
1. מבוא
סקירה כללית
מסגרות לניתוח נתונים בזמן אמת נעשות חשובות יותר ויותר באחסון נתונים עכשווי, בתור משתמשים עסקיים הביקוש לניתוח נתונים בזמן אמת לא ישתנה. השקענו מאמצים רבים כדי לשפר את עדכניות הנתונים במחסנים ולתמוך בניתוח נתונים בסטרימינג באופן כללי, אבל מהנדסי הנתונים עדיין נתקלים באתגרים במהלך התאמת מקורות הסטרימינג האלה לארכיטקטורת מחסן הנתונים (data warehouse) שלהם.
בבלוג הזה נדון בכמה מהאתגרים הנפוצים ביותר שמהנדסי מערכות מידע מתמודדים איתם כשהם פותרים תרחישים לדוגמה כאלה. נפרט כמה רעיונות עיצוב ודפוסים ארכיטקטוניים לצבירה יעילה של נתוני סטרימינג באמצעות BigQuery.
עדכניות ודיוק הנתונים
המשמעות של עדכניות היא שזמן האחזור של הנתונים הנצבר נמוך מסף מסוים, למשל "up up as of the last hours" העדכניות נקבעת לפי קבוצת המשנה של הנתונים הגולמיים שנכללים בנתונים המצטברים.
כשמדובר בנתונים בסטרימינג, מקובל מאוד שאירועים מגיעים מאוחר במערכת עיבוד הנתונים שלנו. כלומר, השעה שבה המערכת שלנו מעבדת אירוע היא מאוחרת משמעותית מהשעה שבה האירוע מתרחש.
כשאנחנו מעבדים את העובדות שמגיעות מאוחר יותר, הערכים של הנתונים הסטטיסטיים הנצברים משתנים. כלומר, במהלך היום, הערכים שהאנליסטים רואים משתנים[1]. המשמעות של מדויק היא שהנתונים הסטטיסטיים הנצברים קרובים ככל האפשר לערכים הסופיים המותאמים.
כמובן שיש היבט שלישי שצריך לבצע אופטימיזציה: עלות - גם בדולרים וגם בביצועים. כדי להמחיש זאת, נוכל להשתמש בתצוגה לוגית של האובייקטים של הנתונים ב-Staging ובדיווח. החיסרון של שימוש בתצוגה לוגית הוא שבכל פעם שיש שאילתה לגבי הטבלה המקובצת, כל מערך הנתונים הגולמי נסרק, הפעולה תהיה איטית ויקרה.
תיאור התרחיש
בואו נגדיר את הרקע לתרחיש לדוגמה הזה. אנחנו הולכים להטמיע נתונים של Wikipedia Event Streams שפורסמו על ידי Wikimedia. המטרה שלנו היא ליצור לידרבורד שיראה את המחברים עם הכי הרבה שינויים, שיהיה מעודכן כשיתפרסמו מאמרים חדשים. לוח הלידרבורד שלנו, שיוטמע כמרכז בקרה של BI Engine, יאסוף את האירועים הגולמיים לפי שם משתמש כדי לחשב את הציונים[2].
2. עיצוב
שכבות נתונים
בצינור הנתונים נגדיר כמה רמות של נתונים. אנחנו נשמור את נתוני האירועים הגולמיים ונבנה צינור עיבוד נתונים של טרנספורמציות, העשרה וצבירת נתונים. אנחנו לא מקשרים טבלאות דיווח ישירות לנתונים ששמורים בטבלאות גולמיות, כי אנחנו רוצים לאחד ולרכז את השינויים שצוותים שונים מבצעים בנתונים המבוימים.
עיקרון חשוב בארכיטקטורה הזו הוא ששכבות גבוהות יותר – Staging ודיווח – ניתן לחשב מחדש בכל שלב על סמך הנתונים הגולמיים בלבד.
חלוקה למחיצות (partitioning)
BigQuery תומך בשני סגנונות של חלוקה למחיצות (partitioning): חלוקה למחיצות (partitioning) של טווח מספרים שלמים וחלוקה למחיצות של תאריכים. אנחנו נביא בחשבון רק את האפשרות לחלוקה למחיצות (partitioning) לפי תאריכים עבור הפוסט הזה.
לצורך חלוקת תאריכים למחיצות, אנחנו יכולים לבחור בין מחיצות זמן של הטמעת נתונים או מחיצות מבוססות שדות. זמן הטמעת הנתונים שבו מתבצע החלוקה למחיצות (partitioning) של הנתונים במחיצה על סמך מועד הצירוף של הנתונים. המשתמשים גם יכולים לבחור מחיצה בזמן הטעינה על ידי ציון מעצב מחיצות.
חלוקה למחיצות (partitioning) של נתונים בשדות על סמך הערך של התאריך או חותמת הזמן בעמודה.
כדי לבצע הטמעת אירועים, נעביר את הנתונים לטבלה מחולקת למחיצות (Partitions) לפי זמן הטמעת הנתונים. הסיבה לכך היא שזמן הטמעת הנתונים רלוונטי לעיבוד או לעיבוד מחדש של נתונים שהתקבלו בעבר. ניתן גם לאחסן מילוי חוסרים של נתונים היסטוריים במחיצות זמן של הטמעת נתונים, לפי המועד שבו הם היו הגיעו.
ב-Codelab הזה, נצא מנקודת הנחה שלא נקבל עובדות שמגיעות באיחור[3] מזרם האירוע של Wikimedia. כך תפשט את הטעינה המצטברת של טבלת ה-Staging, כפי שמתואר בהמשך.
בטבלת ה-Staging, יחולקו למחיצות לפי שעת האירוע. הסיבה לכך היא שהאנליסטים שלנו רוצים להריץ שאילתות על נתונים על סמך מועד האירוע – המועד שבו הכתבה פורסמה בוויקיפדיה – ולא השעה שבה האירוע עובד בצינור עיבוד הנתונים.
3. ארכיטקטורה
מה תפַתחו
כדי לקרוא את זרם האירועים מ-Wikimedia, נשתמש בפרוטוקול SSE. אנחנו נכתוב שירות תווכה קטן שיקרא מזרם האירועים כלקוח SSE ויפורסם בנושא Pub/Sub בסביבת GCP שלנו.
אחרי שהאירועים יהיו זמינים ב-Pub/Sub, ניצור משימת Cloud Dataflow באמצעות תבנית. המשימה הזו תשדר את הרשומות לרמת הנתונים הגולמיים במחסן הנתונים (data warehouse) ב-BigQuery. השלב הבא הוא לחשב את הנתונים הסטטיסטיים המצטברים כדי לתמוך ברשימת המובילים שלנו בשידור חי.
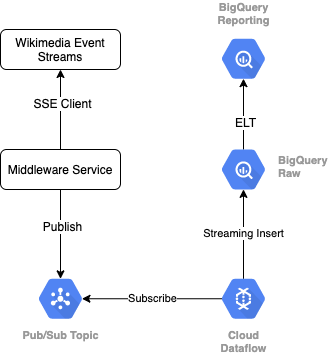
תזמון ותזמור
לתזמור של ELT שמאכלס את רמות ה-Staging והדיווח של המחסן, נשתמש ב-Dataform. Dataform "כולל כלים, שיטות מומלצות ותהליכי עבודה בהשראת הנדסת תוכנה" לצוותים של הנדסת מערכות מידע. בנוסף לתזמור ותזמון, Dataform מספק פונקציונליות כמו טענות נכונות (Assertions) ובדיקות (בדיקות) להבטחת איכות, הגדרת פעולות מחסן בהתאמה אישית לניהול מסדי נתונים ותכונות תיעוד לתמיכה בגילוי נתונים.
המחברים תודה לצוות Dataform על המשוב החשוב במהלך בדיקת שיעור ה-Lab והבלוג.
ב-Dataform, הנתונים הגולמיים שמועברים מ-Dataflow יוצהרו כקבוצת נתונים חיצונית. טבלאות ה-Staging והדיווח יוגדרו באופן דינמי באמצעות תחביר SQLX של Dataform.
אנחנו נשתמש בתכונת הטעינה המצטברת של Dataform כדי לאכלס את טבלת ה-Staging, ונתזמן את הפרויקט ב-Dataform כך שיפעל מדי שעה. בהתאם למפורט למעלה, אנחנו נצא מנקודת הנחה שלא נקבל עובדות שיגיעו מאוחרות, ולכן הלוגיקה שלנו תהיה הטמעת רשומות שיש בהן מועד אירוע מאוחר יותר משעת האירוע האחרונה מבין הרשומות המבוימות הקיימות.
בשיעורי Lab מאוחרים יותר בסדרה הזו, נדון בטיפול בעובדות שמגיעים מאוחר יותר.
כאשר נריץ את הפרויקט כולו, יתווספו כל הרשומות החדשות לשכבות הנתונים ב-upstream, והצבירה שלנו יחושבה מחדש. באופן ספציפי, כל הפעלה תגרום לרענון מלא של הטבלה המצטברת. העיצוב הפיזי יכלול קיבוץ של טבלת ה-Staging לפי שם משתמש, כדי לשפר עוד יותר את הביצועים של שאילתת הצבירה שתרענן את טבלת ה-Leaderboard הזו באופן מלא.
מה צריך להכין
- גרסה עדכנית של Chrome
- ידע בסיסי ב-SQL והיכרות בסיסית עם BigQuery
4. בתהליך ההגדרה
יצירת מערך נתונים וטבלה ב-BigQuery לרמה גולמית
יוצרים מערך נתונים חדש שיכיל את סכימת המחסן. כמו כן נשתמש במשתנים האלה מאוחר יותר, לכן חשוב להשתמש באותו סשן מעטפת עבור השלבים הבאים, או להגדיר את המשתנים לפי הצורך. חשוב להחליף את החלק <PROJECT_ID> במזהה הפרויקט שלכם.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
בשלב הבא ניצור טבלה שתכלול את האירועים הגולמיים באמצעות מסוף GCP. הסכימה תתאים לשדות שאנחנו מקרינים מזרם האירועים של השינויים שפורסמו, שאנחנו צורכים מ-Wikimedia.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
יצירת נושא Pub/Sub ומינוי
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
יצירת חשבון ופרויקט ב-Dataform
עוברים לכתובת https://app.dataform.co ויוצרים חשבון חדש. לאחר ההתחברות, יוצרים פרויקט חדש.
בתוך הפרויקט, תצטרכו להגדיר את השילוב עם BigQuery. צריך לחבר את Dataform למחסן, ולכן נצטרך להקצות פרטי כניסה של חשבון שירות.
כדי להגדיר את החיבור ל-BigQuery בדף Database, צריך לפעול לפי השלבים שמפורטים למעלה במסמכים של Dataform. חשוב לבחור באותו מזהה פרויקט שיצרתם למעלה, ואז להעלות את פרטי הכניסה ולבדוק את החיבור.
אחרי שתגדירו את השילוב עם BigQuery, מערכי הנתונים יהיו זמינים בכרטיסייה 'מודלים'. באופן ספציפי, הטבלה הגולמית שבה אנחנו משתמשים כדי לתעד אירועים מ-Dataflow תופיע כאן. נחזור לזה עוד מעט.
5. הטמעה
יצירת שירות Python לקריאה ופרסום של אירועים ב-Pub/Sub
ניתן לעיין בקוד Python בהמשך, שזמין גם בבסיס הנתונים הזה. אנחנו פועלים לפי מסמכי Pub/Sub API בדוגמה הזו.
בואו נעיין ברשימת המפתחות בקוד. אלה השדות שאנחנו מתכננים להקרין מהאירוע ה-JSON המלא, שיישארו בהודעות שפורסמו, ובסופו של דבר בטבלה wiki_changes שברמה הגולמית של מערך הנתונים ב-BigQuery.
הערכים האלה תואמים לסכימת הטבלה wiki_changes שהגדרנו במערך הנתונים ב-BigQuery עבור wiki_changes
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. הטמעה, המשך
יצירת משימת Dataflow מתבנית לקריאה מ-Pub/Sub ולכתיבה ב-BigQuery
אחרי שאירועי השינוי האחרונים יתפרסמו בנושא Pub/Sub, נוכל להשתמש במשימה ב-Cloud Dataflow כדי לקרוא את האירועים האלה ולכתוב אותם ב-BigQuery.
אם היו לנו צרכים מתוחכמים בזמן העיבוד של השידורים – חשבו על חיבור של שידורים נפרדים, בניית צבירת נתונים בחלון נפרד, שימוש בחיפושים כדי להעשיר את הנתונים – היינו יכולים ליישם אותם בקוד Apache Beam.
מכיוון שהצרכים שלנו פשוטים יותר בתרחיש לדוגמה הזה, אנחנו יכולים להשתמש בתבנית Dataflow מובנית ולא נצטרך לבצע בה התאמות אישיות. נוכל לעשות זאת ישירות ממסוף GCP ב-Cloud Dataflow.
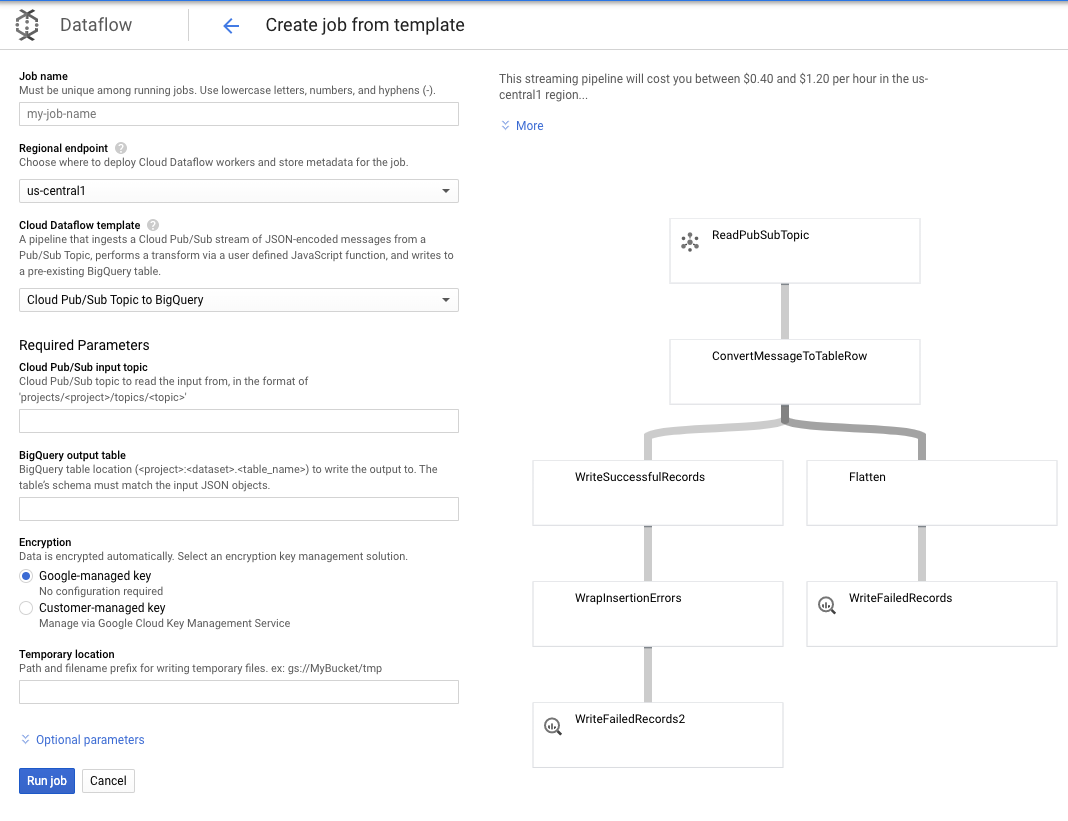
נשתמש בנושא Pub/Sub בתבנית של BigQuery, ואז נצטרך להגדיר כמה דברים בתבנית Dataflow, כולל נושא הקלט של Pub/Sub וטבלת הפלט של BigQuery.
7. הטמעה, שלבים בטופס הנתונים
טבלאות של מודלים ב-Dataform
מודל ה-Dataform מקושר למאגר הבא של GitHub – תיקיית ההגדרות מכילה את קובצי ה-SQLX שמגדירים את מודל הנתונים.
כפי שצוין בקטע 'תזמון ותזמור', נגדיר טבלת ביניים ב-Dataform שמרכזת את הרשומות הגולמיות מ-wiki_changes. נבחן את ה-DDL של טבלת ה-Staging (מקושר גם במאגר GitHub שקשור לפרויקט Dataform).
בטבלה הזו נפרט כמה תכונות חשובות:
- הוא מוגדר בתור סוג מצטבר, לכן כשמשימות ה-ELT המתוזמנות שלנו פועלות, יתווספו רק רשומות חדשות.
- כפי שמבוטא בקוד when() בחלק התחתון, הלוגיקה של הפעולה הזו מבוססת על שדה חותמת הזמן, שמשקף את חותמת הזמן בזרם האירוע, כלומר event_time של השינוי.
- היא מקובצות באמצעות השדה user, כך שהרשומות בכל מחיצה מסודרות לפי משתמש, וכך מפחיתה את מידת האקראיות הנדרשת על ידי השאילתה שיוצרת את הלידרבורד.
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
הטבלה הנוספת שעלינו להגדיר בפרויקט שלנו היא הטבלה 'רמת הדיווח', שתתמוך בשאילתות מסוג Leaderboard. הטבלאות ברמת הדיווח מצטברות, כי המשתמשים שלנו חוששים מספירות עדכניות ומדויקות של שינויים בוויקיפדיה שפורסמו.
הגדרת הטבלה היא פשוטה, והיא משתמשת בהפניות של Dataform. אחד היתרונות הגדולים של ההתייחסויות האלה הוא שהם יוצרים יחסי תלות בין אובייקטים, כך שהם תומכים בתקינות של צינור עיבוד הנתונים באמצעות הבטחה שיחסי התלות תמיד מופעלים לפני שאילתות תלויות.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
תזמון פרויקט Dataform
השלב האחרון הוא פשוט ליצור לוח זמנים שיופעל על בסיס שעתי. במהלך ההפעלה של הפרויקט שלנו, Dataform יריץ את הצהרות ה-SQL הנדרשות כדי לרענן את טבלת ה-staging המצטברת וכדי לטעון מחדש את הטבלה המצטברת.
ניתן להפעיל את לוח הזמנים הזה בכל שעה – או בתדירות גבוהה יותר, עד בערך כל 5-10 דקות – כדי שהלידרבורד יהיה מעודכן באירועים האחרונים ששודרו במערכת.
8. מזל טוב
כל הכבוד! פיתחתם בהצלחה ארכיטקטורת נתונים מדורגת לנתונים הסטרימינג שלכם!
התחלנו עם זרם אירוע ב-Wikimedia ושינינו אותו לטבלת דיווח ב-BigQuery שמתעדכנת באופן עקבי.
מה השלב הבא?
קריאה נוספת
- חדש: Dataform
- הנדסת מערכות מידע – פרדיגמה מודרנית לעיבוד נתונים באצווה
- איך צוברים נתונים ל-BigQuery באמצעות Apache Airflow
[1] לעיתים קרובות מהנדסי נתונים מפעילים טרנספורמציה יומית באצווה כדי להחליף את הנתונים הנצברים שמתקבלים במהלך היום (למשל, מדי שעה). התהליך הזה נקרא התאמה.
[2] פרטים על ההטמעה אפשר למצוא בקטע 'ארכיטקטורה'.
[3] עובדה על הגעה מאוחרת היא אירוע עם event_time שחל מאוחר יותר מהרשומות שכבר עובדו על ידי המערכת באותו זרם אירוע