
1. Introduzione
Panoramica
I framework per l'analisi dei flussi di dati sono diventati sempre più importanti nel data warehousing contemporaneo, in quanto gli utenti aziendali la domanda di analisi in tempo reale continua senza sosta. Sono stati compiuti grandi passi per migliorare l'aggiornamento dei dati all'interno dei data warehouse e per supportare l'analisi dei flussi di dati in generale, ma i data engineer devono ancora affrontare sfide quando adattano queste origini dei flussi di dati all'architettura del loro data warehouse.
In questo blog, illustriamo alcune delle sfide più comuni che i data engineer devono affrontare quando risolvono questi casi d'uso. Descriviamo alcune idee di progettazione e modelli architetturali per l'aggregazione efficiente dei flussi di dati utilizzando BigQuery.
Aggiornamento e accuratezza dei dati
Per aggiornamento intendiamo che la latenza dei dati dell'aggregato è inferiore ad una certa soglia, ad esempio "aggiornato all'ultima ora". L'aggiornamento è determinato dal sottoinsieme dei dati non elaborati inclusi nei dati aggregati.
Quando si gestiscono i flussi di dati, è molto comune che gli eventi arrivino in ritardo nel nostro sistema di elaborazione dei dati, il che significa che il momento in cui il nostro sistema elabora un evento è molto più tardi di quello in cui si verifica l'evento.
Quando elaboriamo i dati che arrivano in ritardo, i valori delle nostre statistiche aggregate cambiano, il che significa che su base infragiornaliera, i valori visualizzati dagli analisti cambiano[1]. Per accurata intendiamo che le statistiche aggregate sono il più possibile simili ai valori finali riconciliati.
C'è una terza dimensione da ottimizzare, naturalmente: il costo, nel senso sia in termini di denaro sia di rendimento. Per spiegarci meglio, potremmo utilizzare una vista logica per gli oggetti dati in Staging e Reporting. Lo svantaggio di usare una vista logica è che ogni volta che viene eseguita una query sulla tabella aggregata, viene eseguita la scansione dell'intero set di dati non elaborati, il che sarà lento e costoso.
Descrizione dello scenario
Mettiamo il contesto per questo caso d'uso. Importare i dati degli eventi di Wikipedia pubblicati da Wikimedia. Il nostro obiettivo è creare una classifica che mostri gli autori con il maggior numero di modifiche e che venga aggiornata man mano che vengono pubblicati nuovi articoli. La nostra classifica, che verrà implementata come dashboard di BI Engine, aggregherà gli eventi non elaborati per nome utente per calcolare i punteggi[2].
2. Design
Livelli dei dati
Nella pipeline di dati, definiremo più livelli di dati. Terremo i dati non elaborati degli eventi e creeremo una pipeline di successive trasformazioni, arricchimento e aggregazione. Non colleghiamo le tabelle dei report direttamente ai dati contenuti nelle tabelle non elaborate, perché vogliamo unificare e centralizzare le trasformazioni che interessano ai diversi team per i dati in fasi.
Un principio importante di questa architettura è che i livelli superiori, ovvero gestione temporanea e report, possono essere ricalcolati in qualsiasi momento utilizzando solo i dati non elaborati.
Partizionamento
BigQuery supporta due stili di partizionamento: il partizionamento di intervalli di numeri interi e il partizionamento delle date. Per questo post prenderemo in considerazione solo il partizionamento delle date nell'ambito.
Per il partizionamento delle date, possiamo scegliere tra partizioni basate sull'ora di importazione o basate sui campi. Il partizionamento in base alla data/ora di importazione fa arrivare i dati a una partizione in base alla data di acquisizione dei dati. Gli utenti possono anche selezionare una partizione al momento del caricamento specificando un decorator della partizione.
Il partizionamento dei campi partiziona i dati in base al valore della data o del timestamp in una colonna.
Per l'importazione di eventi, i dati verranno inseriti in una tabella partizionata per data di importazione. Questo perché la data e l'ora di importazione sono importanti per l'elaborazione o la rielaborazione dei dati ricevuti in passato. I backfill dati storici possono essere archiviati anche all'interno di partizioni temporali di importazione, in base a quando sarebbero arrivati.
In questo codelab, supporremo di non ricevere informazioni recenti[3] dal flusso di eventi Wikimedia. Ciò semplificherà il caricamento incrementale della tabella temporanea, come discusso di seguito.
Per la tabella temporanea, eseguiremo la partizione in base all'ora dell'evento. Questo perché i nostri analisti sono interessati a eseguire query sui dati in base all'ora dell'evento, ovvero all'ora in cui l'articolo è stato pubblicato su Wikipedia, e non al momento in cui l'evento è stato elaborato all'interno della pipeline.
3. Architettura
Cosa creerai
Per leggere il flusso di eventi da Wikimedia, utilizzeremo il protocollo SSE. Scriveremo un piccolo servizio middleware che leggerà dal flusso di eventi come client SSE e verrà pubblicato in un argomento Pub/Sub all'interno del nostro ambiente Google Cloud.
Una volta che gli eventi sono disponibili in Pub/Sub, creeremo un job Cloud Dataflow, utilizzando un modello, che trasmetterà i record in modalità flusso nel nostro livello di dati non elaborati nel data warehouse BigQuery. Il passaggio successivo consiste nel calcolare le statistiche aggregate per supportare la nostra classifica live.
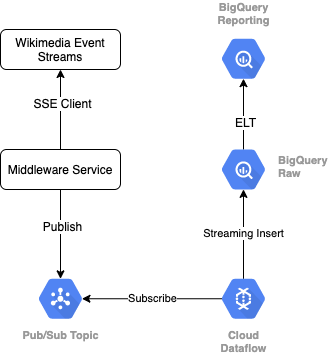
Programmazione e orchestrazione
Per orchestrare l'ELT che compila i livelli di gestione temporanea e generazione di report del warehouse, utilizzeremo Dataform. Dataform "offre strumenti, best practice e flussi di lavoro ispirati al software engineering" ai team di data engineering. Oltre all'orchestrazione e alla pianificazione, Dataform fornisce funzionalità come asserzioni e test per garantire la qualità, definendo operazioni di warehouse personalizzate per la gestione dei database e funzionalità di documentazione per supportare l'individuazione dei dati.
Gli autori ringraziano il team di Dataform per il prezioso feedback fornito nella revisione di questo lab e del blog.
All'interno di Dataform, i dati non elaborati trasmessi in flusso da Dataflow verranno dichiarati come set di dati esterni. Le tabelle di gestione temporanea e di reporting verranno definite in modo dinamico utilizzando la sintassi SQLX di Dataform.
Utilizzeremo la funzionalità di caricamento incrementale di Dataform per compilare la tabella temporanea, pianificando l'esecuzione del progetto Dataform ogni ora. In base a quanto riportato sopra, presupporremo di non ricevere le informazioni relative agli eventi in ritardo, quindi la nostra logica sarà quella di importare record con una data e un'ora dell'evento successiva all'ora più recente dell'evento tra i record inscenati esistenti.
Nei prossimi lab di questa serie, discuteremo della gestione dei fatti recenti.
Quando eseguiamo l'intero progetto, ai livelli dati upstream vengono aggiunti tutti i nuovi record e le nostre aggregazioni vengono ricalcolate. In particolare, ogni esecuzione comporterà un aggiornamento completo della tabella aggregata. La nostra progettazione fisica includerà il clustering della tabella temporanea per nome utente, aumentando ulteriormente le prestazioni della query di aggregazione che aggiornerà completamente la classifica.
Che cosa ti serve
- Avere una versione recente di Chrome
- Conoscenza di base di SQL e familiarità di base con BigQuery
4. Preparazione
Crea un set di dati e una tabella BigQuery per il livello non elaborato
Creare un nuovo set di dati che contenga lo schema del warehouse. Useremo queste variabili anche in un secondo momento, quindi assicurati di usare la stessa sessione di shell per i passaggi seguenti o imposta le variabili in base alle necessità. Assicurati di sostituire <PROJECT_ID> con l'ID del tuo progetto.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
Ora creeremo una tabella che conterrà gli eventi non elaborati utilizzando la console di Google Cloud. Lo schema corrisponderà ai campi che proiettiamo dal flusso di eventi delle modifiche pubblicate che stiamo utilizzando da Wikimedia.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
Crea un argomento e una sottoscrizione Pub/Sub
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
Crea un account e un progetto Dataform
Vai alla pagina https://app.dataform.co e crea un nuovo account. Una volta effettuato l'accesso, dovrai creare un nuovo progetto.
All'interno del progetto, dovrai configurare l'integrazione con BigQuery. Poiché Dataform dovrà connettersi al warehouse, dobbiamo eseguire il provisioning delle credenziali dell'account di servizio.
Segui i passaggi indicati sopra nella documentazione di Dataform: configurerai la connessione a BigQuery nella pagina Database. Assicurati di selezionare lo stesso projectId che hai creato in precedenza, quindi carica le credenziali e testa la connessione.
Dopo aver configurato l'integrazione di BigQuery, i set di dati saranno disponibili all'interno della scheda Modelli. In particolare, qui sarà presente la tabella non elaborata che utilizziamo per acquisire gli eventi da Dataflow. Torniamo su questo argomento tra poco.
5. Implementazione
Crea un servizio Python per leggere e pubblicare eventi in Pub/Sub
Vedi il codice Python riportato di seguito, disponibile anche in questa sintesi. In questo esempio stiamo seguendo la documentazione relativa all'API Pub/Sub.
Prendiamo nota dell'elenco delle chiavi nel codice, questi sono i campi che verranno proiettati dall'evento JSON completo, che verranno conservati nei messaggi pubblicati e, infine, nella tabella wiki_changes all'interno del livello Raw del nostro set di dati BigQuery.
Queste corrispondono allo schema della tabella wiki_changes che abbiamo definito nel nostro set di dati BigQuery per wiki_changes
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. Implementazione, continua
Crea un job Dataflow da un modello per leggere da Pub/Sub e scrivere in BigQuery
Una volta pubblicati gli eventi di modifica recenti nell'argomento Pub/Sub, possiamo utilizzare un job di Cloud Dataflow per leggere questi eventi e scriverli in BigQuery.
Se avessimo esigenze sofisticate durante l'elaborazione del flusso, ad esempio unire flussi disparati, creare aggregazioni con finestra, utilizzare ricerche per arricchire i dati, potremmo implementarle nel nostro codice Apache Beam.
Poiché le nostre esigenze sono più semplici per questo caso d'uso, possiamo utilizzare il modello Dataflow pronto all'uso senza dover apportare alcuna personalizzazione. Possiamo farlo direttamente dalla console Google Cloud in Cloud Dataflow.
Utilizzeremo il modello Argomento Pub/Sub a BigQuery e poi dobbiamo solo configurare alcune cose nel modello Dataflow, tra cui l'argomento di input Pub/Sub e la tabella di output di BigQuery.
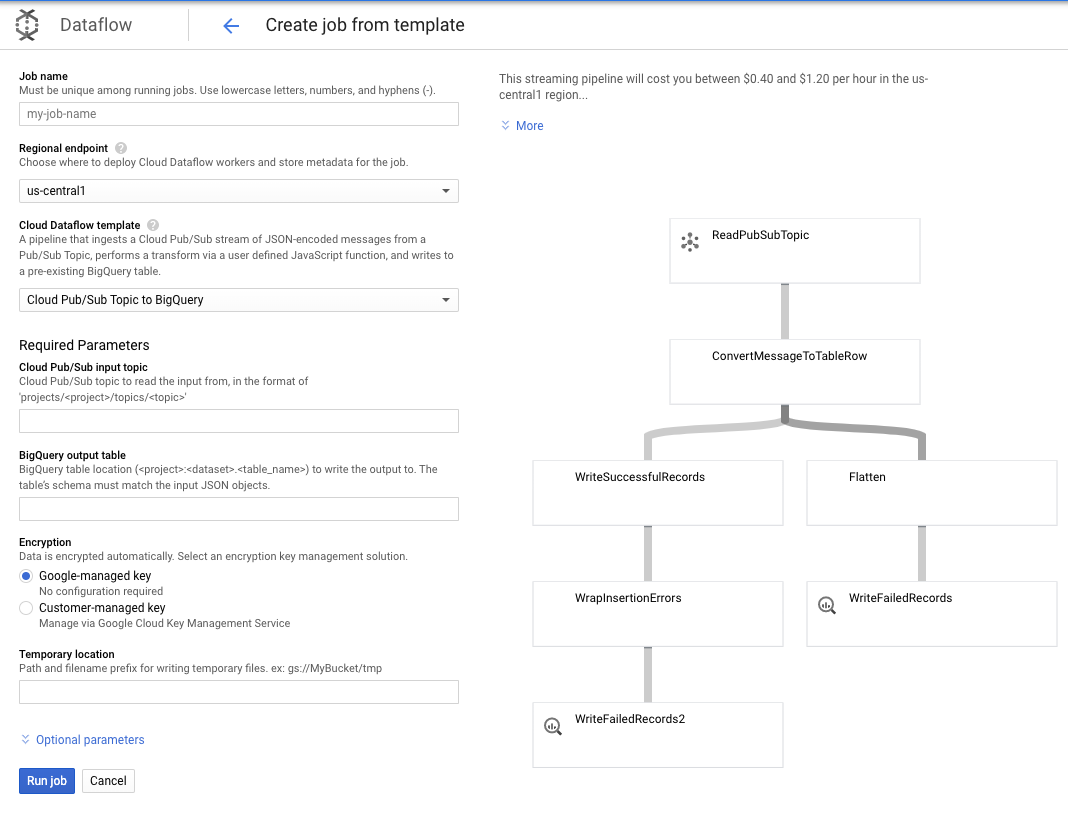
7. Implementazione, passaggi Dataform
Tabelle modelli in Dataform
Il nostro modello Dataform è collegato al seguente repository GitHub: la cartella delle definizioni contiene i file SQLX che definiscono il modello dei dati.
Come discusso nella sezione Pianificazione e orchestrazione, definiremo una tabella temporanea in Dataform che aggrega i record non elaborati di wiki_changes. Diamo un'occhiata al DDL per la tabella temporanea (che trovi anche nel repository GitHub collegato al nostro progetto Dataform).
Diamo un'occhiata ad alcune importanti funzionalità di questa tabella:
- È configurato come un tipo incrementale, quindi quando vengono eseguiti i nostri job ELT pianificati, verranno aggiunti solo i nuovi record
- Come espresso dal codice quando() in basso, la logica di questa operazione si basa sul campo timestamp, che riflette il timestamp nel flusso di eventi, ovvero event_time della modifica
- Il cluster viene eseguito in cluster utilizzando il campo user, il che significa che i record all'interno di ogni partizione verranno ordinati per utente, riducendo lo shuffling richiesto dalla query che crea la classifica.
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
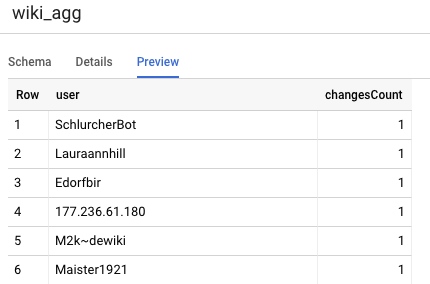
L'altra tabella che dobbiamo definire nel nostro progetto è la tabella del livello dei report, che supporterà le query del leaderboard. Le tabelle nel livello dei report vengono aggregate, poiché i nostri utenti sono preoccupati per conteggi aggiornati e accurati delle modifiche pubblicate su Wikipedia.
La definizione della tabella è diretta e utilizza i riferimenti Dataform. Un grande vantaggio di questi elementi fa riferimento al fatto che rendono esplicite le dipendenze tra gli oggetti, supportando la correttezza della pipeline garantendo che le dipendenze vengano sempre eseguite prima delle query dipendenti.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
Pianifica progetto Dataform
Il passaggio finale consiste semplicemente nel creare una pianificazione da eseguire ogni ora. Quando il nostro progetto viene richiamato, Dataform eseguirà le istruzioni SQL richieste per aggiornare la tabella di gestione temporanea incrementale e ricaricare la tabella aggregata.
Questa programmazione può essere richiamata ogni ora, o anche più spesso, fino a circa ogni 5-10 minuti, per mantenere la classifica aggiornata con gli eventi recenti trasmessi in streaming nel sistema.
8. Complimenti
Congratulazioni, hai creato correttamente un'architettura dei dati a più livelli per i flussi di dati.
Abbiamo iniziato con un flusso di eventi Wikimedia che abbiamo trasformato in una tabella di reporting in BigQuery costantemente aggiornata.
Passaggi successivi
Per approfondire
- Introduzione a Dataform
- Functional Data Engineering: un paradigma moderno per l'elaborazione dei dati in batch
- Come aggregare i dati per BigQuery utilizzando Apache Airflow
[1] È comune per i data engineer eseguire una trasformazione giornaliera batch per sovrascrivere gli aggregati infragiornalieri (ad esempio, orari). Questo processo è noto come riconciliazione.
[2] Per i dettagli dell'implementazione, consulta la sezione Architettura.
[3] Un fatto che si verifica in ritardo è un evento il cui valore event_time è successivo ai record già elaborati dal sistema all'interno dello stesso flusso di eventi