
1. Einführung
In diesem Codelab erfahren Sie, wie Sie mit BigQuery Graph ein Netzwerk für Arzneimittel-Ziel-Interaktionen modellieren und analysieren. Sie nutzen die Leistungsfähigkeit von Graph-Abfragen (GQL), um zu untersuchen, wie Arzneimittel mit biologischen Zielen interagieren, potenzielle Nebenwirkungen (z. B. Herzrisiken) zu identifizieren und potenzielle Kombinationstherapien zu finden.
🧬 Anwendungsfall: Netzwerk für Arzneimittel-Ziel-Interaktionen
Geschäftliche Frage:Wie groß ist der vollständige Wirkungsradius einer Verbindung? An welche Ziele bindet sie sich, welche biologischen Prozesse sind betroffen und welche Krankheitsbereiche sind beteiligt?
Tabellen :
Tabelle | Beschreibung |
| Arzneimittelmoleküle mit Wirkmechanismus und Entwicklungsstadium |
| Proteinziele mit Gen-Namen und UniProt-IDs |
| Bindungsaffinität zwischen Verbindung und Ziel (primäre Ziele + Off-Targets) |
| Biologische Prozesse mit Zuordnungen zu Krankheitsbereichen |
| Verknüpfungstabelle, die Ziele mit den Prozessen verknüpft, an denen sie beteiligt sind |
Eigenschaftsgraphmodell :
(Compound)-[BINDS_TO {affinity_nm, ic50_nm, interaction_type}]->(Target)
(Target)-[PARTICIPATES_IN {role, importance_score}]->(Pathway)
🔍 Demoabfragen
Abfrage | Enthaltene Informationen |
Abfrage 1: Zielbindungsprofil | Traversal mit einem Hop: Verbindung zu allen primären und Off-Targets |
Abfrage 2: Erkennung von hERG-Herzrisiken | Traversal mit zwei Hops: Verbindung → hERG-Ziel → Herzprozess |
Abfrage 3: Verbindungspaare mit gemeinsamem Ziel | Bidirektionale Übereinstimmung: Zwei Verbindungen, die auf denselben Zielknoten zulaufen |
Abfrage 4: Wirkungsradius des Krankheitsprozesses | Aggregation mit zwei Hops: Vollständige Abdeckung von Prozess und Krankheitsbereich pro Verbindung |
Abfrage 5: Auswahl sicherer Verbindungen | Verbindungen mit hoher onkologischer Abdeckung, aber ohne hERG-Herzrisiko |
Aufgaben
- BigQuery-Dataset und -Schema für das Netzwerk für Arzneimittel-Ziel-Interaktionen erstellen
- Beispieldaten laden (Verbindungen, Ziele, Interaktionen, Prozesse, Zielprozesse)
- Eigenschaftsgraph in BigQuery erstellen, der diese Entitäten verknüpft
- Graph abfragen, um Verbindungsinteraktionen, biologische Prozesse und den Wirkungsradius von Krankheiten mithilfe von Graph-Traversals (
GRAPH_TABLEundMATCH) zu verstehen - GQL und Standard-SQL nebeneinander vergleichen, um die Einfachheit und Ausdrucksstärke der Graph-Syntax zu verstehen
Voraussetzungen
- Ein Webbrowser wie Chrome
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
Dieses Codelab richtet sich an Entwickler aller Erfahrungsstufen, auch an Anfänger.
2. Hinweis
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein.
Cloud Shell starten
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.
- Authentifizierung überprüfen:
gcloud auth list
- Bestätigen Sie Ihr Projekt:
gcloud config get project
- Legen Sie es bei Bedarf fest:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
APIs aktivieren
Führen Sie diesen Befehl aus, um die erforderliche BigQuery API zu aktivieren:
gcloud services enable bigquery.googleapis.com
3. Schema definieren und Daten laden
Zuerst müssen Sie ein Dataset erstellen, um Ihre graphbezogenen Tabellen zu speichern und sie mit Beispieldaten zu füllen.
- Wechseln Sie in der Google Cloud Console zu BigQuery Studio.
- Klicken Sie auf den SQL-Editor , um einen neuen Abfragetab zu öffnen.
- Führen Sie die folgende Anweisung aus, um das Dataset
drug_target_graphzu erstellen:
CREATE SCHEMA IF NOT EXISTS drug_target_graph
OPTIONS (location = 'US');
Erstellen Sie nun die fünf Quelltabellen, indem Sie die folgenden DDL-Abfragen in BigQuery Studio ausführen.
1. Tabelle compounds erstellen
Enthält Arzneimittelmoleküle, ihren Wirkmechanismus, das Entwicklungsstadium und den therapeutischen Bereich.
CREATE OR REPLACE TABLE drug_target_graph.compounds AS
SELECT 'CPD001' AS compound_id, 'Imatinib' AS compound_name, 'Kinase Inhibitor' AS mechanism_of_action, 'Approved' AS dev_stage, 'Oncology' AS therapeutic_area, 479.6 AS molecular_weight UNION ALL
SELECT 'CPD002', 'Gefitinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 446.9 UNION ALL
SELECT 'CPD003', 'Erlotinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 393.4 UNION ALL
SELECT 'CPD004', 'Sorafenib', 'Multi-Kinase Inhibitor', 'Approved', 'Oncology', 464.8 UNION ALL
SELECT 'CPD005', 'Vemurafenib', 'BRAF Inhibitor', 'Approved', 'Oncology', 489.9 UNION ALL
SELECT 'CPD006', 'Crizotinib', 'ALK Inhibitor', 'Approved', 'Oncology', 450.3 UNION ALL
SELECT 'CPD007', 'Idelalisib', 'PI3K Inhibitor', 'Approved', 'Oncology', 415.4 UNION ALL
SELECT 'CPD008', 'Trametinib', 'MEK Inhibitor', 'Approved', 'Oncology', 615.4 UNION ALL
SELECT 'CPD009', 'Palbociclib', 'CDK Inhibitor', 'Approved', 'Oncology', 447.5 UNION ALL
SELECT 'CPD010', 'Compound-X1', 'Kinase Inhibitor', 'Phase II', 'Oncology', 412.3 UNION ALL
SELECT 'CPD011', 'Compound-X2', 'PI3K Inhibitor', 'Phase I', 'Oncology', 398.7 UNION ALL
SELECT 'CPD012', 'Saquinavir', 'Protease Inhibitor', 'Approved', 'Infectious Disease', 670.8 UNION ALL
SELECT 'CPD013', 'Metformin', 'AMPK Activator', 'Approved', 'Metabolic', 165.6 UNION ALL
SELECT 'CPD014', 'Rapamycin', 'mTOR Inhibitor', 'Approved', 'Immunology', 914.2 UNION ALL
SELECT 'CPD015', 'Compound-X3', 'Multi-Kinase Inhibitor', 'Preclinical', 'Oncology', 502.1;
2. Tabelle targets erstellen
Enthält Proteinziele, Gen-Namen, UniProt-IDs und Zielklassen.
CREATE OR REPLACE TABLE drug_target_graph.targets AS
SELECT 'TGT001' AS target_id, 'BCR-ABL1' AS target_name, 'ABL1' AS gene_name, 'P00519' AS uniprot_id, 'Kinase' AS target_class, TRUE AS is_oncogene UNION ALL
SELECT 'TGT002', 'EGFR', 'EGFR', 'P00533', 'Kinase', TRUE UNION ALL
SELECT 'TGT003', 'VEGFR2', 'KDR', 'P35968', 'Kinase', FALSE UNION ALL
SELECT 'TGT004', 'BRAF', 'BRAF', 'P15056', 'Kinase', TRUE UNION ALL
SELECT 'TGT005', 'ALK', 'ALK', 'Q9UM73', 'Kinase', TRUE UNION ALL
SELECT 'TGT006', 'PI3K-alpha','PIK3CA', 'P42336', 'Lipid Kinase', TRUE UNION ALL
SELECT 'TGT007', 'MEK1', 'MAP2K1', 'Q02750', 'Kinase', FALSE UNION ALL
SELECT 'TGT008', 'CDK4', 'CDK4', 'P11802', 'Kinase', FALSE UNION ALL
SELECT 'TGT009', 'CDK6', 'CDK6', 'P30279', 'Kinase', FALSE UNION ALL
SELECT 'TGT010', 'mTOR', 'MTOR', 'P42345', 'Kinase', FALSE UNION ALL
SELECT 'TGT011', 'PDGFR-beta','PDGFRB', 'P09619', 'Kinase', FALSE UNION ALL
SELECT 'TGT012', 'c-KIT', 'KIT', 'P10721', 'Kinase', TRUE UNION ALL
SELECT 'TGT013', 'hERG', 'KCNH2', 'Q12809', 'Ion Channel', FALSE UNION ALL
SELECT 'TGT014', 'AMPK', 'PRKAA1', 'Q13131', 'Kinase', FALSE UNION ALL
SELECT 'TGT015', 'RAF1', 'RAF1', 'P04049', 'Kinase', FALSE UNION ALL
SELECT 'TGT016', 'RET', 'RET', 'P07949', 'Kinase', TRUE UNION ALL
SELECT 'TGT017', 'FLT3', 'FLT3', 'P36888', 'Kinase', TRUE UNION ALL
SELECT 'TGT018', 'AKT1', 'AKT1', 'P31749', 'Kinase', FALSE UNION ALL
SELECT 'TGT019', 'ERK2', 'MAPK1', 'P28482', 'Kinase', FALSE UNION ALL
SELECT 'TGT020', 'HIV-Protease','HIV1-PR','Q72547', 'Protease', FALSE;
3. Tabelle interactions erstellen
Enthält Daten zur Bindungsaffinität zwischen Verbindung und Ziel (primäre Ziele im Vergleich zu Off-Targets).
CREATE OR REPLACE TABLE drug_target_graph.interactions AS
SELECT 'INT001' AS interaction_id, 'CPD001' AS compound_id, 'TGT001' AS target_id, 0.025 AS affinity_nm, 0.038 AS ic50_nm, 'primary' AS interaction_type, 9.8 AS pchembl_value UNION ALL
SELECT 'INT002', 'CPD001', 'TGT011', 0.1, 0.15, 'primary', 8.8 UNION ALL
SELECT 'INT003', 'CPD001', 'TGT012', 0.068, 0.1, 'primary', 9.2 UNION ALL
SELECT 'INT004', 'CPD001', 'TGT016', 0.5, 0.8, 'off-target', 7.4 UNION ALL
SELECT 'INT005', 'CPD001', 'TGT013', 5.2, 8.1, 'off-target', 6.1 UNION ALL
SELECT 'INT006', 'CPD002', 'TGT002', 0.02, 0.033, 'primary', 9.7 UNION ALL
SELECT 'INT007', 'CPD002', 'TGT013', 3.1, 4.8, 'off-target', 6.5 UNION ALL
SELECT 'INT008', 'CPD003', 'TGT002', 0.058, 0.079, 'primary', 9.2 UNION ALL
SELECT 'INT009', 'CPD003', 'TGT013', 8.5, 12.0, 'off-target', 5.9 UNION ALL
SELECT 'INT010', 'CPD004', 'TGT003', 0.09, 0.12, 'primary', 9.1 UNION ALL
SELECT 'INT011', 'CPD004', 'TGT004', 0.038, 0.055, 'primary', 8.9 UNION ALL
SELECT 'INT012', 'CPD004', 'TGT015', 0.22, 0.31, 'primary', 8.5 UNION ALL
SELECT 'INT013', 'CPD004', 'TGT016', 0.58, 0.75, 'primary', 8.1 UNION ALL
SELECT 'INT014', 'CPD004', 'TGT017', 0.33, 0.48, 'primary', 8.4 UNION ALL
SELECT 'INT015', 'CPD004', 'TGT013', 2.8, 4.1, 'off-target', 6.6 UNION ALL
SELECT 'INT016', 'CPD005', 'TGT004', 0.031, 0.044, 'primary', 9.5 UNION ALL
SELECT 'INT017', 'CPD005', 'TGT015', 0.48, 0.65, 'off-target', 7.3 UNION ALL
SELECT 'INT018', 'CPD006', 'TGT005', 0.02, 0.028, 'primary', 9.8 UNION ALL
SELECT 'INT019', 'CPD006', 'TGT003', 0.41, 0.59, 'off-target', 7.4 UNION ALL
SELECT 'INT020', 'CPD007', 'TGT006', 0.019, 0.025, 'primary', 9.8 UNION ALL
SELECT 'INT021', 'CPD007', 'TGT018', 0.55, 0.78, 'off-target', 7.2 UNION ALL
SELECT 'INT022', 'CPD008', 'TGT007', 0.0092, 0.014, 'primary', 10.1 UNION ALL
SELECT 'INT023', 'CPD008', 'TGT019', 0.38, 0.51, 'off-target', 7.4 UNION ALL
SELECT 'INT024', 'CPD009', 'TGT008', 0.011, 0.017, 'primary', 9.9 UNION ALL
SELECT 'INT025', 'CPD009', 'TGT009', 0.015, 0.022, 'primary', 9.8 UNION ALL
SELECT 'INT026', 'CPD010', 'TGT002', 0.041, 0.058, 'primary', 9.4 UNION ALL
SELECT 'INT027', 'CPD010', 'TGT001', 0.38, 0.52, 'off-target', 7.3 UNION ALL
SELECT 'INT028', 'CPD010', 'TGT013', 1.2, 1.8, 'off-target', 7.1 UNION ALL
SELECT 'INT029', 'CPD011', 'TGT006', 0.029, 0.041, 'primary', 9.5 UNION ALL
SELECT 'INT030', 'CPD011', 'TGT010', 0.71, 0.95, 'off-target', 7.0 UNION ALL
SELECT 'INT031', 'CPD012', 'TGT020', 0.39, 0.55, 'primary', 7.3 UNION ALL
SELECT 'INT032', 'CPD013', 'TGT014', 12.0, 18.5, 'primary', 5.7 UNION ALL
SELECT 'INT033', 'CPD014', 'TGT010', 0.0018, 0.0025, 'primary', 11.8 UNION ALL
SELECT 'INT034', 'CPD015', 'TGT004', 0.055, 0.078, 'primary', 9.2 UNION ALL
SELECT 'INT035', 'CPD015', 'TGT003', 0.12, 0.17, 'primary', 8.9 UNION ALL
SELECT 'INT036', 'CPD015', 'TGT016', 0.29, 0.41, 'primary', 8.5 UNION ALL
SELECT 'INT037', 'CPD015', 'TGT013', 0.95, 1.35, 'off-target', 7.2;
4. Tabelle pathways erstellen
Enthält biologische Prozesse, zugehörige Krankheitsbereiche und die Relevanz für Krebs.
CREATE OR REPLACE TABLE drug_target_graph.pathways AS
SELECT 'PWY001' AS pathway_id, 'MAPK Signaling' AS pathway_name, 'hsa04010' AS kegg_id, 'Cell Proliferation' AS biological_process, 'Oncology' AS disease_area, 'high' AS cancer_relevance UNION ALL
SELECT 'PWY002', 'PI3K-AKT Signaling', 'hsa04151', 'Cell Survival', 'Oncology', 'high' UNION ALL
SELECT 'PWY003', 'VEGF Signaling', 'hsa04370', 'Angiogenesis', 'Oncology', 'high' UNION ALL
SELECT 'PWY004', 'ErbB Signaling', 'hsa04012', 'Cell Growth', 'Oncology', 'high' UNION ALL
SELECT 'PWY005', 'mTOR Signaling', 'hsa04150', 'Cell Growth', 'Oncology', 'medium' UNION ALL
SELECT 'PWY006', 'Cell Cycle', 'hsa04110', 'Cell Division', 'Oncology', 'high' UNION ALL
SELECT 'PWY007', 'Cardiac Muscle Contraction', 'hsa04260', 'Cardiac Function', 'Cardiovascular', 'low' UNION ALL
SELECT 'PWY008', 'hERG Cardiac Channel', 'hsa04022', 'Cardiac Repolarisation','Cardiovascular', 'low' UNION ALL
SELECT 'PWY009', 'AMPK Signaling', 'hsa04152', 'Energy Metabolism', 'Metabolic', 'low' UNION ALL
SELECT 'PWY010', 'ALK Signaling', 'hsa04915', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY011', 'RAS Signaling', 'hsa04014', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY012', 'HIV Replication', 'hsa05170', 'Viral Replication', 'Infectious Disease', 'low';
5. Tabelle target_pathways erstellen
Eine Verknüpfungstabelle, die Ziele mit den biologischen Prozessen verknüpft, an denen sie beteiligt sind.
CREATE OR REPLACE TABLE drug_target_graph.target_pathways AS
SELECT 'TP001' AS tp_id, 'TGT001' AS target_id, 'PWY001' AS pathway_id, 'activator' AS role, 0.95 AS importance_score UNION ALL
SELECT 'TP002', 'TGT001', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP003', 'TGT002', 'PWY004', 'activator', 0.98 UNION ALL
SELECT 'TP004', 'TGT002', 'PWY001', 'activator', 0.82 UNION ALL
SELECT 'TP005', 'TGT002', 'PWY002', 'activator', 0.75 UNION ALL
SELECT 'TP006', 'TGT003', 'PWY003', 'activator', 0.96 UNION ALL
SELECT 'TP007', 'TGT003', 'PWY001', 'activator', 0.71 UNION ALL
SELECT 'TP008', 'TGT004', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP009', 'TGT004', 'PWY011', 'activator', 0.89 UNION ALL
SELECT 'TP010', 'TGT005', 'PWY010', 'activator', 0.99 UNION ALL
SELECT 'TP011', 'TGT005', 'PWY001', 'activator', 0.78 UNION ALL
SELECT 'TP012', 'TGT006', 'PWY002', 'activator', 0.98 UNION ALL
SELECT 'TP013', 'TGT006', 'PWY005', 'activator', 0.85 UNION ALL
SELECT 'TP014', 'TGT007', 'PWY001', 'activator', 0.94 UNION ALL
SELECT 'TP015', 'TGT007', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP016', 'TGT008', 'PWY006', 'activator', 0.95 UNION ALL
SELECT 'TP017', 'TGT009', 'PWY006', 'activator', 0.93 UNION ALL
SELECT 'TP018', 'TGT010', 'PWY005', 'activator', 0.99 UNION ALL
SELECT 'TP019', 'TGT010', 'PWY002', 'activator', 0.91 UNION ALL
SELECT 'TP020', 'TGT011', 'PWY003', 'activator', 0.87 UNION ALL
SELECT 'TP021', 'TGT011', 'PWY001', 'activator', 0.72 UNION ALL
SELECT 'TP022', 'TGT012', 'PWY001', 'activator', 0.83 UNION ALL
SELECT 'TP023', 'TGT012', 'PWY011', 'activator', 0.79 UNION ALL
SELECT 'TP024', 'TGT013', 'PWY008', 'substrate', 0.99 UNION ALL
SELECT 'TP025', 'TGT013', 'PWY007', 'substrate', 0.95 UNION ALL
SELECT 'TP026', 'TGT014', 'PWY009', 'activator', 0.97 UNION ALL
SELECT 'TP027', 'TGT015', 'PWY001', 'activator', 0.91 UNION ALL
SELECT 'TP028', 'TGT015', 'PWY011', 'activator', 0.86 UNION ALL
SELECT 'TP029', 'TGT016', 'PWY001', 'activator', 0.84 UNION ALL
SELECT 'TP030', 'TGT016', 'PWY003', 'activator', 0.77 UNION ALL
SELECT 'TP031', 'TGT017', 'PWY001', 'activator', 0.88 UNION ALL
SELECT 'TP032', 'TGT017', 'PWY011', 'activator', 0.82 UNION ALL
SELECT 'TP033', 'TGT018', 'PWY002', 'activator', 0.96 UNION ALL
SELECT 'TP034', 'TGT018', 'PWY005', 'activator', 0.88 UNION ALL
SELECT 'TP035', 'TGT019', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP036', 'TGT019', 'PWY011', 'activator', 0.91 UNION ALL
SELECT 'TP037', 'TGT020', 'PWY012', 'substrate', 0.99;
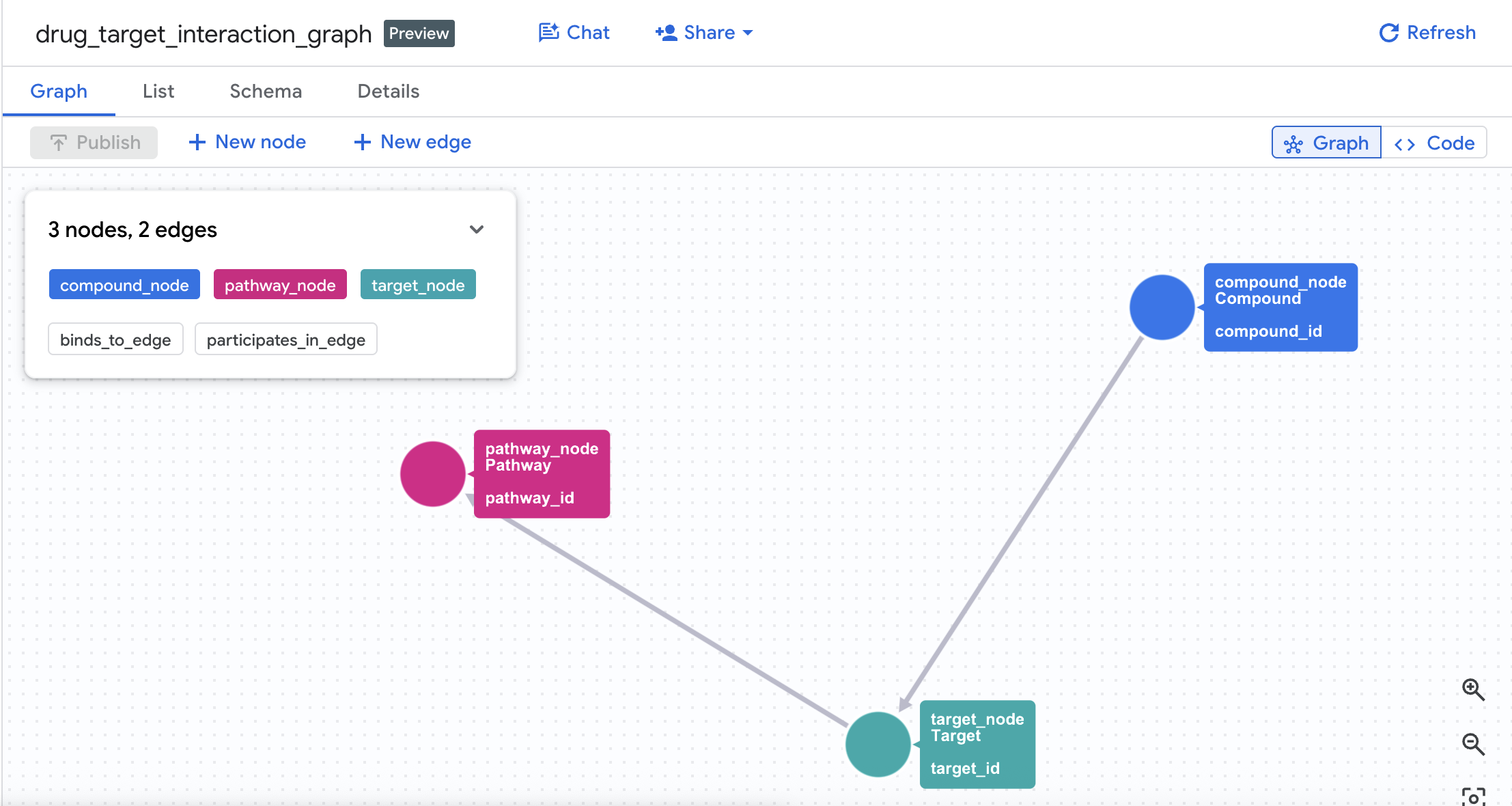
4. Eigenschaftsgraph erstellen
Nachdem die Tabellen erstellt wurden, können Sie nun den Eigenschaftsgraph erstellen. Dabei werden Knoten (Verbindungen, Ziele, Prozesse) mithilfe von Kantentabellen (Interactions und Target Pathways) verknüpft.
Führen Sie die folgende Anweisung im SQL-Editor von BigQuery Studio aus:
CREATE OR REPLACE PROPERTY GRAPH drug_target_graph.drug_target_interaction_graph
NODE TABLES (
drug_target_graph.compounds
AS compound_node
KEY (compound_id)
LABEL Compound
PROPERTIES (compound_id, compound_name, mechanism_of_action, dev_stage, therapeutic_area, molecular_weight),
drug_target_graph.targets
AS target_node
KEY (target_id)
LABEL Target
PROPERTIES (target_id, target_name, gene_name, uniprot_id, target_class, is_oncogene),
drug_target_graph.pathways
AS pathway_node
KEY (pathway_id)
LABEL Pathway
PROPERTIES (pathway_id, pathway_name, kegg_id, biological_process, disease_area, cancer_relevance)
)
EDGE TABLES (
drug_target_graph.interactions
AS binds_to_edge
KEY (interaction_id)
SOURCE KEY (compound_id) REFERENCES compound_node (compound_id)
DESTINATION KEY (target_id) REFERENCES target_node (target_id)
LABEL BINDS_TO
PROPERTIES (interaction_id, affinity_nm, ic50_nm, interaction_type, pchembl_value),
drug_target_graph.target_pathways
AS participates_in_edge
KEY (tp_id)
SOURCE KEY (target_id) REFERENCES target_node (target_id)
DESTINATION KEY (pathway_id) REFERENCES pathway_node (pathway_id)
LABEL PARTICIPATES_IN
PROPERTIES (tp_id, role, importance_score)
);
Dadurch wird in Ihrem Dataset ein Graph mit dem Namen drug_target_interaction_graph erstellt.
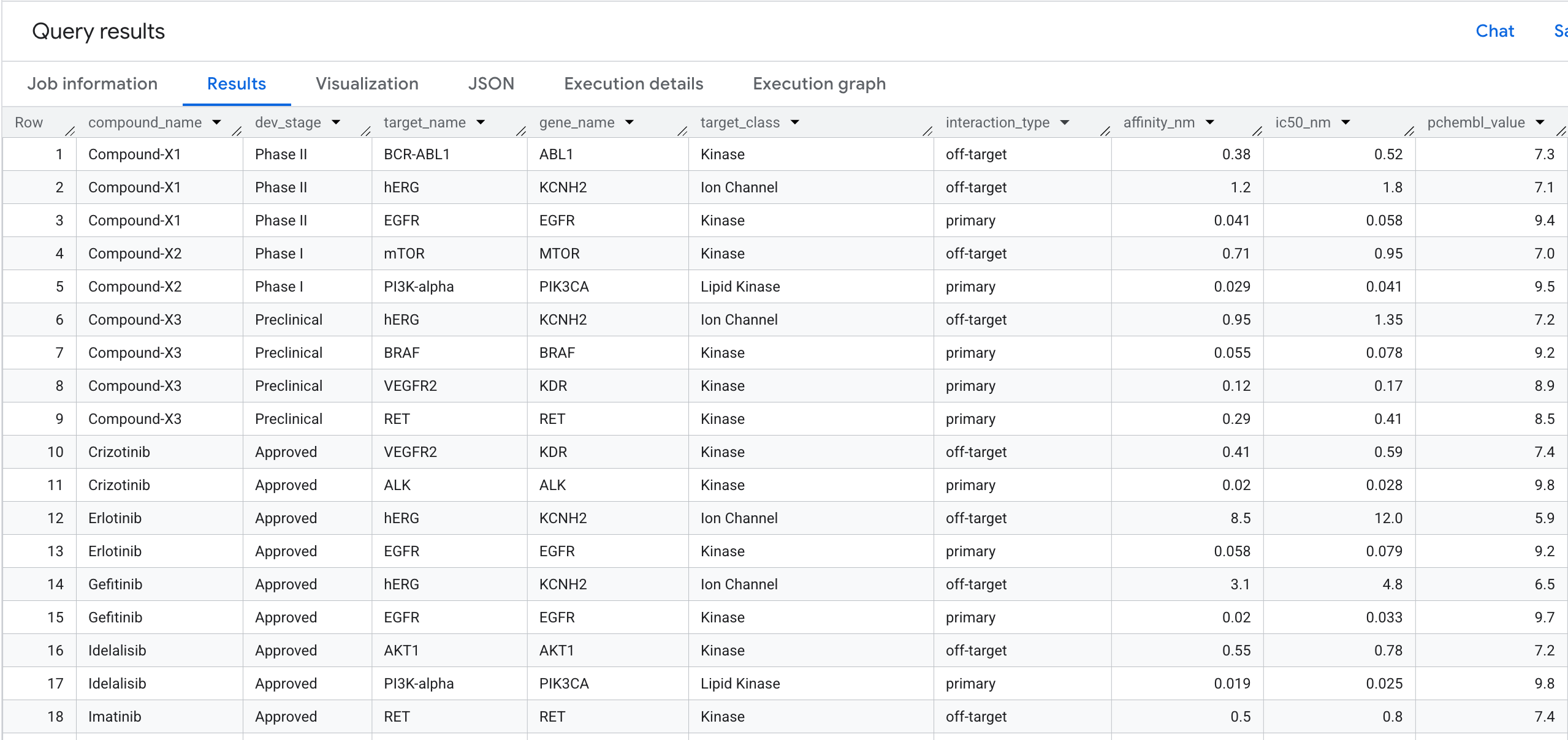
5. Abfrage 1: Vollständiges Zielbindungsprofil pro Verbindung
Führen wir unsere erste Graph-Abfrage aus. Dies ist ein Traversal mit einem Hop, der folgende Frage beantwortet: Welche Verbindungen binden sich an welche Ziele und wie hoch ist ihre Affinität?
GQL-Abfrage
Führen Sie die folgende Abfrage im SQL-Editor aus:
SELECT
compound_name,
dev_stage,
target_name,
gene_name,
target_class,
interaction_type,
ROUND(affinity_nm, 3) AS affinity_nm,
ROUND(ic50_nm, 3) AS ic50_nm,
pchembl_value
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_name AS target_name,
t.gene_name AS gene_name,
t.target_class AS target_class,
b.interaction_type AS interaction_type,
b.affinity_nm AS affinity_nm,
b.ic50_nm AS ic50_nm,
b.pchembl_value AS pchembl_value
)
)
ORDER BY compound_name, interaction_type, affinity_nm;
So sehen die Ergebnisse aus:
6. Abfrage 2: Erkennung von Herzrisiken
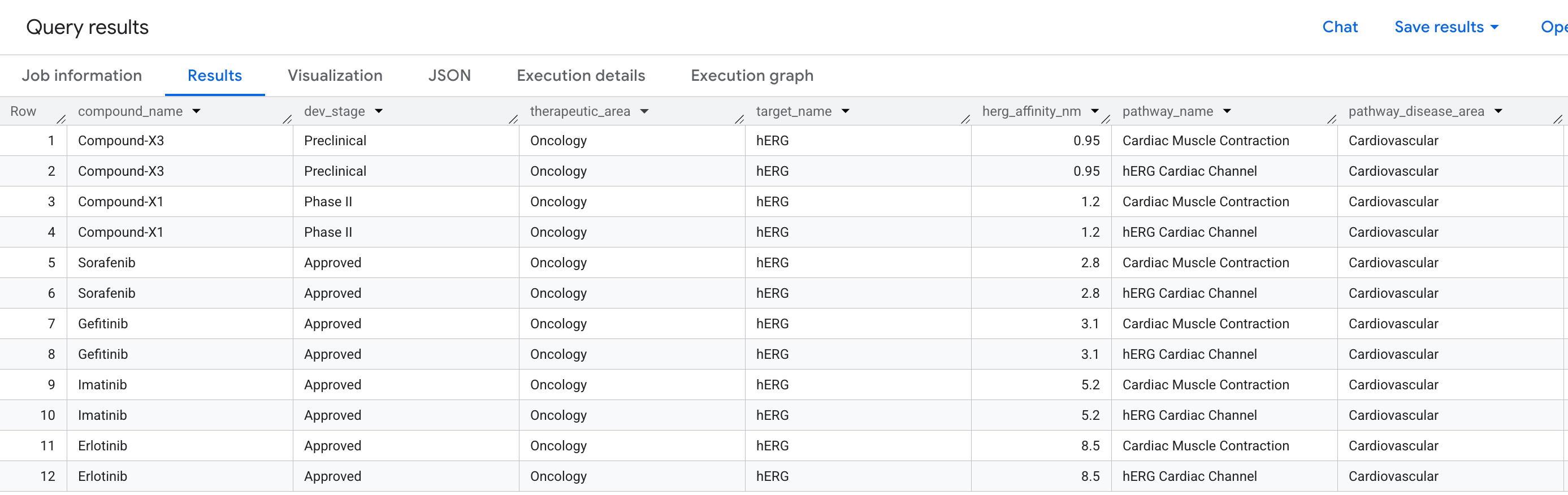
Die geschäftliche Frage
Bei der Entwicklung von Arzneimitteln ist Kardiotoxizität einer der häufigsten Gründe, warum eine vielversprechende Verbindung in klinischen Studien scheitert. Insbesondere die unbeabsichtigte Bindung an das hERG-Protein (Gen: KCNH2), einen Kaliumionenkanal, der den Herzrhythmus reguliert. Ein Off-Target-Treffer auf hERG kann zu tödlichen Arrhythmien führen und war für mehrere hochkarätige Arzneimittelrückrufe verantwortlich.
Die Frage, die wir beantworten möchten, lautet:
"Welche Verbindungen in unserer Pipeline haben ein Off-Target-Bindungsereignis auf dem hERG-Protein und welche Herzprozesse sind dadurch gefährdet?"
Dies ist eine Frage mit zwei Hops: Wir müssen von einer Verbindung über ein Ziel (hERG) zu einem Prozess wechseln. Dabei werden drei Entitätstypen über zwei Beziehungen in einer einzigen Abfrage verknüpft.
GQL-Abfrage schreiben
Führen Sie die folgende Abfrage im BQ-SQL-Editor aus:
SELECT
compound_name,
dev_stage,
therapeutic_area,
target_name,
ROUND(affinity_nm, 3) AS herg_affinity_nm,
pathway_name,
disease_area AS pathway_disease_area
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND b.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
c.therapeutic_area AS therapeutic_area,
t.target_name AS target_name,
b.affinity_nm AS affinity_nm,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
ORDER BY herg_affinity_nm;
Beachten Sie, dass die MATCH-Klausel fast wie ein Satz klingt: "Finde eine Verbindung, die sich an ein Ziel bindet, das an einem Prozess beteiligt ist" . Die Filter werden an jedem Knoten und jeder Kante entlang des Pfads angewendet.
So sehen die Ergebnisse aus:
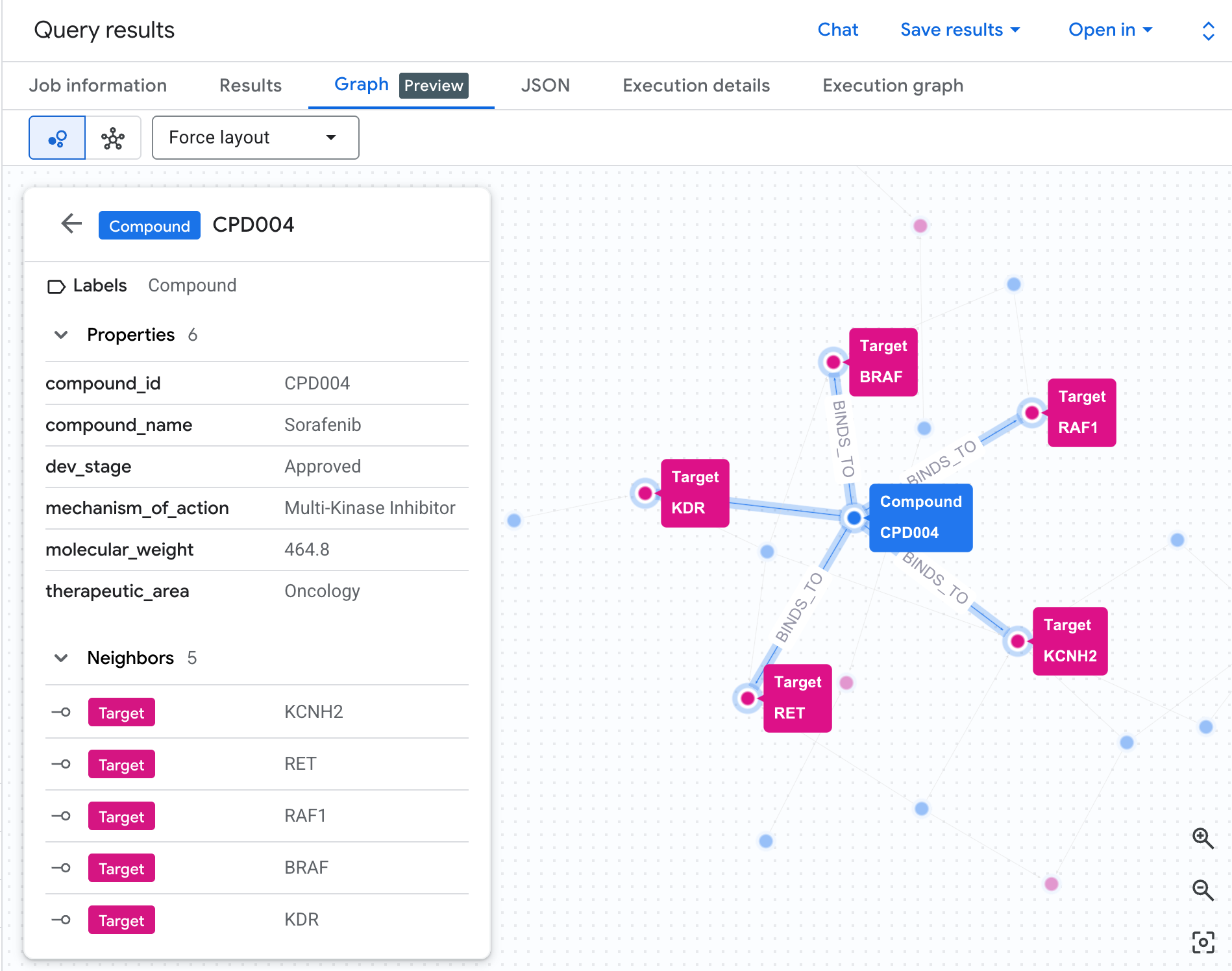
Risikonetzwerk als Graph visualisieren
In einer Tabelle sind die Daten zu sehen, aber nicht die Struktur des Risikos. Laufen mehrere Verbindungen auf denselben Prozess zu? Gibt es eine oder mehrere Verbindungen mit hohem Risiko?
Eine Graph-Visualisierung macht dies sofort sichtbar. Führen Sie die Zelle unten aus, um denselben Traversal mit zwei Hops als interaktives Netzwerk zu rendern:
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH pt = (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND pw.disease_area = 'Cardiovascular'
RETURN
TO_JSON(pt) AS path
So sollte der Graph aussehen:
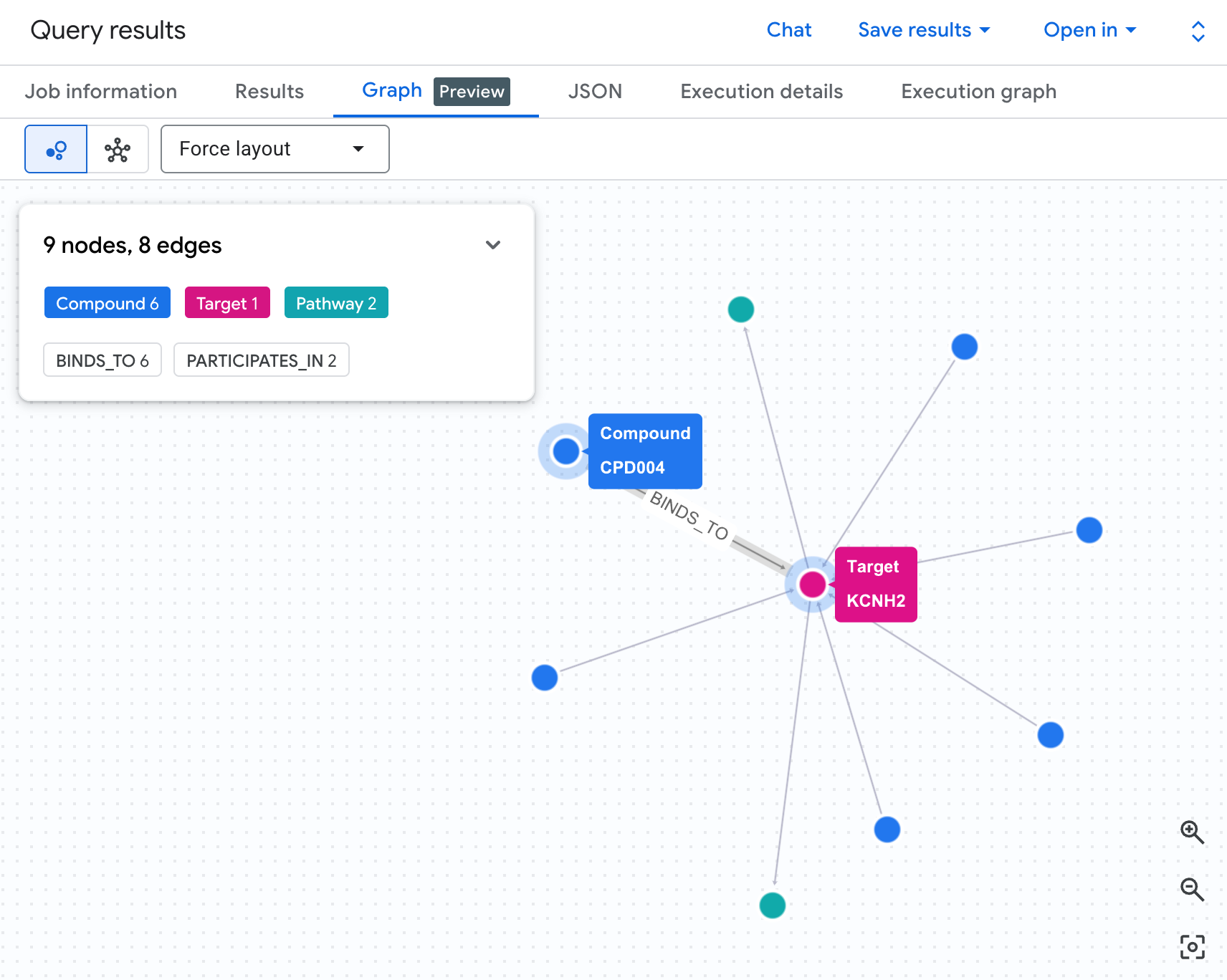
Jeder Pfad im Graph zeichnet eine vollständige Haftungskette nach: Eine Verbindung (blaue Knoten) bindet sich an das hERG-Protein in der Mitte, das mit einem oder mehreren Herzprozessen (grüne Knoten) verbunden ist. Was in der Tabelle eine flache Liste von Zeilen war, ist jetzt ein sichtbares Risikonetzwerk. Verbindungen mit mehreren Prozessbeteiligungen haben sofort eine höhere Priorität für die Sicherheitsprüfung.
GQL ist eleganter als SQL
Um dieselbe Abfrage mit zwei Hops in Standard-SQL auszuführen, benötigen Sie vier explizite Joins. Sie verwenden kognitive Ressourcen, um zu beschreiben, wie Tabellen verknüpft werden sollen, anstatt welche Beziehung Sie suchen. Mit GQL können Sie sich auf die Frage konzentrieren.
SELECT
c.compound_name,
c.dev_stage,
c.therapeutic_area,
t.target_name,
ROUND(i.affinity_nm, 3) AS herg_affinity_nm,
pw.pathway_name,
pw.disease_area AS pathway_disease_area
FROM drug_target_graph.compounds c
JOIN drug_target_graph.interactions i ON c.compound_id = i.compound_id
JOIN drug_target_graph.targets t ON i.target_id = t.target_id
JOIN drug_target_graph.target_pathways tp ON t.target_id = tp.target_id
JOIN drug_target_graph.pathways pw ON tp.pathway_id = pw.pathway_id
WHERE t.gene_name = 'KCNH2'
AND i.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
ORDER BY herg_affinity_nm;
Detailliertere Informationen: Erkennung von Metabolitenrisiken mit mehreren Hops
Mit der obigen Abfrage werden Verbindungen identifiziert, die sich direkt an das hERG-Protein binden. In realen Arbeitsabläufen zur Arzneimittelsicherheit ist das Risiko jedoch manchmal einen Schritt entfernt: Eine Verbindung kann im Körper metabolisch in ein sekundäres Molekül (einen Metaboliten) umgewandelt werden, das sich dann an hERG bindet. Diese Haftung kann bei direkten Bindungsassays vollständig übersehen werden.
Wenn Ihr Eigenschaftsgraph eine Knotentabelle für Metaboliten und eine Kante METABOLISES_INTO enthält, können Sie dasselbe MATCH-Muster auf einen Traversal mit drei Hops erweitern:
(Compound)-[METABOLISES_INTO]->(Metabolite)-[BINDS_TO]->
(Target)-[PARTICIPATES_IN]->(Pathway)
Die GQL-Abfragestruktur ändert sich um genau einen Knoten und eine Kante. Für das entsprechende SQL sind zwei zusätzliche Joins erforderlich. Dieses Muster macht den Graph-Traversal besonders leistungsstark für die Analyse von Sicherheitskaskaden. Die Abfragekomplexität wächst linear, während die biologischen Erkenntnisse exponentiell zunehmen.
7. Abfrage 3: Verbindungspaare mit gemeinsamem Ziel
Um Kandidaten für die Kombinationstherapie zu finden, können wir ermitteln, wann sich zwei verschiedene Verbindungen an denselben Zielknoten binden. Wir verwenden eine bidirektionale Übereinstimmung , um folgende Frage zu beantworten: Welche onkologischen Verbindungen laufen auf genau dasselbe Ziel zu?
Führen Sie die folgende Abfrage im SQL-Editor aus:
SELECT
compound_a,
compound_b,
shared_target,
gene_name,
ROUND(affinity_a_nm, 3) AS affinity_a_nm,
ROUND(affinity_b_nm, 3) AS affinity_b_nm
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
AND c2.therapeutic_area = 'Oncology'
COLUMNS (
c1.compound_name AS compound_a,
c2.compound_name AS compound_b,
t.target_name AS shared_target,
t.gene_name AS gene_name,
b1.affinity_nm AS affinity_a_nm,
b2.affinity_nm AS affinity_b_nm
)
)
ORDER BY compound_a, compound_b, affinity_a_nm;
So sehen die Ergebnisse aus:
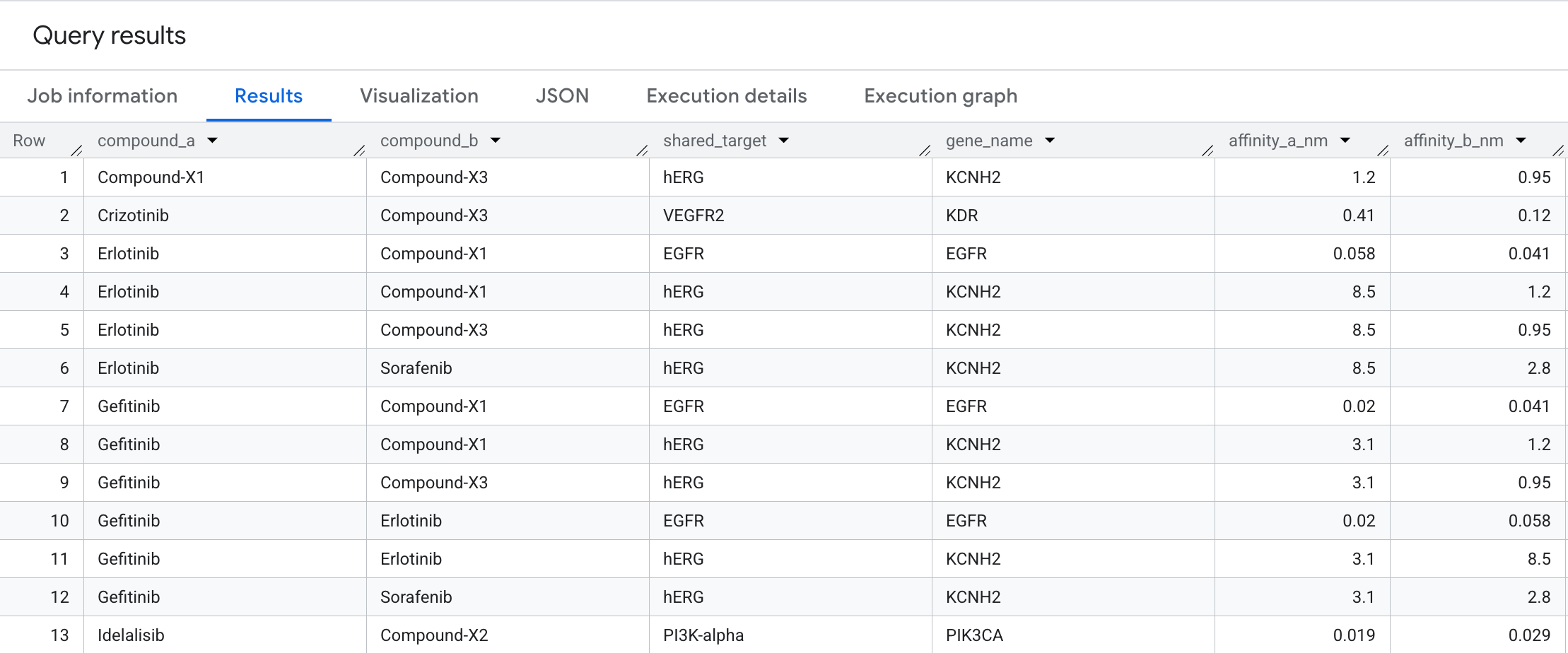
Graph-Visualisierung
Sie können den Graph direkt in BigQuery visualisieren, indem Sie den folgenden Code im SQL-Editor ausführen.
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH p = (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
RETURN
TO_JSON(p) AS path
Dieser bidirektionale Traversal zeigt Verbindungspaare, die auf dasselbe Proteinziel zulaufen. Dieses Muster ist in einer flachen Interaktionstabelle schwer zu erkennen, aber als Graph sofort sichtbar. Bei der Entwicklung von Arzneimitteln sind Paare mit gemeinsamem Ziel der Ausgangspunkt für das Design von Kombinationstherapien: Zwei Verbindungen, die auf denselben Knoten in einem Krebsprozess wirken, können einen synergistischen Effekt erzielen oder alternativ auf eine unbeabsichtigte Redundanz in der Pipeline hinweisen.
8. Abfrage 4: Wirkungsradius des Krankheitsprozesses
Wie breit sind die biologischen Auswirkungen der einzelnen Verbindungen? Führen wir einen Traversal mit zwei Hops und Aggregation aus, um folgende Frage zu beantworten: Wie viele biologische Prozesse und unterschiedliche Ziele werden von jeder Verbindung beeinflusst, gruppiert nach Krankheitsbereich?
Führen Sie die folgende Abfrage im SQL-Editor aus:
SELECT
compound_name,
dev_stage,
disease_area,
COUNT(DISTINCT pathway_id) AS pathways_affected,
COUNT(DISTINCT target_id) AS targets_involved,
STRING_AGG(DISTINCT pathway_name ORDER BY pathway_name) AS pathway_list
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_id AS target_id,
pw.pathway_id AS pathway_id,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
GROUP BY compound_name, dev_stage, disease_area
ORDER BY compound_name, pathways_affected DESC;
So sehen die Ergebnisse aus:
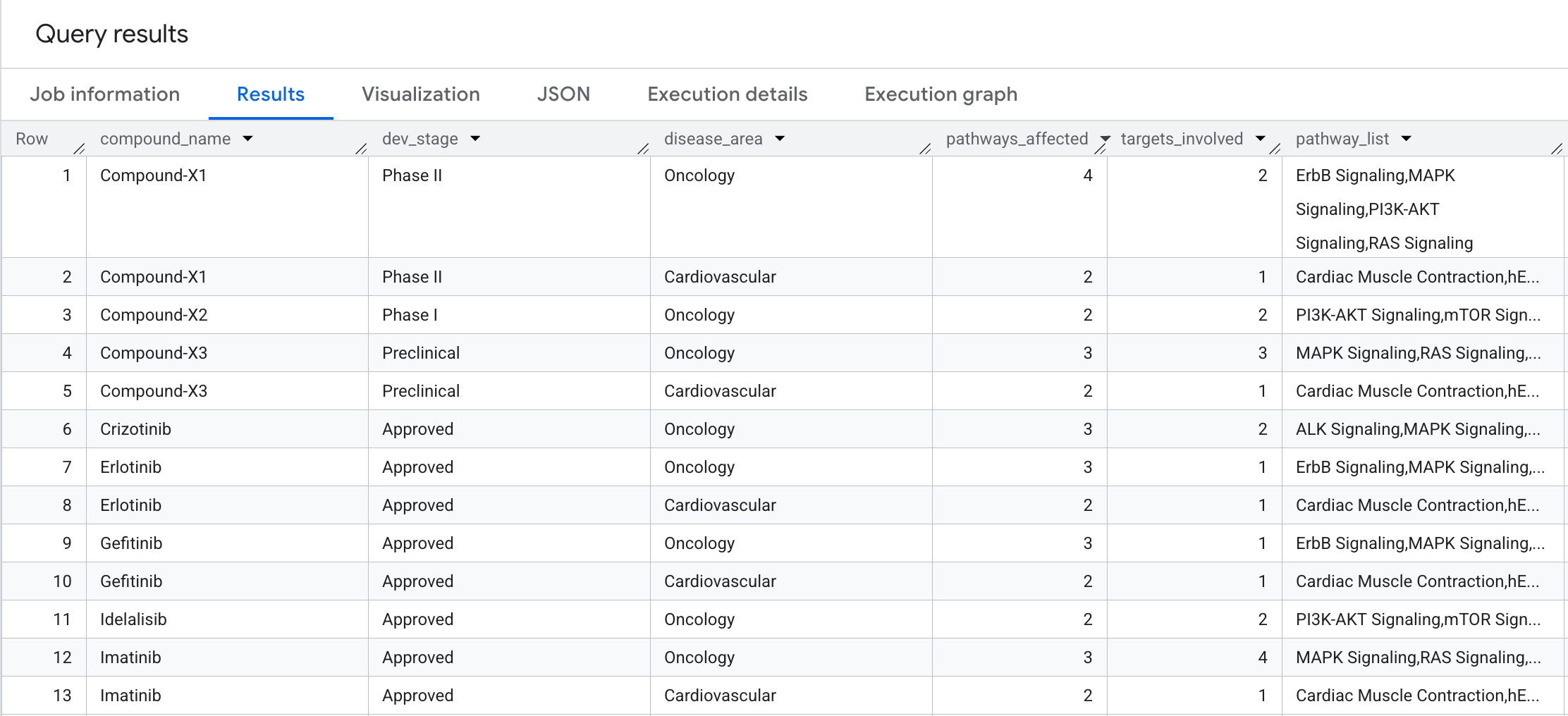
9. Abfrage 5: Auswahl sicherer Verbindungen
Zum Schluss fragen wir nach Verbindungen, die eine hohe onkologische Abdeckung haben, aber Off-Target-Haftungen für hERG (Herz) vermeiden. Dies entspricht gängigen Auswahlmustern, bei denen die Sicherheit im Vordergrund steht, in Pipelines für die Entwicklung von Arzneimitteln.
Führen Sie die folgende Abfrage im SQL-Editor aus:
WITH oncology_compounds AS (
SELECT DISTINCT compound_id, compound_name, dev_stage
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE pw.disease_area = 'Oncology'
AND pw.cancer_relevance = 'high'
COLUMNS (
c.compound_id AS compound_id,
c.compound_name AS compound_name,
c.dev_stage AS dev_stage
)
)
),
herg_risk_compounds AS (
SELECT DISTINCT compound_id
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
WHERE t.gene_name = 'KCNH2'
COLUMNS (c.compound_id AS compound_id)
)
)
SELECT
o.compound_name,
o.dev_stage,
'Clean cardiac profile' AS cardiac_safety
FROM oncology_compounds o
LEFT JOIN herg_risk_compounds h ON o.compound_id = h.compound_id
WHERE h.compound_id IS NULL
ORDER BY o.dev_stage, o.compound_name;
So sieht die Ausgabe in den Ergebnissen aus:
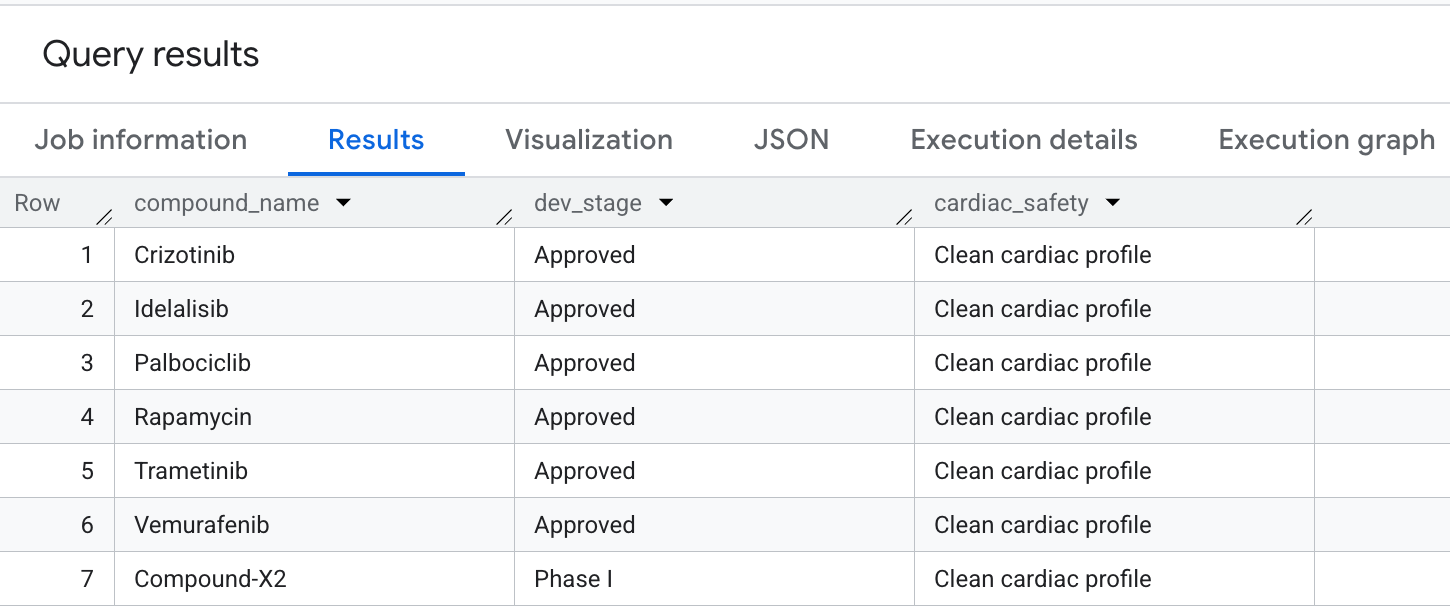
Sie haben in BigQuery erweiterte Graph-Traversals ausgeführt, um wichtige Sicherheits- und Wirksamkeitsprofile zu extrahieren.
10. Bonusabschnitt: Mit dem Graph chatten
BigQuery Conversational Analytics unterstützt jetzt Graphen als Wissensquelle. So können Sie in natürlicher Sprache mit dem gerade erstellten Graph chatten.
Erste Schritte: Graph als Wissensquelle hinzufügen
Erstellen Sie zuerst einen Conversational Agent. Folgen Sie dazu der Anleitung hier. Wählen Sie den erstellten Graph in der Suchleiste aus.
Mit BigQuery Conversational Analytics mit dem Graph chatten
Nachdem Sie den Graph als Wissensquelle hinzugefügt haben, richten Sie den Rest des Conversational Analytics-Agents ein.
Anschließend können Sie in natürlicher Sprache mit dem Graph chatten.
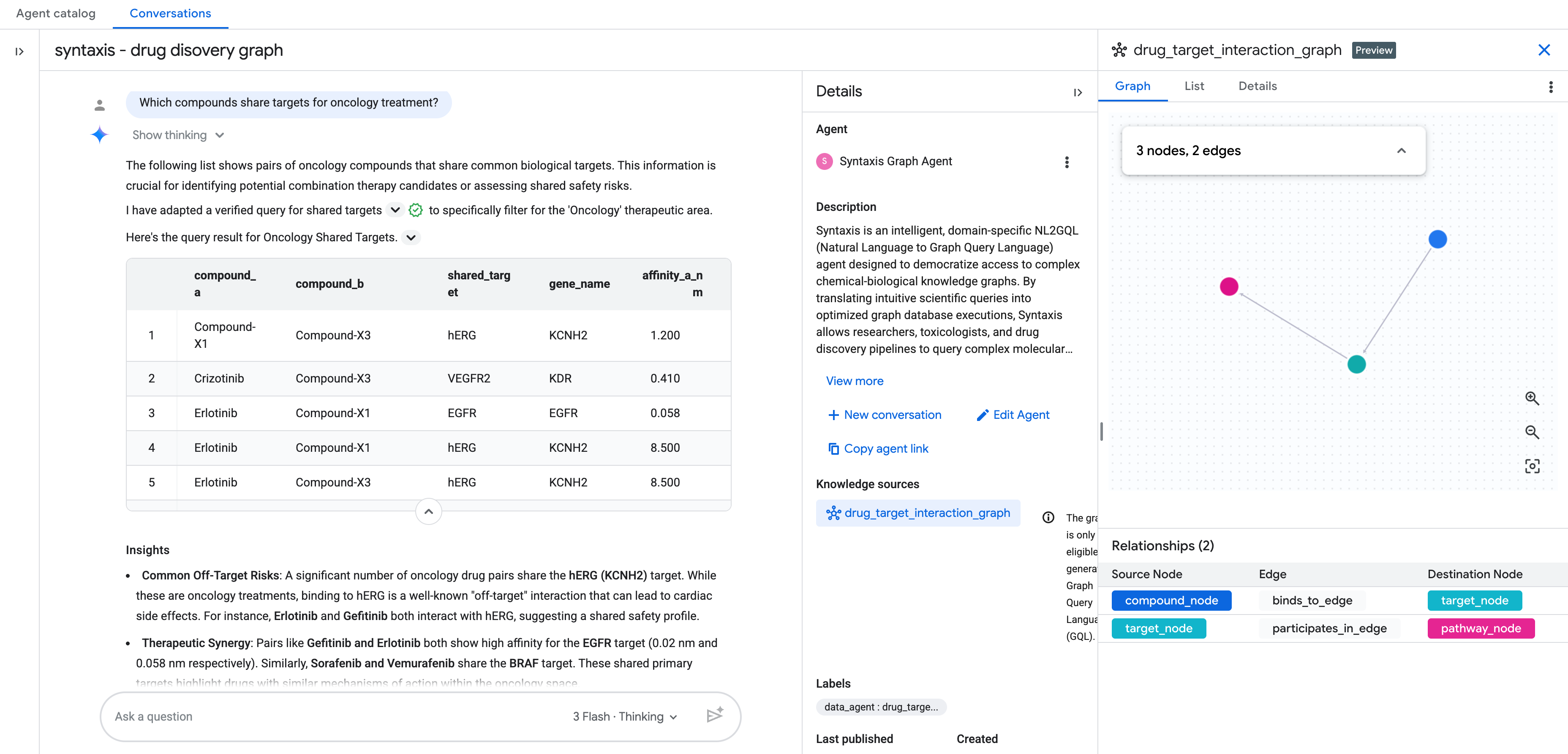
Weitere Fragen
- Welche Ziele gibt es für Verbindungen, die sich derzeit in Phase-2-Studien befinden?
- Welche Ziele werden von Verbindungen für Herz-Kreislauf-Erkrankungen und onkologischen Verbindungen gemeinsam genutzt?
11. Bereinigen
Um laufende Kosten für Ihr Google Cloud-Konto zu vermeiden, löschen Sie die Ressourcen, die während dieses Codelabs erstellt wurden.
Führen Sie die folgende Abfrage aus, um das Schema und alle Tabellen kaskadierend zu löschen:
DROP SCHEMA IF EXISTS drug_target_graph CASCADE;
12. Glückwunsch
Glückwunsch! Sie haben mit BigQuery Graph erfolgreich ein Netzwerk für Arzneimittel-Ziel-Interaktionen modelliert und analysiert.
Lerninhalte
- Entitätsbeziehungen (Verbindungen, Ziele, Prozesse) als Eigenschaftsgraph modellieren.
- Schema definieren und Eigenschaftsgraph in BigQuery erstellen.
- Komplexe Graph-Traversals mit GQL schreiben und mit herkömmlichem SQL vergleichen.
GRAPH_TABLE,MATCHund bidirektionale Übereinstimmung nutzen, um Probleme im Bereich Biowissenschaften zu lösen.