
1. はじめに
この Codelab では、BigQuery Graph を使用して薬物と標的の相互作用ネットワークをモデル化し、分析する方法を学習します。グラフクエリ(GQL)の機能を利用して、薬物が生物学的標的とどのように相互作用するかを調べ、潜在的な副作用(心臓病のリスクなど)を特定し、潜在的な併用療法を発見します。
🧬 ユースケース - 薬物と標的の相互作用ネットワーク
ビジネス上の質問: 化合物の完全な影響範囲は何ですか?どのターゲットに結合し、どの生物学的経路が影響を受け、どの疾患領域が関与していますか?
テーブル:
テーブル | 説明 |
| 作用機序と開発段階が記載された医薬品分子 |
| 遺伝子名と UniProt ID を含むタンパク質ターゲット |
| 複合ターゲット結合親和性(プライマリ ターゲット + オフターゲット) |
| 疾患領域との関連性を示す生物学的経路 |
| ターゲットを参加する経路にリンクするジャンクション テーブル |
プロパティ グラフモデル:
(Compound)-[BINDS_TO {affinity_nm, ic50_nm, interaction_type}]->(Target)
(Target)-[PARTICIPATES_IN {role, importance_score}]->(Pathway)
🔍 デモクエリ
クエリ | 表示される情報 |
Q1: ターゲット バインディング プロファイル | 1 ホップのトラバーサル - すべてのプライマリ ターゲットとオフターゲットに複合 |
Q2: hERG 心臓リスクの検出 | 2 ホップ トラバーサル - 化合物 → hERG ターゲット → 心臓経路 |
Q3: 共有ターゲットの複合ペア | 双方向一致 - 2 つの化合物が同じターゲット ノードに収束する |
第 4 四半期: 疾患経路の影響範囲 | 2 ホップ集計 - 化合物ごとの完全な経路と疾患領域の範囲 |
Q5: 安全な化合物の選択 | オンコロジーのカバー率が高いが、hERG 心臓毒性がない化合物 |
演習内容
- 薬物相互作用ネットワークの BigQuery データセットとスキーマを作成する
- サンプルデータを読み込む(化合物、ターゲット、相互作用、経路、ターゲット経路)
- これらのエンティティを接続する BigQuery でプロパティ グラフを作成する
- グラフをクエリして、グラフ走査(
GRAPH_TABLEとMATCH)を使用して化合物の相互作用、生物学的経路、疾患の影響範囲を理解する - GQL と標準 SQL を並べて比較し、グラフ構文のシンプルさと表現力を理解する
必要なもの
- ウェブブラウザ(Chrome など)
- 課金を有効にした Google Cloud プロジェクト
この Codelab は、初心者を含むあらゆるレベルのデベロッパーを対象としています。
2. 始める前に
Google Cloud プロジェクトの作成
- Google Cloud コンソールで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトで課金が有効になっていることを確認します。
Cloud Shell の起動
- Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
- 認証を確認します。
gcloud auth list
- プロジェクトを確認します。
gcloud config get project
- 必要に応じて設定します。
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
API を有効にする
次のコマンドを実行して、必要な BigQuery API を有効にします。
gcloud services enable bigquery.googleapis.com
3. スキーマを定義してデータを読み込む
まず、グラフ関連のテーブルを保存するデータセットを作成し、サンプルデータを入力する必要があります。
- Google Cloud コンソールで BigQuery Studio に移動します。
- [SQL エディタ] をクリックして、新しいクエリタブを開きます。
- 次のステートメントを実行して、
drug_target_graphデータセットを作成します。
CREATE SCHEMA IF NOT EXISTS drug_target_graph
OPTIONS (location = 'US');
次に、BigQuery Studio で次の DDL クエリを実行して、5 つのソーステーブルを作成します。
1. compounds テーブルを作成する
薬物分子、その作用機序、開発段階、治療領域が含まれます。
CREATE OR REPLACE TABLE drug_target_graph.compounds AS
SELECT 'CPD001' AS compound_id, 'Imatinib' AS compound_name, 'Kinase Inhibitor' AS mechanism_of_action, 'Approved' AS dev_stage, 'Oncology' AS therapeutic_area, 479.6 AS molecular_weight UNION ALL
SELECT 'CPD002', 'Gefitinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 446.9 UNION ALL
SELECT 'CPD003', 'Erlotinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 393.4 UNION ALL
SELECT 'CPD004', 'Sorafenib', 'Multi-Kinase Inhibitor', 'Approved', 'Oncology', 464.8 UNION ALL
SELECT 'CPD005', 'Vemurafenib', 'BRAF Inhibitor', 'Approved', 'Oncology', 489.9 UNION ALL
SELECT 'CPD006', 'Crizotinib', 'ALK Inhibitor', 'Approved', 'Oncology', 450.3 UNION ALL
SELECT 'CPD007', 'Idelalisib', 'PI3K Inhibitor', 'Approved', 'Oncology', 415.4 UNION ALL
SELECT 'CPD008', 'Trametinib', 'MEK Inhibitor', 'Approved', 'Oncology', 615.4 UNION ALL
SELECT 'CPD009', 'Palbociclib', 'CDK Inhibitor', 'Approved', 'Oncology', 447.5 UNION ALL
SELECT 'CPD010', 'Compound-X1', 'Kinase Inhibitor', 'Phase II', 'Oncology', 412.3 UNION ALL
SELECT 'CPD011', 'Compound-X2', 'PI3K Inhibitor', 'Phase I', 'Oncology', 398.7 UNION ALL
SELECT 'CPD012', 'Saquinavir', 'Protease Inhibitor', 'Approved', 'Infectious Disease', 670.8 UNION ALL
SELECT 'CPD013', 'Metformin', 'AMPK Activator', 'Approved', 'Metabolic', 165.6 UNION ALL
SELECT 'CPD014', 'Rapamycin', 'mTOR Inhibitor', 'Approved', 'Immunology', 914.2 UNION ALL
SELECT 'CPD015', 'Compound-X3', 'Multi-Kinase Inhibitor', 'Preclinical', 'Oncology', 502.1;
2. targets テーブルを作成する
タンパク質ターゲット、遺伝子名、UniProt ID、ターゲット クラスが含まれます。
CREATE OR REPLACE TABLE drug_target_graph.targets AS
SELECT 'TGT001' AS target_id, 'BCR-ABL1' AS target_name, 'ABL1' AS gene_name, 'P00519' AS uniprot_id, 'Kinase' AS target_class, TRUE AS is_oncogene UNION ALL
SELECT 'TGT002', 'EGFR', 'EGFR', 'P00533', 'Kinase', TRUE UNION ALL
SELECT 'TGT003', 'VEGFR2', 'KDR', 'P35968', 'Kinase', FALSE UNION ALL
SELECT 'TGT004', 'BRAF', 'BRAF', 'P15056', 'Kinase', TRUE UNION ALL
SELECT 'TGT005', 'ALK', 'ALK', 'Q9UM73', 'Kinase', TRUE UNION ALL
SELECT 'TGT006', 'PI3K-alpha','PIK3CA', 'P42336', 'Lipid Kinase', TRUE UNION ALL
SELECT 'TGT007', 'MEK1', 'MAP2K1', 'Q02750', 'Kinase', FALSE UNION ALL
SELECT 'TGT008', 'CDK4', 'CDK4', 'P11802', 'Kinase', FALSE UNION ALL
SELECT 'TGT009', 'CDK6', 'CDK6', 'P30279', 'Kinase', FALSE UNION ALL
SELECT 'TGT010', 'mTOR', 'MTOR', 'P42345', 'Kinase', FALSE UNION ALL
SELECT 'TGT011', 'PDGFR-beta','PDGFRB', 'P09619', 'Kinase', FALSE UNION ALL
SELECT 'TGT012', 'c-KIT', 'KIT', 'P10721', 'Kinase', TRUE UNION ALL
SELECT 'TGT013', 'hERG', 'KCNH2', 'Q12809', 'Ion Channel', FALSE UNION ALL
SELECT 'TGT014', 'AMPK', 'PRKAA1', 'Q13131', 'Kinase', FALSE UNION ALL
SELECT 'TGT015', 'RAF1', 'RAF1', 'P04049', 'Kinase', FALSE UNION ALL
SELECT 'TGT016', 'RET', 'RET', 'P07949', 'Kinase', TRUE UNION ALL
SELECT 'TGT017', 'FLT3', 'FLT3', 'P36888', 'Kinase', TRUE UNION ALL
SELECT 'TGT018', 'AKT1', 'AKT1', 'P31749', 'Kinase', FALSE UNION ALL
SELECT 'TGT019', 'ERK2', 'MAPK1', 'P28482', 'Kinase', FALSE UNION ALL
SELECT 'TGT020', 'HIV-Protease','HIV1-PR','Q72547', 'Protease', FALSE;
3. interactions テーブルを作成する
複合ターゲット結合親和性データ(プライマリ ターゲットとオフターゲット)が含まれます。
CREATE OR REPLACE TABLE drug_target_graph.interactions AS
SELECT 'INT001' AS interaction_id, 'CPD001' AS compound_id, 'TGT001' AS target_id, 0.025 AS affinity_nm, 0.038 AS ic50_nm, 'primary' AS interaction_type, 9.8 AS pchembl_value UNION ALL
SELECT 'INT002', 'CPD001', 'TGT011', 0.1, 0.15, 'primary', 8.8 UNION ALL
SELECT 'INT003', 'CPD001', 'TGT012', 0.068, 0.1, 'primary', 9.2 UNION ALL
SELECT 'INT004', 'CPD001', 'TGT016', 0.5, 0.8, 'off-target', 7.4 UNION ALL
SELECT 'INT005', 'CPD001', 'TGT013', 5.2, 8.1, 'off-target', 6.1 UNION ALL
SELECT 'INT006', 'CPD002', 'TGT002', 0.02, 0.033, 'primary', 9.7 UNION ALL
SELECT 'INT007', 'CPD002', 'TGT013', 3.1, 4.8, 'off-target', 6.5 UNION ALL
SELECT 'INT008', 'CPD003', 'TGT002', 0.058, 0.079, 'primary', 9.2 UNION ALL
SELECT 'INT009', 'CPD003', 'TGT013', 8.5, 12.0, 'off-target', 5.9 UNION ALL
SELECT 'INT010', 'CPD004', 'TGT003', 0.09, 0.12, 'primary', 9.1 UNION ALL
SELECT 'INT011', 'CPD004', 'TGT004', 0.038, 0.055, 'primary', 8.9 UNION ALL
SELECT 'INT012', 'CPD004', 'TGT015', 0.22, 0.31, 'primary', 8.5 UNION ALL
SELECT 'INT013', 'CPD004', 'TGT016', 0.58, 0.75, 'primary', 8.1 UNION ALL
SELECT 'INT014', 'CPD004', 'TGT017', 0.33, 0.48, 'primary', 8.4 UNION ALL
SELECT 'INT015', 'CPD004', 'TGT013', 2.8, 4.1, 'off-target', 6.6 UNION ALL
SELECT 'INT016', 'CPD005', 'TGT004', 0.031, 0.044, 'primary', 9.5 UNION ALL
SELECT 'INT017', 'CPD005', 'TGT015', 0.48, 0.65, 'off-target', 7.3 UNION ALL
SELECT 'INT018', 'CPD006', 'TGT005', 0.02, 0.028, 'primary', 9.8 UNION ALL
SELECT 'INT019', 'CPD006', 'TGT003', 0.41, 0.59, 'off-target', 7.4 UNION ALL
SELECT 'INT020', 'CPD007', 'TGT006', 0.019, 0.025, 'primary', 9.8 UNION ALL
SELECT 'INT021', 'CPD007', 'TGT018', 0.55, 0.78, 'off-target', 7.2 UNION ALL
SELECT 'INT022', 'CPD008', 'TGT007', 0.0092, 0.014, 'primary', 10.1 UNION ALL
SELECT 'INT023', 'CPD008', 'TGT019', 0.38, 0.51, 'off-target', 7.4 UNION ALL
SELECT 'INT024', 'CPD009', 'TGT008', 0.011, 0.017, 'primary', 9.9 UNION ALL
SELECT 'INT025', 'CPD009', 'TGT009', 0.015, 0.022, 'primary', 9.8 UNION ALL
SELECT 'INT026', 'CPD010', 'TGT002', 0.041, 0.058, 'primary', 9.4 UNION ALL
SELECT 'INT027', 'CPD010', 'TGT001', 0.38, 0.52, 'off-target', 7.3 UNION ALL
SELECT 'INT028', 'CPD010', 'TGT013', 1.2, 1.8, 'off-target', 7.1 UNION ALL
SELECT 'INT029', 'CPD011', 'TGT006', 0.029, 0.041, 'primary', 9.5 UNION ALL
SELECT 'INT030', 'CPD011', 'TGT010', 0.71, 0.95, 'off-target', 7.0 UNION ALL
SELECT 'INT031', 'CPD012', 'TGT020', 0.39, 0.55, 'primary', 7.3 UNION ALL
SELECT 'INT032', 'CPD013', 'TGT014', 12.0, 18.5, 'primary', 5.7 UNION ALL
SELECT 'INT033', 'CPD014', 'TGT010', 0.0018, 0.0025, 'primary', 11.8 UNION ALL
SELECT 'INT034', 'CPD015', 'TGT004', 0.055, 0.078, 'primary', 9.2 UNION ALL
SELECT 'INT035', 'CPD015', 'TGT003', 0.12, 0.17, 'primary', 8.9 UNION ALL
SELECT 'INT036', 'CPD015', 'TGT016', 0.29, 0.41, 'primary', 8.5 UNION ALL
SELECT 'INT037', 'CPD015', 'TGT013', 0.95, 1.35, 'off-target', 7.2;
4. pathways テーブルを作成する
生物学的経路、関連する疾患領域、がんとの関連性を含みます。
CREATE OR REPLACE TABLE drug_target_graph.pathways AS
SELECT 'PWY001' AS pathway_id, 'MAPK Signaling' AS pathway_name, 'hsa04010' AS kegg_id, 'Cell Proliferation' AS biological_process, 'Oncology' AS disease_area, 'high' AS cancer_relevance UNION ALL
SELECT 'PWY002', 'PI3K-AKT Signaling', 'hsa04151', 'Cell Survival', 'Oncology', 'high' UNION ALL
SELECT 'PWY003', 'VEGF Signaling', 'hsa04370', 'Angiogenesis', 'Oncology', 'high' UNION ALL
SELECT 'PWY004', 'ErbB Signaling', 'hsa04012', 'Cell Growth', 'Oncology', 'high' UNION ALL
SELECT 'PWY005', 'mTOR Signaling', 'hsa04150', 'Cell Growth', 'Oncology', 'medium' UNION ALL
SELECT 'PWY006', 'Cell Cycle', 'hsa04110', 'Cell Division', 'Oncology', 'high' UNION ALL
SELECT 'PWY007', 'Cardiac Muscle Contraction', 'hsa04260', 'Cardiac Function', 'Cardiovascular', 'low' UNION ALL
SELECT 'PWY008', 'hERG Cardiac Channel', 'hsa04022', 'Cardiac Repolarisation','Cardiovascular', 'low' UNION ALL
SELECT 'PWY009', 'AMPK Signaling', 'hsa04152', 'Energy Metabolism', 'Metabolic', 'low' UNION ALL
SELECT 'PWY010', 'ALK Signaling', 'hsa04915', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY011', 'RAS Signaling', 'hsa04014', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY012', 'HIV Replication', 'hsa05170', 'Viral Replication', 'Infectious Disease', 'low';
5. target_pathways テーブルを作成する
ターゲットを、それらが関与する生物学的経路にリンクするジャンクション テーブル。
CREATE OR REPLACE TABLE drug_target_graph.target_pathways AS
SELECT 'TP001' AS tp_id, 'TGT001' AS target_id, 'PWY001' AS pathway_id, 'activator' AS role, 0.95 AS importance_score UNION ALL
SELECT 'TP002', 'TGT001', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP003', 'TGT002', 'PWY004', 'activator', 0.98 UNION ALL
SELECT 'TP004', 'TGT002', 'PWY001', 'activator', 0.82 UNION ALL
SELECT 'TP005', 'TGT002', 'PWY002', 'activator', 0.75 UNION ALL
SELECT 'TP006', 'TGT003', 'PWY003', 'activator', 0.96 UNION ALL
SELECT 'TP007', 'TGT003', 'PWY001', 'activator', 0.71 UNION ALL
SELECT 'TP008', 'TGT004', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP009', 'TGT004', 'PWY011', 'activator', 0.89 UNION ALL
SELECT 'TP010', 'TGT005', 'PWY010', 'activator', 0.99 UNION ALL
SELECT 'TP011', 'TGT005', 'PWY001', 'activator', 0.78 UNION ALL
SELECT 'TP012', 'TGT006', 'PWY002', 'activator', 0.98 UNION ALL
SELECT 'TP013', 'TGT006', 'PWY005', 'activator', 0.85 UNION ALL
SELECT 'TP014', 'TGT007', 'PWY001', 'activator', 0.94 UNION ALL
SELECT 'TP015', 'TGT007', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP016', 'TGT008', 'PWY006', 'activator', 0.95 UNION ALL
SELECT 'TP017', 'TGT009', 'PWY006', 'activator', 0.93 UNION ALL
SELECT 'TP018', 'TGT010', 'PWY005', 'activator', 0.99 UNION ALL
SELECT 'TP019', 'TGT010', 'PWY002', 'activator', 0.91 UNION ALL
SELECT 'TP020', 'TGT011', 'PWY003', 'activator', 0.87 UNION ALL
SELECT 'TP021', 'TGT011', 'PWY001', 'activator', 0.72 UNION ALL
SELECT 'TP022', 'TGT012', 'PWY001', 'activator', 0.83 UNION ALL
SELECT 'TP023', 'TGT012', 'PWY011', 'activator', 0.79 UNION ALL
SELECT 'TP024', 'TGT013', 'PWY008', 'substrate', 0.99 UNION ALL
SELECT 'TP025', 'TGT013', 'PWY007', 'substrate', 0.95 UNION ALL
SELECT 'TP026', 'TGT014', 'PWY009', 'activator', 0.97 UNION ALL
SELECT 'TP027', 'TGT015', 'PWY001', 'activator', 0.91 UNION ALL
SELECT 'TP028', 'TGT015', 'PWY011', 'activator', 0.86 UNION ALL
SELECT 'TP029', 'TGT016', 'PWY001', 'activator', 0.84 UNION ALL
SELECT 'TP030', 'TGT016', 'PWY003', 'activator', 0.77 UNION ALL
SELECT 'TP031', 'TGT017', 'PWY001', 'activator', 0.88 UNION ALL
SELECT 'TP032', 'TGT017', 'PWY011', 'activator', 0.82 UNION ALL
SELECT 'TP033', 'TGT018', 'PWY002', 'activator', 0.96 UNION ALL
SELECT 'TP034', 'TGT018', 'PWY005', 'activator', 0.88 UNION ALL
SELECT 'TP035', 'TGT019', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP036', 'TGT019', 'PWY011', 'activator', 0.91 UNION ALL
SELECT 'TP037', 'TGT020', 'PWY012', 'substrate', 0.99;
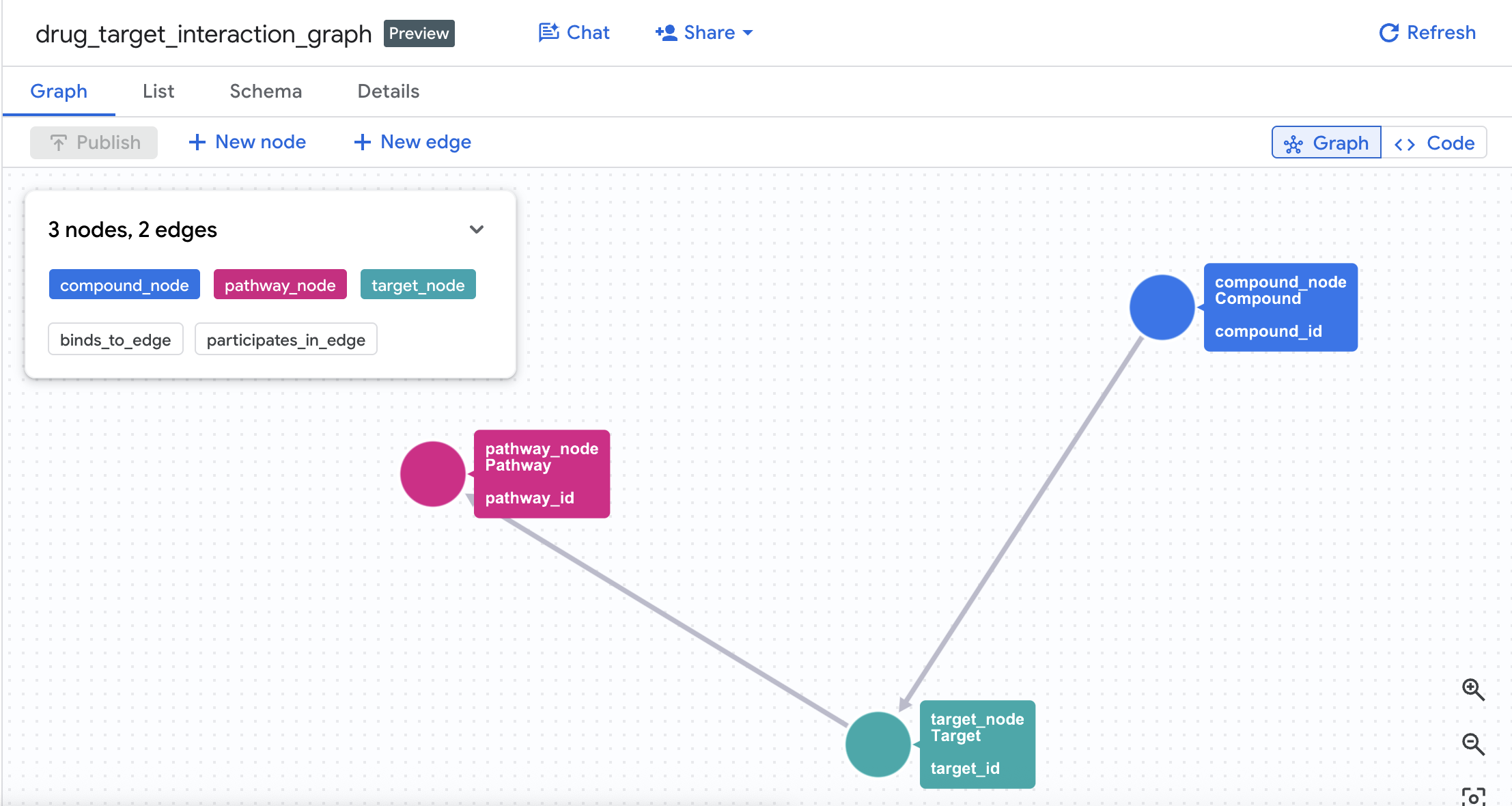
4. プロパティ グラフを作成する
テーブルが正常に作成されたら、プロパティ グラフを構築できます。これにより、エッジテーブル(Interactions と Target Pathways)を使用してノード(化合物、ターゲット、経路)がリンクされます。
BigQuery Studio SQL エディタで次のステートメントを実行します。
CREATE OR REPLACE PROPERTY GRAPH drug_target_graph.drug_target_interaction_graph
NODE TABLES (
drug_target_graph.compounds
AS compound_node
KEY (compound_id)
LABEL Compound
PROPERTIES (compound_id, compound_name, mechanism_of_action, dev_stage, therapeutic_area, molecular_weight),
drug_target_graph.targets
AS target_node
KEY (target_id)
LABEL Target
PROPERTIES (target_id, target_name, gene_name, uniprot_id, target_class, is_oncogene),
drug_target_graph.pathways
AS pathway_node
KEY (pathway_id)
LABEL Pathway
PROPERTIES (pathway_id, pathway_name, kegg_id, biological_process, disease_area, cancer_relevance)
)
EDGE TABLES (
drug_target_graph.interactions
AS binds_to_edge
KEY (interaction_id)
SOURCE KEY (compound_id) REFERENCES compound_node (compound_id)
DESTINATION KEY (target_id) REFERENCES target_node (target_id)
LABEL BINDS_TO
PROPERTIES (interaction_id, affinity_nm, ic50_nm, interaction_type, pchembl_value),
drug_target_graph.target_pathways
AS participates_in_edge
KEY (tp_id)
SOURCE KEY (target_id) REFERENCES target_node (target_id)
DESTINATION KEY (pathway_id) REFERENCES pathway_node (pathway_id)
LABEL PARTICIPATES_IN
PROPERTIES (tp_id, role, importance_score)
);
これにより、データセットに drug_target_interaction_graph というグラフが作成されます。
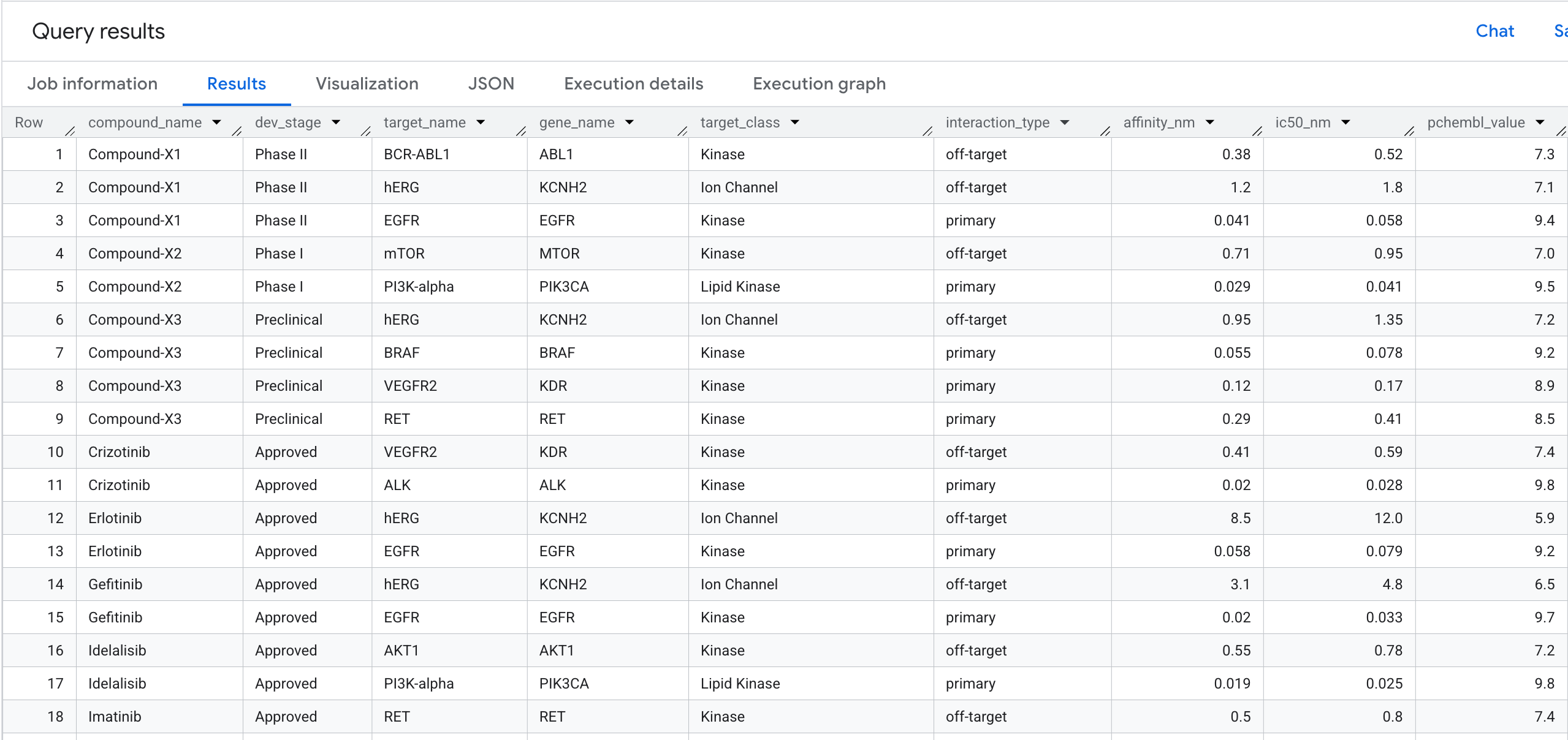
5. クエリ 1: 化合物ごとの完全なターゲット結合プロファイル
最初のグラフクエリを実行しましょう。これは、どの化合物がどのターゲットに結合し、その親和性はどの程度かという質問に答える 1 ホップ トラバーサルです。
GQL クエリ
SQL エディタで次のクエリを実行します。
SELECT
compound_name,
dev_stage,
target_name,
gene_name,
target_class,
interaction_type,
ROUND(affinity_nm, 3) AS affinity_nm,
ROUND(ic50_nm, 3) AS ic50_nm,
pchembl_value
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_name AS target_name,
t.gene_name AS gene_name,
t.target_class AS target_class,
b.interaction_type AS interaction_type,
b.affinity_nm AS affinity_nm,
b.ic50_nm AS ic50_nm,
b.pchembl_value AS pchembl_value
)
)
ORDER BY compound_name, interaction_type, affinity_nm;
結果には次の情報が表示されます。
6. クエリ 2: 心臓病リスクの検出
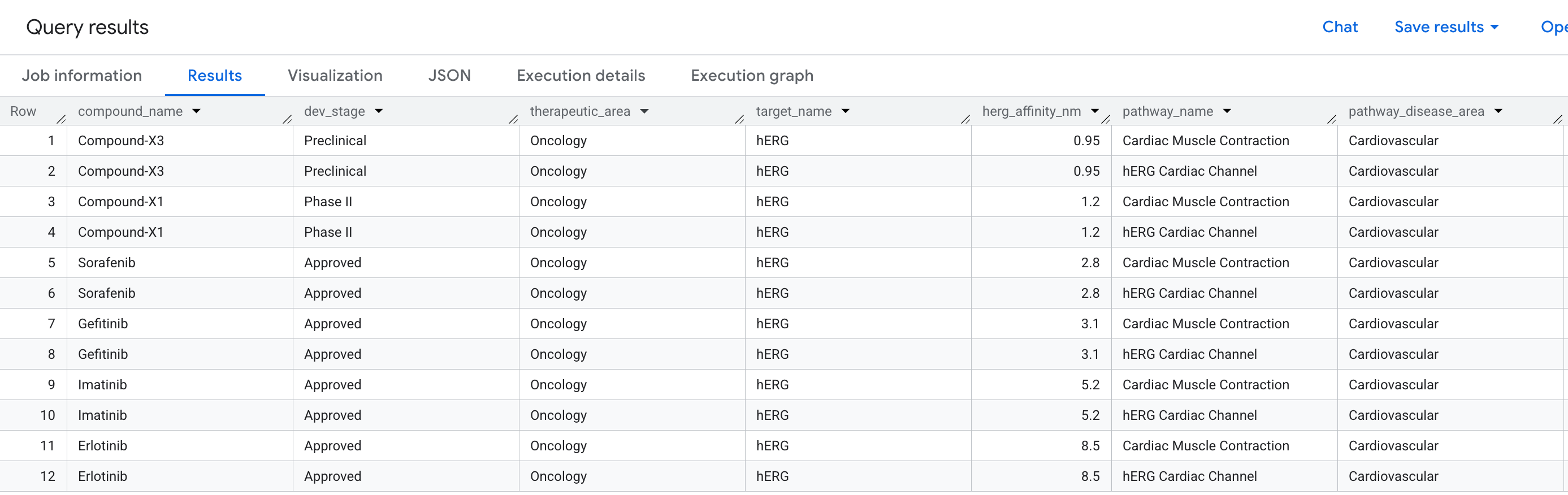
ビジネス上の疑問点
創薬において、有望な化合物が臨床試験で失敗する最も一般的な理由の 1 つは、心臓毒性です。具体的には、心拍リズムを調節するカリウム イオン チャネルである hERG タンパク質(遺伝子: KCNH2)への意図しない結合です。hERG へのオフターゲット ヒットは致死性不整脈を引き起こす可能性があり、いくつかの注目度の高い薬剤の撤回につながっています。
この質問に答えるには、次の手順を行います。
「パイプライン内のどの化合物が hERG タンパク質にオフターゲット結合イベントを起こし、どの心臓経路が危険にさらされるか?」
これは 2 ホップの質問です。Compound から Target(hERG)を経由して Pathway に移動し、1 つのクエリで 2 つの関係にまたがる 3 つのエンティティ タイプを接続する必要があります。
GQL クエリを作成する
BQ SQL エディタで次のクエリを実行します。
SELECT
compound_name,
dev_stage,
therapeutic_area,
target_name,
ROUND(affinity_nm, 3) AS herg_affinity_nm,
pathway_name,
disease_area AS pathway_disease_area
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND b.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
c.therapeutic_area AS therapeutic_area,
t.target_name AS target_name,
b.affinity_nm AS affinity_nm,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
ORDER BY herg_affinity_nm;
MATCH 句は、「Pathway に参加する Target に結合する Compound を見つける」という文のように読み取ることができます。パスに沿った各ノードとエッジにフィルタが適用されます。
結果に表示されるデータは次のとおりです。
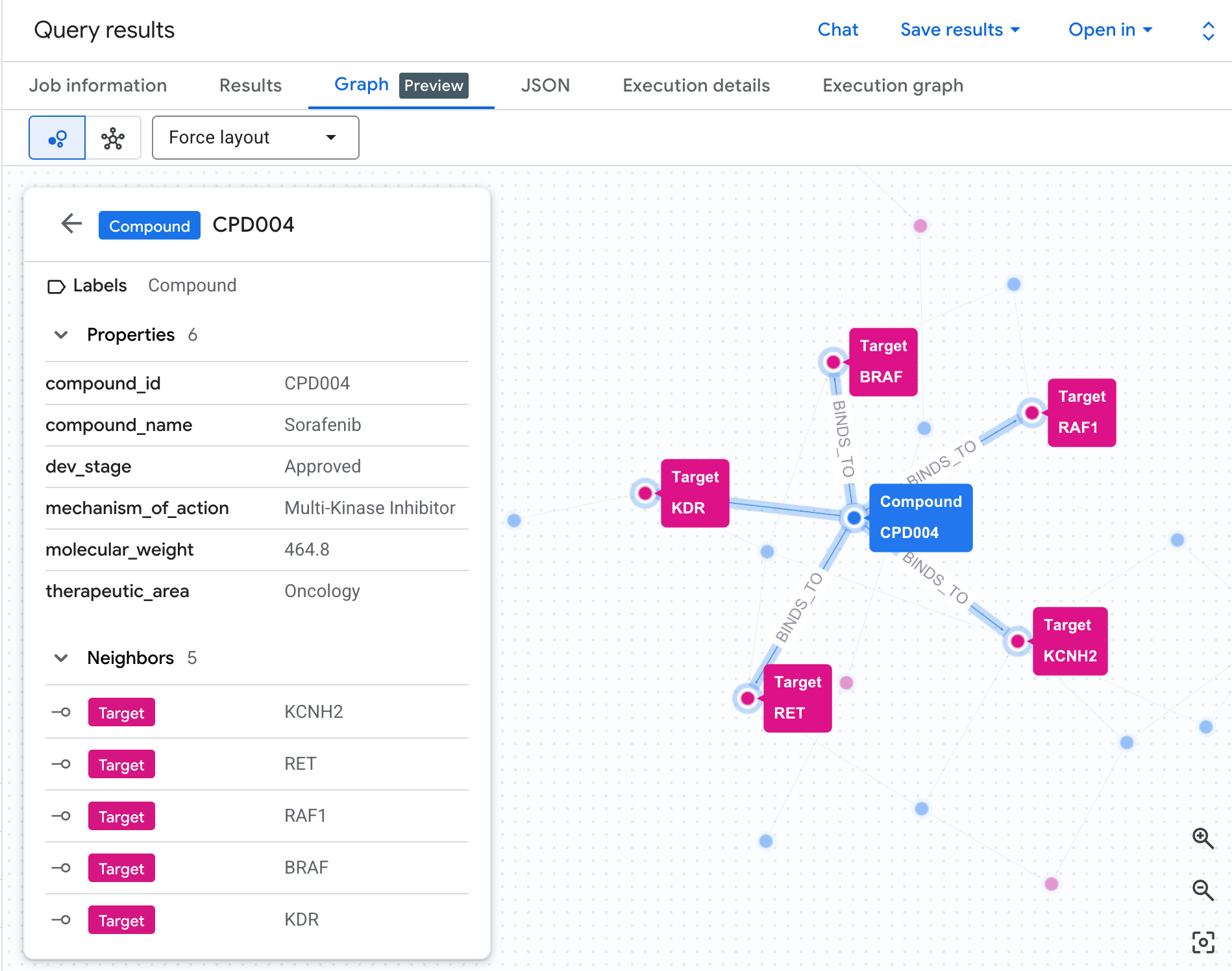
リスク ネットワークをグラフとして可視化する
表にはデータが表示されますが、リスクの構造は表示されません。複数の化合物が同じ経路に収束しているのか、高リスクの化合物が 1 つなのか複数なのか、といったことはわかりません。
グラフの可視化により、これをすぐに確認できます。次のセルを実行して、同じ 2 ホップのトラバーサルをインタラクティブなネットワークとしてレンダリングします。
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH pt = (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND pw.disease_area = 'Cardiovascular'
RETURN
TO_JSON(pt) AS path
次のようなグラフが表示されます。
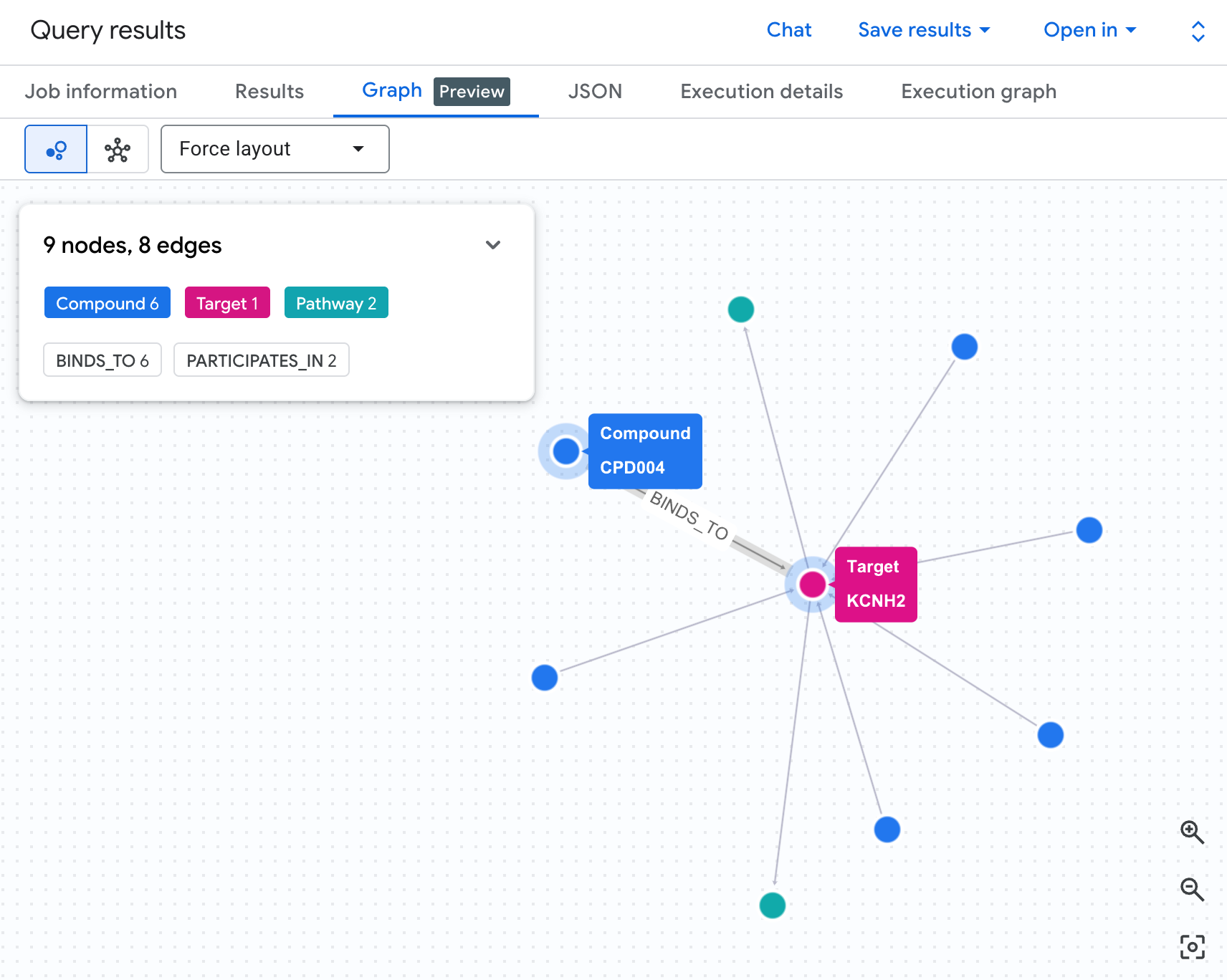
グラフの各パスは、完全な責任連鎖をトレースします。化合物(青いノード)は中央の hERG タンパク質に結合し、1 つ以上の心臓経路(緑色のノード)に接続します。テーブルの行のフラットなリストが、リスク ネットワークとして可視化されました。複数の経路にさらされている化合物は、安全性レビューの優先度が高いものとしてすぐに認識できます。
GQL が SQL より優れている理由をご覧ください
標準 SQL で同じ 2 ホップクエリを実行するには、4 つの明示的な結合が必要です。探している関係性(what)ではなく、テーブルの結合方法(how)を説明するのに認知的な労力を費やしています。GQL を使用すると、質問に集中できます。
SELECT
c.compound_name,
c.dev_stage,
c.therapeutic_area,
t.target_name,
ROUND(i.affinity_nm, 3) AS herg_affinity_nm,
pw.pathway_name,
pw.disease_area AS pathway_disease_area
FROM drug_target_graph.compounds c
JOIN drug_target_graph.interactions i ON c.compound_id = i.compound_id
JOIN drug_target_graph.targets t ON i.target_id = t.target_id
JOIN drug_target_graph.target_pathways tp ON t.target_id = tp.target_id
JOIN drug_target_graph.pathways pw ON tp.pathway_id = pw.pathway_id
WHERE t.gene_name = 'KCNH2'
AND i.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
ORDER BY herg_affinity_nm;
詳細 - マルチホップ代謝産物のリスク検出
上記のクエリは、hERG タンパク質に直接結合する化合物を特定します。しかし、実際の薬物安全性ワークフローでは、リスクが 1 つのステップで取り除かれることがあります。化合物が体内で代謝的に二次分子(代謝産物)に変換され、それが hERG に結合する可能性があります。これは、直接結合アッセイでは完全に検出できない可能性があります。
プロパティ グラフに Metabolite ノードテーブルと METABOLISES_INTO エッジが含まれている場合は、同じ MATCH パターンを 3 ホップのトラバーサルに拡張できます。
(Compound)-[METABOLISES_INTO]->(Metabolite)-[BINDS_TO]->
(Target)-[PARTICIPATES_IN]->(Pathway)
GQL クエリ構造は、ノードとエッジが 1 つずつ変更されます。同等の SQL では、2 つの JOIN が追加で必要になります。このパターンにより、グラフ トラバーサルは安全性カスケード分析に特に強力なツールとなります。クエリの複雑さは線形に増加しますが、生物学的洞察は指数関数的に増加します。
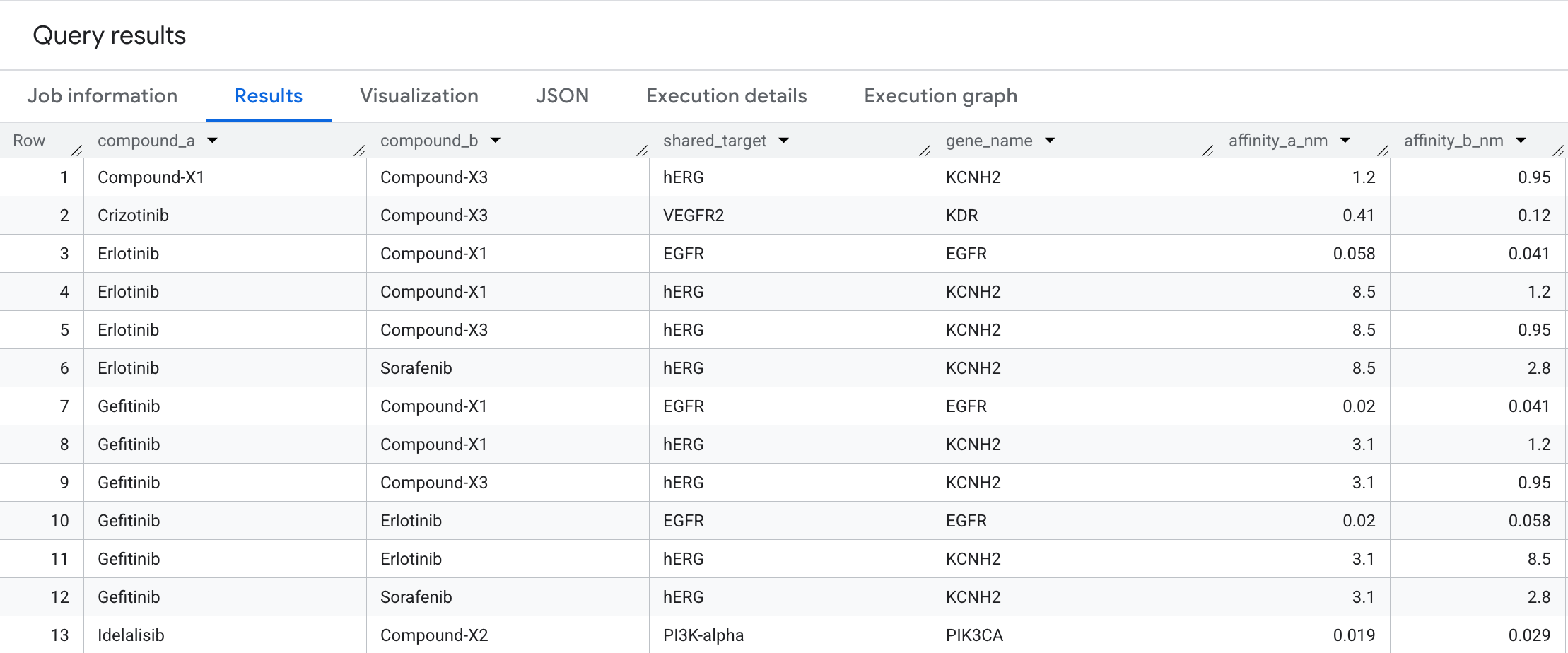
7. クエリ 3: 共有ターゲットの複合ペア
併用療法の候補を見つけるには、2 つの異なる化合物が同じターゲット ノードに結合するタイミングを特定します。双方向一致を使用して、「どの腫瘍化合物がまったく同じターゲットに収束するのか」という質問に答えます。
SQL エディタで次のクエリを実行します。
SELECT
compound_a,
compound_b,
shared_target,
gene_name,
ROUND(affinity_a_nm, 3) AS affinity_a_nm,
ROUND(affinity_b_nm, 3) AS affinity_b_nm
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
AND c2.therapeutic_area = 'Oncology'
COLUMNS (
c1.compound_name AS compound_a,
c2.compound_name AS compound_b,
t.target_name AS shared_target,
t.gene_name AS gene_name,
b1.affinity_nm AS affinity_a_nm,
b2.affinity_nm AS affinity_b_nm
)
)
ORDER BY compound_a, compound_b, affinity_a_nm;
結果に表示されるデータは次のとおりです。
グラフの可視化
SQL エディタで次のコードを実行すると、グラフを BigQuery で直接可視化できます。
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH p = (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
RETURN
TO_JSON(p) AS path
この双方向トラバーサルでは、同じタンパク質ターゲットに収束する複合ペアが検出されます。このパターンは、フラットな相互作用テーブルでは見つけにくいですが、グラフとして表示するとすぐにわかります。創薬では、共有ターゲット ペアは併用療法の設計の出発点となります。がん経路の同じノードに作用する 2 つの化合物は、相乗効果を生み出す可能性があります。また、パイプラインで意図しない冗長性を示す可能性もあります。
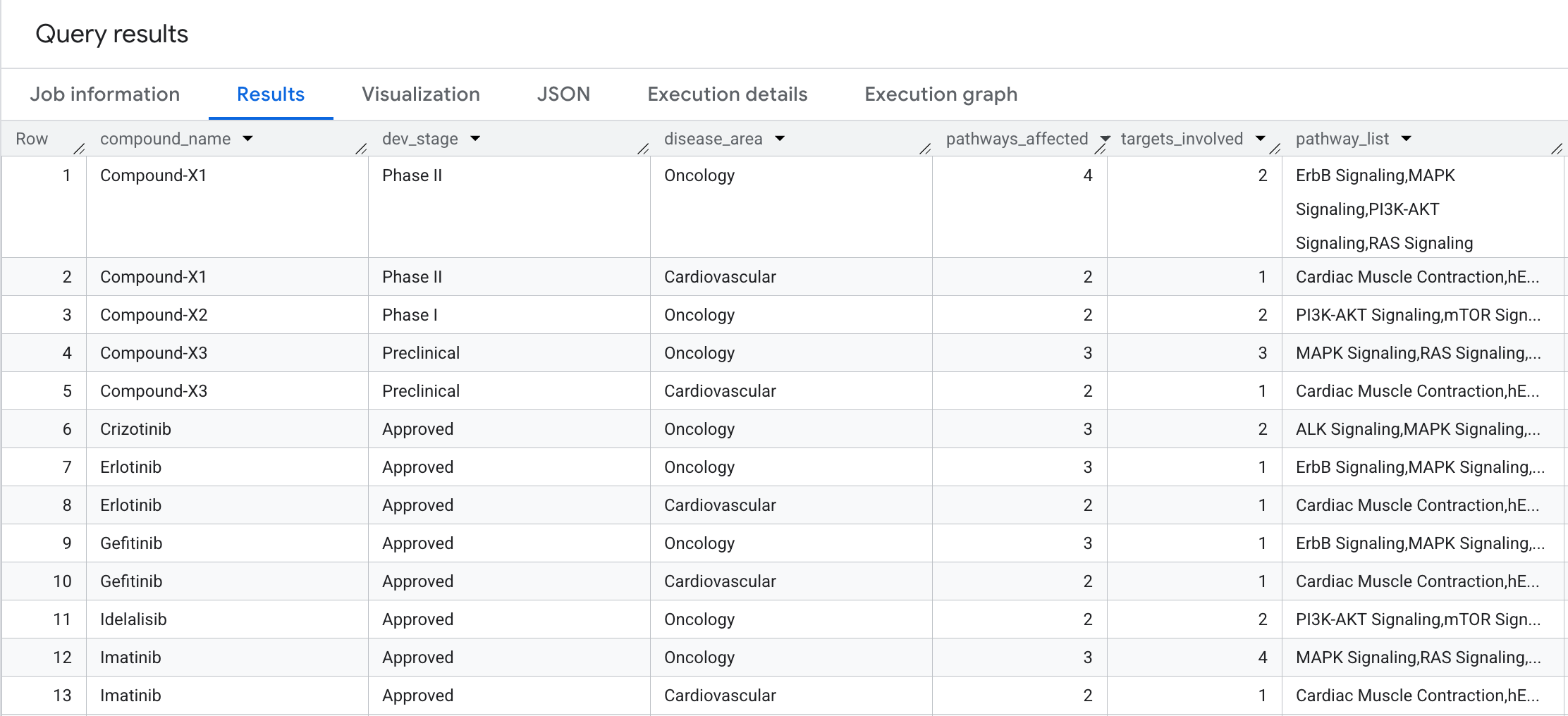
8. クエリ 4: 疾患経路の爆発半径
各化合物の生物学的影響はどの程度広範囲に及ぶか。集計を使用した 2 ホップ トラバーサルを実行して、各化合物が影響を与える生物学的経路と個別のターゲットの数を疾患領域別にグループ化して調べます。
SQL エディタで次のクエリを実行します。
SELECT
compound_name,
dev_stage,
disease_area,
COUNT(DISTINCT pathway_id) AS pathways_affected,
COUNT(DISTINCT target_id) AS targets_involved,
STRING_AGG(DISTINCT pathway_name ORDER BY pathway_name) AS pathway_list
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_id AS target_id,
pw.pathway_id AS pathway_id,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
GROUP BY compound_name, dev_stage, disease_area
ORDER BY compound_name, pathways_affected DESC;
結果には次の情報が表示されます。
9. クエリ 5: 安全な化合物の選択
最後に、オンコロジーの対象範囲が広く、hERG(心臓)のオフターゲットの負債を明示的に回避する化合物をクエリします。これは、創薬パイプラインで一般的な安全第一の選択パターンに一致します。
SQL エディタで次のクエリを実行します。
WITH oncology_compounds AS (
SELECT DISTINCT compound_id, compound_name, dev_stage
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE pw.disease_area = 'Oncology'
AND pw.cancer_relevance = 'high'
COLUMNS (
c.compound_id AS compound_id,
c.compound_name AS compound_name,
c.dev_stage AS dev_stage
)
)
),
herg_risk_compounds AS (
SELECT DISTINCT compound_id
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
WHERE t.gene_name = 'KCNH2'
COLUMNS (c.compound_id AS compound_id)
)
)
SELECT
o.compound_name,
o.dev_stage,
'Clean cardiac profile' AS cardiac_safety
FROM oncology_compounds o
LEFT JOIN herg_risk_compounds h ON o.compound_id = h.compound_id
WHERE h.compound_id IS NULL
ORDER BY o.dev_stage, o.compound_name;
結果には次の出力が表示されます。
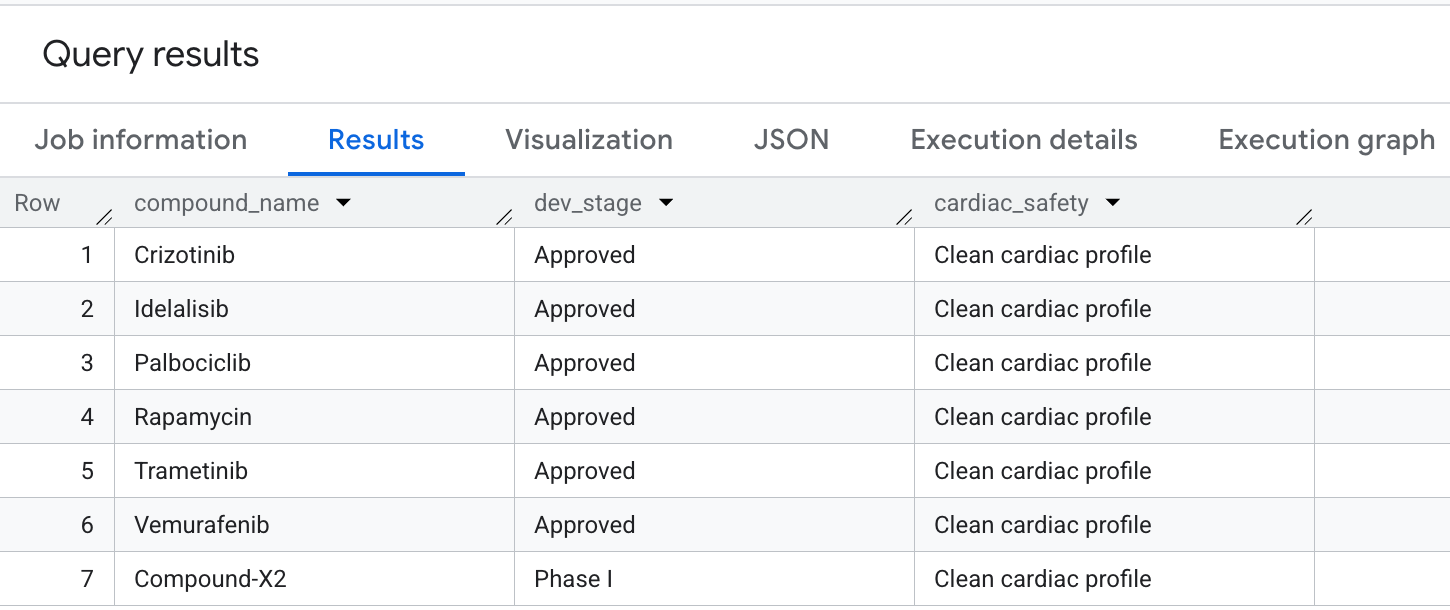
BigQuery で高度なグラフ トラバーサルを実行して、安全性と有効性の重要なプロファイルを抽出できました。
10. ボーナス セクション: グラフとチャットする
BigQuery の会話型分析で、ナレッジソースとしてグラフがサポートされるようになりました。これにより、作成したグラフと自然言語でチャットできます。
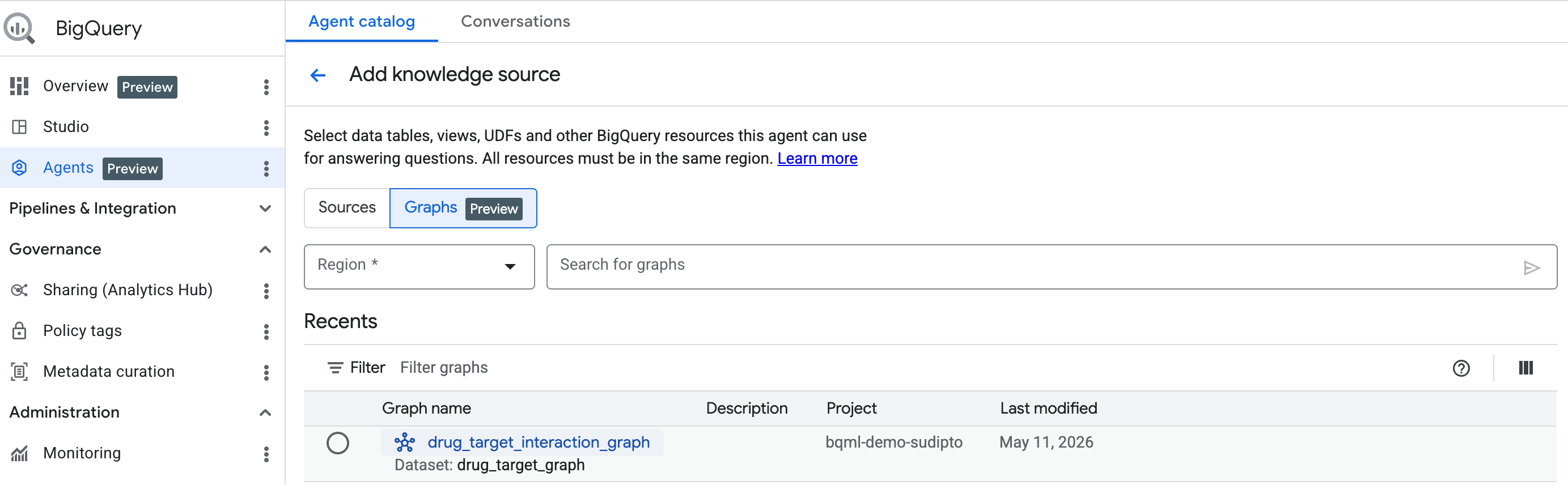
スタートガイド: グラフをナレッジソースとして追加する
まず、こちらの手順に沿って会話型エージェントを作成します。検索バーから作成したグラフを選択します。
BigQuery 会話型分析を使用してグラフとチャットする
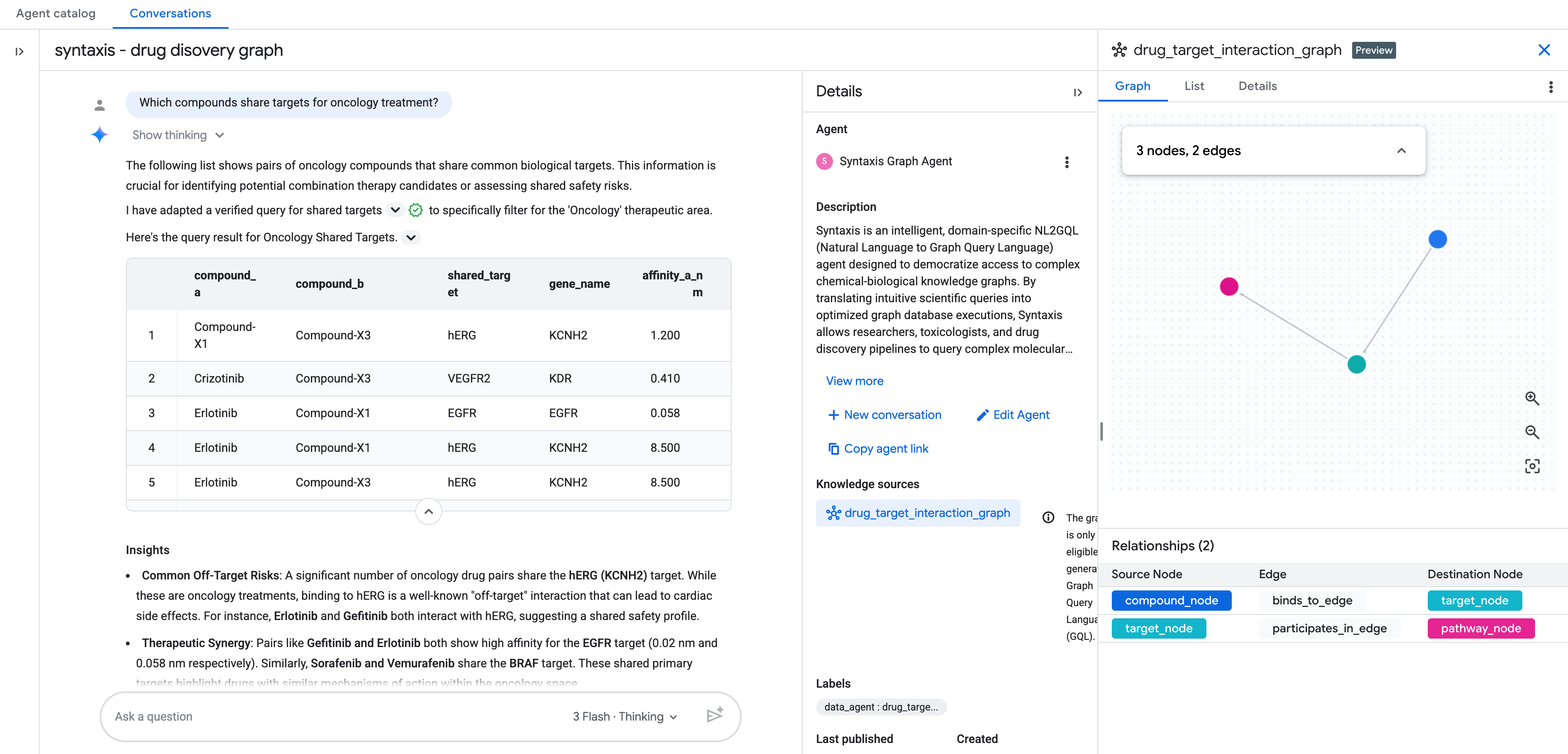
ナレッジソースをグラフとして追加したら、会話分析エージェントの残りの設定を完了します。
その後、自然言語でグラフとのチャットを開始できます。
その他の質問
- 現在第 2 相試験中の化合物の標的をすべて教えてください。
- 心血管疾患と腫瘍学の化合物間で共有されているターゲットはどれですか?
11. クリーンアップ
Google Cloud アカウントに継続的に課金されないようにするには、この Codelab で作成したリソースを削除します。
次のクエリを実行して、スキーマとすべてのテーブルをカスケード削除します。
DROP SCHEMA IF EXISTS drug_target_graph CASCADE;
12. 完了
おめでとうございます!BigQuery Graph を使用して、薬物と標的の相互作用ネットワークをモデル化して分析できました。
学習した内容
- エンティティ関係(化合物、ターゲット、経路)をプロパティ グラフとしてモデル化する方法。
- BigQuery でスキーマを定義してプロパティ グラフを作成する方法。
- GQL を使用して複雑なグラフ トラバーサルを作成し、従来の SQL と比較する方法。
GRAPH_TABLE、MATCH、双方向一致を活用してライフ サイエンス ドメインの問題を解決する方法。