
1. Introduction
Dans cet atelier, vous apprendrez à utiliser BigQuery Graph pour modéliser et analyser un réseau d'interaction médicament-cible. Vous exploiterez la puissance des requêtes de graphe (GQL) pour découvrir comment les médicaments interagissent avec les cibles biologiques, identifier les effets secondaires potentiels (tels que les risques cardiaques) et découvrir des thérapies combinées potentielles.
🧬 Cas d'utilisation : réseau d'interaction médicament-cible
Question commerciale : Quel est le rayon d'action complet d'un composé ? Quelles sont les cibles auxquelles il se lie, quelles voies biologiques sont affectées et quels domaines de maladies sont impliqués ?
Tableaux :
Tableau | Description |
| Molécules médicamenteuses avec mécanisme d'action et stade de développement |
| Cibles protéiques avec noms de gènes et ID UniProt |
| Affinité de liaison composé-cible (cibles principales + hors cible) |
| Voies biologiques avec associations de domaines de maladies |
| Table de jonction reliant les cibles aux voies auxquelles elles participent |
Modèle de graphe de propriétés :
(Compound)-[BINDS_TO {affinity_nm, ic50_nm, interaction_type}]->(Target)
(Target)-[PARTICIPATES_IN {role, importance_score}]->(Pathway)
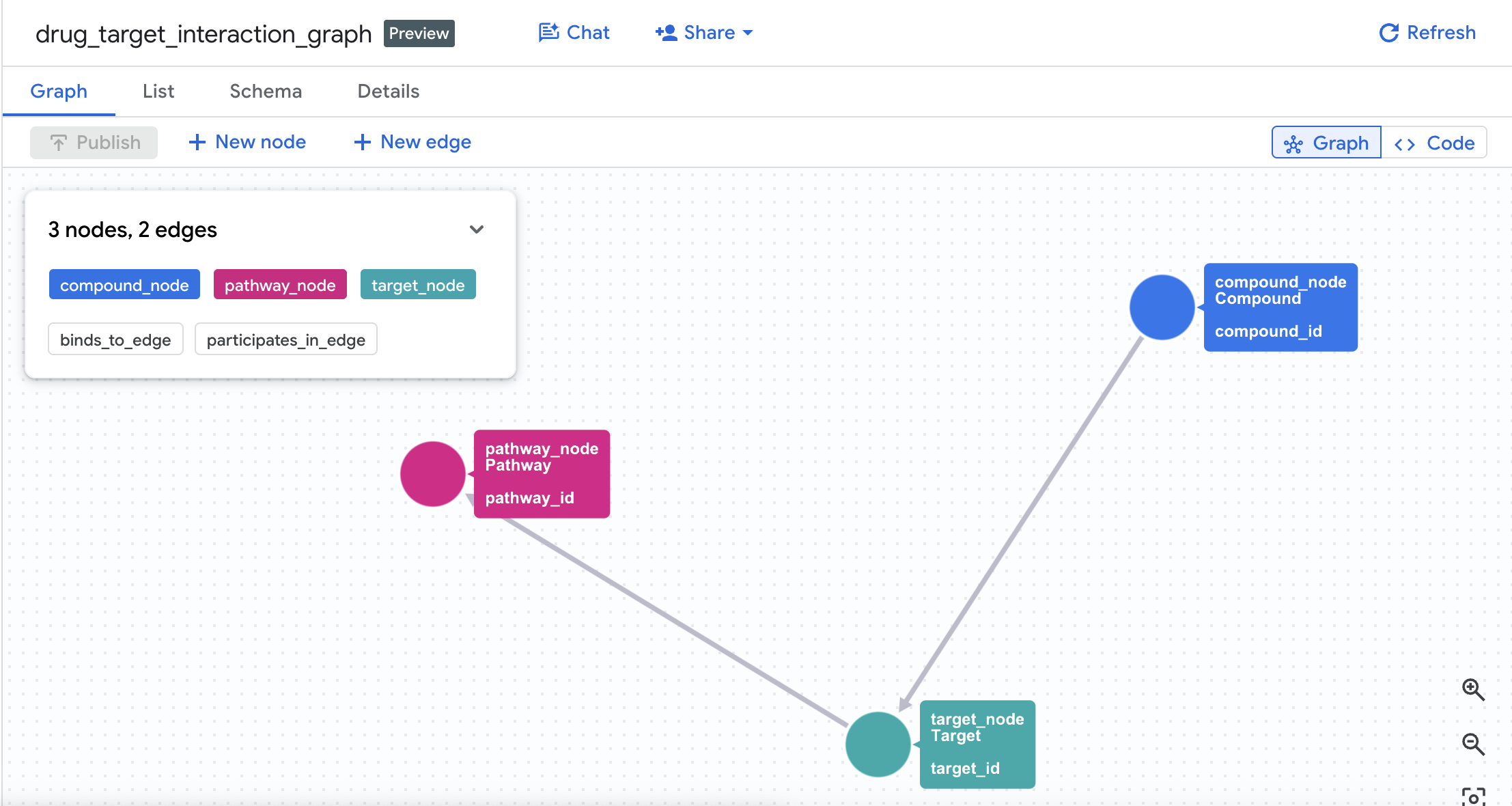
🔍 Exemples de requêtes
Requête | Description |
Q1 : Profil de liaison cible | Traversée à 1 saut : composé vers toutes les cibles principales et hors cible |
Q2 : Détection du risque cardiaque hERG | Traversée à 2 sauts : composé → cible hERG → voie cardiaque |
Q3 : Paires de composés à cible partagée | Correspondance bidirectionnelle : deux composés convergeant sur le même nœud cible |
Q4 : Rayon d'action de la voie de la maladie | Agrégation à 2 sauts : couverture complète de la voie et du domaine de la maladie par composé |
Q5 : Sélection de composés sûrs | Composés à forte couverture oncologique, mais sans responsabilité cardiaque hERG |
Objectifs de l'atelier
- Créer un ensemble de données et un schéma BigQuery pour le réseau d'interaction médicamenteuse
- Charger des exemples de données (composés, cibles, interactions, voies, voies cibles)
- Créer un graphe de propriétés dans BigQuery reliant ces entités
- Interroger le graphe pour comprendre les interactions des composés, les voies biologiques et le potentiel néfaste de la maladie à l'aide de traversées de graphe (
GRAPH_TABLEetMATCH) - Comparer GQL et SQL standard côte à côte pour comprendre la simplicité et la puissance expressive de la syntaxe de graphe
Ce dont vous avez besoin
- Un navigateur Web (par exemple, Chrome)
- Un projet Google Cloud avec facturation activée
Cet atelier s'adresse aux développeurs de tous niveaux, y compris aux débutants.
2. Avant de commencer
Créer un projet Google Cloud
- Dans la console Google Cloud, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud.
Démarrer Cloud Shell
- Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.
- Vérifiez l'authentification :
gcloud auth list
- Confirmez votre projet :
gcloud config get project
- Définissez-le si nécessaire :
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Activer les API
Exécutez cette commande pour activer l'API BigQuery requise :
gcloud services enable bigquery.googleapis.com
3. Définir le schéma et charger les données
Vous devez d'abord créer un ensemble de données pour stocker vos tables associées au graphe et les remplir avec des exemples de données.
- Accédez à BigQuery Studio dans la console Google Cloud.
- Cliquez sur l'éditeur SQL pour ouvrir un nouvel onglet de requête.
- Exécutez l'instruction suivante pour créer l'ensemble de données
drug_target_graph:
CREATE SCHEMA IF NOT EXISTS drug_target_graph
OPTIONS (location = 'US');
Créez maintenant les cinq tables sources en exécutant les requêtes DDL suivantes dans BigQuery Studio.
1. Créer la table compounds
Contient des molécules médicamenteuses, leur mécanisme d'action, leur stade de développement et leur domaine thérapeutique.
CREATE OR REPLACE TABLE drug_target_graph.compounds AS
SELECT 'CPD001' AS compound_id, 'Imatinib' AS compound_name, 'Kinase Inhibitor' AS mechanism_of_action, 'Approved' AS dev_stage, 'Oncology' AS therapeutic_area, 479.6 AS molecular_weight UNION ALL
SELECT 'CPD002', 'Gefitinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 446.9 UNION ALL
SELECT 'CPD003', 'Erlotinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 393.4 UNION ALL
SELECT 'CPD004', 'Sorafenib', 'Multi-Kinase Inhibitor', 'Approved', 'Oncology', 464.8 UNION ALL
SELECT 'CPD005', 'Vemurafenib', 'BRAF Inhibitor', 'Approved', 'Oncology', 489.9 UNION ALL
SELECT 'CPD006', 'Crizotinib', 'ALK Inhibitor', 'Approved', 'Oncology', 450.3 UNION ALL
SELECT 'CPD007', 'Idelalisib', 'PI3K Inhibitor', 'Approved', 'Oncology', 415.4 UNION ALL
SELECT 'CPD008', 'Trametinib', 'MEK Inhibitor', 'Approved', 'Oncology', 615.4 UNION ALL
SELECT 'CPD009', 'Palbociclib', 'CDK Inhibitor', 'Approved', 'Oncology', 447.5 UNION ALL
SELECT 'CPD010', 'Compound-X1', 'Kinase Inhibitor', 'Phase II', 'Oncology', 412.3 UNION ALL
SELECT 'CPD011', 'Compound-X2', 'PI3K Inhibitor', 'Phase I', 'Oncology', 398.7 UNION ALL
SELECT 'CPD012', 'Saquinavir', 'Protease Inhibitor', 'Approved', 'Infectious Disease', 670.8 UNION ALL
SELECT 'CPD013', 'Metformin', 'AMPK Activator', 'Approved', 'Metabolic', 165.6 UNION ALL
SELECT 'CPD014', 'Rapamycin', 'mTOR Inhibitor', 'Approved', 'Immunology', 914.2 UNION ALL
SELECT 'CPD015', 'Compound-X3', 'Multi-Kinase Inhibitor', 'Preclinical', 'Oncology', 502.1;
2. Créer la table targets
Contient des cibles protéiques, des noms de gènes, des ID UniProt et des classes cibles.
CREATE OR REPLACE TABLE drug_target_graph.targets AS
SELECT 'TGT001' AS target_id, 'BCR-ABL1' AS target_name, 'ABL1' AS gene_name, 'P00519' AS uniprot_id, 'Kinase' AS target_class, TRUE AS is_oncogene UNION ALL
SELECT 'TGT002', 'EGFR', 'EGFR', 'P00533', 'Kinase', TRUE UNION ALL
SELECT 'TGT003', 'VEGFR2', 'KDR', 'P35968', 'Kinase', FALSE UNION ALL
SELECT 'TGT004', 'BRAF', 'BRAF', 'P15056', 'Kinase', TRUE UNION ALL
SELECT 'TGT005', 'ALK', 'ALK', 'Q9UM73', 'Kinase', TRUE UNION ALL
SELECT 'TGT006', 'PI3K-alpha','PIK3CA', 'P42336', 'Lipid Kinase', TRUE UNION ALL
SELECT 'TGT007', 'MEK1', 'MAP2K1', 'Q02750', 'Kinase', FALSE UNION ALL
SELECT 'TGT008', 'CDK4', 'CDK4', 'P11802', 'Kinase', FALSE UNION ALL
SELECT 'TGT009', 'CDK6', 'CDK6', 'P30279', 'Kinase', FALSE UNION ALL
SELECT 'TGT010', 'mTOR', 'MTOR', 'P42345', 'Kinase', FALSE UNION ALL
SELECT 'TGT011', 'PDGFR-beta','PDGFRB', 'P09619', 'Kinase', FALSE UNION ALL
SELECT 'TGT012', 'c-KIT', 'KIT', 'P10721', 'Kinase', TRUE UNION ALL
SELECT 'TGT013', 'hERG', 'KCNH2', 'Q12809', 'Ion Channel', FALSE UNION ALL
SELECT 'TGT014', 'AMPK', 'PRKAA1', 'Q13131', 'Kinase', FALSE UNION ALL
SELECT 'TGT015', 'RAF1', 'RAF1', 'P04049', 'Kinase', FALSE UNION ALL
SELECT 'TGT016', 'RET', 'RET', 'P07949', 'Kinase', TRUE UNION ALL
SELECT 'TGT017', 'FLT3', 'FLT3', 'P36888', 'Kinase', TRUE UNION ALL
SELECT 'TGT018', 'AKT1', 'AKT1', 'P31749', 'Kinase', FALSE UNION ALL
SELECT 'TGT019', 'ERK2', 'MAPK1', 'P28482', 'Kinase', FALSE UNION ALL
SELECT 'TGT020', 'HIV-Protease','HIV1-PR','Q72547', 'Protease', FALSE;
3. Créer la table interactions
Contient des données d'affinité de liaison composé-cible (cibles principales par rapport aux cibles hors cible).
CREATE OR REPLACE TABLE drug_target_graph.interactions AS
SELECT 'INT001' AS interaction_id, 'CPD001' AS compound_id, 'TGT001' AS target_id, 0.025 AS affinity_nm, 0.038 AS ic50_nm, 'primary' AS interaction_type, 9.8 AS pchembl_value UNION ALL
SELECT 'INT002', 'CPD001', 'TGT011', 0.1, 0.15, 'primary', 8.8 UNION ALL
SELECT 'INT003', 'CPD001', 'TGT012', 0.068, 0.1, 'primary', 9.2 UNION ALL
SELECT 'INT004', 'CPD001', 'TGT016', 0.5, 0.8, 'off-target', 7.4 UNION ALL
SELECT 'INT005', 'CPD001', 'TGT013', 5.2, 8.1, 'off-target', 6.1 UNION ALL
SELECT 'INT006', 'CPD002', 'TGT002', 0.02, 0.033, 'primary', 9.7 UNION ALL
SELECT 'INT007', 'CPD002', 'TGT013', 3.1, 4.8, 'off-target', 6.5 UNION ALL
SELECT 'INT008', 'CPD003', 'TGT002', 0.058, 0.079, 'primary', 9.2 UNION ALL
SELECT 'INT009', 'CPD003', 'TGT013', 8.5, 12.0, 'off-target', 5.9 UNION ALL
SELECT 'INT010', 'CPD004', 'TGT003', 0.09, 0.12, 'primary', 9.1 UNION ALL
SELECT 'INT011', 'CPD004', 'TGT004', 0.038, 0.055, 'primary', 8.9 UNION ALL
SELECT 'INT012', 'CPD004', 'TGT015', 0.22, 0.31, 'primary', 8.5 UNION ALL
SELECT 'INT013', 'CPD004', 'TGT016', 0.58, 0.75, 'primary', 8.1 UNION ALL
SELECT 'INT014', 'CPD004', 'TGT017', 0.33, 0.48, 'primary', 8.4 UNION ALL
SELECT 'INT015', 'CPD004', 'TGT013', 2.8, 4.1, 'off-target', 6.6 UNION ALL
SELECT 'INT016', 'CPD005', 'TGT004', 0.031, 0.044, 'primary', 9.5 UNION ALL
SELECT 'INT017', 'CPD005', 'TGT015', 0.48, 0.65, 'off-target', 7.3 UNION ALL
SELECT 'INT018', 'CPD006', 'TGT005', 0.02, 0.028, 'primary', 9.8 UNION ALL
SELECT 'INT019', 'CPD006', 'TGT003', 0.41, 0.59, 'off-target', 7.4 UNION ALL
SELECT 'INT020', 'CPD007', 'TGT006', 0.019, 0.025, 'primary', 9.8 UNION ALL
SELECT 'INT021', 'CPD007', 'TGT018', 0.55, 0.78, 'off-target', 7.2 UNION ALL
SELECT 'INT022', 'CPD008', 'TGT007', 0.0092, 0.014, 'primary', 10.1 UNION ALL
SELECT 'INT023', 'CPD008', 'TGT019', 0.38, 0.51, 'off-target', 7.4 UNION ALL
SELECT 'INT024', 'CPD009', 'TGT008', 0.011, 0.017, 'primary', 9.9 UNION ALL
SELECT 'INT025', 'CPD009', 'TGT009', 0.015, 0.022, 'primary', 9.8 UNION ALL
SELECT 'INT026', 'CPD010', 'TGT002', 0.041, 0.058, 'primary', 9.4 UNION ALL
SELECT 'INT027', 'CPD010', 'TGT001', 0.38, 0.52, 'off-target', 7.3 UNION ALL
SELECT 'INT028', 'CPD010', 'TGT013', 1.2, 1.8, 'off-target', 7.1 UNION ALL
SELECT 'INT029', 'CPD011', 'TGT006', 0.029, 0.041, 'primary', 9.5 UNION ALL
SELECT 'INT030', 'CPD011', 'TGT010', 0.71, 0.95, 'off-target', 7.0 UNION ALL
SELECT 'INT031', 'CPD012', 'TGT020', 0.39, 0.55, 'primary', 7.3 UNION ALL
SELECT 'INT032', 'CPD013', 'TGT014', 12.0, 18.5, 'primary', 5.7 UNION ALL
SELECT 'INT033', 'CPD014', 'TGT010', 0.0018, 0.0025, 'primary', 11.8 UNION ALL
SELECT 'INT034', 'CPD015', 'TGT004', 0.055, 0.078, 'primary', 9.2 UNION ALL
SELECT 'INT035', 'CPD015', 'TGT003', 0.12, 0.17, 'primary', 8.9 UNION ALL
SELECT 'INT036', 'CPD015', 'TGT016', 0.29, 0.41, 'primary', 8.5 UNION ALL
SELECT 'INT037', 'CPD015', 'TGT013', 0.95, 1.35, 'off-target', 7.2;
4. Créer la table pathways
Contient des voies biologiques, des domaines de maladies associés et la pertinence du cancer.
CREATE OR REPLACE TABLE drug_target_graph.pathways AS
SELECT 'PWY001' AS pathway_id, 'MAPK Signaling' AS pathway_name, 'hsa04010' AS kegg_id, 'Cell Proliferation' AS biological_process, 'Oncology' AS disease_area, 'high' AS cancer_relevance UNION ALL
SELECT 'PWY002', 'PI3K-AKT Signaling', 'hsa04151', 'Cell Survival', 'Oncology', 'high' UNION ALL
SELECT 'PWY003', 'VEGF Signaling', 'hsa04370', 'Angiogenesis', 'Oncology', 'high' UNION ALL
SELECT 'PWY004', 'ErbB Signaling', 'hsa04012', 'Cell Growth', 'Oncology', 'high' UNION ALL
SELECT 'PWY005', 'mTOR Signaling', 'hsa04150', 'Cell Growth', 'Oncology', 'medium' UNION ALL
SELECT 'PWY006', 'Cell Cycle', 'hsa04110', 'Cell Division', 'Oncology', 'high' UNION ALL
SELECT 'PWY007', 'Cardiac Muscle Contraction', 'hsa04260', 'Cardiac Function', 'Cardiovascular', 'low' UNION ALL
SELECT 'PWY008', 'hERG Cardiac Channel', 'hsa04022', 'Cardiac Repolarisation','Cardiovascular', 'low' UNION ALL
SELECT 'PWY009', 'AMPK Signaling', 'hsa04152', 'Energy Metabolism', 'Metabolic', 'low' UNION ALL
SELECT 'PWY010', 'ALK Signaling', 'hsa04915', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY011', 'RAS Signaling', 'hsa04014', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY012', 'HIV Replication', 'hsa05170', 'Viral Replication', 'Infectious Disease', 'low';
5. Créer la table target_pathways
Table de jonction reliant les cibles aux voies biologiques auxquelles elles participent.
CREATE OR REPLACE TABLE drug_target_graph.target_pathways AS
SELECT 'TP001' AS tp_id, 'TGT001' AS target_id, 'PWY001' AS pathway_id, 'activator' AS role, 0.95 AS importance_score UNION ALL
SELECT 'TP002', 'TGT001', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP003', 'TGT002', 'PWY004', 'activator', 0.98 UNION ALL
SELECT 'TP004', 'TGT002', 'PWY001', 'activator', 0.82 UNION ALL
SELECT 'TP005', 'TGT002', 'PWY002', 'activator', 0.75 UNION ALL
SELECT 'TP006', 'TGT003', 'PWY003', 'activator', 0.96 UNION ALL
SELECT 'TP007', 'TGT003', 'PWY001', 'activator', 0.71 UNION ALL
SELECT 'TP008', 'TGT004', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP009', 'TGT004', 'PWY011', 'activator', 0.89 UNION ALL
SELECT 'TP010', 'TGT005', 'PWY010', 'activator', 0.99 UNION ALL
SELECT 'TP011', 'TGT005', 'PWY001', 'activator', 0.78 UNION ALL
SELECT 'TP012', 'TGT006', 'PWY002', 'activator', 0.98 UNION ALL
SELECT 'TP013', 'TGT006', 'PWY005', 'activator', 0.85 UNION ALL
SELECT 'TP014', 'TGT007', 'PWY001', 'activator', 0.94 UNION ALL
SELECT 'TP015', 'TGT007', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP016', 'TGT008', 'PWY006', 'activator', 0.95 UNION ALL
SELECT 'TP017', 'TGT009', 'PWY006', 'activator', 0.93 UNION ALL
SELECT 'TP018', 'TGT010', 'PWY005', 'activator', 0.99 UNION ALL
SELECT 'TP019', 'TGT010', 'PWY002', 'activator', 0.91 UNION ALL
SELECT 'TP020', 'TGT011', 'PWY003', 'activator', 0.87 UNION ALL
SELECT 'TP021', 'TGT011', 'PWY001', 'activator', 0.72 UNION ALL
SELECT 'TP022', 'TGT012', 'PWY001', 'activator', 0.83 UNION ALL
SELECT 'TP023', 'TGT012', 'PWY011', 'activator', 0.79 UNION ALL
SELECT 'TP024', 'TGT013', 'PWY008', 'substrate', 0.99 UNION ALL
SELECT 'TP025', 'TGT013', 'PWY007', 'substrate', 0.95 UNION ALL
SELECT 'TP026', 'TGT014', 'PWY009', 'activator', 0.97 UNION ALL
SELECT 'TP027', 'TGT015', 'PWY001', 'activator', 0.91 UNION ALL
SELECT 'TP028', 'TGT015', 'PWY011', 'activator', 0.86 UNION ALL
SELECT 'TP029', 'TGT016', 'PWY001', 'activator', 0.84 UNION ALL
SELECT 'TP030', 'TGT016', 'PWY003', 'activator', 0.77 UNION ALL
SELECT 'TP031', 'TGT017', 'PWY001', 'activator', 0.88 UNION ALL
SELECT 'TP032', 'TGT017', 'PWY011', 'activator', 0.82 UNION ALL
SELECT 'TP033', 'TGT018', 'PWY002', 'activator', 0.96 UNION ALL
SELECT 'TP034', 'TGT018', 'PWY005', 'activator', 0.88 UNION ALL
SELECT 'TP035', 'TGT019', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP036', 'TGT019', 'PWY011', 'activator', 0.91 UNION ALL
SELECT 'TP037', 'TGT020', 'PWY012', 'substrate', 0.99;
4. Créer le graphe de propriétés
Une fois les tables créées, vous pouvez créer le graphe de propriétés. Il relie les nœuds (composés, cibles, voies) à l'aide de tables d'arêtes (Interactions et Target Pathways).
Exécutez l'instruction suivante dans l'éditeur SQL de BigQuery Studio :
CREATE OR REPLACE PROPERTY GRAPH drug_target_graph.drug_target_interaction_graph
NODE TABLES (
drug_target_graph.compounds
AS compound_node
KEY (compound_id)
LABEL Compound
PROPERTIES (compound_id, compound_name, mechanism_of_action, dev_stage, therapeutic_area, molecular_weight),
drug_target_graph.targets
AS target_node
KEY (target_id)
LABEL Target
PROPERTIES (target_id, target_name, gene_name, uniprot_id, target_class, is_oncogene),
drug_target_graph.pathways
AS pathway_node
KEY (pathway_id)
LABEL Pathway
PROPERTIES (pathway_id, pathway_name, kegg_id, biological_process, disease_area, cancer_relevance)
)
EDGE TABLES (
drug_target_graph.interactions
AS binds_to_edge
KEY (interaction_id)
SOURCE KEY (compound_id) REFERENCES compound_node (compound_id)
DESTINATION KEY (target_id) REFERENCES target_node (target_id)
LABEL BINDS_TO
PROPERTIES (interaction_id, affinity_nm, ic50_nm, interaction_type, pchembl_value),
drug_target_graph.target_pathways
AS participates_in_edge
KEY (tp_id)
SOURCE KEY (target_id) REFERENCES target_node (target_id)
DESTINATION KEY (pathway_id) REFERENCES pathway_node (pathway_id)
LABEL PARTICIPATES_IN
PROPERTIES (tp_id, role, importance_score)
);
Cette action crée un graphe appelé drug_target_interaction_graph dans votre ensemble de données.
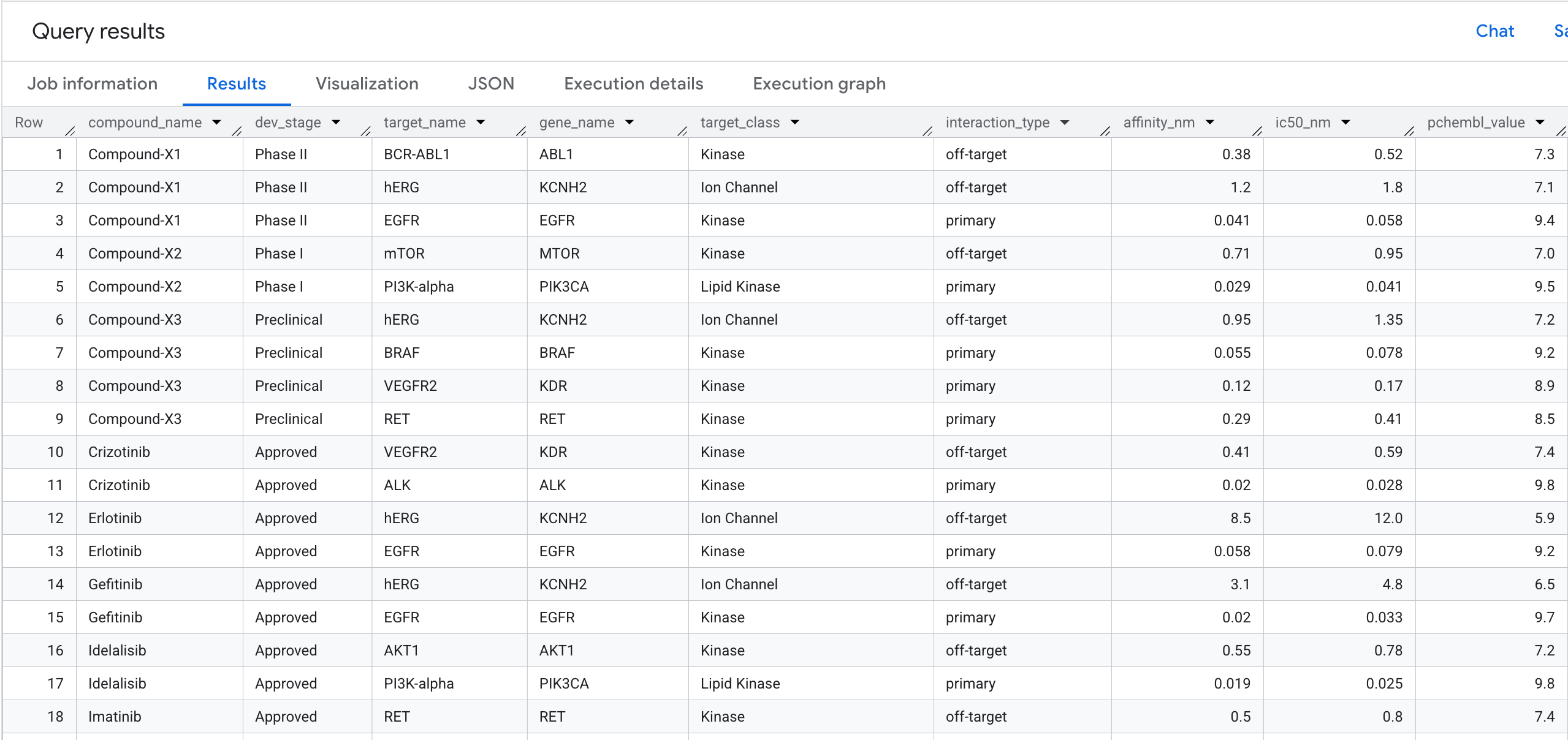
5. Requête 1 : Profil de liaison cible complet par composé
Exécutons notre première requête de graphe. Il s'agit d'une traversée à 1 saut qui répond à la question suivante : Quels composés se lient à quelles cibles et quelle est leur affinité ?
Requête GQL
Exécutez la requête suivante dans l'éditeur SQL :
SELECT
compound_name,
dev_stage,
target_name,
gene_name,
target_class,
interaction_type,
ROUND(affinity_nm, 3) AS affinity_nm,
ROUND(ic50_nm, 3) AS ic50_nm,
pchembl_value
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_name AS target_name,
t.gene_name AS gene_name,
t.target_class AS target_class,
b.interaction_type AS interaction_type,
b.affinity_nm AS affinity_nm,
b.ic50_nm AS ic50_nm,
b.pchembl_value AS pchembl_value
)
)
ORDER BY compound_name, interaction_type, affinity_nm;
Voici ce qui s'affiche dans les résultats :
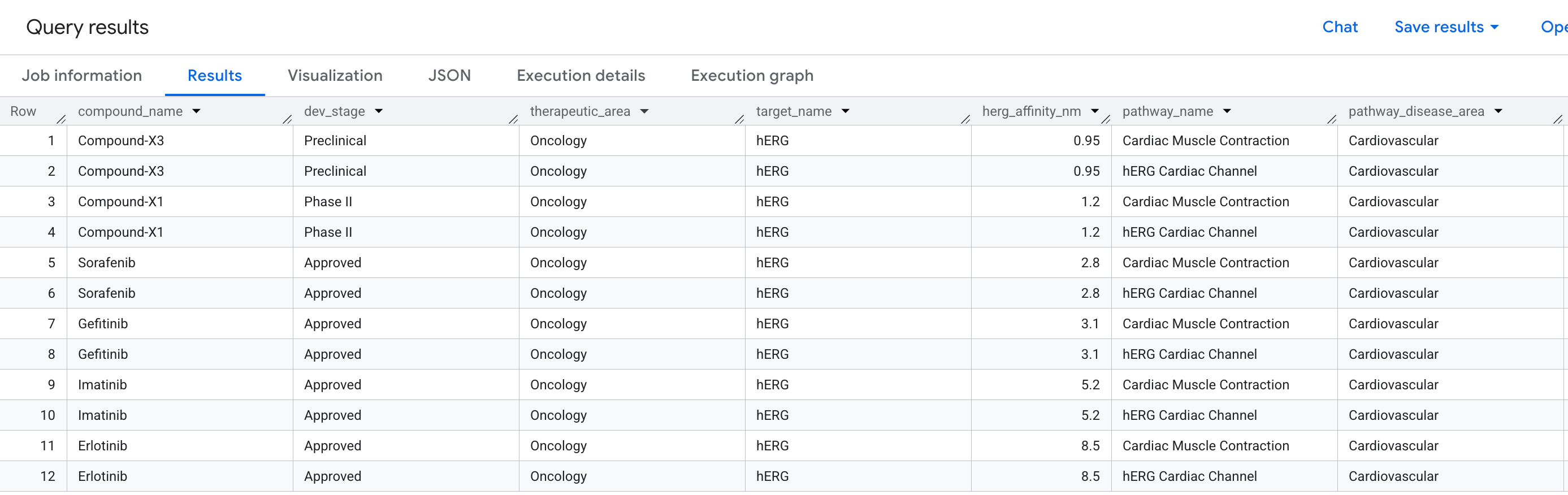
6. Requête 2 : Détection du risque cardiaque
La question commerciale
Dans la découverte de médicaments, l'une des raisons les plus courantes pour lesquelles un composé prometteur échoue lors des essais cliniques est la cardiotoxicité, en particulier la liaison involontaire à la protéine hERG (gène : KCNH2), un canal ionique potassique qui régule le rythme cardiaque. Un impact hors cible sur hERG peut provoquer des arythmies mortelles et a été responsable de plusieurs retraits de médicaments très médiatisés.
La question à laquelle nous voulons répondre est la suivante :
"Quels composés de notre pipeline ont un événement de liaison hors cible sur la protéine hERG et quelles voies cardiaques cela met-il en danger ?"
Il s'agit d'une question à 2 sauts : nous devons passer d'un composé à une cible (hERG) à une voie, en connectant trois types d'entités sur deux relations dans une seule requête.
Écrire la requête GQL
Exécutez la requête suivante dans l'éditeur SQL BQ :
SELECT
compound_name,
dev_stage,
therapeutic_area,
target_name,
ROUND(affinity_nm, 3) AS herg_affinity_nm,
pathway_name,
disease_area AS pathway_disease_area
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND b.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
c.therapeutic_area AS therapeutic_area,
t.target_name AS target_name,
b.affinity_nm AS affinity_nm,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
ORDER BY herg_affinity_nm;
Notez que la clause MATCH se lit presque comme une phrase : "Rechercher un composé qui se lie à une cible participant à une voie" , avec les filtres appliqués à chaque nœud et arête le long du chemin.
Voici les données qui s'affichent dans les résultats :
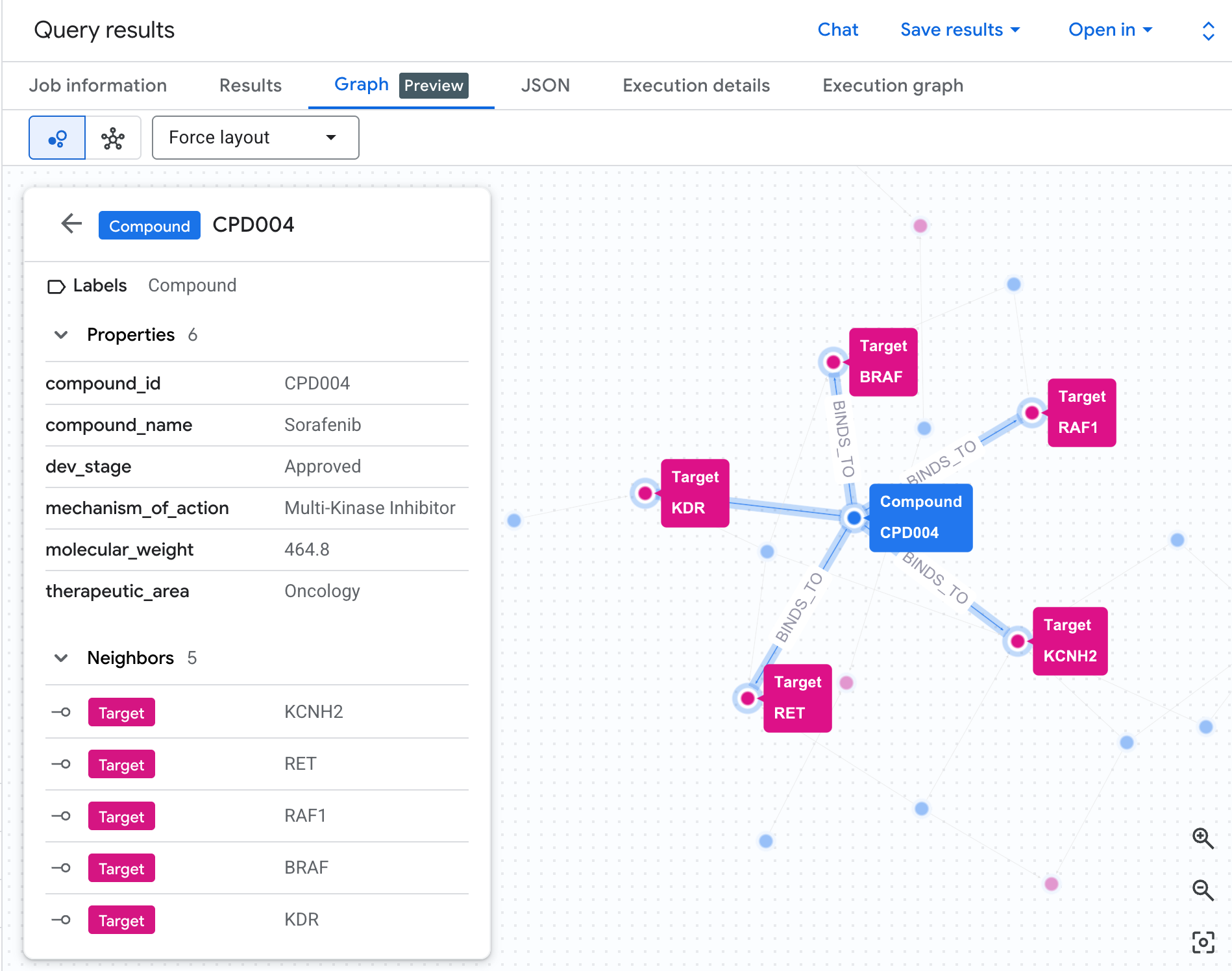
Visualiser le réseau de risques sous forme de graphe
Un tableau nous montre les données, mais pas la structure du risque. Plusieurs composés convergent-ils sur la même voie ? Existe-t-il un composé à haut risque ou plusieurs ?
Une visualisation de graphe rend cela immédiatement visible. Exécutez la cellule ci-dessous pour afficher la même traversée à 2 sauts sous forme de réseau interactif :
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH pt = (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND pw.disease_area = 'Cardiovascular'
RETURN
TO_JSON(pt) AS path
Un graphique semblable à celui-ci s'affiche :
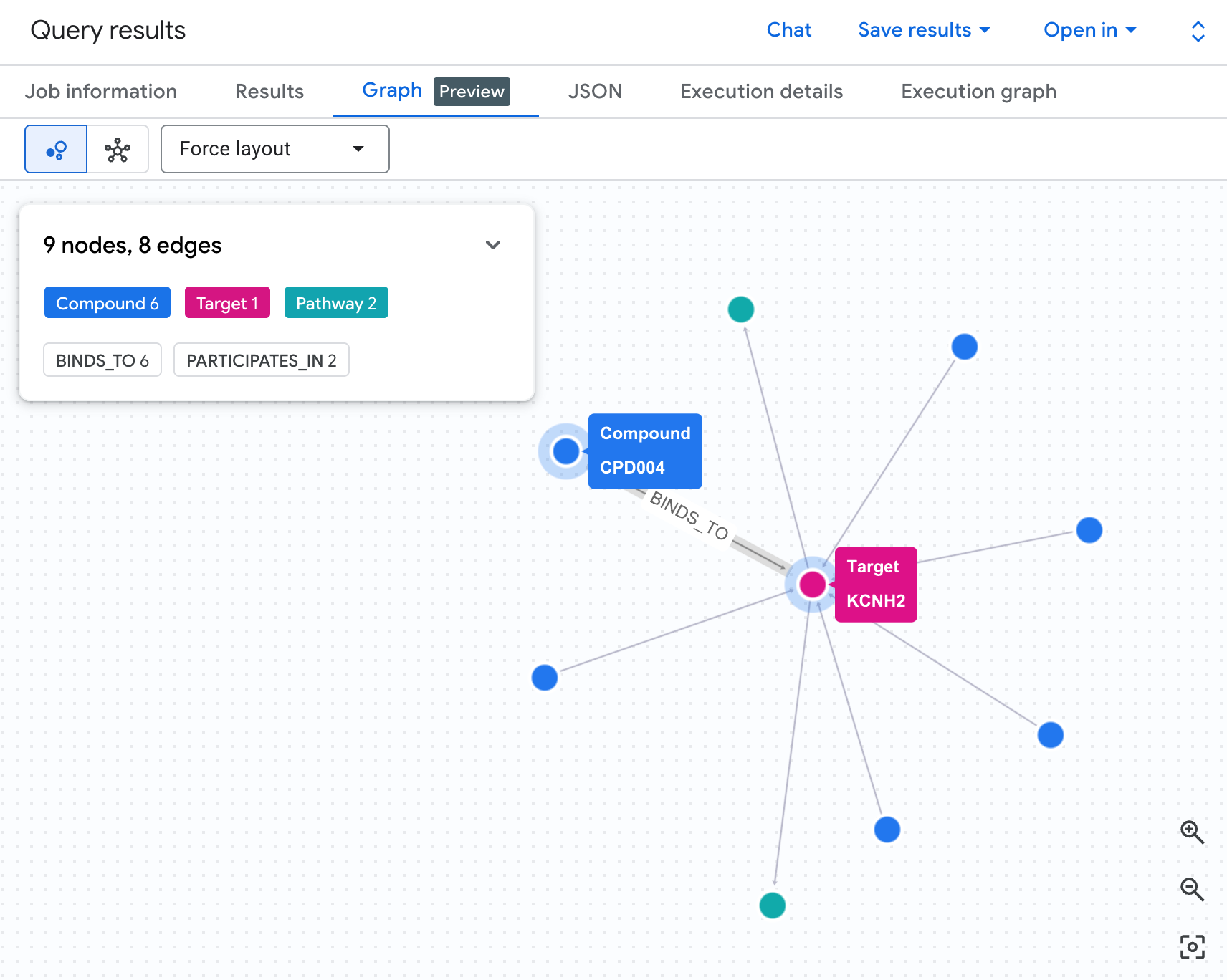
Chaque chemin du graphe retrace une chaîne de responsabilité complète : un composé (nœuds bleus) se lie à la protéine hERG au centre, qui se connecte à une ou plusieurs voies cardiaques (nœuds verts). Ce qui était une liste plate de lignes dans le tableau est désormais un réseau de risques visible : les composés présentant plusieurs expositions aux voies se distinguent immédiatement comme étant prioritaires pour l'examen de la sécurité.
Découvrez pourquoi GQL est plus élégant que SQL
Pour exécuter la même requête à 2 sauts en SQL standard, vous avez besoin de quatre jointures explicites. Vous consacrez des efforts cognitifs à décrire comment joindre des tables plutôt que quelle relation vous recherchez. GQL vous permet de rester concentré sur la question.
SELECT
c.compound_name,
c.dev_stage,
c.therapeutic_area,
t.target_name,
ROUND(i.affinity_nm, 3) AS herg_affinity_nm,
pw.pathway_name,
pw.disease_area AS pathway_disease_area
FROM drug_target_graph.compounds c
JOIN drug_target_graph.interactions i ON c.compound_id = i.compound_id
JOIN drug_target_graph.targets t ON i.target_id = t.target_id
JOIN drug_target_graph.target_pathways tp ON t.target_id = tp.target_id
JOIN drug_target_graph.pathways pw ON tp.pathway_id = pw.pathway_id
WHERE t.gene_name = 'KCNH2'
AND i.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
ORDER BY herg_affinity_nm;
Aller plus loin : détection des risques liés aux métabolites à plusieurs sauts
La requête ci-dessus identifie les composés qui se lient directement à la protéine hERG. Toutefois, dans les workflows de sécurité des médicaments réels, le risque est parfois supprimé : un composé peut être converti métaboliquement dans le corps en une molécule secondaire (un métabolite) qui se lie ensuite à hERG, une responsabilité que les tests de liaison directe peuvent manquer complètement.
Si votre graphe de propriétés inclut une table de nœuds de métabolite et une arête METABOLISES_INTO, vous pouvez étendre le même modèle MATCH à une traversée à 3 sauts :
(Compound)-[METABOLISES_INTO]->(Metabolite)-[BINDS_TO]->
(Target)-[PARTICIPATES_IN]->(Pathway)
La structure de la requête GQL ne change que d'un nœud et d'une arête. L'équivalent SQL nécessiterait deux jointures supplémentaires. C'est le modèle qui rend la traversée de graphe particulièrement puissante pour l'analyse en cascade de la sécurité : la complexité de la requête augmente de manière linéaire, tandis que l'insight biologique augmente de manière exponentielle.
7. Requête 3 : Paires de composés à cible partagée
Pour trouver des candidats à une thérapie combinée, nous pouvons identifier le moment où deux composés différents se lient au même nœud cible. Nous utilisons une correspondance bidirectionnelle pour répondre à la question suivante : Quels composés oncologiques convergent sur la même cible exacte ?
Exécutez la requête suivante dans l'éditeur SQL :
SELECT
compound_a,
compound_b,
shared_target,
gene_name,
ROUND(affinity_a_nm, 3) AS affinity_a_nm,
ROUND(affinity_b_nm, 3) AS affinity_b_nm
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
AND c2.therapeutic_area = 'Oncology'
COLUMNS (
c1.compound_name AS compound_a,
c2.compound_name AS compound_b,
t.target_name AS shared_target,
t.gene_name AS gene_name,
b1.affinity_nm AS affinity_a_nm,
b2.affinity_nm AS affinity_b_nm
)
)
ORDER BY compound_a, compound_b, affinity_a_nm;
Voici les données qui s'affichent dans les résultats :
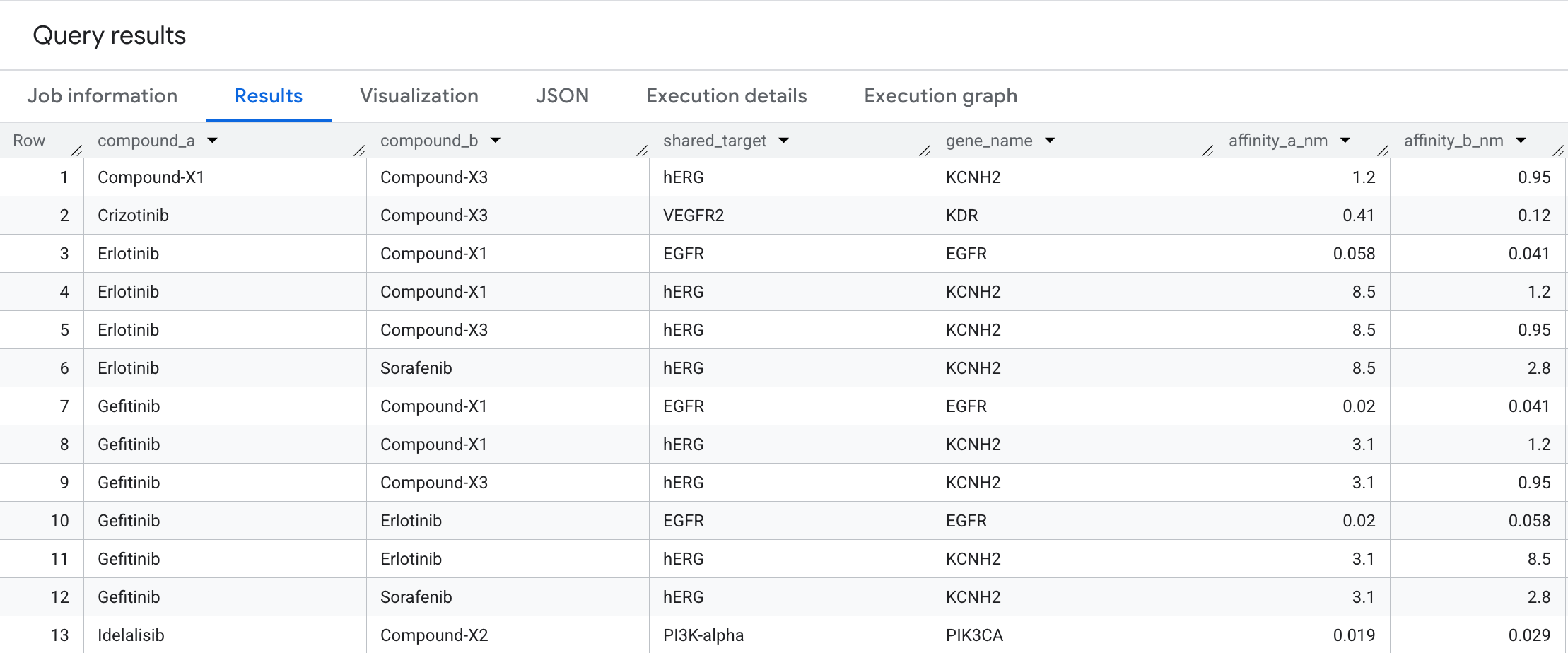
Visualisation de graphe
Vous pouvez visualiser le graphe directement dans BigQuery en exécutant le code suivant dans l'éditeur SQL.
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH p = (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
RETURN
TO_JSON(p) AS path
Cette traversée bidirectionnelle fait apparaître des paires de composés qui convergent sur la même cible protéique, un modèle difficile à repérer dans un tableau d'interactions plat, mais immédiatement visible sous forme de graphe. Dans la découverte de médicaments, les paires à cible partagée sont le point de départ de la conception de la thérapie combinée : deux composés atteignant le même nœud dans une voie cancéreuse peuvent produire un effet synergique ou signaler une redondance involontaire dans le pipeline.
8. Requête 4 : Rayon d'action de la voie de la maladie
Quelle est l'étendue de l'impact biologique de chaque composé ? Effectuons une traversée à 2 sauts avec agrégation pour répondre à la question suivante : Combien de voies biologiques et de cibles distinctes chaque composé affecte-t-il, regroupés par domaine de maladie ?
Exécutez la requête suivante dans l'éditeur SQL :
SELECT
compound_name,
dev_stage,
disease_area,
COUNT(DISTINCT pathway_id) AS pathways_affected,
COUNT(DISTINCT target_id) AS targets_involved,
STRING_AGG(DISTINCT pathway_name ORDER BY pathway_name) AS pathway_list
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_id AS target_id,
pw.pathway_id AS pathway_id,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
GROUP BY compound_name, dev_stage, disease_area
ORDER BY compound_name, pathways_affected DESC;
Voici ce qui s'affiche dans les résultats :
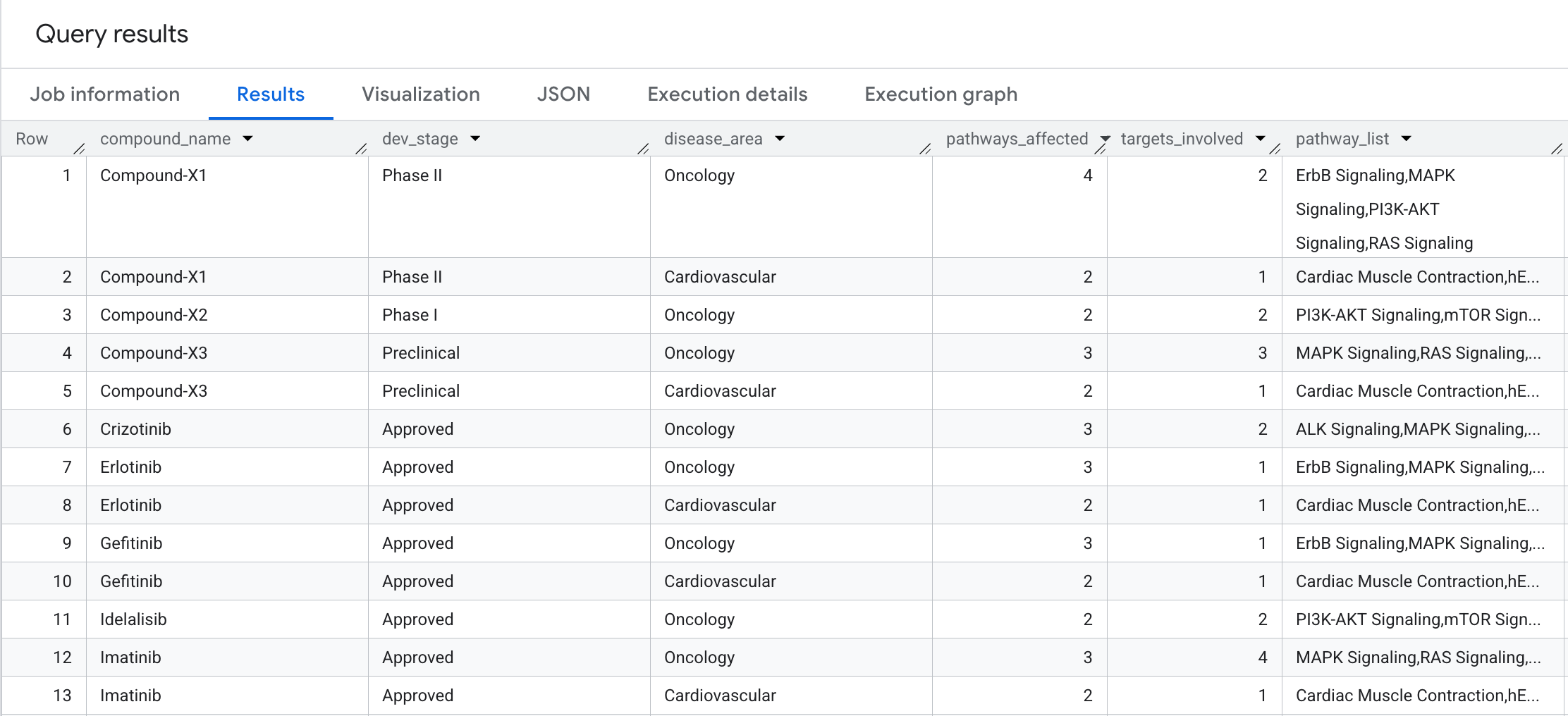
9. Requête 5 : Sélection de composés sûrs
Enfin, interrogeons les composés qui ont une forte couverture oncologique, mais qui évitent explicitement les responsabilités hors cible hERG (cardiaques). Cela correspond aux modèles de sélection courants axés sur la sécurité dans les pipelines de découverte de médicaments.
Exécutez la requête suivante dans l'éditeur SQL :
WITH oncology_compounds AS (
SELECT DISTINCT compound_id, compound_name, dev_stage
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE pw.disease_area = 'Oncology'
AND pw.cancer_relevance = 'high'
COLUMNS (
c.compound_id AS compound_id,
c.compound_name AS compound_name,
c.dev_stage AS dev_stage
)
)
),
herg_risk_compounds AS (
SELECT DISTINCT compound_id
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
WHERE t.gene_name = 'KCNH2'
COLUMNS (c.compound_id AS compound_id)
)
)
SELECT
o.compound_name,
o.dev_stage,
'Clean cardiac profile' AS cardiac_safety
FROM oncology_compounds o
LEFT JOIN herg_risk_compounds h ON o.compound_id = h.compound_id
WHERE h.compound_id IS NULL
ORDER BY o.dev_stage, o.compound_name;
Voici le résultat qui s'affiche dans les résultats :
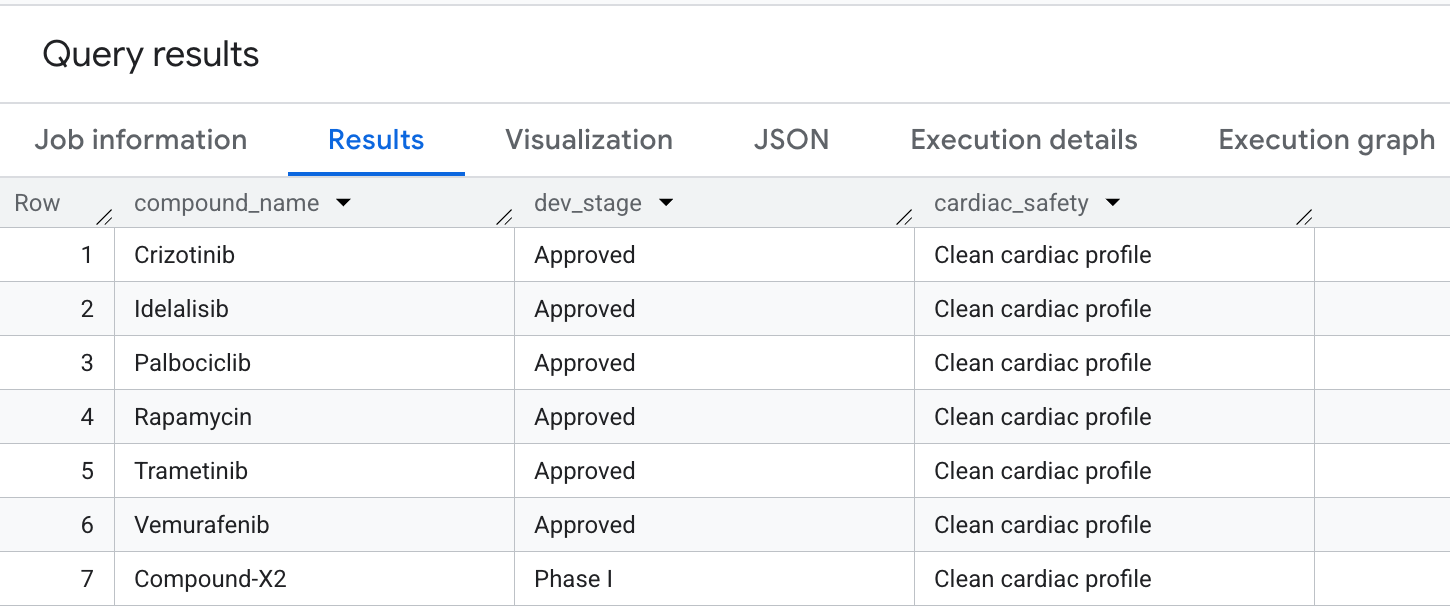
Vous avez exécuté avec succès des traversées de graphe avancées dans BigQuery pour extraire les principaux profils de sécurité et d'efficacité.
10. Section bonus : Discuter avec votre graphe
BigQuery Conversational Analytics est désormais compatible avec le graphe en tant que source de connaissances. Vous pouvez ainsi discuter avec le graphe que vous venez de créer en langage naturel.
Premiers pas : Ajouter un graphe en tant que source de connaissances
Pour commencer, créez un agent conversationnel en suivant les étapes décrites ici. Sélectionnez le graphe que vous avez créé dans la barre de recherche.
Utiliser BigQuery Conversational Analytics pour discuter avec votre graphe
Une fois que vous avez ajouté la source de connaissances en tant que graphe, terminez la configuration du conversational analytics agent setup.
Vous pouvez ensuite commencer à discuter avec votre graphe en langage naturel.
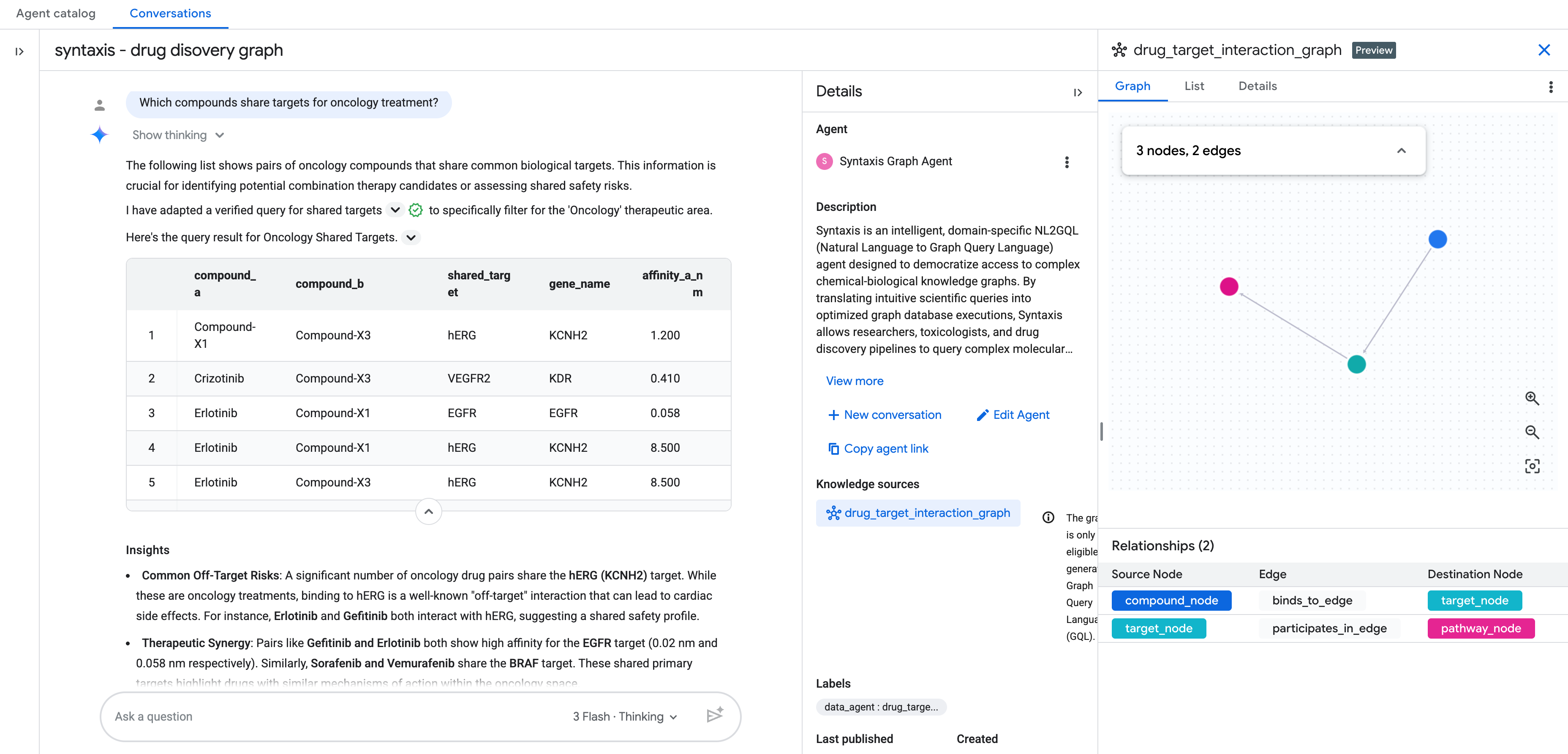
Questions supplémentaires
- Quelles sont toutes les cibles des composés actuellement en essais de phase 2 ?
- Quelles cibles sont partagées entre les composés cardiovasculaires et oncologiques ?
11. Libérer de l'espace
Pour éviter que votre compte Google Cloud ne soit facturé en permanence, supprimez les ressources créées lors de cet atelier.
Exécutez la requête suivante pour supprimer le schéma et toutes les tables en cascade :
DROP SCHEMA IF EXISTS drug_target_graph CASCADE;
12. Félicitations
Félicitations ! Vous avez modélisé et analysé avec succès un réseau d'interaction médicament-cible à l'aide de BigQuery Graph.
Connaissances acquises
- Comment modéliser les relations entre entités (composés, cibles, voies) sous forme de graphe de propriétés
- Comment définir le schéma et créer un graphe de propriétés dans BigQuery
- Comment écrire des traversées de graphe complexes à l'aide de GQL et les comparer à SQL traditionnel
- Comment exploiter
GRAPH_TABLE,MATCHet la correspondance bidirectionnelle pour résoudre les problèmes liés au domaine des sciences de la vie