
1. 簡介
總覽
現今的資料倉儲技術,串流分析架構的重要性已日益提高,因為企業使用者即時分析的需求持續增加。我們大幅改善了倉儲中的資料更新間隔,並支援串流分析,但資料工程師在改用資料倉儲架構時,還是面臨各種難題。
在這篇網誌文章中,我們會討論資料工程師在解決這些用途時最常面臨的幾項挑戰。我們概述了使用 BigQuery 有效率地匯總串流資料的設計概念和架構模式。
資料更新間隔和準確性
「最近」是指匯總資料延遲時間低於某個門檻,例如「截至最近一小時的資料」。更新間隔取決於匯總所含原始資料。
處理串流資料時,事件通常會在 Google 資料處理系統內延遲,也就是說,系統處理事件的時間明顯晚於事件發生時間。
處理遲到的資料時,匯總統計資料的值會有所改變,這表示分析師看到的資料在一天內會發生變化 [1]。所謂的「準確」,是指匯總統計資料會盡可能接近最終且已對帳金額。
最佳化的第三個維度當然是費用和成效的三大要素。舉例說明,我們可以使用「測試環境」和「報表」中的資料物件邏輯資料檢視。使用邏輯檢視的缺點是,每次查詢匯總資料表時,系統就會掃描整個原始資料集,因此會很慢且成本高昂。
情境說明
我們來設定這個用途的階段。我們將擷取 Wikimedia 發布的 Wikipedia 事件串流資料。我們的目標是建立一個排行榜,向作者顯示變化最多的項目,並在發布新文章時立即更新。我們的排行榜會以 BI Engine 資訊主頁的形式實作,並依使用者名稱匯總原始事件並計算分數 [2]。
2. 設計
資料階層
在資料管道中,我們將定義多個資料層級。我們會保留原始事件資料,並建立後續轉換、擴充和匯總的管道。我們不會將報表表格直接連結至原始資料表中的資料,因為我們希望統合及集中處理不同團隊在階段性資料上所關心的轉換作業。
這個架構的一個重要原則,是較高的層級 (Staging 和 Reporting) 隨時可以只使用原始資料重新計算。
分區
BigQuery 支援兩種分區樣式;整數範圍分區和日期分區。本文只考量日期分區。
以日期分區時,您可以選擇擷取時間分區或以欄位為基礎的分區。擷取時間分區會根據取得資料的時間,將資料傳入分區。使用者也可以指定分區修飾符,在載入時選取分區。
欄位分區會根據資料欄中的日期或時間戳記值將資料分區。
為擷取事件,我們會將資料放入擷取時間分區的資料表。這是因為擷取時間與處理或重新處理過去收到的資料有關。歷來資料的補充作業也可以根據資料的抵達時間分區,儲存在擷取時間分區中。
在本程式碼研究室中,我們假設將不會收到 Wikimedia 事件串流的延遲資訊 [3]。這樣可簡化暫存資料表的漸進式載入程序,如下所述。
在測試表格中,我們會根據事件時間進行分區。這是因為我們的分析人員想根據事件的發生時間 (也就是文章在 Wikipedia 的發布時間) 來查詢資料,而不是根據事件在管道中處理的時間。
3. 建築
建構項目
為了從 Wikimedia 讀取事件串流,我們會使用 SSE 通訊協定。我們會編寫一個小型中介軟體服務,以 SSE 用戶端的形式讀取事件串流,並發布至 GCP 環境中的 Pub/Sub 主題。
Pub/Sub 能取得事件後,我們會使用範本建立 Cloud Dataflow 工作,以便將記錄串流至 BigQuery 資料倉儲中的「原始」資料層。下一步是計算匯總統計資料,支援即時排行榜功能。
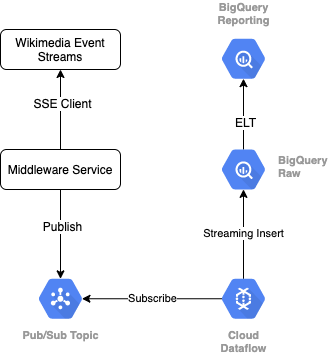
排程和協調
針對用於填入倉儲準備階段和報表層級的 ELT,我們會使用 Dataform。Dataform:「提供工具、最佳做法及軟體工程導向的工作流程」資料工程團隊除了自動化調度管理和排程作業外,Dataform 還提供用於確保品質的宣告和測試等功能,以及定義用於資料庫管理作業的自訂倉儲作業,以及支援資料探索的說明文件功能。
作者感謝 Dataform 團隊在審查本研究室和網誌時提供寶貴意見。
在 Dataform 中,從 Dataflow 串流的原始資料串流會宣告為外部資料集。系統會使用 Dataform 的 SQLX 語法,以動態方式定義準備時間與報表表格。
我們會利用 Dataform 的漸進式載入功能填入暫存資料表,並安排 Dataform 專案每小時執行一次。如上所述,我們假設我們不會收到遲到的資訊,因此邏輯會擷取事件時間晚於現有暫存記錄的事件時間的記錄。
在本系列的後續研究室中,我們會討論如何處理遲到的資訊。
執行整個專案時,上游資料層會新增所有新的記錄,並重新計算匯總結果。請特別注意,每項執行作業都會重新整理匯總資料表。我們的實體設計包括依 username 將暫存資料表分群,進一步提升匯總查詢的效能,讓匯總查詢在重新整理這個排行榜時更得心應手。
軟硬體需求
- 新版 Chrome
- 具備 SQL 基本知識以及 BigQuery 基本知識
4. 開始設定
為原始層級建立 BigQuery 資料集和資料表
建立包含倉儲結構定義的新資料集。我們稍後也會使用這些變數,因此請務必使用相同的殼層工作階段進行下列步驟,或視需要設定變數。請務必替換 <PROJECT_ID>替換為您的專案 ID。
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
接下來,我們會使用 GCP 控制台建立用來保存原始事件的資料表。這個結構定義會與透過 Wikimedia 使用的已發布變更事件串流中專案串流相符的欄位。
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
建立 Pub/Sub 主題和訂閱項目
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
建立 Dataform 帳戶和專案
前往 https://app.dataform.co 建立新帳戶。登入後,您將會建立新專案。
在專案中,您必須設定與 BigQuery 的整合。Dataform 需要連結至倉儲,因此我們必須佈建服務帳戶憑證。
請按照 Dataform 文件上方連結的步驟操作,在「Database」頁面設定與 BigQuery 的連線。請務必選取您在上述步驟中建立的 projectId,然後上傳憑證並測試連線。
設定 BigQuery 整合功能後,您會在「模型」分頁中看到可用的資料集。這裡特別列出了我們用來從 Dataflow 擷取事件的原始資料表。讓我們等一下再回頭討論。
5. 實作
建立 Python 服務以讀取事件並發布至 Pub/Sub
請一併參閱這份參考指南中的 Python 程式碼。我們將參考這個範例中的 Pub/Sub API 說明文件。
請記下程式碼中的「鍵」清單,這些欄位是從完整 JSON 事件投影出來的欄位,會保留在已發布的訊息中,最後則是 BigQuery 資料集原始級的 wiki_changes 資料表中。
這些資料表與我們在 BigQuery 資料集內針對 wiki_changes 所定義的 wiki_changes 資料表結構定義相符
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. 導入 (續)
使用範本建立 Dataflow 工作,以便從 Pub/Sub 讀取及寫入 BigQuery
將最近的變更事件發布至 Pub/Sub 主題後,我們就能使用 Cloud Dataflow 工作讀取這些事件,並將這些事件寫入 BigQuery。
如果我們在處理串流時有複雜需求 (例如彙整不同的串流、建構視窗式匯總作業,以及使用查詢功能充實資料),則可在 Apache Beam 程式碼中實作。
這個用途的需求更加簡單,因此我們可以使用立即可用的 Dataflow 範本,不需要自訂任何自訂項目。我們可以直接透過 Cloud Dataflow 中的 GCP 控制台執行這項作業。
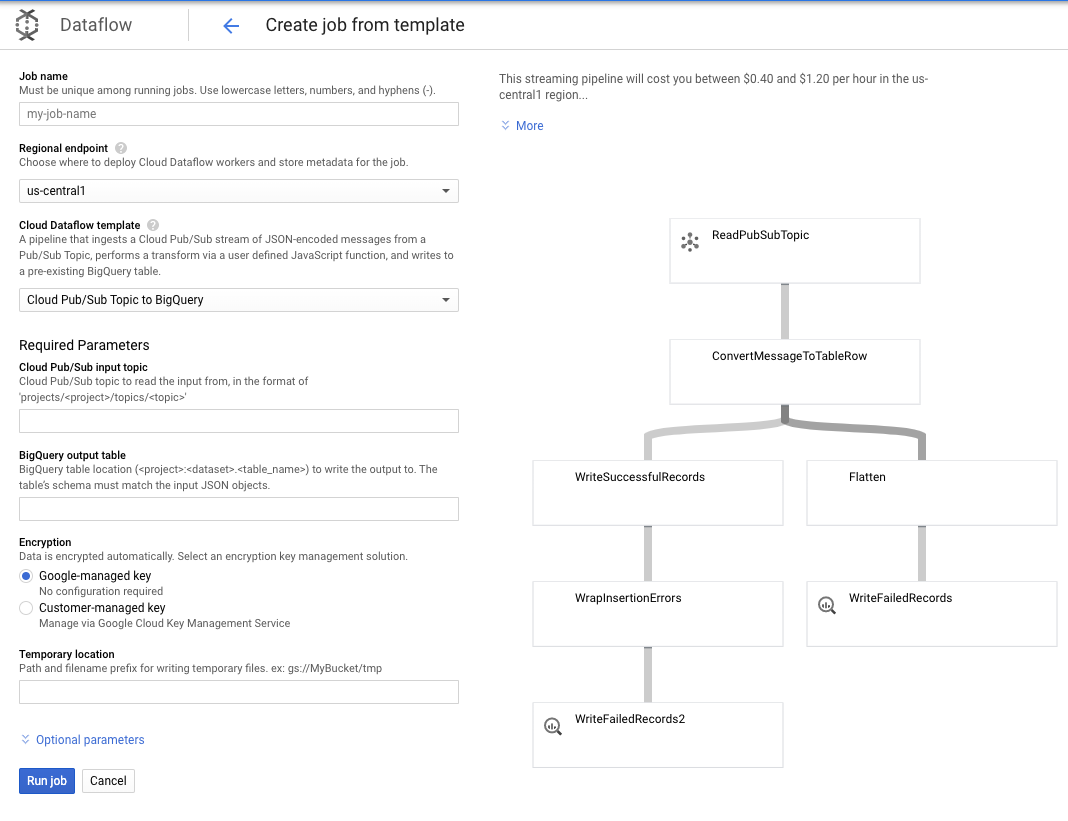
我們會使用「Pub/Sub 主題到 BigQuery」範本,接著只需要在 Dataflow 範本中設定幾項內容,包括 Pub/Sub 輸入主題和 BigQuery 輸出資料表。
7. 導入、Dataform 步驟
Dataform 中的模型資料表
我們的 Dataform 模型與下列 GitHub 存放區連結,定義資料夾包含定義資料模型的 SQLX 檔案。
如「排程和協調」一節所述,我們會在 Dataform 中定義暫存表格,用來匯總 wiki_changes 的原始記錄。我們來看看暫存資料表的 DDL (也可在與 Dataform 專案連結的 GitHub 存放區中連結)。
請留意此表格的幾項重要功能:
- 其設定為遞增類型,因此當排定的 ELT 工作執行時,只會加入新的記錄
- 如底部的 when() 程式碼所示,此邏輯的邏輯以 timestamp 欄位為準,後者反映事件串流中的時間戳記,也就是變更的 event_time
- 這會使用 user 欄位建立叢集,也就是說,每個分區內的記錄會按 user 排序,從而減少建構排行榜的查詢需要的重組
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
我們需要在專案中定義的另一個表格是「報表層級」表格,此表格將支援排行榜查詢。報表層級的表格會經過匯總,因為使用者關注的是已發布 Wikipedia 中即時更新且準確的數量。
資料表定義相當簡單,並使用 Dataform 參照。在這些參照中,它們可明確表示物件之間的依附關係,確保依附元件一律在相依查詢「之前」執行,可支援管道正確性。
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
安排 Dataform 專案
最後一步是建立每小時執行的排程。叫用專案時,Dataform 會執行必要的 SQL 陳述式,以重新整理漸進式暫存資料表,並重新載入匯總資料表。
這個排程可以每小時叫用 (甚至更頻繁,大約每 5 到 10 分鐘),讓排行榜能夠根據已串流到系統的最新事件更新排行榜。
8. 恭喜
恭喜!您已成功為串流資料建立分層資料架構!
我們首先從 Wikimedia 事件串流著手,並已將這個事件轉換為 BigQuery 中的報表表格,顯示持續最新的資料。
後續步驟
其他資訊
[1] 資料工程師常常執行每日批次轉換,以覆寫當天 (例如每小時) 的匯總資料,這就稱為對帳。
[2] 如需實作詳情,請參閱架構一節。
[3] 延遲事件是指含有 event_time 的事件,此事件晚於系統在同一事件串流中已處理的記錄