
1. Einführung
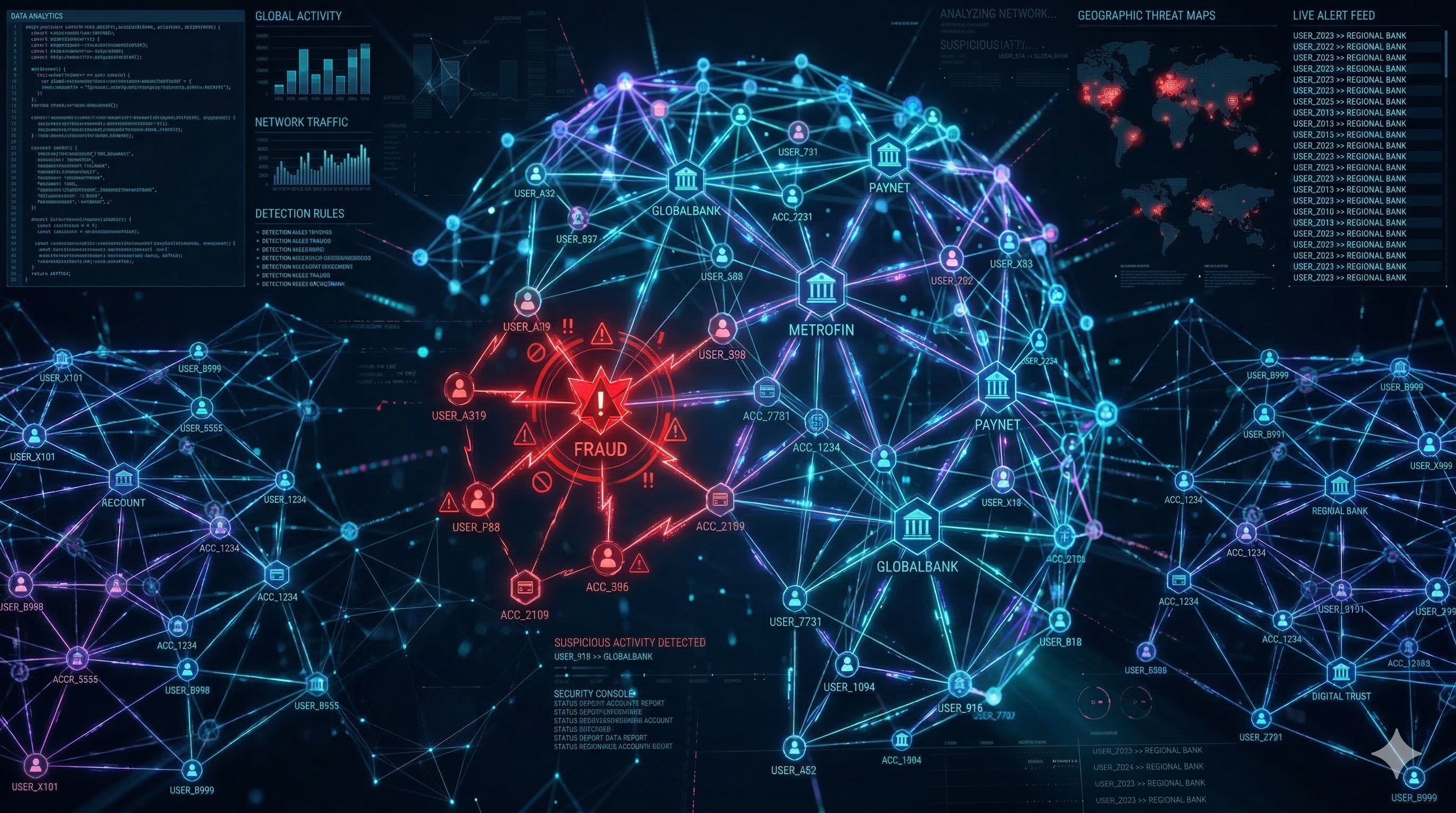
Betrügerische Aktivitäten umfassen oft verborgene Netzwerke verbundener Entitäten, z. B. mehrere Konten, die dieselbe E-Mail-Adresse, Telefonnummer oder physische Adresse verwenden. Herkömmliche relationale Datenbanken haben Schwierigkeiten, diese komplexen Beziehungen mit mehreren Schritten effizient abzufragen.
Mit BigQuery Graph können Sie diese Netzwerke mithilfe von Graphdatenbanken in großem Maßstab analysieren. Sie können einen Attributgraphen auf Ihren vorhandenen BigQuery-Tabellen definieren und mit der Graph Query Language (GQL) Muster in Ihren Daten finden.
Eine häufige Anwendung von Graphnetzwerken zur Betrugserkennung besteht darin, Bestellungen zu stoppen, bei denen eine Lieferadresse mit einem Betrugsnetzwerk verknüpft ist, oder Zahlungen zu stoppen, die zu gehören .
In diesem Codelab erstellen Sie eine Lösung zur Betrugserkennung mit BigQuery Graph. Sie laden Daten aus Cloud Storage, erstellen einen Attributgraphen und verwenden Graphabfragen, um verdächtige Verbindungen zu identifizieren.
Lerninhalte
- BigQuery-Dataset erstellen und Daten laden.
- Attributgraphen mit DDL definieren.
- Graphen mit GQL abfragen.
- Graphanalysen zur Betrugserkennung verwenden.
Voraussetzungen
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
- BigQuery-Notebook-Umgebung (BigQuery Studio oder Colab Enterprise).
Kosten
In diesem Lab werden kostenpflichtige Google Cloud-Ressourcen verwendet. Die geschätzten Kosten liegen unter 5 $, wenn Sie die Ressourcen nach Abschluss löschen.
2. Hinweis
Google Cloud-Projekt auswählen oder erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie ein Google Cloud-Projekt.
- Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein. Informationen zum Prüfen, ob die Abrechnung aktiviert ist.
Umgebung auswählen
Für dieses Lab benötigen Sie eine Notebook-Umgebung. Sie können BigQuery Studio oder Colab Enterprise verwenden.
- Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
- Sie verwenden das Python-Notebook, um die Graphabfragen auszuführen.
Cloud Shell starten
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.
- Authentifizierung überprüfen:
gcloud auth list
- Projekt bestätigen:
gcloud config get project
- Bei Bedarf festlegen:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
APIs aktivieren
Führen Sie diesen Befehl aus, um die erforderliche BigQuery API zu aktivieren:
gcloud services enable bigquery.googleapis.com
3. Daten laden
In diesem Schritt erstellen Sie ein BigQuery-Dataset und laden die Beispieldaten aus Cloud Storage.
Die Beispieldaten bestehen aus mehreren CSV-Dateien, die eine simulierte Einzelhandelsumgebung darstellen:
customers.csv: Kundenkontoinformationen.emails.csv: E-Mail-Adressen.phones.csv: Telefonnummern.addresses.csv: Physische Adressen.customer_emails.csv,customer_phones.csv,customer_addresses.csv: Verknüpfungstabellen.orders.csv: Bestellverlauf, einschließlich Betrugsflags.
Dataset erstellen
Erstellen Sie ein Dataset mit dem Namen fraud_demo, um die Tabellen zu speichern.
- In diesem Codelab führen wir SQL-Befehle aus. Sie können diese Befehle in BigQuery Studio > SQL-Editor ausführen oder den Befehl
bq queryin Cloud Shell verwenden. Wir gehen davon aus, dass Sie den BigQuery SQL-Editor verwenden, um mehrzeilige Erstellungsanweisungen besser zu verarbeiten.
Wir gehen davon aus, dass Sie den BigQuery SQL-Editor verwenden, um mehrzeilige Erstellungsanweisungen besser zu verarbeiten.
CREATE SCHEMA IF NOT EXISTS `fraud_demo` OPTIONS(location="US");
Tabellen laden
Führen Sie die folgenden SQL-Anweisungen aus, um Daten aus Cloud Storage in Ihr Dataset zu laden.
LOAD DATA OVERWRITE `fraud_demo.customers`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customers.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.emails`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/emails.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.phones`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/phones.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.addresses`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/addresses.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.customer_emails`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customer_emails.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.customer_phones`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customer_phones.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.customer_addresses`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customer_addresses.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.orders`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/orders.csv'],
skip_leading_rows = 1
);
4. Attributgraphen erstellen
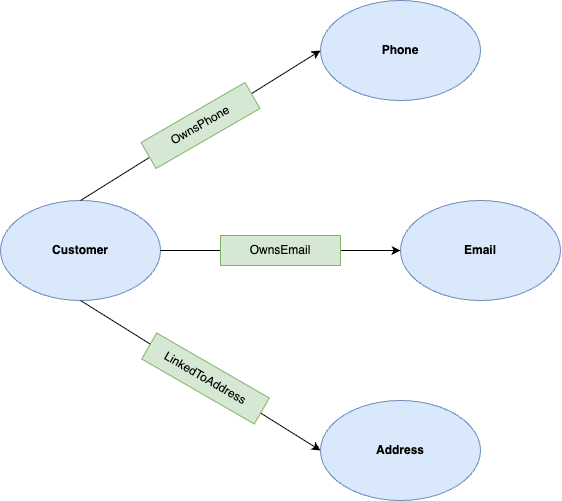
Nachdem die Daten geladen wurden, können Sie den Attributgraphen definieren. Ein Attributgraph besteht aus Knoten (Entitäten) und Kanten (Beziehungen).
In diesem Lab sind die Knoten:
- Customer: Stellt den Kontoinhaber dar.
- Telefon: Stellt eine Telefonnummer dar.
- E-Mail: Stellt eine E-Mail-Adresse dar.
- Adresse: Stellt eine physische Adresse dar.
Die Kanten sind:
- OwnsPhone: Verbindet einen Kunden mit einem Telefon.
- OwnsEmail: Verbindet einen Kunden mit einer E-Mail-Adresse.
- LinkedToAddress: Verbindet einen Kunden mit einer Adresse.
Graph erstellen
Führen Sie die folgende DDL-Anweisung aus, um den Graphen FraudDemo in Ihrem Dataset fraud_demo zu erstellen.
CREATE OR REPLACE PROPERTY GRAPH fraud_demo.FraudDemo
NODE TABLES(
fraud_demo.customers
KEY(account_id)
LABEL Customer PROPERTIES(
account_id,
name),
fraud_demo.emails
KEY(email)
LABEL Email PROPERTIES(
email,
email_type),
fraud_demo.phones
KEY(phone_number)
LABEL Phone PROPERTIES(
phone_number,
phone_type),
fraud_demo.addresses
KEY(address)
LABEL Address PROPERTIES(
address,
address_type)
)
EDGE TABLES(
fraud_demo.customer_emails
KEY(account_id, email)
SOURCE KEY(account_id) REFERENCES customers(account_id)
DESTINATION KEY(email) REFERENCES emails(email)
LABEL OwnsEmail PROPERTIES(
account_id,
email,
last_updated_ts),
fraud_demo.customer_phones
KEY(account_id, phone_number)
SOURCE KEY(account_id) REFERENCES customers(account_id)
DESTINATION KEY(phone_number) REFERENCES phones(phone_number)
LABEL OwnsPhone PROPERTIES(
account_id,
phone_number,
last_updated_ts),
fraud_demo.customer_addresses
KEY(account_id, address)
SOURCE KEY(account_id) REFERENCES customers(account_id)
DESTINATION KEY(address) REFERENCES addresses(address)
LABEL LinkedToAddress PROPERTIES(
account_id,
address,
last_updated_ts)
);
5. Netzwerke analysieren (2 Schritte)
Öffnen Sie in BigQuery Studio Neues Notebook.
Für die Visualisierungs- und Empfehlungsteile dieses Codelabs verwenden wir ein Google Colab -Notebook in BigQuery Studio. So können wir die Graphergebnisse ganz einfach visualisieren.
Fügen Sie Folgendes in eine Codezelle ein:
!pip install bigquery-magics==0.12.1
Das BigQuery Graph-Notebook wird als IPython Magics implementiert. Wenn Sie den magischen Befehl %%bigquery mit der Funktion TO_JSON hinzufügen, können Sie die Ergebnisse wie in den folgenden Abschnitten gezeigt visualisieren. In diesem Schritt führen Sie eine Graphabfrage aus, um einfache Verbindungen zwischen Konten zu finden. Dies ist eine Abfrage mit zwei Schritten, da sie zwei Schritte von einem Startknoten entfernt ist, um verwandte Knoten zu finden (z.B. Kunde -> E-Mail -> Kunde).
Wir beginnen mit der Untersuchung des Kontos von Nicole Wade. Wir möchten alle Konten finden, die über zwei Schritte mit ihr verbunden sind.
Abfrage mit zwei Schritten ausführen
Führen Sie die folgende Abfrage in Ihrem Notebook aus.
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH
p=(a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress WHERE e.last_updated_ts < '2025-07-30']- (n) ){2}
WHERE a.account_id IN ("d2f1f992-d116-41b3-955b-6c76a3352657")
-- Verify the final node in the hop array is a Customer
AND 'Customer' IN UNNEST(LABELS(n[OFFSET(1)]))
RETURN TO_JSON(p) AS paths
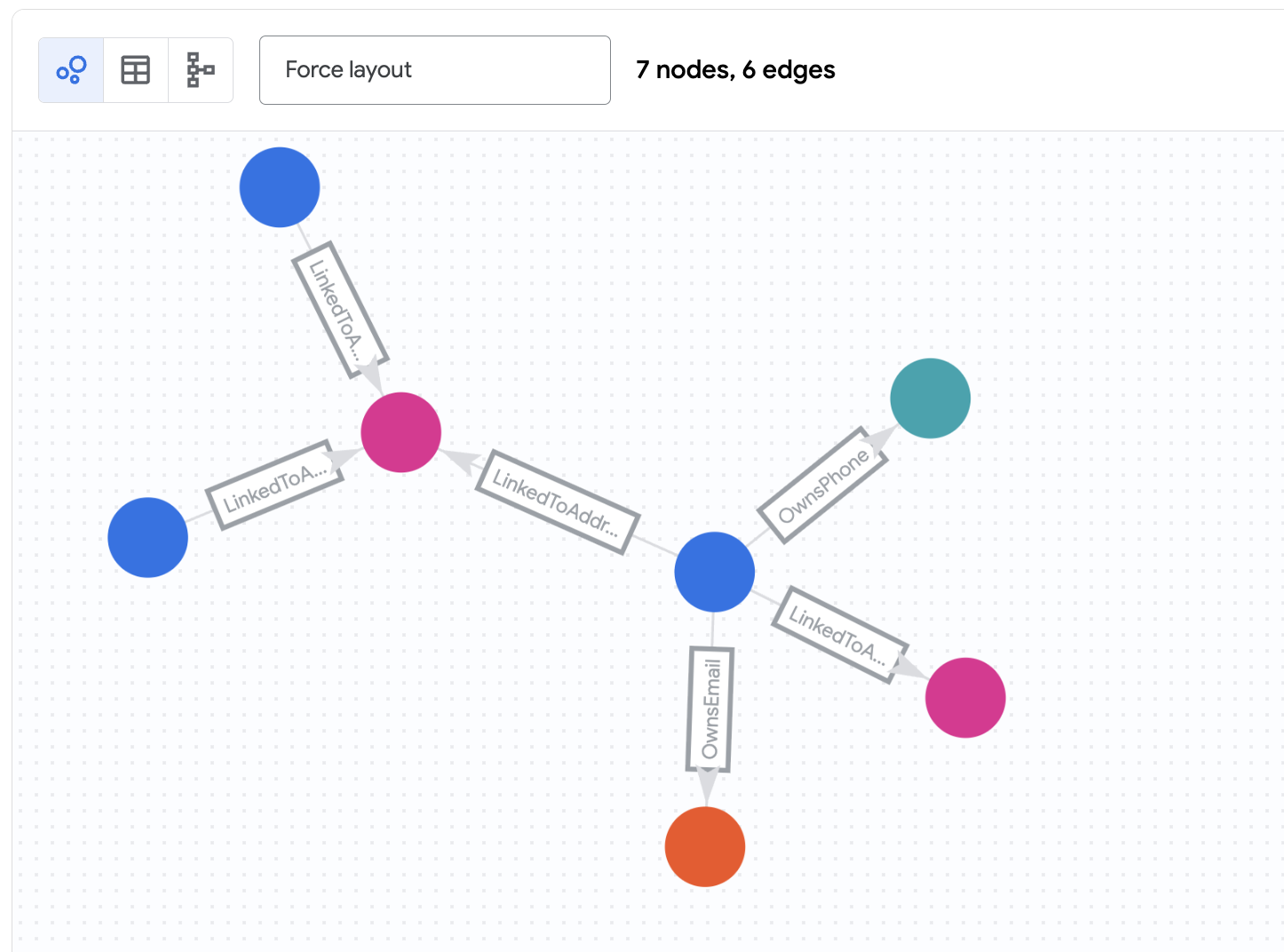
Das bedeuten die Ergebnisse
Diese Abfrage bewirkt Folgendes:
- Beginnt am Knoten
Customermitaccount_id„d2f1f992-d116-41b3-955b-6c76a3352657“ (Nicole Wade). - Folgt einer der Kanten
OwnsEmail,OwnsPhone, oderLinkedToAddresszu einem Verbindungsknoten (Phone,Email, oderAddress). - Folgt den Kanten von diesem Verbindungsknoten zurück zu anderen
Customer-Knoten. - Filtert Kanten anhand eines Zeitstempels (
last_updated_ts), um den Status des Netzwerks zu einem bestimmten Zeitpunkt zu sehen.
Sie sollten sehen, dass Zachary Cordova und Brenda Brown über dieselbe Adresse mit Nicole verbunden sind.
6. Netzwerke analysieren (4 Schritte)
In diesem Schritt erweitern Sie die Abfrage, um komplexere Beziehungen zu finden. Wir suchen nach Verbindungen mit vier Schritten. So können wir Konten finden, die über mehrere Zwischenentitäten verbunden sind (z.B. Kunde A -> E-Mail -> Kunde B -> Telefon -> Kunde C).
Außerdem beobachten wir, wie sich dieses Netzwerk im Laufe der Zeit verändert.
Status „Vorher“
Sehen wir uns zuerst das Netzwerk an, wie es am 30. Juli 2025 aussah.
Führen Sie die folgende Abfrage aus:
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH p= ANY SHORTEST (a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress WHERE e.last_updated_ts < '2025-07-30']- (n) ){3, 5}(reachable_a:Customer)
WHERE a.account_id IN ("d2f1f992-d116-41b3-955b-6c76a3352657")
-- Ensure the final node in the dynamic chain is actually a Customer
AND 'Customer' IN UNNEST(LABELS(n[OFFSET(ARRAY_LENGTH(n) - 1)]))
RETURN
TO_JSON(p) AS paths, -- Array of all traversed edges
ARRAY_LENGTH(e) AS hop_count
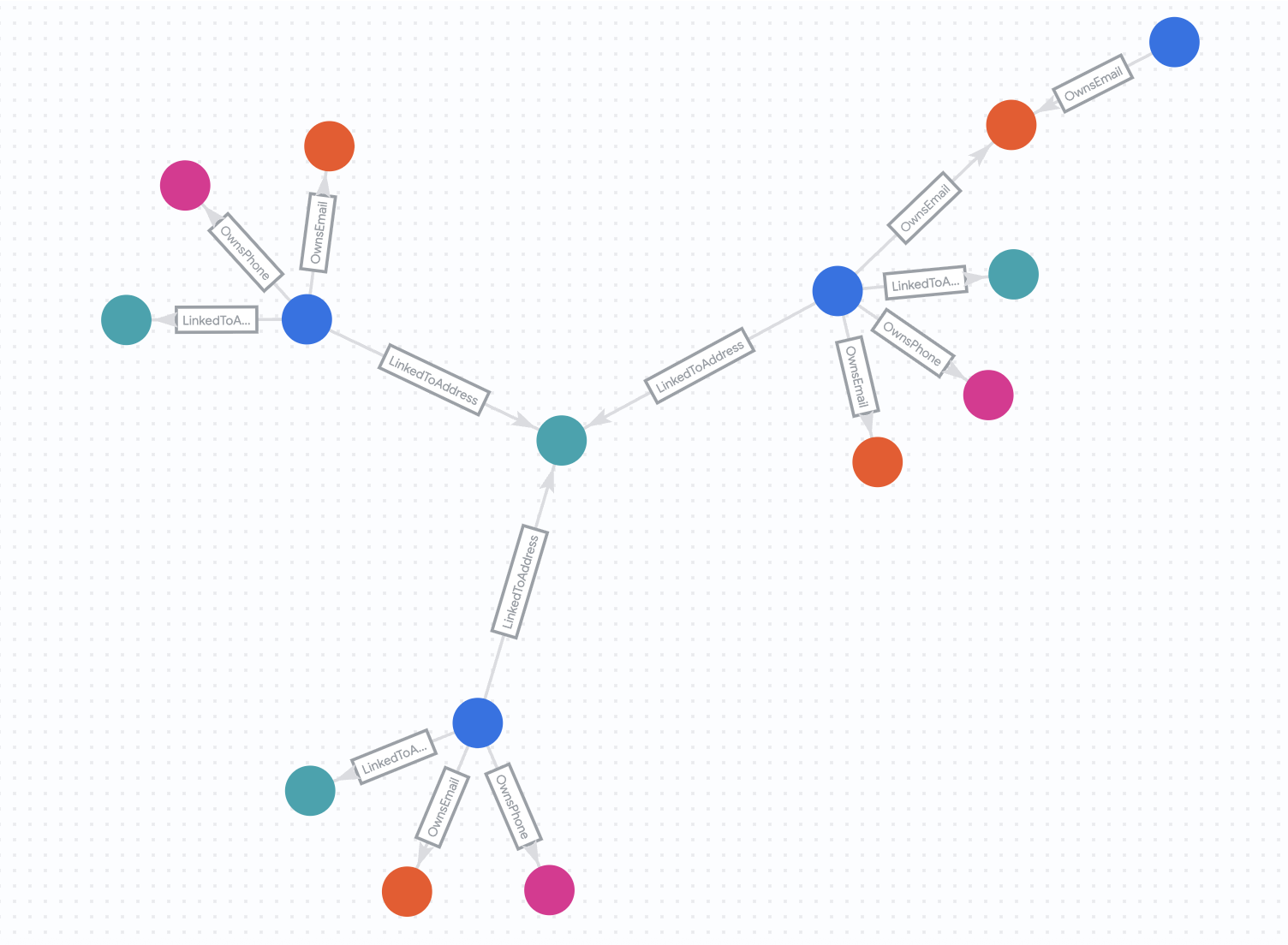
Status „Nachher“
Sehen wir uns nun an, wie das Netzwerk zwei Wochen später aussieht. Wir führen dieselbe Abfrage aus, aber ohne die Datumsbeschränkungen.
Führen Sie die folgende Abfrage aus:
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH p= ANY SHORTEST (a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress]- (n) ){3, 5}(reachable_a:Customer)
WHERE a.account_id IN ("d2f1f992-d116-41b3-955b-6c76a3352657")
-- Ensure the final node in the dynamic chain is actually a Customer
AND 'Customer' IN UNNEST(LABELS(n[OFFSET(ARRAY_LENGTH(n) - 1)]))
RETURN
TO_JSON(p) AS paths, -- Array of all traversed edges
ARRAY_LENGTH(e) AS hop_count
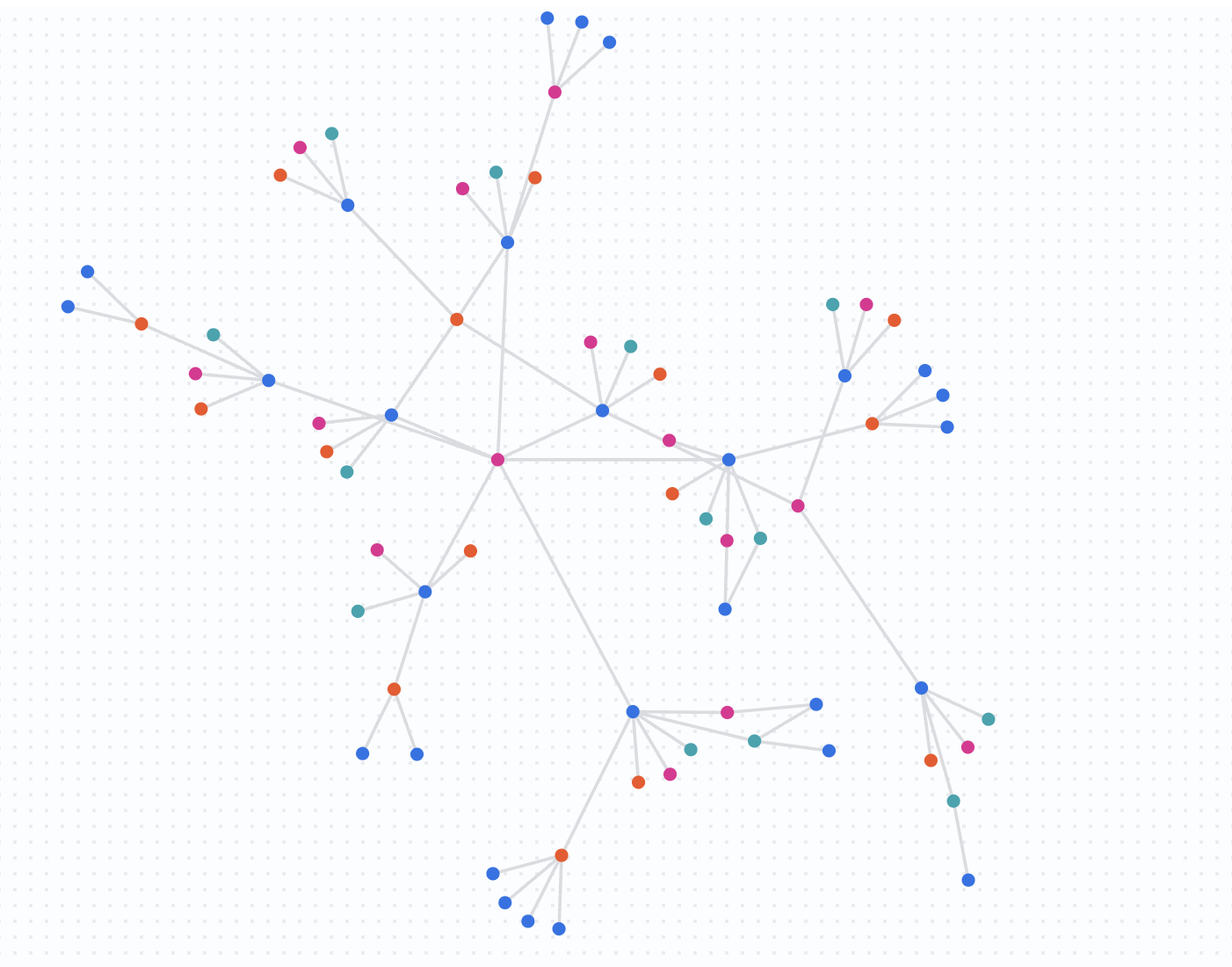
Das bedeuten die Ergebnisse
Wenn Sie die Datumsfilter entfernen, führen Sie eine Abfrage für das gesamte Dataset aus. Sie werden feststellen, dass das Netzwerk deutlich gewachsen ist. Nicole Wade ist jetzt Teil einer viel größeren, stark vernetzten Gruppe. Diese schnelle Erweiterung eines verbundenen Netzwerks ist ein starker Hinweis auf potenziell betrügerische Aktivitäten, z. B. ein Betrugsring, der im Laufe der Zeit Ressourcen gemeinsam nutzt.
7. Betrugsbericht erstellen
In diesem Schritt kombinieren Sie Graphanalysen mit herkömmlichen Geschäftsdaten (Bestellungen), um einen umfassenden Betrugsbericht zu erstellen. Sie identifizieren gefährdete Konten und potenziell betrügerische Bestellungen.
Diese Abfrage ist komplexer. Sie verwendet GRAPH_TABLE, um die Graphabfrage in Standard-SQL auszuführen, und berechnet die Änderung der Netzwerkgröße (diff) zwischen den Status „Vorher“ und „Nachher“, die wir im vorherigen Schritt beobachtet haben.
Abfrage für Betrugsbericht ausführen
Führen Sie die folgende Abfrage in Ihrem Notebook aus.
%%bigquery --graph
WITH num_orders AS (
SELECT account_id, COUNT(1) AS num_order
FROM fraud_demo.orders
WHERE order_time > '2025-07-30'
GROUP BY account_id
),
orders AS (
SELECT account_id, order_id, fraud, order_total
FROM fraud_demo.orders
WHERE order_time > '2025-07-30'
),
-- Use Quantified Path Patterns to find connections up to 4 hops away
latest_connect AS (
SELECT
account_id,
ARRAY_LENGTH(ARRAY_AGG(DISTINCT connected_id)) AS size
FROM GRAPH_TABLE(
fraud_demo.FraudDemo
MATCH (a:Customer)-[:OwnsEmail|OwnsPhone|LinkedToAddress]-{4}(connected:Customer)
RETURN a.account_id AS account_id, connected.account_id AS connected_id
)
GROUP BY account_id
),
prev_connect AS (
SELECT
account_id,
ARRAY_LENGTH(ARRAY_AGG(DISTINCT connected_id)) AS size
FROM GRAPH_TABLE(
fraud_demo.FraudDemo
-- Apply the timestamp filter to EVERY edge in the 4-hop chain
MATCH (a:Customer)
(-[e:OwnsEmail|OwnsPhone|LinkedToAddress WHERE e.last_updated_ts < '2025-07-30']-(n)){4}
WHERE 'Customer' IN UNNEST(LABELS(n[OFFSET(3)]))
RETURN a.account_id AS account_id, n[OFFSET(3)].account_id AS connected_id
)
GROUP BY account_id
),
edge_changes AS (
SELECT account_id, MAX(last_updated_ts) AS max_last_updated_ts
FROM fraud_demo.customer_addresses
GROUP BY account_id
)
SELECT
la.account_id,
o.order_id,
la.size AS latest_size,
COALESCE(pa.size, 0) AS previous_size,
la.size - COALESCE(pa.size, 0) AS diff,
nos.num_order,
o.fraud AS reported_as_fraud,
o.order_total,
CASE
WHEN (la.size - COALESCE(pa.size, 0)) > 10 AND nos.num_order IS NULL THEN "CUSTOMER AT RISK"
WHEN (la.size - COALESCE(pa.size, 0)) > 10 AND nos.num_order IS NOT NULL AND o.fraud THEN "CONFIRMED FRAUD ORDER"
WHEN (la.size - COALESCE(pa.size, 0)) > 10 AND nos.num_order IS NOT NULL AND NOT o.fraud THEN "POTENTIAL FRAUD ORDER"
ELSE ""
END AS notes
FROM latest_connect la
LEFT JOIN prev_connect pa ON la.account_id = pa.account_id
LEFT JOIN num_orders nos ON la.account_id = nos.account_id
LEFT JOIN orders o ON la.account_id = o.account_id
INNER JOIN edge_changes ec ON la.account_id = ec.account_id
WHERE nos.num_order > 1 OR (la.size - COALESCE(pa.size, 0)) > 10
ORDER BY diff DESC
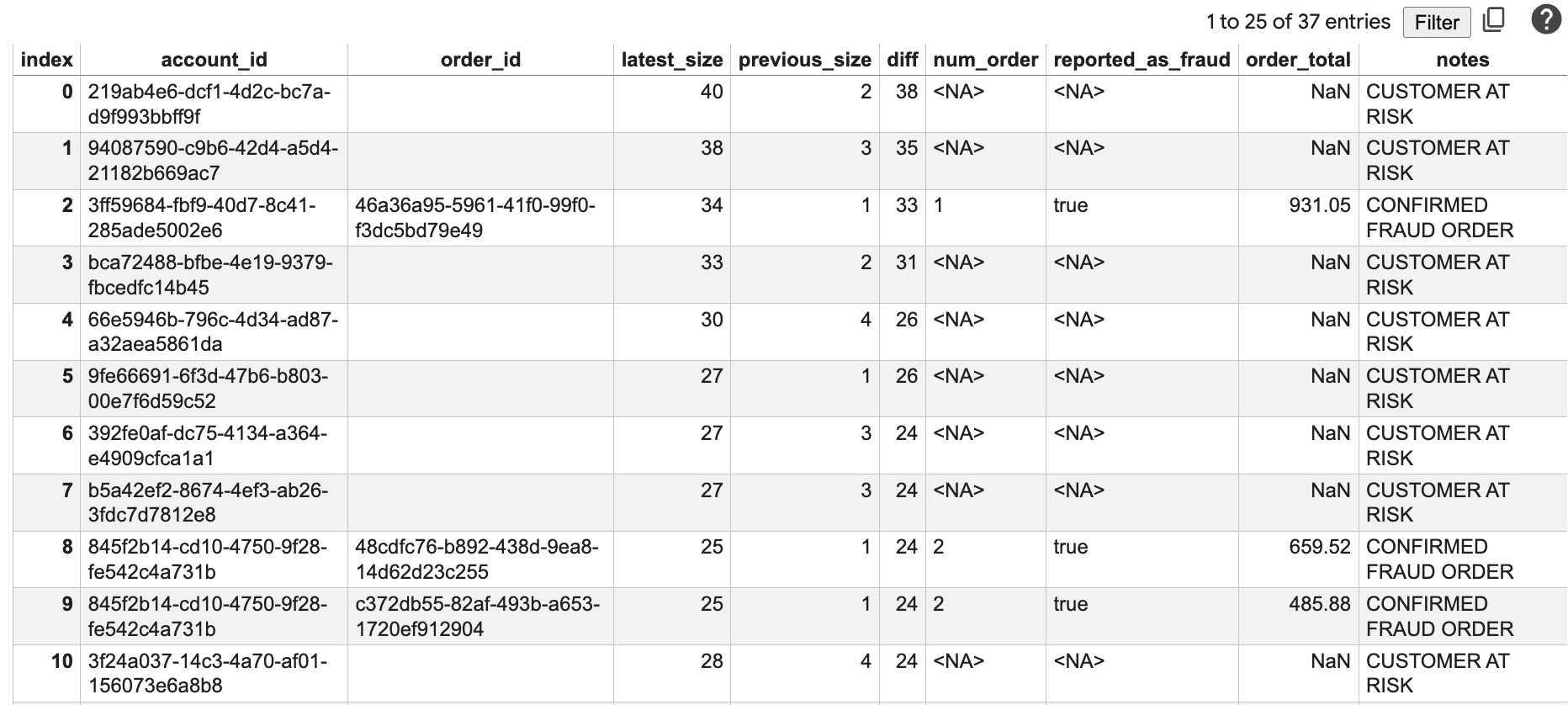
Das bedeuten die Ergebnisse
Dieser Bericht enthält Folgendes:
account_id: Die ID des Kontos, das analysiert wird.order_id: Eine aktuelle Bestell-ID.latest_size: Die Größe des verbundenen Netzwerks heute.previous_size: Die Größe des Netzwerks vor zwei Wochen.diff: Das Wachstum der Netzwerkgröße.num_order: Die Anzahl der letzten Bestellungen.reported_as_fraud: Gibt an, ob die Bestellung als Betrug gekennzeichnet wurde.order_total: Der Gesamtbetrag der Bestellung.notes: Ein berechneter Risikostatus basierend auf dem Netzwerkwachstum und dem Bestellverlauf.
Sie sehen Konten mit großen diff-Werten und hohen Bestellsummen, die sich für weitere Untersuchungen eignen. Die Hinweise „KUNDE MIT RISIKO“ und „POTENZIELLE BETRUGS-BESTELLUNG“ helfen dabei, diese Konten zu priorisieren.
8. Erkennung in großem Maßstab
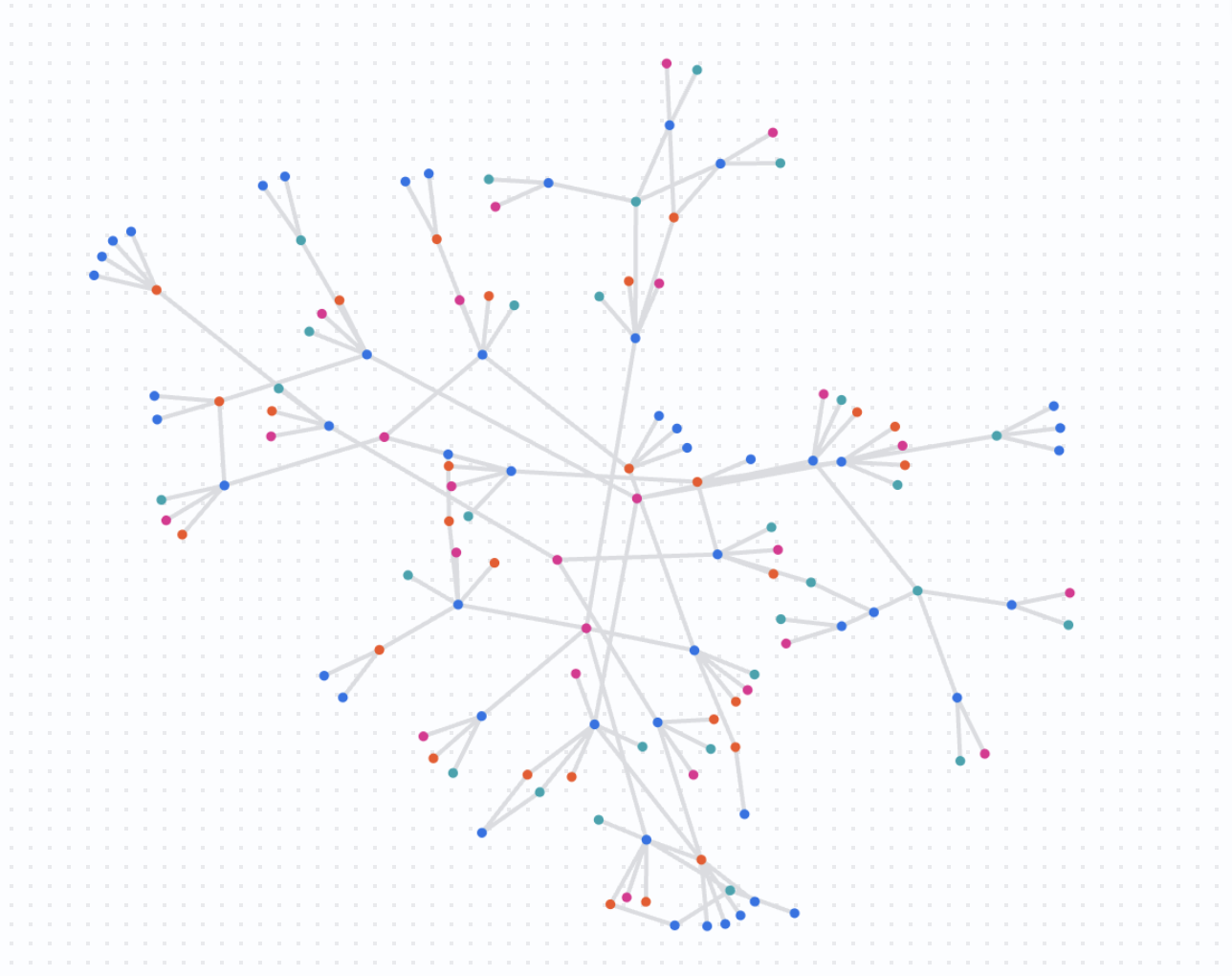
In diesem letzten Analyseschritt visualisieren Sie das Netzwerk in größerem Maßstab. Anstatt mit einem einzelnen Konto zu beginnen, fragen Sie Verbindungen zwischen einer Reihe verdächtiger Konten ab.
So können Sie feststellen, ob mehrere unabhängige Untersuchungen tatsächlich Teil desselben größeren Betrugsrings sind.
Abfrage in großem Maßstab ausführen
Führen Sie die folgende Abfrage in Ihrem Notebook aus.
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH
p= ANY SHORTEST (a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress]- (n) ){3, 5}
(reachable_a:Customer)
-- these IDs are from the previous results
WHERE a.account_id in ( "845f2b14-cd10-4750-9f28-fe542c4a731b"
, "3ff59684-fbf9-40d7-8c41-285ade5002e6"
, "8887c17b-e6fb-4b3b-8c62-cb721aafd028"
, "03e777e5-6fb4-445d-b48c-cf42b7620874"
, "81629832-eb1d-4a0e-86da-81a198604898"
, "845f2b14-cd10-4750-9f28-fe542c4a731b",
"89e9a8fe-ffc4-44eb-8693-a711a3534849"
)
LIMIT 400
RETURN TO_JSON(p) as paths
Das bedeuten die Ergebnisse
Diese Abfrage gibt einen komplexen Graphen zurück, der zeigt, wie sich die angegebenen verdächtigen Konten überschneiden und Ressourcen gemeinsam nutzen. Sie sehen jetzt die Betrugserkennung in großem Maßstab und identifizieren Aktivitätscluster, die möglicherweise eine koordinierte Reaktion erfordern.
9. Bereinigen
Entfernen Sie das Dataset und den Attributgraphen, um zu vermeiden, dass Ihrem Google Cloud-Konto die in diesem Codelab verwendeten Ressourcen in Rechnung gestellt werden.
Führen Sie die folgenden SQL-Anweisungen aus, um Ihre Umgebung zu bereinigen.
DROP PROPERTY GRAPH IF EXISTS fraud_demo.FraudDemo;
DROP SCHEMA IF EXISTS fraud_demo CASCADE;
10. Glückwunsch
Glückwunsch! Sie haben mit BigQuery Graph erfolgreich eine Lösung zur Betrugserkennung erstellt.
Sie haben Folgendes gelernt:
- Daten aus Cloud Storage in BigQuery laden.
- Attributgraphen mit DDL definieren.
- Graphen mit GQL abfragen, um einfache und komplexe Beziehungen zu finden.
- Graphanalysen mit Geschäftsdaten kombinieren, um Risiken zu identifizieren.
- Netzwerke in großem Maßstab visualisieren.