
1. ভূমিকা
ওভারভিউ
স্ট্রিমিং বিশ্লেষণের জন্য ফ্রেমওয়ার্কগুলি সমসাময়িক ডেটা গুদামজাতকরণে ক্রমবর্ধমান গুরুত্বপূর্ণ হয়ে উঠেছে, কারণ রিয়েল-টাইম অ্যানালিটিক্সের জন্য ব্যবসায়িক ব্যবহারকারীদের চাহিদা নিরবচ্ছিন্নভাবে অব্যাহত রয়েছে। গুদামগুলির অভ্যন্তরে ডেটা সতেজতা উন্নত করতে এবং সাধারণত স্ট্রিমিং বিশ্লেষণকে সমর্থন করার জন্য বড় অগ্রগতি করা হয়েছে, তবে ডেটা ইঞ্জিনিয়াররা তাদের ডেটা গুদাম স্থাপত্যে এই স্ট্রিমিং উত্সগুলিকে অভিযোজিত করার সময় এখনও চ্যালেঞ্জের মুখোমুখি হন।
এই ব্লগে, আমরা এই ব্যবহারের ক্ষেত্রে সমাধান করার সময় ডেটা ইঞ্জিনিয়ারদের মুখোমুখি হওয়া কয়েকটি সাধারণ চ্যালেঞ্জ নিয়ে আলোচনা করি। আমরা BigQuery ব্যবহার করে স্ট্রিমিং ডেটার দক্ষ একত্রিত করার জন্য কিছু নকশা ধারণা এবং স্থাপত্য নিদর্শনের রূপরেখা দিই।
ডেটা সতেজতা এবং নির্ভুলতা
ফ্রেশ দ্বারা, আমরা বলতে চাচ্ছি যে সমষ্টির ডেটা লেটেন্সি কিছু থ্রেশহোল্ডের চেয়ে কম, যেমন, "শেষ ঘন্টার হিসাবে আপ টু ডেট"৷ সতেজতা কাঁচা ডেটার উপসেট দ্বারা নির্ধারিত হয় যা সমষ্টিতে অন্তর্ভুক্ত করা হয়।
স্ট্রিমিং ডেটা নিয়ে কাজ করার সময়, আমাদের ডেটা প্রসেসিং সিস্টেমের মধ্যে ইভেন্টগুলি দেরিতে আসা খুবই সাধারণ ব্যাপার, যার অর্থ হল যে সময়ে আমাদের সিস্টেম একটি ইভেন্ট প্রক্রিয়া করে তা ঘটনাটি ঘটার সময়ের চেয়ে উল্লেখযোগ্যভাবে পরে।
যখন আমরা দেরিতে আসা তথ্যগুলিকে প্রক্রিয়া করি, তখন আমাদের সমষ্টিগত পরিসংখ্যানের মানগুলি পরিবর্তিত হবে, যার অর্থ হল একটি অন্তর-দিনের ভিত্তিতে, বিশ্লেষকরা যে মানগুলি দেখেন তা পরিবর্তিত হবে[1]। নির্ভুল দ্বারা, আমরা বলতে চাই যে সমষ্টিগত পরিসংখ্যানগুলি চূড়ান্ত, মিলিত মানগুলির যতটা সম্ভব কাছাকাছি।
অপ্টিমাইজ করার জন্য একটি তৃতীয় মাত্রা আছে, অবশ্যই: খরচ–ডলার এবং পারফরম্যান্স উভয়ের অর্থেই। ব্যাখ্যা করার জন্য, আমরা স্টেজিং এবং রিপোর্টিং-এ ডেটা অবজেক্টের জন্য একটি লজিক্যাল ভিউ ব্যবহার করতে পারি। যৌক্তিক দৃষ্টিভঙ্গি ব্যবহার করার নেতিবাচক দিকটি হবে যে প্রতিবার সমষ্টিগত টেবিলটি জিজ্ঞাসা করা হয়, সমগ্র কাঁচা ডেটাসেটটি স্ক্যান করা হচ্ছে, যা ধীর এবং ব্যয়বহুল হবে।
দৃশ্যের বর্ণনা
আসুন এই ব্যবহারের ক্ষেত্রে স্টেজ সেট করি। আমরা উইকিপিডিয়া ইভেন্ট স্ট্রীম ডেটা গ্রহণ করতে যাচ্ছি যা উইকিমিডিয়া দ্বারা প্রকাশিত হয়েছে। আমাদের লক্ষ্য হল একটি লিডারবোর্ড তৈরি করা যা লেখকদের সর্বাধিক পরিবর্তনের সাথে দেখাবে এবং নতুন নিবন্ধ প্রকাশিত হওয়ার সাথে সাথে এটি আপ-টু-ডেট হবে। আমাদের লিডারবোর্ড, যা একটি BI ইঞ্জিন ড্যাশবোর্ড হিসাবে বাস্তবায়িত হবে, স্কোরগুলি গণনা করতে ব্যবহারকারীর নাম দ্বারা কাঁচা ঘটনাগুলিকে একত্রিত করবে[2]।
2. ডিজাইন
ডেটা টিয়ারিং
ডেটা পাইপলাইনে, আমরা ডেটার একাধিক স্তর সংজ্ঞায়িত করব। আমরা কাঁচা ইভেন্ট ডেটা ধরে রাখব এবং পরবর্তী রূপান্তর, সমৃদ্ধকরণ এবং একত্রিতকরণের একটি পাইপলাইন তৈরি করব। আমরা রিপোর্টিং টেবিলগুলিকে সরাসরি কাঁচা সারণীতে রাখা ডেটার সাথে সংযুক্ত করি না, কারণ আমরা সেই রূপান্তরগুলিকে একীভূত এবং কেন্দ্রীভূত করতে চাই যা বিভিন্ন দল স্টেজ করা ডেটার জন্য যত্ন করে৷
এই আর্কিটেকচারের একটি গুরুত্বপূর্ণ নীতি হল যে উচ্চতর স্তর-মঞ্চায়ন এবং রিপোর্টিং-কে শুধুমাত্র কাঁচা ডেটা ব্যবহার করে যে কোনও সময় পুনঃগণনা করা যেতে পারে।
বিভাজন
BigQuery পার্টিশনের দুটি শৈলী সমর্থন করে; পূর্ণসংখ্যা পরিসীমা পার্টিশন এবং তারিখ বিভাজন। আমরা এই পোস্টের সুযোগে শুধুমাত্র তারিখ বিভাজন বিবেচনা করব।
তারিখ বিভাজনের জন্য, আমরা ইনজেশন টাইম পার্টিশন বা ফিল্ড ভিত্তিক পার্টিশনের মধ্যে বেছে নিতে পারি। ইনজেশন টাইম পার্টিশনিং ডেটা কখন অর্জিত হয়েছিল তার উপর ভিত্তি করে একটি পার্টিশনে ডেটা ল্যান্ড করে। ব্যবহারকারীরা একটি পার্টিশন ডেকোরেটর উল্লেখ করে লোড টাইমে একটি পার্টিশন নির্বাচন করতে পারেন।
একটি কলামে তারিখ বা টাইমস্ট্যাম্প মানের উপর ভিত্তি করে ফিল্ড পার্টিশন পার্টিশন ডেটা।
ইভেন্টের ইনজেশনের জন্য, আমরা ডাটা ইনজেশন টাইম পার্টিশন করা টেবিলে ল্যান্ড করব। এর কারণ হল ইনজেশন সময় অতীতে প্রাপ্ত ডেটা প্রক্রিয়াকরণ বা পুনরায় প্রক্রিয়াকরণের জন্য প্রাসঙ্গিক। ঐতিহাসিক ডেটার ব্যাকফিলগুলি ইনজেশন টাইম পার্টিশনের মধ্যেও সংরক্ষণ করা যেতে পারে, সেগুলি কখন পৌঁছেছিল তার উপর ভিত্তি করে।
এই কোডল্যাবে, আমরা ধরে নেব যে আমরা উইকিমিডিয়া ইভেন্ট স্ট্রীম থেকে দেরিতে আসা তথ্যগুলি [3] পাব না। এটি স্টেজিং টেবিলের ক্রমবর্ধমান লোডিংকে সহজ করবে, যেমনটি নীচে আলোচনা করা হয়েছে।
স্টেজিং টেবিলের জন্য, আমরা ইভেন্টের সময় অনুসারে বিভাজন করব। এর কারণ হল আমাদের বিশ্লেষকরা ইভেন্টের সময়-উইকিপিডিয়াতে নিবন্ধটি প্রকাশিত হওয়ার সময়-এর উপর ভিত্তি করে ডেটা অনুসন্ধান করতে আগ্রহী এবং যে সময়ে ইভেন্টটি পাইপলাইনের মধ্যে প্রক্রিয়া করা হয়েছিল তা নয়।
3. স্থাপত্য
আপনি কি নির্মাণ করবেন
উইকিমিডিয়া থেকে ইভেন্ট স্ট্রীম পড়ার জন্য, আমরা SSE প্রোটোকল ব্যবহার করব। আমরা একটি ছোট মিডলওয়্যার পরিষেবা লিখব যা একটি SSE ক্লায়েন্ট হিসাবে ইভেন্ট স্ট্রীম থেকে পড়বে এবং আমাদের GCP পরিবেশের মধ্যে একটি পাব/সাব বিষয়ে প্রকাশ করবে৷
Pub/Sub-এ ইভেন্টগুলি উপলব্ধ হয়ে গেলে, আমরা একটি টেমপ্লেট ব্যবহার করে একটি ক্লাউড ডেটাফ্লো কাজ তৈরি করব, যা আমাদের BigQuery ডেটা গুদামে আমাদের Raw ডেটা স্তরে রেকর্ডগুলিকে স্ট্রিম করবে। পরবর্তী ধাপ হল আমাদের লাইভ লিডারবোর্ডকে সমর্থন করার জন্য সমষ্টিগত পরিসংখ্যান গণনা করা।
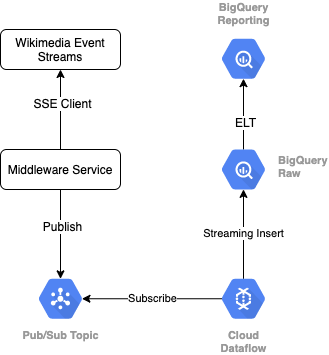
সময়সূচী এবং অর্কেস্ট্রেশন
ওয়্যারহাউসের স্টেজিং এবং রিপোর্টিং স্তরগুলিকে পূর্ণ করে এমন ELT-কে অর্কেস্ট্রেট করার জন্য, আমরা ডেটাফর্ম ব্যবহার করব। ডেটাফর্ম ডেটা ইঞ্জিনিয়ারিং দলগুলিতে "টুলিং, সেরা অনুশীলন এবং সফ্টওয়্যার ইঞ্জিনিয়ারিং-অনুপ্রাণিত কর্মপ্রবাহ নিয়ে আসে"। অর্কেস্ট্রেশন এবং সময়সূচী ছাড়াও, ডেটাফর্ম গুণমান নিশ্চিত করার জন্য দাবী এবং পরীক্ষার মতো কার্যকারিতা প্রদান করে, ডাটাবেস পরিচালনার জন্য কাস্টম গুদাম পরিচালনার সংজ্ঞা এবং ডেটা আবিষ্কারকে সমর্থন করার জন্য ডকুমেন্টেশন বৈশিষ্ট্যগুলি প্রদান করে।
লেখক এই ল্যাব এবং ব্লগ পর্যালোচনা করার জন্য তাদের মূল্যবান প্রতিক্রিয়া জন্য Dataform টিম ধন্যবাদ.
ডেটাফর্মের মধ্যে, ডেটাফ্লো থেকে স্ট্রিম করা কাঁচা ডেটা একটি বাহ্যিক ডেটা সেট হিসাবে ঘোষণা করা হবে। Dataform এর SQLX সিনট্যাক্স ব্যবহার করে স্টেজিং এবং রিপোর্টিং টেবিলগুলি গতিশীলভাবে সংজ্ঞায়িত করা হবে।
আমরা ডেটাফর্মের ক্রমবর্ধমান লোডিং বৈশিষ্ট্যটি ব্যবহার করব স্টেজিং টেবিলটি পূরণ করতে, ডেটাফর্ম প্রকল্পটি প্রতি ঘন্টায় চালানোর জন্য নির্ধারিত। উপরোক্ত অনুসারে, আমরা ধরে নেব যে আমরা দেরীতে আসা তথ্যগুলি পাব না, তাই আমাদের যুক্তি হবে এমন রেকর্ডগুলি গ্রহণ করা যাতে একটি ইভেন্টের সময় থাকে যা বিদ্যমান স্টেজ করা রেকর্ডগুলির মধ্যে সাম্প্রতিক ইভেন্ট সময়ের চেয়ে পরে।
এই সিরিজের পরবর্তী ল্যাবগুলিতে, আমরা দেরিতে আসা তথ্যগুলি পরিচালনার বিষয়ে আলোচনা করব।
যখন আমরা পুরো প্রকল্পটি চালাব, আপস্ট্রিম ডেটা স্তরগুলিতে সমস্ত নতুন রেকর্ড যুক্ত হবে এবং আমাদের একত্রিতকরণগুলি পুনরায় গণনা করা হবে। বিশেষ করে, প্রতিটি রানের ফলে একত্রিত টেবিলের সম্পূর্ণ রিফ্রেশ হবে। আমাদের ফিজিক্যাল ডিজাইনে ইউজারনেম দ্বারা স্টেজিং টেবিলের ক্লাস্টারিং অন্তর্ভুক্ত থাকবে, যা এই লিডারবোর্ডকে সম্পূর্ণরূপে রিফ্রেশ করবে।
আপনি কি প্রয়োজন হবে
- Chrome এর সাম্প্রতিক সংস্করণ
- SQL এর প্রাথমিক জ্ঞান এবং BigQuery এর সাথে প্রাথমিক পরিচিতি
4. সেট আপ হচ্ছে
Raw Tier-এর জন্য BigQuery ডেটাসেট এবং টেবিল তৈরি করুন
আমাদের গুদাম স্কিমা ধারণ করার জন্য একটি নতুন ডেটাসেট তৈরি করুন। আমরা পরে এই ভেরিয়েবলগুলিও ব্যবহার করব, তাই নিম্নলিখিত ধাপগুলির জন্য একই শেল সেশন ব্যবহার করতে ভুলবেন না বা প্রয়োজন অনুসারে ভেরিয়েবল সেট করুন। আপনার প্রকল্পের ID দিয়ে <PROJECT_ID> প্রতিস্থাপন করতে ভুলবেন না।
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
এর পরে, আমরা একটি টেবিল তৈরি করব যা GCP কনসোল ব্যবহার করে কাঁচা ইভেন্টগুলিকে ধরে রাখবে। উইকিমিডিয়া থেকে প্রকাশিত পরিবর্তনের ইভেন্ট স্ট্রীম থেকে আমরা যে ক্ষেত্রগুলি প্রজেক্ট করি তার সাথে স্কিমা মিলবে।
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
পাব/সাব বিষয় এবং সদস্যতা তৈরি করুন
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
ডেটাফর্ম অ্যাকাউন্ট এবং প্রকল্প তৈরি করুন
https://app.dataform.co- এ নেভিগেট করুন এবং একটি নতুন অ্যাকাউন্ট তৈরি করুন। একবার লগ ইন করলে, আপনি একটি নতুন প্রকল্প তৈরি করবেন।
আপনার প্রকল্পের মধ্যে, আপনাকে BigQuery-এর সাথে ইন্টিগ্রেশন কনফিগার করতে হবে। যেহেতু ডেটাফর্মকে গুদামের সাথে সংযোগ করতে হবে, তাই আমাদের পরিষেবা অ্যাকাউন্টের শংসাপত্রগুলি সরবরাহ করতে হবে৷
Dataform ডক্সের মধ্যে উপরে লিঙ্ক করা ধাপগুলি অনুগ্রহ করে অনুসরণ করুন, আপনি ডেটাবেস পৃষ্ঠায় BigQuery-এর সাথে সংযোগ কনফিগার করবেন। আপনি উপরে যে প্রজেক্ট আইডি তৈরি করেছেন সেটি নির্বাচন করতে ভুলবেন না, তারপর শংসাপত্র আপলোড করুন এবং সংযোগ পরীক্ষা করুন।
একবার আপনি BigQuery ইন্টিগ্রেশন কনফিগার করলে, আপনি মডেলিং ট্যাবের মধ্যে উপলভ্য ডেটাসেটগুলি দেখতে পাবেন। বিশেষ করে, Dataflow থেকে ইভেন্ট ক্যাপচার করতে আমরা যে Raw টেবিল ব্যবহার করি তা এখানে উপস্থিত থাকবে। এর শীঘ্রই এই ফিরে আসা যাক.
5. বাস্তবায়ন
Pub/Sub-এ ইভেন্টগুলি পড়া এবং প্রকাশ করার জন্য পাইথন পরিষেবা তৈরি করুন
অনুগ্রহ করে নীচের পাইথন কোডটি দেখুন, এই সারাংশের মধ্যেও উপলব্ধ। আমরা এই উদাহরণে Pub/Sub API ডক্স অনুসরণ করছি।
আসুন কোডের কী তালিকাটি নোট করি, এইগুলি হল সেই ক্ষেত্রগুলি যা আমরা সম্পূর্ণ JSON ইভেন্ট থেকে প্রজেক্ট করতে যাচ্ছি, প্রকাশিত বার্তাগুলিতে স্থির থাকব এবং শেষ পর্যন্ত আমাদের BigQuery ডেটাসেটের কাঁচা স্তরের মধ্যে wiki_changes টেবিলে।
এগুলো wiki_changes টেবিল স্কিমার সাথে মেলে যা আমরা আমাদের BigQuery ডেটাসেটের মধ্যে wiki_changes-এর জন্য সংজ্ঞায়িত করেছি
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. বাস্তবায়ন, অব্যাহত
Pub/Sub থেকে পড়তে এবং BigQuery-এ লিখতে টেমপ্লেট থেকে Dataflow জব তৈরি করুন
সাম্প্রতিক পরিবর্তন ইভেন্টগুলি পাব/সাব বিষয়ে প্রকাশিত হলে, আমরা এই ইভেন্টগুলি পড়তে এবং BigQuery-এ লিখতে ক্লাউড ডেটাফ্লো কাজ ব্যবহার করতে পারি।
স্ট্রীম প্রক্রিয়া করার সময় যদি আমাদের অত্যাধুনিক প্রয়োজন থাকে-বিচ্ছিন্ন স্ট্রীমগুলিতে যোগদান, উইন্ডোড এগ্রিগেশন তৈরি করা, ডেটা সমৃদ্ধ করার জন্য লুকআপ ব্যবহার করার কথা ভাবুন-তাহলে আমরা সেগুলি আমাদের অ্যাপাচি বিম কোডে প্রয়োগ করতে পারি।
যেহেতু আমাদের প্রয়োজনগুলি এই ব্যবহারের ক্ষেত্রে আরও সহজবোধ্য, তাই আমরা আউট-অফ-দ্য-বক্স ডেটাফ্লো টেমপ্লেট ব্যবহার করতে পারি এবং আমাদের এটিতে কোনও কাস্টমাইজেশন করতে হবে না। আমরা ক্লাউড ডেটাফ্লোতে জিসিপি কনসোল থেকে সরাসরি এটি করতে পারি।
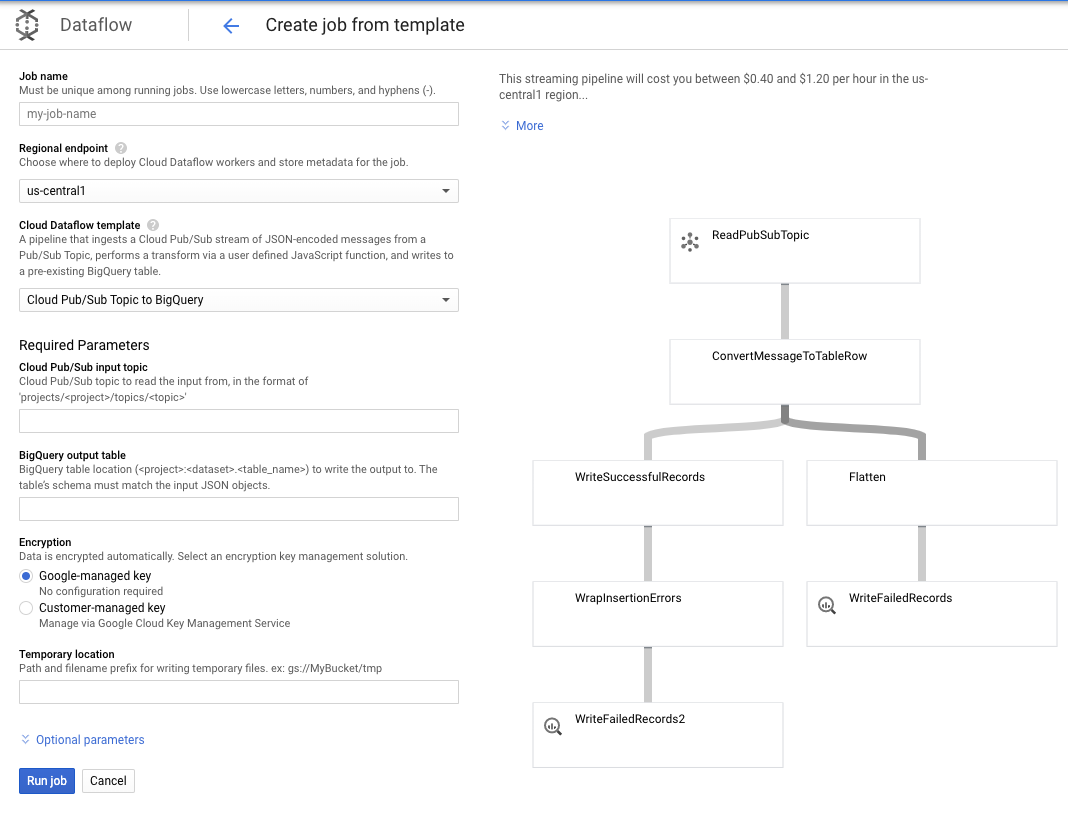
আমরা BigQuery টেমপ্লেটে পাব/সাব টপিক ব্যবহার করব, এবং তারপরে পাব/সাব ইনপুট বিষয় এবং BigQuery আউটপুট টেবিল সহ ডেটাফ্লো টেমপ্লেটে কিছু জিনিস কনফিগার করতে হবে।
7. বাস্তবায়ন, ডেটাফর্ম পদক্ষেপ
ডেটাফর্মে মডেল টেবিল
আমাদের ডেটাফর্ম মডেলটি নিম্নলিখিত GitHub সংগ্রহস্থলের সাথে আবদ্ধ - সংজ্ঞা ফোল্ডারে SQLX ফাইল রয়েছে যা ডেটা মডেলকে সংজ্ঞায়িত করে।
সময়সূচী এবং অর্কেস্ট্রেশন বিভাগে যেমন আলোচনা করা হয়েছে, আমরা ডেটাফর্মে একটি স্টেজিং টেবিল সংজ্ঞায়িত করব যা wiki_changes থেকে কাঁচা রেকর্ডগুলিকে একত্রিত করে। চলুন স্টেজিং টেবিলের জন্য DDL দেখে নেওয়া যাক (আমাদের ডেটাফর্ম প্রকল্পের সাথে যুক্ত GitHub রেপোতেও লিঙ্ক করা হয়েছে)।
আসুন এই টেবিলের কয়েকটি গুরুত্বপূর্ণ বৈশিষ্ট্য নোট করি:
- এটি একটি ক্রমবর্ধমান প্রকার হিসাবে কনফিগার করা হয়েছে, তাই যখন আমাদের নির্ধারিত ELT কাজগুলি চলে, শুধুমাত্র নতুন রেকর্ড যোগ করা হবে
- নীচে কখন() কোড দ্বারা প্রকাশ করা হয়েছে, এর জন্য যুক্তি টাইমস্ট্যাম্প ক্ষেত্রের উপর ভিত্তি করে, যা ইভেন্ট স্ট্রিমে টাইমস্ট্যাম্পকে প্রতিফলিত করে, অর্থাৎ পরিবর্তনের ঘটনা_সময়।
- এটি ব্যবহারকারীর ক্ষেত্র ব্যবহার করে ক্লাস্টার করা হয়, যার অর্থ হল প্রতিটি পার্টিশনের মধ্যে রেকর্ডগুলি ব্যবহারকারীর দ্বারা অর্ডার করা হবে, লিডারবোর্ড তৈরি করে এমন প্রশ্নের দ্বারা প্রয়োজনীয় শাফেল হ্রাস করে
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
আমাদের প্রকল্পে অন্য যে টেবিলটি সংজ্ঞায়িত করতে হবে তা হল রিপোর্টিং টিয়ার টেবিল, যা লিডারবোর্ডের প্রশ্নগুলিকে সমর্থন করবে। রিপোর্টিং স্তরের সারণীগুলি একত্রিত করা হয়েছে, কারণ আমাদের ব্যবহারকারীরা প্রকাশিত উইকিপিডিয়া পরিবর্তনের নতুন এবং সঠিক গণনা নিয়ে উদ্বিগ্ন।
টেবিলের সংজ্ঞা সহজবোধ্য, এবং ডেটাফর্ম রেফারেন্স ব্যবহার করে। এই উল্লেখগুলির একটি বড় সুবিধা হল যে তারা বস্তুর মধ্যে নির্ভরতাকে স্পষ্ট করে তোলে, পাইপলাইনের সঠিকতাকে সমর্থন করে যে নির্ভরতাগুলি সর্বদা নির্ভরশীল প্রশ্নের আগে কার্যকর করা হয়।
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
ডেটাফর্ম প্রকল্পের সময়সূচী
চূড়ান্ত পদক্ষেপটি হল একটি সময়সূচী তৈরি করা যা প্রতি ঘন্টায় কার্যকর হবে। যখন আমাদের প্রকল্পটি চালু করা হয়, তখন ডেটাফর্ম ক্রমবর্ধমান স্টেজিং টেবিলটি রিফ্রেশ করতে এবং সমষ্টিযুক্ত টেবিলটি পুনরায় লোড করতে প্রয়োজনীয় SQL স্টেটমেন্টগুলি কার্যকর করবে।
সিস্টেমে স্ট্রীম হওয়া সাম্প্রতিক ইভেন্টগুলির সাথে লিডারবোর্ডকে আপডেট রাখতে এই সময়সূচীটি প্রতি ঘন্টায়-অথবা আরও ঘন ঘন, মোটামুটিভাবে প্রতি 5-10 মিনিট পর্যন্ত-আমন্ত্রণ করা যেতে পারে।
8. অভিনন্দন
অভিনন্দন, আপনি সফলভাবে আপনার স্ট্রিম করা ডেটার জন্য একটি টায়ার্ড ডেটা আর্কিটেকচার তৈরি করেছেন!
আমরা একটি উইকিমিডিয়া ইভেন্ট স্ট্রীম দিয়ে শুরু করেছি এবং আমরা এটিকে BigQuery-এ একটি রিপোর্টিং টেবিলে রূপান্তরিত করেছি যা ধারাবাহিকভাবে আপ-টু-ডেট।
এরপর কি?
আরও পড়া
- ডেটাফর্ম প্রবর্তন করা হচ্ছে
- কার্যকরী ডেটা ইঞ্জিনিয়ারিং - ব্যাচ ডেটা প্রক্রিয়াকরণের জন্য একটি আধুনিক দৃষ্টান্ত
- কিভাবে Apache Airflow ব্যবহার করে BigQuery-এর জন্য ডেটা একত্রিত করবেন
[১] তথ্য প্রকৌশলীদের জন্য প্রতিদিন, ব্যাচ ট্রান্সফরমেশন চালানোর জন্য ইন্ট্রা-ডে (বলুন, ঘন্টায়) সমষ্টিগুলিকে ওভাররাইট করা সাধারণ- এটি পুনর্মিলন হিসাবে পরিচিত।
[২] বাস্তবায়নের বিশদ বিবরণের জন্য, অনুগ্রহ করে আর্কিটেকচার বিভাগে পড়ুন।
[৩] একটি দেরীতে পৌঁছানো ঘটনা হল একটি ইভেন্ট_টাইম সহ একটি ইভেন্ট যা এই একই ইভেন্ট স্ট্রীমের মধ্যে সিস্টেম দ্বারা ইতিমধ্যে প্রক্রিয়াকৃত রেকর্ডের চেয়ে পরে।