
1. परिचय
खास जानकारी
मौजूदा समय में डेटा इकट्ठा करने के तरीकों में, स्ट्रीमिंग से जुड़े आंकड़ों के फ़्रेमवर्क का तेज़ी से ध्यान रखा जा रहा है. ऐसा करना, कारोबारी उपयोगकर्ताओं के लिए काफ़ी अहम होता जा रहा है रीयल-टाइम ऐनलिटिक्स की मांग में कोई बढ़ोतरी नहीं हो रही है. वेयरहाउस के अंदर डेटा को अप-टू-डेट रखने और आम तौर पर स्ट्रीमिंग से जुड़े आंकड़ों को बेहतर बनाने के लिए कई कदम उठाए गए हैं. हालांकि, डेटा वेयरहाउस की बनावट के हिसाब से स्ट्रीमिंग करने वाले सोर्स को अपनाने में अब भी डेटा इंजीनियर को चुनौतियों का सामना करना पड़ रहा है.
इस ब्लॉग में, हमने उन सबसे आम चुनौतियों के बारे में बताया है जिनका सामना डेटा इंजीनियरों को इन कामों को हल करने में करना पड़ता है. हम BigQuery का इस्तेमाल करके, स्ट्रीमिंग डेटा को बेहतर तरीके से इकट्ठा करने के लिए, डिज़ाइन के कुछ आइडिया और आर्किटेक्चरल पैटर्न के बारे में बताते हैं.
डेटा अपडेट होने की फ़्रीक्वेंसी और सटीक होने की जानकारी
फ़्रेश से हमारा मतलब है कि एग्रीगेट डेटा के लिए इंतज़ार का समय कुछ थ्रेशोल्ड से कम है, जैसे कि "पिछले घंटे तक अप-टू-डेट है". डेटा अपडेट होने की फ़्रीक्वेंसी, रॉ डेटा के उस सबसेट से तय होती है जिसे एग्रीगेट किया गया है.
स्ट्रीमिंग डेटा के साथ काम करते समय, हमारे डेटा प्रोसेसिंग सिस्टम में इवेंट का देर से पहुंचना बहुत आम बात है. इसका मतलब है कि हमारा सिस्टम किसी इवेंट को प्रोसेस करने का समय, इवेंट के होने के समय से काफ़ी बाद का है.
जब हम देर से मिलने वाले तथ्यों को प्रोसेस करते हैं, तो हमारे इकट्ठा किए गए आंकड़ों की वैल्यू बदल जाएगी. इसका मतलब यह है कि दिन के हिसाब से, ऐनलिस्ट को दिखने वाली वैल्यू बदल जाएंगी[1]. सटीक से हमारा मतलब है कि एग्रीगेट किए गए आंकड़े, उन वैल्यू के ज़्यादा से ज़्यादा करीब हैं जिनका समाधान सबसे सटीक है.
हालांकि, ऑप्टिमाइज़ करने के लिए एक तीसरा डाइमेंशन भी है. रुपया और परफ़ॉर्मेंस, दोनों के लिहाज़ से लागत. उदाहरण के लिए, हम स्टेजिंग और रिपोर्टिंग में डेटा ऑब्जेक्ट के लिए लॉजिकल व्यू का इस्तेमाल कर सकते हैं. लॉजिकल व्यू का इस्तेमाल करने का एक नकारात्मक पहलू यह है कि जब भी एग्रीगेट की गई टेबल के बारे में क्वेरी की जाती है, तब पूरे रॉ डेटासेट को स्कैन किया जाता है. यह प्रोसेस धीमी होने के साथ-साथ महंगा भी होता है.
स्थिति की जानकारी
चलिए, इस्तेमाल के इस उदाहरण को समझने की कोशिश करते हैं. हम Wikipedia के पब्लिश किए गए इवेंट स्ट्रीम का डेटा डालने वाले हैं. हमारा मकसद ऐसा लीडरबोर्ड बनाना है जिसमें लेखकों के सबसे ज़्यादा बदलाव किए जाने चाहिए. नए लेख पब्लिश होने पर, उपयोगकर्ताओं की जानकारी अप-टू-डेट रहेगी. हमारा लीडरबोर्ड, बीआई इंजन डैशबोर्ड के तौर पर लागू किया जाएगा. इसमें स्कोर का हिसाब लगाने के लिए, प्रोसेस नहीं किए गए इवेंट को उपयोगकर्ता नाम के हिसाब से एग्रीगेट किया जाएगा[2].
2. डिज़ाइन
डेटा टियरिंग
डेटा पाइपलाइन में, हम डेटा के कई लेवल तय करेंगे. हम इवेंट के रॉ डेटा को अपने पास रखेंगे. साथ ही, बाद में होने वाले ट्रांसफ़ॉर्मेशन, एनटाइटलमेंट, और एग्रीगेशन की एक पाइपलाइन बनाएंगे. हम रिपोर्टिंग टेबल को रॉ टेबल में मौजूद डेटा से सीधे कनेक्ट नहीं करते. ऐसा इसलिए, क्योंकि हम उन ट्रांसफ़ॉर्मेशन को एक ही जगह पर लाना और उन्हें एक ही जगह पर उपलब्ध कराना चाहते हैं जो अलग-अलग टीमें, स्टेज किए गए डेटा के लिए ज़रूरी हैं.
इस आर्किटेक्चर में एक अहम सिद्धांत यह है कि सिर्फ़ रॉ डेटा का इस्तेमाल करके, हायर टीयर, स्टेजिंग और रिपोर्टिंग – का कभी भी फिर से हिसाब लगाया जा सकता है.
पार्टिशन
BigQuery में, सेगमेंट को दो अलग-अलग स्टाइल में बांटा जा सकता है; पूर्णांक श्रेणी विभाजन और तारीख विभाजन. इस पोस्ट के दायरे में, हम सिर्फ़ तारीख के बंटवारे पर ध्यान देंगे.
तारीख के बंटवारे के लिए, हम डेटा डालने के समय के सेगमेंट या फ़ील्ड के आधार पर बने सेगमेंट में से कोई एक चुन सकते हैं. डेटा डालने के समय के बंटवारे की सुविधा से, डेटा को उस हिस्से में बांटा जा सकता है जिस दिन उसे हासिल किया गया था. उपयोगकर्ता किसी पार्टिशन डेकोरेटर को तय करके, लोड होने के समय के लिए भी पार्टिशन चुन सकते हैं.
डेटा को किसी कॉलम में तारीख या टाइमस्टैंप की वैल्यू के आधार पर बांटा जाता है.
इवेंट का डेटा डालने के लिए, हम डेटा को समय के हिसाब से सेगमेंट में बांटी गई टेबल में डाल देंगे. ऐसा इसलिए होता है, क्योंकि डेटा डालने का समय, पहले मिले डेटा को प्रोसेस या फिर से प्रोसेस करने के लिए ज़रूरी होता है. पुराने डेटा के बैकफ़िल, डेटा डालने के समय के सेगमेंट में भी सेव किए जा सकते हैं. यह इस बात पर निर्भर करता है कि वे कब आए थे.
इस कोडलैब में, हम यह मानेंगे कि हमें विकीमीडिया इवेंट स्ट्रीम से, देर से आने वाले तथ्य[3] नहीं मिलेंगे. इससे स्टेजिंग टेबल का इंंक्रीमेंटल लोड होना आसान हो जाएगा, जैसा कि नीचे बताया गया है.
स्टेजिंग टेबल के लिए, हम इवेंट के समय के हिसाब से पार्टीशन करेंगे. ऐसा इसलिए है, क्योंकि हमारे विश्लेषक, इवेंट के समय– Wikipedia पर लेख पब्लिश होने के समय–न कि पाइपलाइन में इवेंट के प्रोसेस होने के समय के आधार पर डेटा क्वेरी करना चाहते हैं.
3. आर्किटेक्चर
आपको क्या बनाना होगा
Wikimedia से इवेंट की स्ट्रीम पढ़ने के लिए, हम SSE प्रोटोकॉल का इस्तेमाल करेंगे. हम एक छोटी मिडलवेयर सेवा बनाएंगे, जो एक एसएसई क्लाइंट के तौर पर इवेंट स्ट्रीम से पढ़ेगी. साथ ही, हमारे GCP एनवायरमेंट में, Pub/Sub विषय पर पब्लिश होगी.
Pub/Sub में इवेंट उपलब्ध होने के बाद, हम एक टेंप्लेट का इस्तेमाल करके Cloud Dataflow जॉब बनाएंगे, जो हमारे BigQuery डेटा वेयरहाउस में रॉ डेटा टीयर में रिकॉर्ड को स्ट्रीम करेगा. अगला चरण हमारे लाइव लीडरबोर्ड को सपोर्ट करने के लिए एग्रीगेट किए गए आंकड़ों का हिसाब लगाना है.
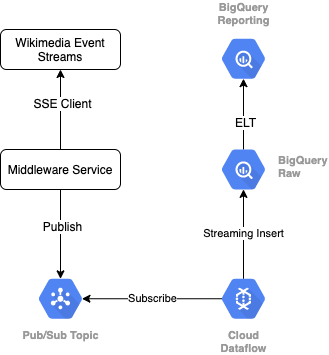
शेड्यूल बनाना और व्यवस्थित करना
वेयरहाउस के स्टेजिंग और रिपोर्टिंग टियर में जानकारी डालने वाले ईएलटी को व्यवस्थित करने के लिए, हम डेटाफ़ॉर्म का इस्तेमाल करेंगे. डेटाफ़ॉर्म "टूलिंग, सबसे सही तरीके, और सॉफ़्टवेयर इंजीनियरिंग से प्रेरित वर्कफ़्लो लाएं" को ट्रैक किया जा सकता है. व्यवस्थित और शेड्यूल करने के अलावा, Dataform, क्वालिटी को पक्का करने के लिए दावे और टेस्ट जैसी सुविधाएं देता है. साथ ही, डेटाबेस मैनेजमेंट के लिए कस्टम वेयरहाउस ऑपरेशन तय करता है और डेटा खोजने में मदद करने के लिए दस्तावेज़ की सुविधाएं देता है.
इस लैब और ब्लॉग की समीक्षा करने के लिए लेखक, Dataform टीम को अपने अहम सुझाव या राय देने के लिए धन्यवाद देते हैं.
Dataform में, Dataflow से स्ट्रीम किए गए रॉ डेटा को बाहरी डेटा सेट के तौर पर एलान किया जाएगा. Dataform के SQLX सिंटैक्स का इस्तेमाल करके, स्टेजिंग और रिपोर्टिंग टेबल को डाइनैमिक तौर पर तय किया जाएगा.
हम स्टेजिंग टेबल को भरने के लिए, डेटाफ़ॉर्म की इंक्रीमेंटल लोडिंग सुविधा का इस्तेमाल करेंगे. साथ ही, डेटाफ़ॉर्म प्रोजेक्ट को हर घंटे चलाने के लिए शेड्यूल करेंगे. ऊपर दी गई जानकारी के हिसाब से, हम यह मानेंगे कि हमें देर से आने वाले तथ्य नहीं मिलेंगे. इसलिए, हमारा तर्क ऐसे रिकॉर्ड अपनाना होगा जिनका इवेंट का समय, मौजूदा चरण वाले रिकॉर्ड में सबसे हाल के इवेंट के समय के बाद का हो.
इस सीरीज़ की बाद की लैब में, हम देर से मिलने वाले तथ्यों के इस्तेमाल के बारे में चर्चा करेंगे.
जब हम पूरा प्रोजेक्ट चलाएंगे, तो अपस्ट्रीम डेटा टियर में सभी नए रिकॉर्ड जोड़े जाएंगे. साथ ही, हमारे एग्रीगेशन की फिर से गिनती की जाएगी. खास तौर पर, हर बार चलाने पर एग्रीगेट की गई टेबल पूरी तरह रीफ़्रेश होगी. हमारे फ़िज़िकल डिज़ाइन में, स्टेजिंग टेबल को उपयोगकर्ता नाम से क्लस्टर किया जाएगा. इससे एग्रीगेशन क्वेरी की परफ़ॉर्मेंस बेहतर होगी, जो इस लीडरबोर्ड को पूरी तरह से रीफ़्रेश कर देगी.
आपको इन चीज़ों की ज़रूरत होगी
- Chrome का नया वर्शन
- एसक्यूएल के बारे में बुनियादी जानकारी और BigQuery के बारे में बुनियादी जानकारी
4. सेट अप किया जा रहा है
रॉ टियर के लिए BigQuery डेटासेट और टेबल बनाना
हमारा वेयरहाउस स्कीमा शामिल करने के लिए, एक नया डेटासेट बनाएं. हम बाद में भी इन वैरिएबल का इस्तेमाल करेंगे, इसलिए नीचे दिए गए चरणों के लिए उसी शेल सेशन का इस्तेमाल करें या ज़रूरत के मुताबिक वैरिएबल सेट करें. <PROJECT_ID> को बदलना न भूलें आईडी की मदद से सबमिट करें.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
इसके बाद, हम एक टेबल बनाएंगे, जिसमें GCP कंसोल का इस्तेमाल करके प्रोसेस नहीं किए गए इवेंट होंगे. स्कीमा उन फ़ील्ड से मेल खाएगा जिन्हें हम प्रकाशित किए गए बदलावों की इवेंट स्ट्रीम से प्रोजेक्ट करते हैं. इन बदलावों का हम Wikimedia से इस्तेमाल कर रहे हैं.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
Pub/Sub का विषय और सदस्यता बनाना
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
डेटाफ़ॉर्म खाता और प्रोजेक्ट बनाना
https://app.dataform.co पर जाएं और नया खाता बनाएं. लॉग इन करने के बाद, आपको एक नया प्रोजेक्ट बनाना होगा.
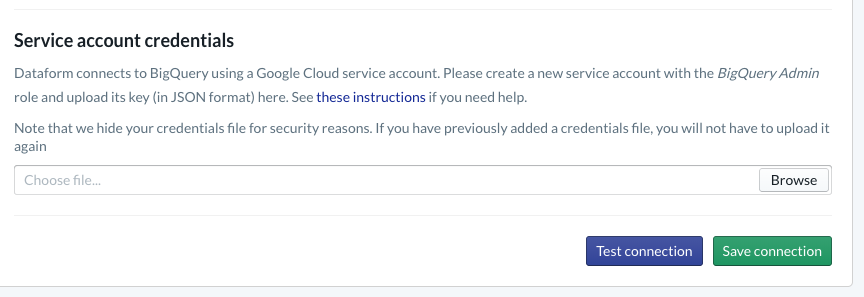
अपने प्रोजेक्ट में, आपको BigQuery के साथ इंटिग्रेशन को कॉन्फ़िगर करना होगा. Dataform को वेयरहाउस से कनेक्ट करना होगा, इसलिए हमें सेवा खाते के क्रेडेंशियल का प्रावधान करना होगा.
कृपया डेटाफ़ॉर्म दस्तावेज़ में ऊपर दिए गए तरीके का पालन करें. आपको डेटाबेस पेज पर BigQuery से कनेक्शन कॉन्फ़िगर करना होगा. पक्का करें कि आपने वही ProjectId चुना हो जिसे आपने ऊपर बनाया है. इसके बाद, क्रेडेंशियल अपलोड करें और कनेक्शन की जांच करें.
BigQuery इंटिग्रेशन कॉन्फ़िगर करने के बाद, आपको मॉडलिंग टैब में उपलब्ध डेटासेट दिखेंगे. खास तौर पर, Dataflow से इवेंट कैप्चर करने के लिए, हम जिस रॉ टेबल का इस्तेमाल करते हैं वह यहां मौजूद होगी. हम जल्द ही इस पर वापस आएंगे.
5. लागू करना
Pub/Sub में इवेंट पढ़ने और पब्लिश करने के लिए Python सेवा बनाना
कृपया नीचे दिया गया Python कोड देखें, जो इस Gist में भी उपलब्ध है. हम इस उदाहरण में, Pub/Sub एपीआई दस्तावेज़ों को फ़ॉलो कर रहे हैं.
कोड में मौजूद पासकोड की सूची पर गौर करते हैं. ये फ़ील्ड हैं जिन्हें हम पूरे JSON इवेंट से प्रोजेक्ट करने जा रहे हैं. ये फ़ील्ड पब्लिश किए गए मैसेज में बने रहते हैं और आखिर में हमारे BigQuery डेटासेट के रॉ टियर में wiki_changes टेबल में मौजूद होते हैं.
ये उन wiki_changes टेबल स्कीमा से मेल खाते हैं जिन्हें हमने wiki_changes के लिए अपने BigQuery डेटासेट में तय किया था
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. लागू करना, जारी है
Pub/Sub से पढ़ने और BigQuery में लिखने के लिए, टेंप्लेट से Dataflow जॉब बनाना
Pub/Sub विषय में हाल ही में किए गए बदलाव वाले इवेंट पब्लिश होने के बाद, हम इन इवेंट को पढ़ने और उन्हें BigQuery में लिखने के लिए, Cloud Dataflow जॉब का इस्तेमाल कर सकते हैं.
अगर स्ट्रीम को प्रोसेस करते समय हमारी ज़रूरतें पूरी होती थीं, तो अलग-अलग स्ट्रीम में शामिल होने, विंडो में एग्रीगेशन बनाने, डेटा को बेहतर बनाने के लिए लुकअप का इस्तेमाल करके, उन्हें अपने Apache बीम कोड में लागू किया जा सकता था.
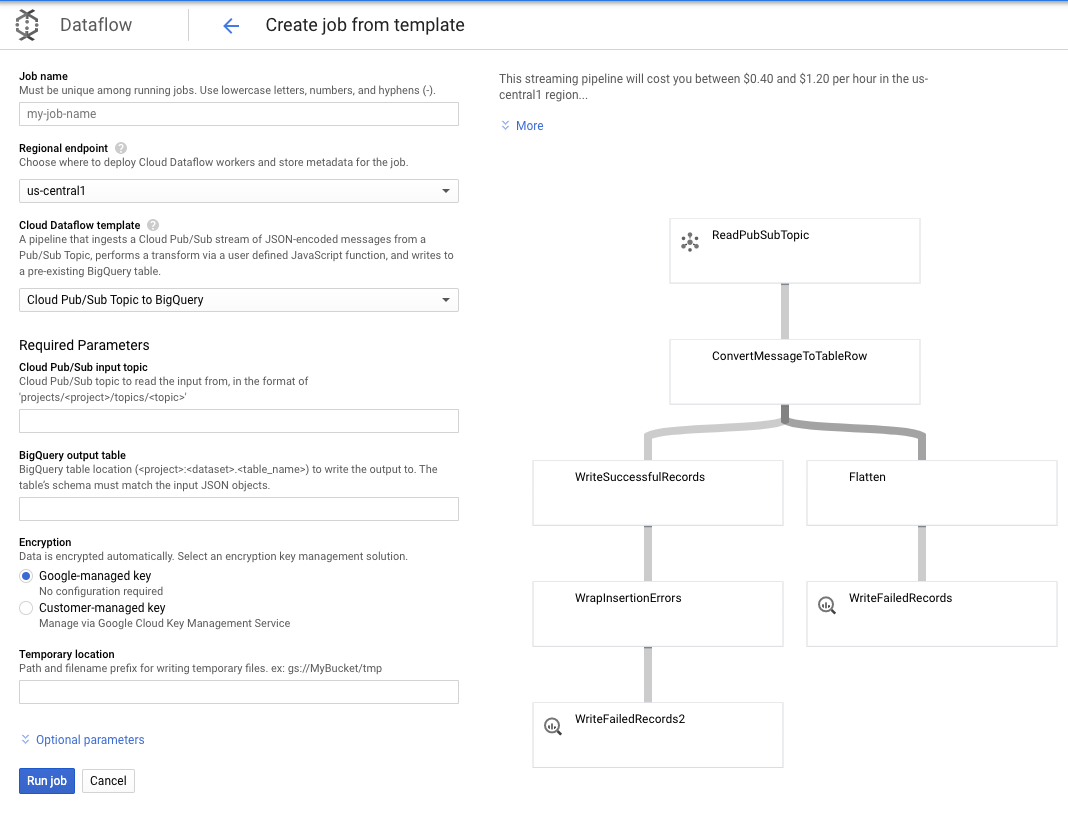
इस इस्तेमाल के लिए, हमारी ज़रूरतें और भी आसान हैं. इसलिए, हम सबसे अलग Dataflow टेंप्लेट का इस्तेमाल कर सकते हैं. साथ ही, हमें इसमें अपनी ज़रूरत के हिसाब से कोई बदलाव नहीं करना होगा. ऐसा सीधे तौर पर Cloud Dataflow में GCP कंसोल से किया जा सकता है.
हम BigQuery टेंप्लेट में Pub/Sub विषय का इस्तेमाल करेंगे और उसके बाद हमें Dataflow टेंप्लेट में कुछ चीज़ें कॉन्फ़िगर करनी होंगी. इनमें Pub/Sub इनपुट का विषय और BigQuery आउटपुट टेबल शामिल है.
7. लागू करना, डेटाफ़ॉर्म के चरण
डेटाफ़ॉर्म में मॉडल टेबल
हमारा डेटा फ़ॉर्म मॉडल, GitHub की यहां दी गई डेटा स्टोर करने की जगह से जुड़ा है. डेफ़िनिशन फ़ोल्डर में, SQLX फ़ाइलें होती हैं, जो डेटा मॉडल के बारे में बताती हैं.
जैसा कि शेड्यूलिंग और ऑर्केस्ट्राशन सेक्शन में बताया गया है, हम Dataform में एक स्टेजिंग टेबल तय करेंगे, जो wiki_changes से रॉ रिकॉर्ड को इकट्ठा करती है. आइए, स्टेजिंग टेबल के डीडीएल पर नज़र डालते हैं. यह हमारे डेटाफ़ॉर्म प्रोजेक्ट से जुड़े GitHub रेपो में भी जुड़ा है.
चलिए, इस टेबल की कुछ अहम सुविधाओं पर ध्यान देते हैं:
- इसे इंक्रीमेंटल टाइप के तौर पर कॉन्फ़िगर किया जाता है. इसलिए, शेड्यूल किए गए ईएलटी जॉब चलने पर, सिर्फ़ नए रिकॉर्ड जोड़े जाएंगे
- जैसा कि नीचे दिए गए if() कोड से पता चलता है, इसका लॉजिक टाइमस्टैंप फ़ील्ड पर आधारित होता है.टाइमस्टैंप फ़ील्ड, इवेंट स्ट्रीम में टाइमस्टैंप दिखाता है. जैसे, बदलाव का event_time
- इसे user फ़ील्ड का इस्तेमाल करके क्लस्टर में बांटा जाता है. इसका मतलब है कि हर सेगमेंट में मौजूद रिकॉर्ड, user के हिसाब से क्रम में होंगे. इससे लीडरबोर्ड बनाने वाली क्वेरी के लिए, शफ़ल करना ज़रूरी नहीं होगा
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
हमारे प्रोजेक्ट में एक और टेबल है, जो रिपोर्टिंग टीयर टेबल है. इससे लीडरबोर्ड क्वेरी इस्तेमाल की जा सकती हैं. रिपोर्टिंग श्रेणी में टेबल एग्रीगेट की गई हैं, क्योंकि हमारे उपयोगकर्ता प्रकाशित Wikipedia में किए गए बदलावों की ताज़ा और सटीक गिनती को लेकर चिंतित हैं.
टेबल की परिभाषा आसान है और इसमें डेटाफ़ॉर्म की पहचान फ़ाइलों का इस्तेमाल किया जाता है. इन चीज़ों का एक बड़ा फ़ायदा यह है कि ये ऑब्जेक्ट के बीच की डिपेंडेंसी के बारे में साफ़ तौर पर जानकारी देते हैं. साथ ही, यह पक्का करते हैं कि डिपेंडेंसी हमेशा डिपेंडेंट क्वेरी से पहले एक्ज़ीक्यूट की जाए, ताकि पाइपलाइन सही हो.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
डेटाफ़ॉर्म प्रोजेक्ट शेड्यूल करें
आखिरी चरण बस एक शेड्यूल बनाना है, जो हर घंटे के हिसाब से लागू होगा. जब हमारा प्रोजेक्ट शुरू होता है, तब इंक्रीमेंटल स्टेजिंग टेबल को रीफ़्रेश करने और एग्रीगेट की गई टेबल को फिर से लोड करने के लिए, Dataform ज़रूरी एसक्यूएल स्टेटमेंट एक्ज़ीक्यूट करेगा.
इस शेड्यूल को हर घंटे या ज़्यादा बार, करीब हर 5 से 10 मिनट में शुरू किया जा सकता है, ताकि सिस्टम में स्ट्रीम हो चुके हाल ही के इवेंट के हिसाब से लीडरबोर्ड को अपडेट रखा जा सके.
8. बधाई हो
बधाई हो, आपने अपने स्ट्रीम किए गए डेटा के लिए अलग-अलग टीयर वाला डेटा आर्किटेक्चर बना लिया है!
हमने Wikimedia इवेंट स्ट्रीम के साथ शुरुआत की थी. हमने इसे BigQuery में रिपोर्टिंग टेबल में बदल दिया है, जो लगातार अप-टू-डेट है.
आगे क्या होगा?
आगे पढ़ें
- पेश है डेटाफ़ॉर्म
- फ़ंक्शनल डेटा इंजीनियरिंग — बैच डेटा प्रोसेसिंग के लिए एक आधुनिक मॉडल
- Apache Airflow का इस्तेमाल करके, BigQuery के लिए डेटा इकट्ठा करने का तरीका
[1] इंट्रा-डे (जैसे कि हर घंटे) एग्रीगेट को ओवरराइट करने के लिए, डेटा इंजीनियर रोज़ बैच ट्रांसफ़ॉर्मेशन चलाना बहुत आम बात है. इसे समाधान कहा जाता है.
[2] लागू करने से जुड़ी जानकारी के लिए, कृपया आर्किटेक्चर सेक्शन देखें.
[3] देर से आने वाला तथ्य, event_time वाला एक इवेंट है जो इस इवेंट स्ट्रीम में सिस्टम के प्रोसेस किए गए रिकॉर्ड के बाद का है