
1. Wprowadzenie
W tym module dowiesz się, jak używać BigQuery Graph do modelowania i analizowania sieci interakcji między lekami a ich celami. Wykorzystasz możliwości zapytań grafowych (GQL), aby sprawdzić, jak leki oddziałują na cele biologiczne, zidentyfikować potencjalne skutki uboczne (np. ryzyko kardiologiczne) i odkryć potencjalne terapie kombinowane.
🧬 Przypadek użycia – sieć interakcji między lekami a ich celami
Pytanie biznesowe: jaki jest pełny promień działania związku – z jakimi celami się wiąże, na jakie szlaki biologiczne wpływa i jakie obszary chorób obejmuje?
Tabele:
Tabela | Opis |
| Cząsteczki leków z mechanizmem działania i etapem rozwoju |
| Cele białkowe z nazwami genów i identyfikatorami UniProt |
| Powinowactwo wiązania związku z celem (cele podstawowe + cele poza celem) |
| Szlaki biologiczne z powiązaniami z obszarami chorób |
| Tabela łącząca cele ze szlakami, w których uczestniczą |
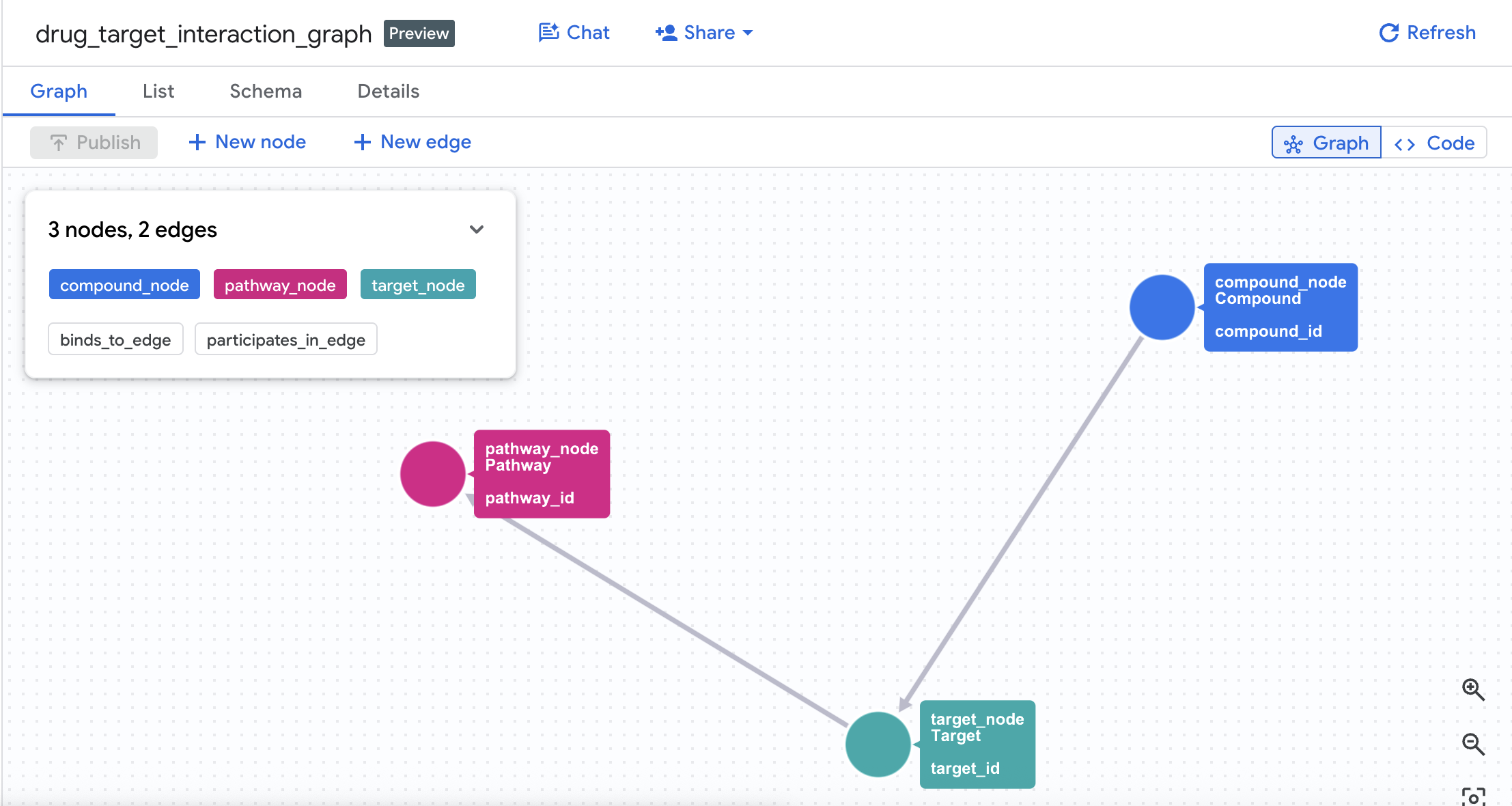
Model grafu właściwości:
(Compound)-[BINDS_TO {affinity_nm, ic50_nm, interaction_type}]->(Target)
(Target)-[PARTICIPATES_IN {role, importance_score}]->(Pathway)
🔍 Zapytania demonstracyjne
Zapytanie | Co to znaczy |
Pytanie 1. Profil wiązania z celem | Przejście 1-hop – związek do wszystkich celów podstawowych i poza celem |
Pytanie 2. Wykrywanie ryzyka kardiologicznego hERG | Przejście 2-hop – związek → cel hERG → szlak kardiologiczny |
Pytanie 3. Pary związków o wspólnym celu | Dopasowanie dwukierunkowe – 2 związki zbiegające się w tym samym węźle docelowym |
Pytanie 4. Promień działania szlaku choroby | Agregacja 2-hop – pełne pokrycie szlaku i obszaru choroby na związek |
Pytanie 5. Wybór bezpiecznego związku | Związki o wysokim pokryciu onkologicznym, ale bez ryzyka kardiologicznego hERG |
Jakie zadania wykonasz
- Utworzysz zbiór danych i schemat BigQuery dla sieci interakcji między lekami
- Wczytasz przykładowe dane (związki, cele, interakcje, szlaki, szlaki docelowe)
- Utworzysz graf właściwości w BigQuery łączący te encje
- Wykonasz zapytanie na grafie, aby poznać interakcje między związkami, szlaki biologiczne i promień działania choroby za pomocą przejść grafowych (
GRAPH_TABLEiMATCH) - Porównasz GQL i standardową wersję SQL, aby poznać prostotę i możliwości składni grafu
Czego potrzebujesz
- Przeglądarka internetowa, np. Chrome
- Projekt Google Cloud z włączonymi płatnościami
Ten moduł jest przeznaczony dla deweloperów na wszystkich poziomach zaawansowania, w tym dla początkujących.
2. Zanim zaczniesz
Utwórz projekt Google Cloud
- W konsoli Google Cloud wybierz lub utwórz projekt w chmurze Google Cloud.
- Sprawdź, czy w projekcie w chmurze włączone są płatności.
Uruchamianie Cloud Shell
- U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.
- Zweryfikuj uwierzytelnianie:
gcloud auth list
- Potwierdź wybór projektu:
gcloud config get project
- W razie potrzeby ustaw projekt:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Włącz interfejsy API
Aby włączyć wymagany interfejs BigQuery API, uruchom to polecenie:
gcloud services enable bigquery.googleapis.com
3. Zdefiniuj schemat i wczytaj dane
Najpierw musisz utworzyć zbiór danych, w którym będą przechowywane tabele związane z grafem, i wypełnić je przykładowymi danymi.
- W konsoli Google Cloud otwórz BigQuery Studio.
- Kliknij Edytor SQL , aby otworzyć nową kartę zapytania.
- Aby utworzyć zbiór danych
drug_target_graph(graf_celów_lekowych), uruchom to polecenie:
CREATE SCHEMA IF NOT EXISTS drug_target_graph
OPTIONS (location = 'US');
Teraz utwórz 5 tabel źródłowych, uruchamiając w BigQuery Studio te zapytania DDL.
1. Utwórz tabelę compounds (związki)
Zawiera cząsteczki leków, ich mechanizm działania, etap rozwoju i obszar terapeutyczny.
CREATE OR REPLACE TABLE drug_target_graph.compounds AS
SELECT 'CPD001' AS compound_id, 'Imatinib' AS compound_name, 'Kinase Inhibitor' AS mechanism_of_action, 'Approved' AS dev_stage, 'Oncology' AS therapeutic_area, 479.6 AS molecular_weight UNION ALL
SELECT 'CPD002', 'Gefitinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 446.9 UNION ALL
SELECT 'CPD003', 'Erlotinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 393.4 UNION ALL
SELECT 'CPD004', 'Sorafenib', 'Multi-Kinase Inhibitor', 'Approved', 'Oncology', 464.8 UNION ALL
SELECT 'CPD005', 'Vemurafenib', 'BRAF Inhibitor', 'Approved', 'Oncology', 489.9 UNION ALL
SELECT 'CPD006', 'Crizotinib', 'ALK Inhibitor', 'Approved', 'Oncology', 450.3 UNION ALL
SELECT 'CPD007', 'Idelalisib', 'PI3K Inhibitor', 'Approved', 'Oncology', 415.4 UNION ALL
SELECT 'CPD008', 'Trametinib', 'MEK Inhibitor', 'Approved', 'Oncology', 615.4 UNION ALL
SELECT 'CPD009', 'Palbociclib', 'CDK Inhibitor', 'Approved', 'Oncology', 447.5 UNION ALL
SELECT 'CPD010', 'Compound-X1', 'Kinase Inhibitor', 'Phase II', 'Oncology', 412.3 UNION ALL
SELECT 'CPD011', 'Compound-X2', 'PI3K Inhibitor', 'Phase I', 'Oncology', 398.7 UNION ALL
SELECT 'CPD012', 'Saquinavir', 'Protease Inhibitor', 'Approved', 'Infectious Disease', 670.8 UNION ALL
SELECT 'CPD013', 'Metformin', 'AMPK Activator', 'Approved', 'Metabolic', 165.6 UNION ALL
SELECT 'CPD014', 'Rapamycin', 'mTOR Inhibitor', 'Approved', 'Immunology', 914.2 UNION ALL
SELECT 'CPD015', 'Compound-X3', 'Multi-Kinase Inhibitor', 'Preclinical', 'Oncology', 502.1;
2. Utwórz tabelę targets (cele)
Zawiera cele białkowe, nazwy genów, identyfikatory UniProt i klasy celów.
CREATE OR REPLACE TABLE drug_target_graph.targets AS
SELECT 'TGT001' AS target_id, 'BCR-ABL1' AS target_name, 'ABL1' AS gene_name, 'P00519' AS uniprot_id, 'Kinase' AS target_class, TRUE AS is_oncogene UNION ALL
SELECT 'TGT002', 'EGFR', 'EGFR', 'P00533', 'Kinase', TRUE UNION ALL
SELECT 'TGT003', 'VEGFR2', 'KDR', 'P35968', 'Kinase', FALSE UNION ALL
SELECT 'TGT004', 'BRAF', 'BRAF', 'P15056', 'Kinase', TRUE UNION ALL
SELECT 'TGT005', 'ALK', 'ALK', 'Q9UM73', 'Kinase', TRUE UNION ALL
SELECT 'TGT006', 'PI3K-alpha','PIK3CA', 'P42336', 'Lipid Kinase', TRUE UNION ALL
SELECT 'TGT007', 'MEK1', 'MAP2K1', 'Q02750', 'Kinase', FALSE UNION ALL
SELECT 'TGT008', 'CDK4', 'CDK4', 'P11802', 'Kinase', FALSE UNION ALL
SELECT 'TGT009', 'CDK6', 'CDK6', 'P30279', 'Kinase', FALSE UNION ALL
SELECT 'TGT010', 'mTOR', 'MTOR', 'P42345', 'Kinase', FALSE UNION ALL
SELECT 'TGT011', 'PDGFR-beta','PDGFRB', 'P09619', 'Kinase', FALSE UNION ALL
SELECT 'TGT012', 'c-KIT', 'KIT', 'P10721', 'Kinase', TRUE UNION ALL
SELECT 'TGT013', 'hERG', 'KCNH2', 'Q12809', 'Ion Channel', FALSE UNION ALL
SELECT 'TGT014', 'AMPK', 'PRKAA1', 'Q13131', 'Kinase', FALSE UNION ALL
SELECT 'TGT015', 'RAF1', 'RAF1', 'P04049', 'Kinase', FALSE UNION ALL
SELECT 'TGT016', 'RET', 'RET', 'P07949', 'Kinase', TRUE UNION ALL
SELECT 'TGT017', 'FLT3', 'FLT3', 'P36888', 'Kinase', TRUE UNION ALL
SELECT 'TGT018', 'AKT1', 'AKT1', 'P31749', 'Kinase', FALSE UNION ALL
SELECT 'TGT019', 'ERK2', 'MAPK1', 'P28482', 'Kinase', FALSE UNION ALL
SELECT 'TGT020', 'HIV-Protease','HIV1-PR','Q72547', 'Protease', FALSE;
3. Utwórz tabelę interactions (interakcje)
Zawiera dane o powinowactwie wiązania związku z celem (cele podstawowe vs cele poza celem).
CREATE OR REPLACE TABLE drug_target_graph.interactions AS
SELECT 'INT001' AS interaction_id, 'CPD001' AS compound_id, 'TGT001' AS target_id, 0.025 AS affinity_nm, 0.038 AS ic50_nm, 'primary' AS interaction_type, 9.8 AS pchembl_value UNION ALL
SELECT 'INT002', 'CPD001', 'TGT011', 0.1, 0.15, 'primary', 8.8 UNION ALL
SELECT 'INT003', 'CPD001', 'TGT012', 0.068, 0.1, 'primary', 9.2 UNION ALL
SELECT 'INT004', 'CPD001', 'TGT016', 0.5, 0.8, 'off-target', 7.4 UNION ALL
SELECT 'INT005', 'CPD001', 'TGT013', 5.2, 8.1, 'off-target', 6.1 UNION ALL
SELECT 'INT006', 'CPD002', 'TGT002', 0.02, 0.033, 'primary', 9.7 UNION ALL
SELECT 'INT007', 'CPD002', 'TGT013', 3.1, 4.8, 'off-target', 6.5 UNION ALL
SELECT 'INT008', 'CPD003', 'TGT002', 0.058, 0.079, 'primary', 9.2 UNION ALL
SELECT 'INT009', 'CPD003', 'TGT013', 8.5, 12.0, 'off-target', 5.9 UNION ALL
SELECT 'INT010', 'CPD004', 'TGT003', 0.09, 0.12, 'primary', 9.1 UNION ALL
SELECT 'INT011', 'CPD004', 'TGT004', 0.038, 0.055, 'primary', 8.9 UNION ALL
SELECT 'INT012', 'CPD004', 'TGT015', 0.22, 0.31, 'primary', 8.5 UNION ALL
SELECT 'INT013', 'CPD004', 'TGT016', 0.58, 0.75, 'primary', 8.1 UNION ALL
SELECT 'INT014', 'CPD004', 'TGT017', 0.33, 0.48, 'primary', 8.4 UNION ALL
SELECT 'INT015', 'CPD004', 'TGT013', 2.8, 4.1, 'off-target', 6.6 UNION ALL
SELECT 'INT016', 'CPD005', 'TGT004', 0.031, 0.044, 'primary', 9.5 UNION ALL
SELECT 'INT017', 'CPD005', 'TGT015', 0.48, 0.65, 'off-target', 7.3 UNION ALL
SELECT 'INT018', 'CPD006', 'TGT005', 0.02, 0.028, 'primary', 9.8 UNION ALL
SELECT 'INT019', 'CPD006', 'TGT003', 0.41, 0.59, 'off-target', 7.4 UNION ALL
SELECT 'INT020', 'CPD007', 'TGT006', 0.019, 0.025, 'primary', 9.8 UNION ALL
SELECT 'INT021', 'CPD007', 'TGT018', 0.55, 0.78, 'off-target', 7.2 UNION ALL
SELECT 'INT022', 'CPD008', 'TGT007', 0.0092, 0.014, 'primary', 10.1 UNION ALL
SELECT 'INT023', 'CPD008', 'TGT019', 0.38, 0.51, 'off-target', 7.4 UNION ALL
SELECT 'INT024', 'CPD009', 'TGT008', 0.011, 0.017, 'primary', 9.9 UNION ALL
SELECT 'INT025', 'CPD009', 'TGT009', 0.015, 0.022, 'primary', 9.8 UNION ALL
SELECT 'INT026', 'CPD010', 'TGT002', 0.041, 0.058, 'primary', 9.4 UNION ALL
SELECT 'INT027', 'CPD010', 'TGT001', 0.38, 0.52, 'off-target', 7.3 UNION ALL
SELECT 'INT028', 'CPD010', 'TGT013', 1.2, 1.8, 'off-target', 7.1 UNION ALL
SELECT 'INT029', 'CPD011', 'TGT006', 0.029, 0.041, 'primary', 9.5 UNION ALL
SELECT 'INT030', 'CPD011', 'TGT010', 0.71, 0.95, 'off-target', 7.0 UNION ALL
SELECT 'INT031', 'CPD012', 'TGT020', 0.39, 0.55, 'primary', 7.3 UNION ALL
SELECT 'INT032', 'CPD013', 'TGT014', 12.0, 18.5, 'primary', 5.7 UNION ALL
SELECT 'INT033', 'CPD014', 'TGT010', 0.0018, 0.0025, 'primary', 11.8 UNION ALL
SELECT 'INT034', 'CPD015', 'TGT004', 0.055, 0.078, 'primary', 9.2 UNION ALL
SELECT 'INT035', 'CPD015', 'TGT003', 0.12, 0.17, 'primary', 8.9 UNION ALL
SELECT 'INT036', 'CPD015', 'TGT016', 0.29, 0.41, 'primary', 8.5 UNION ALL
SELECT 'INT037', 'CPD015', 'TGT013', 0.95, 1.35, 'off-target', 7.2;
4. Utwórz tabelę pathways (szlaki)
Zawiera szlaki biologiczne, powiązane obszary chorób i znaczenie w kontekście raka.
CREATE OR REPLACE TABLE drug_target_graph.pathways AS
SELECT 'PWY001' AS pathway_id, 'MAPK Signaling' AS pathway_name, 'hsa04010' AS kegg_id, 'Cell Proliferation' AS biological_process, 'Oncology' AS disease_area, 'high' AS cancer_relevance UNION ALL
SELECT 'PWY002', 'PI3K-AKT Signaling', 'hsa04151', 'Cell Survival', 'Oncology', 'high' UNION ALL
SELECT 'PWY003', 'VEGF Signaling', 'hsa04370', 'Angiogenesis', 'Oncology', 'high' UNION ALL
SELECT 'PWY004', 'ErbB Signaling', 'hsa04012', 'Cell Growth', 'Oncology', 'high' UNION ALL
SELECT 'PWY005', 'mTOR Signaling', 'hsa04150', 'Cell Growth', 'Oncology', 'medium' UNION ALL
SELECT 'PWY006', 'Cell Cycle', 'hsa04110', 'Cell Division', 'Oncology', 'high' UNION ALL
SELECT 'PWY007', 'Cardiac Muscle Contraction', 'hsa04260', 'Cardiac Function', 'Cardiovascular', 'low' UNION ALL
SELECT 'PWY008', 'hERG Cardiac Channel', 'hsa04022', 'Cardiac Repolarisation','Cardiovascular', 'low' UNION ALL
SELECT 'PWY009', 'AMPK Signaling', 'hsa04152', 'Energy Metabolism', 'Metabolic', 'low' UNION ALL
SELECT 'PWY010', 'ALK Signaling', 'hsa04915', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY011', 'RAS Signaling', 'hsa04014', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY012', 'HIV Replication', 'hsa05170', 'Viral Replication', 'Infectious Disease', 'low';
5. Utwórz tabelę target_pathways (szlaki_docelowe)
Tabela łącząca cele ze szlakami biologicznymi, w których uczestniczą.
CREATE OR REPLACE TABLE drug_target_graph.target_pathways AS
SELECT 'TP001' AS tp_id, 'TGT001' AS target_id, 'PWY001' AS pathway_id, 'activator' AS role, 0.95 AS importance_score UNION ALL
SELECT 'TP002', 'TGT001', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP003', 'TGT002', 'PWY004', 'activator', 0.98 UNION ALL
SELECT 'TP004', 'TGT002', 'PWY001', 'activator', 0.82 UNION ALL
SELECT 'TP005', 'TGT002', 'PWY002', 'activator', 0.75 UNION ALL
SELECT 'TP006', 'TGT003', 'PWY003', 'activator', 0.96 UNION ALL
SELECT 'TP007', 'TGT003', 'PWY001', 'activator', 0.71 UNION ALL
SELECT 'TP008', 'TGT004', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP009', 'TGT004', 'PWY011', 'activator', 0.89 UNION ALL
SELECT 'TP010', 'TGT005', 'PWY010', 'activator', 0.99 UNION ALL
SELECT 'TP011', 'TGT005', 'PWY001', 'activator', 0.78 UNION ALL
SELECT 'TP012', 'TGT006', 'PWY002', 'activator', 0.98 UNION ALL
SELECT 'TP013', 'TGT006', 'PWY005', 'activator', 0.85 UNION ALL
SELECT 'TP014', 'TGT007', 'PWY001', 'activator', 0.94 UNION ALL
SELECT 'TP015', 'TGT007', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP016', 'TGT008', 'PWY006', 'activator', 0.95 UNION ALL
SELECT 'TP017', 'TGT009', 'PWY006', 'activator', 0.93 UNION ALL
SELECT 'TP018', 'TGT010', 'PWY005', 'activator', 0.99 UNION ALL
SELECT 'TP019', 'TGT010', 'PWY002', 'activator', 0.91 UNION ALL
SELECT 'TP020', 'TGT011', 'PWY003', 'activator', 0.87 UNION ALL
SELECT 'TP021', 'TGT011', 'PWY001', 'activator', 0.72 UNION ALL
SELECT 'TP022', 'TGT012', 'PWY001', 'activator', 0.83 UNION ALL
SELECT 'TP023', 'TGT012', 'PWY011', 'activator', 0.79 UNION ALL
SELECT 'TP024', 'TGT013', 'PWY008', 'substrate', 0.99 UNION ALL
SELECT 'TP025', 'TGT013', 'PWY007', 'substrate', 0.95 UNION ALL
SELECT 'TP026', 'TGT014', 'PWY009', 'activator', 0.97 UNION ALL
SELECT 'TP027', 'TGT015', 'PWY001', 'activator', 0.91 UNION ALL
SELECT 'TP028', 'TGT015', 'PWY011', 'activator', 0.86 UNION ALL
SELECT 'TP029', 'TGT016', 'PWY001', 'activator', 0.84 UNION ALL
SELECT 'TP030', 'TGT016', 'PWY003', 'activator', 0.77 UNION ALL
SELECT 'TP031', 'TGT017', 'PWY001', 'activator', 0.88 UNION ALL
SELECT 'TP032', 'TGT017', 'PWY011', 'activator', 0.82 UNION ALL
SELECT 'TP033', 'TGT018', 'PWY002', 'activator', 0.96 UNION ALL
SELECT 'TP034', 'TGT018', 'PWY005', 'activator', 0.88 UNION ALL
SELECT 'TP035', 'TGT019', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP036', 'TGT019', 'PWY011', 'activator', 0.91 UNION ALL
SELECT 'TP037', 'TGT020', 'PWY012', 'substrate', 0.99;
4. Utwórz graf właściwości
Po utworzeniu tabel możesz teraz utworzyć graf właściwości. Łączy on węzły (związki, cele, szlaki) za pomocą tabel krawędzi (Interactions i Target Pathways).
W edytorze SQL BigQuery Studio uruchom to polecenie:
CREATE OR REPLACE PROPERTY GRAPH drug_target_graph.drug_target_interaction_graph
NODE TABLES (
drug_target_graph.compounds
AS compound_node
KEY (compound_id)
LABEL Compound
PROPERTIES (compound_id, compound_name, mechanism_of_action, dev_stage, therapeutic_area, molecular_weight),
drug_target_graph.targets
AS target_node
KEY (target_id)
LABEL Target
PROPERTIES (target_id, target_name, gene_name, uniprot_id, target_class, is_oncogene),
drug_target_graph.pathways
AS pathway_node
KEY (pathway_id)
LABEL Pathway
PROPERTIES (pathway_id, pathway_name, kegg_id, biological_process, disease_area, cancer_relevance)
)
EDGE TABLES (
drug_target_graph.interactions
AS binds_to_edge
KEY (interaction_id)
SOURCE KEY (compound_id) REFERENCES compound_node (compound_id)
DESTINATION KEY (target_id) REFERENCES target_node (target_id)
LABEL BINDS_TO
PROPERTIES (interaction_id, affinity_nm, ic50_nm, interaction_type, pchembl_value),
drug_target_graph.target_pathways
AS participates_in_edge
KEY (tp_id)
SOURCE KEY (target_id) REFERENCES target_node (target_id)
DESTINATION KEY (pathway_id) REFERENCES pathway_node (pathway_id)
LABEL PARTICIPATES_IN
PROPERTIES (tp_id, role, importance_score)
);
Spowoduje to utworzenie w zbiorze danych grafu o nazwie drug_target_interaction_graph (graf_interakcji_celów_lekowych).
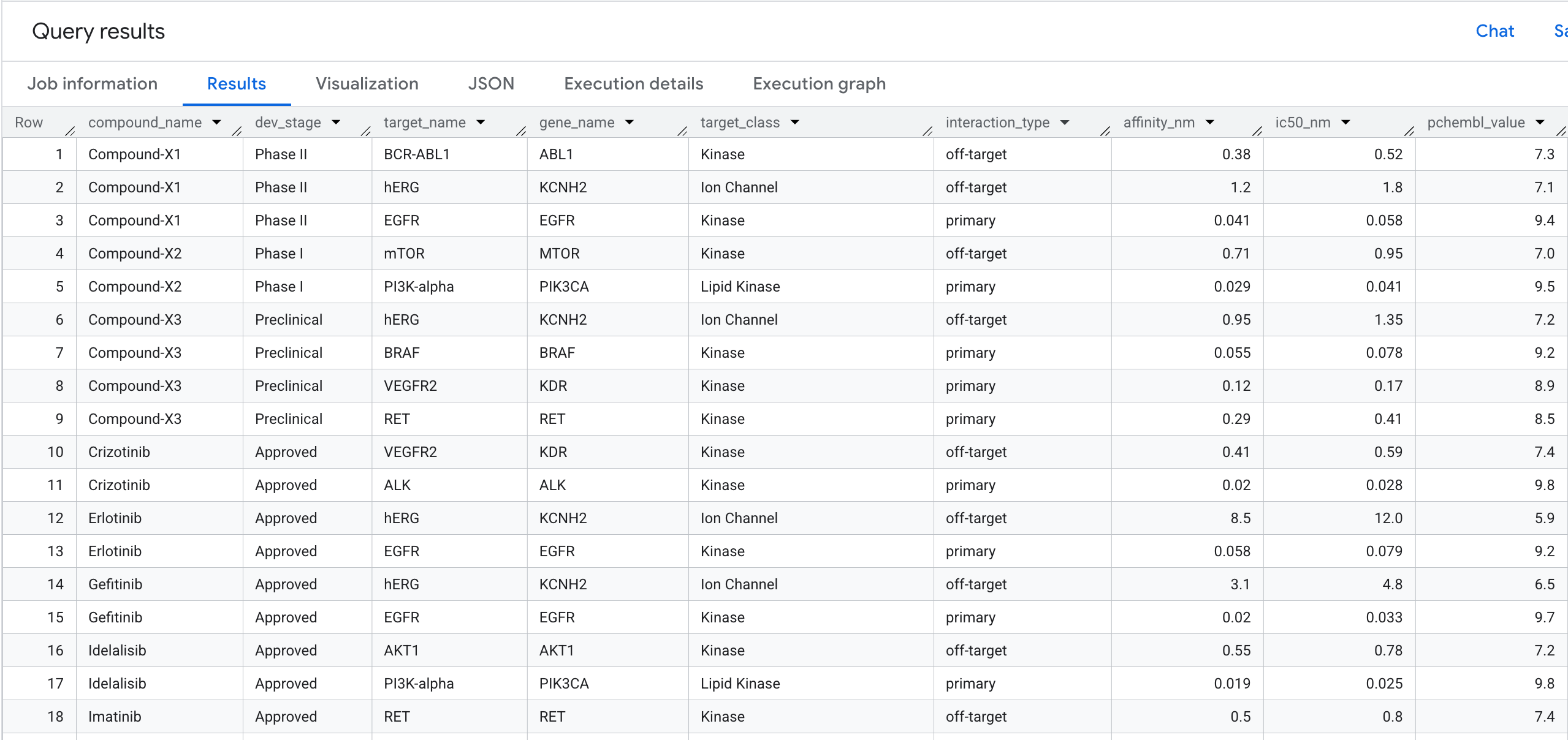
5. Zapytanie 1. Pełny profil wiązania z celem na związek
Uruchommy pierwsze zapytanie grafowe. Jest to przejście 1-hop, które odpowiada na pytanie: Które związki wiążą się z którymi celami i jakie jest ich powinowactwo?
Zapytanie GQL
W edytorze SQL uruchom to zapytanie:
SELECT
compound_name,
dev_stage,
target_name,
gene_name,
target_class,
interaction_type,
ROUND(affinity_nm, 3) AS affinity_nm,
ROUND(ic50_nm, 3) AS ic50_nm,
pchembl_value
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_name AS target_name,
t.gene_name AS gene_name,
t.target_class AS target_class,
b.interaction_type AS interaction_type,
b.affinity_nm AS affinity_nm,
b.ic50_nm AS ic50_nm,
b.pchembl_value AS pchembl_value
)
)
ORDER BY compound_name, interaction_type, affinity_nm;
Oto, co zobaczysz w wynikach:
6. Zapytanie 2. Wykrywanie ryzyka kardiologicznego
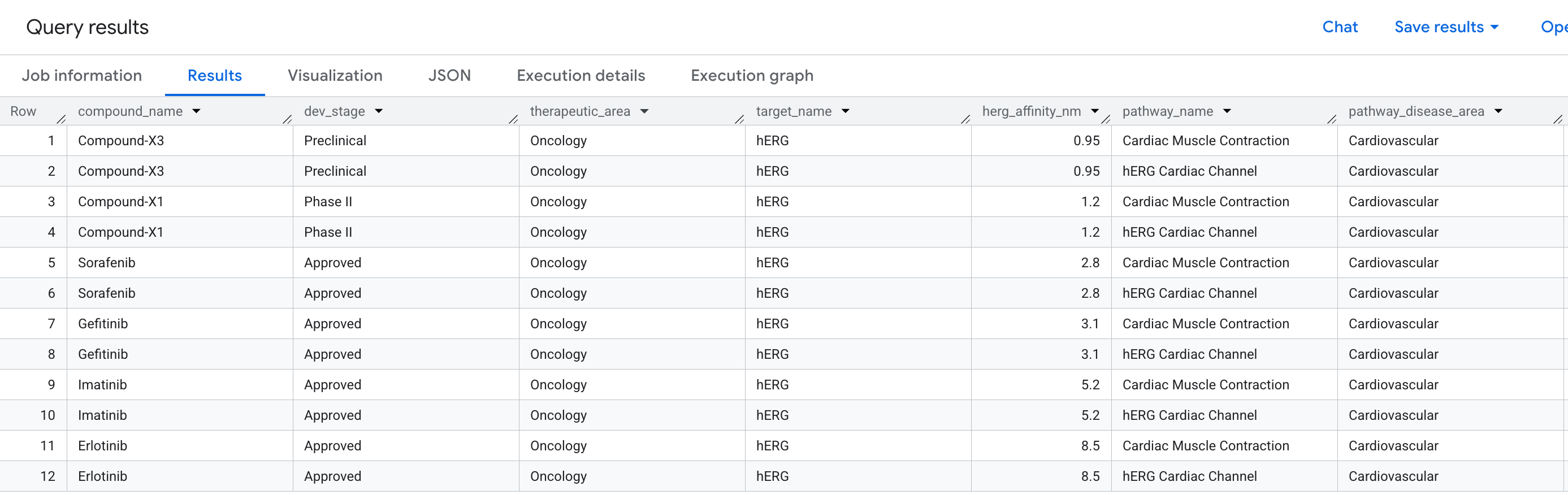
Pytanie biznesowe
W procesie odkrywania leków jedną z najczęstszych przyczyn niepowodzenia obiecującego związku w badaniach klinicznych jest kardiotoksyczność, a konkretnie niezamierzone wiązanie z białkiem hERG (gen: KCNH2), kanałem jonów potasu, który reguluje rytm serca. Uderzenie poza celem w hERG może powodować śmiertelne arytmie i było przyczyną wycofania z rynku kilku głośnych leków.
Chcemy odpowiedzieć na to pytanie:
„Które związki w naszym pipeline mają zdarzenie wiązania poza celem z białkiem hERG i jakie szlaki kardiologiczne są przez to zagrożone?”
Jest to pytanie 2-hop: musimy przejść od związku przez cel (hERG) do szlaku, łącząc 3 typy encji za pomocą 2 relacji w jednym zapytaniu.
Napisz zapytanie GQL
W edytorze SQL BQ uruchom to zapytanie:
SELECT
compound_name,
dev_stage,
therapeutic_area,
target_name,
ROUND(affinity_nm, 3) AS herg_affinity_nm,
pathway_name,
disease_area AS pathway_disease_area
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND b.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
c.therapeutic_area AS therapeutic_area,
t.target_name AS target_name,
b.affinity_nm AS affinity_nm,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
ORDER BY herg_affinity_nm;
Zwróć uwagę, jak klauzula MATCH brzmi niemal jak zdanie: "Znajdź związek, który wiąże się z celem uczestniczącym w szlaku" – z filtrami stosowanymi do każdego węzła i krawędzi na ścieżce.
Oto dane, które zobaczysz w wynikach:
Wizualizuj sieć ryzyka jako graf
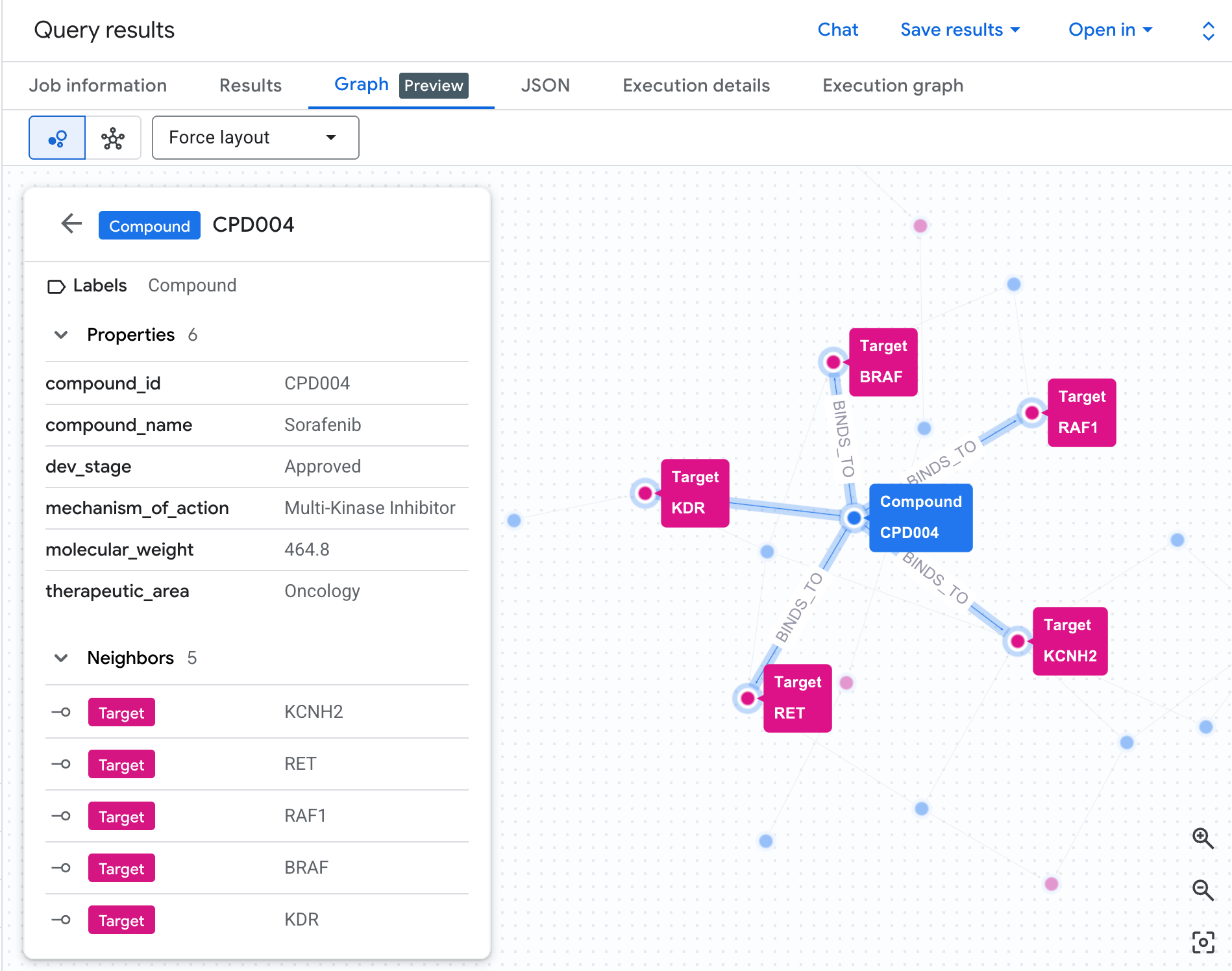
Tabela pokazuje nam dane, ale nie pokazuje struktury ryzyka. Czy wiele związków zbiega się na tym samym szlaku? Czy jest jeden związek o wysokim ryzyku, czy kilka?
Wizualizacja grafu sprawia, że jest to od razu widoczne. Aby wyrenderować to samo przejście 2-hop jako interaktywną sieć, uruchom komórkę poniżej:
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH pt = (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND pw.disease_area = 'Cardiovascular'
RETURN
TO_JSON(pt) AS path
Powinien pojawić się taki graf:
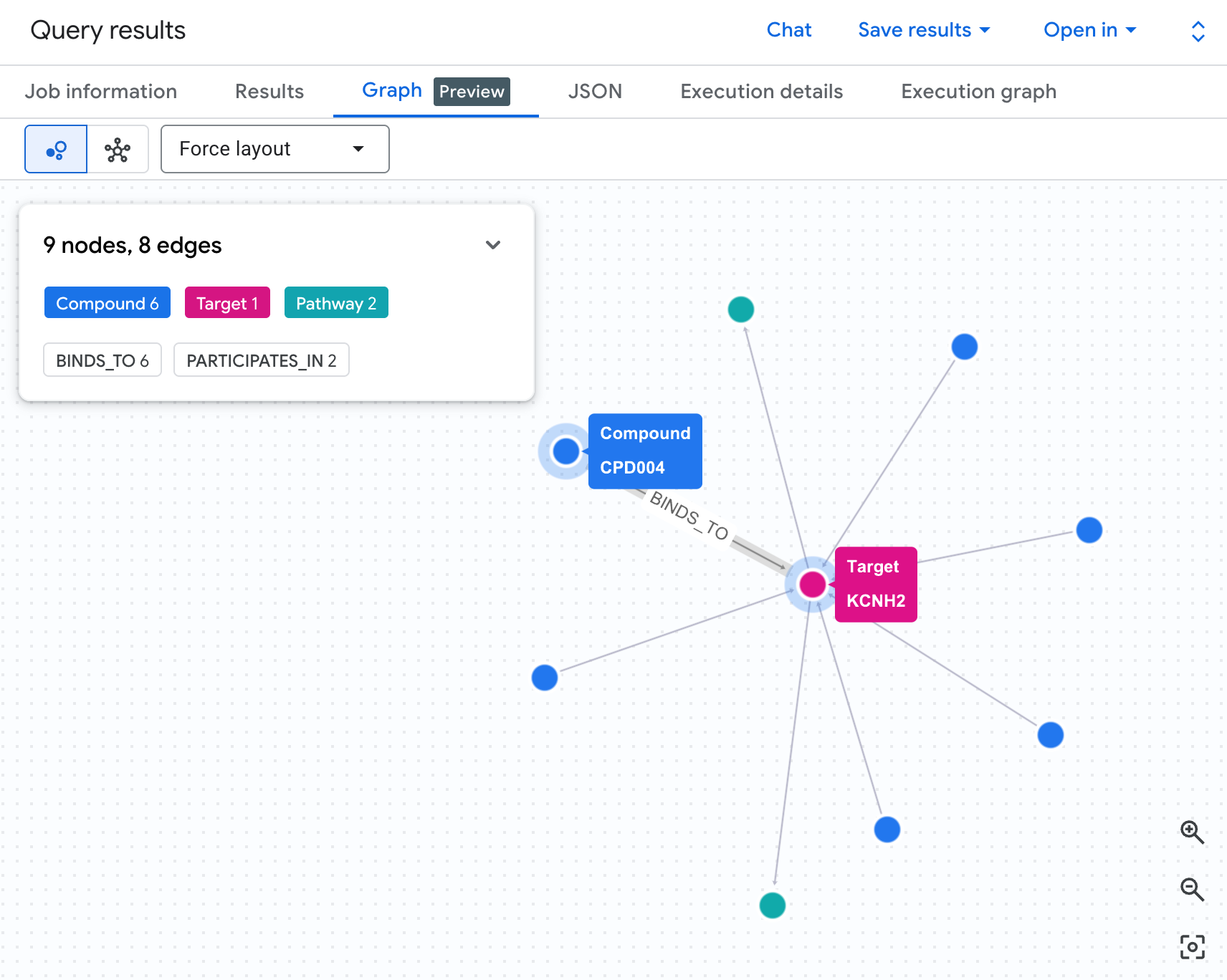
Każda ścieżka w grafie śledzi pełny łańcuch odpowiedzialności: związek (niebieskie węzły) wiąże się z białkiem hERG w środku, które łączy się z co najmniej jednym szlakiem kardiologicznym (zielone węzły). To, co było płaską listą wierszy w tabeli, jest teraz widoczną siecią ryzyka – związki z wieloma ekspozycjami na szlaki od razu wyróżniają się jako priorytetowe do sprawdzenia pod kątem bezpieczeństwa.
Zobacz, dlaczego GQL jest bardziej elegancki niż SQL
Aby wykonać to samo zapytanie 2-hop w standardowej wersji SQL, potrzebujesz 4 jawnych złączeń. Wkładasz wysiłek poznawczy w opisanie sposobu łączenia tabel, a nie relacji, której szukasz. GQL pozwala Ci skupić się na pytaniu.
SELECT
c.compound_name,
c.dev_stage,
c.therapeutic_area,
t.target_name,
ROUND(i.affinity_nm, 3) AS herg_affinity_nm,
pw.pathway_name,
pw.disease_area AS pathway_disease_area
FROM drug_target_graph.compounds c
JOIN drug_target_graph.interactions i ON c.compound_id = i.compound_id
JOIN drug_target_graph.targets t ON i.target_id = t.target_id
JOIN drug_target_graph.target_pathways tp ON t.target_id = tp.target_id
JOIN drug_target_graph.pathways pw ON tp.pathway_id = pw.pathway_id
WHERE t.gene_name = 'KCNH2'
AND i.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
ORDER BY herg_affinity_nm;
Głębiej – wykrywanie ryzyka metabolitów wielohopowych
Powyższe zapytanie identyfikuje związki, które bezpośrednio wiążą się z białkiem hERG. Jednak w rzeczywistych procesach bezpieczeństwa leków ryzyko jest czasami o krok dalej: związek może być metabolizowany w organizmie do cząsteczki wtórnej (metabolitu), która następnie wiąże się z hERG – jest to ryzyko, którego bezpośrednie testy wiązania mogą w ogóle nie wykryć.
Jeśli graf właściwości zawierałby tabelę węzłów Metabolit i krawędź METABOLIZUJE_SIĘ_DO, można by rozszerzyć ten sam wzorzec MATCH do przejścia 3-hop:
(Compound)-[METABOLISES_INTO]->(Metabolite)-[BINDS_TO]->
(Target)-[PARTICIPATES_IN]->(Pathway)
Struktura zapytania GQL zmieniłaby się o dokładnie 1 węzeł i 1 krawędź. Odpowiednik SQL wymagałby 2 dodatkowych złączeń. Jest to wzorzec, który sprawia, że przejście grafu jest szczególnie przydatne do analizy kaskadowej bezpieczeństwa – złożoność zapytania rośnie liniowo, a wgląd biologiczny – wykładniczo.
7. Zapytanie 3. Pary związków o wspólnym celu
Aby znaleźć kandydatów do terapii kombinowanej, możemy zidentyfikować, kiedy 2 różne związki wiążą się z tym samym węzłem docelowym. Używamy dopasowania dwukierunkowego , aby odpowiedzieć na pytanie: Które związki onkologiczne zbiegają się na dokładnie tym samym celu?
W edytorze SQL uruchom to zapytanie:
SELECT
compound_a,
compound_b,
shared_target,
gene_name,
ROUND(affinity_a_nm, 3) AS affinity_a_nm,
ROUND(affinity_b_nm, 3) AS affinity_b_nm
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
AND c2.therapeutic_area = 'Oncology'
COLUMNS (
c1.compound_name AS compound_a,
c2.compound_name AS compound_b,
t.target_name AS shared_target,
t.gene_name AS gene_name,
b1.affinity_nm AS affinity_a_nm,
b2.affinity_nm AS affinity_b_nm
)
)
ORDER BY compound_a, compound_b, affinity_a_nm;
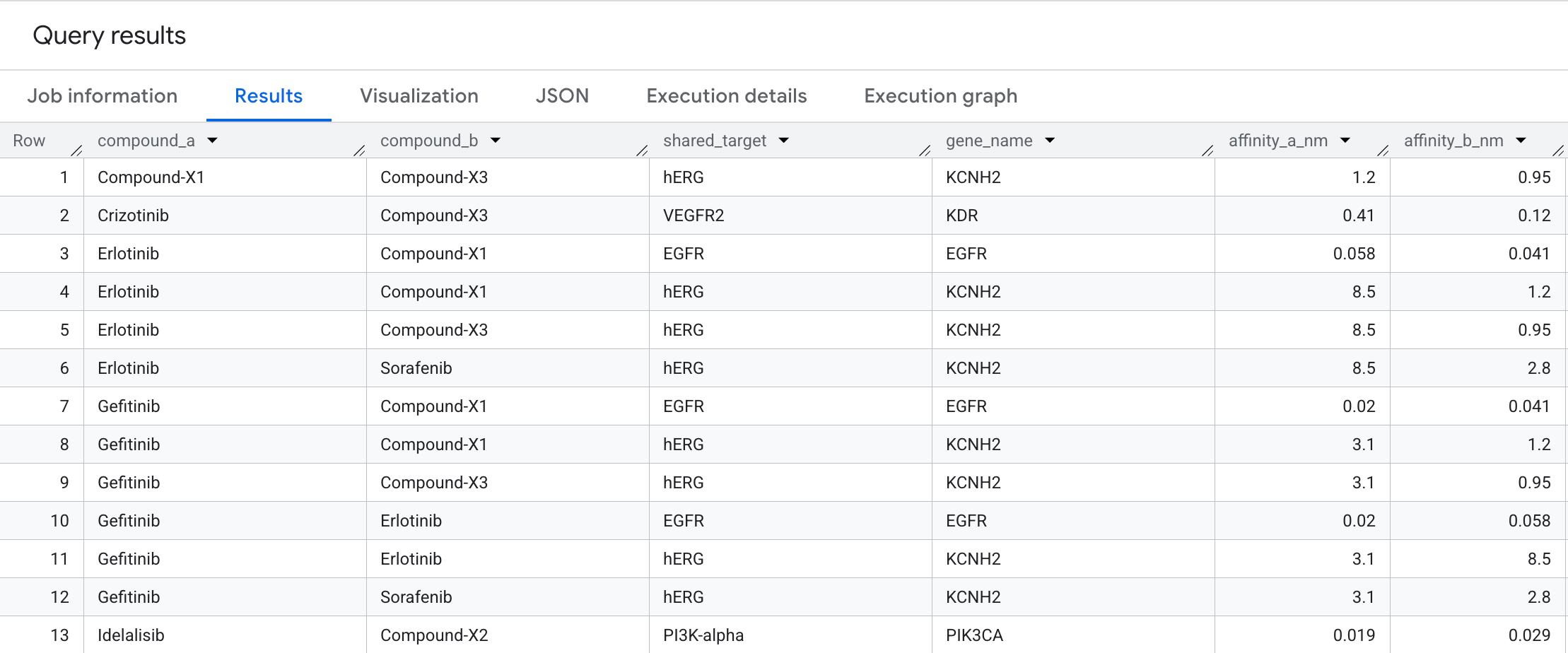
Oto dane, które zobaczysz w wynikach:
Wizualizacja grafu
Graf możesz wizualizować bezpośrednio w BigQuery, uruchamiając ten kod w edytorze SQL.
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH p = (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
RETURN
TO_JSON(p) AS path
To przejście dwukierunkowe ujawnia pary związków, które zbiegają się na tym samym celu białkowym – wzorzec, który trudno zauważyć w płaskiej tabeli interakcji, ale jest od razu widoczny jako graf. W procesie odkrywania leków pary o wspólnym celu są punktem wyjścia do projektowania terapii kombinowanej: 2 związki uderzające w ten sam węzeł na szlaku raka mogą wywołać efekt synergiczny lub wskazywać na niezamierzoną redundancję w pipeline.
8. Zapytanie 4. Promień działania szlaku choroby
Jak szeroki jest wpływ biologiczny każdego związku? Aby odpowiedzieć na pytanie: Na ile szlaków biologicznych i różnych celów wpływa każdy związek, pogrupowany według obszaru choroby?, wykonajmy przejście 2-hop z agregacją.
W edytorze SQL uruchom to zapytanie:
SELECT
compound_name,
dev_stage,
disease_area,
COUNT(DISTINCT pathway_id) AS pathways_affected,
COUNT(DISTINCT target_id) AS targets_involved,
STRING_AGG(DISTINCT pathway_name ORDER BY pathway_name) AS pathway_list
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_id AS target_id,
pw.pathway_id AS pathway_id,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
GROUP BY compound_name, dev_stage, disease_area
ORDER BY compound_name, pathways_affected DESC;
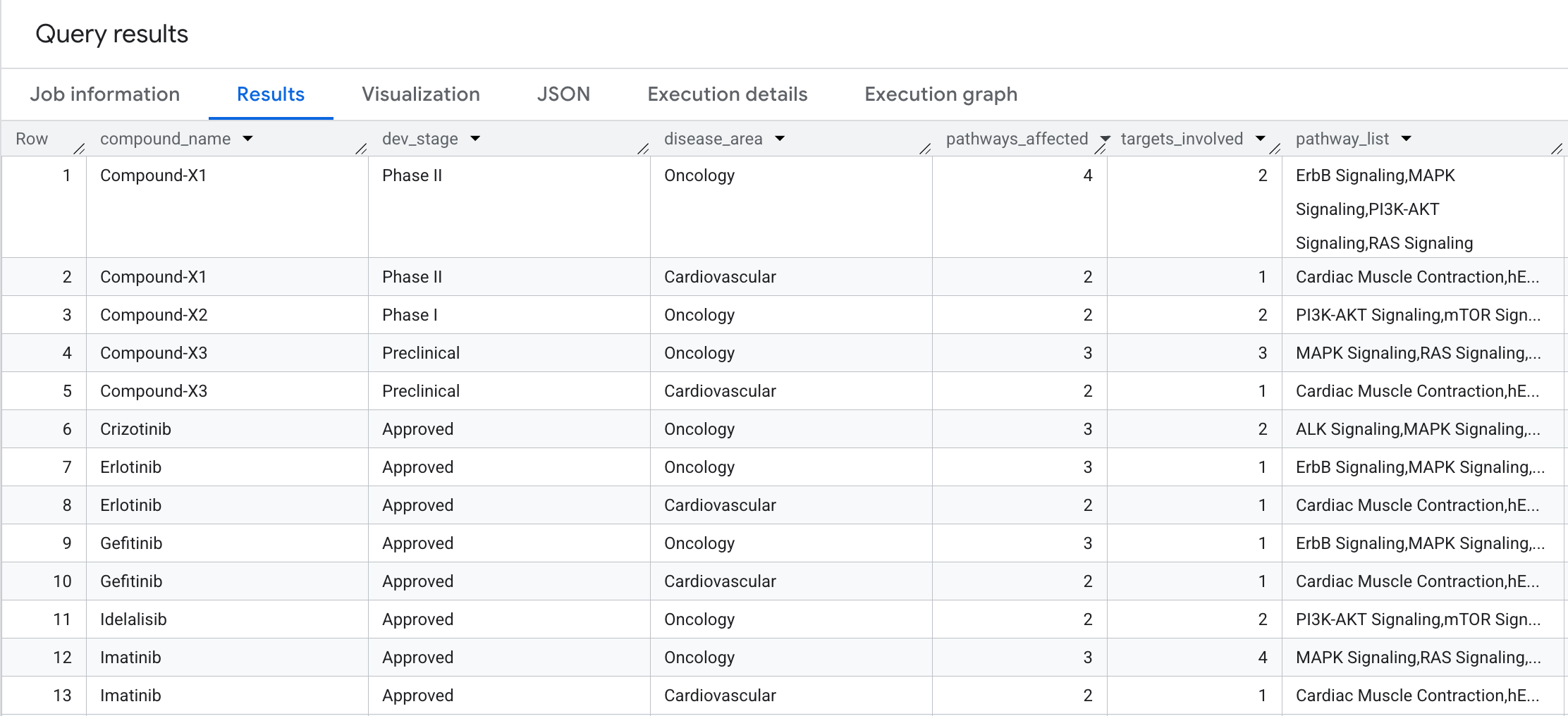
Oto, co zobaczysz w wynikach:
9. Zapytanie 5. Wybór bezpiecznego związku
Na koniec wykonajmy zapytanie o związki, które mają wysokie pokrycie onkologiczne, ale wyraźnie unikają ryzyka poza celem hERG (kardiologicznego). Odpowiada to typowym wzorcom wyboru w pipeline odkrywania leków, w których priorytetem jest bezpieczeństwo.
W edytorze SQL uruchom to zapytanie:
WITH oncology_compounds AS (
SELECT DISTINCT compound_id, compound_name, dev_stage
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE pw.disease_area = 'Oncology'
AND pw.cancer_relevance = 'high'
COLUMNS (
c.compound_id AS compound_id,
c.compound_name AS compound_name,
c.dev_stage AS dev_stage
)
)
),
herg_risk_compounds AS (
SELECT DISTINCT compound_id
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
WHERE t.gene_name = 'KCNH2'
COLUMNS (c.compound_id AS compound_id)
)
)
SELECT
o.compound_name,
o.dev_stage,
'Clean cardiac profile' AS cardiac_safety
FROM oncology_compounds o
LEFT JOIN herg_risk_compounds h ON o.compound_id = h.compound_id
WHERE h.compound_id IS NULL
ORDER BY o.dev_stage, o.compound_name;
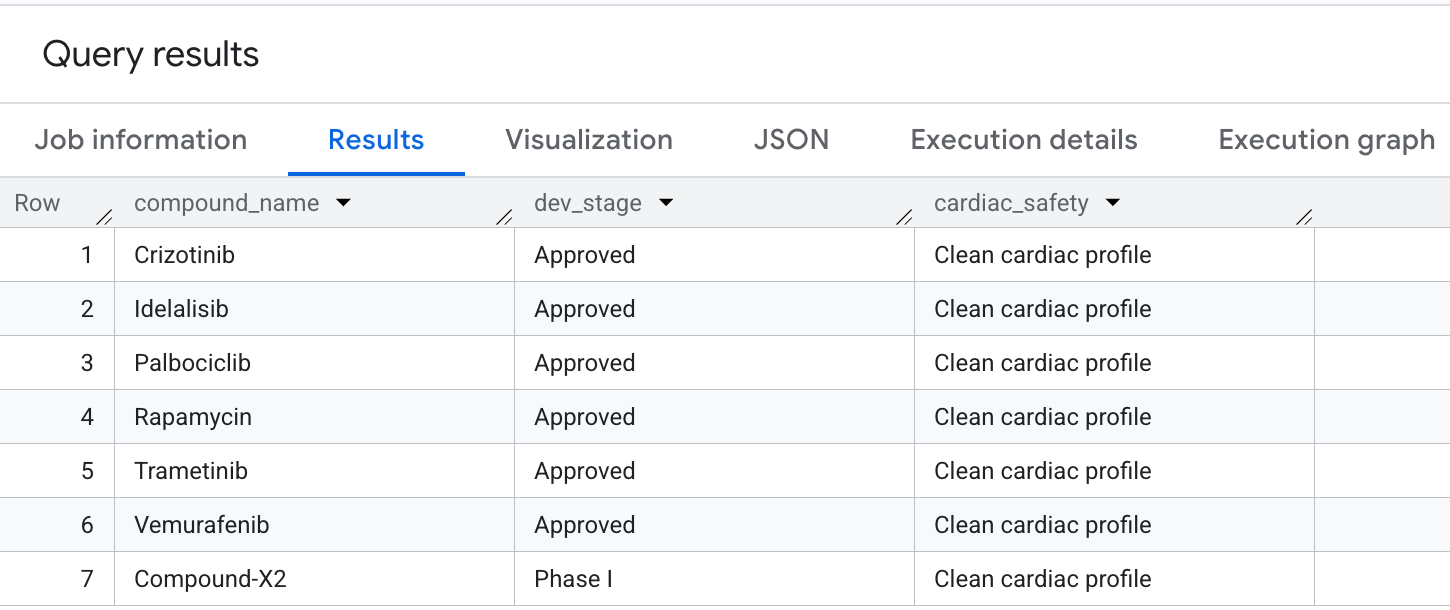
Oto dane wyjściowe, które zobaczysz w wynikach:
Udało Ci się wykonać zaawansowane przejścia grafowe w BigQuery, aby wyodrębnić kluczowe profile bezpieczeństwa i skuteczności.
10. Sekcja dodatkowa: czat z grafem
Analityka konwersacyjna BigQuery obsługuje teraz graf jako źródło wiedzy. Umożliwia to czatowanie z utworzonym grafem w języku naturalnym.
Pierwsze kroki: dodaj graf jako źródło wiedzy
Aby rozpocząć, utwórz agenta konwersacyjnego, wykonując te czynności tutaj. Na pasku wyszukiwania wybierz utworzony graf.
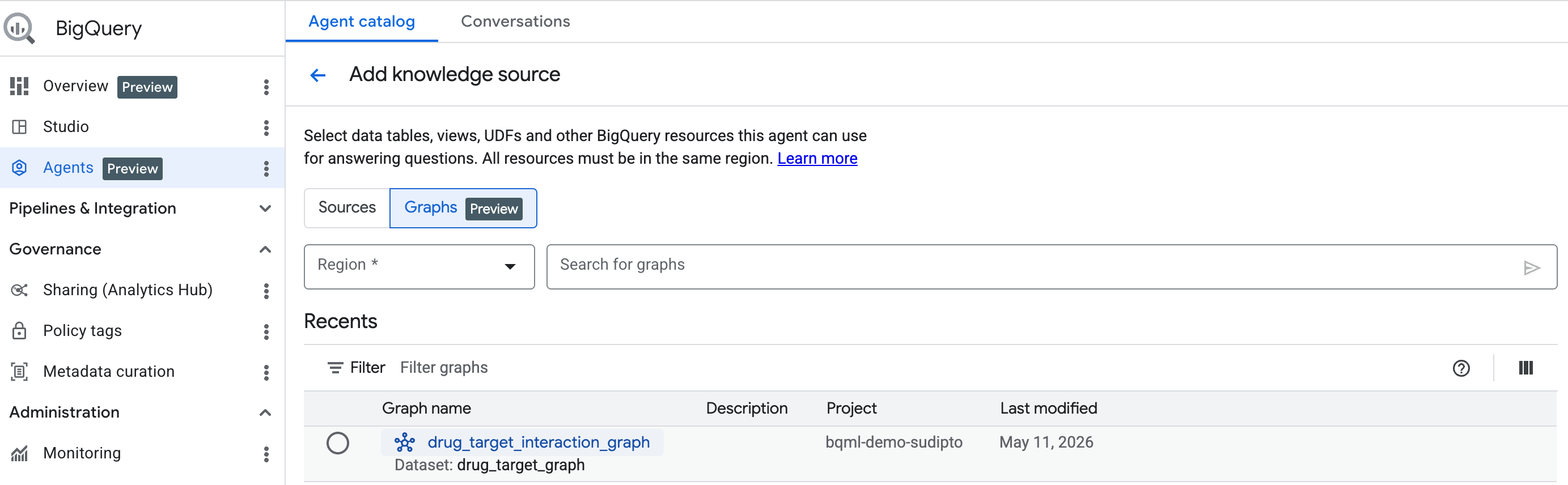
Użyj analityki konwersacyjnej BigQuery, aby czatować z grafem
Po dodaniu źródła wiedzy jako grafu dokończ konfigurowanie pozostałej części agenta analityki konwersacyjnej.
Możesz wtedy zacząć czatować z grafem w języku naturalnym.
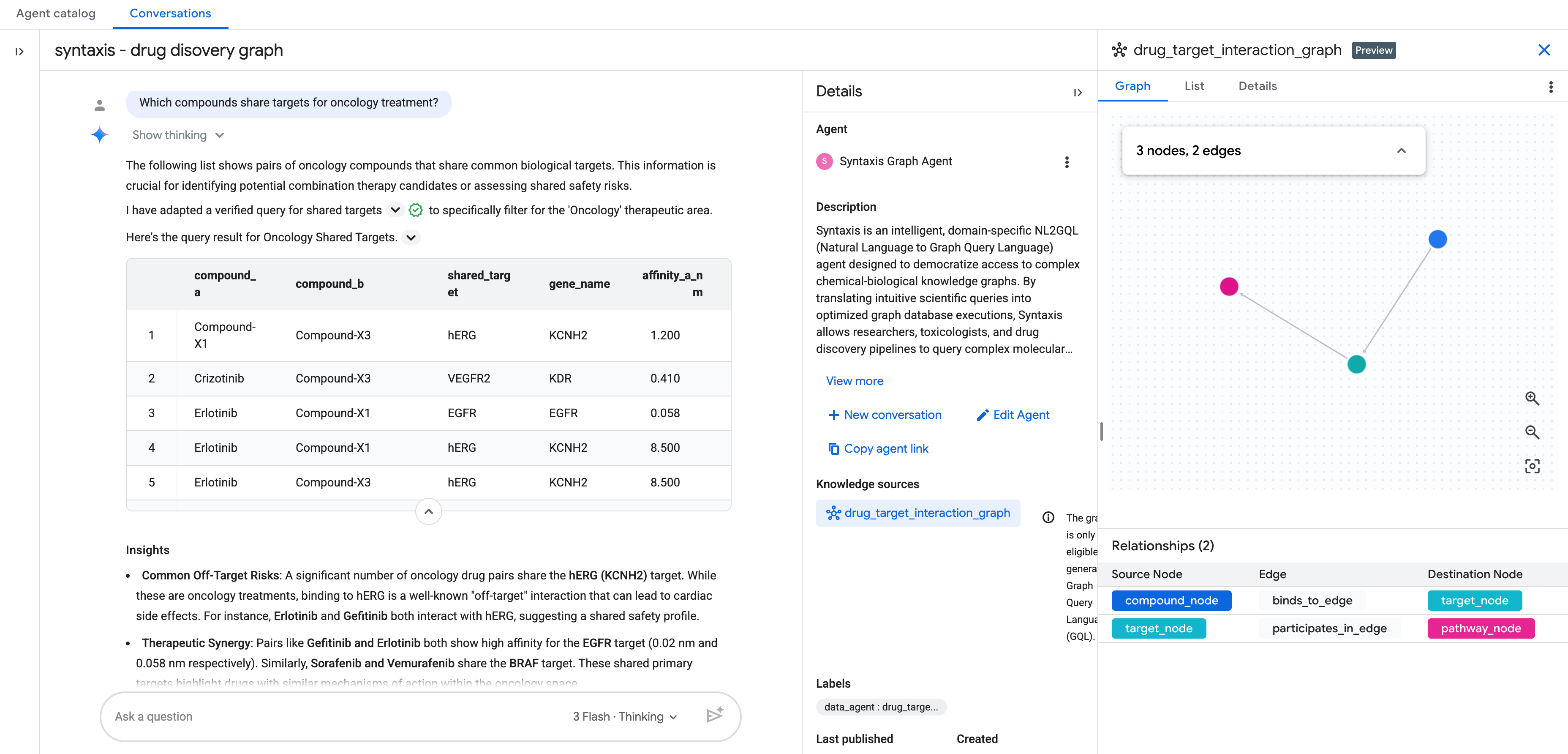
Pytania dodatkowe
- Jakie są wszystkie cele związków, które są obecnie w fazie 2 badań?
- Które cele są wspólne dla związków sercowo-naczyniowych i onkologicznych?
11. Zwalnianie miejsca
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami, usuń zasoby utworzone podczas tego modułu.
Aby usunąć schemat i wszystkie tabele kaskadowo, uruchom to zapytanie:
DROP SCHEMA IF EXISTS drug_target_graph CASCADE;
12. Gratulacje
Gratulacje! Udało Ci się modelować i analizować sieć interakcji między lekami a ich celami za pomocą BigQuery Graph.
Czego się nauczysz
- Jak modelować relacje między encjami (związki, cele, szlaki) jako graf właściwości.
- Jak zdefiniować schemat i utworzyć graf właściwości w BigQuery.
- Jak pisać złożone przejścia grafowe za pomocą GQL i porównywać je z tradycyjnym SQL.
- Jak wykorzystać
GRAPH_TABLE,MATCHi dopasowanie dwukierunkowe do rozwiązywania problemów w dziedzinie nauk przyrodniczych.