
۱. مقدمه
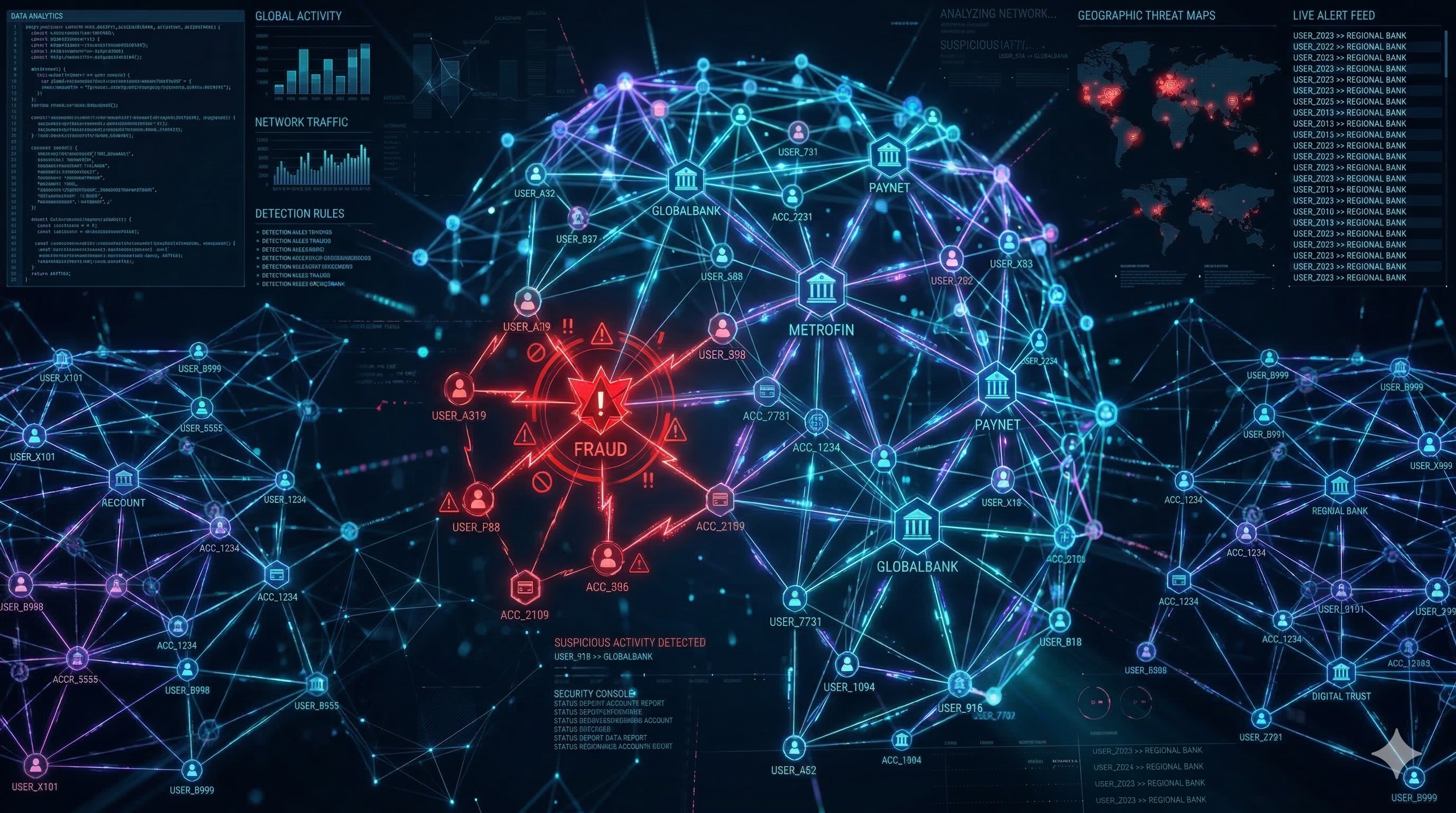
فعالیتهای کلاهبردارانه اغلب شامل شبکههای پنهان از موجودیتهای متصل است - برای مثال، چندین حساب کاربری که آدرس ایمیل، شماره تلفن یا آدرس فیزیکی یکسانی را به اشتراک میگذارند. پایگاههای داده رابطهای سنتی میتوانند برای پرسوجوی کارآمد از این روابط پیچیده و چندگامی با مشکل مواجه شوند.
BigQuery Graph به شما امکان میدهد تا این شبکهها را در مقیاس بزرگ با استفاده از پایگاههای داده گراف تجزیه و تحلیل کنید. میتوانید یک گراف ویژگی را روی جداول BigQuery موجود خود تعریف کنید و از زبان پرسوجوی گراف (GQL) برای یافتن الگوها در دادههای خود استفاده کنید.
یک کاربرد رایج شبکههای گراف برای تشخیص کلاهبرداری، متوقف کردن سفارشهایی است که آدرس تحویل آنها با یک شبکه کلاهبرداری مرتبط است یا متوقف کردن پرداختهای متعلق به ...
در این آزمایشگاه کد، شما با استفاده از BigQuery Graph یک راهکار تشخیص تقلب خواهید ساخت. دادهها را از فضای ذخیرهسازی ابری بارگذاری خواهید کرد، یک نمودار ویژگی ایجاد خواهید کرد و از پرسوجوهای نموداری برای شناسایی اتصالات مشکوک استفاده خواهید کرد.
آنچه یاد خواهید گرفت
- نحوه ایجاد مجموعه داده BigQuery و بارگذاری دادهها.
- نحوه تعریف نمودار ویژگی با استفاده از DDL.
- نحوه پرس و جو از گراف با استفاده از GQL.
- چگونه از تحلیل نموداری برای تشخیص تقلب استفاده کنیم؟
آنچه نیاز دارید
- یک پروژه گوگل کلود با قابلیت پرداخت.
- یک محیط نوتبوک BigQuery (BigQuery Studio یا Colab Enterprise).
هزینه
این آزمایشگاه از منابع ابری گوگل استفاده میکند که قابل پرداخت هستند. هزینه تخمینی کمتر از ۵ دلار است، البته با فرض اینکه منابع را پس از اتمام کار حذف کنید.
۲. قبل از شروع
یک پروژه Google Cloud انتخاب یا ایجاد کنید
- در کنسول گوگل کلود، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه Google Cloud شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب فعال است یا خیر .
محیط خود را انتخاب کنید
برای اجرای این آزمایش به یک محیط نوتبوک نیاز دارید. میتوانید از BigQuery Studio یا Colab Enterprise استفاده کنید.
- به صفحه BigQuery در کنسول Google Cloud بروید.
- شما از دفترچه یادداشت پایتون برای اجرای کوئریهای گراف استفاده خواهید کرد.
شروع پوسته ابری
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید.
- تأیید اعتبار:
gcloud auth list
- پروژه خود را تایید کنید:
gcloud config get project
- در صورت نیاز آن را تنظیم کنید:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
فعال کردن APIها
برای فعال کردن API مورد نیاز BigQuery، این دستور را اجرا کنید:
gcloud services enable bigquery.googleapis.com
۳. بارگذاری دادهها
در این مرحله، یک مجموعه داده BigQuery ایجاد میکنید و دادههای نمونه را از Cloud Storage بارگذاری میکنید.
دادههای نمونه شامل چندین فایل CSV است که نشاندهنده یک محیط خردهفروشی شبیهسازی شده هستند:
-
customers.csv: اطلاعات حساب مشتری. -
emails.csv: آدرسهای ایمیل. -
phones.csv: شماره تلفنها. -
addresses.csv: آدرسهای فیزیکی. -
customer_emails.csv،customer_phones.csv،customer_addresses.csv: لینک کردن جداول. -
orders.csv: تاریخچه سفارشها، شامل پرچمهای تقلب.
ایجاد مجموعه داده
یک مجموعه داده با نام fraud_demo برای نگهداری جداول ایجاد کنید.
- برای این آزمایشگاه کد، ما دستورات SQL را اجرا خواهیم کرد. میتوانید این دستورات را در BigQuery Studio > SQL Editor اجرا کنید، یا از دستور
bq queryدر Cloud Shell استفاده کنید. ما فرض میکنیم که شما برای تجربه بهتر با دستورات create چندخطی، از ویرایشگر BigQuery SQL استفاده میکنید.
ما فرض میکنیم که شما برای تجربه بهتر با دستورات create چندخطی، از ویرایشگر BigQuery SQL استفاده میکنید.
CREATE SCHEMA IF NOT EXISTS `fraud_demo` OPTIONS(location="US");
بارگذاری جداول
برای بارگذاری دادهها از فضای ذخیرهسازی ابری در مجموعه دادههای خود، دستورات SQL زیر را اجرا کنید.
LOAD DATA OVERWRITE `fraud_demo.customers`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customers.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.emails`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/emails.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.phones`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/phones.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.addresses`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/addresses.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.customer_emails`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customer_emails.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.customer_phones`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customer_phones.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.customer_addresses`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customer_addresses.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.orders`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/orders.csv'],
skip_leading_rows = 1
);
۴. نمودار ویژگیها را ایجاد کنید
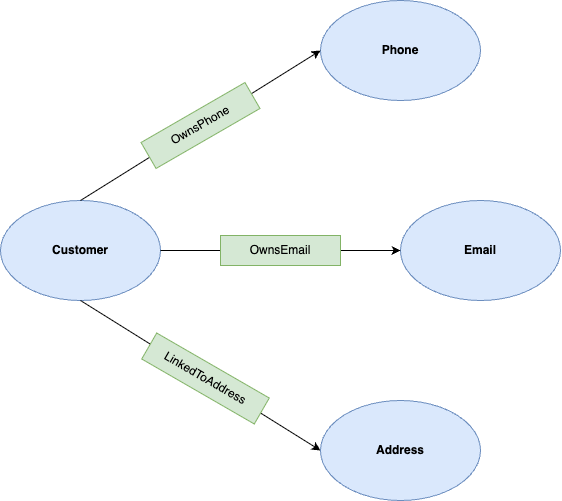
اکنون که دادهها بارگذاری شدهاند، میتوانید نمودار ویژگی را تعریف کنید. یک نمودار ویژگی شامل گرهها (موجودیتها) و لبهها (روابط) است.
در این آزمایشگاه، گرهها عبارتند از:
- مشتری : نماینده دارنده حساب است.
- تلفن : نشان دهنده شماره تلفن است.
- ایمیل : نشاندهنده آدرس ایمیل است.
- آدرس : نشان دهنده یک آدرس فیزیکی است.
لبهها عبارتند از:
- OwnsPhone : یک مشتری را به یک تلفن متصل میکند.
- OwnsEmail : یک مشتری را به یک ایمیل متصل میکند.
- LinkedToAddress : یک مشتری را به یک آدرس متصل میکند.
نمودار را ایجاد کنید
دستور DDL زیر را اجرا کنید تا گرافی با نام FraudDemo در مجموعه داده fraud_demo شما ایجاد شود.
CREATE OR REPLACE PROPERTY GRAPH fraud_demo.FraudDemo
NODE TABLES(
fraud_demo.customers
KEY(account_id)
LABEL Customer PROPERTIES(
account_id,
name),
fraud_demo.emails
KEY(email)
LABEL Email PROPERTIES(
email,
email_type),
fraud_demo.phones
KEY(phone_number)
LABEL Phone PROPERTIES(
phone_number,
phone_type),
fraud_demo.addresses
KEY(address)
LABEL Address PROPERTIES(
address,
address_type)
)
EDGE TABLES(
fraud_demo.customer_emails
KEY(account_id, email)
SOURCE KEY(account_id) REFERENCES customers(account_id)
DESTINATION KEY(email) REFERENCES emails(email)
LABEL OwnsEmail PROPERTIES(
account_id,
email,
last_updated_ts),
fraud_demo.customer_phones
KEY(account_id, phone_number)
SOURCE KEY(account_id) REFERENCES customers(account_id)
DESTINATION KEY(phone_number) REFERENCES phones(phone_number)
LABEL OwnsPhone PROPERTIES(
account_id,
phone_number,
last_updated_ts),
fraud_demo.customer_addresses
KEY(account_id, address)
SOURCE KEY(account_id) REFERENCES customers(account_id)
DESTINATION KEY(address) REFERENCES addresses(address)
LABEL LinkedToAddress PROPERTIES(
account_id,
address,
last_updated_ts)
);
۵. تحلیل شبکهها (دو-هاپ)
یک دفترچه یادداشت جدید در BigQuery Studio باز کنید.
برای بخشهای تجسم و توصیه این آزمایشگاه کد، از یک دفترچه یادداشت Google Colab در BigQuery Studio استفاده خواهیم کرد. این به ما امکان میدهد تا به راحتی نتایج نمودار را تجسم کنیم.
کد زیر را در یک سلول کد پیست کنید:
!pip install bigquery-magics==0.12.1
دفترچه یادداشت نمودار BigQuery به عنوان یک IPython Magics پیادهسازی شده است. با اضافه کردن دستور جادویی %%bigquery به همراه تابع TO_JSON ، میتوانید نتایج را همانطور که در بخشهای بعدی نشان داده شده است، تجسم کنید. در این مرحله، یک پرسوجوی نموداری برای یافتن ارتباطات ساده بین حسابها اجرا خواهید کرد. این یک پرسوجوی "دو گامی" است زیرا از یک گره شروع، دو گام به بیرون حرکت میکند تا گرههای مرتبط را پیدا کند (مثلاً مشتری -> ایمیل -> مشتری).
ما با بررسی حساب کاربری متعلق به نیکول وید شروع خواهیم کرد. ما میخواهیم از طریق دو مسیر، هر حساب کاربری مرتبط با او را پیدا کنیم.
اجرای کوئری دو-هاپ
کوئری زیر را در نوتبوک خود اجرا کنید.
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH
p=(a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress WHERE e.last_updated_ts < '2025-07-30']- (n) ){2}
WHERE a.account_id IN ("d2f1f992-d116-41b3-955b-6c76a3352657")
-- Verify the final node in the hop array is a Customer
AND 'Customer' IN UNNEST(LABELS(n[OFFSET(1)]))
RETURN TO_JSON(p) AS paths
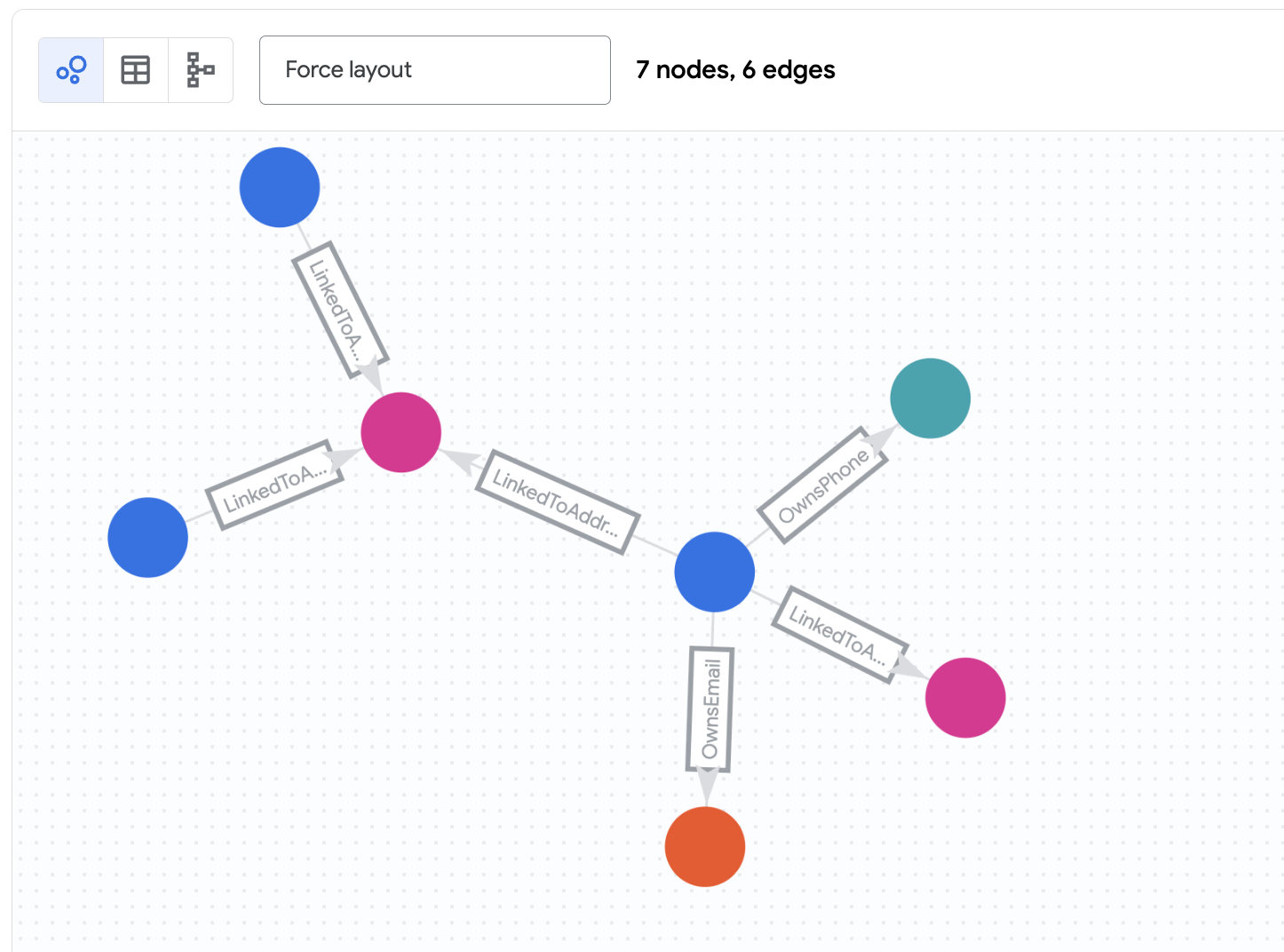
نتایج را درک کنید
این پرس و جو:
- از گره
Customerباaccount_id"d2f1f992-d116-41b3-955b-6c76a3352657" (نیکول وید) شروع میشود. - هر یک از لبههای
OwnsEmail،OwnsPhoneیاLinkedToAddressرا تا یک گره اتصال (Phone،EmailیاAddress) دنبال میکند. - لبهها را از آن گره اتصال به گرههای
Customerدیگر دنبال میکند. - لبهها را بر اساس یک مهر زمانی (
last_updated_ts) فیلتر میکند تا وضعیت شبکه را در یک زمان خاص مشاهده کند.
باید ببینید که زاخاری کوردووا و برندا براون از طریق یک آدرس به نیکول متصل هستند.
۶. تحلیل شبکهها (۴-هاپ)
در این مرحله، شما پرسوجو را برای یافتن روابط پیچیدهتر گسترش خواهید داد. ما به دنبال اتصالات ۴ گامی خواهیم بود. این به ما امکان میدهد حسابهایی را پیدا کنیم که از طریق چندین موجودیت واسطه به هم متصل هستند (مثلاً مشتری A -> ایمیل -> مشتری B -> تلفن -> مشتری C).
همچنین مشاهده خواهیم کرد که چگونه این شبکه با گذشت زمان تغییر میکند.
حالت «قبل»
ابتدا، بیایید نگاهی به شبکه در زمانی که در 30 جولای 2025 وجود داشت، بیندازیم.
کوئری زیر را اجرا کنید:
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH p= ANY SHORTEST (a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress WHERE e.last_updated_ts < '2025-07-30']- (n) ){3, 5}(reachable_a:Customer)
WHERE a.account_id IN ("d2f1f992-d116-41b3-955b-6c76a3352657")
-- Ensure the final node in the dynamic chain is actually a Customer
AND 'Customer' IN UNNEST(LABELS(n[OFFSET(ARRAY_LENGTH(n) - 1)]))
RETURN
TO_JSON(p) AS paths, -- Array of all traversed edges
ARRAY_LENGTH(e) AS hop_count
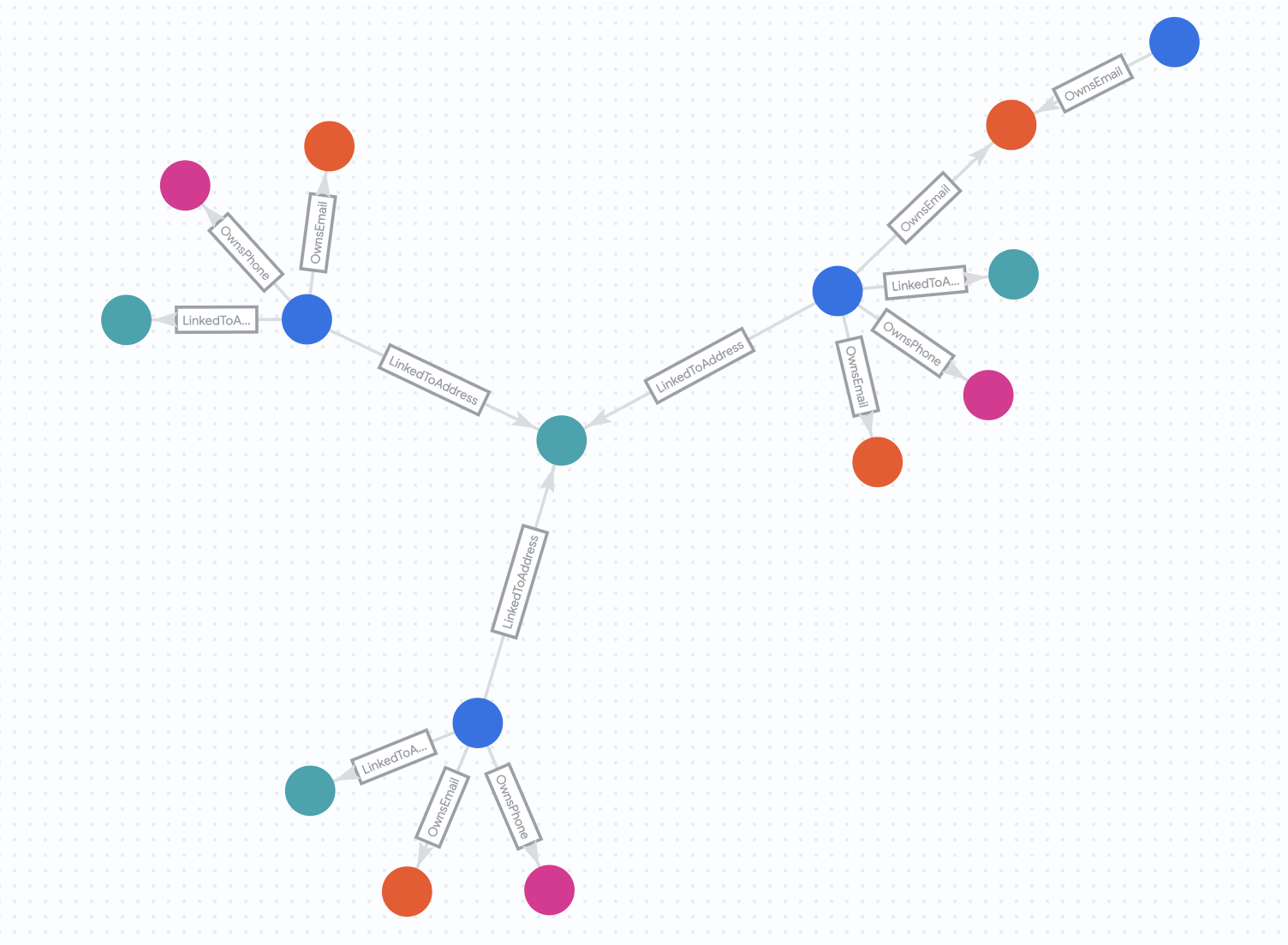
دولت «بعد»
حالا، بیایید ببینیم شبکه ۲ هفته بعد چگونه به نظر میرسد. ما همان پرس و جو را اجرا خواهیم کرد اما بدون محدودیتهای تاریخ.
کوئری زیر را اجرا کنید:
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH p= ANY SHORTEST (a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress]- (n) ){3, 5}(reachable_a:Customer)
WHERE a.account_id IN ("d2f1f992-d116-41b3-955b-6c76a3352657")
-- Ensure the final node in the dynamic chain is actually a Customer
AND 'Customer' IN UNNEST(LABELS(n[OFFSET(ARRAY_LENGTH(n) - 1)]))
RETURN
TO_JSON(p) AS paths, -- Array of all traversed edges
ARRAY_LENGTH(e) AS hop_count
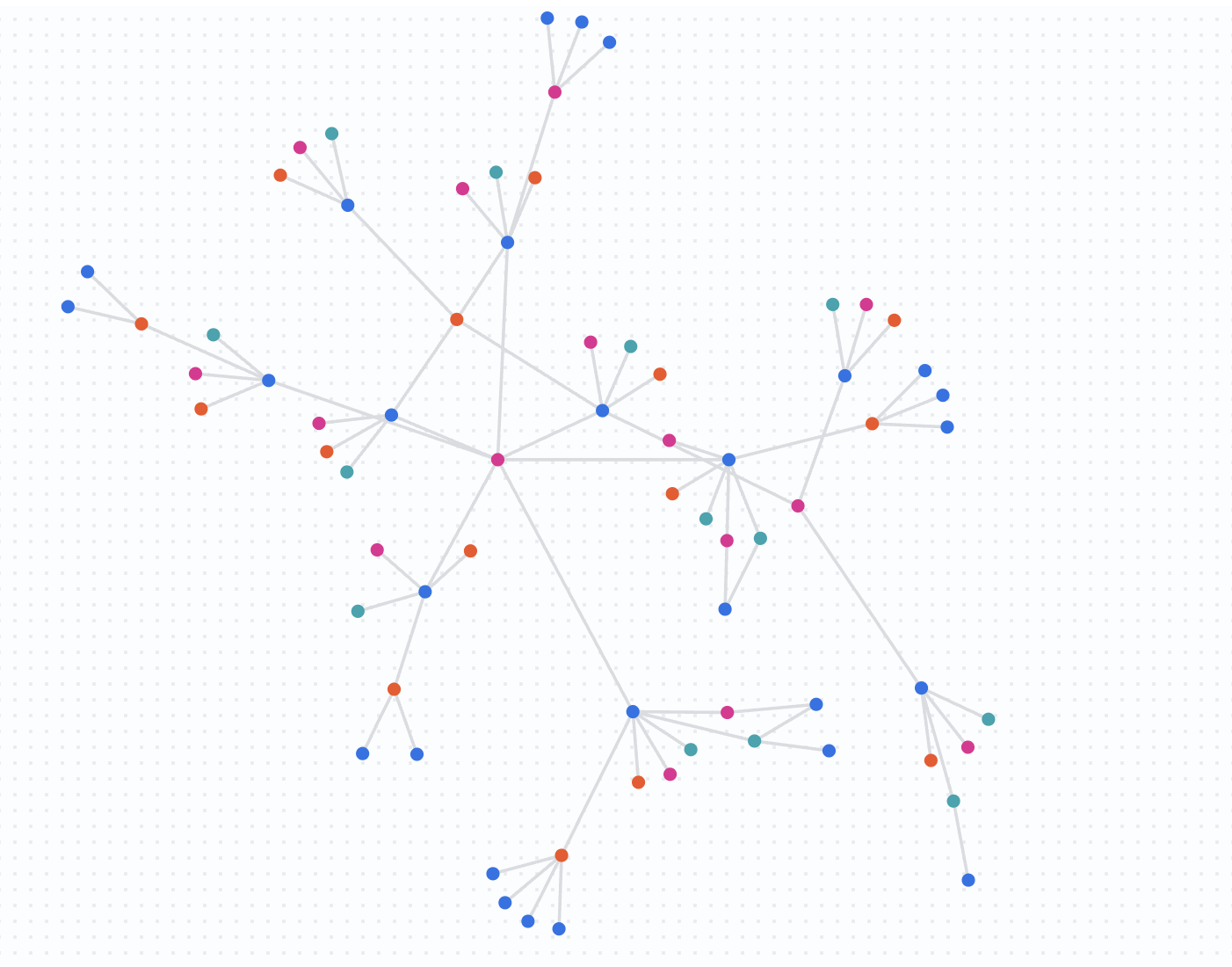
نتایج را درک کنید
با حذف فیلترهای تاریخ، شما در برابر کل مجموعه دادهها پرسوجو میکنید. متوجه خواهید شد که شبکه به طور قابل توجهی رشد کرده است. نیکول وید اکنون بخشی از یک گروه بسیار بزرگتر و بسیار متصل است. این گسترش سریع یک شبکه متصل، شاخص قوی از فعالیتهای بالقوه کلاهبرداری، مانند یک حلقه کلاهبرداری است که منابع را در طول زمان به اشتراک میگذارد.
۷. گزارش کلاهبرداری تهیه کنید
در این مرحله، شما تجزیه و تحلیل نمودار را با دادههای تجاری سنتی (سفارشها) ترکیب خواهید کرد تا یک گزارش جامع کلاهبرداری تهیه کنید. شما حسابهای در معرض خطر و سفارشهای بالقوه کلاهبرداری را شناسایی خواهید کرد.
این پرسوجو پیچیدهتر است. از GRAPH_TABLE برای اجرای پرسوجوی گراف در داخل SQL استاندارد استفاده میکند و تغییر در اندازه شبکه ( diff ) را بین حالتهای «قبل» و «بعد» که در مرحله قبل مشاهده کردیم، محاسبه میکند.
اجرای کوئری گزارش کلاهبرداری
کوئری زیر را در نوتبوک خود اجرا کنید.
%%bigquery --graph
WITH num_orders AS (
SELECT account_id, COUNT(1) AS num_order
FROM fraud_demo.orders
WHERE order_time > '2025-07-30'
GROUP BY account_id
),
orders AS (
SELECT account_id, order_id, fraud, order_total
FROM fraud_demo.orders
WHERE order_time > '2025-07-30'
),
-- Use Quantified Path Patterns to find connections up to 4 hops away
latest_connect AS (
SELECT
account_id,
ARRAY_LENGTH(ARRAY_AGG(DISTINCT connected_id)) AS size
FROM GRAPH_TABLE(
fraud_demo.FraudDemo
MATCH (a:Customer)-[:OwnsEmail|OwnsPhone|LinkedToAddress]-{4}(connected:Customer)
RETURN a.account_id AS account_id, connected.account_id AS connected_id
)
GROUP BY account_id
),
prev_connect AS (
SELECT
account_id,
ARRAY_LENGTH(ARRAY_AGG(DISTINCT connected_id)) AS size
FROM GRAPH_TABLE(
fraud_demo.FraudDemo
-- Apply the timestamp filter to EVERY edge in the 4-hop chain
MATCH (a:Customer)
(-[e:OwnsEmail|OwnsPhone|LinkedToAddress WHERE e.last_updated_ts < '2025-07-30']-(n)){4}
WHERE 'Customer' IN UNNEST(LABELS(n[OFFSET(3)]))
RETURN a.account_id AS account_id, n[OFFSET(3)].account_id AS connected_id
)
GROUP BY account_id
),
edge_changes AS (
SELECT account_id, MAX(last_updated_ts) AS max_last_updated_ts
FROM fraud_demo.customer_addresses
GROUP BY account_id
)
SELECT
la.account_id,
o.order_id,
la.size AS latest_size,
COALESCE(pa.size, 0) AS previous_size,
la.size - COALESCE(pa.size, 0) AS diff,
nos.num_order,
o.fraud AS reported_as_fraud,
o.order_total,
CASE
WHEN (la.size - COALESCE(pa.size, 0)) > 10 AND nos.num_order IS NULL THEN "CUSTOMER AT RISK"
WHEN (la.size - COALESCE(pa.size, 0)) > 10 AND nos.num_order IS NOT NULL AND o.fraud THEN "CONFIRMED FRAUD ORDER"
WHEN (la.size - COALESCE(pa.size, 0)) > 10 AND nos.num_order IS NOT NULL AND NOT o.fraud THEN "POTENTIAL FRAUD ORDER"
ELSE ""
END AS notes
FROM latest_connect la
LEFT JOIN prev_connect pa ON la.account_id = pa.account_id
LEFT JOIN num_orders nos ON la.account_id = nos.account_id
LEFT JOIN orders o ON la.account_id = o.account_id
INNER JOIN edge_changes ec ON la.account_id = ec.account_id
WHERE nos.num_order > 1 OR (la.size - COALESCE(pa.size, 0)) > 10
ORDER BY diff DESC
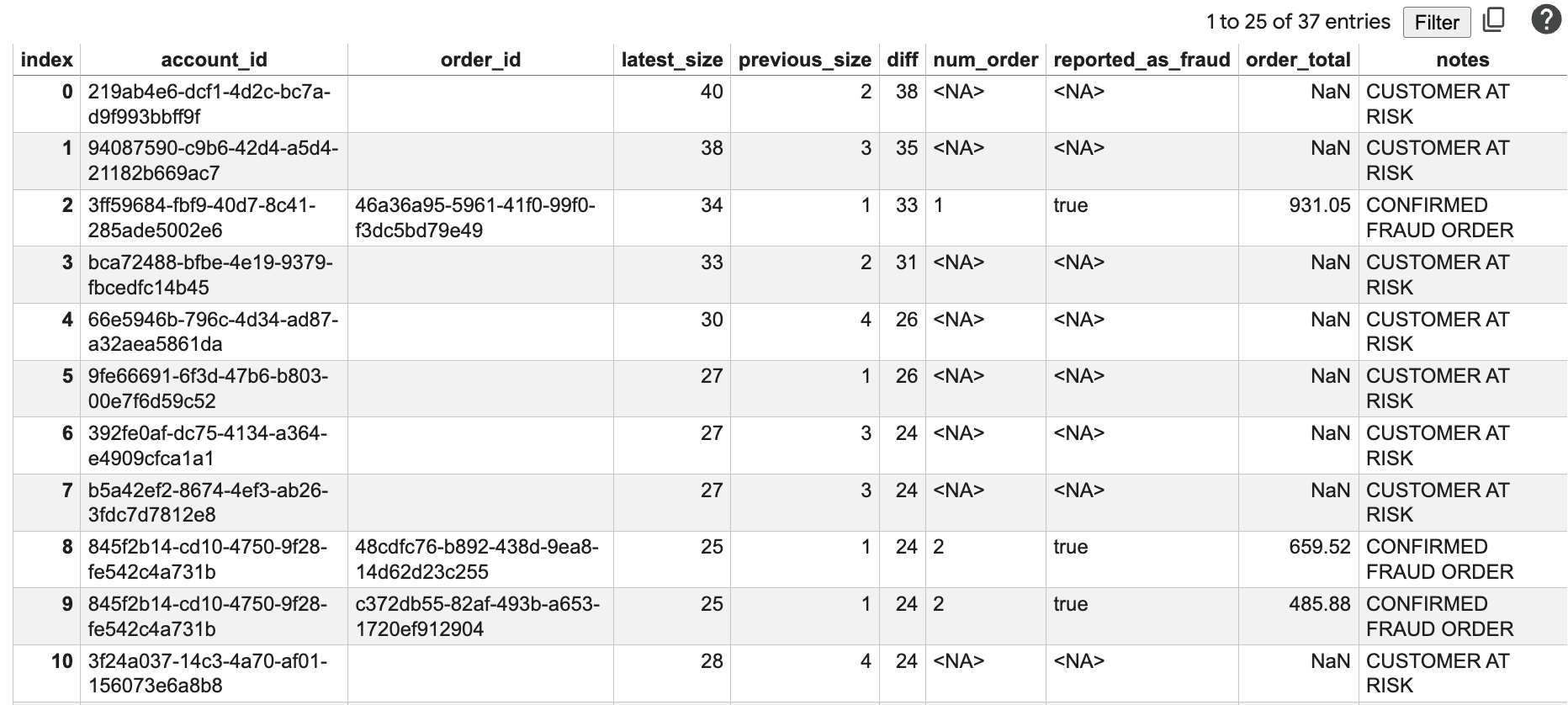
نتایج را درک کنید
این گزارش نشان میدهد:
-
account_id: شناسه حساب کاربری که مورد تجزیه و تحلیل قرار میگیرد. -
order_id: شناسه سفارش اخیر. -
latest_size: اندازه شبکه متصل امروز. -
previous_size: اندازه شبکه ۲ هفته پیش. -
diff: رشد اندازه شبکه. -
num_order: تعداد سفارشهای اخیر. -
reported_as_fraud: آیا سفارش به عنوان تقلب علامتگذاری شده است یا خیر. -
order_total: مبلغ کل سفارش. -
notes: وضعیت ریسک محاسبهشده بر اساس رشد شبکه و تاریخچه سفارش.
حسابهایی با مقادیر diff بزرگ و مجموع سفارش بالا را مشاهده خواهید کرد که کاندیداهای اصلی برای بررسی بیشتر هستند. یادداشتهای «مشتری در معرض خطر» و «سفارش کلاهبرداری بالقوه» به اولویتبندی این حسابها کمک میکند.
۸. تشخیص در مقیاس بزرگ
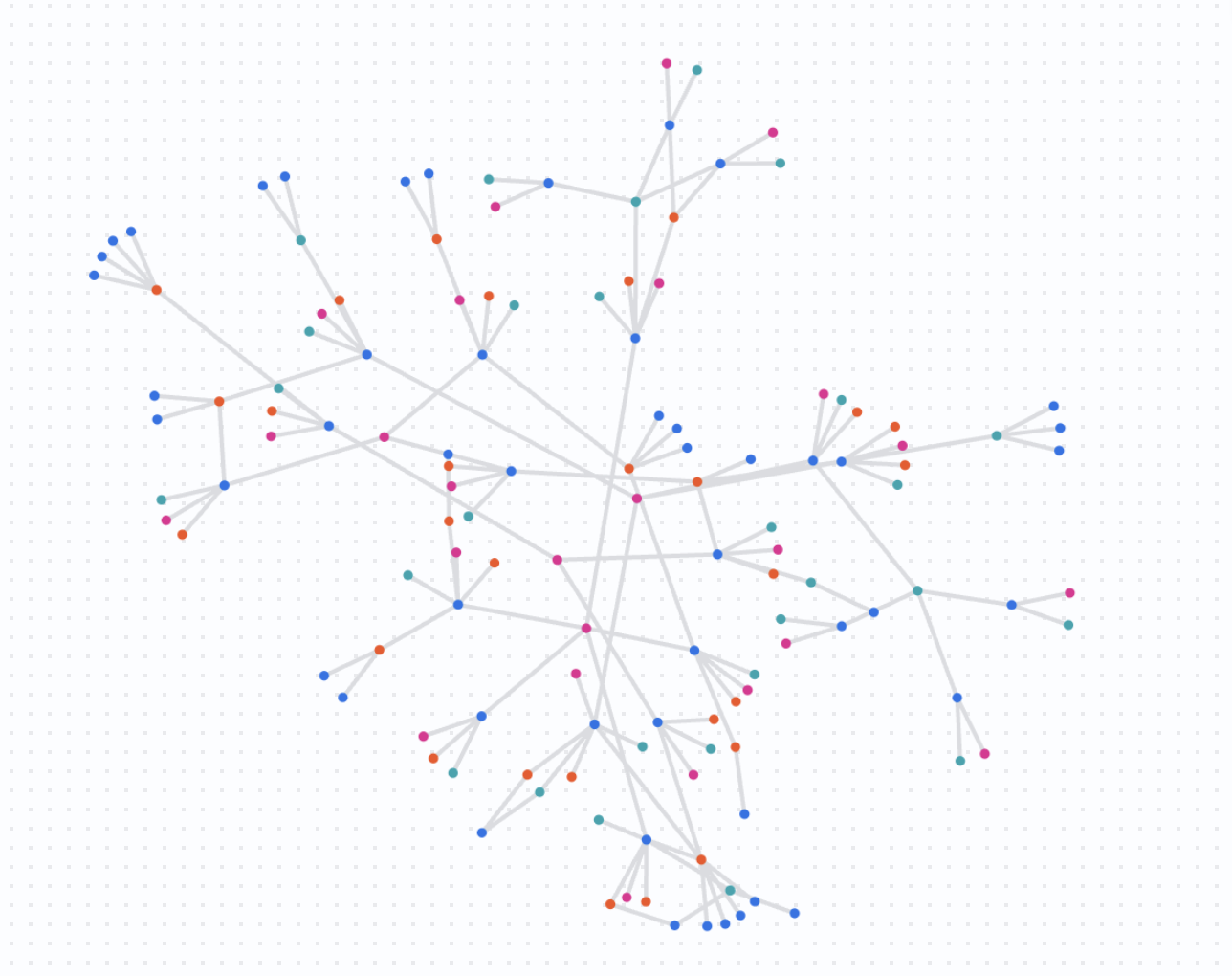
در این مرحله تحلیل نهایی، شما شبکه را در مقیاس بزرگتری تجسم خواهید کرد. به جای شروع با یک حساب کاربری، به دنبال ارتباطات بین مجموعهای از حسابهای کاربری مشکوک خواهید گشت.
این به شما کمک میکند تا ببینید آیا چندین تحقیق مستقل در واقع بخشی از یک حلقه کلاهبرداری بزرگتر هستند یا خیر.
اجرای پرسوجوی مقیاسپذیر
کوئری زیر را در نوتبوک خود اجرا کنید.
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH
p= ANY SHORTEST (a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress]- (n) ){3, 5}
(reachable_a:Customer)
-- these IDs are from the previous results
WHERE a.account_id in ( "845f2b14-cd10-4750-9f28-fe542c4a731b"
, "3ff59684-fbf9-40d7-8c41-285ade5002e6"
, "8887c17b-e6fb-4b3b-8c62-cb721aafd028"
, "03e777e5-6fb4-445d-b48c-cf42b7620874"
, "81629832-eb1d-4a0e-86da-81a198604898"
, "845f2b14-cd10-4750-9f28-fe542c4a731b",
"89e9a8fe-ffc4-44eb-8693-a711a3534849"
)
LIMIT 400
RETURN TO_JSON(p) as paths
نتایج را درک کنید
این پرسوجو یک نمودار پیچیده را نشان میدهد که نشان میدهد چگونه حسابهای مشکوک مشخصشده همپوشانی دارند و منابع را به اشتراک میگذارند. اکنون شما در حال بررسی تشخیص کلاهبرداری در مقیاس بزرگ هستید و خوشههای فعالیتی را شناسایی میکنید که ممکن است نیاز به یک پاسخ هماهنگ داشته باشند.
۹. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این آزمایشگاه کد، باید مجموعه دادهها و نمودار ویژگی را حذف کنید.
برای پاکسازی محیط خود، دستورات SQL زیر را اجرا کنید.
DROP PROPERTY GRAPH IF EXISTS fraud_demo.FraudDemo;
DROP SCHEMA IF EXISTS fraud_demo CASCADE;
۱۰. تبریک
تبریک! شما با موفقیت یک راهکار تشخیص تقلب با استفاده از BigQuery Graph ساختید.
شما یاد گرفتهاید که چگونه:
- بارگذاری دادهها از فضای ذخیرهسازی ابری در BigQuery.
- با استفاده از DDL یک نمودار ویژگی تعریف کنید.
- با استفاده از GQL، نمودار را برای یافتن روابط ساده و پیچیده جستجو کنید.
- برای شناسایی ریسک، تجزیه و تحلیل نمودار را با دادههای تجاری ترکیب کنید.
- شبکهها را در مقیاس بزرگ تجسم کنید.