
1. Wprowadzenie
Omówienie
platformy do analizy strumieni danych stają się coraz ważniejsze we współczesnym magazynie danych, ponieważ użytkownicy biznesowi zapotrzebowanie na analitykę w czasie rzeczywistym nie słabnie. Poczyniono znaczne kroki w celu zwiększenia częstotliwości aktualizacji danych w magazynach i ogólnej obsługi analiz strumieniowych, ale inżynierowie danych wciąż mają problemy z adaptacją tych źródeł strumieniowania do architektury hurtowni danych.
Na tym blogu omawiamy kilka najczęstszych wyzwań, z jakimi mierzą się inżynierowie danych. Aby umożliwić sprawną agregację strumieniowych danych przy użyciu BigQuery, przedstawiamy kilka pomysłów projektowych i wzorców architektonicznych.
Częstotliwość aktualizacji i dokładność danych
Określenie aktualne oznacza, że czas oczekiwania na dane zbiorcze jest krótszy niż określony próg, np. „aktualność z ostatniej godziny”. Aktualność jest określana na podstawie podzbioru nieprzetworzonych danych uwzględnianych w danych zbiorczych.
W przypadku strumieniowych danych bardzo często zdarzenia pojawiają się w systemie przetwarzania danych z opóźnieniem, co oznacza, że czas przetwarzania zdarzenia przez nasz system jest znacznie późniejszy niż moment jego wystąpienia.
Gdy przetwarzamy informacje otrzymane z opóźnieniem, wartości zagregowanych statystyk zmieniają się, co oznacza, że wartości widoczne dla analityków zmieniają się w ciągu dnia[1]. Dokładność oznacza, że zagregowane statystyki są jak najbardziej zbliżone do ostatecznych, uzgodnionych wartości.
Istnieją oczywiście trzeci wymiar optymalizacji: koszty – zarówno w kontekście pieniędzy, jak i skuteczności. Aby to zilustrować, możemy użyć widoku logicznego obiektów danych w sekcji Etap przejściowy i raportowanie. Wadą widoku logicznego jest to, że przy każdym wysyłaniu zapytania do tabeli zbiorczej skanowany jest cały nieprzetworzony zbiór danych, co jest powolne i kosztowne.
Opis scenariusza
Zacznijmy od tego przypadku użycia. Zamierzamy przetwarzać dane ze strumieni zdarzeń z Wikipedii opublikowane przez Wikimedia. Naszym celem jest stworzenie tabeli wyników, w której widać autorów, w których wprowadzono najwięcej zmian, i która będzie aktualna w miarę publikowania nowych artykułów. Nasza tablica wyników, która zostanie wdrożona jako panel mechanizmu analityki biznesowej, będzie agregować nieprzetworzone zdarzenia według nazwy użytkownika, aby obliczać wyniki[2].
2. Projektowanie
Podział danych na poziomy
W potoku danych zdefiniujemy wiele poziomów danych. Zachowamy nieprzetworzone dane zdarzeń i stworzymy potok kolejnych przekształceń, wzbogacania i agregacji. Nie łączymy tabel raportowania bezpośrednio z danymi przechowywanymi w tabelach nieprzetworzonych, ponieważ chcemy ujednolicić i scentralizować przekształcenia, których potrzebują różne zespoły na potrzeby danych etapowych.
Ważną zasadą tej architektury jest to, że wyższe poziomy – etapowe i raportowanie – mogą być w dowolnym momencie przeliczane tylko przy użyciu nieprzetworzonych danych.
partycjonowanie
BigQuery obsługuje 2 style partycjonowania: partycjonowanie zakresu liczb całkowitych i partycjonowanie daty. W przypadku tego posta bierzemy pod uwagę tylko partycjonowanie daty.
W przypadku partycjonowania daty można wybrać partycje oparte na czasie przetwarzania lub partycje oparte na polach. Czas pozyskania, partycjonowanie, powoduje przeniesienie danych do partycji na podstawie daty ich pozyskania. Użytkownicy mogą też wybrać partycję podczas wczytywania, określając dekoratora partycji.
Pole partycjonowanie danych partycjonuje dane na podstawie wartości daty lub sygnatury czasowej w kolumnie.
Dane dotyczące pozyskiwania zdarzeń trafiają do tabeli partycjonowanej według czasu przetwarzania. Dzieje się tak, ponieważ czas przetwarzania ma znaczenie w przypadku przetwarzania lub ponownego przetwarzania danych otrzymanych w przeszłości. Uzupełnienia danych historycznych mogą być też przechowywane w ramach partycji czasu przetwarzania w zależności od tego, kiedy powinny zostać dostarczone.
W tym ćwiczeniu zakładamy, że nie będziemy otrzymywać informacji ze strumienia Wikimedia z opóźnieniem[3]. Uprości to przyrostowe wczytywanie tabeli przejściowej, co zostało omówione poniżej.
Tabela przejściowa jest podzielona według czasu trwania wydarzenia. Wynika to z faktu, że nasi analitycy chcą analizować dane na podstawie daty zdarzenia, czyli daty opublikowania artykułu w Wikipedii, a nie czasu przetworzenia zdarzenia w ramach procesu.
3. Architektura
Co utworzysz
Do odczytu strumienia zdarzeń z Wikimedia używamy protokołu SSE. Napiszemy małą usługę pośredniczącą, która będzie odczytywała dane ze strumienia zdarzeń jako klient SSE i będzie publikować w temacie Pub/Sub w naszym środowisku GCP.
Gdy zdarzenia będą dostępne w Pub/Sub, utworzymy zadanie Cloud Dataflow za pomocą szablonu, które będzie przesyłać rekordy do poziomu nieprzetworzonych danych w naszej hurtowni danych BigQuery. Następnym krokiem jest obliczenie zbiorczych statystyk na potrzeby naszej tabeli wyników na żywo.
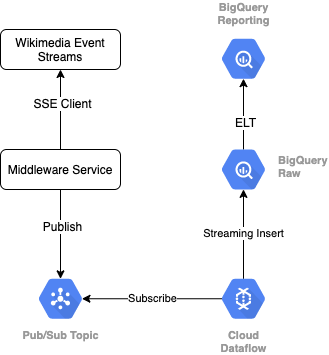
Harmonogram i administracja
Do administrowania narzędziem ELT, które wypełnia się poziomami przejściowymi i raportowania w hurtowni, korzystamy z Dataform. Dataform „udostępni narzędzia, sprawdzone metody i przepływy pracy inspirowane inżynierią oprogramowania” w zespołach inżynierów danych. Oprócz administrowania i planowania Dataform udostępnia funkcje takie jak asercje i testy do zapewniania jakości, definiowanie operacji w magazynie niestandardowej do zarządzania bazami danych oraz funkcje dokumentacji do wykrywania danych.
Autorzy dziękują zespołowi Dataform za opinie i opinie na temat tego modułu oraz bloga.
W Dataform nieprzetworzone dane przesyłane strumieniowo z Dataflow będą zadeklarowane jako zewnętrzny zbiór danych. Tabele przejściowe i raportowanie będą definiowane dynamicznie za pomocą składni SQLX w Dataform.
Wykorzystamy funkcję wczytywania przyrostowego w Dataform, aby wypełnić tabelę przejściową i zaplanować uruchamianie projektu Dataform co godzinę. Zgodnie z powyższymi założymy, że nie otrzymamy informacji z opóźnieniem, więc naszą zasadą będzie przetwarzanie rekordów, których czas zdarzenia jest późniejszy niż data najnowszego zdarzenia wśród istniejących rekordów etapów.
W kolejnych modułach tej serii omówimy obsługę informacji, które dotarły z opóźnieniem.
Gdy uruchomimy cały projekt, do nadrzędnych poziomów danych zostaną dodane wszystkie nowe rekordy, a nasze agregacje zostaną obliczone ponownie. W szczególności każde uruchomienie będzie skutkować pełnym odświeżeniem tabeli zbiorczej. Nasz fizyczny projekt obejmuje pogrupowanie tabeli przejściowej według nazwy użytkownika. Pozwoli to jeszcze bardziej zwiększyć wydajność zapytania agregującego, które w pełni odświeży tę tabelę wyników.
Czego potrzebujesz
- Mieć najnowszą wersję Chrome
- Podstawowa znajomość języka SQL i podstawowa znajomość BigQuery
4. Przygotowanie
Utwórz zbiór danych i tabelę BigQuery dla poziomu nieprzetworzonego
Utwórz nowy zbiór danych zawierający schemat naszej hurtowni. Użyjemy tych zmiennych również później, więc użyj tej samej sesji powłoki w kolejnych krokach lub ustaw zmienne zależnie od potrzeb. Pamiętaj, aby zastąpić <PROJECT_ID> identyfikatorem projektu.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
Następnie utworzymy w konsoli GCP tabelę, w której będą przechowywane nieprzetworzone zdarzenia. Schemat będzie dopasowywany do pól przewidzianych przez nas ze strumienia zdarzeń opublikowanych przez nas zmian z Wikimedia.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
Utwórz temat i subskrypcję Pub/Sub
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
Utwórz konto i projekt Dataform
Wejdź na https://app.dataform.co i utwórz nowe konto. Po zalogowaniu się utworzysz nowy projekt.
Musisz skonfigurować integrację z BigQuery w swoim projekcie. Ponieważ Dataform będzie musiała połączyć się z hurtownią, musimy udostępnić dane logowania do konta usługi.
Aby skonfigurować połączenie z BigQuery na stronie Baza danych, wykonaj podane wyżej czynności w dokumentacji Dataform. Pamiętaj, aby wybrać taki sam identyfikator projektu, który został utworzony powyżej, a następnie przesłać dane logowania i przetestować połączenie.
Po skonfigurowaniu integracji z BigQuery na karcie Modelowanie zobaczysz dostępne zbiory danych. W tym miejscu będzie dostępna tabela nieprzetworzona, której używamy do przechwytywania zdarzeń z Dataflow. Wracamy do tego za chwilę.
5. Implementacja
Tworzenie usługi Python do odczytu i publikowania zdarzeń w Pub/Sub
Zobacz poniższy kod Pythona, który jest również dostępny w tym artykule. W tym przykładzie przestrzegamy dokumentacji interfejsu Pub/Sub API.
Zwróćmy uwagę na listę kluczy w kodzie. Są to pola, które będziemy przesyłać z pełnego zdarzenia JSON, pozostaną w opublikowanych wiadomościach, a ostatecznie w tabeli wiki_changes w warstwie nieprzetworzonej naszego zbioru danych BigQuery.
Wartości te pasują do schematu tabeli wiki_changes zdefiniowanego w zbiorze danych BigQuery na potrzeby zmian wiki_changes
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. Wdrożenie, ciąg dalszy
Utwórz zadanie Dataflow na podstawie szablonu, aby móc odczytywać dane z Pub/Sub i zapisywać je w BigQuery
Gdy ostatnie zdarzenia zmiany zostaną opublikowane w temacie Pub/Sub, będziemy mogli użyć zadania Cloud Dataflow, aby je odczytać i zapisać w BigQuery.
Gdyby podczas przetwarzania strumienia mieliśmy wyrafinowane potrzeby, np. łączenie z różnych strumieni, tworzenie agregacji okiennych i korzystanie z wyszukiwania w celu wzbogacenia danych, moglibyśmy wdrożyć je w naszym kodzie Apache Beam.
W tym przypadku nasze potrzeby są prostsze, dlatego możemy użyć gotowego szablonu Dataflow, który nie wymaga dostosowywania. Możemy to zrobić bezpośrednio w konsoli GCP w Cloud Dataflow.
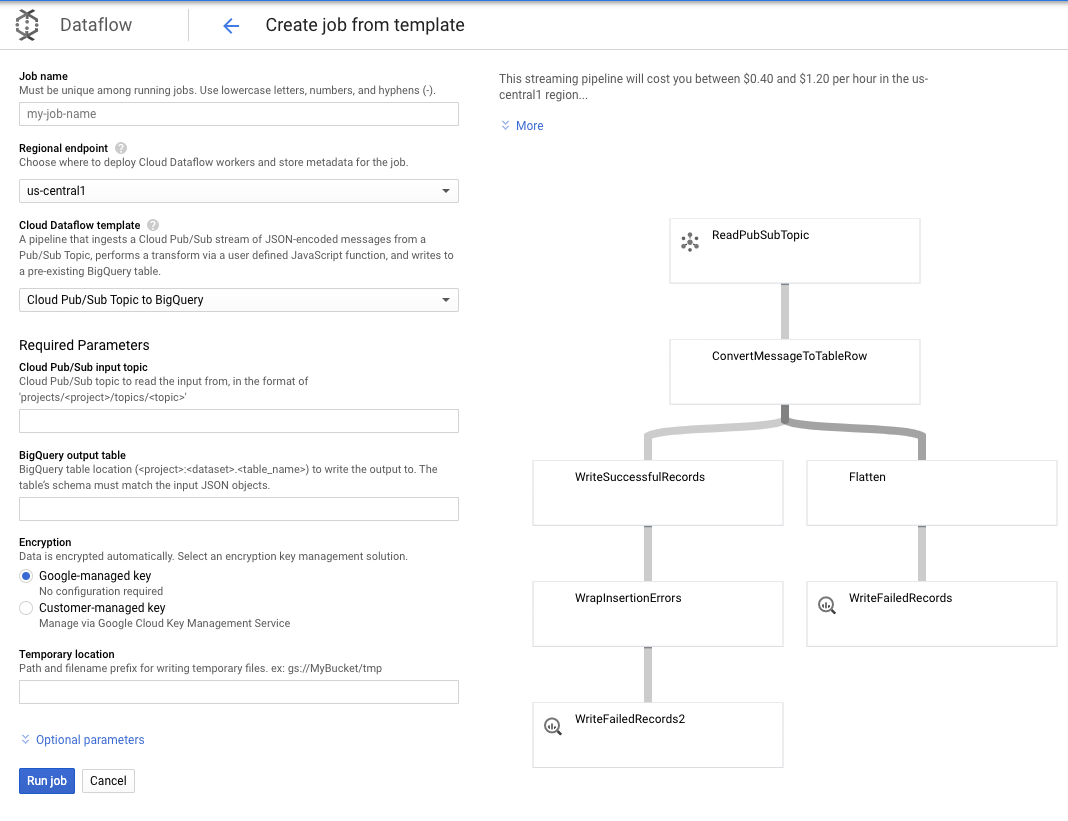
Wykorzystamy temat Pub/Sub do BigQuery. Następnie musimy skonfigurować kilka rzeczy w szablonie Dataflow, w tym temat wejściowy Pub/Sub i tabelę wyjściową BigQuery.
7. Implementacja, kroki Dataform
Tabele modeli w Dataform
Nasz model Dataform jest powiązany z tym repozytorium GitHub – folder definicji zawiera pliki SQLX, które definiują model danych.
Jak wspomnieliśmy w sekcji Harmonogram i administracja, w Dataform zdefiniujemy tabelę przejściową, która będzie gromadzić nieprzetworzone rekordy z parametru wiki_changes. Spójrzmy na DDL dla tabeli przejściowej (link znajduje się też w repozytorium GitHub powiązanego z naszym projektem Dataform).
Zwróćmy uwagę na kilka ważnych funkcji tej tabeli:
- Jest skonfigurowany jako typ przyrostowy, więc po uruchomieniu naszych zaplanowanych zadań ELT dodawane są tylko nowe rekordy
- Zgodnie z kodem when() u dołu logiką tego działania opiera się pole sygnatury czasowej, które odzwierciedla sygnaturę czasową strumienia zdarzeń, tj.parametr event_time zmiany.
- Jest on grupowany przy użyciu pola user, co oznacza, że rekordy w każdej partycji są porządkowane według użytkownika, co zmniejsza ilość tasowania wymaganego przez zapytanie tworzące tabelę wyników.
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
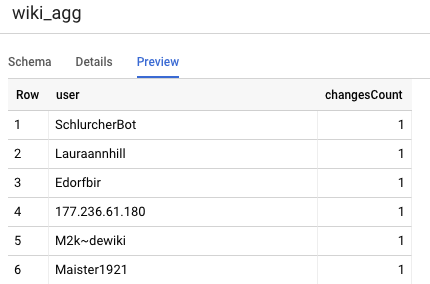
Kolejną tabelą, którą musimy zdefiniować w naszym projekcie, jest tabela poziomów raportowania. Obsługuje ona zapytania o tablice wyników. Tabele na poziomie Raportowanie są przedstawiane zbiorczo, ponieważ nasi użytkownicy podają aktualne i dokładne liczby zmian opublikowanych w Wikipedii.
Definicja tabeli jest prosta i korzysta z odwołań do Dataform. Ogromną zaletą tych rozwiązań jest to, że wyraźnie określają zależności między obiektami, co wspiera prawidłowość potoku, zapewniając, że zależności są zawsze wykonywane przed zapytaniami zależnymi.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
Zaplanuj projekt Dataform
Ostatnim krokiem jest utworzenie harmonogramu, który będzie wykonywany co godzinę. Po wywołaniu projektu Dataform wykona wymagane instrukcje SQL, aby odświeżyć tabelę przyrostową testowania i ponownie załadować tabelę zbiorczą.
Ten harmonogram może być wywoływany co godzinę lub jeszcze częściej, maksymalnie co 5–10 minut, aby aktualizować tablicę wyników o najnowsze wydarzenia przesłane strumieniowo do systemu.
8. Gratulacje
Gratulujemy! Udało Ci się utworzyć wielopoziomową architekturę danych przesyłanych strumieniowo.
Zaczęliśmy od strumienia zdarzeń Wikimedia, a następnie przekształciliśmy go w tabelę raportowania w BigQuery, która jest zawsze aktualna.
Co dalej?
Więcej informacji
- Przedstawiamy Dataform
- Funkcjonalna inżynieria danych – nowoczesny model przetwarzania danych wsadowych
- Jak agregować dane do BigQuery przy użyciu Apache Airflow
[1] Inżynierowie danych często przeprowadzają codzienne, zbiorcze przekształcanie w celu zastąpienia danych zbiorczych z ciągu dnia (np. co godzinę) – nazywamy to uzgadnianiem.
[2] Szczegółowe informacje o implementacji znajdziesz w sekcji Architektura.
[3] Fakt z opóźnieniem to zdarzenie z parametrem event_time, który jest późniejszy niż rekordy przetworzone przez system w ramach tego samego strumienia zdarzeń.