
1. Tworzenie aplikacji we Flutterze opartej na Gemini
Co utworzysz
W tym ćwiczeniu stworzysz Colorist – interaktywną aplikację Flutter, która wprowadza możliwości Gemini API bezpośrednio do Twojej aplikacji Flutter. Czy kiedykolwiek chciałeś(-aś) umożliwić użytkownikom sterowanie aplikacją za pomocą języka naturalnego, ale nie wiedziałeś(-aś), od czego zacząć? Z tego ćwiczenia dowiesz się, jak to zrobić.
Colorist umożliwia użytkownikom opisywanie kolorów w języku naturalnym (np. „pomarańczowy zachód słońca” lub „głęboki niebieski oceanu”), a aplikacja:
- przetwarza te opisy za pomocą interfejsu Gemini API od Google;
- interpretuje opisy na precyzyjne wartości kolorów RGB,
- Wyświetla kolor na ekranie w czasie rzeczywistym.
- zawiera szczegóły techniczne dotyczące koloru i ciekawy kontekst;
- Zachowuje historię ostatnio wygenerowanych kolorów.
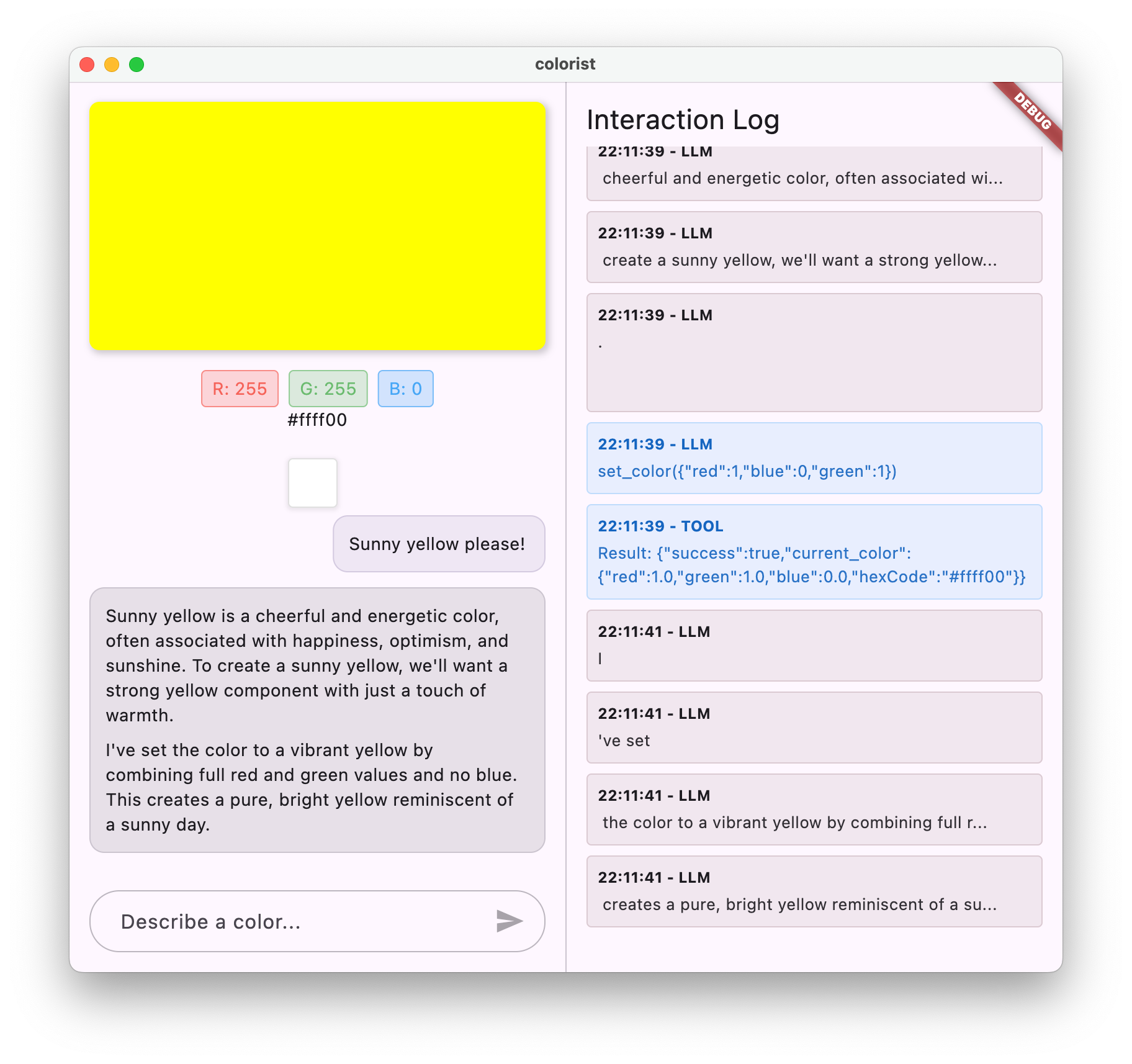
Aplikacja ma interfejs z podzielonym ekranem, na którym po jednej stronie znajduje się kolorowy obszar wyświetlania i interaktywny system czatu, a po drugiej stronie – szczegółowy panel dziennika pokazujący interakcje z LLM w formie nieprzetworzonej. Ten dziennik pozwala lepiej zrozumieć, jak naprawdę działa integracja z LLM.
Dlaczego jest to ważne dla deweloperów Fluttera
Duże modele językowe rewolucjonizują sposób, w jaki użytkownicy wchodzą w interakcje z aplikacjami, ale ich efektywne zintegrowanie z aplikacjami mobilnymi i na komputery stacjonarne wiąże się z wyjątkowymi wyzwaniami. W tym ćwiczeniu z programowania poznasz praktyczne wzorce, które wykraczają poza zwykłe wywołania interfejsu API.
Twoja ścieżka szkoleniowa
W tym ćwiczeniu poznasz krok po kroku proces tworzenia aplikacji Colorist:
- Konfiguracja projektu – zaczniesz od podstawowej struktury aplikacji Flutter i pakietu
colorist_ui. - Podstawowa integracja z Gemini – połącz aplikację z Firebase AI Logic i wdroż komunikację z LLM.
- Skuteczne promptowanie – tworzenie promptu systemowego, który pomaga LLM zrozumieć opisy kolorów.
- Deklaracje funkcji – definiują narzędzia, których LLM może używać do ustawiania kolorów w aplikacji.
- Obsługa narzędzi – przetwarzanie wywołań funkcji z LLM i łączenie ich ze stanem aplikacji.
- Strumieniowanie odpowiedzi – zwiększ komfort użytkowników dzięki strumieniowaniu odpowiedzi LLM w czasie rzeczywistym.
- Synchronizacja kontekstu LLM – zapewnij spójność, informując LLM o działaniach użytkownika.
Czego się nauczysz
- Konfigurowanie Firebase AI Logic w aplikacjach Flutter
- Tworzenie skutecznych promptów systemowych, które będą kierować działaniem LLM
- Wdrażaj deklaracje funkcji, które łączą język naturalny z funkcjami aplikacji.
- Przetwarzanie odpowiedzi strumieniowych w celu zapewnienia użytkownikom szybkiego działania
- Synchronizowanie stanu między zdarzeniami interfejsu a LLM
- Zarządzanie stanem rozmowy z modelem LLM za pomocą Riverpod
- Płynna obsługa błędów w aplikacjach opartych na LLM
Podgląd kodu: zobacz, co będziesz wdrażać
Oto fragment deklaracji funkcji, którą utworzysz, aby umożliwić LLM ustawianie kolorów w aplikacji:
FunctionDeclaration get setColorFuncDecl => FunctionDeclaration(
'set_color',
'Set the color of the display square based on red, green, and blue values.',
parameters: {
'red': Schema.number(description: 'Red component value (0.0 - 1.0)'),
'green': Schema.number(description: 'Green component value (0.0 - 1.0)'),
'blue': Schema.number(description: 'Blue component value (0.0 - 1.0)'),
},
);
Film z omówieniem tych ćwiczeń z programowania
Obejrzyj odcinek 59 programu Observable Flutter, w którym Craig Labenz i Andrew Brogdon omawiają te warsztaty:
Wymagania wstępne
Aby w pełni wykorzystać możliwości tego ćwiczenia, musisz:
- Doświadczenie w programowaniu w Flutterze – znajomość podstaw Fluttera i składni języka Dart.
- Znajomość programowania asynchronicznego – znajomość przyszłości, async/await i strumieni.
- Konto Firebase – do skonfigurowania Firebase potrzebujesz konta Google.
Zacznijmy tworzyć pierwszą aplikację Flutter opartą na LLM.
2. Konfigurowanie projektu i usługa echo
W tym pierwszym kroku skonfigurujesz strukturę projektu i wdrożysz usługę echo, która zostanie później zastąpiona integracją z Gemini API. Ustanawia to architekturę aplikacji i zapewnia prawidłowe działanie interfejsu przed dodaniem złożoności wywołań LLM.
Czego się dowiesz w tym kroku
- Konfigurowanie projektu Flutter z wymaganymi zależnościami
- Praca z pakietem
colorist_uidla komponentów interfejsu - Implementowanie usługi wiadomości zwrotnej i łączenie jej z interfejsem
Tworzenie nowego projektu Fluttera
Zacznij od utworzenia nowego projektu Flutter za pomocą tego polecenia:
flutter create -e colorist --platforms=android,ios,macos,web,windows
Flaga -e oznacza, że chcesz utworzyć pusty projekt bez domyślnej aplikacji counter. Aplikacja jest przeznaczona do działania na komputerach, urządzeniach mobilnych i w internecie. Należy jednak pamiętać, że flutterfire nie obsługuje obecnie systemu Linux.
Dodawanie zależności
Otwórz katalog projektu i dodaj wymagane zależności:
cd colorist
flutter pub add colorist_ui flutter_riverpod riverpod_annotation
flutter pub add --dev build_runner riverpod_generator riverpod_lint json_serializable custom_lint
Spowoduje to dodanie tych kluczowych pakietów:
colorist_ui: niestandardowy pakiet, który udostępnia komponenty interfejsu aplikacji Colorist.flutter_riverpodiriverpod_annotation: zarządzanie stanemlogging: do logowania uporządkowanego- Zależności programistyczne na potrzeby generowania i sprawdzania kodu
Twój pubspec.yaml będzie wyglądać podobnie do tego:
pubspec.yaml
name: colorist
description: "A new Flutter project."
publish_to: 'none'
version: 0.1.0
environment:
sdk: ^3.9.2
dependencies:
flutter:
sdk: flutter
colorist_ui: ^0.3.0
flutter_riverpod: ^3.0.0
riverpod_annotation: ^3.0.0
dev_dependencies:
flutter_test:
sdk: flutter
flutter_lints: ^6.0.0
build_runner: ^2.7.1
riverpod_generator: ^3.0.0
riverpod_lint: ^3.0.0
json_serializable: ^6.11.1
flutter:
uses-material-design: true
Konfigurowanie opcji analizy
Dodaj custom_lint do pliku analysis_options.yaml w katalogu głównym projektu:
include: package:flutter_lints/flutter.yaml
analyzer:
plugins:
- custom_lint
Ta konfiguracja umożliwia korzystanie z lintów specyficznych dla Riverpoda, które pomagają utrzymać wysoką jakość kodu.
Wdrażanie pliku main.dart
Zastąp zawartość pliku lib/main.dart tym kodem:
lib/main.dart
import 'package:colorist_ui/colorist_ui.dart';
import 'package:flutter/material.dart';
import 'package:flutter_riverpod/flutter_riverpod.dart';
void main() async {
runApp(ProviderScope(child: MainApp()));
}
class MainApp extends ConsumerWidget {
const MainApp({super.key});
@override
Widget build(BuildContext context, WidgetRef ref) {
return MaterialApp(
theme: ThemeData(
colorScheme: ColorScheme.fromSeed(seedColor: Colors.deepPurple),
),
home: MainScreen(
sendMessage: (message) {
sendMessage(message, ref);
},
),
);
}
// A fake LLM that just echoes back what it receives.
void sendMessage(String message, WidgetRef ref) {
final chatStateNotifier = ref.read(chatStateProvider.notifier);
final logStateNotifier = ref.read(logStateProvider.notifier);
chatStateNotifier.addUserMessage(message);
logStateNotifier.logUserText(message);
chatStateNotifier.addLlmMessage(message, MessageState.complete);
logStateNotifier.logLlmText(message);
}
}
W ten sposób skonfigurujesz aplikację we Flutterze, która implementuje usługę echo, która naśladuje działanie LLM, zwracając wiadomość użytkownika.
Zapoznanie się z architekturą
Poświęćmy chwilę na zapoznanie się z architekturą aplikacji colorist:
Pakiet colorist_ui
Pakiet colorist_ui zawiera gotowe komponenty interfejsu i narzędzia do zarządzania stanem:
- MainScreen: główny komponent interfejsu, który wyświetla:
- Układ podzielonego ekranu na komputerze (obszar interakcji i panel logów)
- Interfejs z kartami na urządzeniu mobilnym
- Kolorowy wyświetlacz, interfejs czatu i miniatury historii
- Zarządzanie stanem: aplikacja korzysta z kilku powiadomień o stanie:
- ChatStateNotifier: zarządza wiadomościami na czacie.
- ColorStateNotifier: zarządza bieżącym kolorem i historią.
- LogStateNotifier: zarządza wpisami dziennika na potrzeby debugowania.
- Obsługa wiadomości: aplikacja używa modelu wiadomości z różnymi stanami:
- Wiadomości dla użytkowników: wpisane przez użytkownika.
- Wiadomości LLM: generowane przez LLM (lub na razie przez usługę echo).
- MessageState: śledzi, czy wiadomości z LLM są kompletne, czy nadal są przesyłane strumieniowo.
Architektura aplikacji
Aplikacja ma taką architekturę:
- Warstwa interfejsu: dostarczana przez pakiet
colorist_ui - Zarządzanie stanem: korzysta z Riverpod do reaktywnego zarządzania stanem.
- Warstwa usługi: obecnie zawiera prostą usługę echo, która zostanie zastąpiona usługą Gemini Chat.
- Integracja z LLM: zostanie dodana w późniejszych krokach.
Dzięki temu możesz skupić się na wdrożeniu integracji z LLM, a komponenty interfejsu użytkownika są już gotowe.
Uruchamianie aplikacji
Uruchom aplikację za pomocą tego polecenia:
flutter run -d DEVICE
Zastąp DEVICE urządzeniem docelowym, np. macos, windows, chrome lub identyfikatorem urządzenia.
Powinna się wyświetlić aplikacja Colorist z tymi elementami:
- obszar wyświetlania koloru z domyślnym kolorem;
- interfejs czatu, w którym możesz pisać wiadomości;
- Panel logu z interakcjami na czacie
Wpisz wiadomość, np. „Chcę kolor ciemnoniebieski”, i kliknij Wyślij. Usługa echo po prostu powtórzy Twoją wiadomość. W dalszych krokach zastąpisz to rzeczywistą interpretacją kolorów za pomocą logiki AI Firebase.
Co dalej?
W następnym kroku skonfigurujesz Firebase i wdrożysz podstawową integrację interfejsu Gemini API, aby zastąpić usługę echo usługą czatu Gemini. Dzięki temu aplikacja będzie mogła interpretować opisy kolorów i udzielać inteligentnych odpowiedzi.
Rozwiązywanie problemów
Problemy z pakietem interfejsu
Jeśli masz problemy z pakietem colorist_ui:
- Upewnij się, że używasz najnowszej wersji.
- Sprawdź, czy zależność została dodana prawidłowo.
- Sprawdź, czy nie ma sprzecznych wersji pakietów.
Błędy kompilacji
Jeśli zobaczysz błędy kompilacji:
- Sprawdź, czy masz zainstalowany najnowszy pakiet SDK Flutter w wersji stabilnej.
- Bieg
flutter clean, a potemflutter pub get - Sprawdź, czy w danych wyjściowych konsoli są konkretne komunikaty o błędach.
Kluczowe pojęcia
- Konfigurowanie projektu Flutter z niezbędnymi zależnościami
- Poznanie architektury aplikacji i odpowiedzialności poszczególnych komponentów
- Wdrożenie prostej usługi, która naśladuje działanie dużego modelu językowego
- Łączenie usługi z komponentami interfejsu
- Używanie Riverpod do zarządzania stanem
3. Podstawowa integracja z Gemini Chat
W tym kroku zastąpisz usługę echo z poprzedniego kroku integracją z Gemini API za pomocą Firebase AI Logic. Skonfigurujesz Firebase, ustawisz niezbędnych dostawców i wdrożysz podstawową usługę czatu, która komunikuje się z interfejsem Gemini API.
Czego się dowiesz w tym kroku
- Konfigurowanie Firebase w aplikacji Flutter
- Konfigurowanie Firebase AI Logic pod kątem dostępu do Gemini
- Tworzenie dostawców Riverpod dla usług Firebase i Gemini
- Implementowanie podstawowej usługi czatu za pomocą interfejsu Gemini API
- Obsługa asynchronicznych odpowiedzi interfejsu API i stanów błędów
Konfigurowanie Firebase
Najpierw musisz skonfigurować Firebase w projekcie Flutter. Wymaga to utworzenia projektu Firebase, dodania do niego aplikacji i skonfigurowania niezbędnych ustawień Firebase AI Logic.
Tworzenie projektu Firebase
- Otwórz konsolę Firebase i zaloguj się na swoje konto Google.
- Kliknij Utwórz projekt Firebase lub wybierz istniejący projekt.
- Aby utworzyć projekt, postępuj zgodnie z instrukcjami w kreatorze konfiguracji.
Konfigurowanie Firebase AI Logic w projekcie Firebase
- W konsoli Firebase otwórz swój projekt.
- Na pasku bocznym po lewej stronie wybierz AI.
- W menu AI wybierz Logika AI.
- Na karcie Firebase AI Logic kliknij Rozpocznij.
- Postępuj zgodnie z instrukcjami, aby włączyć interfejs Gemini Developer API w projekcie.
Instalowanie interfejsu wiersza poleceń FlutterFire
Wiersz poleceń FlutterFire upraszcza konfigurację Firebase w aplikacjach Flutter:
dart pub global activate flutterfire_cli
Dodawanie Firebase do aplikacji we Flutterze
- Dodaj do projektu pakiety Firebase Core i Firebase AI Logic:
flutter pub add firebase_core firebase_ai
- Uruchom polecenie konfiguracji FlutterFire:
flutterfire configure
To polecenie:
- poprosić Cię o wybranie utworzonego projektu Firebase,
- Rejestrowanie aplikacji Flutter w Firebase
- Wygeneruj plik
firebase_options.dartz konfiguracją projektu.
Polecenie automatycznie wykryje wybrane platformy (iOS, Android, macOS, Windows, sieć) i odpowiednio je skonfiguruje.
Konfiguracja dla konkretnej platformy
Firebase wymaga minimalnych wersji wyższych niż domyślne w przypadku Fluttera. Wymaga też dostępu do sieci, aby komunikować się z serwerami Firebase AI Logic.
Konfigurowanie uprawnień w systemie macOS
W systemie macOS musisz włączyć dostęp do sieci w uprawnieniach aplikacji:
- Otwórz
macos/Runner/DebugProfile.entitlementsi dodaj:
macos/Runner/DebugProfile.entitlements
<key>com.apple.security.network.client</key>
<true/>
- Otwórz też plik
macos/Runner/Release.entitlementsi dodaj ten sam wpis.
Konfigurowanie ustawień iOS
W przypadku iOS zaktualizuj minimalną wersję u góry strony ios/Podfile:
ios/Podfile
# Firebase requires at least iOS 15.0
platform :ios, '15.0'
Tworzenie dostawców modeli Gemini
Teraz utworzysz dostawców Riverpod dla Firebase i Gemini. Utwórz nowy plik lib/providers/gemini.dart:
lib/providers/gemini.dart
import 'dart:async';
import 'package:firebase_ai/firebase_ai.dart';
import 'package:firebase_core/firebase_core.dart';
import 'package:riverpod_annotation/riverpod_annotation.dart';
import '../firebase_options.dart';
part 'gemini.g.dart';
@Riverpod(keepAlive: true)
Future<FirebaseApp> firebaseApp(Ref ref) =>
Firebase.initializeApp(options: DefaultFirebaseOptions.currentPlatform);
@Riverpod(keepAlive: true)
Future<GenerativeModel> geminiModel(Ref ref) async {
await ref.watch(firebaseAppProvider.future);
final model = FirebaseAI.googleAI().generativeModel(
model: 'gemini-3.1-flash-lite',
);
return model;
}
@Riverpod(keepAlive: true)
Future<ChatSession> chatSession(Ref ref) async {
final model = await ref.watch(geminiModelProvider.future);
return model.startChat();
}
Ten plik stanowi podstawę dla 3 głównych dostawców. Te elementy są generowane podczas uruchamiania dart run build_runner przez generatory kodu Riverpod. Ten kod korzysta z podejścia opartego na adnotacjach w Riverpod 3 z zaktualizowanymi wzorcami dostawców.
firebaseAppProvider: inicjuje Firebase za pomocą konfiguracji projektu.geminiModelProvider: tworzy instancję generatywnego modelu Gemini.chatSessionProvider: tworzy i utrzymuje sesję czatu z modelem Gemini.
Adnotacja keepAlive: true w sesji czatu zapewnia jej trwałość przez cały cykl życia aplikacji, co pozwala zachować kontekst rozmowy.
Wdrażanie usługi Gemini Chat
Utwórz nowy plik lib/services/gemini_chat_service.dart, aby wdrożyć usługę czatu:
lib/services/gemini_chat_service.dart
import 'dart:async';
import 'package:colorist_ui/colorist_ui.dart';
import 'package:firebase_ai/firebase_ai.dart';
import 'package:riverpod_annotation/riverpod_annotation.dart';
import '../providers/gemini.dart';
part 'gemini_chat_service.g.dart';
class GeminiChatService {
GeminiChatService(this.ref);
final Ref ref;
Future<void> sendMessage(String message) async {
final chatSession = await ref.read(chatSessionProvider.future);
final chatStateNotifier = ref.read(chatStateProvider.notifier);
final logStateNotifier = ref.read(logStateProvider.notifier);
chatStateNotifier.addUserMessage(message);
logStateNotifier.logUserText(message);
final llmMessage = chatStateNotifier.createLlmMessage();
try {
final response = await chatSession.sendMessage(Content.text(message));
final responseText = response.text;
if (responseText != null) {
logStateNotifier.logLlmText(responseText);
chatStateNotifier.appendToMessage(llmMessage.id, responseText);
}
} catch (e, st) {
logStateNotifier.logError(e, st: st);
chatStateNotifier.appendToMessage(
llmMessage.id,
"\nI'm sorry, I encountered an error processing your request. "
"Please try again.",
);
} finally {
chatStateNotifier.finalizeMessage(llmMessage.id);
}
}
}
@Riverpod(keepAlive: true)
GeminiChatService geminiChatService(Ref ref) => GeminiChatService(ref);
Ta usługa:
- przyjmuje wiadomości od użytkownika i wysyła je do interfejsu Gemini API;
- Aktualizuje interfejs czatu odpowiedziami modelu
- Rejestruje wszystkie komunikaty, aby ułatwić zrozumienie rzeczywistego przepływu LLM.
- Obsługuje błędy i wyświetla odpowiednie informacje dla użytkownika.
Uwaga: w tym momencie okno dziennika będzie wyglądać niemal identycznie jak okno czatu. Dziennik stanie się ciekawszy, gdy wprowadzisz wywołania funkcji, a potem strumieniowanie odpowiedzi.
Generowanie kodu Riverpod
Uruchom polecenie narzędzia do kompilacji, aby wygenerować niezbędny kod Riverpod:
dart run build_runner build --delete-conflicting-outputs
Spowoduje to utworzenie plików .g.dart, których Riverpod potrzebuje do działania.
Aktualizowanie pliku main.dart
Zaktualizuj plik lib/main.dart, aby korzystać z nowej usługi czatu Gemini:
lib/main.dart
import 'package:colorist_ui/colorist_ui.dart';
import 'package:flutter/material.dart';
import 'package:flutter_riverpod/flutter_riverpod.dart';
import 'providers/gemini.dart';
import 'services/gemini_chat_service.dart';
void main() async {
runApp(ProviderScope(child: MainApp()));
}
class MainApp extends ConsumerWidget {
const MainApp({super.key});
@override
Widget build(BuildContext context, WidgetRef ref) {
final model = ref.watch(geminiModelProvider);
return MaterialApp(
theme: ThemeData(
colorScheme: ColorScheme.fromSeed(seedColor: Colors.deepPurple),
),
home: model.when(
data: (data) => MainScreen(
sendMessage: (text) {
ref.read(geminiChatServiceProvider).sendMessage(text);
},
),
loading: () => LoadingScreen(message: 'Initializing Gemini Model'),
error: (err, st) => ErrorScreen(error: err),
),
);
}
}
Najważniejsze zmiany w tej aktualizacji:
- Zastępowanie usługi echo usługą czatu opartą na Gemini API
- Dodawanie ekranów ładowania i błędów za pomocą wzorca
AsyncValuew Riverpod z metodąwhen - Łączenie interfejsu z nową usługą czatu za pomocą wywołania zwrotnego
sendMessage
Uruchamianie aplikacji
Uruchom aplikację za pomocą tego polecenia:
flutter run -d DEVICE
Zastąp DEVICE urządzeniem docelowym, np. macos, windows, chrome lub identyfikatorem urządzenia.
Teraz, gdy wpiszesz wiadomość, zostanie ona wysłana do interfejsu Gemini API, a Ty otrzymasz odpowiedź z LLM, a nie echo. W panelu dziennika będą wyświetlane interakcje z API.
Omówienie komunikacji z LLM
Poświęćmy chwilę na zrozumienie, co się dzieje, gdy komunikujesz się z interfejsem Gemini API:
Przepływ komunikacji
- Dane wejściowe użytkownika: użytkownik wpisuje tekst w interfejsie czatu.
- Formatowanie żądania: aplikacja formatuje tekst jako obiekt
Contentdla interfejsu Gemini API. - Komunikacja z interfejsem API: tekst jest wysyłany do interfejsu Gemini API za pomocą Firebase AI Logic.
- Przetwarzanie przez LLM: model Gemini przetwarza tekst i generuje odpowiedź.
- Obsługa odpowiedzi: aplikacja otrzymuje odpowiedź i aktualizuje interfejs.
- Logowanie: cała komunikacja jest rejestrowana w celu zapewnienia przejrzystości.
Sesje czatu i kontekst rozmowy
Sesja czatu z Gemini zachowuje kontekst między wiadomościami, co umożliwia interakcje w formie rozmowy. Oznacza to, że LLM „zapamiętuje” poprzednie wymiany zdań w bieżącej sesji, co umożliwia prowadzenie bardziej spójnych rozmów.
Adnotacja keepAlive: true w przypadku dostawcy sesji czatu zapewnia, że ten kontekst będzie utrzymywany przez cały cykl życia aplikacji. Ten stały kontekst ma kluczowe znaczenie dla utrzymania naturalnego przebiegu rozmowy z modelem LLM.
Co dalej?
Na tym etapie możesz zapytać Gemini API o cokolwiek, ponieważ nie ma ograniczeń dotyczących tego, na co odpowie. Możesz na przykład poprosić o streszczenie Wojny Dwóch Róż, która nie jest związana z przeznaczeniem aplikacji do kolorowania.
W następnym kroku utworzysz prompt systemowy, który pomoże Gemini skuteczniej interpretować opisy kolorów. Pokażemy, jak dostosować działanie LLM do potrzeb konkretnej aplikacji i skupić jej możliwości na domenie aplikacji.
Rozwiązywanie problemów
Problemy z konfiguracją Firebase
Jeśli podczas inicjowania Firebase wystąpią błędy:
- Sprawdź, czy plik
firebase_options.dartzostał prawidłowo wygenerowany. - Sprawdź, czy masz abonament Blaze, aby uzyskać dostęp do Firebase AI Logic
Błędy dostępu do interfejsu API
Jeśli podczas uzyskiwania dostępu do interfejsu Gemini API pojawią się błędy:
- Sprawdź, czy w projekcie Firebase prawidłowo skonfigurowano płatności.
- Sprawdź, czy w projekcie Firebase włączone są Firebase AI Logic i Cloud AI API.
- Sprawdź połączenie sieciowe i ustawienia zapory sieciowej
- Sprawdź, czy nazwa modelu (
gemini-3.1-flash-lite) jest prawidłowa i dostępna.
Problemy z kontekstem rozmowy
Jeśli zauważysz, że Gemini nie pamięta wcześniejszego kontekstu czatu:
- Sprawdź, czy funkcja
chatSessionjest oznaczona adnotacją@Riverpod(keepAlive: true) - Sprawdź, czy używasz tej samej sesji czatu do wszystkich wymian wiadomości.
- Przed wysłaniem wiadomości sprawdź, czy sesja czatu została prawidłowo zainicjowana.
Problemy związane z konkretną platformą
W przypadku problemów związanych z konkretną platformą:
- iOS/macOS: sprawdź, czy ustawiono odpowiednie uprawnienia i skonfigurowano minimalne wersje.
- Android: sprawdzanie, czy minimalna wersja pakietu SDK jest prawidłowo ustawiona
- Sprawdzanie w konsoli komunikatów o błędach dotyczących konkretnej platformy
Kluczowe pojęcia
- Konfigurowanie Firebase w aplikacji Flutter
- Konfigurowanie Firebase AI Logic pod kątem dostępu do Gemini
- Tworzenie dostawców Riverpod dla usług asynchronicznych
- Wdrażanie usługi czatu, która komunikuje się z LLM
- Obsługa asynchronicznych stanów interfejsu API (wczytywanie, błąd, dane)
- Opis przepływu komunikacji LLM i sesji czatu
4. Skuteczne prompty do opisywania kolorów
W tym kroku utworzysz i wdrożysz prompt systemowy, który będzie pomagać Gemini w interpretowaniu opisów kolorów. Prompty systemowe to skuteczny sposób na dostosowywanie działania modelu LLM do konkretnych zadań bez zmiany kodu.
Czego się dowiesz w tym kroku
- Omówienie promptów systemowych i ich znaczenia w aplikacjach wykorzystujących duże modele językowe
- Tworzenie skutecznych promptów do zadań w określonych domenach
- Wczytywanie i używanie promptów systemowych w aplikacji we Flutterze
- kierowanie modelem LLM w celu uzyskiwania spójnych odpowiedzi,
- Sprawdzanie, jak prompty systemowe wpływają na działanie LLM
Informacje o promptach systemowych
Zanim przejdziemy do implementacji, dowiedzmy się, czym są prompt systemowy i dlaczego są ważne:
Czym są prompty systemowe?
Prompt systemowy to specjalny rodzaj instrukcji przekazywanej do modelu LLM, która określa kontekst, wytyczne dotyczące zachowania i oczekiwania dotyczące odpowiedzi. W przeciwieństwie do wiadomości użytkownika, prompty systemowe:
- Określ rolę i osobowość LLM
- Określanie specjalistycznej wiedzy lub umiejętności
- Podawanie instrukcji formatowania
- Ustawianie ograniczeń dotyczących odpowiedzi
- Opisz, jak postępować w różnych sytuacjach
Prompt systemowy to „opis stanowiska” dla LLM – informuje model, jak ma się zachowywać podczas rozmowy.
Dlaczego prompty systemowe są ważne
Prompty systemowe mają kluczowe znaczenie dla tworzenia spójnych i przydatnych interakcji z LLM, ponieważ:
- Zapewnij spójność: poproś model o udzielanie odpowiedzi w spójnym formacie.
- Zwiększanie trafności: skup model na konkretnej domenie (w tym przypadku na kolorach).
- Wyznacz granice: określ, co model powinien, a czego nie powinien robić.
- Lepsze wrażenia użytkowników: tworzenie bardziej naturalnych i przydatnych interakcji.
- Ograniczanie przetwarzania końcowego: otrzymywanie odpowiedzi w formatach, które są łatwiejsze do analizowania lub wyświetlania.
W przypadku aplikacji Colorist musisz zadbać o to, aby model LLM konsekwentnie interpretował opisy kolorów i podawał wartości RGB w określonym formacie.
Tworzenie komponentu z promptem systemowym
Najpierw utworzysz plik z promptem systemowym, który będzie wczytywany w czasie działania. Dzięki temu możesz modyfikować prompt bez ponownej kompilacji aplikacji.
Utwórz nowy plik assets/system_prompt.md o tej treści:
assets/system_prompt.md
# Colorist System Prompt
You are a color expert assistant integrated into a desktop app called Colorist. Your job is to interpret natural language color descriptions and provide the appropriate RGB values that best represent that description.
## Your Capabilities
You are knowledgeable about colors, color theory, and how to translate natural language descriptions into specific RGB values. When users describe a color, you should:
1. Analyze their description to understand the color they are trying to convey
2. Determine the appropriate RGB values (values should be between 0.0 and 1.0)
3. Respond with a conversational explanation and explicitly state the RGB values
## How to Respond to User Inputs
When users describe a color:
1. First, acknowledge their color description with a brief, friendly response
2. Interpret what RGB values would best represent that color description
3. Always include the RGB values clearly in your response, formatted as: `RGB: (red=X.X, green=X.X, blue=X.X)`
4. Provide a brief explanation of your interpretation
Example:
User: "I want a sunset orange"
You: "Sunset orange is a warm, vibrant color that captures the golden-red hues of the setting sun. It combines a strong red component with moderate orange tones.
RGB: (red=1.0, green=0.5, blue=0.25)
I've selected values with high red, moderate green, and low blue to capture that beautiful sunset glow. This creates a warm orange with a slightly reddish tint, reminiscent of the sun low on the horizon."
## When Descriptions are Unclear
If a color description is ambiguous or unclear, please ask the user clarifying questions, one at a time.
## Important Guidelines
- Always keep RGB values between 0.0 and 1.0
- Always format RGB values as: `RGB: (red=X.X, green=X.X, blue=X.X)` for easy parsing
- Provide thoughtful, knowledgeable responses about colors
- When possible, include color psychology, associations, or interesting facts about colors
- Be conversational and engaging in your responses
- Focus on being helpful and accurate with your color interpretations
Struktura promptu systemowego
Przyjrzyjmy się, co robi ten prompt:
- Definicja roli: określa model LLM jako „asystenta eksperta w zakresie kolorów”.
- Wyjaśnienie zadania: określa główne zadanie jako interpretowanie opisów kolorów na wartości RGB.
- Format odpowiedzi: określa, jak dokładnie należy formatować wartości RGB, aby zachować spójność.
- Przykład wymiany: zawiera konkretny przykład oczekiwanego wzorca interakcji.
- Obsługa przypadków skrajnych: instrukcje dotyczące postępowania w przypadku niejasnych opisów.
- Ograniczenia i wskazówki: ustawia ograniczenia, np.utrzymuje wartości RGB w zakresie od 0,0 do 1,0.
Takie podejście zapewnia, że odpowiedzi LLM będą spójne, informacyjne i sformatowane w sposób, który ułatwi analizowanie, jeśli zechcesz programowo wyodrębnić wartości RGB.
Aktualizowanie pliku pubspec.yaml
Teraz zaktualizuj dolną część pliku pubspec.yaml, aby uwzględnić katalog zasobów:
pubspec.yaml
flutter:
uses-material-design: true
assets:
- assets/
Uruchom flutter pub get, aby odświeżyć pakiet komponentów.
Tworzenie dostawcy promptów systemowych
Utwórz nowy plik lib/providers/system_prompt.dart, aby wczytać prompt systemowy:
lib/providers/system_prompt.dart
import 'package:flutter/services.dart';
import 'package:riverpod_annotation/riverpod_annotation.dart';
part 'system_prompt.g.dart';
@Riverpod(keepAlive: true)
Future<String> systemPrompt(Ref ref) =>
rootBundle.loadString('assets/system_prompt.md');
Ten dostawca używa systemu wczytywania zasobów Fluttera do odczytywania pliku prompta w czasie działania.
Aktualizowanie dostawcy modelu Gemini
Teraz zmodyfikuj plik lib/providers/gemini.dart, aby uwzględnić prompt systemowy:
lib/providers/gemini.dart
import 'dart:async';
import 'package:firebase_ai/firebase_ai.dart';
import 'package:firebase_core/firebase_core.dart';
import 'package:riverpod_annotation/riverpod_annotation.dart';
import '../firebase_options.dart';
import 'system_prompt.dart'; // Add this import
part 'gemini.g.dart';
@Riverpod(keepAlive: true)
Future<FirebaseApp> firebaseApp(Ref ref) =>
Firebase.initializeApp(options: DefaultFirebaseOptions.currentPlatform);
@Riverpod(keepAlive: true)
Future<GenerativeModel> geminiModel(Ref ref) async {
await ref.watch(firebaseAppProvider.future);
final systemPrompt = await ref.watch(systemPromptProvider.future); // Add this line
final model = FirebaseAI.googleAI().generativeModel(
model: 'gemini-3.1-flash-lite',
systemInstruction: Content.system(systemPrompt), // And this line
);
return model;
}
@Riverpod(keepAlive: true)
Future<ChatSession> chatSession(Ref ref) async {
final model = await ref.watch(geminiModelProvider.future);
return model.startChat();
}
Kluczową zmianą jest dodanie systemInstruction: Content.system(systemPrompt) podczas tworzenia modelu generatywnego. Dzięki temu Gemini będzie używać Twoich instrukcji jako prompta systemowego we wszystkich interakcjach w tej sesji czatu.
Generowanie kodu Riverpod
Uruchom polecenie narzędzia do kompilacji, aby wygenerować potrzebny kod Riverpod:
dart run build_runner build --delete-conflicting-outputs
Uruchamianie i testowanie aplikacji
Teraz uruchom aplikację:
flutter run -d DEVICE
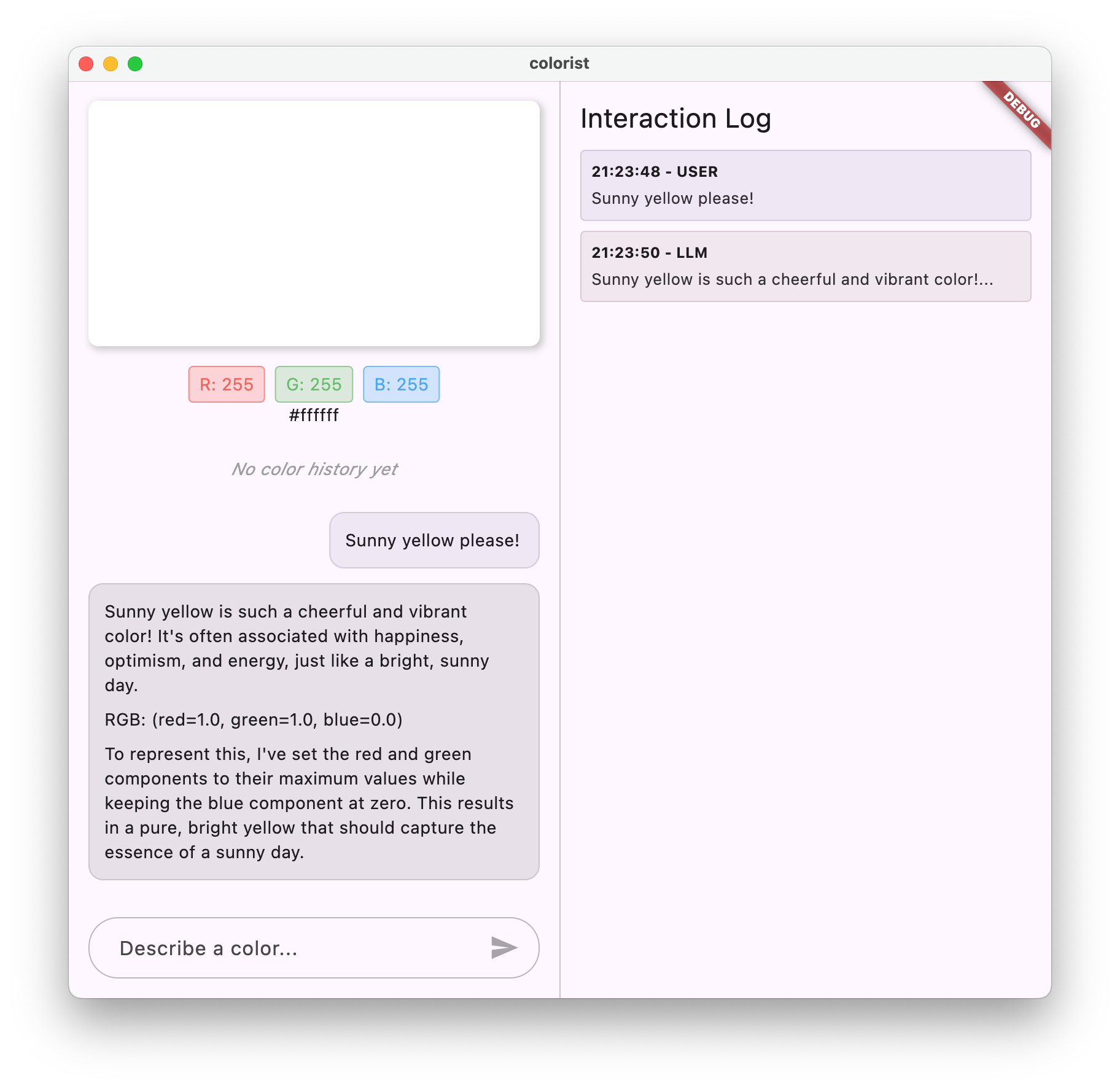
Spróbuj przetestować go z różnymi opisami kolorów:
- „Chcę niebieski”.
- „Pokaż mi ciemną zieleń”.
- „Zmień kolor na intensywny pomarańczowy zachód słońca”
- „Chcę kolor świeżej lawendy”
- „Pokaż mi coś w rodzaju głębokiego błękitu oceanu”
Zauważysz, że Gemini odpowiada teraz wyjaśnieniami w formie rozmowy na temat kolorów oraz wartościami RGB w jednolitym formacie. Prompt systemowy skutecznie nakierował LLM na udzielenie odpowiedzi, których potrzebujesz.
Spróbuj też poprosić o treści niezwiązane z kolorami. Na przykład główne przyczyny wojen dwóch róż. Powinna być widoczna różnica w porównaniu z poprzednim krokiem.
Znaczenie techniki tworzenia promptów w przypadku specjalistycznych zadań
Prompty systemowe to zarówno sztuka, jak i nauka. Są one kluczowym elementem integracji LLM, który może znacząco wpłynąć na przydatność modelu w konkretnej aplikacji. To, co tu robisz, to forma inżynierii promptów – dostosowywanie instrukcji, aby model zachowywał się w sposób odpowiedni do potrzeb Twojej aplikacji.
Skuteczne tworzenie promptów obejmuje:
- Jasne określenie roli: ustalenie, do czego ma służyć LLM.
- Wyraźne instrukcje: szczegółowe informacje o tym, jak model LLM powinien odpowiadać.
- Konkretne przykłady: pokazuj, a nie tylko mów, jak wyglądają dobre odpowiedzi.
- Obsługa przypadków skrajnych: instruowanie LLM, jak radzić sobie z niejednoznacznymi scenariuszami.
- Specyfikacje formatowania: zapewnianie spójnej i użytecznej struktury odpowiedzi.
Utworzony przez Ciebie prompt systemowy przekształca ogólne możliwości Gemini w specjalistycznego asystenta interpretacji kolorów, który udziela odpowiedzi sformatowanych specjalnie pod kątem potrzeb Twojej aplikacji. To skuteczny wzorzec, który możesz zastosować w wielu różnych dziedzinach i zadaniach.
Co dalej?
W następnym kroku rozbudujesz tę podstawę, dodając deklaracje funkcji, które pozwolą LLM nie tylko sugerować wartości RGB, ale też wywoływać funkcje w aplikacji, aby bezpośrednio ustawiać kolor. Pokazuje to, jak duże modele językowe mogą wypełniać lukę między językiem naturalnym a konkretnymi funkcjami aplikacji.
Rozwiązywanie problemów
Problemy z wczytywaniem komponentów
Jeśli podczas wczytywania promptu systemowego wystąpią błędy:
- Sprawdź, czy w
pubspec.yamlprawidłowo wymieniono katalog zasobów. - Sprawdź, czy ścieżka w
rootBundle.loadString()jest zgodna z lokalizacją pliku. - Uruchom
flutter clean, a potemflutter pub get, aby odświeżyć pakiet plików.
Niespójne odpowiedzi
Jeśli LLM nie przestrzega konsekwentnie instrukcji dotyczących formatu:
- Spróbuj bardziej wyraźnie określić wymagania dotyczące formatu w prompcie systemowym.
- Dodaj więcej przykładów, aby pokazać oczekiwany wzorzec
- Upewnij się, że format, o który prosisz, jest odpowiedni dla modelu.
Ograniczanie częstotliwości żądań interfejsu API
Jeśli napotkasz błędy związane z ograniczaniem liczby żądań:
- Pamiętaj, że usługa Firebase AI Logic ma limity wykorzystania
- Rozważ wdrożenie logiki ponawiania ze wzrastającym czasem do ponowienia
- Sprawdź w konsoli Firebase, czy nie ma problemów z limitami.
Kluczowe pojęcia
- Rola i znaczenie promptów systemowych w aplikacjach wykorzystujących duże modele językowe
- Tworzenie skutecznych promptów z jasnymi instrukcjami, przykładami i ograniczeniami
- Wczytywanie i używanie promptów systemowych w aplikacji Flutter
- Określanie zachowania LLM w przypadku zadań specyficznych dla domeny
- Wykorzystanie inżynierii promptów do kształtowania odpowiedzi LLM
Ten krok pokazuje, jak można znacznie dostosować działanie LLM bez zmiany kodu – wystarczy podać jasne instrukcje w prompcie systemowym.
5. Deklaracje funkcji w przypadku narzędzi LLM
W tym kroku rozpoczniesz proces umożliwiania Gemini wykonywania działań w Twojej aplikacji przez zaimplementowanie deklaracji funkcji. Ta zaawansowana funkcja umożliwia modelowi LLM nie tylko sugerowanie wartości RGB, ale także ustawianie ich w interfejsie aplikacji za pomocą specjalistycznych wywołań narzędzi. Aby zobaczyć żądania LLM wykonane w aplikacji Flutter, musisz jednak wykonać następny krok.
Czego się dowiesz w tym kroku
- Omówienie wywoływania funkcji LLM i jego zalet w przypadku aplikacji Flutter
- Definiowanie deklaracji funkcji opartych na schemacie dla Gemini
- Integrowanie deklaracji funkcji z modelem Gemini
- Aktualizowanie promptu systemowego w celu wykorzystania możliwości narzędzia
Wywoływanie funkcji
Zanim wdrożysz deklaracje funkcji, dowiedz się, czym są i dlaczego są przydatne:
Co to jest wywoływanie funkcji?
Wywoływanie funkcji (czasem nazywane „korzystaniem z narzędzi”) to funkcja, która umożliwia LLM:
- rozpoznawać, kiedy w odpowiedzi na prośbę użytkownika warto wywołać konkretną funkcję;
- Wygeneruj uporządkowany obiekt JSON z parametrami potrzebnymi do działania tej funkcji.
- Umożliwiaj aplikacji wykonywanie funkcji z tymi parametrami.
- Otrzymywanie wyniku funkcji i włączanie go do odpowiedzi
Wywoływanie funkcji umożliwia LLM nie tylko opisywanie, co należy zrobić, ale też wywoływanie konkretnych działań w aplikacji.
Dlaczego wywoływanie funkcji jest ważne w przypadku aplikacji Flutter
Wywoływanie funkcji tworzy silny pomost między językiem naturalnym a funkcjami aplikacji:
- Bezpośrednie działanie: użytkownicy mogą opisać, czego chcą, w języku naturalnym, a aplikacja odpowie konkretnymi działaniami.
- Uporządkowane dane wyjściowe: LLM generuje przejrzyste, uporządkowane dane zamiast tekstu, który wymaga analizowania.
- Złożone operacje: umożliwiają LLM dostęp do danych zewnętrznych, wykonywanie obliczeń lub modyfikowanie stanu aplikacji.
- Lepsze wrażenia użytkowników: zapewnia płynną integrację rozmowy z funkcjonalnością.
W aplikacji Colorist wywoływanie funkcji umożliwia użytkownikom powiedzenie „Chcę kolor leśnej zieleni”, a interfejs natychmiast aktualizuje się o ten kolor bez konieczności analizowania wartości RGB z tekstu.
Definiowanie deklaracji funkcji
Utwórz nowy plik lib/services/gemini_tools.dart, aby zdefiniować deklaracje funkcji:
lib/services/gemini_tools.dart
import 'package:firebase_ai/firebase_ai.dart';
import 'package:riverpod_annotation/riverpod_annotation.dart';
part 'gemini_tools.g.dart';
class GeminiTools {
GeminiTools(this.ref);
final Ref ref;
FunctionDeclaration get setColorFuncDecl => FunctionDeclaration(
'set_color',
'Set the color of the display square based on red, green, and blue values.',
parameters: {
'red': Schema.number(description: 'Red component value (0.0 - 1.0)'),
'green': Schema.number(description: 'Green component value (0.0 - 1.0)'),
'blue': Schema.number(description: 'Blue component value (0.0 - 1.0)'),
},
);
List<Tool> get tools => [
Tool.functionDeclarations([setColorFuncDecl]),
];
}
@Riverpod(keepAlive: true)
GeminiTools geminiTools(Ref ref) => GeminiTools(ref);
Deklaracje funkcji
Przyjrzyjmy się, co robi ten kod:
- Nazewnictwo funkcji: nadaj funkcji nazwę
set_color, aby wyraźnie wskazać jej przeznaczenie. - Opis funkcji: podaj jasny opis, który pomoże modelowi LLM zrozumieć, kiedy używać funkcji.
- Definicje parametrów: definiujesz parametry strukturalne z własnymi opisami:
red: składowa czerwona RGB określona jako liczba z zakresu od 0,0 do 1,0.green: składowa zielona RGB określona jako liczba z zakresu od 0,0 do 1,0.blue: składowa niebieska RGB określona jako liczba z zakresu od 0,0 do 1,0.
- Typy schematów: użyj
Schema.number(), aby wskazać, że są to wartości liczbowe. - Kolekcja narzędzi: tworzysz listę narzędzi zawierającą deklarację funkcji.
To uporządkowane podejście pomaga modelowi LLM Gemini zrozumieć:
- Kiedy ma wywoływać tę funkcję
- Jakie parametry musi podać
- jakie ograniczenia dotyczą tych parametrów (np. zakres wartości);
Aktualizowanie dostawcy modelu Gemini
Teraz zmodyfikuj plik lib/providers/gemini.dart, aby podczas inicjowania modelu Gemini zawierał deklaracje funkcji:
lib/providers/gemini.dart
import 'dart:async';
import 'package:firebase_ai/firebase_ai.dart';
import 'package:firebase_core/firebase_core.dart';
import 'package:riverpod_annotation/riverpod_annotation.dart';
import '../firebase_options.dart';
import '../services/gemini_tools.dart'; // Add this import
import 'system_prompt.dart';
part 'gemini.g.dart';
@Riverpod(keepAlive: true)
Future<FirebaseApp> firebaseApp(Ref ref) =>
Firebase.initializeApp(options: DefaultFirebaseOptions.currentPlatform);
@Riverpod(keepAlive: true)
Future<GenerativeModel> geminiModel(Ref ref) async {
await ref.watch(firebaseAppProvider.future);
final systemPrompt = await ref.watch(systemPromptProvider.future);
final geminiTools = ref.watch(geminiToolsProvider); // Add this line
final model = FirebaseAI.googleAI().generativeModel(
model: 'gemini-3.1-flash-lite',
systemInstruction: Content.system(systemPrompt),
tools: geminiTools.tools, // And this line
);
return model;
}
@Riverpod(keepAlive: true)
Future<ChatSession> chatSession(Ref ref) async {
final model = await ref.watch(geminiModelProvider.future);
return model.startChat();
}
Kluczową zmianą jest dodanie parametru tools: geminiTools.tools podczas tworzenia modelu generatywnego. Dzięki temu Gemini wie, które funkcje może wywołać.
Aktualizowanie prompta systemowego
Teraz musisz zmodyfikować prompt systemowy, aby poinstruować LLM, jak korzystać z nowego narzędzia set_color. Zaktualizuj urządzenie assets/system_prompt.md:
assets/system_prompt.md
# Colorist System Prompt
You are a color expert assistant integrated into a desktop app called Colorist. Your job is to interpret natural language color descriptions and set the appropriate color values using a specialized tool.
## Your Capabilities
You are knowledgeable about colors, color theory, and how to translate natural language descriptions into specific RGB values. You have access to the following tool:
`set_color` - Sets the RGB values for the color display based on a description
## How to Respond to User Inputs
When users describe a color:
1. First, acknowledge their color description with a brief, friendly response
2. Interpret what RGB values would best represent that color description
3. Use the `set_color` tool to set those values (all values should be between 0.0 and 1.0)
4. After setting the color, provide a brief explanation of your interpretation
Example:
User: "I want a sunset orange"
You: "Sunset orange is a warm, vibrant color that captures the golden-red hues of the setting sun. It combines a strong red component with moderate orange tones."
[Then you would call the set_color tool with approximately: red=1.0, green=0.5, blue=0.25]
After the tool call: "I've set a warm orange with strong red, moderate green, and minimal blue components that is reminiscent of the sun low on the horizon."
## When Descriptions are Unclear
If a color description is ambiguous or unclear, please ask the user clarifying questions, one at a time.
## Important Guidelines
- Always keep RGB values between 0.0 and 1.0
- Provide thoughtful, knowledgeable responses about colors
- When possible, include color psychology, associations, or interesting facts about colors
- Be conversational and engaging in your responses
- Focus on being helpful and accurate with your color interpretations
Najważniejsze zmiany w prompcie systemowym:
- Wprowadzenie do narzędzia: zamiast prosić o sformatowane wartości RGB, możesz teraz poinformować LLM o
set_colornarzędziu. - Zmodyfikowany proces: zmieniasz krok 3 z „sformatuj wartości w odpowiedzi” na „użyj narzędzia do ustawiania wartości”.
- Zaktualizowany przykład: pokazujesz, jak odpowiedź powinna zawierać wywołanie narzędzia zamiast sformatowanego tekstu.
- Usunięte wymagania dotyczące formatowania: ponieważ używasz wywołań funkcji strukturalnych, nie potrzebujesz już określonego formatu tekstu.
Zaktualizowany prompt nakazuje LLM używanie wywoływania funkcji zamiast podawania wartości RGB w formie tekstowej.
Generowanie kodu Riverpod
Uruchom polecenie narzędzia do kompilacji, aby wygenerować potrzebny kod Riverpod:
dart run build_runner build --delete-conflicting-outputs
Uruchamianie aplikacji
Na tym etapie Gemini wygeneruje treści, które będą próbować używać wywoływania funkcji, ale nie masz jeszcze zaimplementowanych modułów obsługi wywołań funkcji. Gdy uruchomisz aplikację i opiszesz kolor, zobaczysz, że Gemini odpowiada tak, jakby wywołał narzędzie, ale zmiany koloru w interfejsie zobaczysz dopiero w następnym kroku.
Uruchom aplikację:
flutter run -d DEVICE
Spróbuj opisać kolor, np. „głęboki niebieski oceanu” lub „leśna zieleń”, i obserwuj odpowiedzi. LLM próbuje wywołać funkcje zdefiniowane powyżej, ale Twój kod nie wykrywa jeszcze wywołań funkcji.
Proces wywoływania funkcji
Sprawdźmy, co się dzieje, gdy Gemini używa wywoływania funkcji:
- Wybór funkcji: model LLM decyduje, czy wywołanie funkcji będzie przydatne w odpowiedzi na prośbę użytkownika.
- Generowanie parametrów: LLM generuje wartości parametrów pasujące do schematu funkcji.
- Format wywołania funkcji: model LLM wysyła w odpowiedzi obiekt wywołania funkcji w formacie strukturalnym.
- Obsługa aplikacji: aplikacja otrzyma to wywołanie i wykona odpowiednią funkcję (wdrożoną w następnym kroku).
- Integracja odpowiedzi: w rozmowach wieloetapowych LLM oczekuje, że wynik funkcji zostanie zwrócony.
W obecnej wersji aplikacji pierwsze 3 kroki są wykonywane, ale nie zostały jeszcze zaimplementowane kroki 4 i 5 (obsługa wywołań funkcji), co zrobisz w następnym kroku.
Szczegóły techniczne: jak Gemini decyduje, kiedy używać funkcji
Gemini podejmuje inteligentne decyzje o tym, kiedy używać funkcji, na podstawie tych czynników:
- Intencje użytkownika: czy prośba użytkownika jest najlepiej realizowana przez funkcję.
- Trafność funkcji: jak dobrze dostępne funkcje pasują do zadania.
- Dostępność parametru: czy można z dużą pewnością określić wartości parametru.
- Instrukcje systemowe: wskazówki z promptu systemowego dotyczące korzystania z funkcji.
Dzięki podaniu jasnych deklaracji funkcji i instrukcji systemowych usługa Gemini rozpoznaje prośby o opis koloru jako okazję do wywołania funkcji set_color.
Co dalej?
W następnym kroku zaimplementujesz obsługę wywołań funkcji pochodzących z Gemini. Dzięki temu zamkniemy pętlę, umożliwiając opisom użytkowników wywoływanie rzeczywistych zmian kolorów w interfejsie za pomocą wywołań funkcji LLM.
Rozwiązywanie problemów
Problemy z deklaracją funkcji
Jeśli napotkasz błędy w deklaracjach funkcji:
- Sprawdź, czy nazwy i typy parametrów są zgodne z oczekiwaniami.
- Sprawdź, czy nazwa funkcji jest jasna i opisowa.
- Upewnij się, że opis funkcji dokładnie wyjaśnia jej przeznaczenie.
Problemy z promptami systemowymi
Jeśli LLM nie próbuje użyć funkcji:
- Sprawdź, czy prompt systemowy wyraźnie instruuje LLM, aby używał narzędzia
set_color. - Sprawdź, czy przykład w prompcie systemowym pokazuje użycie funkcji.
- Spróbuj bardziej precyzyjnie opisać, jak używać narzędzia.
Problemy ogólne
Jeśli napotkasz inne problemy:
- Sprawdź konsolę pod kątem błędów związanych z deklaracjami funkcji.
- Sprawdź, czy narzędzia są prawidłowo przekazywane do modelu.
- Sprawdź, czy cały wygenerowany przez Riverpod kod jest aktualny
Kluczowe pojęcia
- Definiowanie deklaracji funkcji w celu rozszerzenia możliwości LLM w aplikacjach Flutter
- Tworzenie schematów parametrów na potrzeby zbierania danych strukturalnych
- Integracja deklaracji funkcji z modelem Gemini
- Aktualizowanie promptów systemowych, aby zachęcać do korzystania z funkcji
- Jak duże modele językowe wybierają i wywołują funkcje
Ten krok pokazuje, jak duże modele językowe mogą wypełnić lukę między danymi wejściowymi w języku naturalnym a strukturalnymi wywołaniami funkcji, tworząc podstawę do płynnej integracji między rozmową a funkcjami aplikacji.
6. Implementowanie obsługi narzędzi
W tym kroku zaimplementujesz obsługę wywołań funkcji pochodzących z Gemini. Dzięki temu zamyka się cykl komunikacji między danymi wejściowymi w języku naturalnym a konkretnymi funkcjami aplikacji, co pozwala LLM bezpośrednio manipulować interfejsem na podstawie opisów użytkowników.
Czego się dowiesz w tym kroku
- Omówienie pełnego potoku wywoływania funkcji w aplikacjach LLM
- Przetwarzanie wywołań funkcji z Gemini w aplikacji we Flutterze
- Implementowanie funkcji obsługi, które modyfikują stan aplikacji
- Obsługa odpowiedzi funkcji i przekazywanie wyników do LLM
- Tworzenie pełnego przepływu komunikacji między LLM a interfejsem
- Logowanie wywołań funkcji i odpowiedzi w celu zapewnienia przejrzystości
Omówienie potoku wywoływania funkcji
Zanim przejdziemy do implementacji, zapoznajmy się z pełnym procesem wywoływania funkcji:
Proces kompleksowy
- Dane wejściowe użytkownika: użytkownik opisuje kolor w języku naturalnym (np. „leśna zieleń”).
- Przetwarzanie przez LLM: Gemini analizuje opis i decyduje o wywołaniu funkcji
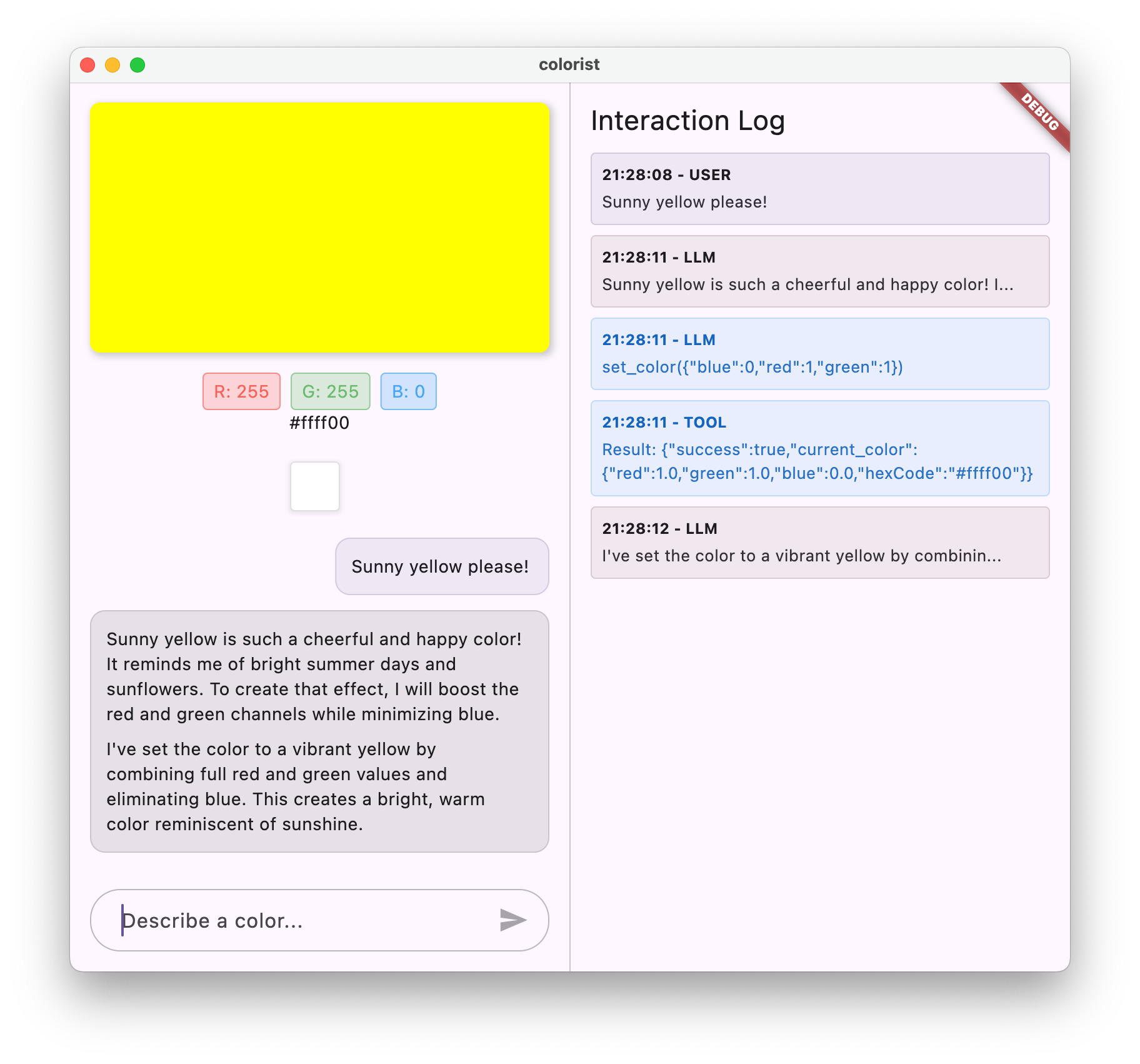
set_color. - Generowanie wywołania funkcji: Gemini tworzy uporządkowany plik JSON z parametrami (wartości czerwony, zielony, niebieski).
- Odbieranie wywołania funkcji: aplikacja otrzymuje te dane strukturalne od Gemini.
- Wykonanie funkcji: aplikacja wykonuje funkcję z podanymi parametrami.
- Aktualizacja stanu: funkcja aktualizuje stan aplikacji (zmienia wyświetlany kolor).
- Generowanie odpowiedzi: funkcja zwraca wyniki do LLM.
- Włączenie odpowiedzi: model LLM włącza te wyniki do swojej odpowiedzi końcowej.
- Aktualizacja interfejsu: interfejs reaguje na zmianę stanu i wyświetla nowy kolor.
Pełny cykl komunikacji jest niezbędny do prawidłowej integracji LLM. Gdy LLM wywołuje funkcję, nie wysyła po prostu żądania i nie przechodzi do następnego kroku. Zamiast tego czeka, aż aplikacja wykona funkcję i zwróci wyniki. Następnie LLM wykorzystuje te wyniki do sformułowania ostatecznej odpowiedzi, tworząc naturalny przebieg rozmowy, który uwzględnia podjęte działania.
Implementowanie procedur obsługi funkcji
Zaktualizujmy plik lib/services/gemini_tools.dart, aby dodać obsługę wywołań funkcji:
lib/services/gemini_tools.dart
import 'package:colorist_ui/colorist_ui.dart';
import 'package:firebase_ai/firebase_ai.dart';
import 'package:riverpod_annotation/riverpod_annotation.dart';
part 'gemini_tools.g.dart';
class GeminiTools {
GeminiTools(this.ref);
final Ref ref;
FunctionDeclaration get setColorFuncDecl => FunctionDeclaration(
'set_color',
'Set the color of the display square based on red, green, and blue values.',
parameters: {
'red': Schema.number(description: 'Red component value (0.0 - 1.0)'),
'green': Schema.number(description: 'Green component value (0.0 - 1.0)'),
'blue': Schema.number(description: 'Blue component value (0.0 - 1.0)'),
},
);
List<Tool> get tools => [
Tool.functionDeclarations([setColorFuncDecl]),
];
Map<String, Object?> handleFunctionCall( // Add from here
String functionName,
Map<String, Object?> arguments,
) {
final logStateNotifier = ref.read(logStateProvider.notifier);
logStateNotifier.logFunctionCall(functionName, arguments);
return switch (functionName) {
'set_color' => handleSetColor(arguments),
_ => handleUnknownFunction(functionName),
};
}
Map<String, Object?> handleSetColor(Map<String, Object?> arguments) {
final colorStateNotifier = ref.read(colorStateProvider.notifier);
final red = (arguments['red'] as num).toDouble();
final green = (arguments['green'] as num).toDouble();
final blue = (arguments['blue'] as num).toDouble();
final functionResults = {
'success': true,
'current_color': colorStateNotifier
.updateColor(red: red, green: green, blue: blue)
.toLLMContextMap(),
};
final logStateNotifier = ref.read(logStateProvider.notifier);
logStateNotifier.logFunctionResults(functionResults);
return functionResults;
}
Map<String, Object?> handleUnknownFunction(String functionName) {
final logStateNotifier = ref.read(logStateProvider.notifier);
logStateNotifier.logWarning('Unsupported function call $functionName');
return {
'success': false,
'reason': 'Unsupported function call $functionName',
};
} // To here.
}
@Riverpod(keepAlive: true)
GeminiTools geminiTools(Ref ref) => GeminiTools(ref);
Omówienie funkcji obsługi
Przyjrzyjmy się, co robią te funkcje obsługi:
handleFunctionCall: centralny dyspozytor, który:- Rejestruje wywołanie funkcji w panelu dziennika, aby zapewnić przejrzystość.
- Kieruje do odpowiedniego modułu obsługi na podstawie nazwy funkcji.
- Zwraca ustrukturyzowaną odpowiedź, która zostanie odesłana do LLM.
handleSetColor: konkretny moduł obsługi funkcjiset_color, który:- Wyodrębnia wartości RGB z mapy argumentów.
- Konwertuje je na oczekiwane typy (liczby zmiennoprzecinkowe podwójnej precyzji).
- Aktualizuje stan koloru aplikacji za pomocą
colorStateNotifier - Tworzy uporządkowaną odpowiedź ze stanem powodzenia i aktualnymi informacjami o kolorze.
- Rejestruje wyniki funkcji na potrzeby debugowania.
handleUnknownFunction: awaryjny moduł obsługi nieznanych funkcji, który:- Rejestruje ostrzeżenie o nieobsługiwanej funkcji.
- Zwraca do LLM komunikat o błędzie
Funkcja handleSetColor jest szczególnie ważna, ponieważ wypełnia lukę między rozumieniem języka naturalnego przez LLM a konkretnymi zmianami w interfejsie.
Zaktualizuj usługę Gemini Chat, aby przetwarzała wywołania funkcji i odpowiedzi
Teraz zmodyfikujmy plik lib/services/gemini_chat_service.dart, aby przetwarzać wywołania funkcji z odpowiedzi LLM i wysyłać wyniki z powrotem do LLM:
lib/services/gemini_chat_service.dart
import 'dart:async';
import 'package:colorist_ui/colorist_ui.dart';
import 'package:firebase_ai/firebase_ai.dart';
import 'package:riverpod_annotation/riverpod_annotation.dart';
import '../providers/gemini.dart';
import 'gemini_tools.dart'; // Add this import
part 'gemini_chat_service.g.dart';
class GeminiChatService {
GeminiChatService(this.ref);
final Ref ref;
Future<void> sendMessage(String message) async {
final chatSession = await ref.read(chatSessionProvider.future);
final chatStateNotifier = ref.read(chatStateProvider.notifier);
final logStateNotifier = ref.read(logStateProvider.notifier);
chatStateNotifier.addUserMessage(message);
logStateNotifier.logUserText(message);
final llmMessage = chatStateNotifier.createLlmMessage();
try {
final response = await chatSession.sendMessage(Content.text(message));
final responseText = response.text;
if (responseText != null) {
logStateNotifier.logLlmText(responseText);
chatStateNotifier.appendToMessage(llmMessage.id, responseText);
}
if (response.functionCalls.isNotEmpty) { // Add from here
final geminiTools = ref.read(geminiToolsProvider);
final functionResultResponse = await chatSession.sendMessage(
Content.functionResponses([
for (final functionCall in response.functionCalls)
FunctionResponse(
functionCall.name,
geminiTools.handleFunctionCall(
functionCall.name,
functionCall.args,
),
),
]),
);
final responseText = functionResultResponse.text;
if (responseText != null) {
logStateNotifier.logLlmText(responseText);
chatStateNotifier.appendToMessage(llmMessage.id, responseText);
}
} // To here.
} catch (e, st) {
logStateNotifier.logError(e, st: st);
chatStateNotifier.appendToMessage(
llmMessage.id,
"\nI'm sorry, I encountered an error processing your request. "
"Please try again.",
);
} finally {
chatStateNotifier.finalizeMessage(llmMessage.id);
}
}
}
@Riverpod(keepAlive: true)
GeminiChatService geminiChatService(Ref ref) => GeminiChatService(ref);
Omówienie przepływu komunikacji
Najważniejszą nowością jest pełna obsługa wywołań funkcji i odpowiedzi:
if (response.functionCalls.isNotEmpty) {
final geminiTools = ref.read(geminiToolsProvider);
final functionResultResponse = await chatSession.sendMessage(
Content.functionResponses([
for (final functionCall in response.functionCalls)
FunctionResponse(
functionCall.name,
geminiTools.handleFunctionCall(
functionCall.name,
functionCall.args,
),
),
]),
);
final responseText = functionResultResponse.text;
if (responseText != null) {
logStateNotifier.logLlmText(responseText);
chatStateNotifier.appendToMessage(llmMessage.id, responseText);
}
}
Ten kod:
- Sprawdza, czy odpowiedź LLM zawiera wywołania funkcji
- W przypadku każdego wywołania funkcji wywołuje metodę
handleFunctionCallz nazwą funkcji i argumentami. - Zbiera wyniki każdego wywołania funkcji
- Przesyła te wyniki z powrotem do LLM za pomocą funkcji
Content.functionResponses. - Przetwarza odpowiedź LLM na wyniki funkcji
- Aktualizuje interfejs użytkownika o ostateczną odpowiedź tekstową.
Spowoduje to utworzenie przepływu w obie strony:
- Użytkownik → LLM: prośba o kolor
- LLM → aplikacja: wywołania funkcji z parametrami
- Aplikacja → Użytkownik: wyświetlany jest nowy kolor
- Aplikacja → LLM: wyniki funkcji
- LLM → Użytkownik: ostateczna odpowiedź uwzględniająca wyniki funkcji
Generowanie kodu Riverpod
Uruchom polecenie narzędzia do kompilacji, aby wygenerować potrzebny kod Riverpod:
dart run build_runner build --delete-conflicting-outputs
Uruchamianie i testowanie pełnego przepływu
Teraz uruchom aplikację:
flutter run -d DEVICE
Spróbuj wpisać różne opisy kolorów:
- „Chcę głęboką, karmazynową czerwień”.
- „Pokaż mi uspokajający błękit nieba”
- „Podaj mi kolor świeżych liści mięty”.
- „Chcę zobaczyć ciepły pomarańczowy zachód słońca”
- „Zmień kolor na bogaty, królewski fiolet”
Powinny się wyświetlić te informacje:
- Twoja wiadomość wyświetlana w interfejsie czatu
- Odpowiedź Gemini pojawiająca się na czacie
- Wywołania funkcji są rejestrowane w panelu logów.
- Wyniki funkcji są rejestrowane natychmiast po jej wykonaniu.
- Prostokąt koloru aktualizowany w celu wyświetlenia opisanego koloru
- Wartości RGB aktualizują się, aby wyświetlać komponenty nowego koloru
- Wyświetlenie ostatecznej odpowiedzi Gemini, często z komentarzem na temat ustawionego koloru.
Panel dziennika zawiera informacje o tym, co dzieje się w tle. Zobaczysz:
- Dokładne wywołania funkcji, których używa Gemini
- parametry, które wybiera dla każdej wartości RGB;
- wyniki zwracane przez funkcję,
- odpowiedzi uzupełniające od Gemini.
Wskaźnik stanu koloru
colorStateNotifier, którego używasz do aktualizowania kolorów, jest częścią pakietu colorist_ui. Zarządza on:
- Obecny kolor wyświetlany w interfejsie
- Historia kolorów (ostatnie 10 kolorów)
- Powiadamianie o zmianach stanu komponentów interfejsu
Gdy wywołasz funkcję updateColor z nowymi wartościami RGB, wykona ona te czynności:
- Tworzy nowy obiekt
ColorDataz podanymi wartościami. - Aktualizuje bieżący kolor w stanie aplikacji.
- Dodaje kolor do historii
- Wywołuje aktualizacje interfejsu za pomocą zarządzania stanem Riverpod
Komponenty interfejsu w pakiecie colorist_ui obserwują ten stan i automatycznie aktualizują się, gdy się on zmienia, co zapewnia interaktywność.
Informacje o obsłudze błędów
Wdrożenie obejmuje solidną obsługę błędów:
- Blok try-catch: obejmuje wszystkie interakcje z dużym modelem językowym, aby przechwytywać wyjątki.
- Rejestrowanie błędów: rejestruje błędy w panelu dziennika ze śladami stosu.
- Opinie użytkowników: wyświetla w czacie przyjazny komunikat o błędzie.
- Czyszczenie stanu: finalizuje stan wiadomości nawet w przypadku wystąpienia błędu.
Dzięki temu aplikacja zachowuje stabilność i zapewnia odpowiednie informacje zwrotne nawet w przypadku problemów z usługą LLM lub wykonywaniem funkcji.
Potencjał wywoływania funkcji w kontekście wrażeń użytkownika
To, co udało Ci się osiągnąć, pokazuje, jak duże modele językowe mogą tworzyć zaawansowane interfejsy naturalne:
- Interfejs w języku naturalnym: użytkownicy wyrażają intencje w języku codziennym.
- Inteligentna interpretacja: LLM tłumaczy niejasne opisy na dokładne wartości.
- Bezpośrednia manipulacja: interfejs użytkownika aktualizuje się w odpowiedzi na język naturalny.
- Odpowiedzi kontekstowe: LLM podaje kontekst rozmowy dotyczący zmian.
- Niewielkie obciążenie poznawcze: użytkownicy nie muszą rozumieć wartości RGB ani teorii kolorów.
Ten wzorzec używania wywoływania funkcji LLM do łączenia języka naturalnego i działań interfejsu użytkownika można rozszerzyć na niezliczone inne obszary poza wyborem koloru.
Co dalej?
W następnym kroku poprawisz wrażenia użytkowników, wdrażając przesyłanie strumieniowe odpowiedzi. Zamiast czekać na pełną odpowiedź, będziesz przetwarzać fragmenty tekstu i wywołania funkcji w miarę ich otrzymywania, co pozwoli Ci stworzyć bardziej responsywną i angażującą aplikację.
Rozwiązywanie problemów
Problemy z wywoływaniem funkcji
Jeśli Gemini nie wywołuje funkcji lub parametry są nieprawidłowe:
- Sprawdź, czy deklaracja funkcji jest zgodna z opisem w prompcie systemowym.
- Sprawdź, czy nazwy i typy parametrów są spójne
- Upewnij się, że prompt systemowy zawiera wyraźne instrukcje dla LLM, aby używał narzędzia.
- Sprawdź, czy nazwa funkcji w obsłudze zdarzeń jest dokładnie taka sama jak w deklaracji.
- Sprawdź panel logów, aby uzyskać szczegółowe informacje o wywołaniach funkcji.
Problemy z odpowiedzią funkcji
Jeśli wyniki funkcji nie są prawidłowo przesyłane z powrotem do LLM:
- Sprawdź, czy funkcja zwraca prawidłowo sformatowaną mapę.
- Sprawdź, czy Content.functionResponses jest prawidłowo tworzony.
- Sprawdź, czy w logu nie ma błędów związanych z odpowiedziami funkcji.
- Upewnij się, że używasz tej samej sesji czatu, aby uzyskać odpowiedź.
Problemy z wyświetlaniem kolorów
Jeśli kolory nie wyświetlają się prawidłowo:
- Sprawdź, czy wartości RGB są prawidłowo konwertowane na liczby zmiennoprzecinkowe (LLM może wysyłać je jako liczby całkowite).
- Sprawdź, czy wartości mieszczą się w oczekiwanym zakresie (od 0,0 do 1,0).
- Sprawdź, czy powiadomienie o stanie koloru jest wywoływane prawidłowo
- Sprawdź log, aby poznać dokładne wartości przekazywane do funkcji.
Ogólne problemy
W przypadku problemów ogólnych:
- Sprawdź dzienniki pod kątem błędów lub ostrzeżeń.
- Sprawdzanie łączności z Firebase AI Logic
- Sprawdź, czy w parametrach funkcji nie ma niezgodności typów.
- Sprawdź, czy cały wygenerowany przez Riverpod kod jest aktualny
Kluczowe pojęcia
- Implementowanie pełnego potoku wywoływania funkcji w Flutterze
- Tworzenie pełnej komunikacji między LLM a aplikacją
- Przetwarzanie danych strukturalnych z odpowiedzi LLM
- Przesyłanie wyników funkcji z powrotem do LLM w celu włączenia ich do odpowiedzi.
- Korzystanie z panelu logów w celu uzyskania wglądu w interakcje między LLM a aplikacją
- Łączenie danych wejściowych w języku naturalnym z konkretnymi zmianami w interfejsie
Po wykonaniu tego kroku aplikacja będzie korzystać z jednego z najskuteczniejszych wzorców integracji LLM: tłumaczenia danych wejściowych w języku naturalnym na konkretne działania w interfejsie, przy jednoczesnym zachowaniu spójnej rozmowy, która uwzględnia te działania. Dzięki temu powstaje intuicyjny interfejs konwersacyjny, który użytkownicy uważają za magiczny.
7. Strumieniowanie odpowiedzi w celu zwiększenia wygody użytkowników
W tym kroku poprawisz komfort użytkowników, wdrażając przesyłanie strumieniowe odpowiedzi z Gemini. Zamiast czekać na wygenerowanie całej odpowiedzi, będziesz przetwarzać fragmenty tekstu i wywołania funkcji w miarę ich otrzymywania, co pozwoli Ci stworzyć bardziej interaktywną i angażującą aplikację.
Zakres tego kroku
- Dlaczego przesyłanie strumieniowe jest ważne w przypadku aplikacji opartych na LLM
- Implementowanie strumieniowania odpowiedzi LLM w aplikacji Flutter
- Przetwarzanie częściowych fragmentów tekstu w miarę ich przesyłania z interfejsu API
- Zarządzanie stanem rozmowy, aby zapobiegać konfliktom wiadomości
- Obsługa wywołań funkcji w odpowiedziach strumieniowych
- Tworzenie wizualnych wskaźników odpowiedzi w trakcie pisania
Dlaczego przesyłanie strumieniowe jest ważne w przypadku aplikacji LLM
Zanim wdrożysz tę funkcję, dowiedz się, dlaczego przesyłanie strumieniowe odpowiedzi jest kluczowe dla zapewnienia użytkownikom doskonałych wrażeń podczas korzystania z modeli LLM:
Lepsze wrażenia użytkowników
Odpowiedzi przesyłane strumieniowo zapewniają kilka istotnych korzyści dla użytkowników:
- Zmniejszone opóźnienie: użytkownicy widzą tekst, który zaczyna się pojawiać natychmiast (zwykle w ciągu 100–300 ms), zamiast czekać kilka sekund na pełną odpowiedź. To poczucie natychmiastowości znacznie zwiększa zadowolenie użytkowników.
- Naturalny rytm rozmowy: stopniowe pojawianie się tekstu naśladuje sposób, w jaki ludzie się komunikują, co zapewnia bardziej naturalne wrażenia podczas rozmowy.
- Progresywne przetwarzanie informacji: użytkownicy mogą rozpocząć przetwarzanie informacji w miarę ich napływania, zamiast być przytłoczeni dużą ilością tekstu naraz.
- Możliwość wcześniejszego przerwania: w pełnej aplikacji użytkownicy mogą przerwać działanie LLM lub przekierować je, jeśli zauważą, że zmierza w nieprzydatnym kierunku.
- Wizualne potwierdzenie aktywności: strumieniowany tekst zapewnia natychmiastową informację zwrotną o tym, że system działa, co zmniejsza niepewność.
Zalety techniczne
Oprócz poprawy UX strumieniowanie zapewnia korzyści techniczne:
- Wczesne wykonywanie funkcji: wywołania funkcji można wykrywać i wykonywać od razu po pojawieniu się w strumieniu, bez czekania na pełną odpowiedź.
- Przyrostowe aktualizacje interfejsu: możesz stopniowo aktualizować interfejs w miarę pojawiania się nowych informacji, co zapewnia bardziej dynamiczne działanie.
- Zarządzanie stanem rozmowy: przesyłanie strumieniowe zapewnia jasne sygnały o tym, kiedy odpowiedzi są gotowe, a kiedy nadal są w trakcie generowania, co umożliwia lepsze zarządzanie stanem.
- Mniejsze ryzyko przekroczenia limitu czasu: w przypadku odpowiedzi bez przesyłania strumieniowego długotrwałe generowanie może spowodować przekroczenie limitu czasu połączenia. Streaming nawiązuje połączenie wcześniej i utrzymuje je.
W przypadku aplikacji Colorist wdrożenie przesyłania strumieniowego oznacza, że użytkownicy będą szybciej widzieć zarówno odpowiedzi tekstowe, jak i zmiany kolorów, co znacznie poprawi komfort korzystania z aplikacji.
Dodawanie zarządzania stanem rozmowy
Najpierw dodajmy dostawcę stanu, aby śledzić, czy aplikacja obsługuje obecnie odpowiedź strumieniową. Zaktualizuj plik lib/services/gemini_chat_service.dart:
lib/services/gemini_chat_service.dart
import 'dart:async';
import 'package:colorist_ui/colorist_ui.dart';
import 'package:firebase_ai/firebase_ai.dart';
import 'package:flutter_riverpod/flutter_riverpod.dart';
import 'package:riverpod_annotation/riverpod_annotation.dart';
import '../providers/gemini.dart';
import 'gemini_tools.dart';
part 'gemini_chat_service.g.dart';
class ConversationStateNotifier extends Notifier<ConversationState> { // Add from here...
@override
ConversationState build() => ConversationState.idle;
void busy() {
state = ConversationState.busy;
}
void idle() {
state = ConversationState.idle;
}
}
final conversationStateProvider =
NotifierProvider<ConversationStateNotifier, ConversationState>(
ConversationStateNotifier.new,
); // To here.
class GeminiChatService {
GeminiChatService(this.ref);
final Ref ref;
Future<void> sendMessage(String message) async {
final chatSession = await ref.read(chatSessionProvider.future);
final conversationState = ref.read(conversationStateProvider); // Add this line
final chatStateNotifier = ref.read(chatStateProvider.notifier);
final logStateNotifier = ref.read(logStateProvider.notifier);
if (conversationState == ConversationState.busy) { // Add from here...
logStateNotifier.logWarning(
"Can't send a message while a conversation is in progress",
);
throw Exception(
"Can't send a message while a conversation is in progress",
);
}
final conversationStateNotifier = ref.read(
conversationStateProvider.notifier,
);
conversationStateNotifier.busy(); // To here.
chatStateNotifier.addUserMessage(message);
logStateNotifier.logUserText(message);
final llmMessage = chatStateNotifier.createLlmMessage();
try { // Modify from here...
final responseStream = chatSession.sendMessageStream(
Content.text(message),
);
await for (final block in responseStream) {
await _processBlock(block, llmMessage.id);
} // To here.
} catch (e, st) {
logStateNotifier.logError(e, st: st);
chatStateNotifier.appendToMessage(
llmMessage.id,
"\nI'm sorry, I encountered an error processing your request. "
"Please try again.",
);
} finally {
chatStateNotifier.finalizeMessage(llmMessage.id);
conversationStateNotifier.idle(); // Add this line.
}
}
Future<void> _processBlock( // Add from here...
GenerateContentResponse block,
String llmMessageId,
) async {
final chatSession = await ref.read(chatSessionProvider.future);
final chatStateNotifier = ref.read(chatStateProvider.notifier);
final logStateNotifier = ref.read(logStateProvider.notifier);
final blockText = block.text;
if (blockText != null) {
logStateNotifier.logLlmText(blockText);
chatStateNotifier.appendToMessage(llmMessageId, blockText);
}
if (block.functionCalls.isNotEmpty) {
final geminiTools = ref.read(geminiToolsProvider);
final responseStream = chatSession.sendMessageStream(
Content.functionResponses([
for (final functionCall in block.functionCalls)
FunctionResponse(
functionCall.name,
geminiTools.handleFunctionCall(
functionCall.name,
functionCall.args,
),
),
]),
);
await for (final response in responseStream) {
final responseText = response.text;
if (responseText != null) {
logStateNotifier.logLlmText(responseText);
chatStateNotifier.appendToMessage(llmMessageId, responseText);
}
}
}
} // To here.
}
@Riverpod(keepAlive: true)
GeminiChatService geminiChatService(Ref ref) => GeminiChatService(ref);
Informacje o wdrażaniu przesyłania strumieniowego
Przyjrzyjmy się, co robi ten kod:
- Śledzenie stanu rozmowy:
conversationStateProviderśledzi, czy aplikacja przetwarza obecnie odpowiedź.- Podczas przetwarzania stan zmienia się z
idlenabusy, a następnie wraca doidle. - Zapobiega to wielu jednoczesnym żądaniom, które mogłyby powodować konflikty.
- Inicjowanie strumienia:
sendMessageStream()zwraca strumień fragmentów odpowiedzi zamiastFuturez pełną odpowiedzią.- Każdy fragment może zawierać tekst, wywołania funkcji lub oba te elementy.
- Przetwarzanie progresywne:
await forprzetwarza każdy fragment w czasie rzeczywistym, gdy tylko dotrze do usługi.- Tekst jest natychmiast dodawany do interfejsu, co daje efekt strumieniowania.
- Wywołania funkcji są wykonywane natychmiast po wykryciu.
- Obsługa wywoływania funkcji:
- Gdy w bloku zostanie wykryte wywołanie funkcji, jest ono natychmiast wykonywane.
- Wyniki są odsyłane do LLM w ramach innego połączenia strumieniowego.
- Odpowiedź LLM na te wyniki jest również przetwarzana w trybie strumieniowym.
- Obsługa błędów i czyszczenie:
try/catchzapewnia niezawodną obsługę błędów.- Blok
finallyzapewnia prawidłowe zresetowanie stanu rozmowy. - Wiadomość jest zawsze finalizowana, nawet jeśli wystąpią błędy
Dzięki temu wdrożeniu można zapewnić responsywną i niezawodną transmisję strumieniową przy zachowaniu odpowiedniego stanu rozmowy.
Aktualizowanie ekranu głównego w celu połączenia stanu rozmowy
Zmodyfikuj plik lib/main.dart, aby przekazywać stan rozmowy na ekran główny:
lib/main.dart
import 'package:colorist_ui/colorist_ui.dart';
import 'package:flutter/material.dart';
import 'package:flutter_riverpod/flutter_riverpod.dart';
import 'providers/gemini.dart';
import 'services/gemini_chat_service.dart';
void main() async {
runApp(ProviderScope(child: MainApp()));
}
class MainApp extends ConsumerWidget {
const MainApp({super.key});
@override
Widget build(BuildContext context, WidgetRef ref) {
final model = ref.watch(geminiModelProvider);
final conversationState = ref.watch(conversationStateProvider); // Add this line
return MaterialApp(
theme: ThemeData(
colorScheme: ColorScheme.fromSeed(seedColor: Colors.deepPurple),
),
home: model.when(
data: (data) => MainScreen(
conversationState: conversationState, // And this line
sendMessage: (text) {
ref.read(geminiChatServiceProvider).sendMessage(text);
},
),
loading: () => LoadingScreen(message: 'Initializing Gemini Model'),
error: (err, st) => ErrorScreen(error: err),
),
);
}
}
Kluczową zmianą jest przekazywanie conversationState do widżetu MainScreen. Komponent MainScreen (dostarczany przez pakiet colorist_ui) użyje tego stanu, aby wyłączyć wprowadzanie tekstu podczas przetwarzania odpowiedzi.
Zapewnia to spójność interfejsu, który odzwierciedla bieżący stan rozmowy.
Generowanie kodu Riverpod
Uruchom polecenie narzędzia do kompilacji, aby wygenerować potrzebny kod Riverpod:
dart run build_runner build --delete-conflicting-outputs
Uruchamianie i testowanie odpowiedzi strumieniowych
Uruchom aplikację:
flutter run -d DEVICE
Teraz przetestuj działanie strumieniowania z różnymi opisami kolorów. Spróbuj użyć opisów takich jak:
- „Pokaż mi głęboki turkusowy kolor oceanu o zmierzchu”
- „Chcę zobaczyć żywy koral, który przypomina mi tropikalne kwiaty”.
- „Utwórz stonowany oliwkowy kolor zieleni, taki jak na starych mundurach wojskowych”.
Szczegółowy techniczny przepływ strumieniowania
Przyjrzyjmy się dokładnie, co się dzieje podczas przesyłania strumieniowego odpowiedzi:
Nawiązywanie połączenia
Gdy zadzwonisz pod numer sendMessageStream():
- Aplikacja nawiązuje połączenie z usługą Firebase AI Logic.
- Prośba użytkownika jest wysyłana do usługi.
- Serwer rozpoczyna przetwarzanie żądania.
- Połączenie strumieniowe pozostaje otwarte i gotowe do przesyłania fragmentów.
Przesyłanie fragmentów
Gdy Gemini generuje treści, fragmenty są przesyłane strumieniowo:
- Serwer wysyła fragmenty tekstu w miarę ich generowania (zwykle kilka słów lub zdań).
- Gdy Gemini zdecyduje się na wywołanie funkcji, wysyła informacje o wywołaniu funkcji.
- Po wywołaniach funkcji mogą pojawiać się dodatkowe fragmenty tekstu.
- Strumień będzie kontynuowany do momentu zakończenia generowania.
Przetwarzanie progresywne
Aplikacja przetwarza każdy fragment przyrostowo:
- Każdy fragment tekstu jest dołączany do istniejącej odpowiedzi.
- Wywołania funkcji są wykonywane natychmiast po wykryciu.
- Interfejs użytkownika aktualizuje się w czasie rzeczywistym, wyświetlając zarówno tekst, jak i wyniki funkcji.
- Stan jest śledzony, aby pokazać, że odpowiedź jest nadal przesyłana strumieniowo.
Zakończenie transmisji
Po zakończeniu generowania:
- Strumień został zamknięty przez serwer
- Pętla
await forzakończy się naturalnie. - Wiadomość jest oznaczona jako ukończona
- Stan rozmowy zostanie przywrócony do stanu bezczynności.
- Interfejs zostanie zaktualizowany, aby odzwierciedlać stan ukończenia.
Porównanie strumieniowania z odtwarzaniem bez strumieniowania
Aby lepiej zrozumieć korzyści wynikające z odtwarzania strumieniowego, porównajmy je z metodami nieopartymi na tej technologii:
Aspekt | Nie strumieniowe | Streaming |
Odczuwalne opóźnienie | Użytkownik nie widzi niczego, dopóki nie jest gotowa pełna odpowiedź. | Użytkownik widzi pierwsze słowa w ciągu milisekund |
Interfejs użytkownika | Długie oczekiwanie, po którym nagle pojawia się tekst | Naturalne, stopniowe pojawianie się tekstu |
Zarządzanie stanem | Prostsze (wiadomości są w stanie oczekiwania lub zostały wysłane) | Bardziej złożone (wiadomości mogą być w stanie przesyłania strumieniowego) |
Wykonywanie funkcji | Występuje tylko po pełnej odpowiedzi | Występuje podczas generowania odpowiedzi |
Złożoność implementacji | Łatwiejsze wdrożenie | Wymaga dodatkowego zarządzania stanem |
Odzyskiwanie danych po wystąpieniu błędu | Odpowiedź typu „wszystko albo nic” | Odpowiedzi częściowe mogą być nadal przydatne |
Złożoność kodu | Mniej złożone | Bardziej złożone ze względu na obsługę strumieni |
W przypadku aplikacji takiej jak Colorist korzyści dla użytkowników wynikające ze streamingu przeważają nad złożonością implementacji, zwłaszcza w przypadku interpretacji kolorów, których wygenerowanie może zająć kilka sekund.
Sprawdzone metody dotyczące wrażeń użytkowników podczas streamowania
Podczas wdrażania przesyłania strumieniowego we własnych aplikacjach z dużymi modelami językowymi weź pod uwagę te sprawdzone metody:
- Wyraźne wskaźniki wizualne: zawsze podawaj wyraźne wskazówki wizualne, które odróżniają przesyłanie strumieniowe od pełnych wiadomości.
- Blokowanie wprowadzania danych: wyłącz wprowadzanie danych przez użytkownika podczas przesyłania strumieniowego, aby zapobiec nakładaniu się wielu żądań.
- Obsługa błędów: zaprojektuj interfejs użytkownika tak, aby w przypadku przerwania transmisji strumieniowej można było ją płynnie wznowić.
- Przejścia między stanami: zapewnij płynne przejścia między stanami bezczynności, przesyłania strumieniowego i zakończenia.
- Wizualizacja postępu: rozważ zastosowanie subtelnych animacji lub wskaźników, które pokazują aktywne przetwarzanie.
- Opcje anulowania: w pełnej wersji aplikacji udostępnij użytkownikom sposoby anulowania generowania treści.
- Integracja wyników funkcji: zaprojektuj interfejs, aby obsługiwał wyniki funkcji pojawiające się w trakcie strumienia.
- Optymalizacja wydajności: minimalizowanie ponownego tworzenia interfejsu podczas szybkich aktualizacji strumienia.
Pakiet colorist_ui wdraża wiele z tych sprawdzonych metod, ale są one ważne w przypadku każdej implementacji strumieniowego modelu LLM.
Co dalej?
W następnym kroku zaimplementujesz synchronizację LLM, powiadamiając Gemini, gdy użytkownicy wybierają kolory z historii. Zapewni to bardziej spójne działanie, ponieważ model LLM będzie znać zmiany w stanie aplikacji zainicjowane przez użytkownika.
Rozwiązywanie problemów
Problemy z przetwarzaniem strumieniowym
Jeśli masz problemy z przetwarzaniem strumienia:
- Objawy: częściowe odpowiedzi, brakujący tekst lub nagłe zakończenie strumienia.
- Rozwiązanie: sprawdź połączenie sieciowe i upewnij się, że w kodzie używasz prawidłowych wzorców async/await.
- Diagnostyka: sprawdź panel dziennika pod kątem komunikatów o błędach lub ostrzeżeń związanych z przetwarzaniem strumienia.
- Rozwiązanie: upewnij się, że całe przetwarzanie strumieniowe korzysta z odpowiedniej obsługi błędów za pomocą bloków
try/catch.
Brakujące wywołania funkcji
Jeśli wywołania funkcji nie są wykrywane w strumieniu:
- Objawy: tekst się wyświetla, ale kolory nie są aktualizowane lub w dzienniku nie ma wywołań funkcji.
- Rozwiązanie: sprawdź instrukcje w prompcie systemowym dotyczące korzystania z wywołań funkcji.
- Diagnostyka: sprawdź panel logów, aby zobaczyć, czy otrzymywane są wywołania funkcji.
- Rozwiązanie: dostosuj prompt systemowy, aby bardziej wyraźnie nakazać LLM używanie narzędzia
set_color.
Ogólna obsługa błędów
W przypadku innych problemów:
- Krok 1. Sprawdź, czy w panelu dziennika są komunikaty o błędach
- Krok 2. Sprawdź połączenie z Firebase AI Logic
- Krok 3. Sprawdź, czy cały wygenerowany kod Riverpod jest aktualny.
- Krok 4. Sprawdź implementację przesyłania strumieniowego pod kątem brakujących instrukcji await
Kluczowe pojęcia
- Implementowanie odpowiedzi strumieniowych za pomocą Gemini API w celu zwiększenia responsywności UX
- Zarządzanie stanem rozmowy w celu prawidłowego obsługiwania interakcji strumieniowych
- Przetwarzanie tekstu w czasie rzeczywistym i wywołań funkcji w miarę ich przychodzenia
- tworzenie interfejsów użytkownika, które reagują na działania użytkownika i są aktualizowane przyrostowo podczas przesyłania strumieniowego;
- Obsługa równoczesnych strumieni za pomocą odpowiednich wzorców asynchronicznych
- zapewnianie odpowiednich sygnałów wizualnych podczas przesyłania strumieniowego odpowiedzi;
Dzięki wdrożeniu przesyłania strumieniowego znacznie poprawiłeś komfort użytkowników aplikacji Colorist, tworząc bardziej responsywny i angażujący interfejs, który sprawia wrażenie prawdziwej rozmowy.
8. Synchronizacja kontekstu LLM
W tym dodatkowym kroku zaimplementujesz synchronizację kontekstu LLM, powiadamiając Gemini, gdy użytkownicy wybierają kolory z historii. Zapewnia to bardziej spójne działanie, ponieważ LLM zna działania użytkownika w interfejsie, a nie tylko jego wyraźne wiadomości.
Zakres tego kroku
- Tworzenie synchronizacji kontekstu modelu LLM między interfejsem a modelem LLM
- Przekształcanie zdarzeń interfejsu w kontekst zrozumiały dla LLM
- Aktualizowanie kontekstu rozmowy na podstawie działań użytkownika
- Tworzenie spójnego środowiska w przypadku różnych metod interakcji
- Zwiększanie świadomości kontekstowej LLM poza wyraźnymi wiadomościami na czacie
Informacje o synchronizacji kontekstu LLM
Tradycyjne chatboty odpowiadają tylko na wyraźne wiadomości użytkowników, co powoduje brak spójności, gdy użytkownicy wchodzą w interakcję z aplikacją w inny sposób. Synchronizacja kontekstu LLM rozwiązuje to ograniczenie:
Dlaczego synchronizacja kontekstu LLM jest ważna
Gdy użytkownicy wchodzą w interakcję z aplikacją za pomocą elementów interfejsu (np. wybierają kolor z historii), model LLM nie ma możliwości dowiedzenia się, co się stało, chyba że wyraźnie go o tym poinformujesz. Synchronizacja kontekstu LLM:
- Zachowuje kontekst: informuje LLM o wszystkich istotnych działaniach użytkownika.
- Zapewnia spójność: tworzy spójne środowisko, w którym LLM rozpoznaje interakcje z interfejsem.
- Zwiększa inteligencję: umożliwia LLM odpowiednie reagowanie na wszystkie działania użytkownika.
- Zwiększa wygodę użytkowników: sprawia, że cała aplikacja jest bardziej zintegrowana i szybciej reaguje.
- Zmniejsza wysiłek użytkownika: eliminuje konieczność ręcznego wyjaśniania przez użytkowników działań w interfejsie.
Gdy użytkownik wybierze kolor z historii w aplikacji Colorist, chcesz, aby Gemini potwierdził tę czynność i inteligentnie skomentował wybrany kolor, zachowując iluzję płynnego działania świadomego asystenta.
Aktualizacja usługi Gemini Chat w celu otrzymywania powiadomień o wyborze koloru
Najpierw dodasz do GeminiChatService metodę powiadamiania LLM, gdy użytkownik wybierze kolor z historii. Zaktualizuj plik lib/services/gemini_chat_service.dart:
lib/services/gemini_chat_service.dart
import 'dart:async';
import 'dart:convert'; // Add this import
import 'package:colorist_ui/colorist_ui.dart';
import 'package:firebase_ai/firebase_ai.dart';
import 'package:flutter_riverpod/flutter_riverpod.dart';
import 'package:riverpod_annotation/riverpod_annotation.dart';
import '../providers/gemini.dart';
import 'gemini_tools.dart';
part 'gemini_chat_service.g.dart';
class ConversationStateNotifier extends Notifier<ConversationState> {
@override
ConversationState build() => ConversationState.idle;
void busy() {
state = ConversationState.busy;
}
void idle() {
state = ConversationState.idle;
}
}
final conversationStateProvider =
NotifierProvider<ConversationStateNotifier, ConversationState>(
ConversationStateNotifier.new,
);
class GeminiChatService {
GeminiChatService(this.ref);
final Ref ref;
Future<void> notifyColorSelection(ColorData color) => sendMessage( // Add from here...
'User selected color from history: ${json.encode(color.toLLMContextMap())}',
); // To here.
Future<void> sendMessage(String message) async {
final chatSession = await ref.read(chatSessionProvider.future);
final conversationState = ref.read(conversationStateProvider);
final chatStateNotifier = ref.read(chatStateProvider.notifier);
final logStateNotifier = ref.read(logStateProvider.notifier);
if (conversationState == ConversationState.busy) {
logStateNotifier.logWarning(
"Can't send a message while a conversation is in progress",
);
throw Exception(
"Can't send a message while a conversation is in progress",
);
}
final conversationStateNotifier = ref.read(
conversationStateProvider.notifier,
);
conversationStateNotifier.busy();
chatStateNotifier.addUserMessage(message);
logStateNotifier.logUserText(message);
final llmMessage = chatStateNotifier.createLlmMessage();
try {
final responseStream = chatSession.sendMessageStream(
Content.text(message),
);
await for (final block in responseStream) {
await _processBlock(block, llmMessage.id);
}
} catch (e, st) {
logStateNotifier.logError(e, st: st);
chatStateNotifier.appendToMessage(
llmMessage.id,
"\nI'm sorry, I encountered an error processing your request. "
"Please try again.",
);
} finally {
chatStateNotifier.finalizeMessage(llmMessage.id);
conversationStateNotifier.idle();
}
}
Future<void> _processBlock(
GenerateContentResponse block,
String llmMessageId,
) async {
final chatSession = await ref.read(chatSessionProvider.future);
final chatStateNotifier = ref.read(chatStateProvider.notifier);
final logStateNotifier = ref.read(logStateProvider.notifier);
final blockText = block.text;
if (blockText != null) {
logStateNotifier.logLlmText(blockText);
chatStateNotifier.appendToMessage(llmMessageId, blockText);
}
if (block.functionCalls.isNotEmpty) {
final geminiTools = ref.read(geminiToolsProvider);
final responseStream = chatSession.sendMessageStream(
Content.functionResponses([
for (final functionCall in block.functionCalls)
FunctionResponse(
functionCall.name,
geminiTools.handleFunctionCall(
functionCall.name,
functionCall.args,
),
),
]),
);
await for (final response in responseStream) {
final responseText = response.text;
if (responseText != null) {
logStateNotifier.logLlmText(responseText);
chatStateNotifier.appendToMessage(llmMessageId, responseText);
}
}
}
}
}
@Riverpod(keepAlive: true)
GeminiChatService geminiChatService(Ref ref) => GeminiChatService(ref);
Kluczową nowością jest metoda notifyColorSelection, która:
- Przyjmuje obiekt
ColorDatareprezentujący wybrany kolor. - koduje go do formatu JSON, który można uwzględnić w wiadomości.
- Wysyła do LLM specjalnie sformatowaną wiadomość wskazującą wybór użytkownika.
- Ponownie używa istniejącej metody
sendMessagedo obsługi powiadomienia.
Dzięki temu unikniesz duplikowania, ponieważ wykorzystasz istniejącą infrastrukturę obsługi wiadomości.
Zaktualizuj główną aplikację, aby połączyć powiadomienia o wyborze koloru
Teraz zmodyfikuj plik lib/main.dart, aby przekazać funkcję powiadomienia o wyborze koloru na ekran główny:
lib/main.dart
import 'package:colorist_ui/colorist_ui.dart';
import 'package:flutter/material.dart';
import 'package:flutter_riverpod/flutter_riverpod.dart';
import 'providers/gemini.dart';
import 'services/gemini_chat_service.dart';
void main() async {
runApp(ProviderScope(child: MainApp()));
}
class MainApp extends ConsumerWidget {
const MainApp({super.key});
@override
Widget build(BuildContext context, WidgetRef ref) {
final model = ref.watch(geminiModelProvider);
final conversationState = ref.watch(conversationStateProvider);
return MaterialApp(
theme: ThemeData(
colorScheme: ColorScheme.fromSeed(seedColor: Colors.deepPurple),
),
home: model.when(
data: (data) => MainScreen(
conversationState: conversationState,
notifyColorSelection: (color) { // Add from here...
ref.read(geminiChatServiceProvider).notifyColorSelection(color);
}, // To here.
sendMessage: (text) {
ref.read(geminiChatServiceProvider).sendMessage(text);
},
),
loading: () => LoadingScreen(message: 'Initializing Gemini Model'),
error: (err, st) => ErrorScreen(error: err),
),
);
}
}
Kluczową zmianą jest dodanie wywołania zwrotnego notifyColorSelection, które łączy zdarzenie interfejsu (wybranie koloru z historii) z systemem powiadomień LLM.
Aktualizowanie prompta systemowego
Teraz musisz zaktualizować prompt systemowy, aby poinstruować LLM, jak ma reagować na powiadomienia o wyborze koloru. Zmodyfikuj plik assets/system_prompt.md:
assets/system_prompt.md
# Colorist System Prompt
You are a color expert assistant integrated into a desktop app called Colorist. Your job is to interpret natural language color descriptions and set the appropriate color values using a specialized tool.
## Your Capabilities
You are knowledgeable about colors, color theory, and how to translate natural language descriptions into specific RGB values. You have access to the following tool:
`set_color` - Sets the RGB values for the color display based on a description
## How to Respond to User Inputs
When users describe a color:
1. First, acknowledge their color description with a brief, friendly response
2. Interpret what RGB values would best represent that color description
3. Use the `set_color` tool to set those values (all values should be between 0.0 and 1.0)
4. After setting the color, provide a brief explanation of your interpretation
Example:
User: "I want a sunset orange"
You: "Sunset orange is a warm, vibrant color that captures the golden-red hues of the setting sun. It combines a strong red component with moderate orange tones."
[Then you would call the set_color tool with approximately: red=1.0, green=0.5, blue=0.25]
After the tool call: "I've set a warm orange with strong red, moderate green, and minimal blue components that is reminiscent of the sun low on the horizon."
## When Descriptions are Unclear
If a color description is ambiguous or unclear, please ask the user clarifying questions, one at a time.
## When Users Select Historical Colors
Sometimes, the user will manually select a color from the history panel. When this happens, you'll receive a notification about this selection that includes details about the color. Acknowledge this selection with a brief response that recognizes what they've done and comments on the selected color.
Example notification:
User: "User selected color from history: {red: 0.2, green: 0.5, blue: 0.8, hexCode: #3380CC}"
You: "I see you've selected an ocean blue from your history. This tranquil blue with a moderate intensity has a calming, professional quality to it. Would you like to explore similar shades or create a contrasting color?"
## Important Guidelines
- Always keep RGB values between 0.0 and 1.0
- Provide thoughtful, knowledgeable responses about colors
- When possible, include color psychology, associations, or interesting facts about colors
- Be conversational and engaging in your responses
- Focus on being helpful and accurate with your color interpretations
Kluczową nowością jest sekcja „Gdy użytkownicy wybierają kolory historyczne”, która:
- Wyjaśnia LLM koncepcję powiadomień o wyborze historii.
- Zawiera przykład tego, jak wyglądają te powiadomienia
- Pokazuje przykład odpowiedniej odpowiedzi
- Określa oczekiwania dotyczące potwierdzenia wyboru i komentarza do koloru.
Pomoże to modelowi LLM zrozumieć, jak odpowiednio reagować na te specjalne wiadomości.
Generowanie kodu Riverpod
Uruchom polecenie narzędzia do kompilacji, aby wygenerować potrzebny kod Riverpod:
dart run build_runner build --delete-conflicting-outputs
Uruchamianie i testowanie synchronizacji kontekstu LLM
Uruchom aplikację:
flutter run -d DEVICE
Testowanie synchronizacji kontekstu LLM obejmuje:
- Najpierw wygeneruj kilka kolorów, opisując je na czacie.
- „Pokaż mi intensywny fiolet”
- „Chcę kolor ciemnozielony”
- „Daj mi jasnoczerwony”
- Następnie kliknij jedną z miniatur kolorów na pasku historii.
Zwróć uwagę na:
- Wybrany kolor pojawi się na głównym wyświetlaczu.
- W czacie pojawi się wiadomość użytkownika z informacją o wybranym kolorze.
- LLM odpowiada, potwierdzając wybór i komentując kolor.
- Cała interakcja jest naturalna i spójna.
Zapewnia to płynną obsługę, ponieważ LLM rozpoznaje zarówno bezpośrednie wiadomości, jak i interakcje z interfejsem i odpowiednio na nie reaguje.
Jak działa synchronizacja kontekstu LLM
Przyjrzyjmy się szczegółom technicznym tej synchronizacji:
Przepływ danych
- Działanie użytkownika: użytkownik klika kolor na pasku historii.
- Zdarzenie interfejsu: widżet
MainScreenwykrywa ten wybór. - Wykonanie wywołania zwrotnego: wywołanie zwrotne
notifyColorSelectionjest wywoływane. - Tworzenie wiadomości: tworzona jest specjalnie sformatowana wiadomość z danymi o kolorach.
- Przetwarzanie przez LLM: wiadomość jest wysyłana do Gemini, które rozpoznaje format.
- Odpowiedź kontekstowa: Gemini odpowiada w odpowiedni sposób na podstawie promptu systemowego.
- Aktualizacja interfejsu: odpowiedź pojawia się na czacie, co zapewnia spójność.
Serializacja danych
Kluczowym aspektem tego podejścia jest sposób serializacji danych o kolorze:
'User selected color from history: ${json.encode(color.toLLMContextMap())}'
Metoda toLLMContextMap() (udostępniana przez pakiet colorist_ui) przekształca obiekt ColorData w mapę z kluczowymi właściwościami, które są zrozumiałe dla LLM. Zwykle obejmuje to:
- wartości RGB (czerwony, zielony, niebieski),
- Reprezentacja w postaci kodu szesnastkowego
- dowolna nazwa lub opis powiązane z kolorem;
Dzięki konsekwentnemu formatowaniu tych danych i uwzględnianiu ich w wiadomości masz pewność, że LLM ma wszystkie informacje potrzebne do udzielenia odpowiedniej odpowiedzi.
Szersze zastosowania synchronizacji kontekstu LLM
Ten sposób powiadamiania modelu LLM o zdarzeniach interfejsu użytkownika ma wiele zastosowań poza wyborem koloru:
Inne przypadki użycia
- Zmiany filtrów: powiadamianie LLM, gdy użytkownicy zastosują filtry do danych.
- Zdarzenia nawigacji: informują LLM, gdy użytkownicy przechodzą do różnych sekcji.
- Zmiany wyboru: aktualizowanie LLM, gdy użytkownicy wybierają elementy z list lub siatek.
- Aktualizacje preferencji: informuj LLM, gdy użytkownicy zmieniają ustawienia lub preferencje.
- Manipulowanie danymi: powiadamianie LLM, gdy użytkownicy dodają, edytują lub usuwają dane.
W każdym przypadku wzorzec pozostaje taki sam:
- Wykrywanie zdarzenia interfejsu
- Serializowanie odpowiednich danych
- wysyłać do LLM powiadomienia w specjalnym formacie;
- Kierowanie modelem LLM, aby odpowiednio reagował na prompt systemowy
Sprawdzone metody synchronizacji kontekstu LLM
W zależności od wdrożenia oto kilka sprawdzonych metod skutecznej synchronizacji kontekstu LLM:
1. Spójny format
Używaj spójnego formatu powiadomień, aby LLM mógł je łatwo identyfikować:
"User [action] [object]: [structured data]"
2. Szczegółowy kontekst
Powiadomienia powinny zawierać wystarczająco dużo szczegółów, aby model LLM mógł inteligentnie odpowiadać. W przypadku kolorów oznacza to wartości RGB, kody szesnastkowe i inne odpowiednie właściwości.
3. Jasne instrukcje
W prompcie systemowym podaj wyraźne instrukcje dotyczące obsługi powiadomień, najlepiej z przykładami.
4. Naturalna integracja
Zaprojektuj powiadomienia tak, aby naturalnie wplatały się w rozmowę, a nie były technicznymi przerwami.
5. Powiadomienie selektywne
Powiadamiaj LLM tylko o działaniach związanych z rozmową. Nie każde zdarzenie interfejsu użytkownika musi być przekazywane.
Rozwiązywanie problemów
Problemy dotyczące powiadomień
Jeśli LLM nie reaguje prawidłowo na wybór kolorów:
- Sprawdź, czy format wiadomości z powiadomieniem jest zgodny z opisem w prompcie systemowym.
- Sprawdź, czy dane o kolorze są prawidłowo serializowane.
- Upewnij się, że prompt systemowy zawiera jasne instrukcje dotyczące obsługi wyborów.
- Sprawdź, czy podczas wysyłania powiadomień nie występują błędy w usłudze czatu.
Zarządzanie kontekstem
Jeśli LLM wydaje się tracić kontekst:
- Sprawdź, czy sesja czatu jest prawidłowo obsługiwana.
- Sprawdzanie, czy stany rozmowy zmieniają się prawidłowo
- Sprawdź, czy powiadomienia są wysyłane w ramach tej samej sesji czatu.
Ogólne problemy
W przypadku problemów ogólnych:
- Sprawdź dzienniki pod kątem błędów lub ostrzeżeń.
- Sprawdzanie łączności z Firebase AI Logic
- Sprawdź, czy w parametrach funkcji nie ma niezgodności typów.
- Sprawdź, czy cały wygenerowany przez Riverpod kod jest aktualny
Kluczowe pojęcia
- Tworzenie synchronizacji kontekstu LLM między interfejsem a modelem LLM
- Przekształcanie zdarzeń interfejsu w kontekst zrozumiały dla LLM
- Określanie działania LLM w przypadku różnych wzorców interakcji
- Tworzenie spójnych doświadczeń w przypadku interakcji z użyciem wiadomości i bez nich
- Zwiększanie świadomości modelu LLM na temat szerszego stanu aplikacji
Dzięki wdrożeniu synchronizacji kontekstu LLM udało Ci się stworzyć prawdziwie zintegrowane środowisko, w którym LLM działa jak świadomy, reagujący asystent, a nie tylko generator tekstu. Ten wzorzec można zastosować w niezliczonych innych aplikacjach, aby tworzyć bardziej naturalne i intuicyjne interfejsy oparte na AI.
9. Gratulacje!
Udało Ci się ukończyć ćwiczenie w Codelabs dotyczące korekcji kolorów. 🎉
Co utworzysz
Udało Ci się utworzyć w pełni funkcjonalną aplikację Flutter, która integruje interfejs Google Gemini API do interpretowania opisów kolorów w języku naturalnym. Twoja aplikacja może teraz:
- przetwarzać opisy w języku naturalnym, takie jak „pomarańcz zachodzącego słońca” lub „głęboki błękit oceanu”;
- Używaj Gemini do inteligentnego tłumaczenia tych opisów na wartości RGB
- Wyświetlanie zinterpretowanych kolorów w czasie rzeczywistym dzięki przesyłaniu strumieniowemu odpowiedzi
- Obsługa interakcji użytkowników za pomocą czatu i elementów interfejsu
- Zachowywanie świadomości kontekstowej w przypadku różnych metod interakcji
Co dalej
Teraz gdy znasz już podstawy integracji Gemini z Flutterem, możesz kontynuować naukę w jeden z tych sposobów:
Ulepszanie aplikacji Colorist
- Palety kolorów: dodaj funkcję generowania uzupełniających się lub pasujących do siebie schematów kolorów.
- Wprowadzanie głosowe: integracja rozpoznawania mowy w celu opisywania kolorów za pomocą głosu.
- Zarządzanie historią: dodawanie opcji do nazywania, porządkowania i eksportowania zestawów kolorów.
- Niestandardowe promptowanie: utwórz interfejs, w którym użytkownicy będą mogli dostosowywać prompty systemowe.
- Zaawansowane możliwości analityczne: śledź, które opisy działają najlepiej lub sprawiają trudności.
Poznaj więcej funkcji Gemini
- Dane wejściowe multimodalne: dodawanie danych wejściowych w postaci obrazów w celu wyodrębniania kolorów ze zdjęć.
- Generowanie treści: używaj Gemini do generowania treści związanych z kolorami, takich jak opisy czy opowiadania.
- Ulepszenia wywoływania funkcji: tworzenie bardziej złożonych integracji narzędzi z wieloma funkcjami.
- Ustawienia bezpieczeństwa: poznaj różne ustawienia bezpieczeństwa i ich wpływ na odpowiedzi.
Zastosuj te wzorce do innych domen
- Analiza dokumentów: tworzenie aplikacji, które potrafią rozumieć i analizować dokumenty.
- Pomoc w kreatywnym pisaniu: twórz narzędzia do pisania z propozycjami opartymi na LLM.
- Automatyzacja zadań: projektowanie aplikacji, które tłumaczą język naturalny na automatyczne zadania.
- Aplikacje oparte na wiedzy: tworzenie systemów eksperckich w określonych dziedzinach.
Zasoby
Oto przydatne materiały, które pomogą Ci poszerzyć wiedzę:
Oficjalna dokumentacja
Kurs i przewodnik po promptach
Społeczność
Observable Flutter Agentic series
W odcinku 59 Craig Labenz i Andrew Brogden omawiają to ćwiczenie, zwracając uwagę na ciekawe elementy tworzenia aplikacji.
W odcinku 60 Craig i Andrew ponownie rozbudowują aplikację z codelabu o nowe funkcje i walczą o to, aby modele LLM robiły to, co im się każe.
W odcinku 61 Craig rozmawia z Chrisem Sellsem o analizowaniu nagłówków wiadomości i generowaniu odpowiadających im obrazów.
Prześlij opinię
Chętnie poznamy Twoją opinię o tym laboratorium. Prześlij opinię za pomocą:
Dziękujemy za ukończenie tego laboratorium. Mamy nadzieję, że będziesz dalej odkrywać ekscytujące możliwości, jakie daje połączenie Fluttera i AI.