
1. परिचय
इस कोडलैब में, दवा और टारगेट के बीच इंटरैक्शन नेटवर्क को मॉडल बनाने और उसका विश्लेषण करने के लिए, BigQuery Graph का इस्तेमाल करने का तरीका बताया गया है. इसमें, ग्राफ़ क्वेरी (जीक्यूएल) की मदद से यह पता लगाया जाता है कि दवाएं, बायोलॉजिकल टारगेट के साथ कैसे इंटरैक्ट करती हैं. साथ ही, संभावित साइड इफ़ेक्ट (जैसे, दिल से जुड़ी समस्याएं) की पहचान की जाती है और संभावित कॉम्बिनेशन थेरेपी का पता लगाया जाता है.
🧬 इस्तेमाल का उदाहरण — ड्रग-टारगेट इंटरैक्शन नेटवर्क
कारोबार से जुड़ा सवाल: किसी कंपाउंड का असर कितने टारगेट पर होता है — यह किन टारगेट से जुड़ता है, किन बायोलॉजिकल पाथवे पर असर डालता है, और किन बीमारियों से जुड़ा है?
टेबल:
टेबल | ब्यौरा |
| दवा के मॉलिक्यूल, उनके काम करने का तरीका, और डेवलपमेंट स्टेज |
| जीन के नाम और UniProt आईडी के साथ प्रोटीन टारगेट |
| कंपाउंड-टारगेट बाइंडिंग अफ़िनिटी (प्राइमरी टारगेट + ऑफ़-टारगेट) |
| बीमारी से जुड़े जैविक रास्ते |
| जंक्शन टेबल, जो टारगेट को उन पाथवे से लिंक करती है जिनमें वे शामिल होते हैं |
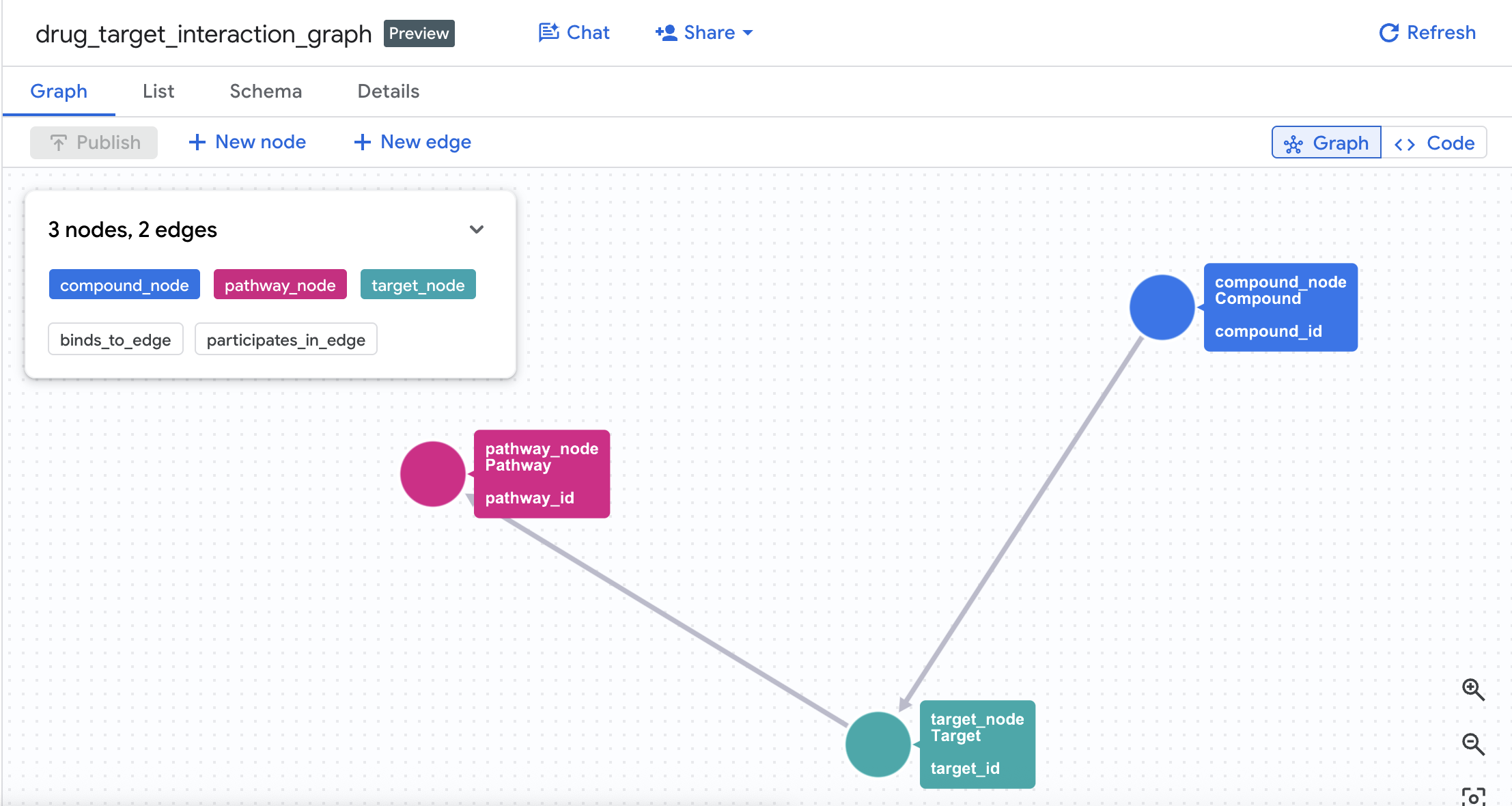
प्रॉपर्टी ग्राफ़ मॉडल:
(Compound)-[BINDS_TO {affinity_nm, ic50_nm, interaction_type}]->(Target)
(Target)-[PARTICIPATES_IN {role, importance_score}]->(Pathway)
🔍 डेमो क्वेरी
क्वेरी | यह क्या दिखाती है |
Q1: टारगेट बाइंडिंग प्रोफ़ाइल | एक हॉप ट्रैवर्सल — कंपाउंड से सभी प्राइमरी और ऑफ़-टारगेट तक |
Q2: hERG कार्डियक जोखिम का पता लगाना | दो हॉप ट्रैवर्सल — कंपाउंड → hERG टारगेट → कार्डियक पाथवे |
Q3: Shared-target compound pairs | दोनों ओर से मैच होना — दो कंपाउंड एक ही टारगेट नोड पर कन्वर्ज हो रहे हैं |
चौथी तिमाही: बीमारी के फैलने की संभावना | दो हॉप वाला एग्रीगेशन — हर कंपाउंड के हिसाब से, पूरे पाथवे और बीमारी के क्षेत्र को कवर करना |
Q5: Safe compound selection | ऐसे कंपाउंड जिनमें ऑन्कोलॉजी की ज़्यादा कवरेज हो, लेकिन hERG कार्डियक लायबिलिटी न हो |
आपको क्या करना होगा
- दवाओं के इंटरैक्शन नेटवर्क के लिए, BigQuery डेटासेट और स्कीमा बनाना
- सैंपल डेटा लोड करें (कंपाउंड, टारगेट, इंटरैक्शन, पाथवे, टारगेट पाथवे)
- इन इकाइयों को कनेक्ट करके, BigQuery में प्रॉपर्टी ग्राफ़ बनाएं
- ग्राफ़ ट्रैवर्सल (
GRAPH_TABLEऔरMATCH) का इस्तेमाल करके, कंपाउंड इंटरैक्शन, बायोलॉजिकल पाथवे, और रोग के असर को समझने के लिए ग्राफ़ को क्वेरी करें - ग्राफ़ सिंटैक्स को समझने के लिए, जीक्यूएल और स्टैंडर्ड एसक्यूएल की तुलना करें. इससे आपको यह समझने में मदद मिलेगी कि ग्राफ़ सिंटैक्स कितना आसान है और इसमें कितनी जानकारी शामिल की जा सकती है
आपको किन चीज़ों की ज़रूरत होगी
- कोई वेब ब्राउज़र, जैसे कि Chrome
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट
यह कोडलैब, सभी लेवल के डेवलपर के लिए है. इसमें शुरुआती डेवलपर भी शामिल हैं.
2. शुरू करने से पहले
Google Cloud प्रोजेक्ट बनाना
- Google Cloud Console में, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो.
Cloud Shell शुरू करना
- Google Cloud कंसोल में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.
- पुष्टि करें:
gcloud auth list
- अपने प्रोजेक्ट की पुष्टि करें:
gcloud config get project
- अगर ज़रूरी हो, तो इसे सेट करें:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
एपीआई चालू करें
ज़रूरी BigQuery API को चालू करने के लिए, यह निर्देश चलाएं:
gcloud services enable bigquery.googleapis.com
3. स्कीमा तय करना और डेटा लोड करना
सबसे पहले, आपको एक डेटासेट बनाना होगा. इसमें ग्राफ़ से जुड़ी टेबल सेव की जाती हैं. साथ ही, इसमें सैंपल डेटा डाला जाता है.
- Google Cloud Console में BigQuery Studio पर जाएं.
- नई क्वेरी टैब खोलने के लिए, SQL एडिटर पर क्लिक करें.
drug_target_graphडेटासेट बनाने के लिए, यह स्टेटमेंट चलाएं:
CREATE SCHEMA IF NOT EXISTS drug_target_graph
OPTIONS (location = 'US');
अब BigQuery Studio में, यहां दी गई DDL क्वेरी चलाकर पांच सोर्स टेबल बनाएं.
1. compounds टेबल बनाएं
इसमें दवा के मॉलिक्यूल, उनके काम करने का तरीका, डेवलपमेंट स्टेज, और थेरेप्यूटिक एरिया शामिल होता है.
CREATE OR REPLACE TABLE drug_target_graph.compounds AS
SELECT 'CPD001' AS compound_id, 'Imatinib' AS compound_name, 'Kinase Inhibitor' AS mechanism_of_action, 'Approved' AS dev_stage, 'Oncology' AS therapeutic_area, 479.6 AS molecular_weight UNION ALL
SELECT 'CPD002', 'Gefitinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 446.9 UNION ALL
SELECT 'CPD003', 'Erlotinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 393.4 UNION ALL
SELECT 'CPD004', 'Sorafenib', 'Multi-Kinase Inhibitor', 'Approved', 'Oncology', 464.8 UNION ALL
SELECT 'CPD005', 'Vemurafenib', 'BRAF Inhibitor', 'Approved', 'Oncology', 489.9 UNION ALL
SELECT 'CPD006', 'Crizotinib', 'ALK Inhibitor', 'Approved', 'Oncology', 450.3 UNION ALL
SELECT 'CPD007', 'Idelalisib', 'PI3K Inhibitor', 'Approved', 'Oncology', 415.4 UNION ALL
SELECT 'CPD008', 'Trametinib', 'MEK Inhibitor', 'Approved', 'Oncology', 615.4 UNION ALL
SELECT 'CPD009', 'Palbociclib', 'CDK Inhibitor', 'Approved', 'Oncology', 447.5 UNION ALL
SELECT 'CPD010', 'Compound-X1', 'Kinase Inhibitor', 'Phase II', 'Oncology', 412.3 UNION ALL
SELECT 'CPD011', 'Compound-X2', 'PI3K Inhibitor', 'Phase I', 'Oncology', 398.7 UNION ALL
SELECT 'CPD012', 'Saquinavir', 'Protease Inhibitor', 'Approved', 'Infectious Disease', 670.8 UNION ALL
SELECT 'CPD013', 'Metformin', 'AMPK Activator', 'Approved', 'Metabolic', 165.6 UNION ALL
SELECT 'CPD014', 'Rapamycin', 'mTOR Inhibitor', 'Approved', 'Immunology', 914.2 UNION ALL
SELECT 'CPD015', 'Compound-X3', 'Multi-Kinase Inhibitor', 'Preclinical', 'Oncology', 502.1;
2. targets टेबल बनाएं
इसमें प्रोटीन टारगेट, जीन के नाम, UniProt आईडी, और टारगेट क्लास शामिल होती हैं.
CREATE OR REPLACE TABLE drug_target_graph.targets AS
SELECT 'TGT001' AS target_id, 'BCR-ABL1' AS target_name, 'ABL1' AS gene_name, 'P00519' AS uniprot_id, 'Kinase' AS target_class, TRUE AS is_oncogene UNION ALL
SELECT 'TGT002', 'EGFR', 'EGFR', 'P00533', 'Kinase', TRUE UNION ALL
SELECT 'TGT003', 'VEGFR2', 'KDR', 'P35968', 'Kinase', FALSE UNION ALL
SELECT 'TGT004', 'BRAF', 'BRAF', 'P15056', 'Kinase', TRUE UNION ALL
SELECT 'TGT005', 'ALK', 'ALK', 'Q9UM73', 'Kinase', TRUE UNION ALL
SELECT 'TGT006', 'PI3K-alpha','PIK3CA', 'P42336', 'Lipid Kinase', TRUE UNION ALL
SELECT 'TGT007', 'MEK1', 'MAP2K1', 'Q02750', 'Kinase', FALSE UNION ALL
SELECT 'TGT008', 'CDK4', 'CDK4', 'P11802', 'Kinase', FALSE UNION ALL
SELECT 'TGT009', 'CDK6', 'CDK6', 'P30279', 'Kinase', FALSE UNION ALL
SELECT 'TGT010', 'mTOR', 'MTOR', 'P42345', 'Kinase', FALSE UNION ALL
SELECT 'TGT011', 'PDGFR-beta','PDGFRB', 'P09619', 'Kinase', FALSE UNION ALL
SELECT 'TGT012', 'c-KIT', 'KIT', 'P10721', 'Kinase', TRUE UNION ALL
SELECT 'TGT013', 'hERG', 'KCNH2', 'Q12809', 'Ion Channel', FALSE UNION ALL
SELECT 'TGT014', 'AMPK', 'PRKAA1', 'Q13131', 'Kinase', FALSE UNION ALL
SELECT 'TGT015', 'RAF1', 'RAF1', 'P04049', 'Kinase', FALSE UNION ALL
SELECT 'TGT016', 'RET', 'RET', 'P07949', 'Kinase', TRUE UNION ALL
SELECT 'TGT017', 'FLT3', 'FLT3', 'P36888', 'Kinase', TRUE UNION ALL
SELECT 'TGT018', 'AKT1', 'AKT1', 'P31749', 'Kinase', FALSE UNION ALL
SELECT 'TGT019', 'ERK2', 'MAPK1', 'P28482', 'Kinase', FALSE UNION ALL
SELECT 'TGT020', 'HIV-Protease','HIV1-PR','Q72547', 'Protease', FALSE;
3. interactions टेबल बनाएं
इसमें कंपाउंड-टारगेट बाइंडिंग अफ़िनिटी डेटा होता है. जैसे, प्राइमरी टारगेट बनाम ऑफ़-टारगेट.
CREATE OR REPLACE TABLE drug_target_graph.interactions AS
SELECT 'INT001' AS interaction_id, 'CPD001' AS compound_id, 'TGT001' AS target_id, 0.025 AS affinity_nm, 0.038 AS ic50_nm, 'primary' AS interaction_type, 9.8 AS pchembl_value UNION ALL
SELECT 'INT002', 'CPD001', 'TGT011', 0.1, 0.15, 'primary', 8.8 UNION ALL
SELECT 'INT003', 'CPD001', 'TGT012', 0.068, 0.1, 'primary', 9.2 UNION ALL
SELECT 'INT004', 'CPD001', 'TGT016', 0.5, 0.8, 'off-target', 7.4 UNION ALL
SELECT 'INT005', 'CPD001', 'TGT013', 5.2, 8.1, 'off-target', 6.1 UNION ALL
SELECT 'INT006', 'CPD002', 'TGT002', 0.02, 0.033, 'primary', 9.7 UNION ALL
SELECT 'INT007', 'CPD002', 'TGT013', 3.1, 4.8, 'off-target', 6.5 UNION ALL
SELECT 'INT008', 'CPD003', 'TGT002', 0.058, 0.079, 'primary', 9.2 UNION ALL
SELECT 'INT009', 'CPD003', 'TGT013', 8.5, 12.0, 'off-target', 5.9 UNION ALL
SELECT 'INT010', 'CPD004', 'TGT003', 0.09, 0.12, 'primary', 9.1 UNION ALL
SELECT 'INT011', 'CPD004', 'TGT004', 0.038, 0.055, 'primary', 8.9 UNION ALL
SELECT 'INT012', 'CPD004', 'TGT015', 0.22, 0.31, 'primary', 8.5 UNION ALL
SELECT 'INT013', 'CPD004', 'TGT016', 0.58, 0.75, 'primary', 8.1 UNION ALL
SELECT 'INT014', 'CPD004', 'TGT017', 0.33, 0.48, 'primary', 8.4 UNION ALL
SELECT 'INT015', 'CPD004', 'TGT013', 2.8, 4.1, 'off-target', 6.6 UNION ALL
SELECT 'INT016', 'CPD005', 'TGT004', 0.031, 0.044, 'primary', 9.5 UNION ALL
SELECT 'INT017', 'CPD005', 'TGT015', 0.48, 0.65, 'off-target', 7.3 UNION ALL
SELECT 'INT018', 'CPD006', 'TGT005', 0.02, 0.028, 'primary', 9.8 UNION ALL
SELECT 'INT019', 'CPD006', 'TGT003', 0.41, 0.59, 'off-target', 7.4 UNION ALL
SELECT 'INT020', 'CPD007', 'TGT006', 0.019, 0.025, 'primary', 9.8 UNION ALL
SELECT 'INT021', 'CPD007', 'TGT018', 0.55, 0.78, 'off-target', 7.2 UNION ALL
SELECT 'INT022', 'CPD008', 'TGT007', 0.0092, 0.014, 'primary', 10.1 UNION ALL
SELECT 'INT023', 'CPD008', 'TGT019', 0.38, 0.51, 'off-target', 7.4 UNION ALL
SELECT 'INT024', 'CPD009', 'TGT008', 0.011, 0.017, 'primary', 9.9 UNION ALL
SELECT 'INT025', 'CPD009', 'TGT009', 0.015, 0.022, 'primary', 9.8 UNION ALL
SELECT 'INT026', 'CPD010', 'TGT002', 0.041, 0.058, 'primary', 9.4 UNION ALL
SELECT 'INT027', 'CPD010', 'TGT001', 0.38, 0.52, 'off-target', 7.3 UNION ALL
SELECT 'INT028', 'CPD010', 'TGT013', 1.2, 1.8, 'off-target', 7.1 UNION ALL
SELECT 'INT029', 'CPD011', 'TGT006', 0.029, 0.041, 'primary', 9.5 UNION ALL
SELECT 'INT030', 'CPD011', 'TGT010', 0.71, 0.95, 'off-target', 7.0 UNION ALL
SELECT 'INT031', 'CPD012', 'TGT020', 0.39, 0.55, 'primary', 7.3 UNION ALL
SELECT 'INT032', 'CPD013', 'TGT014', 12.0, 18.5, 'primary', 5.7 UNION ALL
SELECT 'INT033', 'CPD014', 'TGT010', 0.0018, 0.0025, 'primary', 11.8 UNION ALL
SELECT 'INT034', 'CPD015', 'TGT004', 0.055, 0.078, 'primary', 9.2 UNION ALL
SELECT 'INT035', 'CPD015', 'TGT003', 0.12, 0.17, 'primary', 8.9 UNION ALL
SELECT 'INT036', 'CPD015', 'TGT016', 0.29, 0.41, 'primary', 8.5 UNION ALL
SELECT 'INT037', 'CPD015', 'TGT013', 0.95, 1.35, 'off-target', 7.2;
4. pathways टेबल बनाएं
इसमें बायोलॉजिकल पाथवे, उनसे जुड़ी बीमारियों के क्षेत्र, और कैंसर से जुड़ी जानकारी होती है.
CREATE OR REPLACE TABLE drug_target_graph.pathways AS
SELECT 'PWY001' AS pathway_id, 'MAPK Signaling' AS pathway_name, 'hsa04010' AS kegg_id, 'Cell Proliferation' AS biological_process, 'Oncology' AS disease_area, 'high' AS cancer_relevance UNION ALL
SELECT 'PWY002', 'PI3K-AKT Signaling', 'hsa04151', 'Cell Survival', 'Oncology', 'high' UNION ALL
SELECT 'PWY003', 'VEGF Signaling', 'hsa04370', 'Angiogenesis', 'Oncology', 'high' UNION ALL
SELECT 'PWY004', 'ErbB Signaling', 'hsa04012', 'Cell Growth', 'Oncology', 'high' UNION ALL
SELECT 'PWY005', 'mTOR Signaling', 'hsa04150', 'Cell Growth', 'Oncology', 'medium' UNION ALL
SELECT 'PWY006', 'Cell Cycle', 'hsa04110', 'Cell Division', 'Oncology', 'high' UNION ALL
SELECT 'PWY007', 'Cardiac Muscle Contraction', 'hsa04260', 'Cardiac Function', 'Cardiovascular', 'low' UNION ALL
SELECT 'PWY008', 'hERG Cardiac Channel', 'hsa04022', 'Cardiac Repolarisation','Cardiovascular', 'low' UNION ALL
SELECT 'PWY009', 'AMPK Signaling', 'hsa04152', 'Energy Metabolism', 'Metabolic', 'low' UNION ALL
SELECT 'PWY010', 'ALK Signaling', 'hsa04915', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY011', 'RAS Signaling', 'hsa04014', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY012', 'HIV Replication', 'hsa05170', 'Viral Replication', 'Infectious Disease', 'low';
5. target_pathways टेबल बनाएं
टारगेट को उन बायोलॉजिकल पाथवे से जोड़ने वाली जंक्शन टेबल जिनमें वे हिस्सा लेते हैं.
CREATE OR REPLACE TABLE drug_target_graph.target_pathways AS
SELECT 'TP001' AS tp_id, 'TGT001' AS target_id, 'PWY001' AS pathway_id, 'activator' AS role, 0.95 AS importance_score UNION ALL
SELECT 'TP002', 'TGT001', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP003', 'TGT002', 'PWY004', 'activator', 0.98 UNION ALL
SELECT 'TP004', 'TGT002', 'PWY001', 'activator', 0.82 UNION ALL
SELECT 'TP005', 'TGT002', 'PWY002', 'activator', 0.75 UNION ALL
SELECT 'TP006', 'TGT003', 'PWY003', 'activator', 0.96 UNION ALL
SELECT 'TP007', 'TGT003', 'PWY001', 'activator', 0.71 UNION ALL
SELECT 'TP008', 'TGT004', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP009', 'TGT004', 'PWY011', 'activator', 0.89 UNION ALL
SELECT 'TP010', 'TGT005', 'PWY010', 'activator', 0.99 UNION ALL
SELECT 'TP011', 'TGT005', 'PWY001', 'activator', 0.78 UNION ALL
SELECT 'TP012', 'TGT006', 'PWY002', 'activator', 0.98 UNION ALL
SELECT 'TP013', 'TGT006', 'PWY005', 'activator', 0.85 UNION ALL
SELECT 'TP014', 'TGT007', 'PWY001', 'activator', 0.94 UNION ALL
SELECT 'TP015', 'TGT007', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP016', 'TGT008', 'PWY006', 'activator', 0.95 UNION ALL
SELECT 'TP017', 'TGT009', 'PWY006', 'activator', 0.93 UNION ALL
SELECT 'TP018', 'TGT010', 'PWY005', 'activator', 0.99 UNION ALL
SELECT 'TP019', 'TGT010', 'PWY002', 'activator', 0.91 UNION ALL
SELECT 'TP020', 'TGT011', 'PWY003', 'activator', 0.87 UNION ALL
SELECT 'TP021', 'TGT011', 'PWY001', 'activator', 0.72 UNION ALL
SELECT 'TP022', 'TGT012', 'PWY001', 'activator', 0.83 UNION ALL
SELECT 'TP023', 'TGT012', 'PWY011', 'activator', 0.79 UNION ALL
SELECT 'TP024', 'TGT013', 'PWY008', 'substrate', 0.99 UNION ALL
SELECT 'TP025', 'TGT013', 'PWY007', 'substrate', 0.95 UNION ALL
SELECT 'TP026', 'TGT014', 'PWY009', 'activator', 0.97 UNION ALL
SELECT 'TP027', 'TGT015', 'PWY001', 'activator', 0.91 UNION ALL
SELECT 'TP028', 'TGT015', 'PWY011', 'activator', 0.86 UNION ALL
SELECT 'TP029', 'TGT016', 'PWY001', 'activator', 0.84 UNION ALL
SELECT 'TP030', 'TGT016', 'PWY003', 'activator', 0.77 UNION ALL
SELECT 'TP031', 'TGT017', 'PWY001', 'activator', 0.88 UNION ALL
SELECT 'TP032', 'TGT017', 'PWY011', 'activator', 0.82 UNION ALL
SELECT 'TP033', 'TGT018', 'PWY002', 'activator', 0.96 UNION ALL
SELECT 'TP034', 'TGT018', 'PWY005', 'activator', 0.88 UNION ALL
SELECT 'TP035', 'TGT019', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP036', 'TGT019', 'PWY011', 'activator', 0.91 UNION ALL
SELECT 'TP037', 'TGT020', 'PWY012', 'substrate', 0.99;
4. प्रॉपर्टी ग्राफ़ बनाना
टेबल बन जाने के बाद, अब प्रॉपर्टी ग्राफ़ बनाया जा सकता है. यह नोड (कंपाउंड, टारगेट, पाथवे) को एज टेबल (Interactions और Target Pathways) का इस्तेमाल करके लिंक करता है.
BigQuery Studio के SQL एडिटर में यह स्टेटमेंट चलाएं:
CREATE OR REPLACE PROPERTY GRAPH drug_target_graph.drug_target_interaction_graph
NODE TABLES (
drug_target_graph.compounds
AS compound_node
KEY (compound_id)
LABEL Compound
PROPERTIES (compound_id, compound_name, mechanism_of_action, dev_stage, therapeutic_area, molecular_weight),
drug_target_graph.targets
AS target_node
KEY (target_id)
LABEL Target
PROPERTIES (target_id, target_name, gene_name, uniprot_id, target_class, is_oncogene),
drug_target_graph.pathways
AS pathway_node
KEY (pathway_id)
LABEL Pathway
PROPERTIES (pathway_id, pathway_name, kegg_id, biological_process, disease_area, cancer_relevance)
)
EDGE TABLES (
drug_target_graph.interactions
AS binds_to_edge
KEY (interaction_id)
SOURCE KEY (compound_id) REFERENCES compound_node (compound_id)
DESTINATION KEY (target_id) REFERENCES target_node (target_id)
LABEL BINDS_TO
PROPERTIES (interaction_id, affinity_nm, ic50_nm, interaction_type, pchembl_value),
drug_target_graph.target_pathways
AS participates_in_edge
KEY (tp_id)
SOURCE KEY (target_id) REFERENCES target_node (target_id)
DESTINATION KEY (pathway_id) REFERENCES pathway_node (pathway_id)
LABEL PARTICIPATES_IN
PROPERTIES (tp_id, role, importance_score)
);
इससे आपके डेटासेट में drug_target_interaction_graph नाम का ग्राफ़ बन जाता है.
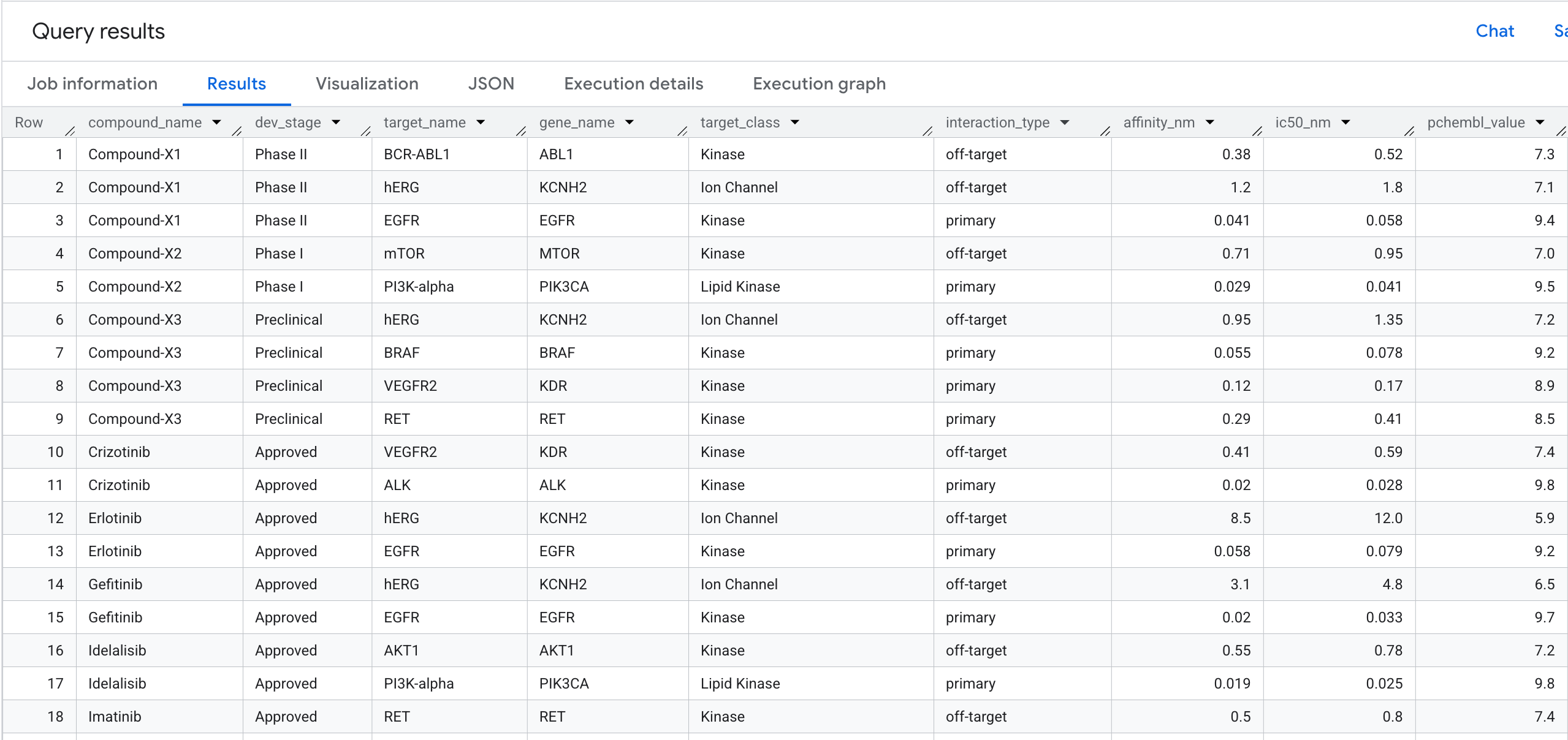
5. क्वेरी 1: हर कंपाउंड के लिए, टारगेट बाइंडिंग प्रोफ़ाइल की पूरी जानकारी
आइए, अपनी पहली ग्राफ़ क्वेरी चलाएं. यह 1-हॉप ट्रैवर्सल है. इससे इस सवाल का जवाब मिलता है: कौनसे कंपाउंड, किन टारगेट से जुड़ते हैं और उनकी अफ़िनिटी क्या है?
GQL क्वेरी
SQL एडिटर में यह क्वेरी चलाएं:
SELECT
compound_name,
dev_stage,
target_name,
gene_name,
target_class,
interaction_type,
ROUND(affinity_nm, 3) AS affinity_nm,
ROUND(ic50_nm, 3) AS ic50_nm,
pchembl_value
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_name AS target_name,
t.gene_name AS gene_name,
t.target_class AS target_class,
b.interaction_type AS interaction_type,
b.affinity_nm AS affinity_nm,
b.ic50_nm AS ic50_nm,
b.pchembl_value AS pchembl_value
)
)
ORDER BY compound_name, interaction_type, affinity_nm;
आपको नतीजों में यह जानकारी दिखेगी:
6. क्वेरी 2: दिल की बीमारी के जोखिम का पता लगाना
कारोबार से जुड़ा सवाल
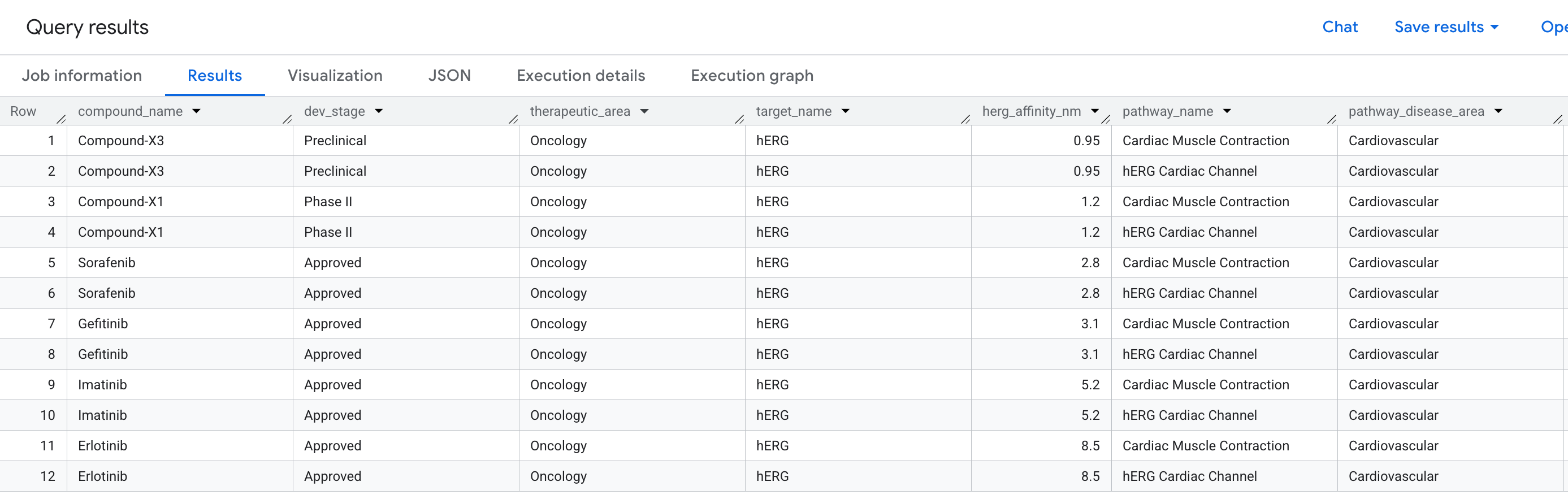
दवा की खोज में, क्लिनिकल ट्रायल के दौरान किसी कंपाउंड के फ़ेल होने की सबसे आम वजहों में से एक कार्डियोटॉक्सिसिटी है. खास तौर पर, hERG प्रोटीन (जीन: KCNH2) से अनचाहे तरीके से जुड़ना. यह पोटैशियम आयन चैनल है, जो दिल की धड़कन को कंट्रोल करता है. hERG पर ऑफ़-टारगेट हिट की वजह से, जानलेवा अतालता हो सकती है. साथ ही, इसकी वजह से कई दवाएं वापस ली गई हैं.
हमें इस सवाल का जवाब देना है:
"हमारी पाइपलाइन में मौजूद किन कंपाउंड में hERG प्रोटीन पर ऑफ़-टारगेट बाइंडिंग इवेंट होता है और इससे दिल की कौनसी समस्याएं हो सकती हैं?"
यह दो चरणों वाला सवाल है: हमें एक क्वेरी में दो संबंधों के ज़रिए तीन तरह की इकाइयों को कनेक्ट करने के लिए, कंपाउंड से टारगेट (hERG) और फिर पाथवे तक जाना होगा.
GQL क्वेरी लिखना
BQ SQL एडिटर में यह क्वेरी चलाएं:
SELECT
compound_name,
dev_stage,
therapeutic_area,
target_name,
ROUND(affinity_nm, 3) AS herg_affinity_nm,
pathway_name,
disease_area AS pathway_disease_area
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND b.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
c.therapeutic_area AS therapeutic_area,
t.target_name AS target_name,
b.affinity_nm AS affinity_nm,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
ORDER BY herg_affinity_nm;
ध्यान दें कि MATCH क्लॉज़, वाक्य की तरह दिखता है: "Find a Compound that binds to a Target that participates in a Pathway" — इसमें पाथ के हर नोड और एज पर फ़िल्टर लागू किए जाते हैं.
यहां वह डेटा दिया गया है जो आपको नतीजों में दिखेगा:
रिस्क नेटवर्क को ग्राफ़ के तौर पर विज़ुअलाइज़ करना
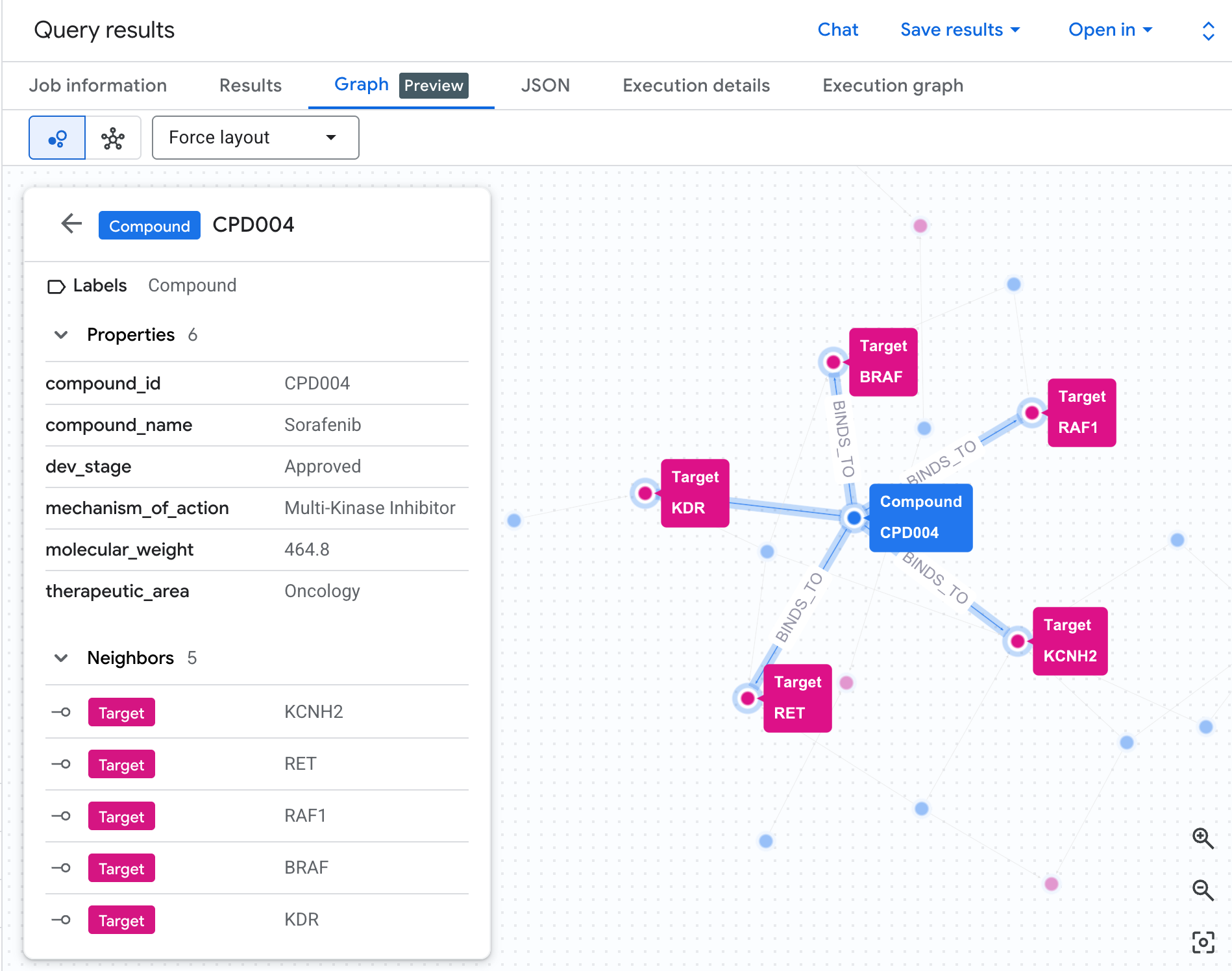
टेबल में हमें डेटा दिखता है, लेकिन इससे हमें जोखिम का स्ट्रक्चर नहीं दिखता. क्या कई कंपाउंड एक ही पाथवे पर मिल रहे हैं? क्या कोई एक कंपाउंड ज़्यादा जोखिम वाला है या कई?
ग्राफ़ विज़ुअलाइज़ेशन से यह तुरंत पता चल जाता है. यहां दी गई सेल को चलाकर, दो हॉप वाले ट्रैवर्सल को इंटरैक्टिव नेटवर्क के तौर पर रेंडर करें:
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH pt = (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND pw.disease_area = 'Cardiovascular'
RETURN
TO_JSON(pt) AS path
आपको इस तरह का ग्राफ़ दिखेगा:
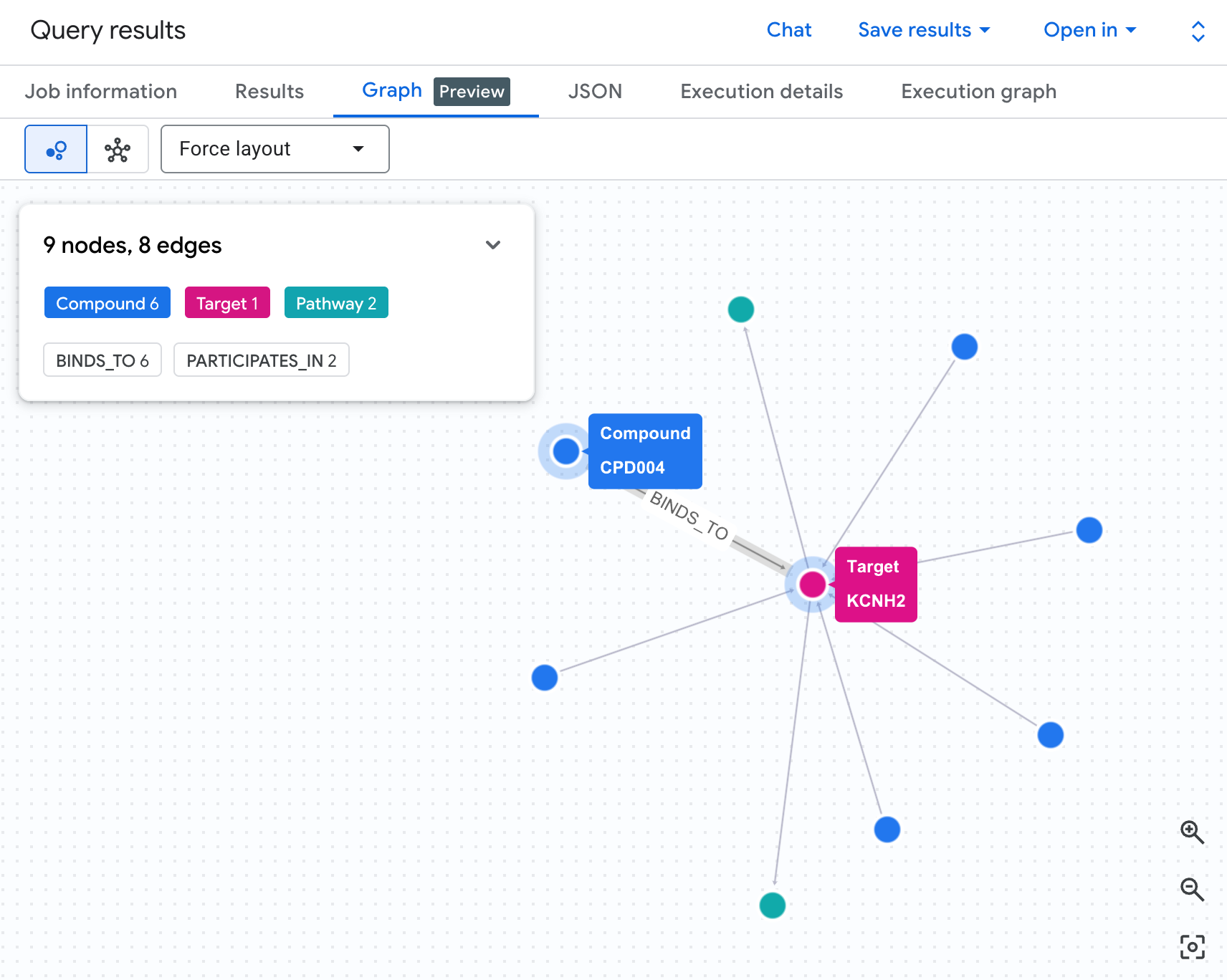
ग्राफ़ में मौजूद हर पाथ, पूरी जवाबदेही चेन को दिखाता है: एक कंपाउंड (नीले नोड), बीच में मौजूद hERG प्रोटीन से जुड़ता है. यह एक या उससे ज़्यादा कार्डियक पाथवे (हरे नोड) से कनेक्ट होता है. टेबल में मौजूद लाइनों की फ़्लैट सूची, अब जोखिम दिखाने वाला नेटवर्क बन गई है. इसमें, एक से ज़्यादा पाथवे के संपर्क में आने वाले कंपाउंड, सुरक्षा की समीक्षा के लिए तुरंत ज़्यादा प्राथमिकता वाले कंपाउंड के तौर पर दिखते हैं.
देखें कि GQL, SQL से ज़्यादा बेहतर क्यों है
स्टैंडर्ड एसक्यूएल में एक ही 2-हॉप क्वेरी को चलाने के लिए, आपको चार एक्सप्लिसिट जॉइन की ज़रूरत होती है. इसमें, आपको यह बताने में ज़्यादा समय लगता है कि टेबल को कैसे जॉइन करना है. इसके बजाय, आपको यह बताना चाहिए कि आपको किस तरह का संबंध चाहिए. GQL की मदद से, सवाल पर फ़ोकस किया जा सकता है.
SELECT
c.compound_name,
c.dev_stage,
c.therapeutic_area,
t.target_name,
ROUND(i.affinity_nm, 3) AS herg_affinity_nm,
pw.pathway_name,
pw.disease_area AS pathway_disease_area
FROM drug_target_graph.compounds c
JOIN drug_target_graph.interactions i ON c.compound_id = i.compound_id
JOIN drug_target_graph.targets t ON i.target_id = t.target_id
JOIN drug_target_graph.target_pathways tp ON t.target_id = tp.target_id
JOIN drug_target_graph.pathways pw ON tp.pathway_id = pw.pathway_id
WHERE t.gene_name = 'KCNH2'
AND i.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
ORDER BY herg_affinity_nm;
ज़्यादा जानकारी — मेटाबोलाइट से जुड़े जोखिम का पता लगाने के लिए, मल्टी-हॉप की सुविधा
ऊपर दी गई क्वेरी से, ऐसे कंपाउंड की पहचान होती है जो सीधे तौर पर hERG प्रोटीन से जुड़ते हैं. हालाँकि, दवा की सुरक्षा से जुड़े असल वर्कफ़्लो में, जोखिम कभी-कभी एक चरण आगे बढ़ जाता है: कोई कंपाउंड, शरीर में मेटाबॉलिक तौर पर बदलकर सेकंडरी मॉलिक्यूल (मेटाबोलाइट) में बदल सकता है. इसके बाद, यह hERG से जुड़ जाता है. यह एक ऐसी देनदारी है जिसे सीधे तौर पर बाइंडिंग ऐसे से पूरी तरह से अनदेखा किया जा सकता है.
अगर आपकी प्रॉपर्टी ग्राफ़ में मेटाबोलाइट नोड टेबल और METABOLISES_INTO एज शामिल है, तो उसी MATCH पैटर्न को 3-हॉप ट्रैवर्सल तक बढ़ाया जा सकता है:
(Compound)-[METABOLISES_INTO]->(Metabolite)-[BINDS_TO]->
(Target)-[PARTICIPATES_IN]->(Pathway)
जीक्यूएल क्वेरी का स्ट्रक्चर, एक नोड और एक एज से बदल जाएगा. इसके बराबर एसक्यूएल के लिए, दो और JOIN की ज़रूरत होगी. यह ऐसा पैटर्न है जो सुरक्षा से जुड़े कैस्केड विश्लेषण के लिए, ग्राफ़ ट्रैवर्सल को खास तौर पर असरदार बनाता है. इसमें क्वेरी की जटिलता रैखिक रूप से बढ़ती है, जबकि जैविक जानकारी तेज़ी से बढ़ती है.
7. क्वेरी 3: शेयर किए गए टारगेट वाले कंपाउंड पेयर
कॉम्बिनेशन थेरेपी के लिए संभावित दवाएं ढूंढने के लिए, हम यह पता लगा सकते हैं कि दो अलग-अलग कंपाउंड, एक ही टारगेट नोड से कब जुड़ते हैं. हम दोनों दिशाओं में मैच करने वाले फ़ंक्शन का इस्तेमाल करके, इस सवाल का जवाब देते हैं: कौनसे ऑन्कोलॉजी कंपाउंड, एक ही टारगेट पर मिलते हैं?
SQL एडिटर में यह क्वेरी चलाएं:
SELECT
compound_a,
compound_b,
shared_target,
gene_name,
ROUND(affinity_a_nm, 3) AS affinity_a_nm,
ROUND(affinity_b_nm, 3) AS affinity_b_nm
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
AND c2.therapeutic_area = 'Oncology'
COLUMNS (
c1.compound_name AS compound_a,
c2.compound_name AS compound_b,
t.target_name AS shared_target,
t.gene_name AS gene_name,
b1.affinity_nm AS affinity_a_nm,
b2.affinity_nm AS affinity_b_nm
)
)
ORDER BY compound_a, compound_b, affinity_a_nm;
यहां वह डेटा दिया गया है जो आपको नतीजों में दिखेगा:
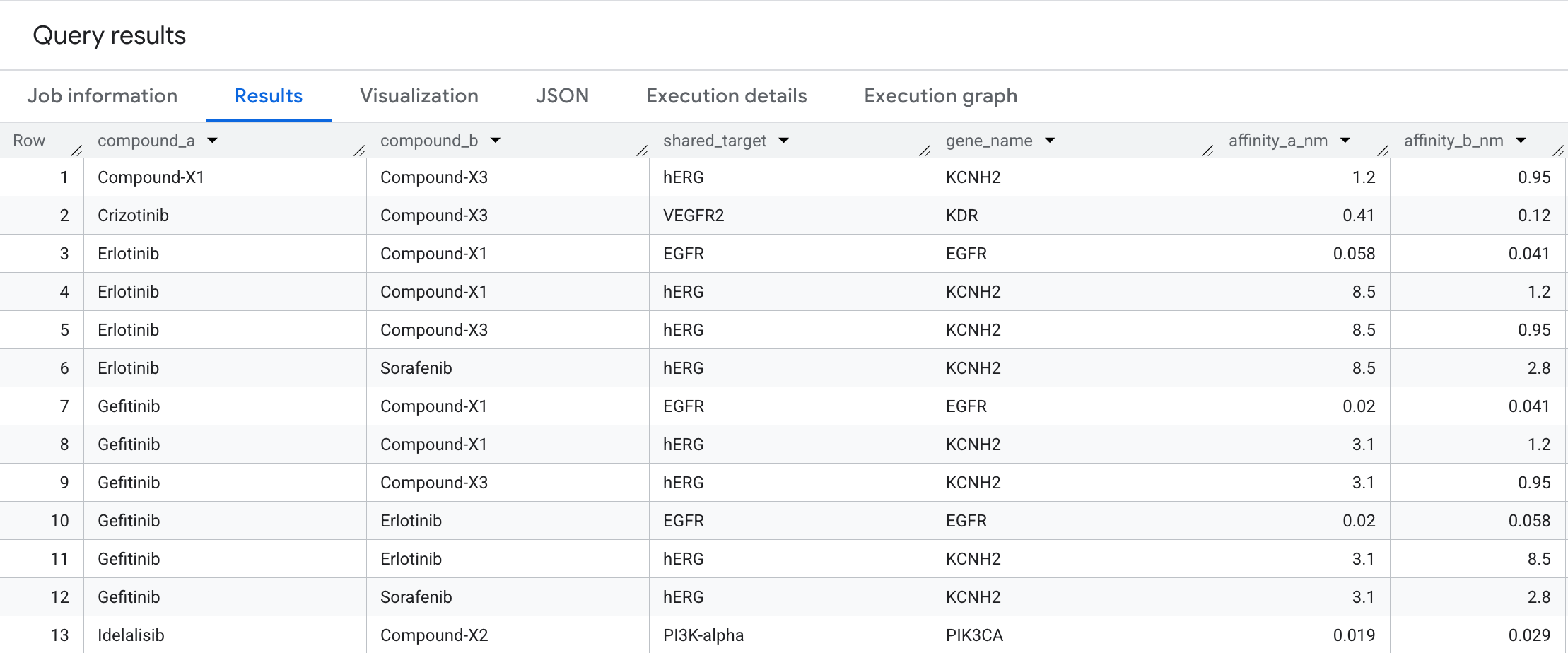
ग्राफ़ विज़ुअलाइज़ेशन
एसक्यूएल एडिटर में यह कोड चलाकर, सीधे तौर पर BigQuery में ग्राफ़ को विज़ुअलाइज़ किया जा सकता है.
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH p = (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
RETURN
TO_JSON(p) AS path
दोनों दिशाओं में ट्रैवर्सल करने से, ऐसे कंपाउंड पेयर सामने आते हैं जो एक ही प्रोटीन टारगेट पर मिलते हैं. इस पैटर्न को इंटरैक्शन की फ़्लैट टेबल में ढूंढना मुश्किल होता है, लेकिन यह ग्राफ़ के तौर पर तुरंत दिख जाता है. दवा की खोज में, शेयर किए गए टारगेट वाले पेयर, कॉम्बिनेशन थेरेपी डिज़ाइन करने के लिए शुरुआती पॉइंट होते हैं: कैंसर पाथवे में एक ही नोड को टारगेट करने वाले दो कंपाउंड, सिनर्जिस्टिक इफ़ेक्ट पैदा कर सकते हैं. इसके अलावा, ये पाइपलाइन में अनचाही रिडंडेंसी का सिग्नल भी दे सकते हैं
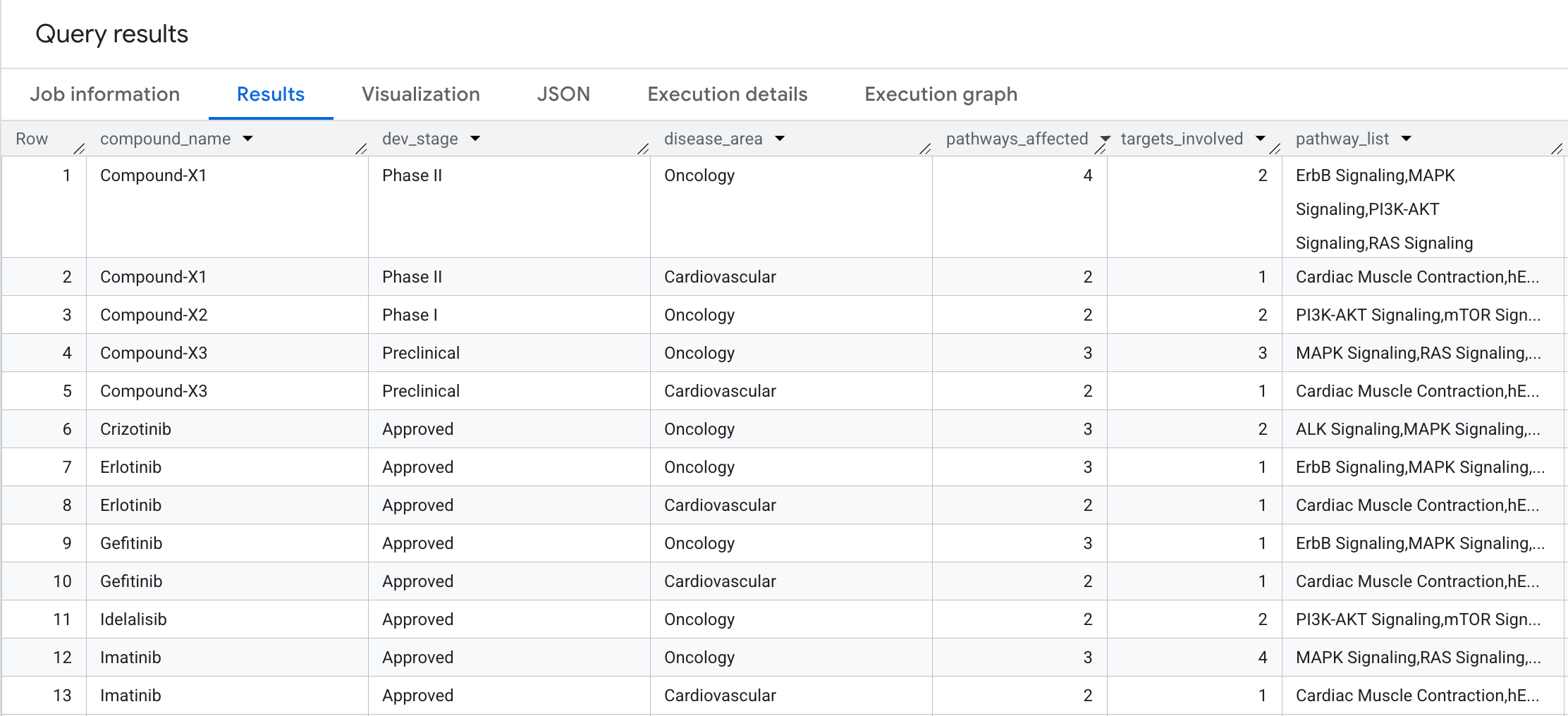
8. चौथी क्वेरी: बीमारी के पाथवे का ब्लास्ट रेडियस
हर कंपाउंड का जैविक असर कितना व्यापक है? इस सवाल का जवाब पाने के लिए, एग्रीगेशन के साथ दो हॉप ट्रैवर्सल करते हैं: हर कंपाउंड, बीमारी के हिसाब से ग्रुप किए गए कितने जैविक पाथवे और अलग-अलग टारगेट पर असर डालता है?
SQL एडिटर में यह क्वेरी चलाएं:
SELECT
compound_name,
dev_stage,
disease_area,
COUNT(DISTINCT pathway_id) AS pathways_affected,
COUNT(DISTINCT target_id) AS targets_involved,
STRING_AGG(DISTINCT pathway_name ORDER BY pathway_name) AS pathway_list
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_id AS target_id,
pw.pathway_id AS pathway_id,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
GROUP BY compound_name, dev_stage, disease_area
ORDER BY compound_name, pathways_affected DESC;
आपको नतीजों में यह जानकारी दिखेगी:
9. क्वेरी 5: सुरक्षित कंपाउंड सिलेक्शन
आखिर में, हम उन कंपाउंड के बारे में क्वेरी करते हैं जिनमें ऑन्कोलॉजी कवरेज ज़्यादा है, लेकिन hERG (कार्डियक) ऑफ़-टारगेट लायबिलिटी को साफ़ तौर पर शामिल नहीं किया गया है. यह दवा की खोज से जुड़ी पाइपलाइन में, सुरक्षा को प्राथमिकता देने वाले सामान्य पैटर्न से मेल खाता है.
SQL एडिटर में यह क्वेरी चलाएं:
WITH oncology_compounds AS (
SELECT DISTINCT compound_id, compound_name, dev_stage
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE pw.disease_area = 'Oncology'
AND pw.cancer_relevance = 'high'
COLUMNS (
c.compound_id AS compound_id,
c.compound_name AS compound_name,
c.dev_stage AS dev_stage
)
)
),
herg_risk_compounds AS (
SELECT DISTINCT compound_id
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
WHERE t.gene_name = 'KCNH2'
COLUMNS (c.compound_id AS compound_id)
)
)
SELECT
o.compound_name,
o.dev_stage,
'Clean cardiac profile' AS cardiac_safety
FROM oncology_compounds o
LEFT JOIN herg_risk_compounds h ON o.compound_id = h.compound_id
WHERE h.compound_id IS NULL
ORDER BY o.dev_stage, o.compound_name;
आपको नतीजों में यह आउटपुट दिखेगा:
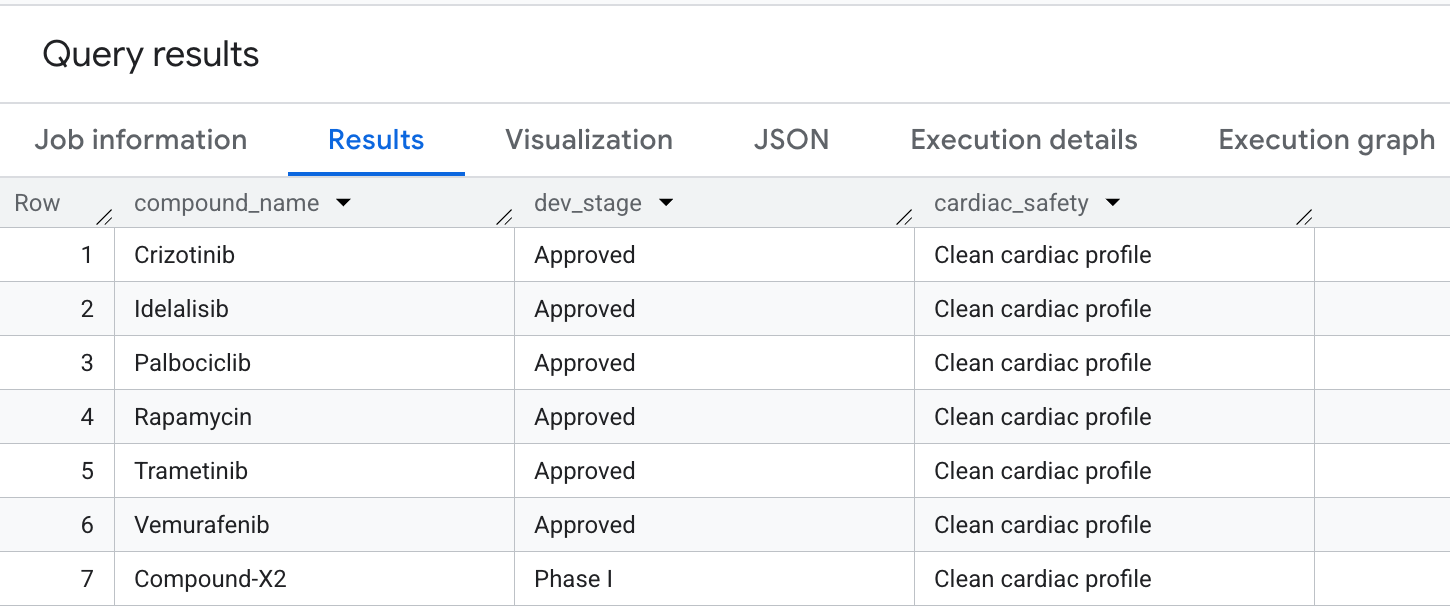
आपने BigQuery में ऐड्वांस ग्राफ़ ट्रैवर्सल को सफलतापूर्वक लागू किया है, ताकि सुरक्षा और असरदार होने की मुख्य प्रोफ़ाइलें निकाली जा सकें!
10. बोनस सेक्शन: अपने ग्राफ़ के बारे में चैट करना
BigQuery Conversational Analytics अब ग्राफ़ को नॉलेज सोर्स के तौर पर इस्तेमाल कर सकता है. इसकी मदद से, अभी-अभी बनाए गए ग्राफ़ के साथ नैचुरल लैंग्वेज में चैट की जा सकती है.
शुरू करना: ग्राफ़ को नॉलेज सोर्स के तौर पर जोड़ना
शुरू करने के लिए, यहां दिया गया तरीका अपनाकर, बातचीत करने वाला एजेंट बनाएं. सर्च बार में जाकर, बनाया गया ग्राफ़ चुनें.
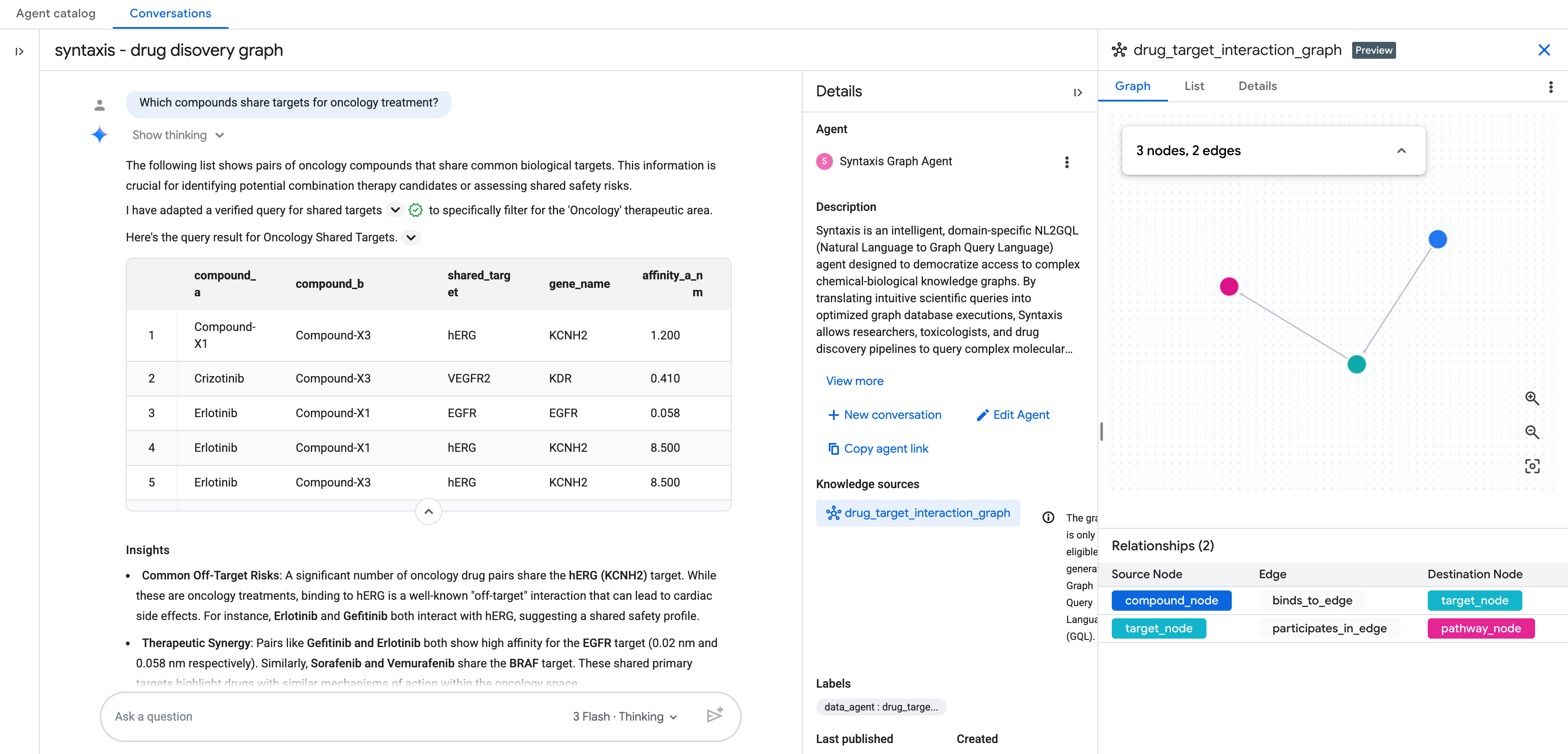
अपने ग्राफ़ के साथ चैट करने के लिए, BigQuery Conversational Analytics का इस्तेमाल करना
नॉलेज सोर्स को ग्राफ़ के तौर पर जोड़ने के बाद, बातचीत वाली Analytics एजेंट की सुविधा का सेटअप पूरा करें.
इसके बाद, नैचुरल लैंग्वेज में अपने ग्राफ़ के साथ चैट की जा सकती है!
कुछ दूसरे सवाल
- फ़िलहाल, फ़ेज़ 2 के ट्रायल में शामिल कंपाउंड के सभी टारगेट क्या हैं?
- कार्डियोवैस्कुलर और ऑन्कोलॉजी कंपाउंड के बीच कौनसे टारगेट शेयर किए जाते हैं?
11. व्यवस्थित करें
अपने Google Cloud खाते से लगातार शुल्क लिए जाने से बचने के लिए, इस कोडलैब के दौरान बनाई गई संसाधन मिटाएं.
स्कीमा और सभी टेबल को एक साथ हटाने के लिए, यह क्वेरी चलाएं:
DROP SCHEMA IF EXISTS drug_target_graph CASCADE;
12. बधाई हो
बधाई हो! आपने BigQuery Graph का इस्तेमाल करके, दवा और टारगेट के बीच इंटरैक्शन नेटवर्क को मॉडल और उसका विश्लेषण कर लिया है.
आपने क्या सीखा
- किसी प्रॉपर्टी ग्राफ़ के तौर पर, इकाई के संबंधों (कंपाउंड, टारगेट, पाथवे) को कैसे मॉडल करें.
- BigQuery में स्कीमा तय करने और प्रॉपर्टी ग्राफ़ बनाने का तरीका.
- जीक्यूएल का इस्तेमाल करके, जटिल ग्राफ़ ट्रैवर्सल लिखने का तरीका और उनकी तुलना पारंपरिक एसक्यूएल से करना.
- लाइफ़ साइंस डोमेन की समस्याओं को हल करने के लिए,
GRAPH_TABLE,MATCH, और दोनों दिशाओं में मैचिंग का इस्तेमाल कैसे करें.