
1. مقدمة
نظرة عامة
تزايدت أهمية أطر عمل تحليل بيانات البث في عمليات تخزين البيانات المعاصرة، مع ازدياد أهمية الطلب على التحليلات في الوقت الفعلي بلا انقطاع. تم اتخاذ خطوات كبيرة لتحسين حداثة البيانات داخل المستودعات ولدعم تحليلات البث بشكل عام، ولكن لا يزال مهندسو البيانات يواجهون صعوبات عند تكييف مصادر البث هذه مع بنية مستودعات البيانات الخاصة بهم.
في هذه المدونة، نناقش بعض التحديات الأكثر شيوعًا التي يواجهها مهندسو البيانات عند حل حالات الاستخدام هذه. نحدّد بعض أفكار التصميم والأنماط الهندسية لإجراء تجميع فعال للبيانات المتدفقة باستخدام BigQuery.
حداثة البيانات ودقتها
ونعني بكلمة حداثة أنّ وقت استجابة البيانات المجمّعة يقل عن حدّ معيّن، على سبيل المثال "محدَّثًا اعتبارًا من الساعة الأخيرة". يتم تحديد الحداثة من خلال مجموعة فرعية من البيانات الأولية التي يتم تضمينها في التجميعات.
عند التعامل مع بيانات البثّ، من الشائع جدًا أن تتأخّر الأحداث في نظام معالجة البيانات، ما يعني أنّ الوقت الذي يعالج فيه النظام أحد الأحداث يقع بعد وقت كبير من وقت وقوع الحدث.
عندما نعالج الحقائق التي وصلت متأخرة، ستتغير قيم إحصاءاتنا المجمّعة، مما يعني أنه على أساس يومي، ستتغير القيم التي يراها المحللون[1]. ونعني بكلمة دقيق أنّ الإحصاءات المجمّعة تكون أقرب ما يمكن إلى القيم النهائية التي تمت مطابقتها.
وبالطبع، هناك جانب ثالث للتحسين، وهو: التكلفة - بمعنى بالدولار والأداء. للتوضيح، يمكننا الاستفادة من طريقة عرض منطقية لكائنات البيانات في التقسيم وإعداد التقارير. يتمثل الجانب السلبي لاستخدام طريقة عرض منطقية في أنه في كل مرة يتم فيها الاستعلام عن الجدول المجمّع، يتم فحص مجموعة البيانات الأولية بالكامل، والتي ستكون بطيئة ومكلفة.
وصف السيناريو
لنمهد الطريق لحالة الاستخدام هذه. نحن بصدد نقل بيانات "ساحات أحداث Wikipedia" التي تنشرها موسوعة ويكيبيديا. وهدفنا هو إنشاء قائمة صدارة تعرض المؤلفين الذين أجروا أكبر قدر من التغييرات، وسيتم تحديثها عند نشر مقالات جديدة. ستُجمِّع "لوحة الصدارة"، التي سيتم تنفيذها على أنها لوحة بيانات محرّك ذكاء الأعمال، الأحداث الأولية حسب اسم المستخدم لاحتساب النتائج[2].
2. التصميم
تقسيم البيانات إلى مستويات
في مسار البيانات، سنحدد مستويات متعددة من البيانات. وسنحتفظ ببيانات الأحداث الأوليّة وسنُنشئ مسارًا لعمليات التحويل والإثراء والتجميع اللاحقة. لا نربط جداول إعداد التقارير مباشرةً بالبيانات المحفوظة في الجداول الأولية، لأنّنا نريد توحيد عمليات التحويل التي تهتم بها الفِرق المختلفة بشأن البيانات المرحلية وجعلها مركزية.
أحد المبادئ المهمة في هذه البنية هو إمكانية إعادة حساب المستويات الأعلى - وهي التقسيم المرحلي وإعداد التقارير - في أي وقت باستخدام البيانات الأولية فقط.
التقسيم
يدعم BigQuery نمطين للتقسيم؛ تقسيم نطاق العدد الصحيح وتقسيم التاريخ. سوف نتناول فقط تقسيم التاريخ في النطاق لهذه المشاركة.
بالنسبة إلى تقسيم التاريخ، يمكننا الاختيار بين أقسام وقت النقل أو التقسيمات المستندة إلى الحقول. يؤدي تقسيم وقت النقل إلى تجميع البيانات في قسم استنادًا إلى وقت الحصول على البيانات. ويمكن للمستخدمين أيضًا اختيار قسم في وقت التحميل من خلال تحديد أداة تصميم الأقسام.
يؤدي هذا الخيار إلى تقسيم بيانات الأقسام استنادًا إلى قيمة التاريخ أو الطابع الزمني في العمود.
بالنسبة إلى عرض الأحداث، سننقل البيانات إلى جدول مقسّم لوقت نقل البيانات. ويرجع ذلك إلى أنّ وقت العرض مرتبط بمعالجة أو إعادة معالجة البيانات التي تم تلقّيها في الماضي. يمكن أيضًا تخزين البيانات السابقة التي تمت إعادة عرضها ضمن أقسام وقت العرض، وذلك استنادًا إلى وقت وصولها.
نفترض في هذا الدرس التطبيقي حول الترميز أنّنا لن نتلقّى حقائق متأخرة[3] من سلسلة أحداث "ويكيميديا". سيؤدي هذا إلى تبسيط التحميل التدريجي لجدول التقسيم المرحلي، كما هو موضَّح أدناه.
في جدول التقسيم المرحلي، سيتم تقسيم الجدول حسب وقت الحدث. وذلك لأن المحللين لدينا مهتمون بالاستعلام عن البيانات بناءً على وقت الحدث - الوقت الذي تم فيه نشر المقالة على ويكيبيديا - وليس الوقت الذي تم فيه معالجة الحدث في مسار الأحداث.
3- البنية
ما الذي ستنشئه
للاطّلاع على بث الأحداث من Wikimedia، سنستخدم بروتوكول SSE. سنكتب خدمة وسيطة صغيرة للقراءة من تدفق الحدث كعميل SSE، وسيتم نشرها في موضوع النشر/الاشتراك في بيئة Google Cloud Platform.
بعد توفُّر الأحداث في النشر/الاشتراك، سننشئ مهمة Cloud Dataflow باستخدام نموذج لبث السجلات إلى مستوى البيانات الأولية في مستودع بيانات BigQuery. والخطوة التالية هي احتساب الإحصاءات المجمّعة لدعم قائمة الصدارة المباشرة.
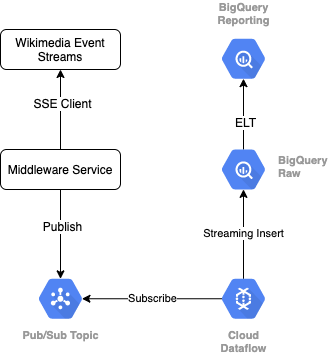
الجدولة والتنظيم
من أجل تنسيق تقنية ELT التي تملأ مستويَي "التنظيم" و"إعداد التقارير" في المستودع، سنستخدم نموذج البيانات. Dataform "يجمع الأدوات وأفضل الممارسات وسير العمل المستوحى من هندسة البرامج" إلى فرق هندسة البيانات. بالإضافة إلى التنسيق والجدولة، توفر أداة Dataform وظائف مثل التأكيدات والاختبارات لضمان الجودة وتحديد عمليات المستودع المخصصة لإدارة قاعدة البيانات وميزات التوثيق لدعم اكتشاف البيانات.
يشكر المؤلفون فريق Dataform على ملاحظاتهم القيمة في مراجعة هذا التمرين المعملي والمدونة.
ضمن Dataform، سيتم الإعلان عن البيانات الأولية التي يتم تدفقها من Dataflow كمجموعة بيانات خارجية. سيتم تحديد جدولَي "التقسيم المرحلي" و"إعداد التقارير" ديناميكيًا، باستخدام بنية SQLX في Dataform.
سنستخدم ميزة التحميل التزايدي في Dataform لتعبئة جدول التقسيم المرحلي وجدولة مشروع Dataform لتشغيله كل ساعة. وفقًا لما سبق، سنفترض أنّنا لن نتلقّا الحقائق التي يصل عددها متأخرًا، وبالتالي سيتم نقل السجلات التي تتضمّن وقت حدث يأتي بعد وقت أحدث حدث من بين السجلات المرحلية الحالية.
في الدروس التطبيقية اللاحقة ضمن هذه السلسلة، سنناقش كيفية معالجة الحقائق التي تظهر في وقت متأخر.
عندما ندير المشروع بأكمله، ستتم إضافة جميع السجلات الجديدة لمستويات البيانات الأولية، وستتم إعادة حساب التجميعات. وعلى وجه الخصوص، ستؤدي كل عملية تشغيل إلى إعادة تحميل الجدول المجمّع بالكامل. سيتضمن تصميمنا الفعلي تجميع الجدول المرحلي حسب اسم المستخدم، ما يزيد من أداء طلب تجميع البيانات الذي سيؤدي إلى إعادة تحميل قائمة الصدارة بشكل كامل.
المتطلبات
- إصدار حديث من Chrome
- معرفة أساسية بـ SQL والمعرفة الأساسية بـ BigQuery
4. بدء الإعداد
إنشاء مجموعة بيانات وجدول في BigQuery للطبقة الأولية
قم بإنشاء مجموعة بيانات جديدة لتحتوي على مخطط مستودعنا. سنستخدم أيضًا هذه المتغيرات لاحقًا، لذا تأكد من استخدام نفس جلسة الغلاف للخطوات التالية، أو قم بتعيين المتغيرات حسب الحاجة. التأكّد من استبدال <PROJECT_ID> بمعرف مشروعك.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
بعد ذلك، سننشئ جدولاً يضم الأحداث الأولية باستخدام وحدة تحكُّم Google Cloud Platform. سيطابق المخطط الحقول التي نعرضها من تدفق أحداث التغييرات المنشورة التي نستند إليها من Wikimedia.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
إنشاء اشتراك وموضوع نشر/الاشتراك
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
إنشاء حساب ومشروع على Dataform
انتقِل إلى https://app.dataform.co وأنشِئ حسابًا جديدًا. بعد تسجيل الدخول، عليك إنشاء مشروع جديد.
ضمن مشروعك، ستحتاج إلى ضبط الدمج مع BigQuery. بما أنّه يجب ربط نموذج البيانات بالمستودع، سنحتاج إلى توفير بيانات اعتماد حساب الخدمة.
يرجى اتباع الخطوات المرتبطة أعلاه داخل مستندات نموذج البيانات، ستقوم بتهيئة الاتصال بـ BigQuery في صفحة "قاعدة البيانات". تأكد من اختيار رقم تعريف المشروع نفسه الذي أنشأته أعلاه، ثم حمّل بيانات الاعتماد واختبر الاتصال.
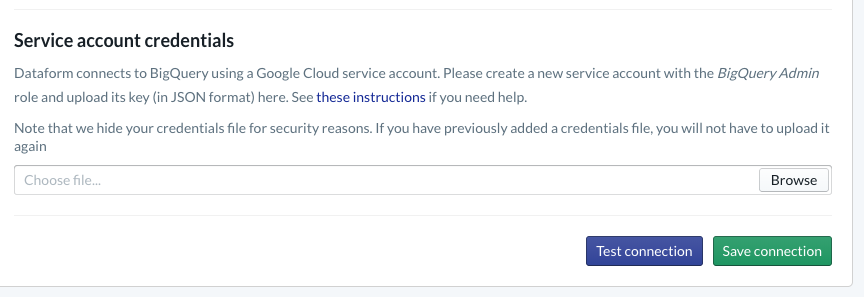
بعد ضبط تكامل BigQuery، ستظهر لك "مجموعات البيانات" متاحة ضمن علامة التبويب "إعداد النماذج". على وجه الخصوص، سيتوفّر هنا الجدول Raw الذي نستخدمه لتسجيل الأحداث من Dataflow. لنعد إلى هذه النقطة بعد قليل.
5- التنفيذ
إنشاء خدمة Python لقراءة الأحداث ونشرها في Pub/Sub
يُرجى الاطّلاع على رمز Python أدناه والمتاح ضمن هذا المعرّف أيضًا. ونحن نتابع مستندات واجهة برمجة تطبيقات Pub/Sub في هذا المثال.
يجب تدوين قائمة المفاتيح في الرمز البرمجي، وهي الحقول التي سننشئ مشروعًا خلالها من حدث JSON الكامل، وستستمر في الرسائل المنشورة، وفي النهاية في جدول wiki_changes ضمن الفئة الأولية من مجموعة بيانات BigQuery.
تتطابق هذه مع مخطط جدول wiki_changes الذي حددناه ضمن مجموعة بيانات BigQuery لـ wiki_changes
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6- التنفيذ: تابع
إنشاء مهمة Dataflow من النموذج للقراءة من Pub/Sub والكتابة في BigQuery
بعد نشر أحداث التغيير الأخيرة في موضوع النشر/الاشتراك، يمكننا الاستفادة من مهمة Cloud Dataflow لقراءة هذه الأحداث وكتابتها في BigQuery.
إذا كانت هناك احتياجات متطوّرة أثناء معالجة البث، يمكن مثلاً الانضمام إلى مجموعات بث مختلفة أو إنشاء مجموعات بيانات في نوافذ واستخدام عمليات البحث لتحسين البيانات، يمكننا عندئذٍ تنفيذها في رمز Apache Beam.
ولأن احتياجاتنا تكون أكثر وضوحًا في حالة الاستخدام هذه، يمكننا استخدام نموذج Dataflow غير الجاهز ولن نضطر إلى إجراء أي عمليات تخصيص عليه. يمكننا إجراء ذلك مباشرةً من وحدة تحكُّم Google Cloud Platform في Cloud Dataflow.
سنستخدم موضوع Pub/Sub to BigQuery، ثم نحتاج فقط إلى تكوين بعض الأشياء في قالب Dataflow، بما في ذلك موضوع إدخال Pub/Sub وجدول إخراج BigQuery.
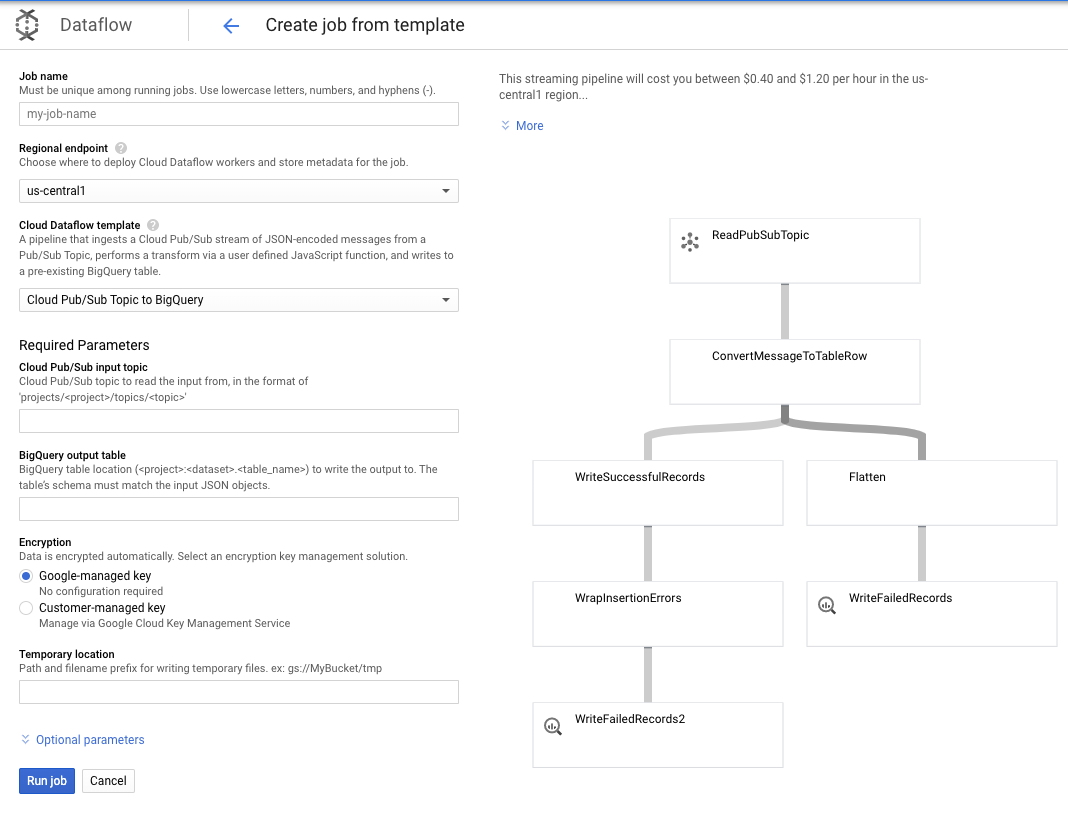
7. التنفيذ، خطوات شكل البيانات
جداول النماذج في نموذج البيانات
يرتبط نموذج "نموذج البيانات" بمستودع GitHub التالي، يحتوي مجلد التعريفات على ملفات SQLX التي تحدِّد نموذج البيانات.
كما هو موضح في قسم "الجدولة والتنظيم"، سنحدِّد جدول تقسيم مرحلي في Dataform يجمع السجلات الأولية من wiki_changes. لنلقِ نظرة على رابط DDL لجدول التقسيم المرحلي (مرتبط أيضًا في مستودع GitHub المرتبط بمشروع Dataform).
في ما يلي بعض الميزات المهمة في هذا الجدول:
- وقد تم إعداده كنوع تدريجي، لذلك عند تشغيل مهام ELT المجدولة، ستتم إضافة السجلات الجديدة فقط.
- كما يتم التعبير عنه بالرمز when() في الأسفل، يستند منطق حدوث ذلك إلى حقل الطابع الزمني، الذي يعكس الطابع الزمني في تدفق الحدث، أي event_time للتغيير
- ويتم تجميعها باستخدام الحقل user، ما يعني أنه سيتم ترتيب السجلات داخل كل قسم حسب المستخدم، ما يقلل الترتيب العشوائي الذي يتطلبه طلب البحث الذي ينشئ لوحة الصدارة.
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
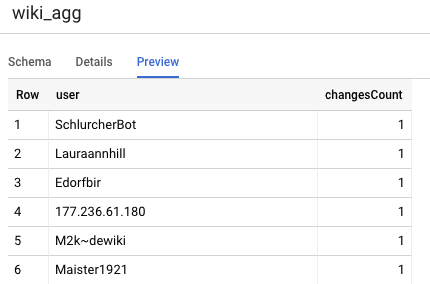
الجدول الآخر الذي نحتاج إلى تعريفه في مشروعنا هو جدول طبقة إعداد التقارير، والذي سيدعم استعلامات لوحة الصدارة. يتم تجميع الجداول في طبقة التقارير، حيث يشعر المستخدمون بالقلق بشأن الأعداد الحديثة والدقيقة للتغييرات التي تم نشرها على موسوعة ويكيبيديا.
تعريف الجدول واضح ومباشر، يستخدم مراجع شكل البيانات. تتمثل الميزة الكبيرة لهذه الإشارات في أنها توضح التبعيات بين الكائنات بوضوح، مما يدعم صحة خط الأنابيب من خلال التأكد من أن التبعيات يتم تنفيذها دائمًا قبل الاستعلامات التابعة.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
جدولة مشروع نموذج البيانات
الخطوة الأخيرة هي ببساطة إنشاء جدول يتم تنفيذه على أساس كل ساعة. عندما يتم استدعاء مشروعنا، سينفذ Dataform عبارات SQL المطلوبة لإعادة تحميل جدول التقسيم المرحلي وإعادة تحميل الجدول المجمّع.
ويمكن استدعاء هذا الجدول الزمني كل ساعة، أو حتى أكثر من ذلك، كل 5 إلى 10 دقائق تقريبًا، حتى يتم تحديث لوحة الصدارة بالأحداث الأخيرة التي تم بثها إلى النظام.
8. تهانينا
تهانينا، لقد نجحت في إنشاء بنية بيانات متدرجة للبيانات المتدفقة!
لقد بدأنا بتدفق أحداث Wikimedia وتم تحويله إلى جدول "إعداد التقارير" في BigQuery الذي يتم تحديثه باستمرار.
الخطوات التالية
قراءة إضافية
- التعرّف على نموذج البيانات
- هندسة البيانات الوظيفية: نموذج حديث لمعالجة البيانات المجمّعة
- كيفية تجميع البيانات في BigQuery باستخدام Apache Airflow
[1] من الشائع أن يقوم مهندسو البيانات بإجراء تحويل مجمّع يوميًا لاستبدال البيانات المجمَّعة خلال اليوم (على سبيل المثال، كل ساعة)، وهذا ما يُعرف باسم التسوية.
[2] للحصول على تفاصيل التنفيذ، يُرجى الرجوع إلى قسم "التصميم".
[3] تَأخُّر الوصول إلى حدث يتضمّن حدث event_time متأخرًا عن السجلّات التي عالجها النظام ضمن سلسلة الأحداث نفسها