
1. 소개
이 Codelab에서는 BigQuery Graph를 사용하여 약물-표적 상호작용 네트워크를 모델링하고 분석하는 방법을 알아봅니다. 그래프 쿼리 (GQL)의 기능을 활용하여 약물이 생물학적 표적과 상호작용하는 방식, 잠재적 부작용 (예: 심장 위험)을 식별하고 잠재적 병용 요법을 발견합니다.
🧬 사용 사례 — 약물-표적 상호작용 네트워크
비즈니스 질문: 화합물의 전체 영향 범위는 무엇인가요? 어떤 표적에 결합하고, 어떤 생물학적 경로가 영향을 받으며, 어떤 질병 영역이 관련되어 있나요?
테이블:
표 | 설명 |
| 작용 메커니즘 및 개발 단계가 있는 약물 분자 |
| 유전자 이름 및 UniProt ID가 있는 단백질 표적 |
| 화합물-표적 결합 친화도 (기본 표적 + 오프 표적) |
| 질병 영역 연결이 있는 생물학적 경로 |
| 표적을 참여하는 경로에 연결하는 교차 테이블 |
속성 그래프 모델:
(Compound)-[BINDS_TO {affinity_nm, ic50_nm, interaction_type}]->(Target)
(Target)-[PARTICIPATES_IN {role, importance_score}]->(Pathway)
🔍 데모 쿼리
쿼리 | 표시되는 정보 |
Q1: 표적 결합 프로필 | 1홉 순회 — 화합물에서 모든 기본 및 오프 표적으로 |
Q2: hERG 심장 위험 감지 | 2홉 순회 — 화합물 → hERG 표적 → 심장 경로 |
Q3: 공유 표적 화합물 쌍 | 양방향 일치 — 동일한 표적 노드로 수렴하는 두 화합물 |
Q4: 질병 경로 폭발 반경 | 2홉 집계 — 화합물당 전체 경로 및 질병 영역 범위 |
Q5: 안전한 화합물 선택 | 종양학 범위가 넓지만 hERG 심장 책임이 없는 화합물 |
실습할 내용
- 약물 상호작용 네트워크를 위한 BigQuery 데이터 세트 및 스키마 만들기
- 샘플 데이터 로드 (화합물, 표적, 상호작용, 경로, 표적 경로)
- 이러한 항목을 연결하는 BigQuery에서 속성 그래프 만들기
- 그래프 순회 (
GRAPH_TABLE및MATCH)를 사용하여 화합물 상호작용, 생물학적 경로, 질병 영향 범위를 파악하기 위해 그래프 쿼리 - GQL과 표준 SQL을 나란히 비교하여 그래프 구문의 단순성과 표현력 이해
필요한 항목
- 웹브라우저(예: Chrome)
- 결제가 사용 설정된 Google Cloud 프로젝트
이 Codelab은 초보자를 포함한 모든 수준의 개발자를 대상으로 합니다.
2. 시작하기 전에
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔에서 Google Cloud 프로젝트를 선택하거나 생성합니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다.
Cloud Shell 시작
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화 를 클릭합니다.
- 인증 확인
gcloud auth list
- 프로젝트 확인하기
gcloud config get project
- 필요한 경우 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
API 사용 설정
이 명령어를 실행하여 필수 BigQuery API를 사용 설정합니다.
gcloud services enable bigquery.googleapis.com
3. 스키마 정의 및 데이터 로드
먼저 그래프 관련 테이블을 저장할 데이터 세트를 만들고 샘플 데이터로 채워야 합니다.
- Google Cloud 콘솔에서 BigQuery Studio 로 이동합니다.
- SQL 편집기 를 클릭하여 새 쿼리 탭을 엽니다.
- 다음 문을 실행하여
drug_target_graph데이터 세트를 만듭니다.
CREATE SCHEMA IF NOT EXISTS drug_target_graph
OPTIONS (location = 'US');
이제 BigQuery Studio에서 다음 DDL 쿼리를 실행하여 5개의 소스 테이블을 만듭니다.
1. compounds 테이블 만들기
의약품 분자, 작용 메커니즘, 개발 단계, 치료 영역이 포함됩니다.
CREATE OR REPLACE TABLE drug_target_graph.compounds AS
SELECT 'CPD001' AS compound_id, 'Imatinib' AS compound_name, 'Kinase Inhibitor' AS mechanism_of_action, 'Approved' AS dev_stage, 'Oncology' AS therapeutic_area, 479.6 AS molecular_weight UNION ALL
SELECT 'CPD002', 'Gefitinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 446.9 UNION ALL
SELECT 'CPD003', 'Erlotinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 393.4 UNION ALL
SELECT 'CPD004', 'Sorafenib', 'Multi-Kinase Inhibitor', 'Approved', 'Oncology', 464.8 UNION ALL
SELECT 'CPD005', 'Vemurafenib', 'BRAF Inhibitor', 'Approved', 'Oncology', 489.9 UNION ALL
SELECT 'CPD006', 'Crizotinib', 'ALK Inhibitor', 'Approved', 'Oncology', 450.3 UNION ALL
SELECT 'CPD007', 'Idelalisib', 'PI3K Inhibitor', 'Approved', 'Oncology', 415.4 UNION ALL
SELECT 'CPD008', 'Trametinib', 'MEK Inhibitor', 'Approved', 'Oncology', 615.4 UNION ALL
SELECT 'CPD009', 'Palbociclib', 'CDK Inhibitor', 'Approved', 'Oncology', 447.5 UNION ALL
SELECT 'CPD010', 'Compound-X1', 'Kinase Inhibitor', 'Phase II', 'Oncology', 412.3 UNION ALL
SELECT 'CPD011', 'Compound-X2', 'PI3K Inhibitor', 'Phase I', 'Oncology', 398.7 UNION ALL
SELECT 'CPD012', 'Saquinavir', 'Protease Inhibitor', 'Approved', 'Infectious Disease', 670.8 UNION ALL
SELECT 'CPD013', 'Metformin', 'AMPK Activator', 'Approved', 'Metabolic', 165.6 UNION ALL
SELECT 'CPD014', 'Rapamycin', 'mTOR Inhibitor', 'Approved', 'Immunology', 914.2 UNION ALL
SELECT 'CPD015', 'Compound-X3', 'Multi-Kinase Inhibitor', 'Preclinical', 'Oncology', 502.1;
2. targets 테이블 만들기
단백질 표적, 유전자 이름, UniProt ID, 표적 클래스가 포함됩니다.
CREATE OR REPLACE TABLE drug_target_graph.targets AS
SELECT 'TGT001' AS target_id, 'BCR-ABL1' AS target_name, 'ABL1' AS gene_name, 'P00519' AS uniprot_id, 'Kinase' AS target_class, TRUE AS is_oncogene UNION ALL
SELECT 'TGT002', 'EGFR', 'EGFR', 'P00533', 'Kinase', TRUE UNION ALL
SELECT 'TGT003', 'VEGFR2', 'KDR', 'P35968', 'Kinase', FALSE UNION ALL
SELECT 'TGT004', 'BRAF', 'BRAF', 'P15056', 'Kinase', TRUE UNION ALL
SELECT 'TGT005', 'ALK', 'ALK', 'Q9UM73', 'Kinase', TRUE UNION ALL
SELECT 'TGT006', 'PI3K-alpha','PIK3CA', 'P42336', 'Lipid Kinase', TRUE UNION ALL
SELECT 'TGT007', 'MEK1', 'MAP2K1', 'Q02750', 'Kinase', FALSE UNION ALL
SELECT 'TGT008', 'CDK4', 'CDK4', 'P11802', 'Kinase', FALSE UNION ALL
SELECT 'TGT009', 'CDK6', 'CDK6', 'P30279', 'Kinase', FALSE UNION ALL
SELECT 'TGT010', 'mTOR', 'MTOR', 'P42345', 'Kinase', FALSE UNION ALL
SELECT 'TGT011', 'PDGFR-beta','PDGFRB', 'P09619', 'Kinase', FALSE UNION ALL
SELECT 'TGT012', 'c-KIT', 'KIT', 'P10721', 'Kinase', TRUE UNION ALL
SELECT 'TGT013', 'hERG', 'KCNH2', 'Q12809', 'Ion Channel', FALSE UNION ALL
SELECT 'TGT014', 'AMPK', 'PRKAA1', 'Q13131', 'Kinase', FALSE UNION ALL
SELECT 'TGT015', 'RAF1', 'RAF1', 'P04049', 'Kinase', FALSE UNION ALL
SELECT 'TGT016', 'RET', 'RET', 'P07949', 'Kinase', TRUE UNION ALL
SELECT 'TGT017', 'FLT3', 'FLT3', 'P36888', 'Kinase', TRUE UNION ALL
SELECT 'TGT018', 'AKT1', 'AKT1', 'P31749', 'Kinase', FALSE UNION ALL
SELECT 'TGT019', 'ERK2', 'MAPK1', 'P28482', 'Kinase', FALSE UNION ALL
SELECT 'TGT020', 'HIV-Protease','HIV1-PR','Q72547', 'Protease', FALSE;
3. interactions 테이블 만들기
화합물-표적 결합 친화도 데이터 (기본 표적과 오프 표적)가 포함됩니다.
CREATE OR REPLACE TABLE drug_target_graph.interactions AS
SELECT 'INT001' AS interaction_id, 'CPD001' AS compound_id, 'TGT001' AS target_id, 0.025 AS affinity_nm, 0.038 AS ic50_nm, 'primary' AS interaction_type, 9.8 AS pchembl_value UNION ALL
SELECT 'INT002', 'CPD001', 'TGT011', 0.1, 0.15, 'primary', 8.8 UNION ALL
SELECT 'INT003', 'CPD001', 'TGT012', 0.068, 0.1, 'primary', 9.2 UNION ALL
SELECT 'INT004', 'CPD001', 'TGT016', 0.5, 0.8, 'off-target', 7.4 UNION ALL
SELECT 'INT005', 'CPD001', 'TGT013', 5.2, 8.1, 'off-target', 6.1 UNION ALL
SELECT 'INT006', 'CPD002', 'TGT002', 0.02, 0.033, 'primary', 9.7 UNION ALL
SELECT 'INT007', 'CPD002', 'TGT013', 3.1, 4.8, 'off-target', 6.5 UNION ALL
SELECT 'INT008', 'CPD003', 'TGT002', 0.058, 0.079, 'primary', 9.2 UNION ALL
SELECT 'INT009', 'CPD003', 'TGT013', 8.5, 12.0, 'off-target', 5.9 UNION ALL
SELECT 'INT010', 'CPD004', 'TGT003', 0.09, 0.12, 'primary', 9.1 UNION ALL
SELECT 'INT011', 'CPD004', 'TGT004', 0.038, 0.055, 'primary', 8.9 UNION ALL
SELECT 'INT012', 'CPD004', 'TGT015', 0.22, 0.31, 'primary', 8.5 UNION ALL
SELECT 'INT013', 'CPD004', 'TGT016', 0.58, 0.75, 'primary', 8.1 UNION ALL
SELECT 'INT014', 'CPD004', 'TGT017', 0.33, 0.48, 'primary', 8.4 UNION ALL
SELECT 'INT015', 'CPD004', 'TGT013', 2.8, 4.1, 'off-target', 6.6 UNION ALL
SELECT 'INT016', 'CPD005', 'TGT004', 0.031, 0.044, 'primary', 9.5 UNION ALL
SELECT 'INT017', 'CPD005', 'TGT015', 0.48, 0.65, 'off-target', 7.3 UNION ALL
SELECT 'INT018', 'CPD006', 'TGT005', 0.02, 0.028, 'primary', 9.8 UNION ALL
SELECT 'INT019', 'CPD006', 'TGT003', 0.41, 0.59, 'off-target', 7.4 UNION ALL
SELECT 'INT020', 'CPD007', 'TGT006', 0.019, 0.025, 'primary', 9.8 UNION ALL
SELECT 'INT021', 'CPD007', 'TGT018', 0.55, 0.78, 'off-target', 7.2 UNION ALL
SELECT 'INT022', 'CPD008', 'TGT007', 0.0092, 0.014, 'primary', 10.1 UNION ALL
SELECT 'INT023', 'CPD008', 'TGT019', 0.38, 0.51, 'off-target', 7.4 UNION ALL
SELECT 'INT024', 'CPD009', 'TGT008', 0.011, 0.017, 'primary', 9.9 UNION ALL
SELECT 'INT025', 'CPD009', 'TGT009', 0.015, 0.022, 'primary', 9.8 UNION ALL
SELECT 'INT026', 'CPD010', 'TGT002', 0.041, 0.058, 'primary', 9.4 UNION ALL
SELECT 'INT027', 'CPD010', 'TGT001', 0.38, 0.52, 'off-target', 7.3 UNION ALL
SELECT 'INT028', 'CPD010', 'TGT013', 1.2, 1.8, 'off-target', 7.1 UNION ALL
SELECT 'INT029', 'CPD011', 'TGT006', 0.029, 0.041, 'primary', 9.5 UNION ALL
SELECT 'INT030', 'CPD011', 'TGT010', 0.71, 0.95, 'off-target', 7.0 UNION ALL
SELECT 'INT031', 'CPD012', 'TGT020', 0.39, 0.55, 'primary', 7.3 UNION ALL
SELECT 'INT032', 'CPD013', 'TGT014', 12.0, 18.5, 'primary', 5.7 UNION ALL
SELECT 'INT033', 'CPD014', 'TGT010', 0.0018, 0.0025, 'primary', 11.8 UNION ALL
SELECT 'INT034', 'CPD015', 'TGT004', 0.055, 0.078, 'primary', 9.2 UNION ALL
SELECT 'INT035', 'CPD015', 'TGT003', 0.12, 0.17, 'primary', 8.9 UNION ALL
SELECT 'INT036', 'CPD015', 'TGT016', 0.29, 0.41, 'primary', 8.5 UNION ALL
SELECT 'INT037', 'CPD015', 'TGT013', 0.95, 1.35, 'off-target', 7.2;
4. pathways 테이블 만들기
생물학적 경로, 관련 질병 영역, 암 관련성이 포함됩니다.
CREATE OR REPLACE TABLE drug_target_graph.pathways AS
SELECT 'PWY001' AS pathway_id, 'MAPK Signaling' AS pathway_name, 'hsa04010' AS kegg_id, 'Cell Proliferation' AS biological_process, 'Oncology' AS disease_area, 'high' AS cancer_relevance UNION ALL
SELECT 'PWY002', 'PI3K-AKT Signaling', 'hsa04151', 'Cell Survival', 'Oncology', 'high' UNION ALL
SELECT 'PWY003', 'VEGF Signaling', 'hsa04370', 'Angiogenesis', 'Oncology', 'high' UNION ALL
SELECT 'PWY004', 'ErbB Signaling', 'hsa04012', 'Cell Growth', 'Oncology', 'high' UNION ALL
SELECT 'PWY005', 'mTOR Signaling', 'hsa04150', 'Cell Growth', 'Oncology', 'medium' UNION ALL
SELECT 'PWY006', 'Cell Cycle', 'hsa04110', 'Cell Division', 'Oncology', 'high' UNION ALL
SELECT 'PWY007', 'Cardiac Muscle Contraction', 'hsa04260', 'Cardiac Function', 'Cardiovascular', 'low' UNION ALL
SELECT 'PWY008', 'hERG Cardiac Channel', 'hsa04022', 'Cardiac Repolarisation','Cardiovascular', 'low' UNION ALL
SELECT 'PWY009', 'AMPK Signaling', 'hsa04152', 'Energy Metabolism', 'Metabolic', 'low' UNION ALL
SELECT 'PWY010', 'ALK Signaling', 'hsa04915', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY011', 'RAS Signaling', 'hsa04014', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY012', 'HIV Replication', 'hsa05170', 'Viral Replication', 'Infectious Disease', 'low';
5. target_pathways 테이블 만들기
표적을 참여하는 생물학적 경로에 연결하는 교차 테이블입니다.
CREATE OR REPLACE TABLE drug_target_graph.target_pathways AS
SELECT 'TP001' AS tp_id, 'TGT001' AS target_id, 'PWY001' AS pathway_id, 'activator' AS role, 0.95 AS importance_score UNION ALL
SELECT 'TP002', 'TGT001', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP003', 'TGT002', 'PWY004', 'activator', 0.98 UNION ALL
SELECT 'TP004', 'TGT002', 'PWY001', 'activator', 0.82 UNION ALL
SELECT 'TP005', 'TGT002', 'PWY002', 'activator', 0.75 UNION ALL
SELECT 'TP006', 'TGT003', 'PWY003', 'activator', 0.96 UNION ALL
SELECT 'TP007', 'TGT003', 'PWY001', 'activator', 0.71 UNION ALL
SELECT 'TP008', 'TGT004', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP009', 'TGT004', 'PWY011', 'activator', 0.89 UNION ALL
SELECT 'TP010', 'TGT005', 'PWY010', 'activator', 0.99 UNION ALL
SELECT 'TP011', 'TGT005', 'PWY001', 'activator', 0.78 UNION ALL
SELECT 'TP012', 'TGT006', 'PWY002', 'activator', 0.98 UNION ALL
SELECT 'TP013', 'TGT006', 'PWY005', 'activator', 0.85 UNION ALL
SELECT 'TP014', 'TGT007', 'PWY001', 'activator', 0.94 UNION ALL
SELECT 'TP015', 'TGT007', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP016', 'TGT008', 'PWY006', 'activator', 0.95 UNION ALL
SELECT 'TP017', 'TGT009', 'PWY006', 'activator', 0.93 UNION ALL
SELECT 'TP018', 'TGT010', 'PWY005', 'activator', 0.99 UNION ALL
SELECT 'TP019', 'TGT010', 'PWY002', 'activator', 0.91 UNION ALL
SELECT 'TP020', 'TGT011', 'PWY003', 'activator', 0.87 UNION ALL
SELECT 'TP021', 'TGT011', 'PWY001', 'activator', 0.72 UNION ALL
SELECT 'TP022', 'TGT012', 'PWY001', 'activator', 0.83 UNION ALL
SELECT 'TP023', 'TGT012', 'PWY011', 'activator', 0.79 UNION ALL
SELECT 'TP024', 'TGT013', 'PWY008', 'substrate', 0.99 UNION ALL
SELECT 'TP025', 'TGT013', 'PWY007', 'substrate', 0.95 UNION ALL
SELECT 'TP026', 'TGT014', 'PWY009', 'activator', 0.97 UNION ALL
SELECT 'TP027', 'TGT015', 'PWY001', 'activator', 0.91 UNION ALL
SELECT 'TP028', 'TGT015', 'PWY011', 'activator', 0.86 UNION ALL
SELECT 'TP029', 'TGT016', 'PWY001', 'activator', 0.84 UNION ALL
SELECT 'TP030', 'TGT016', 'PWY003', 'activator', 0.77 UNION ALL
SELECT 'TP031', 'TGT017', 'PWY001', 'activator', 0.88 UNION ALL
SELECT 'TP032', 'TGT017', 'PWY011', 'activator', 0.82 UNION ALL
SELECT 'TP033', 'TGT018', 'PWY002', 'activator', 0.96 UNION ALL
SELECT 'TP034', 'TGT018', 'PWY005', 'activator', 0.88 UNION ALL
SELECT 'TP035', 'TGT019', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP036', 'TGT019', 'PWY011', 'activator', 0.91 UNION ALL
SELECT 'TP037', 'TGT020', 'PWY012', 'substrate', 0.99;
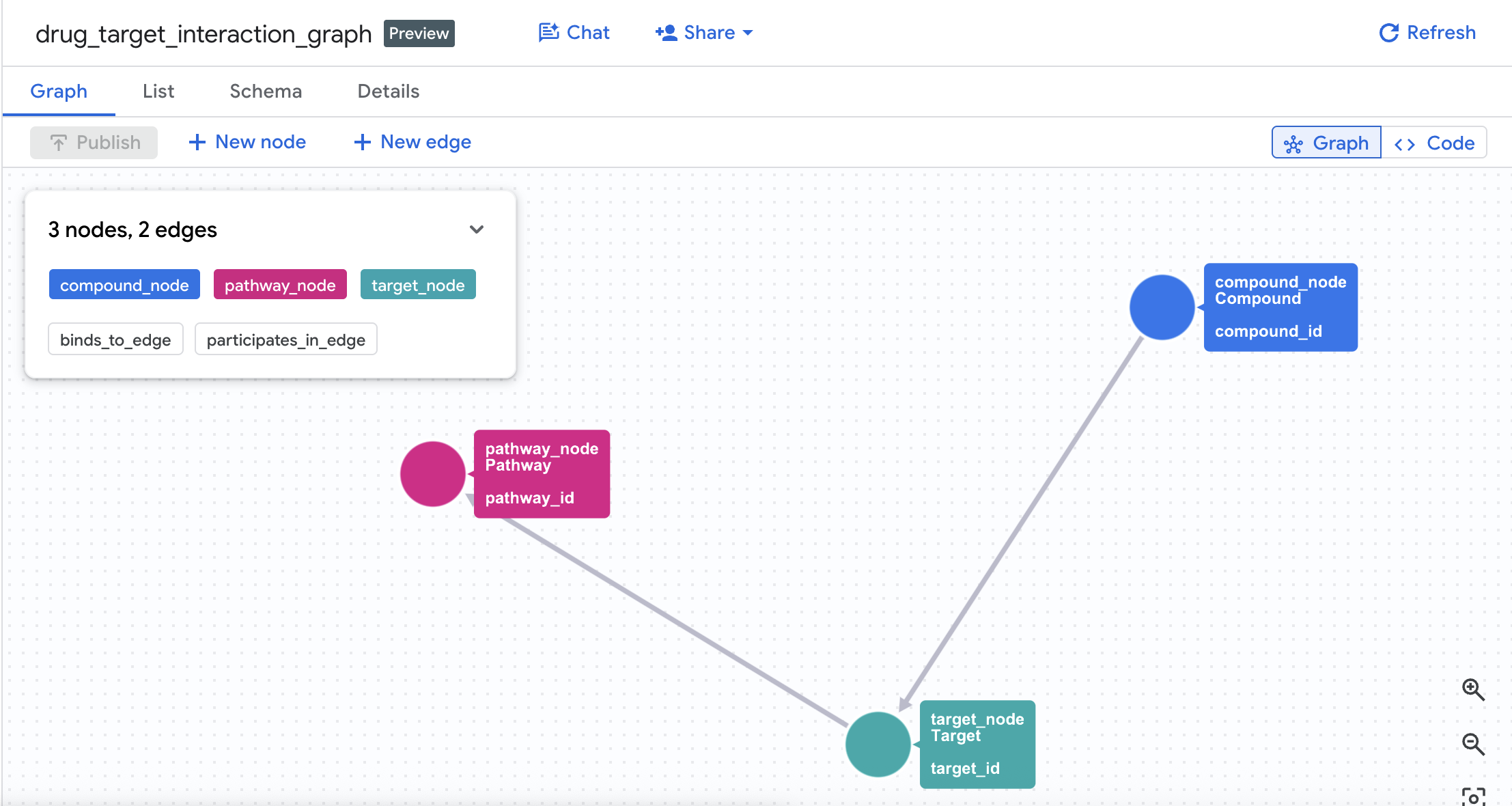
4. 속성 그래프 만들기
테이블이 생성되었으므로 이제 속성 그래프 를 구성할 수 있습니다. 이렇게 하면 에지 테이블 (Interactions 및 Target Pathways)을 사용하여 노드 (화합물, 표적, 경로)가 연결됩니다.
BigQuery Studio SQL 편집기에서 다음 문을 실행합니다.
CREATE OR REPLACE PROPERTY GRAPH drug_target_graph.drug_target_interaction_graph
NODE TABLES (
drug_target_graph.compounds
AS compound_node
KEY (compound_id)
LABEL Compound
PROPERTIES (compound_id, compound_name, mechanism_of_action, dev_stage, therapeutic_area, molecular_weight),
drug_target_graph.targets
AS target_node
KEY (target_id)
LABEL Target
PROPERTIES (target_id, target_name, gene_name, uniprot_id, target_class, is_oncogene),
drug_target_graph.pathways
AS pathway_node
KEY (pathway_id)
LABEL Pathway
PROPERTIES (pathway_id, pathway_name, kegg_id, biological_process, disease_area, cancer_relevance)
)
EDGE TABLES (
drug_target_graph.interactions
AS binds_to_edge
KEY (interaction_id)
SOURCE KEY (compound_id) REFERENCES compound_node (compound_id)
DESTINATION KEY (target_id) REFERENCES target_node (target_id)
LABEL BINDS_TO
PROPERTIES (interaction_id, affinity_nm, ic50_nm, interaction_type, pchembl_value),
drug_target_graph.target_pathways
AS participates_in_edge
KEY (tp_id)
SOURCE KEY (target_id) REFERENCES target_node (target_id)
DESTINATION KEY (pathway_id) REFERENCES pathway_node (pathway_id)
LABEL PARTICIPATES_IN
PROPERTIES (tp_id, role, importance_score)
);
그러면 데이터 세트에 drug_target_interaction_graph라는 그래프가 생성됩니다.
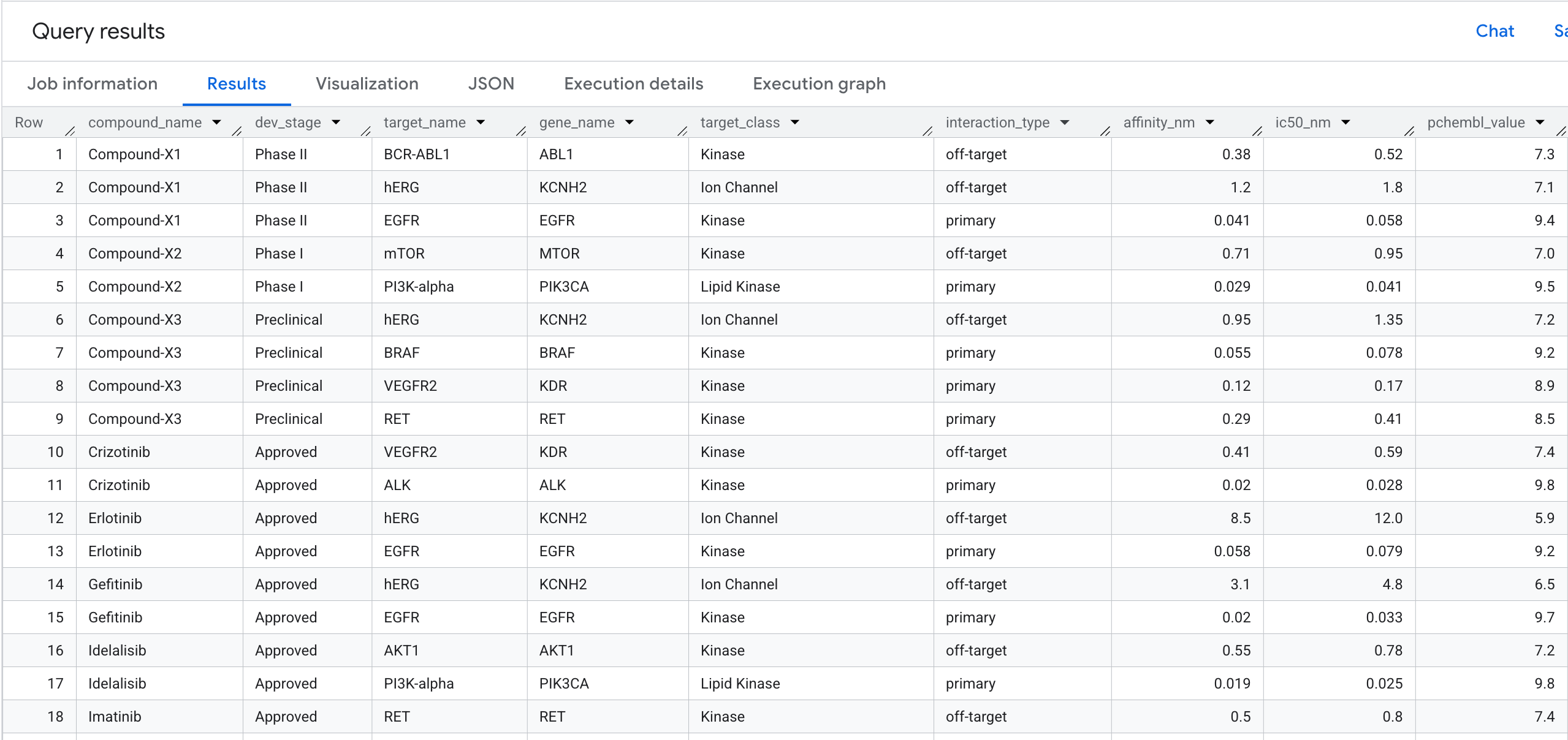
5. 쿼리 1: 화합물당 전체 표적 결합 프로필
첫 번째 그래프 쿼리를 실행해 보겠습니다. 이는 어떤 화합물이 어떤 표적에 결합하고 친화도는 무엇인가요? 라는 질문에 답하는 1홉 순회 입니다.
GQL 쿼리
SQL 편집기에서 다음 쿼리를 실행합니다.
SELECT
compound_name,
dev_stage,
target_name,
gene_name,
target_class,
interaction_type,
ROUND(affinity_nm, 3) AS affinity_nm,
ROUND(ic50_nm, 3) AS ic50_nm,
pchembl_value
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_name AS target_name,
t.gene_name AS gene_name,
t.target_class AS target_class,
b.interaction_type AS interaction_type,
b.affinity_nm AS affinity_nm,
b.ic50_nm AS ic50_nm,
b.pchembl_value AS pchembl_value
)
)
ORDER BY compound_name, interaction_type, affinity_nm;
결과에 표시되는 내용은 다음과 같습니다.
6. 쿼리 2: 심장 위험 감지
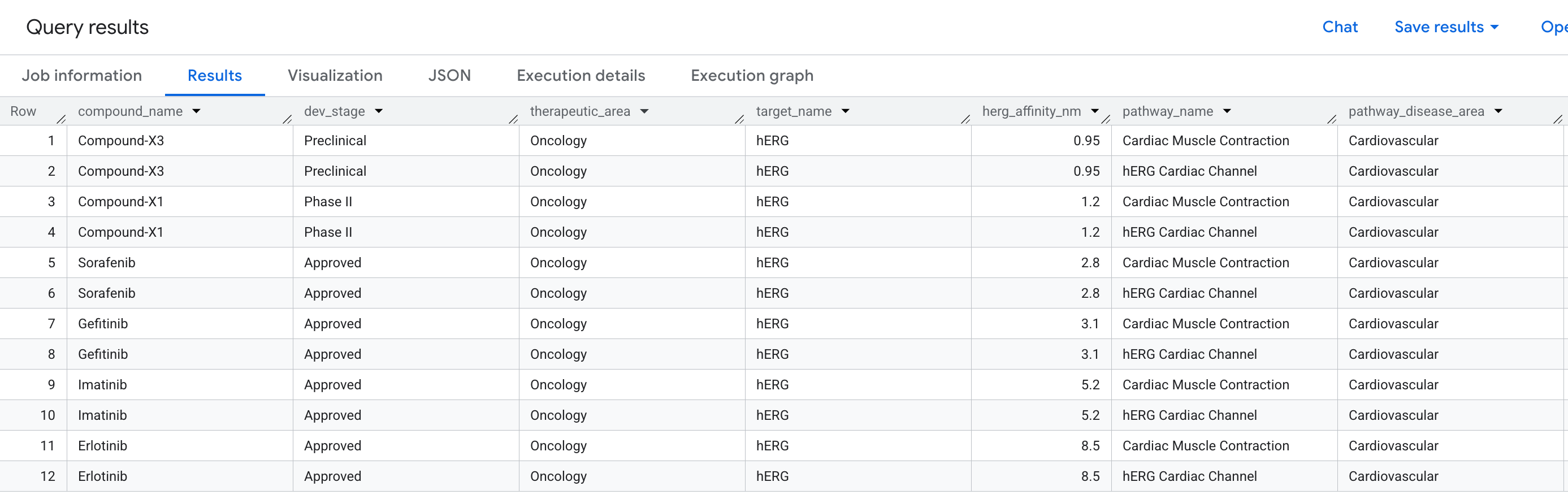
비즈니스 질문
신약 개발에서 유망한 화합물이 임상시험에 실패하는 가장 일반적인 이유 중 하나는 심장 독성 입니다. 특히 심장 박동을 조절하는 칼륨 이온 채널인 hERG 단백질 (유전자: KCNH2)에 의도하지 않은 결합이 발생합니다. hERG에 대한 오프 표적 적중은 치명적인 부정맥을 유발할 수 있으며 여러 유명한 약물 철회의 원인이 되었습니다.
다음과 같은 질문에 답하려고 합니다.
"파이프라인의 어떤 화합물이 hERG 단백질에 오프 표적 결합 이벤트를 가지고 있으며, 어떤 심장 경로가 위험에 처해 있나요?"
이는 2홉 질문 입니다. 단일 쿼리에서 두 관계에 걸쳐 세 가지 항목 유형을 연결하는 경로를 통해 화합물에서 표적 (hERG)으로 이동해야 합니다.
GQL 쿼리 작성
BQ SQL 편집기에서 다음 쿼리를 실행합니다.
SELECT
compound_name,
dev_stage,
therapeutic_area,
target_name,
ROUND(affinity_nm, 3) AS herg_affinity_nm,
pathway_name,
disease_area AS pathway_disease_area
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND b.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
c.therapeutic_area AS therapeutic_area,
t.target_name AS target_name,
b.affinity_nm AS affinity_nm,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
ORDER BY herg_affinity_nm;
MATCH 절이 "경로에 참여하는 표적에 결합하는 화합물 찾기" 와 같이 문장처럼 읽히는 것을 확인하세요. 경로를 따라 각 노드와 에지에 필터가 적용됩니다.
결과에 표시되는 데이터는 다음과 같습니다.
위험 네트워크를 그래프로 시각화
테이블에는 데이터가 표시되지만 위험의 구조 는 표시되지 않습니다. 여러 화합물이 동일한 경로로 수렴하나요? 위험도가 높은 화합물이 하나인가요, 아니면 여러 개인가요?
그래프 시각화를 사용하면 즉시 확인할 수 있습니다. 아래 셀을 실행하여 동일한 2홉 순회를 대화형 네트워크로 렌더링합니다.
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH pt = (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND pw.disease_area = 'Cardiovascular'
RETURN
TO_JSON(pt) AS path
다음과 같은 그래프가 표시됩니다.
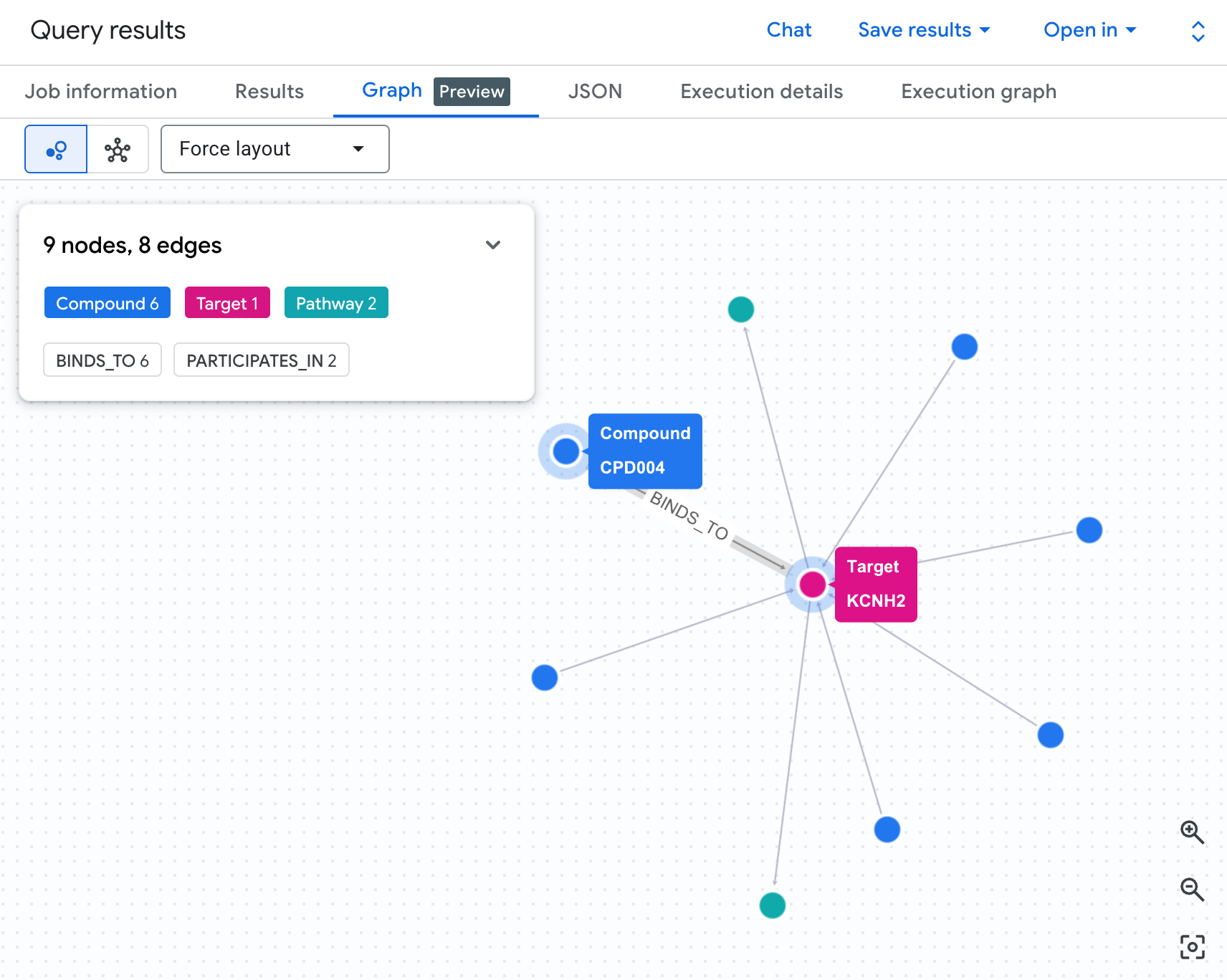
그래프의 각 경로는 완전한 책임 체인을 추적합니다. 화합물 (파란색 노드)은 중앙의 hERG 단백질에 결합하고, 이는 하나 이상의 심장 경로 (녹색 노드)에 연결됩니다. 테이블의 평면 목록이었던 것이 이제 눈에 보이는 위험 네트워크가 되었습니다. 여러 경로에 노출된 화합물은 안전 검토를 위한 우선순위가 높은 것으로 즉시 눈에 띕니다.
GQL이 SQL보다 더 우아한 이유 알아보기
표준 SQL에서 동일한 2홉 쿼리를 실행하려면 4개의 명시적 조인이 필요합니다. 찾고 있는 관계가 무엇 인지 설명하는 대신 테이블을 조인하는 방법 을 설명하는 데 인지적 노력을 기울이고 있습니다. GQL을 사용하면 질문에 집중할 수 있습니다.
SELECT
c.compound_name,
c.dev_stage,
c.therapeutic_area,
t.target_name,
ROUND(i.affinity_nm, 3) AS herg_affinity_nm,
pw.pathway_name,
pw.disease_area AS pathway_disease_area
FROM drug_target_graph.compounds c
JOIN drug_target_graph.interactions i ON c.compound_id = i.compound_id
JOIN drug_target_graph.targets t ON i.target_id = t.target_id
JOIN drug_target_graph.target_pathways tp ON t.target_id = tp.target_id
JOIN drug_target_graph.pathways pw ON tp.pathway_id = pw.pathway_id
WHERE t.gene_name = 'KCNH2'
AND i.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
ORDER BY herg_affinity_nm;
더 자세히 알아보기 — 다중 홉 대사물 위험 감지
위 쿼리는 hERG 단백질에 직접 결합하는 화합물을 식별합니다. 하지만 실제 약물 안전 워크플로에서는 위험이 한 단계 제거되는 경우가 있습니다. 화합물이 체내에서 hERG에 결합하는 2차 분자 (대사물)로 대사적으로 전환될 수 있습니다. 이는 직접 결합 분석에서 완전히 놓칠 수 있는 책임입니다.
속성 그래프에 대사물 노드 테이블과 METABOLISES_INTO 에지가 포함되어 있다면 동일한 MATCH 패턴을 3홉 순회로 확장할 수 있습니다.
(Compound)-[METABOLISES_INTO]->(Metabolite)-[BINDS_TO]->
(Target)-[PARTICIPATES_IN]->(Pathway)
GQL 쿼리 구조는 정확히 하나의 노드와 하나의 에지로 변경됩니다. 이에 상응하는 SQL에는 두 개의 추가 JOIN이 필요합니다. 이 패턴은 안전 캐스케이드 분석에 그래프 순회를 특히 강력하게 만듭니다. 생물학적 통찰력이 기하급수적으로 증가하는 반면 쿼리 복잡성은 선형으로 증가합니다.
7. 쿼리 3: 공유 표적 화합물 쌍
병용 요법 후보를 찾으려면 두 가지 다른 화합물이 동일한 표적 노드에 결합하는 시점을 식별할 수 있습니다. 양방향 일치 를 사용하여 어떤 종양학 화합물이 정확히 동일한 표적으로 수렴하나요? 라는 질문에 답합니다.
SQL 편집기에서 다음 쿼리를 실행합니다.
SELECT
compound_a,
compound_b,
shared_target,
gene_name,
ROUND(affinity_a_nm, 3) AS affinity_a_nm,
ROUND(affinity_b_nm, 3) AS affinity_b_nm
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
AND c2.therapeutic_area = 'Oncology'
COLUMNS (
c1.compound_name AS compound_a,
c2.compound_name AS compound_b,
t.target_name AS shared_target,
t.gene_name AS gene_name,
b1.affinity_nm AS affinity_a_nm,
b2.affinity_nm AS affinity_b_nm
)
)
ORDER BY compound_a, compound_b, affinity_a_nm;
결과에 표시되는 데이터는 다음과 같습니다.
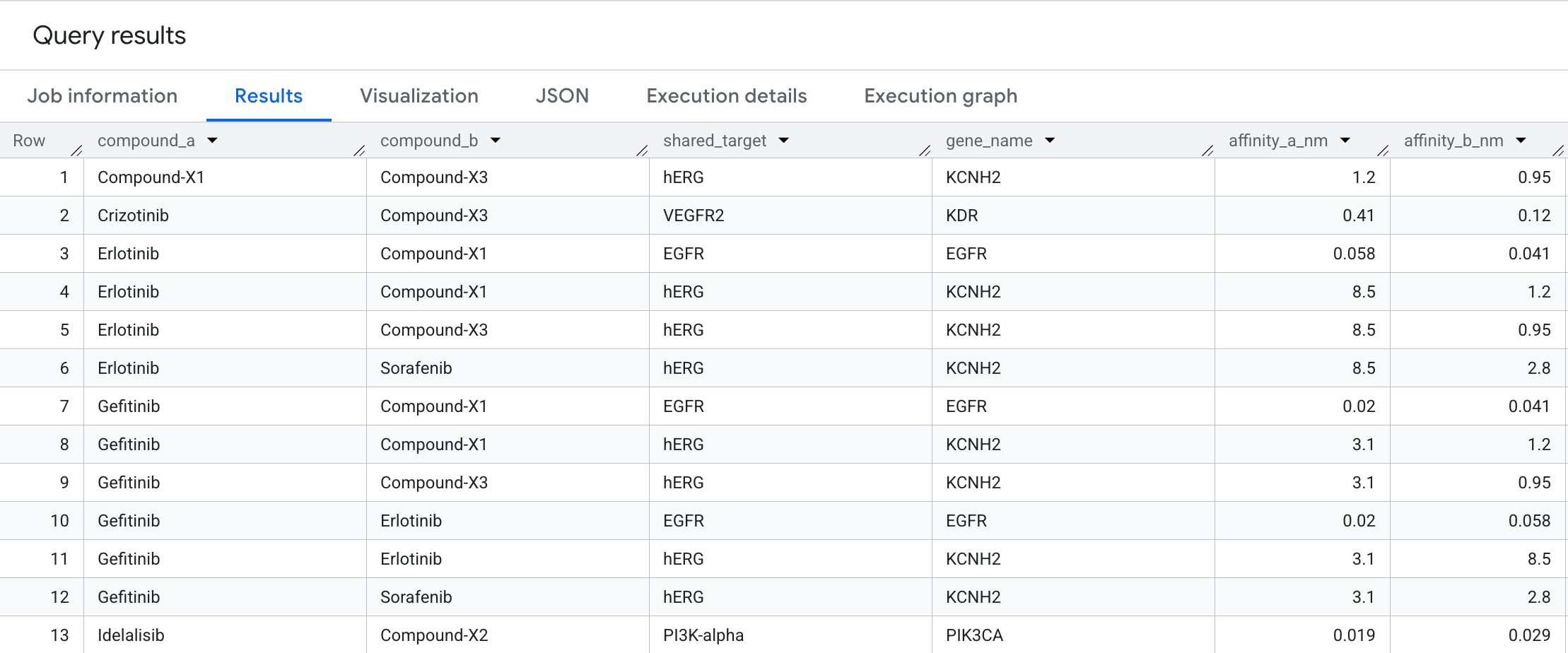
그래프 시각화
SQL 편집기에서 다음 코드를 실행하여 BigQuery에서 직접 그래프를 시각화할 수 있습니다.
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH p = (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
RETURN
TO_JSON(p) AS path
이 양방향 순회는 동일한 단백질 표적으로 수렴하는 화합물 쌍을 표시합니다. 이는 평면 상호작용 테이블에서 찾기 어렵지만 그래프로 즉시 확인할 수 있는 패턴입니다. 신약 개발에서 공유 표적 쌍은 병용 요법 설계의 시작점입니다. 암 경로에서 동일한 노드를 공격하는 두 화합물은 시너지 효과를 내거나 파이프라인에서 의도하지 않은 중복을 나타낼 수 있습니다.
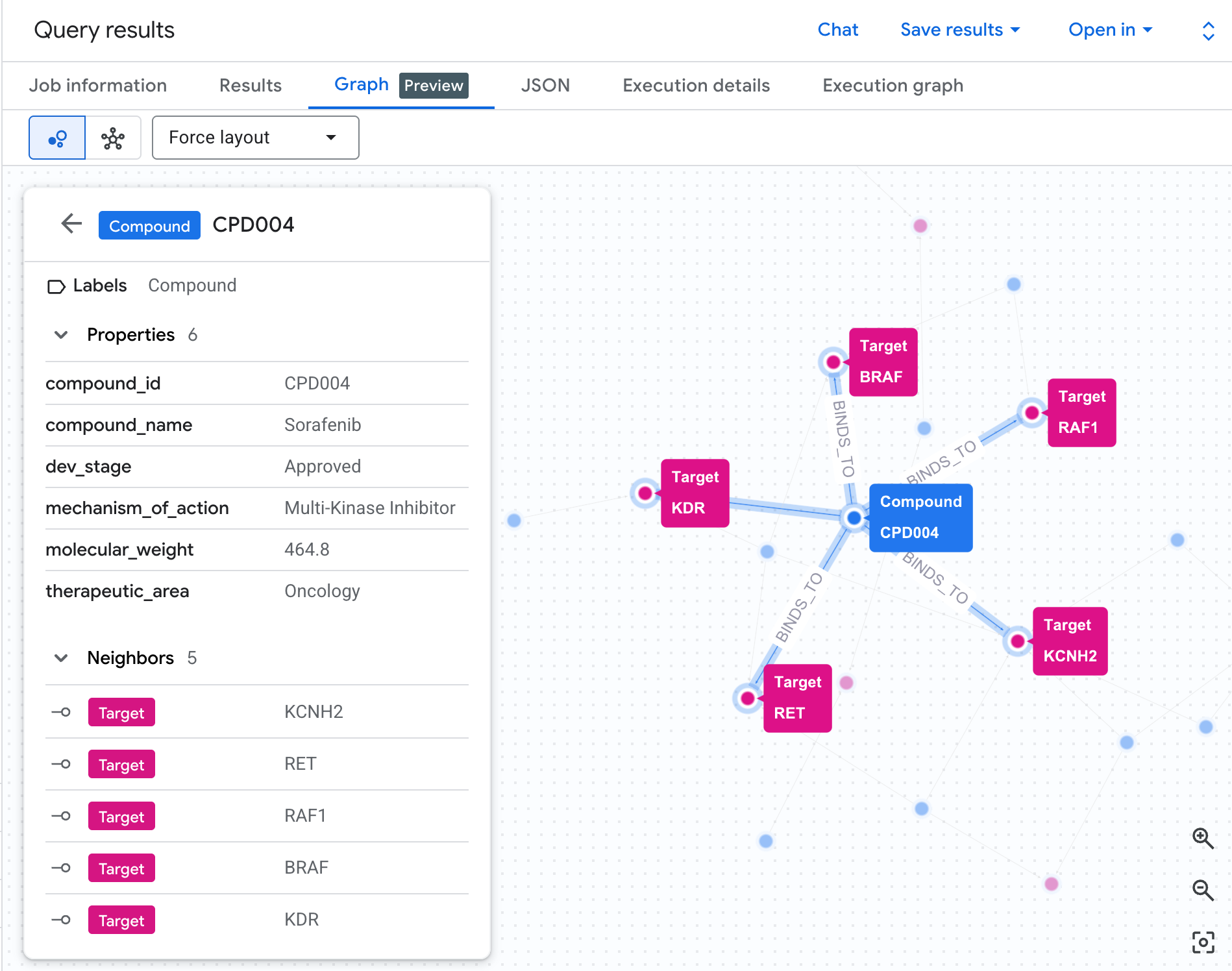
8. 쿼리 4: 질병 경로 폭발 반경
각 화합물의 생물학적 영향은 얼마나 광범위한가요? 집계가 포함된 2홉 순회 를 실행하여 각 화합물이 질병 영역별로 그룹화된 생물학적 경로와 고유한 표적에 얼마나 영향을 미치나요? 라는 질문에 답해 보겠습니다.
SQL 편집기에서 다음 쿼리를 실행합니다.
SELECT
compound_name,
dev_stage,
disease_area,
COUNT(DISTINCT pathway_id) AS pathways_affected,
COUNT(DISTINCT target_id) AS targets_involved,
STRING_AGG(DISTINCT pathway_name ORDER BY pathway_name) AS pathway_list
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_id AS target_id,
pw.pathway_id AS pathway_id,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
GROUP BY compound_name, dev_stage, disease_area
ORDER BY compound_name, pathways_affected DESC;
결과에 표시되는 내용은 다음과 같습니다.
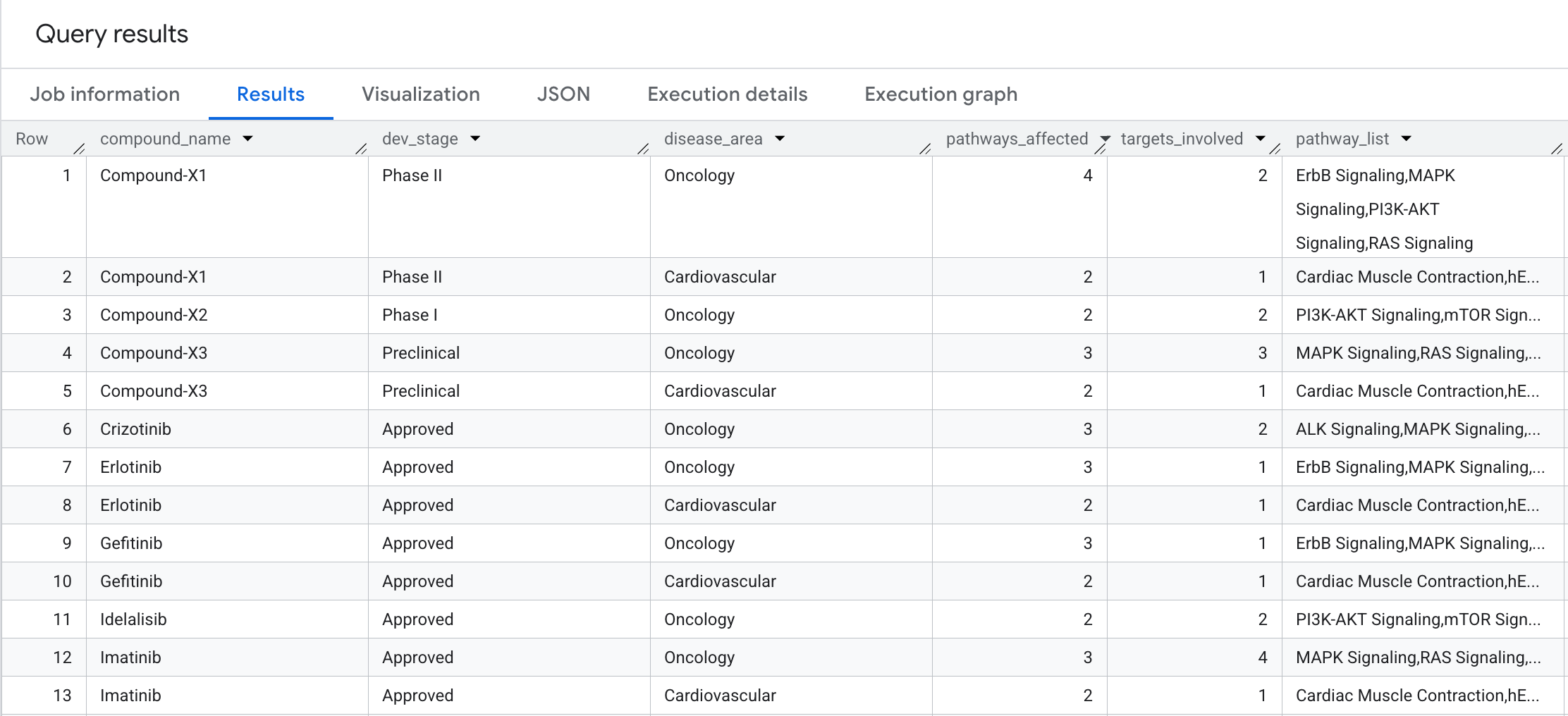
9. 쿼리 5: 안전한 화합물 선택
마지막으로 종양학 범위가 넓지만 hERG (심장) 오프 표적 책임은 명시적으로 피하는 화합물을 쿼리해 보겠습니다. 이는 신약 개발 파이프라인에서 일반적인 안전 우선 선택 패턴과 일치합니다.
SQL 편집기에서 다음 쿼리를 실행합니다.
WITH oncology_compounds AS (
SELECT DISTINCT compound_id, compound_name, dev_stage
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE pw.disease_area = 'Oncology'
AND pw.cancer_relevance = 'high'
COLUMNS (
c.compound_id AS compound_id,
c.compound_name AS compound_name,
c.dev_stage AS dev_stage
)
)
),
herg_risk_compounds AS (
SELECT DISTINCT compound_id
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
WHERE t.gene_name = 'KCNH2'
COLUMNS (c.compound_id AS compound_id)
)
)
SELECT
o.compound_name,
o.dev_stage,
'Clean cardiac profile' AS cardiac_safety
FROM oncology_compounds o
LEFT JOIN herg_risk_compounds h ON o.compound_id = h.compound_id
WHERE h.compound_id IS NULL
ORDER BY o.dev_stage, o.compound_name;
결과에 표시되는 출력은 다음과 같습니다.
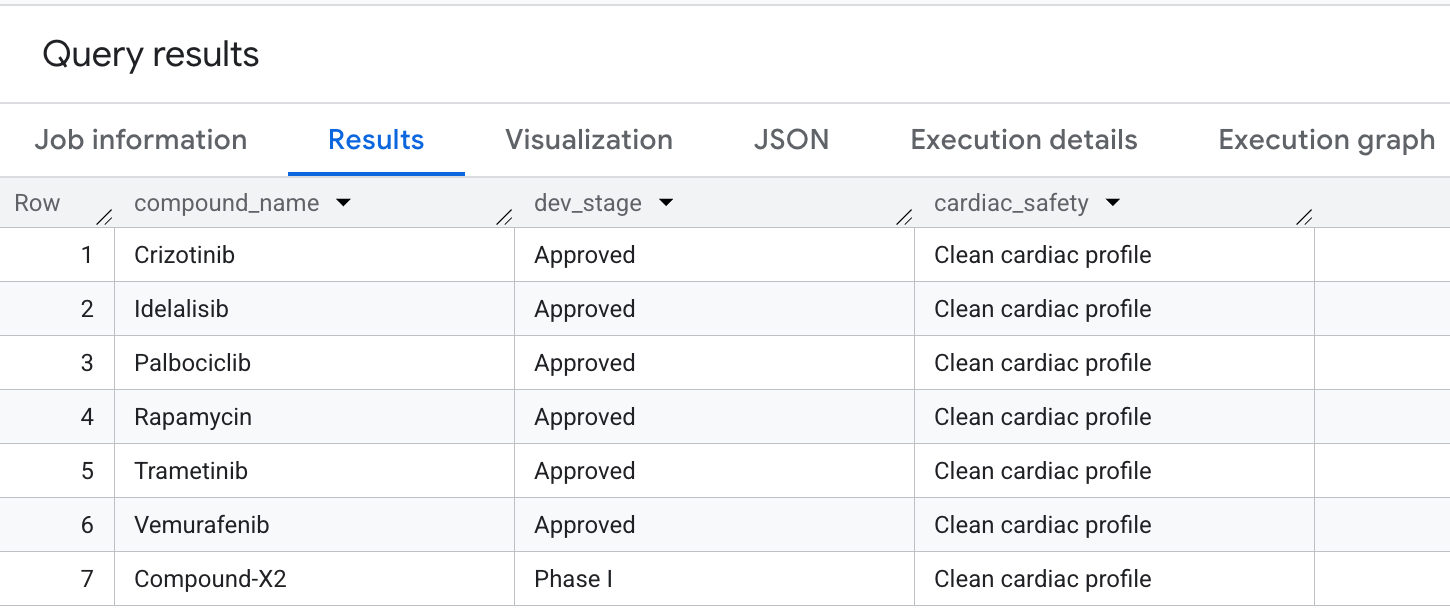
BigQuery에서 고급 그래프 순회를 실행하여 주요 안전 및 효능 프로필을 추출했습니다.
10. 보너스 섹션: 그래프와 채팅하기
이제 BigQuery 대화형 분석에서 그래프를 지식 소스로 지원합니다. 이렇게 하면 자연어로 방금 만든 그래프와 채팅할 수 있습니다.
시작하기: 그래프를 지식 소스로 추가
시작하려면 여기에 있는 단계에 따라 대화형 에이전트를 만듭니다. 검색창에서 만든 그래프를 선택합니다.
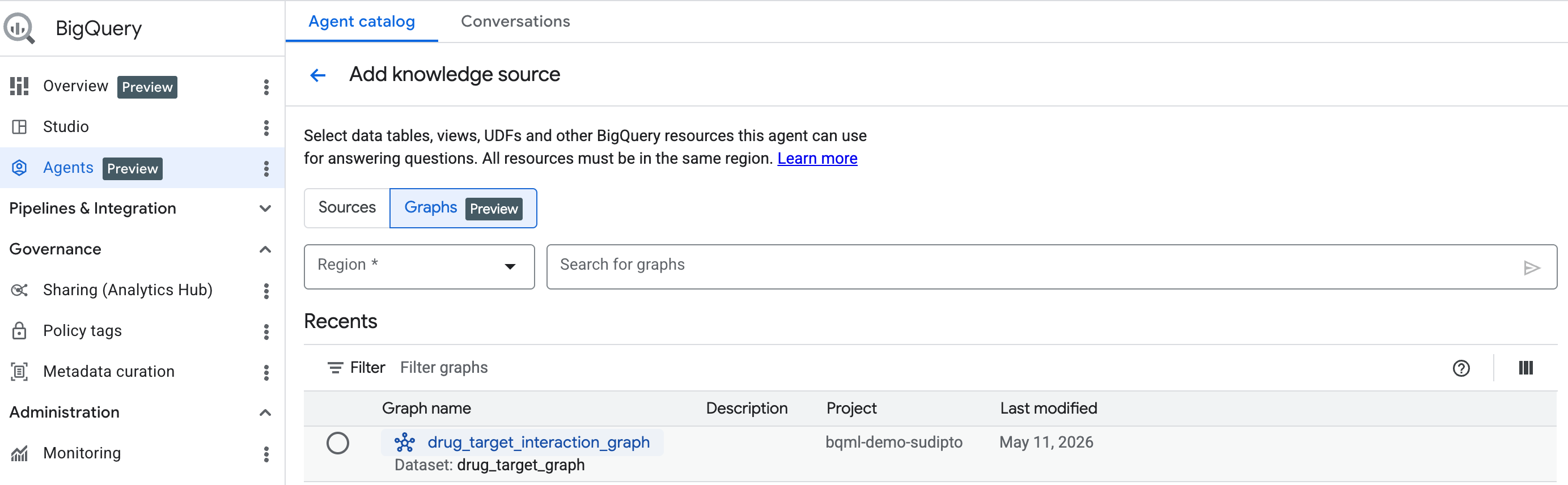
BigQuery 대화형 분석을 사용하여 그래프와 채팅
지식 소스를 그래프로 추가한 후 나머지 대화형 분석 에이전트 설정을 완료합니다.
그러면 자연어로 그래프와 채팅을 시작할 수 있습니다.
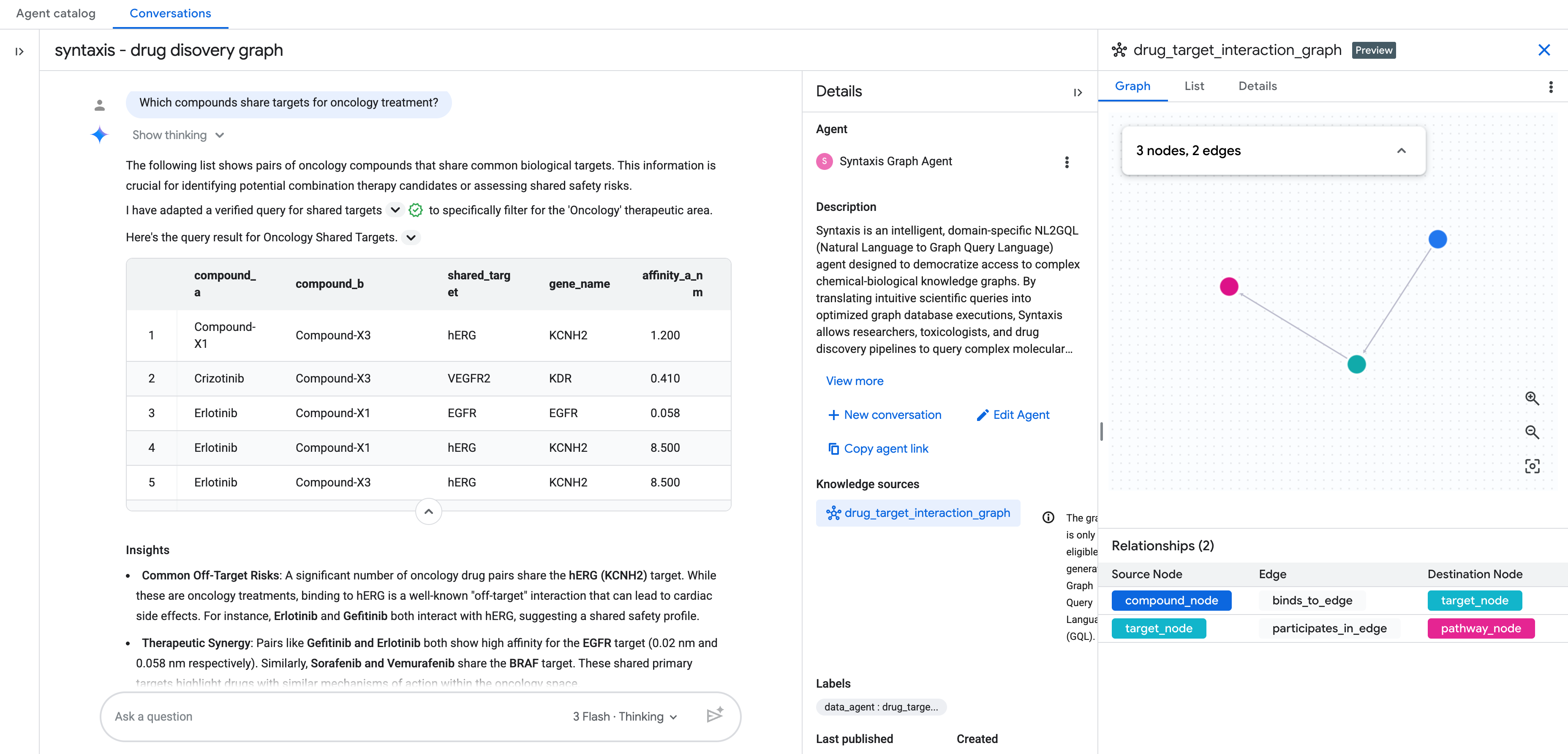
더 궁금한 점이 있나요?
- 현재 2상 임상시험 중인 화합물의 모든 표적은 무엇인가요?
- 심혈관 화합물과 종양학 화합물 간에 공유되는 표적은 무엇인가요?
11. 정리
Google Cloud 계정에 지속적으로 비용이 청구되지 않도록 하려면 이 Codelab 중에 만든 리소스를 삭제합니다.
다음 쿼리를 실행하여 스키마와 모든 테이블을 캐스케이드 방식으로 삭제합니다.
DROP SCHEMA IF EXISTS drug_target_graph CASCADE;
12. 축하합니다
축하합니다. BigQuery Graph를 사용하여 약물-표적 상호작용 네트워크를 모델링하고 분석했습니다.
학습한 내용
- 항목 관계 (화합물, 표적, 경로)를 속성 그래프로 모델링하는 방법
- BigQuery에서 스키마를 정의하고 속성 그래프를 만드는 방법
- GQL을 사용하여 복잡한 그래프 순회를 작성하고 기존 SQL과 비교하는 방법
GRAPH_TABLE,MATCH, 양방향 일치를 활용하여 생명과학 도메인 문제를 해결하는 방법