
1. מבוא
בשיעור Codelab הזה תלמדו איך להשתמש ב-BigQuery Graph כדי ליצור מודל של רשת אינטראקציות בין תרופות לבין מטרות ביולוגיות ולנתח אותה. תשתמשו בעוצמה של שאילתות גרף (GQL) כדי לבדוק איך תרופות מגיבות למטרות ביולוגיות, לזהות תופעות לוואי פוטנציאליות (כמו סיכונים לבביים) ולגלות טיפולים פוטנציאליים בשילוב תרופות.
🧬 תרחיש לדוגמה – רשת אינטראקציות בין תרופות למטרות
שאלה עסקית: מהו רדיוס הפיצוץ המלא של תרכובת – אילו מטרות היא משיגה, אילו מסלולים ביולוגיים מושפעים, ואילו תחומים של מחלות רלוונטיים?
טבלאות:
טבלה | תיאור |
| מולקולות של תרופות עם מנגנון פעולה ושלב פיתוח |
| יעדי חלבונים עם שמות גנים ומזהי UniProt |
| זיקה משולבת של תרכובת ליעד (יעדים ראשוניים + יעדים לא רצויים) |
| מסלולים ביולוגיים עם קשרים לאזורי מחלות |
| טבלת צמתים שמקשרת בין יעדים לבין הנתיבים שהם משתתפים בהם |
מודל גרף הנכסים:
(Compound)-[BINDS_TO {affinity_nm, ic50_nm, interaction_type}]->(Target)
(Target)-[PARTICIPATES_IN {role, importance_score}]->(Pathway)
🔍 שאילתות לדוגמה
שאילתה | מה הוא מראה |
Q1: Target binding profile | מעבר של קפיצה אחת – מורכב לכל היעדים העיקריים והלא-מטורגטים |
Q2: hERG cardiac risk detection | 2-hop traversal — compound → hERG target → cardiac pathway |
רבעון 3: צמדים מורכבים של יעדים משותפים | התאמה דו-כיוונית – שתי תרכובות מתכנסות לאותו צומת יעד |
שאלה 4: רדיוס ההשפעה של מסלול המחלה | צבירה של 2 קפיצות – כיסוי מלא של מסלול ושל תחום המחלה לכל תרכובת |
שאלה 5: בחירה בטוחה של תרכובות | תרכובות עם כיסוי גבוה של אונקולוגיה אבל ללא סיכון קרדיאלי של hERG |
הפעולות שתבצעו:
- יצירת מערך נתונים וסכימה ב-BigQuery לרשת האינטראקציות בין התרופות
- טעינת נתונים לדוגמה (תרכובות, מטרות, אינטראקציות, מסלולים, מסלולי מטרות)
- יצירת גרף מאפיינים ב-BigQuery שמקשר בין הישויות האלה
- הרצת שאילתה בתרשים כדי להבין אינטראקציות מורכבות, מסלולים ביולוגיים ורדיוס פיצוץ של מחלות באמצעות מעברים בתרשים (
GRAPH_TABLEו-MATCH) - להשוות בין GQL לבין SQL סטנדרטי כדי להבין את הפשטות והעוצמה של תחביר הגרף
הדרישות
- דפדפן אינטרנט כמו Chrome
- פרויקט ב-Google Cloud שהחיוב בו מופעל
ה-Codelab הזה מיועד למפתחים בכל הרמות, כולל מתחילים.
2. לפני שמתחילים
יצירת פרויקט ב-Google Cloud
- ב-Google Cloud Console, בוחרים פרויקט או יוצרים פרויקט חדש ב-Google Cloud.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud.
הפעלת Cloud Shell
- לוחצים על Activate Cloud Shell בחלק העליון של מסוף Google Cloud.
- אימות האימות:
gcloud auth list
- מאשרים את הפרויקט:
gcloud config get project
- מגדירים אותו לפי הצורך:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
הפעלת ממשקי ה-API
מריצים את הפקודה הבאה כדי להפעיל את BigQuery API הנדרש:
gcloud services enable bigquery.googleapis.com
3. הגדרת הסכימה וטעינת הנתונים
קודם צריך ליצור מערך נתונים לאחסון הטבלאות שקשורות לגרף, ולאכלס אותן בנתוני דוגמה.
- עוברים אל BigQuery Studio במסוף Google Cloud.
- לוחצים על SQL Editor כדי לפתוח כרטיסייה חדשה של שאילתה.
- מריצים את ההצהרה הבאה כדי ליצור את מערך הנתונים
drug_target_graph:
CREATE SCHEMA IF NOT EXISTS drug_target_graph
OPTIONS (location = 'US');
עכשיו יוצרים את 5 טבלאות המקור על ידי הרצת שאילתות ה-DDL הבאות ב-BigQuery Studio.
1. יצירת טבלת compounds
מכיל מולקולות של תרופות, מנגנון הפעולה שלהן, שלב הפיתוח והאזור הטיפולי.
CREATE OR REPLACE TABLE drug_target_graph.compounds AS
SELECT 'CPD001' AS compound_id, 'Imatinib' AS compound_name, 'Kinase Inhibitor' AS mechanism_of_action, 'Approved' AS dev_stage, 'Oncology' AS therapeutic_area, 479.6 AS molecular_weight UNION ALL
SELECT 'CPD002', 'Gefitinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 446.9 UNION ALL
SELECT 'CPD003', 'Erlotinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 393.4 UNION ALL
SELECT 'CPD004', 'Sorafenib', 'Multi-Kinase Inhibitor', 'Approved', 'Oncology', 464.8 UNION ALL
SELECT 'CPD005', 'Vemurafenib', 'BRAF Inhibitor', 'Approved', 'Oncology', 489.9 UNION ALL
SELECT 'CPD006', 'Crizotinib', 'ALK Inhibitor', 'Approved', 'Oncology', 450.3 UNION ALL
SELECT 'CPD007', 'Idelalisib', 'PI3K Inhibitor', 'Approved', 'Oncology', 415.4 UNION ALL
SELECT 'CPD008', 'Trametinib', 'MEK Inhibitor', 'Approved', 'Oncology', 615.4 UNION ALL
SELECT 'CPD009', 'Palbociclib', 'CDK Inhibitor', 'Approved', 'Oncology', 447.5 UNION ALL
SELECT 'CPD010', 'Compound-X1', 'Kinase Inhibitor', 'Phase II', 'Oncology', 412.3 UNION ALL
SELECT 'CPD011', 'Compound-X2', 'PI3K Inhibitor', 'Phase I', 'Oncology', 398.7 UNION ALL
SELECT 'CPD012', 'Saquinavir', 'Protease Inhibitor', 'Approved', 'Infectious Disease', 670.8 UNION ALL
SELECT 'CPD013', 'Metformin', 'AMPK Activator', 'Approved', 'Metabolic', 165.6 UNION ALL
SELECT 'CPD014', 'Rapamycin', 'mTOR Inhibitor', 'Approved', 'Immunology', 914.2 UNION ALL
SELECT 'CPD015', 'Compound-X3', 'Multi-Kinase Inhibitor', 'Preclinical', 'Oncology', 502.1;
2. יצירת טבלת targets
מכיל מטרות חלבון, שמות גנים, מזהי UniProt וסיווגי מטרות.
CREATE OR REPLACE TABLE drug_target_graph.targets AS
SELECT 'TGT001' AS target_id, 'BCR-ABL1' AS target_name, 'ABL1' AS gene_name, 'P00519' AS uniprot_id, 'Kinase' AS target_class, TRUE AS is_oncogene UNION ALL
SELECT 'TGT002', 'EGFR', 'EGFR', 'P00533', 'Kinase', TRUE UNION ALL
SELECT 'TGT003', 'VEGFR2', 'KDR', 'P35968', 'Kinase', FALSE UNION ALL
SELECT 'TGT004', 'BRAF', 'BRAF', 'P15056', 'Kinase', TRUE UNION ALL
SELECT 'TGT005', 'ALK', 'ALK', 'Q9UM73', 'Kinase', TRUE UNION ALL
SELECT 'TGT006', 'PI3K-alpha','PIK3CA', 'P42336', 'Lipid Kinase', TRUE UNION ALL
SELECT 'TGT007', 'MEK1', 'MAP2K1', 'Q02750', 'Kinase', FALSE UNION ALL
SELECT 'TGT008', 'CDK4', 'CDK4', 'P11802', 'Kinase', FALSE UNION ALL
SELECT 'TGT009', 'CDK6', 'CDK6', 'P30279', 'Kinase', FALSE UNION ALL
SELECT 'TGT010', 'mTOR', 'MTOR', 'P42345', 'Kinase', FALSE UNION ALL
SELECT 'TGT011', 'PDGFR-beta','PDGFRB', 'P09619', 'Kinase', FALSE UNION ALL
SELECT 'TGT012', 'c-KIT', 'KIT', 'P10721', 'Kinase', TRUE UNION ALL
SELECT 'TGT013', 'hERG', 'KCNH2', 'Q12809', 'Ion Channel', FALSE UNION ALL
SELECT 'TGT014', 'AMPK', 'PRKAA1', 'Q13131', 'Kinase', FALSE UNION ALL
SELECT 'TGT015', 'RAF1', 'RAF1', 'P04049', 'Kinase', FALSE UNION ALL
SELECT 'TGT016', 'RET', 'RET', 'P07949', 'Kinase', TRUE UNION ALL
SELECT 'TGT017', 'FLT3', 'FLT3', 'P36888', 'Kinase', TRUE UNION ALL
SELECT 'TGT018', 'AKT1', 'AKT1', 'P31749', 'Kinase', FALSE UNION ALL
SELECT 'TGT019', 'ERK2', 'MAPK1', 'P28482', 'Kinase', FALSE UNION ALL
SELECT 'TGT020', 'HIV-Protease','HIV1-PR','Q72547', 'Protease', FALSE;
3. יצירת טבלת interactions
מכיל נתוני זיקה של קשירת תרכובות למטרות (מטרות ראשוניות לעומת מטרות משניות).
CREATE OR REPLACE TABLE drug_target_graph.interactions AS
SELECT 'INT001' AS interaction_id, 'CPD001' AS compound_id, 'TGT001' AS target_id, 0.025 AS affinity_nm, 0.038 AS ic50_nm, 'primary' AS interaction_type, 9.8 AS pchembl_value UNION ALL
SELECT 'INT002', 'CPD001', 'TGT011', 0.1, 0.15, 'primary', 8.8 UNION ALL
SELECT 'INT003', 'CPD001', 'TGT012', 0.068, 0.1, 'primary', 9.2 UNION ALL
SELECT 'INT004', 'CPD001', 'TGT016', 0.5, 0.8, 'off-target', 7.4 UNION ALL
SELECT 'INT005', 'CPD001', 'TGT013', 5.2, 8.1, 'off-target', 6.1 UNION ALL
SELECT 'INT006', 'CPD002', 'TGT002', 0.02, 0.033, 'primary', 9.7 UNION ALL
SELECT 'INT007', 'CPD002', 'TGT013', 3.1, 4.8, 'off-target', 6.5 UNION ALL
SELECT 'INT008', 'CPD003', 'TGT002', 0.058, 0.079, 'primary', 9.2 UNION ALL
SELECT 'INT009', 'CPD003', 'TGT013', 8.5, 12.0, 'off-target', 5.9 UNION ALL
SELECT 'INT010', 'CPD004', 'TGT003', 0.09, 0.12, 'primary', 9.1 UNION ALL
SELECT 'INT011', 'CPD004', 'TGT004', 0.038, 0.055, 'primary', 8.9 UNION ALL
SELECT 'INT012', 'CPD004', 'TGT015', 0.22, 0.31, 'primary', 8.5 UNION ALL
SELECT 'INT013', 'CPD004', 'TGT016', 0.58, 0.75, 'primary', 8.1 UNION ALL
SELECT 'INT014', 'CPD004', 'TGT017', 0.33, 0.48, 'primary', 8.4 UNION ALL
SELECT 'INT015', 'CPD004', 'TGT013', 2.8, 4.1, 'off-target', 6.6 UNION ALL
SELECT 'INT016', 'CPD005', 'TGT004', 0.031, 0.044, 'primary', 9.5 UNION ALL
SELECT 'INT017', 'CPD005', 'TGT015', 0.48, 0.65, 'off-target', 7.3 UNION ALL
SELECT 'INT018', 'CPD006', 'TGT005', 0.02, 0.028, 'primary', 9.8 UNION ALL
SELECT 'INT019', 'CPD006', 'TGT003', 0.41, 0.59, 'off-target', 7.4 UNION ALL
SELECT 'INT020', 'CPD007', 'TGT006', 0.019, 0.025, 'primary', 9.8 UNION ALL
SELECT 'INT021', 'CPD007', 'TGT018', 0.55, 0.78, 'off-target', 7.2 UNION ALL
SELECT 'INT022', 'CPD008', 'TGT007', 0.0092, 0.014, 'primary', 10.1 UNION ALL
SELECT 'INT023', 'CPD008', 'TGT019', 0.38, 0.51, 'off-target', 7.4 UNION ALL
SELECT 'INT024', 'CPD009', 'TGT008', 0.011, 0.017, 'primary', 9.9 UNION ALL
SELECT 'INT025', 'CPD009', 'TGT009', 0.015, 0.022, 'primary', 9.8 UNION ALL
SELECT 'INT026', 'CPD010', 'TGT002', 0.041, 0.058, 'primary', 9.4 UNION ALL
SELECT 'INT027', 'CPD010', 'TGT001', 0.38, 0.52, 'off-target', 7.3 UNION ALL
SELECT 'INT028', 'CPD010', 'TGT013', 1.2, 1.8, 'off-target', 7.1 UNION ALL
SELECT 'INT029', 'CPD011', 'TGT006', 0.029, 0.041, 'primary', 9.5 UNION ALL
SELECT 'INT030', 'CPD011', 'TGT010', 0.71, 0.95, 'off-target', 7.0 UNION ALL
SELECT 'INT031', 'CPD012', 'TGT020', 0.39, 0.55, 'primary', 7.3 UNION ALL
SELECT 'INT032', 'CPD013', 'TGT014', 12.0, 18.5, 'primary', 5.7 UNION ALL
SELECT 'INT033', 'CPD014', 'TGT010', 0.0018, 0.0025, 'primary', 11.8 UNION ALL
SELECT 'INT034', 'CPD015', 'TGT004', 0.055, 0.078, 'primary', 9.2 UNION ALL
SELECT 'INT035', 'CPD015', 'TGT003', 0.12, 0.17, 'primary', 8.9 UNION ALL
SELECT 'INT036', 'CPD015', 'TGT016', 0.29, 0.41, 'primary', 8.5 UNION ALL
SELECT 'INT037', 'CPD015', 'TGT013', 0.95, 1.35, 'off-target', 7.2;
4. יצירת טבלת pathways
כולל מסלולים ביולוגיים, תחומים קשורים של מחלות ורלוונטיות לסרטן.
CREATE OR REPLACE TABLE drug_target_graph.pathways AS
SELECT 'PWY001' AS pathway_id, 'MAPK Signaling' AS pathway_name, 'hsa04010' AS kegg_id, 'Cell Proliferation' AS biological_process, 'Oncology' AS disease_area, 'high' AS cancer_relevance UNION ALL
SELECT 'PWY002', 'PI3K-AKT Signaling', 'hsa04151', 'Cell Survival', 'Oncology', 'high' UNION ALL
SELECT 'PWY003', 'VEGF Signaling', 'hsa04370', 'Angiogenesis', 'Oncology', 'high' UNION ALL
SELECT 'PWY004', 'ErbB Signaling', 'hsa04012', 'Cell Growth', 'Oncology', 'high' UNION ALL
SELECT 'PWY005', 'mTOR Signaling', 'hsa04150', 'Cell Growth', 'Oncology', 'medium' UNION ALL
SELECT 'PWY006', 'Cell Cycle', 'hsa04110', 'Cell Division', 'Oncology', 'high' UNION ALL
SELECT 'PWY007', 'Cardiac Muscle Contraction', 'hsa04260', 'Cardiac Function', 'Cardiovascular', 'low' UNION ALL
SELECT 'PWY008', 'hERG Cardiac Channel', 'hsa04022', 'Cardiac Repolarisation','Cardiovascular', 'low' UNION ALL
SELECT 'PWY009', 'AMPK Signaling', 'hsa04152', 'Energy Metabolism', 'Metabolic', 'low' UNION ALL
SELECT 'PWY010', 'ALK Signaling', 'hsa04915', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY011', 'RAS Signaling', 'hsa04014', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY012', 'HIV Replication', 'hsa05170', 'Viral Replication', 'Infectious Disease', 'low';
5. יצירת טבלת target_pathways
טבלת צומת שמקשרת בין יעדים לבין המסלולים הביולוגיים שבהם הם משתתפים.
CREATE OR REPLACE TABLE drug_target_graph.target_pathways AS
SELECT 'TP001' AS tp_id, 'TGT001' AS target_id, 'PWY001' AS pathway_id, 'activator' AS role, 0.95 AS importance_score UNION ALL
SELECT 'TP002', 'TGT001', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP003', 'TGT002', 'PWY004', 'activator', 0.98 UNION ALL
SELECT 'TP004', 'TGT002', 'PWY001', 'activator', 0.82 UNION ALL
SELECT 'TP005', 'TGT002', 'PWY002', 'activator', 0.75 UNION ALL
SELECT 'TP006', 'TGT003', 'PWY003', 'activator', 0.96 UNION ALL
SELECT 'TP007', 'TGT003', 'PWY001', 'activator', 0.71 UNION ALL
SELECT 'TP008', 'TGT004', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP009', 'TGT004', 'PWY011', 'activator', 0.89 UNION ALL
SELECT 'TP010', 'TGT005', 'PWY010', 'activator', 0.99 UNION ALL
SELECT 'TP011', 'TGT005', 'PWY001', 'activator', 0.78 UNION ALL
SELECT 'TP012', 'TGT006', 'PWY002', 'activator', 0.98 UNION ALL
SELECT 'TP013', 'TGT006', 'PWY005', 'activator', 0.85 UNION ALL
SELECT 'TP014', 'TGT007', 'PWY001', 'activator', 0.94 UNION ALL
SELECT 'TP015', 'TGT007', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP016', 'TGT008', 'PWY006', 'activator', 0.95 UNION ALL
SELECT 'TP017', 'TGT009', 'PWY006', 'activator', 0.93 UNION ALL
SELECT 'TP018', 'TGT010', 'PWY005', 'activator', 0.99 UNION ALL
SELECT 'TP019', 'TGT010', 'PWY002', 'activator', 0.91 UNION ALL
SELECT 'TP020', 'TGT011', 'PWY003', 'activator', 0.87 UNION ALL
SELECT 'TP021', 'TGT011', 'PWY001', 'activator', 0.72 UNION ALL
SELECT 'TP022', 'TGT012', 'PWY001', 'activator', 0.83 UNION ALL
SELECT 'TP023', 'TGT012', 'PWY011', 'activator', 0.79 UNION ALL
SELECT 'TP024', 'TGT013', 'PWY008', 'substrate', 0.99 UNION ALL
SELECT 'TP025', 'TGT013', 'PWY007', 'substrate', 0.95 UNION ALL
SELECT 'TP026', 'TGT014', 'PWY009', 'activator', 0.97 UNION ALL
SELECT 'TP027', 'TGT015', 'PWY001', 'activator', 0.91 UNION ALL
SELECT 'TP028', 'TGT015', 'PWY011', 'activator', 0.86 UNION ALL
SELECT 'TP029', 'TGT016', 'PWY001', 'activator', 0.84 UNION ALL
SELECT 'TP030', 'TGT016', 'PWY003', 'activator', 0.77 UNION ALL
SELECT 'TP031', 'TGT017', 'PWY001', 'activator', 0.88 UNION ALL
SELECT 'TP032', 'TGT017', 'PWY011', 'activator', 0.82 UNION ALL
SELECT 'TP033', 'TGT018', 'PWY002', 'activator', 0.96 UNION ALL
SELECT 'TP034', 'TGT018', 'PWY005', 'activator', 0.88 UNION ALL
SELECT 'TP035', 'TGT019', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP036', 'TGT019', 'PWY011', 'activator', 0.91 UNION ALL
SELECT 'TP037', 'TGT020', 'PWY012', 'substrate', 0.99;
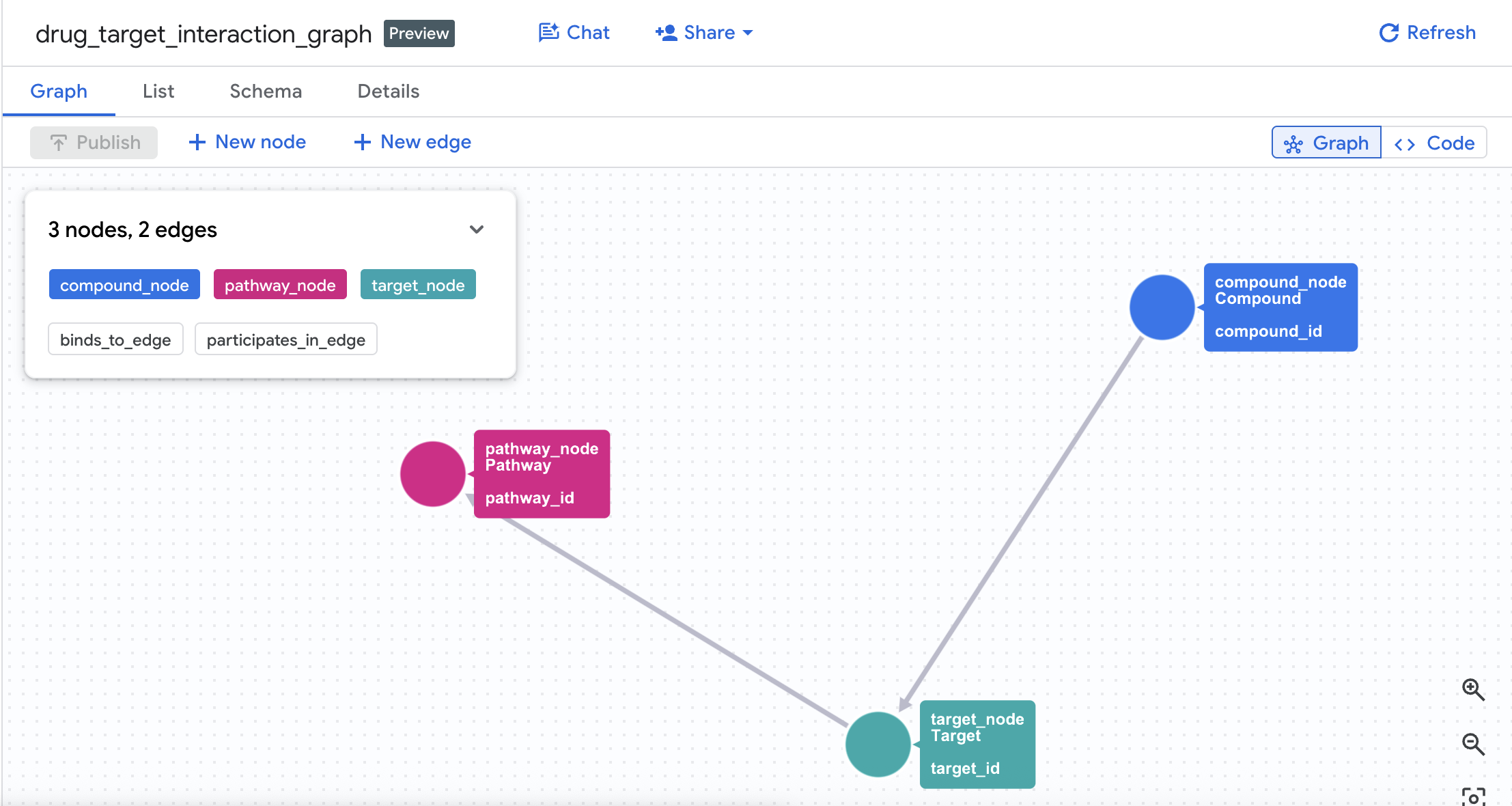
4. יצירת גרף הנכסים
אחרי שיוצרים את הטבלאות, אפשר ליצור את גרף הנכסים. הגרף הזה מקשר בין צמתים (תרכובות, מטרות, מסלולים) באמצעות טבלאות קצוות (Interactions ו-Target Pathways).
מריצים את ההצהרה הבאה בעורך ה-SQL של BigQuery Studio:
CREATE OR REPLACE PROPERTY GRAPH drug_target_graph.drug_target_interaction_graph
NODE TABLES (
drug_target_graph.compounds
AS compound_node
KEY (compound_id)
LABEL Compound
PROPERTIES (compound_id, compound_name, mechanism_of_action, dev_stage, therapeutic_area, molecular_weight),
drug_target_graph.targets
AS target_node
KEY (target_id)
LABEL Target
PROPERTIES (target_id, target_name, gene_name, uniprot_id, target_class, is_oncogene),
drug_target_graph.pathways
AS pathway_node
KEY (pathway_id)
LABEL Pathway
PROPERTIES (pathway_id, pathway_name, kegg_id, biological_process, disease_area, cancer_relevance)
)
EDGE TABLES (
drug_target_graph.interactions
AS binds_to_edge
KEY (interaction_id)
SOURCE KEY (compound_id) REFERENCES compound_node (compound_id)
DESTINATION KEY (target_id) REFERENCES target_node (target_id)
LABEL BINDS_TO
PROPERTIES (interaction_id, affinity_nm, ic50_nm, interaction_type, pchembl_value),
drug_target_graph.target_pathways
AS participates_in_edge
KEY (tp_id)
SOURCE KEY (target_id) REFERENCES target_node (target_id)
DESTINATION KEY (pathway_id) REFERENCES pathway_node (pathway_id)
LABEL PARTICIPATES_IN
PROPERTIES (tp_id, role, importance_score)
);
כך נוצר תרשים בשם drug_target_interaction_graph במערך הנתונים.
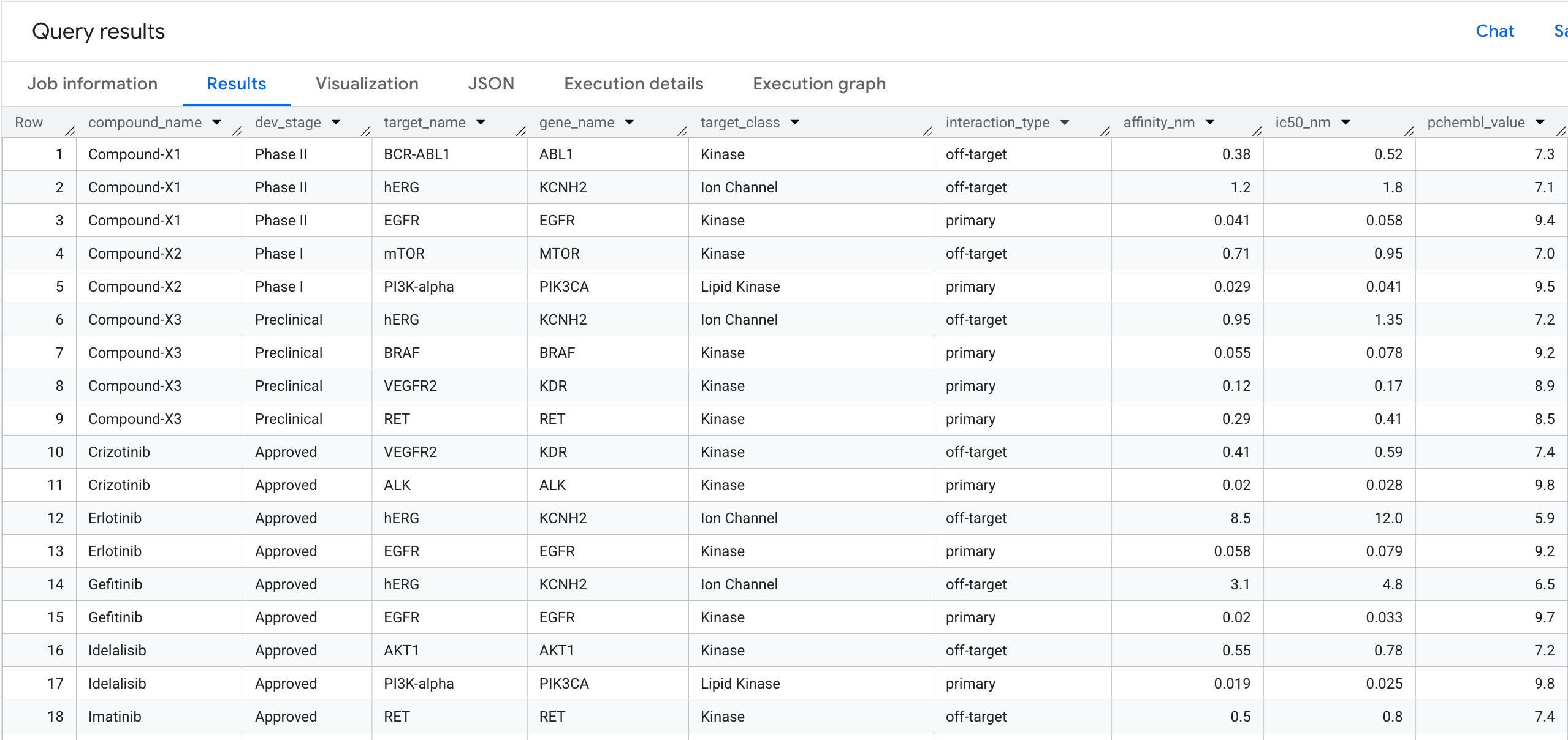
5. שאילתה 1: פרופיל מלא של קשירת מטרות לכל תרכובת
נריץ את שאילתת הגרף הראשונה שלנו. זו שאילתת מעבר ברמה אחת שעונה על השאלה: אילו תרכובות נקשרות לאילו מטרות, ומה הזיקה שלהן?
שאילתת GQL
מריצים את השאילתה הבאה ב-SQL Editor:
SELECT
compound_name,
dev_stage,
target_name,
gene_name,
target_class,
interaction_type,
ROUND(affinity_nm, 3) AS affinity_nm,
ROUND(ic50_nm, 3) AS ic50_nm,
pchembl_value
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_name AS target_name,
t.gene_name AS gene_name,
t.target_class AS target_class,
b.interaction_type AS interaction_type,
b.affinity_nm AS affinity_nm,
b.ic50_nm AS ic50_nm,
b.pchembl_value AS pchembl_value
)
)
ORDER BY compound_name, interaction_type, affinity_nm;
אלה הפרטים שיופיעו בתוצאות:
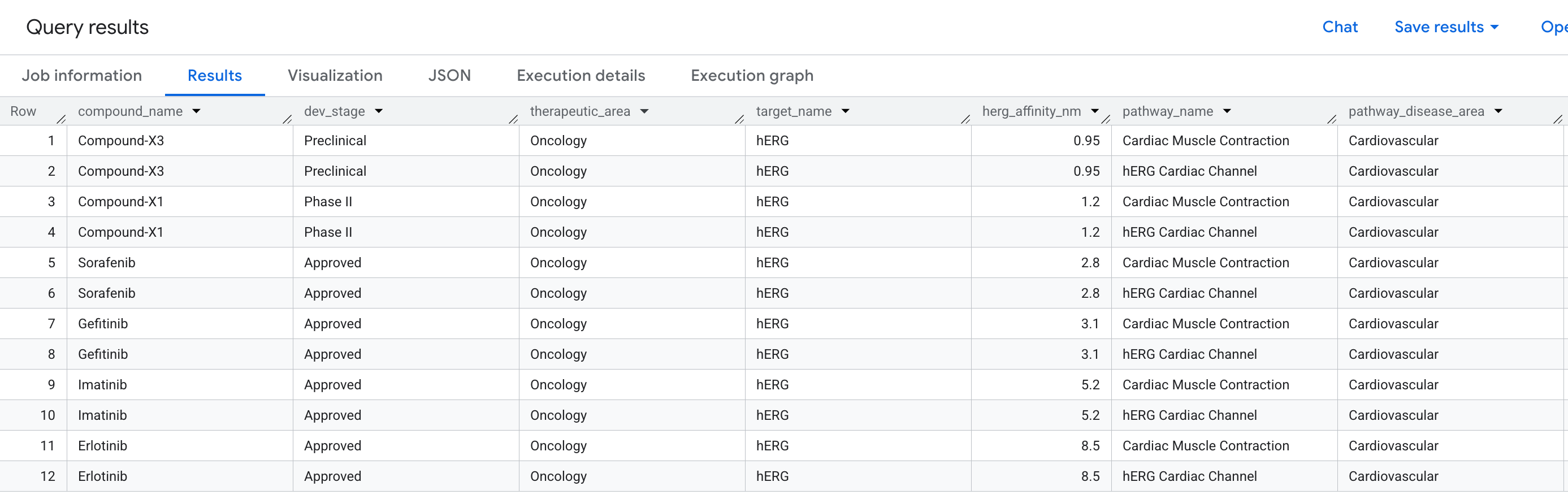
6. שאילתה 2: זיהוי סיכון לבבי
השאלה העסקית
בתהליך גילוי התרופות, אחת הסיבות הנפוצות ביותר לכך שתרכובת מבטיחה נכשלת בניסויים קליניים היא קרדיוטוקסיות – במיוחד, קשירה לא מכוונת לחלבון hERG (גן: KCNH2), תעלת יוני אשלגן שמווסתת את קצב הלב. פגיעה לא ספציפית ב-hERG עלולה לגרום להפרעות קצב קטלניות, והיא אחראית לכמה מקרים של משיכת תרופות מהשוק.
השאלה שאנחנו רוצים לענות עליה היא:
"אילו תרכובות בצינור שלנו כוללות אירוע קשירה לא ספציפי לחלבון hERG – ואילו מסלולים קרדיאליים נמצאים בסיכון בגלל זה?"
זו שאלה עם שני שלבים: אנחנו צריכים לעבור מ-Compound, דרך Target (hERG), אל Pathway – כלומר לקשר בין שלושה סוגי ישויות באמצעות שני קשרים בשאילתה אחת.
כתיבת שאילתת GQL
מריצים את השאילתה הבאה בעורך ה-SQL של BQ:
SELECT
compound_name,
dev_stage,
therapeutic_area,
target_name,
ROUND(affinity_nm, 3) AS herg_affinity_nm,
pathway_name,
disease_area AS pathway_disease_area
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND b.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
c.therapeutic_area AS therapeutic_area,
t.target_name AS target_name,
b.affinity_nm AS affinity_nm,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
ORDER BY herg_affinity_nm;
שימו לב שהמשפט MATCH נראה כמעט כמו משפט רגיל: "Find a Compound that binds to a Target that participates in a Pathway" (חיפוש של תרכובת שנקשרת למטרה שמשתתפת בנתיב) – עם המסננים שמוחלים על כל צומת וקצה לאורך הנתיב.
אלה הנתונים שיופיעו בתוצאות:
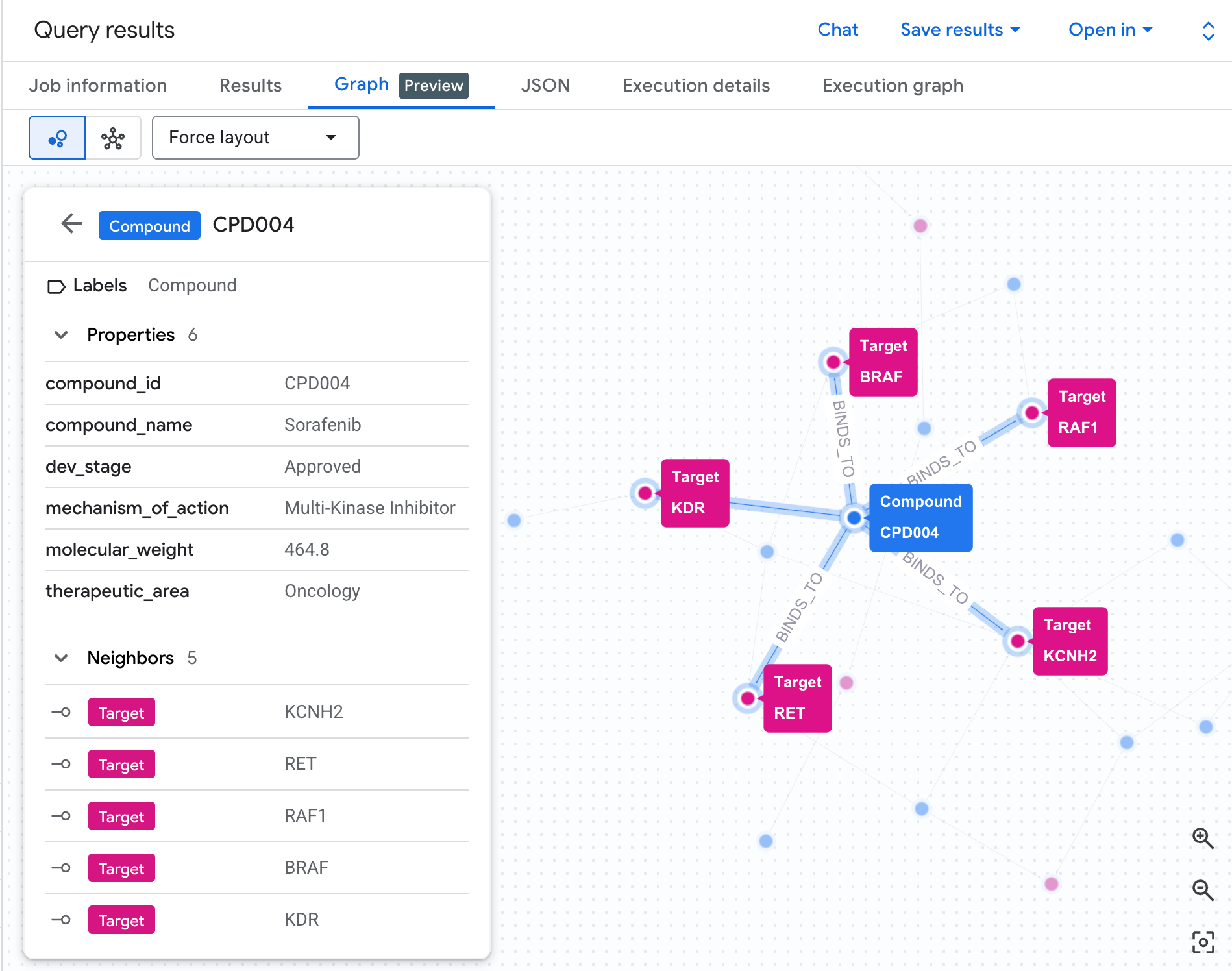
הצגה חזותית של רשת הסיכון כתרשים
הטבלה מציגה את הנתונים, אבל לא את המבנה של הסיכון. האם יש כמה תרכובות שמתכנסות לאותו מסלול? האם יש תרכובת אחת בסיכון גבוה או כמה?
הדמיה של התרשים מאפשרת לראות את זה באופן מיידי. מריצים את התא שלמטה כדי להציג את אותו מעבר של 2 קפיצות כרשת אינטראקטיבית:
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH pt = (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND pw.disease_area = 'Cardiovascular'
RETURN
TO_JSON(pt) AS path
אמור להופיע תרשים כזה:
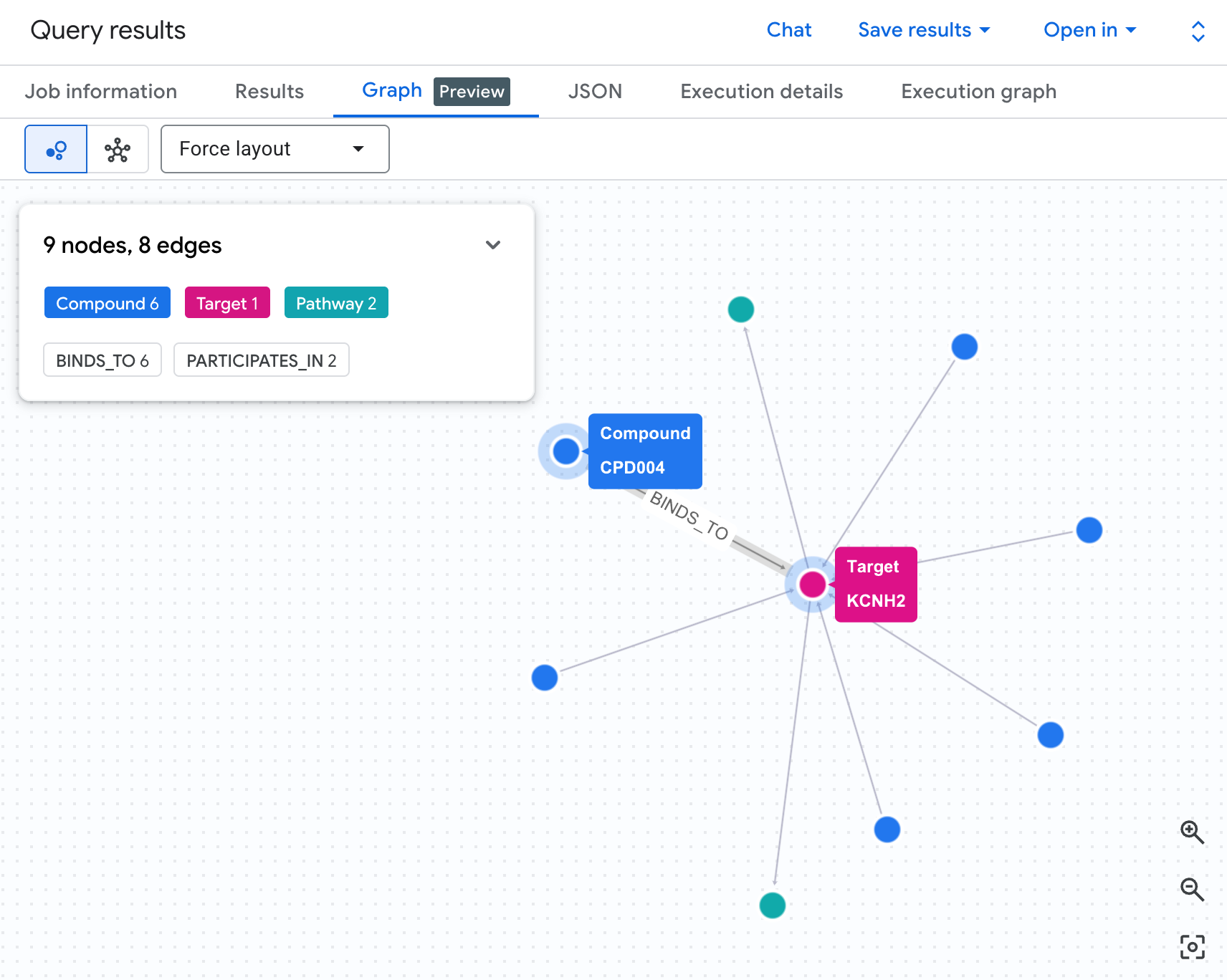
כל נתיב בתרשים מתאר שרשרת שלמה של חבות: תרכובת (צמתים כחולים) נקשרת לחלבון hERG במרכז, שמתחבר לנתיב לבבי אחד או יותר (צמתים ירוקים). מה שהיה רשימה שטוחה של שורות בטבלה הוא עכשיו רשת סיכונים גלויה – תרכובות עם חשיפות למסלולים מרובים בולטות מיד כבעלות עדיפות גבוהה יותר לבדיקת בטיחות.
למה GQL אלגנטית יותר מ-SQL
כדי להריץ את אותה שאילתת 2-hop ב-SQL סטנדרטי, צריך 4 פעולות join מפורשות. אתם משקיעים מאמץ קוגניטיבי בתיאור האופן שבו מאחדים טבלאות, במקום להתמקד בקשר שאתם מחפשים. GQL מאפשר לכם להישאר ממוקדים בשאלה.
SELECT
c.compound_name,
c.dev_stage,
c.therapeutic_area,
t.target_name,
ROUND(i.affinity_nm, 3) AS herg_affinity_nm,
pw.pathway_name,
pw.disease_area AS pathway_disease_area
FROM drug_target_graph.compounds c
JOIN drug_target_graph.interactions i ON c.compound_id = i.compound_id
JOIN drug_target_graph.targets t ON i.target_id = t.target_id
JOIN drug_target_graph.target_pathways tp ON t.target_id = tp.target_id
JOIN drug_target_graph.pathways pw ON tp.pathway_id = pw.pathway_id
WHERE t.gene_name = 'KCNH2'
AND i.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
ORDER BY herg_affinity_nm;
ניתוח מעמיק יותר – זיהוי סיכון של מטבוליטים בכמה שלבים
השאילתה שלמעלה מזהה תרכובות שנקשרות ישירות לחלבון hERG. אבל בתהליכי עבודה אמיתיים של בטיחות תרופות, הסיכון לפעמים מוסתר: תרכובת עשויה לעבור המרה מטבולית בגוף למולקולה משנית (מטבוליט) שנקשרת ל-hERG – סיכון שלא ניתן לזהות בבדיקות קשירה ישירות.
אם גרף הנכס שלכם כלל טבלת צמתים של מטבוליט וקצה METABOLISES_INTO, תוכלו להרחיב את אותו דפוס MATCH לחיפוש של 3 קפיצות:
(Compound)-[METABOLISES_INTO]->(Metabolite)-[BINDS_TO]->
(Target)-[PARTICIPATES_IN]->(Pathway)
מבנה השאילתה של GQL ישתנה בדיוק בצומת אחת ובקצה אחד. ה-SQL המקביל ידרוש שני JOIN נוספים. זהו הדפוס שהופך את מעבר הגרפים ליעיל במיוחד לניתוח של שרשרת בטיחות – מורכבות השאילתה גדלה באופן ליניארי, בעוד התובנה הביולוגית גדלה באופן אקספוננציאלי.
7. שאילתה 3: צמדים מורכבים של מילים עם יעד משותף
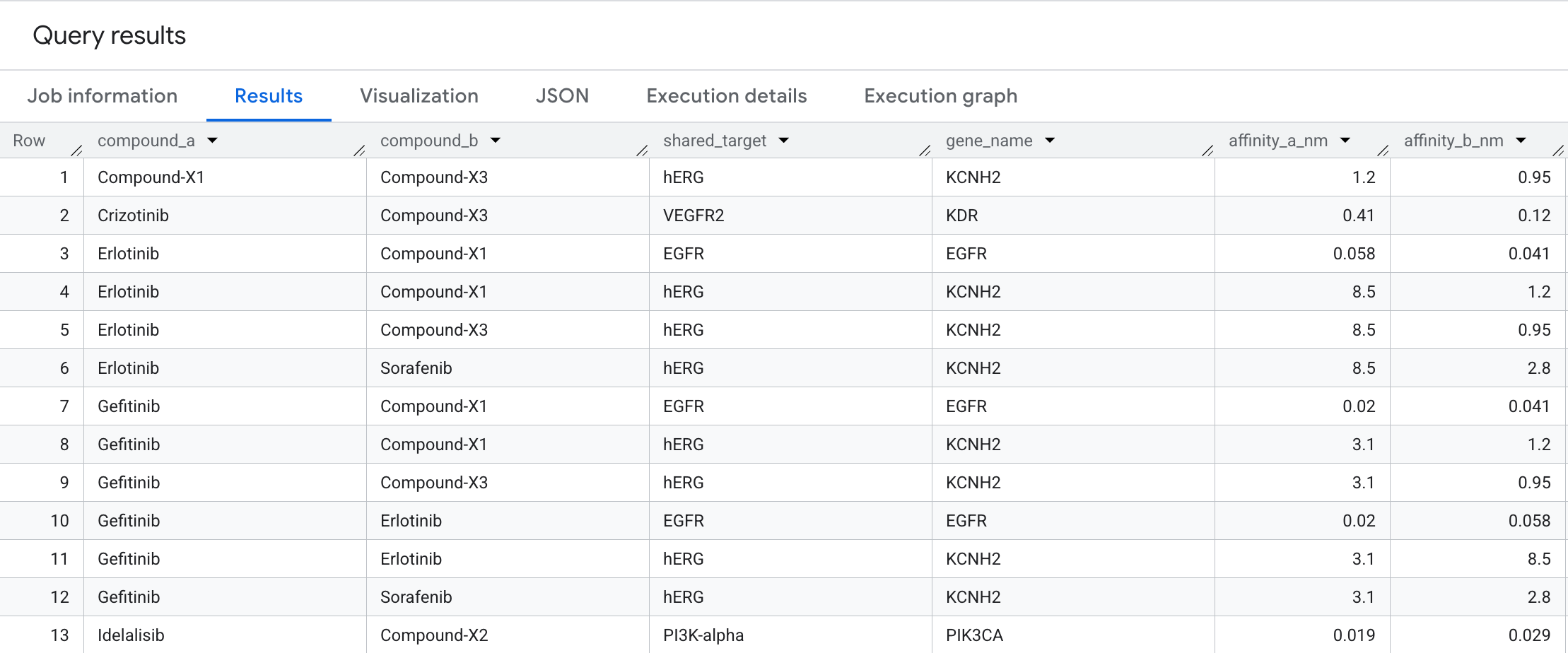
כדי למצוא מועמדים לטיפול משולב, אפשר לזהות מקרים שבהם שתי תרכובות שונות נקשרות לאותו צומת מטרה. אנחנו משתמשים בהתאמה דו-כיוונית כדי לענות על השאלה: אילו תרכובות אונקולוגיות מתכנסות לאותו יעד בדיוק?
מריצים את השאילתה הבאה ב-SQL Editor:
SELECT
compound_a,
compound_b,
shared_target,
gene_name,
ROUND(affinity_a_nm, 3) AS affinity_a_nm,
ROUND(affinity_b_nm, 3) AS affinity_b_nm
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
AND c2.therapeutic_area = 'Oncology'
COLUMNS (
c1.compound_name AS compound_a,
c2.compound_name AS compound_b,
t.target_name AS shared_target,
t.gene_name AS gene_name,
b1.affinity_nm AS affinity_a_nm,
b2.affinity_nm AS affinity_b_nm
)
)
ORDER BY compound_a, compound_b, affinity_a_nm;
אלה הנתונים שיופיעו בתוצאות:
המחשת נתונים באמצעות תרשים
כדי להציג את הגרף ישירות ב-BigQuery, מריצים את הקוד הבא בעורך ה-SQL.
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH p = (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
RETURN
TO_JSON(p) AS path
המעבר הדו-כיווני הזה מאפשר לראות זוגות של תרכובות שמתכנסות לאותה מטרה של חלבון – דפוס שקשה לזהות בטבלה שטוחה של אינטראקציות, אבל קל לראות אותו כגרף. בתהליך של גילוי תרופות, זוגות של תרכובות שפועלות על אותה מטרה הם נקודת ההתחלה לתכנון של טיפול משולב: שתי תרכובות שפועלות על אותו צומת במסלול של סרטן עשויות ליצור אפקט סינרגטי, או לחלופין להצביע על כפילות לא מכוונת בצינור.
8. שאילתה 4: רדיוס ההשפעה של נתיב המחלה
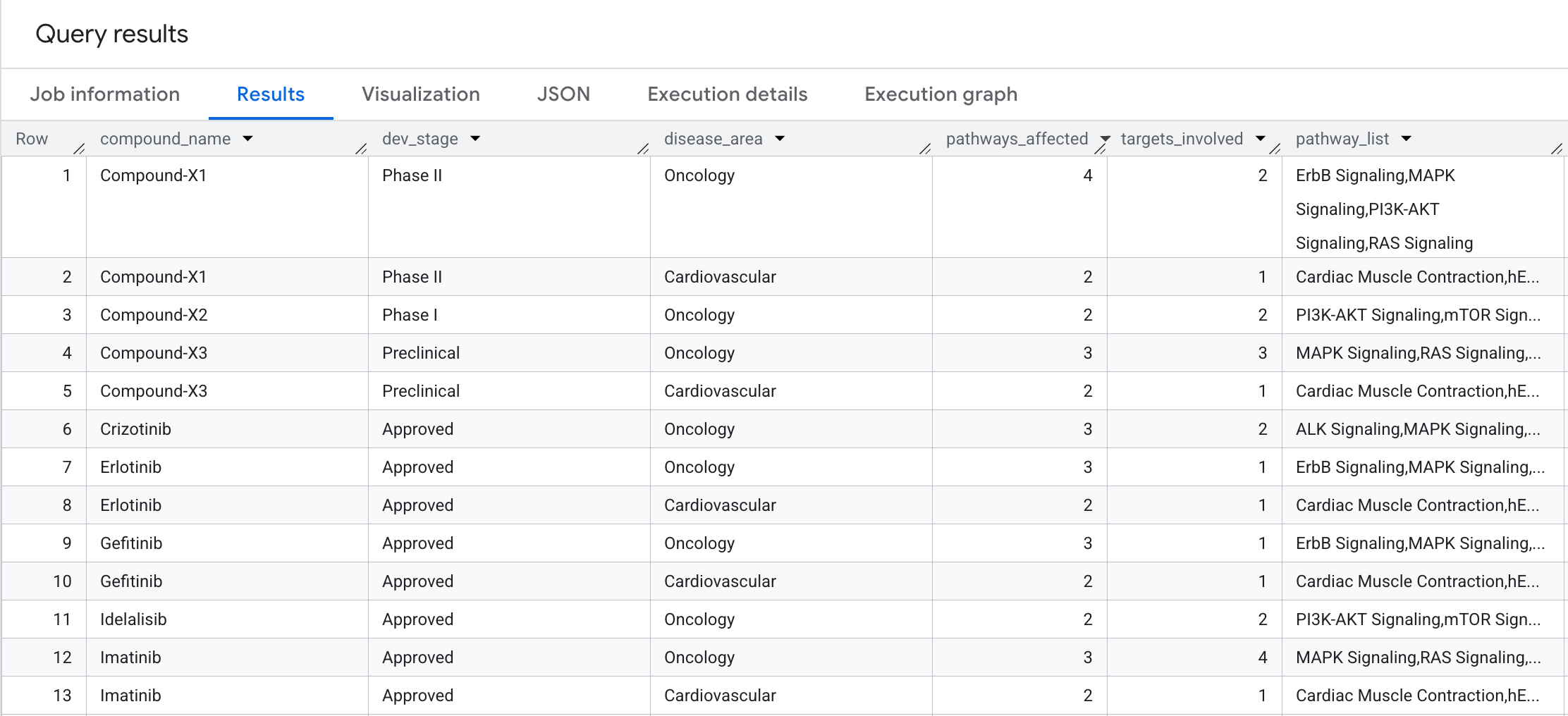
מה היקף ההשפעה הביולוגית של כל תרכובת? בואו נבצע מעבר של 2 קפיצות עם צבירה כדי לענות על השאלה: כמה מסלולים ביולוגיים ומטרות נפרדות מושפעים מכל תרכובת, מקובצים לפי תחום מחלה?
מריצים את השאילתה הבאה ב-SQL Editor:
SELECT
compound_name,
dev_stage,
disease_area,
COUNT(DISTINCT pathway_id) AS pathways_affected,
COUNT(DISTINCT target_id) AS targets_involved,
STRING_AGG(DISTINCT pathway_name ORDER BY pathway_name) AS pathway_list
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_id AS target_id,
pw.pathway_id AS pathway_id,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
GROUP BY compound_name, dev_stage, disease_area
ORDER BY compound_name, pathways_affected DESC;
אלה הפרטים שיופיעו בתוצאות:
9. שאילתה 5: בחירת תרכובת בטוחה
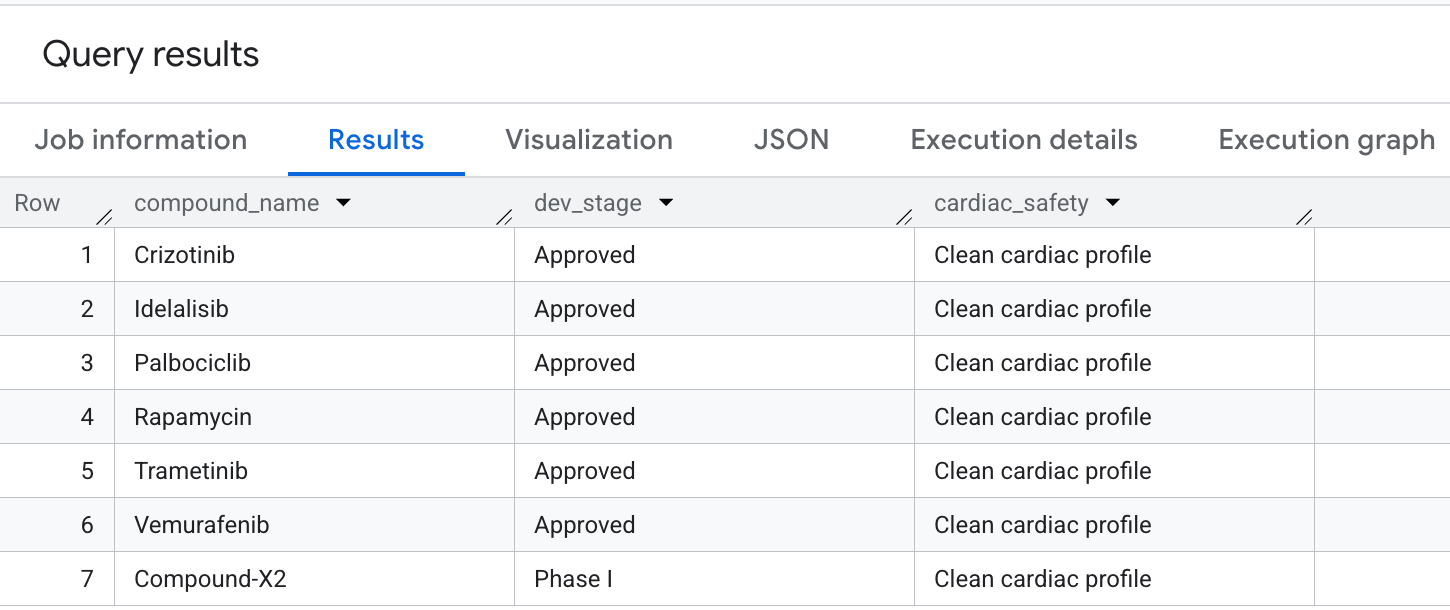
לבסוף, נריץ שאילתה לגבי תרכובות עם כיסוי גבוה בתחום האונקולוגיה, אבל ללא חשיפה ל-hERG (לבבי) מחוץ למטרה. ההתאמה הזו נפוצה בדפוסי בחירה שמתמקדים בבטיחות בצינורות של גילוי תרופות.
מריצים את השאילתה הבאה ב-SQL Editor:
WITH oncology_compounds AS (
SELECT DISTINCT compound_id, compound_name, dev_stage
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE pw.disease_area = 'Oncology'
AND pw.cancer_relevance = 'high'
COLUMNS (
c.compound_id AS compound_id,
c.compound_name AS compound_name,
c.dev_stage AS dev_stage
)
)
),
herg_risk_compounds AS (
SELECT DISTINCT compound_id
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
WHERE t.gene_name = 'KCNH2'
COLUMNS (c.compound_id AS compound_id)
)
)
SELECT
o.compound_name,
o.dev_stage,
'Clean cardiac profile' AS cardiac_safety
FROM oncology_compounds o
LEFT JOIN herg_risk_compounds h ON o.compound_id = h.compound_id
WHERE h.compound_id IS NULL
ORDER BY o.dev_stage, o.compound_name;
זה הפלט שיוצג בתוצאות:
הצלחתם לבצע מעברים מתקדמים בגרף ב-BigQuery כדי לחלץ פרופילים חשובים של בטיחות ויעילות!
10. חלק הבונוס: שיחה עם התרשים
מעכשיו, ניתוח נתוני שיחות ב-BigQuery תומך בגרף כמקור ידע. כך תוכלו לשוחח עם הגרף שיצרתם בשפה טבעית.
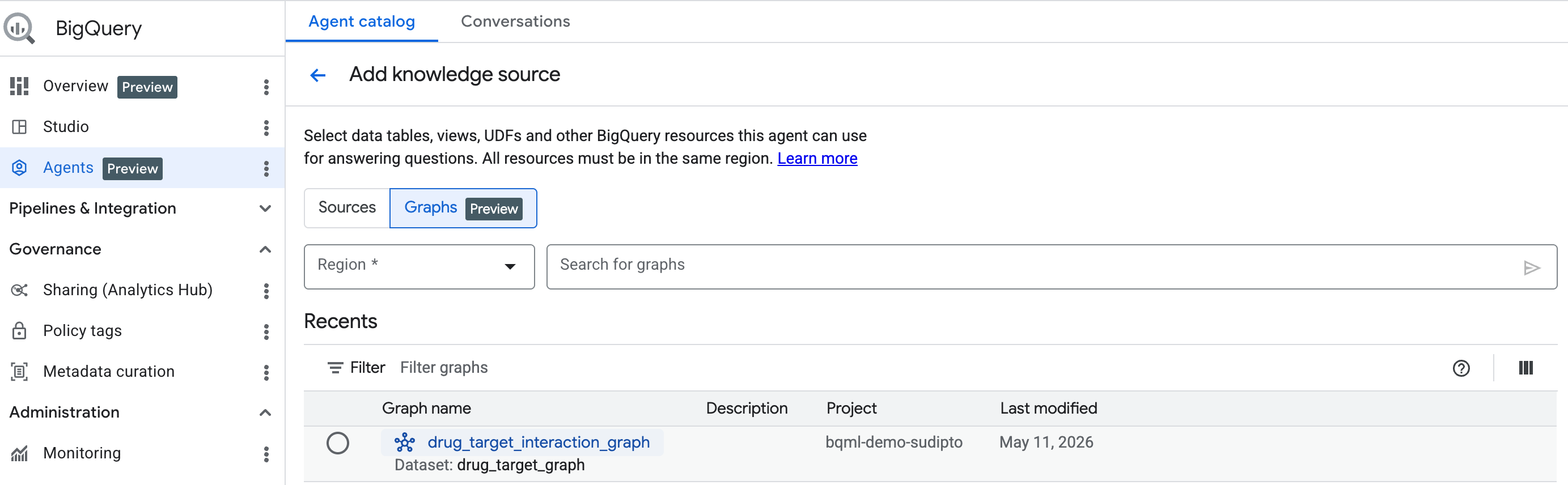
תחילת העבודה: הוספת תרשים כמקור מידע
כדי להתחיל, יוצרים צ'אט בוט לפי השלבים שמפורטים כאן. בסרגל החיפוש, בוחרים את הגרף שיצרתם.
שימוש ב-BigQuery Conversational Analytics כדי לשוחח עם הגרף
אחרי שמוסיפים את מקור הידע כגרף, משלימים את שאר השלבים בהגדרת הסוכן לניתוח נתונים בשיחה.
אחרי זה תוכלו להתחיל לשוחח עם הגרף בשפה טבעית.
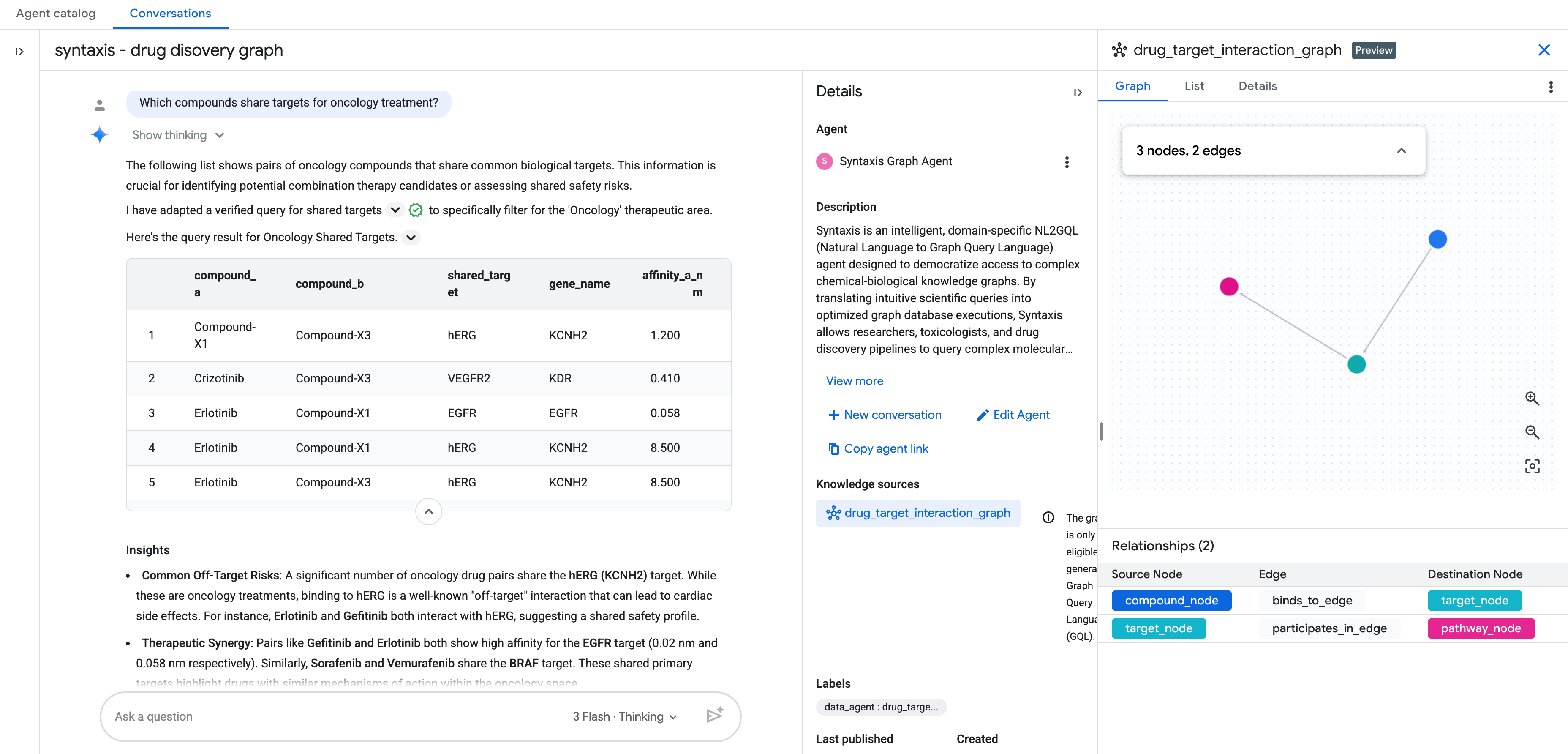
שאלות נוספות
- מהם כל יעדי התרכובות שנמצאות כרגע בניסויים בשלב 2?
- אילו יעדים משותפים בין תרכובות קרדיווסקולריות ואונקולוגיות?
11. הסרת המשאבים
כדי להימנע מחיובים שוטפים בחשבון Google Cloud, מוחקים את המשאבים שנוצרו במהלך ה-codelab הזה.
מריצים את השאילתה הבאה כדי להשליך את הסכימה ואת כל הטבלאות באופן מדורג:
DROP SCHEMA IF EXISTS drug_target_graph CASCADE;
12. מזל טוב
מעולה! יצרתם מודל וניתחתם בהצלחה רשת של אינטראקציות בין תרופות למטרות באמצעות BigQuery Graph.
מה למדתם
- איך ליצור מודל של קשרים בין ישויות (תרכובות, יעדים, מסלולים) כגרף מאפיינים.
- איך מגדירים את הסכימה ויוצרים גרף נכסים ב-BigQuery.
- איך לכתוב מעברים מורכבים בגרף באמצעות GQL ולהשוות אותם ל-SQL מסורתי.
- איך אפשר להשתמש ב-
GRAPH_TABLE, ב-MATCHובהתאמה דו-כיוונית כדי לפתור בעיות בדומיין של מדעי החיים.