
۱. مقدمه
در این آزمایشگاه کد، شما یاد خواهید گرفت که چگونه از BigQuery Graph برای مدلسازی و تجزیه و تحلیل شبکه تعامل دارو-هدف استفاده کنید. شما از قدرت پرسوجوهای گراف (GQL) برای بررسی چگونگی تعامل داروها با اهداف بیولوژیکی، شناسایی عوارض جانبی بالقوه (مانند خطرات قلبی) و کشف درمانهای ترکیبی بالقوه استفاده خواهید کرد.
🧬 مورد استفاده — شبکه تعامل دارو-هدف
سوال تجاری: شعاع کامل انفجار یک ترکیب چقدر است - به کدام اهداف متصل میشود، کدام مسیرهای بیولوژیکی را تحت تأثیر قرار میدهد و کدام نواحی بیماری را درگیر میکند؟
جداول:
میز | توضیحات |
| مولکولهای دارویی به همراه مکانیسم اثر و مرحله توسعه |
| اهداف پروتئینی با نام ژنها و شناسههای UniProt |
| میل ترکیبی اتصال به هدف (اهداف اصلی + اهداف غیر اصلی) |
| مسیرهای بیولوژیکی با ارتباط با حوزههای بیماری |
| جدول اتصال که اهداف را به مسیرهایی که در آنها شرکت میکنند، متصل میکند |
مدل نمودار ویژگی:
(Compound)-[BINDS_TO {affinity_nm, ic50_nm, interaction_type}]->(Target)
(Target)-[PARTICIPATES_IN {role, importance_score}]->(Pathway)
🔍 سوالات نمایشی
پرس و جو | آنچه نشان میدهد |
سوال ۱: پروفایل اتصال هدف | پیمایش تکگامی - ترکیبی برای همه اهداف اصلی و فرعی |
Q2: تشخیص خطر قلبی hERG | پیمایش دو گامی — ترکیب → هدف hERG → مسیر قلبی |
سوال ۳: جفتهای مرکب با هدف مشترک | تطابق دوطرفه - دو ترکیب که در یک گره هدف همگرا میشوند |
Q4: شعاع انفجار مسیر بیماری | تجمیع دو مرحلهای - پوشش کامل مسیر و منطقه بیماری در هر ترکیب |
سوال ۵: انتخاب ترکیب ایمن | ترکیباتی با پوشش بالای سرطانشناسی اما بدون مسئولیت قلبی hERG |
کاری که انجام خواهید داد
- ایجاد یک مجموعه داده و طرحواره BigQuery برای شبکه تداخلات دارویی
- بارگذاری دادههای نمونه (ترکیبات، اهداف، تعاملات، مسیرها، مسیرهای هدف)
- یک نمودار ویژگی در BigQuery ایجاد کنید که این موجودیتها را به هم متصل میکند.
- با استفاده از پیمایش گراف (
GRAPH_TABLEوMATCH) نمودار را برای درک تعاملات ترکیبات، مسیرهای بیولوژیکی و شعاع انفجار بیماری جستجو کنید. - GQL و SQL استاندارد را در کنار هم مقایسه کنید تا سادگی و قدرت بیان نحو گراف را درک کنید.
آنچه نیاز دارید
- یک مرورگر وب مانند کروم
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب
این آزمایشگاه کد برای توسعهدهندگان در تمام سطوح، از جمله مبتدیان، مناسب است.
۲. قبل از شروع
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، یک پروژه گوگل کلود انتخاب یا ایجاد کنید.
- مطمئن شوید که پرداخت برای پروژه ابری شما فعال است.
شروع پوسته ابری
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید.
- تأیید اعتبار:
gcloud auth list
- پروژه خود را تایید کنید:
gcloud config get project
- در صورت نیاز آن را تنظیم کنید:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
فعال کردن APIها
برای فعال کردن API مورد نیاز BigQuery، این دستور را اجرا کنید:
gcloud services enable bigquery.googleapis.com
۳. تعریف طرحواره و بارگذاری دادهها
ابتدا، باید یک مجموعه داده برای ذخیره جداول مربوط به نمودار خود ایجاد کنید و آنها را با دادههای نمونه پر کنید.
- در کنسول گوگل کلود به BigQuery Studio بروید.
- برای باز کردن یک تب کوئری جدید، روی ویرایشگر SQL کلیک کنید.
- برای ایجاد مجموعه داده
drug_target_graphدستور زیر را اجرا کنید:
CREATE SCHEMA IF NOT EXISTS drug_target_graph
OPTIONS (location = 'US');
اکنون، با اجرای کوئریهای DDL زیر در BigQuery Studio، 5 جدول منبع را ایجاد کنید.
۱. ایجاد جدول compounds
شامل مولکولهای دارو، مکانیسم اثر آنها، مرحله توسعه و ناحیه درمانی است.
CREATE OR REPLACE TABLE drug_target_graph.compounds AS
SELECT 'CPD001' AS compound_id, 'Imatinib' AS compound_name, 'Kinase Inhibitor' AS mechanism_of_action, 'Approved' AS dev_stage, 'Oncology' AS therapeutic_area, 479.6 AS molecular_weight UNION ALL
SELECT 'CPD002', 'Gefitinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 446.9 UNION ALL
SELECT 'CPD003', 'Erlotinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 393.4 UNION ALL
SELECT 'CPD004', 'Sorafenib', 'Multi-Kinase Inhibitor', 'Approved', 'Oncology', 464.8 UNION ALL
SELECT 'CPD005', 'Vemurafenib', 'BRAF Inhibitor', 'Approved', 'Oncology', 489.9 UNION ALL
SELECT 'CPD006', 'Crizotinib', 'ALK Inhibitor', 'Approved', 'Oncology', 450.3 UNION ALL
SELECT 'CPD007', 'Idelalisib', 'PI3K Inhibitor', 'Approved', 'Oncology', 415.4 UNION ALL
SELECT 'CPD008', 'Trametinib', 'MEK Inhibitor', 'Approved', 'Oncology', 615.4 UNION ALL
SELECT 'CPD009', 'Palbociclib', 'CDK Inhibitor', 'Approved', 'Oncology', 447.5 UNION ALL
SELECT 'CPD010', 'Compound-X1', 'Kinase Inhibitor', 'Phase II', 'Oncology', 412.3 UNION ALL
SELECT 'CPD011', 'Compound-X2', 'PI3K Inhibitor', 'Phase I', 'Oncology', 398.7 UNION ALL
SELECT 'CPD012', 'Saquinavir', 'Protease Inhibitor', 'Approved', 'Infectious Disease', 670.8 UNION ALL
SELECT 'CPD013', 'Metformin', 'AMPK Activator', 'Approved', 'Metabolic', 165.6 UNION ALL
SELECT 'CPD014', 'Rapamycin', 'mTOR Inhibitor', 'Approved', 'Immunology', 914.2 UNION ALL
SELECT 'CPD015', 'Compound-X3', 'Multi-Kinase Inhibitor', 'Preclinical', 'Oncology', 502.1;
۲. ایجاد جدول targets
شامل اهداف پروتئینی، نام ژنها، شناسههای UniProt و کلاسهای هدف است.
CREATE OR REPLACE TABLE drug_target_graph.targets AS
SELECT 'TGT001' AS target_id, 'BCR-ABL1' AS target_name, 'ABL1' AS gene_name, 'P00519' AS uniprot_id, 'Kinase' AS target_class, TRUE AS is_oncogene UNION ALL
SELECT 'TGT002', 'EGFR', 'EGFR', 'P00533', 'Kinase', TRUE UNION ALL
SELECT 'TGT003', 'VEGFR2', 'KDR', 'P35968', 'Kinase', FALSE UNION ALL
SELECT 'TGT004', 'BRAF', 'BRAF', 'P15056', 'Kinase', TRUE UNION ALL
SELECT 'TGT005', 'ALK', 'ALK', 'Q9UM73', 'Kinase', TRUE UNION ALL
SELECT 'TGT006', 'PI3K-alpha','PIK3CA', 'P42336', 'Lipid Kinase', TRUE UNION ALL
SELECT 'TGT007', 'MEK1', 'MAP2K1', 'Q02750', 'Kinase', FALSE UNION ALL
SELECT 'TGT008', 'CDK4', 'CDK4', 'P11802', 'Kinase', FALSE UNION ALL
SELECT 'TGT009', 'CDK6', 'CDK6', 'P30279', 'Kinase', FALSE UNION ALL
SELECT 'TGT010', 'mTOR', 'MTOR', 'P42345', 'Kinase', FALSE UNION ALL
SELECT 'TGT011', 'PDGFR-beta','PDGFRB', 'P09619', 'Kinase', FALSE UNION ALL
SELECT 'TGT012', 'c-KIT', 'KIT', 'P10721', 'Kinase', TRUE UNION ALL
SELECT 'TGT013', 'hERG', 'KCNH2', 'Q12809', 'Ion Channel', FALSE UNION ALL
SELECT 'TGT014', 'AMPK', 'PRKAA1', 'Q13131', 'Kinase', FALSE UNION ALL
SELECT 'TGT015', 'RAF1', 'RAF1', 'P04049', 'Kinase', FALSE UNION ALL
SELECT 'TGT016', 'RET', 'RET', 'P07949', 'Kinase', TRUE UNION ALL
SELECT 'TGT017', 'FLT3', 'FLT3', 'P36888', 'Kinase', TRUE UNION ALL
SELECT 'TGT018', 'AKT1', 'AKT1', 'P31749', 'Kinase', FALSE UNION ALL
SELECT 'TGT019', 'ERK2', 'MAPK1', 'P28482', 'Kinase', FALSE UNION ALL
SELECT 'TGT020', 'HIV-Protease','HIV1-PR','Q72547', 'Protease', FALSE;
۳. ایجاد جدول interactions
شامل دادههای مربوط به میل ترکیبی اتصال به هدف (اهداف اصلی در مقابل اهداف غیر اصلی) است.
CREATE OR REPLACE TABLE drug_target_graph.interactions AS
SELECT 'INT001' AS interaction_id, 'CPD001' AS compound_id, 'TGT001' AS target_id, 0.025 AS affinity_nm, 0.038 AS ic50_nm, 'primary' AS interaction_type, 9.8 AS pchembl_value UNION ALL
SELECT 'INT002', 'CPD001', 'TGT011', 0.1, 0.15, 'primary', 8.8 UNION ALL
SELECT 'INT003', 'CPD001', 'TGT012', 0.068, 0.1, 'primary', 9.2 UNION ALL
SELECT 'INT004', 'CPD001', 'TGT016', 0.5, 0.8, 'off-target', 7.4 UNION ALL
SELECT 'INT005', 'CPD001', 'TGT013', 5.2, 8.1, 'off-target', 6.1 UNION ALL
SELECT 'INT006', 'CPD002', 'TGT002', 0.02, 0.033, 'primary', 9.7 UNION ALL
SELECT 'INT007', 'CPD002', 'TGT013', 3.1, 4.8, 'off-target', 6.5 UNION ALL
SELECT 'INT008', 'CPD003', 'TGT002', 0.058, 0.079, 'primary', 9.2 UNION ALL
SELECT 'INT009', 'CPD003', 'TGT013', 8.5, 12.0, 'off-target', 5.9 UNION ALL
SELECT 'INT010', 'CPD004', 'TGT003', 0.09, 0.12, 'primary', 9.1 UNION ALL
SELECT 'INT011', 'CPD004', 'TGT004', 0.038, 0.055, 'primary', 8.9 UNION ALL
SELECT 'INT012', 'CPD004', 'TGT015', 0.22, 0.31, 'primary', 8.5 UNION ALL
SELECT 'INT013', 'CPD004', 'TGT016', 0.58, 0.75, 'primary', 8.1 UNION ALL
SELECT 'INT014', 'CPD004', 'TGT017', 0.33, 0.48, 'primary', 8.4 UNION ALL
SELECT 'INT015', 'CPD004', 'TGT013', 2.8, 4.1, 'off-target', 6.6 UNION ALL
SELECT 'INT016', 'CPD005', 'TGT004', 0.031, 0.044, 'primary', 9.5 UNION ALL
SELECT 'INT017', 'CPD005', 'TGT015', 0.48, 0.65, 'off-target', 7.3 UNION ALL
SELECT 'INT018', 'CPD006', 'TGT005', 0.02, 0.028, 'primary', 9.8 UNION ALL
SELECT 'INT019', 'CPD006', 'TGT003', 0.41, 0.59, 'off-target', 7.4 UNION ALL
SELECT 'INT020', 'CPD007', 'TGT006', 0.019, 0.025, 'primary', 9.8 UNION ALL
SELECT 'INT021', 'CPD007', 'TGT018', 0.55, 0.78, 'off-target', 7.2 UNION ALL
SELECT 'INT022', 'CPD008', 'TGT007', 0.0092, 0.014, 'primary', 10.1 UNION ALL
SELECT 'INT023', 'CPD008', 'TGT019', 0.38, 0.51, 'off-target', 7.4 UNION ALL
SELECT 'INT024', 'CPD009', 'TGT008', 0.011, 0.017, 'primary', 9.9 UNION ALL
SELECT 'INT025', 'CPD009', 'TGT009', 0.015, 0.022, 'primary', 9.8 UNION ALL
SELECT 'INT026', 'CPD010', 'TGT002', 0.041, 0.058, 'primary', 9.4 UNION ALL
SELECT 'INT027', 'CPD010', 'TGT001', 0.38, 0.52, 'off-target', 7.3 UNION ALL
SELECT 'INT028', 'CPD010', 'TGT013', 1.2, 1.8, 'off-target', 7.1 UNION ALL
SELECT 'INT029', 'CPD011', 'TGT006', 0.029, 0.041, 'primary', 9.5 UNION ALL
SELECT 'INT030', 'CPD011', 'TGT010', 0.71, 0.95, 'off-target', 7.0 UNION ALL
SELECT 'INT031', 'CPD012', 'TGT020', 0.39, 0.55, 'primary', 7.3 UNION ALL
SELECT 'INT032', 'CPD013', 'TGT014', 12.0, 18.5, 'primary', 5.7 UNION ALL
SELECT 'INT033', 'CPD014', 'TGT010', 0.0018, 0.0025, 'primary', 11.8 UNION ALL
SELECT 'INT034', 'CPD015', 'TGT004', 0.055, 0.078, 'primary', 9.2 UNION ALL
SELECT 'INT035', 'CPD015', 'TGT003', 0.12, 0.17, 'primary', 8.9 UNION ALL
SELECT 'INT036', 'CPD015', 'TGT016', 0.29, 0.41, 'primary', 8.5 UNION ALL
SELECT 'INT037', 'CPD015', 'TGT013', 0.95, 1.35, 'off-target', 7.2;
۴. ایجاد جدول pathways
شامل مسیرهای بیولوژیکی، حوزههای بیماری مرتبط و ارتباط آن با سرطان است.
CREATE OR REPLACE TABLE drug_target_graph.pathways AS
SELECT 'PWY001' AS pathway_id, 'MAPK Signaling' AS pathway_name, 'hsa04010' AS kegg_id, 'Cell Proliferation' AS biological_process, 'Oncology' AS disease_area, 'high' AS cancer_relevance UNION ALL
SELECT 'PWY002', 'PI3K-AKT Signaling', 'hsa04151', 'Cell Survival', 'Oncology', 'high' UNION ALL
SELECT 'PWY003', 'VEGF Signaling', 'hsa04370', 'Angiogenesis', 'Oncology', 'high' UNION ALL
SELECT 'PWY004', 'ErbB Signaling', 'hsa04012', 'Cell Growth', 'Oncology', 'high' UNION ALL
SELECT 'PWY005', 'mTOR Signaling', 'hsa04150', 'Cell Growth', 'Oncology', 'medium' UNION ALL
SELECT 'PWY006', 'Cell Cycle', 'hsa04110', 'Cell Division', 'Oncology', 'high' UNION ALL
SELECT 'PWY007', 'Cardiac Muscle Contraction', 'hsa04260', 'Cardiac Function', 'Cardiovascular', 'low' UNION ALL
SELECT 'PWY008', 'hERG Cardiac Channel', 'hsa04022', 'Cardiac Repolarisation','Cardiovascular', 'low' UNION ALL
SELECT 'PWY009', 'AMPK Signaling', 'hsa04152', 'Energy Metabolism', 'Metabolic', 'low' UNION ALL
SELECT 'PWY010', 'ALK Signaling', 'hsa04915', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY011', 'RAS Signaling', 'hsa04014', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY012', 'HIV Replication', 'hsa05170', 'Viral Replication', 'Infectious Disease', 'low';
۵. ایجاد جدول target_pathways
یک جدول اتصال که اهداف را به مسیرهای بیولوژیکی که در آنها شرکت میکنند، مرتبط میکند.
CREATE OR REPLACE TABLE drug_target_graph.target_pathways AS
SELECT 'TP001' AS tp_id, 'TGT001' AS target_id, 'PWY001' AS pathway_id, 'activator' AS role, 0.95 AS importance_score UNION ALL
SELECT 'TP002', 'TGT001', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP003', 'TGT002', 'PWY004', 'activator', 0.98 UNION ALL
SELECT 'TP004', 'TGT002', 'PWY001', 'activator', 0.82 UNION ALL
SELECT 'TP005', 'TGT002', 'PWY002', 'activator', 0.75 UNION ALL
SELECT 'TP006', 'TGT003', 'PWY003', 'activator', 0.96 UNION ALL
SELECT 'TP007', 'TGT003', 'PWY001', 'activator', 0.71 UNION ALL
SELECT 'TP008', 'TGT004', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP009', 'TGT004', 'PWY011', 'activator', 0.89 UNION ALL
SELECT 'TP010', 'TGT005', 'PWY010', 'activator', 0.99 UNION ALL
SELECT 'TP011', 'TGT005', 'PWY001', 'activator', 0.78 UNION ALL
SELECT 'TP012', 'TGT006', 'PWY002', 'activator', 0.98 UNION ALL
SELECT 'TP013', 'TGT006', 'PWY005', 'activator', 0.85 UNION ALL
SELECT 'TP014', 'TGT007', 'PWY001', 'activator', 0.94 UNION ALL
SELECT 'TP015', 'TGT007', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP016', 'TGT008', 'PWY006', 'activator', 0.95 UNION ALL
SELECT 'TP017', 'TGT009', 'PWY006', 'activator', 0.93 UNION ALL
SELECT 'TP018', 'TGT010', 'PWY005', 'activator', 0.99 UNION ALL
SELECT 'TP019', 'TGT010', 'PWY002', 'activator', 0.91 UNION ALL
SELECT 'TP020', 'TGT011', 'PWY003', 'activator', 0.87 UNION ALL
SELECT 'TP021', 'TGT011', 'PWY001', 'activator', 0.72 UNION ALL
SELECT 'TP022', 'TGT012', 'PWY001', 'activator', 0.83 UNION ALL
SELECT 'TP023', 'TGT012', 'PWY011', 'activator', 0.79 UNION ALL
SELECT 'TP024', 'TGT013', 'PWY008', 'substrate', 0.99 UNION ALL
SELECT 'TP025', 'TGT013', 'PWY007', 'substrate', 0.95 UNION ALL
SELECT 'TP026', 'TGT014', 'PWY009', 'activator', 0.97 UNION ALL
SELECT 'TP027', 'TGT015', 'PWY001', 'activator', 0.91 UNION ALL
SELECT 'TP028', 'TGT015', 'PWY011', 'activator', 0.86 UNION ALL
SELECT 'TP029', 'TGT016', 'PWY001', 'activator', 0.84 UNION ALL
SELECT 'TP030', 'TGT016', 'PWY003', 'activator', 0.77 UNION ALL
SELECT 'TP031', 'TGT017', 'PWY001', 'activator', 0.88 UNION ALL
SELECT 'TP032', 'TGT017', 'PWY011', 'activator', 0.82 UNION ALL
SELECT 'TP033', 'TGT018', 'PWY002', 'activator', 0.96 UNION ALL
SELECT 'TP034', 'TGT018', 'PWY005', 'activator', 0.88 UNION ALL
SELECT 'TP035', 'TGT019', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP036', 'TGT019', 'PWY011', 'activator', 0.91 UNION ALL
SELECT 'TP037', 'TGT020', 'PWY012', 'substrate', 0.99;
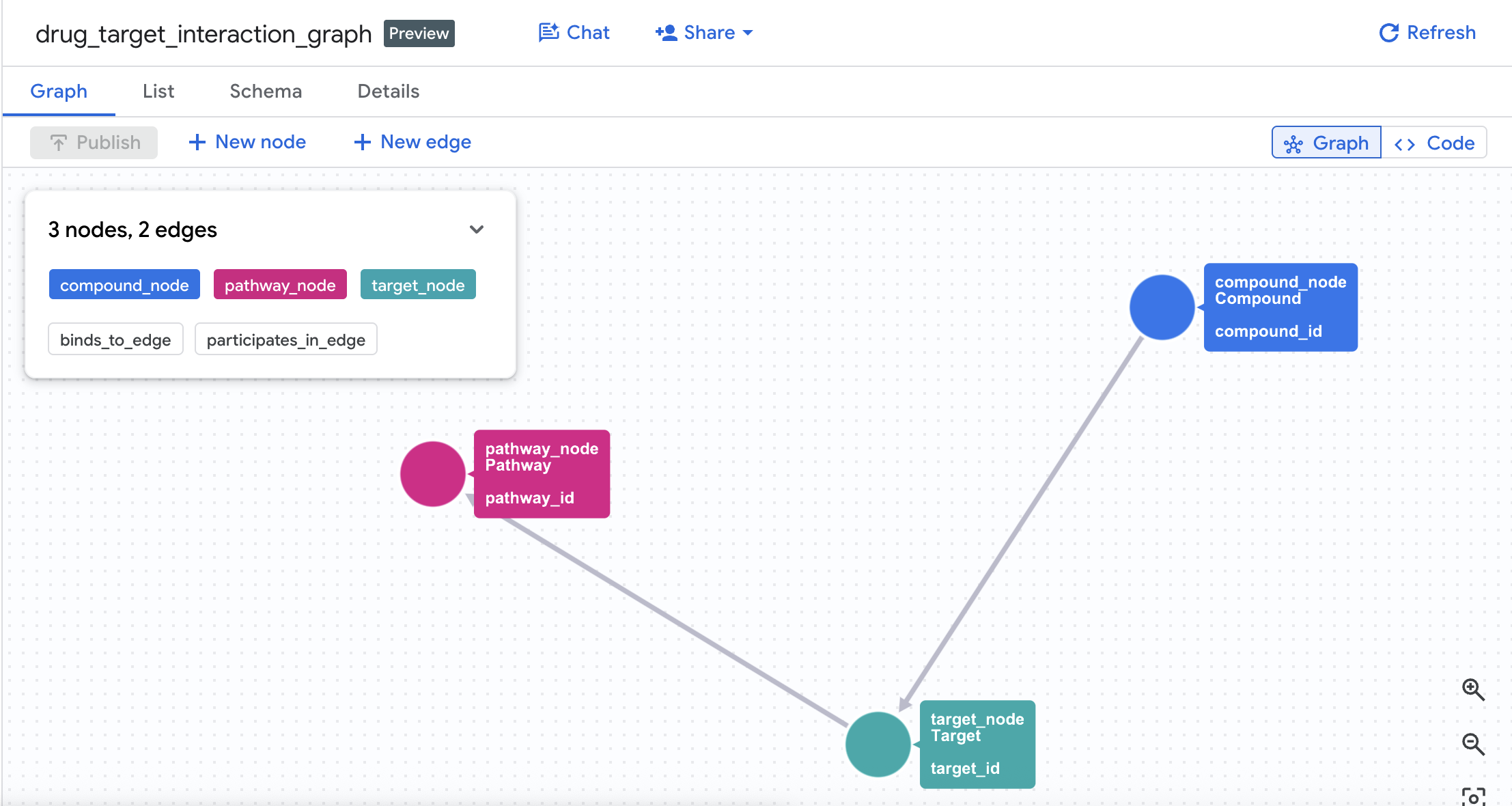
۴. نمودار ویژگیها را ایجاد کنید
با ایجاد موفقیتآمیز جداول، اکنون میتوانید نمودار ویژگیها را بسازید. این نمودار، گرهها (ترکیبات، اهداف، مسیرها) را با استفاده از جداول لبهها ( Interactions و Target Pathways ) به هم پیوند میدهد.
دستور زیر را در ویرایشگر SQL BigQuery Studio اجرا کنید:
CREATE OR REPLACE PROPERTY GRAPH drug_target_graph.drug_target_interaction_graph
NODE TABLES (
drug_target_graph.compounds
AS compound_node
KEY (compound_id)
LABEL Compound
PROPERTIES (compound_id, compound_name, mechanism_of_action, dev_stage, therapeutic_area, molecular_weight),
drug_target_graph.targets
AS target_node
KEY (target_id)
LABEL Target
PROPERTIES (target_id, target_name, gene_name, uniprot_id, target_class, is_oncogene),
drug_target_graph.pathways
AS pathway_node
KEY (pathway_id)
LABEL Pathway
PROPERTIES (pathway_id, pathway_name, kegg_id, biological_process, disease_area, cancer_relevance)
)
EDGE TABLES (
drug_target_graph.interactions
AS binds_to_edge
KEY (interaction_id)
SOURCE KEY (compound_id) REFERENCES compound_node (compound_id)
DESTINATION KEY (target_id) REFERENCES target_node (target_id)
LABEL BINDS_TO
PROPERTIES (interaction_id, affinity_nm, ic50_nm, interaction_type, pchembl_value),
drug_target_graph.target_pathways
AS participates_in_edge
KEY (tp_id)
SOURCE KEY (target_id) REFERENCES target_node (target_id)
DESTINATION KEY (pathway_id) REFERENCES pathway_node (pathway_id)
LABEL PARTICIPATES_IN
PROPERTIES (tp_id, role, importance_score)
);
این کار گرافی به نام drug_target_interaction_graph در مجموعه داده شما ایجاد میکند.
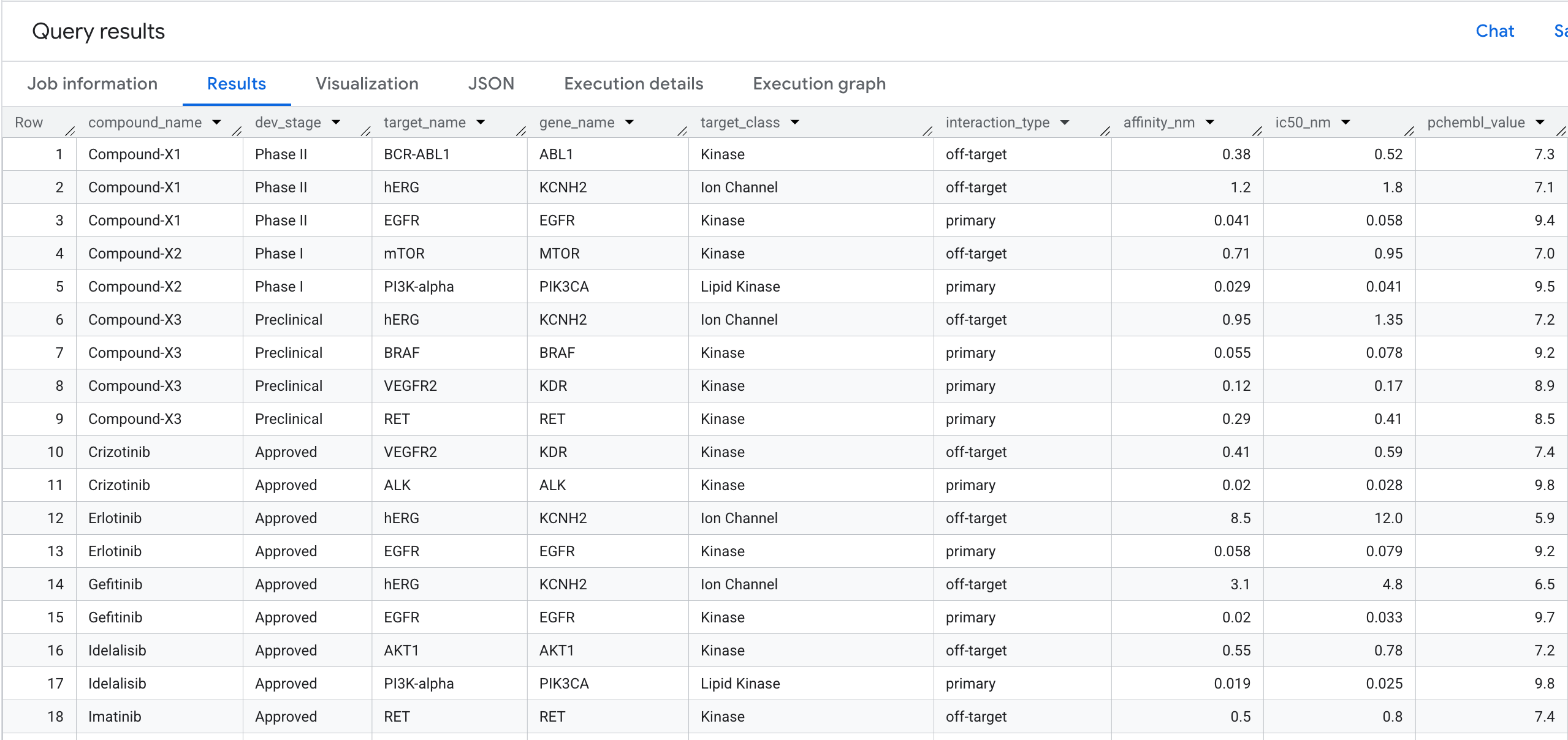
۵. پرس و جوی ۱: پروفایل کامل اتصال هدف به ازای هر ترکیب
بیایید اولین کوئری گراف خود را اجرا کنیم. این یک پیمایش تکگامی است که به این سوالات پاسخ میدهد: کدام ترکیبات به کدام اهداف متصل میشوند و میل ترکیبی آنها چیست؟
پرس و جوی GQL
کوئری زیر را در ویرایشگر SQL اجرا کنید:
SELECT
compound_name,
dev_stage,
target_name,
gene_name,
target_class,
interaction_type,
ROUND(affinity_nm, 3) AS affinity_nm,
ROUND(ic50_nm, 3) AS ic50_nm,
pchembl_value
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_name AS target_name,
t.gene_name AS gene_name,
t.target_class AS target_class,
b.interaction_type AS interaction_type,
b.affinity_nm AS affinity_nm,
b.ic50_nm AS ic50_nm,
b.pchembl_value AS pchembl_value
)
)
ORDER BY compound_name, interaction_type, affinity_nm;
آنچه در نتایج مشاهده خواهید کرد به شرح زیر است:
۶. پرسش ۲: تشخیص خطر قلبی
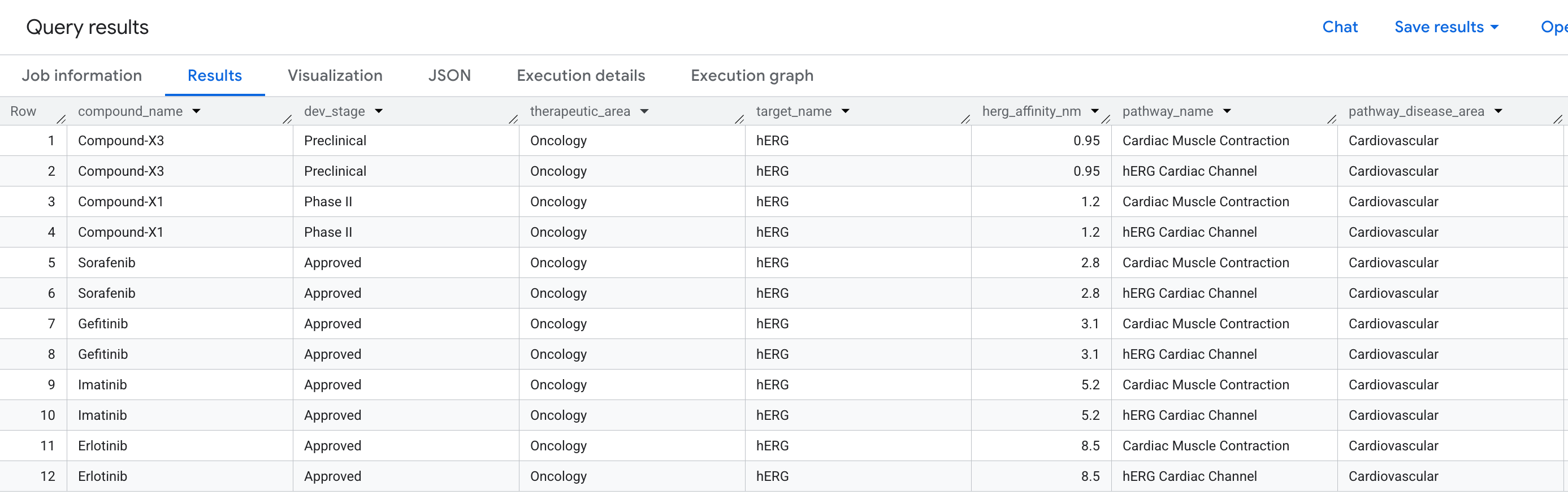
سوال کسب و کار
در کشف دارو، یکی از رایجترین دلایل شکست یک ترکیب امیدوارکننده در آزمایشهای بالینی، سمیت قلبی است - به طور خاص، اتصال ناخواسته به پروتئین hERG (ژن: KCNH2 )، یک کانال یونی پتاسیم که ریتم قلب را تنظیم میکند. یک ضربه خارج از هدف به hERG میتواند باعث آریتمیهای کشنده شود و مسئول چندین مورد انصراف از مصرف داروهای پر سر و صدا بوده است.
سوالی که میخواهیم به آن پاسخ دهیم این است:
«کدام ترکیبات در خط تولید ما یک رویداد اتصال خارج از هدف روی پروتئین hERG دارند - و این کدام مسیرهای قلبی را در معرض خطر قرار میدهد؟»
این یک سوال دو مرحلهای است: ما باید از یک ترکیب، از طریق یک هدف (hERG) و به یک مسیر عبور کنیم - که سه نوع موجودیت را در دو رابطه در یک پرسوجوی واحد به هم متصل میکند.
کوئری GQL را بنویسید
کوئری زیر را در ویرایشگر BQ SQL اجرا کنید:
SELECT
compound_name,
dev_stage,
therapeutic_area,
target_name,
ROUND(affinity_nm, 3) AS herg_affinity_nm,
pathway_name,
disease_area AS pathway_disease_area
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND b.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
c.therapeutic_area AS therapeutic_area,
t.target_name AS target_name,
b.affinity_nm AS affinity_nm,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
ORDER BY herg_affinity_nm;
توجه کنید که عبارت MATCH تقریباً مانند یک جمله خوانده میشود: «یک ترکیب پیدا کنید که به یک هدف که در یک مسیر شرکت میکند، متصل شود» - با فیلترهایی که در هر گره و لبه در امتداد مسیر اعمال میشوند.
در اینجا دادههایی که در نتایج مشاهده خواهید کرد، آمده است:
شبکه ریسک را به صورت نمودار تجسم کنید
یک جدول دادهها را به ما نشان میدهد - اما ساختار خطر را به ما نشان نمیدهد. آیا چندین ترکیب در یک مسیر همگرا میشوند؟ آیا یک ترکیب پرخطر وجود دارد یا چندین ترکیب؟
یک نمودار بصریسازیشده این موضوع را فوراً قابل مشاهده میکند. سلول زیر را اجرا کنید تا همان پیمایش دوگامی را به عنوان یک شبکه تعاملی رندر کنید:
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH pt = (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND pw.disease_area = 'Cardiovascular'
RETURN
TO_JSON(pt) AS path
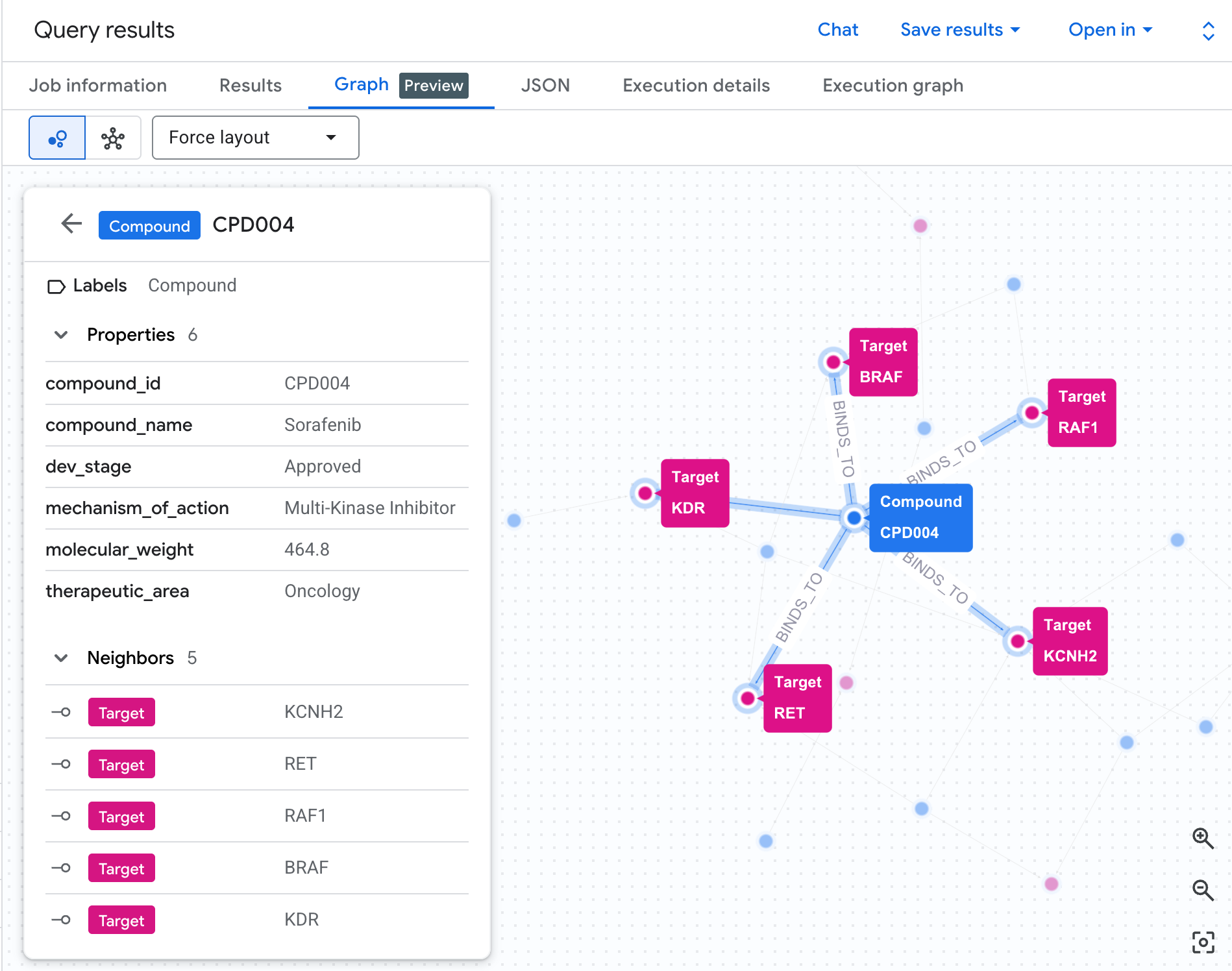
شما باید نموداری مانند این را ببینید:
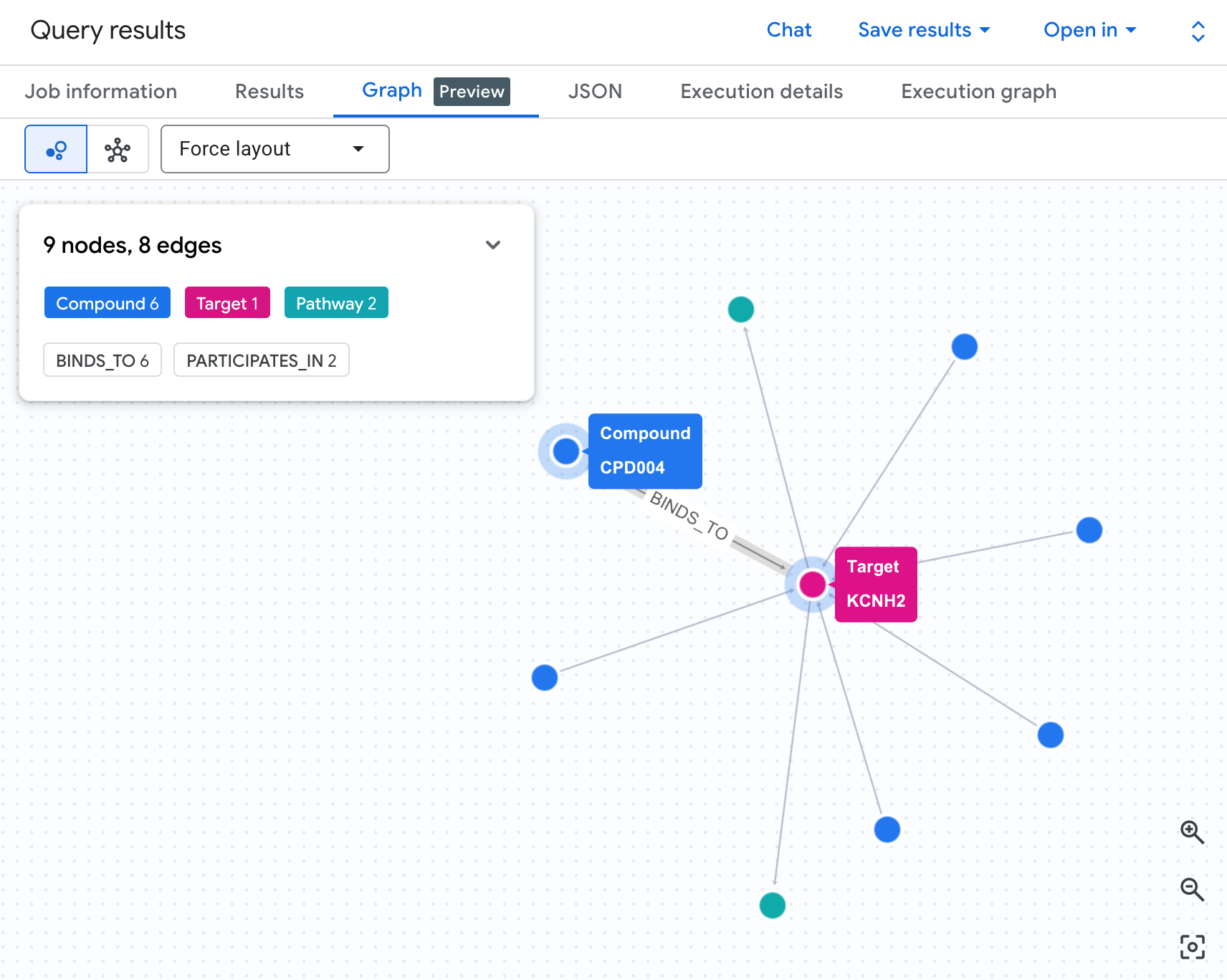
هر مسیر در نمودار، یک زنجیره کامل مسئولیت را دنبال میکند: یک ترکیب (گرههای آبی) به پروتئین hERG در مرکز متصل میشود که به یک یا چند مسیر قلبی (گرههای سبز) متصل میشود. آنچه که قبلاً یک لیست مسطح از ردیفها در جدول بود، اکنون یک شبکه خطر قابل مشاهده است - ترکیباتی که در معرض مسیرهای متعدد قرار دارند، بلافاصله به عنوان اولویت بالاتر برای بررسی ایمنی برجسته میشوند.
ببینید چرا GQL از SQL زیباتر است
برای اجرای همان کوئری دو مرحلهای در SQL استاندارد، به ۴ پیوند صریح نیاز دارید. شما به جای اینکه به دنبال چه رابطهای باشید، تلاش شناختی خود را صرف توصیف نحوهی پیوند جداول میکنید. GQL به شما امکان میدهد روی سوال متمرکز بمانید.
SELECT
c.compound_name,
c.dev_stage,
c.therapeutic_area,
t.target_name,
ROUND(i.affinity_nm, 3) AS herg_affinity_nm,
pw.pathway_name,
pw.disease_area AS pathway_disease_area
FROM drug_target_graph.compounds c
JOIN drug_target_graph.interactions i ON c.compound_id = i.compound_id
JOIN drug_target_graph.targets t ON i.target_id = t.target_id
JOIN drug_target_graph.target_pathways tp ON t.target_id = tp.target_id
JOIN drug_target_graph.pathways pw ON tp.pathway_id = pw.pathway_id
WHERE t.gene_name = 'KCNH2'
AND i.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
ORDER BY herg_affinity_nm;
عمیقتر شدن - تشخیص خطر متابولیت چند جهشی
عبارت بالا ترکیباتی را شناسایی میکند که مستقیماً به پروتئین hERG متصل میشوند. اما در گردشهای کاری واقعی ایمنی دارو، گاهی اوقات این خطر یک مرحله حذف میشود: یک ترکیب ممکن است به صورت متابولیکی در بدن به یک مولکول ثانویه (یک متابولیت) تبدیل شود که سپس به hERG متصل میشود - قابلیتی که سنجشهای اتصال مستقیم میتوانند آن را به طور کامل از دست بدهند.
اگر نمودار ویژگی شما شامل یک جدول گره Metabolite و یک یال METABOLISES_INTO بود، میتوانستید همان الگوی MATCH را به یک پیمایش سه گامی تعمیم دهید:
(Compound)-[METABOLISES_INTO]->(Metabolite)-[BINDS_TO]->
(Target)-[PARTICIPATES_IN]->(Pathway)
ساختار پرسوجوی GQL دقیقاً به اندازه یک گره و یک لبه تغییر میکند. SQL معادل آن به دو JOIN اضافی نیاز دارد. این الگویی است که پیمایش گراف را به ویژه برای تحلیل آبشاری ایمنی قدرتمند میکند - پیچیدگی پرسوجو به صورت خطی افزایش مییابد در حالی که بینش بیولوژیکی به صورت نمایی رشد میکند.
۷. پرس و جوی ۳: جفتهای مرکب با هدف مشترک
برای یافتن کاندیداهای مناسب برای درمان ترکیبی، میتوانیم تشخیص دهیم که چه زمانی دو ترکیب مختلف به یک گره هدف متصل میشوند. ما از یک تطابق دو طرفه برای پاسخ به این سوال استفاده میکنیم: کدام ترکیبات سرطان دقیقاً به یک هدف واحد همگرا میشوند؟
کوئری زیر را در ویرایشگر SQL اجرا کنید:
SELECT
compound_a,
compound_b,
shared_target,
gene_name,
ROUND(affinity_a_nm, 3) AS affinity_a_nm,
ROUND(affinity_b_nm, 3) AS affinity_b_nm
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
AND c2.therapeutic_area = 'Oncology'
COLUMNS (
c1.compound_name AS compound_a,
c2.compound_name AS compound_b,
t.target_name AS shared_target,
t.gene_name AS gene_name,
b1.affinity_nm AS affinity_a_nm,
b2.affinity_nm AS affinity_b_nm
)
)
ORDER BY compound_a, compound_b, affinity_a_nm;
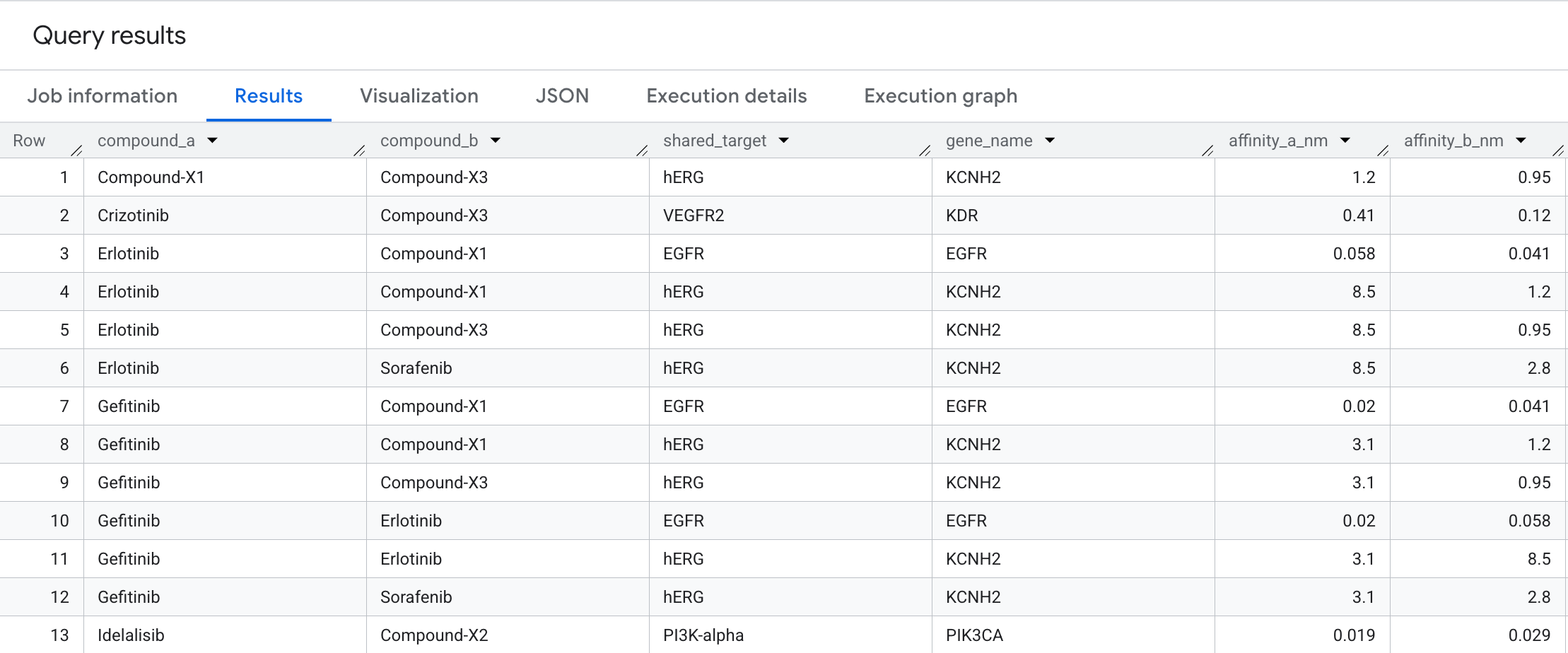
در اینجا دادههایی که در نتایج مشاهده خواهید کرد، آمده است:
تجسم نمودار
شما میتوانید با اجرای کد زیر در ویرایشگر SQL، نمودار را مستقیماً در BigQuery تجسم کنید.
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH p = (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
RETURN
TO_JSON(p) AS path
این پیمایش دوطرفه، جفتهای ترکیبی را که به یک هدف پروتئینی یکسان میرسند، سطحبندی میکند - الگویی که تشخیص آن در یک جدول برهمکنشهای مسطح دشوار است اما بلافاصله به صورت نمودار قابل مشاهده است. در کشف دارو، جفتهای هدف مشترک نقطه شروع طراحی درمان ترکیبی هستند: دو ترکیب که به یک گره در مسیر سرطان برخورد میکنند، ممکن است اثر همافزایی ایجاد کنند، یا به طور متناوب، افزونگی ناخواستهای را در خط لوله نشان دهند.
۸. پرسش ۴: شعاع انفجار مسیر بیماری
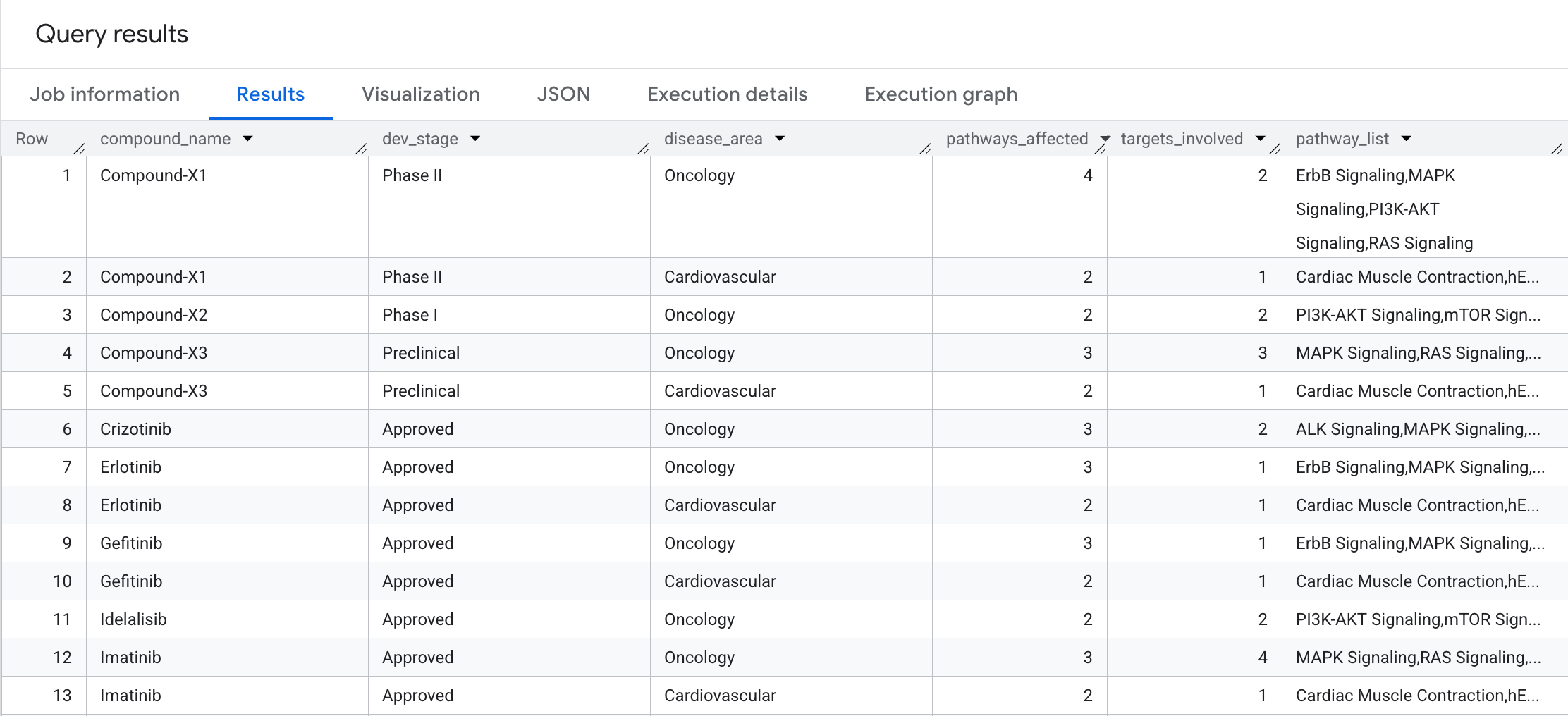
تأثیر بیولوژیکی هر ترکیب چقدر گسترده است؟ بیایید یک پیمایش دو مرحلهای با تجمیع انجام دهیم تا به این سوال پاسخ دهیم: هر ترکیب بر چند مسیر بیولوژیکی و هدف متمایز، که بر اساس منطقه بیماری گروهبندی شدهاند، تأثیر میگذارد؟
کوئری زیر را در ویرایشگر SQL اجرا کنید:
SELECT
compound_name,
dev_stage,
disease_area,
COUNT(DISTINCT pathway_id) AS pathways_affected,
COUNT(DISTINCT target_id) AS targets_involved,
STRING_AGG(DISTINCT pathway_name ORDER BY pathway_name) AS pathway_list
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_id AS target_id,
pw.pathway_id AS pathway_id,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
GROUP BY compound_name, dev_stage, disease_area
ORDER BY compound_name, pathways_affected DESC;
آنچه در نتایج مشاهده خواهید کرد به شرح زیر است:
۹. پرسش ۵: انتخاب ایمن ترکیب
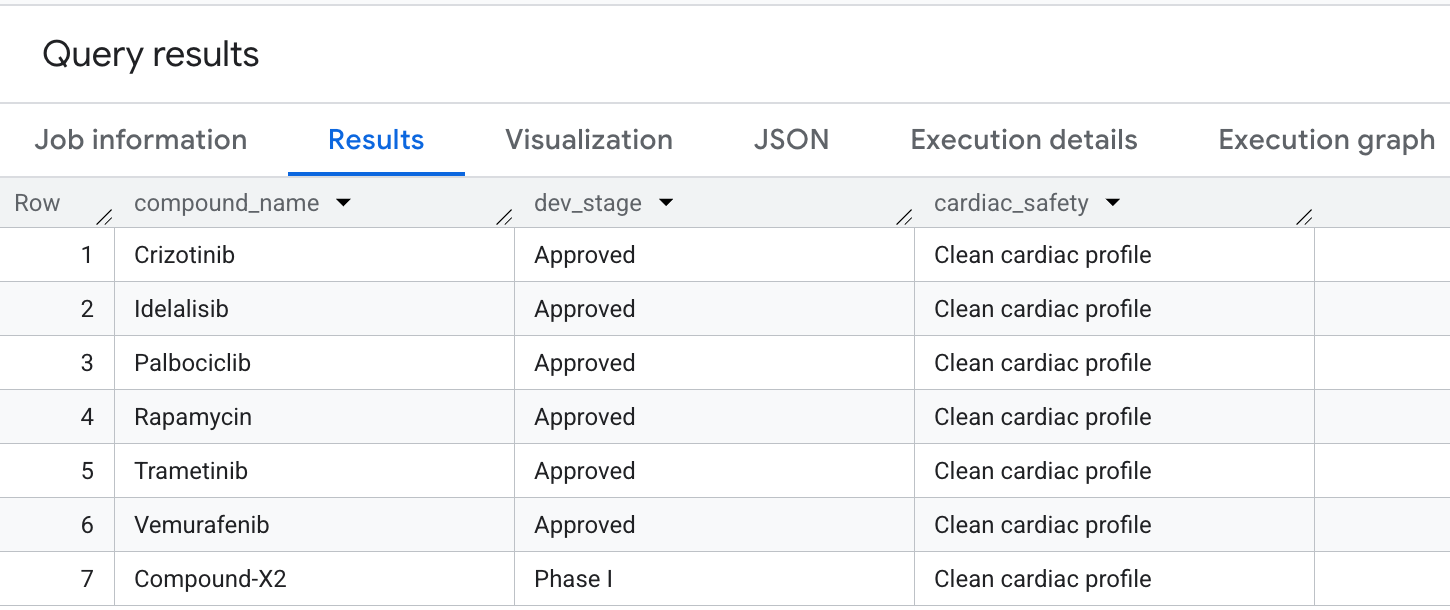
در نهایت، بیایید ترکیباتی را جستجو کنیم که پوشش سرطانشناسی بالایی دارند اما صراحتاً از خطرات خارج از هدف hERG (قلبی) اجتناب میکنند . این با الگوهای انتخاب ایمنی-اولویت رایج در خطوط لوله کشف دارو مطابقت دارد.
کوئری زیر را در ویرایشگر SQL اجرا کنید:
WITH oncology_compounds AS (
SELECT DISTINCT compound_id, compound_name, dev_stage
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE pw.disease_area = 'Oncology'
AND pw.cancer_relevance = 'high'
COLUMNS (
c.compound_id AS compound_id,
c.compound_name AS compound_name,
c.dev_stage AS dev_stage
)
)
),
herg_risk_compounds AS (
SELECT DISTINCT compound_id
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
WHERE t.gene_name = 'KCNH2'
COLUMNS (c.compound_id AS compound_id)
)
)
SELECT
o.compound_name,
o.dev_stage,
'Clean cardiac profile' AS cardiac_safety
FROM oncology_compounds o
LEFT JOIN herg_risk_compounds h ON o.compound_id = h.compound_id
WHERE h.compound_id IS NULL
ORDER BY o.dev_stage, o.compound_name;
خروجی که در نتایج مشاهده خواهید کرد به صورت زیر است:
شما با موفقیت پیمایشهای گراف پیشرفته را در BigQuery اجرا کردید تا پروفایلهای کلیدی ایمنی و اثربخشی را استخراج کنید!
۱۰. بخش ویژه: با نمودار خود چت کنید
BigQuery Conversational Analytics اکنون از نمودار به عنوان منبع دانش پشتیبانی میکند. این به شما امکان میدهد با نموداری که اخیراً ایجاد کردهاید به زبان طبیعی چت کنید.
شروع کار: افزودن نمودار به عنوان منبع دانش
برای شروع، با دنبال کردن مراحل اینجا ، یک عامل مکالمه ایجاد کنید. نموداری را که ایجاد کردهاید از نوار جستجو انتخاب کنید.
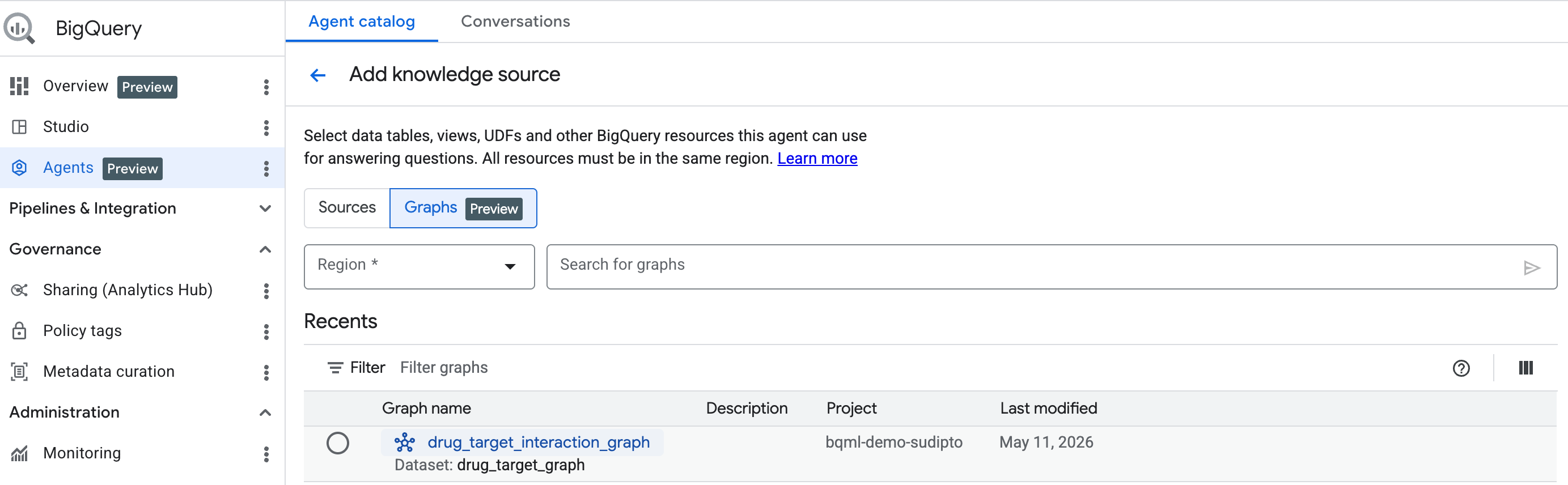
از BigQuery Conversational Analytics برای چت کردن با نمودار خود استفاده کنید
پس از افزودن منبع دانش به عنوان نمودار، بقیه مراحل راهاندازی عامل تحلیل مکالمه را تکمیل کنید.
سپس میتوانید با نمودار خود به زبان طبیعی چت کنید!
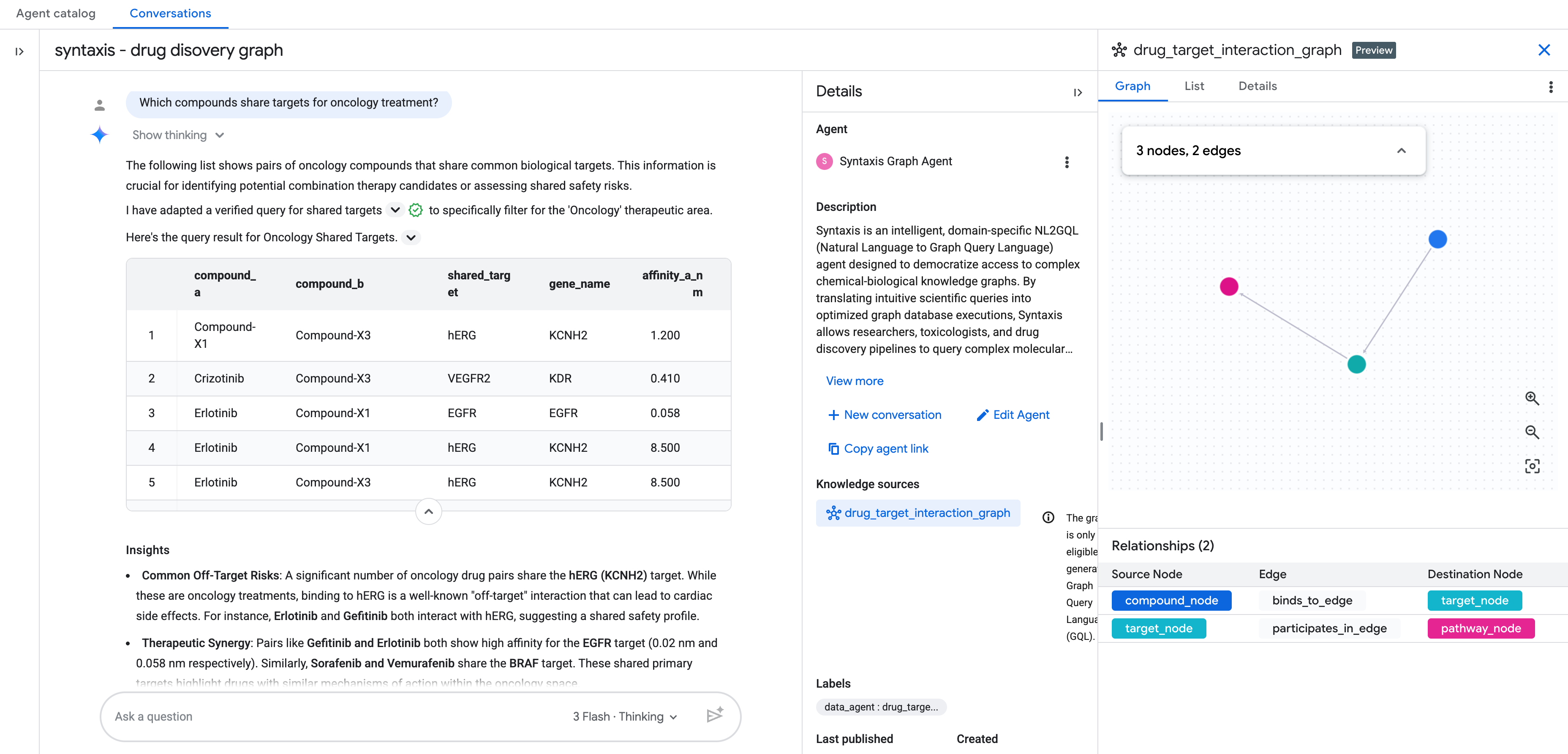
سوالات تکمیلی
- ترکیبات هدف در حال حاضر در آزمایشهای فاز ۲ چه هستند؟
- کدام اهداف بین ترکیبات قلبی عروقی و انکولوژی مشترک هستند؟
۱۱. تمیز کردن
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود، منابع ایجاد شده در طول این codelab را حذف کنید.
برای حذف طرحواره و تمام جداول به صورت آبشاری، کوئری زیر را اجرا کنید:
DROP SCHEMA IF EXISTS drug_target_graph CASCADE;
۱۲. تبریک
تبریک! شما با موفقیت یک شبکه تعامل دارو-هدف را با استفاده از BigQuery Graph مدلسازی و تحلیل کردید.
آنچه آموختهاید
- چگونه روابط موجودیتها (ترکیبات، اهداف، مسیرها) را به عنوان یک نمودار ویژگی مدلسازی کنیم.
- نحوه تعریف طرحواره و ایجاد نمودار ویژگی در BigQuery.
- نحوه نوشتن پیمایشهای پیچیده گراف با استفاده از GQL و مقایسه آنها با SQL سنتی.
- چگونه میتوان از
GRAPH_TABLE،MATCHو تطبیق دوطرفه برای حل مسائل حوزه علوم زیستی استفاده کرد.