
1. مقدمه
نمای کلی
چارچوبها برای تجزیه و تحلیل جریانی در انبار دادههای معاصر اهمیت فزایندهای پیدا کردهاند، زیرا تقاضای کاربران تجاری برای تجزیه و تحلیل بلادرنگ همچنان ادامه دارد. گامهای بزرگی برای بهبود تازگی دادهها در انبارها و به طور کلی پشتیبانی از تجزیه و تحلیل جریان برداشته شده است، اما مهندسان داده هنوز با چالشهایی در هنگام تطبیق این منابع جریان در معماری انبار داده خود مواجه هستند.
در این وبلاگ، ما چند مورد از رایج ترین چالش هایی را که مهندسان داده هنگام حل این موارد استفاده می کنند، مورد بحث قرار می دهیم. ما برخی از ایدههای طراحی و الگوهای معماری را برای تجمیع کارآمد جریان دادهها با استفاده از BigQuery بیان میکنیم.
تازگی و دقت داده ها
منظور ما از تازه ، این است که تأخیر داده کل کمتر از آستانه است، به عنوان مثال، "به روز از آخرین ساعت". تازگی توسط زیرمجموعه داده های خامی که در مجموع ها گنجانده شده است تعیین می شود.
هنگامی که با داده های جریانی سروکار داریم، بسیار معمول است که رویدادها در سیستم پردازش داده ما دیر به دست می آیند، به این معنی که زمانی که سیستم ما یک رویداد را پردازش می کند به طور قابل توجهی دیرتر از زمانی است که در آن رویداد رخ می دهد.
هنگامی که ما حقایق دیررس را پردازش می کنیم، مقادیر آمارهای انبوه ما تغییر می کند، به این معنی که به صورت روزانه، مقادیری که تحلیلگران می بینند تغییر می کند[1]. منظور ما از دقیق این است که آمارهای انباشته تا حد امکان به مقادیر نهایی و تطبیق شده نزدیک هستند.
البته بعد سومی برای بهینه سازی وجود دارد: هزینه - هم به معنای دلار و هم عملکرد. برای نشان دادن، می توانیم از یک نمای منطقی برای اشیاء داده در مرحله بندی و گزارش استفاده کنیم. نقطه ضعف استفاده از یک نمای منطقی این است که هر بار که جدول انبوه پرس و جو می شود، کل مجموعه داده خام اسکن می شود که کند و گران خواهد بود.
شرح سناریو
بیایید زمینه را برای این مورد استفاده فراهم کنیم. ما قرار است دادههای جریان رویدادهای ویکیپدیا را که توسط ویکیمدیا منتشر شده است، جذب کنیم. هدف ما ایجاد تابلوی امتیازاتی است که بیشترین تغییرات را به نویسندگان نشان دهد و با انتشار مقالات جدید به روز شود. تابلوی امتیازات ما، که به عنوان داشبورد BI Engine پیاده سازی خواهد شد، رویدادهای خام را با نام کاربری جمع آوری می کند تا امتیازات را محاسبه کند[2].
2. طراحی
ردیف بندی داده ها
در خط لوله داده، ما چندین لایه داده را تعریف خواهیم کرد. ما دادههای رویداد خام را نگه میداریم و خط لولهای از تحولات، غنیسازی و تجمیع بعدی ایجاد میکنیم. ما جداول گزارش را مستقیماً به دادههای ذخیره شده در جداول خام وصل نمیکنیم، زیرا میخواهیم تحولاتی را که تیمهای مختلف برای دادههای مرحلهبندیشده به آنها اهمیت میدهند، متحد و متمرکز کنیم.
یک اصل مهم در این معماری این است که سطوح بالاتر - مرحله بندی و گزارش - را می توان در هر زمان تنها با استفاده از داده های خام دوباره محاسبه کرد.
پارتیشن بندی
BigQuery از دو سبک پارتیشن بندی پشتیبانی می کند. پارتیشن بندی محدوده عدد صحیح و پارتیشن بندی تاریخ. ما فقط پارتیشن بندی تاریخ را در محدوده این پست در نظر خواهیم گرفت.
برای پارتیشن بندی تاریخ، می توانیم بین پارتیشن های زمان جذب یا پارتیشن های مبتنی بر فیلد یکی را انتخاب کنیم. پارتیشن بندی زمان جذب داده ها را بر اساس زمان به دست آوردن داده ها در یک پارتیشن قرار می دهد. کاربران همچنین می توانند با تعیین دکوراتور پارتیشن، یک پارتیشن را در زمان بارگذاری انتخاب کنند.
پارتیشن بندی فیلد داده ها را بر اساس تاریخ یا مهر زمان در یک ستون تقسیم بندی کنید.
برای دریافت رویدادها، دادهها را در یک جدول تقسیمبندی شده زمان جذب قرار میدهیم. این به این دلیل است که زمان مصرف برای پردازش یا پردازش مجدد دادههای دریافتشده در گذشته مرتبط است. پسپرهای دادههای تاریخی را میتوان در پارتیشنهای زمان جذب نیز ذخیره کرد، بر اساس اینکه چه زمانی میرسیدند.
در این Codelab، فرض میکنیم که حقایق دیررس[3] را از جریان رویداد ویکیمدیا دریافت نخواهیم کرد. این کار بارگذاری افزایشی جدول مرحله بندی را که در زیر توضیح داده شده است، ساده می کند.
برای جدول مرحله بندی، بر اساس زمان رویداد تقسیم بندی می کنیم. این به این دلیل است که تحلیلگران ما علاقه مند هستند که داده ها را بر اساس زمان رویداد -زمانی که مقاله در ویکی پدیا منتشر شده است- جستجو کنند و نه زمانی که رویداد در خط لوله پردازش شده است.
3. معماری
چیزی که خواهی ساخت
برای خواندن جریان رویداد از ویکیمدیا، از پروتکل SSE استفاده میکنیم. ما یک سرویس میانافزار کوچک مینویسیم که از جریان رویداد بهعنوان مشتری SSE خوانده میشود و در یک موضوع Pub/Sub در محیط GCP ما منتشر میشود.
هنگامی که رویدادها در Pub/Sub در دسترس هستند، با استفاده از یک الگو، یک کار Cloud Dataflow ایجاد می کنیم که سوابق را در ردیف داده خام ما در انبار داده BigQuery ما پخش می کند. مرحله بعدی محاسبه آمار انبوه برای پشتیبانی از تابلوی امتیازات زنده ما است.
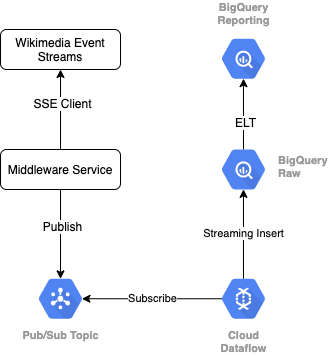
برنامه ریزی و ارکستراسیون
برای هماهنگ کردن ELT که لایه های مرحله بندی و گزارش انبار را پر می کند، از Dataform استفاده می کنیم. Dataform «ابزار، بهترین شیوهها و جریانهای کاری الهامگرفته از مهندسی نرمافزار» را برای تیمهای مهندسی داده به ارمغان میآورد. علاوه بر هماهنگی و زمانبندی، Dataform عملکردهایی مانند ادعاها و آزمایشها را برای اطمینان از کیفیت، تعریف عملیات انبار سفارشی برای مدیریت پایگاه داده و ویژگیهای Documentation برای پشتیبانی از کشف دادهها ارائه میکند.
نویسندگان از تیم Dataform برای بازخورد ارزشمندشان در بررسی این آزمایشگاه و وبلاگ تشکر می کنند.
در Dataform، داده های خام وارد شده از Dataflow به عنوان یک مجموعه داده خارجی اعلام می شود. جداول Staging و Reporting به صورت پویا با استفاده از دستور SQLX Dataform تعریف خواهند شد.
ما از ویژگی بارگذاری افزایشی Dataform برای پر کردن جدول مرحلهبندی استفاده میکنیم و پروژه Dataform را برای اجرای هر ساعت برنامهریزی میکنیم. با توجه به موارد فوق، فرض میکنیم که حقایق دیررس را دریافت نخواهیم کرد، بنابراین منطق ما این است که رکوردهایی را دریافت کنیم که دارای زمان رویدادی هستند که دیرتر از آخرین زمان رویداد در میان رکوردهای مرحلهای موجود است.
در آزمایشگاههای بعدی این مجموعه، در مورد رسیدگی به حقایق دیررس بحث خواهیم کرد.
هنگامی که کل پروژه را اجرا می کنیم، سطوح داده های بالادستی تمام رکوردهای جدید اضافه می شوند و تجمیع های ما دوباره محاسبه می شوند. به طور خاص، هر اجرا منجر به بهروزرسانی کامل جدول جمعآوری میشود. طراحی فیزیکی ما شامل خوشهبندی جدول مرحلهبندی بر اساس نام کاربری ، افزایش بیشتر عملکرد جستجوی تجمع است که این تابلوی امتیازات را کاملاً تازه میکند.
آنچه شما نیاز دارید
- نسخه اخیر کروم
- دانش اولیه SQL و آشنایی اولیه با BigQuery
4. راه اندازی
مجموعه داده و جدول BigQuery را برای Raw Tier ایجاد کنید
یک مجموعه داده جدید ایجاد کنید تا حاوی طرح انبار ما باشد. بعداً از این متغیرها نیز استفاده خواهیم کرد، بنابراین حتماً از همان جلسه پوسته برای مراحل زیر استفاده کنید یا متغیرها را در صورت نیاز تنظیم کنید. حتماً شناسه پروژه خود را جایگزین <PROJECT_ID> کنید.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
در مرحله بعد، جدولی ایجاد می کنیم که رویدادهای خام را با استفاده از کنسول GCP نگه می دارد. این طرح با فیلدهایی که ما از جریان رویداد تغییرات منتشر شده که از ویکیمدیا مصرف میکنیم، نمایش میدهیم مطابقت دارد.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
موضوع Pub/Sub و اشتراک ایجاد کنید
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
ایجاد حساب و پروژه Dataform
به https://app.dataform.co بروید و یک حساب کاربری جدید ایجاد کنید. پس از ورود به سیستم، یک پروژه جدید ایجاد خواهید کرد.
در پروژه خود، باید ادغام را با BigQuery پیکربندی کنید . از آنجایی که Dataform باید به انبار متصل شود، ما باید اعتبار حساب خدمات را ارائه کنیم .
لطفاً مراحل پیوند داده شده در بالا را در اسناد Dataform دنبال کنید، اتصال به BigQuery را در صفحه پایگاه داده پیکربندی خواهید کرد. حتماً همان projectId را انتخاب کنید که در بالا ایجاد کرده اید، سپس اعتبارنامه ها را آپلود کرده و اتصال را آزمایش کنید.
هنگامی که یکپارچه سازی BigQuery را پیکربندی کردید، مجموعه داده های موجود در برگه Modeling را مشاهده خواهید کرد. به طور خاص، جدول Raw که برای ثبت رویدادها از Dataflow استفاده می کنیم، در اینجا وجود دارد. اجازه دهید به زودی به این موضوع برگردیم.
5. اجرا
سرویس Python را برای خواندن و انتشار رویدادها در Pub/Sub ایجاد کنید
لطفاً کد پایتون زیر را که در این خلاصه موجود است نیز مشاهده کنید. ما در این مثال اسناد Pub/Sub API را دنبال می کنیم.
بیایید به لیست کلیدها در کد توجه کنیم، اینها فیلدهایی هستند که می خواهیم از رویداد JSON کامل نمایش دهیم، در پیام های منتشر شده باقی بمانند، و در نهایت در جدول wiki_changes در ردیف خام مجموعه داده BigQuery خودمان باقی بمانند.
اینها با طرح جدول wiki_changes مطابقت دارند که ما در مجموعه داده BigQuery برای wiki_changes تعریف کردیم.
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. اجرا، ادامه یافت
برای خواندن از Pub/Sub و نوشتن در BigQuery Job Dataflow را از Template ایجاد کنید
هنگامی که رویدادهای تغییر اخیر در موضوع Pub/Sub منتشر شد، میتوانیم از یک کار Cloud Dataflow برای خواندن این رویدادها و نوشتن آنها در BigQuery استفاده کنیم.
اگر در حین پردازش جریان نیازهای پیچیده ای داشتیم - به پیوستن به جریان های متفاوت، ایجاد تجمعات پنجره ای، استفاده از جستجوها برای غنی سازی داده ها فکر می کردیم - می توانستیم آنها را در کد Apache Beam خود پیاده سازی کنیم.
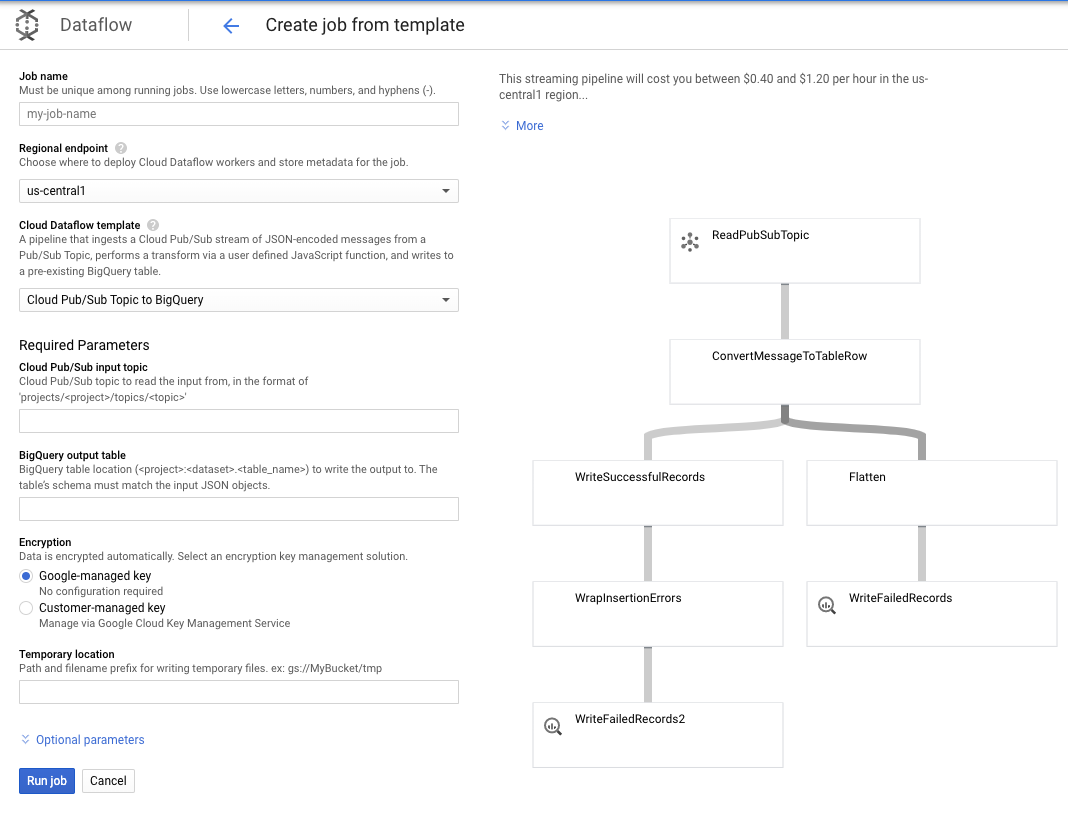
از آنجایی که نیازهای ما برای این مورد سادهتر است، میتوانیم از قالب خارج از جعبه Dataflow استفاده کنیم و نیازی به سفارشیسازی آن نخواهیم داشت. ما می توانیم این کار را مستقیماً از کنسول GCP در Cloud Dataflow انجام دهیم.
ما از قالب Pub/Sub Topic به BigQuery استفاده می کنیم، و سپس فقط باید چند چیز را در قالب Dataflow پیکربندی کنیم، از جمله موضوع ورودی Pub/Sub و جدول خروجی BigQuery.
7. پیاده سازی، مراحل فرم داده
جداول مدل در فرم داده
مدل Dataform ما به مخزن GitHub زیر گره خورده است - پوشه تعریف ها حاوی فایل های SQLX است که مدل داده را تعریف می کند.
همانطور که در بخش زمانبندی و ارکستراسیون بحث شد، ما یک جدول مرحلهبندی را در Dataform تعریف میکنیم که رکوردهای خام را از wiki_changes جمعآوری میکند. بیایید نگاهی به DDL برای جدول مرحله بندی بیندازیم (همچنین در مخزن GitHub مرتبط با پروژه Dataform ما پیوند داده شده است).
بیایید به چند ویژگی مهم این جدول توجه کنیم:
- به عنوان یک نوع افزایشی پیکربندی شده است، بنابراین هنگامی که کارهای برنامه ریزی شده ELT ما اجرا می شوند، فقط رکوردهای جدید اضافه می شوند
- همانطور که توسط کد When() در پایین بیان می شود، منطق این کار بر اساس فیلد مهر زمانی است که مهر زمانی را در جریان رویداد منعکس می کند، یعنی رویداد_time تغییر را نشان می دهد.
- با استفاده از فیلد کاربر خوشهبندی میشود، به این معنی که رکوردهای داخل هر پارتیشن توسط کاربر مرتب میشوند، و این باعث کاهش درهمآمیزی مورد نیاز درخواستی میشود که تابلوی امتیازات را میسازد.
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
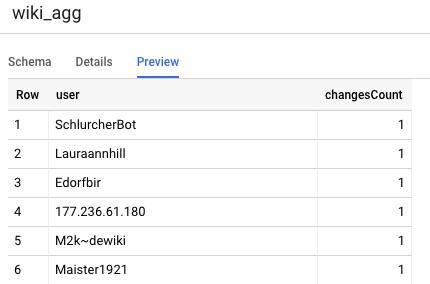
جدول دیگری که باید در پروژه خود تعریف کنیم جدول ردیف گزارش است که از کوئری های تابلوی امتیازات پشتیبانی می کند. جداول در ردیف گزارش جمعآوری شدهاند، زیرا کاربران ما نگران تعداد جدید و دقیق تغییرات منتشر شده ویکیپدیا هستند.
تعریف جدول ساده است و از مراجع Dataform استفاده می کند. مزیت بزرگ این ارجاعات این است که وابستگی های بین اشیاء را آشکار می کنند و با اطمینان از اینکه وابستگی ها همیشه قبل از پرس و جوهای وابسته اجرا می شوند از صحت خط لوله پشتیبانی می کنند.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
برنامه ریزی پروژه داده فرم
مرحله آخر صرفاً ایجاد برنامه ای است که به صورت ساعتی اجرا می شود. هنگامی که پروژه ما فراخوانی می شود، Dataform دستورات SQL مورد نیاز را اجرا می کند تا جدول مرحله بندی افزایشی را به روز کند و جدول تجمیع شده را دوباره بارگذاری کند.
این برنامه را می توان هر ساعت – یا حتی بیشتر، تقریباً هر 5 تا 10 دقیقه – فراخوانی کرد تا تابلوی امتیازات را با رویدادهای اخیری که در سیستم پخش شده است به روز نگه دارد.
8. تبریک می گویم
تبریک میگوییم، شما با موفقیت یک معماری دادههای طبقهبندی شده برای دادههای جریانی خود ایجاد کردید!
ما با یک جریان رویداد Wikimedia شروع کردیم و آن را به یک جدول گزارش در BigQuery تبدیل کردیم که به طور مداوم به روز است.
بعدش چی؟
در ادامه مطلب
- معرفی Dataform
- مهندسی داده عملکردی - پارادایم مدرن برای پردازش دسته ای داده ها
- چگونه داده ها را برای BigQuery با استفاده از Apache Airflow جمع آوری کنیم
[1] برای مهندسان داده معمول است که یک تبدیل دستهای روزانه را برای بازنویسی مجموعهای درون روزی (مثلاً ساعتی) اجرا میکنند – این به عنوان آشتی شناخته میشود.
[2] برای جزئیات پیاده سازی، لطفاً به بخش معماری مراجعه کنید.
[3] یک واقعیت دیررس رویدادی با رویداد_time است که دیرتر از رکوردهایی است که قبلاً توسط سیستم در همین جریان رویداد پردازش شده است.