
1. Введение
В этом практическом занятии вы научитесь использовать BigQuery Graph для моделирования и анализа сети взаимодействия лекарственных препаратов и мишеней. Вы сможете использовать возможности запросов к графам (GQL) для изучения взаимодействия лекарств с биологическими мишенями, выявления потенциальных побочных эффектов (таких как кардиотоксичность) и поиска потенциальных комбинированных методов лечения.
🧬 Пример использования — Сеть взаимодействий между лекарственными препаратами и мишенями
Деловой вопрос: Каков полный радиус поражения соединения — к каким мишеням оно связывается, какие биологические пути затрагиваются и какие области заболеваний вовлечены?
Таблицы:
Стол | Описание |
| Молекулы лекарственных препаратов: механизм действия и стадия разработки. |
| Целевые белки с названиями генов и идентификаторами UniProt. |
| Сродство связывания соединения с мишенью (первичные мишени + нецелевые мишени) |
| Биологические пути, связанные с областями заболеваний. |
| Таблица соединений, связывающая целевые объекты с путями, в которых они участвуют. |
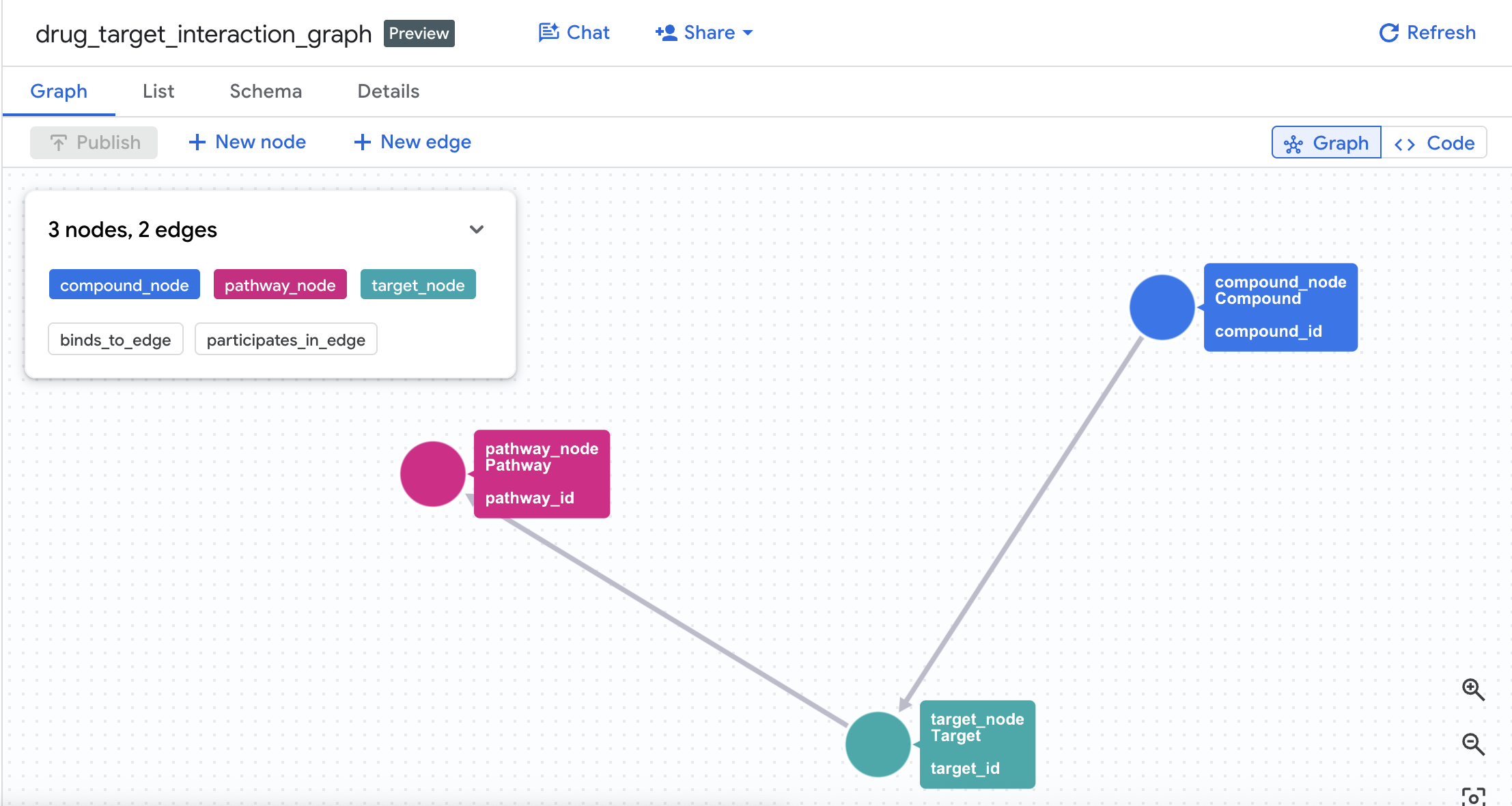
Модель графа свойств:
(Compound)-[BINDS_TO {affinity_nm, ic50_nm, interaction_type}]->(Target)
(Target)-[PARTICIPATES_IN {role, importance_score}]->(Pathway)
🔍 Запросы на демонстрацию
Запрос | Что это показывает |
Q1: Профиль связывания целевого объекта | Обход в один шаг — суммируется со всеми основными и второстепенными целями. |
Вопрос 2: Выявление кардиориска с помощью hERG | Двухэтапное перемещение — соединение → мишень hERG → сердечный путь |
Q3: Пары соединений с общей мишенью | Двунаправленное совпадение — два соединения сходятся к одному и тому же целевому узлу. |
В4: Радиус поражения, определяемый путем развития заболевания | Двухэтапная агрегация — полное покрытие сигнальных путей и областей заболеваний для каждого соединения. |
Вопрос 5: Выбор безопасного соединения | Препараты с широким спектром действия в онкологии, но без риска развития кардиотоксичности, связанной с hERG. |
Что вы будете делать
- Создайте набор данных и схему BigQuery для сети лекарственных взаимодействий.
- Загрузка выборочных данных (Соединения, Цели, Взаимодействия, Пути, Пути действия целевых веществ)
- Создайте в BigQuery граф свойств, соединяющий эти сущности.
- Для анализа взаимодействий соединений, биологических путей и радиуса поражения при заболеваниях используйте обход графа (
GRAPH_TABLEиMATCH). - Сравните GQL и стандартный SQL, чтобы понять простоту и выразительные возможности синтаксиса графов.
Что вам понадобится
- Веб-браузер, например Chrome.
- Проект Google Cloud с включенной функцией выставления счетов.
Этот практический семинар предназначен для разработчиков всех уровней, включая начинающих.
2. Прежде чем начать
Создайте проект в Google Cloud.
- В консоли Google Cloud выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов.
Запустить Cloud Shell
- В верхней части консоли Google Cloud нажмите кнопку «Активировать Cloud Shell» .
- Проверка подлинности:
gcloud auth list
- Подтвердите свой проект:
gcloud config get project
- При необходимости установите значение:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Включить API
Выполните эту команду, чтобы включить необходимый API BigQuery:
gcloud services enable bigquery.googleapis.com
3. Определите схему и загрузите данные.
Для начала вам необходимо создать набор данных для хранения таблиц, связанных с графиками, и заполнить их примерами данных.
- Перейдите в BigQuery Studio в консоли Google Cloud.
- Нажмите на кнопку « Редактор SQL» , чтобы открыть новую вкладку с запросами.
- Выполните следующую команду для создания набора данных
drug_target_graph:
CREATE SCHEMA IF NOT EXISTS drug_target_graph
OPTIONS (location = 'US');
Теперь создайте 5 исходных таблиц, выполнив следующие DDL-запросы в BigQuery Studio.
1. Создайте таблицу compounds .
Содержит информацию о молекулах лекарственных препаратов, механизме их действия, стадии разработки и терапевтической области.
CREATE OR REPLACE TABLE drug_target_graph.compounds AS
SELECT 'CPD001' AS compound_id, 'Imatinib' AS compound_name, 'Kinase Inhibitor' AS mechanism_of_action, 'Approved' AS dev_stage, 'Oncology' AS therapeutic_area, 479.6 AS molecular_weight UNION ALL
SELECT 'CPD002', 'Gefitinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 446.9 UNION ALL
SELECT 'CPD003', 'Erlotinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 393.4 UNION ALL
SELECT 'CPD004', 'Sorafenib', 'Multi-Kinase Inhibitor', 'Approved', 'Oncology', 464.8 UNION ALL
SELECT 'CPD005', 'Vemurafenib', 'BRAF Inhibitor', 'Approved', 'Oncology', 489.9 UNION ALL
SELECT 'CPD006', 'Crizotinib', 'ALK Inhibitor', 'Approved', 'Oncology', 450.3 UNION ALL
SELECT 'CPD007', 'Idelalisib', 'PI3K Inhibitor', 'Approved', 'Oncology', 415.4 UNION ALL
SELECT 'CPD008', 'Trametinib', 'MEK Inhibitor', 'Approved', 'Oncology', 615.4 UNION ALL
SELECT 'CPD009', 'Palbociclib', 'CDK Inhibitor', 'Approved', 'Oncology', 447.5 UNION ALL
SELECT 'CPD010', 'Compound-X1', 'Kinase Inhibitor', 'Phase II', 'Oncology', 412.3 UNION ALL
SELECT 'CPD011', 'Compound-X2', 'PI3K Inhibitor', 'Phase I', 'Oncology', 398.7 UNION ALL
SELECT 'CPD012', 'Saquinavir', 'Protease Inhibitor', 'Approved', 'Infectious Disease', 670.8 UNION ALL
SELECT 'CPD013', 'Metformin', 'AMPK Activator', 'Approved', 'Metabolic', 165.6 UNION ALL
SELECT 'CPD014', 'Rapamycin', 'mTOR Inhibitor', 'Approved', 'Immunology', 914.2 UNION ALL
SELECT 'CPD015', 'Compound-X3', 'Multi-Kinase Inhibitor', 'Preclinical', 'Oncology', 502.1;
2. Создайте таблицу targets .
Содержит информацию о целевых белках, названиях генов, идентификаторах UniProt и классах целевых белков.
CREATE OR REPLACE TABLE drug_target_graph.targets AS
SELECT 'TGT001' AS target_id, 'BCR-ABL1' AS target_name, 'ABL1' AS gene_name, 'P00519' AS uniprot_id, 'Kinase' AS target_class, TRUE AS is_oncogene UNION ALL
SELECT 'TGT002', 'EGFR', 'EGFR', 'P00533', 'Kinase', TRUE UNION ALL
SELECT 'TGT003', 'VEGFR2', 'KDR', 'P35968', 'Kinase', FALSE UNION ALL
SELECT 'TGT004', 'BRAF', 'BRAF', 'P15056', 'Kinase', TRUE UNION ALL
SELECT 'TGT005', 'ALK', 'ALK', 'Q9UM73', 'Kinase', TRUE UNION ALL
SELECT 'TGT006', 'PI3K-alpha','PIK3CA', 'P42336', 'Lipid Kinase', TRUE UNION ALL
SELECT 'TGT007', 'MEK1', 'MAP2K1', 'Q02750', 'Kinase', FALSE UNION ALL
SELECT 'TGT008', 'CDK4', 'CDK4', 'P11802', 'Kinase', FALSE UNION ALL
SELECT 'TGT009', 'CDK6', 'CDK6', 'P30279', 'Kinase', FALSE UNION ALL
SELECT 'TGT010', 'mTOR', 'MTOR', 'P42345', 'Kinase', FALSE UNION ALL
SELECT 'TGT011', 'PDGFR-beta','PDGFRB', 'P09619', 'Kinase', FALSE UNION ALL
SELECT 'TGT012', 'c-KIT', 'KIT', 'P10721', 'Kinase', TRUE UNION ALL
SELECT 'TGT013', 'hERG', 'KCNH2', 'Q12809', 'Ion Channel', FALSE UNION ALL
SELECT 'TGT014', 'AMPK', 'PRKAA1', 'Q13131', 'Kinase', FALSE UNION ALL
SELECT 'TGT015', 'RAF1', 'RAF1', 'P04049', 'Kinase', FALSE UNION ALL
SELECT 'TGT016', 'RET', 'RET', 'P07949', 'Kinase', TRUE UNION ALL
SELECT 'TGT017', 'FLT3', 'FLT3', 'P36888', 'Kinase', TRUE UNION ALL
SELECT 'TGT018', 'AKT1', 'AKT1', 'P31749', 'Kinase', FALSE UNION ALL
SELECT 'TGT019', 'ERK2', 'MAPK1', 'P28482', 'Kinase', FALSE UNION ALL
SELECT 'TGT020', 'HIV-Protease','HIV1-PR','Q72547', 'Protease', FALSE;
3. Создайте таблицу interactions .
Содержит данные об аффинности связывания соединения с мишенью (первичные мишени против нецелевых мишеней).
CREATE OR REPLACE TABLE drug_target_graph.interactions AS
SELECT 'INT001' AS interaction_id, 'CPD001' AS compound_id, 'TGT001' AS target_id, 0.025 AS affinity_nm, 0.038 AS ic50_nm, 'primary' AS interaction_type, 9.8 AS pchembl_value UNION ALL
SELECT 'INT002', 'CPD001', 'TGT011', 0.1, 0.15, 'primary', 8.8 UNION ALL
SELECT 'INT003', 'CPD001', 'TGT012', 0.068, 0.1, 'primary', 9.2 UNION ALL
SELECT 'INT004', 'CPD001', 'TGT016', 0.5, 0.8, 'off-target', 7.4 UNION ALL
SELECT 'INT005', 'CPD001', 'TGT013', 5.2, 8.1, 'off-target', 6.1 UNION ALL
SELECT 'INT006', 'CPD002', 'TGT002', 0.02, 0.033, 'primary', 9.7 UNION ALL
SELECT 'INT007', 'CPD002', 'TGT013', 3.1, 4.8, 'off-target', 6.5 UNION ALL
SELECT 'INT008', 'CPD003', 'TGT002', 0.058, 0.079, 'primary', 9.2 UNION ALL
SELECT 'INT009', 'CPD003', 'TGT013', 8.5, 12.0, 'off-target', 5.9 UNION ALL
SELECT 'INT010', 'CPD004', 'TGT003', 0.09, 0.12, 'primary', 9.1 UNION ALL
SELECT 'INT011', 'CPD004', 'TGT004', 0.038, 0.055, 'primary', 8.9 UNION ALL
SELECT 'INT012', 'CPD004', 'TGT015', 0.22, 0.31, 'primary', 8.5 UNION ALL
SELECT 'INT013', 'CPD004', 'TGT016', 0.58, 0.75, 'primary', 8.1 UNION ALL
SELECT 'INT014', 'CPD004', 'TGT017', 0.33, 0.48, 'primary', 8.4 UNION ALL
SELECT 'INT015', 'CPD004', 'TGT013', 2.8, 4.1, 'off-target', 6.6 UNION ALL
SELECT 'INT016', 'CPD005', 'TGT004', 0.031, 0.044, 'primary', 9.5 UNION ALL
SELECT 'INT017', 'CPD005', 'TGT015', 0.48, 0.65, 'off-target', 7.3 UNION ALL
SELECT 'INT018', 'CPD006', 'TGT005', 0.02, 0.028, 'primary', 9.8 UNION ALL
SELECT 'INT019', 'CPD006', 'TGT003', 0.41, 0.59, 'off-target', 7.4 UNION ALL
SELECT 'INT020', 'CPD007', 'TGT006', 0.019, 0.025, 'primary', 9.8 UNION ALL
SELECT 'INT021', 'CPD007', 'TGT018', 0.55, 0.78, 'off-target', 7.2 UNION ALL
SELECT 'INT022', 'CPD008', 'TGT007', 0.0092, 0.014, 'primary', 10.1 UNION ALL
SELECT 'INT023', 'CPD008', 'TGT019', 0.38, 0.51, 'off-target', 7.4 UNION ALL
SELECT 'INT024', 'CPD009', 'TGT008', 0.011, 0.017, 'primary', 9.9 UNION ALL
SELECT 'INT025', 'CPD009', 'TGT009', 0.015, 0.022, 'primary', 9.8 UNION ALL
SELECT 'INT026', 'CPD010', 'TGT002', 0.041, 0.058, 'primary', 9.4 UNION ALL
SELECT 'INT027', 'CPD010', 'TGT001', 0.38, 0.52, 'off-target', 7.3 UNION ALL
SELECT 'INT028', 'CPD010', 'TGT013', 1.2, 1.8, 'off-target', 7.1 UNION ALL
SELECT 'INT029', 'CPD011', 'TGT006', 0.029, 0.041, 'primary', 9.5 UNION ALL
SELECT 'INT030', 'CPD011', 'TGT010', 0.71, 0.95, 'off-target', 7.0 UNION ALL
SELECT 'INT031', 'CPD012', 'TGT020', 0.39, 0.55, 'primary', 7.3 UNION ALL
SELECT 'INT032', 'CPD013', 'TGT014', 12.0, 18.5, 'primary', 5.7 UNION ALL
SELECT 'INT033', 'CPD014', 'TGT010', 0.0018, 0.0025, 'primary', 11.8 UNION ALL
SELECT 'INT034', 'CPD015', 'TGT004', 0.055, 0.078, 'primary', 9.2 UNION ALL
SELECT 'INT035', 'CPD015', 'TGT003', 0.12, 0.17, 'primary', 8.9 UNION ALL
SELECT 'INT036', 'CPD015', 'TGT016', 0.29, 0.41, 'primary', 8.5 UNION ALL
SELECT 'INT037', 'CPD015', 'TGT013', 0.95, 1.35, 'off-target', 7.2;
4. Создайте таблицу pathways .
Содержит информацию о биологических процессах, связанных с ними областях заболеваний и их значении для онкологии.
CREATE OR REPLACE TABLE drug_target_graph.pathways AS
SELECT 'PWY001' AS pathway_id, 'MAPK Signaling' AS pathway_name, 'hsa04010' AS kegg_id, 'Cell Proliferation' AS biological_process, 'Oncology' AS disease_area, 'high' AS cancer_relevance UNION ALL
SELECT 'PWY002', 'PI3K-AKT Signaling', 'hsa04151', 'Cell Survival', 'Oncology', 'high' UNION ALL
SELECT 'PWY003', 'VEGF Signaling', 'hsa04370', 'Angiogenesis', 'Oncology', 'high' UNION ALL
SELECT 'PWY004', 'ErbB Signaling', 'hsa04012', 'Cell Growth', 'Oncology', 'high' UNION ALL
SELECT 'PWY005', 'mTOR Signaling', 'hsa04150', 'Cell Growth', 'Oncology', 'medium' UNION ALL
SELECT 'PWY006', 'Cell Cycle', 'hsa04110', 'Cell Division', 'Oncology', 'high' UNION ALL
SELECT 'PWY007', 'Cardiac Muscle Contraction', 'hsa04260', 'Cardiac Function', 'Cardiovascular', 'low' UNION ALL
SELECT 'PWY008', 'hERG Cardiac Channel', 'hsa04022', 'Cardiac Repolarisation','Cardiovascular', 'low' UNION ALL
SELECT 'PWY009', 'AMPK Signaling', 'hsa04152', 'Energy Metabolism', 'Metabolic', 'low' UNION ALL
SELECT 'PWY010', 'ALK Signaling', 'hsa04915', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY011', 'RAS Signaling', 'hsa04014', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY012', 'HIV Replication', 'hsa05170', 'Viral Replication', 'Infectious Disease', 'low';
5. Создайте таблицу target_pathways .
Соединительная таблица, связывающая целевые объекты с биологическими путями, в которых они участвуют.
CREATE OR REPLACE TABLE drug_target_graph.target_pathways AS
SELECT 'TP001' AS tp_id, 'TGT001' AS target_id, 'PWY001' AS pathway_id, 'activator' AS role, 0.95 AS importance_score UNION ALL
SELECT 'TP002', 'TGT001', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP003', 'TGT002', 'PWY004', 'activator', 0.98 UNION ALL
SELECT 'TP004', 'TGT002', 'PWY001', 'activator', 0.82 UNION ALL
SELECT 'TP005', 'TGT002', 'PWY002', 'activator', 0.75 UNION ALL
SELECT 'TP006', 'TGT003', 'PWY003', 'activator', 0.96 UNION ALL
SELECT 'TP007', 'TGT003', 'PWY001', 'activator', 0.71 UNION ALL
SELECT 'TP008', 'TGT004', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP009', 'TGT004', 'PWY011', 'activator', 0.89 UNION ALL
SELECT 'TP010', 'TGT005', 'PWY010', 'activator', 0.99 UNION ALL
SELECT 'TP011', 'TGT005', 'PWY001', 'activator', 0.78 UNION ALL
SELECT 'TP012', 'TGT006', 'PWY002', 'activator', 0.98 UNION ALL
SELECT 'TP013', 'TGT006', 'PWY005', 'activator', 0.85 UNION ALL
SELECT 'TP014', 'TGT007', 'PWY001', 'activator', 0.94 UNION ALL
SELECT 'TP015', 'TGT007', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP016', 'TGT008', 'PWY006', 'activator', 0.95 UNION ALL
SELECT 'TP017', 'TGT009', 'PWY006', 'activator', 0.93 UNION ALL
SELECT 'TP018', 'TGT010', 'PWY005', 'activator', 0.99 UNION ALL
SELECT 'TP019', 'TGT010', 'PWY002', 'activator', 0.91 UNION ALL
SELECT 'TP020', 'TGT011', 'PWY003', 'activator', 0.87 UNION ALL
SELECT 'TP021', 'TGT011', 'PWY001', 'activator', 0.72 UNION ALL
SELECT 'TP022', 'TGT012', 'PWY001', 'activator', 0.83 UNION ALL
SELECT 'TP023', 'TGT012', 'PWY011', 'activator', 0.79 UNION ALL
SELECT 'TP024', 'TGT013', 'PWY008', 'substrate', 0.99 UNION ALL
SELECT 'TP025', 'TGT013', 'PWY007', 'substrate', 0.95 UNION ALL
SELECT 'TP026', 'TGT014', 'PWY009', 'activator', 0.97 UNION ALL
SELECT 'TP027', 'TGT015', 'PWY001', 'activator', 0.91 UNION ALL
SELECT 'TP028', 'TGT015', 'PWY011', 'activator', 0.86 UNION ALL
SELECT 'TP029', 'TGT016', 'PWY001', 'activator', 0.84 UNION ALL
SELECT 'TP030', 'TGT016', 'PWY003', 'activator', 0.77 UNION ALL
SELECT 'TP031', 'TGT017', 'PWY001', 'activator', 0.88 UNION ALL
SELECT 'TP032', 'TGT017', 'PWY011', 'activator', 0.82 UNION ALL
SELECT 'TP033', 'TGT018', 'PWY002', 'activator', 0.96 UNION ALL
SELECT 'TP034', 'TGT018', 'PWY005', 'activator', 0.88 UNION ALL
SELECT 'TP035', 'TGT019', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP036', 'TGT019', 'PWY011', 'activator', 0.91 UNION ALL
SELECT 'TP037', 'TGT020', 'PWY012', 'substrate', 0.99;
4. Создайте граф свойств.
После успешного создания таблиц можно построить граф свойств . Он связывает узлы (Соединения, Цели, Пути) с помощью таблиц ребер ( Interactions и Target Pathways ).
Выполните следующее выражение в редакторе SQL BigQuery Studio:
CREATE OR REPLACE PROPERTY GRAPH drug_target_graph.drug_target_interaction_graph
NODE TABLES (
drug_target_graph.compounds
AS compound_node
KEY (compound_id)
LABEL Compound
PROPERTIES (compound_id, compound_name, mechanism_of_action, dev_stage, therapeutic_area, molecular_weight),
drug_target_graph.targets
AS target_node
KEY (target_id)
LABEL Target
PROPERTIES (target_id, target_name, gene_name, uniprot_id, target_class, is_oncogene),
drug_target_graph.pathways
AS pathway_node
KEY (pathway_id)
LABEL Pathway
PROPERTIES (pathway_id, pathway_name, kegg_id, biological_process, disease_area, cancer_relevance)
)
EDGE TABLES (
drug_target_graph.interactions
AS binds_to_edge
KEY (interaction_id)
SOURCE KEY (compound_id) REFERENCES compound_node (compound_id)
DESTINATION KEY (target_id) REFERENCES target_node (target_id)
LABEL BINDS_TO
PROPERTIES (interaction_id, affinity_nm, ic50_nm, interaction_type, pchembl_value),
drug_target_graph.target_pathways
AS participates_in_edge
KEY (tp_id)
SOURCE KEY (target_id) REFERENCES target_node (target_id)
DESTINATION KEY (pathway_id) REFERENCES pathway_node (pathway_id)
LABEL PARTICIPATES_IN
PROPERTIES (tp_id, role, importance_score)
);
Это создаст в вашем наборе данных граф с именем drug_target_interaction_graph .
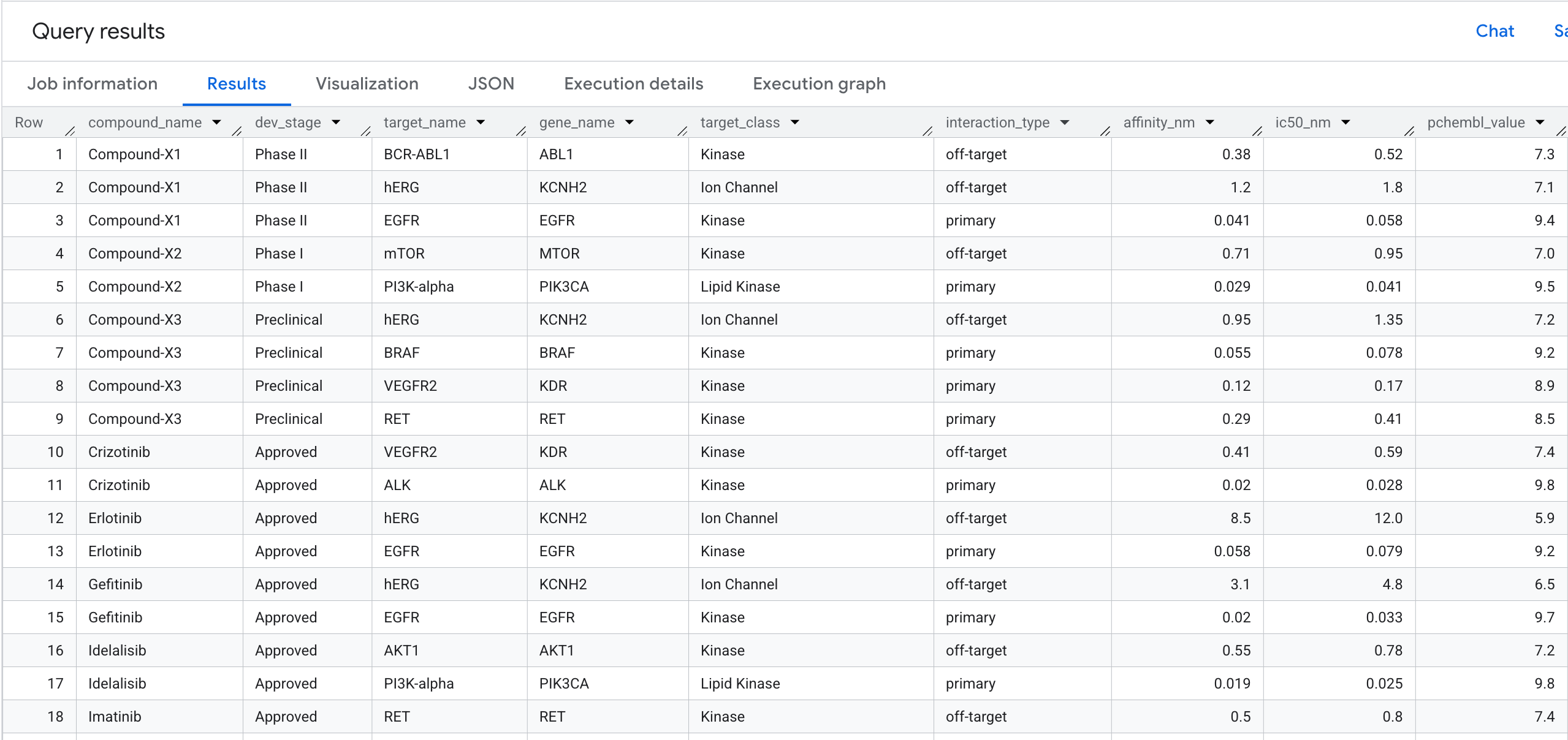
5. Запрос 1: Полный профиль связывания с целевым белком для каждого соединения.
Давайте выполним наш первый запрос к графу. Это одношаговый обход , который отвечает на вопрос: какие соединения связываются с какими мишенями и какова их аффинность?
GQL-запрос
Выполните следующий запрос в редакторе SQL:
SELECT
compound_name,
dev_stage,
target_name,
gene_name,
target_class,
interaction_type,
ROUND(affinity_nm, 3) AS affinity_nm,
ROUND(ic50_nm, 3) AS ic50_nm,
pchembl_value
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_name AS target_name,
t.gene_name AS gene_name,
t.target_class AS target_class,
b.interaction_type AS interaction_type,
b.affinity_nm AS affinity_nm,
b.ic50_nm AS ic50_nm,
b.pchembl_value AS pchembl_value
)
)
ORDER BY compound_name, interaction_type, affinity_nm;
Вот что вы увидите в результатах:
6. Запрос 2: Выявление риска сердечно-сосудистых заболеваний
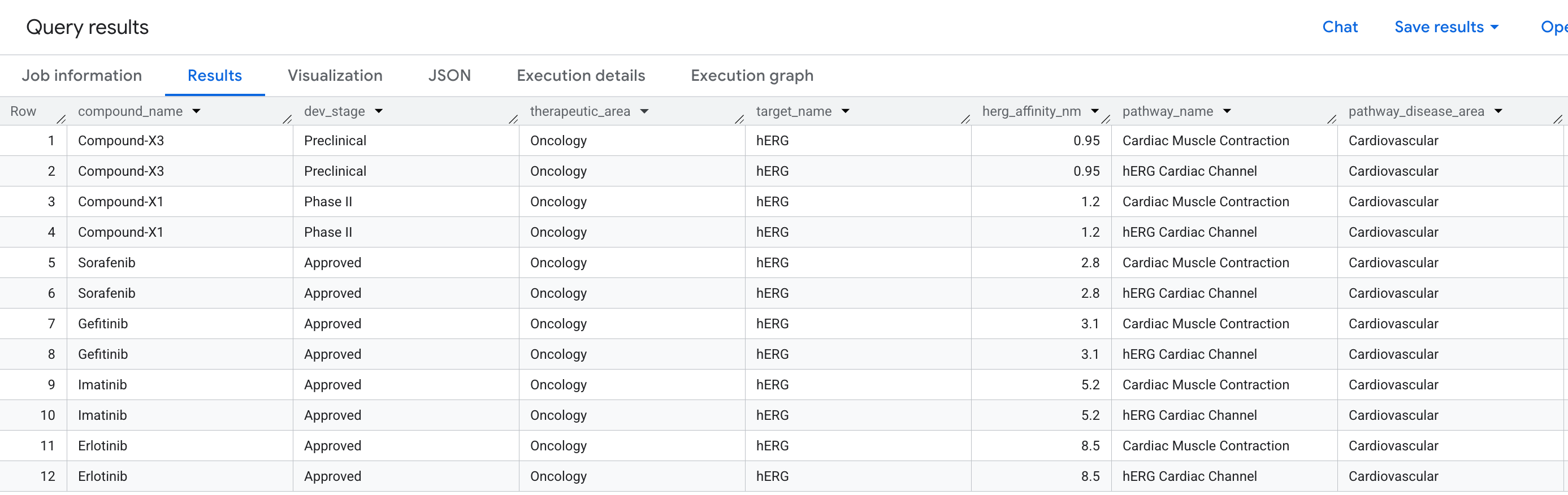
Деловой вопрос
В разработке лекарств одной из наиболее распространенных причин провала перспективного соединения в клинических испытаниях является кардиотоксичность — а именно, непреднамеренное связывание с белком hERG (ген: KCNH2 ), калиевым ионным каналом, регулирующим сердечный ритм. Нецелевое воздействие на hERG может вызвать фатальные аритмии и стало причиной нескольких громких случаев отзыва лекарств.
Вопрос, на который мы хотим ответить, звучит так:
«Какие соединения из нашей линейки разработок имеют нецелевое связывание с белком hERG — и какие сердечно-сосудистые пути это подвергает риску?»
Это вопрос с двумя переходами : нам нужно пройти от составного объекта (Compound) через целевой объект (Target, hERG) к пути (Pathway) — соединив три типа сущностей в двух отношениях в одном запросе.
Напишите GQL-запрос.
Выполните следующий запрос в редакторе SQL-запросов SQL:
SELECT
compound_name,
dev_stage,
therapeutic_area,
target_name,
ROUND(affinity_nm, 3) AS herg_affinity_nm,
pathway_name,
disease_area AS pathway_disease_area
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND b.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
c.therapeutic_area AS therapeutic_area,
t.target_name AS target_name,
b.affinity_nm AS affinity_nm,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
ORDER BY herg_affinity_nm;
Обратите внимание, как условие MATCH читается почти как предложение: «Найти соединение, которое связывается с целевым объектом, участвующим в пути» — с применением фильтров к каждому узлу и ребру вдоль пути.
Вот данные, которые вы увидите в результатах:
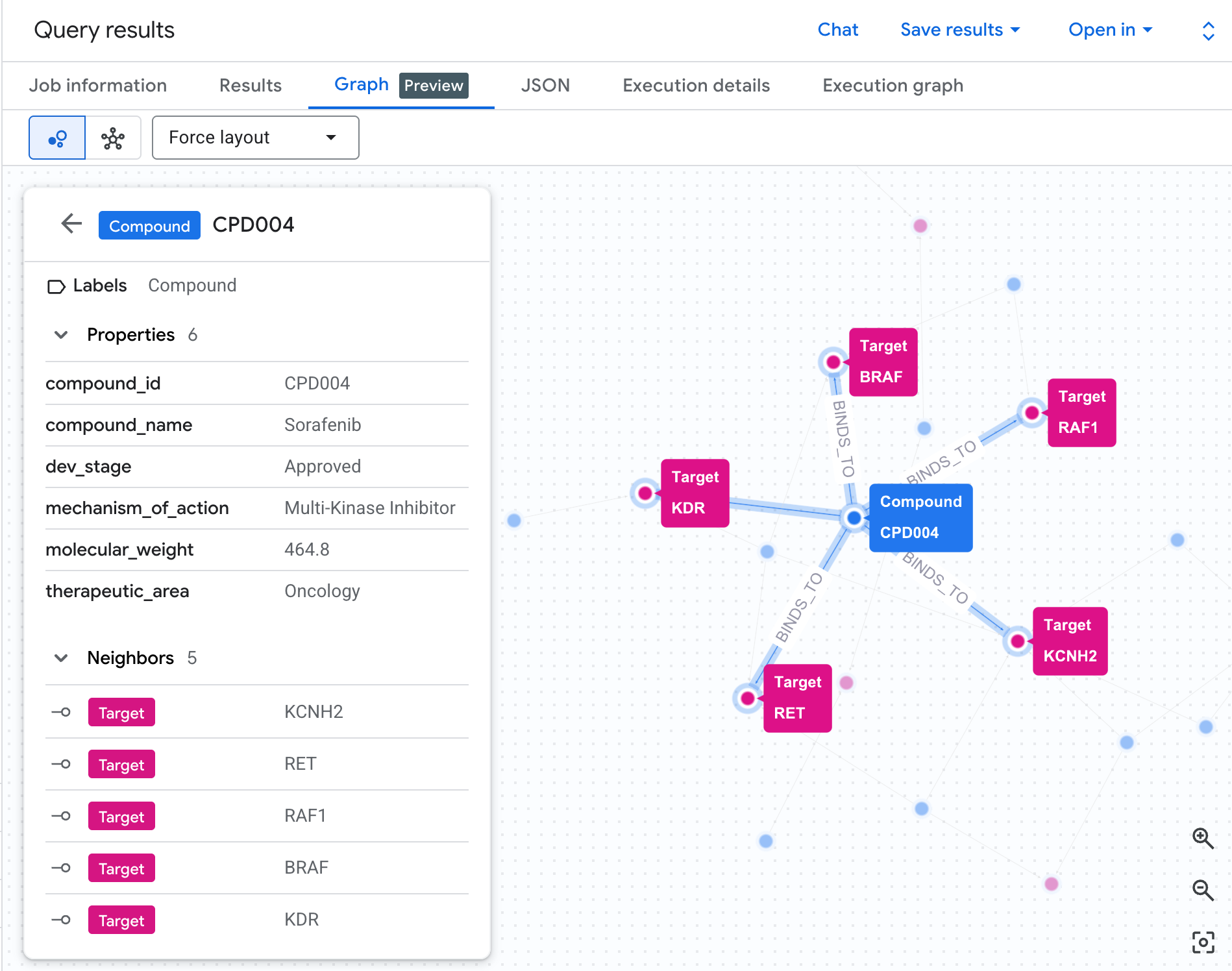
Визуализируйте сеть рисков в виде графа.
Таблица показывает нам данные, но не раскрывает структуру риска. Действуют ли несколько соединений по одному и тому же пути? Существует ли одно соединение с высоким риском или несколько?
Визуализация в виде графа делает это сразу очевидным. Запустите ячейку ниже, чтобы отобразить тот же двухэтапный обход сети в интерактивном режиме:
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH pt = (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND pw.disease_area = 'Cardiovascular'
RETURN
TO_JSON(pt) AS path
Вы должны увидеть график примерно такого вида:
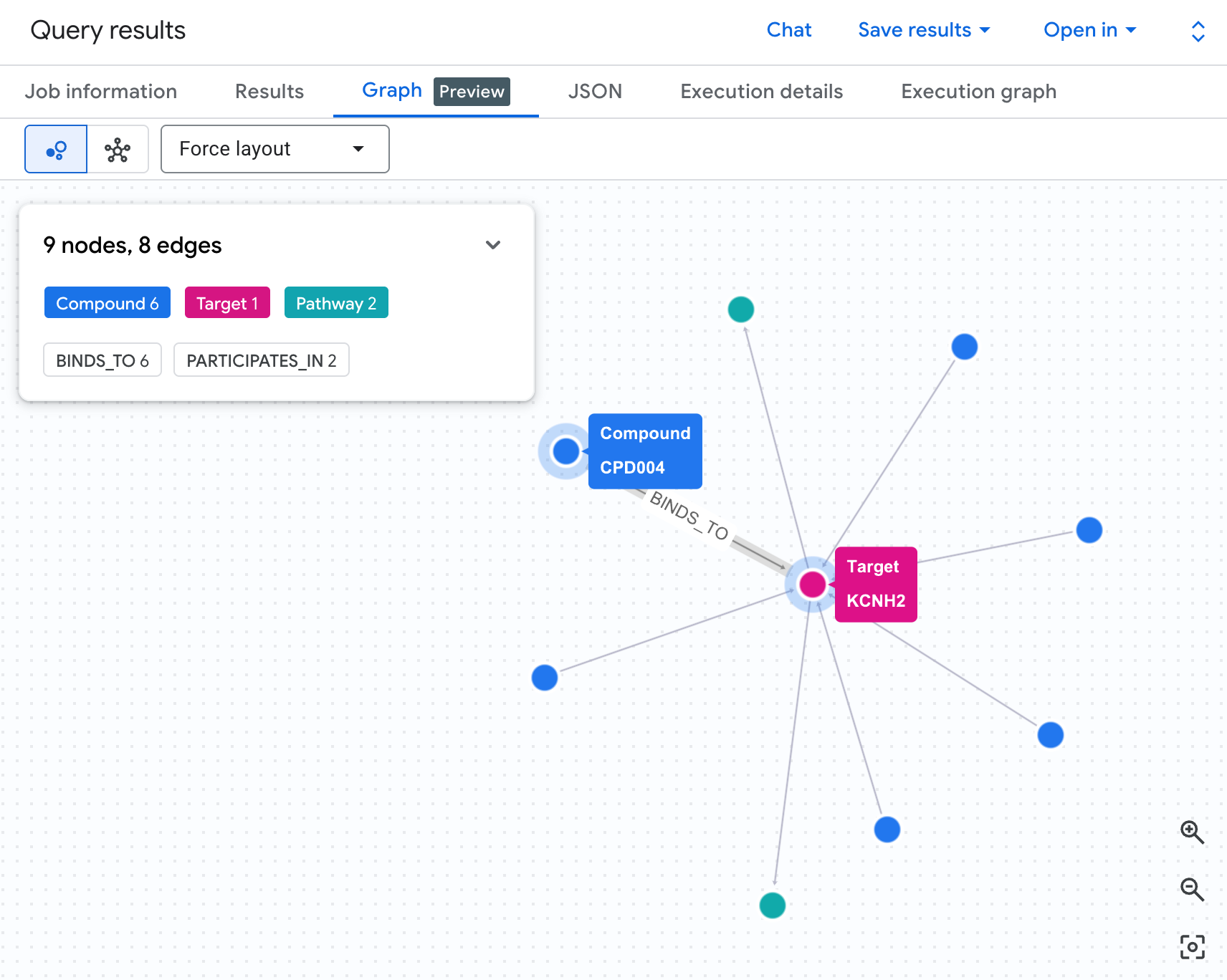
Каждый путь на графике отслеживает полную цепочку рисков: соединение (синие узлы) связывается с белком hERG в центре, который, в свою очередь, соединяется с одним или несколькими сердечными сигнальными путями (зеленые узлы). То, что раньше было простым списком строк в таблице, теперь представляет собой видимую сеть рисков — соединения с воздействием на несколько сигнальных путей сразу же выделяются как более приоритетные для анализа безопасности.
Узнайте, почему GQL элегантнее, чем SQL.
Для выполнения того же двухэтапного запроса в стандартном SQL требуется 4 явных соединения. Вы тратите умственные усилия на описание того, как соединять таблицы, а не на то, какое именно отношение вы ищете. GQL позволяет сосредоточиться на вопросе.
SELECT
c.compound_name,
c.dev_stage,
c.therapeutic_area,
t.target_name,
ROUND(i.affinity_nm, 3) AS herg_affinity_nm,
pw.pathway_name,
pw.disease_area AS pathway_disease_area
FROM drug_target_graph.compounds c
JOIN drug_target_graph.interactions i ON c.compound_id = i.compound_id
JOIN drug_target_graph.targets t ON i.target_id = t.target_id
JOIN drug_target_graph.target_pathways tp ON t.target_id = tp.target_id
JOIN drug_target_graph.pathways pw ON tp.pathway_id = pw.pathway_id
WHERE t.gene_name = 'KCNH2'
AND i.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
ORDER BY herg_affinity_nm;
Более детальное изучение — выявление рисков, связанных с метаболитами на нескольких этапах эксперимента.
Приведенный выше запрос идентифицирует соединения, которые непосредственно связываются с белком hERG. Однако в реальных процессах обеспечения безопасности лекарственных препаратов риск иногда находится на другом этапе: соединение может метаболически преобразовываться в организме во вторичную молекулу (метаболит), которая затем связывается с hERG — уязвимость, которую прямые анализы связывания могут полностью упустить.
Если ваш граф свойств включает таблицу узлов Metabolite и ребро METABOLISES_INTO, вы можете расширить тот же шаблон MATCH до обхода с тремя шагами:
(Compound)-[METABOLISES_INTO]->(Metabolite)-[BINDS_TO]->
(Target)-[PARTICIPATES_IN]->(Pathway)
Структура запроса GQL изменится ровно на один узел и одно ребро. Эквивалентный SQL потребует двух дополнительных операций JOIN. Именно эта закономерность делает обход графа особенно эффективным для анализа каскадов безопасности — сложность запроса растет линейно, а биологическая глубина понимания — экспоненциально.
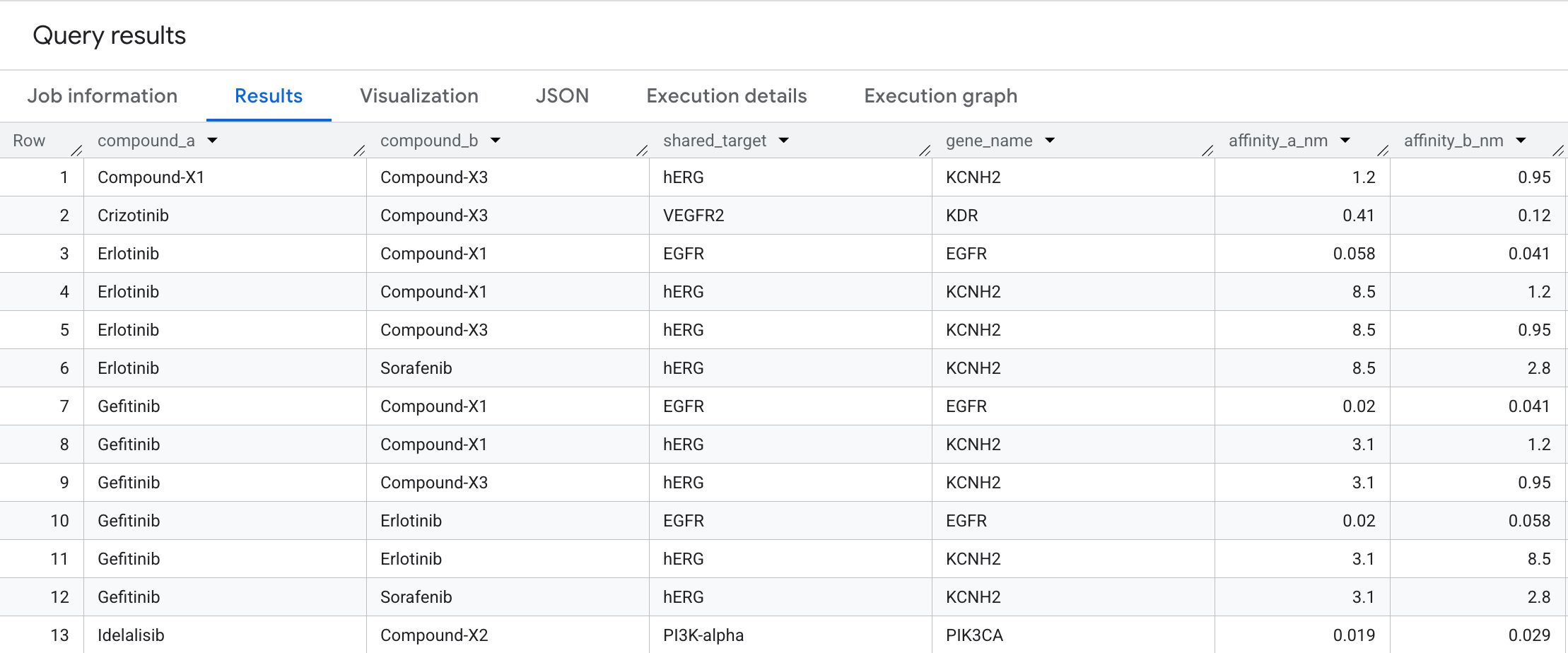
7. Запрос 3: Составные пары с общими целевыми объектами
Для поиска кандидатов на комбинированную терапию мы можем определить, когда два разных соединения связываются с одним и тем же целевым узлом. Мы используем двунаправленное сопоставление , чтобы ответить на вопрос: какие онкологические соединения нацелены на одну и ту же мишень?
Выполните следующий запрос в редакторе SQL:
SELECT
compound_a,
compound_b,
shared_target,
gene_name,
ROUND(affinity_a_nm, 3) AS affinity_a_nm,
ROUND(affinity_b_nm, 3) AS affinity_b_nm
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
AND c2.therapeutic_area = 'Oncology'
COLUMNS (
c1.compound_name AS compound_a,
c2.compound_name AS compound_b,
t.target_name AS shared_target,
t.gene_name AS gene_name,
b1.affinity_nm AS affinity_a_nm,
b2.affinity_nm AS affinity_b_nm
)
)
ORDER BY compound_a, compound_b, affinity_a_nm;
Вот данные, которые вы увидите в результатах:
Визуализация графиков
Вы можете визуализировать граф непосредственно в BigQuery, выполнив следующий код в редакторе SQL.
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH p = (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
RETURN
TO_JSON(p) AS path
Этот двунаправленный обход выявляет пары соединений, которые сходятся на одной и той же белковой мишени — закономерность, которую трудно заметить в плоской таблице взаимодействий, но которая сразу видна на графике. В разработке лекарств пары соединений с общими мишенями являются отправной точкой для создания комбинированной терапии: два соединения, воздействующие на один и тот же узел в раковом сигнальном пути, могут оказывать синергетический эффект или, наоборот, сигнализировать о непреднамеренной избыточности в процессе разработки.
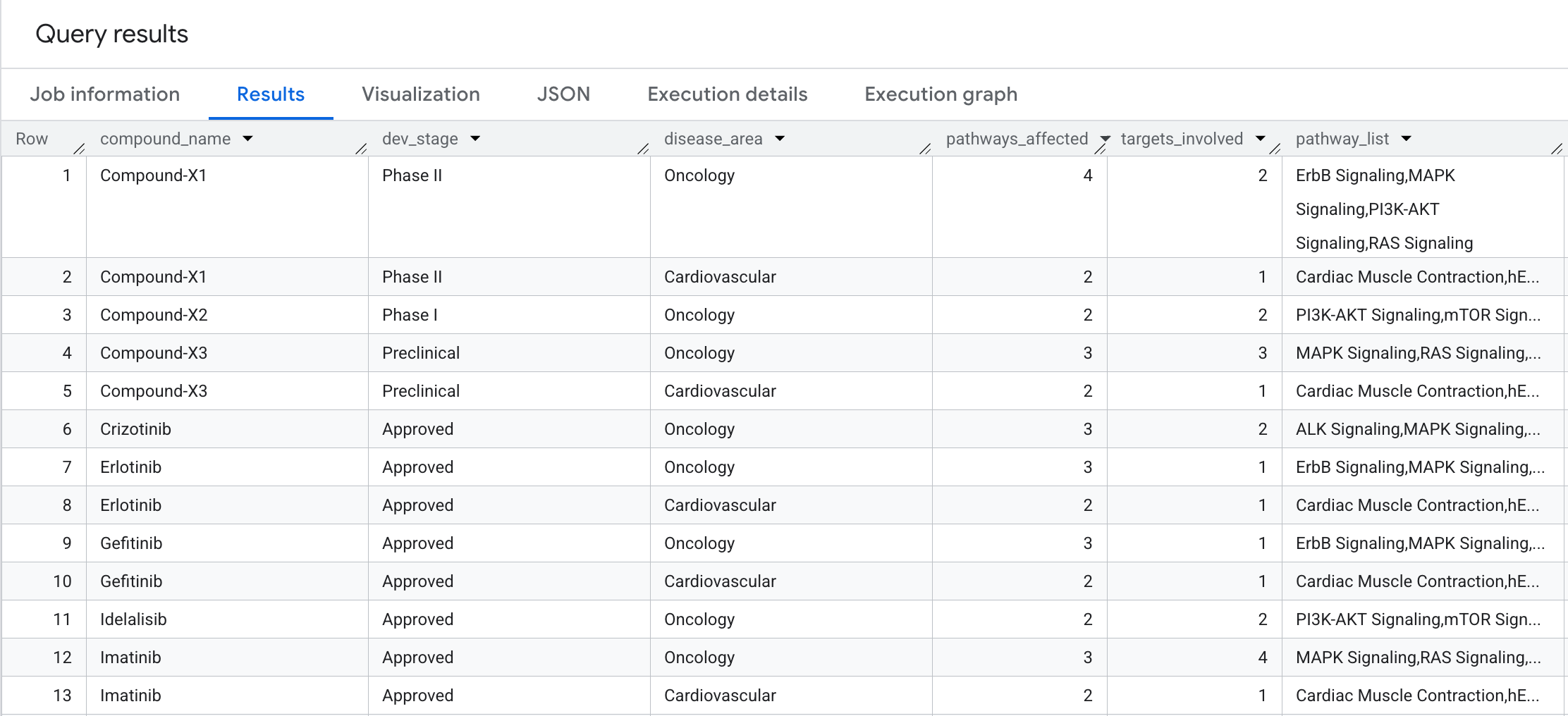
8. Запрос 4: Путь развития заболевания Радиус поражения
Насколько широко распространено биологическое воздействие каждого соединения? Давайте выполним двухэтапный обход с агрегацией, чтобы ответить на вопрос: на сколько биологических путей и различных мишеней влияет каждое соединение, сгруппированных по областям заболеваний?
Выполните следующий запрос в редакторе SQL:
SELECT
compound_name,
dev_stage,
disease_area,
COUNT(DISTINCT pathway_id) AS pathways_affected,
COUNT(DISTINCT target_id) AS targets_involved,
STRING_AGG(DISTINCT pathway_name ORDER BY pathway_name) AS pathway_list
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_id AS target_id,
pw.pathway_id AS pathway_id,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
GROUP BY compound_name, dev_stage, disease_area
ORDER BY compound_name, pathways_affected DESC;
Вот что вы увидите в результатах:
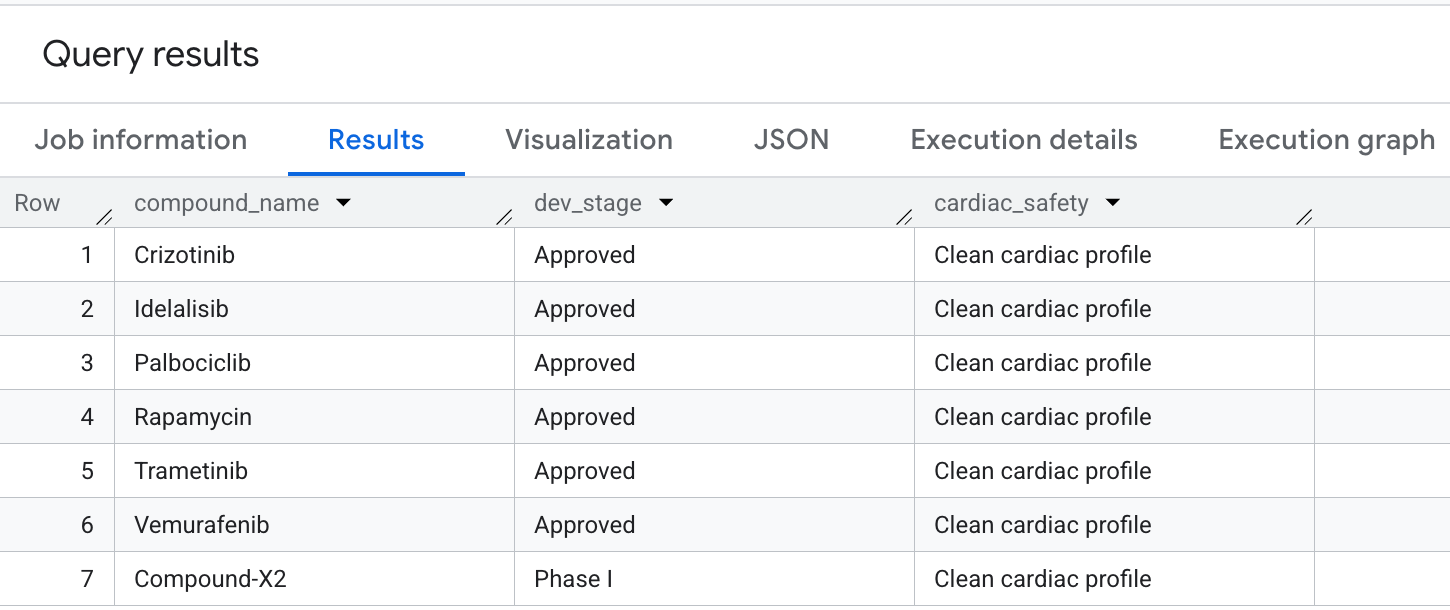
9. Вопрос 5: Выбор безопасного соединения
Наконец, давайте поищем соединения, обладающие широким спектром действия в онкологии, но при этом явно избегающие нежелательных побочных эффектов, связанных с hERG (сердечной системой). Это соответствует распространенным моделям отбора лекарственных препаратов, основанным на приоритете безопасности.
Выполните следующий запрос в редакторе SQL:
WITH oncology_compounds AS (
SELECT DISTINCT compound_id, compound_name, dev_stage
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE pw.disease_area = 'Oncology'
AND pw.cancer_relevance = 'high'
COLUMNS (
c.compound_id AS compound_id,
c.compound_name AS compound_name,
c.dev_stage AS dev_stage
)
)
),
herg_risk_compounds AS (
SELECT DISTINCT compound_id
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
WHERE t.gene_name = 'KCNH2'
COLUMNS (c.compound_id AS compound_id)
)
)
SELECT
o.compound_name,
o.dev_stage,
'Clean cardiac profile' AS cardiac_safety
FROM oncology_compounds o
LEFT JOIN herg_risk_compounds h ON o.compound_id = h.compound_id
WHERE h.compound_id IS NULL
ORDER BY o.dev_stage, o.compound_name;
Вот результат, который вы увидите в итоговой таблице:
Вы успешно выполнили сложные обходы графов в BigQuery для извлечения ключевых профилей безопасности и эффективности!
10. Бонусная секция: Пообщайтесь со своим графиком.
В BigQuery Conversational Analytics теперь поддерживается использование графов в качестве источника знаний. Это позволяет общаться с только что созданным графом на естественном языке.
Начало работы: Добавьте график в качестве источника знаний.
Для начала создайте диалогового агента, следуя инструкциям здесь . Выберите созданный вами граф в строке поиска.
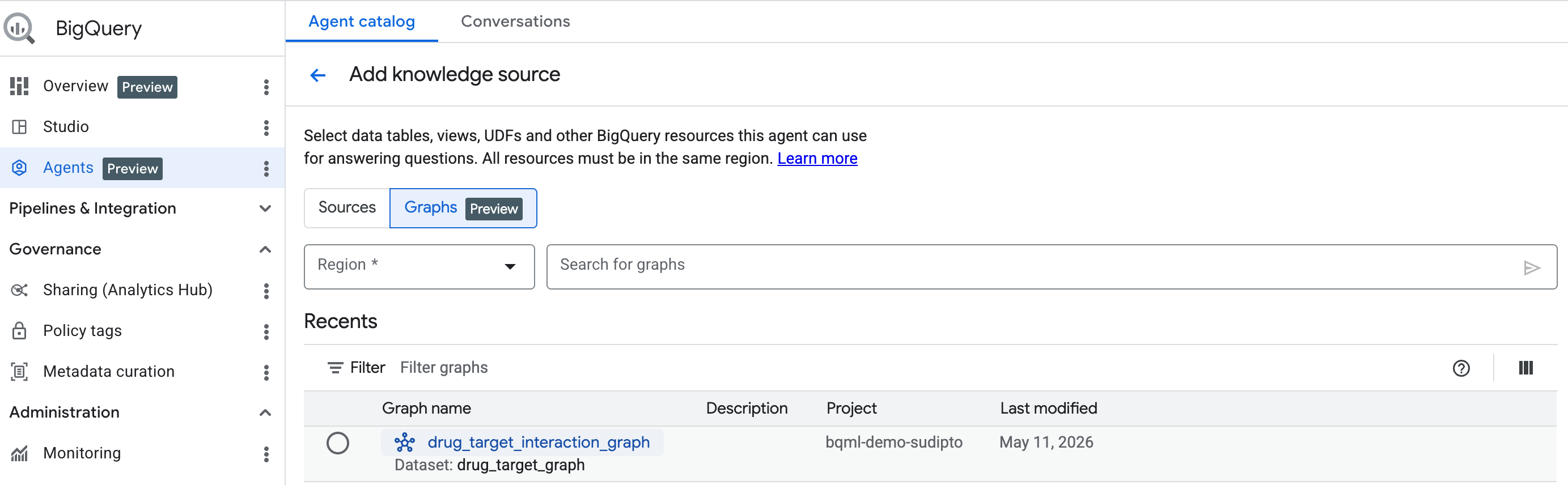
Используйте аналитику диалогов BigQuery для общения с вашим графом.
После добавления источника знаний в виде графа завершите остальную настройку агента разговорной аналитики .
После этого вы сможете начать общаться со своим графом на естественном языке!
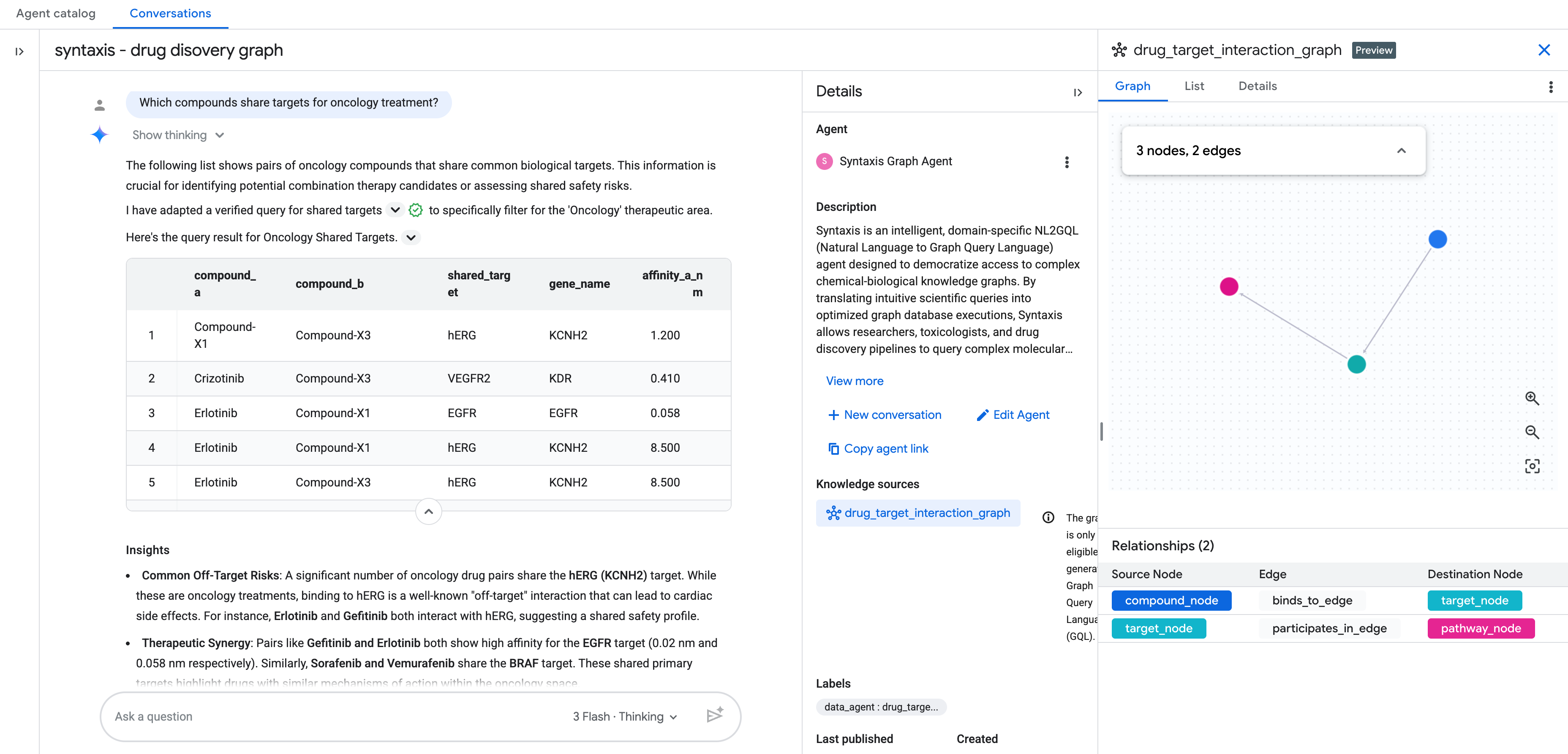
Дополнительные вопросы
- Каковы целевые объекты для всех соединений, находящихся в настоящее время на второй фазе клинических испытаний?
- Какие мишени являются общими для препаратов, применяемых в кардиологии и онкологии?
11. Уборка
Чтобы избежать дальнейших списаний средств с вашего аккаунта Google Cloud, удалите ресурсы, созданные в ходе этого практического занятия.
Выполните следующий запрос, чтобы последовательно удалить схему и все таблицы:
DROP SCHEMA IF EXISTS drug_target_graph CASCADE;
12. Поздравляем!
Поздравляем! Вы успешно смоделировали и проанализировали сеть взаимодействия лекарственного препарата и мишени с помощью BigQuery Graph.
Что вы узнали
- Как моделировать взаимосвязи между сущностями (соединениями, мишенями, путями) в виде графа свойств.
- Как определить схему и создать граф свойств в BigQuery.
- Как писать сложные обходы графов с использованием GQL и сравнивать их с традиционным SQL.
- Как использовать
GRAPH_TABLE,MATCHи двунаправленное сопоставление для решения задач в области биологических наук.