
1. Introduction
Présentation
Les frameworks d'analyse de flux sont devenus de plus en plus importants dans l'entreposage de données contemporain, car les utilisateurs professionnels la demande d'analyses en temps réel ne diminue pas. Des progrès importants ont été réalisés pour améliorer la fraîcheur des données dans les entrepôts et prendre en charge l'analyse de flux de manière générale. Toutefois, les ingénieurs de données rencontrent encore des difficultés lorsqu'ils doivent adapter ces sources de flux à leur architecture d'entrepôt de données.
Dans ce blog, nous abordons quelques-uns des défis les plus courants auxquels les ingénieurs de données sont confrontés lorsqu'ils résolvent ces cas d'utilisation. Nous présentons quelques idées de conception et modèles architecturaux pour une agrégation efficace de flux de données à l'aide de BigQuery.
Fraîcheur et précision des données
Par fraîcheur, nous entendons que la latence des données de l'agrégat est inférieure à un certain seuil, par exemple "à jour depuis la dernière heure". L'actualisation est déterminée par le sous-ensemble de données brutes inclus dans les agrégations.
Lorsque vous traitez des flux de données, il est très courant que les événements arrivent en retard dans notre système de traitement des données, ce qui signifie que l'heure à laquelle notre système traite un événement est beaucoup plus tardive que celle où l'événement se produit.
Lorsque nous traitons les faits arrivant tardivement, les valeurs de nos statistiques agrégées changent, ce qui signifie que dans une journée, les valeurs que les analystes voient changent[1]. Par précis, nous entendons que les statistiques agrégées sont aussi proches que possible des valeurs rapprochées finales.
Il existe bien sûr un troisième critère d'optimisation: le coût, aussi bien en termes de dollars que de performances. Par exemple, nous pourrions utiliser une vue logique pour les objets de données dans la préproduction et la création de rapports. L'inconvénient d'une vue logique est qu'à chaque fois que la table agrégée est interrogée, l'intégralité de l'ensemble de données brut est analysée, ce qui est lent et coûteux.
Description du scénario
Préparons le terrain pour ce cas d'utilisation. Nous allons ingérer les flux d'événements Wikipédia publiés par Wikimedia. Notre objectif est de créer un classement qui indiquera les auteurs ayant le plus de modifications, et qui sera actualisé à mesure que de nouveaux articles seront publiés. Notre classement, qui sera implémenté sous forme de tableau de bord BI Engine, regroupera les événements bruts par nom d'utilisateur pour calculer les scores[2].
2. Conception
Hiérarchisation des données
Dans le pipeline de données, nous allons définir plusieurs niveaux de données. Nous conserverons les données d'événement brutes et créerons un pipeline de transformations, d'enrichissements et d'agrégations ultérieurs. Nous ne connectons pas directement les tables de reporting aux données contenues dans les tables brutes, car nous souhaitons unifier et centraliser les transformations dont les différentes équipes se soucient pour les données provisoires.
L'un des principes importants de cette architecture est que les niveaux supérieurs (Staging et Reporting) peuvent être recalculés à tout moment en n'utilisant que les données brutes.
Partitionnement
BigQuery accepte deux styles de partitionnement : le partitionnement par plages d'entiers et le partitionnement par date. Nous ne considérerons que le partitionnement des dates dans le champ d'application de cet article.
Pour le partitionnement par date, nous avons le choix entre des partitions avec date d'ingestion ou des partitions basées sur des champs. Le partitionnement au moment de l'ingestion répartit les données dans une partition en fonction de leur date d'acquisition. Les utilisateurs peuvent également sélectionner une partition au moment du chargement en spécifiant un décorateur de partition.
Le partitionnement par champs partitionne les données en fonction de la valeur de date ou d'horodatage d'une colonne.
Pour l'ingestion des événements, nous allons ajouter les données dans une table partitionnée par date d'ingestion. En effet, le temps d'ingestion est pertinent pour le traitement ou le retraitement des données reçues par le passé. Les remplissages de données historiques peuvent également être stockés dans des partitions de temps d'ingestion, en fonction de leur date d'arrivée.
Dans cet atelier de programmation, nous partirons du principe que nous ne recevrons pas de faits tardifs[3] du flux d'événements Wikimedia. Cela simplifiera le chargement incrémentiel de la table de préproduction, comme indiqué ci-dessous.
Nous allons partitionner la table de préproduction par heure d'événement. En effet, nos analystes souhaitent interroger les données en fonction de l'heure de l'événement (l'heure à laquelle l'article a été publié sur Wikipédia) et non de l'heure à laquelle l'événement a été traité dans le pipeline.
3. Architecture
Objectifs de l'atelier
Pour lire le flux d'événements à partir de Wikimedia, nous utilisons le protocole SSE. Nous allons écrire un petit service de middleware qui lira le flux d'événements en tant que client SSE et publiera dans un sujet Pub/Sub au sein de notre environnement GCP.
Une fois les événements disponibles dans Pub/Sub, nous allons créer un job Cloud Dataflow, à l'aide d'un modèle, qui diffusera les enregistrements vers le niveau de données brutes de notre entrepôt de données BigQuery. L'étape suivante consiste à calculer les statistiques agrégées pour étayer notre classement en temps réel.
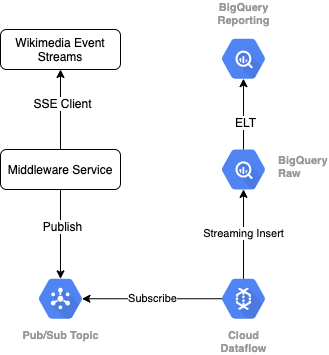
Planification et orchestration
Pour orchestrer l'ELT qui renseigne les niveaux de préproduction et de création de rapports de l'entrepôt, nous allons utiliser Dataform. Dataform "apporte des outils, des bonnes pratiques et des workflows inspirés de l'ingénierie logicielle" aux équipes d'ingénierie des données. En plus de l'orchestration et de la planification, Dataform fournit des fonctionnalités telles que des assertions et des tests pour assurer la qualité, définir des opérations d'entrepôt personnalisées pour la gestion de base de données, et des fonctionnalités de documentation pour prendre en charge la découverte de données.
Les auteurs remercient l'équipe Dataform pour ses précieux commentaires lors de l'examen de cet atelier et de ce blog.
Dans Dataform, les données brutes transmises par Dataflow seront déclarées en tant qu'ensemble de données externe. Les tables de préproduction et de création de rapports seront définies de manière dynamique à l'aide de la syntaxe SQLX de Dataform.
Nous allons utiliser la fonctionnalité de chargement incrémentiel de Dataform pour remplir la table de préproduction, en planifiant l'exécution du projet Dataform toutes les heures. Conformément à ce qui précède, nous partons du principe que nous ne recevons pas de faits tardifs. Notre logique consiste donc à ingérer les enregistrements dont l'heure d'événement est postérieure à l'heure de l'événement le plus récent parmi les enregistrements en préproduction existants.
Dans les prochains ateliers de cette série, nous aborderons la gestion des faits tardifs.
Lorsque nous exécutons l'ensemble du projet, tous les nouveaux enregistrements sont ajoutés aux niveaux de données en amont, et nos agrégations sont recalculées. En particulier, chaque exécution entraînera une actualisation complète de la table agrégée. Notre conception physique comprendra le clustering de la table de préproduction par username, ce qui augmentera encore plus les performances de la requête d'agrégation qui actualisera complètement ce classement.
Prérequis
- Une version récente de Chrome
- Connaissances de base du langage SQL et de BigQuery
4. Configuration
Créer un ensemble de données et une table BigQuery pour le niveau brut
Créez un ensemble de données qui contiendra notre schéma d'entrepôt. Nous utiliserons également ces variables ultérieurement. Veillez donc à utiliser la même session de shell pour les étapes suivantes ou à les définir si nécessaire. Veillez à remplacer <PROJECT_ID> par l'ID de votre projet.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
À présent, nous allons créer une table qui contiendra les événements bruts à l'aide de la console GCP. Le schéma correspondra aux champs projetés à partir du flux d'événements des modifications publiées que nous utilisons à partir de Wikimedia.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
Créer un sujet et un abonnement Pub/Sub
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
Créer un compte et un projet Dataform
Accédez à https://app.dataform.co et créez un compte. Une fois connecté, vous pourrez créer un projet.
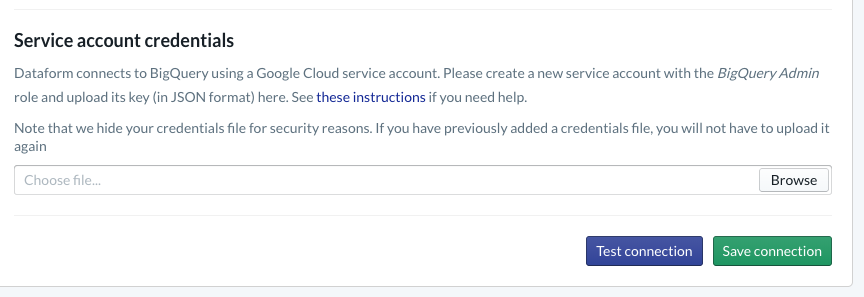
Dans votre projet, vous devez configurer l'intégration à BigQuery. Étant donné que Dataform devra se connecter à l'entrepôt, nous devrons provisionner les identifiants du compte de service.
Veuillez suivre les étapes indiquées ci-dessus dans la documentation Dataform pour configurer la connexion à BigQuery sur la page "Base de données". Veillez à sélectionner le même ID de projet que celui que vous avez créé ci-dessus, puis importez les identifiants et testez la connexion.
Une fois l'intégration de BigQuery configurée, les ensembles de données sont disponibles dans l'onglet "Modélisation". En particulier, la table brute que nous utilisons pour capturer des événements à partir de Dataflow sera présente ici. Nous y reviendrons plus tard.
5. Implémentation
Créer un service Python pour lire et publier des événements dans Pub/Sub
Veuillez consulter le code Python ci-dessous, également disponible dans cet article général. Nous suivons la documentation de l'API Pub/Sub dans cet exemple.
Regardons la liste keys dans le code. Il s'agit des champs que nous allons projeter à partir de l'événement JSON complet, qui seront conservés dans les messages publiés, et finalement dans la table "wiki_changes" sur le niveau brut de notre ensemble de données BigQuery.
Ils correspondent au schéma de la table wiki_changes que nous avons défini dans l'ensemble de données BigQuery pour wiki_changes.
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. Implémentation, suite
Créer un job Dataflow à partir d'un modèle pour lire des données depuis Pub/Sub et les écrire dans BigQuery
Une fois que les événements de modification récents ont été publiés dans le sujet Pub/Sub, nous pouvons utiliser un job Cloud Dataflow pour les lire et les écrire dans BigQuery.
Si nous avions des besoins complexes lors du traitement des flux (fusion de flux disparates, création d'agrégations fenêtrées, utilisation de recherches pour enrichir les données, par exemple), nous pourrions les implémenter dans notre code Apache Beam.
Comme nos besoins sont plus simples pour ce cas d'utilisation, nous pouvons utiliser le modèle Dataflow prêt à l'emploi, sans avoir à le personnaliser. Nous pouvons le faire directement depuis la console GCP dans Cloud Dataflow.
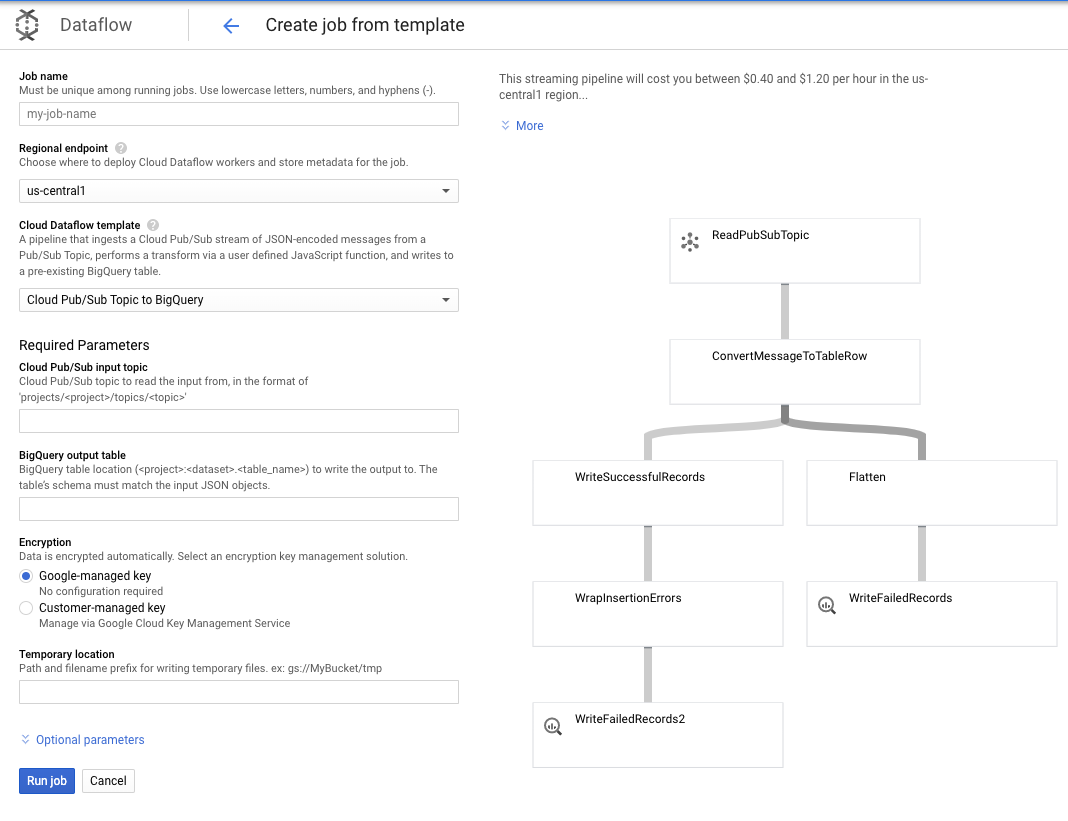
Nous allons utiliser le modèle Sujet Pub/Sub vers BigQuery, puis configurer quelques éléments dans le modèle Dataflow, y compris le sujet d'entrée Pub/Sub et la table de sortie BigQuery.
7. Implémentation, étapes Dataform
Créer des modèles de tables dans Dataform
Notre modèle Dataform est lié au dépôt GitHub suivant, qui contient les fichiers SQLX qui définissent le modèle de données.
Comme indiqué dans la section "Planification et orchestration", nous allons définir une table de préproduction dans Dataform qui agrège les enregistrements bruts de wiki_changes. Examinons le LDD de la table de préproduction (également accessible via le lien dans le dépôt GitHub associé à notre projet Dataform).
Remarquons quelques caractéristiques importantes de ce tableau:
- Il est configuré en tant que type incrémentiel. Par conséquent, lorsque nos jobs ELT planifiés s'exécutent, seuls les nouveaux enregistrements sont ajoutés.
- Comme indiqué par le code "when()" en bas, la logique est basée sur le champ "timestamp", qui reflète l'horodatage du flux d'événements, c'est-à-dire l'événement event_time de la modification
- Il est mis en cluster à l'aide du champ user, ce qui signifie que les enregistrements de chaque partition sont classés par user (utilisateur), ce qui réduit le brassage requis par la requête qui crée le classement.
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
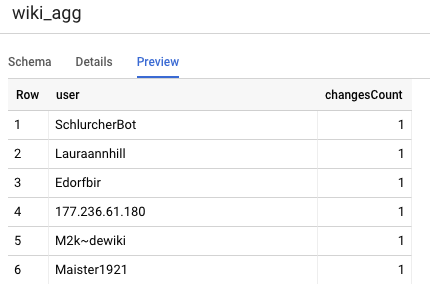
L'autre tableau que nous devons définir pour notre projet est celui du niveau de reporting. Il prendra en charge les requêtes de classement. Les tableaux du niveau Reporting sont agrégés, car nos utilisateurs s'intéressent à un décompte précis et récent des modifications publiées sur Wikipédia.
La définition de table est simple et utilise des références Dataform. L'un des principaux avantages de ces références est qu'elles rendent explicites les dépendances entre les objets, ce qui assure l'exactitude du pipeline en garantissant que les dépendances sont toujours exécutées avant les requêtes dépendantes.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
Planifier un projet Dataform
La dernière étape consiste simplement à créer une planification qui s'exécutera toutes les heures. Lorsque notre projet est appelé, Dataform exécute les instructions SQL requises pour actualiser la table de préproduction incrémentielle et la table agrégée.
Cette programmation peut être appelée toutes les heures (ou même plus fréquemment, toutes les 5 à 10 minutes environ) pour que le classement soit mis à jour avec les événements récents qui ont été diffusés dans le système.
8. Félicitations
Félicitations, vous avez réussi à créer une architecture de données à plusieurs niveaux pour vos données diffusées par flux !
Nous avons commencé avec un flux d'événements Wikimedia, que nous avons transformé en tableau de reporting dans BigQuery, qui est constamment à jour.
Et ensuite ?
Complément d'informations
- Présentation de Dataform
- Ingénierie des données fonctionnelles : un paradigme moderne pour le traitement des données par lot
- Agréger des données pour BigQuery à l'aide d'Apache Airflow
[1] Il est courant que les ingénieurs de données effectuent une transformation quotidienne par lot pour écraser les agrégations intrajournalières (par exemple, toutes les heures). C'est ce qu'on appelle le rapprochement.
[2] Pour en savoir plus sur l'implémentation, veuillez consulter la section "Architecture".
[3] Un fait tardif est un événement dont l'attribut event_time est ultérieur aux enregistrements déjà traités par le système dans ce même flux d'événements.