
1. 소개
개요
스트리밍 분석을 위한 프레임워크는 현대 데이터 웨어하우징에서 점점 더 중요해지고 있습니다. 비즈니스 사용자는 실시간 분석에 대한 수요는 계속 줄어들지 않습니다. 웨어하우스 내부의 데이터 최신 상태를 개선하고 스트리밍 분석을 전반적으로 지원하기 위한 노력이 크게 이루어졌지만 데이터 엔지니어는 이러한 스트리밍 소스를 데이터 웨어하우스 아키텍처에 적용할 때 여전히 어려움에 직면하고 있습니다.
이 블로그에서는 데이터 엔지니어가 이러한 사용 사례를 해결할 때 직면하는 가장 일반적인 문제 몇 가지를 살펴봅니다. BigQuery를 사용하여 스트리밍 데이터를 효율적으로 집계하기 위한 몇 가지 설계 아이디어와 아키텍처 패턴을 간략히 설명합니다.
데이터 최신성 및 정확성
최신이란 집계의 데이터 지연 시간이 일부 기준점 미만임을 의미합니다. 예를 들어 '최근 1시간을 기준으로 최신 상태'입니다. 최신성은 집계에 포함된 원시 데이터의 하위 집합에 따라 결정됩니다.
스트리밍 데이터를 다룰 때는 데이터 처리 시스템 내에서 이벤트가 늦게 도착하는 경우가 매우 많습니다. 즉, Google 시스템에서 이벤트를 처리하는 시간은 이벤트가 발생한 시점보다 훨씬 늦은 시점입니다.
늦게 도착하는 사실을 처리하면 집계된 통계의 값이 변경됩니다. 즉, 하루 중 분석가가 보는 값이 변경됩니다[1]. 정확성이란 집계된 통계가 최종 조정된 값에 최대한 가깝다는 것을 의미합니다.
최적화해야 할 세 번째 측정기준도 있습니다. 바로 비용과 실적 측면에서 비용 절감입니다. 예를 들어 스테이징 및 보고에서 데이터 객체에 대한 논리적 보기를 사용할 수 있습니다. 논리적 뷰를 사용하면 집계 테이블이 쿼리될 때마다 전체 원시 데이터 세트가 스캔되어 속도가 느리고 비용이 많이 든다는 단점이 있습니다.
시나리오 설명
이 사용 사례를 위한 단계를 설정해 보겠습니다. 위키미디어에서 게시한 위키백과 이벤트 스트림 데이터를 수집합니다. Google의 목표는 가장 많은 변경사항이 발생한 저자를 표시하고 새로운 기사가 게시되면 최신 상태로 유지되는 리더보드를 구축하는 것입니다. BI Engine 대시보드로 구현될 리더보드는 사용자 이름별로 원시 이벤트를 집계하여 점수를 계산합니다[2].
2. 디자인
데이터 계층화
데이터 파이프라인에서는 여러 계층의 데이터를 정의합니다. 원시 이벤트 데이터를 유지하고 후속 변환, 보강, 집계 파이프라인을 빌드합니다. 보고 테이블을 원시 테이블에 저장된 데이터에 직접 연결하지 않습니다. 스테이징된 데이터에 대해 서로 다른 팀이 관심을 두는 변환을 통합하고 중앙 집중화하기 위해서입니다.
이 아키텍처에서 중요한 원칙은 원시 데이터만을 사용하여 언제든지 더 높은 계층(스테이징 및 보고)을 다시 계산할 수 있다는 것입니다.
파티션 나누기
BigQuery는 두 가지 스타일의 파티션 나누기를 지원합니다. 정수 범위로 파티셔닝 및 날짜 파티션 나누기를 사용할 수 있습니다 이 게시물의 범위에는 날짜 파티셔닝만 고려됩니다.
날짜 파티셔닝의 경우 수집 시간 파티션 또는 필드 기반 파티션 중에서 선택할 수 있습니다. 수집 시간으로 파티션 나누기는 데이터를 획득한 시점을 기준으로 파티션에 데이터를 배치합니다. 사용자는 파티션 데코레이터를 지정하여 로드 시 파티션을 선택할 수도 있습니다.
필드 파티션 나누기는 열의 날짜 또는 타임스탬프 값을 기준으로 데이터의 파티션을 나눕니다.
이벤트를 수집하기 위해 수집 시간으로 파티션을 나눈 테이블에 데이터를 배치합니다. 수집 시간이 과거에 수신된 데이터의 처리 또는 재처리와 관련이 있기 때문입니다. 이전 데이터의 백필은 데이터가 도착한 시점을 기준으로 수집 시간 파티션에도 저장할 수 있습니다.
이 Codelab에서는 Wikimedia 이벤트 스트림에서 늦게 도착한 사실[3] 을 수신하지 않는다고 가정합니다. 이렇게 하면 아래에 설명된 것처럼 스테이징 테이블의 증분 로드가 간소화됩니다.
스테이징 테이블의 경우 이벤트 시간을 기준으로 파티션을 나눕니다. 이는 분석가들이 파이프라인 내에서 이벤트가 처리된 시간이 아니라 이벤트 시간(위키백과에 문서가 게시된 시간)을 기준으로 데이터를 쿼리하는 데 관심이 있기 때문입니다.
3. 아키텍처
빌드할 항목
Wikimedia에서 이벤트 스트림을 읽기 위해 SSE 프로토콜을 사용합니다. 이벤트 스트림에서 SSE 클라이언트로 읽고 GCP 환경 내의 Pub/Sub 주제에 게시하는 소규모 미들웨어 서비스를 작성해 보겠습니다.
Pub/Sub에서 이벤트를 사용할 수 있게 되면 템플릿을 사용하여 Cloud Dataflow 작업을 만들어 BigQuery 데이터 웨어하우스의 원시 데이터 계층으로 레코드를 스트리밍합니다. 다음 단계는 실시간 리더보드를 지원하기 위해 집계된 통계를 계산하는 것입니다.

예약 및 조정
웨어하우스의 스테이징 및 보고 단계를 채우는 ELT를 조정하기 위해 Dataform을 사용합니다. '도구, 권장사항, 소프트웨어 엔지니어링에서 영감을 받은 워크플로를 제공하는 Dataform' 데이터 엔지니어링팀에 부합할 수 있습니다 조정 및 예약 외에도 Dataform은 품질 보장을 위한 어설션 및 테스트, 데이터베이스 관리를 위한 커스텀 웨어하우스 운영 정의, 데이터 탐색을 지원하는 문서 기능과 같은 기능을 제공합니다.
저자들은 이 실습과 블로그를 검토하는 과정에서 소중한 의견을 제공해 준 Dataform팀에 감사의 말을 전합니다.
Dataform 내에서 Dataflow에서 스트리밍된 원시 데이터는 외부 데이터 세트로 선언됩니다. Staging 및 Reporting 테이블은 Dataform의 SQLX 구문을 사용하여 동적으로 정의됩니다.
Dataform의 증분 로드 기능을 사용하여 스테이징 테이블을 채우고 Dataform 프로젝트가 매시간 실행되도록 예약합니다. 위에서 설명한 내용에 따라, 늦게 도착하는 사실은 수신하지 않는다고 가정하겠습니다. 따라서 이벤트 시간이 기존의 스테이징된 레코드 중에서 가장 최근 이벤트 시간 이후인 레코드를 수집하는 것이 논리입니다.
이 시리즈의 후반부 실습에서 늦게 도착한 사실의 처리에 대해 알아보겠습니다.
전체 프로젝트를 실행하면 업스트림 데이터 계층에 모든 새 레코드가 추가되고 집계가 다시 계산됩니다. 특히 실행할 때마다 집계 테이블이 완전히 새로고침됩니다. Google의 물리적 설계는 사용자 이름으로 스테이징 테이블을 클러스터링하여 이 리더보드를 완전히 새로고침하는 집계 쿼리의 성능을 높이는 것입니다.
필요한 항목
- 최신 버전의 Chrome
- SQL에 관한 기본 지식 및 BigQuery에 관한 기본 지식
4. 설정
원시 등급의 BigQuery 데이터 세트 및 테이블 만들기
웨어하우스 스키마를 포함할 새 데이터 세트를 만듭니다. 이러한 변수도 나중에 사용할 것이므로 다음 단계에서 동일한 셸 세션을 사용하거나 필요에 따라 변수를 설정해야 합니다. <PROJECT_ID> 프로젝트 ID로 바꿉니다.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
다음으로 GCP 콘솔을 사용하여 원시 이벤트를 저장할 테이블을 만듭니다. 스키마는 Wikimedia에서 사용 중인 게시된 변경사항의 이벤트 스트림에서 프로젝션하는 필드와 일치합니다.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
Pub/Sub 주제 및 구독 만들기
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
Dataform 계정 및 프로젝트 만들기
https://app.dataform.co로 이동하여 새 계정을 만듭니다. 로그인하면 새 프로젝트를 만들 수 있습니다.
프로젝트 내에서 BigQuery와의 통합을 구성해야 합니다. Dataform을 웨어하우스에 연결해야 하므로 서비스 계정 사용자 인증 정보를 프로비저닝해야 합니다.
Dataform 문서 내에 위에 링크된 단계를 따르세요. 데이터베이스 페이지에서 BigQuery에 대한 연결을 구성합니다. 위에서 만든 것과 동일한 projectId를 선택한 다음 사용자 인증 정보를 업로드하고 연결을 테스트해야 합니다.
BigQuery 통합을 구성하면 모델링 탭에 사용 가능한 데이터 세트가 표시됩니다. 특히 Dataflow에서 이벤트를 캡처하는 데 사용하는 원시 테이블이 여기에 표시됩니다. 잠시 후에 다시 이 주제로 돌아오겠습니다.
5. 구현
이벤트를 읽고 Pub/Sub에 게시하는 Python 서비스 만들기
이 gist에서 사용할 수 있는 아래의 Python 코드도 참조하세요. 이 예에서는 Pub/Sub API 문서를 따릅니다.
코드의 keys 목록을 살펴보겠습니다. 이 필드는 전체 JSON 이벤트에서 프로젝션되고 게시된 메시지에 유지되며 궁극적으로 BigQuery 데이터 세트의 원시 계층 내 wiki_changes 테이블에 저장됩니다.
이는 wiki_changes용 BigQuery 데이터 세트 내에서 정의한 wiki_changes 테이블 스키마와 일치합니다.
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. 구현(계속)
템플릿에서 Dataflow 작업을 만들어 Pub/Sub에서 읽고 BigQuery에 쓰기
최근 변경 이벤트가 Pub/Sub 주제에 게시되면 Cloud Dataflow 작업을 사용하여 이러한 이벤트를 읽고 BigQuery에 쓸 수 있습니다.
스트림을 처리하는 동안 서로 다른 스트림 결합, 기간이 지정된 집계 빌드, 조회를 사용하여 데이터 보강 등의 복잡한 요구사항이 있다면 Apache Beam 코드에서 구현할 수 있습니다.
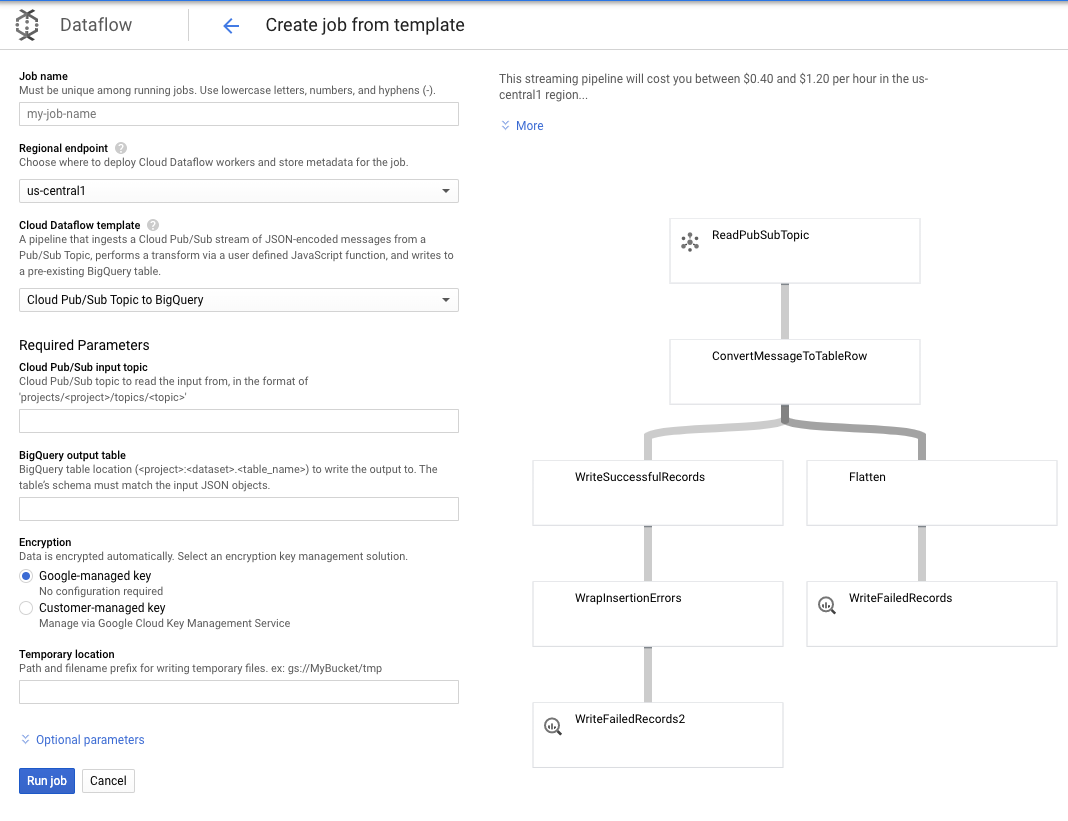
이 사용 사례의 경우 요구사항이 더 간단하므로 바로 사용할 수 있는 Dataflow 템플릿을 사용할 수 있으며 맞춤설정할 필요가 없습니다. Cloud Dataflow의 GCP 콘솔에서 직접 이 작업을 수행할 수 있습니다.

Pub/Sub Topic to BigQuery 템플릿을 사용한 다음, Pub/Sub 입력 주제와 BigQuery 출력 테이블을 포함하여 Dataflow 템플릿에서 몇 가지만 구성하면 됩니다.
7. 구현, Dataform 단계
Dataform의 모델 테이블
Dataform 모델은 다음 GitHub 저장소와 연결되어 있습니다. 정의 폴더에는 데이터 모델을 정의하는 SQLX 파일이 있습니다.
예약 및 조정 섹션에 설명된 대로 Dataform에서 wiki_changes의 원시 레코드를 집계하는 스테이징 테이블을 정의합니다. 스테이징 테이블의 DDL (Dataform 프로젝트에 연결된 GitHub 저장소에도 링크되어 있음)을 살펴보겠습니다.
이 표의 몇 가지 중요한 기능을 살펴보겠습니다.
- 증분 유형으로 구성되므로 예약된 ELT 작업이 실행될 때 새 레코드만 추가됩니다.
- 하단의 when() 코드에서 표현하듯이, 이에 대한 로직은 이벤트 스트림의 타임스탬프를 반영하는 타임스탬프 필드(즉, 변경의 event_time)를 기반으로 합니다.
- 이는 user 필드를 사용하여 클러스터링됩니다. 즉, 각 파티션 내의 레코드가 user를 기준으로 정렬되므로 리더보드를 구축하는 쿼리에 필요한 셔플이 줄어듭니다.
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
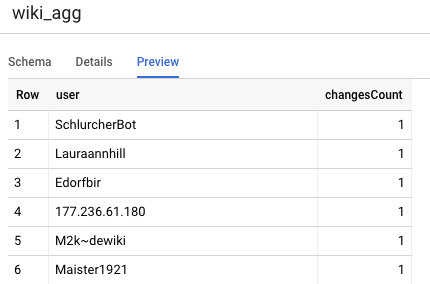
프로젝트에서 정의해야 하는 다른 테이블은 보고 등급 테이블로, 리더보드 쿼리를 지원합니다. 사용자는 게시된 위키백과 변경사항의 정확한 최신 개수에 관심을 가지기 때문에 보고 등급의 표는 집계됩니다.
테이블 정의는 간단하며 Dataform 참조를 사용합니다. 이러한 참조의 큰 이점은 객체 간 종속 항목을 명시하고 종속 쿼리가 종속 쿼리 전에 항상 실행되도록 함으로써 파이프라인의 정확성을 지원한다는 것입니다.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
Dataform 프로젝트 예약
마지막 단계는 시간별로 실행되는 일정을 만드는 것입니다. 프로젝트가 호출되면 Dataform이 필요한 SQL 문을 실행하여 증분 스테이징 테이블을 새로고침하고 집계된 테이블을 다시 로드합니다.
이 일정은 매시간 또는 더 자주(최대 약 5~10분마다) 호출하여 시스템에 스트리밍된 최근 이벤트로 리더보드를 계속 업데이트할 수 있습니다.

8. 축하합니다
수고하셨습니다. 스트리밍된 데이터를 위한 계층형 데이터 아키텍처를 빌드했습니다.
Wikimedia 이벤트 스트림으로 시작하여 이 스트림을 BigQuery에서 일관되게 최신 상태인 보고 테이블로 변환했습니다.
다음 단계
추가 자료
- Dataform 소개
- Functional Data Engineering — 일괄 데이터 처리를 위한 최신 패러다임
- Apache Airflow를 사용하여 BigQuery 데이터를 집계하는 방법
[1] 데이터 엔지니어는 일일 일괄 변환을 실행하여 그날 (예: 시간별) 집계를 덮어쓰는 것이 일반적이며 이를 조정이라고 합니다.
[2] 구현 세부정보는 아키텍처 섹션을 참고하세요.
[3] 늦게 도착하는 사실은 event_time이 동일한 이벤트 스트림 내에서 시스템이 이미 처리한 레코드보다 이후인 이벤트입니다.