
1. はじめに
不正行為には、多くの場合、関連するエンティティの隠れたネットワークが関与しています。たとえば、同じメールアドレス、電話番号、住所を共有する複数のアカウントなどです。従来のリレーショナル データベースでは、このような複雑なマルチホップ関係を効率的にクエリするのは困難です。
BigQuery Graph を使用すると、グラフ データベースを使用してこれらのネットワークを大規模に分析できます。既存の BigQuery テーブルの上にプロパティ グラフを定義し、Graph Query Language(GQL)を使用してデータ内のパターンを見つけることができます。
不正行為の検出にグラフ ネットワークを適用する一般的な方法としては、不正行為ネットワークに関連付けられているお届け先住所の注文を停止したり、不正行為ネットワークに属する支払いを停止したりすることが挙げられます。
この Codelab では、BigQuery Graph を使用して不正行為検出ソリューションを構築します。Cloud Storage からデータを読み込み、プロパティ グラフを作成し、グラフクエリを使用して不審な接続を特定します。
学習内容
- BigQuery データセットを作成してデータを読み込む方法。
- DDL を使用してプロパティ グラフを定義する方法。
- GQL を使用してグラフをクエリする方法。
- グラフ分析を使用して不正行為を検出する方法。
必要なもの
- 課金を有効にした Google Cloud プロジェクト
- BigQuery ノートブック環境(BigQuery Studio または Colab Enterprise)。
費用
このラボでは、課金対象の Google Cloud リソースを使用します。完了後にリソースを削除すると、推定費用は 5 ドル未満になります。
2. 始める前に
Google Cloud プロジェクトを選択または作成する
- Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
- Google Cloud プロジェクトの課金が有効になっていることを確認します。詳しくは、課金が有効になっているかどうかを確認する方法をご覧ください。
環境を選択する
このラボを実行するには、ノートブック環境が必要です。BigQuery Studio または Colab Enterprise を使用できます。
- Google Cloud コンソールで [BigQuery] ページに移動します。
- Python ノートブックを使用してグラフクエリを実行します。
Cloud Shell の起動
- Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
- 認証を確認します。
gcloud auth list
- プロジェクトを確認します。
gcloud config get project
- 必要に応じて設定します。
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
API を有効にする
次のコマンドを実行して、必要な BigQuery API を有効にします。
gcloud services enable bigquery.googleapis.com
3. データを読み込む
このステップでは、BigQuery データセットを作成し、Cloud Storage からサンプルデータを読み込みます。
サンプルデータは、シミュレートされた小売環境を表す複数の CSV ファイルで構成されています。
customers.csv: お客様のアカウント情報。emails.csv: メールアドレス。phones.csv: 電話番号。addresses.csv: 住所。customer_emails.csv、customer_phones.csv、customer_addresses.csv: リンク テーブル。orders.csv: 不正行為のフラグを含む注文履歴。
データセットの作成
テーブルを保持する fraud_demo という名前のデータセットを作成します。
- この Codelab では、SQL コマンドを実行します。これらのコマンドは、[BigQuery Studio] > [SQL エディタ] で実行するか、Cloud Shell で
bq queryコマンドを使用します。 複数行の CREATE ステートメントをより快適に使用するために、BigQuery SQL エディタを使用していることを前提とします。
複数行の CREATE ステートメントをより快適に使用するために、BigQuery SQL エディタを使用していることを前提とします。
CREATE SCHEMA IF NOT EXISTS `fraud_demo` OPTIONS(location="US");
テーブルを読み込む
次の SQL ステートメントを実行して、Cloud Storage からデータセットにデータを読み込みます。
LOAD DATA OVERWRITE `fraud_demo.customers`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customers.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.emails`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/emails.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.phones`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/phones.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.addresses`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/addresses.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.customer_emails`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customer_emails.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.customer_phones`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customer_phones.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.customer_addresses`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/customer_addresses.csv'],
skip_leading_rows = 1
);
LOAD DATA OVERWRITE `fraud_demo.orders`
FROM FILES (
format = 'CSV',
uris = ['gs://sample-data-and-media/fraud-demo-data/orders.csv'],
skip_leading_rows = 1
);
4. プロパティ グラフを作成する
データが読み込まれたので、プロパティ グラフを定義できます。プロパティ グラフは、ノード(エンティティ)とエッジ(関係)で構成されます。
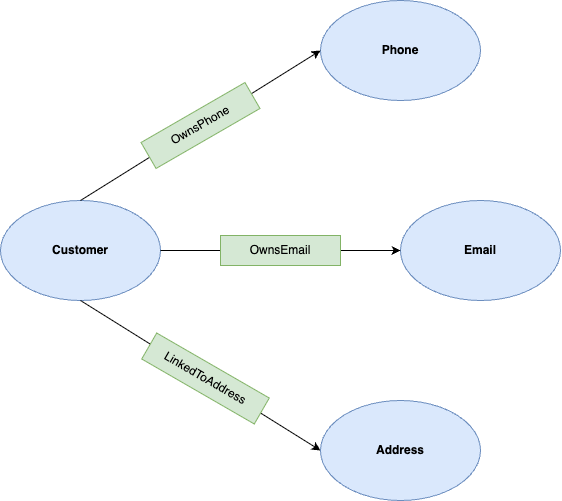
このラボでは、ノードは次のとおりです。
- 顧客: アカウント所有者を表します。
- 電話: 電話番号を表します。
- メール: メールアドレスを表します。
- Address: 住所を表します。
エッジは次のとおりです。
- OwnsPhone: お客様とスマートフォンを関連付けます。
- OwnsEmail: お客様とメールを関連付けます。
- LinkedToAddress: お客様と住所を関連付けます。
グラフを作成する
次の DDL ステートメントを実行して、fraud_demo データセットに FraudDemo という名前のグラフを作成します。
CREATE OR REPLACE PROPERTY GRAPH fraud_demo.FraudDemo
NODE TABLES(
fraud_demo.customers
KEY(account_id)
LABEL Customer PROPERTIES(
account_id,
name),
fraud_demo.emails
KEY(email)
LABEL Email PROPERTIES(
email,
email_type),
fraud_demo.phones
KEY(phone_number)
LABEL Phone PROPERTIES(
phone_number,
phone_type),
fraud_demo.addresses
KEY(address)
LABEL Address PROPERTIES(
address,
address_type)
)
EDGE TABLES(
fraud_demo.customer_emails
KEY(account_id, email)
SOURCE KEY(account_id) REFERENCES customers(account_id)
DESTINATION KEY(email) REFERENCES emails(email)
LABEL OwnsEmail PROPERTIES(
account_id,
email,
last_updated_ts),
fraud_demo.customer_phones
KEY(account_id, phone_number)
SOURCE KEY(account_id) REFERENCES customers(account_id)
DESTINATION KEY(phone_number) REFERENCES phones(phone_number)
LABEL OwnsPhone PROPERTIES(
account_id,
phone_number,
last_updated_ts),
fraud_demo.customer_addresses
KEY(account_id, address)
SOURCE KEY(account_id) REFERENCES customers(account_id)
DESTINATION KEY(address) REFERENCES addresses(address)
LABEL LinkedToAddress PROPERTIES(
account_id,
address,
last_updated_ts)
);
5. ネットワークを分析する(2 ホップ)
BigQuery Studio で [新しいノートブック] を開きます。
この Codelab の可視化と推奨事項の部分では、BigQuery Studio の Google Colab ノートブックを使用します。これにより、グラフの結果を簡単に可視化できます。
次のコードをコードセルに貼り付けます。
!pip install bigquery-magics==0.12.1
BigQuery Graph Notebook は IPython マジックとして実装されています。TO_JSON 関数で %%bigquery マジック コマンドを追加すると、次のセクションに示すように結果を可視化できます。このステップでは、グラフクエリを実行して、アカウント間の単純な接続を見つけます。これは「2 ホップ」クエリです。開始ノードから 2 ホップ移動して、関連ノード(顧客 -> メール -> 顧客など)を見つけます。
まず、Nicole Wade のアカウントを調査します。2 ホップで彼女に関連するアカウントを見つけたい。
2 ホップクエリを実行する
ノートブックで次のクエリを実行します。
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH
p=(a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress WHERE e.last_updated_ts < '2025-07-30']- (n) ){2}
WHERE a.account_id IN ("d2f1f992-d116-41b3-955b-6c76a3352657")
-- Verify the final node in the hop array is a Customer
AND 'Customer' IN UNNEST(LABELS(n[OFFSET(1)]))
RETURN TO_JSON(p) AS paths
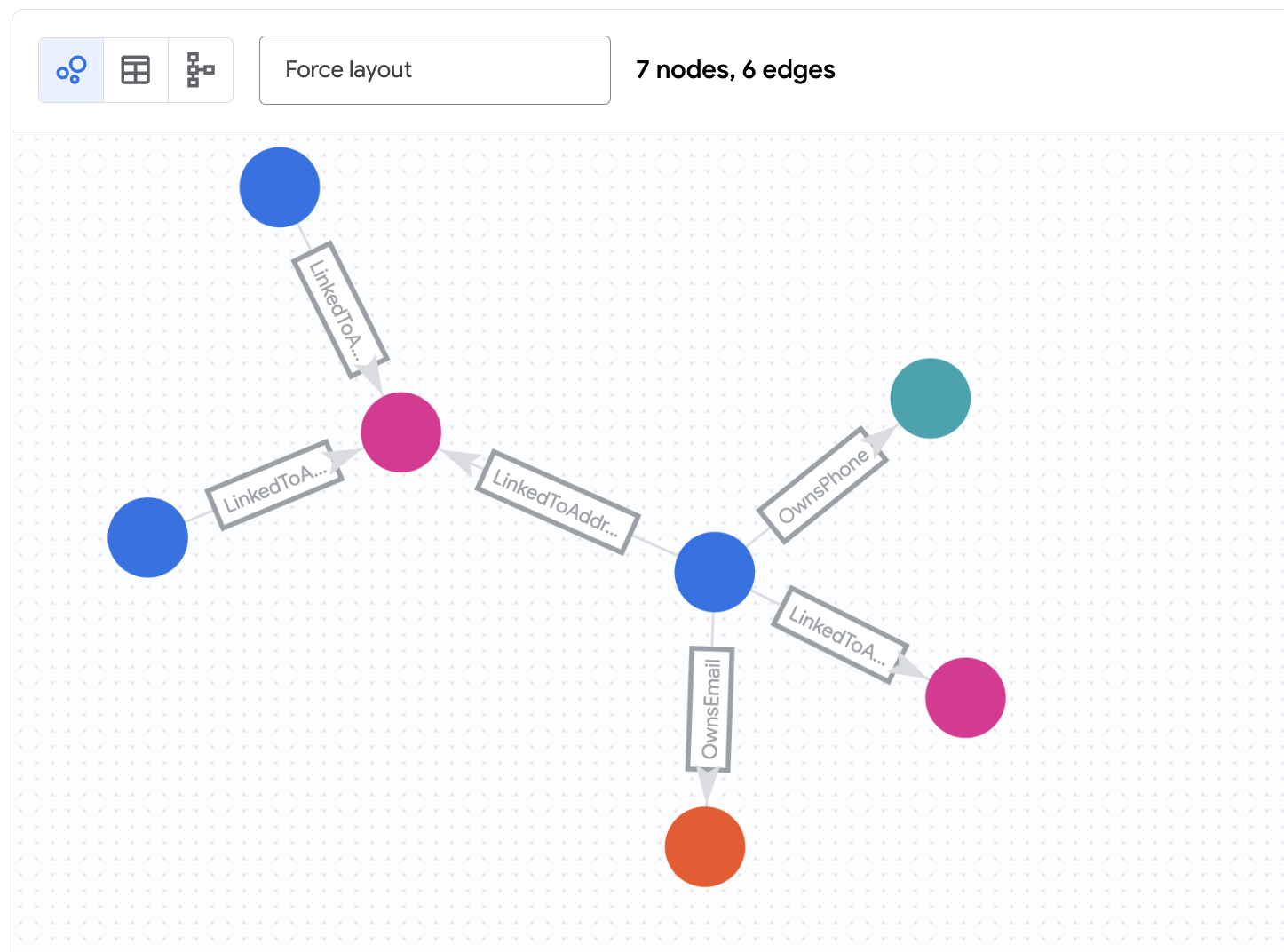
結果を把握する
このクエリは次の処理を行います。
account_id「d2f1f992-d116-41b3-955b-6c76a3352657」(Nicole Wade)のCustomerノードから開始します。- エッジ
OwnsEmail、OwnsPhone、LinkedToAddressのいずれかに沿って、接続ノード(Phone、Email、Address)に移動します。 - その接続ノードから他の
Customerノードにエッジをたどります。 - タイムスタンプ(
last_updated_ts)に基づいてエッジをフィルタし、特定の時点のネットワークの状態を確認します。
Zachary Cordova と Brenda Brown が同じアドレスで Nicole に接続されていることがわかります。
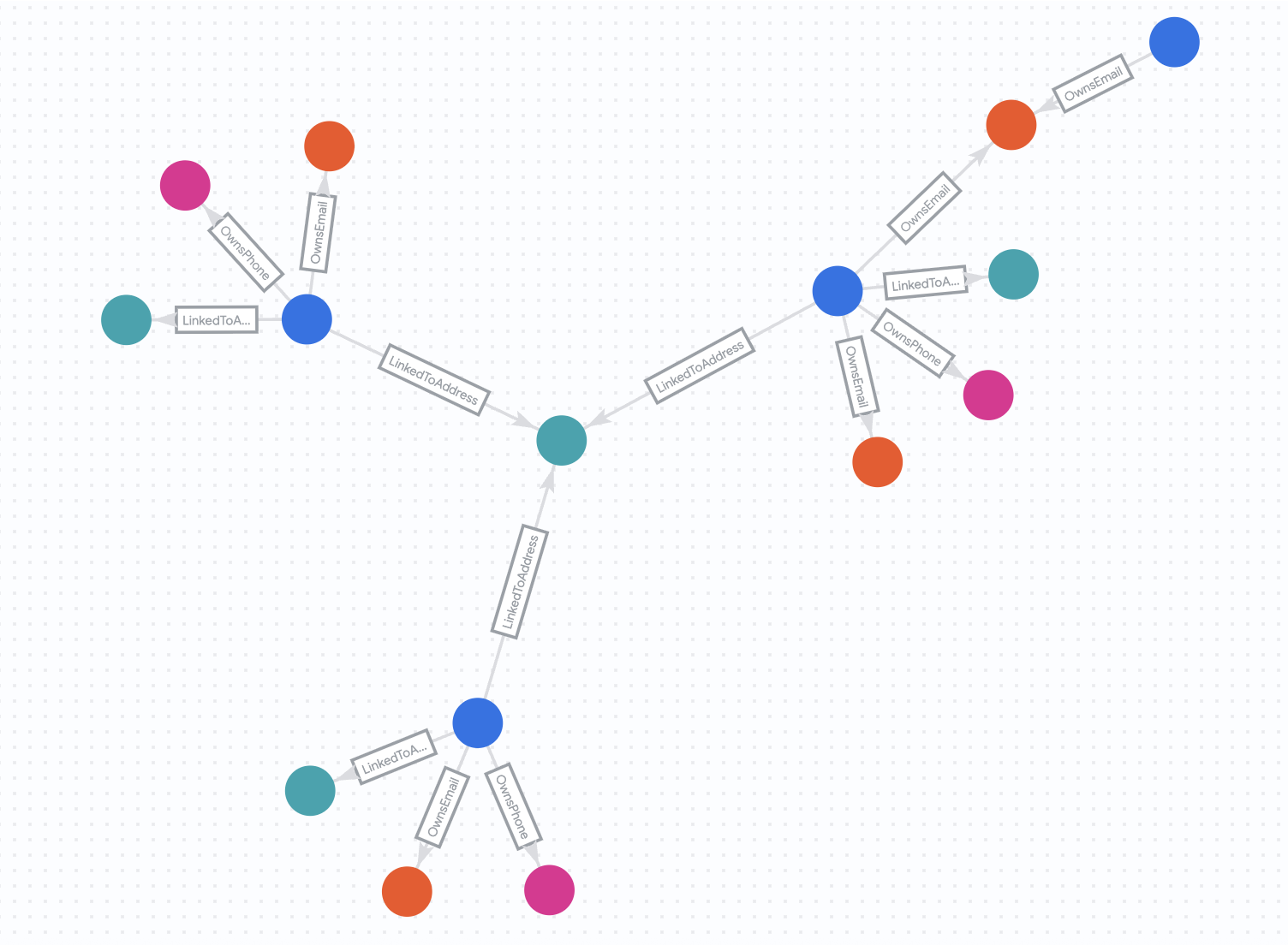
6. ネットワークを分析する(4 ホップ)
このステップでは、より複雑な関係を見つけるようにクエリを拡張します。4 ホップ接続を探します。これにより、複数の仲介エンティティ(顧客 A -> メール -> 顧客 B -> 電話 -> 顧客 C など)を介して接続されているアカウントを見つけることができます。
また、このネットワークが時間の経過とともにどのように変化するかを観察します。
「Before」の状態
まず、2025 年 7 月 30 日時点のネットワークを見てみましょう。
次のクエリを実行します。
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH p= ANY SHORTEST (a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress WHERE e.last_updated_ts < '2025-07-30']- (n) ){3, 5}(reachable_a:Customer)
WHERE a.account_id IN ("d2f1f992-d116-41b3-955b-6c76a3352657")
-- Ensure the final node in the dynamic chain is actually a Customer
AND 'Customer' IN UNNEST(LABELS(n[OFFSET(ARRAY_LENGTH(n) - 1)]))
RETURN
TO_JSON(p) AS paths, -- Array of all traversed edges
ARRAY_LENGTH(e) AS hop_count
「After」の状態
次に、2 週間後のネットワークを見てみましょう。同じクエリを日付制限なしで実行します。
次のクエリを実行します。
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH p= ANY SHORTEST (a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress]- (n) ){3, 5}(reachable_a:Customer)
WHERE a.account_id IN ("d2f1f992-d116-41b3-955b-6c76a3352657")
-- Ensure the final node in the dynamic chain is actually a Customer
AND 'Customer' IN UNNEST(LABELS(n[OFFSET(ARRAY_LENGTH(n) - 1)]))
RETURN
TO_JSON(p) AS paths, -- Array of all traversed edges
ARRAY_LENGTH(e) AS hop_count
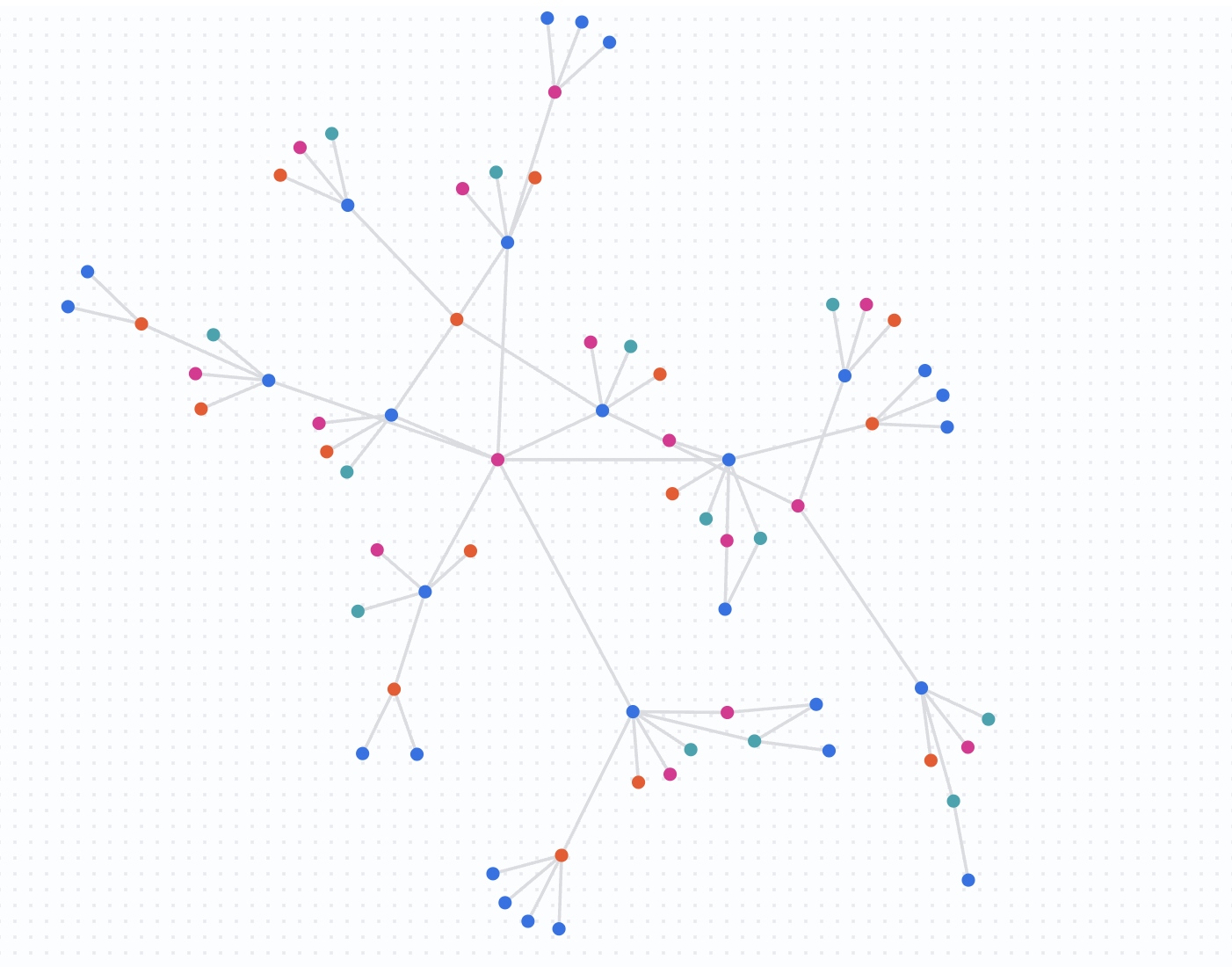
結果を把握する
日付フィルタを削除すると、データセット全体に対してクエリが実行されます。ネットワークが大幅に拡大していることがわかります。Nicole Wade は、より大規模でつながりの強いグループの一員になりました。接続されたネットワークの急速な拡大は、詐欺グループがリソースを共有しているなど、不正行為の可能性が高いことを示す強力な指標です。
7. 不正行為レポートを生成する
このステップでは、グラフ分析と従来のビジネスデータ(注文)を組み合わせて、包括的な不正行為レポートを生成します。リスクのあるアカウントと不正な注文の可能性を特定します。
このクエリはより複雑です。GRAPH_TABLE を使用して標準 SQL 内でグラフクエリを実行し、前のステップで確認した「前」の状態と「後」の状態のネットワーク サイズの変化(diff)を計算します。
不正行為レポートのクエリを実行する
ノートブックで次のクエリを実行します。
%%bigquery --graph
WITH num_orders AS (
SELECT account_id, COUNT(1) AS num_order
FROM fraud_demo.orders
WHERE order_time > '2025-07-30'
GROUP BY account_id
),
orders AS (
SELECT account_id, order_id, fraud, order_total
FROM fraud_demo.orders
WHERE order_time > '2025-07-30'
),
-- Use Quantified Path Patterns to find connections up to 4 hops away
latest_connect AS (
SELECT
account_id,
ARRAY_LENGTH(ARRAY_AGG(DISTINCT connected_id)) AS size
FROM GRAPH_TABLE(
fraud_demo.FraudDemo
MATCH (a:Customer)-[:OwnsEmail|OwnsPhone|LinkedToAddress]-{4}(connected:Customer)
RETURN a.account_id AS account_id, connected.account_id AS connected_id
)
GROUP BY account_id
),
prev_connect AS (
SELECT
account_id,
ARRAY_LENGTH(ARRAY_AGG(DISTINCT connected_id)) AS size
FROM GRAPH_TABLE(
fraud_demo.FraudDemo
-- Apply the timestamp filter to EVERY edge in the 4-hop chain
MATCH (a:Customer)
(-[e:OwnsEmail|OwnsPhone|LinkedToAddress WHERE e.last_updated_ts < '2025-07-30']-(n)){4}
WHERE 'Customer' IN UNNEST(LABELS(n[OFFSET(3)]))
RETURN a.account_id AS account_id, n[OFFSET(3)].account_id AS connected_id
)
GROUP BY account_id
),
edge_changes AS (
SELECT account_id, MAX(last_updated_ts) AS max_last_updated_ts
FROM fraud_demo.customer_addresses
GROUP BY account_id
)
SELECT
la.account_id,
o.order_id,
la.size AS latest_size,
COALESCE(pa.size, 0) AS previous_size,
la.size - COALESCE(pa.size, 0) AS diff,
nos.num_order,
o.fraud AS reported_as_fraud,
o.order_total,
CASE
WHEN (la.size - COALESCE(pa.size, 0)) > 10 AND nos.num_order IS NULL THEN "CUSTOMER AT RISK"
WHEN (la.size - COALESCE(pa.size, 0)) > 10 AND nos.num_order IS NOT NULL AND o.fraud THEN "CONFIRMED FRAUD ORDER"
WHEN (la.size - COALESCE(pa.size, 0)) > 10 AND nos.num_order IS NOT NULL AND NOT o.fraud THEN "POTENTIAL FRAUD ORDER"
ELSE ""
END AS notes
FROM latest_connect la
LEFT JOIN prev_connect pa ON la.account_id = pa.account_id
LEFT JOIN num_orders nos ON la.account_id = nos.account_id
LEFT JOIN orders o ON la.account_id = o.account_id
INNER JOIN edge_changes ec ON la.account_id = ec.account_id
WHERE nos.num_order > 1 OR (la.size - COALESCE(pa.size, 0)) > 10
ORDER BY diff DESC
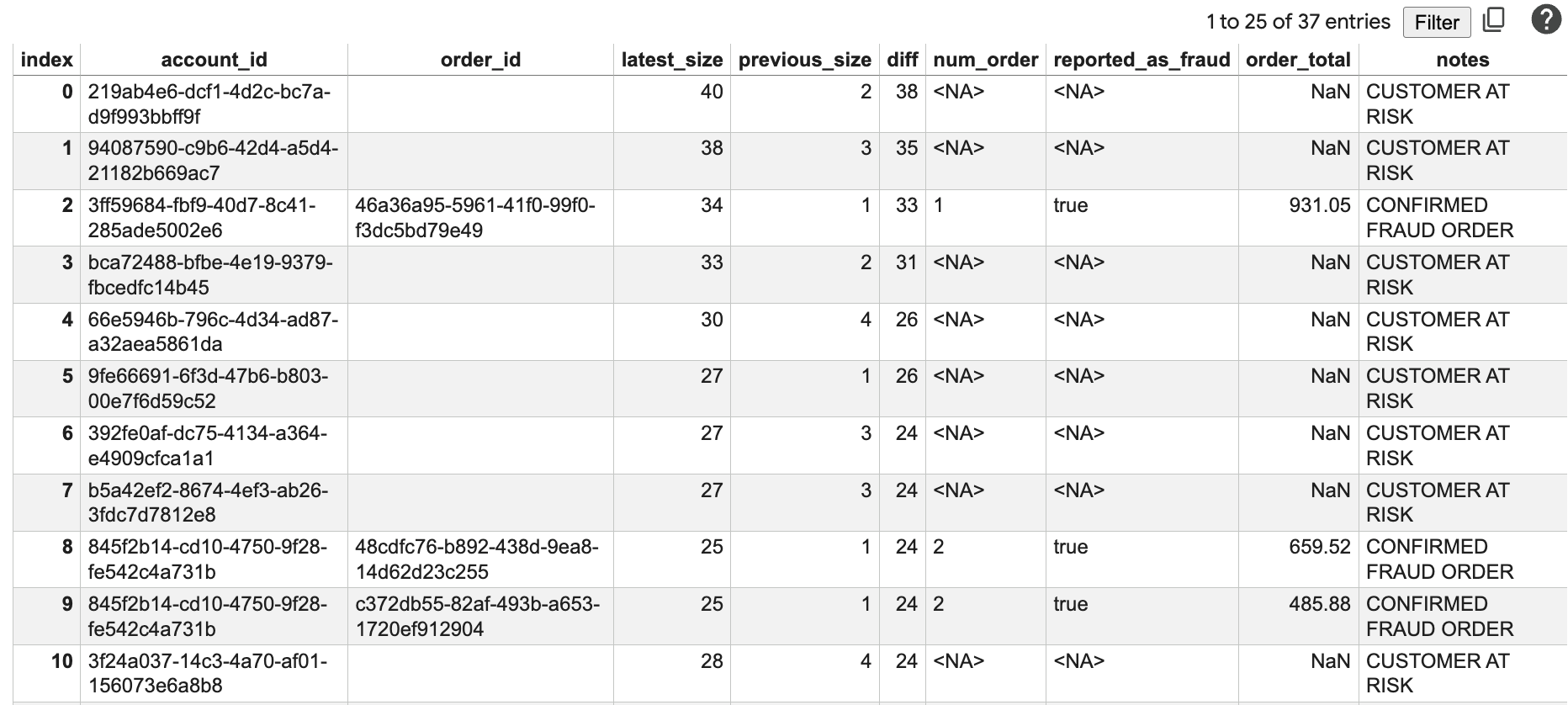
結果を把握する
このレポートには次の情報が表示されます。
account_id: 分析対象のアカウントの ID。order_id: 最近の注文 ID。latest_size: 現在の接続済みネットワークのサイズ。previous_size: 2 週間前のネットワークのサイズ。diff: ネットワーク サイズの増加。num_order: 最近の注文数。reported_as_fraud: 注文が不正行為としてフラグ設定されているかどうか。order_total: 注文の合計金額。notes: ネットワークの拡大と注文履歴に基づいて計算されたリスク ステータス。
diff の値が大きく、注文合計額が高いアカウントが表示されます。これらのアカウントは、さらに調査する候補となります。「CUSTOMER AT RISK」と「POTENTIAL FRAUD ORDER」のメモは、これらのアカウントの優先順位付けに役立ちます。
8. 大規模な検出
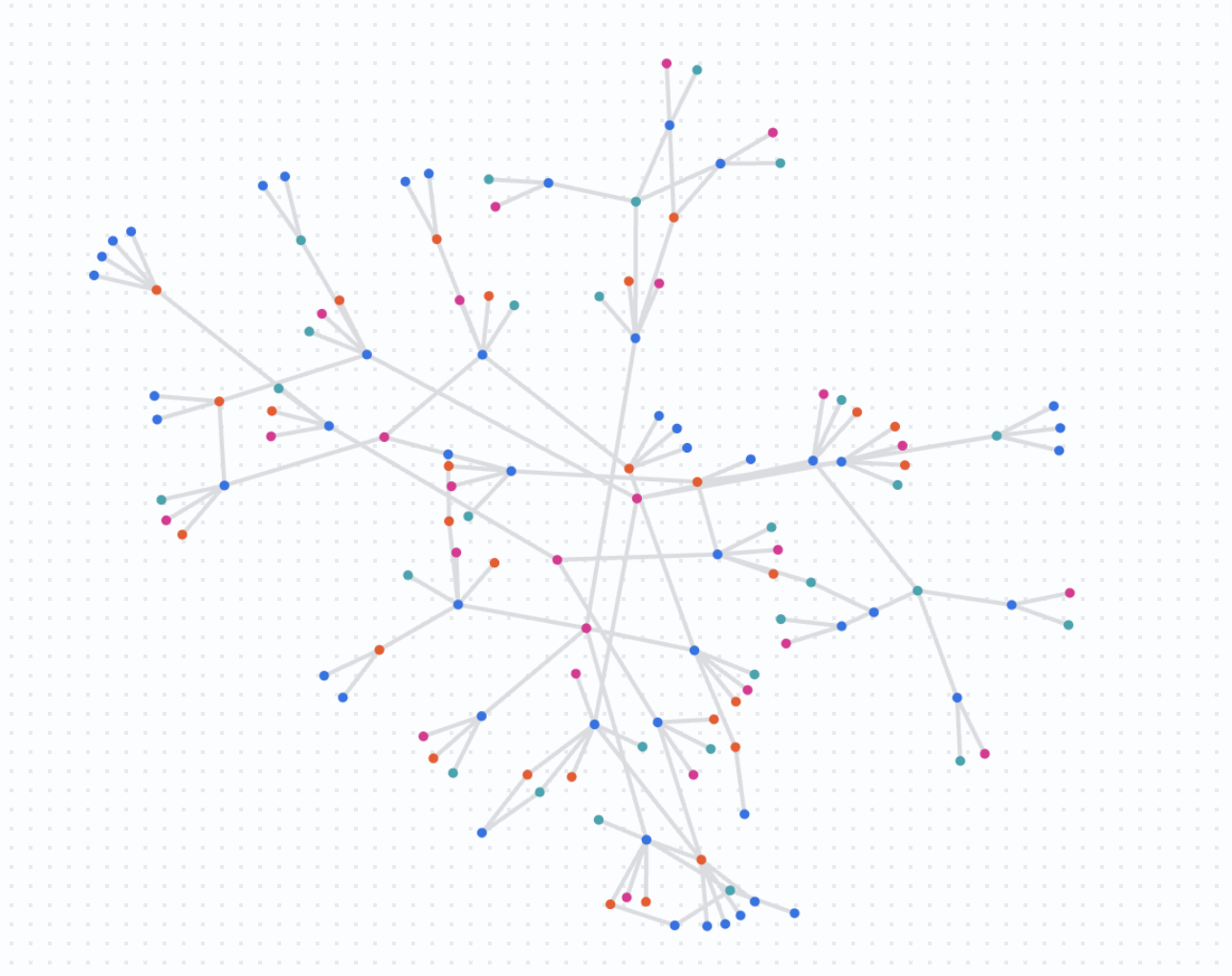
この最後の分析ステップでは、ネットワークをより大きなスケールで可視化します。単一のアカウントから開始するのではなく、一連の疑わしいアカウント間の接続をクエリします。
これにより、複数の独立した調査が実際には同じ大規模な不正行為グループの一部であるかどうかを確認できます。
スケーリングされたクエリを実行する
ノートブックで次のクエリを実行します。
%%bigquery --graph
GRAPH fraud_demo.FraudDemo
MATCH
p= ANY SHORTEST (a:Customer)
( -[e:OwnsEmail|OwnsPhone|LinkedToAddress]- (n) ){3, 5}
(reachable_a:Customer)
-- these IDs are from the previous results
WHERE a.account_id in ( "845f2b14-cd10-4750-9f28-fe542c4a731b"
, "3ff59684-fbf9-40d7-8c41-285ade5002e6"
, "8887c17b-e6fb-4b3b-8c62-cb721aafd028"
, "03e777e5-6fb4-445d-b48c-cf42b7620874"
, "81629832-eb1d-4a0e-86da-81a198604898"
, "845f2b14-cd10-4750-9f28-fe542c4a731b",
"89e9a8fe-ffc4-44eb-8693-a711a3534849"
)
LIMIT 400
RETURN TO_JSON(p) as paths
結果を把握する
このクエリは、指定された不審なアカウントがどのように重複し、リソースを共有しているかを示す複雑なグラフを返します。大規模な不正行為の検出を行い、連携した対応が必要となる可能性のあるアクティビティのクラスタを特定します。
9. クリーンアップ
この Codelab で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、データセットとプロパティ グラフを削除します。
次の SQL ステートメントを実行して、環境をクリーンアップします。
DROP PROPERTY GRAPH IF EXISTS fraud_demo.FraudDemo;
DROP SCHEMA IF EXISTS fraud_demo CASCADE;
10. 完了
おめでとうございます!BigQuery Graph を使用して不正行為検出ソリューションを構築できました。
ここでは次の内容を学習しました。
- Cloud Storage から BigQuery にデータを読み込む。
- DDL を使用してプロパティ グラフを定義します。
- GQL を使用してグラフをクエリし、単純な関係と複雑な関係を見つけます。
- グラフ分析とビジネスデータを組み合わせてリスクを特定します。
- ネットワークを大規模に可視化する。