
이 Codelab은 기업에서 수행될 수 있는 가상의 이미지 보관처리, 분석, 보고서 생성 워크플로를 진행합니다. 귀하의 조직에서 제한된 리소스 공간을 차지하고 있는 일련의 이미지가 있다고 가정해보세요. 데이터를 보관처리하고, 이미지를 분석하고, 무엇보다도 경영진에서 사용할 수 있도록 정리된 분석 결과와 함께 보관처리된 위치 요약 정보가 담긴 보고서를 생성해야 합니다. Google Cloud는 자사 제품 라인에 해당하는 G Suite 및 Google Cloud Platform(GCP)의 API를 활용해서 이러한 작업을 수행할 수 있게 해주는 도구를 제공합니다.
이 시나리오에서 비즈니스 사용자는 Google 드라이브에 있는 이미지를 사용한다고 가정합니다. 이러한 이미지는 Google Cloud Storage에서 제공되는 스토리지 클래스와 같이 '더 차갑고' 더 저렴한 스토리지에 백업하는 것이 합리적입니다. 개발자는 Google Cloud Vision을 사용하여 물체 및 랜드마크 인식, 광학 문자 인식(OCR) 등의 시각적 인식 기능을 애플리케이션 내에 쉽게 통합할 수 있습니다. 마지막으로 Google Sheets와 같은 스프레드시트는 경영진을 위해 이 모든 정보를 요약할 수 있는 유용한 시각화 도구입니다.
이 Codelab을 완료하여 Google Cloud의 모든 기능을 활용하는 솔루션을 빌드한 후 귀하가 귀하의 조직 또는 귀하의 고객들에게 더 큰 영향력을 발휘할 수 있는 훌륭한 결과물을 만들 수 있게 되기를 희망합니다.
학습 내용
- Cloud Shell을 사용하는 방법
- API 요청 인증 방법
- Python용 Google API 클라이언트 라이브러리 설치 방법
- Google API 사용 설정 방법
- Google 드라이브에서 파일 다운로드 방법
- Cloud Storage에 객체/Blob 업로드 방법
- Cloud Vision으로 데이터 분석 방법
- Google Sheets에 행 기록 방법
필요한 사항
- Google 계정(G Suite 계정의 경우 관리자 승인이 필요할 수 있음)
- 활성 GCP 결제 계정이 있는 Google Cloud Platform 프로젝트
- 운영체제 터미널/셸 명령어 기본 지식
- Python(2 또는 3) 기본 기술 또는 다른 지원되는 언어 사용 가능
위에 나열된 4개 Google Cloud 제품에 대한 기본 지식은 필수가 아니지만 있으면 도움이 많이 됩니다. 이러한 각 제품을 개별적으로 먼저 둘러볼 시간이 있다면 이 연습을 시작하기에 앞서 각 제품의 Codelab을 먼저 수행해보는 것이 좋습니다.
- Google 드라이브(G Suite API 사용) 소개(Python)
- Python과 함께 Cloud Vision 사용(Python)
- Sheets API로 맞춤설정된 보고 도구 빌드(JS/Node)
- Google Cloud Storage에 객체 업로드(코드 불필요)
설문조사
본 가이드를 어떻게 사용하실 계획인가요?
귀하의 Python 사용 경험이 어떤지 평가해 주세요.
귀하의 Google Cloud Platform 서비스 사용 경험을 평가해 주세요.
귀하의 G Suite 개발자 서비스 사용 경험을 평가해 주세요.
제품 기능 소개보다 '업무 지향적인' Codelab을 더 많이 보고 싶으신가요?
자습형 환경 설정
- Cloud Console에 로그인하고 새 프로젝트를 만들거나 기존 프로젝트를 다시 사용합니다. (Gmail 또는 G Suite 계정이 없으면 만들어야 합니다.)



모든 Google Cloud 프로젝트에서 고유한 이름인 프로젝트 ID를 기억하세요(위의 이름은 이미 사용되었으므로 사용할 수 없습니다). 이 ID는 나중에 이 Codelab에서 PROJECT_ID라고 부릅니다.
- 그런 후 Google Cloud 리소스를 사용할 수 있도록 Cloud Console에서 결제를 사용 설정해야 합니다.
이 Codelab 실행에는 많은 비용이 들지 않습니다. 이 가이드를 마친 후 비용이 결제되지 않도록 리소스 종료 방법을 알려주는 '삭제' 섹션의 안내를 따르세요. Google Cloud 새 사용자에게는 $300USD 상당의 무료 체험판 프로그램 참여 자격이 부여됩니다.
Cloud Shell 시작
요약
노트북에서 로컬로 코드를 개발할 수도 있지만, 이 Codelab의 부차적인 목표는 최신 웹브라우저를 통해 클라우드에서 실행되는 명령줄 환경인 Google Cloud Shell 사용 방법을 알려주는 것입니다.
Cloud Shell 활성화
- Cloud Console에서 Cloud Shell 활성화
를 클릭합니다.

이전에 Cloud Shell을 시작하지 않았으면 설명이 포함된 중간 화면(스크롤해야 볼 수 있는 부분)이 제공됩니다. 이 경우 계속을 클릭합니다(이후 다시 표시되지 않음). 이 일회성 화면은 다음과 같습니다.

Cloud Shell을 프로비저닝하고 연결하는 데 몇 분 정도만 걸립니다.

가상 머신은 필요한 모든 개발 도구와 함께 로드됩니다. 영구적인 5GB 홈 디렉터리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 이 Codelab에서 대부분의 작업은 브라우저나 Chromebook만 사용하여 수행할 수 있습니다.
Cloud Shell에 연결되면 인증이 완료되었고 프로젝트가 해당 프로젝트 ID로 이미 설정된 것을 볼 수 있습니다.
- Cloud Shell에서 다음 명령어를 실행하여 인증되었는지 확인합니다.
gcloud auth list
명령어 결과
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
명령어 결과
[core] project = <PROJECT_ID>
또는 다음 명령어로 설정할 수 있습니다.
gcloud config set project <PROJECT_ID>
명령어 결과
Updated property [core/project].
이 Codelab을 사용하려면 Python 언어를 사용해야 합니다. 하지만 Google API 클라이언트 라이브러리에서 지원되는 많은 언어들도 지원됩니다. 따라서 해당 개발 도구에서 이와 상응하는 것을 빌드하고 단순히 의사코드로서 Python을 사용해도 좋습니다. 특히 이 Codelab은 Python 2 및 3을 지원하지만, 가능한 한 빨리 3.x로 이동하는 것이 좋습니다.
Cloud Shell은 Cloud Console에서 직접 사용자에게 제공되는 편리한 기능이며, 로컬 개발 환경이 필요하지 않습니다. 따라서 클라우드에서 웹브라우저를 사용하여 이 가이드의 내용을 완전히 수행할 수 있습니다. Cloud Shell은 GCP 제품 및 API를 사용하여 개발 중이거나 개발을 지속하려는 경우 특히 유용합니다. 특히 이 Codelab에서는 Cloud Shell에 두 Python 버전이 모두 미리 설치되어 있습니다.
Cloud Shell에는 또한 IPython이 설치되어 있습니다. 이것은 특히 데이터 과학 또는 머신러닝 커뮤니티에서 권장되는 상위 수준의 대화형 Python 인터프리터입니다. 이 경우에는 IPython이 Google Research에서 호스팅되는 Jupyter 노트북인 Colab은 물론 Jupyter 노트북의 기본 인터프리터입니다.
IPython에서는 Python 3 인터프리터가 선호되지만 3.x를 사용할 수 없는 경우 Python 2로 대체됩니다. Cloud Shell에서 IPython에 액세스할 수 있지만, 로컬 개발 환경에 IPython을 설치할 수도 있습니다. ^D(Ctrl-d)로 종료하고 종료 제안을 수락합니다. ipython 시작의 예시 출력은 다음과 같습니다.
$ ipython Python 3.7.3 (default, Mar 4 2020, 23:11:43) Type 'copyright', 'credits' or 'license' for more information IPython 7.13.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
IPython을 선호하지 않을 경우에는 표준 Python 대화형 인터프리터(Cloud Shell 또는 로컬 개발 환경) 사용도 문제 없이 허용됩니다(^D로 종료).
$ python Python 2.7.13 (default, Sep 26 2018, 18:42:22) [GCC 6.3.0 20170516] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> $ python3 Python 3.7.3 (default, Mar 10 2020, 02:33:39) [GCC 6.3.0 20170516] on linux Type "help", "copyright", "credits" or "license" for more information. >>>
또한 이 Codelab에서는 pip 설치 도구(Python 패키지 관리자 및 종속성 리졸버)가 있다고 가정합니다. 이 도구는 2.7.9+ 또는 3.4+ 버전과 함께 제공됩니다. 이전 Python 버전이 있으면 이 가이드에서 설치 안내를 참조하세요. 권한에 따라 sudo 또는 수퍼유저 액세스 권한이 필요할 수 있지만, 일반적이지는 않습니다. 또한 특정 Python 버전의 경우 pip2 또는 pip3를 명시적으로 사용하여 pip를 실행할 수 있습니다.
이 Codelab의 남은 부분에서는 Python 3를 사용한다고 가정합니다. Python 2에서의 방법이 3.x와 크게 다른 경우에는 해당 안내가 제공됩니다.
*가상 환경 만들기 및 사용
이 섹션은 선택사항이며 이 Codelab에 가상 환경을 사용해야 하는 사용자에게만 필요합니다(위에 표시된 경고 사이드바 참조). 컴퓨터에 Python 3만 있으면 단순히 이 명령어를 실행하여 my_env라는 가상 환경을 만들 수 있습니다(필요에 따라 이름 변경 가능).
virtualenv my_env
하지만 컴퓨터에 Python 2 및 3가 모두 있으면 다음과 같이 -p flag를 사용하여 Python 3 가상 환경을 설치하는 것이 좋습니다.
virtualenv -p python3 my_env
다음과 같이 '활성화'를 수행하여 새로 만든 가상 환경에 들어갑니다.
source my_env/bin/activate
다음과 같이 셸 프롬프트 앞에 가상 환경 이름이 표시되는 것을 보고 가상 환경에 들어왔는지 확인할 수 있습니다.
(my_env) $
이제 모든 필요한 패키지를 pip install하고, 이 환경 내에서 코드를 실행할 수 있습니다. 환경이 뒤죽박죽되거나, Python 설치가 손상된 경우에도 나머지 시스템에 영향을 주지 않고 전체 환경을 없앨 수 있다는 장점도 있습니다.
이 Codelab에서는 Python용 Google API 클라이언트 라이브러리를 사용해야 합니다. 이를 위해 간단한 설치 프로세스를 수행하거나 아무 것도 수행하지 않도록 선택할 수도 있습니다.
편의를 위해서는 앞에서 Cloud Shell을 사용하는 것이 좋다고 알려드렸습니다. 이 가이드 전체는 클라우드에서 웹브라우저로 완료할 수 있습니다. Cloud Shell을 사용하는 또 다른 이유는 많은 인기 있는 개발 도구 및 필요한 라이브러리가 이미 사전 설치되어 있기 때문입니다.
*클라이언트 라이브러리 설치
(선택사항) 클라이언트 라이브러리를 이미 설치한 로컬 환경 또는 Cloud Shell을 사용하는 경우 이 단계를 건너뛸 수 있습니다. 로컬로 개발을 수행 중이고 라이브러리를 설치하지 않았거나 확실하지 않은 경우에만 이를 수행하면 됩니다. 가장 쉬운 방법은 pip(또는 pip3)를 사용하여 설치를 수행하는 것입니다(필요한 경우 pip 자체 업데이트 포함).
pip install -U pip google-api-python-client oauth2client
설치 확인
이 명령은 종속된 모든 패키지는 물론 클라이언트 라이브러리를 설치합니다. Cloud Shell 또는 고유 환경을 사용하든 간에 필수 패키지를 가져와서 클라이언트 라이브러리가 설치되었는지 확인하고 가져오기 오류(또는 출력 오류)가 없는지 확인합니다.
python3 -c "import googleapiclient, httplib2, oauth2client"
대신 Python 2(Cloud Shell에서)를 사용하는 경우 지원이 종료되었다는 경고가 표시됩니다.
******************************************************************************* Python 2 is deprecated. Upgrade to Python 3 as soon as possible. See https://cloud.google.com/python/docs/python2-sunset To suppress this warning, create an empty ~/.cloudshell/no-python-warning file. The command will automatically proceed in seconds or on any key. *******************************************************************************
가져오기 '테스트' 명령어를 성공적으로 실행할 수 있으면(오류/출력 없음), Google API 사용을 시작할 수 있습니다.
요약
이 Codelab은 중급 수준의 Codelab이기 때문에 대상 독자가 Console에서 프로젝트를 만들고 사용한 경험이 이미 있다고 가정합니다. Google API와 특히 G Suite API를 처음 사용하는 경우에는 G Suite API 소개 Codelab을 먼저 시도해보세요. 또한 사용자 계정(서비스 계정 아님) 사용자 인증 정보를 만들거나 기존 항목을 다시 사용하는 방법을 알고 있으면 client_secret.json 파일을 작업 디렉터리에 놓고, 다음 모듈을 건너뛰고, 'Google API 사용 설정'을 진행하세요.
사용자 계정 승인 사용자 인증 정보를 이미 만들었고 이 프로세스에 익숙한 경우에는 이 섹션을 건너뛸 수 있습니다. 다른 기술을 사용하는 서비스 계정 승인과는 다릅니다. 따라서 아래 단계를 계속하세요.
승인 소개(및 일부 인증)
API에 요청을 수행하기 위해서는 애플리케이션이 적절한 승인을 수행해야 합니다. 비슷한 단어인 인증은 로그인 사용자 인증 정보를 설명합니다. 사용자가 Google 계정에 로그인할 때는 로그인 및 비밀번호를 사용하여 자신을 인증해야 합니다. 인증 후에는 Cloud Storage에 있는 Blob 파일 또는 Google 드라이브에 있는 사용자의 개인 파일과 같은 데이터에 액세스할 수 있도록 사용자 또는 사용자의 코드가 승인됩니다.
Google API는 여러 유형의 승인을 지원하지만, G Suite API 사용자에게 가장 일반적인 것은 사용자 승인입니다. 이 Codelab의 예시 애플리케이션은 최종 사용자에게 속하는 데이터에 액세스합니다. 이러한 최종 사용자는 자신의 데이터에 액세스하기 위해 귀하의 앱에 대해 권한을 부여해야 합니다. 즉, 귀하의 코드가 사용자 계정 OAuth2 사용자 인증 정보를 획득해야 합니다.
사용자 승인을 위해 OAuth2 사용자 인증 정보를 가져오기 위해서는 API 관리자로 돌아가고 왼쪽 탐색에서 '사용자 인증 정보' 탭을 선택합니다.
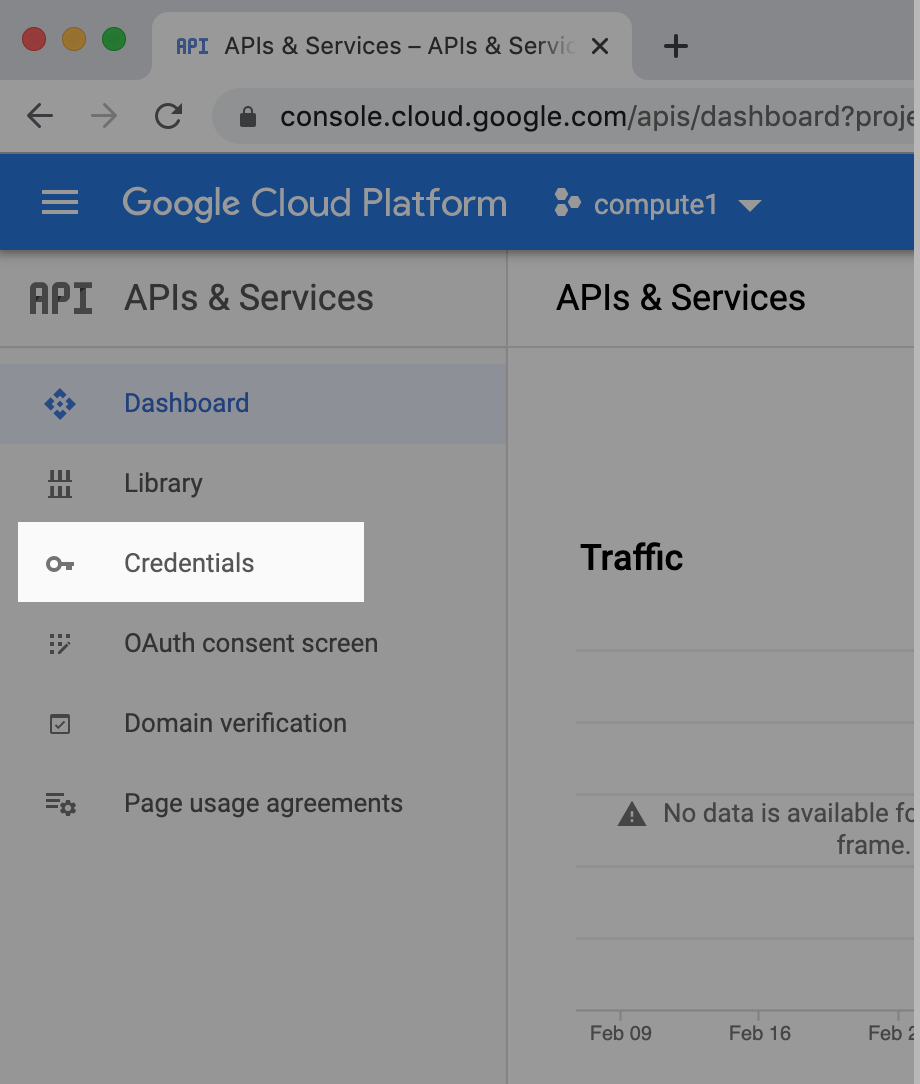
여기에 도착하면 3개의 개별 섹션에 모든 사용자 인증 정보가 표시됩니다.
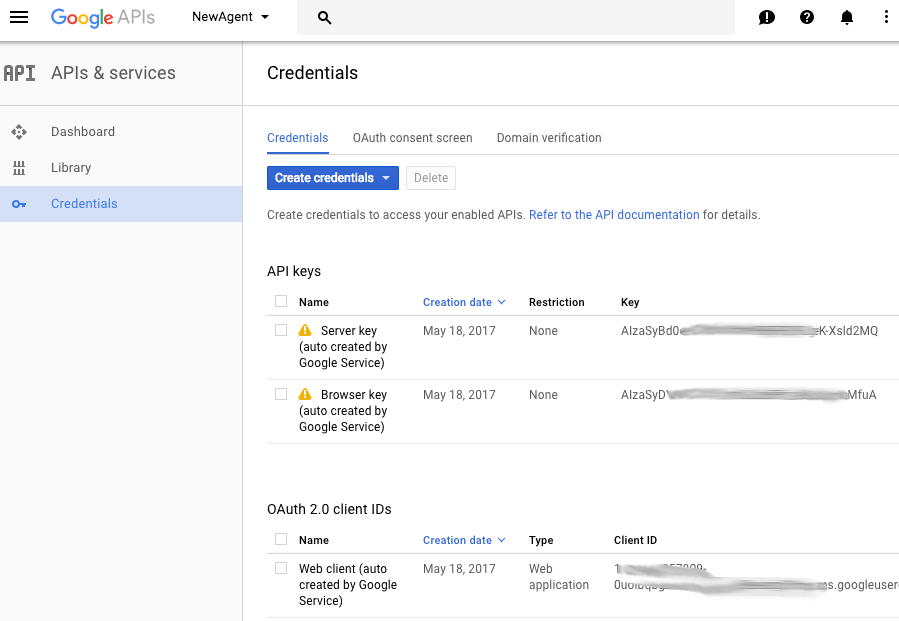
첫 번째는 API 키에 대한 것이고, 두 번째는 OAuth 2.0 클라이언트 ID, 마지막은 OAuth2 서비스 계정을 위한 것입니다. 여기에서는 가운데 항목을 사용합니다.
사용자 인증 정보 만들기
사용자 인증 정보 페이지에서 위에 있는 + 사용자 인증 정보 만들기 버튼을 클릭하면 'OAuth 클라이언트 ID'를 선택할 수 있는 대화상자가 표시됩니다.

다음 화면에서는 앱의 승인 '동의 화면'을 구성하고 애플리케이션 유형을 선택하는 두 가지 작업을 수행할 수 있습니다.

동의 화면을 설정하지 않으면 Console에 경고가 표시되고, 지금 작업을 수행해야 합니다. (동의 화면이 이미 설정되었으면 이를 건너뛰고 다음 단계를 진행합니다.)
OAuth 동의 화면
'동의 화면 구성'을 클릭하고 '외부' 앱(G Suite 고객의 경우에는 '내부')을 선택합니다.
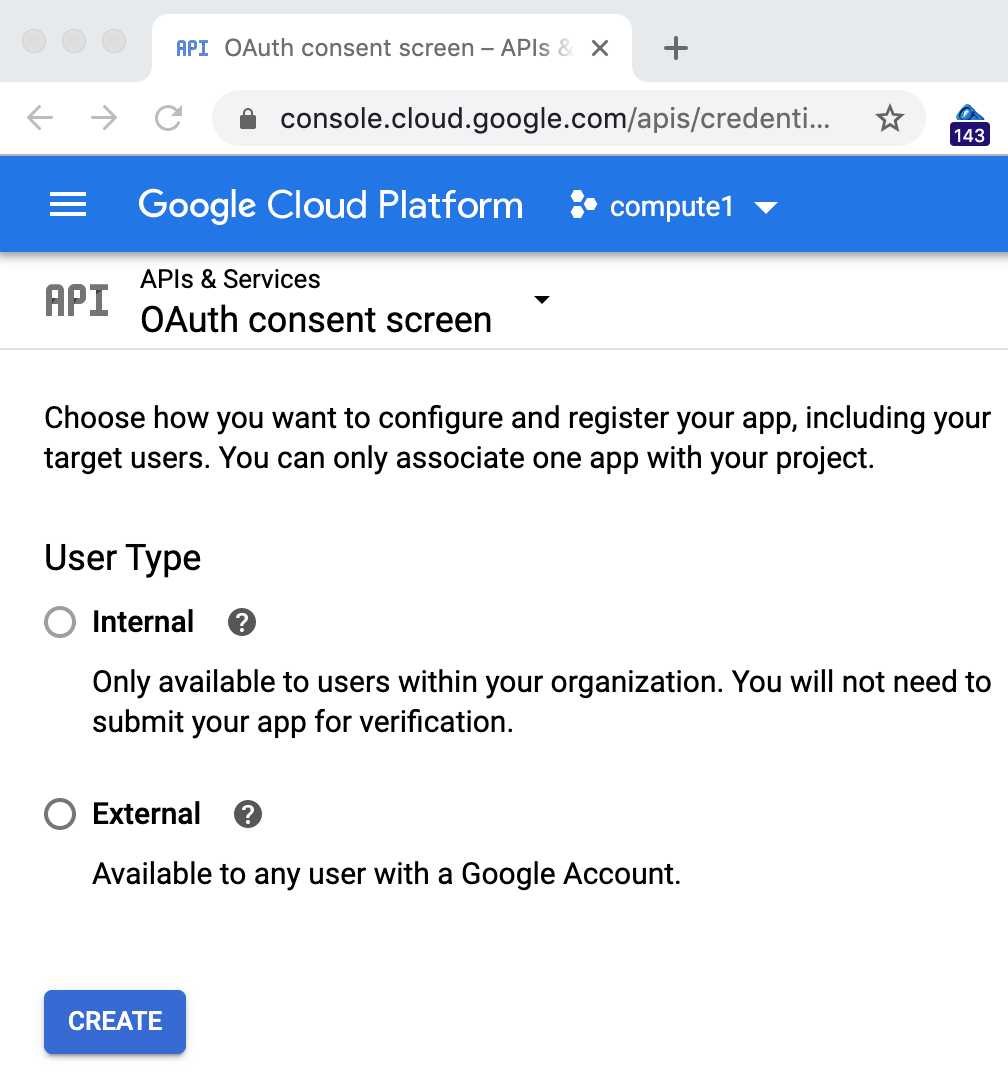
이 연습에서는 Codelab 샘플을 게시하지 않기 때문에 무엇을 선택하든 중요하지 않습니다. 대부분의 경우 '외부'를 선택하여 더 복잡한 화면으로 연결되지만, 실제로 맨 위에 있는 '애플리케이션 이름' 필드만 작성하면 됩니다.
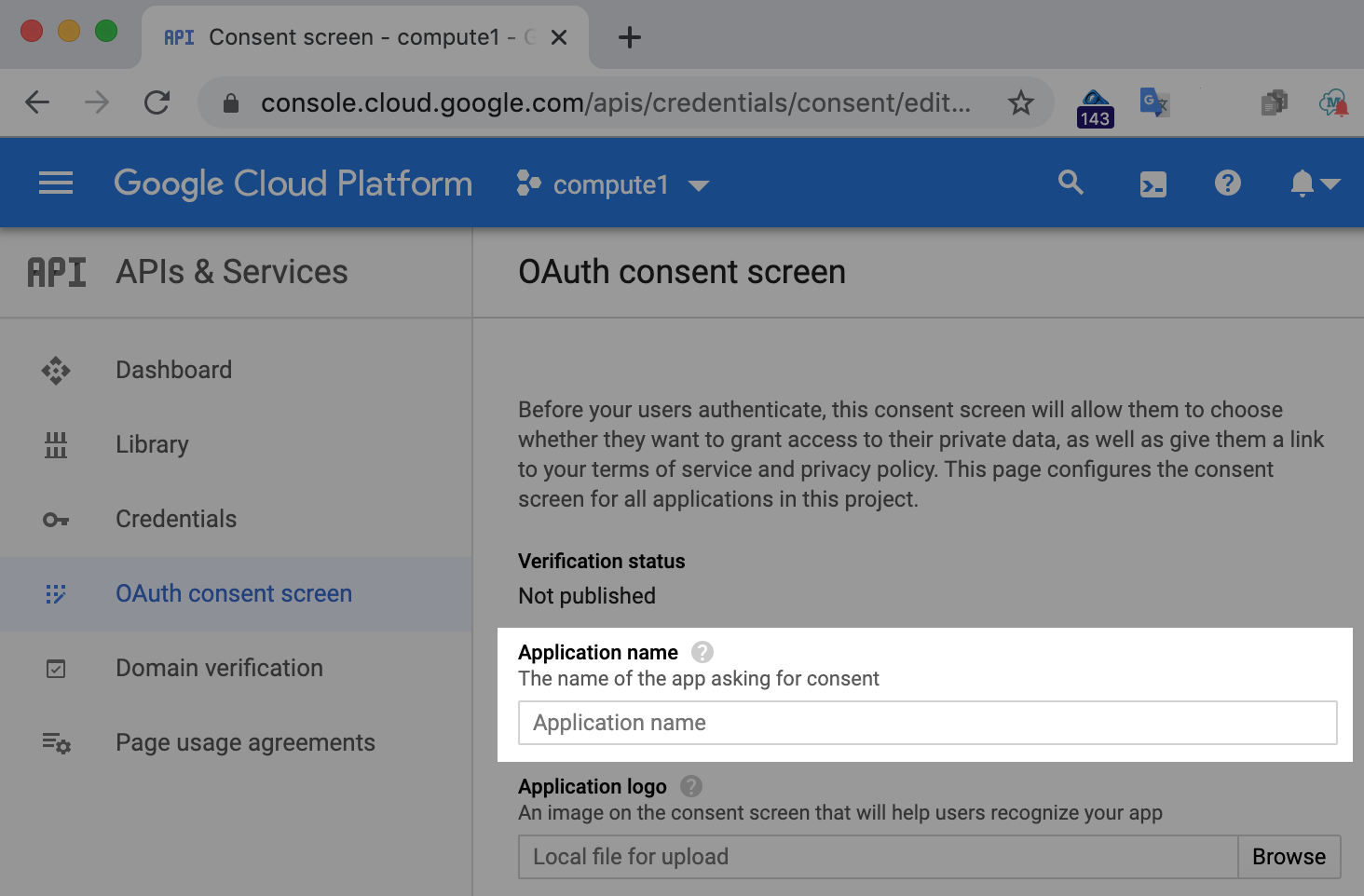
지금은 애플리케이션 이름만 필요하므로, 수행 중인 Codelab을 나타내는 사람을 선택한 후 저장을 클릭합니다.
OAuth 클라이언트 ID 만들기(사용자 계정 인증)
이제 사용자 인증 정보 탭으로 돌아가서 OAuth2 클라이언트 ID를 만듭니다. 여기에는 만들 수 있는 여러 OAuth 클라이언트 ID가 표시됩니다.
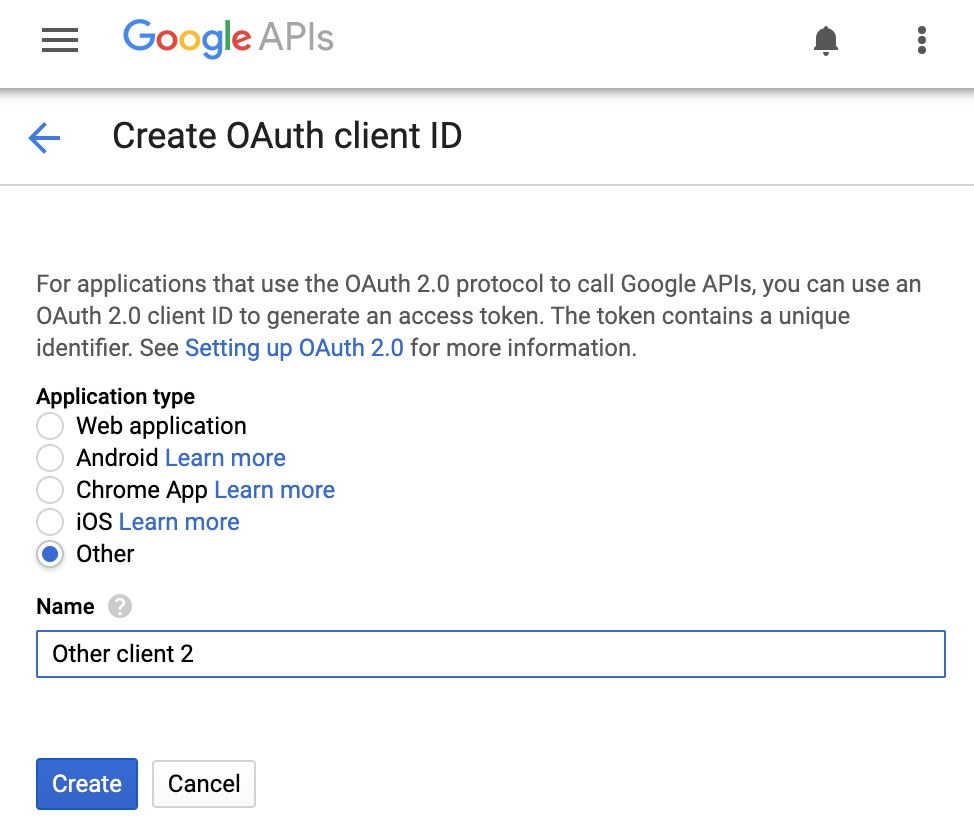
기타에 해당하는 명령줄 도구를 개발하는 중이므로, 이를 선택하고 만들기 버튼을 클릭합니다. 만들려는 앱을 나타내는 클라이언트 ID를 선택하거나 단순히 일반적으로 'Other client N'인 기본 이름을 선택합니다.
사용자 인증 정보 저장
- 새 사용자 인증 정보 대화상자가 나타나면 확인을 클릭하여 닫습니다.

- 사용자 인증 정보 페이지로 돌아와서 'OAuth2 클라이언트 ID' 섹션으로 스크롤하고 새로 생성된 클라이언트 ID의 오른쪽 끝에 있는 다운로드 아이콘
을 찾아서 클릭합니다.
- 그러면
client_secret-LONG-HASH-STRING.apps.googleusercontent.com.json과 같은 이름의 파일을 다운로드 폴더에 저장하는 대화상자가 열립니다.client_secret.json(샘플 앱에 사용되는 이름)과 같이 쉬운 이름으로 줄이고, 이 Codelab에서 샘플 앱을 만드는 디렉터리/폴더에 저장하는 것이 좋습니다.

요약
이제 이 Codelab에 사용된 Google API를 사용 설정할 수 있습니다. 또한 OAuth 동의 화면에 있는 애플리케이션 이름으로 'Vision API demo'가 사용되었으므로, 앞으로 표시될 스크린샷에 이 이름이 표시될 것입니다.
소개
이 Codelab에는 GCP의 한 쌍(Cloud Storage 및 Cloud Vision)과 G Suite의 다른 한 쌍(Google 드라이브 및 Google Sheets)인 4개(4)의 Google Cloud API가 사용됩니다. 다음은 Vision API만 사용 설정할 때의 안내입니다. API 하나를 사용 설정하는 방법을 알았으면 나머지 3개를 직접 사용 설정해야 합니다.
Google API 사용을 시작하려면 먼저 이를 사용 설정해야 합니다. 아래 예시에서는 Cloud Vision API를 사용 설정하기 위해 필요한 항목을 보여줍니다. 이 Codelab에서는 하나 이상의 API가 사용될 수 있으며, 이를 사용하기 전 비슷한 단계에 따라 사용 설정해야 합니다.
Cloud Shell 사용
Cloud Shell을 사용하는 경우 다음 명령어를 사용하여 API를 사용 설정할 수 있습니다.
gcloud services enable vision.googleapis.com
Cloud Console 사용
또한 API 관리자에서 Vision API를 사용 설정할 수 있습니다. Cloud Console에서 API 관리자로 이동하고 '라이브러리'를 선택합니다.

검색 창에 'vsion'을 입력하면서 표시된 Vision API를 선택합니다. 입력을 시작하면 다음과 같이 표시됩니다.

Cloud Vision API를 선택하여 아래 보이는 대화상자가 표시되면 '사용 설정' 버튼을 클릭합니다.

비용
많은 Google API가 비용 없이 사용될 수 있지만 GCP(제품 및 API) 사용은 무료가 아닙니다. 위에 설명된 것처럼 Vision API를 사용 설정하면 활성 결제 계정을 묻는 메시지가 표시될 수 있습니다. 이를 사용 설정하기 전 Vision API의 가격 책정 정보를 확인해야 합니다. 특정 Google Cloud Platform(GCP) 제품에는 '항상 무료' 등급이 포함되며, 이를 초과할 경우에만 결제가 발생할 수 있습니다. 이 Codelab에서는 Vision API에 대한 각 호출이 이 무료 등급에 해당하므로, 1개월 내 총 사용량이 한도 내로 유지되는 한 비용이 발생하지 않습니다.
G Suite와 같은 일부 Google API는 월별 구독에 사용량이 포함되어 있으므로, Gmail, Google 드라이브, Calendar, Docs, Sheets, Slides API와 같은 서비스 사용 비용이 직접 청구되지 않습니다. 각 Google 제품마다 결제 방식이 다르므로, API 문서에서 해당 정보를 확인해야 합니다.
요약
이제 Cloud Vision이 사용 설정되었으므로 다른 3개의 API(Google 드라이브, Cloud Storage, Google Sheets)도 Cloud Shell, gcloud services enable, Cloud Console을 사용해서 동일한 방법으로 설정합니다.
- API 라이브러리로 돌아가기
- 이름 중 몇 글자만 입력하여 검색을 시작합니다.
- 원하는 API를 선택합니다.
- 사용 설정합니다.
거품을 칠하고, 헹구고, 반복합니다. Cloud Storage의 경우 몇 가지 옵션이 있습니다. 'Google Cloud Storage JSON API'를 선택합니다. Cloud Storage API에도 활성 결제 계정이 요구됩니다.
이 단계는 중간 규모의 코드 조각 중 시작 부분에 해당합니다. 따라서 다소 유연한 방식으로 주 애플리케이션 작업을 시작하기 전 인프라 부분이 일반적이고, 안정적이며, 작동하는지 확인하고자 합니다. 현재 디렉터리에서 client_secret.json을 사용할 수 있는지 다시 확인하고 ipython을 시작하고 다음 코드 스니펫을 입력하거나, 이를 analyze_gsimg.py에 저장하고 셸에서 실행합니다(코드 샘플에 계속 추가할 것이기 때문에 후자 방식이 선호됨).
from __future__ import print_function
from googleapiclient import discovery, http
from httplib2 import Http
from oauth2client import file, client, tools
# process credentials for OAuth2 tokens
SCOPES = 'https://www.googleapis.com/auth/drive.readonly'
store = file.Storage('storage.json')
creds = store.get()
if not creds or creds.invalid:
flow = client.flow_from_clientsecrets('client_secret.json', SCOPES)
creds = tools.run_flow(flow, store)
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
이 핵심 구성요소에는 사용자 인증 사용자 인증 정보를 처리하고 API 서비스 엔드포인트를 만드는 모듈/패키지 가져오기를 위한 코드 블록이 포함됩니다. 코드에서 검토해야 할 핵심 부분은 다음과 같습니다.
print()함수 가져오기를 수행하면 이 샘플이 Python 2-3과 호환되고, Google 라이브러리 가져오기로 Google API와 통신하는 데 필요한 모든 도구를 가져옵니다.SCOPES변수는 사용자의 요청에 대한 권한을 나타냅니다. 현재는 사용자의 Google 드라이브에서 데이터를 읽을 수 있는 권한만 있습니다.- 사용자 인증 정보 처리 코드의 남은 부분은 캐시된 OAuth2 토큰에서 읽기를 수행하고, 원래 액세스 토큰이 만료된 경우 새로고침 토큰으로 새 액세스 토큰에 업데이트를 수행합니다.
- 토큰이 생성되지 않았거나 올바른 액세스 토큰을 검색하려고 할 때 다른 이유로 작업이 실패한 경우, 사용자가 OAuth2 3-legged 흐름(3LO)을 수행해야 합니다. 요청된 권한으로 대화상자를 만들고 사용자에게 수락하도록 프롬프트를 표시합니다. 그런 다음 앱이 계속 실행되고, 그렇지 않으면
tools.run_flow()이 예외를 일으키고 실행이 중단됩니다. - 사용자가 권한을 부여했으면 서버와 통신하기 위해 HTTP 클라이언트가 생성되고 보안을 위해 모든 요청이 사용자의 사용자 인증 정보로 서명됩니다. 그런 후 Google Drive API(버전 3)에 대한 서비스 엔드포인트가 HTTP 클라이언트에 생성된 후
DRIVE에 할당됩니다.
애플리케이션 실행
스크립트를 처음 실행할 때는 Drive(귀하의)에서 사용자 파일에 액세스하도록 승인을 받지 않은 상태입니다. 실행이 일시 중지되고 다음과 같이 출력이 표시됩니다.
$ python3 ./analyze_gsimg.py
/usr/local/lib/python3.6/site-packages/oauth2client/_helpers.py:255: UserWarning: Cannot access storage.json: No such file or directory
warnings.warn(_MISSING_FILE_MESSAGE.format(filename))
Your browser has been opened to visit:
https://accounts.google.com/o/oauth2/auth?client_id=LONG-STRING.apps.googleusercontent.com&redirect_uri=http%3A%2F%2Flocalhost%3A8080%2F&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive.readonly&access_type=offline&response_type=code
If your browser is on a different machine then exit and re-run this
application with the command-line parameter
--noauth_local_webserver
Cloud Shell에서 실행하는 경우 필요에 따라 'Cloud Shell 사용' 섹션을 확인한 후 다시 돌아와서 '로컬 개발 환경 사용'의 관련 화면을 검토합니다.
로컬 개발 환경 사용
브라우저 창이 열릴 때 명령줄 스크립트가 일시 중지됩니다. 다음과 같이 무섭게 보이는 경고 페이지가 표시될 수 있습니다.

이것은 사용자 데이터에 액세스하는 앱을 실행하려고 시도할 때 나타나는 정상적인 현상입니다. 이것은 데모 앱일 뿐이고 귀하가 개발자이므로, 귀하는 자신을 신뢰하여 작업을 계속할 수 있습니다. 이해를 돕기 위해 귀하가 사용자의 입장이라고 생각해보세요. 이것은 누군가의 코드가 귀하의 데이터에 액세스할 수 있도록 허용해달라는 요청을 받는 것과 같습니다. 이와 같이 앱을 게시할 생각이라면 이 화면이 사용자에게 표시되지 않도록 확인 프로세스를 거쳐야 합니다.
''안전하지 않은' 앱으로 이동' 링크를 클릭한 후에는 아래와 같이 보이는 OAuth2 권한 대화상자가 표시됩니다. 인터페이스가 항상 개선되고 있으니까, 딱 맞는 모양이 아니더라도 걱정할 필요는 없습니다.

OAuth2 흐름 대화상자에는 개발자가 요청 중인 권한이 표시됩니다(SCOPES 변수 사용). 여기에서는 사용자의 Google 드라이브를 보고 다운로드할 수 있는 기능입니다. 애플리케이션 코드에서 이러한 권한 범위는 URI로 표시되지만, 사용자의 지역에 따라 지정된 언어로 번역됩니다. 여기에서 사용자는 요청된 권한에 대해 명시적인 승인을 제공해야 합니다. 그렇지 않으면 예외가 발생되어 스크립트가 더 이상 진행되지 않습니다.
심지어 확인을 요청하는 대화상자가 하나 더 표시될 수도 있습니다.

참고: 일부는 여러 웹브라우저를 사용하여 서로 다른 계정에 로그인합니다. 따라서 이러한 승인 요청이 잘못된 브라우저 탭/창으로 연결될 수도 있고, 이 요청에 대한 링크를 올바른 계정으로 로그인된 브라우저에 잘라내어 붙여넣어야 할 수 있습니다.
Cloud Shell 사용
Cloud Shell에서는 브라우저 창이 팝업되지 않고 멈춘 상태로 유지됩니다. 하단에 표시된 아래 진단 메시지가 귀하를 기다리고 있습니다.
If your browser is on a different machine then exit and re-run this application with the command-line parameter --noauth_local_webserver
^C(Ctrl-C 또는 스크립트 실행을 중지하기 위한 기타 키 입력)를 누르고, 추가 플래그를 사용하여 셸에서 실행해야 합니다. 이 방법으로 실행하면 다음 출력이 대신 표시됩니다.
$ python3 analyze_gsimg.py --noauth_local_webserver
/usr/local/lib/python3.7/site-packages/oauth2client/_helpers.py:255: UserWarning: Cannot access storage.json: No such file or directory
warnings.warn(_MISSING_FILE_MESSAGE.format(filename))
Go to the following link in your browser:
https://accounts.google.com/o/oauth2/auth?client_id=LONG-STRING.apps.googleusercontent.com&redirect_uri=urn%3Aietf%3Awg%3Aoauth%3A2.0%3Aoob&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive.readonly&access_type=offline&response_type=code
Enter verification code:
(storage.json이 아직 생성되지 않았다는 것은 알고 있으므로 이 경고 무시) 해당 URL을 사용해서 다른 브라우저 탭에서 안내를 따라가면 로컬 개발 환경에서 수행된 것에 대해 위에서 설명한 것과 거의 동일한 결과가 발생합니다(위 스크린샷 참조). 마지막에는 Cloud Shell에 입력할 확인 코드가 있는 최종 화면이 표시됩니다.

이 코드를 복사하여 터미널 창에 붙여넣습니다.
요약
'Authentication successful' 외에는 추가 출력이 없습니다. 이 단계는 단지 설정 단계일 뿐입니다. 아직 아무 것도 수행한 작업이 없습니다. 지금까지 수행된 작업은 처음부터 올바르게 실행될 가능성이 조금 더 높은 결과를 얻기 위해 이 과정을 성공적으로 시작한 것입니다. 그래도 좋은 점은 승인 요청 프롬프트가 한 번만 표시되었다는 것입니다. 이후의 모든 실행 작업에서는 권한이 캐시되었기 때문에 승인 요청이 생략됩니다. 이제 실제 출력에서 현실적인 작업을 수행하도록 코드를 만들어보겠습니다.
문제 해결
출력이 표시되지 않고 오류가 표시될 경우 한 두 가지의 원인 때문일 수 있지만, 다음 이유 때문일 수 있습니다.
이전 단계에서는 코드를 analyze_gsimg.py로 만들고 이를 수정하는 방식을 추천했습니다. 또한 모든 것을 한 번에 iPython 또는 표준 Python 셸에 직접 잘라내어 붙여넣는 것도 가능하지만, 앞으로도 계속 앱을 한 조각씩 덧붙이는 방식이 사용되므로, 오히려 번거로울 수 있습니다.
앱이 승인되었고 API 서비스 엔드포인트가 생성되었다고 가정합니다. 코드에서 이는 DRIVE 변수로 표시됩니다. 이제 Google 드라이브에서 이미지 파일을 찾고
이를 NAME이라는 변수로 설정합니다. 0단계의 코드 바로 아래에 다음 drive_get_img() 함수를 추가합니다.
FILE = 'YOUR_IMG_ON_DRIVE' # fill-in with name of your Drive file
def drive_get_img(fname):
'download file from Drive and return file info & binary if found'
# search for file on Google Drive
rsp = DRIVE.files().list(q="name='%s'" % fname,
fields='files(id,name,mimeType,modifiedTime)'
).execute().get('files', [])
# download binary & return file info if found, else return None
if rsp:
target = rsp[0] # use first matching file
fileId = target['id']
fname = target['name']
mtype = target['mimeType']
binary = DRIVE.files().get_media(fileId=fileId).execute()
return fname, mtype, target['modifiedTime'], binary
Drive files() 컬렉션에는 지정된 파일에 대해 쿼리(q 매개변수)를 수행하는 list() 메서드가 있습니다. fields 매개변수는 원하는 값을 반환할 항목을 지정하기 위해 사용됩니다. 다른 값이 필요하지 않다면 일부러 모든 것을 다시 가져와서 작업을 느리게 할 필요가 없습니다. API 반환 값을 필터링하기 위한 필드 마스크를 처음 사용하는 경우 이 블로그 게시물 및 동영상을 확인해보세요. 그렇지 않으면 쿼리를 실행하고 반환된 files 속성을 가져오고, 일치하는 항목이 없으면 빈 목록 배열을 기본으로 지정합니다.
결과가 없으면 함수의 나머지 부분을 건너뛰고 None이 반환됩니다(암시적). 그렇지 않으면 첫 번째 일치하는 응답(rsp[0])을 가져와서, 파일 이름, MIMEtype, 마지막 수정 타임스탬프, 그리고 마지막으로 files() 컬렉션에도 있고 get_media() 함수(해당 파일 ID 사용)로 검색된 바이너리 페이로드를 반환합니다. (다른 언어 클라이언트 라이브러리의 경우 메서드 이름이 약간 다를 수 있습니다.)
마지막 부분은 전체 애플리케이션을 구동하는 'main' 본문입니다.
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
else:
print('ERROR: Cannot download %r from Drive' % fname)
Drive에서 이름이 section-work-card-img_2x.jpg인 이미지가 있고 FILE로 설정되었다고 가정할 때, 스크립트 실행에 성공하면 Drive에서 파일을 읽을 수 있지만 컴퓨터에 저장할 수 없음을 확인하는 출력이 표시됩니다.
$ python3 analyze_gsimg.py Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
문제 해결
위와 같은 성공한 출력이 표시되지 않으면 한 두 가지의 원인 때문일 수 있지만, 다음 이유 때문일 수 있습니다.
요약
이 섹션에서는 2개의 개별 API 호출로 Drive API에 연결하여 특정 파일을 쿼리한 후 이를 다운로드하는 방법을 배웠습니다. 비즈니스 사용 사례: Drive 데이터를 보관처리하고, GCP 도구 등으로 이를 분석합니다. 이 단계의 앱 코드는 step1-drive/analyze_gsimg.py의 저장소에 있는 것과 일치합니다.
Google 드라이브에서 파일 다운로드에 대한 자세한 내용을 여기에서 살펴보거나 이 블로그 게시물 및 동영상을 확인해보세요. 이 Codelab 부분은 전체 G Suite API Codelab 소개와 거의 동일합니다. 파일을 다운로드하는 대신 사용자의 Google 드라이브에 있는 처음 100개의 파일/폴더를 표시하고 보다 제한적인 범위를 사용합니다.
다음 단계에서는 Google Cloud Storage에 대한 지원을 추가합니다. 이를 위해 또 다른 Python 패키지 io를 가져와야 합니다. 가져오기의 맨 위 섹션은 이제 다음과 같이 표시됩니다.
from __future__ import print_function
import io
Drive 파일 이름 외에도 Cloud Storage에서 이 파일을 저장할 위치에 대한 정보가 필요하고, 특히 파일을 놓으려는 '버킷'의 이름과 현재 이 항목의 '상위 폴더' 프리픽스가 필요합니다.
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
버킷에 대한 표현... Cloud Storage는 무정형의 Blob 스토리지를 제공합니다. 여기에 파일을 업로드할 때 버킷은 Google 드라이브가 하듯이 파일 유형, 확장자 등의 개념을 이해하지 않습니다. 버킷은 단지 Cloud Storage에 대한 'Blob'일 뿐입니다. 또한 Cloud Storage에는 폴더 또는 하위 디렉터리라는 개념도 없습니다.
물론 파일 이름에 슬래시(/)를 사용해서 여러 하위 폴더를 추상적으로 표현할 수는 있습니다. 하지만 결국 모든 Blob은 버킷에 저장되고 '/'는 단지 해당 파일 이름에 포함된 문자에 지나지 않습니다. 자세한 내용은 버킷 및 객체 이름 지정 규칙 페이지를 참조하세요.
위 1단계에서는 Drive 읽기 전용 범위를 요청했습니다. 앞에서는 이 범위만 필요했습니다. 이제는 Cloud Storage에 업로드(읽기-쓰기) 권한이 필요합니다. 다음과 같이 보이도록 SCOPES를 단일 문자열 변수에서 권한 범위의 배열(Python 튜플 [또는 목록])로 변경합니다.
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
)
이제 Drive 바로 아래에서 Cloud Storage에 대한 서비스 엔드포인트를 만듭니다. 여기에서는 리소스 공유가 가능하여 새 리소스를 만들 필요가 없으므로 동일한 HTTP 클라이언트 객체를 다시 사용하도록 호출이 약간 수정되었습니다.
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
이제 Cloud Storage에 업로드되는 이 함수(drive_get_img() 다음)를 추가합니다.
def gcs_blob_upload(fname, bucket, media, mimetype):
'upload an object to a Google Cloud Storage bucket'
# build blob metadata and upload via GCS API
body = {'name': fname, 'uploadType': 'multipart', 'contentType': mimetype}
return GCS.objects().insert(bucket=bucket, body=body,
media_body=http.MediaIoBaseUpload(io.BytesIO(media), mimetype),
fields='bucket,name').execute()
objects.().insert() 호출은 버킷 이름, 파일 메타데이터, 바이너리 Blob 자체가 필요합니다. 반환 값을 필터링하기 위해 fields 변수는 API에서 반환된 버킷 및 객체 이름만 요청합니다. API 읽기 요청에서 이러한 필드 마스크에 대한 자세한 내용은 이 게시물 및 동영상을 참조하세요.
이제 gcs_blob_upload() 사용을 기본 애플리케이션에 통합합니다.
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
gcsname 변수는 파일 이름 자체가 추가된 모든 '상위에 있는 하위 디렉터리' 이름을 병합하고, 버킷 이름으로 프리픽스가 추가되었을 때 '/bucket/parent.../filename'에서 파일을 보관처리하는 느낌을 줍니다. 이 청크를 else 절 바로 위에 있는 첫 번째 print() 함수 바로 다음으로 밀어서, 전체 'main'이 다음과 같이 표시되도록 합니다.
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
else:
print('ERROR: Cannot download %r from Drive' % fname)
'vision-demo'라는 이름의 버킷을 'analyzed_imgs'를 '상위 하위 디렉터리'로 사용하여 구체화한다고 가정해보세요. 이러한 변수를 설정하고 스크립트를 다시 실행하면 section-work-card-img_2x.jpg가 Drive에서 다운로드된 후 Cloud Storage에 업로드됩니다.그렇죠? 아닙니다!
$ python3 analyze_gsimg.py
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Traceback (most recent call last):
File "analyze_gsimg.py", line 85, in <module>
io.BytesIO(data), mimetype=mtype), mtype)
File "analyze_gsimg.py", line 72, in gcs_blob_upload
media_body=media, fields='bucket,name').execute()
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/googleapiclient/_helpers.py", line 134, in positional_wrapper
return wrapped(*args, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/googleapiclient/http.py", line 898, in execute
raise HttpError(resp, content, uri=self.uri)
googleapiclient.errors.HttpError: <HttpError 403 when requesting https://storage.googleapis.com/upload/storage/v1/b/PROJECT_ID/o?fields=bucket%2Cname&alt=json&uploadType=multipart returned "Insufficient Permission">
자세히 보면 Drive 다운로드가 성공했지만 Cloud Storage 업로드가 실패했습니다. 이유가 무엇인가요?
처음 1단계에서 이 애플리케이션을 승인했을 때 Google 드라이브에 대해 읽기 전용 액세스만 승인했기 때문입니다. Cloud Storage에 읽기-쓰기 범위를 추가했을 때 사용자에게 이 액세스를 승인하도록 요청하지 않았습니다. 이를 작동하게 하려면 이 범위가 누락된 storage.json 파일을 없애고 다시 실행해야 합니다.
storage.json 안을 보고 두 범위가 모두 있는지 확인하여, 다시 승인을 마친 후에는 출력이 예상한 대로 표시됩니다.
$ python3 analyze_gsimg.py
. . .
Authentication successful.
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Uploaded 'analyzed_imgs/section-work-card-img_2x.jpg' to GCS bucket 'vision-demo'
요약
이것은 비교적 적은 수의 코드로 두 클라우드 기반 스토리지 시스템 간에 파일을 전송하는 방법을 보여주는 중요한 내용입니다. 여기에서 비즈니스 사용 사례는 제한적일 수 있는 리소스를 앞에서 설명한 것처럼 '더 차갑고', 더 저렴한 스토리지로 백업하는 것에 있습니다. Cloud Storage는 데이터를 월, 분기, 연도 등 정기적으로 액세스하는지 여부에 따라 서로 다른 스토리지 클래스를 제공합니다.
물론 개발자들은 Google 드라이브와 Cloud Storage가 모두 있는 이유를 가끔 물어보곤 합니다. 결국 둘 다 클라우드의 파일 스토리지가 아닌가요? 이 동영상을 제작한 이유가 바로 여기에 있습니다. 이 단계에서의 코드는 the repo atstep2-gcs/analyze_gsimg.py의 저장소에 있는 것과 일치합니다.
이제 GCP와 G Suite 사이에 데이터를 이동할 수 있다는 것을 알았지만 아직 어떠한 분석도 수행하지 않았습니다. 따라서 이제 객체 감지라고 부르는 라벨 주석을 위해 Cloud Vision에 이미지를 전송해야 할 시간입니다. 이렇게 하려면 또 다른 Python 모듈인 base64로 데이터를 Base64 인코딩해야 합니다. 위쪽의 가져오기 섹션이 이제 다음과 같이 표시되는지 확인합니다.
from __future__ import print_function
import base64
import io
기본적으로 Vision API는 발견되는 모든 라벨을 반환합니다. 일관성을 위해 상위 5개 항목(물론 사용자가 조정 가능한)만 요청해보겠습니다. 이를 위해서는 상수 변수 TOP가 사용됩니다. 이를 다른 모든 상수 아래에 추가합니다.
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
TOP = 5 # TOP # of VISION LABELS TO SAVE
이전 단계에서와 같이 또 다른 권한 범위가 필요합니다. 이번에는 Vision API입니다. 해당 문자열로 SCOPES를 업데이트합니다.
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
'https://www.googleapis.com/auth/cloud-vision',
)
이제 다음과 같이 다른 항목들과 일치하도록 Cloud Vision에 서비스 엔드포인트를 만듭니다.
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
VISION = discovery.build('vision', 'v1', http=HTTP)
이제 이미지 페이로드를 Cloud Vision으로 전송하는 이 함수를 추가합니다.
def vision_label_img(img, top):
'send image to Vision API for label annotation'
# build image metadata and call Vision API to process
body = {'requests': [{
'image': {'content': img},
'features': [{'type': 'LABEL_DETECTION', 'maxResults': top}],
}]}
rsp = VISION.images().annotate(body=body).execute().get('responses', [{}])[0]
# return top labels for image as CSV for Sheet (row)
if 'labelAnnotations' in rsp:
return ', '.join('(%.2f%%) %s' % (
label['score']*100., label['description']) \
for label in rsp['labelAnnotations'])
images().annotate() 호출은 데이터 및 필요한 API 기능이 필요합니다. 상위 5개 라벨 제한은 페이로드의 일부이기도 합니다(하지만 완전히 선택사항임). 호출이 성공하면 페이로드가 상위 5개 객체 라벨과 이미지에서 객체의 신뢰도 점수를 반환합니다. (응답이 없으면 다음 if 문이 실패하지 않도록 빈 Python 사전을 할당합니다.) 이 함수는 결국 보고서에서 사용할 수 있도록 데이터를 CSV 문자열로 단순히 조합합니다.
vision_label_img()를 호출하는 이 5개 줄은 Cloud Storage 업로드가 성공한 직후 배치되어야 합니다.
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'), TOP)
if rsp:
print('Top %d labels from Vision API: %s' % (TOP, rsp))
else:
print('ERROR: Vision API cannot analyze %r' % fname)
또한 전체 기본 드라이버가 다음과 같아야 합니다.
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'), TOP)
if rsp:
print('Top %d labels from Vision API: %s' % (TOP, rsp))
else:
print('ERROR: Vision API cannot analyze %r' % fname)
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
else:
print('ERROR: Cannot download %r from Drive' % fname)
범위를 새로고침하기 위해 storage.json을 삭제하고 업데이트된 애플리케이션을 다시 실행하면 다음과 비슷한 출력이 표시됩니다. 여기에서는 Cloud Vision 분석이 추가된 것에 주의하세요.
$ python3 analyze_gsimg.py
. . .
Authentication successful.
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Uploaded 'analyzed_imgs/section-work-card-img_2x.jpg' to GCS bucket 'vision-demo'
Top 5 labels from Vision API: (89.94%) Sitting, (86.09%) Interior design, (82.08%) Furniture, (81.52%) Table, (80.85%) Room
요약
모든 사람들이 데이터 분석을 위해 자신의 고유 ML 모델을 만들고 학습시키는 머신러닝 전문 지식을 갖고 있지는 않습니다. Google Cloud 팀은 일반 용도로 사용할 수 있는 몇 가지 Google에서 사전 학습된 모델을 제공하고, 모든 사람이 AI 및 ML을 활용할 수 있도록 API에 포함시켰습니다.
API를 호출할 수 있는 개발자라면 머신러닝을 이용할 수 있습니다. Cloud Vision은 데이터 분석을 위해 사용할 수 있는 API 서비스 중 하나에 불과합니다. 다른 여러 서비스에 대해 알아보려면 여기를 참조하세요. 이제 코드는 step3-vision/analyze_gsimg.py의 저장소에 있는 것과 일치합니다.
지금까지 회사 데이터를 보관처리하고 이를 분석할 수 있었지만, 이러한 작업에 대한 요약이 부족합니다. 이제 모든 결과를 경영진에 전달할 수 있는 하나의 보고서로 정리해보세요. 경영진에 스프레드시트보다 더 효과적으로 보여줄 수 있는 방법은 무엇일까요?
Google Sheets API는 추가적인 가져오기가 필요하지 않으며, 이미 형식이 지정되어 있고 새로운 데이터 행을 기다리는 즉, SHEET 상수를 기다리는 기존 스프레드시트에서 파일 ID만 새로 가져오면 됩니다. 다음과 비슷하게 보이는 새 스프레드시트를 만드는 것이 좋습니다.

해당 스프레드시트의 URL은 https://docs.google.com/spreadsheets/d/FILE_ID/edit입니다. FILE_ID를 가져와서 이를 SHEET에 문자열로 할당합니다.
또한 간단한 1줄짜리 코드이기 때문에 바이트를 킬로바이트로 변환하는 k_ize()라는 작은 함수를 숨겨놓고, 이를 Python lambda로 정의했습니다. 다른 상수와 통합된 이것들은 모두 다음과 같습니다.
k_ize = lambda b: '%6.2fK' % (b/1000.) # bytes to kBs
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
SHEET = 'YOUR_SHEET_ID'
TOP = 5 # TOP # of VISION LABELS TO SAVE
이전 단계에서와 같이 또 다른 권한 범위가 필요하며, 이번에는 Sheets API에 대한 읽기-쓰기입니다. SCOPES에 이제 모두 4개가 필요합니다.
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
'https://www.googleapis.com/auth/cloud-vision',
'https://www.googleapis.com/auth/spreadsheets',
)
이제 다른 것들 근처에 Google Sheets에 서비스 엔드포인트를 만듭니다. 이것은 다음과 같습니다.
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
VISION = discovery.build('vision', 'v1', http=HTTP)
SHEETS = discovery.build('sheets', 'v4', http=HTTP)
sheet_append_row()의 기능은 직관적입니다. 데이터의 행과 Sheet의 ID를 가져와서 이 행을 해당 Sheet에 추가합니다.
def sheet_append_row(sheet, row):
'append row to a Google Sheet, return #cells added'
# call Sheets API to write row to Sheet (via its ID)
rsp = SHEETS.spreadsheets().values().append(
spreadsheetId=sheet, range='Sheet1',
valueInputOption='USER_ENTERED', body={'values': [row]}
).execute()
if rsp:
return rsp.get('updates').get('updatedCells')
spreadsheets().values().append() 호출에는 Sheet의 파일 ID, 셀 범위, 데이터 입력 방법, 데이터 자체가 필요합니다. 파일 ID는 직관적입니다. 셀 범위는 A1 주석에 지정됩니다. 'Sheet1' 범위는 전체 Sheet를 의미합니다. 이것은 Sheet의 모든 데이터 다음에 행을 추가하도록 API에 신호를 보냅니다. Sheet에 데이터를 추가하는 방법으로는 'RAW'(문자열 데이터를 그대로 입력) 또는 'USER_ENTERED'(Google Sheets 애플리케이션에서 사용자가 자신의 키보드로 입력하는 것과 같이 데이터를 기록하여 모든 셀 형식 특성을 보존) 옵션 중에서 선택할 수 있습니다.
호출이 성공해도 반환 값에는 특별히 유용한 것이 실제로 포함되지 않으므로, API 요청으로 업데이트되는 셀 수를 가져오도록 했습니다. 다음은 이 함수를 호출하는 코드입니다.
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [PARENT,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
BUCKET, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(SHEET, row)
if rsp:
print('Updated %d cells in Google Sheet' % rsp)
else:
print('ERROR: Cannot write row to Google Sheets')
Google Sheet에는 상위 '하위 디렉터리', Cloud Storage에 있는 보관처리된 파일의 위치(버킷 + 파일 이름), 파일의 MIMEtype, 파일 크기(원래 바이트 단위이지만, k_ize()를 사용해서 킬로바이트로 변환됨), Cloud Vision 라벨 문자열과 같은 데이터를 제공하는 열이 포함됩니다. 또한 보관처리된 위치는 관리자가 클릭하여 안전하게 백업되었는지 확인할 수 있는 하이퍼링크입니다.
구조적으로 약간 복잡해 보일 수도 있지만 Cloud Vision의 결과를 표시한 바로 직후 위의 코드 블록을 추가하여, 앱을 구동하는 주요 부분이 이제 완료되었습니다.
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'))
if rsp:
print('Top %d labels from Vision API: %s' % (TOP, rsp))
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [PARENT,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
BUCKET, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(SHEET, row)
if rsp:
print('Updated %d cells in Google Sheet' % rsp)
else:
print('ERROR: Cannot write row to Google Sheets')
else:
print('ERROR: Vision API cannot analyze %r' % fname)
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
else:
print('ERROR: Cannot download %r from Drive' % fname)
마지막으로 한 번 더 storage.json을 삭제하고 업데이트된 애플리케이션을 다시 실행하면 다음과 같은 출력이 표시됩니다. Cloud Vision 분석이 추가된 것에 주의하세요.
$ python3 analyze_gsimg.py
. . .
Authentication successful.
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Uploaded 'analyzed_imgs/section-work-card-img_2x.jpg' to GCS bucket 'vision-demo'
Top 5 labels from Vision API: (89.94%) Sitting, (86.09%) Interior design, (82.08%) Furniture, (81.52%) Table, (80.85%) Room
Updated 6 cells in Google Sheet
유용하지만 출력의 추가 행은 업데이트된 Google Sheet를 살펴볼 때 더 효과적으로 시각화됩니다. 아래 예시에서 7번 행에 있는 마지막 줄은 기존 데이터 집합에 추가되었습니다.

요약
이 가이드의 처음 3개 단계에서는 데이터를 이동하고 분석하기 위해 G Suite 및 GCP API에 연결했습니다. 이것은 모든 작업의 80%에 해당합니다. 하지만 수행한 모든 작업을 경영진에 제대로 보여줄 수 없다면, 결국 이 모든 노력이 아무 의미 없는 일이 될 수 있습니다. 결과를 더 효과적으로 시각화하기 위해서는 생성된 보고서로 모든 결과를 요약해야 합니다.
분석에 따른 유용성을 더 향상시키기 위해 결과를 스프레드시트에 기록하는 것 외에도 한 가지 가능한 향상 방법은 각 이미지에 이러한 상위 5개 라벨을 색인으로 생성하는 것입니다. 이렇게 하면 승인된 직원이 검색 팀에 이미지를 쿼리할 수 있게 허용하도록 내부 데이터베이스를 빌드할 수 있지만, 이것은 독자를 위한 연습으로 남겨두었습니다.
지금으로서는 결과가 Sheet에 저장되었고 경영진이 볼 수 있도록 준비되었습니다. 이 단계의 앱 코드는 step4-sheets/analyze_gsimg.py의 저장소에 있는 것과 일치합니다. 마지막 단계는 코드를 삭제하고 사용 가능한 스크립트로 전환하는 것입니다.
(선택사항) 앱이 작동은 잘 됩니다. 이를 더 개선할 수 있나요? 예, 특히 엉망진창으로 뒤범벅된 것처럼 보이는 기본 애플리케이션이라면 더욱 그렇습니다. 이를 수정된 상수 대신 고유 함수로 놓고 사용자 입력을 허용하도록 만들어 보겠습니다. 이를 위해서는 argparse 모듈을 사용합니다. 또한 데이터 행을 기록한 후 Sheet를 표시하도록 웹브라우저 탭을 시작합니다. 이 작업은 webbrowser 모듈을 사용하여 수행할 수 있습니다. 이러한 가져오기를 다른 작업과 엮어서 다음과 같이 표시되도록 합니다.
from __future__ import print_function
import argparse
import base64
import io
import webbrowser
다른 애플리케이션에서 이 코드를 사용할 수 있도록 하려면 출력을 숨기는 기능이 필요합니다. 따라서 이렇게 되도록 DEBUG 플래그를 추가해보겠습니다. 이 줄을 상단 근처의 상수 섹션 끝에 추가합니다.
DEBUG = False
이제 기본 본문을 처리합니다. 이 샘플을 빌드할 때 귀하는 각 서비스가 추가될 때마다 코드가 계속 중첩되는 것을 보면서 '불편함'을 갖기 시작했을 것입니다. 그렇게 느꼈다면, 귀하는 혼자가 아닙니다. 이러한 방식은 이 Google Testing 블로그 게시물에 설명된 것처럼 코드에 복잡성을 더하기 때문입니다.
이 권장사항에 따라 이제는 중첩 대신 각 '중단점'에서 앱의 주요 부분을 함수 및 return으로 다시 정리해봅시다(단계가 실패하면 None을 반환하고, 모두 성공하면 True 반환).
def main(fname, bucket, sheet_id, folder, top, debug):
'"main()" drives process from image download through report generation'
# download img file & info from Drive
rsp = drive_get_img(fname)
if not rsp:
return
fname, mtype, ftime, data = rsp
if debug:
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (folder, fname)
rsp = gcs_blob_upload(gcsname, bucket, data, mtype)
if not rsp:
return
if debug:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'))
if not rsp:
return
if debug:
print('Top %d labels from Vision API: %s' % (top, rsp))
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [folder,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
bucket, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(sheet_id, row)
if not rsp:
return
if debug:
print('Added %d cells to Google Sheet' % rsp)
return True
위에 설명한 대로 코드 복잡성을 줄이는 것과 재귀적인 if-else 체인은 뒤에 남겨두고 이렇게 하는 것이 더 간단하고 깨끗합니다. 이 퍼즐의 마지막 조각은 '실제의' 기본 드라이버를 만들어서, 사용자 맞춤설정을 어용하고 (필요한 경우가 아니라면) 출력을 최소화하는 것입니다.
if __name__ == '__main__':
# args: [-hv] [-i imgfile] [-b bucket] [-f folder] [-s Sheet ID] [-t top labels]
parser = argparse.ArgumentParser()
parser.add_argument("-i", "--imgfile", action="store_true",
default=FILE, help="image file filename")
parser.add_argument("-b", "--bucket_id", action="store_true",
default=BUCKET, help="Google Cloud Storage bucket name")
parser.add_argument("-f", "--folder", action="store_true",
default=PARENT, help="Google Cloud Storage image folder")
parser.add_argument("-s", "--sheet_id", action="store_true",
default=SHEET, help="Google Sheet Drive file ID (44-char str)")
parser.add_argument("-t", "--viz_top", action="store_true",
default=TOP, help="return top N (default %d) Vision API labels" % TOP)
parser.add_argument("-v", "--verbose", action="store_true",
default=DEBUG, help="verbose display output")
args = parser.parse_args()
print('Processing file %r... please wait' % args.imgfile)
rsp = main(args.imgfile, args.bucket_id,
args.sheet_id, args.folder, args.viz_top, args.verbose)
if rsp:
sheet_url = 'https://docs.google.com/spreadsheets/d/%s/edit' % args.sheet_id
print('DONE: opening web browser to it, or see %s' % sheet_url)
webbrowser.open(sheet_url, new=1, autoraise=True)
else:
print('ERROR: could not process %r' % args.imgfile)
모든 단계가 성공하면 스크립트가 웹브라우저를 시작하여 새 데이터 행이 추가된 위치에 지정된 스프레드시트로 연결합니다.
요약
범위 변경이 없으므로 storage.json을 삭제할 필요가 없습니다. 업데이트된 애플리케이션을 다시 실행하면 새 브라우저 창이 출력 행 수가 더 적은 수정된 Sheet로 열리고, -h 옵션을 실행하면 사용자에게 이전에 표시된 출력의 현재 숨겨진 줄을 복원하기 위한 -v를 포함한 옵션이 표시됩니다.
$ python3 analyze_gsimg.py Processing file 'section-work-card-img_2x.jpg'... please wait DONE: opening web browser to it, or see https://docs.google.com/spreadsheets/d/SHEET_ID/edit $ python3 analyze_gsimg.py -h usage: analyze_gsimg.py [-h] [-i] [-t] [-f] [-b] [-s] [-v] optional arguments: -h, --help show this help message and exit -i, --imgfile image file filename -t, --viz_top return top N (default 5) Vision API labels -f, --folder Google Cloud Storage image folder -b, --bucket_id Google Cloud Storage bucket name -s, --sheet_id Google Sheet Drive file ID (44-char str) -v, --verbose verbose display output
이러한 다른 옵션을 사용하여 사용자가 여러 Drive 파일 이름, Cloud Storage '하위 디렉터리' 및 버킷 이름, Cloud Vision의 상위 'N'개 결과, 스프레드시트 Sheets 파일 ID를 선택할 수 있습니다. 마지막 업데이트로 최종 코드 버전은 여기에 표시된 것은 물론 final/analyze_gsimg.py의 저장소에 있는 것과 일치합니다.
## Copyright 2020 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
'''
analyze_gsimg.py - analyze G Suite image processing workflow
Download image from Google Drive, archive to Google Cloud Storage, send
to Google Cloud Vision for processing, add results row to Google Sheet.
'''
from __future__ import print_function
import argparse
import base64
import io
import webbrowser
from googleapiclient import discovery, http
from httplib2 import Http
from oauth2client import file, client, tools
k_ize = lambda b: '%6.2fK' % (b/1000.) # bytes to kBs
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
SHEET = 'YOUR_SHEET_ID'
TOP = 5 # TOP # of VISION LABELS TO SAVE
DEBUG = False
# process credentials for OAuth2 tokens
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
'https://www.googleapis.com/auth/cloud-vision',
'https://www.googleapis.com/auth/spreadsheets',
)
store = file.Storage('storage.json')
creds = store.get()
if not creds or creds.invalid:
flow = client.flow_from_clientsecrets('client_secret.json', SCOPES)
creds = tools.run_flow(flow, store)
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
VISION = discovery.build('vision', 'v1', http=HTTP)
SHEETS = discovery.build('sheets', 'v4', http=HTTP)
def drive_get_img(fname):
'download file from Drive and return file info & binary if found'
# search for file on Google Drive
rsp = DRIVE.files().list(q="name='%s'" % fname,
fields='files(id,name,mimeType,modifiedTime)'
).execute().get('files', [])
# download binary & return file info if found, else return None
if rsp:
target = rsp[0] # use first matching file
fileId = target['id']
fname = target['name']
mtype = target['mimeType']
binary = DRIVE.files().get_media(fileId=fileId).execute()
return fname, mtype, target['modifiedTime'], binary
def gcs_blob_upload(fname, bucket, media, mimetype):
'upload an object to a Google Cloud Storage bucket'
# build blob metadata and upload via GCS API
body = {'name': fname, 'uploadType': 'multipart', 'contentType': mimetype}
return GCS.objects().insert(bucket=bucket, body=body,
media_body=http.MediaIoBaseUpload(io.BytesIO(media), mimetype),
fields='bucket,name').execute()
def vision_label_img(img, top):
'send image to Vision API for label annotation'
# build image metadata and call Vision API to process
body = {'requests': [{
'image': {'content': img},
'features': [{'type': 'LABEL_DETECTION', 'maxResults': top}],
}]}
rsp = VISION.images().annotate(body=body).execute().get('responses', [{}])[0]
# return top labels for image as CSV for Sheet (row)
if 'labelAnnotations' in rsp:
return ', '.join('(%.2f%%) %s' % (
label['score']*100., label['description']) \
for label in rsp['labelAnnotations'])
def sheet_append_row(sheet, row):
'append row to a Google Sheet, return #cells added'
# call Sheets API to write row to Sheet (via its ID)
rsp = SHEETS.spreadsheets().values().append(
spreadsheetId=sheet, range='Sheet1',
valueInputOption='USER_ENTERED', body={'values': [row]}
).execute()
if rsp:
return rsp.get('updates').get('updatedCells')
def main(fname, bucket, sheet_id, folder, top, debug):
'"main()" drives process from image download through report generation'
# download img file & info from Drive
rsp = drive_get_img(fname)
if not rsp:
return
fname, mtype, ftime, data = rsp
if debug:
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (folder, fname)
rsp = gcs_blob_upload(gcsname, bucket, data, mtype)
if not rsp:
return
if debug:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'), top)
if not rsp:
return
if debug:
print('Top %d labels from Vision API: %s' % (top, rsp))
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [folder,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
bucket, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(sheet_id, row)
if not rsp:
return
if debug:
print('Added %d cells to Google Sheet' % rsp)
return True
if __name__ == '__main__':
# args: [-hv] [-i imgfile] [-b bucket] [-f folder] [-s Sheet ID] [-t top labels]
parser = argparse.ArgumentParser()
parser.add_argument("-i", "--imgfile", action="store_true",
default=FILE, help="image file filename")
parser.add_argument("-b", "--bucket_id", action="store_true",
default=BUCKET, help="Google Cloud Storage bucket name")
parser.add_argument("-f", "--folder", action="store_true",
default=PARENT, help="Google Cloud Storage image folder")
parser.add_argument("-s", "--sheet_id", action="store_true",
default=SHEET, help="Google Sheet Drive file ID (44-char str)")
parser.add_argument("-t", "--viz_top", action="store_true",
default=TOP, help="return top N (default %d) Vision API labels" % TOP)
parser.add_argument("-v", "--verbose", action="store_true",
default=DEBUG, help="verbose display output")
args = parser.parse_args()
print('Processing file %r... please wait' % args.imgfile)
rsp = main(args.imgfile, args.bucket_id,
args.sheet_id, args.folder, args.viz_top, args.verbose)
if rsp:
sheet_url = 'https://docs.google.com/spreadsheets/d/%s/edit' % args.sheet_id
print('DONE: opening web browser to it, or see %s' % sheet_url)
webbrowser.open(sheet_url, new=1, autoraise=True)
else:
print('ERROR: could not process %r' % args.imgfile)
이 가이드의 내용을 항상 최신 상태로 유지하기 위해 노력하더라도, 경우에 따라 저장소에 최신 버전의 코드가 포함될 수 있습니다.
이 Codelab에는 분명히 많은 학습 사항이 포함되었으며, 귀하도 이를 달성하여, 긴 Codelab 중 하나에서 살아남으셨습니다. 결과적으로 약 130줄에 달하는 Python 코드가 포함된 가상 기업 시나리오를 진행하면서, 모든 Google Cloud(GCP + G Suite) 제품을 활용하고, 작동 가능한 솔루션을 빌드하기 위해 이들 간의 데이터 이동까지 수행했습니다. 이 앱의 모든 버전을 보기 위해서는 언제든지 오픈소스 저장소를 살펴보시기 바랍니다(아래 참조).
삭제
- GCP API는 무료가 아닙니다. 하지만 G Suite API는 월간 G Suite 구독 요금에 포함되며, Gmail 소비자 사용자로서 월간 요금이 0일 수 있습니다. 따라서 G Suite 사용자의 경우 API 삭제/거부가 필요하지 않습니다. GCP의 경우 Cloud Console 대시보드로 이동하고 결제 '카드'에서 예상 비용을 확인할 수 있습니다.
- Cloud Vision의 경우 매월 고정된 숫자의 API 호출이 무료로 허용됩니다. 따라서 이러한 제한을 넘지 않는 한 아무 것도 종료하거나 프로젝트를 사용 중지/삭제할 필요가 없습니다. Vision APIㅇ의 결제 및 무료 할당량에 대한 자세한 내용은 해당 가격 책정 페이지를 참조하세요.
- 일부 Cloud Storage 사용자에게는 매월 무료 스토리지 용량이 제공됩니다. 이 Codelab을 사용하여 보관처리하는 이미지로 인해 할당량을 초과하지 않을 경우에는 비용이 발생하지 않습니다. GCS 결제 및 무료 할당량에 대한 자세한 내용은 가격 책정 페이지를 참조하세요. Cloud Storage 브라우저에서 Blob을 보고 쉽게 삭제할 수 있습니다.
- Google 드라이브 사용도 저장용량 할당량을 포함할 수 있고, 이를 초과하거나 근접하면, Drive에서 공간을 늘리기 위해 Cloud Storage에 이러한 이미지를 보관처리하기 위해 실제로 이 Codelab에서 빌드한 도구를 사용할 것을 고려할 수 있습니다. Google 드라이브 스토리지에 대한 자세한 내용은 G Suite Basic 사용자 또는 Gmail/소비자 사용자에 대한 적합한 가격 책정 페이지를 참조하세요.
대부분의 G Suite Business 및 Enterprise 요금제에는 스토리지가 무제한이지만, 이로 인해 Drive 폴더가 가득차고 관리가 어려워질 수 있습니다. 이 가이드에서 빌드하는 앱은 여분의 파일을 보관처리하고 Google 드라이브를 삭제하기 위한 좋은 방법입니다.
대체 버전
final/analyze_gsimg.py가 이 가이드에서 작업하는 '마지막' 공식 버전이지만, 이것이 끝은 아닙니다. 이 앱의 최종 버전에서 한 가지 문제는 지원이 중단된 오래된 인증 라이브러리를 사용한다는 것입니다. 이 글을 작성할 당시에는 새로운 인증 라이브러리에서 몇 가지 핵심 요소인 OAuth 토큰 스토리지 관리 및 스레드 안전성을 지원하지 않았기 때문에 이 경로가 선택되었습니다.
현재(새로운) 인증 라이브러리
하지만 어느 시점에서든 이전의 인증 라이브러리는 더 이상 지원되지 않을 것이므로, 스레드에 안전하지 않더라도(하지만 스레드에 안전한 고유 솔루션을 빌드할 수 있음) 저장소의 alt 폴더에 있는 새로운(현재) 인증 라이브러리를 사용하는 버전들을 검토하는 것이 좋습니다. 이름에 *newauth*가 있는 파일을 찾으면 됩니다.
GCP 제품 클라이언트 라이브러리
Google Cloud은 모든 개발자가 GCP API를 사용할 때 제품 클라이언트 라이브러리를 사용할 것을 권장합니다. 하지만 지금은 비GCP API 중 이러한 라이브러리가 포함된 것이 없습니다. 하위 수준의 플랫폼 라이브러리를 사용하면 API 사용 일관성과 가독성을 높일 수 있습니다. 위의 권장사항과 비슷하게, GCP 제품 클라이언트 라이브러리를 사용하는 대체 버전이 사용자가 검토해볼 수 있도록 저장소의 alt 폴더에 제공됩니다. 이름에 *-gcp*가 있는 파일을 찾으면 됩니다.
서비스 계정 승인
클라우드에서만 작업할 때는 일반적으로 사람 또는 사람인 사용자가 소유하는 데이터가 없습니다. 따라서 서비스 계정 및 서비스 계정 승인이 주로 GCP에 사용됩니다. 하지만 G Suite 문서는 일반적으로 사람인 사용자에 의해 소유됩니다. 따라서 이 가이드에서는 사용자 계정 승인을 사용합니다. 그렇다고 해서 G Suite API를 서비스 계정에 사용할 수 없는 것은 아닙니다. 이러한 계정에 적합한 액세스 수준이 포함되어 있는 한 애플리케이션에 확실히 사용될 수 있습니다. 위와 비슷하게 서비스 계정 승인을 사용하는 대체 버전이 사용자가 검토해볼 수 있도록 저장소의 alt 폴더에 제공됩니다. 이름에 *-svc*가 있는 파일을 찾으면 됩니다.
대체 버전 카탈로그
아래에서는 각각 위의 속성 중 하나 이상이 포함된 final/analyze_gsimg.py의 모든 대체 버전을 찾을 수 있습니다. 각 버전의 파일 이름에서 다음을 찾습니다.
- 이전 인증 라이브러리를 사용하는 버전의 경우 '
oldauth'(final/analyze_gsimg.py추가) - 현재/새로운 인증 라이브러리를 사용하는 버전의 경우 '
newauth' - GCP 제품 클라이언트 라이브러리(즉, google-cloud-storage 등)를 사용하는 버전의 경우 '
gcp' - 사용자 계정 대신 서비스 계정('svc acct') 인증을 사용하는 버전의 경우 '
svc'
모든 버전은 다음과 같습니다.
파일 이름 | 설명 |
| 기본 샘플, 이전 인증 라이브러리 사용 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
원래 final/analyze_gsimg.py와 결합된, Google API 개발 환경에 관계없이 최종 솔루션의 모든 가능한 조합을 사용할 수 있고, 자신의 요구에 가장 적합한 것을 선택할 수 있습니다. 또한 alt/README.md에서 비슷한 설명을 참조하세요.
추가 연구
다음은 이 연습을 한 두 단계 더 진행하기 위한 몇 가지 아이디어입니다. 현재 솔루션이 처리할 수 있는 문제를 확장하여 다음과 같은 기능 개선을 가져올 수 있습니다.
- (폴더의 여러 이미지) 이미지 하나를 처리하는 대신 Google 드라이브 폴더에 이미지가 여러 개 있다고 가정해보세요.
- (ZIP 파일의 여러 이미지) 이미지 폴더 대신 이미지 파일이 포함된 ZIP 아카이브가 있다고 가정해보세요. Python을 사용하는 경우
zipfile모듈을 고려하세요. - (Vision 라벨 분석) 비슷한 이미지를 하나로 묶고, 일반적인 순서에 따라 라벨을 찾을 수 있습니다.
- (차트 만들기) 후속 조치 3번, Vision API 분석 및 분류를 기준으로 Sheets API로 차트를 생성합니다.
- (문서 분류) 이미지를 Cloud Vision API로 분석하는 대신 PDF 파일을 사용하여 Cloud Natural Language API로 분류한다고 가정해보세요. 위 솔루션을 사용하면 이러한 PDF를 Drive 폴더 또는 Drive의 ZIP 아카이브에 둘 수 있습니다.
- (프레젠테이션 만들기) Slides API를 사용하여 Google Sheet 보고서의 내용으로부터 슬라이드 덱을 생성합니다. 아이디어를 얻으려면 스프레드시트 데이터에서 슬라이드 생성에 대한 이 블로그 게시물 및 동영상을 참조하세요.
- (PDF로 내보내기) 스프레드시트 및/또는 슬라이드 덱을 PDF로 내보내지만, 이것은 Sheets 또는 Slides API의 기능이 아닙니다. 힌트: Google Drive API. 추가 크레딧: Ghostscript(Linux, Windows) 또는
Combine PDF Pages.action(Mac OS X)과 같은 도구를 사용하여 Sheets 및 Slides PDF를 하나의 마스터 PDF로 병합합니다.
자세히 알아보기
Codelab
- G Suite API 소개(Google Drive API)(Python)
- Python과 함께 Cloud Vision 사용(Python)
- 맞춤설정된 보고 도구 빌드(Google Sheets API)(JS/Node)
- Google Cloud Storage에 객체 업로드(코드 불필요)
일반
G Suite
Google Cloud Platform(GCP)
- Google Cloud Storage 홈페이지
- Google Cloud Vision 홈페이지 및 라이브 데모
- Cloud Vision API 문서
- Vision API 이미지 라벨 지정 문서
- Google Cloud Platform의 Python
- GCP 제품 클라이언트 라이브러리
- GCP 문서
라이선스
이 작업물은 Creative Commons Attribution 2.0 일반 라이선스에 따라 사용이 허가되었습니다.