
1. บทนำ
ใน Codelab นี้ คุณจะได้เรียนรู้วิธีใช้ BigQuery Graph เพื่อสร้างแบบจำลองและวิเคราะห์เครือข่ายการโต้ตอบระหว่างยาและเป้าหมาย โดยจะใช้ประโยชน์จากความสามารถของการค้นหากราฟ (GQL) เพื่อสำรวจว่ายามีปฏิสัมพันธ์กับเป้าหมายทางชีวภาพอย่างไร ระบุผลข้างเคียงที่อาจเกิดขึ้น (เช่น ความเสี่ยงต่อหัวใจ) และค้นพบการรักษาแบบผสมที่อาจเป็นไปได้
🧬 กรณีการใช้งาน - เครือข่ายการโต้ตอบระหว่างยาและเป้าหมาย
คำถามทางธุรกิจ: สารประกอบหนึ่งๆ มีรัศมีการระเบิดเต็มรูปแบบอย่างไร กล่าวคือ สารประกอบนั้นจับกับเป้าหมายใดบ้าง เส้นทางชีวภาพใดได้รับผลกระทบ และเกี่ยวข้องกับโรคใดบ้าง
ตาราง:
ตาราง | คำอธิบาย |
| โมเลกุลของยาที่มีกลไกการออกฤทธิ์และระยะการพัฒนา |
| เป้าหมายโปรตีนที่มีชื่อยีนและรหัส UniProt |
| ความสามารถในการจับกับเป้าหมายของสารประกอบ (เป้าหมายหลัก + เป้าหมายรอง) |
| เส้นทางชีวภาพที่มีความเกี่ยวข้องกับโรค |
| ตาราง Junction ที่ลิงก์เป้าหมายกับเส้นทางที่เป้าหมายมีส่วนร่วม |
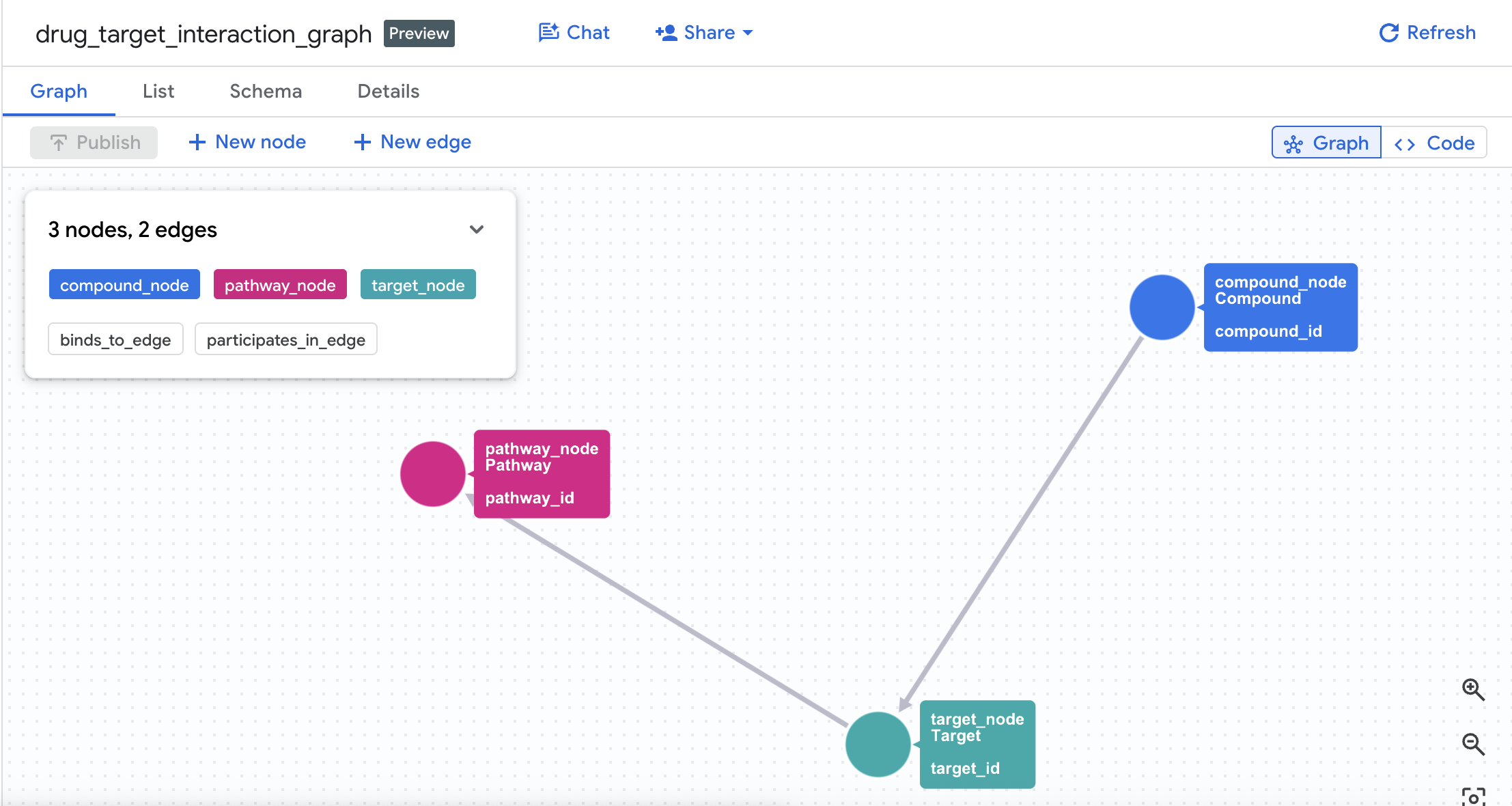
โมเดลกราฟพร็อพเพอร์ตี้:
(Compound)-[BINDS_TO {affinity_nm, ic50_nm, interaction_type}]->(Target)
(Target)-[PARTICIPATES_IN {role, importance_score}]->(Pathway)
🔍 ตัวอย่างการค้นหา
การค้นหา | สิ่งที่แสดง |
คำถามที่ 1: โปรไฟล์การจับกับเป้าหมาย | การข้าม 1 Hop - สารประกอบไปยังเป้าหมายหลักและเป้าหมายรองทั้งหมด |
คำถามที่ 2: การตรวจหาความเสี่ยงต่อหัวใจจาก hERG | การข้าม 2 Hop - สารประกอบ → เป้าหมาย hERG → เส้นทางหัวใจ |
คำถามที่ 3: คู่สารประกอบที่มีเป้าหมายร่วมกัน | การจับคู่แบบ 2 ทิศทาง - สารประกอบ 2 รายการมาบรรจบกันที่โหนดเป้าหมายเดียวกัน |
คำถามที่ 4: รัศมีการระเบิดของเส้นทางโรค | การรวม 2 Hop - เส้นทางทั้งหมดและความครอบคลุมของโรคต่อสารประกอบ |
คำถามที่ 5: การเลือกสารประกอบที่ปลอดภัย | สารประกอบที่มีความครอบคลุมด้านเนื้องอกวิทยาในระดับสูงแต่ไม่มีความเสี่ยงต่อหัวใจจาก hERG |
สิ่งที่คุณจะได้ทำ
- สร้างชุดข้อมูลและสคีมา BigQuery สำหรับเครือข่ายการโต้ตอบระหว่างยา
- โหลดข้อมูลตัวอย่าง (สารประกอบ, เป้าหมาย, การโต้ตอบ, เส้นทาง, เส้นทางเป้าหมาย)
- สร้างกราฟพร็อพเพอร์ตี้ใน BigQuery ที่เชื่อมต่อเอนทิตีเหล่านี้
- ค้นหากราฟเพื่อทำความเข้าใจการโต้ตอบของสารประกอบ เส้นทางชีวภาพ และรัศมีการระเบิดของโรคโดยใช้การข้ามกราฟ (
GRAPH_TABLEและMATCH) - เปรียบเทียบ GQL กับ SQL มาตรฐานแบบเคียงข้างกันเพื่อทำความเข้าใจความเรียบง่ายและพลังการแสดงออกของไวยากรณ์กราฟ
สิ่งที่คุณต้องมี
- เว็บเบราว์เซอร์ เช่น Chrome
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
Codelab นี้เหมาะสำหรับนักพัฒนาซอฟต์แวร์ทุกระดับ รวมถึงผู้เริ่มต้น
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์ Google Cloud
- ใน Google Cloud Console ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าโปรเจ็กต์ที่อยู่ในระบบคลาวด์เปิดใช้การเรียกเก็บเงินแล้ว
เริ่มต้น Cloud Shell
- คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud
- ยืนยันการตรวจสอบสิทธิ์โดยทำดังนี้
gcloud auth list
- ยืนยันโปรเจ็กต์โดยทำดังนี้
gcloud config get project
- ตั้งค่าหากจำเป็นโดยทำดังนี้
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
เปิดใช้ API
เรียกใช้คำสั่งนี้เพื่อเปิดใช้ BigQuery API ที่จำเป็น
gcloud services enable bigquery.googleapis.com
3. กำหนดสคีมาและโหลดข้อมูล
ก่อนอื่นคุณต้องสร้างชุดข้อมูลเพื่อจัดเก็บตารางที่เกี่ยวข้องกับกราฟและป้อนข้อมูลตัวอย่างลงในตาราง
- ไปที่ BigQuery Studio ในคอนโซล Google Cloud
- คลิกตัวแก้ไข SQL เพื่อเปิดแท็บการค้นหาใหม่
- เรียกใช้คำสั่งต่อไปนี้เพื่อสร้างชุดข้อมูล
drug_target_graph
CREATE SCHEMA IF NOT EXISTS drug_target_graph
OPTIONS (location = 'US');
ตอนนี้ให้สร้างตารางแหล่งที่มา 5 ตารางโดยเรียกใช้การค้นหา DDL ต่อไปนี้ใน BigQuery Studio
1. สร้างตาราง compounds
ประกอบด้วยโมเลกุลของยา กลไกการออกฤทธิ์ ระยะการพัฒนา และพื้นที่การรักษา
CREATE OR REPLACE TABLE drug_target_graph.compounds AS
SELECT 'CPD001' AS compound_id, 'Imatinib' AS compound_name, 'Kinase Inhibitor' AS mechanism_of_action, 'Approved' AS dev_stage, 'Oncology' AS therapeutic_area, 479.6 AS molecular_weight UNION ALL
SELECT 'CPD002', 'Gefitinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 446.9 UNION ALL
SELECT 'CPD003', 'Erlotinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 393.4 UNION ALL
SELECT 'CPD004', 'Sorafenib', 'Multi-Kinase Inhibitor', 'Approved', 'Oncology', 464.8 UNION ALL
SELECT 'CPD005', 'Vemurafenib', 'BRAF Inhibitor', 'Approved', 'Oncology', 489.9 UNION ALL
SELECT 'CPD006', 'Crizotinib', 'ALK Inhibitor', 'Approved', 'Oncology', 450.3 UNION ALL
SELECT 'CPD007', 'Idelalisib', 'PI3K Inhibitor', 'Approved', 'Oncology', 415.4 UNION ALL
SELECT 'CPD008', 'Trametinib', 'MEK Inhibitor', 'Approved', 'Oncology', 615.4 UNION ALL
SELECT 'CPD009', 'Palbociclib', 'CDK Inhibitor', 'Approved', 'Oncology', 447.5 UNION ALL
SELECT 'CPD010', 'Compound-X1', 'Kinase Inhibitor', 'Phase II', 'Oncology', 412.3 UNION ALL
SELECT 'CPD011', 'Compound-X2', 'PI3K Inhibitor', 'Phase I', 'Oncology', 398.7 UNION ALL
SELECT 'CPD012', 'Saquinavir', 'Protease Inhibitor', 'Approved', 'Infectious Disease', 670.8 UNION ALL
SELECT 'CPD013', 'Metformin', 'AMPK Activator', 'Approved', 'Metabolic', 165.6 UNION ALL
SELECT 'CPD014', 'Rapamycin', 'mTOR Inhibitor', 'Approved', 'Immunology', 914.2 UNION ALL
SELECT 'CPD015', 'Compound-X3', 'Multi-Kinase Inhibitor', 'Preclinical', 'Oncology', 502.1;
2. สร้างตาราง targets
ประกอบด้วยเป้าหมายโปรตีน ชื่อยีน รหัส UniProt และคลาสเป้าหมาย
CREATE OR REPLACE TABLE drug_target_graph.targets AS
SELECT 'TGT001' AS target_id, 'BCR-ABL1' AS target_name, 'ABL1' AS gene_name, 'P00519' AS uniprot_id, 'Kinase' AS target_class, TRUE AS is_oncogene UNION ALL
SELECT 'TGT002', 'EGFR', 'EGFR', 'P00533', 'Kinase', TRUE UNION ALL
SELECT 'TGT003', 'VEGFR2', 'KDR', 'P35968', 'Kinase', FALSE UNION ALL
SELECT 'TGT004', 'BRAF', 'BRAF', 'P15056', 'Kinase', TRUE UNION ALL
SELECT 'TGT005', 'ALK', 'ALK', 'Q9UM73', 'Kinase', TRUE UNION ALL
SELECT 'TGT006', 'PI3K-alpha','PIK3CA', 'P42336', 'Lipid Kinase', TRUE UNION ALL
SELECT 'TGT007', 'MEK1', 'MAP2K1', 'Q02750', 'Kinase', FALSE UNION ALL
SELECT 'TGT008', 'CDK4', 'CDK4', 'P11802', 'Kinase', FALSE UNION ALL
SELECT 'TGT009', 'CDK6', 'CDK6', 'P30279', 'Kinase', FALSE UNION ALL
SELECT 'TGT010', 'mTOR', 'MTOR', 'P42345', 'Kinase', FALSE UNION ALL
SELECT 'TGT011', 'PDGFR-beta','PDGFRB', 'P09619', 'Kinase', FALSE UNION ALL
SELECT 'TGT012', 'c-KIT', 'KIT', 'P10721', 'Kinase', TRUE UNION ALL
SELECT 'TGT013', 'hERG', 'KCNH2', 'Q12809', 'Ion Channel', FALSE UNION ALL
SELECT 'TGT014', 'AMPK', 'PRKAA1', 'Q13131', 'Kinase', FALSE UNION ALL
SELECT 'TGT015', 'RAF1', 'RAF1', 'P04049', 'Kinase', FALSE UNION ALL
SELECT 'TGT016', 'RET', 'RET', 'P07949', 'Kinase', TRUE UNION ALL
SELECT 'TGT017', 'FLT3', 'FLT3', 'P36888', 'Kinase', TRUE UNION ALL
SELECT 'TGT018', 'AKT1', 'AKT1', 'P31749', 'Kinase', FALSE UNION ALL
SELECT 'TGT019', 'ERK2', 'MAPK1', 'P28482', 'Kinase', FALSE UNION ALL
SELECT 'TGT020', 'HIV-Protease','HIV1-PR','Q72547', 'Protease', FALSE;
3. สร้างตาราง interactions
ประกอบด้วยข้อมูลความสามารถในการจับกับเป้าหมายของสารประกอบ (เป้าหมายหลักเทียบกับเป้าหมายรอง)
CREATE OR REPLACE TABLE drug_target_graph.interactions AS
SELECT 'INT001' AS interaction_id, 'CPD001' AS compound_id, 'TGT001' AS target_id, 0.025 AS affinity_nm, 0.038 AS ic50_nm, 'primary' AS interaction_type, 9.8 AS pchembl_value UNION ALL
SELECT 'INT002', 'CPD001', 'TGT011', 0.1, 0.15, 'primary', 8.8 UNION ALL
SELECT 'INT003', 'CPD001', 'TGT012', 0.068, 0.1, 'primary', 9.2 UNION ALL
SELECT 'INT004', 'CPD001', 'TGT016', 0.5, 0.8, 'off-target', 7.4 UNION ALL
SELECT 'INT005', 'CPD001', 'TGT013', 5.2, 8.1, 'off-target', 6.1 UNION ALL
SELECT 'INT006', 'CPD002', 'TGT002', 0.02, 0.033, 'primary', 9.7 UNION ALL
SELECT 'INT007', 'CPD002', 'TGT013', 3.1, 4.8, 'off-target', 6.5 UNION ALL
SELECT 'INT008', 'CPD003', 'TGT002', 0.058, 0.079, 'primary', 9.2 UNION ALL
SELECT 'INT009', 'CPD003', 'TGT013', 8.5, 12.0, 'off-target', 5.9 UNION ALL
SELECT 'INT010', 'CPD004', 'TGT003', 0.09, 0.12, 'primary', 9.1 UNION ALL
SELECT 'INT011', 'CPD004', 'TGT004', 0.038, 0.055, 'primary', 8.9 UNION ALL
SELECT 'INT012', 'CPD004', 'TGT015', 0.22, 0.31, 'primary', 8.5 UNION ALL
SELECT 'INT013', 'CPD004', 'TGT016', 0.58, 0.75, 'primary', 8.1 UNION ALL
SELECT 'INT014', 'CPD004', 'TGT017', 0.33, 0.48, 'primary', 8.4 UNION ALL
SELECT 'INT015', 'CPD004', 'TGT013', 2.8, 4.1, 'off-target', 6.6 UNION ALL
SELECT 'INT016', 'CPD005', 'TGT004', 0.031, 0.044, 'primary', 9.5 UNION ALL
SELECT 'INT017', 'CPD005', 'TGT015', 0.48, 0.65, 'off-target', 7.3 UNION ALL
SELECT 'INT018', 'CPD006', 'TGT005', 0.02, 0.028, 'primary', 9.8 UNION ALL
SELECT 'INT019', 'CPD006', 'TGT003', 0.41, 0.59, 'off-target', 7.4 UNION ALL
SELECT 'INT020', 'CPD007', 'TGT006', 0.019, 0.025, 'primary', 9.8 UNION ALL
SELECT 'INT021', 'CPD007', 'TGT018', 0.55, 0.78, 'off-target', 7.2 UNION ALL
SELECT 'INT022', 'CPD008', 'TGT007', 0.0092, 0.014, 'primary', 10.1 UNION ALL
SELECT 'INT023', 'CPD008', 'TGT019', 0.38, 0.51, 'off-target', 7.4 UNION ALL
SELECT 'INT024', 'CPD009', 'TGT008', 0.011, 0.017, 'primary', 9.9 UNION ALL
SELECT 'INT025', 'CPD009', 'TGT009', 0.015, 0.022, 'primary', 9.8 UNION ALL
SELECT 'INT026', 'CPD010', 'TGT002', 0.041, 0.058, 'primary', 9.4 UNION ALL
SELECT 'INT027', 'CPD010', 'TGT001', 0.38, 0.52, 'off-target', 7.3 UNION ALL
SELECT 'INT028', 'CPD010', 'TGT013', 1.2, 1.8, 'off-target', 7.1 UNION ALL
SELECT 'INT029', 'CPD011', 'TGT006', 0.029, 0.041, 'primary', 9.5 UNION ALL
SELECT 'INT030', 'CPD011', 'TGT010', 0.71, 0.95, 'off-target', 7.0 UNION ALL
SELECT 'INT031', 'CPD012', 'TGT020', 0.39, 0.55, 'primary', 7.3 UNION ALL
SELECT 'INT032', 'CPD013', 'TGT014', 12.0, 18.5, 'primary', 5.7 UNION ALL
SELECT 'INT033', 'CPD014', 'TGT010', 0.0018, 0.0025, 'primary', 11.8 UNION ALL
SELECT 'INT034', 'CPD015', 'TGT004', 0.055, 0.078, 'primary', 9.2 UNION ALL
SELECT 'INT035', 'CPD015', 'TGT003', 0.12, 0.17, 'primary', 8.9 UNION ALL
SELECT 'INT036', 'CPD015', 'TGT016', 0.29, 0.41, 'primary', 8.5 UNION ALL
SELECT 'INT037', 'CPD015', 'TGT013', 0.95, 1.35, 'off-target', 7.2;
4. สร้างตาราง pathways
ประกอบด้วยเส้นทางชีวภาพ พื้นที่โรคที่เกี่ยวข้อง และความเกี่ยวข้องกับมะเร็ง
CREATE OR REPLACE TABLE drug_target_graph.pathways AS
SELECT 'PWY001' AS pathway_id, 'MAPK Signaling' AS pathway_name, 'hsa04010' AS kegg_id, 'Cell Proliferation' AS biological_process, 'Oncology' AS disease_area, 'high' AS cancer_relevance UNION ALL
SELECT 'PWY002', 'PI3K-AKT Signaling', 'hsa04151', 'Cell Survival', 'Oncology', 'high' UNION ALL
SELECT 'PWY003', 'VEGF Signaling', 'hsa04370', 'Angiogenesis', 'Oncology', 'high' UNION ALL
SELECT 'PWY004', 'ErbB Signaling', 'hsa04012', 'Cell Growth', 'Oncology', 'high' UNION ALL
SELECT 'PWY005', 'mTOR Signaling', 'hsa04150', 'Cell Growth', 'Oncology', 'medium' UNION ALL
SELECT 'PWY006', 'Cell Cycle', 'hsa04110', 'Cell Division', 'Oncology', 'high' UNION ALL
SELECT 'PWY007', 'Cardiac Muscle Contraction', 'hsa04260', 'Cardiac Function', 'Cardiovascular', 'low' UNION ALL
SELECT 'PWY008', 'hERG Cardiac Channel', 'hsa04022', 'Cardiac Repolarisation','Cardiovascular', 'low' UNION ALL
SELECT 'PWY009', 'AMPK Signaling', 'hsa04152', 'Energy Metabolism', 'Metabolic', 'low' UNION ALL
SELECT 'PWY010', 'ALK Signaling', 'hsa04915', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY011', 'RAS Signaling', 'hsa04014', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY012', 'HIV Replication', 'hsa05170', 'Viral Replication', 'Infectious Disease', 'low';
5. สร้างตาราง target_pathways
ตาราง Junction ที่ลิงก์เป้าหมายกับเส้นทางชีวภาพที่เป้าหมายมีส่วนร่วม
CREATE OR REPLACE TABLE drug_target_graph.target_pathways AS
SELECT 'TP001' AS tp_id, 'TGT001' AS target_id, 'PWY001' AS pathway_id, 'activator' AS role, 0.95 AS importance_score UNION ALL
SELECT 'TP002', 'TGT001', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP003', 'TGT002', 'PWY004', 'activator', 0.98 UNION ALL
SELECT 'TP004', 'TGT002', 'PWY001', 'activator', 0.82 UNION ALL
SELECT 'TP005', 'TGT002', 'PWY002', 'activator', 0.75 UNION ALL
SELECT 'TP006', 'TGT003', 'PWY003', 'activator', 0.96 UNION ALL
SELECT 'TP007', 'TGT003', 'PWY001', 'activator', 0.71 UNION ALL
SELECT 'TP008', 'TGT004', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP009', 'TGT004', 'PWY011', 'activator', 0.89 UNION ALL
SELECT 'TP010', 'TGT005', 'PWY010', 'activator', 0.99 UNION ALL
SELECT 'TP011', 'TGT005', 'PWY001', 'activator', 0.78 UNION ALL
SELECT 'TP012', 'TGT006', 'PWY002', 'activator', 0.98 UNION ALL
SELECT 'TP013', 'TGT006', 'PWY005', 'activator', 0.85 UNION ALL
SELECT 'TP014', 'TGT007', 'PWY001', 'activator', 0.94 UNION ALL
SELECT 'TP015', 'TGT007', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP016', 'TGT008', 'PWY006', 'activator', 0.95 UNION ALL
SELECT 'TP017', 'TGT009', 'PWY006', 'activator', 0.93 UNION ALL
SELECT 'TP018', 'TGT010', 'PWY005', 'activator', 0.99 UNION ALL
SELECT 'TP019', 'TGT010', 'PWY002', 'activator', 0.91 UNION ALL
SELECT 'TP020', 'TGT011', 'PWY003', 'activator', 0.87 UNION ALL
SELECT 'TP021', 'TGT011', 'PWY001', 'activator', 0.72 UNION ALL
SELECT 'TP022', 'TGT012', 'PWY001', 'activator', 0.83 UNION ALL
SELECT 'TP023', 'TGT012', 'PWY011', 'activator', 0.79 UNION ALL
SELECT 'TP024', 'TGT013', 'PWY008', 'substrate', 0.99 UNION ALL
SELECT 'TP025', 'TGT013', 'PWY007', 'substrate', 0.95 UNION ALL
SELECT 'TP026', 'TGT014', 'PWY009', 'activator', 0.97 UNION ALL
SELECT 'TP027', 'TGT015', 'PWY001', 'activator', 0.91 UNION ALL
SELECT 'TP028', 'TGT015', 'PWY011', 'activator', 0.86 UNION ALL
SELECT 'TP029', 'TGT016', 'PWY001', 'activator', 0.84 UNION ALL
SELECT 'TP030', 'TGT016', 'PWY003', 'activator', 0.77 UNION ALL
SELECT 'TP031', 'TGT017', 'PWY001', 'activator', 0.88 UNION ALL
SELECT 'TP032', 'TGT017', 'PWY011', 'activator', 0.82 UNION ALL
SELECT 'TP033', 'TGT018', 'PWY002', 'activator', 0.96 UNION ALL
SELECT 'TP034', 'TGT018', 'PWY005', 'activator', 0.88 UNION ALL
SELECT 'TP035', 'TGT019', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP036', 'TGT019', 'PWY011', 'activator', 0.91 UNION ALL
SELECT 'TP037', 'TGT020', 'PWY012', 'substrate', 0.99;
4. สร้างกราฟพร็อพเพอร์ตี้
เมื่อสร้างตารางเรียบร้อยแล้ว ตอนนี้คุณก็สร้างกราฟพร็อพเพอร์ตี้ ได้แล้ว ซึ่งจะลิงก์โหนด (สารประกอบ, เป้าหมาย, เส้นทาง) โดยใช้ตารางขอบ (Interactions และ Target Pathways)
เรียกใช้คำสั่งต่อไปนี้ในตัวแก้ไข SQL ของ BigQuery Studio
CREATE OR REPLACE PROPERTY GRAPH drug_target_graph.drug_target_interaction_graph
NODE TABLES (
drug_target_graph.compounds
AS compound_node
KEY (compound_id)
LABEL Compound
PROPERTIES (compound_id, compound_name, mechanism_of_action, dev_stage, therapeutic_area, molecular_weight),
drug_target_graph.targets
AS target_node
KEY (target_id)
LABEL Target
PROPERTIES (target_id, target_name, gene_name, uniprot_id, target_class, is_oncogene),
drug_target_graph.pathways
AS pathway_node
KEY (pathway_id)
LABEL Pathway
PROPERTIES (pathway_id, pathway_name, kegg_id, biological_process, disease_area, cancer_relevance)
)
EDGE TABLES (
drug_target_graph.interactions
AS binds_to_edge
KEY (interaction_id)
SOURCE KEY (compound_id) REFERENCES compound_node (compound_id)
DESTINATION KEY (target_id) REFERENCES target_node (target_id)
LABEL BINDS_TO
PROPERTIES (interaction_id, affinity_nm, ic50_nm, interaction_type, pchembl_value),
drug_target_graph.target_pathways
AS participates_in_edge
KEY (tp_id)
SOURCE KEY (target_id) REFERENCES target_node (target_id)
DESTINATION KEY (pathway_id) REFERENCES pathway_node (pathway_id)
LABEL PARTICIPATES_IN
PROPERTIES (tp_id, role, importance_score)
);
ซึ่งจะสร้างกราฟชื่อ drug_target_interaction_graph ในชุดข้อมูล
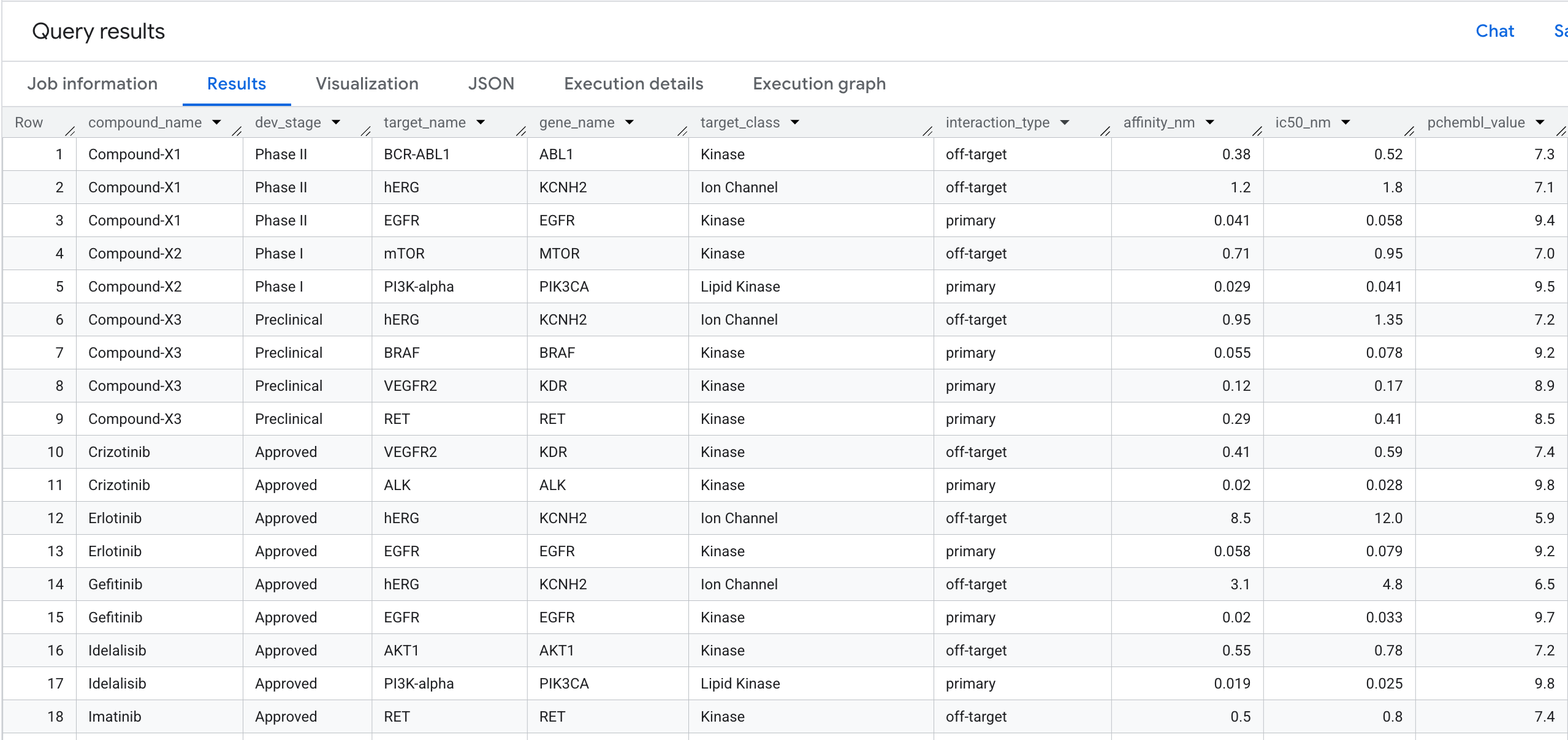
5. การค้นหาที่ 1: โปรไฟล์การจับกับเป้าหมายแบบเต็มต่อสารประกอบ
มาเรียกใช้การค้นหากราฟครั้งแรกกัน ซึ่งเป็นการข้าม 1 Hop ที่ตอบคำถามว่า สารประกอบใดจับกับเป้าหมายใด และมีความสามารถในการจับกับเป้าหมายนั้นๆ มากน้อยเพียงใด
การค้นหา GQL
เรียกใช้การค้นหาต่อไปนี้ในตัวแก้ไข SQL
SELECT
compound_name,
dev_stage,
target_name,
gene_name,
target_class,
interaction_type,
ROUND(affinity_nm, 3) AS affinity_nm,
ROUND(ic50_nm, 3) AS ic50_nm,
pchembl_value
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_name AS target_name,
t.gene_name AS gene_name,
t.target_class AS target_class,
b.interaction_type AS interaction_type,
b.affinity_nm AS affinity_nm,
b.ic50_nm AS ic50_nm,
b.pchembl_value AS pchembl_value
)
)
ORDER BY compound_name, interaction_type, affinity_nm;
สิ่งที่คุณจะเห็นในผลลัพธ์มีดังนี้
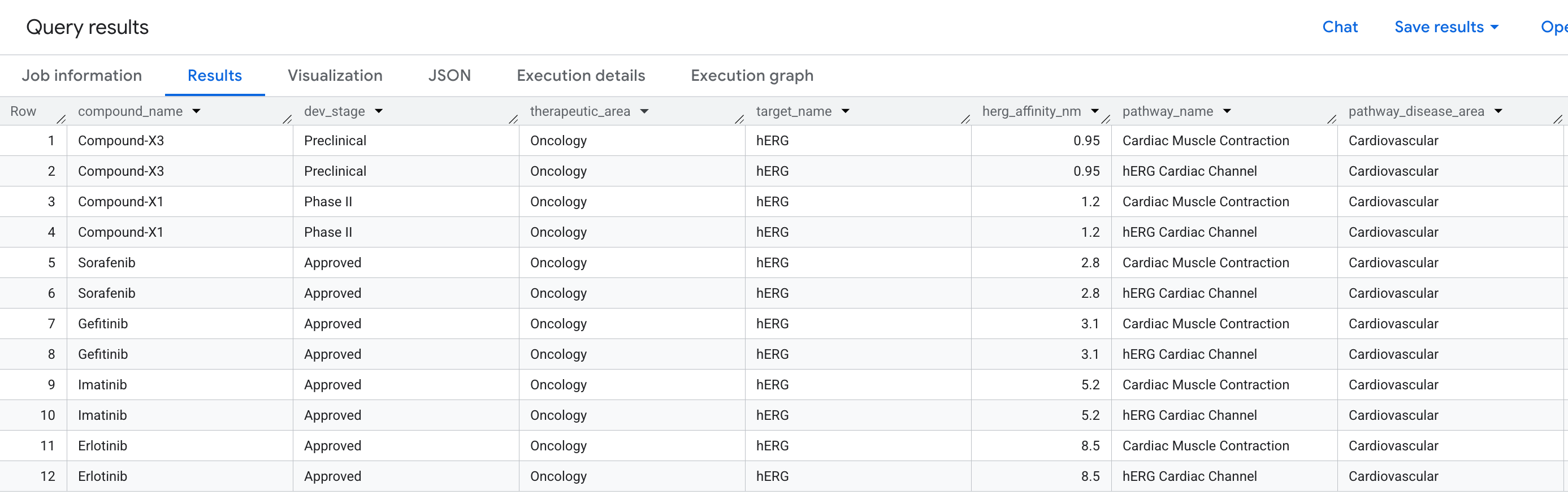
6. การค้นหาที่ 2: การตรวจหาความเสี่ยงต่อหัวใจ
คำถามทางธุรกิจ
ในการค้นพบยา สาเหตุที่พบบ่อยที่สุดที่ทำให้สารประกอบที่ดูมีแนวโน้มดีไม่ผ่านการทดลองทางคลินิกคือความเป็นพิษต่อหัวใจ ซึ่งโดยเฉพาะอย่างยิ่งคือการจับกับโปรตีน hERG (ยีน: KCNH2) โดยไม่ตั้งใจ ซึ่งเป็นช่องทางไอออนโพแทสเซียมที่ควบคุมจังหวะการเต้นของหัวใจ การจับกับ hERG โดยไม่ตั้งใจอาจทำให้เกิดภาวะหัวใจเต้นผิดจังหวะที่เป็นอันตรายถึงชีวิต และเป็นสาเหตุที่ทำให้มีการถอนยาออกจากตลาดหลายครั้ง
คำถามที่เราต้องการตอบคือ
"สารประกอบใดในไปป์ไลน์ของเรามีการจับกับโปรตีน hERG โดยไม่ตั้งใจ และการจับกับโปรตีน hERG โดยไม่ตั้งใจนั้นทำให้เกิดความเสี่ยงต่อเส้นทางหัวใจใดบ้าง"
นี่คือคำถามแบบ 2 Hop ซึ่งเราต้องข้ามจากสารประกอบ ผ่านเป้าหมาย (hERG) ไปยังเส้นทาง โดยเชื่อมต่อเอนทิตี 3 ประเภทผ่านความสัมพันธ์ 2 รายการในการค้นหาเดียว
เขียนการค้นหา GQL
เรียกใช้การค้นหาต่อไปนี้ในตัวแก้ไข SQL ของ BQ
SELECT
compound_name,
dev_stage,
therapeutic_area,
target_name,
ROUND(affinity_nm, 3) AS herg_affinity_nm,
pathway_name,
disease_area AS pathway_disease_area
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND b.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
c.therapeutic_area AS therapeutic_area,
t.target_name AS target_name,
b.affinity_nm AS affinity_nm,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
ORDER BY herg_affinity_nm;
โปรดสังเกตว่าอนุประโยค MATCH อ่านได้เกือบเหมือนประโยคที่ว่า "ค้นหาสารประกอบที่จับกับเป้าหมายที่มีส่วนร่วมในเส้นทาง"
ข้อมูลที่คุณจะเห็นในผลลัพธ์มีดังนี้
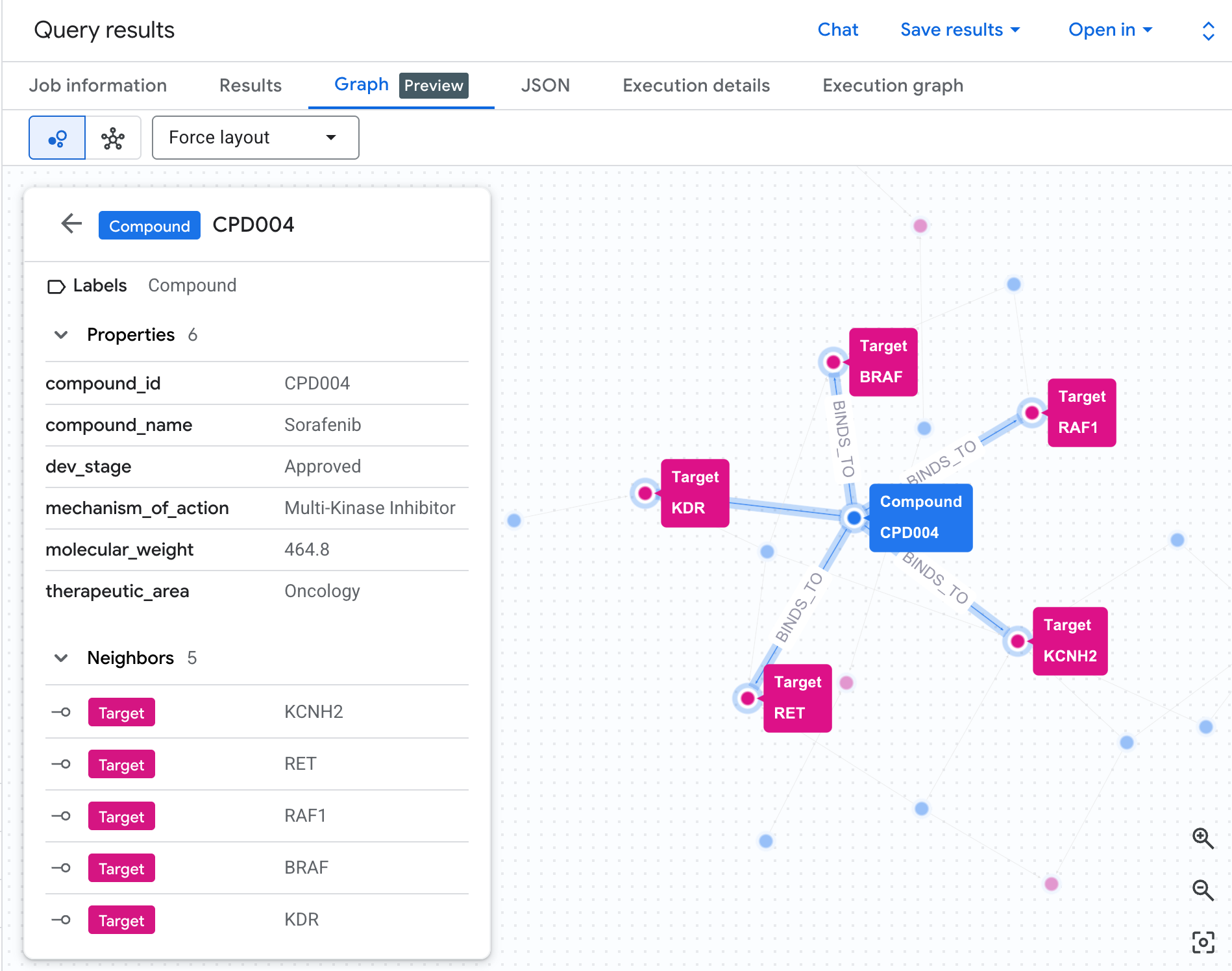
แสดงเครือข่ายความเสี่ยงเป็นกราฟ
ตารางจะแสดงข้อมูล แต่ไม่แสดงโครงสร้าง ของความเสี่ยง มีสารประกอบหลายรายการมาบรรจบกันในเส้นทางเดียวกันหรือไม่ มีสารประกอบที่มีความเสี่ยงสูง 1 รายการหรือหลายรายการ
การแสดงกราฟเป็นภาพจะทำให้เห็นสิ่งนี้ได้ทันที เรียกใช้เซลล์ด้านล่างเพื่อแสดงการข้าม 2 Hop เดียวกันเป็นเครือข่ายแบบอินเทอร์แอกทีฟ
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH pt = (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND pw.disease_area = 'Cardiovascular'
RETURN
TO_JSON(pt) AS path
คุณควรเห็นกราฟลักษณะนี้
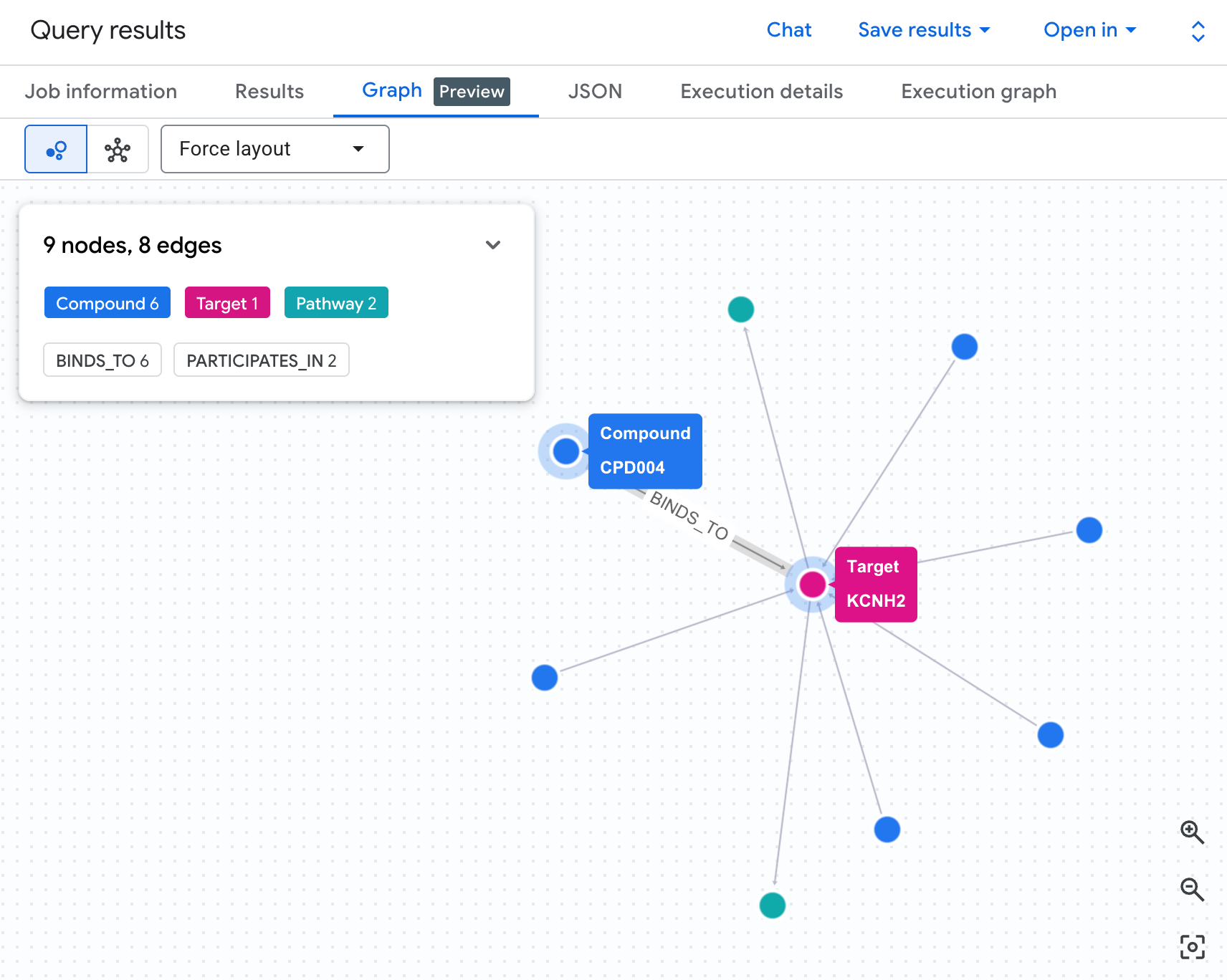
แต่ละเส้นทางในกราฟจะแสดงห่วงโซ่ความรับผิดทั้งหมด กล่าวคือ สารประกอบ (โหนดสีน้ำเงิน) จับกับโปรตีน hERG ตรงกลาง ซึ่งเชื่อมต่อกับเส้นทางหัวใจอย่างน้อย 1 เส้นทาง (โหนดสีเขียว) สิ่งที่เคยเป็นรายการแถวแบบแบนในตาราง ตอนนี้กลายเป็นเครือข่ายความเสี่ยงที่มองเห็นได้แล้ว สารประกอบที่มีการสัมผัสเส้นทางหลายเส้นทางจะโดดเด่นขึ้นมาทันทีในฐานะสารประกอบที่มีลำดับความสำคัญสูงกว่าสำหรับการตรวจสอบความปลอดภัย
ดูว่าทำไม GQL จึงดูดีกว่า SQL
หากต้องการเรียกใช้การค้นหาแบบ 2 Hop เดียวกันใน SQL มาตรฐาน คุณต้องใช้การรวมอย่างชัดเจน 4 รายการ คุณต้องใช้ความพยายามทางความคิดในการอธิบาย วิธี รวมตารางแทนที่จะอธิบาย ความสัมพันธ์ ที่คุณต้องการ GQL ช่วยให้คุณโฟกัสกับคำถามได้
SELECT
c.compound_name,
c.dev_stage,
c.therapeutic_area,
t.target_name,
ROUND(i.affinity_nm, 3) AS herg_affinity_nm,
pw.pathway_name,
pw.disease_area AS pathway_disease_area
FROM drug_target_graph.compounds c
JOIN drug_target_graph.interactions i ON c.compound_id = i.compound_id
JOIN drug_target_graph.targets t ON i.target_id = t.target_id
JOIN drug_target_graph.target_pathways tp ON t.target_id = tp.target_id
JOIN drug_target_graph.pathways pw ON tp.pathway_id = pw.pathway_id
WHERE t.gene_name = 'KCNH2'
AND i.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
ORDER BY herg_affinity_nm;
เจาะลึกยิ่งขึ้น - การตรวจหาความเสี่ยงของสารเมแทบอไลต์แบบหลาย Hop
การค้นหาข้างต้นจะระบุสารประกอบที่จับกับโปรตีน hERG โดยตรง แต่ในเวิร์กโฟลว์ความปลอดภัยของยาจริง ความเสี่ยงอาจอยู่ห่างออกไป 1 ขั้นตอน กล่าวคือ สารประกอบอาจถูกเปลี่ยนเป็นโมเลกุลรอง (สารเมแทบอไลต์) ในร่างกายผ่านกระบวนการเมแทบอลิซึม ซึ่งจากนั้นจะจับกับ hERG ซึ่งเป็นการรับผิดที่การทดสอบการจับแบบโดยตรงอาจพลาดไปโดยสิ้นเชิง
หากกราฟพร็อพเพอร์ตี้มีตารางโหนดสารเมแทบอไลต์และขอบ METABOLISES_INTO คุณสามารถขยายรูปแบบ MATCH เดียวกันเป็นการข้าม 3 Hop ได้
(Compound)-[METABOLISES_INTO]->(Metabolite)-[BINDS_TO]->
(Target)-[PARTICIPATES_IN]->(Pathway)
โครงสร้างการค้นหา GQL จะเปลี่ยนไป 1 โหนดและ 1 ขอบพอดี ส่วน SQL ที่เทียบเท่าจะต้องมีการรวมเพิ่มเติม 2 รายการ นี่คือรูปแบบที่ทำให้การข้ามกราฟมีประสิทธิภาพอย่างยิ่งสำหรับการวิเคราะห์การล้มเหลวแบบต่อเนื่องด้านความปลอดภัย เนื่องจากความซับซ้อนของการค้นหาเพิ่มขึ้นแบบเชิงเส้น ในขณะที่ข้อมูลเชิงลึกทางชีวภาพเพิ่มขึ้นแบบทวีคูณ
7. การค้นหาที่ 3: คู่สารประกอบที่มีเป้าหมายร่วมกัน
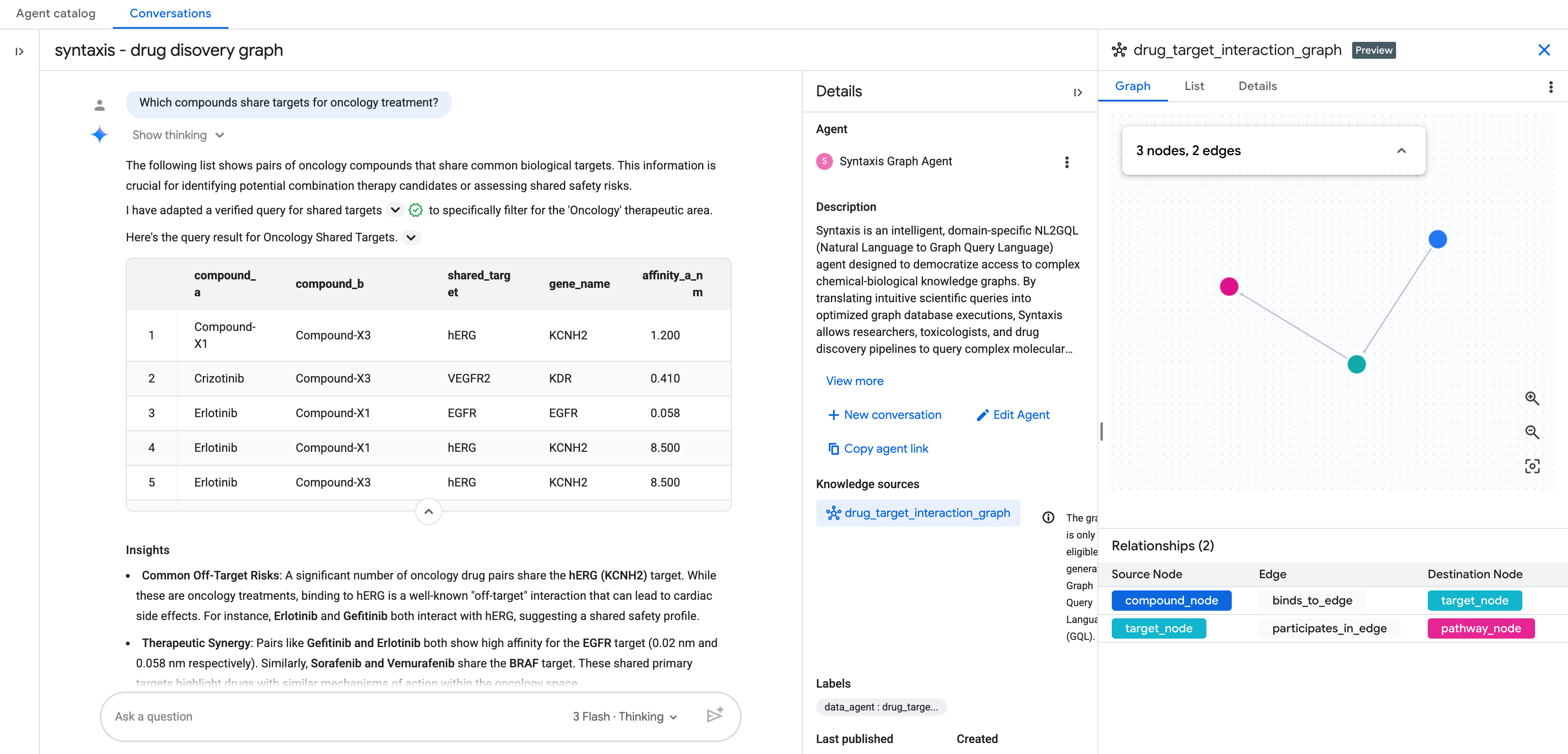
หากต้องการค้นหาผู้สมัครสำหรับการรักษาแบบผสม เราสามารถระบุได้เมื่อสารประกอบ 2 รายการที่แตกต่างกันจับกับโหนดเป้าหมายเดียวกัน เราใช้การจับคู่แบบ 2 ทิศทาง เพื่อตอบคำถามว่า สารประกอบด้านเนื้องอกวิทยาใดมาบรรจบกันที่เป้าหมายเดียวกัน
เรียกใช้การค้นหาต่อไปนี้ในตัวแก้ไข SQL
SELECT
compound_a,
compound_b,
shared_target,
gene_name,
ROUND(affinity_a_nm, 3) AS affinity_a_nm,
ROUND(affinity_b_nm, 3) AS affinity_b_nm
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
AND c2.therapeutic_area = 'Oncology'
COLUMNS (
c1.compound_name AS compound_a,
c2.compound_name AS compound_b,
t.target_name AS shared_target,
t.gene_name AS gene_name,
b1.affinity_nm AS affinity_a_nm,
b2.affinity_nm AS affinity_b_nm
)
)
ORDER BY compound_a, compound_b, affinity_a_nm;
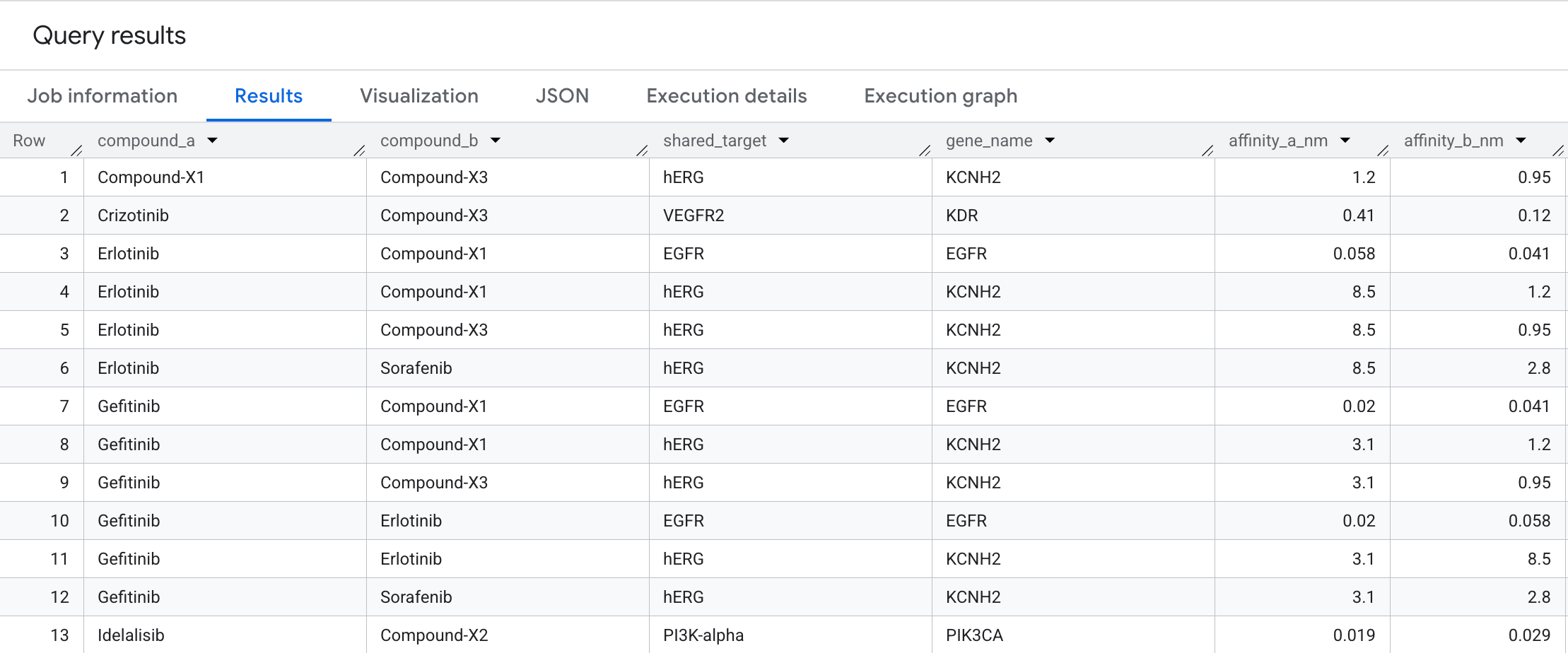
ข้อมูลที่คุณจะเห็นในผลลัพธ์มีดังนี้
การแสดงกราฟเป็นภาพ
คุณสามารถแสดงกราฟเป็นภาพได้โดยตรงใน BigQuery โดยเรียกใช้โค้ดต่อไปนี้ในตัวแก้ไข SQL
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH p = (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
RETURN
TO_JSON(p) AS path
การข้ามแบบ 2 ทิศทางนี้จะแสดงคู่สารประกอบที่มาบรรจบกันที่เป้าหมายโปรตีนเดียวกัน ซึ่งเป็นรูปแบบที่สังเกตได้ยากในตารางการโต้ตอบแบบแบน แต่จะมองเห็นได้ทันทีเมื่อแสดงเป็นกราฟ ในการค้นพบยา คู่สารประกอบที่มีเป้าหมายร่วมกันเป็นจุดเริ่มต้นสำหรับการออกแบบการรักษาแบบผสม สารประกอบ 2 รายการที่จับกับโหนดเดียวกันในเส้นทางมะเร็งอาจทำให้เกิดผลเสริมฤทธิ์กัน หรืออาจส่งสัญญาณถึงความซ้ำซ้อนโดยไม่ตั้งใจในกระบวนการพัฒนา
8. การค้นหาที่ 4: รัศมีการระเบิดของเส้นทางโรค
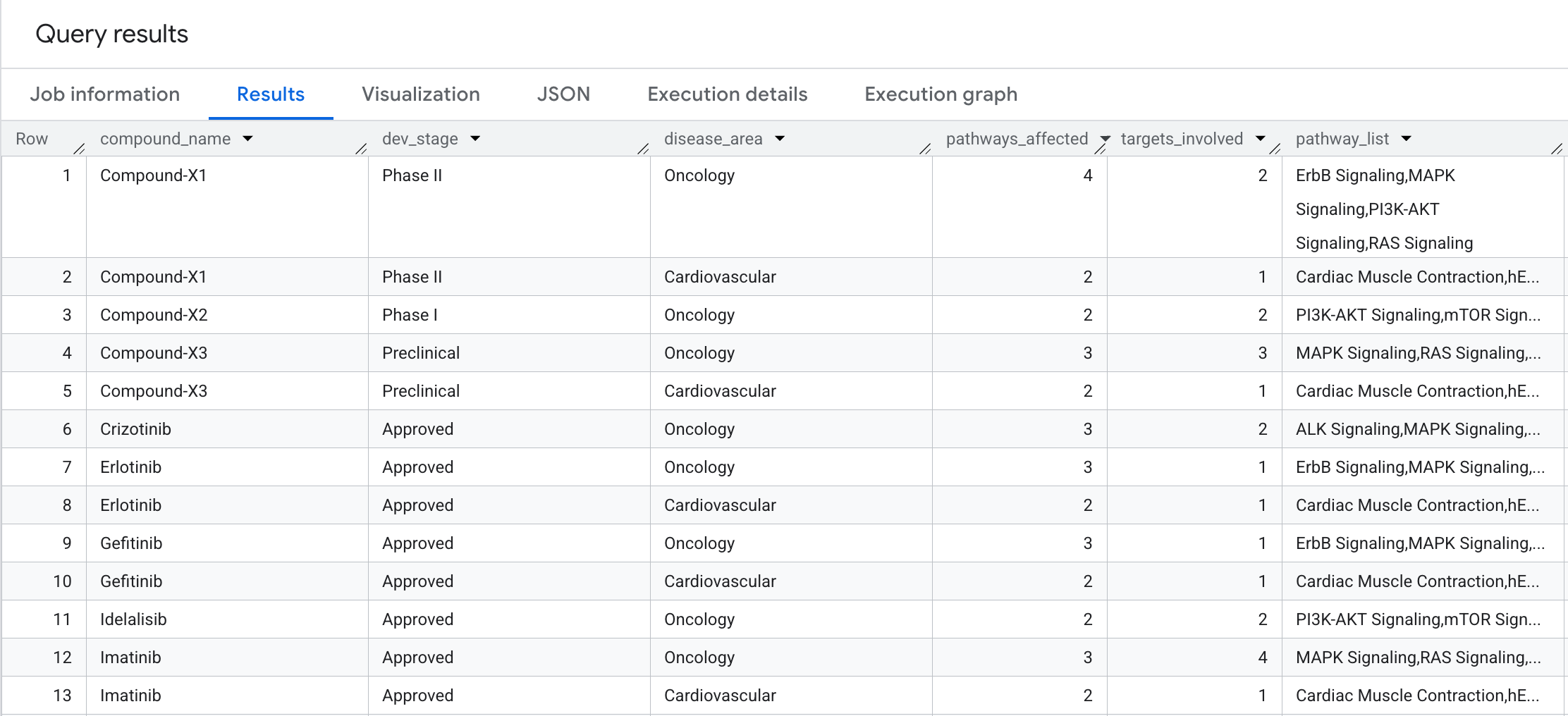
ผลกระทบทางชีวภาพของสารประกอบแต่ละรายการกว้างขวางเพียงใด มาทำการข้าม 2 Hop พร้อมการรวม เพื่อตอบคำถามว่า สารประกอบแต่ละรายการส่งผลต่อเส้นทางชีวภาพและเป้าหมายที่แตกต่างกันกี่รายการ โดยจัดกลุ่มตามพื้นที่โรค
เรียกใช้การค้นหาต่อไปนี้ในตัวแก้ไข SQL
SELECT
compound_name,
dev_stage,
disease_area,
COUNT(DISTINCT pathway_id) AS pathways_affected,
COUNT(DISTINCT target_id) AS targets_involved,
STRING_AGG(DISTINCT pathway_name ORDER BY pathway_name) AS pathway_list
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_id AS target_id,
pw.pathway_id AS pathway_id,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
GROUP BY compound_name, dev_stage, disease_area
ORDER BY compound_name, pathways_affected DESC;
สิ่งที่คุณจะเห็นในผลลัพธ์มีดังนี้
9. การค้นหาที่ 5: การเลือกสารประกอบที่ปลอดภัย
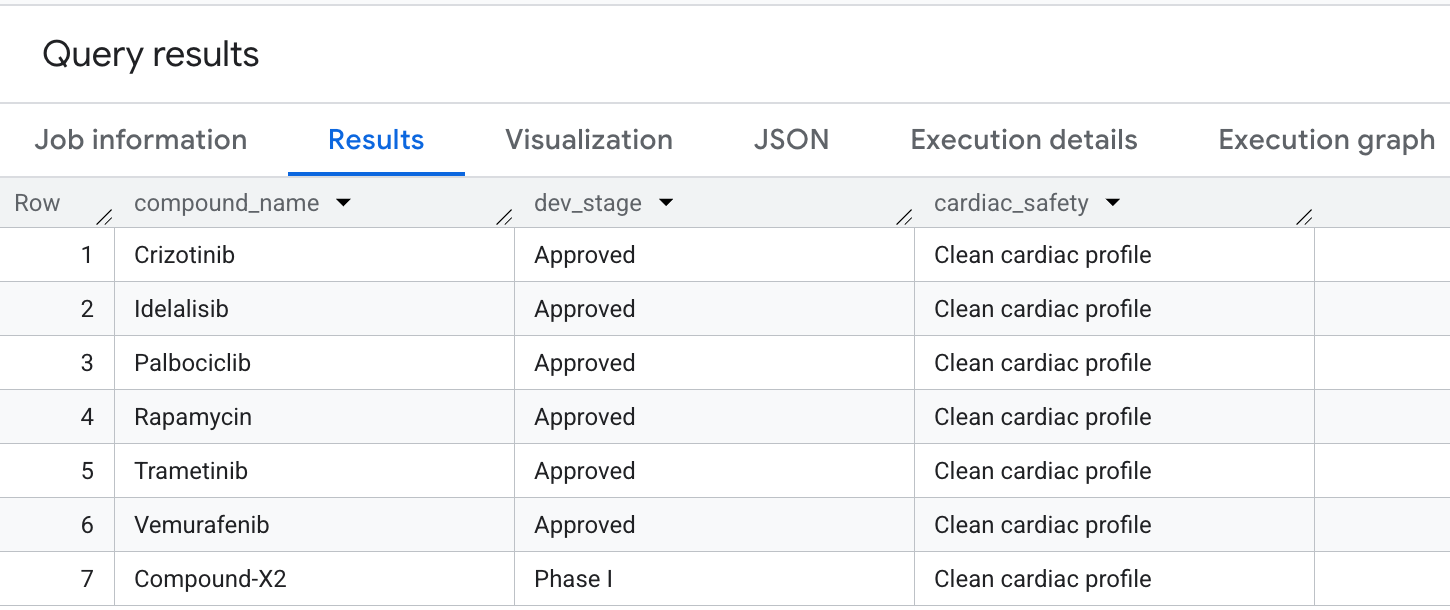
สุดท้ายนี้ มาค้นหาสารประกอบที่มีความครอบคลุมด้านเนื้องอกวิทยาในระดับสูงแต่หลีกเลี่ยง ความรับผิดต่อเป้าหมายรอง hERG (หัวใจ) อย่างชัดเจน ซึ่งตรงกับรูปแบบการเลือกที่เน้นความปลอดภัยเป็นอันดับแรกที่พบบ่อยในกระบวนการค้นพบยา
เรียกใช้การค้นหาต่อไปนี้ในตัวแก้ไข SQL
WITH oncology_compounds AS (
SELECT DISTINCT compound_id, compound_name, dev_stage
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE pw.disease_area = 'Oncology'
AND pw.cancer_relevance = 'high'
COLUMNS (
c.compound_id AS compound_id,
c.compound_name AS compound_name,
c.dev_stage AS dev_stage
)
)
),
herg_risk_compounds AS (
SELECT DISTINCT compound_id
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
WHERE t.gene_name = 'KCNH2'
COLUMNS (c.compound_id AS compound_id)
)
)
SELECT
o.compound_name,
o.dev_stage,
'Clean cardiac profile' AS cardiac_safety
FROM oncology_compounds o
LEFT JOIN herg_risk_compounds h ON o.compound_id = h.compound_id
WHERE h.compound_id IS NULL
ORDER BY o.dev_stage, o.compound_name;
เอาต์พุตที่คุณจะเห็นในผลลัพธ์มีดังนี้
คุณเรียกใช้การข้ามกราฟขั้นสูงใน BigQuery เพื่อดึงโปรไฟล์ความปลอดภัยและประสิทธิภาพที่สำคัญออกมาได้สำเร็จแล้ว
10. ส่วนโบนัส: แชทกับกราฟ
ตอนนี้ Conversational Analytics ของ BigQuery รองรับกราฟเป็นแหล่งความรู้แล้ว ซึ่งช่วยให้คุณแชทกับกราฟที่สร้างขึ้นเมื่อสักครู่ด้วยภาษาธรรมชาติได้
เริ่มต้นใช้งาน: เพิ่มกราฟเป็นแหล่งความรู้
หากต้องการเริ่มต้นใช้งาน ให้สร้าง Agent การสนทนาโดยทำตามขั้นตอนที่นี่ เลือกกราฟที่สร้างขึ้นจากแถบค้นหา
ใช้ Conversational Analytics ของ BigQuery เพื่อแชทกับกราฟ
เมื่อเพิ่มแหล่งความรู้เป็นกราฟแล้ว ให้ตั้งค่า Agent Conversational Analytics ที่เหลือให้เสร็จสมบูรณ์
จากนั้นคุณก็เริ่มแชทกับกราฟด้วยภาษาธรรมชาติได้เลย
คำถามเพิ่มเติม
- เป้าหมายทั้งหมดสำหรับสารประกอบที่อยู่ระหว่างการทดลองระยะที่ 2 ในปัจจุบันคืออะไร
- สารประกอบด้านหัวใจและหลอดเลือดและด้านเนื้องอกวิทยามีเป้าหมายร่วมกันใดบ้าง
11. ล้างข้อมูล
หากต้องการหลีกเลี่ยงการเรียกเก็บเงินอย่างต่อเนื่องจากบัญชี Google Cloud ให้ลบทรัพยากรที่สร้างขึ้นระหว่าง Codelab นี้
เรียกใช้การค้นหาต่อไปนี้เพื่อลบสคีมาและตารางทั้งหมดแบบต่อเนื่อง
DROP SCHEMA IF EXISTS drug_target_graph CASCADE;
12. ขอแสดงความยินดี
ขอแสดงความยินดี คุณสร้างแบบจำลองและวิเคราะห์เครือข่ายการโต้ตอบระหว่างยาและเป้าหมายโดยใช้ BigQuery Graph ได้สำเร็จแล้ว
สิ่งที่คุณได้เรียนรู้
- วิธีสร้างแบบจำลองความสัมพันธ์ของเอนทิตี (สารประกอบ, เป้าหมาย, เส้นทาง) เป็นกราฟพร็อพเพอร์ตี้
- วิธีกำหนดสคีมาและสร้างกราฟพร็อพเพอร์ตี้ใน BigQuery
- วิธีการเขียนการข้ามกราฟที่ซับซ้อนโดยใช้ GQL และเปรียบเทียบกับการใช้ SQL แบบดั้งเดิม
- วิธีใช้ประโยชน์จาก
GRAPH_TABLE,MATCHและการจับคู่แบบ 2 ทิศทางเพื่อแก้ปัญหาในโดเมนวิทยาศาสตร์เพื่อชีวิต