
1. はじめに
概要
現代のデータ ウェアハウジングでは、ストリーミング分析のフレームワークがますます重要になっています。これは、ビジネス ユーザーがリアルタイム分析に対する需要は衰えることがありません。ウェアハウス内のデータの更新頻度を改善し、ストリーミング分析全般をサポートするという大きな進歩があっても、データ エンジニアは、こうしたストリーミング ソースをデータ ウェアハウス アーキテクチャに適応させるにあたって、依然として課題に直面しています。
このブログ投稿では、このようなユースケースを解決する際にデータ エンジニアが直面する最も一般的な課題をいくつか取り上げます。BigQuery を使用してストリーミング データを効率的に集約するための設計アイデアとアーキテクチャ パターンについて説明します。
データの更新速度と精度
「鮮度」とは、集計のデータ レイテンシがあるしきい値未満であることを意味します。たとえば、"up to date as of the last hour"鮮度は、集計に含まれる元データのサブセットによって決定されます。
ストリーミング データを扱う際、イベントがデータ処理システム内で遅れて到着することは非常によくあります。つまり、Google のシステムがイベントを処理する時刻は、イベントが発生した時刻よりもかなり遅くなります。
遅れて到着した事実を処理すると、集計された統計の値が変化します。 つまり、1 日のうちにアナリストが見る値は変化します [1]。「正確」とは、集計された統計情報が最終的な調整値にできるだけ近いことを意味します。
もちろん、最適化する 3 つ目の側面があります。費用とパフォーマンスの両方の観点から、費用です。たとえば、[Staging and Reporting] ではデータ オブジェクトの論理ビューを利用できます。論理ビューを使用するデメリットは、集計テーブルに対してクエリが実行されるたびに、未加工のデータセット全体がスキャンされるために時間がかかり、コストがかかることです。
シナリオの説明
このユースケースの舞台を整えましょう。ここでは、Wikimedia が公開している Wikipedia のイベント ストリームデータを取り込みます。Google の目標は、変更数が最も多い著者を表示し、新しい記事が公開されると最新の情報を表示するリーダーボードを構築することです。BI Engine ダッシュボードとして実装される当社のリーダーボードは、未加工のイベントをユーザー名別に集計してスコアを計算します [2]。
2. デザイン
データ階層化
データ パイプラインでは、データの複数の層を定義します。未加工のイベントデータを保持し、その後の変換、拡充、集約のパイプラインを構築します。ステージング済みデータを扱う各チームが扱う変換を 1 か所にまとめ、一元化したいので、レポート テーブルを元テーブル内のデータに直接接続することはありません。
このアーキテクチャの重要な原則は、元データのみを使用して、上位階層(ステージングとレポート)をいつでも再計算できることです。
パーティショニング
BigQuery は、2 つのスタイルのパーティショニングをサポートしています。整数範囲パーティショニングと 日付パーティショニングですこの投稿では、日付パーティショニングのみを取り上げます。
日付パーティショニングでは、取り込み時間パーティションまたはフィールド ベースのパーティションを選択できます。取り込み時間パーティショニングでは、データが取得された日時に基づいてパーティションにデータが格納されます。読み込み時にパーティション デコレータを指定してパーティションを選択することもできます。
フィールド パーティショニングでは、列の日付またはタイムスタンプ値に基づいてデータが分割されます。
イベントを取り込むには、取り込み時間パーティション分割テーブルにデータを取り込みます。これは、取り込み時間が過去に受信したデータの処理または再処理に関連するためです。過去のデータのバックフィルも、データの到着時刻に基づいて取り込み時間パーティション内に保存できます。
この Codelab では、Wikimedia のイベント ストリームから遅れて到着したファクト [3] を受け取らないと仮定します。これにより、以下で説明するように、ステージング テーブルの増分読み込みが簡素化されます。
ステージング テーブルについては、イベント時間でパーティション分割します。これは、当社のアナリストが、パイプライン内でイベントが処理された時刻ではなく、イベントの時刻(記事が Wikipedia で公開された時刻)に基づいてデータを照会するためです。
3. アーキテクチャ
作成するアプリの概要
Wikimedia からイベント ストリームを読み取るには、SSE プロトコルを使用します。ここでは、SSE クライアントとしてイベント ストリームから読み取り、GCP 環境内の Pub/Sub トピックにパブリッシュする小さなミドルウェア サービスを作成します。
Pub/Sub でイベントが利用可能になったら、テンプレートを使用して Cloud Dataflow ジョブを作成します。このジョブは、レコードを BigQuery データ ウェアハウスの元データ層にストリーミングします。次のステップでは、ライブ リーダーボードをサポートするため、集計された統計情報を計算します。
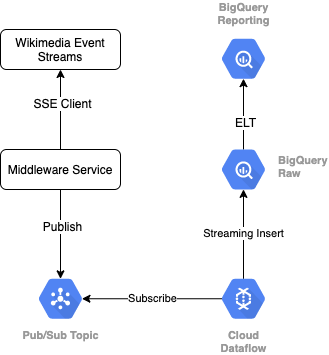
スケジューリングとオーケストレーション
ウェアハウスのステージング ティアとレポート ティアにデータを入力する ELT をオーケストレートするには、Dataform を使用します。Dataform は「ツール、ベスト プラクティス、ソフトウェア エンジニアリングにヒントを得たワークフローを提供します」データエンジニアリングチームに提供しますDataform は、オーケストレーションとスケジューリングに加えて、品質を確保するためのアサーションやテスト、データベース管理用のカスタム ウェアハウス オペレーションの定義、データ検出をサポートするドキュメント機能などの機能も備えています。
執筆者は、このラボとブログのレビューにおいて貴重なフィードバックを提供してくれた Dataform チームに感謝します。
Dataform では、Dataflow からストリーミングされる元データが外部データセットとして宣言されます。Staging テーブルと Reporting テーブルは、Dataform の SQLX 構文を使用して動的に定義されます。
Dataform の増分読み込み機能を使用してステージング テーブルにデータを入力し、Dataform プロジェクトが 1 時間ごとに実行されるようにスケジュール設定します。上記に基づき、遅れて到着した事実は受け取らないと仮定します。したがって、既存のステージング済みレコードのうち、イベント時刻が最新のイベント時刻より後のレコードを取り込むことがロジックになります。
このシリーズの後のラボでは、遅れて到着した事実の処理について説明します。
プロジェクト全体を実行すると、アップストリームのデータ階層にすべての新しいレコードが追加され、集計が再計算されます。特に、実行のたびに集計テーブルは完全に更新されます。Google の物理的設計には、ステージング テーブルをユーザー名でクラスタ化することが含まれます。これにより、このリーダーボードを完全に更新する集計クエリのパフォーマンスがさらに向上します。
必要なもの
- Chrome の最新バージョン
- SQL に関する基本的な知識と BigQuery の基本的な知識
4. 設定方法
未加工階層用の BigQuery データセットとテーブルを作成する
ウェアハウス スキーマを含む新しいデータセットを作成します。これらの変数は後で使用するため、以降のステップでも同じシェル セッションを使用するか、必要に応じて変数を設定してください。<PROJECT_ID> はプロジェクト ID に置き換えます。
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
次に、GCP コンソールを使用して、未加工のイベントを保持するテーブルを作成します。スキーマは、Wikimedia から利用する公開済みの変更のイベント ストリームから投影するフィールドと一致します。
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
Pub/Sub トピックとサブスクリプションを作成する
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
Dataform アカウントとプロジェクトの作成
https://app.dataform.co に移動して新しいアカウントを作成します。ログインしたら、新しいプロジェクトを作成します。
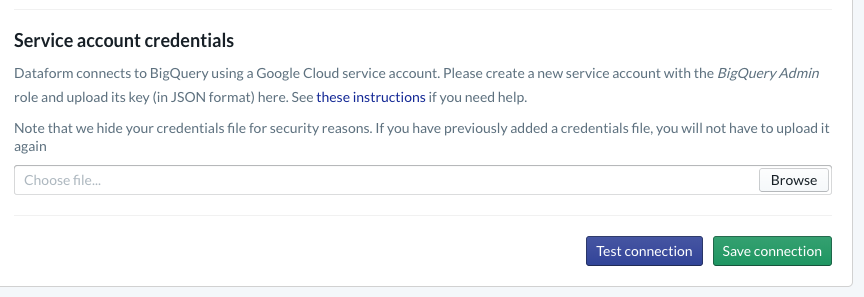
プロジェクト内で BigQuery との統合を構成する必要があります。Dataform はウェアハウスに接続する必要があるため、サービス アカウントの認証情報をプロビジョニングする必要があります。
Dataform のドキュメントにある上記のリンク先の手順に従って、[Database] ページで BigQuery への接続を構成します。上記で作成したものと同じプロジェクト ID を選択してから、認証情報をアップロードして接続をテストしてください。
BigQuery インテグレーションを設定すると、[モデリング] タブにデータセットが表示されます。特に、Dataflow からイベントをキャプチャするために使用する未加工テーブルがここに表示されます。これについては後ほど説明します
5. 実装
イベントを読み取り、Pub/Sub にパブリッシュするための Python サービスを作成する
以下の Python コードもご覧ください。こちらの gist でも確認できます。この例では、Pub/Sub API ドキュメントに従います。
コードの keys リストに注目しましょう。これらは完全な JSON イベントから射影され、パブリッシュされたメッセージで永続化され、最終的に BigQuery データセットの未加工階層にある wiki_changes テーブルに格納されるフィールドです。
これらは、wiki_changes の BigQuery データセット内で定義した wiki_changes テーブル スキーマと一致します。
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. 実装(続き)
Pub/Sub から読み取り、BigQuery に書き込む Dataflow ジョブをテンプレートから作成する
最近の変更イベントが Pub/Sub トピックにパブリッシュされたら、Cloud Dataflow ジョブを使用してこれらのイベントを読み取り、BigQuery に書き込むことができます。
ストリームの処理中に高度なニーズがあれば(異なるストリームの結合、ウィンドウ集計の構築、ルックアップを使用したデータの拡充など)、Apache Beam のコードでそれらを実装できます。
このユースケースではニーズが単純であるため、すぐに使える Dataflow テンプレートを使用できます。カスタマイズする必要はありません。これは、Cloud Dataflow の GCP コンソールから直接行うことができます。
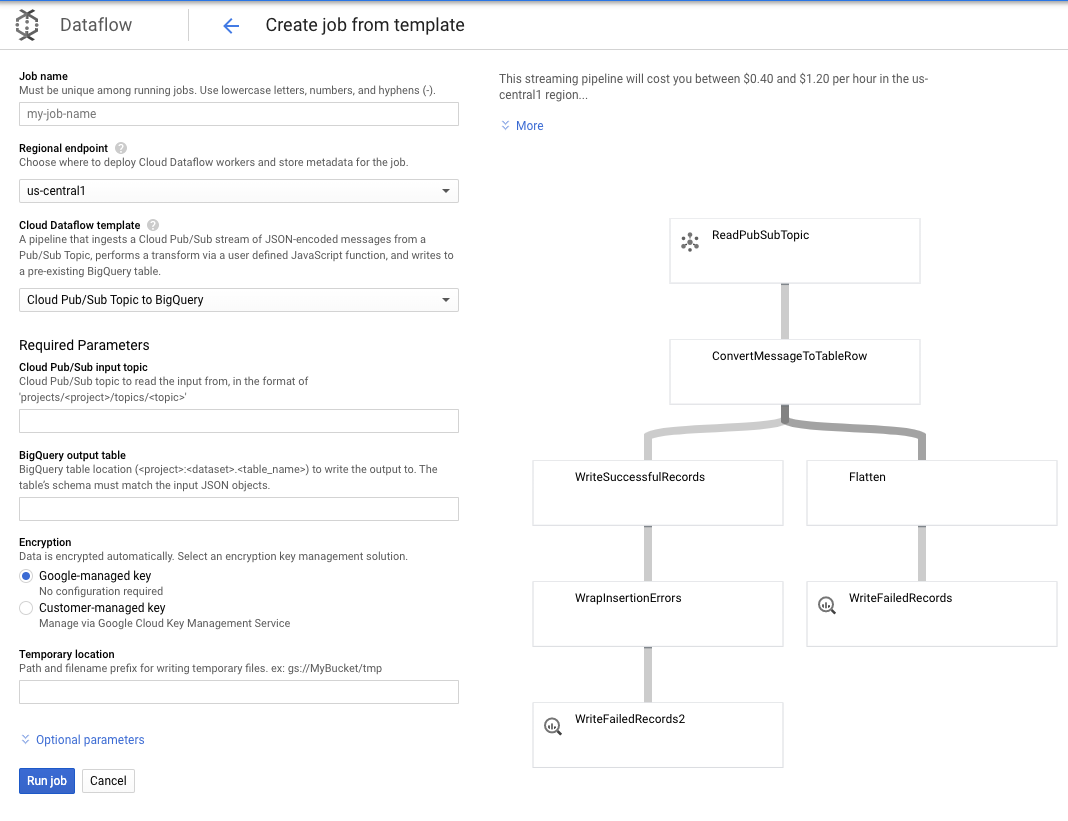
Pub/Sub Topic to BigQuery テンプレートを使用します。あとは Pub/Sub 入力トピックや BigQuery 出力テーブルなど、Dataflow テンプレートでいくつかの項目を構成する必要があります。
7. 実装、Dataform のステップ
Dataform のモデルテーブル
Dataform モデルは、次の GitHub リポジトリに関連付けられています。定義フォルダには、データモデルを定義する SQLX ファイルが含まれています。
スケジューリングとオーケストレーションのセクションで説明したように、wiki_changes の未加工レコードを集約するステージング テーブルを Dataform で定義します。ステージング テーブルの DDL を見てみましょう(Dataform プロジェクトに関連付けられた GitHub リポジトリにもリンクされています)。
この表の重要な機能をいくつか確認しましょう。
- 増分タイプとして構成されているため、スケジュールされた ELT ジョブを実行すると、新しいレコードのみが追加されます。
- 一番下の when() コードで示されているように、このロジックは、イベント ストリームのタイムスタンプ(変更の event_time)を反映するタイムスタンプ フィールドに基づいています。
- user フィールドを使用してクラスタ化されます。つまり、各パーティション内のレコードは user 順に並べられるため、リーダーボードを作成するクエリに必要なシャッフルが少なくなります。
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
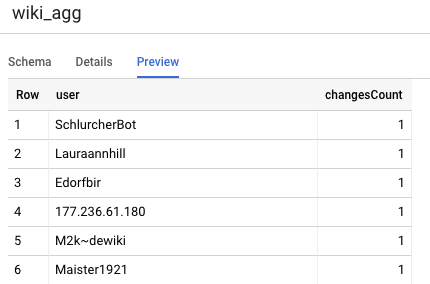
このプロジェクトで定義する必要があるもう一つのテーブルは、レポート階層テーブルです。このテーブルは、リーダーボード クエリをサポートします。レポート階層の表は、公開された Wikipedia の変更件数が最新かつ正確なものであることを考慮するため、集計されます。
テーブル定義は単純で、Dataform の参照を利用しています。この手法の大きな利点は、オブジェクト間の依存関係を明確にし、依存関係が依存クエリの前に常に実行されることを保証することで、パイプラインの正確性をサポートすることです。
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
Dataform プロジェクトのスケジュール
最後に、1 時間ごとに実行されるスケジュールを作成します。プロジェクトが呼び出されると、Dataform は必要な SQL ステートメントを実行して、増分ステージング テーブルを更新し、集計テーブルを再読み込みします。
このスケジュールは 1 時間ごと、またはそれ以上の頻度で(最大で約 5 ~ 10 分ごと)呼び出すことができます。これにより、システムにストリーミングされた最近のイベントでリーダーボードを最新の状態に保つことができます。
8. 完了
これで、ストリーミング データ用の階層型データ アーキテクチャが構築できました。
Wikimedia のイベント ストリームからスタートし、これを常に最新の BigQuery のレポート テーブルに変換しました。
次のステップ
参考資料
- Dataform のご紹介
- Functional Data Engineering - バッチデータ処理の最新のパラダイム
- Apache Airflow を使用して BigQuery のデータを集約する方法
[1] データ エンジニアが毎日バッチ変換を実行して、その日(たとえば 1 時間ごと)の集計を上書きするのが一般的です。これを調整と呼びます。
[2] 実装の詳細については、「アーキテクチャ」のセクションをご覧ください。
[3] 遅れて到着したファクトとは、event_time が、この同じイベント ストリーム内のシステムで処理済みのレコードよりも遅いイベントのことです。