
1. 简介
在此 Codelab 中,您将学习如何使用 BigQuery Graph 来建模和分析药物-靶标相互作用网络。您将利用图查询 (GQL) 的强大功能来探索药物如何与生物靶标相互作用、识别潜在的副作用(例如心脏风险),并发现潜在的组合疗法。
🧬 使用情形 - 药物-靶标相互作用网络
业务问题:一种化合物的完整影响范围是什么?它会与哪些靶标结合,哪些生物学途径会受到影响,以及哪些疾病领域会受到牵连?
表格:
表 | 说明 |
| 具有作用机制和开发阶段的药物分子 |
| 具有基因名称和 UniProt ID 的蛋白质靶标 |
| 复合目标绑定亲和度(主要目标 + 非目标) |
| 与疾病区域关联的生物学通路 |
| 将目标与它们参与的途径相关联的连接表 |
属性图表模型:
(Compound)-[BINDS_TO {affinity_nm, ic50_nm, interaction_type}]->(Target)
(Target)-[PARTICIPATES_IN {role, importance_score}]->(Pathway)
🔍 演示查询
查询 | 显示内容 |
问题 1:目标绑定配置文件 | 1 跳遍历 - 从复合目标到所有主要目标和非目标 |
第 2 季度:hERG 心脏风险检测 | 2 跳遍历 - 化合物 → hERG 靶标 → 心脏通路 |
问题 3:共享目标复合对 | 双向匹配 - 两种化合物收敛到同一目标节点 |
问题 4:疾病传播途径的影响范围 | 2 跳聚合 - 每种化合物的完整通路和疾病区域覆盖率 |
问题 5:安全化合物选择 | 具有高肿瘤学覆盖率但无 hERG 心脏责任的化合物 |
您将执行的操作
- 为药物相互作用网络创建 BigQuery 数据集和架构
- 加载示例数据(化合物、靶标、相互作用、通路、靶标通路)
- 在 BigQuery 中创建连接这些实体的属性图
- 使用图遍历(
GRAPH_TABLE和MATCH)查询图,以了解复合交互、生物途径和疾病影响范围 - 并排比较 GQL 和标准 SQL,了解图表语法的简洁性和表达能力
所需条件
- 网络浏览器,例如 Chrome
- 启用了结算功能的 Google Cloud 项目
本 Codelab 适合各种水平的开发者,包括新手。
2. 准备工作
创建 Google Cloud 项目
- 在 Google Cloud 控制台中,选择或创建 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。
启动 Cloud Shell
- 点击 Google Cloud 控制台顶部的激活 Cloud Shell。
- 验证身份验证:
gcloud auth list
- 确认您的项目:
gcloud config get project
- 根据需要进行设置:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
启用 API
运行以下命令以启用所需的 BigQuery API:
gcloud services enable bigquery.googleapis.com
3. 定义架构和加载数据
首先,您需要创建一个数据集来存储与图相关的表,并使用示例数据填充这些表。
- 在 Google Cloud 控制台中前往 BigQuery Studio。
- 点击 SQL 编辑器,打开新的查询标签页。
- 运行以下语句以创建
drug_target_graph数据集:
CREATE SCHEMA IF NOT EXISTS drug_target_graph
OPTIONS (location = 'US');
现在,在 BigQuery Studio 中运行以下 DDL 查询,创建 5 个源表。
1. 创建 compounds 表
包含药物分子、其作用机制、开发阶段和治疗领域。
CREATE OR REPLACE TABLE drug_target_graph.compounds AS
SELECT 'CPD001' AS compound_id, 'Imatinib' AS compound_name, 'Kinase Inhibitor' AS mechanism_of_action, 'Approved' AS dev_stage, 'Oncology' AS therapeutic_area, 479.6 AS molecular_weight UNION ALL
SELECT 'CPD002', 'Gefitinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 446.9 UNION ALL
SELECT 'CPD003', 'Erlotinib', 'Kinase Inhibitor', 'Approved', 'Oncology', 393.4 UNION ALL
SELECT 'CPD004', 'Sorafenib', 'Multi-Kinase Inhibitor', 'Approved', 'Oncology', 464.8 UNION ALL
SELECT 'CPD005', 'Vemurafenib', 'BRAF Inhibitor', 'Approved', 'Oncology', 489.9 UNION ALL
SELECT 'CPD006', 'Crizotinib', 'ALK Inhibitor', 'Approved', 'Oncology', 450.3 UNION ALL
SELECT 'CPD007', 'Idelalisib', 'PI3K Inhibitor', 'Approved', 'Oncology', 415.4 UNION ALL
SELECT 'CPD008', 'Trametinib', 'MEK Inhibitor', 'Approved', 'Oncology', 615.4 UNION ALL
SELECT 'CPD009', 'Palbociclib', 'CDK Inhibitor', 'Approved', 'Oncology', 447.5 UNION ALL
SELECT 'CPD010', 'Compound-X1', 'Kinase Inhibitor', 'Phase II', 'Oncology', 412.3 UNION ALL
SELECT 'CPD011', 'Compound-X2', 'PI3K Inhibitor', 'Phase I', 'Oncology', 398.7 UNION ALL
SELECT 'CPD012', 'Saquinavir', 'Protease Inhibitor', 'Approved', 'Infectious Disease', 670.8 UNION ALL
SELECT 'CPD013', 'Metformin', 'AMPK Activator', 'Approved', 'Metabolic', 165.6 UNION ALL
SELECT 'CPD014', 'Rapamycin', 'mTOR Inhibitor', 'Approved', 'Immunology', 914.2 UNION ALL
SELECT 'CPD015', 'Compound-X3', 'Multi-Kinase Inhibitor', 'Preclinical', 'Oncology', 502.1;
2. 创建 targets 表
包含蛋白质靶标、基因名称、UniProt ID 和靶标类别。
CREATE OR REPLACE TABLE drug_target_graph.targets AS
SELECT 'TGT001' AS target_id, 'BCR-ABL1' AS target_name, 'ABL1' AS gene_name, 'P00519' AS uniprot_id, 'Kinase' AS target_class, TRUE AS is_oncogene UNION ALL
SELECT 'TGT002', 'EGFR', 'EGFR', 'P00533', 'Kinase', TRUE UNION ALL
SELECT 'TGT003', 'VEGFR2', 'KDR', 'P35968', 'Kinase', FALSE UNION ALL
SELECT 'TGT004', 'BRAF', 'BRAF', 'P15056', 'Kinase', TRUE UNION ALL
SELECT 'TGT005', 'ALK', 'ALK', 'Q9UM73', 'Kinase', TRUE UNION ALL
SELECT 'TGT006', 'PI3K-alpha','PIK3CA', 'P42336', 'Lipid Kinase', TRUE UNION ALL
SELECT 'TGT007', 'MEK1', 'MAP2K1', 'Q02750', 'Kinase', FALSE UNION ALL
SELECT 'TGT008', 'CDK4', 'CDK4', 'P11802', 'Kinase', FALSE UNION ALL
SELECT 'TGT009', 'CDK6', 'CDK6', 'P30279', 'Kinase', FALSE UNION ALL
SELECT 'TGT010', 'mTOR', 'MTOR', 'P42345', 'Kinase', FALSE UNION ALL
SELECT 'TGT011', 'PDGFR-beta','PDGFRB', 'P09619', 'Kinase', FALSE UNION ALL
SELECT 'TGT012', 'c-KIT', 'KIT', 'P10721', 'Kinase', TRUE UNION ALL
SELECT 'TGT013', 'hERG', 'KCNH2', 'Q12809', 'Ion Channel', FALSE UNION ALL
SELECT 'TGT014', 'AMPK', 'PRKAA1', 'Q13131', 'Kinase', FALSE UNION ALL
SELECT 'TGT015', 'RAF1', 'RAF1', 'P04049', 'Kinase', FALSE UNION ALL
SELECT 'TGT016', 'RET', 'RET', 'P07949', 'Kinase', TRUE UNION ALL
SELECT 'TGT017', 'FLT3', 'FLT3', 'P36888', 'Kinase', TRUE UNION ALL
SELECT 'TGT018', 'AKT1', 'AKT1', 'P31749', 'Kinase', FALSE UNION ALL
SELECT 'TGT019', 'ERK2', 'MAPK1', 'P28482', 'Kinase', FALSE UNION ALL
SELECT 'TGT020', 'HIV-Protease','HIV1-PR','Q72547', 'Protease', FALSE;
3. 创建 interactions 表
包含复合靶标结合亲和力数据(主要靶标与脱靶)。
CREATE OR REPLACE TABLE drug_target_graph.interactions AS
SELECT 'INT001' AS interaction_id, 'CPD001' AS compound_id, 'TGT001' AS target_id, 0.025 AS affinity_nm, 0.038 AS ic50_nm, 'primary' AS interaction_type, 9.8 AS pchembl_value UNION ALL
SELECT 'INT002', 'CPD001', 'TGT011', 0.1, 0.15, 'primary', 8.8 UNION ALL
SELECT 'INT003', 'CPD001', 'TGT012', 0.068, 0.1, 'primary', 9.2 UNION ALL
SELECT 'INT004', 'CPD001', 'TGT016', 0.5, 0.8, 'off-target', 7.4 UNION ALL
SELECT 'INT005', 'CPD001', 'TGT013', 5.2, 8.1, 'off-target', 6.1 UNION ALL
SELECT 'INT006', 'CPD002', 'TGT002', 0.02, 0.033, 'primary', 9.7 UNION ALL
SELECT 'INT007', 'CPD002', 'TGT013', 3.1, 4.8, 'off-target', 6.5 UNION ALL
SELECT 'INT008', 'CPD003', 'TGT002', 0.058, 0.079, 'primary', 9.2 UNION ALL
SELECT 'INT009', 'CPD003', 'TGT013', 8.5, 12.0, 'off-target', 5.9 UNION ALL
SELECT 'INT010', 'CPD004', 'TGT003', 0.09, 0.12, 'primary', 9.1 UNION ALL
SELECT 'INT011', 'CPD004', 'TGT004', 0.038, 0.055, 'primary', 8.9 UNION ALL
SELECT 'INT012', 'CPD004', 'TGT015', 0.22, 0.31, 'primary', 8.5 UNION ALL
SELECT 'INT013', 'CPD004', 'TGT016', 0.58, 0.75, 'primary', 8.1 UNION ALL
SELECT 'INT014', 'CPD004', 'TGT017', 0.33, 0.48, 'primary', 8.4 UNION ALL
SELECT 'INT015', 'CPD004', 'TGT013', 2.8, 4.1, 'off-target', 6.6 UNION ALL
SELECT 'INT016', 'CPD005', 'TGT004', 0.031, 0.044, 'primary', 9.5 UNION ALL
SELECT 'INT017', 'CPD005', 'TGT015', 0.48, 0.65, 'off-target', 7.3 UNION ALL
SELECT 'INT018', 'CPD006', 'TGT005', 0.02, 0.028, 'primary', 9.8 UNION ALL
SELECT 'INT019', 'CPD006', 'TGT003', 0.41, 0.59, 'off-target', 7.4 UNION ALL
SELECT 'INT020', 'CPD007', 'TGT006', 0.019, 0.025, 'primary', 9.8 UNION ALL
SELECT 'INT021', 'CPD007', 'TGT018', 0.55, 0.78, 'off-target', 7.2 UNION ALL
SELECT 'INT022', 'CPD008', 'TGT007', 0.0092, 0.014, 'primary', 10.1 UNION ALL
SELECT 'INT023', 'CPD008', 'TGT019', 0.38, 0.51, 'off-target', 7.4 UNION ALL
SELECT 'INT024', 'CPD009', 'TGT008', 0.011, 0.017, 'primary', 9.9 UNION ALL
SELECT 'INT025', 'CPD009', 'TGT009', 0.015, 0.022, 'primary', 9.8 UNION ALL
SELECT 'INT026', 'CPD010', 'TGT002', 0.041, 0.058, 'primary', 9.4 UNION ALL
SELECT 'INT027', 'CPD010', 'TGT001', 0.38, 0.52, 'off-target', 7.3 UNION ALL
SELECT 'INT028', 'CPD010', 'TGT013', 1.2, 1.8, 'off-target', 7.1 UNION ALL
SELECT 'INT029', 'CPD011', 'TGT006', 0.029, 0.041, 'primary', 9.5 UNION ALL
SELECT 'INT030', 'CPD011', 'TGT010', 0.71, 0.95, 'off-target', 7.0 UNION ALL
SELECT 'INT031', 'CPD012', 'TGT020', 0.39, 0.55, 'primary', 7.3 UNION ALL
SELECT 'INT032', 'CPD013', 'TGT014', 12.0, 18.5, 'primary', 5.7 UNION ALL
SELECT 'INT033', 'CPD014', 'TGT010', 0.0018, 0.0025, 'primary', 11.8 UNION ALL
SELECT 'INT034', 'CPD015', 'TGT004', 0.055, 0.078, 'primary', 9.2 UNION ALL
SELECT 'INT035', 'CPD015', 'TGT003', 0.12, 0.17, 'primary', 8.9 UNION ALL
SELECT 'INT036', 'CPD015', 'TGT016', 0.29, 0.41, 'primary', 8.5 UNION ALL
SELECT 'INT037', 'CPD015', 'TGT013', 0.95, 1.35, 'off-target', 7.2;
4. 创建 pathways 表
包含生物学通路、相关疾病领域和癌症相关性。
CREATE OR REPLACE TABLE drug_target_graph.pathways AS
SELECT 'PWY001' AS pathway_id, 'MAPK Signaling' AS pathway_name, 'hsa04010' AS kegg_id, 'Cell Proliferation' AS biological_process, 'Oncology' AS disease_area, 'high' AS cancer_relevance UNION ALL
SELECT 'PWY002', 'PI3K-AKT Signaling', 'hsa04151', 'Cell Survival', 'Oncology', 'high' UNION ALL
SELECT 'PWY003', 'VEGF Signaling', 'hsa04370', 'Angiogenesis', 'Oncology', 'high' UNION ALL
SELECT 'PWY004', 'ErbB Signaling', 'hsa04012', 'Cell Growth', 'Oncology', 'high' UNION ALL
SELECT 'PWY005', 'mTOR Signaling', 'hsa04150', 'Cell Growth', 'Oncology', 'medium' UNION ALL
SELECT 'PWY006', 'Cell Cycle', 'hsa04110', 'Cell Division', 'Oncology', 'high' UNION ALL
SELECT 'PWY007', 'Cardiac Muscle Contraction', 'hsa04260', 'Cardiac Function', 'Cardiovascular', 'low' UNION ALL
SELECT 'PWY008', 'hERG Cardiac Channel', 'hsa04022', 'Cardiac Repolarisation','Cardiovascular', 'low' UNION ALL
SELECT 'PWY009', 'AMPK Signaling', 'hsa04152', 'Energy Metabolism', 'Metabolic', 'low' UNION ALL
SELECT 'PWY010', 'ALK Signaling', 'hsa04915', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY011', 'RAS Signaling', 'hsa04014', 'Cell Proliferation', 'Oncology', 'high' UNION ALL
SELECT 'PWY012', 'HIV Replication', 'hsa05170', 'Viral Replication', 'Infectious Disease', 'low';
5. 创建 target_pathways 表
一个连接表,用于将靶标与其参与的生物学通路相关联。
CREATE OR REPLACE TABLE drug_target_graph.target_pathways AS
SELECT 'TP001' AS tp_id, 'TGT001' AS target_id, 'PWY001' AS pathway_id, 'activator' AS role, 0.95 AS importance_score UNION ALL
SELECT 'TP002', 'TGT001', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP003', 'TGT002', 'PWY004', 'activator', 0.98 UNION ALL
SELECT 'TP004', 'TGT002', 'PWY001', 'activator', 0.82 UNION ALL
SELECT 'TP005', 'TGT002', 'PWY002', 'activator', 0.75 UNION ALL
SELECT 'TP006', 'TGT003', 'PWY003', 'activator', 0.96 UNION ALL
SELECT 'TP007', 'TGT003', 'PWY001', 'activator', 0.71 UNION ALL
SELECT 'TP008', 'TGT004', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP009', 'TGT004', 'PWY011', 'activator', 0.89 UNION ALL
SELECT 'TP010', 'TGT005', 'PWY010', 'activator', 0.99 UNION ALL
SELECT 'TP011', 'TGT005', 'PWY001', 'activator', 0.78 UNION ALL
SELECT 'TP012', 'TGT006', 'PWY002', 'activator', 0.98 UNION ALL
SELECT 'TP013', 'TGT006', 'PWY005', 'activator', 0.85 UNION ALL
SELECT 'TP014', 'TGT007', 'PWY001', 'activator', 0.94 UNION ALL
SELECT 'TP015', 'TGT007', 'PWY011', 'activator', 0.88 UNION ALL
SELECT 'TP016', 'TGT008', 'PWY006', 'activator', 0.95 UNION ALL
SELECT 'TP017', 'TGT009', 'PWY006', 'activator', 0.93 UNION ALL
SELECT 'TP018', 'TGT010', 'PWY005', 'activator', 0.99 UNION ALL
SELECT 'TP019', 'TGT010', 'PWY002', 'activator', 0.91 UNION ALL
SELECT 'TP020', 'TGT011', 'PWY003', 'activator', 0.87 UNION ALL
SELECT 'TP021', 'TGT011', 'PWY001', 'activator', 0.72 UNION ALL
SELECT 'TP022', 'TGT012', 'PWY001', 'activator', 0.83 UNION ALL
SELECT 'TP023', 'TGT012', 'PWY011', 'activator', 0.79 UNION ALL
SELECT 'TP024', 'TGT013', 'PWY008', 'substrate', 0.99 UNION ALL
SELECT 'TP025', 'TGT013', 'PWY007', 'substrate', 0.95 UNION ALL
SELECT 'TP026', 'TGT014', 'PWY009', 'activator', 0.97 UNION ALL
SELECT 'TP027', 'TGT015', 'PWY001', 'activator', 0.91 UNION ALL
SELECT 'TP028', 'TGT015', 'PWY011', 'activator', 0.86 UNION ALL
SELECT 'TP029', 'TGT016', 'PWY001', 'activator', 0.84 UNION ALL
SELECT 'TP030', 'TGT016', 'PWY003', 'activator', 0.77 UNION ALL
SELECT 'TP031', 'TGT017', 'PWY001', 'activator', 0.88 UNION ALL
SELECT 'TP032', 'TGT017', 'PWY011', 'activator', 0.82 UNION ALL
SELECT 'TP033', 'TGT018', 'PWY002', 'activator', 0.96 UNION ALL
SELECT 'TP034', 'TGT018', 'PWY005', 'activator', 0.88 UNION ALL
SELECT 'TP035', 'TGT019', 'PWY001', 'activator', 0.97 UNION ALL
SELECT 'TP036', 'TGT019', 'PWY011', 'activator', 0.91 UNION ALL
SELECT 'TP037', 'TGT020', 'PWY012', 'substrate', 0.99;
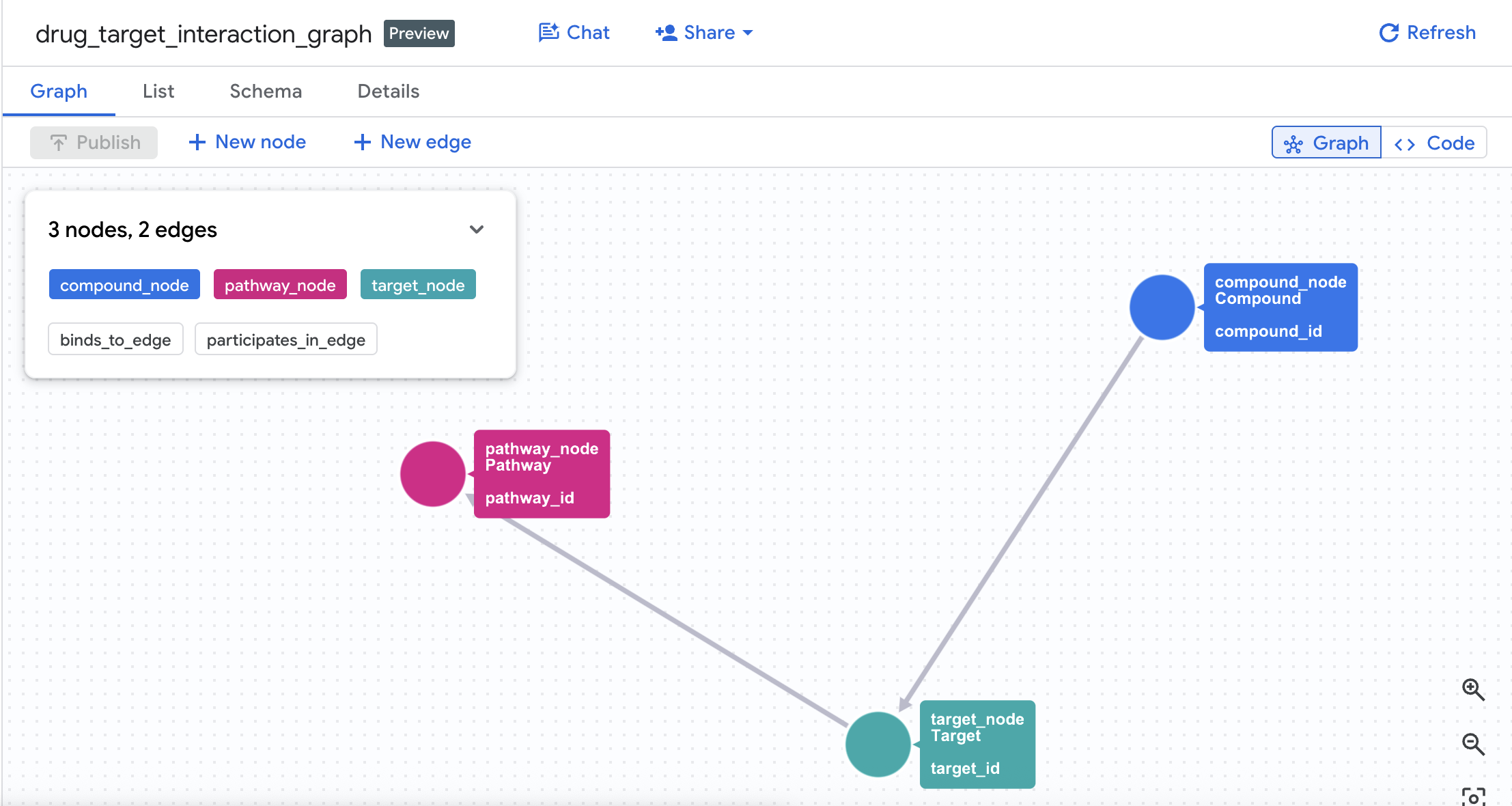
4. 创建属性图
成功创建表后,您现在可以构建属性图。这会使用边表(Interactions 和 Target Pathways)关联节点(化合物、靶标、通路)。
在 BigQuery Studio SQL 编辑器中运行以下语句:
CREATE OR REPLACE PROPERTY GRAPH drug_target_graph.drug_target_interaction_graph
NODE TABLES (
drug_target_graph.compounds
AS compound_node
KEY (compound_id)
LABEL Compound
PROPERTIES (compound_id, compound_name, mechanism_of_action, dev_stage, therapeutic_area, molecular_weight),
drug_target_graph.targets
AS target_node
KEY (target_id)
LABEL Target
PROPERTIES (target_id, target_name, gene_name, uniprot_id, target_class, is_oncogene),
drug_target_graph.pathways
AS pathway_node
KEY (pathway_id)
LABEL Pathway
PROPERTIES (pathway_id, pathway_name, kegg_id, biological_process, disease_area, cancer_relevance)
)
EDGE TABLES (
drug_target_graph.interactions
AS binds_to_edge
KEY (interaction_id)
SOURCE KEY (compound_id) REFERENCES compound_node (compound_id)
DESTINATION KEY (target_id) REFERENCES target_node (target_id)
LABEL BINDS_TO
PROPERTIES (interaction_id, affinity_nm, ic50_nm, interaction_type, pchembl_value),
drug_target_graph.target_pathways
AS participates_in_edge
KEY (tp_id)
SOURCE KEY (target_id) REFERENCES target_node (target_id)
DESTINATION KEY (pathway_id) REFERENCES pathway_node (pathway_id)
LABEL PARTICIPATES_IN
PROPERTIES (tp_id, role, importance_score)
);
这会在您的数据集中创建一个名为 drug_target_interaction_graph 的图。
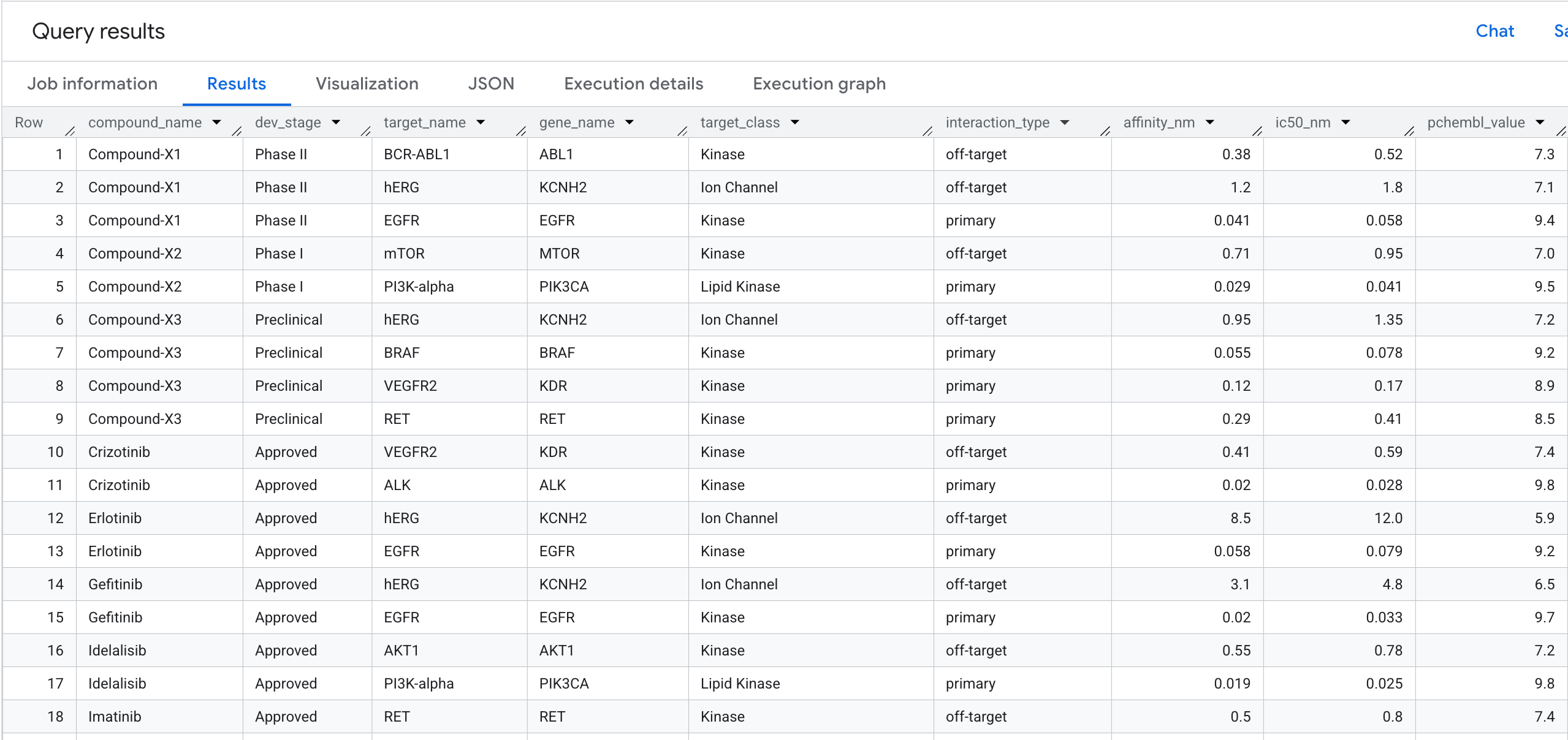
5. 查询 1:每个化合物的完整目标绑定配置文件
我们来运行第一个图表查询。这是一个 1 跳遍历,可回答以下问题:哪些化合物与哪些靶标结合,它们的亲和力如何?
GQL 查询
在 SQL 编辑器中运行以下查询:
SELECT
compound_name,
dev_stage,
target_name,
gene_name,
target_class,
interaction_type,
ROUND(affinity_nm, 3) AS affinity_nm,
ROUND(ic50_nm, 3) AS ic50_nm,
pchembl_value
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_name AS target_name,
t.gene_name AS gene_name,
t.target_class AS target_class,
b.interaction_type AS interaction_type,
b.affinity_nm AS affinity_nm,
b.ic50_nm AS ic50_nm,
b.pchembl_value AS pchembl_value
)
)
ORDER BY compound_name, interaction_type, affinity_nm;
以下是您在结果中看到的内容:
6. 查询 2:心脏风险检测
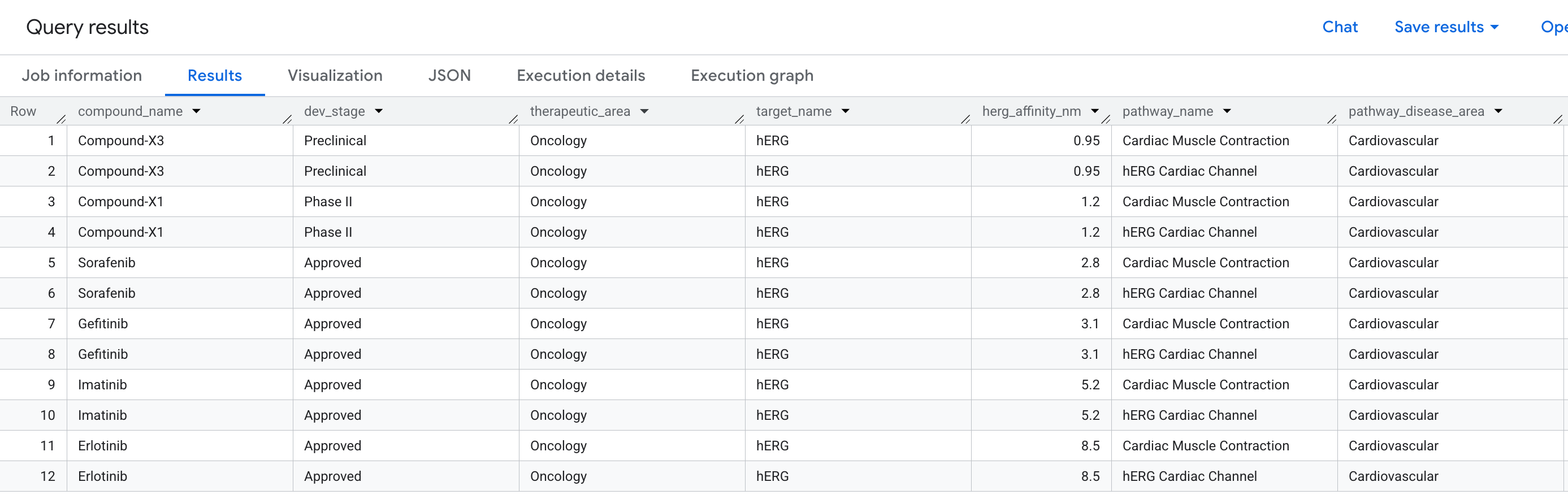
业务问题
在药物发现领域,一种有前景的化合物在临床试验中失败的最常见原因之一是心脏毒性,具体而言,是指意外与 hERG 蛋白(基因:KCNH2)结合,而 hERG 蛋白是一种调节心律的钾离子通道。hERG 的脱靶命中可能会导致致命性心律失常,并导致多款备受瞩目的药物被撤回。
我们要回答的问题是:
“我们流水线中的哪些化合物对 hERG 蛋白有脱靶结合事件,这会使哪些心脏通路面临风险?”
这是一个双跳问题:我们需要在单个查询中,通过一个目标(hERG)从一种化合物遍历到一种通路,从而通过两种关系连接三种实体类型。
编写 GQL 查询
在 BQ SQL 编辑器中运行以下查询:
SELECT
compound_name,
dev_stage,
therapeutic_area,
target_name,
ROUND(affinity_nm, 3) AS herg_affinity_nm,
pathway_name,
disease_area AS pathway_disease_area
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND b.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
c.therapeutic_area AS therapeutic_area,
t.target_name AS target_name,
b.affinity_nm AS affinity_nm,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
ORDER BY herg_affinity_nm;
请注意,MATCH 子句的读法几乎像一个句子:“Find a Compound that binds to a Target that participates in a Pathway”(查找与参与 Pathway 的 Target 绑定的 Compound),其中在路径中的每个节点和边上应用了过滤条件。
以下是您将在结果中看到的数据:
以图表形式直观呈现风险网络
表格可以显示数据,但无法显示风险的结构。多种化合物是否会汇聚到同一通路?是只有一种高风险化合物,还是有多种?
通过图表可视化,可以立即看到这一点。运行以下单元格,将相同的 2 跳遍历呈现为交互式网络:
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH pt = (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE t.gene_name = 'KCNH2'
AND pw.disease_area = 'Cardiovascular'
RETURN
TO_JSON(pt) AS path
您应该会看到类似如下所示的图表:
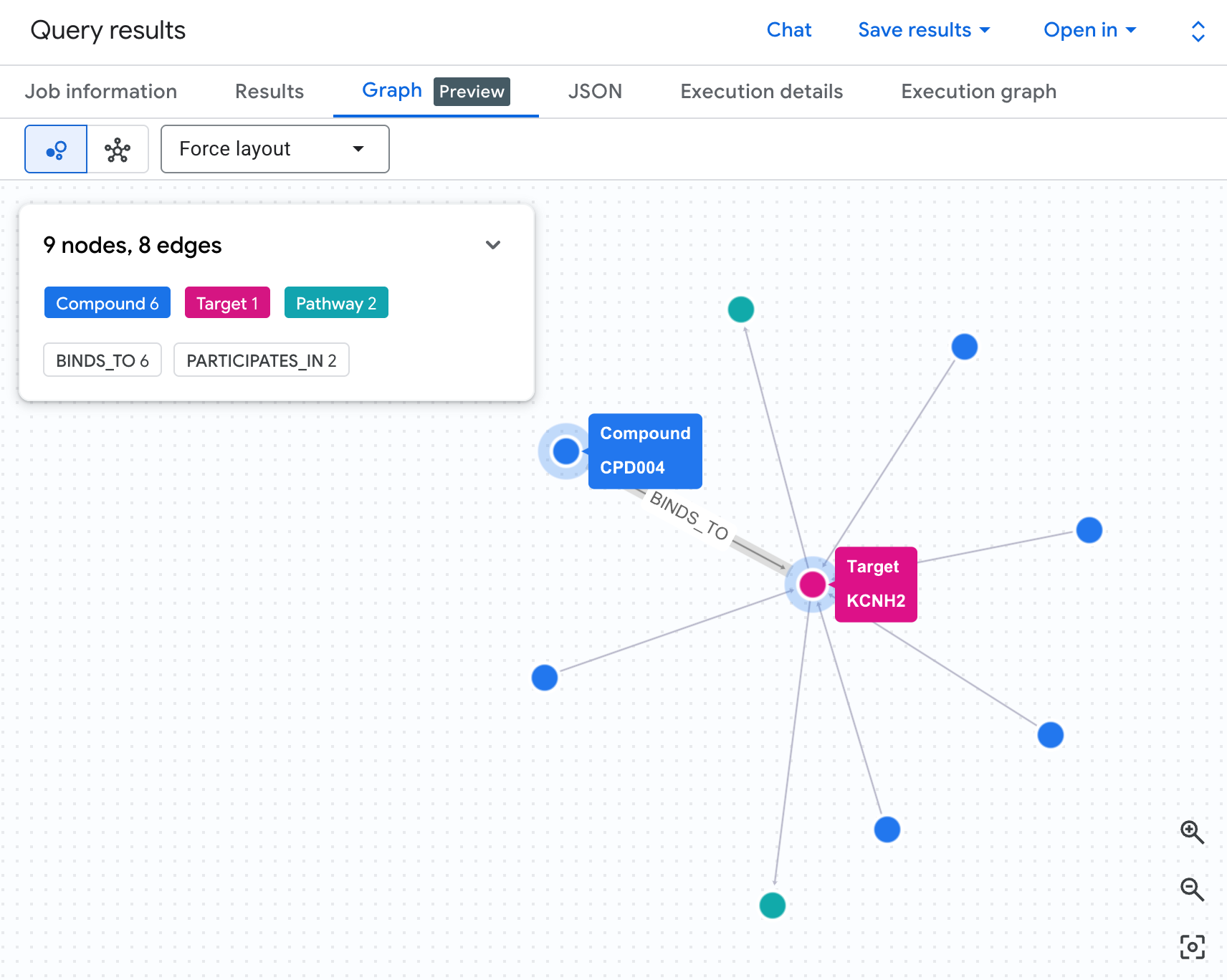
图表中的每条路径都描绘了一条完整的责任链:一种化合物(蓝色节点)与中心的 hERG 蛋白结合,该蛋白与一条或多条心脏通路(绿色节点)相连。表格中原本平铺的行现在变成了一个可见的风险网络 - 具有多条通路暴露的化合物会立即突出显示,成为安全审查的更高优先级。
请参阅“为什么 GQL 比 SQL 更优雅”
若要在标准 SQL 中执行相同的 2 跳查询,您需要 4 个显式联接。您需要花费认知精力来描述如何联接表,而不是您要查找的关系。GQL 可让您专注于问题本身。
SELECT
c.compound_name,
c.dev_stage,
c.therapeutic_area,
t.target_name,
ROUND(i.affinity_nm, 3) AS herg_affinity_nm,
pw.pathway_name,
pw.disease_area AS pathway_disease_area
FROM drug_target_graph.compounds c
JOIN drug_target_graph.interactions i ON c.compound_id = i.compound_id
JOIN drug_target_graph.targets t ON i.target_id = t.target_id
JOIN drug_target_graph.target_pathways tp ON t.target_id = tp.target_id
JOIN drug_target_graph.pathways pw ON tp.pathway_id = pw.pathway_id
WHERE t.gene_name = 'KCNH2'
AND i.interaction_type = 'off-target'
AND pw.disease_area = 'Cardiovascular'
ORDER BY herg_affinity_nm;
深入分析 - 多跳代谢物风险检测
上述查询可识别直接与 hERG 蛋白结合的化合物。但在实际的药物安全性工作流程中,风险有时会隔着一个步骤:化合物可能会在体内代谢转化为次级分子(代谢物),然后与 hERG 结合,而直接结合分析可能会完全忽略这种风险。
如果您的属性图包含代谢物节点表和 METABOLISES_INTO 边,您可以将同一 MATCH 模式扩展为 3 跳遍历:
(Compound)-[METABOLISES_INTO]->(Metabolite)-[BINDS_TO]->
(Target)-[PARTICIPATES_IN]->(Pathway)
GQL 查询结构将恰好更改一个节点和一个边。等效的 SQL 需要两个额外的 JOIN。这种模式使得图遍历在安全级联分析中特别强大 - 查询复杂性呈线性增长,而生物学洞见呈指数增长。
7. 查询 3:共享目标复合配对
为了找到联合治疗的候选药物,我们可以确定两种不同的化合物何时与同一靶节点结合。我们使用双向匹配来回答以下问题:哪些肿瘤学化合物会收敛到完全相同的靶标?
在 SQL 编辑器中运行以下查询:
SELECT
compound_a,
compound_b,
shared_target,
gene_name,
ROUND(affinity_a_nm, 3) AS affinity_a_nm,
ROUND(affinity_b_nm, 3) AS affinity_b_nm
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
AND c2.therapeutic_area = 'Oncology'
COLUMNS (
c1.compound_name AS compound_a,
c2.compound_name AS compound_b,
t.target_name AS shared_target,
t.gene_name AS gene_name,
b1.affinity_nm AS affinity_a_nm,
b2.affinity_nm AS affinity_b_nm
)
)
ORDER BY compound_a, compound_b, affinity_a_nm;
以下是您将在结果中看到的数据:
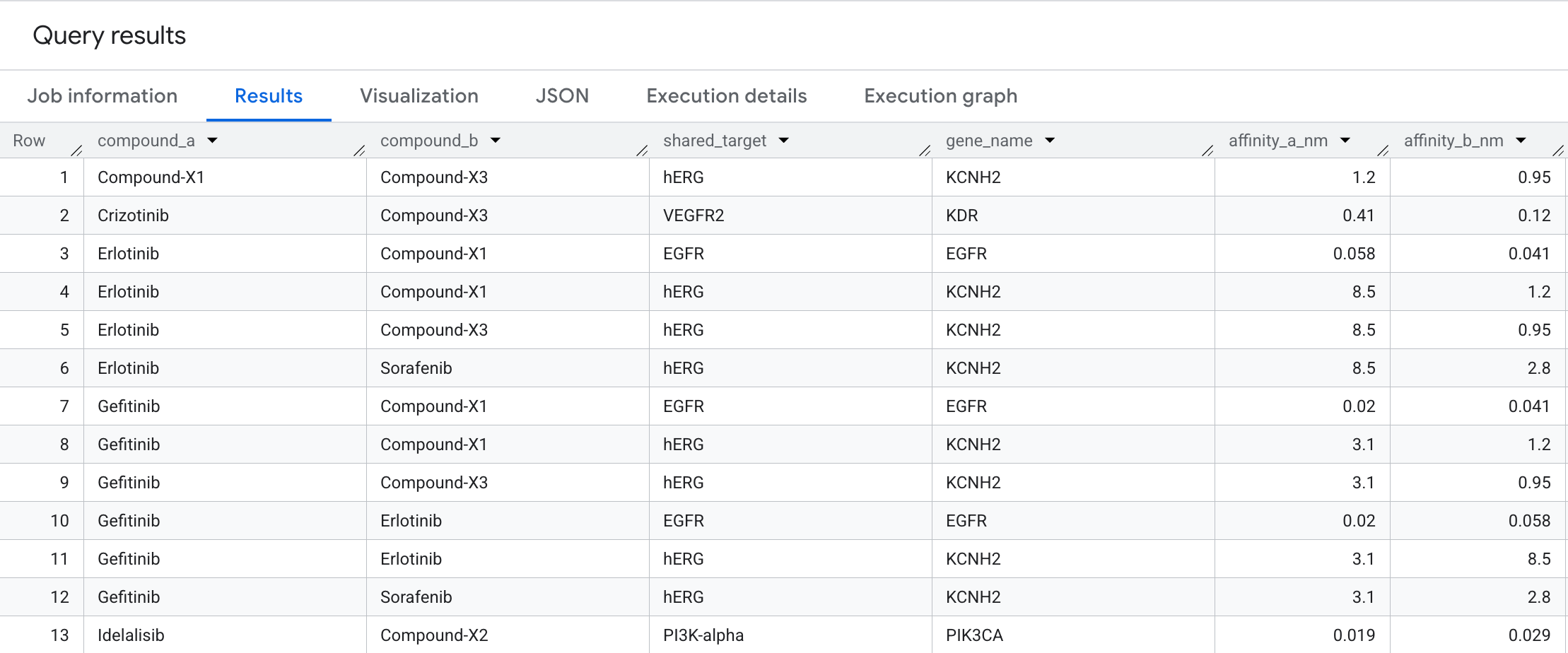
图表可视化
您可以在 SQL 编辑器中运行以下代码,直接在 BigQuery 中直观呈现图。
GRAPH `drug_target_graph.drug_target_interaction_graph`
MATCH p = (c1:Compound)-[b1:BINDS_TO]->(t:Target)<-[b2:BINDS_TO]-(c2:Compound)
WHERE c1.compound_id < c2.compound_id
AND c1.therapeutic_area = 'Oncology'
RETURN
TO_JSON(p) AS path
这种双向遍历可发现收敛于同一蛋白质靶标的化合物对,这种模式在扁平的互动表中很难发现,但在图中却一目了然。在药物发现中,共享靶标对是组合疗法设计的起点:两种命中癌症通路中同一节点的化合物可能会产生协同效应,或者表明管道中存在意外的冗余
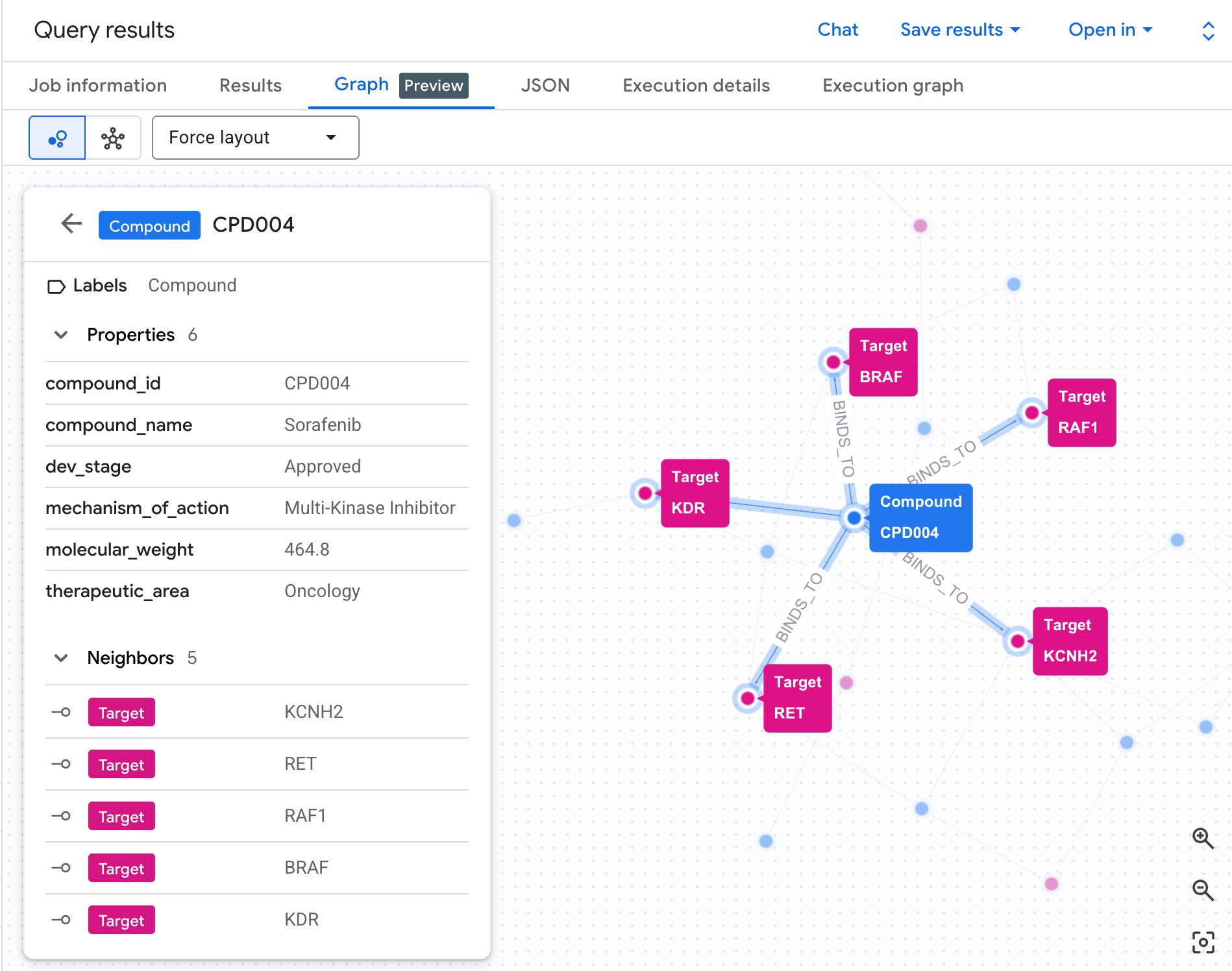
8. 查询 4:疾病传播途径影响范围
每种化合物的生物学影响有多广泛?我们来执行一次包含聚合的 2 跳遍历,以回答以下问题:每种化合物会影响多少条生物学通路和多少个不同的靶标(按疾病领域分组)?
在 SQL 编辑器中运行以下查询:
SELECT
compound_name,
dev_stage,
disease_area,
COUNT(DISTINCT pathway_id) AS pathways_affected,
COUNT(DISTINCT target_id) AS targets_involved,
STRING_AGG(DISTINCT pathway_name ORDER BY pathway_name) AS pathway_list
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
COLUMNS (
c.compound_name AS compound_name,
c.dev_stage AS dev_stage,
t.target_id AS target_id,
pw.pathway_id AS pathway_id,
pw.pathway_name AS pathway_name,
pw.disease_area AS disease_area
)
)
GROUP BY compound_name, dev_stage, disease_area
ORDER BY compound_name, pathways_affected DESC;
以下是您在结果中看到的内容:
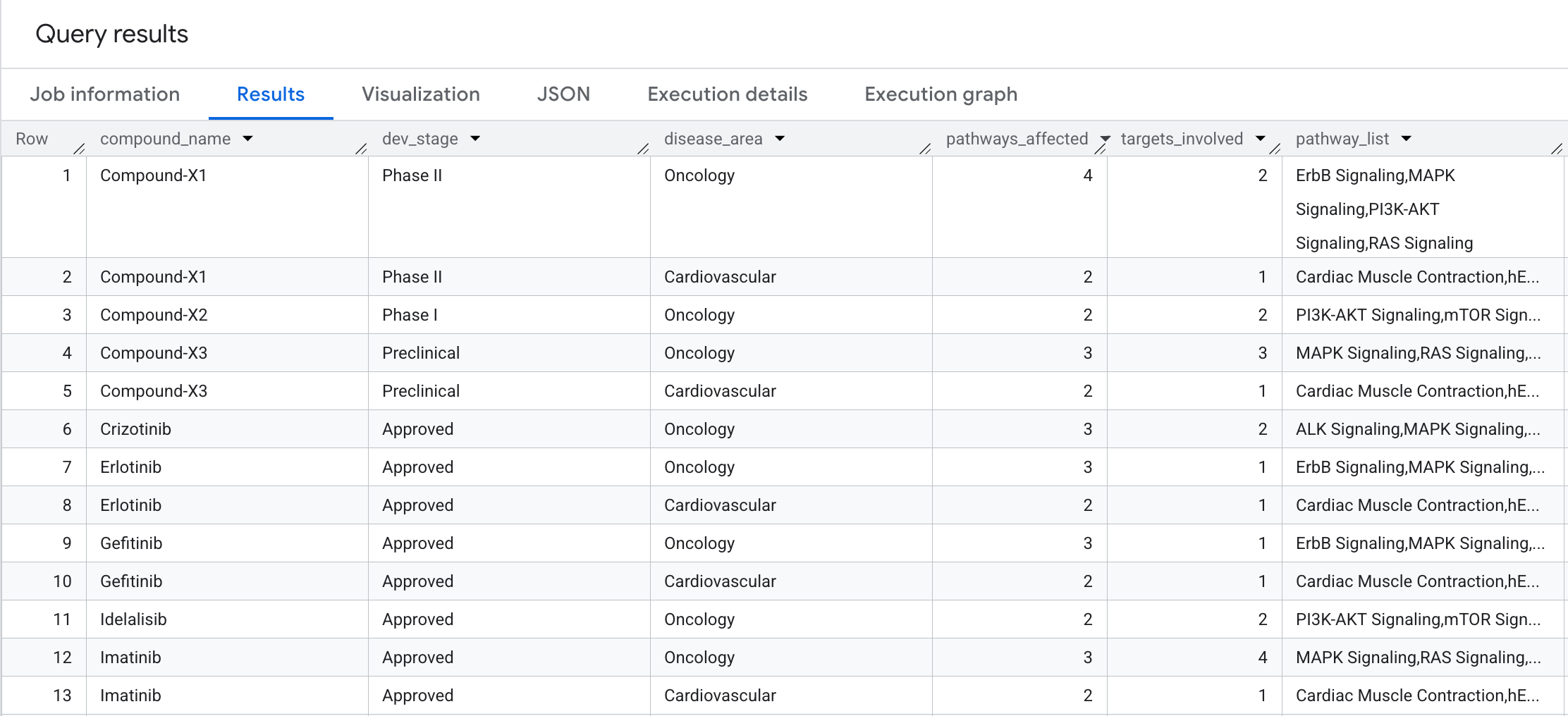
9. 查询 5:安全化合物选择
最后,我们来查询具有高肿瘤覆盖率但明确避免 hERG(心脏)脱靶责任的化合物。这符合药物发现流水线中常见的“安全第一”选择模式。
在 SQL 编辑器中运行以下查询:
WITH oncology_compounds AS (
SELECT DISTINCT compound_id, compound_name, dev_stage
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)-[p:PARTICIPATES_IN]->(pw:Pathway)
WHERE pw.disease_area = 'Oncology'
AND pw.cancer_relevance = 'high'
COLUMNS (
c.compound_id AS compound_id,
c.compound_name AS compound_name,
c.dev_stage AS dev_stage
)
)
),
herg_risk_compounds AS (
SELECT DISTINCT compound_id
FROM GRAPH_TABLE(
drug_target_graph.drug_target_interaction_graph
MATCH (c:Compound)-[b:BINDS_TO]->(t:Target)
WHERE t.gene_name = 'KCNH2'
COLUMNS (c.compound_id AS compound_id)
)
)
SELECT
o.compound_name,
o.dev_stage,
'Clean cardiac profile' AS cardiac_safety
FROM oncology_compounds o
LEFT JOIN herg_risk_compounds h ON o.compound_id = h.compound_id
WHERE h.compound_id IS NULL
ORDER BY o.dev_stage, o.compound_name;
以下是您将在结果中看到的输出内容:
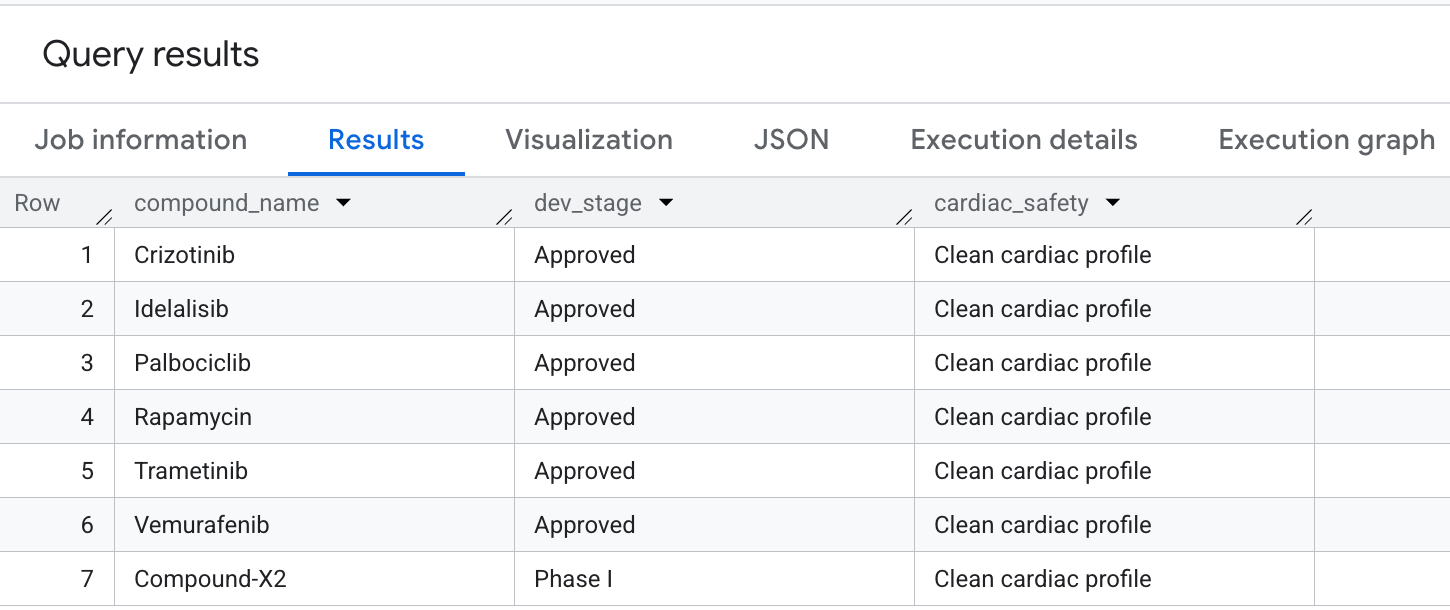
您已成功在 BigQuery 中执行高级图遍历,以提取关键的安全性和疗效剖析!
10. 奖励部分:与图表对话
BigQuery 对话式分析现已支持将图作为知识来源。这样,您就可以用自然语言与刚刚创建的图表进行对话。
使用入门:添加图表作为知识源
如需开始操作,请按照此处的步骤创建对话代理。从搜索栏中选择您创建的图表。
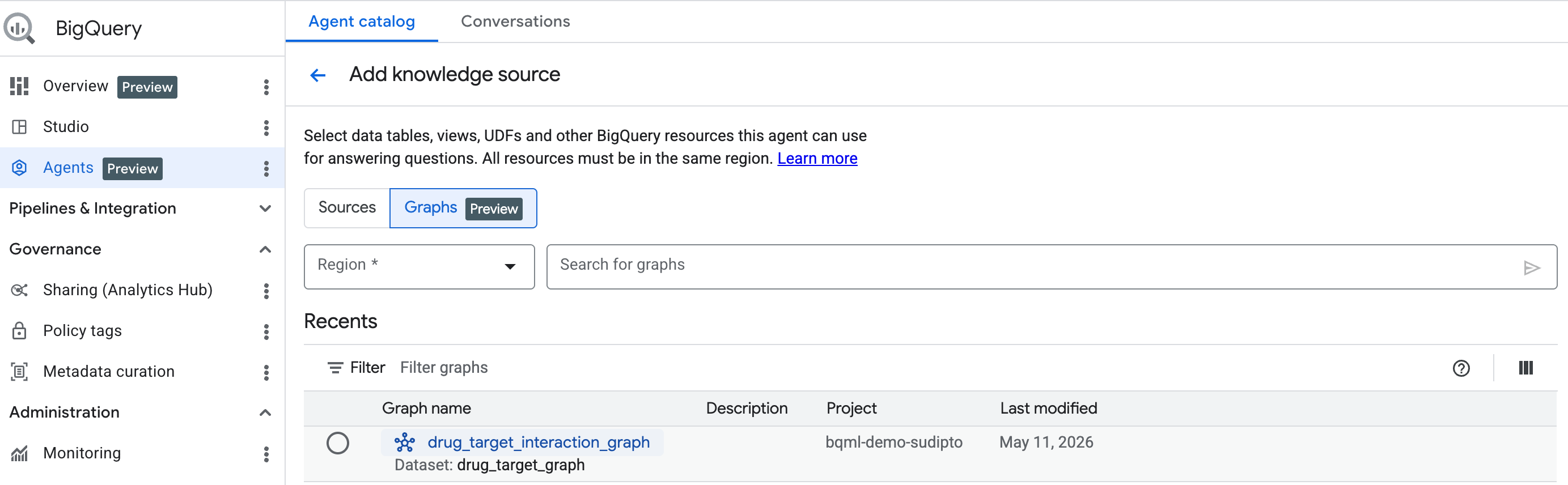
使用 BigQuery 对话式分析功能与图表对话
将知识源添加为图表后,完成其余的对话式分析代理设置。
然后,您就可以开始用自然语言与图表对话了!
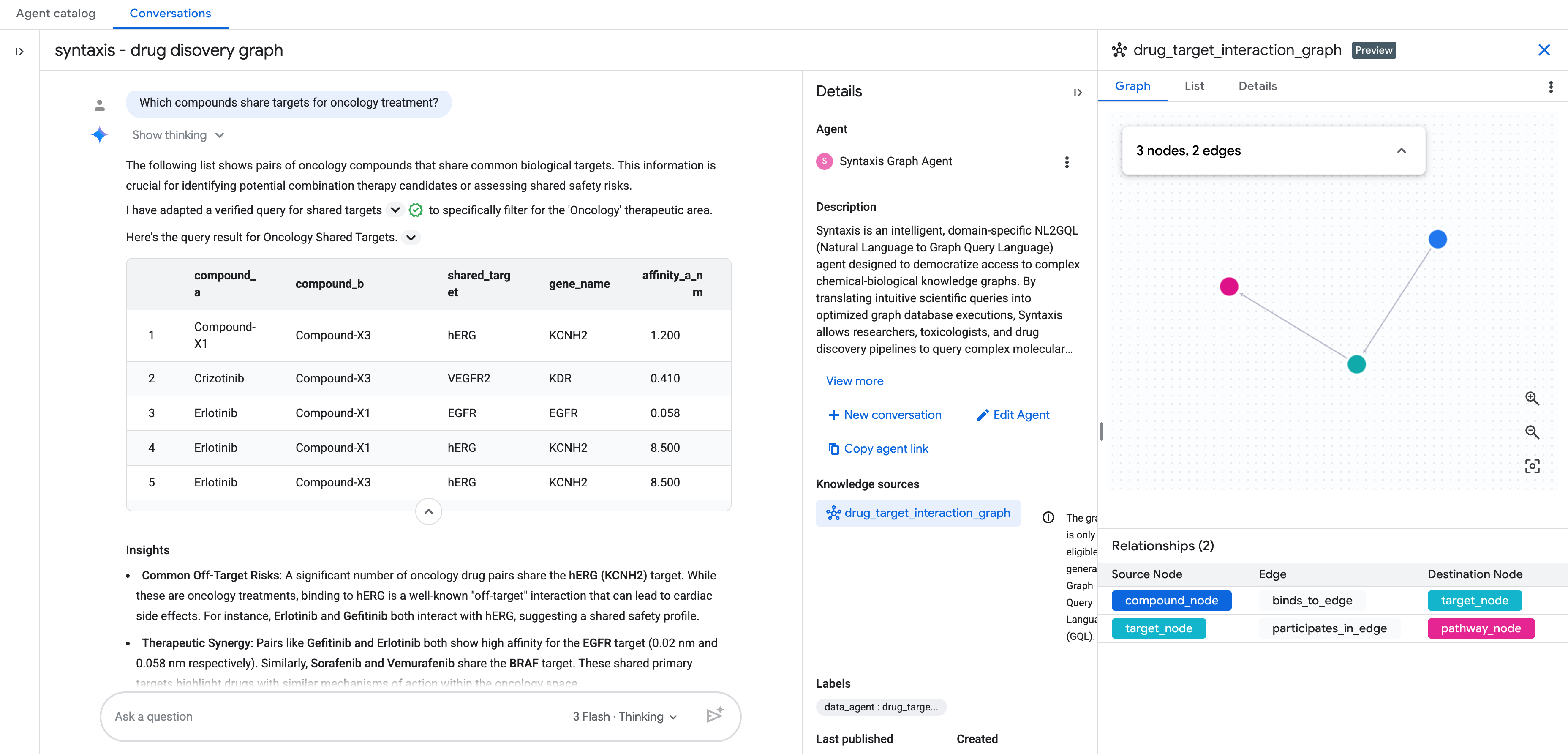
其他问题
- 目前处于 2 期试验中的化合物的所有靶点是什么?
- 心血管和肿瘤学化合物之间共享哪些靶点?
11. 清理
为避免系统向您的 Google Cloud 账号持续收取费用,请删除在此 Codelab 中创建的资源。
运行以下查询,以级联方式舍弃架构和所有表:
DROP SCHEMA IF EXISTS drug_target_graph CASCADE;
12. 恭喜
恭喜!您已成功使用 BigQuery Graph 对药物-靶标互动网络进行了建模和分析。
您学到的内容
- 如何将实体关系(化合物、靶标、通路)建模为属性图。
- 如何在 BigQuery 中定义架构并创建属性图。
- 如何使用 GQL 编写复杂的图遍历,并将其与传统 SQL 进行比较。
- 如何利用
GRAPH_TABLE、MATCH和双向匹配来解决生命科学领域的问题。