
1. Introdução
Visão geral
Estruturas para análise de streaming tornaram-se cada vez mais importantes no armazenamento de dados contemporâneo, à medida que os usuários e a demanda por análises em tempo real continua a mesma. Grandes avanços foram feitos para melhorar a atualização de dados nos armazéns e oferecer suporte à análise de streaming em geral, mas os engenheiros de dados ainda enfrentam desafios ao adaptar essas fontes de streaming para a arquitetura do data warehouse.
Neste blog, discutimos alguns dos desafios mais comuns que os engenheiros de dados enfrentam ao resolver esses casos de uso. Descrevemos algumas ideias de design e padrões de arquitetura para uma agregação eficiente de dados de streaming usando o BigQuery.
Atualização e precisão de dados
Com Fresh, queremos dizer que a latência dos dados agregados é menor que algum limite, por exemplo, "atualizado na última hora". A atualização é determinada pelo subconjunto de dados brutos incluído nos agregados.
Ao lidar com dados de streaming, é muito comum que os eventos cheguem com atraso em nosso sistema de processamento de dados, o que significa que o horário em que nosso sistema processa um evento é significativamente posterior ao horário em que o evento ocorre.
Quando processamos os fatos que chegam tardias, os valores de nossas estatísticas agregadas mudam, o que significa que, a cada dia, os valores que os analistas veem mudam[1]. Com precisão, queremos dizer que as estatísticas agregadas são as mais próximas possíveis dos valores finais e reconciliados.
É claro que há uma terceira dimensão a ser otimizada: custo, no sentido de dinheiro e desempenho. Para ilustrar, podemos usar uma visualização lógica para os objetos de dados em Preparação e relatórios. A desvantagem de usar uma visualização lógica é que sempre que a tabela agregada é consultada, todo o conjunto de dados bruto é verificado, o que é lento e caro.
Descrição do cenário
Vamos preparar o cenário deste caso de uso. Vamos ingerir os dados de streams de eventos da Wikipédia publicados pela Wikimedia. Nosso objetivo é criar um cabeçalho que mostre os autores com mais alterações, e ele será atualizado à medida que novos artigos forem publicados. Nosso quadro de liderança, que será implementado como um painel do BI Engine, agregará os eventos brutos por nome de usuário para calcular as pontuações[2].
2. Design
Níveis de dados
No pipeline de dados, vamos definir várias camadas de dados. Vamos reter os dados brutos de eventos e criar um pipeline de transformações, enriquecimento e agregação subsequentes. Não conectamos tabelas de relatórios diretamente aos dados armazenados em tabelas brutas porque queremos unificar e centralizar as transformações que as equipes consideram importantes para os dados preparados.
Um princípio importante nessa arquitetura é que os níveis mais altos (Preparação e relatórios) podem ser recalculados a qualquer momento usando apenas dados brutos.
particionamento
O BigQuery oferece suporte a dois estilos de particionamento: por intervalo de números inteiros e por data. Vamos considerar apenas o particionamento de datas no escopo desta postagem.
Para particionamento de data, é possível escolher entre partições de tempo de ingestão ou partições baseadas em campo. O particionamento por tempo de ingestão coloca os dados em uma partição com base em quando eles foram adquiridos. Os usuários também podem selecionar uma partição no momento de carregamento especificando um decorador de partição.
O particionamento de campo particiona os dados com base no valor de data ou carimbo de data/hora em uma coluna.
Para ingestão de eventos, vamos colocar os dados em uma tabela particionada por tempo de ingestão. Isso ocorre porque o tempo de ingestão é relevante para o processamento ou reprocessamento de dados recebidos no passado. Os preenchimentos de dados históricos também podem ser armazenados em partições de tempo de processamento, com base em quando eles chegaram.
Neste codelab, vamos supor que não receberemos fatos atrasados[3] do fluxo de eventos da Wikimedia. Isso simplificará o carregamento incremental da tabela de preparo, conforme discutido abaixo.
A tabela de preparo será particionada por horário do evento. Isso ocorre porque nossos analistas estão interessados em consultar dados com base no horário do evento (o horário em que o artigo foi publicado na Wikipédia) e não no horário em que o evento foi processado no pipeline.
3. Arquitetura
O que você vai criar
Para ler o stream de eventos da Wikimedia, vamos usar o protocolo SSE. Criaremos um pequeno serviço de middleware que será lido pelo stream de eventos como um cliente SSE e será publicado em um tópico do Pub/Sub no ambiente do GCP.
Quando os eventos estiverem disponíveis no Pub/Sub, criaremos um job do Cloud Dataflow, usando um modelo, que transmitirá os registros para o nível de dados brutos no nosso data warehouse do BigQuery. A próxima etapa é calcular as estatísticas agregadas para dar suporte ao nosso quadro de liderança ao vivo.
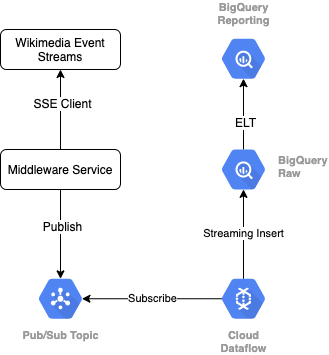
Programação e orquestração
Para orquestrar o ELT que preenche as camadas de preparo e geração de relatórios do warehouse, usaremos o Dataform. O Dataform "oferece fluxos de trabalho inspirados em ferramentas, práticas recomendadas e engenharia de software" às equipes de engenharia de dados. Além de orquestração e programação, o Dataform fornece funcionalidades como declarações e testes para garantir a qualidade, definir operações personalizadas de warehouse para gerenciamento de banco de dados e recursos de documentação para dar suporte à descoberta de dados.
Os autores agradecem à equipe do Dataform pelo feedback valioso ao revisar o laboratório e o blog.
No Dataform, os dados brutos transmitidos do Dataflow serão declarados como um conjunto de dados externo. As tabelas de preparo e relatórios serão definidas dinamicamente, usando a sintaxe SQLX do Dataform.
Vamos usar o recurso de carregamento incremental do Dataform para preencher a tabela de preparo e programar a execução do projeto do Dataform a cada hora. Conforme explicado acima, vamos presumir que não receberemos fatos que chegam atrasados, portanto, nossa lógica será ingerir registros com um horário de evento posterior ao horário do evento mais recente entre os registros preparados existentes.
Em laboratórios posteriores desta série, discutiremos o tratamento de fatos que chegam tardias.
Quando todo o projeto é executado, os níveis de dados upstream têm todos os novos registros adicionados, e nossas agregações são recalculadas. Em particular, cada execução resulta em uma atualização completa da tabela agregada. Nosso design físico vai incluir o agrupamento da tabela de preparo por nome de usuário, aumentando ainda mais o desempenho da consulta de agregação que vai atualizar totalmente o placar.
O que é necessário
- Uma versão recente do Chrome
- Conhecimento básico de SQL e do BigQuery
4. Etapas da configuração
Crie uma tabela e um conjunto de dados do BigQuery para o nível bruto
Crie um conjunto de dados para conter o esquema do warehouse. Também vamos usar essas variáveis mais tarde, portanto, use a mesma sessão de shell para as próximas etapas ou defina as variáveis conforme necessário. Substitua <PROJECT_ID> pelo ID do seu projeto.
export PROJECT=<PROJECT_ID> export DATASET=fresh_streams bq --project_id $PROJECT mk $DATASET
Em seguida, criaremos uma tabela que armazenará os eventos brutos usando o Console do GCP. O esquema vai corresponder aos campos projetados com base no fluxo de eventos das alterações publicadas que estamos consumindo do Wikimedia.
CREATE TABLE fresh_streams.wiki_changes ( id INT64, user STRING, title STRING, timestamp TIMESTAMP ) PARTITION BY DATE(_PARTITIONTIME) CLUSTER BY user
Criar tópico e assinatura do Pub/Sub
export TOPIC=<TOPIC_ID> gcloud pubsub topics create $TOPIC
Criar um projeto e uma conta do Dataform
Acesse https://app.dataform.co e crie uma nova conta. Depois de fazer login, crie um novo projeto.
No seu projeto, você precisará configurar a integração com o BigQuery. Como o Dataform terá que se conectar ao warehouse, vamos precisar provisionar credenciais da conta de serviço.
Siga as etapas nos documentos do Dataform para configurar a conexão com o BigQuery na página do banco de dados. Selecione o mesmo projectId criado acima, faça upload das credenciais e teste a conexão.
Depois de configurar a integração com o BigQuery, você vai encontrar os conjuntos de dados disponíveis na guia "Modelagem". Especificamente, a tabela bruta que usamos para capturar eventos do Dataflow será apresentada aqui. Vamos voltar a isso em breve.
5. Implementação
Crie um serviço Python para ler e publicar eventos no Pub/Sub
Confira o código Python abaixo, disponível também neste gist. Neste exemplo, vamos seguir os documentos da API Pub/Sub.
Vamos anotar a lista de keys no código. Esses são os campos que vamos projetar a partir do evento JSON completo, que vão persistir nas mensagens publicadas e, por fim, na tabela wiki_changes dentro do nível bruto do nosso conjunto de dados do BigQuery.
Elas correspondem ao esquema da tabela wiki_changes definido no conjunto de dados do BigQuery para wiki_change
#!/usr/bin/env python3
import json, time, sys, os
from sseclient import SSEClient as EventSource
from google.cloud import pubsub_v1
project_id = os.environ['PROJECT']
topic_name = os.environ['TOPIC']
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, topic_name)
futures = dict()
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
keys = ['id', 'timestamp', 'user', 'title']
for event in EventSource(url):
if event.event == 'message':
try:
change = json.loads(event.data)
changePub = {k: change.get(k, 0) for k in keys}
except ValueError:
pass
else:
payloadJson = json.dumps(changePub).encode('utf-8')
future = publisher.publish(
topic_path, data=payloadJson)
futures[payloadJson] = future
while futures:
time.sleep(5)
6. Implementação (continuação)
Crie um job do Dataflow com base em um modelo para ler no Pub/Sub e gravar no BigQuery
Depois que os eventos de alteração recentes forem publicados no tópico do Pub/Sub, poderemos usar um job do Cloud Dataflow para ler esses eventos e gravá-los no BigQuery.
Se tivéssemos necessidades sofisticadas ao processar o stream, como mesclar streams diferentes, criar agregações em janelas, usando pesquisas para enriquecer dados, poderíamos implementá-las no nosso código do Apache Beam.
Como nossas necessidades são mais diretas para esse caso de uso, podemos usar o modelo do Dataflow pronto para uso e não precisaremos personalizá-lo. Isso pode ser feito diretamente no console do GCP no Cloud Dataflow.
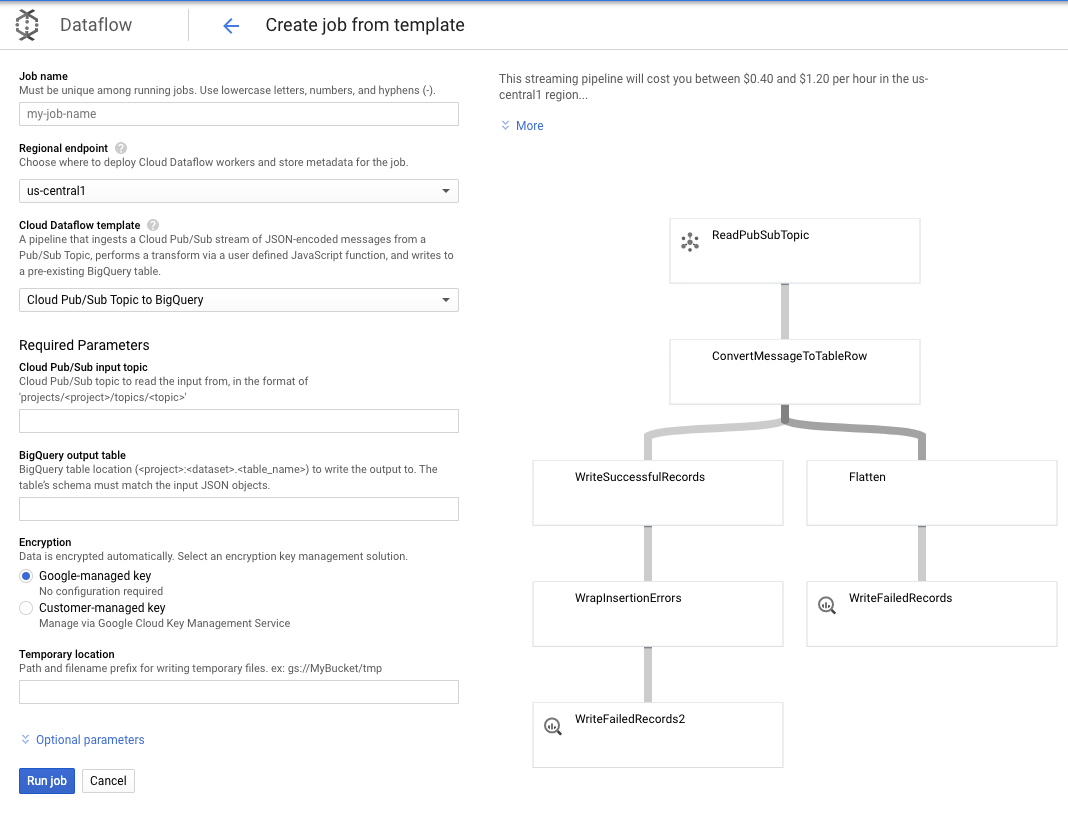
Vamos usar o tópico do Pub/Sub para o modelo do BigQuery. Depois, só precisamos configurar alguns itens no modelo do Dataflow, incluindo o tópico de entrada do Pub/Sub e a tabela de saída do BigQuery.
7. Etapas de implementação e do Dataform
Tabelas de modelo no Dataform
Nosso modelo do Dataform está vinculado ao seguinte repositório do GitHub. A pasta de definições contém os arquivos SQLX que definem o modelo de dados.
Como discutido na seção "Programação e orquestração", vamos definir uma tabela de preparo no Dataform que agrega os registros brutos de wiki_changes. Vamos analisar a DDL da tabela de preparo, que também está vinculada ao repositório do GitHub (link em inglês) vinculado ao nosso projeto do Dataform.
Vamos observar alguns recursos importantes dessa tabela:
- Ele está configurado como um tipo incremental. Portanto, quando nossos jobs de ELT programados forem executados, apenas novos registros serão adicionados
- Conforme expresso pelo código when() na parte inferior, a lógica para isso se baseia no campo "timestamp", que reflete o carimbo de data/hora no fluxo de eventos, ou seja, o event_time da mudança
- Ela é agrupada usando o campo user, o que significa que os registros dentro de cada partição serão ordenados por user, reduzindo o embaralhamento exigido pela consulta que cria o ranking.
config {
type: "incremental",
schema: "wiki_push",
bigquery: {
partitionBy: "date(event_time)",
clusterBy: ["user"]
}
}
select
user,
title,
timestamp as event_time,
current_timestamp() as processed_time
from
wiki_push.wiki_changes
${ when(incremental(), `WHERE timestamp > (SELECT MAX(timestamp) FROM ${self()})`) }
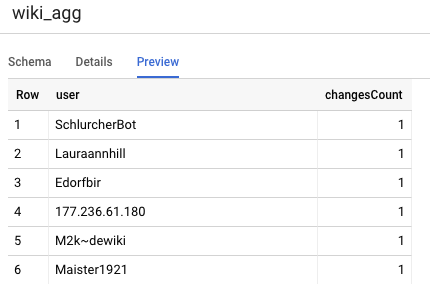
A outra tabela que precisamos definir no projeto é a tabela do nível dos relatórios, que terá suporte para as consultas do quadro de liderança. As tabelas no nível de Relatórios são agregadas, pois nossos usuários estão preocupados com contagens atualizadas e precisas de alterações publicadas da Wikipédia.
A definição da tabela é direta e usa as referências do Dataform. Uma grande vantagem dessas referências é que elas tornam explícitas as dependências entre objetos, apoiando a correção do pipeline, garantindo que as dependências sejam sempre executadas antes das consultas dependentes.
config {
type: "table",
schema: "wiki_push"
}
select
user,
count(*) as changesCount
from
${ref("wiki_staged")}
group by user
Programar projeto do Dataform
A etapa final é simplesmente criar um cronograma que será executado a cada hora. Quando nosso projeto é invocado, o Dataform executa as instruções SQL necessárias para atualizar a tabela de preparo incremental e recarregar a tabela agregada.
Essa programação pode ser invocada a cada hora (ou com mais frequência, até aproximadamente a cada 5 a 10 minutos) para manter o quadro de liderança atualizado com os eventos recentes transmitidos para o sistema.
8. Parabéns
Parabéns, você criou uma arquitetura de dados em camadas para seus dados de streaming.
Começamos com um fluxo de eventos da Wikimedia e o transformamos em uma tabela de relatórios no BigQuery que está sempre atualizada.
Qual é a próxima etapa?
Leia mais
- Introdução ao Dataform
- Engenharia de dados funcionais: um paradigma moderno de processamento de dados em lote (em inglês)
- Como agregar dados para o BigQuery usando o Apache Airflow
[1] É comum que os engenheiros de dados executem uma transformação diária em lote para substituir os agregados intradiários (por exemplo, por hora). Isso é conhecido como reconciliação.
[2] Para conferir detalhes de implementação, consulte a seção "Arquitetura".
[3] Um fato que chega tardiamente é um evento com um event_time que é posterior aos registros já processados pelo sistema nesse mesmo stream de eventos