label['score']*100., label['description']) \
for label in rsp['labelAnnotations'])
def sheet_append_row(sheet, row):
'append row to a Google Sheet, return #cells added'
# call Sheets API to write row to Sheet (via its ID)
rsp = SHEETS.spreadsheets().values().append(
spreadsheetId=sheet, range='Sheet1',
valueInputOption='USER_ENTERED', body={'values': [row]}
).execute()
if rsp:
return rsp.get('updates').get('updatedCells')
def main(fname, bucket, sheet_id, folder, top, debug):
'"main()" drives process from image download through report generation'
# download img file & info from Drive
rsp = drive_get_img(fname)
if not rsp:
return
fname, mtype, ftime, data = rsp
if debug:
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (folder, fname)
rsp = gcs_blob_upload(gcsname, bucket, data, mtype)
if not rsp:
return
if debug:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'), top)
if not rsp:
return
if debug:
print('Top %d labels from Vision API: %s' % (top, rsp))
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [folder,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
bucket, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(sheet_id, row)
if not rsp:
return
if debug:
print('Added %d cells to Google Sheet' % rsp)
return True
if __name__ == '__main__':
# args: [-hv] [-i imgfile] [-b bucket] [-f folder] [-s Sheet ID] [-t top labels]
parser = argparse.ArgumentParser()
parser.add_argument("-i", "--imgfile", action="store_true",
default=FILE, help="image file filename")
parser.add_argument("-b", "--bucket_id", action="store_true",
default=BUCKET, help="Google Cloud Storage bucket name")
parser.add_argument("-f", "--folder", action="store_true",
default=PARENT, help="Google Cloud Storage image folder")
parser.add_argument("-s", "--sheet_id", action="store_true",
default=SHEET, help="Google Sheet Drive file ID (44-char str)")
parser.add_argument("-t", "--viz_top", action="store_true",
default=TOP, help="return top N (default %d) Vision API labels" % TOP)
parser.add_argument("-v", "--verbose", action="store_true",
default=DEBUG, help="verbose display output")
args = parser.parse_args()
print('Processing file %r... please wait' % args.imgfile)
rsp = main(args.imgfile, args.bucket_id,
args.sheet_id, args.folder, args.viz_top, args.verbose)
if rsp:
sheet_url = 'https://docs.google.com/spreadsheets/d/%s/edit' % args.sheet_id
print('DONE: opening web browser to it, or see %s' % sheet_url)
webbrowser.open(sheet_url, new=1, autoraise=True)
else:
print('ERROR: could not process %r' % args.imgfile)
このチュートリアルの内容を最新の状態に保つために、Google はあらゆる努力を行いますが、リポジトリに最新バージョンのコードが含まれる可能性もあります。
このコードラボでは多くのことを学びました。これは、長いコードラボを完了できたために達成したものです。結果として、およそ 130 行の Python を使用して、想定されるエンタープライズ シナリオに取り組み、すべての Google Cloud(GCP と G Suite)を活用し、その間でデータを移動して、有用なソリューションを構築しました。このアプリのすべてのバージョンのオープンソース リポジトリをぜひご覧ください(詳細は以下を参照)。
クリーンアップ
- GCP API の使用は無料ではありませんが、G Suite API は、G Suite の月額サブスクリプション料金か、Gmail コンシューマー ユーザーの月額料金でカバーされるため、G Suite ユーザーであれば、API のクリーンアップ / ターンダウンは必要ありません。GCP の場合は、Cloud Console ダッシュボードに移動して、推定料金の料金カードを確認します。
- Cloud Vision の場合、一定数の API 呼び出しが無料で利用できます(1 か月ごと)。そのため、これらの上限を超えない限り、シャットダウンやプロジェクトの無効化 / 削除を行う必要はありません。Vision API の課金と無料割り当ての詳細については、料金ページをご覧ください。
- 一部の Cloud Storage ユーザーは、1 か月ごとの無料ストレージ枠を利用できます。このコードラボでアーカイブした画像がこの割り当てを超過しない場合、料金は発生しません。GCS の課金と無料割り当てについて詳しくは、料金ページをご覧ください。blob は、Cloud Storage ブラウザから表示して簡単に削除できます。
- Google ドライブの使用に関しても、ストレージ割り当てがある場合があります。割り当てを超える(または割り当てに近い)場合は、このコードラボに組み込まれているツールを使用して、これらの画像を Cloud Storage にアーカイブし、ドライブの空き容量を増やすことを検討してください。Google ドライブ ストレージの詳細については、G Suite Basic ユーザーまたは Gmail / コンシューマー ユーザーの料金ページを参照してください。
ほとんどの G Suite Business および Enterprise プランには無制限のストレージがありますが、そのためにドライブのフォルダが乱雑になったり、その量が大幅に増える可能性があります。このチュートリアルで作成したアプリは、無関係なファイルをアーカイブして Google ドライブをクリーンアップするための優れた手段になります。
代替バージョン
final/analyze_gsimg.py は、このチュートリアルで扱う「最後の」公式バージョンですが、これで終わりではありません。アプリの最終バージョンに関する問題の 1 つに、廃止された古い認証ライブラリを使用することがあります。この記事の執筆時点では、新しい認証ライブラリがいくつかの重要な要素(OAuth トークン ストレージ管理とスレッドセーフ)をサポートしていなかったため、このパスを選択しました。
現在の(新しい)認証ライブラリ
ただし、古い認証ライブラリはいずれサポートされなくなるため、スレッドセーフでなくても、リポジトリの alt フォルダにある新しい(現在の)認証ライブラリを使用するバージョンを確認することをおすすめします(独自のソリューションも構築できます)。名前に *newauth* が含まれるファイルを探します。
GCP プロダクト クライアント ライブラリ
Google Cloud では、GCP API を使用するときにプロダクト クライアント ライブラリを使用することをすべてのデベロッパーにおすすめしています。残念ながら、現時点では GCP 以外の API にはそのようなライブラリはありません。下位レベルのプラットフォーム ライブラリを使用すると、一貫した API の使用が可能になり、読みやすさが向上します。上記の推奨事項と同様に、GCP プロダクト クライアント ライブラリを使用した代替バージョンは、リポジトリの alt フォルダで確認できます。名前に *-gcp* が含まれるファイルを探します。
サービス アカウントの承認
完全にクラウドで作業する場合、通常、人間や人間のユーザーが所有するデータは関与しません。そのため、サービス アカウントとサービス アカウント認証は主に GCP で使用されます。ですが、G Suite ドキュメントは通常の場合、(人間の)ユーザーが所有するため、このチュートリアルではユーザー アカウント承認を使用します。これは、サービス アカウントで G Suite API を使用できないということではありません。それらのアカウントが適切なアクセスレベルを持っている限り、アプリケーションで確実に使用できます。上記と同様に、サービス アカウント認可を使用した代替バージョンは、リポジトリの alt フォルダで確認できます。名前に *-svc* が含まれるファイルを探します。
代替バージョンのカタログ
以下は、final/analyze_gsimg.py の代替バージョンの完全な一覧であり、それぞれが上記のプロパティの 1 つ以上を持っています。各バージョンのファイル名で、以下を探します。
- 「
oldauth」、古い認証ライブラリを使用するバージョン(final/analyze_gsimg.pyに加えて) - 「
newauth」、現在または新しい認証ライブラリを使用するバージョン - 「
gcp」、GCP プロダクト クライアント ライブラリ(google-cloud-storage など)を使用するバージョン - 「
svc」、ユーザー アカウントではなくサービス アカウント(「svc acct」)認証を使用するバージョン
以下は、バージョンの完全な一覧です。
ファイル名 | 説明 |
| メインのサンプル。古い認証ライブラリを使用します |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
元の final/analyze_gsimg.py と組み合わせると、Google API 開発環境に関係なく、最終的なソリューションのすべての可能な組み合わせがあり、ニーズに最適なものを選択できます。同様の説明については、alt/README.md をご覧ください。
追加の演習
この演習をさらに進めるためのアイデアをいくつかご紹介します。現在のソリューションで処理できる問題セットを拡張して、次の機能拡張を実現できます。
- (フォルダ内の複数の画像)処理する画像が 1 つではなく、Google ドライブ フォルダ内に複数あるとしたらどうでしょうか?
- (ZIP ファイル内の複数の画像)画像フォルダではなく、画像ファイルを含む ZIP アーカイブがあるとしたらどうでしょうか?Python を使用する場合は、
zipfileモジュールを検討してください。 - (Vision ラベルの分析)類似した画像を 1 つにまとめます。最も一般的なラベルを探すことから始め、次に 2 番目に一般的なラベルを探すというように行います。
- (グラフの作成)フォローアップ #3、Vision API の分析と分類に基づいて Sheets API でグラフを作成する
- (ドキュメントを分類する)Cloud Vision API で画像を分類するのではなく、Cloud Natural Language API で分類する PDF ファイルがあるとしたらどうでしょうか?上記のソリューションを使用すると、これらの PDF をドライブのフォルダやドライブの ZIP アーカイブに含めることができます。
- (プレゼンテーションを作成)Slides API を使用して、Google スプレッドシート レポートの内容からスライドを生成します。スプレッドシートのデータからスライドを生成する方法については、こちらのブログ投稿と動画をご覧ください。
- (PDF 形式でエクスポート)スプレッドシートやスライドを PDF 形式で書き出します。ただし、これは Sheets API の機能でも Slides API の機能でもありません。ヒント: Google Drive API。追加クレジット: Ghostscript(Linux、Windows)や
Combine PDF Pages.action(Mac OS X)などのツールを使用して、スプレッドシートとスライドの両方の PDF を 1 つのマスター PDF にマージします。
詳細
Codelab
- G Suite API の概要(Google Drive API)(Python)
- Python での Cloud Vision の使用(Python)
- カスタム レポートツールの作成(Google Sheets API)(JS/Node)
- Google Cloud Storage へのオブジェクトのアップロード(コーディング不要)
全般
G Suite
Google Cloud Platform(GCP)
- Google Cloud Storage のホームページ
- Google Cloud Vision のホームページとライブデモ
- Cloud Vision API のドキュメント
- Vision API の画像ラベル付けドキュメント
- Google Cloud Platform での Python
- GCP プロダクト クライアント ライブラリ
- GCP のドキュメント
ライセンス
この作業はクリエイティブ・コモンズの表示 2.0 汎用ライセンスにより使用許諾されています。