
1. Pengantar
Ringkasan
Framework untuk analisis streaming menjadi semakin penting dalam data warehousing kontemporer, karena pengguna bisnis permintaan akan analisis real-time terus berlanjut tanpa henti. Upaya besar telah dilakukan untuk meningkatkan keaktualan data di dalam warehouse dan untuk mendukung analisis streaming secara umum, tetapi data engineer masih dihadapkan pada tantangan saat menyesuaikan sumber streaming ini ke dalam arsitektur data warehouse mereka.
Dalam blog ini, kita akan membahas beberapa tantangan paling umum yang dihadapi para insinyur data saat memecahkan kasus penggunaan ini. Kami menguraikan beberapa ide desain dan pola arsitektur untuk agregasi data streaming yang efisien menggunakan BigQuery.
Keaktualan dan akurasi data
Yang kami maksud baru adalah latensi data gabungan kurang dari batas tertentu, misalnya, "terbaru per jam terakhir". Keaktualan ditentukan oleh subset data mentah yang disertakan dalam agregat.
Saat menangani data streaming, sangat umum peristiwa datang terlambat dalam sistem pemrosesan data kami, yang berarti waktu saat sistem kami memproses peristiwa tersebut jauh lebih lambat dari waktu saat peristiwa tersebut terjadi.
Ketika kami memproses fakta yang terlambat dikumpulkan, nilai statistik gabungan kami akan berubah, artinya dalam basis hari, nilai yang dilihat para analis akan berubah[1]. Yang akurat adalah statistik gabungan sedekat mungkin dengan nilai akhir yang direkonsiliasi.
Tentu saja ada dimensi ketiga yang harus dioptimalkan: biaya, dalam arti uang dan performa. Sebagai ilustrasi, kita dapat menggunakan tampilan logis untuk objek data dalam Staging dan Reporting. Kelemahan penggunaan tampilan logis adalah setiap kali tabel gabungan dikueri, seluruh kumpulan data mentah dipindai, sehingga proses menjadi lambat dan mahal.
Deskripsi Skenario
Mari kita bersiap-siap untuk kasus penggunaan ini. Kami akan menyerap data Aliran Peristiwa Wikipedia yang dipublikasikan oleh Wikimedia. Tujuan kami adalah membuat papan peringkat yang akan menampilkan penulis dengan perubahan terbanyak, dan akan selalu diperbarui saat artikel baru dipublikasikan. Papan peringkat kami, yang akan diimplementasikan sebagai dasbor BI Engine, akan menggabungkan peristiwa mentah berdasarkan nama pengguna untuk menghitung skor[2].
2. Desain
Tingkat Data
Dalam pipeline data, kita akan menentukan beberapa tingkat data. Kami akan menyimpan data peristiwa mentah, dan membangun pipeline transformasi, pengayaan, dan agregasi berikutnya. Kami tidak menghubungkan tabel Pelaporan secara langsung ke data yang disimpan di tabel Mentah, karena kami ingin menyatukan dan memusatkan transformasi yang diperlukan oleh berbagai tim untuk data bertahap.
Prinsip penting dalam arsitektur ini adalah bahwa tingkat yang lebih tinggi, yaitu Staging dan Reporting, dapat dihitung ulang kapan saja, hanya dengan menggunakan data mentah.
Membuat partisi
BigQuery mendukung dua gaya partisi; partisi rentang bilangan bulat dan partisi tanggal. Kami akan mempertimbangkan hanya partisi tanggal dalam cakupan untuk postingan ini.
Untuk partisi tanggal, kita dapat memilih antara partisi waktu penyerapan atau partisi berbasis kolom. partisi waktu penyerapan menempatkan data di partisi berdasarkan waktu data diperoleh. Pengguna juga dapat memilih partisi pada waktu pemuatan dengan menentukan dekorator partisi.
Mempartisi kolom membuat partisi data berdasarkan nilai tanggal atau stempel waktu dalam kolom.
Untuk penyerapan peristiwa, kami akan memasukkan data ke tabel berpartisi dengan waktu penyerapan. Hal ini karena waktu penyerapan relevan untuk pemrosesan atau pemrosesan ulang data yang diterima di masa lalu. Pengisian ulang data historis juga dapat disimpan dalam partisi waktu penyerapan, berdasarkan waktu data tersebut akan tiba.
Dalam Codelab ini, kita akan mengasumsikan bahwa kita tidak akan menerima fakta yang terlambat tiba[3] dari aliran peristiwa Wikimedia. Ini akan menyederhanakan pemuatan inkremental dari tabel staging, seperti yang dibahas di bawah ini.
Untuk tabel staging, kita akan mempartisi berdasarkan waktu peristiwa. Hal ini karena analis kita tertarik untuk membuat kueri data berdasarkan waktu peristiwa–waktu artikel dipublikasikan di Wikipedia–dan bukan waktu saat peristiwa tersebut diproses dalam pipeline.
3. Arsitektur
Yang akan Anda bangun
Untuk membaca streaming acara dari Wikimedia, kami akan menggunakan protokol SSE. Kita akan menulis layanan middleware kecil yang akan membaca dari aliran peristiwa sebagai klien SSE dan akan memublikasikan ke topik Pub/Sub dalam lingkungan GCP kita.
Setelah peristiwa tersedia di Pub/Sub, kita akan membuat tugas Cloud Dataflow, menggunakan template, yang akan mengalirkan kumpulan data ke tingkat data Mentah di data warehouse BigQuery. Langkah berikutnya adalah menghitung statistik gabungan untuk mendukung papan peringkat langsung kami.
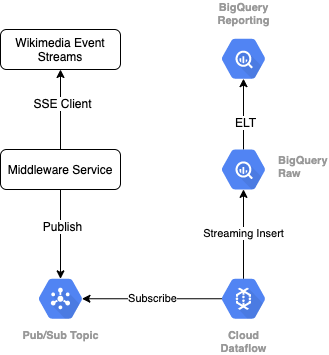
Penjadwalan dan Orkestrasi
Untuk mengorkestrasi ELT yang mengisi tingkat Staging dan Reporting di warehouse, kami akan menggunakan Dataform. Dataform "menghadirkan alat, praktik terbaik, dan alur kerja yang terinspirasi software engineering" kepada tim teknik data. Selain orkestrasi dan penjadwalan, Dataform menyediakan fungsionalitas seperti Assertion and Tests untuk memastikan kualitas, menentukan Operasi warehouse kustom untuk pengelolaan database, dan fitur Dokumentasi untuk mendukung penemuan data.
Penulis berterima kasih kepada tim Dataform atas masukannya yang berharga dalam meninjau lab dan blog ini.
Dalam Dataform, Data mentah yang di-streaming dari Dataflow akan dideklarasikan sebagai set data eksternal. Tabel Staging dan Reporting akan ditentukan secara dinamis, menggunakan sintaksis SQLX Dataform.
Kita akan menggunakan fitur pemuatan inkremental Dataform untuk mengisi tabel staging, sehingga menjadwalkan project Dataform untuk dijalankan setiap jam. Berdasarkan hal di atas, kita akan berasumsi bahwa kita tidak akan menerima fakta yang terlambat tiba, jadi logika kita adalah menyerap kumpulan data yang memiliki waktu peristiwa yang lebih lambat dari waktu peristiwa terbaru di antara kumpulan data bertahap yang sudah ada.
Dalam lab-lab selanjutnya dalam seri ini, kita akan membahas penanganan fakta yang terlambat dikumpulkan.
Saat kita menjalankan seluruh project, semua kumpulan data baru pada tingkat data upstream akan ditambahkan, dan agregasi kita akan dihitung ulang. Secara khusus, setiap proses akan menghasilkan pembaruan penuh pada tabel gabungan. Desain fisik kami akan mencakup pengelompokan tabel staging berdasarkan nama pengguna, yang semakin meningkatkan performa kueri agregasi yang akan sepenuhnya memperbarui papan peringkat ini.
Yang Anda butuhkan
- Chrome versi terbaru
- Pengetahuan dasar tentang SQL dan pemahaman dasar menggunakan BigQuery
4. Mempersiapkan
Membuat Set Data dan Tabel BigQuery untuk Tingkat Mentah
Membuat set data baru untuk menampung skema warehouse. Kita juga akan menggunakan variabel ini nanti, jadi pastikan untuk menggunakan sesi shell yang sama untuk langkah-langkah berikut, atau tetapkan variabel sesuai kebutuhan. Pastikan untuk mengganti <PROJECT_ID> dengan ID project Anda.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
Selanjutnya, kita akan membuat tabel yang akan menyimpan peristiwa mentah menggunakan GCP Console. Skema akan cocok dengan kolom yang kami proyeksikan dari aliran peristiwa perubahan yang dipublikasikan yang kami gunakan dari Wikimedia.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
Membuat Topik dan Langganan Pub/Sub
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
Membuat Project dan Akun Dataform
Buka https://app.dataform.co dan buat akun baru. Setelah login, Anda perlu membuat project baru.
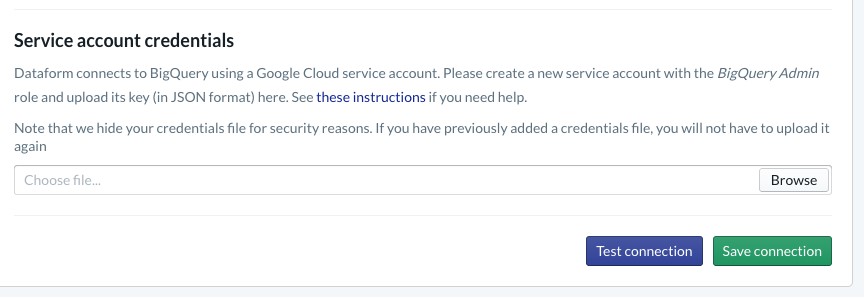
Dalam project, Anda harus mengonfigurasi integrasi dengan BigQuery. Karena Dataform harus terhubung ke warehouse, kita harus menyediakan kredensial akun layanan.
Ikuti langkah-langkah yang ditautkan di atas dalam dokumen Dataform. Anda akan mengonfigurasi koneksi ke BigQuery pada halaman Database. Pastikan untuk memilih projectId yang sama dengan yang Anda buat di atas, lalu upload kredensial dan uji koneksi.
Setelah mengonfigurasi integrasi BigQuery, Anda akan melihat Set Data yang tersedia dalam tab Pemodelan. Secara khusus, tabel Mentah yang kita gunakan untuk mencatat peristiwa dari Dataflow akan ada di sini. Mari kita kembali lagi ke sini sebentar lagi.
5. Penerapan
Membuat Layanan Python untuk membaca dan memublikasikan Peristiwa ke Pub/Sub
Lihat kode Python di bawah, yang juga tersedia dalam gist ini. Kami mengikuti dokumen Pub/Sub API dalam contoh ini.
Mari kita perhatikan daftar keys dalam kode. Ini adalah kolom yang akan kita proyeksikan dari peristiwa JSON lengkap, tetap ada di pesan yang dipublikasikan, dan terakhir di tabel wiki_changes dalam tingkat Mentah dari set data BigQuery kita.
Ini cocok dengan skema tabel wiki_changes yang kita tentukan dalam set data BigQuery untuk wiki_changes
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. Implementasi, lanjutan
Membuat Tugas Dataflow dari Template untuk membaca dari Pub/Sub dan menulis ke BigQuery
Setelah peristiwa perubahan terbaru dipublikasikan ke topik Pub/Sub, kita dapat memanfaatkan tugas Cloud Dataflow untuk membaca peristiwa ini dan menulisnya ke BigQuery.
Jika kita memiliki kebutuhan yang kompleks saat memproses aliran data, coba gabungkan stream yang berbeda, membangun agregasi berdasarkan jendela, dan menggunakan pencarian untuk memperkaya data, maka kita dapat menerapkannya dalam kode Apache Beam.
Karena kebutuhan kita lebih mudah untuk kasus penggunaan ini, kita dapat menggunakan template Dataflow siap pakai dan tidak perlu melakukan penyesuaian. Kita dapat melakukannya langsung dari GCP Console di Cloud Dataflow.
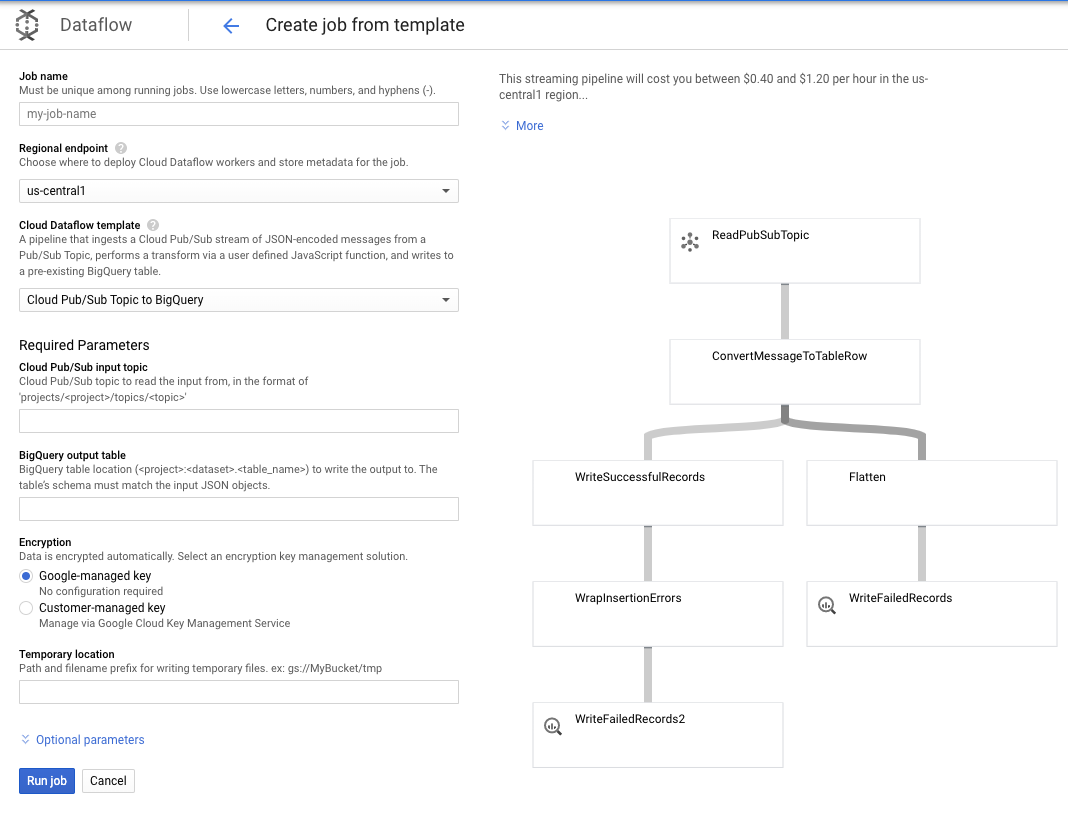
Kita akan menggunakan template Pub/Sub ke template BigQuery, lalu mengonfigurasi beberapa hal di template Dataflow, termasuk topik input Pub/Sub dan tabel output BigQuery.
7. Penerapan, Langkah-Langkah Dataform
Tabel Model di Dataform
Model Dataform kami terkait dengan repositori GitHub berikut, yaitu folder definisi berisi file SQLX yang menentukan model data.
Seperti yang telah dibahas di bagian Penjadwalan dan Orkestrasi, kita akan menentukan tabel staging di Dataform yang menggabungkan kumpulan data mentah dari wiki_changes. Mari kita lihat DDL untuk tabel staging (juga ditautkan dalam repo GitHub yang terkait dengan project Dataform kita).
Mari kita perhatikan beberapa fitur penting dari tabel ini:
- Ini dikonfigurasi sebagai jenis inkremental, jadi saat tugas ELT terjadwal kami berjalan, hanya data baru yang akan ditambahkan
- Seperti yang dinyatakan oleh kode when() di bagian bawah, logika untuk hal ini didasarkan pada kolom stempel waktu, yang mencerminkan stempel waktu dalam aliran peristiwa, yaitu event_time perubahan
- Ini dikelompokkan menggunakan kolom pengguna, yang berarti bahwa kumpulan data dalam setiap partisi akan diurutkan menurut pengguna, mengurangi acak yang diperlukan oleh kueri yang membangun papan peringkat
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
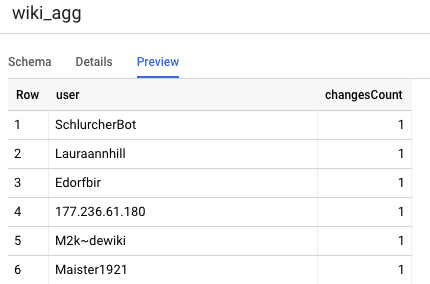
Tabel lain yang perlu ditentukan dalam project kita adalah tabel Tingkat pelaporan, yang akan mendukung kueri papan peringkat. Tabel di tingkat Pelaporan digabungkan, karena pengguna kami berkaitan dengan jumlah baru dan akurat dari perubahan Wikipedia yang dipublikasikan.
Definisi tabel mudah dan menggunakan referensi Formulir data. Keuntungan besar dari referensi ini adalah bahwa metode ini membuat dependensi secara eksplisit antar-objek, sehingga mendukung ketepatan pipeline dengan memastikan bahwa dependensi selalu dieksekusi sebelum kueri dependen.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
Menjadwalkan Project Formulir Data
Langkah terakhir adalah membuat jadwal yang akan dijalankan setiap jam. Ketika project kita dipanggil, Dataform akan mengeksekusi pernyataan SQL yang diperlukan untuk memuat ulang tabel staging inkremental, dan memuat ulang tabel gabungan.
Jadwal ini dapat dipanggil setiap jam–atau bahkan lebih sering, hingga kira-kira setiap 5-10 menit–untuk terus memperbarui papan peringkat dengan peristiwa terbaru yang telah mengalir ke sistem.
8. Selamat
Selamat, Anda telah berhasil membangun arsitektur data bertingkat untuk data streaming.
Kami memulai dengan aliran peristiwa Wikimedia dan kami telah mengubahnya menjadi tabel Pelaporan di BigQuery yang terus diperbarui.
Apa selanjutnya?
Bacaan lebih lanjut
- Memperkenalkan Dataform
- Data Engineering — paradigma modern untuk pemrosesan data batch
- Cara menggabungkan data untuk BigQuery menggunakan Apache Airflow
[1] Sudah umum bagi engineer data untuk menjalankan transformasi batch harian untuk menimpa agregat intrahari (misalnya, per jam)–ini dikenal sebagai rekonsiliasi.
[2] Untuk detail implementasi, lihat bagian Arsitektur.
[3] Fakta yang terlambat adalah peristiwa dengan event_time yang lebih lambat dari kumpulan data yang sudah diproses oleh sistem dalam aliran peristiwa yang sama