
1. Introduzione
In questo codelab imparerai a utilizzare BigQuery Graph per modellare e analizzare una rete di interazione farmaco-target. Sfrutterai la potenza delle query sui grafici (GQL) per esplorare in che modo i farmaci interagiscono con i target biologici, identificare potenziali effetti collaterali (come i rischi cardiaci) e scoprire potenziali terapie combinate.
🧬 Caso d'uso: rete di interazione farmaco-target
Domanda aziendale: qual è il raggio di esplosione completo di un composto: a quali target si lega, quali percorsi biologici sono interessati e quali aree di malattia sono coinvolte?
Tabelle:
Tabella | Descrizione |
| Molecole di farmaci con meccanismo di azione e fase di sviluppo |
| Target proteici con nomi di geni e ID UniProt |
| Affinità di legame composto-target (target primari + off-target) |
| Percorsi biologici con associazioni di aree di malattia |
| Tabella di giunzione che collega i target ai percorsi in cui partecipano |
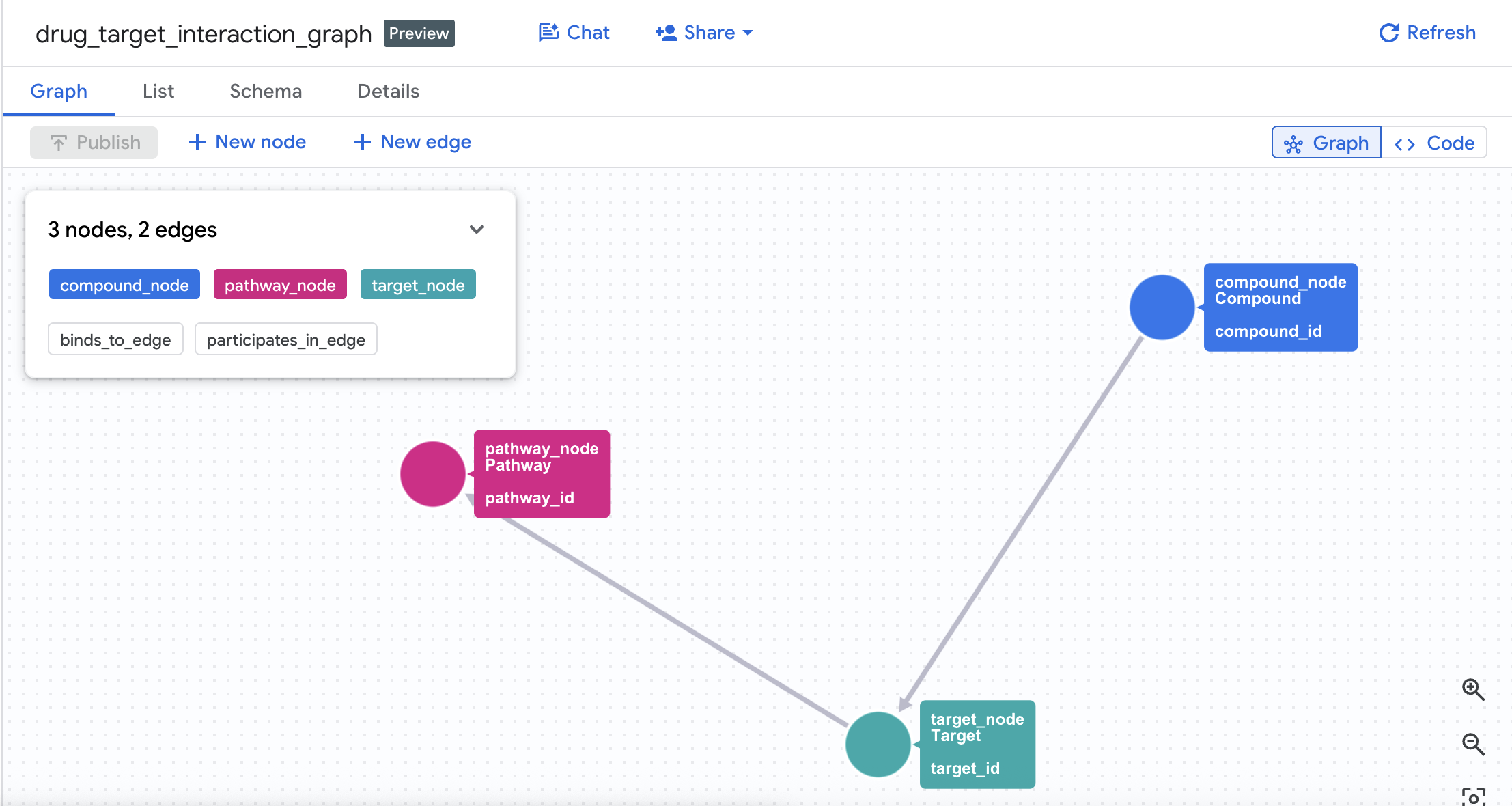
Modello di grafico delle proprietà:
(Compound)-[BINDS_TO {affinity_nm, ic50_nm, interaction_type}]->(Target)
(Target)-[PARTICIPATES_IN {role, importance_score}]->(Pathway)
🔍 Query dimostrative
Query | Informazioni riportate |
Q1: profilo di legame target | Attraversamento di 1 hop: composto a tutti i target primari e off-target |
Q2: rilevamento del rischio cardiaco hERG | Attraversamento di 2 hop: composto → target hERG → percorso cardiaco |
Q3: coppie di composti con target condivisi | Corrispondenza bidirezionale: due composti che convergono sullo stesso nodo target |
Q4: raggio di impatto del percorso della patologia | Aggregazione a 2 hop: copertura completa del percorso e dell'area di patologia per composto |
Q5: selezione di composti sicuri | Composti con elevata copertura oncologica, ma senza responsabilità cardiaca hERG |
In questo lab proverai a:
- Creare un set di dati e uno schema BigQuery per la rete di interazione farmaco-target
- Caricare dati di esempio (composti, target, interazioni, percorsi, percorsi target)
- Creare un grafico delle proprietà in BigQuery che colleghi queste entità
- Eseguire query sul grafo per comprendere le interazioni dei composti, i percorsi biologici e il raggio di impatto della patologia utilizzando gli attraversamenti del grafo (
GRAPH_TABLEeMATCH) - Confrontare GQL e SQL standard per comprendere la semplicità e la potenza espressiva della sintassi del grafico
Che cosa ti serve
- Un browser web come Chrome
- Un progetto cloud Google Cloud con la fatturazione abilitata
Questo codelab è rivolto a sviluppatori di tutti i livelli, inclusi i principianti.
2. Prima di iniziare
Crea un progetto Google Cloud
- Nella console Google Cloud, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud.
Avvia Cloud Shell
- Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.
- Verifica l'autenticazione:
gcloud auth list
- Conferma il progetto:
gcloud config get project
- Impostalo se necessario:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Abilita API
Esegui questo comando per abilitare l'API BigQuery richiesta:
gcloud services enable bigquery.googleapis.com
3. Definisci lo schema e carica i dati
Innanzitutto, devi creare un set di dati per archiviare le tabelle correlate al grafico e popolarle con dati di esempio.
- Vai a BigQuery Studio nella console Google Cloud.
- Fai clic su Editor SQL per aprire una nuova scheda di query.
- Esegui la seguente istruzione per creare il set di dati
drug_target_graph:
CREATE SCHEMA IF NOT EXISTS drug_target_graph
OPTIONS (location = 'US');
Ora crea le 5 tabelle di origine eseguendo le seguenti query DDL in BigQuery Studio.
1. Crea la tabella compounds
Contiene molecole di farmaci, il loro meccanismo di azione, la fase di sviluppo e l'area terapeutica.
CREATE OR REPLACE TABLE drug_target_graph.compounds AS
SELECT 'CPD001' AS compound_id, 'Imatinib' AS compound_name, 'Kinase Inhibitor' AS mechanism_of_action, 'Approved' AS dev_stage, 'Oncology' AS therapeutic_area, 479.6 AS molecular_weight UNION ALL
SELECT 'CPD002', 'Gefitinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 446.9 UNION ALL
SELECT 'CPD003', 'Erlotinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 393.4 UNION ALL
SELECT 'CPD004', 'Sorafenib', 'Multi-Kinase Inhibitor', 'Approved', 'Oncology', 464.8 UNION ALL
SELECT 'CPD005', 'Vemurafenib', 'BRAF Inhibitor', 'Approved', 'Oncology', 489.9 UNION ALL
SELECT 'CPD006', 'Crizotinib', 'ALK Inhibitor', 'Approved', 'Oncology', 450.3 UNION ALL
SELECT 'CPD007', 'Idelalisib', 'PI3K Inhibitor', 'Approved', 'Oncology', 415.4 UNION ALL
SELECT 'CPD008', 'Trametinib', 'MEK Inhibitor', 'Approved', 'Oncology', 615.4 UNION ALL
SELECT 'CPD009', 'Palbociclib', 'CDK Inhibitor', 'Approved', 'Oncology', 447.5 UNION ALL
SELECT 'CPD010', 'Compound-X1', 'Kinase Inhibitor', 'Phase II', 'Oncology', 412.3 UNION ALL
SELECT 'CPD011', 'Compound-X2', 'PI3K Inhibitor', 'Phase I', 'Oncology', 398.7 UNION ALL
SELECT 'CPD012', 'Saquinavir', 'Protease Inhibitor', 'Approved', 'Infectious Disease', 670.8 UNION ALL
SELECT 'CPD013', 'Metformin', 'AMPK Activator', 'Approved', 'Metabolic', 165.6 UNION ALL
SELECT 'CPD014', 'Rapamycin', 'mTOR Inhibitor', 'Approved', 'Immunology', 914.2 UNION ALL
SELECT 'CPD015', 'Compound-X3', 'Multi-Kinase Inhibitor', 'Preclinical', 'Oncology', 502.1;
2. Crea la tabella targets
Contiene target proteici, nomi di geni, ID UniProt e classi di target.
CREATE OR REPLACE TABLE drug_target_graph.targets AS
SELECT 'TGT001' AS target_id, 'BCR-ABL1' AS target_name, 'ABL1' AS gene_name, 'P00519' AS uniprot_id, 'Kinase' AS target_class, TRUE AS is_oncogene UNION ALL
SELECT 'TGT002', 'EGFR', 'EGFR', 'P00533', 'Kinase', TRUE UNION ALL
SELECT 'TGT003', 'VEGFR2', 'KDR', 'P35968', 'Kinase', FALSE UNION ALL
SELECT 'TGT004', 'BRAF', 'BRAF', 'P15056', 'Kinase', TRUE UNION ALL
SELECT 'TGT005', 'ALK', 'ALK', 'Q9UM73', 'Kinase', TRUE UNION ALL
SELECT 'TGT006', 'PI3K-alpha','PIK3CA', 'P42336', 'Lipid Kinase', TRUE UNION ALL
SELECT 'TGT007', 'MEK1', 'MAP2K1', 'Q02750', 'Kinase', FALSE UNION ALL
SELECT 'TGT008', 'CDK4', 'CDK4', 'P11802', 'Kinase', FALSE UNION ALL
SELECT 'TGT009', 'CDK6', 'CDK6', 'P30279', 'Kinase', FALSE UNION ALL
SELECT 'TGT010', 'mTOR', 'MTOR', 'P42345', 'Kinase', FALSE UNION ALL
SELECT 'TGT011', 'PDGFR-beta','PDGFRB', 'P09619', 'Kinase', FALSE UNION ALL
SELECT 'TGT012', 'c-KIT', 'KIT', 'P10721', 'Kinase', TRUE UNION ALL
SELECT 'TGT013', 'hERG', 'KCNH2', 'Q12809', 'Ion Channel', FALSE UNION ALL
SELECT 'TGT014', 'AMPK', 'PRKAA1', 'Q13131', 'Kinase', FALSE UNION ALL
SELECT 'TGT015', 'RAF1', 'RAF1', 'P04049', 'Kinase', FALSE UNION ALL
SELECT 'TGT016', 'RET', 'RET', 'P07949', 'Kinase', TRUE UNION ALL
SELECT 'TGT017', 'FLT3', 'FLT3', 'P36888', 'Kinase', TRUE UNION ALL
SELECT 'TGT018', 'AKT1', 'AKT1', 'P31749', 'Kinase', FALSE UNION ALL
SELECT 'TGT019', 'ERK2', 'MAPK1', 'P28482', 'Kinase', FALSE UNION ALL
SELECT 'TGT020', 'HIV-Protease','HIV1-PR','Q72547', 'Protease', FALSE;
3. Crea la tabella interactions
Contiene i dati sull'affinità di legame composto-target (target primari rispetto a off-target).
CREATE OR REPLACE TABLE drug_target_graph.interactions AS
SELECT 'INT001' AS interaction_id, 'CPD001' AS compound_id, 'TGT001' AS target_id, 0.025 AS affinity_nm, 0.038 AS ic50_nm, 'primary' AS interaction_type, 9.8 AS pchembl_value UNION ALL
SELECT 'INT002', 'CPD001', 'TGT011', 0.1, 0.15, 'primary', 8.8 UNION ALL
SELECT 'INT003', 'CPD001', 'TGT012', 0.068, 0.1, 'primary', 9.2 UNION ALL
SELECT 'INT004', 'CPD001', 'TGT016', 0.5, 0.8, 'off-target', 7.4 UNION ALL
SELECT 'INT005', 'CPD001', 'TGT013', 5.2, 8.1, 'off-target', 6.1 UNION ALL
SELECT 'INT006', 'CPD002', 'TGT002', 0.02, 0.033, 'primary', 9.7 UNION ALL
SELECT 'INT007', 'CPD002', 'TGT013', 3.1, 4.8, 'off-target', 6.5 UNION ALL
SELECT 'INT008', 'CPD003', 'TGT002', 0.058, 0.079, 'primary', 9.2 UNION ALL
SELECT 'INT009', 'CPD003', 'TGT013', 8.5, 12.0, 'off-target', 5.9 UNION ALL
SELECT 'INT010', 'CPD004', 'TGT003', 0.09, 0.12, 'primary', 9.1 UNION ALL
SELECT 'INT011', 'CPD004', 'TGT004', 0.038, 0.055, 'primary', 8.9 UNION ALL
SELECT 'INT012', 'CPD004', 'TGT015', 0.22, 0.31, 'primary', 8.5 UNION ALL
SELECT 'INT013', 'CPD004', 'TGT016', 0.58, 0.75, 'primary', 8.1 UNION ALL
SELECT 'INT014', 'CPD004', 'TGT017', 0.33, 0.48, 'primary', 8.4 UNION ALL
SELECT 'INT015', 'CPD004', 'TGT013', 2.8, 4.1, 'off-target', 6.6 UNION ALL
SELECT 'INT016', 'CPD005', 'TGT004', 0.031, 0.044, 'primary', 9.5 UNION ALL
SELECT 'INT017', 'CPD005', 'TGT015', 0.48, 0.65, 'off-target', 7.3 UNION ALL
SELECT 'INT018', 'CPD006', 'TGT005', 0.02, 0.028, 'primary', 9.8 UNION ALL
SELECT 'INT019', 'CPD006', 'TGT003', 0.41, 0.59, 'off-target', 7.4 UNION ALL
SELECT 'INT020', 'CPD007', 'TGT006', 0.019, 0.025, 'primary', 9.8 UNION ALL
SELECT 'INT021', 'CPD007', 'TGT018', 0.55, 0.78, 'off-target', 7.2 UNION ALL
SELECT 'INT022', 'CPD008', 'TGT007', 0.0092, 0.014, 'primary', 10.1 UNION ALL
SELECT 'INT023', 'CPD008', 'TGT019', 0.38, 0.51, 'off-target', 7.4 UNION ALL
SELECT 'INT024', 'CPD009', 'TGT008', 0.011, 0.017, 'primary', 9.9 UNION ALL
SELECT 'INT025', 'CPD009', 'TGT009', 0.015, 0.022, 'primary', 9.8 UNION ALL
SELECT 'INT026', 'CPD010', 'TGT002', 0.041, 0.058, 'primary', 9.4 UNION ALL
SELECT 'INT027', 'CPD010', 'TGT001', 0.38, 0.52, 'off-target', 7.3 UNION ALL
SELECT 'INT028', 'CPD010', 'TGT013', 1.2, 1.8, 'off-target', 7.1 UNION ALL
SELECT 'INT029', 'CPD011', 'TGT006', 0.029, 0.041, 'primary', 9.5 UNION ALL
SELECT 'INT030', 'CPD011', 'TGT010', 0.71, 0.95, 'off-target', 7.0 UNION ALL
SELECT 'INT031', 'CPD012', 'TGT020', 0.39, 0.55, 'primary', 7.3 UNION ALL
SELECT 'INT032', 'CPD013', 'TGT014', 12.0, 18.5, 'primary', 5.7 UNION ALL
SELECT 'INT033', 'CPD014', 'TGT010', 0.0018, 0.0025, 'primary', 11.8 UNION ALL
SELECT 'INT034', 'CPD015', 'TGT004', 0.055, 0.078, 'primary', 9.2 UNION ALL
SELECT 'INT035', 'CPD015', 'TGT003', 0.12, 0.17, 'primary', 8.9 UNION ALL
SELECT 'INT036', 'CPD015', 'TGT016', 0.29, 0.41, 'primary', 8.5 UNION ALL
SELECT 'INT037', 'CPD015', 'TGT013', 0.95, 1.35, 'off-target', 7.2;
4. Crea la tabella pathways
Contiene percorsi biologici, aree di patologia associate e pertinenza del cancro.
CREATE OR REPLACE TABLE drug_target_graph.pathways AS
SELECT 'PWY001' AS pathway_id, 'MAPK Signaling' AS pathway_name, 'hsa04010' AS kegg_id, 'Cell Proliferation' AS biological_process, 'Oncology' AS disease_area, 'high' AS cancer_relevance UNION ALL
SELECT 'PWY002', 'PI3K-AKT Signaling', 'hsa04151', 'Cell Survival', 'Oncology', 'high' UNION ALL
SELECT 'PWY003', 'VEGF Signaling', 'hsa04370', 'Angiogenesis', 'Oncology', 'high' UNION ALL
SELECT 'PWY004', 'ErbB Signaling', 'hsa04012', 'Cell Growth', 'Oncology', 'high' UNION ALL
SELECT 'PWY005', 'mTOR Signaling', 'hsa04150', 'Cell Growth', 'Oncology', 'medium' UNION ALL
SELECT 'PWY006', 'Cell Cycle', 'hsa04110', 'Cell Division', 'Oncology', 'high' UNION ALL
SELECT 'PWY007', 'Cardiac Muscle Contraction', 'hsa04260', 'Cardiac Function', 'Cardiovascular', 'low' UNION ALL
SELECT 'PWY008', 'hERG Cardiac Channel', 'hsa04022', 'Cardiac Repolarisation','Cardiovascular', 'low' UNION ALL
SELECT 'PWY009', 'AMPK Signaling', 'hsa04152', 'Energy Metabolism', 'Metabolic', 'low' UNION ALL
SELECT 'PWY010', 'ALK Signaling', 'hsa04915', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY011', 'RAS Signaling', 'hsa04014', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY012', 'HIV Replication', 'hsa05170', 'Viral Replication', 'Infectious Disease', 'low';
5. Crea la tabella target_pathways
Una tabella di giunzione che collega i target ai percorsi biologici in cui partecipano.
CREATE OR REPLACE TABLE drug_target_graph.target_pathways AS
SELECT 'TP001' AS tp_id, 'TGT001' AS target_id, 'PWY001' AS pathway_id, 'activator' AS role, 0.95 AS importance_score UNION ALL
SELECT 'TP002', 'TGT001', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP003', 'TGT002', 'PWY004', 'activator', 0.98 UNION ALL
SELECT 'TP004', 'TGT002', 'PWY001', 'activator', 0.82 UNION ALL
SELECT 'TP005', 'TGT002', 'PWY002', 'activator', 0.75 UNION ALL
SELECT 'TP006', 'TGT003', 'PWY003', 'activator', 0.96 UNION ALL
SELECT 'TP007', 'TGT003', 'PWY001', 'activator', 0.71 UNION ALL
SELECT 'TP008', 'TGT004', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP009', 'TGT004', 'PWY011', 'activator', 0.89 UNION ALL
SELECT 'TP010', 'TGT005', 'PWY010', 'activator', 0.99 UNION ALL
SELECT 'TP011', 'TGT005', 'PWY001', 'activator', 0.78 UNION ALL
SELECT 'TP012', 'TGT006', 'PWY002', 'activator', 0.98 UNION ALL
SELECT 'TP013', 'TGT006', 'PWY005', 'activator', 0.85 UNION ALL
SELECT 'TP014', 'TGT007', 'PWY001', 'activator', 0.94 UNION ALL
SELECT 'TP015', 'TGT007', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP016', 'TGT008', 'PWY006', 'activator', 0.95 UNION ALL
SELECT 'TP017', 'TGT009', 'PWY006', 'activator', 0.93 UNION ALL
SELECT 'TP018', 'TGT010', 'PWY005', 'activator', 0.99 UNION ALL
SELECT 'TP019', 'TGT010', 'PWY002', 'activator', 0.91 UNION ALL
SELECT 'TP020', 'TGT011', 'PWY003', 'activator', 0.87 UNION ALL
SELECT 'TP021', 'TGT011', 'PWY001', 'activator', 0.72 UNION ALL
SELECT 'TP022', 'TGT012', 'PWY001', 'activator', 0.83 UNION ALL
SELECT 'TP023', 'TGT012', 'PWY011', 'activator', 0.79 UNION ALL
SELECT 'TP024', 'TGT013', 'PWY008', 'substrate', 0.99 UNION ALL
SELECT 'TP025', 'TGT013', 'PWY007', 'substrate', 0.95 UNION ALL
SELECT 'TP026', 'TGT014', 'PWY009', 'activator', 0.97 UNION ALL
SELECT 'TP027', 'TGT015', 'PWY001', 'activator', 0.91 UNION ALL
SELECT 'TP028', 'TGT015', 'PWY011', 'activator', 0.86 UNION ALL
SELECT 'TP029', 'TGT016', 'PWY001', 'activator', 0.84 UNION ALL
SELECT 'TP030', 'TGT016', 'PWY003', 'activator', 0.77 UNION ALL
SELECT 'TP031', 'TGT017', 'PWY001', 'activator', 0.88 UNION ALL
SELECT 'TP032', 'TGT017', 'PWY011', 'activator', 0.82 UNION ALL
SELECT 'TP033', 'TGT018', 'PWY002', 'activator', 0.96 UNION ALL
SELECT 'TP034', 'TGT018', 'PWY005', 'activator', 0.88 UNION ALL
SELECT 'TP035', 'TGT019', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP036', 'TGT019', 'PWY011', 'activator', 0.91 UNION ALL
SELECT 'TP037', 'TGT020', 'PWY012', 'substrate', 0.99;
4. Crea il grafico delle proprietà
Ora che le tabelle sono state create correttamente, puoi creare il grafico delle proprietà. Questo collega i nodi (composti, target, percorsi) utilizzando le tabelle degli archi (Interactions e Target Pathways).
Esegui la seguente istruzione nell'editor SQL di BigQuery Studio:
CREATE OR REPLACE PROPERTY GRAPH drug_target_graph.drug_target_interaction_graph
NODE TABLES (
drug_target_graph.compounds
AS compound_node
KEY (compound_id)
LABEL Compound
PROPERTIES (compound_id, compound_name, mechanism_of_action, dev_stage, therapeutic_area, molecular_weight),
drug_target_graph.targets
AS target_node
KEY (target_id)
LABEL Target
PROPERTIES (target_id, target_name, gene_name, uniprot_id, target_class, is_oncogene),
drug_target_graph.pathways
AS pathway_node
KEY (pathway_id)
LABEL Pathway
PROPERTIES (pathway_id, pathway_name, kegg_id, biological_process, disease_area, cancer_relevance)
)
EDGE TABLES (
drug_target_graph.interactions
AS binds_to_edge
KEY (interaction_id)
SOURCE KEY (compound_id) REFERENCES compound_node (compound_id)
DESTINATION KEY (target_id) REFERENCES target_node (target_id)
LABEL BINDS_TO
PROPERTIES (interaction_id, affinity_nm, ic50_nm, interaction_type, pchembl_value),
drug_target_graph.target_pathways
AS participates_in_edge
KEY (tp_id)
SOURCE KEY (target_id) REFERENCES target_node (target_id)
DESTINATION KEY (pathway_id) REFERENCES pathway_node (pathway_id)
LABEL PARTICIPATES_IN
PROPERTIES (tp_id, role, importance_score)
);
Viene creato un grafico denominato drug_target_interaction_graph nel set di dati.
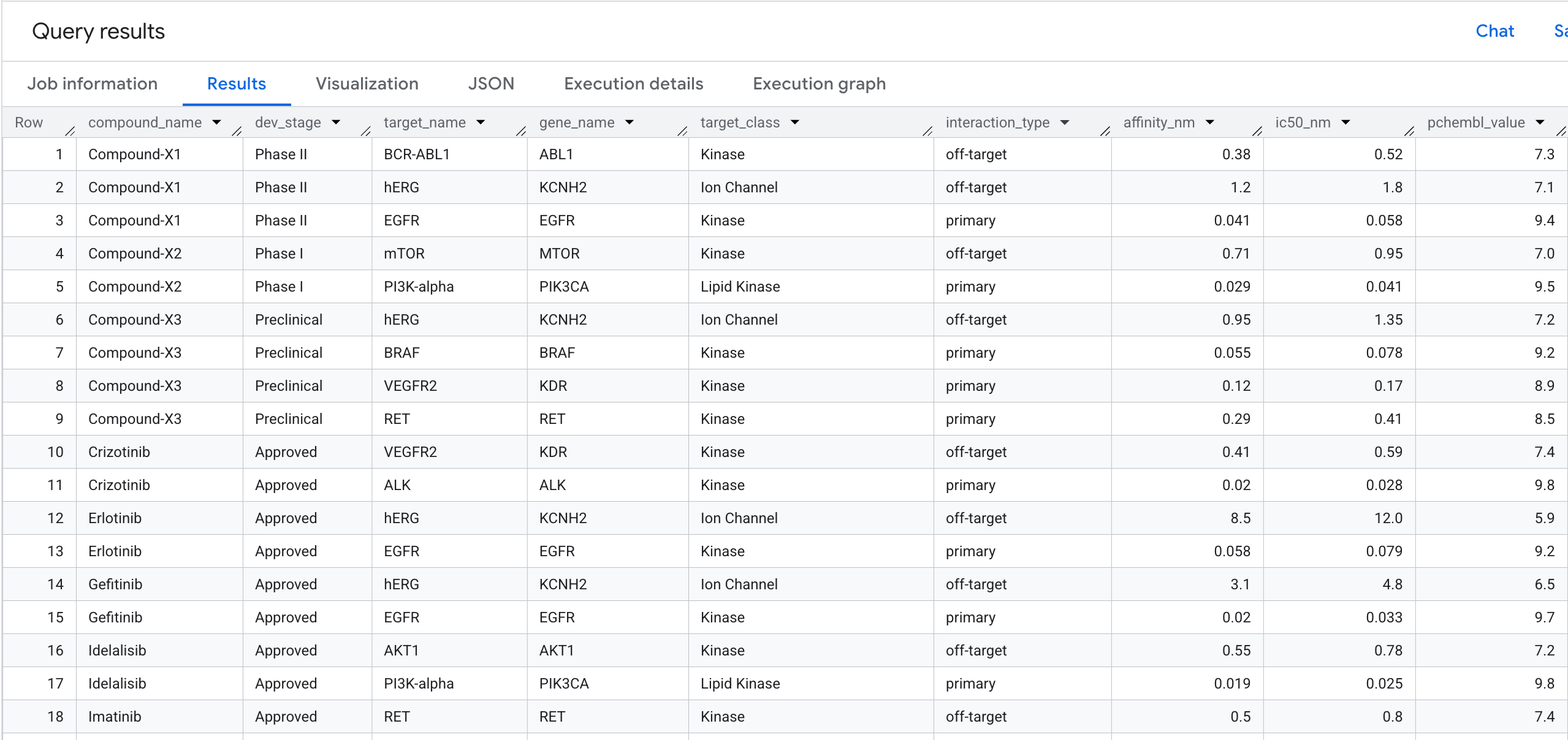
5. Query 1: profilo di legame target completo per composto
Eseguiamo la nostra prima query sul grafico. Si tratta di un attraversamento di 1 hop che risponde alla domanda: quali composti si legano a quali target e qual è la loro affinità?
Query GQL
Esegui la seguente query nell'editor SQL:
SELECT
compound_name,
dev_stage,
target_name,
gene_name,
target_class,
interaction_type,
ROUND(affinity_nm, 3) AS affinity_nm,
ROUND(ic50_nm, 3) AS ic50_nm,
pchembl_value
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_name AS target_name,
t.gene_name AS gene_name,
t.target_class AS target_class,
b.interaction_type AS interaction_type,
b.affinity_nm AS affinity_nm,
b.ic50_nm AS ic50_nm,
b.pchembl_value AS pchembl_value
)
)
ORDER BY compound_name, interaction_type, affinity_nm;
Ecco cosa vedrai nei risultati:
6. Query 2: rilevamento del rischio cardiaco
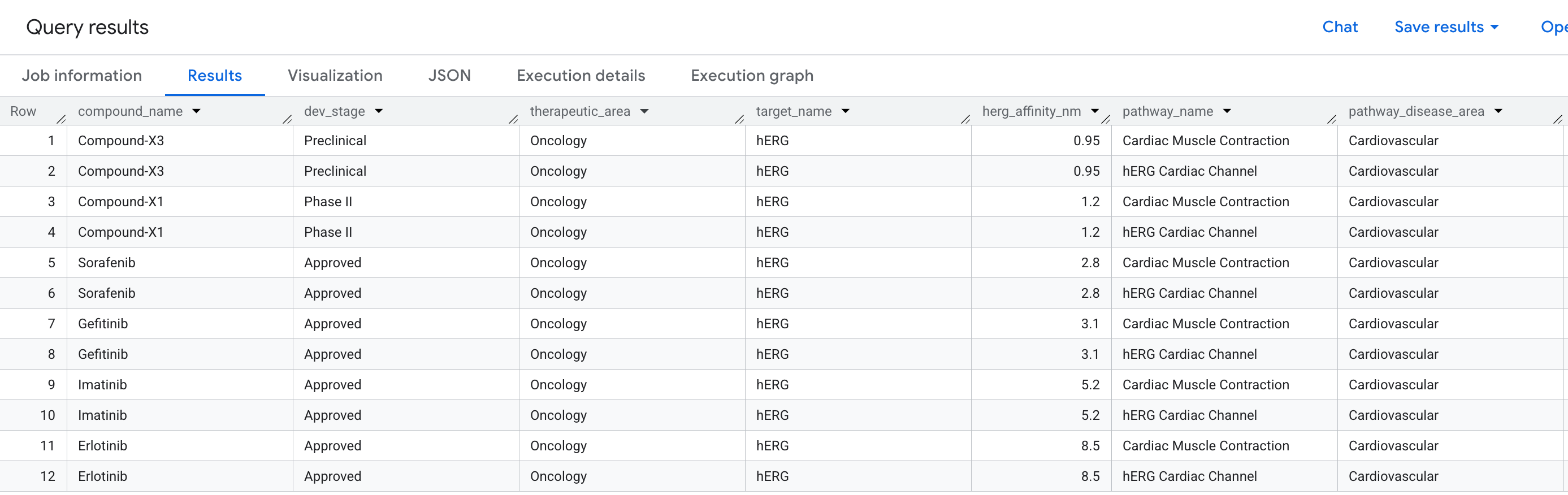
La domanda aziendale
Nella scoperta di farmaci, uno dei motivi più comuni per cui un composto promettente fallisce negli studi clinici è la cardiotossicità, in particolare il legame non intenzionale alla proteina hERG (gene: KCNH2), un canale ionico di potassio che regola il ritmo cardiaco. Un hit off-target su hERG può causare aritmie fatali ed è stato responsabile di diversi ritiri di farmaci di alto profilo.
La domanda a cui vogliamo rispondere è:
"Quali composti nella nostra pipeline hanno un evento di legame off-target sulla proteina hERG e quali percorsi cardiaci mettono a rischio?"
Si tratta di una domanda di 2 hop: dobbiamo attraversare un composto, un target (hERG) e un percorso, collegando tre tipi di entità in due relazioni in una singola query.
Scrivi la query GQL
Esegui la seguente query nell'editor SQL di BQ:
SELECT
compound_name,
dev_stage,
therapeutic_area,
target_name,
ROUND(affinity_nm, 3) AS herg_affinity_nm,
pathway_name,
disease_area AS pathway_disease_area
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND b.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
c.therapeutic_area AS therapeutic_area,
t.target_name AS target_name,
b.affinity_nm AS affinity_nm,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
ORDER BY herg_affinity_nm;
Nota come la clausola MATCH si legge quasi come una frase: "Trova un composto che si lega a un target che partecipa a un percorso" , con i filtri applicati a ogni nodo e arco lungo il percorso.
Ecco i dati che vedrai nei risultati:
Visualizza la rete di rischio come grafico
Una tabella mostra i dati, ma non la struttura del rischio. Più composti convergono sullo stesso percorso? Esiste un composto ad alto rischio o più?
Una visualizzazione del grafico lo rende immediatamente visibile. Esegui la cella seguente per eseguire il rendering dello stesso attraversamento di 2 hop come rete interattiva:
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH pt = (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND pw.disease_area = 'Cardiovascular'
RETURN
TO_JSON(pt) AS path
Dovresti vedere un grafico simile a questo:
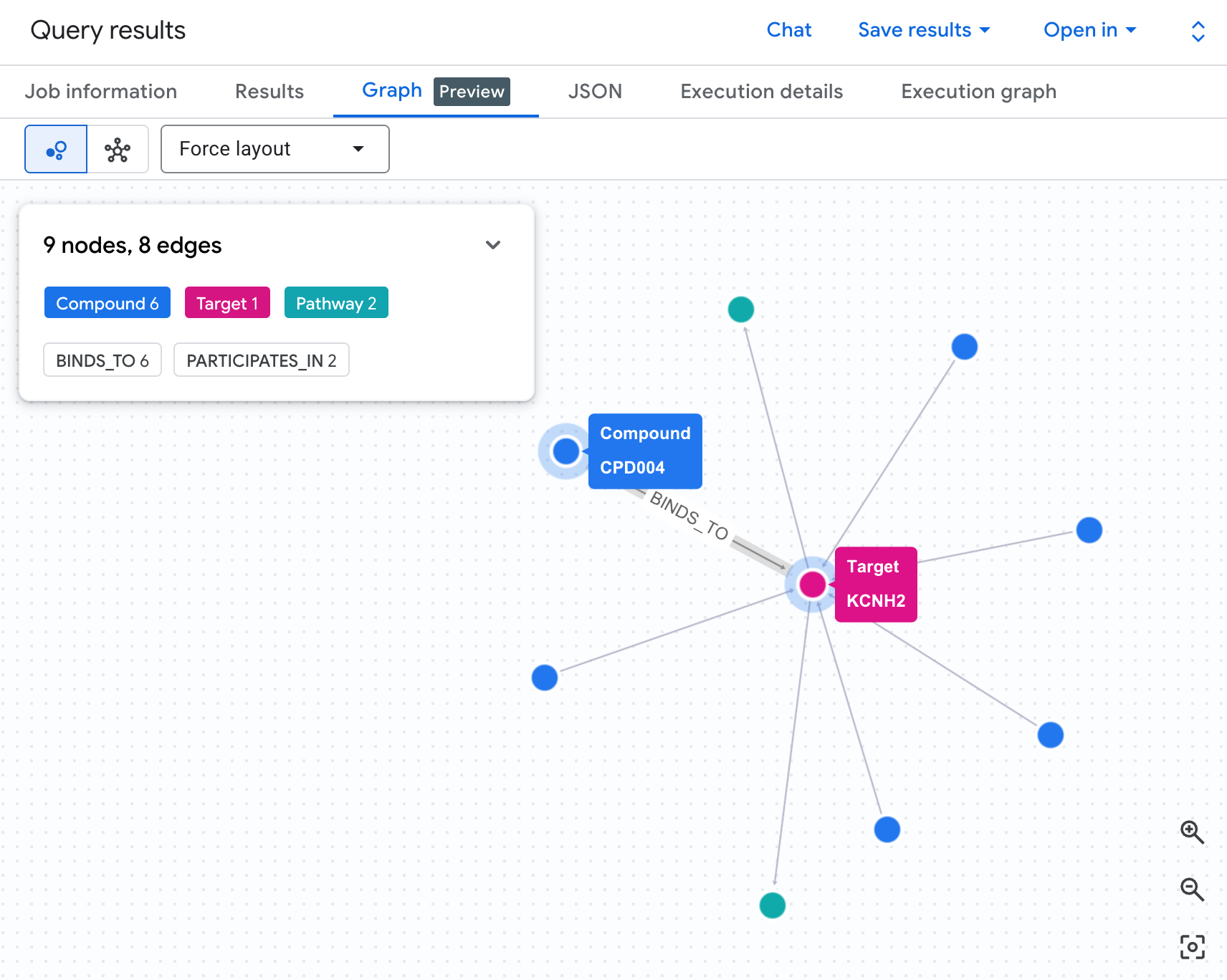
Ogni percorso nel grafico traccia una catena di responsabilità completa: un composto (nodi blu) si lega alla proteina hERG al centro, che si collega a uno o più percorsi cardiaci (nodi verdi). Quella che era una lista piatta di righe nella tabella è ora una rete di rischio visibile: i composti con più esposizioni ai percorsi si distinguono immediatamente come priorità più alta per la revisione della sicurezza.
Scopri perché GQL è più elegante di SQL
Per eseguire la stessa query di 2 hop in SQL standard, sono necessari 4 join espliciti. Stai dedicando uno sforzo cognitivo a descrivere come unire le tabelle anziché quale relazione stai cercando. GQL ti consente di concentrarti sulla domanda.
SELECT
c.compound_name,
c.dev_stage,
c.therapeutic_area,
t.target_name,
ROUND(i.affinity_nm, 3) AS herg_affinity_nm,
pw.pathway_name,
pw.disease_area AS pathway_disease_area
FROM drug_target_graph.compounds c
JOIN drug_target_graph.interactions i ON c.compound_id = i.compound_id
JOIN drug_target_graph.targets t ON i.target_id = t.target_id
JOIN drug_target_graph.target_pathways tp ON t.target_id = tp.target_id
JOIN drug_target_graph.pathways pw ON tp.pathway_id = pw.pathway_id
WHERE t.gene_name = 'KCNH2'
AND i.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
ORDER BY herg_affinity_nm;
Approfondimento: rilevamento del rischio di metaboliti multi-hop
La query precedente identifica i composti che si legano direttamente alla proteina hERG. Tuttavia, nei flussi di lavoro reali per la sicurezza dei farmaci, il rischio è a volte un passo in meno: un composto può essere convertito metabolicamente nel corpo in una molecola secondaria (un metabolita) che poi si lega a hERG, una responsabilità che i test di legame diretto possono perdere completamente.
Se il grafico delle proprietà include una tabella dei nodi Metabolite e un arco METABOLISES_INTO, puoi estendere lo stesso pattern MATCH a un attraversamento di 3 hop:
(Compound)-[METABOLISES_INTO]->(Metabolite)-[BINDS_TO]->
(Target)-[PARTICIPATES_IN]->(Pathway)
La struttura della query GQL cambierebbe esattamente di un nodo e un arco. L'SQL equivalente richiederebbe due JOIN aggiuntivi. Questo è il pattern che rende l'attraversamento del grafico particolarmente potente per l'analisi della cascata di sicurezza: la complessità della query cresce linearmente, mentre l'insight biologico cresce in modo esponenziale.
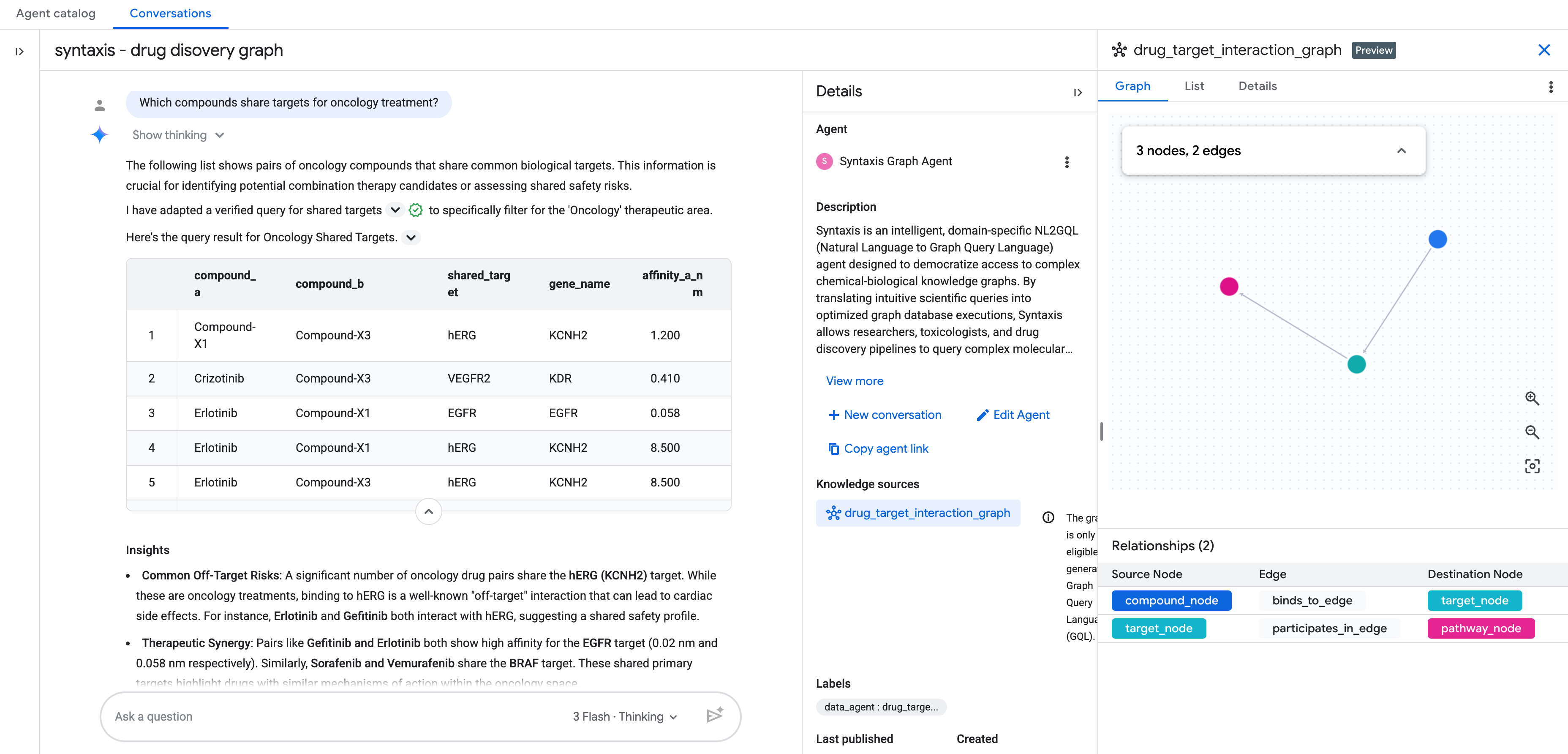
7. Query 3: coppie di composti con target condivisi
Per trovare candidati per la terapia combinata, possiamo identificare quando due composti diversi si legano allo stesso nodo target. Utilizziamo una corrispondenza bidirezionale per rispondere alla domanda: quali composti oncologici convergono sullo stesso target?
Esegui la seguente query nell'editor SQL:
SELECT
compound_a,
compound_b,
shared_target,
gene_name,
ROUND(affinity_a_nm, 3) AS affinity_a_nm,
ROUND(affinity_b_nm, 3) AS affinity_b_nm
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
AND c2.therapeutic_area = 'Oncology'
COLUMNS (
c1.compound_name AS compound_a,
c2.compound_name AS compound_b,
t.target_name AS shared_target,
t.gene_name AS gene_name,
b1.affinity_nm AS affinity_a_nm,
b2.affinity_nm AS affinity_b_nm
)
)
ORDER BY compound_a, compound_b, affinity_a_nm;
Ecco i dati che vedrai nei risultati:

Visualizzazione del grafico
Puoi visualizzare il grafico direttamente in BigQuery eseguendo il seguente codice nell'editor SQL.
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH p = (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
RETURN
TO_JSON(p) AS path
Questo attraversamento bidirezionale mostra le coppie di composti che convergono sullo stesso target proteico, un pattern difficile da individuare in una tabella di interazioni piatta, ma immediatamente visibile come grafico. Nella scoperta di farmaci, le coppie di target condivisi sono il punto di partenza per la progettazione della terapia combinata: due composti che colpiscono lo stesso nodo in un percorso oncologico possono produrre un effetto sinergico o, in alternativa, segnalare una ridondanza non intenzionale nella pipeline
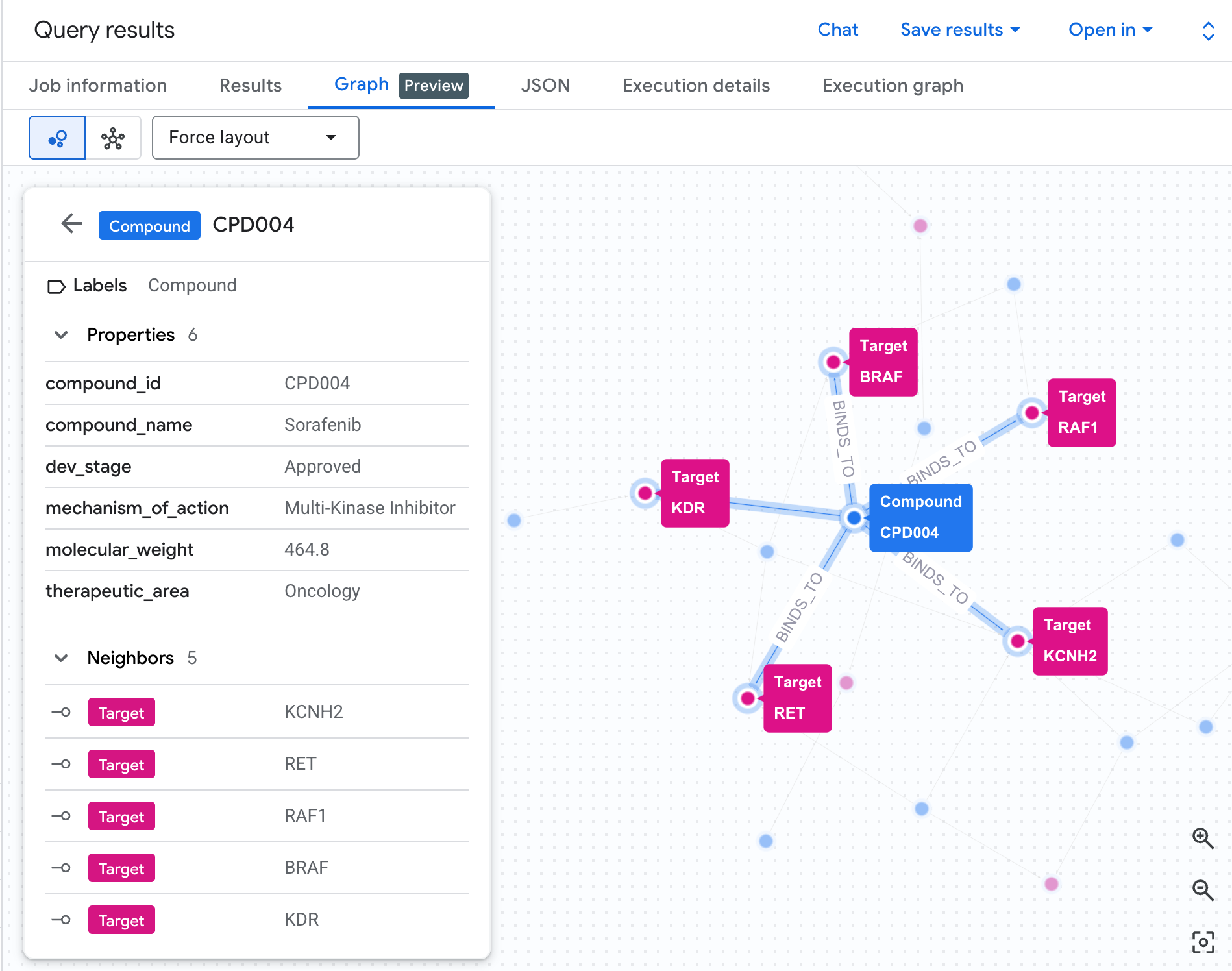
8. Query 4: raggio di impatto del percorso della patologia
Quanto è ampio l'impatto biologico di ogni composto? Eseguiamo un attraversamento di 2 hop con aggregazione per rispondere alla domanda: quanti percorsi biologici e target distinti influiscono su ogni composto, raggruppati per area di malattia?
Esegui la seguente query nell'editor SQL:
SELECT
compound_name,
dev_stage,
disease_area,
COUNT(DISTINCT pathway_id) AS pathways_affected,
COUNT(DISTINCT target_id) AS targets_involved,
STRING_AGG(DISTINCT pathway_name ORDER BY pathway_name) AS pathway_list
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_id AS target_id,
pw.pathway_id AS pathway_id,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
GROUP BY compound_name, dev_stage, disease_area
ORDER BY compound_name, pathways_affected DESC;
Ecco cosa vedrai nei risultati:
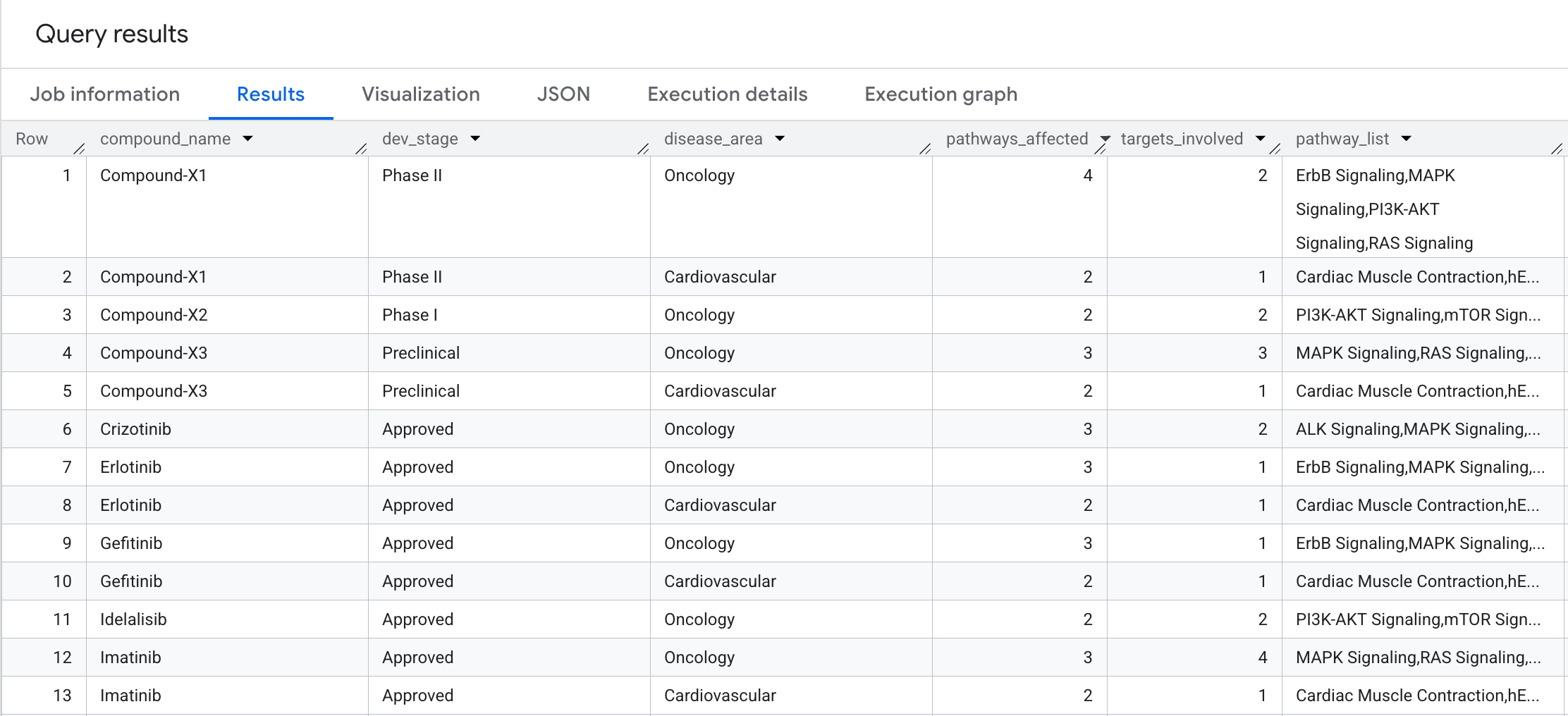
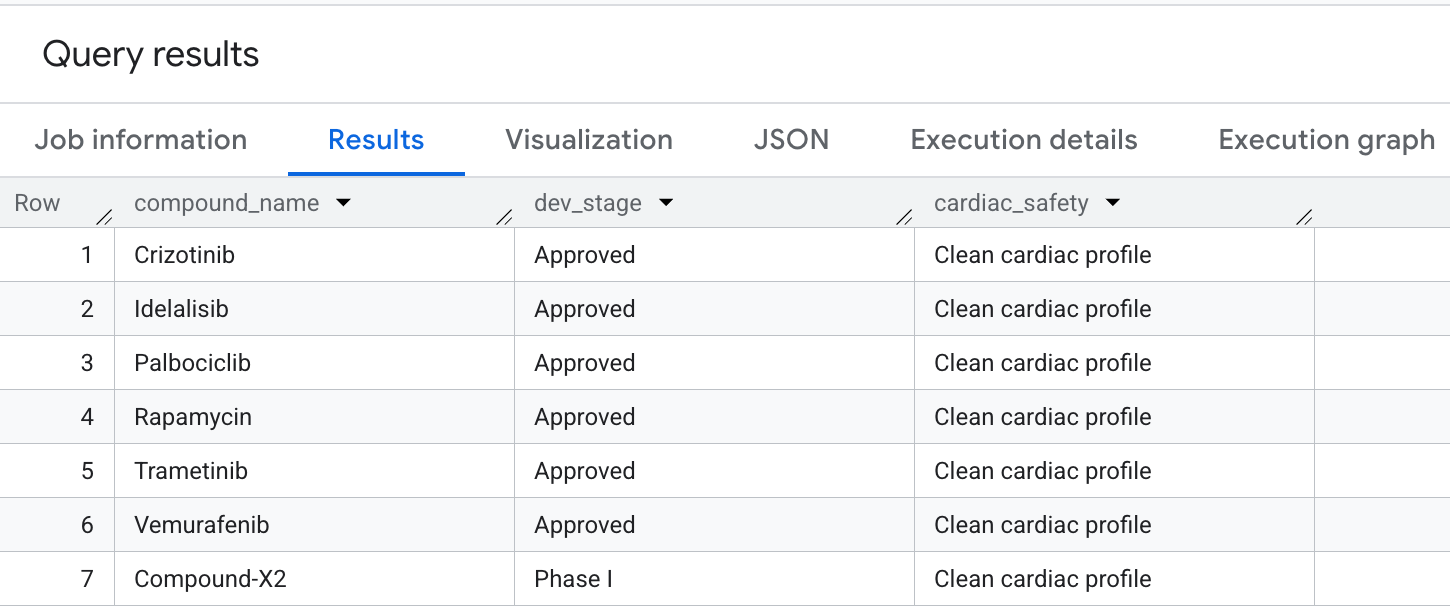
9. Query 5: selezione di composti sicuri
Infine, eseguiamo una query per i composti che hanno un'elevata copertura oncologica, ma evitano esplicitamente le responsabilità off-target hERG (cardiache). Questo corrisponde ai pattern di selezione comuni con priorità alla sicurezza nelle pipeline di scoperta di farmaci.
Esegui la seguente query nell'editor SQL:
WITH oncology_compounds AS (
SELECT DISTINCT compound_id, compound_name, dev_stage
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE pw.disease_area = 'Oncology'
AND pw.cancer_relevance = 'high'
COLUMNS (
c.compound_id AS compound_id,
c.compound_name AS compound_name,
c.dev_stage AS dev_stage
)
)
),
herg_risk_compounds AS (
SELECT DISTINCT compound_id
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
WHERE t.gene_name = 'KCNH2'
COLUMNS (c.compound_id AS compound_id)
)
)
SELECT
o.compound_name,
o.dev_stage,
'Clean cardiac profile' AS cardiac_safety
FROM oncology_compounds o
LEFT JOIN herg_risk_compounds h ON o.compound_id = h.compound_id
WHERE h.compound_id IS NULL
ORDER BY o.dev_stage, o.compound_name;
Ecco l'output che vedrai nei risultati:
Hai eseguito correttamente attraversamenti di grafici avanzati in BigQuery per estrarre i profili chiave di sicurezza ed efficacia.
10. Sezione bonus: chatta con il tuo grafico
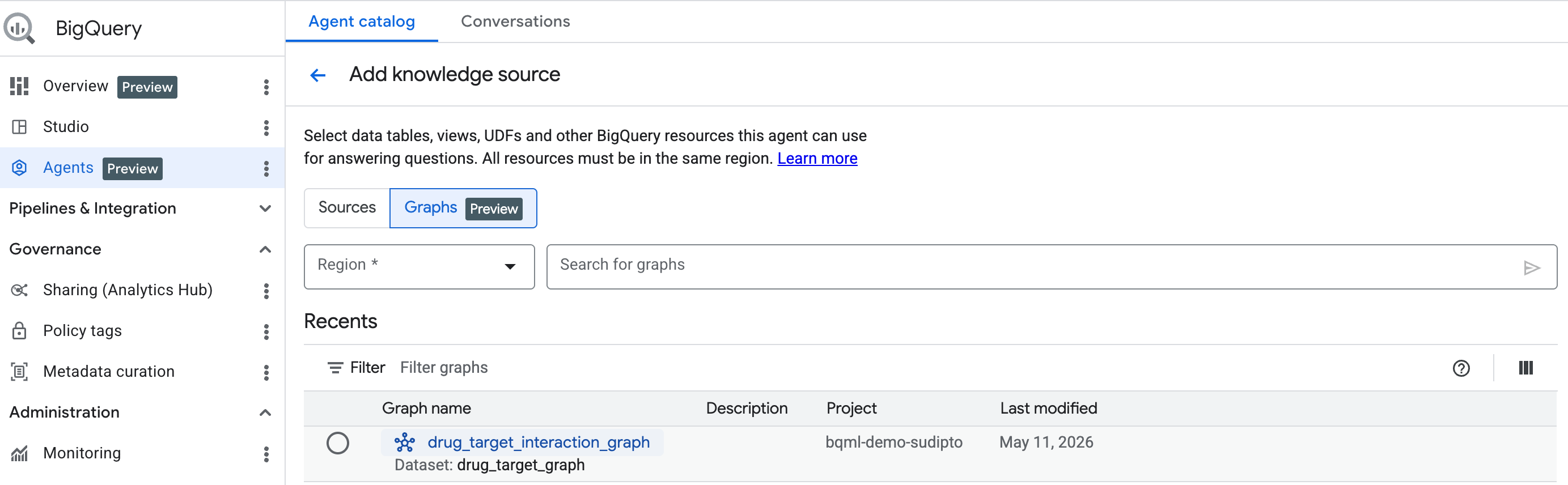
L'analisi conversazionale di BigQuery ora supporta i grafici come fonte di conoscenza. In questo modo puoi chattare con il grafico che hai appena creato in linguaggio naturale.
Inizia: aggiungi un grafico come fonte di conoscenza
Per iniziare, crea un agente conversazionale seguendo i passaggi indicati qui. Seleziona il grafico che hai creato dalla barra di ricerca.
Utilizza l'analisi conversazionale di BigQuery per chattare con il tuo grafico
Dopo aver aggiunto la fonte di conoscenza come grafico, completa il resto della configurazione dell'agente di analisi conversazionale.
A questo punto puoi iniziare a chattare con il tuo grafico in linguaggio naturale.
Ulteriori domande
- Quali sono tutti i target per i composti attualmente in studi di fase 2?
- Quali target sono condivisi tra i composti cardiovascolari e oncologici?
11. Libera spazio
Per evitare addebiti continui sul tuo account Google Cloud, elimina le risorse create durante questo codelab.
Esegui la seguente query per eliminare lo schema e tutte le tabelle in modo a cascata:
DROP SCHEMA IF EXISTS drug_target_graph CASCADE;
12. Complimenti
Complimenti! Hai modellato e analizzato correttamente una rete di interazione farmaco-target utilizzando BigQuery Graph.
Che cosa hai imparato
- Come modellare le relazioni tra entità (composti, target, percorsi) come grafico delle proprietà.
- Come definire lo schema e creare un grafico delle proprietà in BigQuery.
- Come scrivere attraversamenti di grafici complessi utilizzando GQL e confrontarli con SQL tradizionale.
- Come sfruttare
GRAPH_TABLE,MATCHe la corrispondenza bidirezionale per risolvere i problemi del dominio delle scienze della vita.