
1. Introducción
Descripción general
Los frameworks para el análisis de transmisiones se han vuelto cada vez más importantes en el almacenamiento de datos contemporáneo, ya que los usuarios empresariales la demanda de analítica en tiempo real continúa sin cesar. Se han realizado grandes avances para mejorar la actualidad de los datos dentro de los almacenes y para respaldar el análisis de transmisiones en general, pero los ingenieros de datos aún deben enfrentar desafíos a la hora de adaptar estas fuentes de transmisión a su arquitectura de almacén de datos.
En este blog, analizamos algunos de los desafíos más comunes a los que se enfrentan los ingenieros de datos cuando resuelven estos casos de uso. Describiremos algunas ideas de diseño y patrones arquitectónicos para la agregación eficiente de datos de transmisión con BigQuery.
Actualidad y exactitud de los datos
Por actual, nos referimos a que la latencia de los datos del agregado es menor que algún umbral, p.ej., “actualizados en la última hora”. La actualidad se determina según el subconjunto de datos sin procesar que se incluyen en los agregados.
Cuando se trabaja con datos de transmisión, es muy común que los eventos lleguen tarde a nuestro sistema de procesamiento de datos, lo que significa que la hora a la que nuestro sistema procesa un evento es considerablemente posterior a la hora en la que este se produce.
Cuando procesamos los hechos tardíos, los valores de nuestras estadísticas agregadas cambiarán, lo que significa que, durante el día, los valores que ven los analistas cambiarán[1]. Por preciso, nos referimos a que las estadísticas agregadas se acercan lo más posible a los valores finales y conciliados.
Por supuesto, hay una tercera dimensión que se debe optimizar: el costo, en el sentido tanto del dinero como del rendimiento. A modo de ejemplo, podríamos usar una vista lógica para los objetos de datos en la etapa de pruebas y los informes. La desventaja de usar una vista lógica es que cada vez que se consulta la tabla agregada, se analiza todo el conjunto de datos sin procesar, lo que será lento y costoso.
Descripción de la situación
Configuremos el escenario para este caso de uso. Vamos a transferir los datos de Transmisión de eventos de Wikipedia publicados por Wikimedia. Nuestro objetivo es crear una tabla de clasificación que muestre a los autores con la mayor cantidad de cambios, que se actualizará a medida que se publiquen artículos nuevos. Nuestra tabla de clasificación, que se implementará como un panel de BI Engine, agregará los eventos sin procesar por nombre de usuario para calcular las puntuaciones.[2]
2. Diseño
Niveles de datos
En la canalización de datos, definiremos varios niveles de datos. Conservaremos los datos de eventos sin procesar y crearemos una canalización de transformaciones posteriores, enriquecimiento y agregación. No conectamos tablas de informes directamente con los datos almacenados en tablas sin procesar, ya que queremos unificar y centralizar las transformaciones que les interesan a los diferentes equipos para los datos almacenados en etapa intermedia.
Un principio importante en esta arquitectura es que los niveles superiores (etapa de pruebas y generación de informes) se pueden volver a calcular en cualquier momento utilizando solo los datos sin procesar.
Partición
BigQuery admite dos estilos de partición: la partición por rango de números enteros y la partición por fecha. Solo consideraremos la partición de fechas dentro del alcance de esta publicación.
Para la partición por fecha, podemos elegir entre particiones por tiempo de transferencia o particiones basadas en campos. La partición por tiempo de transferencia lleva los datos a una partición según el momento en que se adquirieron. Los usuarios también pueden seleccionar una partición en el momento de la carga si especifican un decorador de partición.
La partición de campos particiona los datos según el valor de fecha o marca de tiempo en una columna.
Para la transferencia de eventos, llevamos los datos a una tabla particionada por tiempo de transferencia. Esto se debe a que el tiempo de transferencia es relevante para procesar o volver a procesar datos recibidos en el pasado. Los reabastecimientos de datos históricos también se pueden almacenar dentro de las particiones de tiempo de transferencia, según la fecha en que habrían llegado.
En este codelab, supondremos que no recibiremos datos tardíos[3] del flujo de eventos de Wikimedia. Esto simplificará la carga incremental de la tabla de etapa de pruebas, como se explica a continuación.
En la tabla de etapa de pruebas, haremos una partición por tiempo del evento. Esto se debe a que nuestros analistas están interesados en consultar datos en función de la hora del evento (la hora en que se publicó el artículo en Wikipedia) y no de la hora a la que el evento se procesó dentro de la canalización.
3. Arquitectura
Qué compilarás
Para leer el flujo de eventos de Wikimedia, usaremos el protocolo SSE. Escribiremos un servicio de middleware pequeño que leerá desde el flujo de eventos como un cliente de SSE y lo publicará en un tema de Pub/Sub dentro de nuestro entorno de GCP.
Una vez que los eventos estén disponibles en Pub/Sub, crearemos un trabajo de Cloud Dataflow, usando una plantilla, que transmitirá los registros a nuestro nivel de datos sin procesar en nuestro almacén de datos de BigQuery. El siguiente paso es calcular las estadísticas agregadas para respaldar nuestra tabla de clasificación en vivo.
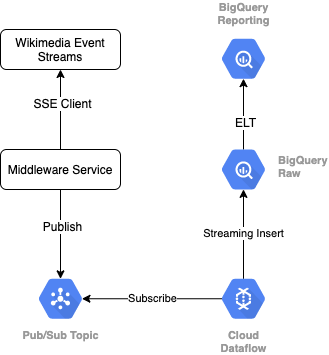
Programación y organización
Para organizar el ELT que propaga los niveles de etapa de pruebas y de informes del almacén, usaremos Dataform. Dataform “aporta herramientas, prácticas recomendadas y flujos de trabajo inspirados en la ingeniería de software” a los equipos de ingeniería de datos. Además de la organización y la programación, Dataform proporciona funciones como aserciones y pruebas para garantizar la calidad, la definición de operaciones de almacén personalizadas para la administración de bases de datos y funciones de documentación para respaldar el descubrimiento de datos.
Los autores agradecen al equipo de Dataform por sus valiosos comentarios durante la revisión de este lab y blog.
En Dataform, los datos sin procesar que se transmitan desde Dataflow se declararán como un conjunto de datos externo. Las tablas de etapa de pruebas y de informes se definirán de forma dinámica con la sintaxis SQLX de Dataform.
Usaremos la función de carga incremental de Dataform para propagar la tabla de etapa de pruebas y programar el proyecto de Dataform para que se ejecute cada hora. Según lo anterior, supondremos que no recibiremos hechos tardíos, por lo que nuestra lógica será transferir los registros que tengan una hora del evento posterior a la hora del evento más reciente entre los registros en etapas existentes.
En labs posteriores de esta serie, analizaremos el manejo de datos tardíos.
Cuando ejecutemos todo el proyecto, los niveles de datos ascendentes tendrán todos los registros nuevos agregados y nuestras agregaciones se volverán a calcular. En particular, cada ejecución dará como resultado una actualización completa de la tabla agregada. Nuestro diseño físico incluirá el agrupamiento en clústeres de la tabla de etapa de pruebas por username, lo que aumentará aún más el rendimiento de la consulta de agregación que actualizará por completo esta tabla de clasificación.
Requisitos
- Una versión reciente de Chrome
- Conocimientos básicos de SQL y conocimientos básicos de BigQuery
4. Cómo prepararte
Crea un conjunto de datos y una tabla de BigQuery para el nivel sin procesar
Crea un conjunto de datos nuevo para que contenga nuestro esquema de almacén. También usaremos estas variables más adelante, así que asegúrate de usar la misma sesión de shell para los siguientes pasos o configura las variables según sea necesario. Asegúrate de reemplazar <PROJECT_ID> por el ID de tu proyecto.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
A continuación, crearemos una tabla que contendrá los eventos sin procesar con la consola de GCP. El esquema coincidirá con los campos que proyectamos a partir del flujo de eventos de los cambios publicados que estamos consumiendo de Wikimedia.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
Crea un tema y una suscripción de Pub/Sub
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
Crea una cuenta y un proyecto en Dataform
Navega a https://app.dataform.co y crea una cuenta nueva. Una vez que accedas, crearás un proyecto nuevo.
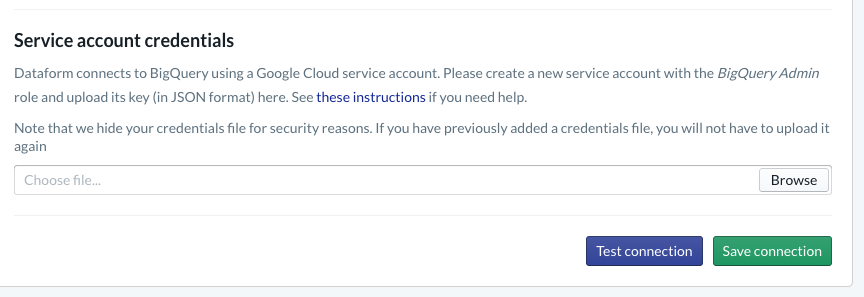
En tu proyecto, deberás configurar la integración con BigQuery. Dado que Dataform deberá conectarse al almacén, tendremos que aprovisionar las credenciales de la cuenta de servicio.
Sigue los pasos vinculados anteriormente en los documentos de Dataform. Configurarás la conexión con BigQuery en la página Base de datos. Asegúrate de seleccionar el mismo projectId que creaste antes y, luego, sube las credenciales y prueba la conexión.
Una vez que hayas configurado la integración de BigQuery, verás Conjuntos de datos disponibles en la pestaña Modelado. En particular, la tabla sin procesar que usamos para capturar eventos de Dataflow estará presente aquí. Volvamos a esto en breve.
5. Implementación
Crea un servicio de Python para leer y publicar eventos en Pub/Sub
Consulta el código de Python que aparece a continuación, también disponible en este gist. Seguimos los documentos de la API de Pub/Sub en este ejemplo.
Tomemos nota de la lista de keys en el código. Estos son los campos que proyectaremos del evento JSON completo, conservaremos en los mensajes publicados y, por último, en la tabla wiki_changes del nivel sin procesar de nuestro conjunto de datos de BigQuery.
Estos coinciden con el esquema de la tabla wiki_changes que definimos en nuestro conjunto de datos de BigQuery para wiki_changes
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. Implementación, continuación
Crea un trabajo de Dataflow a partir de una plantilla para leer desde Pub/Sub y escribir en BigQuery
Una vez que los eventos de cambio recientes se hayan publicado en el tema de Pub/Sub, podemos usar un trabajo de Cloud Dataflow para leer estos eventos y escribirlos en BigQuery.
Si tuviéramos necesidades sofisticadas mientras procesamos la transmisión (pensar en unir transmisiones dispares, compilar agregaciones con ventanas y usar búsquedas para enriquecer los datos), podríamos implementarlas en nuestro código de Apache Beam.
Dado que nuestras necesidades son más sencillas para este caso de uso, podemos usar la plantilla de Dataflow lista para usar y no tendremos que personalizarla. Podemos hacerlo directamente desde la consola de GCP en Cloud Dataflow.
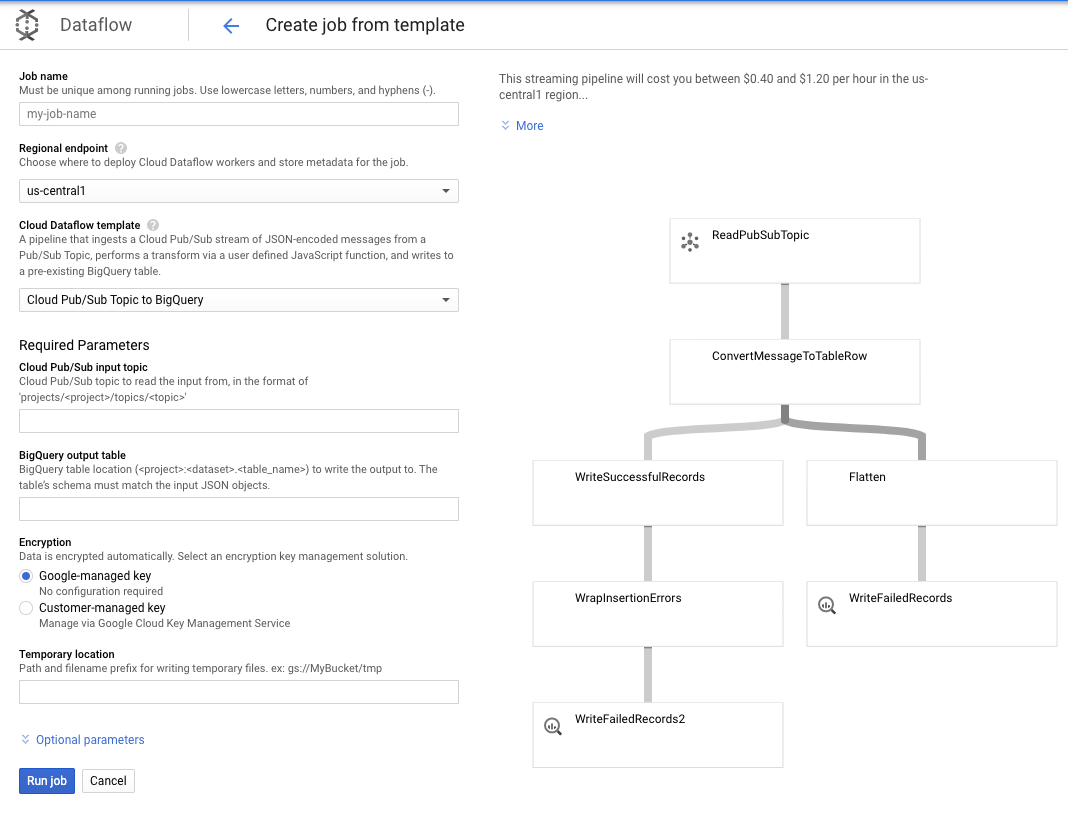
Usaremos la plantilla de tema de Pub/Sub a BigQuery y, luego, solo debemos configurar algunos elementos en la plantilla de Dataflow, como el tema de entrada de Pub/Sub y la tabla de salida de BigQuery.
7. Implementación, pasos de Dataform
Tablas de modelos en Dataform
Nuestro modelo de Dataform está vinculado al siguiente repositorio de GitHub. La carpeta de definiciones contiene los archivos SQLX que definen el modelo de datos.
Como se explicó en la sección Programación y organización, definiremos una tabla de etapa de pruebas en Dataform que agregue los registros sin procesar de wiki_changes. Observemos el DDL de la tabla de etapa de pruebas (también vinculado en el repositorio de GitHub vinculado a nuestro proyecto de Dataform).
Observemos algunas características importantes de esta tabla:
- Se configura como un tipo incremental, por lo que cuando se ejecutan nuestros trabajos ELT programados, solo se agregan los registros nuevos.
- Como se expresa en el código when() de la parte inferior, la lógica para esto se basa en el campo de marca de tiempo, que refleja la marca de tiempo en el flujo de eventos, es decir, el event_time del cambio.
- Se agrupa en clústeres con el campo user, lo que significa que los registros dentro de cada partición se ordenarán por user, lo que reduce el Shuffle requerido por la consulta que compila la tabla de clasificación.
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
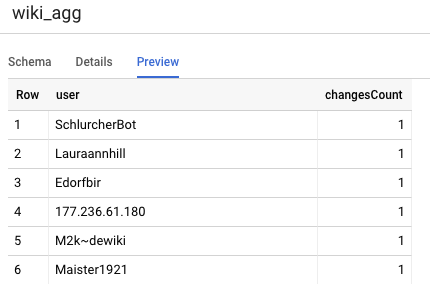
La otra tabla que debemos definir en nuestro proyecto es la tabla de nivel de informes, que admitirá las consultas de la tabla de clasificación. Las tablas del nivel Informes se agregan, ya que nuestros usuarios están preocupados por los recuentos actualizados y precisos de los cambios publicados en Wikipedia.
La definición de la tabla es sencilla y utiliza las referencias de Dataform. Una gran ventaja de estas referencias es que hacen referencia a las dependencias entre objetos, lo que admite la corrección de la canalización, ya que garantiza que las dependencias siempre se ejecuten antes de las consultas dependientes.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
Programar proyecto de Dataform
El último paso consiste simplemente en crear una programación que se ejecutará cada hora. Cuando se invoque nuestro proyecto, Dataform ejecutará las instrucciones de SQL necesarias para actualizar la tabla de etapa de pruebas incremental y volver a cargar la tabla agregada.
Este programa se puede invocar cada hora (o incluso con mayor frecuencia, hasta cada 5 a 10 minutos) para mantener la tabla de clasificación actualizada con los eventos recientes que se transmitieron al sistema.
8. Felicitaciones
¡Felicitaciones! Creaste con éxito una arquitectura de datos por niveles para tus datos transmitidos.
Comenzamos con un flujo de eventos de Wikimedia y lo transformamos en una tabla de informes en BigQuery que está constantemente actualizada.
¿Qué sigue?
Lecturas adicionales
- Presentamos Dataform
- Ingeniería de datos funcional: un paradigma moderno para el procesamiento de datos por lotes
- Cómo agregar datos para BigQuery con Apache Airflow
[1] Es común que los ingenieros de datos ejecuten una transformación por lotes diaria para reemplazar las agregaciones intradía (por ejemplo, por hora), lo que se conoce como conciliación.
[2] Para obtener detalles sobre la implementación, consulta la sección Arquitectura.
[3] Un hecho tardío es un evento con un event_time que es posterior a los registros ya procesados por el sistema dentro de esta misma transmisión de eventos