
1. Introducción
En este codelab, aprenderás a usar BigQuery Graph para modelar y analizar una red de interacción entre fármacos y objetivos. Aprovecharás el poder de las consultas de gráficos (GQL) para explorar cómo los medicamentos interactúan con los objetivos biológicos, identificar posibles efectos secundarios (como riesgos cardíacos) y descubrir posibles terapias combinadas.
🧬 Caso de uso: Red de interacción entre fármacos y objetivos
Pregunta comercial: ¿Cuál es el radio del impacto completo de un compuesto? ¿A qué objetivos se une, qué vías biológicas se ven afectadas y qué áreas de enfermedades están implicadas?
Tablas:
Tabla | Descripción |
| Moléculas de fármacos con mecanismo de acción y etapa de desarrollo |
| Proteínas objetivo con nombres de genes y IDs de UniProt |
| Afinidad de unión a objetivos compuestos (objetivos principales y secundarios) |
| Vías biológicas con asociaciones de áreas de enfermedades |
| Tabla de unión que vincula los objetivos con las rutas en las que participan |
Modelo de gráfico de propiedades:
(Compound)-[BINDS_TO {affinity_nm, ic50_nm, interaction_type}]->(Target)
(Target)-[PARTICIPATES_IN {role, importance_score}]->(Pathway)
🔍 Consultas de demostración
Consulta | Lo que representa |
P1: Perfil de vinculación objetivo | Recorrido de 1 salto: Se combina con todos los destinos principales y secundarios |
P2: Detección del riesgo cardíaco por hERG | Salto de 2 pasos: Compuesto → objetivo hERG → vía cardíaca |
Q3: Pares compuestos de objetivo compartido | Coincidencia bidireccional: Dos compuestos convergen en el mismo nodo objetivo |
P4: Radio de explosión de la ruta de la enfermedad | Agregación de 2 saltos: Cobertura completa de la ruta y el área de la enfermedad por compuesto |
P5: Selección segura de compuestos | Compuestos con alta cobertura oncológica, pero sin responsabilidad cardíaca por hERG |
Actividades
- Crea un esquema y un conjunto de datos de BigQuery para la red de interacción de medicamentos
- Carga datos de muestra (compuestos, objetivos, interacciones, rutas y rutas de objetivos)
- Crea un gráfico de propiedades en BigQuery que conecte estas entidades
- Consulta el grafo para comprender las interacciones de los compuestos, las vías biológicas y el radio del impacto de las enfermedades con el recorrido del grafo (
GRAPH_TABLEyMATCH). - Compara GQL y SQL estándar en paralelo para comprender la simplicidad y el poder expresivo de la sintaxis de gráficos
Requisitos
- Un navegador web, como Chrome
- Un proyecto de Google Cloud con la facturación habilitada.
Este codelab es para desarrolladores de todos los niveles, incluidos los principiantes.
2. Antes de comenzar
Crea un proyecto de Google Cloud
- En la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud.
Inicie Cloud Shell
- Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.
- Verifica la autenticación:
gcloud auth list
- Confirma tu proyecto:
gcloud config get project
- Configúrala si es necesario:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Habilita las APIs
Ejecuta este comando para habilitar la API de BigQuery requerida:
gcloud services enable bigquery.googleapis.com
3. Define el esquema y carga los datos
Primero, debes crear un conjunto de datos para almacenar tus tablas relacionadas con el gráfico y completarlas con datos de muestra.
- Ve a BigQuery Studio en la consola de Google Cloud.
- Haz clic en el Editor de SQL para abrir una nueva pestaña de consulta.
- Ejecuta la siguiente instrucción para crear el conjunto de datos
drug_target_graph:
CREATE SCHEMA IF NOT EXISTS drug_target_graph
OPTIONS (location = 'US');
Ahora, crea las 5 tablas de origen ejecutando las siguientes consultas DDL en BigQuery Studio.
1. Crear tabla de compounds
Contiene moléculas de fármacos, su mecanismo de acción, la etapa de desarrollo y el área terapéutica.
CREATE OR REPLACE TABLE drug_target_graph.compounds AS
SELECT 'CPD001' AS compound_id, 'Imatinib' AS compound_name, 'Kinase Inhibitor' AS mechanism_of_action, 'Approved' AS dev_stage, 'Oncology' AS therapeutic_area, 479.6 AS molecular_weight UNION ALL
SELECT 'CPD002', 'Gefitinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 446.9 UNION ALL
SELECT 'CPD003', 'Erlotinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 393.4 UNION ALL
SELECT 'CPD004', 'Sorafenib', 'Multi-Kinase Inhibitor', 'Approved', 'Oncology', 464.8 UNION ALL
SELECT 'CPD005', 'Vemurafenib', 'BRAF Inhibitor', 'Approved', 'Oncology', 489.9 UNION ALL
SELECT 'CPD006', 'Crizotinib', 'ALK Inhibitor', 'Approved', 'Oncology', 450.3 UNION ALL
SELECT 'CPD007', 'Idelalisib', 'PI3K Inhibitor', 'Approved', 'Oncology', 415.4 UNION ALL
SELECT 'CPD008', 'Trametinib', 'MEK Inhibitor', 'Approved', 'Oncology', 615.4 UNION ALL
SELECT 'CPD009', 'Palbociclib', 'CDK Inhibitor', 'Approved', 'Oncology', 447.5 UNION ALL
SELECT 'CPD010', 'Compound-X1', 'Kinase Inhibitor', 'Phase II', 'Oncology', 412.3 UNION ALL
SELECT 'CPD011', 'Compound-X2', 'PI3K Inhibitor', 'Phase I', 'Oncology', 398.7 UNION ALL
SELECT 'CPD012', 'Saquinavir', 'Protease Inhibitor', 'Approved', 'Infectious Disease', 670.8 UNION ALL
SELECT 'CPD013', 'Metformin', 'AMPK Activator', 'Approved', 'Metabolic', 165.6 UNION ALL
SELECT 'CPD014', 'Rapamycin', 'mTOR Inhibitor', 'Approved', 'Immunology', 914.2 UNION ALL
SELECT 'CPD015', 'Compound-X3', 'Multi-Kinase Inhibitor', 'Preclinical', 'Oncology', 502.1;
2. Crear tabla de targets
Contiene objetivos de proteínas, nombres de genes, IDs de UniProt y clases de objetivos.
CREATE OR REPLACE TABLE drug_target_graph.targets AS
SELECT 'TGT001' AS target_id, 'BCR-ABL1' AS target_name, 'ABL1' AS gene_name, 'P00519' AS uniprot_id, 'Kinase' AS target_class, TRUE AS is_oncogene UNION ALL
SELECT 'TGT002', 'EGFR', 'EGFR', 'P00533', 'Kinase', TRUE UNION ALL
SELECT 'TGT003', 'VEGFR2', 'KDR', 'P35968', 'Kinase', FALSE UNION ALL
SELECT 'TGT004', 'BRAF', 'BRAF', 'P15056', 'Kinase', TRUE UNION ALL
SELECT 'TGT005', 'ALK', 'ALK', 'Q9UM73', 'Kinase', TRUE UNION ALL
SELECT 'TGT006', 'PI3K-alpha','PIK3CA', 'P42336', 'Lipid Kinase', TRUE UNION ALL
SELECT 'TGT007', 'MEK1', 'MAP2K1', 'Q02750', 'Kinase', FALSE UNION ALL
SELECT 'TGT008', 'CDK4', 'CDK4', 'P11802', 'Kinase', FALSE UNION ALL
SELECT 'TGT009', 'CDK6', 'CDK6', 'P30279', 'Kinase', FALSE UNION ALL
SELECT 'TGT010', 'mTOR', 'MTOR', 'P42345', 'Kinase', FALSE UNION ALL
SELECT 'TGT011', 'PDGFR-beta','PDGFRB', 'P09619', 'Kinase', FALSE UNION ALL
SELECT 'TGT012', 'c-KIT', 'KIT', 'P10721', 'Kinase', TRUE UNION ALL
SELECT 'TGT013', 'hERG', 'KCNH2', 'Q12809', 'Ion Channel', FALSE UNION ALL
SELECT 'TGT014', 'AMPK', 'PRKAA1', 'Q13131', 'Kinase', FALSE UNION ALL
SELECT 'TGT015', 'RAF1', 'RAF1', 'P04049', 'Kinase', FALSE UNION ALL
SELECT 'TGT016', 'RET', 'RET', 'P07949', 'Kinase', TRUE UNION ALL
SELECT 'TGT017', 'FLT3', 'FLT3', 'P36888', 'Kinase', TRUE UNION ALL
SELECT 'TGT018', 'AKT1', 'AKT1', 'P31749', 'Kinase', FALSE UNION ALL
SELECT 'TGT019', 'ERK2', 'MAPK1', 'P28482', 'Kinase', FALSE UNION ALL
SELECT 'TGT020', 'HIV-Protease','HIV1-PR','Q72547', 'Protease', FALSE;
3. Crear tabla de interactions
Contiene datos de afinidad de unión de objetivos compuestos (objetivos principales frente a objetivos secundarios).
CREATE OR REPLACE TABLE drug_target_graph.interactions AS
SELECT 'INT001' AS interaction_id, 'CPD001' AS compound_id, 'TGT001' AS target_id, 0.025 AS affinity_nm, 0.038 AS ic50_nm, 'primary' AS interaction_type, 9.8 AS pchembl_value UNION ALL
SELECT 'INT002', 'CPD001', 'TGT011', 0.1, 0.15, 'primary', 8.8 UNION ALL
SELECT 'INT003', 'CPD001', 'TGT012', 0.068, 0.1, 'primary', 9.2 UNION ALL
SELECT 'INT004', 'CPD001', 'TGT016', 0.5, 0.8, 'off-target', 7.4 UNION ALL
SELECT 'INT005', 'CPD001', 'TGT013', 5.2, 8.1, 'off-target', 6.1 UNION ALL
SELECT 'INT006', 'CPD002', 'TGT002', 0.02, 0.033, 'primary', 9.7 UNION ALL
SELECT 'INT007', 'CPD002', 'TGT013', 3.1, 4.8, 'off-target', 6.5 UNION ALL
SELECT 'INT008', 'CPD003', 'TGT002', 0.058, 0.079, 'primary', 9.2 UNION ALL
SELECT 'INT009', 'CPD003', 'TGT013', 8.5, 12.0, 'off-target', 5.9 UNION ALL
SELECT 'INT010', 'CPD004', 'TGT003', 0.09, 0.12, 'primary', 9.1 UNION ALL
SELECT 'INT011', 'CPD004', 'TGT004', 0.038, 0.055, 'primary', 8.9 UNION ALL
SELECT 'INT012', 'CPD004', 'TGT015', 0.22, 0.31, 'primary', 8.5 UNION ALL
SELECT 'INT013', 'CPD004', 'TGT016', 0.58, 0.75, 'primary', 8.1 UNION ALL
SELECT 'INT014', 'CPD004', 'TGT017', 0.33, 0.48, 'primary', 8.4 UNION ALL
SELECT 'INT015', 'CPD004', 'TGT013', 2.8, 4.1, 'off-target', 6.6 UNION ALL
SELECT 'INT016', 'CPD005', 'TGT004', 0.031, 0.044, 'primary', 9.5 UNION ALL
SELECT 'INT017', 'CPD005', 'TGT015', 0.48, 0.65, 'off-target', 7.3 UNION ALL
SELECT 'INT018', 'CPD006', 'TGT005', 0.02, 0.028, 'primary', 9.8 UNION ALL
SELECT 'INT019', 'CPD006', 'TGT003', 0.41, 0.59, 'off-target', 7.4 UNION ALL
SELECT 'INT020', 'CPD007', 'TGT006', 0.019, 0.025, 'primary', 9.8 UNION ALL
SELECT 'INT021', 'CPD007', 'TGT018', 0.55, 0.78, 'off-target', 7.2 UNION ALL
SELECT 'INT022', 'CPD008', 'TGT007', 0.0092, 0.014, 'primary', 10.1 UNION ALL
SELECT 'INT023', 'CPD008', 'TGT019', 0.38, 0.51, 'off-target', 7.4 UNION ALL
SELECT 'INT024', 'CPD009', 'TGT008', 0.011, 0.017, 'primary', 9.9 UNION ALL
SELECT 'INT025', 'CPD009', 'TGT009', 0.015, 0.022, 'primary', 9.8 UNION ALL
SELECT 'INT026', 'CPD010', 'TGT002', 0.041, 0.058, 'primary', 9.4 UNION ALL
SELECT 'INT027', 'CPD010', 'TGT001', 0.38, 0.52, 'off-target', 7.3 UNION ALL
SELECT 'INT028', 'CPD010', 'TGT013', 1.2, 1.8, 'off-target', 7.1 UNION ALL
SELECT 'INT029', 'CPD011', 'TGT006', 0.029, 0.041, 'primary', 9.5 UNION ALL
SELECT 'INT030', 'CPD011', 'TGT010', 0.71, 0.95, 'off-target', 7.0 UNION ALL
SELECT 'INT031', 'CPD012', 'TGT020', 0.39, 0.55, 'primary', 7.3 UNION ALL
SELECT 'INT032', 'CPD013', 'TGT014', 12.0, 18.5, 'primary', 5.7 UNION ALL
SELECT 'INT033', 'CPD014', 'TGT010', 0.0018, 0.0025, 'primary', 11.8 UNION ALL
SELECT 'INT034', 'CPD015', 'TGT004', 0.055, 0.078, 'primary', 9.2 UNION ALL
SELECT 'INT035', 'CPD015', 'TGT003', 0.12, 0.17, 'primary', 8.9 UNION ALL
SELECT 'INT036', 'CPD015', 'TGT016', 0.29, 0.41, 'primary', 8.5 UNION ALL
SELECT 'INT037', 'CPD015', 'TGT013', 0.95, 1.35, 'off-target', 7.2;
4. Crear tabla de pathways
Contiene rutas biológicas, áreas de enfermedades asociadas y relevancia del cáncer.
CREATE OR REPLACE TABLE drug_target_graph.pathways AS
SELECT 'PWY001' AS pathway_id, 'MAPK Signaling' AS pathway_name, 'hsa04010' AS kegg_id, 'Cell Proliferation' AS biological_process, 'Oncology' AS disease_area, 'high' AS cancer_relevance UNION ALL
SELECT 'PWY002', 'PI3K-AKT Signaling', 'hsa04151', 'Cell Survival', 'Oncology', 'high' UNION ALL
SELECT 'PWY003', 'VEGF Signaling', 'hsa04370', 'Angiogenesis', 'Oncology', 'high' UNION ALL
SELECT 'PWY004', 'ErbB Signaling', 'hsa04012', 'Cell Growth', 'Oncology', 'high' UNION ALL
SELECT 'PWY005', 'mTOR Signaling', 'hsa04150', 'Cell Growth', 'Oncology', 'medium' UNION ALL
SELECT 'PWY006', 'Cell Cycle', 'hsa04110', 'Cell Division', 'Oncology', 'high' UNION ALL
SELECT 'PWY007', 'Cardiac Muscle Contraction', 'hsa04260', 'Cardiac Function', 'Cardiovascular', 'low' UNION ALL
SELECT 'PWY008', 'hERG Cardiac Channel', 'hsa04022', 'Cardiac Repolarisation','Cardiovascular', 'low' UNION ALL
SELECT 'PWY009', 'AMPK Signaling', 'hsa04152', 'Energy Metabolism', 'Metabolic', 'low' UNION ALL
SELECT 'PWY010', 'ALK Signaling', 'hsa04915', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY011', 'RAS Signaling', 'hsa04014', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY012', 'HIV Replication', 'hsa05170', 'Viral Replication', 'Infectious Disease', 'low';
5. Crear tabla de target_pathways
Es una tabla de unión que vincula los objetivos a las vías biológicas en las que participan.
CREATE OR REPLACE TABLE drug_target_graph.target_pathways AS
SELECT 'TP001' AS tp_id, 'TGT001' AS target_id, 'PWY001' AS pathway_id, 'activator' AS role, 0.95 AS importance_score UNION ALL
SELECT 'TP002', 'TGT001', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP003', 'TGT002', 'PWY004', 'activator', 0.98 UNION ALL
SELECT 'TP004', 'TGT002', 'PWY001', 'activator', 0.82 UNION ALL
SELECT 'TP005', 'TGT002', 'PWY002', 'activator', 0.75 UNION ALL
SELECT 'TP006', 'TGT003', 'PWY003', 'activator', 0.96 UNION ALL
SELECT 'TP007', 'TGT003', 'PWY001', 'activator', 0.71 UNION ALL
SELECT 'TP008', 'TGT004', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP009', 'TGT004', 'PWY011', 'activator', 0.89 UNION ALL
SELECT 'TP010', 'TGT005', 'PWY010', 'activator', 0.99 UNION ALL
SELECT 'TP011', 'TGT005', 'PWY001', 'activator', 0.78 UNION ALL
SELECT 'TP012', 'TGT006', 'PWY002', 'activator', 0.98 UNION ALL
SELECT 'TP013', 'TGT006', 'PWY005', 'activator', 0.85 UNION ALL
SELECT 'TP014', 'TGT007', 'PWY001', 'activator', 0.94 UNION ALL
SELECT 'TP015', 'TGT007', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP016', 'TGT008', 'PWY006', 'activator', 0.95 UNION ALL
SELECT 'TP017', 'TGT009', 'PWY006', 'activator', 0.93 UNION ALL
SELECT 'TP018', 'TGT010', 'PWY005', 'activator', 0.99 UNION ALL
SELECT 'TP019', 'TGT010', 'PWY002', 'activator', 0.91 UNION ALL
SELECT 'TP020', 'TGT011', 'PWY003', 'activator', 0.87 UNION ALL
SELECT 'TP021', 'TGT011', 'PWY001', 'activator', 0.72 UNION ALL
SELECT 'TP022', 'TGT012', 'PWY001', 'activator', 0.83 UNION ALL
SELECT 'TP023', 'TGT012', 'PWY011', 'activator', 0.79 UNION ALL
SELECT 'TP024', 'TGT013', 'PWY008', 'substrate', 0.99 UNION ALL
SELECT 'TP025', 'TGT013', 'PWY007', 'substrate', 0.95 UNION ALL
SELECT 'TP026', 'TGT014', 'PWY009', 'activator', 0.97 UNION ALL
SELECT 'TP027', 'TGT015', 'PWY001', 'activator', 0.91 UNION ALL
SELECT 'TP028', 'TGT015', 'PWY011', 'activator', 0.86 UNION ALL
SELECT 'TP029', 'TGT016', 'PWY001', 'activator', 0.84 UNION ALL
SELECT 'TP030', 'TGT016', 'PWY003', 'activator', 0.77 UNION ALL
SELECT 'TP031', 'TGT017', 'PWY001', 'activator', 0.88 UNION ALL
SELECT 'TP032', 'TGT017', 'PWY011', 'activator', 0.82 UNION ALL
SELECT 'TP033', 'TGT018', 'PWY002', 'activator', 0.96 UNION ALL
SELECT 'TP034', 'TGT018', 'PWY005', 'activator', 0.88 UNION ALL
SELECT 'TP035', 'TGT019', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP036', 'TGT019', 'PWY011', 'activator', 0.91 UNION ALL
SELECT 'TP037', 'TGT020', 'PWY012', 'substrate', 0.99;
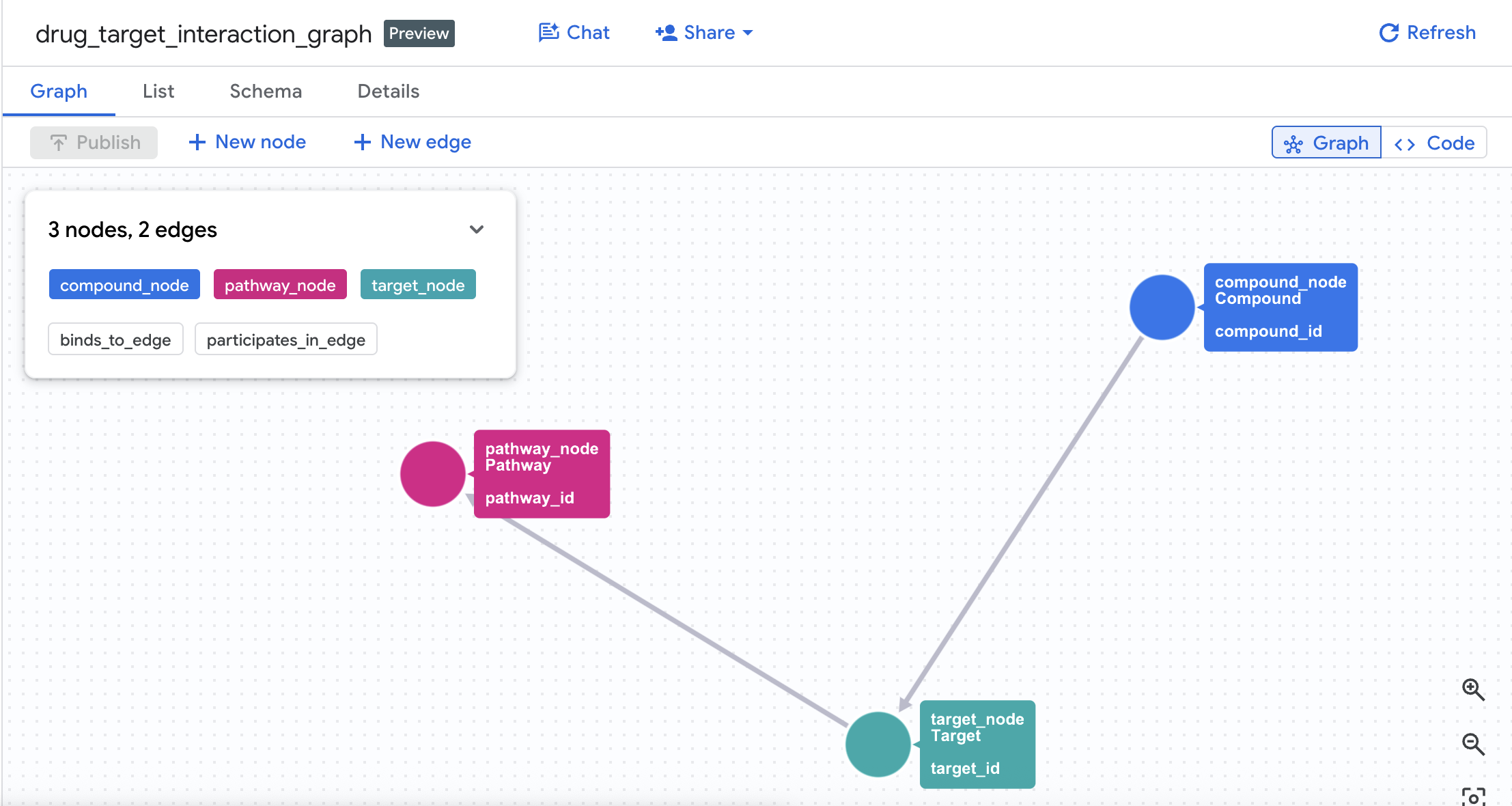
4. Crea el gráfico de propiedades
Una vez que se hayan creado las tablas correctamente, puedes construir el gráfico de propiedades. Esto vincula nodos (compuestos, objetivos, rutas) con tablas de aristas (Interactions y Target Pathways).
Ejecuta la siguiente instrucción en el editor de SQL de BigQuery Studio:
CREATE OR REPLACE PROPERTY GRAPH drug_target_graph.drug_target_interaction_graph
NODE TABLES (
drug_target_graph.compounds
AS compound_node
KEY (compound_id)
LABEL Compound
PROPERTIES (compound_id, compound_name, mechanism_of_action, dev_stage, therapeutic_area, molecular_weight),
drug_target_graph.targets
AS target_node
KEY (target_id)
LABEL Target
PROPERTIES (target_id, target_name, gene_name, uniprot_id, target_class, is_oncogene),
drug_target_graph.pathways
AS pathway_node
KEY (pathway_id)
LABEL Pathway
PROPERTIES (pathway_id, pathway_name, kegg_id, biological_process, disease_area, cancer_relevance)
)
EDGE TABLES (
drug_target_graph.interactions
AS binds_to_edge
KEY (interaction_id)
SOURCE KEY (compound_id) REFERENCES compound_node (compound_id)
DESTINATION KEY (target_id) REFERENCES target_node (target_id)
LABEL BINDS_TO
PROPERTIES (interaction_id, affinity_nm, ic50_nm, interaction_type, pchembl_value),
drug_target_graph.target_pathways
AS participates_in_edge
KEY (tp_id)
SOURCE KEY (target_id) REFERENCES target_node (target_id)
DESTINATION KEY (pathway_id) REFERENCES pathway_node (pathway_id)
LABEL PARTICIPATES_IN
PROPERTIES (tp_id, role, importance_score)
);
Esto crea un gráfico llamado drug_target_interaction_graph en tu conjunto de datos.
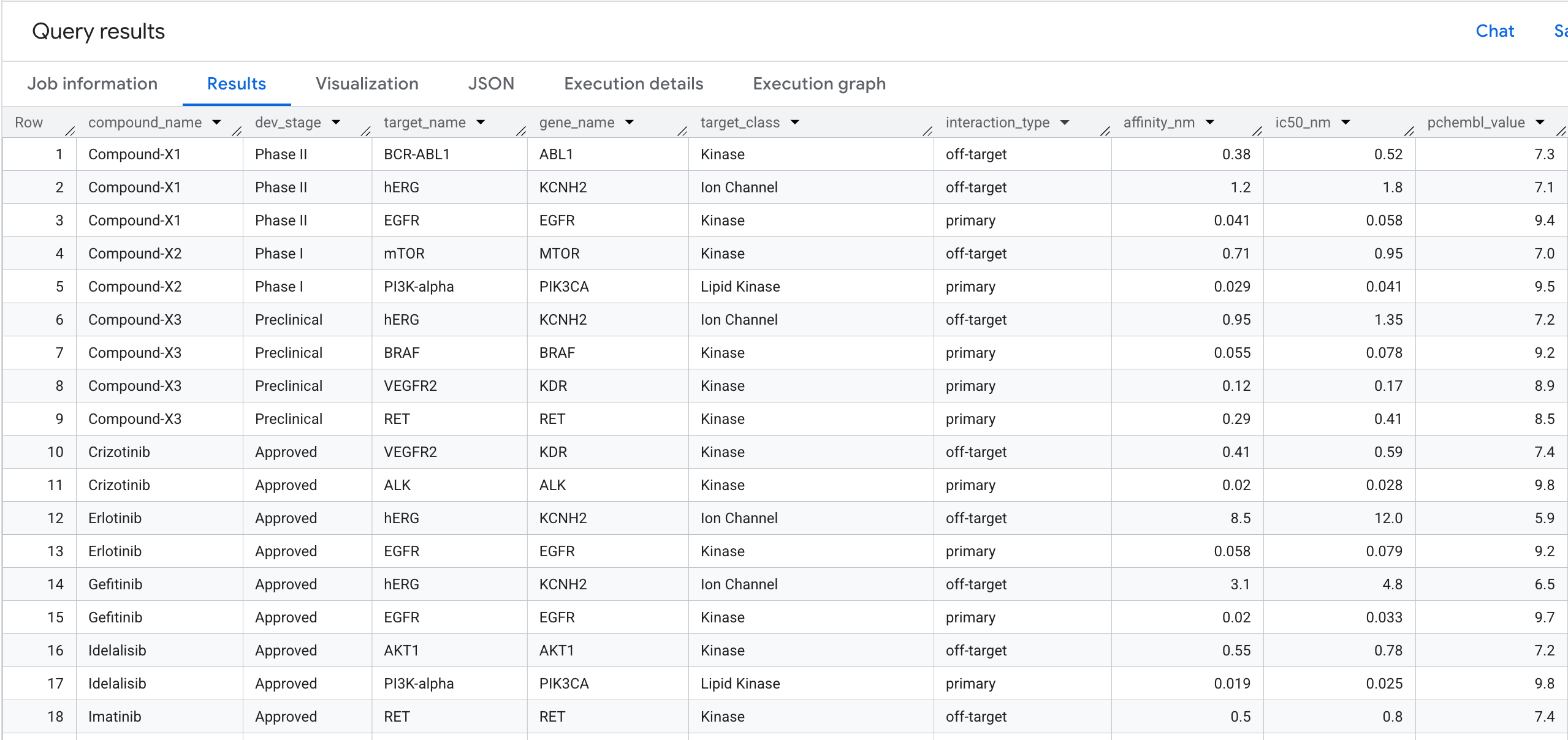
5. Consulta 1: Perfil de vinculación de destino completo por compuesto
Ejecutemos nuestra primera consulta de gráfico. Se trata de una navegación de 1 salto que responde a la siguiente pregunta: ¿Qué compuestos se unen a qué objetivos y cuál es su afinidad?
Consulta en GQL
Ejecuta la siguiente consulta en el editor de SQL:
SELECT
compound_name,
dev_stage,
target_name,
gene_name,
target_class,
interaction_type,
ROUND(affinity_nm, 3) AS affinity_nm,
ROUND(ic50_nm, 3) AS ic50_nm,
pchembl_value
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_name AS target_name,
t.gene_name AS gene_name,
t.target_class AS target_class,
b.interaction_type AS interaction_type,
b.affinity_nm AS affinity_nm,
b.ic50_nm AS ic50_nm,
b.pchembl_value AS pchembl_value
)
)
ORDER BY compound_name, interaction_type, affinity_nm;
Esto es lo que verás en los resultados:
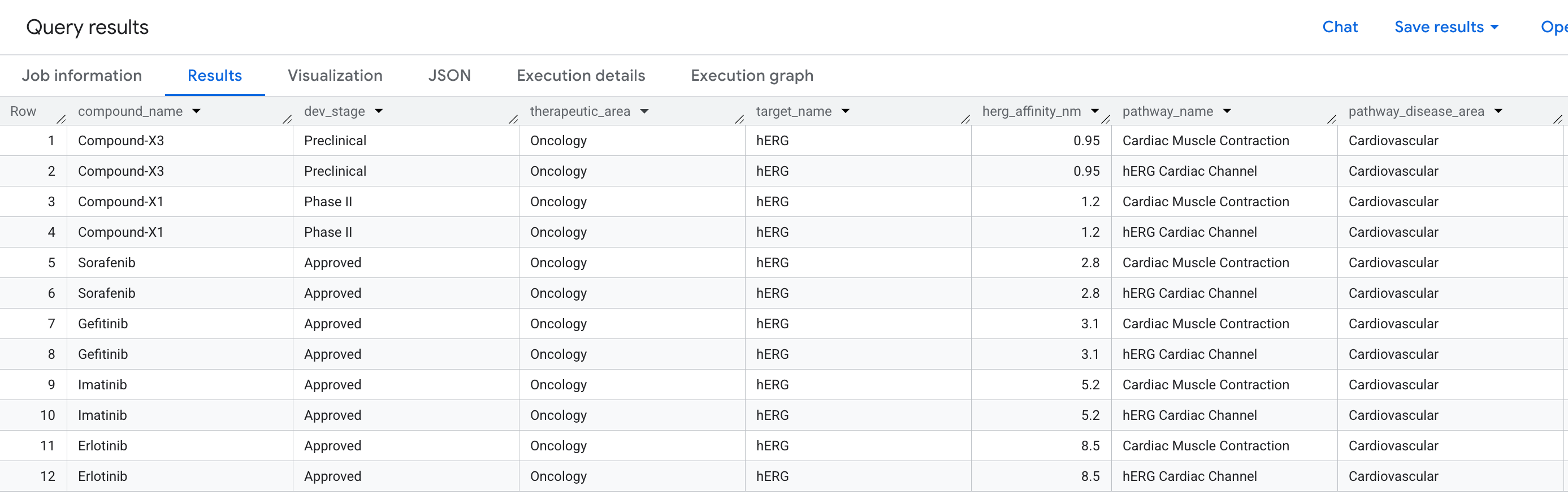
6. Consulta 2: Detección de riesgo cardíaco
La pregunta comercial
En el descubrimiento de fármacos, uno de los motivos más comunes por los que un compuesto prometedor falla en los ensayos clínicos es la cardiotoxicidad, específicamente, la unión no deseada a la proteína hERG (gen: KCNH2), un canal de iones de potasio que regula el ritmo cardíaco. Un impacto fuera del objetivo en hERG puede causar arritmias fatales y ha sido responsable de varias retiradas de medicamentos de alto perfil.
La pregunta que queremos responder es la siguiente:
"¿Qué compuestos de nuestra cartera tienen un evento de unión fuera del objetivo en la proteína hERG y qué vías cardíacas ponen en riesgo?"
Esta es una pregunta de 2 saltos: Necesitamos pasar de un compuesto a través de un objetivo (hERG) a una vía, lo que conecta tres tipos de entidades a través de dos relaciones en una sola búsqueda.
Escribe la consulta en GQL
Ejecuta la siguiente consulta en el editor de SQL de BQ:
SELECT
compound_name,
dev_stage,
therapeutic_area,
target_name,
ROUND(affinity_nm, 3) AS herg_affinity_nm,
pathway_name,
disease_area AS pathway_disease_area
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND b.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
c.therapeutic_area AS therapeutic_area,
t.target_name AS target_name,
b.affinity_nm AS affinity_nm,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
ORDER BY herg_affinity_nm;
Observa cómo la cláusula MATCH se lee casi como una oración: "Encuentra un compuesto que se vincule a un objetivo que participe en una ruta", con los filtros aplicados en cada nodo y borde a lo largo de la ruta.
Estos son los datos que verás en los resultados:
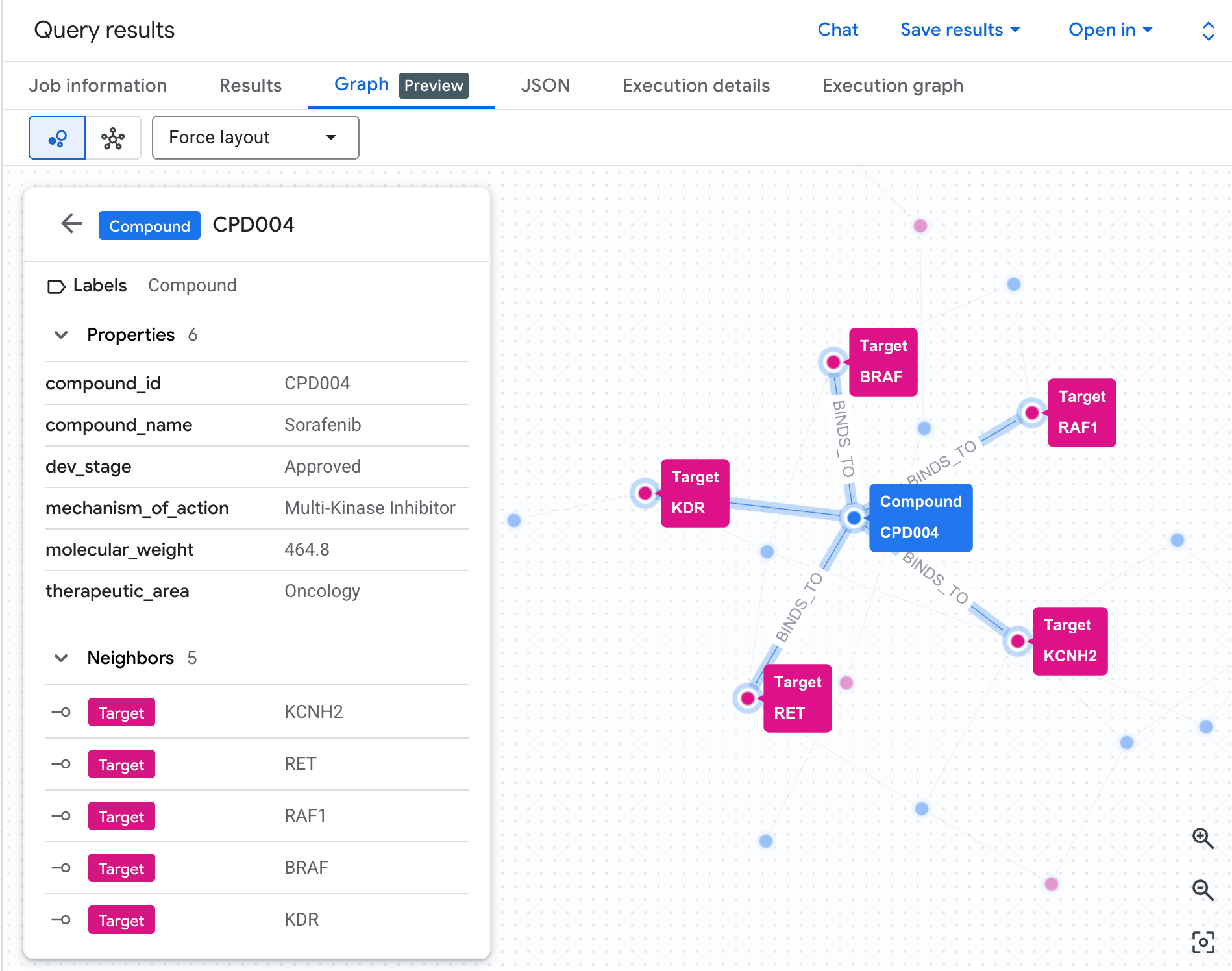
Visualiza la red de riesgo como un gráfico
Una tabla nos muestra los datos, pero no la estructura del riesgo. ¿Hay varios compuestos que convergen en la misma vía? ¿Hay un solo compuesto de alto riesgo o varios?
Una visualización de gráfico hace que esto sea inmediatamente visible. Ejecuta la siguiente celda para renderizar el mismo recorrido de 2 saltos como una red interactiva:
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH pt = (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND pw.disease_area = 'Cardiovascular'
RETURN
TO_JSON(pt) AS path
Deberías ver un gráfico como el siguiente:
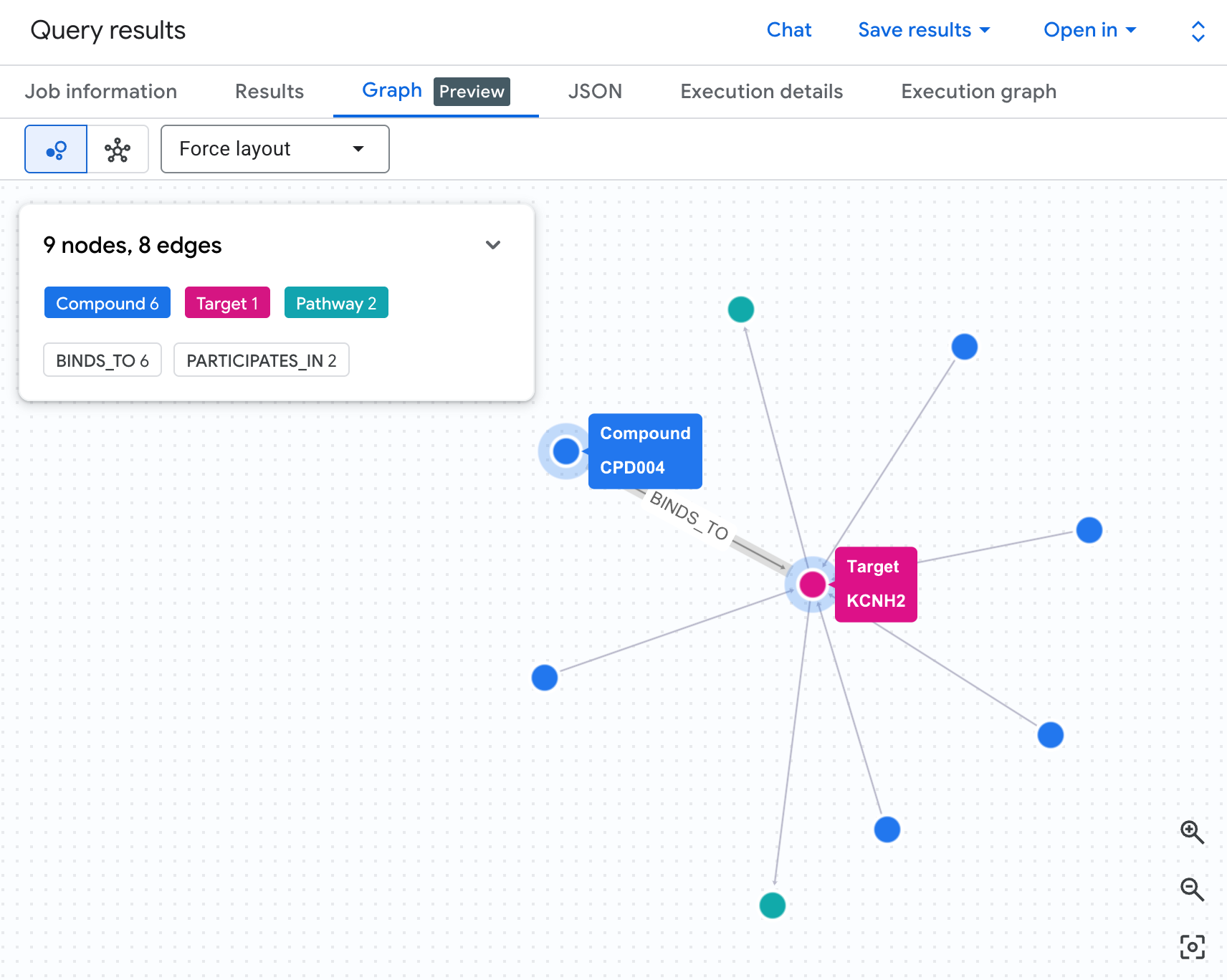
Cada ruta del gráfico traza una cadena de responsabilidad completa: un compuesto (nodos azules) se une a la proteína hERG en el centro, que se conecta a una o más vías cardíacas (nodos verdes). Lo que era una lista plana de filas en la tabla ahora es una red de riesgos visible: los compuestos con múltiples exposiciones a vías se destacan de inmediato como de mayor prioridad para la revisión de seguridad.
Consulta Por qué GQL es más elegante que SQL
Para ejecutar la misma consulta de 2 saltos en SQL estándar, necesitas 4 uniones explícitas. Estás dedicando esfuerzo cognitivo a describir cómo unir tablas en lugar de qué relación buscas. GQL te permite enfocarte en la pregunta.
SELECT
c.compound_name,
c.dev_stage,
c.therapeutic_area,
t.target_name,
ROUND(i.affinity_nm, 3) AS herg_affinity_nm,
pw.pathway_name,
pw.disease_area AS pathway_disease_area
FROM drug_target_graph.compounds c
JOIN drug_target_graph.interactions i ON c.compound_id = i.compound_id
JOIN drug_target_graph.targets t ON i.target_id = t.target_id
JOIN drug_target_graph.target_pathways tp ON t.target_id = tp.target_id
JOIN drug_target_graph.pathways pw ON tp.pathway_id = pw.pathway_id
WHERE t.gene_name = 'KCNH2'
AND i.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
ORDER BY herg_affinity_nm;
Profundización: detección de riesgos de metabolitos de múltiples saltos
La consulta anterior identifica los compuestos que se unen directamente a la proteína hERG. Sin embargo, en los flujos de trabajo reales de seguridad de medicamentos, el riesgo a veces se encuentra a un paso de distancia: un compuesto puede convertirse metabólicamente en el cuerpo en una molécula secundaria (un metabolito) que luego se une a hERG, una responsabilidad que los ensayos de unión directa pueden pasar por alto por completo.
Si tu gráfico de propiedad incluía una tabla de nodos Metabolite y un borde METABOLISES_INTO, podrías extender el mismo patrón MATCH a un recorrido de 3 saltos:
(Compound)-[METABOLISES_INTO]->(Metabolite)-[BINDS_TO]->
(Target)-[PARTICIPATES_IN]->(Pathway)
La estructura de la consulta en GQL cambiaría exactamente en un nodo y una arista. El SQL equivalente requeriría dos JOIN adicionales. Este es el patrón que hace que el recorrido de gráficos sea particularmente potente para el análisis de cascada de seguridad: la complejidad de la consulta crece de forma lineal, mientras que la información biológica crece de forma exponencial.
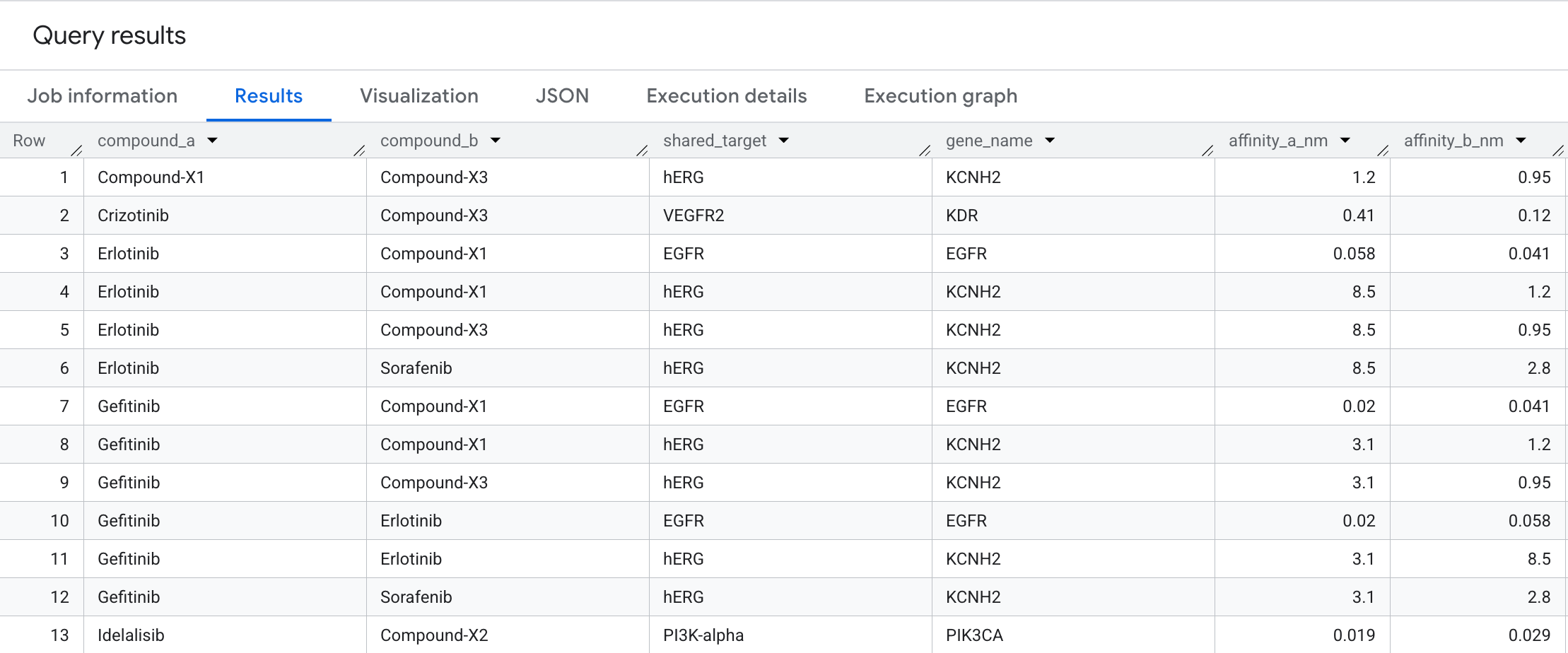
7. Consulta 3: Pares compuestos de objetivo compartido
Para encontrar candidatos para la terapia combinada, podemos identificar cuándo dos compuestos diferentes se unen al mismo nodo objetivo. Usamos una coincidencia bidireccional para responder la siguiente pregunta: ¿Qué compuestos oncológicos convergen en el mismo objetivo exacto?
Ejecuta la siguiente consulta en el editor de SQL:
SELECT
compound_a,
compound_b,
shared_target,
gene_name,
ROUND(affinity_a_nm, 3) AS affinity_a_nm,
ROUND(affinity_b_nm, 3) AS affinity_b_nm
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
AND c2.therapeutic_area = 'Oncology'
COLUMNS (
c1.compound_name AS compound_a,
c2.compound_name AS compound_b,
t.target_name AS shared_target,
t.gene_name AS gene_name,
b1.affinity_nm AS affinity_a_nm,
b2.affinity_nm AS affinity_b_nm
)
)
ORDER BY compound_a, compound_b, affinity_a_nm;
Estos son los datos que verás en los resultados:
Visualización de gráficos
Puedes visualizar el gráfico directamente en BigQuery ejecutando el siguiente código en el editor de SQL.
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH p = (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
RETURN
TO_JSON(p) AS path
Este recorrido bidireccional revela pares de compuestos que convergen en el mismo objetivo proteico, un patrón que es difícil de detectar en una tabla de interacciones plana, pero que se ve de inmediato como un grafo. En el descubrimiento de fármacos, los pares de objetivos compartidos son el punto de partida para el diseño de la terapia combinada: dos compuestos que afectan el mismo nodo en una vía de señalización del cáncer pueden producir un efecto sinérgico o, de lo contrario, indicar una redundancia no deseada en la canalización.
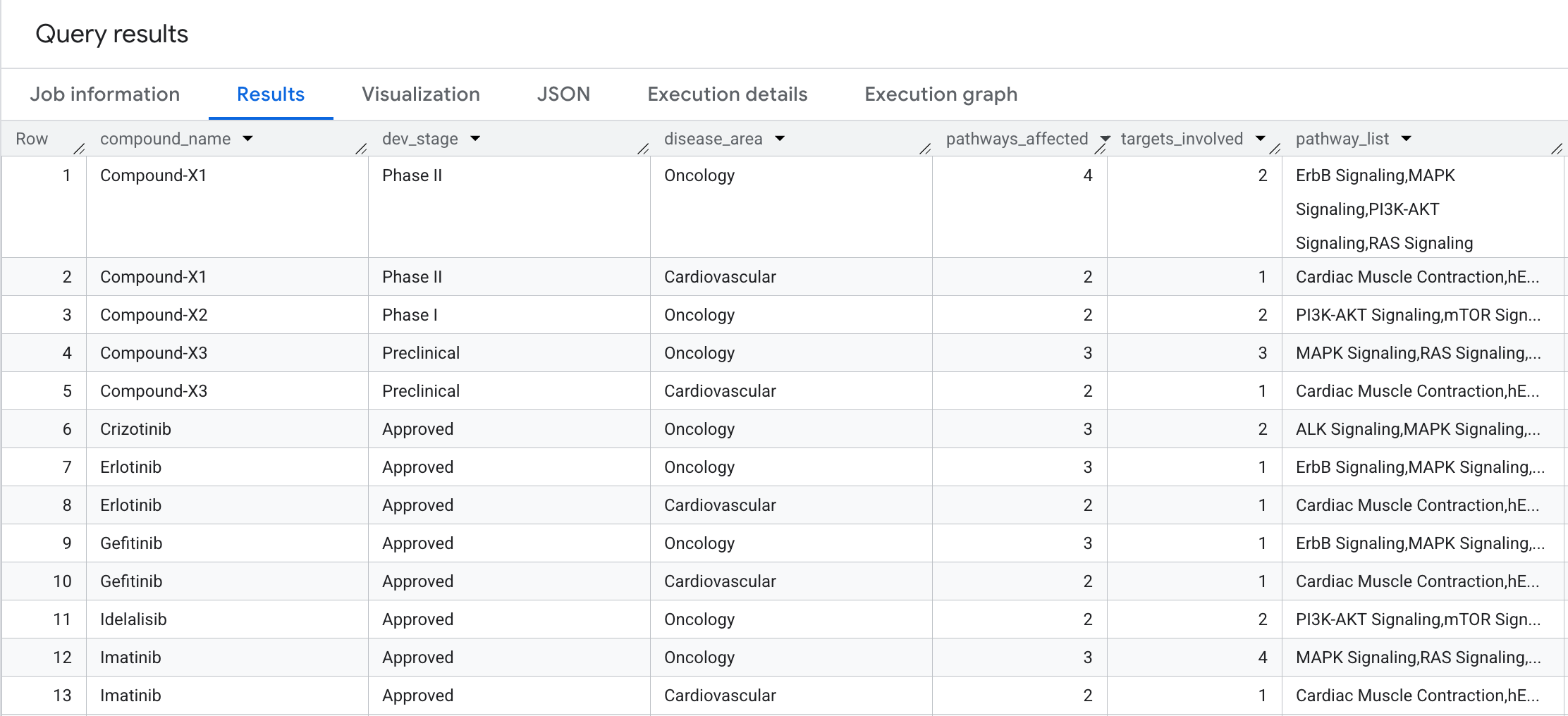
8. Consulta 4: Radio de explosión de la ruta de la enfermedad
¿Qué tan amplio es el impacto biológico de cada compuesto? Realicemos un recorrido de 2 saltos con agregación para responder la siguiente pregunta: ¿Cuántas vías biológicas y objetivos distintos afecta cada compuesto, agrupados por área de enfermedad?
Ejecuta la siguiente consulta en el editor de SQL:
SELECT
compound_name,
dev_stage,
disease_area,
COUNT(DISTINCT pathway_id) AS pathways_affected,
COUNT(DISTINCT target_id) AS targets_involved,
STRING_AGG(DISTINCT pathway_name ORDER BY pathway_name) AS pathway_list
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_id AS target_id,
pw.pathway_id AS pathway_id,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
GROUP BY compound_name, dev_stage, disease_area
ORDER BY compound_name, pathways_affected DESC;
Esto es lo que verás en los resultados:
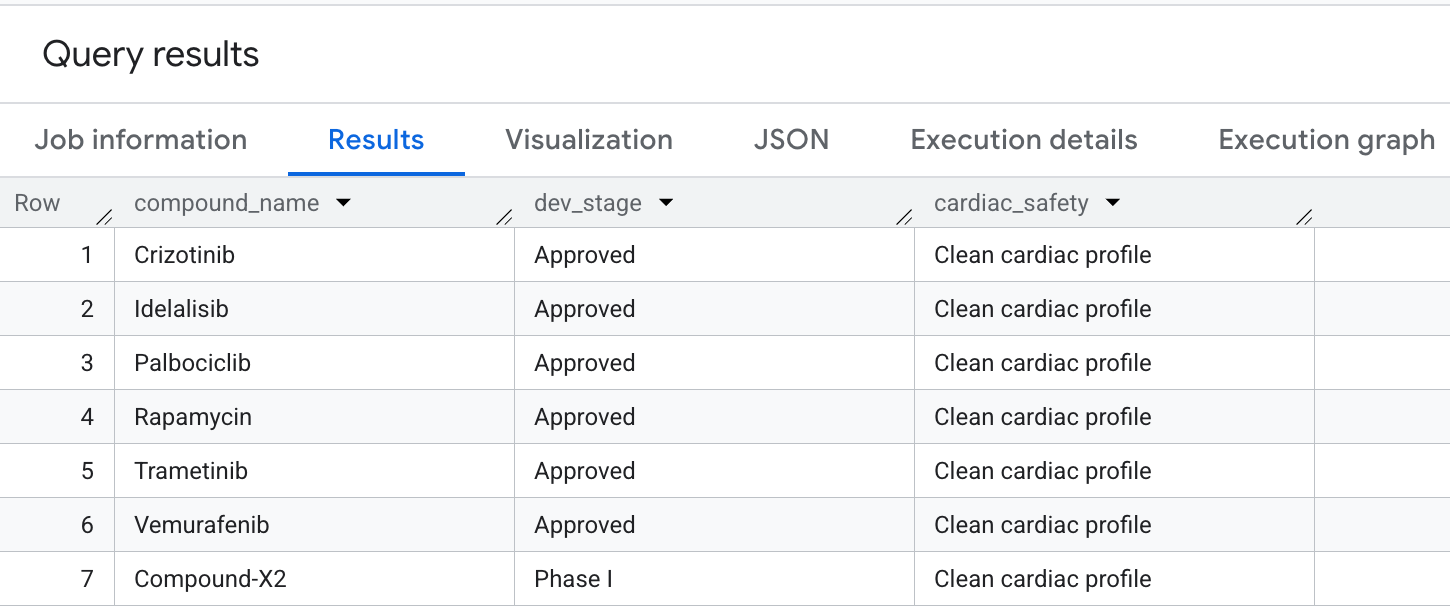
9. Consulta 5: Selección de compuestos seguros
Por último, consultemos los compuestos que tienen una alta cobertura oncológica, pero que evitan explícitamente las responsabilidades fuera del objetivo del hERG (cardíaco). Esto coincide con los patrones de selección comunes que priorizan la seguridad en los procesos de descubrimiento de fármacos.
Ejecuta la siguiente consulta en el editor de SQL:
WITH oncology_compounds AS (
SELECT DISTINCT compound_id, compound_name, dev_stage
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE pw.disease_area = 'Oncology'
AND pw.cancer_relevance = 'high'
COLUMNS (
c.compound_id AS compound_id,
c.compound_name AS compound_name,
c.dev_stage AS dev_stage
)
)
),
herg_risk_compounds AS (
SELECT DISTINCT compound_id
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
WHERE t.gene_name = 'KCNH2'
COLUMNS (c.compound_id AS compound_id)
)
)
SELECT
o.compound_name,
o.dev_stage,
'Clean cardiac profile' AS cardiac_safety
FROM oncology_compounds o
LEFT JOIN herg_risk_compounds h ON o.compound_id = h.compound_id
WHERE h.compound_id IS NULL
ORDER BY o.dev_stage, o.compound_name;
Este es el resultado que verás:
Ejecutaste correctamente recorridos de grafos avanzados en BigQuery para extraer perfiles clave de seguridad y eficacia.
10. Sección adicional: Chatea con tu gráfico
Conversational Analytics de BigQuery ahora admite gráficos como fuente de conocimiento. Esto te permite chatear con el gráfico que acabas de crear en lenguaje natural.
Primeros pasos: Agrega un gráfico como fuente de conocimiento
Para comenzar, crea un agente conversacional siguiendo los pasos que se indican aquí. Selecciona el gráfico que creaste en la barra de búsqueda.
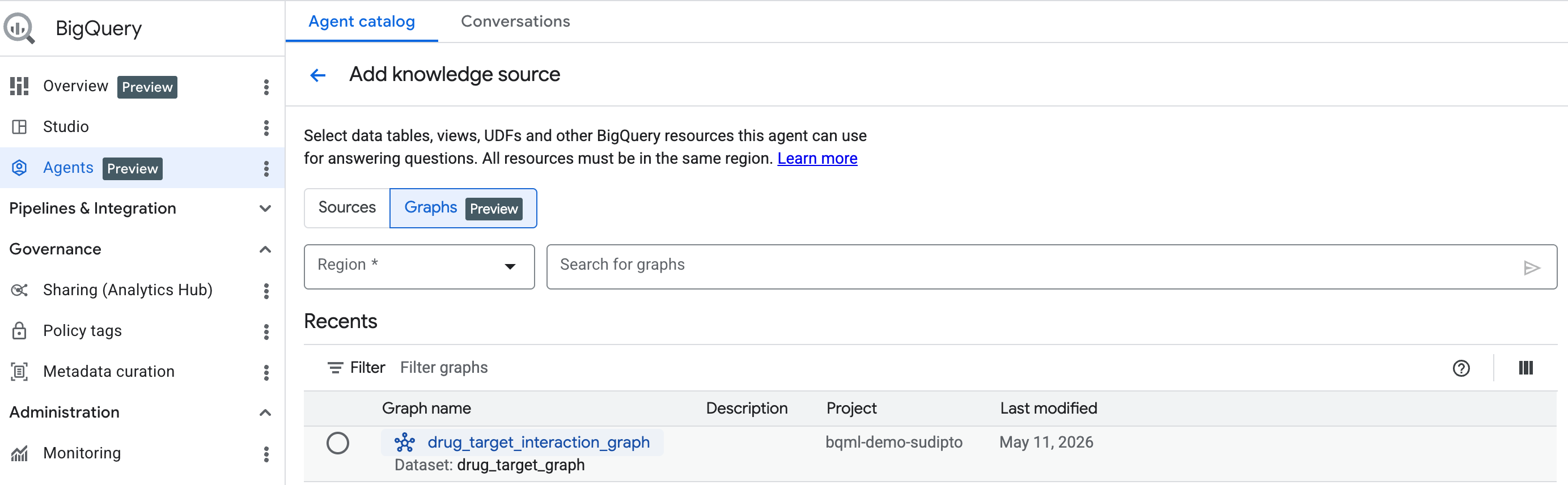
Usa Conversational Analytics de BigQuery para chatear con tu gráfico
Una vez que hayas agregado la fuente de conocimiento como gráfico, completa el resto de la configuración del agente de análisis conversacional.
Luego, puedes comenzar a chatear con tu gráfico en lenguaje natural.
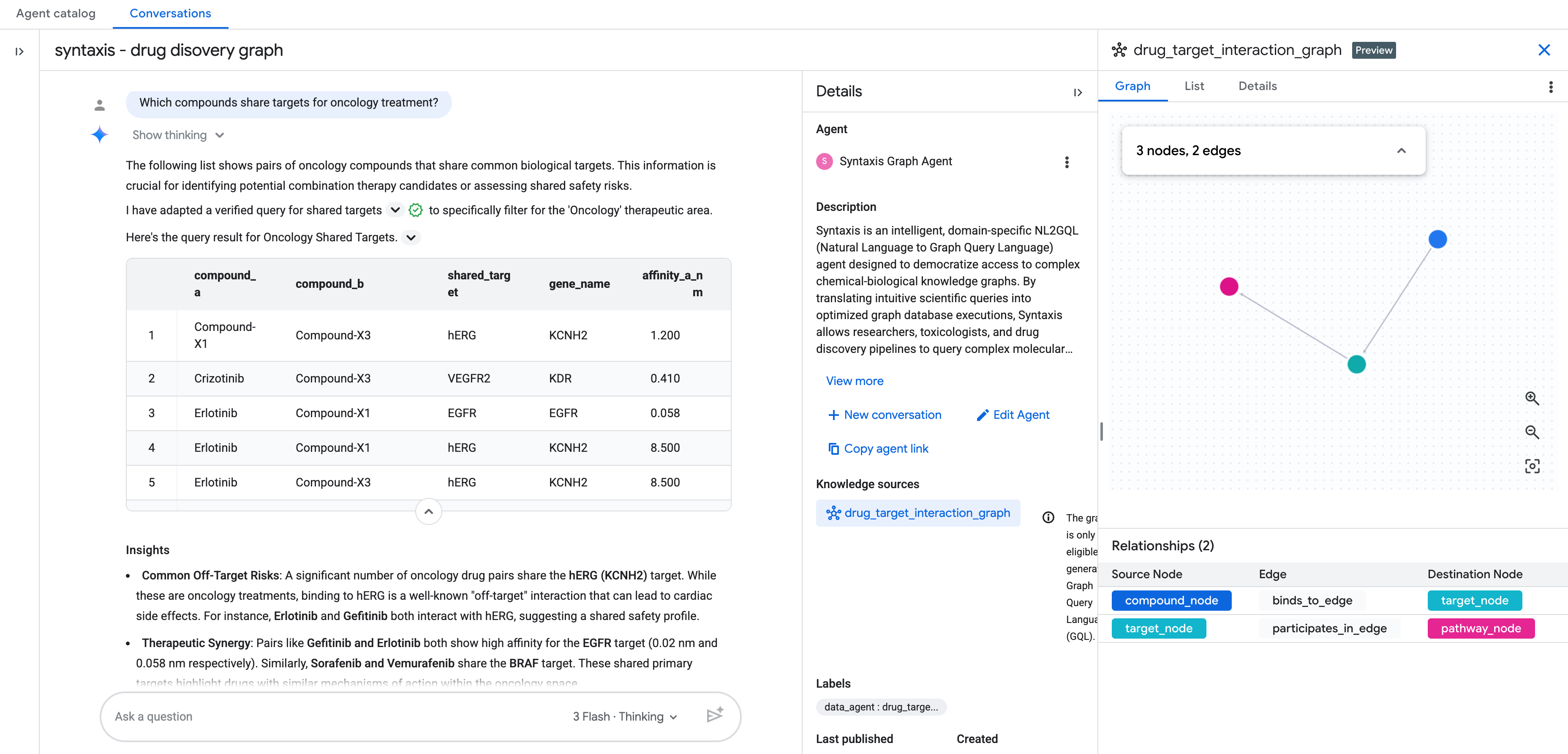
Preguntas adicionales
- ¿Cuáles son todos los objetivos de los compuestos que se encuentran actualmente en ensayos de fase 2?
- ¿Qué objetivos comparten los compuestos cardiovasculares y oncológicos?
11. Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud, borra los recursos que creaste durante este codelab.
Ejecuta la siguiente consulta para descartar el esquema y todas las tablas de forma en cascada:
DROP SCHEMA IF EXISTS drug_target_graph CASCADE;
12. ¡Felicitaciones!
¡Felicitaciones! Modelaste y analizaste correctamente una red de interacción fármaco-objetivo con BigQuery Graph.
Qué aprendiste
- Cómo modelar relaciones entre entidades (compuestos, objetivos, rutas) como un grafo de propiedades
- Cómo definir el esquema y crear un gráfico de propiedades en BigQuery
- Cómo escribir recorridos de gráficos complejos con GQL y compararlos con el SQL tradicional
- Cómo aprovechar
GRAPH_TABLE,MATCHy la correlación bidireccional para resolver problemas del dominio de las ciencias de la vida