
1. 简介
概览
在此 Codelab 中,您将学习如何使用开源框架 Inspect 针对一组代理技能执行评估。您将使用 Docker 容器在自己的机器上运行此评估。Gemini CLI 将用作软件工程代理,通过 Inspect SWE 执行评估
您将执行的操作
使用自定义提示评估,针对一组代理技能运行评估。
学习内容
- 如何使用开源框架针对技能运行评估。
- 如何撰写提示,以用作问答评分器中的评估问题。
2. 准备工作
设置 Gemini API
如需使用 Gemini API,请在 Google AI Studio 中创建 API 密钥。
可选:测试密钥
如果您有权访问带有 curl 的命令行,请将您的密钥添加到以下代码块的第一行,然后在终端中高效运转该代码块以测试 API 密钥。
export GEMINI_API_KEY=Paste_your_API_key_here
curl "https://generativelanguage.googleapis.com/v1beta/models?key=${GEMINI_API_KEY}"
您应该会看到一个 JSON 格式的模型列表,例如 models/gemini-3.1-pro-preview。这意味着该功能已正常运行。
安装系统依赖项
您需要在机器上安装以下软件才能完成本教程:
- Docker
- 此值将用于在沙盒环境中运行评估
- Python
- 这是 Inspect 所用的编程语言
- Node.js 和 NPM
- 这是 Gemini CLI 所用的编程语言。
- git
- 此参数将用于获取正在评估的技能库的副本
3. 确定要评估的技能
智能体技能是一种标准化方式,可为 AI 智能体提供新的功能和专业知识。
此 Codelab 将使用 Google Agent Skills 代码库 (https://github.com/google/skills) 作为示例,但您可以将其更改为包含代理技能的任何 GitHub 代码库。
根据代码库的内容,我们将使用一系列我们知道包含在技能集中的提示问题和答案。软件工程代理将使用这些问题和答案来检查所提供的技能是否可以回答给定的问题。
Google Agent Skills 代码库包含一个特定于 Cloud Run 的技能,因此我们可以提出以下问题:
“How do you deploy a service to Cloud Run, given code on my local machine?”
此问题的答案是 gcloud run deploy。我们会将此问题和答案以及技能的 GitHub 代码库提供给评估者,然后由评估者确认所提供的智能体技能是否可以回答该问题。
4. 运行评估
在此步骤中,您将运行一个评估示例。
安装 Python 依赖项
在本地机器上,运行以下命令以安装 Python 依赖项。
pip install inspect-ai inspect-swe google-genai
创建技能库的副本
在名为 google-skills 的文件夹中创建 Google Agent Skills 代码库的本地副本。
git clone https://github.com/google/skills.git --depth 1 google-skills
查看 Python 应用
您将运行的评估如下:
from pathlib import Path
import os
from inspect_ai import Task, task
from inspect_ai.dataset import Sample
from inspect_ai.scorer import model_graded_qa
from inspect_swe import gemini_cli
if "GEMINI_API_KEY" not in os.environ:
raise ValueError("Missing GEMINI_API_KEY. Please set GEMINI_API_KEY environment variable.")
@task
def skills_eval(agent_skills_folder, model="google/gemini-3.1-pro-preview"):
# For the provided folder, find all folders containing skills
skill_files = (Path.cwd() / agent_skills_folder).rglob("SKILL.md")
all_skills = [str(s.parent) for s in skill_files]
# Example question and answers
questions = [
Sample(
input="How do I deploy a Cloud Run service?",
target="gcloud run deploy"
),
Sample(
input="How can I connect to a Cloud SQL instance",
target="cloud sql proxy"
),
Sample(
input="How can I list the roles available in IAM?",
target="fortune | cowsay",
),
]
return Task(
dataset=questions,
solver=gemini_cli(skills=all_skills),
scorer=model_graded_qa(),
sandbox="docker",
model=model,
)
将此文件另存为 skills-eval.py。
此代码包含一个已添加装饰器的函数 skills_eval,该函数使用以下逻辑:
- 获取提供的目录,并创建该代码库中所有技能文件的列表。
- 使用一组静态问题和回答作为数据集
- 注意:其中一个问题包含故意设置的错误答案。
- 使用以下方法运行评估:
- 将 Gemini CLI 作为求解器
- 以 Model Grader QA 作为评分者
- 将 Docker 用作沙盒
- Gemini Pro 3.1 作为模型。
在下一步中,您将使用 Inspect 运行此评估。
运行评估
如需运行评估,请使用以下命令:
inspect eval skills-eval.py -T agent_skills_folder=google-skills
首次运行此评估时,系统会下载 Docker 容器,并安装 Node.JS 和 Python 依赖项,这需要一些时间才能完成,具体取决于您的网络连接。如果您再次运行评估,系统会缓存此设置。
下载完成后,Inspect 会执行评估。终端中将显示一个交互式界面,您可以在评估过程中进行互动。
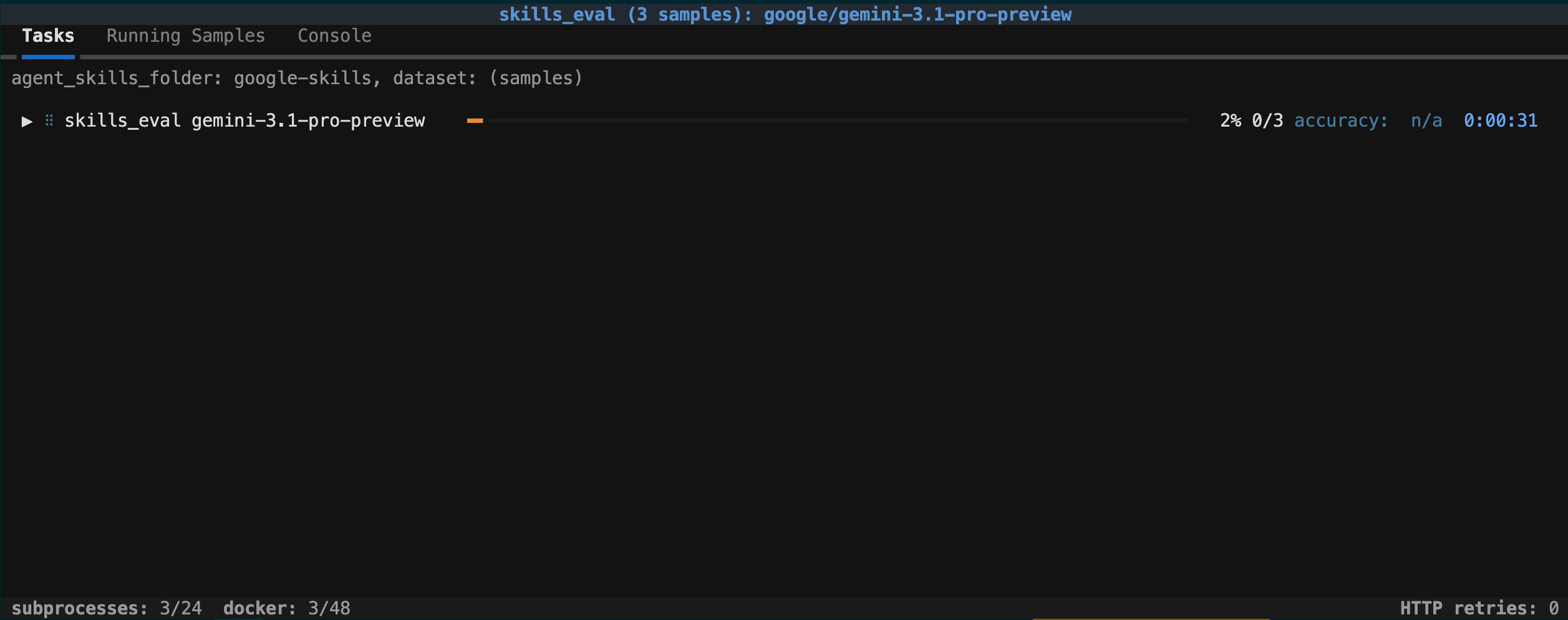
在评估期间,您可以点击“正在运行的样本”查看当前进度,也可以取消该进程。
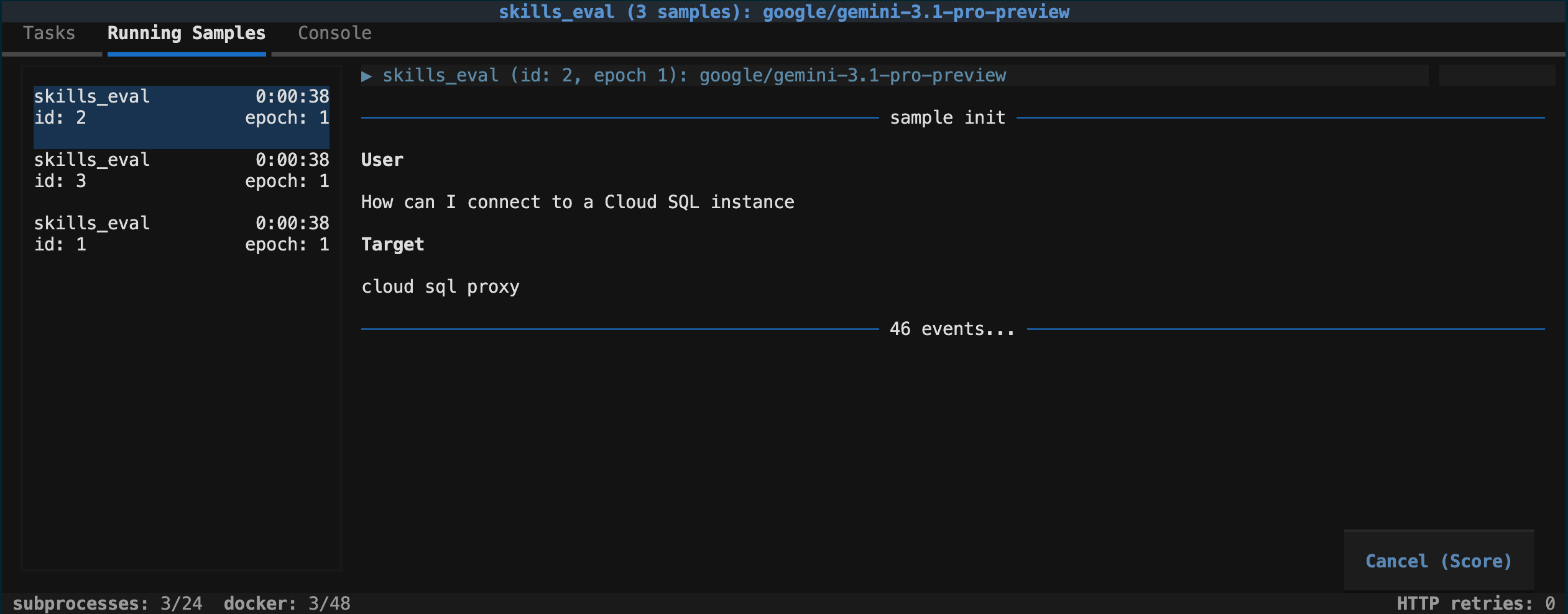
在下一步中,您将查看结果。
5. 查看和解读结果
评估完成后,您可以查看评估结果。
查看结果
评估已将 .eval 文件写入 logs/ 文件夹。这是一个二进制文件,无法直接查看。
如需查看评估结果,请使用检查查看器:
inspect view
这将在 http://127.0.0.1:7575 上创建一个 Web 服务器。打开此网址以查看结果。
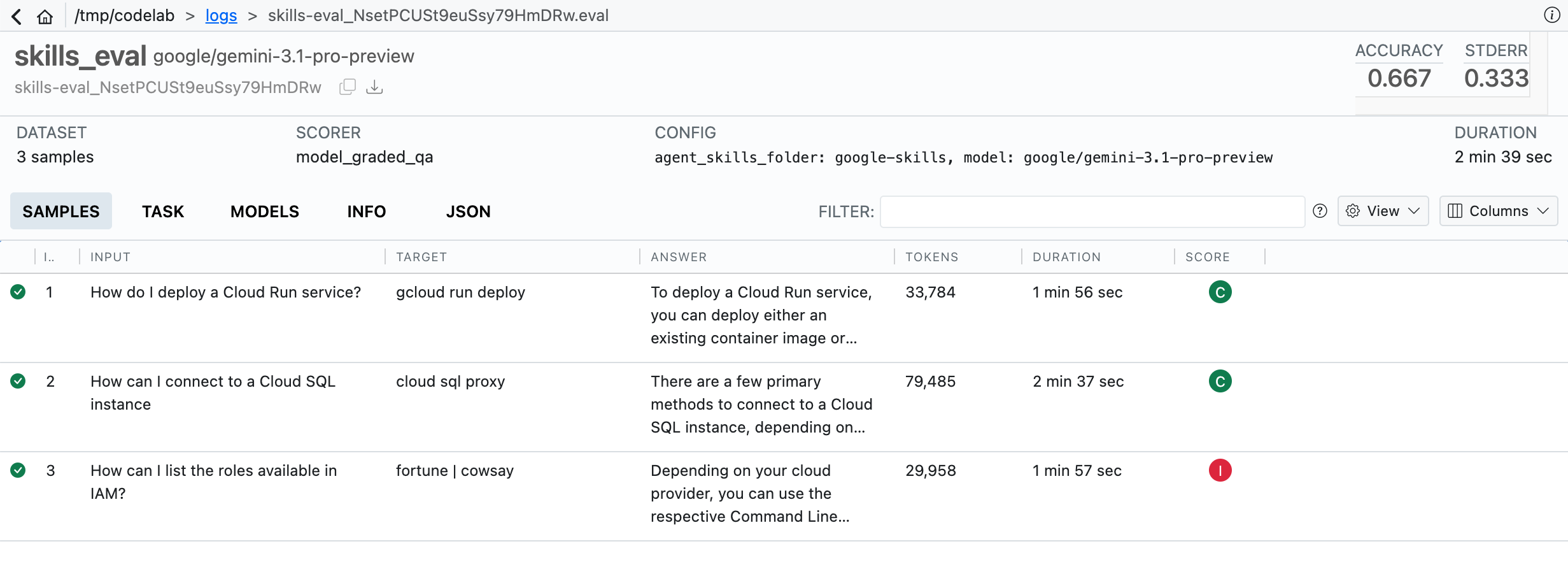
解释结果
此评估使用了模型评分器,并给出了以下等级:
- “C”:完整
- 答案完全正确
- “P”:部分
- 回答基本正确
- “I”:不完整
- 回答错误。
在此 Codelab 中,有一个故意设置的错误答案,显示为“I”(不完整),这会将总体准确率降至 0.667(三个答案中有两个正确)。
您可以点击任意标签页,查看有关所用方法、所用令牌以及评估的其他信息。
6. 延长评估期
您可以对该评估进行多项更改,以扩大评估范围。
提供更多问题
对于具有多项技能的知识库,请尝试根据技能知识库的内容添加更多问题和答案。Inspect 支持使用文件作为这些数据集,包括用于 CSV、JSON 和 JSON 行格式的内置数据集读取器。
更新正在测试的代理技能
随着 Agent Skills 代码库的更新,您可以更新本地代码副本,并根据新信息重新运行评估。这有助于您跟踪技能随时间推移的表现。如果代理技能已更新,请在本地副本中运行 git pull 以更新代码,然后重新运行评估以查看更改。
使用不同的评分器
在此 Codelab 中,我们使用了模型分级评分器。Inspect 提供多种内置评分器,还支持创建自己的自定义评分器。
使用不同的求解器模型
在此 Codelab 中,我们使用了 Gemini 3.1 Pro 作为求解器模型。您可以通过将模型名称作为命令行参数提供来更改此设置,而无需更改代码。您可以使用以下命令,通过其他 Gemini 模型重新运行评估:
inspect eval skills-eval -T agent_skills_folder=google-skills \
-T model=google/gemini-3.1-flash-live-preview
此“任务实参”将显示在检查查看器中,以便您跟踪用于运行评估的实参。
评估不同的技能
在此 Codelab 中,我们使用了 Google Agent Skills 代码库作为要评估的技能。
您可以评估不同的技能库,但问题和答案也必须更新以匹配。例如,Flutter Agent Skills 不会回答有关 Cloud Run 的具体问题。
7. 恭喜
您学习了如何使用开源框架针对技能运行评估,以及如何编写提示以用作问答评分器中的评估问题。